Updated at 2025-02-05 03:30:39.422343
Журнал изменений
На этой странице находится актуальная информация о версиях Tarantool Data Grid.
Формат журнала изменений основан на документе Keep a Changelog,
а версионирование следует правилам Semantic Versioning.
SDK обновлен до версии 2.11.4-0-r658.
Расширена информация о клиенте, записываемая в журнал аудита при неудачных
попытках авторизации.
Исправлена возможность обновления необнуляемого элемента массива на null.
Убран sandboxing из функции, использующейся при миграции спейсов.
Теперь можно использовать произвольные функции Lua/Tarantool.
Исправлена ошибка при запуске миграций в режиме dry_run.
Исправлена некорректная обработка спанов при включенном трейсинге
при ошибке обработки объектов из Kafka.
[Breaking change] Базовый образ для сборки проекта обновлен с CentOS 7 до AlmaLinux 8.
Теперь проект может не работать на более старых дистрибутивах.
[Breaking change] Отключено сопоставление с Lua-шаблоном при поиске содержимого сообщений журнала.
Удалить поле из модели данных теперь можно без запуска миграции.
Исправлены ошибки, возникающие при обновлении полей-массивов.
Kafka consumer теперь логирует offset сообщения в случае возникновения проблем.
Исправлена ошибка, возникающая при запуске миграций в режиме dry_run для спейсов с отключенным версионированием.
Cartridge обновлен до версии 2.12.3.
metrics обновлен до версии 1.2.0.
Добавлен метод connector.http_request в sandbox.
Добавлена подсистема событий events.
Исправлено разыменование nil (nil dereference) при перезагрузке конфигурации в Kafka-клиенте.
Исправлена обработка ошибок маршрутизации.
Исправлен расчет размера журнала TDG (спейса tdg_log).
Добавлен доступ к странице веб-интерфейса Console для пользователей с
привилегией eval.
Cartridge обновлен до версии 2.12.0.
SDK обновлен до версии 2.11.3-0-r636.
Исправлена ошибка: account provider watcher печатал ошибку при инициализации.
Cartridge обновлен до версии 2.10.0.
expirationd обновлен до версии 1.6.0.
SDK обновлен до версии 2.11.3-0-r631.
Добавлен фильтр полей для запросов на получение данных.
Исправлена ошибка table is nil в обнуляемом поле записи.
Исправлена ошибка vshard gc при балансировке.
Исправлена ошибка, связанная с передачей значений cdata в метрики.
Исправлено использование типа Union совместно с массивами.
Исправлено значение версии по умолчанию для схемы GraphQL.
Исправлена нумерация версий PRM-пакета.
Исправлено переполнение в значениях дат.
SDK обновлен до версии 2.11.2-0-r621.
Cartridge обновлен до версии 2.9.0.
[Breaking change] Изменен формат ошибок некоторых функций Repository API.
Добавлена возможность указания заголовков (headers) для Kafka-коннектора.
Исправлено некорректное отображение версии продукта при использовании Docker-образа.
Исправлена обработка параметра if_not_exists в repository.put_batch().
Исправлена неконсистентность ошибок, возвращаемых repository.put_batch().
SDK обновлен до версии 2.11.2-0-r616.
Cartridge обновлен до версии 2.8.6.
[Breaking change] Полностью удалена функциональность тенантов.
Добавлена возможность вызова repository.call_on_storage() без указания типа.
Исправлена некорректная сериализация массивов.
Исправлена обработка параметра pkey функции repository.get() при указании версии.
Исправлены ошибки в триггерах механизма версионирования.
SDK обновлен до версии 2.11.2-0-r609.
Обновления
SDK обновлен до версии 2.11.1-0-r605.
Cartridge обновлен до версии 2.8.4.
Обновлены зависимости web UI.
Новые возможности
[Breaking change] Частично удалена функциональность тенантов.
Добавлена опция handler для Kafka-коннектора.
Добавлена обработка ошибок в Kafka-коннекторе.
Добавлены метрики обработчика исходящих данных.
Добавлена возможность использования (require) кода из конфигурации в расширениях.
Исправленные ошибки
Исправлен вызов deinit до вызова init в роли scheduler.
Исправлено отсутствие сообщений об ошибках в Kafka consumer.
Исправлено удаление частей конфигурации коннекторов в веб-интерфейсе.
Обновления
SDK обновлен до версии 2.11.1-0-r579.
Cartridge обновлен до версии 2.8.2.
expirationd обновлен до версии 1.5.0.
Обновлены зависимости для веб-интерфейса.
Новые возможности
[Breaking change] Удалены настройки тенантов из веб-интерфейса.
Модуль compress добавлен в sandbox.
Добавлены настройки Kafka consumer в sandbox: consumer_seek_partitions и consumer_metadata.
Добавлены настройки Kafka consumer в sandbox: consumer_pause, consumer_resume и consumer_status.
Добавлен параметр initial_state во входящую конфигурацию Kafka.
Добавлен менеджер для управления вводом Kafka с помощью флагов в etcd.
В сообщение Kafka consumer добавлено название коннектора.
Добавлены метрики для обработчика REST.
Для tdg_service_user добавлена возможность вызова функции box.info().
Добавлена поддержка алгоритма сжатия zlib для полей типов данных.
Исправленные ошибки
Исправлен запуск задач перед бутстрапом vshard.
Исправлена обработка сложных нулевых типов в сервисах.
Исправлена визуальная ошибка в EditDataActionForm.
Исправлена обработка параметра lifetime_hours=0.
Cartridge обновлен до версии 2.8.1.
Добавлены аргументы first_n_on_storage и after функций delete и update.
Добавлена возможность чтения данных из Kafka в простом (plain) формате.
Добавлена возможность повтора попытки загрузки первых N объектов из ремонтной очереди.
Улучшена валидация имен функций.
Исправлена потеря обнуляемых полей типа «массив» в возвращаемых типах сервисов.
Исправлено присваивание значения null через GraphQL.
Обновления
SDK обновлен до версии 2.11.0-0-r563.
Cartridge обновлен до версии 2.8.0.
metrics обновлен до версии 1.0.0.
kafka обновлен до версии 1.6.6.
Новые возможности
icu-date заменен на модуль datetime во внутренних механизмах.
Примечание
Поведение модулей datetime и timezone могло измениться в некоторых
редких случаях. В рамках тестирования такие изменения не выявлены.
LuaJIT переведен в режим GC64.
Добавлена функция repository.update_batch.
Добавлена функция repository.call_on_storage_batch.
Добавлен экспериментальный режим построения индексов в фоне. Включается опцией background_index_build.
Модуль clock добавлен в sandbox.
Добавлена возможность установки ключа (key) для отправки сообщений в kafka.
Watchdog выключен по умолчанию. Вместо него используется механизм fiber.slice.
Для HARD_LIMITS_SCANNED установлено значение unlimited. Вместо него используется механизм fiber.slice.
Исправленные ошибки
Запрещены union-типы с одним полем.
Удалены некорректные предупреждения в веб-интерфейсе при выполнении некоторых
GraphQL-запросов.
Исправлена ошибка при передаче аргументов сервисов через REST API.
Исправлена ошибка при изменении union-типа на другой тип.
Исправлено некорректное сообщение об ошибке при валидации объединений (union).
Спейсы в хранилище vinyl теперь создаются только для типов со стратегией удаления
cold_storage.
Исправлена ошибка при открытии вкладки Model до бутстрапа кластера.
Исправлен запуск задач до полного завершения применения конфигурации.
Исправлена ошибка: игнорирование изменений функций по умолчанию, используемых в модели,
при загрузке конфигурации.
Исправлена ошибка, связанная с контекстом запроса Kafka.
Обновления
Cartridge обновлен до сборки (5c30d1cc).
expirationd обновлен до версии 1.4.0.
metrics обновлен до версии 0.17.0.
avro-schema обновлен до версии 3.1.0.
smtp обновлен до версии 0.0.7.
SDK обновлен до версии 2.10.6-0-r549.
Новые возможности
Добавлена поддержка aarch64 в Docker-сборки.
Добавлена проверка двойной индексации полей.
Изменено поведение кнопки Submit в компонентах Model и KeepVersionModel.
Добавлена проверка на положительность значения параметра jobs.max_jobs_in_parallel.
Исправленные ошибки
Исправлена ошибка при добавлении полей обнуляемых логических типов.
Исправлено возможное зависание во время локальных RPC-вызовов.
Исправлено падение файбера, отвечающего за запуск работ на роли Storage.
Обновлен Cartridge.
undici обновлен с версии 5.8.2 до 5.19.1.
SDK обновлен до версии 2.10.5-0-r543.
Добавлена возможность получить count для типов используя REST и GraphQL API.
Исправлена проблема связанная с тем, что время старта задачи могло быть позднее времени завершения.
SDK обновлен до версии 2.10.4-0-r538.
Исправлена проблема с обновлением записей при использовании массивов записей.
Добавлена возможность поместить набор объектов используя REST.
SDK обновлен до версии 2.10.4-0-r532.
Обновлен и улучшен модуль graphiql в WebUI.
Добавлена отдача контекста (yield) в функции cleanup журнала аудита и
обычного журнала.
Обновления
SDK обновлен до версии 2.10.4-0-r518.
Cartridge обновлен до сборки (f4258ae2).
metrics обновлен до версии 0.15.1.
kafka обновлен до версии 1.6.2.
Новые возможности
Добавлена возможность указывать в конфигурации аргументы,
которые будут переданы в функцию задачи планировщика.
Добавлена возможность запускать задачи на конкретных экземплярах Runner,
которые помечены в конфигурации метками.
Улучшены компоненты редактора:
Полнотекстовый поиск на страницах Model и Code.
Отображение номеров строк на страницах Model и Test.
Сохранение состояния страниц GraphQL и Test при переходах и обновлении страниц.
Имя токена теперь отображается в журнале аудита.
Обновления
Cartridge обновлен до версии 2.7.6.
metrics обновлен до версии 0.15.0.
SDK обновлен до версии 2.10.2-0-gf4228cb7d-r502.
Исправленные ошибки
Исправлена маршрутизация запросов при использовании пагинации.
Исправлено некорректное предупреждение в коннекторе Kafka.
Исправлено присвоение для вложенных записей в repository.update.
Новые возможности
Добавлен логический тип Timestamp.
Добавлено значение 0 («неограниченно») для keep_version_count.
Добавлена поддержка параметра skip_result в repository.put и repository.put_batch.
Добавлена функция sandbox tonumber64.
Добавлена возможность задавать правила сопоставления (collations) для отдельных частей индекса.
Журнал аудита теперь работает на основе модуля audit из Tarantool 2.10.
Исправленные ошибки
Добавлена валидация для обнуляемых полей в repository.update.
Убрана поддержка параметра first в repository.delete.
Исправлена маршрутизация запросов при использовании пагинации.
Исправлена некорректная валидация значений полей.
Новые возможности
Добавлена страница настроек LDAP.
Tarantool flightrec включен по умолчанию.
Реализована возможность включать компрессию для полей кортежа.
Добавлена поддержка заголовков Kafka во входящем коннекторе.
В модуль datetime среды sandbox добавлены новые функции модуля Tarantool datetime.
Исправленные ошибки
Исправлен ряд ошибок фронтенда.
Исправлено некорректное предупреждение в коннекторе Kafka.
Исправлено некорректное сообщение об ошибке GraphQL в журнале.
Файловый коннектор теперь ожидает доступности хотя бы одного экземпляра с ролью runner.
Исправлено присвоение для вложенных записей в repository.update.
Новые возможности
Добавлен столбец Config file name в таблицу Configuration Files.
Доступен Docker-образ с включенным режимом разработки.
Исправлена фильтрация по неиндексированным полям логического типа –
добавлено приведение полей к нативному виду.
Исправленные ошибки
Значения метрик Kafka типа boolean заменены на числовые.
Переработана фильтрация журнала и журнала аудита.
Добавлена обработка ошибок в repository.put_batch.
Критические изменения
Теперь для журнала отладки Kafka по умолчанию настроен уровень детализации all.
Поле плана запроса в GraphQL изменено на _query_plan (одно нижнее подчеркивание)
для соответствия спецификации GraphQL.
Из Kafka-коннектора и файлового коннектора удалены все строковые метрики.
Новые возможности
Добавлен флаг skip_result для интерфейсов update и delete (iproto, REST, graphql, repository).
В окно Kafka-коннектора добавлены флажки журнала событий (logger).
Теперь в формах создания и редактирования пользователя/токена можно фильтровать
список ролей по тенантам.
Добавлена настройка GraphQL для проверки консьюмеров Kafka (config.kafka_check_input).
В REST API добавлен параметр indexed_by, позволяющий выбирать индекс для сканирования.
Теперь можно передавать параметры для LDAP-соединений.
В окно конфигурации Kafka добавлена кнопка «Test Connection».
Добавлена возможность загружать в конфигурацию самостоятельно определенные роли.
В пространство sandbox добавлены функции table.make_map и table.make_array.
К метрикам добавлена гистограмма просканированных и возвращенных кортежей.
Исправленные ошибки
Жесткие лимиты (hard limits): значение returned по умолчанию больше не равняется значению scanned.
В окне создания пользователя значение поля tenant по умолчанию теперь «Default».
В журнале событий (logger) Kafka больше нет режима отключения вывода.
Вместе с сообщением Kafka в обработчик теперь передаются параметры topic, key, offset и partition.
Теперь LDAP-пользователи, для которых указаны несколько групп, имеют доступ
ко всем ролям, связанных с этими группами.
Доработана проверка значений поля «Expires in» в окне создания пользователя.
Исправлена ошибка «Cannot perform action with bucket» при вызове repository.put_batch.
Исправлена ошибка, которая появлялась, если среди аргументов сервис-функции были
enum-значения в кодировке utf-8.
Теперь при неполадках с Kafka-коннектором показывается сообщение.
Исправлена ошибка, возникавшая при попытке доступа LDAP-пользователя к GraphQL API.
Удаление профиля доступа, который используется в роли, теперь не допускается.
Новые возможности
Добавлены метрики IProto API.
В окне «Edit tenant» теперь отображаются сообщения об ошибках.
Теперь с LDAP можно использовать UPN без учета регистра.
В конфигурации Kafka-коннекторов появилась настройка enable_debug.
Теперь для GraphQL можно указывать параметры read, balance, mode.
Появилась возможность отправлять запросы к данным с помощью директивы @options.
Плагин auth теперь позволяет возвращать устанавливаемые пользователем заголовки и коды статуса.
Добавлены метрики для Kafka-коннектора.
Добавлены новые метрики для файлового коннектора.
Теперь можно настраивать логирование для Kafka-коннекторов с помощью
параметра logger. Он принимает следующие значения: stderr, tdg, disable.
Теперь можно очистить спейсы определенного типа, передав имя этого типа в API maintenance.clear_data.
Завершение работы роли коннектора теперь происходит мягко (graceful shutdown).
Исправленные ошибки
Доработано окно «Compare configuration».
Стал удобнее формат метрик для REST API (/data).
Отключено автозаполнение в форме редактирования ролей.
Теперь сообщение об ошибке исчезает из окна удаления тенанта, когда ошибка исправлена.
Из веб-интерфейса удален параметр Kafka-коннектора ssl.key.password.
Исправлена проблема, из-за которой задача могла зависнуть, если некоторое время был недоступен экземпляр runner.
Новые возможности
Возможность настраивать время ожидания для функций map_reduce и call_on_storage.
Статистика времени жизни бизнес-объектов добавлена к экспортируемым метрикам.
Добавлена опция use_active_directory для LDAP.
Добавлена опция organizational_units для LDAP.
Исправленные ошибки
Кортежи с истекшим сроком жизни теперь не возвращаются при вызове.
Исправлена обработка пустых фильтров в запросах.
Исправлена ошибка, которая могла приводить к блокировке в нескольких подсистемах TDG.
Исправлено несколько ошибок, связанных с задачами и отложенными работами.
Исправлено присваивание массивов при обновлении данных.
Исправлены ошибки, связанные с подсистемой для работы с LDAP.
Авторизация через cookie-файлы при подключении к кластеру больше не допускается.
Тип null в запросах GraphQL больше не допускается.
Новые возможности
Добавлена поддержка ILIKE, т.е. LIKE без учета регистра.
LIKE и ILIKE разрешены только для строк и в явном виде запрещены для индексов.
При трассировке теперь сохраняется иерархия структуры фрагментов span.
Добавлены метрики для интерфейса управления данными REST.
Добавлен интерфейс GraphQL, позволяющий блокировать секции конфигурации и предотвращать их удаление.
API GraphQL model и expiration заменены на общий API data_type.
Добавлен интерфейс GraphQL для настройки метрик.
Исправленные ошибки
Исправлены некоторые ошибки мультитенантности.
Обратная итерация без курсора теперь запрещена.
В API model больше не допускается использовать поле namespace.
Новые возможности
При обновлении объектов теперь проверяются поля типа enum.
Добавлена проверка input_processor.storage.type.
Появилась возможность добавлять несколько входов Kafka.
Вместо файбера TDG time_delta теперь нужно использовать параметр Cartridge issues_limits.
Добавлена проверка, являются ли несуществующие типы данных элементами
обнуляемого массива и используются ли они в качестве аргументов/возвращаемых
значений.
Исправленные ошибки
Исправлена обработка сценария, при котором в секции expiration указан тип, не указанный в секции types.
Обнуляемые элементы массивов теперь обрабатываются корректно.
Составные индексы, заданные по двум и более полям с логическими типами,
теперь работают корректно.
Стало невозможно назначить разным коннекторам одинаковые имена в конфигурации.
Выпуск первой публичной версии 2.1.0.
Архитектура
В этой главе описывается архитектура Tarantool Data Grid.
Основные архитектурные компоненты TDG изображены на схеме ниже.

Как видно из схемы, различные аспекты работы TDG разделены по
соответствующим кластерным ролям: Storage, Connector, Runner и
Core. Каждый экземпляр (узел) в кластере может иметь одну или более ролей.
Подробнее о кластерных ролях рассказывается в разделе Кластерные роли.
Доступ к данным: GraphQL и REST API
Для доступа к данным TDG используются два основных способа:
GraphQL и REST API.
Оба способа поддерживают запросы с использованием индексов
(первичных, вторичных и составных), операторы сравнения, множественные условия и
другие возможности выборки данных.
Точки доступа создаются автоматически на основе модели данных и доступных
сервисов. Эти сервисы также можно вызывать через
GraphQL и REST API.
Исполнение бизнес-логики: Lua
TDG предоставляет возможность хранения и исполнения пользовательской
бизнес-логики, например, валидации или преобразования данных.
Для добавления необходимой бизнес-логики нужно реализовать её в виде функций
на языке Lua и загрузить их в TDG.
Загруженные функции можно использовать несколькими способами:
Вызывать извне. Для этого нужно добавить их в конфигурацию доступных
сервисов.
Такие сервисы доступны для вызова через GraphQL, REST API или iproto
(бинарный протокол Tarantool).
Привязать к коннектору. В этом случае функции будут вызываться при каждом
взаимодействии через этот коннектор, например, при поступлении нового объекта.
Выполнять по расписанию. Для этого в TDG есть планировщик задач, который
позволяет настроить автоматическое выполнение пользовательской бизнес-логики.
Взаимодействие с внешними системами
Для обмена данными с внешними системами в TDG используются коннекторы.
Коннекторы бывают двух типов: входящие (input) для получения данных извне и
исходящие (output) для отправки данных из TDG.
Коннекторы позволяют обмениваться данными с такими источниками как:
Администрирование и безопасность
TDG предоставляет инструменты для управления различными техническими
функциями, в том числе:
Для управления конфигурацией TDG доступны два способа:
Для мониторинга и расследования инцидентов TDG предоставляет
метрики кластера в формате Prometheus. Метрики
доступны для получения через REST API и визуализации в Grafana.
Встроенные инструменты безопасности TDG позволяют настроить доступ
к различным функциям для пользователей и внешних систем. Для этого используется
ролевая модель доступа. Роли могут
быть приписаны как к профилям (для настройки
доступа пользователей), так и к токенам приложений
– средству авторизации приложений для взаимодействия с TDG. Для
расследования инцидентов безопасности доступен журнал аудита.
Кластерные роли
Экземпляры TDG в кластере выполняют те или иные функции в соответствии
с назначенными им кластерными ролями. Каждый экземпляр может иметь одну или
несколько ролей.
В TDG существует четыре основных кластерных роли:
Core: настройка и администрирование.
Storage: проверка и хранение данных.
Runner: исполнение бизнес-логики с помощью кода на Lua.
Connector: обмен данными с внешними системами.
Еще одна кластерная роль, failover-coordinator, позволяет включать
режим восстановления после сбоев с сохранением состояния (stateful failover).
Подробности можно найти в
документации Tarantool Cartridge.
Кластерные роли назначаются наборам реплик (replica set). Каждый экземпляр получает
роли того набора реплик, в который он входит. В каждом наборе реплик все экземпляры
взаимозаменяемы: на них хранится одно и то же состояние. Таким образом обеспечивается
резервирование и устойчивость к сбоям.

Роль Core
Роль core используется для выполнения собственных функций TDG.
Экземпляры с этой ролью обеспечивают управление моделью данных, сервисами, настройками
безопасности и доступа и другими функциями. На этих экземплярах хранится внутренняя
информация TDG и не хранятся пользовательские данные.
В кластере может быть только один набор реплик с ролью core.
Роль Storage
Роль storage используется для хранения пользовательских данных. На экземплярах
с этой ролью создаются спейсы
Tarantool в соответствии с моделью данных.
Объединение экземпляров storage в наборы реплик обеспечивает шардирование
и репликацию данных: каждый набор реплик хранит своё подмножество данных (shard),
и это подмножество реплицируется на все экземпляры набора реплик.
Количество наборов реплик Storage определяется объемом хранимых данных.
Роль Runner
Роль runner используется для выполнения пользовательской
бизнес-логики. На этих экземплярах с помощью
встроенного в Tarantool Lua-интерпретатора выполняются загруженные в TDG
пользовательские скрипты: сервисы, задачи, обработчики входящих и исходящих данных.
Экземпляры runner не хранят состояние и используются только для исполнения кода.
Таким образом, они все эквивалентны, и объединение в наборы реплик не влияет на их
функциональность.
Роль Connector
Роль connector используется для сетевого взаимодействия с внешними системами.
На экземплярах с этой ролью создаются адреса (endpoints) для обращения к кластеру
через GraphQL и REST API, а также коннекторы для подключения
по различным протоколам: HTTP (JSON или SOAP), Apache Kafka или iproto.
Экземпляры connector не хранят состояние и используются только для внешних подключений.
Таким образом, они все эквивалентны, и объединение в наборы реплик не влияет на их
функциональность.
Руководство администратора
В этом документе объясняется, как администратору работать с системой Tarantool Data Grid (TDG).
Развертывание
В этой главе описаны способы, которыми можно развернуть TDG для
разработки и тестирования (development environment).
Для получения помощи в развертывании кластера TDG для промышленной
эксплуатации (production environment) заполните форму для связи на
этой странице или напишите на sales@tarantool.io.
Первое развертывание с помощью Ansible
В этом руководстве описано, как впервые быстро развернуть Tarantool Data
Grid (TDG) с помощью Ansible. Здесь приведен вариант развертывания TDG на
двух виртуальных машинах с заданной конфигурацией.
Подготовка TGZ-файла для развертывания
Чтобы развернуть Tarantool Data Grid, вам понадобится RPM-файл (.rpm),
TGZ-файл (tar.gz) или Docker-образ (docker-image.tar.gz). Для
развертывания с помощью Ansible подходят только два из них: RPM- и TGZ-файл.
В этом руководстве для примера используется TGZ-файл. Его проще развернуть,
и вам не потребуется root-доступ.
Скачайте TGZ-файл последней версии в личном кабинете на сайте
tarantool.io.
Убедитесь, что ваш браузер не разархивировал скачанный файл: расширение
файла должно быть tar.gz.
Если у вас нет доступа к личному кабинету, отправьте заявку через форму на
этой странице или напишите
на sales@tarantool.io.
Настройка виртуальных машин
Чтобы развернуть TDG, вам нужно запустить две виртуальные машины с ОС Linux
(желательно CentOS 7/RHEL 7) и доступом по SSH. Если у вас уже
установлены приведенные ниже или альтернативные виртуальные машины,
то пропустите эту главу. Если нет, то следуйте
инструкции.
Установите VirtualBox для
запуска виртуальных машин и Vagrant для
автоматизации процесса конфигурации. Vagrant подготовит конфигурацию двух
виртуальных машин с дополнительными сценариями для развертывания TDG.
Примечание
Перед установкой программного обеспечения проверьте, что разработчик не накладывает ограничений
на использование — например, не ставит блокировки по IP-адресам. При возникновении проблем
воспользуйтесь услугами альтернативных провайдеров виртуальных машин.
Убедитесь, что в переменной окружения $PATH у вас есть VBoxManage.
Проверьте такой командой:
В скачанном TGZ-файле есть директория под названием deploy. Там
находится Vagrantfile, который автоматизирует создание тестовой среды
для развертывания кластера.
Откройте терминал, распакуйте архив tar.gz, перейдите в директорию
deploy и запустите виртуальные машины:
tar xzf tdg-<VERSION>.tar.gz # замените <VERSION> на версию скачанного TDG
cd tdg2/deploy
vagrant up
Эта команда поднимет две виртуальные машины с CentOS 7 и доступом по SSH без
пароля для пользователя vagrant. IP-адреса этих машин будут такие:
172.19.0.2 и 172.19.0.3.
Развертывание кластера
Подготовка
После создания виртуальных машин установите локально
Ansible
и Ansible-роль
для Tarantool Cartridge (последняя версия 1.x). Если доступна Ansible-роль версии 2.x,
можно выбрать ее, но тогда вы можете столкнуться с некоторыми трудностями.
Вот один из способов установки Ansible и Ansible-роли:
pip install ansible~=4.1.0 # версия 4.1 или более поздняя, но не 5.x
ansible-galaxy install tarantool.cartridge,1.10.0
Конфигурация
В директории deploy есть файл hosts.yml. В нем лежит конфигурация
кластера.
Откройте этот файл, чтобы указать cookie для кластера и путь до пакета:
all
vars:
# cartridge_package_path: "../../packages/tdg-ENTER-VERSION-HERE.tgz" # путь относительно расположения плейбука
# cartridge_cluster_cookie: "ENTER-SECRET-COOKIE-HERE" # замените на "secret-cookie"
Удалите #, чтобы раскомментировать эти строки, укажите версию TDG, которую
вы скачали, и путь к TGZ-файлу. Также задайте cookie для кластера. Это
должна быть уникальная строка, но для практики достаточно указать
«secret-cookie».
Вот пример:
all
vars:
cartridge_package_path: "../tdg-2.0.0-1132-g2358e716.tgz"
cartridge_cluster_cookie: "secret-cookie"
При необходимости всегда можно отредактировать этот файл, чтобы изменить
конфигурацию кластера. Вот информация о разделах файла:
all.vars — для общих переменных;
all.children.tdg_group.hosts — для параметров экземпляров (инстансов, instances);
all.children.tdg_group.children — для параметров группы экземпляров:
чтобы сгруппировать экземпляры по хосту, задайте для них параметр ansible_host;
чтобы сгруппировать экземпляры по наборам реплик, задайте для них параметры
replicaset_alias, roles, failover_priority и так далее.
Более подробную информацию о параметрах смотрите
в документации по Ansible-роли
в Tarantool Cartridge.
Развертывание
В директории deploy находятся
Ansible-плейбуки,
которые помогут вам завершить развертывание. Есть два способа развернуть TDG с помощью плейбуков:
кластер TDG с полностью сконфигурированной топологией;
кластер TDG со списком экземпляров (инстансов, instances) без заданной конфигурации.
Чтобы полностью развернуть TDG с топологией, выполните эту команду:
$ ansible-playbook -i hosts.yml playbooks/deploy.yml
Если вы хотите cами задать конфигурацию топологии кластера через веб-интерфейс,
запустите плейбук, чтобы развернуть только экземпляры:
$ ansible-playbook -i hosts.yml playbooks/deploy_without_topology.yml
Откройте http://172.19.0.2:8081 в браузере,
чтобы увидеть веб-интерфейс кластера. Вот как будет выглядеть кластер, развернутый без топологии:

Управление кластером
Конфигурация топологии кластера
Если вы развернули экземпляры (инстансы, instances) с топологией, пропустите
эту главу.
Если вы развернули экземпляры без топологии, теперь вы можете редактировать
топологию: создавать наборы реплик и задавать их параметры в веб-интерфейсе:
На вкладке Cluster находятся экземпляры без заданной конфигурации. Выберите
экземпляр core с URL 172.19.0.2:3001 и нажмите Configure.
Появится окно Configure server:

В диалоговом окне Configure server укажите значения двух параметров
набора реплик: replica set name (имя набора реплик) и role (роль).
Для экземпляра core задайте имя набора реплик «core» и выберите роль
«core». После этого нажмите Create replica set, чтобы создать набор реплик.
Для остальных экземпляров без заданной конфигурации установите параметры следующим образом:
URL экземпляра |
Имя набора реплик |
Роли |
|---|
172.19.0.2:3002 |
runner_1 |
runner, connector, failover-coordinator |
172.19.0.2:3003 |
storage_1 |
storage |
172.19.0.2:3004 |
storage_2 |
storage |
172.19.0.3:3001 |
runner_2 |
runner, connector |
Осталось настроить два экземпляра: storage_1_replica с URL
172.19.0.3:3002 и storage_2_replica с URL 172.19.0.3:3003.
Присоедините их к уже существующим наборам реплик с ролями storage:
Выберите storage_1_replica и нажмите Configure.
В диалоговом окне Configure server переключитесь на вкладку Join Replica Set.
Отметьте storage_1 и нажмите Join replica set.

Для storage_2_replica повторите те же действия, но отметьте storage_2.
После того, как вы назначите все роли, нажмите «Bootstrap vshard», чтобы
«включить наборы реплик storage. Это инициализирует модуль Tarantool
vshard. Подробнее об этом модуле можно узнать
в документации по Tarantool.

Вы создали виртуальные сегменты (virtual buckets), которые распределяются по хранилищам —
экземплярам с ролью storage.

Запуск и остановка экземпляров
Этот шаг необязателен.
В директории deploy также есть плейбуки, которые запускают или
останавливают экземпляры. Вы можете остановить и отключить все экземпляры с
помощью плейбука stop.yml:
$ ansible-playbook -i hosts.yml playbooks/stop.yml
Запустить и включить все экземпляры можно с помощью плейбука start.yml:
$ ansible-playbook -i hosts.yml playbooks/start.yml
Первое развертывание вручную
В этом руководстве описано, как впервые быстро развернуть Tarantool Data
Grid (TDG) вручную. В результате вы локально развернете кластер TDG с одним
узлом.
Примечание
Чтобы развернуть TDG, вам понадобится ОС Linux (желательно CentOS 7/RHEL 7).
Если у вас другая ОС, сначала вам нужно будет создать виртуальную машину с
ОС Linux.
Подготовка TGZ-файла для развертывания
Чтобы развернуть Tarantool Data Grid, вам понадобится RPM-файл (.rpm),
TGZ-файл (tar.gz) или Docker-образ (docker-image.tar.gz). Для
первого развертывания подойдет TGZ-файл. Его проще развернуть, и вам не
потребуется root-доступ.
Скачайте TGZ-файл последней версии в личном кабинете на сайте
tarantool.io.
Убедитесь, что ваш браузер не разархивировал скачанный файл: расширение
файла должно быть tar.gz.
Если у вас нет доступа к личному кабинету, заполните эту форму
или напишите на sales@tarantool.io.
Развертывание
Распакуйте файл tar.gz:
$ tar xzf tdg-<VERSION>.tar.gz # замените <VERSION> на версию скачанного TDG
Запустите кластер TDG с одним узлом внутри распакованного архива tar.gz:
$ ./tarantool ./init.lua --bootstrap true
Если у вас уже установлен Tarantool, убедитесь, что для развертывания TDG вы
используете ту версию Tarantool, которая была упакована в только что
скачанный архив tar.gz.
Перейдите на http://127.0.0.1:8080/, чтобы
проверить развернутый кластер TDG:

Выполнив команду tarantool ./init.lua --bootstrap true, вы развернули
настроенный экземпляр с назначенными ролями. Если вы хотите попробовать
назначить роли самостоятельно, выполните:
В результате у вас будет экземпляр TDG в исходном состоянии:

Если вы хотите заново развернуть TDG с нуля, не забудьте сначала удалить
файлы конфигурации, а также xlog- и snap-файлы, которые были созданы при
первом развертывании TDG:
Веб-интерфейс
В этой главе рассказано, как получить доступ к веб-интерфейсу TDG и
авторизоваться в системе. Кроме того, в главе описаны элементы управления и
функции, представленные в веб-интерфейсе.
В примере ниже описана ситуация, когда авторизация в системе TDG уже
включена. Подробнее о том, как включить авторизацию, вы можете узнать из
руководства по авторизации.
Вход в систему
Чтобы получить доступ к веб-интерфейсу TDG, выполните следующие шаги:
Обратитесь к администратору за данными учетной записи.
Username: имя пользователя генерируется автоматически, когда
администратор создает профиль пользователя. Примеры
имени пользователя: ui8896, gz1200.
Password: пароль генерируется автоматически, когда администратор создает профиль пользователя.
Адрес сервера TDG: администратор задает адрес сервера в формате
http://<адрес>:<порт_http> в файле конфигурации. В этом руководстве в
качестве примера используется адрес сервера http://172.19.0.2:8080.
В браузере введите адрес сервера TDG, чтобы открыть диалоговое окно авторизации.

Введите учетные данные: в поле Username – имя пользователя, а в поле Password – пароль.
Нажмите Login.
Во время авторизации система TDG проверяет правильность ваших учетных данных
и права доступа к определенным вкладкам TDG. После успешной авторизации вы
увидите интерфейс TDG с доступом только к определенным вкладкам. Набор
вкладок зависит от роли пользователя, которую
вам назначил администратор.
Если в учетных данных окажется опечатка, TDG не сможет вас
идентифицировать. В этом случае появится сообщение «Authentication failed»:

Попробуйте ввести учетные данные еще раз.
Общее описание веб-интерфейса
Интерфейс TDG состоит из двух частей:
Панель вкладок отображает список вкладок для навигации по разделам TDG.
Рабочая область отображает содержание активной вкладки.
Панель вкладок
Доступ к той или иной вкладке зависит от роли пользователя.
Например, пользователи с ролями «admin» и «supervisor» видят все вкладки,
а пользователю с ролью «user» доступен ограниченный набор.
Кнопка Collapse menu в нижней части страницы служит для переключения панели вкладок в компактный режим и обратно.
На панели расположены следующие вкладки:
Cluster |
Конфигурация и администрирование кластера. |
Configuration files |
Управление параметрами конфигурации TDG. |
Test |
Отправка тестовых запросов в формате JSON или XML (SOAP). |
GraphQL |
Отправка запросов в формате GraphQL. |
Model |
Актуальная модель данных, загруженная в систему. |
Repair Queues: Input |
Ремонтная очередь для загруженных объектов. |
Repair Queues: Output |
Ремонтная очередь для объектов, реплицированных во внешние системы. |
Repair Queues: Jobs |
Ремонтная очередь для завершенных с ошибкой задач. |
Logger |
Журнал событий. |
Audit Log |
Журнал аудита. |
Tasks |
Управление задачами. |
Data types |
Типы данных, представленные в загруженной модели данных. |
Connectors |
Создание коннекторов и управление ими. |
Settings |
Управление настройками системы. |
Doc |
Версия документации TDG на английском языке, доступная локально из
разворачиваемого пакета TDG. Таким образом, она содержит только ту
информацию, которая была опубликована до формирования пакета. Более актуальную
документацию на русском языке вы можете найти на сайте
tarantool.io. |
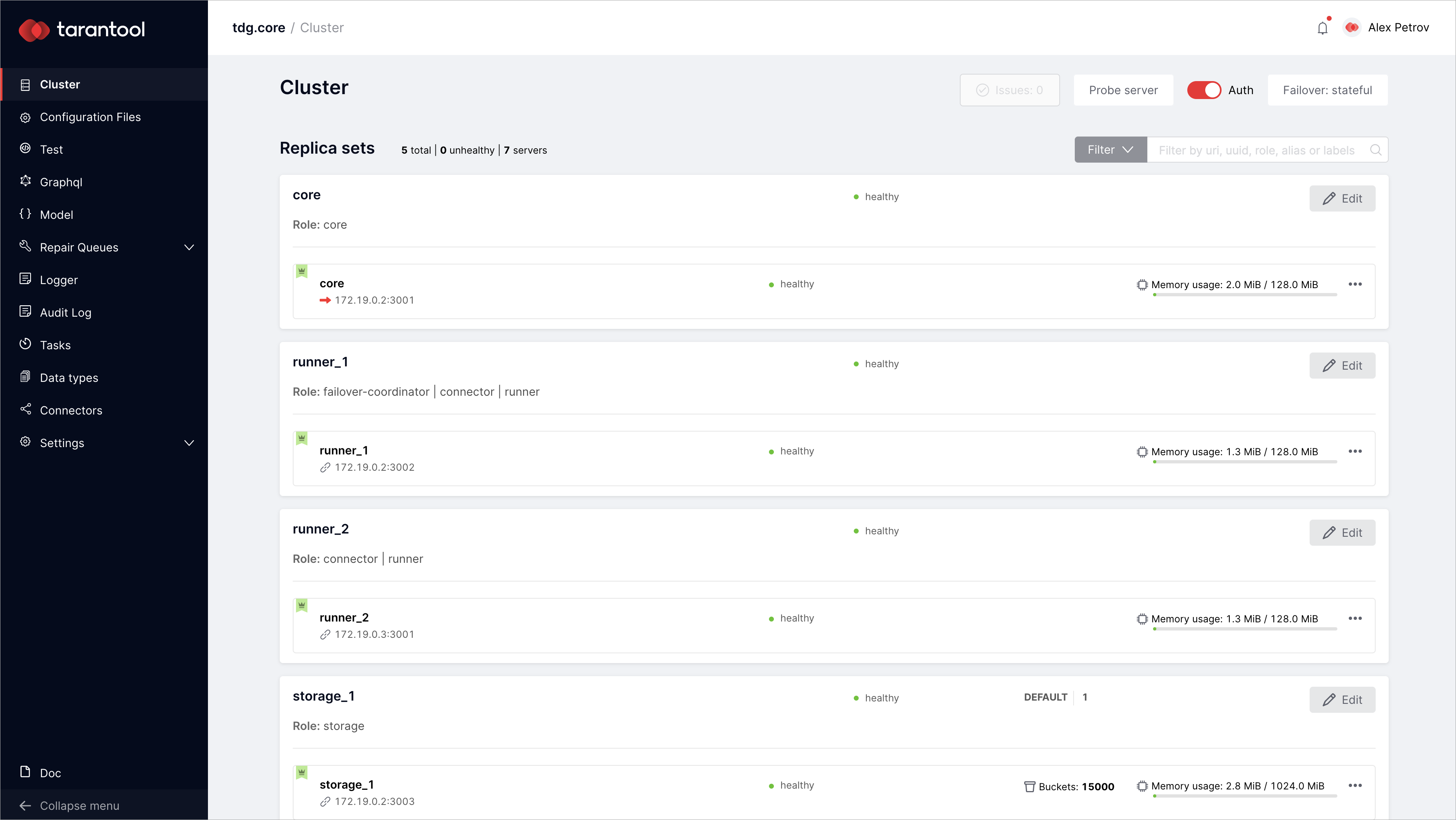
Вкладка Cluster
На вкладке Cluster отображается текущий статус кластера экземпляров TDG.
На этой вкладке вы можете администрировать кластер через веб-интерфейс.
Элементы управления можно разделить на несколько групп:

В выделенной области отображается основная статистика по наборам реплик (replica sets).
Total |
Общее количество наборов реплик в кластере. |
Unhealthy |
Количество наборов реплик в статусе «unhealthy». |
Servers |
Общее количество экземпляров TDG. |
Filter |
Выпадающее меню, позволяющее фильтровать наборы реплик по статусу или кластерной роли. |
Окно поиска |
Поле для поиска наборов реплик с возможностью фильтрации по URI, UUID, роли, алиасу или меткам. |
В виджете набора реплик отображается следующая информация:
Имя и роль |
Например, набор реплик «storage_1» с ролью «storage». |
Статус |
Статус «healthy» означает, что набор реплик функционирует нормально.
Статус «unhealthy» означает, что набор реплик недоступен или функционирует неправильно. |
Вес набора реплик и группа, к которой набор относится |
Только для наборов реплик с ролью «storage».
Например: группа (storage group) — «default», вес (replica set weight) — 1. |
Кнопка Edit |
Открывает диалоговое окно, в котором можно редактировать параметры набора реплик. |
Виджеты экземпляров |
Виджеты экземпляров, включенных в этот набор реплик. |
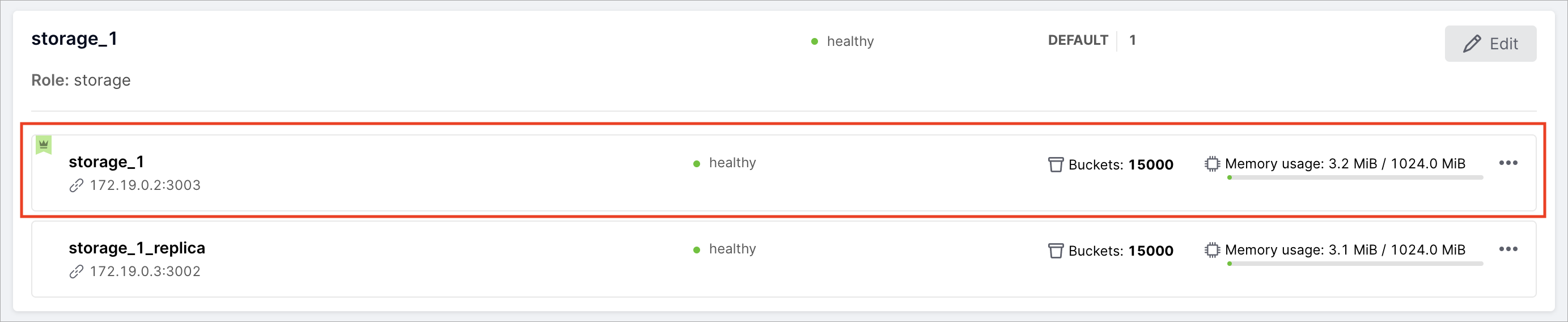
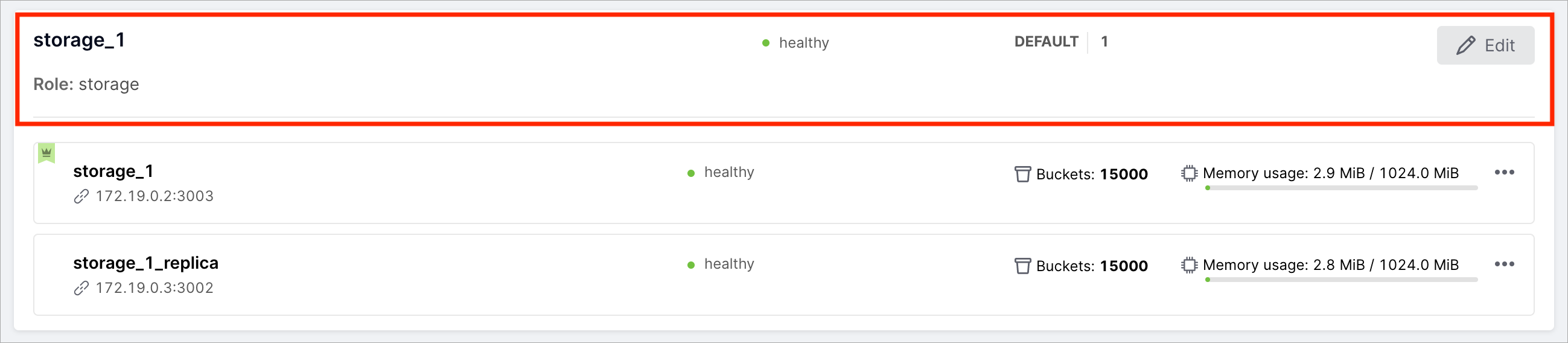
Виджет экземпляра в выделенной области содержит следующую информацию:
Имя экземпляра |
Например, «storage_1» или «storage_1_replica». |
URI |
URI для доступа по бинарному порту.
Задается параметром advertise_uri в конфигурации кластера (например, 172.19.0.2:3003). |
Статус |
Статус «healthy» означает, что экземпляр функционирует нормально.
Статус «unhealthy» означает, что экземпляр недоступен или функционирует неправильно. |
Индикатор лидера |
Показывает, является ли экземпляр лидером (leader) в наборе реплик. |
Индикатор памяти |
Фактически используемая память / лимит памяти, заданный для этого экземпляра.
Например, 3.3 MiB / 1024.0 MiB. |
Индикатор виртуальных сегментов |
Показывает количество виртуальных сегментов экземпляра (только для наборов реплик с ролью «storage»). |
Кнопка … |
Меню с набором функций: просмотр информации об экземпляре, назначение
экземпляра лидера, отключение или исключение экземпляра. |
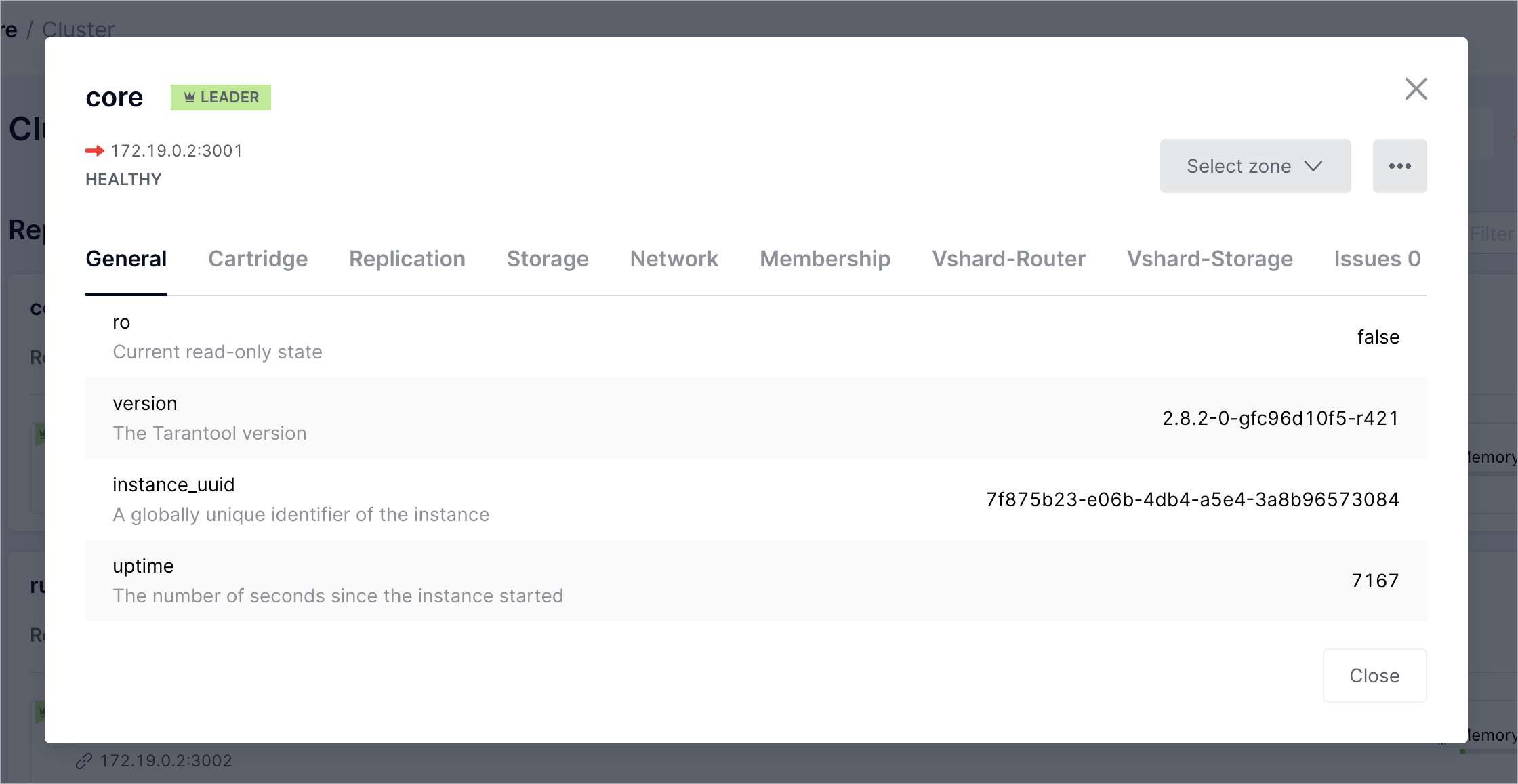
Подробную информацию о параметрах каждого экземпляра можно просмотреть в
режиме только для чтения. Для этого на вкладке Cluster рядом с нужным
экземпляром нажмите … > Server details:
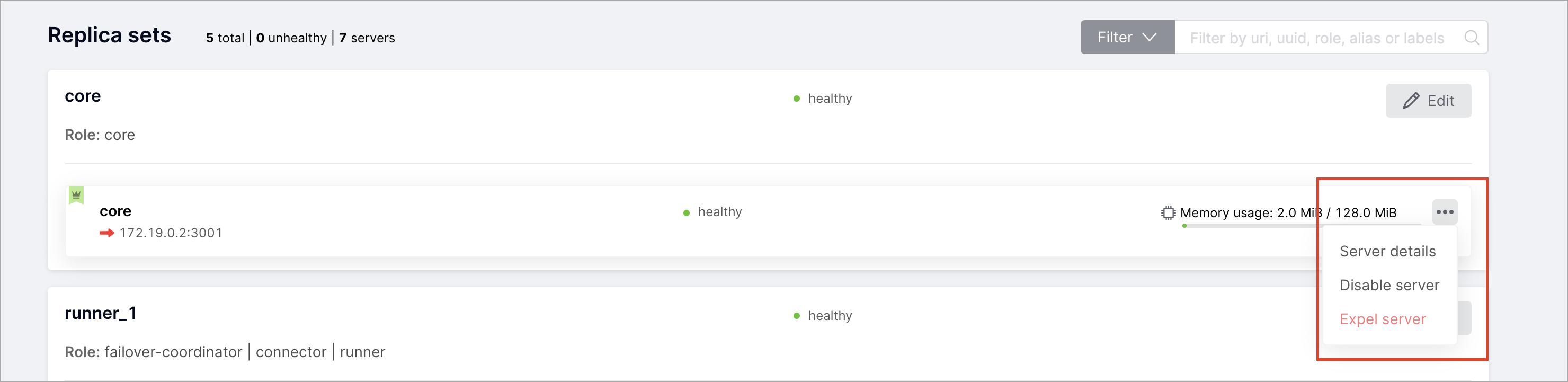
Появится окно с подробной информацией о параметрах экземпляра:
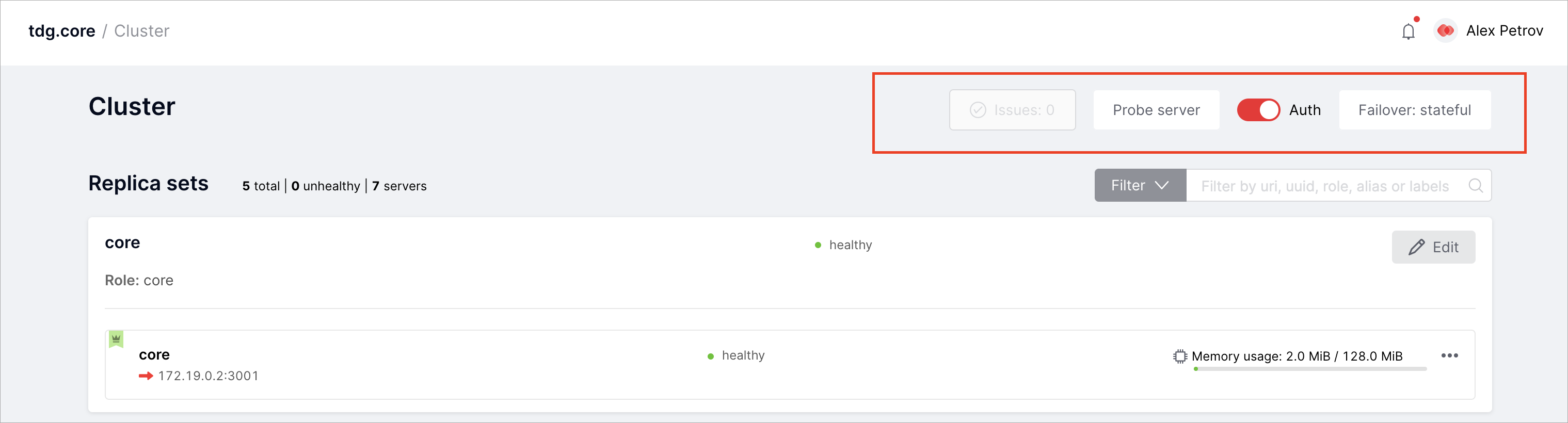
На вкладке Cluster доступны еще несколько функций:
Issues |
Просмотр истории ошибок, возникших при работе кластера |
Probe server |
Ручная проверка доступности сервера (используется при настройке кластера) |
Auth |
Включение и отключение режима обязательной авторизации |
Failover: disabled/eventual/stateful |
Переключение режима автоматического восстановления после отказа |
Вкладка Connectors
В TDG роль connector предназначена для соединения и обмена данными с внешними системами.
Для подключения доступно несколько протоколов соединения:
http – запросы в формате JSON по HTTP;
soap – запросы в формате XML (SOAP) по HTTP;
kafka – для интеграции с шиной данных Apache Kafka;
tarantool_protocol – коннектор iproto.
На вкладке Connectors отображается список всех input-коннекторов.
Здесь вы можете создавать новые коннекторы и управлять их.
Ниже описаны доступные сценарии работы с вкладкой:
Во вкладке Connectors нажмите кнопку Add connector:
Появится окно Create connector, где нужно ввести параметры коннектора:
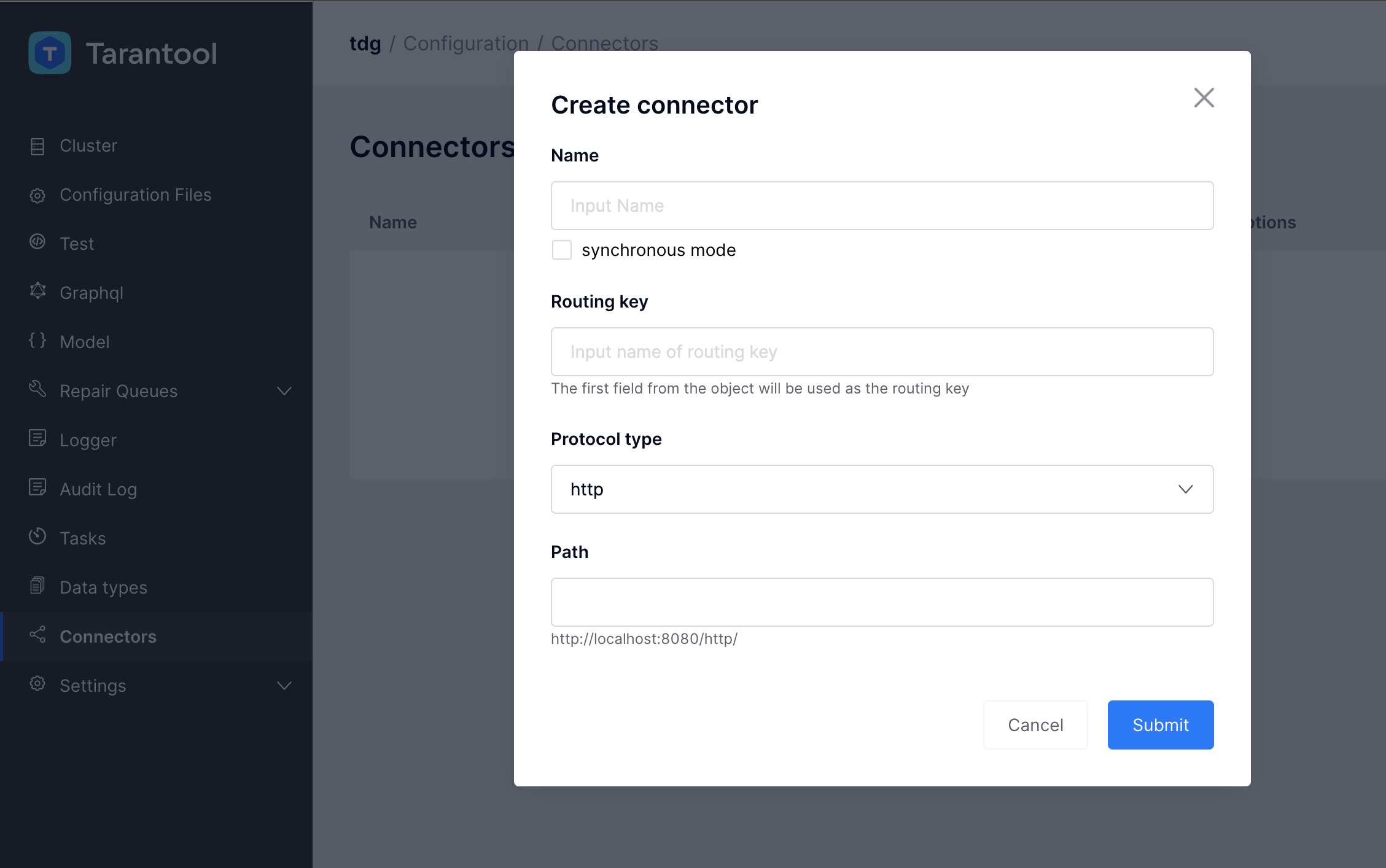
Параметры коннектора
При добавлении коннектора доступна настройка маршрутизации и input-параметров – параметров для получения
и парсинга входящих запросов.
Чтобы узнать больше об этих параметрах, обратитесь к разделу
Параметры коннекторов.
Ниже в таблице приведены поля, доступные для настройки в редакторе:
Название параметра |
Тип коннектора |
Описание |
Обязательный параметр |
|---|
Name |
Любой |
Имя коннектора, должно быть уникальным |
Да |
synchronous mode |
Любой |
Режим работы TDG в качестве producer. По умолчанию, режим асинхронный: подтверждение о доставке
сообщения отправляется сразу после того, как сообщение добавлено в очередь на отправку.
При синхронном режиме подтверждение о доставке
отправляется только после того, как сообщение было доставлено. |
Да |
Routing key |
Любой |
ключ маршрутизации |
Да |
Protocol type |
Любой |
Тип коннектора.
Доступные типы: http (по умолчанию), soap, kafka, tarantool_protocol. |
Да |
Path |
http
|
Адрес для отправки запроса в TDG |
Да |
WSDL |
soap
|
Схема WSDL, описывающая структуру входящего XML |
Да |
Success response template |
soap
|
Шаблон ответа в случае успешной обработки запроса |
Нет |
Error response template |
soap
|
Шаблон ответа в случае ошибки |
Нет |
Brokers |
kafka
|
URL-адреса брокеров сообщений |
Да |
Topics |
kafka
|
Топики в терминологии Kafka |
Да |
Group ID |
kafka
|
Идентификатор группы подписчиков |
Да |
Token name |
kafka
|
Имя токена приложения |
Нет |
Options |
kafka
|
Опции библиотеки
librdkafka |
Нет |
Print debug logs |
kafka
|
Режим отладки.
По умолчанию, отладка отключена.
При включении отладки по умолчанию используется параметр debug: "all".
Если в логах не требуются все атрибуты, установите необходимое значение
параметра debug в секции options при конфигурации. |
Нет |
Direct all non-error logs to TDG logger |
kafka
|
Запись всех логов Kafka, включая сообщения об ошибках, в логи TDG.
Соответствует параметру logger: tdg.
По умолчанию, в редакторе опция включена. |
Нет |
Пример
Создадим новый коннектор типа http:
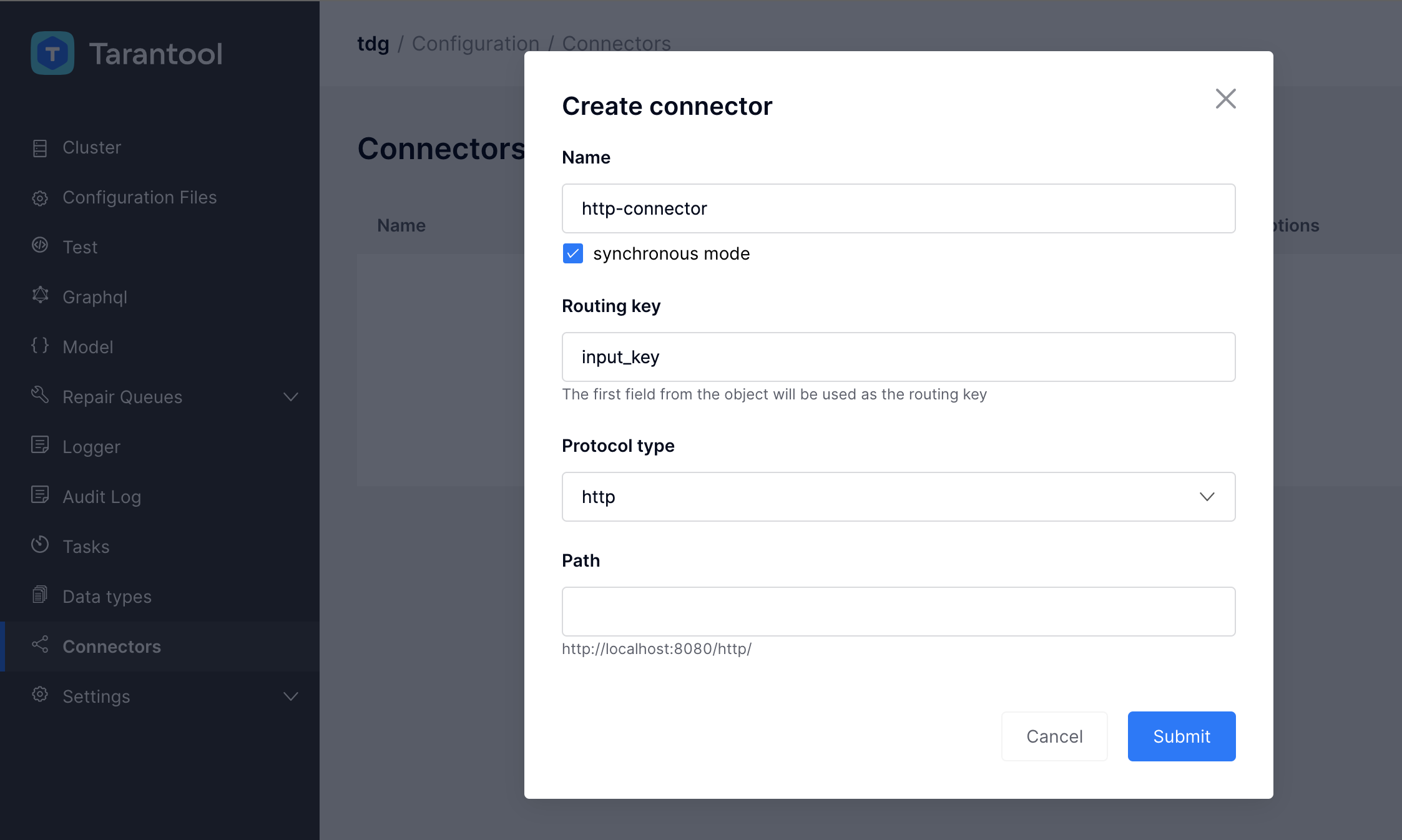
Для поля Path часть адреса определена заранее и не может быть изменена.
Предопределенный адрес – это URL, на котором запущен экземпляр TDG (например, http://localhost:8080/).
В поле можно указать только последнюю часть адреса – endpoint.
Значение по умолчанию для endpoint: http.
Когда все необходимые поля заполнены, нажмите кнопку Submit.
Теперь список коннекторов выглядит следующим образом:

Столбцы Name, Protocol type, Routing key и Options в таблице можно
сортировать по возрастанию и убыванию.
Справа от каждого коннектора в списке находятся кнопки, позволяющие отредактировать его параметры или удалить коннектор:

Доступные функции:
Редактирование коннектора |
При изменении настроек существующего коннектора доступны все параметры, кроме типа коннектора.
Данные о коннекторах в редакторе можно перезаписать и извне.
Например, если загрузить во вкладку Configuration Files файл с новыми настройками
коннектора, созданного ранее в редакторе, новая конфигурация отобразится во вкладке
Connectors после обновления страницы.
|
Удаление коннектора |
При попытке удалить коннектор появится диалоговое окно с подтверждением удаления. |
Кластерные роли
В этой главе приводятся рекомендации и инструкции по настройке кластерных ролей
на экземплярах TDG.
В TDG существует четыре основных кластерных роли:
Core: настройка и администрирование.
Storage: проверка и хранение данных.
Runner: исполнение бизнес-логики с помощью кода на Lua.
Connector: обмен данными с внешними системами.
Подробная информация о кластерных ролях приведена
в разделе Кластерные роли главы Архитектура.
Рекомендации по назначению ролей на экземплярах
Исходя из сущности ролей и механизмов их работы, можно дать следующие рекомендации
по организации кластера и назначению ролей на экземплярах:
Роль core: все экземпляры должны быть объединены в один набор реплик для
обеспечения отказоустойчивой работы ядра TDG. В кластере может быть
только один набор реплик с ролью core.
Роль storage: для обеспечения распределения (sharding) и резервирования
экземпляры должны объединяться в наборы реплик из двух и более экземпляров.
Точное число экземпляров в наборе реплик определяется требованиями бизнес-решения
к избыточности хранения данных. Для большей надёжности рекомендуется объединять
в каждом наборе реплик экземпляры из разных дата-центров. Количество наборов реплик
storage следует масштабировать горизонтально пропорционально объему данных.
Роль runner: все экземпляры runner эквивалентны и не хранят состояние,
поэтому нет необходимости объединять их в наборы реплик. Количество экземпляров
runner следует масштабировать горизонтально в зависимости от входящей нагрузки
и утилизации CPU.
Роль connector: все экземпляры connector эквивалентны и не хранят состояние,
поэтому нет необходимости объединять их в наборы реплик. Количество экземпляров
connector следует масштабировать горизонтально в зависимости от входящей нагрузки
и утилизации CPU.
Объединение ролей connector и runner: обычно имеет смысл назначать роли
connector и runner на экземпляры вместе. Таким образом минимизируется
сетевое взаимодействие при обработке входящих объектов или вызове сервисов извне.
Настройка кластерных ролей через WebUI
Для настройки кластерных ролей через веб-интерфейс TDG используются инструменты
на вкладке Cluster.
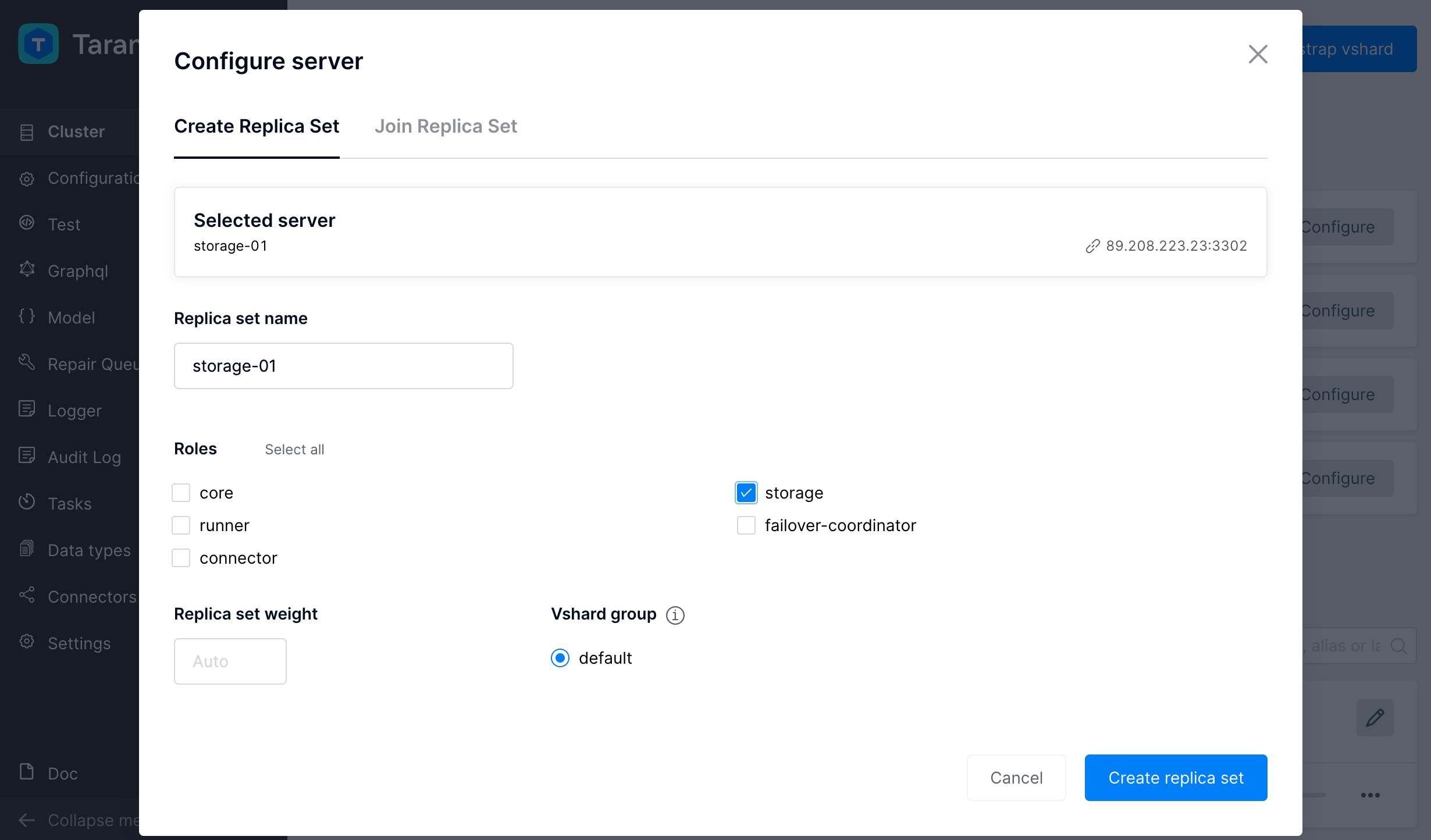
Назначение ролей новым экземплярам
Чтобы назначить роль экземпляру впервые, найдите его в списке Unconfigured Instances
и нажмите соответствующую кнопку Configure.

В открывшемся окне вы можете назначить роль одним из двух способов:
Создать новый набор реплик с нужными ролями.
Для этого введите имя нового набора реплик, выберите необходимые роли и
нажмите Create replica set.
Добавить экземпляр в существующий набор реплик.
Для этого перейдите на вкладку Join replica set, выберите один из
существующих наборов реплик с необходимыми ролями и нажмите
Join replica set.

Изменение ролей
Чтобы изменить роли набора реплик, откройте окно его редактирования (Edit replica set)
и включите или отключите роли. Эти изменения применятся ко всем экземплярам выбранного
набора реплик.

Предупреждение
При отключении роли storage на наборе реплик необходимо перераспределить
сегменты данных, которые на нём хранятся, на другие наборы реплик.
Для этого перед отключением роли storage установите набору реплик вес
(Replica set weight) равным 0 и нажмите Save.
После этого убедитесь, что в наборе реплик не осталось сегментов данных
и отключите на нём роль storage.
Настройка кластерных ролей через Ansible
Если вы разворачиваете кластер TDG с помощью Ansible,
вы можете определить наборы реплик и их роли в inventory-файле hosts.yml.
Наборы реплик и их роли определяются в inventory-файле в разделе all.children.
Для каждого набора реплик необходимо создать узел с именем replicaset_<name>,
где <name> – название, под которым набор реплик будет использоваться в кластере.
Пример создания набора реплик с именем storage_01:
all:
children:
replicaset_storage_01:
В узле набора реплик задаются два раздела:
vars – параметры набора реплик, в том числе параметр roles – список
назначенных ролей.
hosts – список узлов, входящих в набор реплик.
Пример конфигурации набора реплик с ролью storage из двух узлов:
all:
children:
replicaset_storage_01:
vars: # replica set configuration
replicaset_alias: storage-01
weight: 1
failover_priority:
- storage-01 # leader
- storage-01-r
roles:
- 'storage'
Конфигурация кластера из пяти узлов с тремя наборами реплик (два storage и
один с ролями core, runner, connector) может выглядеть следующим образом:
all:
children:
replicaset_storage_01:
vars: # replica set configuration
replicaset_alias: storage-01
weight: 1
failover_priority:
- storage-01 # leader
- storage-01-r
roles:
- 'storage'
hosts: # replica set instances
storage-01:
storage-01-r:
replicaset_storage_02:
vars: # replica set configuration
replicaset_alias: storage-02
weight: 1
failover_priority:
- storage-02 # leader
- storage-02-r
roles:
- 'storage'
hosts: # replica set instances
storage-02:
storage-02-r:
replicaset_app_01:
vars: # replica set configuration
replicaset_alias: app-01
failover_priority:
- app-01 # leader
roles:
- 'core'
- 'connector'
- 'runner'
Настройки безопасности
В этой главе рассказано, как управлять настройками политики безопасности.
Контроль доступа на основе ролей
В Tarantool Data Grid используется основанная на ролях модель доступа к
системным функциям и данным, хранящимся в системе. Администратор настраивает
права доступа к данным, используя UI или такие внешние инструменты, как
LDAP. Каждая роль имеет набор разрешений, которые определяют, что
пользователи или внешние приложения могут просматривать или изменять.
Список ролей можно найти на вкладке Settings > Roles:

Роли по умолчанию
Пользователям и внешним приложениям можно назначать роли. Эти роли позволяют
получать авторизованный доступ к определенным данным и выполнять в системе
те или иные действия. Существует три роли по умолчанию:
Эти роли имеют предопределенный набор прав. Кроме того, такие роли нельзя редактировать или удалять.
Роль |
Доступ к функциям |
Доступ к данным |
|---|
admin |
Полный доступ ко всем функциям TDG |
Доступ для чтения и записи для всех агрегатов |
supervisor |
Полный доступ в режиме «только для чтения» |
Доступ для чтения для всех агрегатов |
user |
По умолчанию: доступ к вкладке Test для отправки объектов тестирования,
а также ко вкладкам Repair Queues, Tasks и GraphQL |
— |
Создание новых ролей пользователей с помощью UI
Новую роль можно создать на основе роли по умолчанию или же ранее созданной роли.
Чтобы создать новую роль пользователя, выполните следующие шаги:
Откройте вкладку Settings > Roles и нажмите Add new role.
В диалоговом окне New role укажите следующие параметры:
Name: название новой роли.
Description: описание роли (опционально).
Roles: существующая роль, на основе которой будет создаваться новая (опционально).
В списке выберите действия, которые будут доступны для роли пользователя.
Не забудьте проверить, есть ли у роли доступ к интерфейсу. Например, если вы
собираетесь дать роли права на выполнение запросов GraphQL, отметьте Pages Access > Show GraphQL page.
Нажмите Add new role.

Создав роль пользователя, вы можете в любое время отредактировать ее или удалить.
Управление пользователями
В этой главе рассматриваются операции управления пользователями TDG:
Список пользователей находится на вкладке Settings > Users:

Создание профиля пользователя
Чтобы создать профиль пользователя TDG, выполните следующие шаги:
Откройте вкладку Settings > Users. Нажмите Add new user.
Откроется диалоговое окно создания пользователя New user:

В окне New user укажите следующие параметры:
Name: имя пользователя.
Email: электронная почта пользователя.
Password: пароль для авторизации в системе. Сгенерируйте пароль сразу,
нажав кнопку Generate, или оставьте поле пустым, чтобы система отправила
автоматически сгенерированный пароль на адрес электронной почты, указанный
в поле Email. В последнем случае необходим настроенный SMTP-сервер.
Expires in: срок действия пароля (опционально). Система проверяет, не
истек ли срок действия паролей, примерно раз в 30 минут. Учетные записи, у
которых истек срок действия пароля, блокируются.
Role: роль пользователя согласно ролевой модели доступа.
Нажмите Submit.
Созданного пользователя вы увидите в общем списке.
Теперь можно отредактировать его профиль: изменить настройки, сбросить пароль, а также
заблокировать или удалить профиль.
Редактирование профиля пользователя
Чтобы отредактировать профиль пользователя, откройте вкладку Settings > Users и нажмите на значок карандаша:

Измените настройки профиля и нажмите Submit.
Удаление профиля пользователя
Администратор может удалить из списка любой профиль пользователя:
В колонке Actions найдите профиль нужного пользователя. В меню действий
... выберите Delete user.
В диалоговом окне подтвердите удаление пользователя, нажав OK.
Пользователь будет удален из общего списка автоматически.
Созданный профиль будет сразу активирован в системе. В списке пользователей
напротив этого профиля в колонке Status появится статус «ACTIVE».
Администратор может изменить этот статус и заблокировать пользователя:
В колонке Actions в меню действий ... выберите Block:

В диалоговом окне опишите причину блокировки пользователя и нажмите Block:

После этого статус пользователя изменится на «BLOCKED». Чтобы
разблокировать пользователя, в меню действий ... выберите Unblock.
Сброс пароля
Администратор может сбросить пароль любого из пользователей:
В колонке Actions найдите профиль пользователя, который вы хотите
отредактировать, и в меню действий ... выберите Reset password.
В диалоговом окне подтвердите сброс пароля, нажав OK.
После этого пользователю придет временный пароль на электронную почту, указанную в его профиле.
Примечание: чтобы отправлять временные пароли, настройте SMTP-сервер.
Чтобы организовать отправку временных паролей, выполните следующие шаги:
Разверните и запустите SMTP-сервер.
В файле конфигурации TDG config.yml пропишите следующие настройки:
connector:
output:
- name: to_smtp
type: smtp
url: <URL SMTP-сервера>
from: <адрес отправителя>
timeout: <время ожидания в секундах>
account_manager:
only_one_time_passwords: true
output:
name: to_smtp
Пример:
output:
- name: to_smtp
type: smtp
url: localhost:2525
from: tdg@example.com
timeout: 5
Загрузите измененную конфигурацию в систему.
Профили пользователей можно экспортировать из системы и импортировать в нее в формате JSON:

Экспорт профилей пользователей
На вкладке Settings > Users нажмите Export. Система сформирует и
экспортирует файл JSON, содержащий массив с профилями всех текущих
пользователей.
Пример профиля пользователя:
[
{
"expires_in":2592000,
"login":"ui8896",
"email":"test@mail.ru",
"created_at":1626360261875418600,
"state_reason":"test@mail.ru state is changed to active: recover from disabled",
"failed_login_attempts":1,
"uid":"bd2e91f3-ce0f-4ff1-8aae-bc4212f99c7d",
"role":"admin",
"state":"active"
,"username":"User1",
"last_login":1628058891852268000,
"last_password_update_time":null
},
{
...
}
]
Импорт профилей пользователей
Для импорта необходим файл в формате JSON с профилями пользователей. Этот
файл можно подготовить вручную или же сформировать его и экспортировать, как
описано выше. В файле JSON нужно задать все поля, указанные выше в примере
профиля пользователя, за исключением state_reason, last_login,
last_password_update_time и password.
Пароль можно задать несколькими способами:
Вручную. В файле JSON укажите для каждого пользователя пароль в поле password.
Пароль должен соответствовать требованиям политики в отношении паролей.
В диалоговом окне импорта профилей пользователей не отмечайте никакие параметры.
Пароли будут загружены из файла JSON как есть.
Сгенерировать автоматически. Задайте null в поле password или вообще не указывайте это поле в файле JSON.
В диалоговом окне импорта профилей пользователей выберите Generate passwords.
Пароль будет создан автоматически в соответствии с требованиями текущей политики в отношении паролей.
Отправить на адрес электронной почты. Для этого необходим SMTP-сервер.
В диалоговом окне Import users from JSON file выберите Send password via users email.
Нужно выбрать единственный вариант создания паролей для всех импортируемых профилей пользователей.
Чтобы импортировать профили пользователей, выполните следующие шаги:
На вкладке Settings > Users нажмите Import.
Если необходимо, в диалоговом окне импорта профилей пользователей отметьте способ создания паролей, который вы выбрали.

Загрузите файл JSON с профилями пользователей и нажмите Apply.
Новые профили пользователей будут добавлены в таблицу Users.
В веб-интерфейсе вы увидите сообщение о результатах импорта, где будут указаны данные профилей.
Вы можете сохранить импортированные данные, в том числе сгенерированные пароли, нажав кнопку Download.
Данные будут сохранены в файле .csv.
Авторизацию пользователей в системе регулирует политика TDG в отношении
паролей. Она применима в равной степени как к паролям, которые пользователи
задают вручную, так и к автоматически сгенерированным паролям. Управлять
политикой в отношении паролей можно на вкладке Settings > Password Policy:

Согласно настройкам по умолчанию пароль должен содержать буквы в нижнем и
верхнем регистре, а также цифры от 0 до 9. Вы можете изменить настройки по
умолчанию и сохранить их, нажав Save.
Токены приложений
Токен приложений – уникальный идентификатор, который генерируется в кластере TDG.
Такой токен служит средством авторизации внешних приложений для взаимодействия с данными и функциями TDG.
Администратор создает токен, назначает для него нужные права доступа к объектам
TDG и передает его разработчикам внешней системы.
Доступны два способа управления токенами приложений – в веб-интерфейсе TDG и
через GraphQL API.
Токен приложений также используется для авторизации HTTP-запросов и авторизации коннекторов.
Подробнее об этих процедурах рассказывается в разделе Авторизация Руководства разработчика.
Управление токенами в веб-интерфейсе
Добавление токена
Сгенерировать токен через веб-интерфейс можно на вкладке Settings > Tokens:
Нажмите кнопку Add token.
В диалоговом окне Create token укажите следующие параметры:
Name: имя (ключ) токена, по которому он будет идентифицироваться в системе;
Expires in: срок действия токена (опционально).
Чтобы создать токен без срока действия, оставьте поле пустым;
Role: роль токена. Аналогична роли пользователя в ролевой модели доступа;

Нажмите кнопку Submit, чтобы сгенерировать токен. В веб-интерфейсе появится сообщение,
где токен будет представлен в явном виде:

Важно
Сохраните созданный токен в надежном месте.
В целях безопасности токен в явном виде показывается только один раз, при его генерации.
Сообщение с токеном исчезнет, как только вы покинете данную страницу или создадите новый токен.
Имя созданного токена редактировать невозможно. Однако вы можете изменять роль токена и его срок
действия.
Как и профили пользователей, токены приложений в веб-интерфейсе можно удалять, блокировать,
экспортировать и импортировать.
Удаление токена
Администратор может удалить из списка любой токен приложения. Для этого:
Найдите нужный токен в колонке Actions. В меню действий
... выберите пункт Delete token.
В диалоговом окне подтвердите удаление токена, нажав кнопку OK.
Токен будет удален из общего списка автоматически.
Блокировка токена
Созданный токен будет сразу активирован в системе, для него в колонке Status появится статус ACTIVE.
Администратор может изменить этот статус и заблокировать токен:
В колонке Actions в меню действий ... выберите Block.
В диалоговом окне опишите причину блокировки токена и нажмите Block.
После этого статус токена изменится на BLOCKED.
Чтобы разблокировать токен, в меню действий ... выберите Unblock и в диалоговом окне опишите
причину разблокировки токена.
Кроме того, токен будет заблокирован автоматически (просрочен), если пользователь будет неактивен в системе дольше
определенного времени. Задать необходимое время (не более 45 дней) можно в параметре ban_inactive_more_seconds
в секции account_manager файла конфигурации.
Разблокировать просроченный токен можно, если задать для него новое значение параметра Expires in.
Экспорт и импорт токенов
Токены приложений можно экспортировать из системы и импортировать в нее в формате JSON.
Для этого на вкладке Settings > Tokens нажмите кнопку Import или Export.
Действия выполняются аналогично экспорту и импорту профилей пользователей.
Пример JSON-файла с токенами:
[
{
"expires_in": 900,
"token": null,
"state_reason": "App01 state is changed to blocked",
"uid": "jdsDAY3Y-wcwYBkdS7Kma2wyEYLwIv_qjQvxeUsFeyh0txDuqgHWmIMzLFCWp8S3GTgbxRQw7dq7Rz-k2Tddyg",
"role": "user",
"state": "blocked",
"last_login": null,
"name": "Token1",
"created_at": 1686839870157890300
},
{
"expires_in": 0,
"token": null,
"state_reason": null,
"uid": "pLQIQDvHvGsymbfI1jt37BUhYLuZOzWNSB8kbDoWDx4mwYLDEdJFz-pUwK7mASyojYl-O83t1Iqtqr4HUGyKbQ",
"role": "user",
"state": "active",
"last_login": null,
"name": "App02",
"created_at": 1686927801987245300
}
]
Управление токенами через GraphQL API
Токенами приложений в TDG можно управлять с помощью GraphQL-запросов на изменение настроек, используя
протокол HTTP.
HTTP-запросы при этом должны иметь заголовок схемы admin и соответствующий заголовок
для авторизации.
Подробнее о таких запросах рассказывается в разделе Управление настройками через GraphQL API.
Пример выполнения curl-запроса на изменение настроек можно найти на странице
Авторизация Руководства разработчика.
Используя GraphQL API, можно выполнять следующие действия:
Все операции, относящиеся к токенам, выполняются внутри блока token {}.
Полный список параметров запросов и их описание приведены на странице Основные настройки TDG.
Чтение информации о токенах
Чтобы вывести список всех токенов приложения, используйте запрос list (query):
query {
token {
list {
name
}
}
}
Чтобы вывести информацию о токене по его имени, используйте запрос get (query):
query {
token {
get(name: "Token1")
{
name
expires_in
created_at
uid
role
state
unblocked_at
state_reason
last_login
}
}
}
Добавление токена
Для создания токена приложения используйте запрос add (mutation):
mutation {
token {
add(
name: "App01"
expires_in: 0
role: "user"
) {
name
token
created_at
}
}
}
При успешной генерации токена система возвращает ответ с указанием токена в явном виде в параметре token:
{
"data": {
"token": {
"add": {
"name": "App01",
"token": "b773dbec-b86b-41aa-5541-887ba722c62e",
"created_at": 1567758613669985599
}
}
}
}
Важно
Сохраните созданный токен в надежном месте.
В целях безопасности токен в явном виде показывается только один раз, при его генерации.
При повторных запросах существующего токена система возвращает его только в виде хеша.
При попытке повторно создать токен с уже существующим именем система возвращает сообщение об ошибке.
Редактирование токена
Изменить можно только срок действия токена и его роль.
Для редактирования токена приложения используйте запрос update (mutation):
mutation {
token {
update(
name: "App01"
expires_in: 25000
role: "admin"
) {
name
expires_in
role
}
}
}
Блокировка токена
Для изменения статуса токена приложения используйте запрос set_state (mutation):
mutation {
token {
set_state(
name: "App01"
state: "blocked"
) {
name
role
state
}
}
}
Кроме того, токен будет заблокирован автоматически (просрочен), если пользователь будет неактивен в системе дольше
определенного времени. Задать необходимое время (не более 45 дней) можно в параметре ban_inactive_more_seconds
в секции account_manager файла конфигурации.
Разблокировать просроченный токен можно, если задать для него новое значение параметра Expires in.
Импорт токена
Для импорта токена приложения используйте запрос import (mutation):
mutation {
token {
import(
uid: "9d9fec89-c1f0-467f-b756-156fe9d29840"
name: "App02"
expires_in: 2592000
role: "admin"
state: "active"
created_at: 1686927801987245300
) {
name
uid
}
}
}
Удаление токена
Для удаления токена приложения используйте запрос remove (mutation):
mutation {
token {
remove(name: "App01") {
name
created_at
role
}
}
}
Режим обязательной аутентификации
Сразу после развертывания TDG любые анонимные пользователи и внешние
приложения могут получать неавторизованный доступ ко всем функциям и данным,
что ненадежно с точки зрения безопасности. Поэтому в TDG появляется
соответствующее предупреждение.

Чтобы включить режим обязательной аутентификации, выполните следующие шаги:
Создайте профиль пользователя с ролью «admin».
Войдите в систему под учетной записью этого пользователя.
На вкладке Cluster нажмите кнопку-переключатель Auth.

В диалоговом окне Authorization нажмите Enable.

Режим обязательной аутентификации включен.
Теперь пользователи могут входить в систему, используя
логин и пароль. В интерфейсе TDG пользователю предоставляется доступ к
определенным вкладкам. Набор вкладок зависит от роли пользователя.
Чтобы предоставить авторизованный доступ к данным и функциям TDG
внешнему приложению, используйте токены приложений.
Авторизация внешних пользователей и систем через LDAP
TDG поддерживает технологию единого входа
(Single Sign-On)
– механизм аутентификации, позволяющий пользователям получать доступ к нескольким приложениям и сервисам c
одним набором учетных данных.
Это означает, что авторизоваться в TDG можно как через пользователей и
токены приложений, так и с использованием такого внешнего инструмента, как LDAP.
LDAP (Lightweight Directory Service Protocol) – открытый протокол
для хранения и получения данных из службы каталогов.
LDAP позволяет централизованно настраивать права доступа к данным.
В TDG доступны три способа настройка протокола LDAP:
В этом руководстве рассмотрим первые два способа настройки протокола.
Для выполнения примера требуются:
Примечание
Для локального тестирования LDAP-авторизации можно использовать сервер GLAuth.
Гарантируется работа с версией GLAuth 2.0.0
Руководство включает в себя следующие шаги:
По умолчанию, логин в систему – это строка вида user@domain, где:
Пример: tdguser@my.domain.ru.
Если подключена Active Directory, служба каталогов Microsoft,
для входа в систему используется адрес электронной почты пользователя LDAP.
В качестве фильтра при этом используется атрибут Active Directory userprincipalname=email,
где email – адрес электронной почты пользователя.
Каждый пользователь LDAP состоит в одной или нескольких группах LDAP (domain group).
Группе LDAP задается определенная роль (например, admin), которая определяет
права доступа для пользователя из этой группы.
Если пользователь LDAP состоит сразу в нескольких группах, он получает разрешения на действия из всех ролей, заданных
для этих групп.
Добавим новую конфигурацию LDAP через веб-интерфейс TDG.
На вкладке Settings > LDAP нажмите кнопку Add Configuration.

В диалоговом окне LDAP укажите параметры, необходимые для вашей конфигурации:
Domain – доменное имя, используемое в доменном логине пользователя (tdguser@my.domain.ru).
Пример: my.domain.ru;
Hosts – адрес подключения к серверу LDAP. Пример: server.my.domain.ru:389;
Organizational units (опционально) – названия организационных подразделений или групп пользователей.
Параметр будет пропущен, если для него не задано явное значение. Пример: tarantool;
Options (опционально) – настройки LDAP. Параметр будет пропущен, если для него не задано явное значение;
Roles – описание ролей, которые будут назначаться пользователю в зависимости от групп LDAP, в которых он
состоит. Для каждой роли описаны название роли и соответствующие ей LDAP-группы.
Описание LDAP-группы состоит из общего имени (CN), названия организационного подразделения или LDAP-группы (OU)
и компонентов домена (DC).
Пример: добавьте роль admin. Для нее в поле Domain Groups укажите значение
CN=tarantool, OU=groups, OU=other_groups, DC=my, DC=domain, DC=ru;
Search timeout (опционально) – время ожидания ответа от сервера LDAP в секундах.
Значение по умолчанию: 2;
Use TLS (опционально) – использование TLS.
Значение по умолчанию: false;
Use Active Directory (опционально) – использование Active Directory.
Значение по умолчанию: false.
При настройке обратите внимание на параметры domain и organizational_units.
Эти параметры используются при аутентификации для поиска пользователя в соответствующем домене и организационном подразделении.
Полное описание параметров LDAP приведено в разделе ldap справочника конфигурации.
Нажмите кнопку Submit, чтобы добавить конфигурацию LDAP.
Чтобы войти в систему как пользователь LDAP, нажмите кнопку Log in в правом верхнем углу.
В диалоговом окне Authorization введите логин (вида user@domain) и пароль пользователя LDAP, затем
нажмите кнопку Login.
Указать конфигурацию LDAP можно:
Полное описание параметров LDAP приведено в разделе
ldap справочника конфигурации.
Пример конфигурации с включенными TLS и Active Directory:
ldap:
- domain: 'my.domain.ru'
organizational_units: ['tarantool']
hosts:
- server.my.domain.ru:389
use_active_directory: true
use_tls: true
search_timeout: 2
options:
- LDAP_OPT_X_TLS_CACERTFILE: /certs/CA_Root.crt
roles:
- domain_groups:
- 'cn=tarantool,ou=groups,ou=other_groups,dc=my,dc=domain,dc=ru'
role: 'admin'
Созданный yml-файл с настройками конфигурации нужно упаковать в zip-архив и загрузить
в TDG согласно инструкции.
Настройка профилей доступа
TDG позволяет управлять правами пользователей на чтение и запись данных,
обрабатываемых и хранимых в системе. Чтобы роль пользователя получила права
доступа к данным, создайте в веб-интерфейсе профиль доступа (data action) и
назначьте этот профиль для нужной роли.
Чтобы создать новый профиль доступа, выполните следующие шаги:
Откройте вкладку Settings > Data actions.
Нажмите Add data action.
В диалоговом окне New data action задайте имя профиля доступа в поле
Name и выберите права Read/ Write для каждого агрегата в списке
Aggregate:

Нажмите Save, чтобы сохранить профиль доступа.
Создав профиль доступа, вы можете отредактировать любой его параметр.
Профиль доступа можно привязать к любой роли пользователя, созданной
администратором. Исключения составляют роли по умолчанию, поскольку их
нельзя редактировать.
Чтобы привязать профиль доступа к роли пользователя, выполните следующие шаги:
Откройте вкладку Settings > Roles.
В списке ролей выберите роль, которую хотите отредактировать, и нажмите на значок карандаша.
В списке действий найдите раздел Data actions и выберите нужный профиль доступа:

Нажмите Apply.
Вы также можете привязывать профили доступа, когда создаете новую роль.
Чек-лист безопасности
Эта глава поможет проверить, безопасно ли настроена система Tarantool Data
Grid. В главе объясняется ряд принципов безопасности, а также
рассказывается, почему они важны и как проверить систему на соответствие им.
Журнал аудита
Журнал аудита содержит записи о событиях безопасности в TDG.
Чтобы посмотреть журнал, нужно:
Сконфигурировать хотя бы один экземпляр с ролью storage.
Включить шардирование кнопкой Bootstrap vshard на вкладке
Cluster.
Перейти на вкладку Audit log.
Включение и выключение журнала аудита
По умолчанию журнал аудита включен и ведется независимо от настроек
авторизации.
Отключить ведение журнала аудита можно, нажав на вкладке Audit log
кнопку Disable logging. Можно также выполнить на вкладке
Graphql следующий запрос:
mutation {
audit_log {
enabled(value: false)
}
}
Чтобы проверить, включен ли журнал аудита, выполните следующий GraphQL-запрос:
query {
audit_log {
enabled
}
}
Очистка журнала аудита
Журнал аудита хранится в memtx и автоматически не очищается.
Полностью очистить спейс с журналом аудита можно следующей командой GraphQL:
mutation {
audit_log {
clear
}
}
Структура
Каждая запись в таблице предоставляет следующую информацию о событии:
Severity (Важность)
From - To (С - По)
Subject ID (ID субъекта)
Subject (Субъект)
Request ID (ID запроса)
Module (Модуль)
Message (Сообщение)
По каждому из параметров журнал аудита можно фильтровать. Подробности о
параметрах можно прочитать ниже.
Severity
Возможные значения (в порядке возрастания важности):
При фильтрации по параметру Severity будут отображаться события, уровень
важности которых совпадает с выбранным или выше него. Чтобы показать все
сообщения, выберите фильтр по параметру VERBOSE.
From - To
Дата и время события. Время отображается в часовом поясе GMT+0 (или UTC).
Subject ID
Внутренний идентификатор субъекта доступа.
Subject
Тип и наименование субъекта доступа. Возможные значения:
system %q: системное сообщение, где %q – имя сущности в системе.
token %q: доступ к HTTP API при помощи токена приложения (например, чтобы получить
данные GraphQL), где %q – имя сущности, запросившей доступ.
user: попытка доступа из GUI.
anonymous: попытка доступа из GUI при отключённой обязательной
«авторизации.
unauthorized: попытка неавторизованного доступа из GUI.
Request ID
Внутренний идентификатор запроса.
Module
Имя модуля системы, инициировавшего событие.
Пример: модуль common.admin.auth отвечает за авторизацию.
Message
Описание события. Может быть пользовательским сообщением.
Примеры
Успешная авторизация пользователя
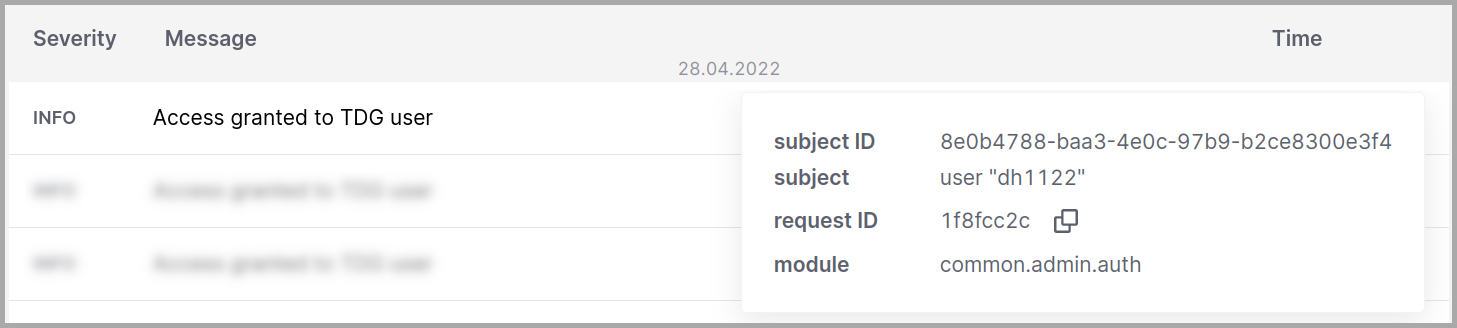
Обновление модели
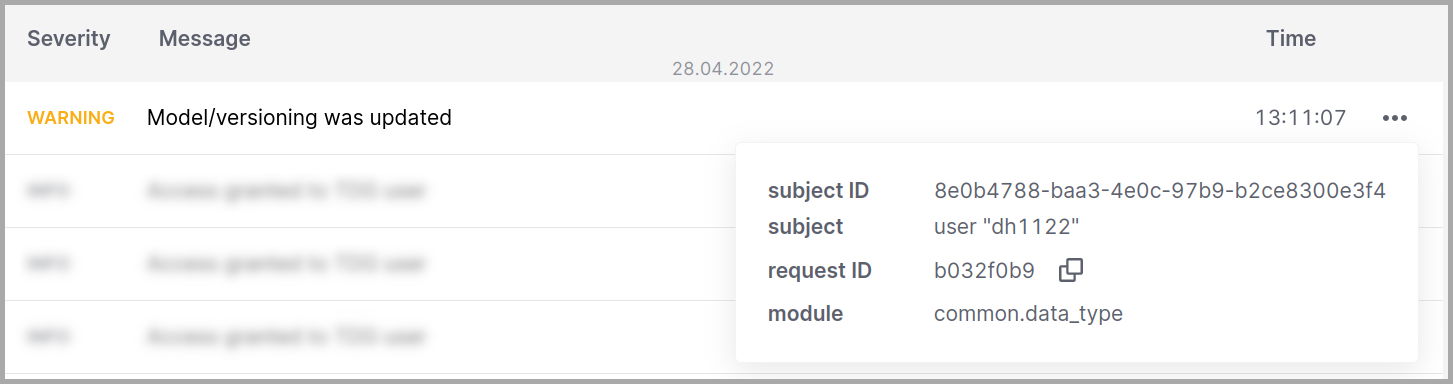
Очистка журнала аудита
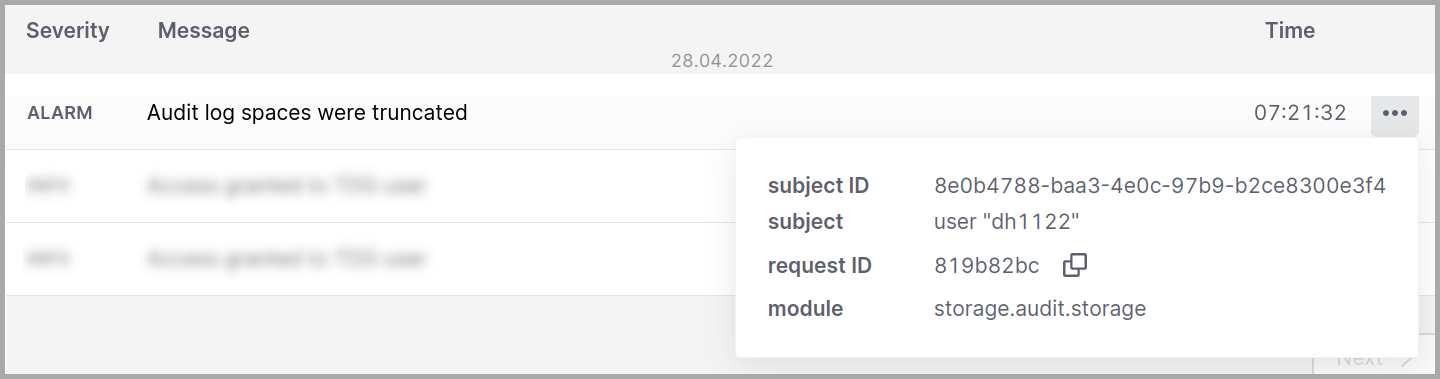
Конфигурация через config.yml
В файле config.yml находятся настройки по умолчанию, с которыми запускается
Tarantool Data Grid. В этом файле конфигурации можно указать и настройки журнала аудита.
audit_log:
remove_older_than_n_hours: 24 # время жизни сообщения в часах
severity: VERBOSE # минимальный уровень важности записываемых событий
enabled: true
Задачи
В этой главе описаны возможности TDG по управлению задачами
через веб-интерфейс.
Задачи позволяют запускать пользовательский код изнутри TDG. Инструкции
по созданию и конфигурированию задач приведены в разделе
Задачи руководства разработчика.
Имя, вид и расписание выполнения задач определяются в
конфигурации бизнес-логики.
Инструменты для управления задачами и отслеживания их выполнения расположены на
вкладке Tasks.
Name: имя задачи.
ID: UUID экземпляра задачи.
Kind: вид задачи. Доступные виды:
Single shot — единоразовая задача;
Continuous — непрерывно выполняемая задача;
Periodical — задача, выполняемая по расписанию. Для таких задач
также отображается расписание.
Status: текущий статус задачи. Доступные статусы:
DID NOT START
PENDING
RUNNING
STOPPED
FAILED
COMPLETED
Started/Finished: дата и время старта или завершения экземпляра задачи.
Launched by: пользователь, запустивший выполнение задачи.
Items: количество завершенных экземпляров задачи.
Примечание
Максимальное количество хранимых в истории экземпляров задачи определяется
параметром keep в конфигурации задачи.
Более старые экземпляры удаляются.
Actions: возможные действия для управления выполнением задач.
Доступные действия:
Start: запустить новый экземпляр неактивной задачи.
Stop: прекратить работу активного экземпляра задачи (в статусе «running»).
Results: просмотреть результаты выполнения экземпляров задачи.
В окне результатов доступен список хранимых экземпляров задачи, возможен
просмотр их результатов и логов и запуск нового экземпляра:
Ремонтная очередь
Если система TDG не может обработать входящий объект, она помещает его в
ремонтную очередь. Затем администратор проверяет его, устраняет проблему и
отправляет объект на повторную обработку.
Вкладка «Input»
На вкладке Repair queues > Input находится ремонтная очередь для отправленных объектов.
Сюда попадают входящие объекты, которые система TDG не смогла обработать.
Вот основные причины, по которым это происходит:
Ошибка при применении обработчика к входящему объекту.
Система TDG ожидает объект в определенном формате, а входящий объект из
внешней системы был отправлен в другом формате.
Внутренняя системная ошибка.
Сбой оборудования.
С объектами ремонтной очереди можно работать через веб-интерфейс на вкладке
Input:
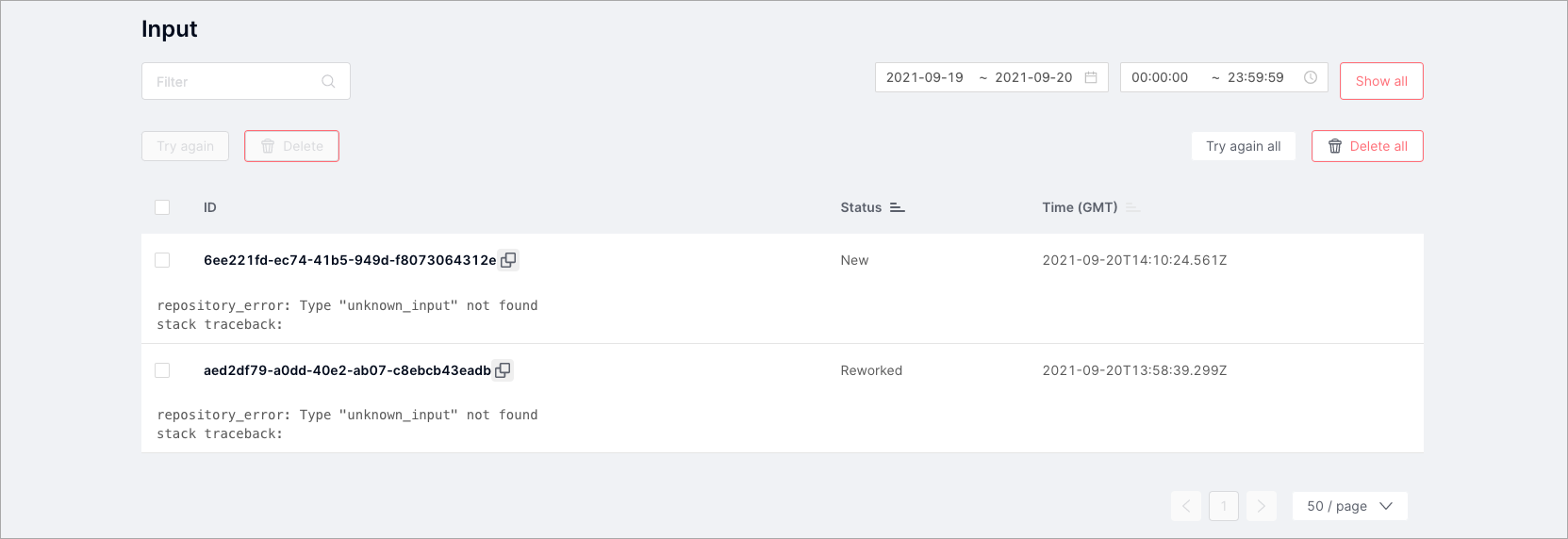
На этой вкладке можно увидеть список объектов, их статус («New» — «Новый»,
«In Progress» — «В процессе», «Reworked» — «Обработан»),
а также дату и время, когда они были помещены в ремонтную очередь.
Интерфейс Repair queue (Ремонтная очередь) позволяет выполнять
следующие действия:
Filter: фильтрация объектов в любом столбце таблицы по любой
комбинации символов, а также по диапазону дат или времени.
Try again: повторно применить к объекту тот же обработчик.
Delete: удалить выбранный объект из ремонтной очереди.
Try again all: повторно обработать все объекты.
Delete all: удалить все объекты из ремонтной очереди.
Выберите объект, чтобы увидеть подробную информацию о нем:
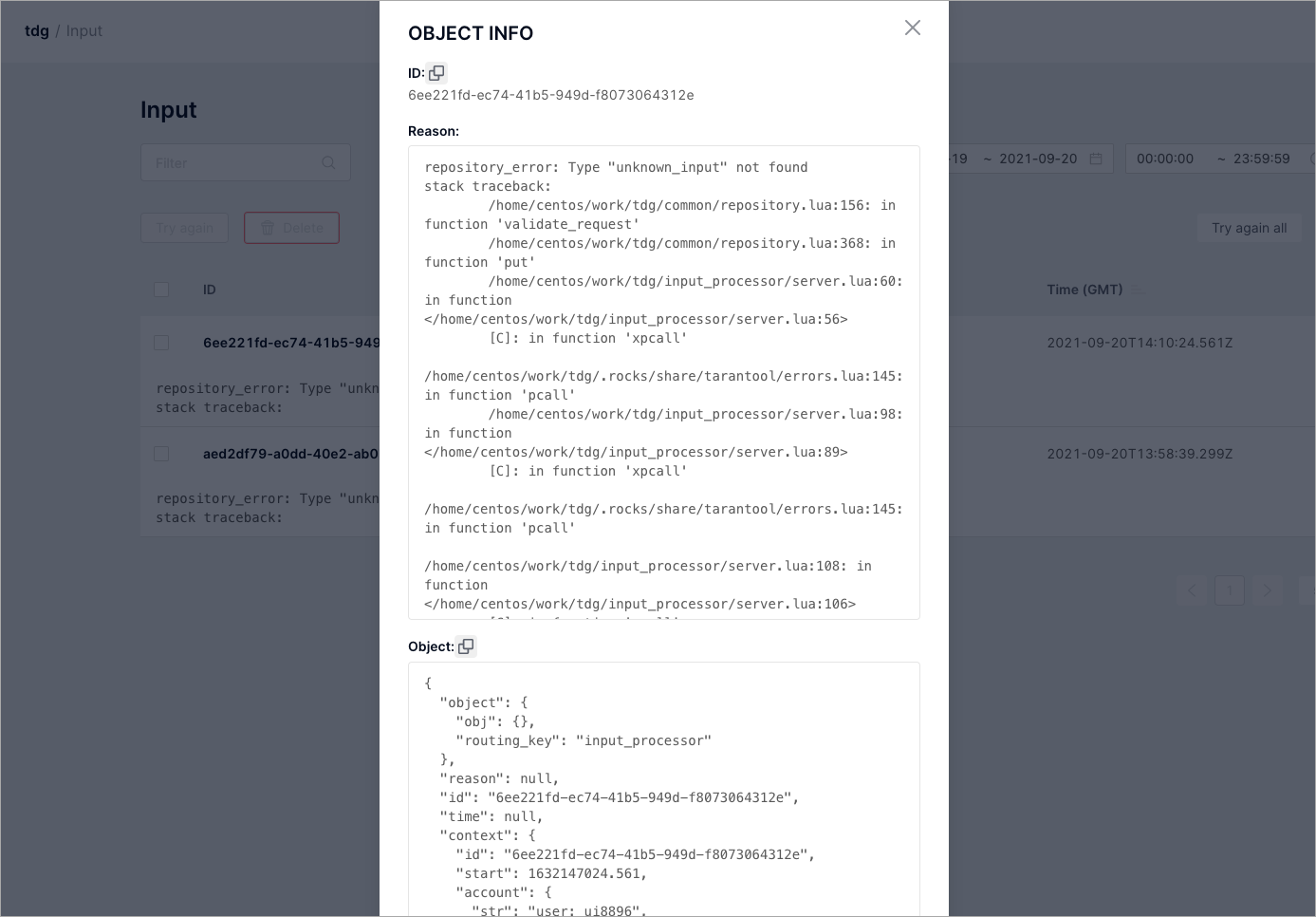
В диалоговом окне Object info находится следующая информация:
ID: UUID объекта.
Reason: описание ошибки и полная трассировка стека.
Object: текущая структура объекта, представленная в формате JSON.
Статус объекта, только что попавшего в ремонтную очередь, — «New». При
повторной обработке статус объекта меняется на «In Progress». Успешно
обработанный объект удаляется из очереди. Если во время повторной обработки
произойдет ошибка, система сообщит об этом, а объект останется в очереди со
статусом «Reworked».
Уведомления
Пользователей системы TDG можно оповещать каждый раз, когда в ремонтную
очередь попадает новый объект. Чтобы включить уведомления, нужен почтовый
сервер и список подписчиков, которые будут их получать.
На вкладке Settings > Mail server установите
следующие параметры:
Url: SMTP-сервер, используемый для отправки уведомлений.
From: отправитель, отображаемый почтовым клиентом.
Username: имя пользователя SMTP-сервера.
Password: пароль пользователя SMTP-сервера.
Timeout (sec): время ожидания ответа от SMTP-сервера в секундах.
Чтобы добавить нового подписчика, на вкладке Settings >
Subscribers (Подписчики) нажмите кнопку Add «subscriber (Добавить подписчика).
Укажите имя и адрес электронной почты.
Позже профиль подписчика можно отредактировать или удалить.
Вкладка «Output»
Механизм репликации объектов позволяет посылать объекты внешней системе в
нужном формате. Если при репликации возникает ошибка, объект помещается в
ремонтную очередь репликации на вкладке Output.
Эта очередь служит для того же, что и ремонтная очередь на вкладке Input.
Единственное отличие: очередь на вкладке
Input предназначена для отправленных объектов, которые не
удалось обработать и сохранить, а ремонтная очередь репликации на вкладке
Output — для объектов, которые не удалось реплицировать.
Для работы с объектами в ремонтной очереди репликации откройте вкладку
Repair queues > Output:
Как и в ремонтной очереди, объекты можно
фильтровать, удалять и пытаться снова реплицировать.
Статус объекта показывает, почему объект оказался в ремонтной очереди
репликации.
Если вы выберете объект и нажмете Try again, он будет обработан
снова. Его статус изменится с «New» на «In progress». Если операция
пройдет успешно, объект будет перемещен на следующий этап или удален из
ремонтной очереди. Если операция завершится с ошибкой, статус объекта
изменится на «Rereplicated (Preprocessing error)» или «Rereplicated «(Sending error)».
При этом объект останется в ремонтной очереди репликации.
Вкладка «Jobs»
Чтобы увидеть ремонтную очередь для отложенных задач, завершенных с ошибкой,
откройте вкладку Repair queues > Jobs:
Эта очередь обладает теми же функциями, что и
ремонтная очередь для отправленных объектов на вкладке Input.
Мониторинг
Для мониторинга работы TDG предоставляются метрики в формате Prometheus.
Для каждого из экземпляров кластера значения метрик доступны по адресу:
http://<IP_адрес_экземпляра>/metrics. В системе-сборщике метрик необходимо
подать на вход адреса для сбора метрик со всех экземпляров кластера.
Все доступные метрики можно разделить на несколько категорий:
Используются следующие типы метрик Prometheus:
counter – монотонно возрастающий счетчик;
gauge – числовое значение, которое может как возрастать, так и убывать;
histogram – выборка из некоторого количества значений.
Тип histogram подсчитывает полученные значения и объединяет их в настраиваемые бакеты (buckets).
summary – выборка из некоторого количества значений.
Тип summary подсчитывает полученные значения и объединяет их в настраиваемые квантили.
Чтобы узнать больше про типы метрик, обратитесь к
документации Prometheus.
Метрики TDG
Метрики запросов GraphQL
Мониторинг и оценка запросов GraphQL.
Метрики имеют теги:
alias – имя экземпляра, на котором собираются метрики. Имя экземпляра было
задано при развертывании кластера;
schema – имя схемы (default или admin), в которую поступил запрос
GraphQL;
entity – тип данных, над которым производится операция;
operation_name – имя запроса GraphQL (может отсутствовать, если имя
запроса не было задано). Рекомендуется указывать имена для всех запросов,
чтобы можно было однозначно идентифицировать, к какому запросу относится
информация в метрике.
Доступные метрики
tdg_graphql_query_time{alias,schema,entity,operation_name} – время обработки
запроса на получение данных (query) в миллисекундах. Тип метрики: histogram;
tdg_graphql_mutation_time{alias,schema,entity,operation_name} – время обработки
запроса на изменения данных (mutation) в миллисекундах. Тип метрики: histogram;
tdg_graphql_query_fail{alias,schema,entity,operation_name} – количество запросов
на получение данных (query) c ошибками. Тип метрики: counter;
tdg_graphql_mutation_fail{alias,schema,entity,operation_name} – количество
запросов на изменение данных (mutation) c ошибками. Тип метрики: counter.
Бакеты (bucket) гистограмм распределены в диапазоне
от 0 до 1000 миллисекунд с интервалом в 100 миллисекунд (см. пример ниже).
Вызов сервиса аналогичен запросу (query) для типа данных.
В тег entity при этом будет записано имя сервиса.
Каждый запрос может состоять из нескольких операций.
В одной операции могут быть получены или модифицированы несколько типов данных.
По каждому типу данных будет выдана отдельная метрика со своим набором тегов.
Пример:
# HELP tdg_graphql_query_time Graphql query execution time
# TYPE tdg_graphql_query_time histogram
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="100"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="200"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="300"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="400"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="500"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="600"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="700"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="800"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="900"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="1000"} 25
tdg_graphql_query_time_bucket{alias="core_1",schema="default",entity="City",operation_name="GetCity",le="+Inf"} 25
tdg_graphql_query_time_sum{alias="core_1",schema="default",entity="City",operation_name="GetCity"} 55
tdg_graphql_query_time_count{alias="core_1",schema="default",entity="City",operation_name="GetCity"} 25
# HELP tdg_graphql_mutation_time Graphql mutation execution time
# TYPE tdg_graphql_mutation_time histogram
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="100"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="200"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="300"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="400"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="500"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="600"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="700"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="800"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="900"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="1000"} 16
tdg_graphql_mutation_time_bucket{alias="core_1",schema="default",entity="City",operation_name="InsCity",le="+Inf"} 16
tdg_graphql_mutation_time_sum{alias="core_1",schema="default",entity="City",operation_name="InsCity"} 34
tdg_graphql_mutation_time_count{alias="core_1",schema="default",entity="City",operation_name="InsCity"} 16
# HELP tdg_graphql_query_fail Graphql query fail count
# TYPE tdg_graphql_query_fail counter
tdg_graphql_query_fail{alias="core_1",schema="default",entity="City",operation_name="GetCity"} 2
# HELP tdg_graphql_mutation_fail Graphql mutation fail count
# TYPE tdg_graphql_mutation_fail counter
tdg_graphql_mutation_fail{alias="core_1",schema="default",entity="City",operation_name="InsCity"} 4
Чтобы получить информацию о среднем количестве запросов GraphQL в секунду
из Prometheus, воспользуйтесь запросом
rate(tdg_graphql_query_time_count[2m])
Период, по которому вычисляется rate() (в примере – 2m),
должен быть как минимум в два раза больше периода сбора метрик.
Если вы добавляете панель на стандартный Grafana Tarantool dashboard,
воспользуйтесь переменной $rate_time_range.
Среднее время выполнения запроса GraphQL можно получить с помощью
rate(tdg_graphql_query_time_sum[2m])/rate(tdg_graphql_query_time_count[2m])
95-й перцентиль времени выполнения запроса GraphQL можно получить с помощью
histogram_quantile(0.95, sum(rate(tdg_graphql_query_time_bucket[2m])) by (le))
Метрики для задач и отложенных работ
Метрики для задач (tasks) и отложенных работ (jobs).
Метрики актуальны только для экземпляров с ролью runner, так как задачи и отложенные работы
запускаются на этих экземплярах.
Метрики задач имеют теги:
Метрики отложенных работ и системных задач имеют только теги alias и name.
В TDG cистемные задачи (system task) используются для версионирования.
Доступные метрики
tdg_tasks_started – число запущенных задач. Тип метрики: counter.
tdg_jobs_started – число запущенных отложенных работ. Тип метрики: counter.
tdg_system_tasks_started – число запущенных системных задач. Тип метрики: counter.
Пример:
# HELP tdg_system_tasks_started Total system tasks started
# TYPE tdg_system_tasks_started counter
tdg_tasks_started{alias="runner_1",name="districts_stat.calc_statistics.call",kind="periodical"} 2
# HELP tdg_jobs_started Total jobs started
# TYPE tdg_jobs_started counter
tdg_jobs_started{name="succeed",alias="runner_1"} 1
# HELP tdg_system_tasks_started Total system tasks started
# TYPE tdg_system_tasks_started counter
tdg_system_tasks_started{name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_tasks_failed – число задач, которые завершились с ошибкой. Тип метрики: counter;
tdg_jobs_failed – число отложенных работ, которые завершились с ошибкой. Тип метрики: counter.
Пример:
# HELP tdg_tasks_failed Total tasks failed
# TYPE tdg_tasks_failed counter
tdg_tasks_succeeded{alias="runner_1",name="districts_stat.calc_statistics.call",kind="periodical"} 1
# HELP tdg_jobs_failed Total jobs failed
# TYPE tdg_jobs_failed counter
tdg_jobs_failed{name="fail",alias="runner_1"} 2
tdg_tasks_succeeded – число успешно выполненных задач. Тип метрики: counter;
tdg_jobs_succeeded – число успешно выполненных отложенных работ. Тип метрики: counter;
tdg_system_tasks_succeeded – число успешно выполненных системных задач. Тип метрики: counter.
Пример:
# HELP tdg_tasks_succeeded Total tasks succeeded
# TYPE tdg_tasks_succeeded counter
tdg_tasks_succeeded{alias="runner_1",name="districts_stat.calc_statistics.call",kind="periodical"} 2
# HELP tdg_jobs_succeeded Total jobs succeeded
# TYPE tdg_jobs_succeeded counter
tdg_jobs_succeeded{name="succeed",alias="runner_1"} 1
# HELP tdg_system_tasks_succeeded Total system tasks succeeded
# TYPE tdg_system_tasks_succeeded counter
tdg_system_tasks_succeeded{name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_tasks_stopped – число приостановленных задач. Тип метрики: counter.
Пример:
# HELP tdg_tasks_stopped Total tasks stopped
# TYPE tdg_tasks_stopped counter
tdg_tasks_stopped{alias="runner_1",name="districts_stat.calc_statistics.call",kind="periodical"} 2
tdg_tasks_running – число задач, запущенных в данный момент. Тип метрики: gauge;
tdg_jobs_running – число отложенных работ, запущенных в данных момент. Тип метрики: gauge;
tdg_system_tasks_running – число системных задач, запущенных в данный момент. Тип метрики: gauge.
Пример:
# HELP tdg_tasks_running Currently running tasks
# TYPE tdg_tasks_running gauge
tdg_tasks_running{alias="runner_1",name="districts_stat.calc_statistics.call",kind="periodical"} 0
# HELP tdg_jobs_running Currently running jobs
# TYPE tdg_jobs_running gauge
tdg_jobs_running{name="succeed",alias="runner_1"} 0
# HELP tdg_system_tasks_running Currently running system tasks
# TYPE tdg_system_tasks_running gauge
tdg_system_tasks_running{name="tasks.system.archivation.start",alias="tnt_net_external_1_runner_1_1"} 0
tdg_tasks_execution_time – время исполнения задачи. Тип метрики: histogram;
tdg_jobs_execution_time – время исполнения отложенной работы. Тип метрики: histogram;
tdg_system_tasks_execution_time – время исполнения системной задачи. Тип метрики: histogram.
Бакеты (bucket) гистограмм распределены в диапазоне
от 0 до 5 секунд: 0.0001, 0.00025, 0.0005, 0.001, 0.0025, 0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1, 2.5, 5.
Пример:
# HELP tdg_tasks_execution_time Tasks execution time statistics
# TYPE tdg_tasks_execution_time histogram
tdg_tasks_execution_time_count{alias="runner_1",name="calc_districts_stat",kind="periodical"} 2
tdg_tasks_execution_time_sum{alias="runner_1",name="calc_districts_stat",kind="periodical"} 0.014632841999969
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.0001",kind="periodical"} 0
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.00025",kind="periodical"} 0
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.0005",kind="periodical"} 0
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.001",kind="periodical"} 0
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.0025",kind="periodical"} 1
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.005",kind="periodical"} 1
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.01",kind="periodical"} 1
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.025",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.05",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.1",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.25",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="0.5",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="1",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="2.5",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="5",kind="periodical"} 2
tdg_tasks_execution_time_bucket{alias="runner_1",name="calc_districts_stat",le="+Inf",kind="periodical"} 2
# HELP tdg_jobs_execution_time Jobs execution time statistics
# TYPE tdg_jobs_execution_time histogram
tdg_jobs_execution_time_count{name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_sum{name="succeed",alias="runner_1"} 1.0725110769272e-05
tdg_jobs_execution_time_bucket{le="0.0001",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.00025",name="succeed",alias="runner_1"}1
tdg_jobs_execution_time_bucket{le="0.0005",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.001",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.0025",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.005",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.01",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.025",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.05",name="succeed",alias="runner_1"}
tdg_jobs_execution_time_bucket{le="0.1",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.25",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="0.5",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="1",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="2.5",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="5",name="succeed",alias="runner_1"} 1
tdg_jobs_execution_time_bucket{le="+Inf",name="succeed",alias="runner_1"} 1
# HELP tdg_system_tasks_execution_time System tasks execution time statistics
# TYPE tdg_system_tasks_execution_time histogram
tdg_system_tasks_execution_time_count{name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_sum{name="tasks.system.archivation.start",alias="runner_1"} 0.052489631809294
tdg_system_tasks_execution_time_bucket{le="0.0001",name="tasks.system.archivation.start",alias="runner_1"} 631
tdg_system_tasks_execution_time_bucket{le="0.00025",name="tasks.system.archivation.start",alias="runner_1"} 715
tdg_system_tasks_execution_time_bucket{le="0.0005",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.001",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.0025",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.005",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.01",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.025",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.05",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.1",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.25",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="0.5",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="1",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="2.5",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="5",name="tasks.system.archivation.start",alias="runner_1"} 718
tdg_system_tasks_execution_time_bucket{le="+Inf",name="tasks.system.archivation.start",alias="runner_1"} 718
Метрики для кортежей
Статистика по операциям поиска кортежей в базе данных, где хранятся пользовательские данные:
tdg_scanned_tuples – число просканированных кортежей. Тип метрики: summary;
tdg_returned_tuples – число возвращенных кортежей. Тип метрики: histogram;
tdg_scanned_tuples_max – максимальное количество просканированных кортежей. Тип метрики: gauge;
tdg_returned_tuples_max – максимальное количество возвращаемых кортежей. Тип метрики: gauge.
Метрики запросов iproto
Мониторинг и оценка запросов к данным через iproto:
tdg_iproto_data_query_exec_time – время исполнения запроса по протоколу iproto. Тип метрики: summary;
tdg_iproto_data_query_exec_time – время исполнения запроса по протоколу iproto. Тип метрики: histogram.
Метрики файлового коннектора
Общая статистика по файловым коннекторам и статистика обработки файлов:
tdg_connector_input_file_processed_count – общее число обработанных файлов. Тип метрики: counter;
tdg_connector_input_file_processed_objects_count – общее число обработанных объектов. Тип метрики: counter;
tdg_connector_input_file_failed_count – общее число файлов, которые не удалось обработать.
Тип метрики: counter;
tdg_connector_input_file_size – размер файла в байтах. Тип метрики: gauge;
tdg_connector_input_file_current_bytes_processed – количество обработанных байтов от текущего файла.
Тип метрики: counter;
tdg_connector_input_file_current_processed_objects – число обработанных объектов от текущего файла.
Тип метрики: counter.
Метрики expirationd
Статистика модуля expirationd (время жизни объектов).
Сбор статистики включен по умолчанию.
Тип метрик – counter.
Метрики имеют тег name – название задачи (task).
Доступные метрики
expirationd_checked_count{name} – количество кортежей, проверенных на истечение lifetime_hours.
Включает в себя:
- кортежи с истекшим lifetime_hours (expired);
- пропущенные кортежи (skipped);
expirationd_expired_count{name} – количество кортежей c истекшим lifetime_hours;
expirationd_restarts{name} – количество перезапусков (restart) с начала работы (старта).
При старте принимает значение 1.
expirationd_working_time{name} – время исполнения задачи в секундах.
Метрики Kafka
В TDG доступен мониторинг сведений о коннекторе Kafka с помощью
librdkafka.
librdkafka – это реализация С-библиотеки протокола Apache Kafka, которая поддерживает как producer, так и
consumer. Для библиотеки по умолчанию включено регулярное предоставление внутренней статистики.
Интервал обновления метрик можно настроить, используя опцию statistics.interval.ms.
По умолчанию, значение statistics.interval.ms составляет 15000 миллисекунд.
Диапазон доступных значений для параметра: 0–86400000 мс.
Отключить сбор статистики можно, установив значение 0.
Полное описание параметров конфигурации для коннектора Kafka приведено в
справочнике по настройке коннектора.
Метрики имеют тип gauge, если не указано иначе.
Имеют префикс tdg_kafka_, общий для всех метрик Kafka.
Метрики Kafka состоят из нескольких уровней:
Большая часть операций – это оконные функции, которые применяются на отрезках времени.
Поэтому уровни Topics и Brokers также включают
в себя раздел про плавающие окна (Rolling Window Statistics), например,
скользящую среднюю, наименьшую и наибольшую величины, сумму значений и процентные значения.
Общая статистика
Общая статистика по всем брокерам:
tdg_kafka_ts – внутренние монотонные часы библиотеки librdkafka в микросекундах;
tdg_kafka_time – время с начала эпохи в секундах;
tdg_kafka_age – время существования экземпляра клиента в микросекундах;
tdg_kafka_replyq – количество операций (триггеров, событий и т.д.) в очереди на обслуживание
с помощью rd_kafka_poll();
tdg_kafka_msg_cnt – текущее количество сообщений в очереди продюсера;
tdg_kafka_msg_size – текущий общий размер сообщений в очередях продюсера;
tdg_kafka_msg_max – максимальное количество сообщений, разрешенное в очередях продюсера;
tdg_kafka_msg_size_max – общий размер сообщений, разрешенный в очередях продюсера;
tdg_kafka_tx – общее количество запросов, отправленных брокерам Kafka;
tdg_kafka_tx_bytes – общее количество байтов, отправленных брокерам Kafka;
tdg_kafka_rx – общее количество запросов, полученных от брокеров Kafka;
tdg_kafka_rx_bytes – общее количество байтов, полученных от брокеров Kafka;
tdg_kafka_txmsgs – общее количество сообщений, отправленных брокерам Kafka;
tdg_kafka_txmsg_bytes – общее количество байтов сообщений, отправленных брокерам Kafka
(включая фрейм – например, фрейм по каждому сообщению и фрейм MessageSet/пакета);
tdg_kafka_rxmsgs – общее количество сообщений, полученных от брокеров Kafka.
Не включает в себя сообщения, которые были проигнорированы – например, из-за смещения;
tdg_kafka_rxmsg_bytes – общее количество байтов сообщений (включая фрейм), полученных от брокеров Kafka;
tdg_kafka_simple_cnt – внутреннее отслеживание устаревшего и нового состояния API consumer;
tdg_kafka_metadata_cache_cnt – количество топиков в кэше метаданных.
Плавающее окно (Rolling Window Statistics)
Постфиксы для метрик, связанные с оконными функциями. Например, к ним относятся стандартное отклонение,
наибольшая и наименьшая величина и процентные значения (процентили).
Позволяют получить получать дополнительную информацию о значении некоторых метрик с уровней
Topics и Brokers.
Полный список доступных метрик вместе с постфиксами указан в описаниях соответствующих уровней.
Переменная {name} – имя метрики вместе с префиксом tdg_kafka_.
Например, tdg_kafka_broker_int_latency_max – наибольшее значение метрики tdg_kafka_broker_int_latency.
name_min – наименьшее значение;
name_max – наибольшее значение;
name_avg – среднее значение;
name_sum – сумма значений;
name_cnt – количество выбранных значений;
name_stddev – стандартное отклонение на основе гистограммы;
name_hdrsize – объем памяти Hdr Histogram;
name_outofrange – значения, пропущенные из-за выхода за пределы диапазона гистограммы.
Процентные значения:
Значения процентилей можно просмотреть для следующих метрик:
уровень Broker – tdg_kafka_broker_int_latency, tdg_kafka_broker_outbuf_latency, tdg_kafka_broker_rtt,
tdg_kafka_broker_throttle;
уровень Topic – tdg_kafka_topic_batchcnt, tdg_kafka_topic_batchsize.
Статистика по брокеру
tdg_kafka_broker_stateage – время с момента последнего изменения состояния брокера в микросекундах;
tdg_kafka_broker_outbuf_cnt – количество запросов, ожидающих отправки брокеру;
tdg_kafka_broker_outbuf_msg_cnt – количество сообщений, ожидающих отправки брокеру;
tdg_kafka_broker_waitresp_cnt – количество запросов на пути к брокеру, ожидающих ответа;
tdg_kafka_broker_waitresp_msg_cnt – количество сообщений на пути к брокеру, ожидающих ответа;
tdg_kafka_broker_tx – общее количество отправленных запросов;
tdg_kafka_broker_txbytes – исходящий трафик в байтах;
tdg_kafka_broker_txerrs – число ошибок при передаче;
tdg_kafka_broker_txretries – общее количество повторных запросов;
tdg_kafka_broker_txidle – время с момента, как был отправлен последний сокет, в микросекундах.
Если для текущего подключения еще ничего не отправлялось, имеет значение -1;
tdg_kafka_broker_req_timeouts – общее количество запросов, время ожидания для которых истекло;
tdg_kafka_broker_rx – общее число полученных ответов;
tdg_kafka_broker_rxbytes – входящий трафик в байтах;
tdg_kafka_broker_rxerrs – число ошибок при получении;
tdg_kafka_broker_rxcorriderrs – общее количество различающихся идентификаторов корреляции в ответе
(обычно для запросов с истекшим временем ожидания);
tdg_kafka_broker_rxpartial – общее количество частично полученных MessageSets;
tdg_kafka_broker_rxidle – время с момента получения последнего сокета в микросекундах.
Если для текущего соединенния еще нет полученных данных, имеет значение -1;
tdg_kafka_broker_zbuf_grow – общее количество увеличений размера для буфера декомпрессии;
tdg_kafka_broker_buf_grow – общее количество увеличений размера буфера (deprecated, не используется);
tdg_kafka_broker_wakeups – пробуждения пула потоков брокера;
tdg_kafka_broker_connects – количество попыток соединения.
Включает в себя успешные и неудачные попытки, а также количество неудачных попыток разрешения имен;
tdg_kafka_broker_disconnects – количество разорванных соединений, вызванных брокером, сетью,
балансировщиком нагрузки и т. д;
tdg_kafka_broker_req – счетчики типа запроса. Ключ объекта – это имя запроса,
значение – количество отправленных запросов;
tdg_kafka_broker_int_latency – задержка внутренней очереди продюсера в микросекундах. Метрика используется
только вместе с постфиксами из раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_broker_int_latency_avg,
tdg_kafka_broker_int_latency_cnt, tdg_kafka_broker_int_latency_hdrsize,
tdg_kafka_broker_int_latency_max, tdg_kafka_broker_int_latency_min,
tdg_kafka_broker_int_latency_outofrange, tdg_kafka_broker_int_latency_stddev,
tdg_kafka_broker_int_latency_sum;
tdg_kafka_broker_outbuf_latency – задержка внутренней очереди запросов в микросекундах. Можно использовать
самостоятельно или вместе с постфиксами из раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_broker_outbuf_latency_avg,
tdg_kafka_broker_outbuf_latency_cnt, tdg_kafka_broker_outbuf_latency_hdrsize,
tdg_kafka_broker_outbuf_latency_max, tdg_kafka_broker_outbuf_latency_min,
tdg_kafka_broker_outbuf_latency_outofrange, tdg_kafka_broker_outbuf_latency_stddev,
tdg_kafka_broker_outbuf_latency_sum;
tdg_kafka_broker_rtt – задержка брокера, время обхода в микросекундах. Можно использовать самостоятельно или
вместе с постфиксами из раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_broker_rtt_avg, tdg_kafka_broker_rtt_cnt,
tdg_kafka_broker_rtt_hdrsize, tdg_kafka_broker_rtt_max, tdg_kafka_broker_rtt_min,
tdg_kafka_broker_rtt_outofrange, tdg_kafka_broker_rtt_stddev, tdg_kafka_broker_rtt_sum;
tdg_kafka_broker_throttle – время регулирования брокера в миллисекундах. Можно использовать самостоятельно или
вместе с постфиксами из раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_broker_throttle_avg, tdg_kafka_broker_throttle_cnt,
tdg_kafka_broker_throttle_hdrsize, tdg_kafka_broker_throttle_max, tdg_kafka_broker_throttle_min,
tdg_kafka_broker_throttle_outofrange, tdg_kafka_broker_throttle_stddev, tdg_kafka_broker_throttle_sum.
Статистика по топику
tdg_kafka_topic_age – возраст объекта клиентского топика в миллисекундах;
tdg_kafka_topic_metadata_age – возраст метаданных от брокера для данного топика в миллисекундах;
tdg_kafka_topic_batchsize – размер пакета в байтах. Метрика используется только вместе с постфиксами из
раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_topic_batchsize_avg,
tdg_kafka_topic_batchsize_cnt, tdg_kafka_topic_batchsize_hdrsize, tdg_kafka_topic_batchsize_max,
tdg_kafka_topic_batchsize_min, tdg_kafka_topic_batchsize_outofrange, tdg_kafka_topic_batchsize_stddev,
tdg_kafka_topic_batchsize_sum;
tdg_kafka_topic_batchcnt – счетчик пакетных сообщений. Можно использовать самостоятельно или вместе с
постфиксами из раздела Rolling Window Statistics.
Список доступных метрик: tdg_kafka_topic_batchcnt_avg, tdg_kafka_topic_batchcnt_cnt,
tdg_kafka_topic_batchcnt_hdrsize, tdg_kafka_topic_batchcnt_max, tdg_kafka_topic_batchcnt_min,
tdg_kafka_topic_batchcnt_outofrange, tdg_kafka_topic_batchcnt_stddev, tdg_kafka_topic_batchcnt_sum;
tdg_kafka_topic_partitions – разделы. Метрика используется только вместе с постфиксами из
раздела Partitions.
Статистика по разделам топика
Метрики, связанные с разделами топика.
Позволяют получить получать информацию о метрике
tdg_kafka_topic_partitions.
tdg_kafka_topic_partitions_broker – ID брокера, сообщения из раздела которого извлекают в текущий момент;
tdg_kafka_topic_partitions_leader – ID текущего лидера брокеров;
tdg_kafka_topic_partitions_desired – раздел, явно требуемый при применении;
tdg_kafka_topic_partitions_unknown – раздел, который не отображен в метаданных топика брокера;
tdg_kafka_topic_partitions_msgq_cnt – количество сообщений, ожидающих отправки в очереди первого уровня;
tdg_kafka_topic_partitions_msgq_bytes – количество байтов в msgq_cnt;
tdg_kafka_topic_partitions_xmit_msgq_cnt – количество сообщений в очереди выборки, готовых к отправке;
tdg_kafka_topic_partitions_xmit_msgq_bytes – количество байтов в xmit_msgq;
tdg_kafka_topic_partitions_fetchq_cnt – количество предварительно выбранных сообщений в очереди выборки;
tdg_kafka_topic_partitions_fetchq_size – размер очереди выборки в байтах;
tdg_kafka_topic_partitions_query_offset – текущий/последний запрос на логическое смещение;
tdg_kafka_topic_partitions_next_offset – следующее смещение для выборки;
tdg_kafka_topic_partitions_app_offset – смещение в разделе последнего сообщения, переданного приложению, +1;
tdg_kafka_topic_partitions_stored_offset – смещение для фиксации в разделе;
tdg_kafka_topic_partitions_committed_offset – последнее зафиксированное смещение в разделе;
tdg_kafka_topic_partitions_eof_offset – последнее сигнализированное смещение PARTITION_EOF;
tdg_kafka_topic_partitions_lo_offset – минимальное доступное смещение для раздела на брокере;
tdg_kafka_topic_partitions_hi_offset – максимальное доступное смещение для раздела на брокере;
tdg_kafka_topic_partitions_ls_offset – последнее стабильное смещение раздела на брокере;
tdg_kafka_topic_partitions_consumer_lag – разница между hi_offset или ls_offset и commit_offset;
tdg_kafka_topic_partitions_consumer_lag_stored – разница между hi_offset или ls_offset и stored_offset;
tdg_kafka_topic_partitions_txmsgs – общее количество отправленных сообщений
tdg_kafka_topic_partitions_txbytes – общее количество байтов, переданных для txmsgs
tdg_kafka_topic_partitions_rxmsgs – общее количество полученных сообщений, за исключением игнорируемых сообщений;
tdg_kafka_topic_partitions_rxbytes – общее количество байтов, полученных для rxmsgs;
tdg_kafka_topic_partitions_msgs – общее количество полученных или общее количество отправленных сообщений;
tdg_kafka_topic_partitions_rx_ver_drops – удаленные устаревшие сообщения;
tdg_kafka_topic_partitions_msgs_inflight – текущее количество сообщений на пути к брокеру или от него (in-flight);
tdg_kafka_topic_partitions_next_ack_seq – следующая ожидаемая подтвержденная последовательность (идемпотентный продюсер);
tdg_kafka_topic_partitions_next_err_seq – следующая ожидаемая последовательность с ошибкой (идемпотентный продюсер);
tdg_kafka_topic_partitions_acked_msgid – ID внутреннего сообщения c последним подтверждением (идемпотентный продюсер).
Статистика группы consumer (cgrp)
tdg_kafka_cgrp_stateage – время с момента последнего изменения состояния в миллисекундах;
tdg_kafka_cgrp_rebalance_age – время с момента последней ребалансировки в миллисекундах;
tdg_kafka_cgrp_rebalance_cnt – общее количество ребалансировок;
tdg_kafka_cgrp_assignment_size – количество разделов для текущего назначения.
Статистика идемпотентного продюсера (EOS)
Библиотека librdkafka поддерживает семантику Exactly-Once Delivery (EOS) для доставки сообщений.
Такая семантика гарантирует, что сообщения будут доставлены строго один раз.
За реализацию семантики отвечает свойство идемпотентности в настройках продюсера и число подтверждений об успешной записи.
tdg_kafka_eos_idemp_stateage – время с момента последнего изменения состояния ID идемпотентного продюсера
(idemp_state) в миллисекундах;
tdg_kafka_eos_txn_stateage – время с момента последнего изменения состояния транзакционного продюсера
txn_state в миллисекундах;
tdg_kafka_eos_txn_may_enq – состояние транзакции позволяет добавлять в очередь новые сообщения;
tdg_kafka_eos_producer_id – текущий ID продюсера (или -1);
tdg_kafka_eos_producer_epoch – текущая эпоха (или -1);
tdg_kafka_eos_epoch_cnt – число назначений ID продюсера с момента запуска.
Рекомендации по анализу метрик
При мониторинге системы рекомендуется в первую очередь обращать внимание на следующие группы метрик:
Примечание
Рекомендуемые и критические значения для большинства метрик из списка ниже рассчитываются на основе статистических
данных промышленной эксплуатации или предварительной статистики, собранной на стенде нагрузочного тестирования.
Для получения помощи в настройке таких метрик обратитесь к команде поддержки.
Рекомендуемые и критические значения для метрик ниже определяются исходя из конкретного проекта.
Узнать подробнее о метриках, связанных с использованием процессора, можно в разделе Статистика CPU.
tnt_cpu_user_time
Среднее время использования CPU в секундах, затраченное процессом экземпляра на исполнение логики базы данных.
Срабатывает при высокой нагрузке на заданном сервере.
Решение
Определите место в коде приложения, которое вызывает всплеск нагрузки на CPU.
Постоянно высокая загрузка CPU может говорить о нехватке вычислительных мощностей.
tnt_cpu_system_time
Среднее время использования CPU в секундах, затраченное процессом экземпляра на исполнение системного вызова.
Решение
Большое значение метрики указывает на проблему в одной из подсистем.
Одна из причин проблемы – выросшее значение параметра iowait(), в этой ситуации приложение тратит много
ресурсов на чтение или запись на диск.
Рекомендуемые и критические значения для метрик ниже определяются исходя из конкретного проекта, если не указано иначе.
tnt_info_memory_lua
Объем памяти в байтах, используемый средой выполнения Lua-кода.
Объем памяти Lua ограничен 2 Гб на каждый экземпляр (более 2 Гб на версиях GC64).
Отслеживание метрики помогает предотвратить переполнение памяти и выявить некорректные методы работы с Lua-кодом.
Рекомендуемое значение метрики: 25-100 МБ.
Порог срабатывания: значение больше 1 Гб (за исключением версий GC64).
Решение
Одна из причин большой загруженности памяти – утечка памяти.
Чтобы выяснить точную причину, вызовите функцию
fiber.top().
Перезагрузите экземпляр после того, как определите причину проблемы.
tnt_runtime_used
Объем памяти в байтах, используемый средой выполнения Lua-кода (runtime arena) в данный момент.
Среда выполнения хранит:
сетевые буферы;
кортежи, созданные с помощью box.tuple.new();
другие объекты, выделенные приложением, которые не охватывают базовые механизмы Lua.
Отслеживание метрики помогает предотвратить переполнение памяти и выявить некорректные методы работы с Lua-кодом.
Рекомендуемое значение метрики близко к 0.
Порог срабатывания: значение заметно больше 0.
Решение
Обратитесь к разработчику приложения для анализа проблемы.
tnt_info_memory_tx
Объем памяти в байтах, используемый активными транзакциями.
Для движка vinyl это общий размер всех выделенных объектов и кортежей, закрепленных для этих объектов.
Рекомендуемое значение метрики близко к 0.
Порог срабатывания: значение заметно больше 0.
Решение
Обратитесь к разработчику приложения для анализа проблемы.
tnt_ev_loop_time
Продолжительность последней итерации цикла событий (поток TX) в миллисекундах.
Порог срабатывания: значение больше 1 секунды. Большое значение метрики может быть причиной ошибки
Too long WAL write.
Решение
Обратитесь к разработчику приложения для анализа проблемы.
Статистика распределения slab
Использование выделенной оперативной памяти в процентах.
Узнать подробнее о метриках, связанных с распределением slab, можно в разделе
Статистика использования памяти для распределения slab.
Полезные метрики:
tnt_slab_quota_used_ratio – соотношение занятого объема памяти (tnt_slab_quota_used) к
максимальному объему памяти, который можно выделить для slab (tnt_slab_quota_size);
tnt_slab_arena_used_ratio – соотношение занятого объема памяти (tnt_slab_arena_used) к
максимальному объему памяти, который можно выделить для кортежей и индексов (tnt_slab_quota_size);
tnt_slab_items_used_ratio – соотношение занятого объема памяти (tnt_slab_items_used) к
максимальному объему памяти, который можно выделить для кортежей (tnt_slab_items_size).
Отслеживание статистики распределения slab позволяет увидеть объем свободной оперативной памяти для хранения
memtx кортежей и индексов на экземпляре.
Если Tarantool превышает ограничения, экземпляр становится недоступен для записи.
Оповещение может помочь понять, когда пора увеличить лимит
box.cfg.memtx_memory
или добавить новое хранилище в кластер vshard.
Порог срабатывания:
(tnt_slab_quota_used_ratio >= 80) и (tnt_slab_arena_used_ratio >= 80) – у экземпляра заканчивается
выделенный объем оперативной памяти.
(tnt_slab_quota_used_ratio >= 90) и (tnt_slab_arena_used_ratio >= 90) – у экземпляра закончился выделенный
объем оперативной памяти.
Решение:
Увеличьте лимит памяти Tarantool
box.cfg.memtx_memory.
Порог срабатывания:
(tnt_slab_quota_used_ratio >= 80) и (tnt_slab_items_used_ratio <= 85) – у экземпляра заканчивается
выделенный объем оперативной памяти. Возможна большая фрагментация данных.
(tnt_slab_quota_used_ratio >= 90) и (tnt_slab_items_used_ratio <= 85) – у экземпляра закончился
выделенный объем оперативной памяти. Возможна большая фрагментация данных.
Решение:
Чтобы избавиться от фрагментации, выполните перезагрузку экземпляра.
Если после перезагрузки значения метрик не изменились, рассмотрите возможность увеличения лимита памяти Tarantool
box.cfg.memtx_memory.
Рекомендуемые и критические значения для метрик ниже определяются исходя из конкретного проекта.
tnt_fiber_csw – количество контекстных переключений для всех текущих файберов экземпляра;
tnt_fiber_amount – текущее количество файберов в потоке процессора транзакций (потоке TX). Скорость работы
снижается, если количество файберов приближается к 10000. Большое значение tnt_fiber_amount отразится на
значениях метрик tnt_fiber_csw и tnt_ev_loop_time;
tnt_fiber_memused – объем памяти в байтах, используемый файберами;
tnt_fiber_memalloc – общий объем памяти в байтах, выделенный под файберы.
Решение
Обратитесь к разработчику приложения для анализа проблемы.
Рекомендуемые и критические значения для метрик ниже определяются исходя из конкретного проекта.
Узнать подробнее о метриках, связанных с работой сети, можно в разделе Статистика сетевой активности.
tnt_info_memory_net – объем памяти в байтах, используемый для буферов сетевого ввода и вывода. Может быть
ограничен параметром конфигурации
readahead;
tnt_net_sent_total – исходящий трафик в байтах;
tnt_net_received_total – входящий трафик в байтах;
tnt_net_requests_in_progress_total – общее количество сетевых запросов, обработанных
потоком процессора транзакций (поток TX);
tnt_net_requests_in_progress_current – количество сетевых запросов, которые обрабатывает поток процессора
транзакций в текущий момент;
tnt_net_requests_in_stream_queue_total – общее количество сетевых запросов, помещенных в очереди стримов за
все время потоком процессора транзакций.
tnt_net_requests_total
Общее количество входящих сетевых запросов, обработанных с момента запуска экземпляра.
Решение
При возникновении проблем проверьте сетевую доступность экземпляров Tarantool и наличие нагрузки с внешних сервисов.
tnt_net_requests_current
Текущее количество входящих сетевых запросов в обработке.
Может быть ограничено параметром конфигурации базы данных
net_msg_max.
Решение
Если количество сетевых запросов достигло лимита, заданного в параметре net_msg_max (по умолчанию 768), увеличьте
значение этого параметра.
Если Tarantool не успевает обрабатывать поступающие запросы, необходимо провести анализ поступающей нагрузки.
tnt_net_requests_in_stream_queue_current
Количество сетевых запросов, ожидающих обработки в очередях стримов в текущий момент.
Решение
Проверьте скорость работы жесткого диска при помощи системных утилит.
Проведите анализ потока процессора транзакций, используя функцию
fiber.top().
tnt_net_connections_total
Общее количество входящих сетевых соединений с момента запуска экземпляра.
Решение
Проверьте профиль нагрузки в функции box.stat.net().
tnt_net_connections_current
Текущее количество входящих сетевых соединений.
Решение
Проверьте профиль нагрузки в функции box.stat.net().
tnt_cartridge_issues
Количество ошибок в работе экземпляра кластера.
Срабатывает, когда возникает хотя бы одна ошибка:
Имеет два уровня критичности ошибок:
warning. Возможные причины: большой лаг или длительный простой репликации, проблемы с восстановлением
после сбоев (failover) и переключением (switchover), проблемы со временем, фрагментация памяти,
ошибки конфигурации, предупреждение о посторонних экземплярах в кластере;
critical. Возможные причины: критические сбои процесса репликации, нехватка доступной памяти.
Решение
При возникновении таких предупреждений обратите внимание на наличие ошибок в веб-интерфейсе Cartridge.
В TDG доступен мониторинг статистики HTTP-сервера, в том числе отслеживание задержки HTTP-запросов.
http_server_request_latency
Задержка HTTP-запросов.
Порог срабатывания:
Решение:
Повышение значения метрики означает, что кластер не успевает обрабатывать поступающие изменения.
Возможные причины:
http_server_request_latency_count
Количество обработанных HTTP-запросов.
Большое количество ответов с ошибками говорит о проблемах с API или неисправности приложения.
Порог срабатывания: зависит от проекта. Как правило, это больше 20 запросов, обработанных на стороне Tarantool с
ошибкой 4xx.
Решение:
Проверьте работоспособность экземпляров и их сетевую доступность.
Порог срабатывания: зависит от проекта. Как правило, это больше 1 запроса, обработанного на стороне Tarantool с
ошибкой 5xx.
Решение:
Возникла проблема с приложением.
Определите экземпляр, на котором возникла проблема, проверьте файлы логов.
Обслуживание
В этой главе описано, как обслуживать систему TDG, в том числе сохранять
резервные копии данных и настроек, собирать сведения для отладки и выполнять
другие действия.
Резервное копирование
Создание резервной копии
Для создания резервной копии кластера TDG, включая пользовательские данные
и конфигурацию кластера, скопируйте и сохраните следующие файлы и директории из
рабочих директорий всех экземпляров кластера:
файлы-снимки (*.snap);
WAL-файлы (*.xlog);
файл .tarantool.cookie;
директорию /config.
Инструкции по резервному копированию экземпляров Tarantool приведены в
документации Tarantool.
Восстановление из резервной копии
Для восстановления кластера TDG из резервной копии поместите содержимое
резервной копии каждого экземпляра в соответствующую рабочую директорию.
Содержимое резервной копии экземпляра включает:
файлы-снимки (*.snap);
WAL-файлы (*.xlog);
файл .tarantool.cookie;
директорию /config.
После этого запустите кластер.
Управление кластером
В этой главе рассказано, как управлять кластером TDG: изменять топологию,
добавляя и исключая узлы, задавать настройки восстановления после сбоев
(failover) и так далее.
Добавление узлов в кластер
Добавление нового узла (экземпляра) в кластер TDG – это фактически та же
операция развертывания.
В этом примере мы возьмем уже развернутый кластер TDG,
развернем новый экземпляр
TDG и настроим его через веб-интерфейс,
создав новый набор реплик с кластерной ролью «storage».
Чтобы развернуть новый экземпляр, требуются те же ресурсы, что и для
первоначального развертывания кластера: пакет tar.gz и инструмент
Ansible с предопределенными файлом инвентаря и конфигурацией плейбука.
Перейдите в директорию развертывания,
извлеченную ранее из пакета tar.gz, и отредактируйте файл инвентаря
Ansible hosts.yml. Добавьте описание и параметры нового экземпляра. В
приведенном ниже примере кода параметры, которые нужно заполнить, отмечены
комментариями # <-- Добавьте....
children:
tdg_group:
### Instances ###
hosts:
...
storage_3: # <-- Добавьте новый экземпляр и параметры конфигурации для него
config:
advertise_uri: "172.19.0.2:3005"
http_port: 8085
memtx_memory: 1073741824 # 1024 МБ
children:
### Machines ###
vm1:
hosts:
stateboard_instance:
core:
runner_1:
storage_1:
storage_2:
storage_3: # <-- Добавьте этот экземпляр к hosts на vm1
vars:
ansible_host: "172.19.0.2"
Важно
Внимательно проверьте следующие параметры при редактировании hosts.yml:
cartridge_package_path — используйте ту же версию пакета, что и при
первоначальном развертывании кластера.
cartridge_cluster_cookie — cookie должен быть тем же, что и во время
первоначального развертывания, иначе новый экземпляр не будет включен в
кластер.
Выполните развертывание нового экземпляра, используя плейбук
deploy_without_topology.yml:
$ ansible-playbook -i hosts.yml --limit storage_3 playbooks/deploy_without_topology.yml
Параметр --limit указывает, что шаги плейбука следует применить только к
конкретному экземпляру, не затрагивая другие экземпляры.
Откройте или обновите страницу с интерфейсом TDG. В нашем примере она
находится по адресу http://172.19.0.2:8081.
Новый экземпляр появится на вкладке Cluster в разделе Unconfigured servers.
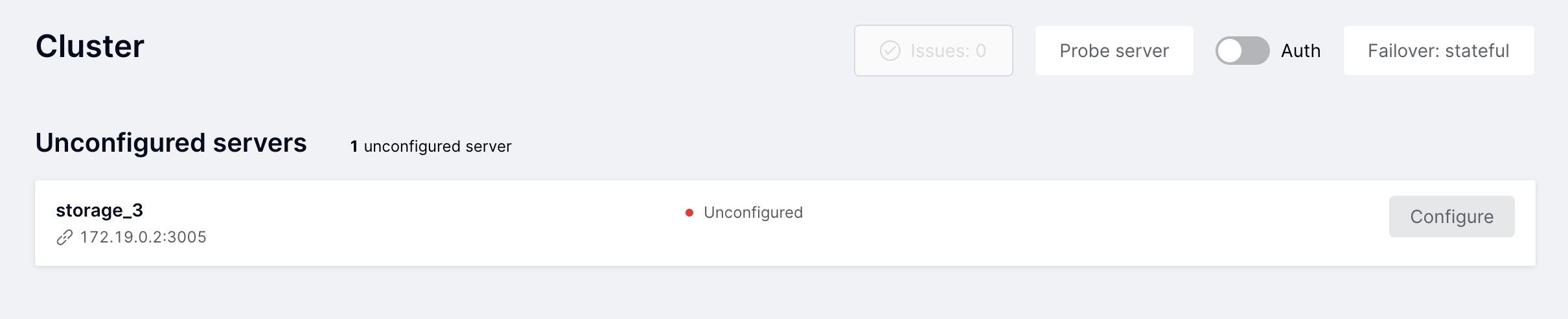
Последний шаг — создание нового набора реплик с ролью «storage». Нажмите
Configure напротив экземпляра «storage_3». В диалоговом окне
Configure server укажите следующие параметры и нажмите Create replica set:
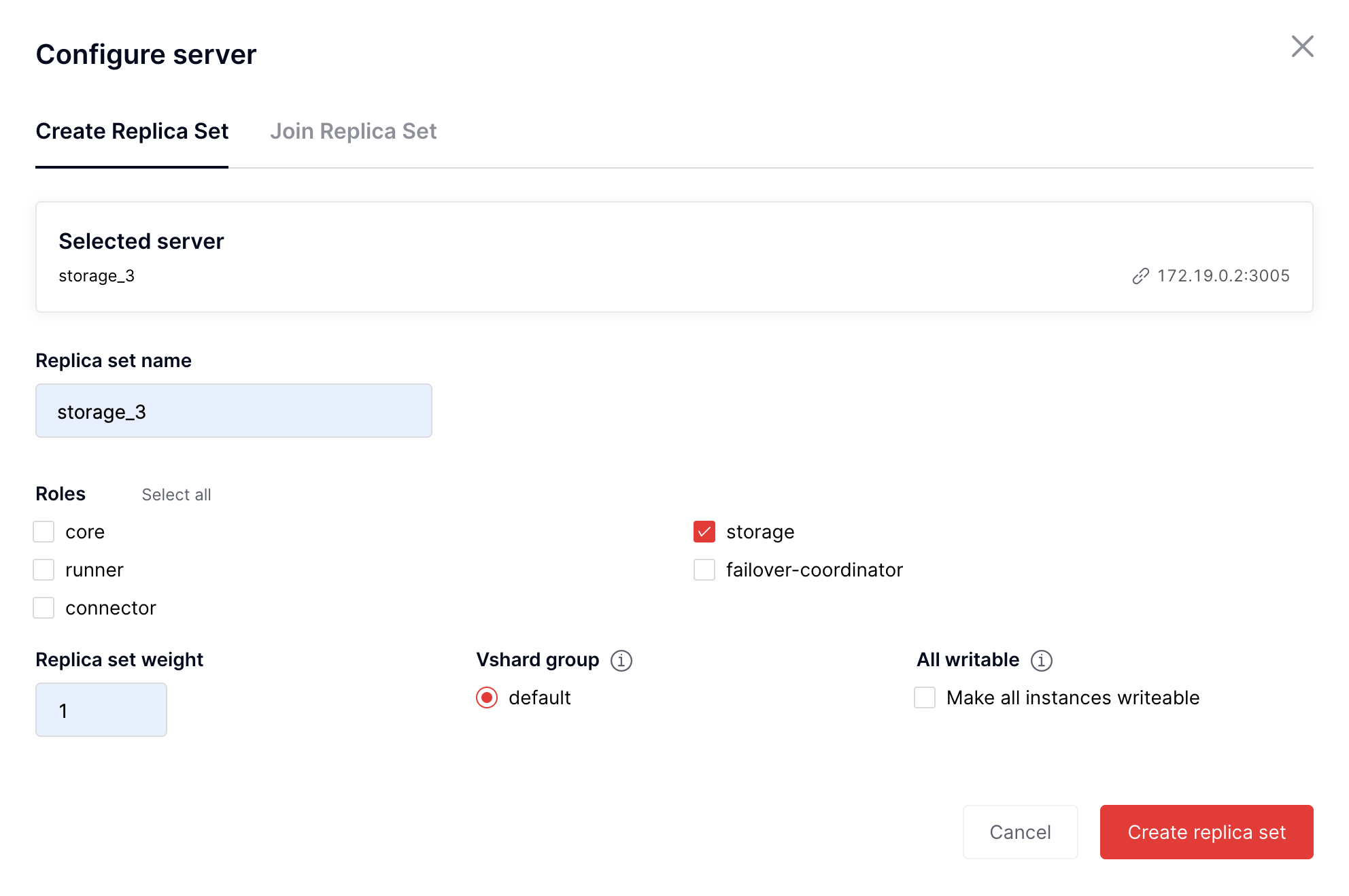
Значение параметра Replica set weight должно быть таким же, как и в
остальных наборах реплик с ролью «storage». Тогда после добавления нового
хранилища запустится автоматическая балансировка данных между всеми
хранилищами.
Вы можете проверить, корректно ли была проведена балансировка, обратившись к
параметру Buckets. Его значение должно совпадать для всех экземпляров с
ролью «storage» на одном сервере (172.19.0.2 в этом примере).
Балансировка займет некоторое время, поэтому результат в веб-интерфейсе
появится не сразу: немного подождите и обновите страницу.

Руководство разработчика
В этом документе объясняется, как разработчику пользоваться системой Tarantool Data Grid (TDG).
Hello world на Lua
Из этого руководства вы узнаете, как настраивать модель данных, выполнять
запросы и создавать хранимые процедуры на языке Lua.
Для начала вам понадобится запущенный экземпляр TDG.
Можно запустить TDG в Docker-контейнере
или же развернуть его на локальной машине
вручную
или с помощью Ansible.
Затем вы сможете:
настроить модель данных;
выполнить запрос данных;
написать хранимые процедуры.
Настройка модели данных
В этом руководстве используется модель данных, содержащая два типа объектов:
музыкальные группы и исполнители. У каждой музыкальной группы есть
название, жанр и год ее создания. Для исполнителей указываются имена, страны
происхождения и инструменты, на которых они играют.
Вот пример такой модели:
[
{
"name": "MusicBand",
"type": "record",
"fields": [
{"name": "name", "type": "string"},
{"name": "genre", "type": {"type":"array", "items":"string"}},
{"name": "wasformed", "type":"long"}
],
"indexes": ["name", "genre", "wasformed"]
},
{
"name": "Artist",
"type": "record",
"fields": [
{"name": "fullname", "type": "string"},
{"name": "country", "type": "string"},
{"name": "instruments", "type": {"type":"array", "items":"string"}}
],
"indexes": ["fullname"]
}
]
В меню слева есть вкладка Model. Откройте ее и вставьте модель в поле
Request. Нажмите Submit:
Вы настроили модель данных. Теперь можно выполнять загрузку, выборку и удаление данных.
Загрузка данных в TDG
В меню слева есть вкладка под названием Graphql. Откройте эту вкладку,
выберите необходимую схему default и удалите всё из поля запроса:
В поле запроса вставьте такие данные:
mutation all {
rammstein:MusicBand(insert: {
name: "Rammstein",
genre: ["metal", "industrial", "gothic"],
wasformed: 1994}) {
name
genre
wasformed
}
linkinpark:MusicBand(insert: {
name: "Linkin Park",
genre: ["alternative", "metal"],
wasformed: 1996}) {
name
genre
wasformed
}
blacksabbath:MusicBand(insert: {
name: "Black Sabbath",
genre: ["gothic", "metal"],
wasformed: 1968}) {
name
genre
wasformed
}
deeppurple:MusicBand(insert:{
name: "Deep Purple",
genre: ["metal", "rock"],
wasformed: 1968}) {
name
genre
wasformed
}
maxkorzh:MusicBand(insert:{
name:"Max Korzh",
genre:["rap", "electro"],
wasformed: 2006}) {
name
genre
wasformed
}
}
Нажмите кнопку воспроизведения, чтобы выполнить запрос:
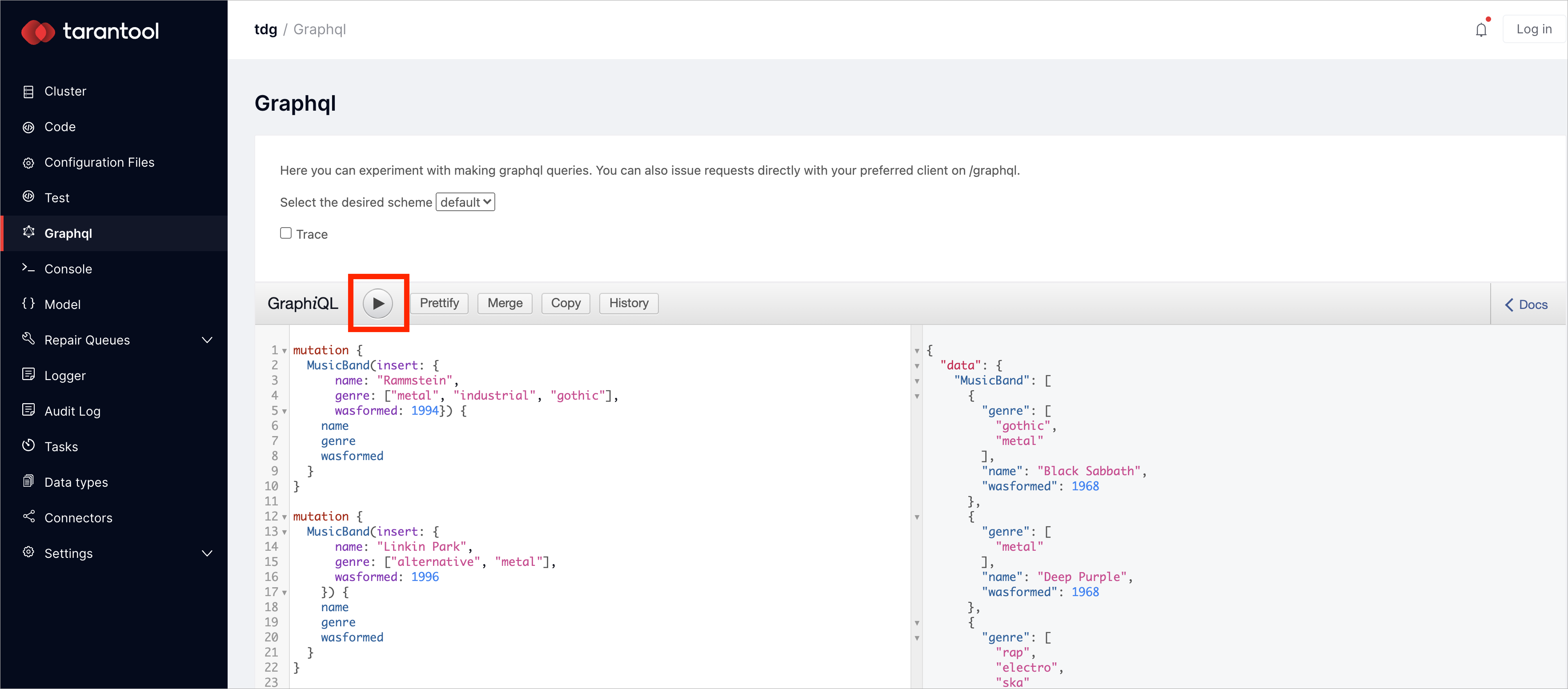
Данные загружены.
Выполнение запросов к данным
Чтение данных
Читать данные можно на вкладке Graphql. Убедитесь, что выбрана схема
default, удалите всё из поля слева и напишите запрос на выборку всех
музыкальных групп:
query {
MusicBand {
name
wasformed
genre
}
}
Нажмите кнопку воспроизведения. В поле справа вы увидите результат:
Выполните выборку данных по первичному ключу:
query {
MusicBand(name:"Black Sabbath") {
name
wasformed
genre
}
}
Нажав на кнопку воспроизведения, вы получите всю сохраненную информацию о группе Black Sabbath:
Изменение данных
Добавьте еще один музыкальный жанр для одной из групп.
Для этого на вкладке Graphql внесите информацию о двух жанрах для группы:
mutation {
MusicBand(insert:{
name: "Deep Purple",
genre: ["metal", "rock"],
wasformed: 1968}) {
name
genre
wasformed
}
}
Нажмите кнопку воспроизведения. Информация о группе Deep Purple обновилась.
Удаление данных
На вкладке Graphql напишите запрос на удаление всех данных об одной из музыкальных групп:
mutation {
MusicBand(name:"Linkin Park" delete:true) {
name
genre
wasformed
}
}
Нажмите кнопку воспроизведения. Все данные о музыкальной группе Linkin Park удалены.
Написание хранимых процедур
Hello World
В меню слева есть вкладка Code. Откройте эту вкладку и создайте
директорию src. В директории src создайте файл hello.lua,
представляющий собой Lua-модуль для экспорта функций:
function hello()
return "Hello World"
end
return {
hello = hello
}
Нажмите Apply:
Для этого Lua-модуля необходим GraphQL-интерфейс.
На вкладке Code создайте файл под названием services.yml и задайте сигнатуру GraphQL-вызова:
hello_world:
doc: "Hello World script"
function: hello.hello
return_type: string
Нажмите Apply:
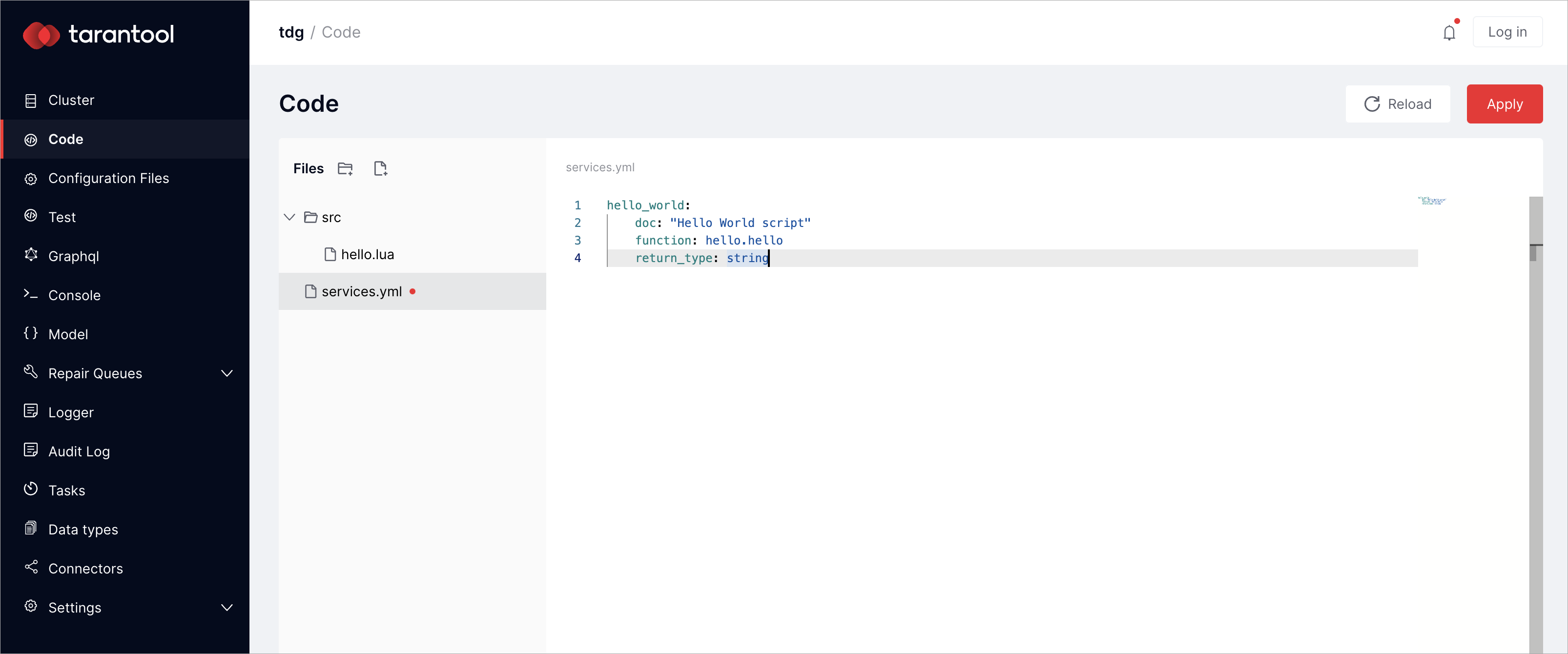
Код проверяется и загружается в кластер. Если произойдет ошибка, в правом
нижнем углу вы увидите уведомление с ее описанием.
Откройте вкладку Graphql, выберите необходимую схему default и вызовите хранимую процедуру:
В поле справа вы получите результат:
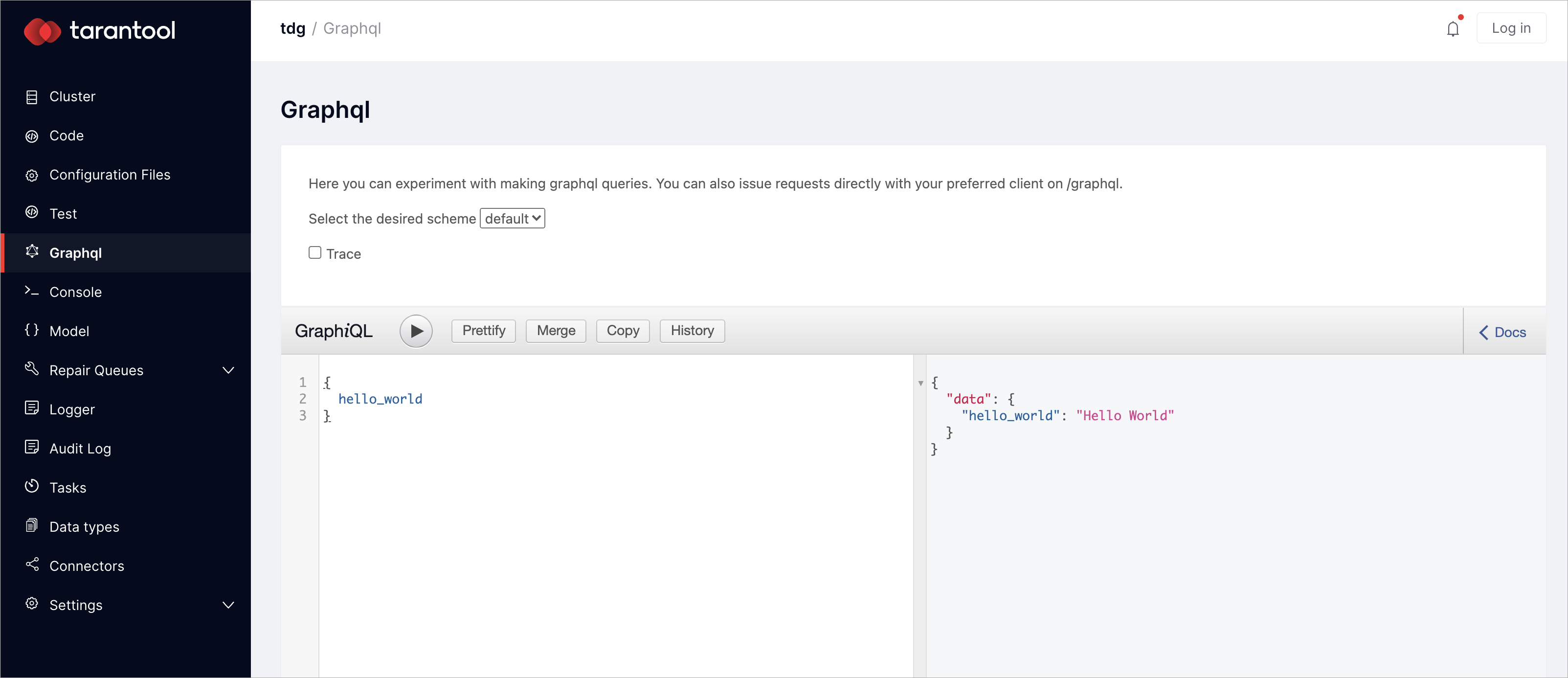
Плейлист со случайным порядком воспроизведения
В наборе данных есть разные музыкальные группы. Создайте хранимую процедуру
для создания плейлиста, который будет воспроизводить песни в случайном
порядке.
На вкладке Code откройте директорию src и создайте файл под
названием playlist.lua. В этом файле задайте логику для создания
плейлиста со случайным порядком воспроизведения:
local repository = require('repository')
function shuffle(tbl)
for i = #tbl, 2, -1 do
local j = math.random(i)
tbl[i], tbl[j] = tbl[j], tbl[i]
end
return tbl
end
function playlist()
local result = repository.find("MusicBand", {})
result = result or {}
shuffle(result)
return result
end
return {
playlist=playlist
}
В файле services.yml задайте сигнатуру GraphQL-вызова:
playlist:
doc: "Return randomized playlist"
function: playlist.playlist
return_type: {"type":"array", "items":"MusicBand"}
Перейдите на вкладку Graphql и выполните такую команду:
Нажмите кнопку воспроизведения. В результате вы получите плейлист, в котором группы представлены в случайном порядке:
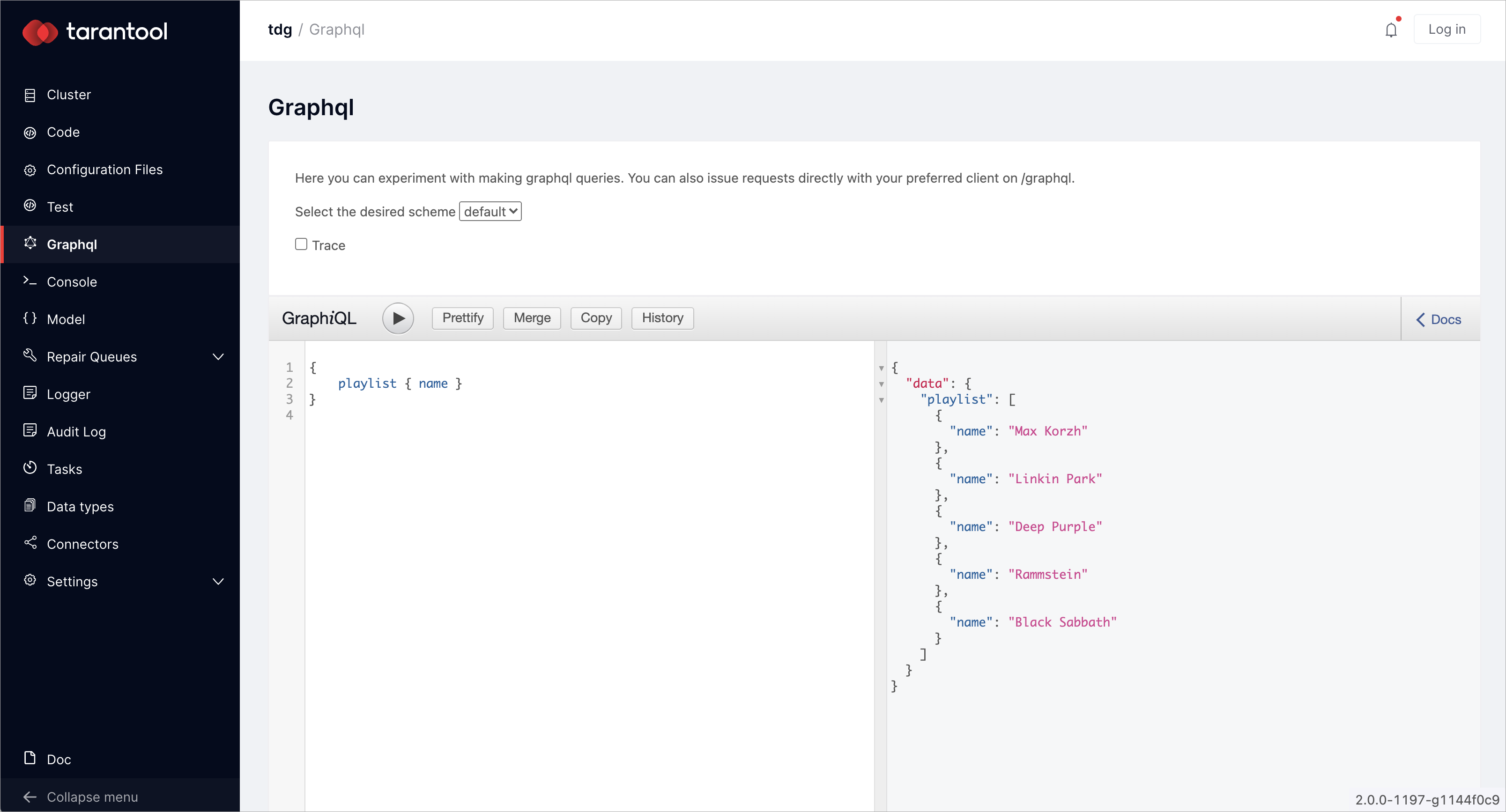
Выполняя эту команду, вы каждый раз будете получать новый плейлист.
Модель данных
В этой главе подробно описана структура модели данных TDG, а также перечислены доступные способы работы с ней – в файле
и в веб-интерфейсе.
В главе рассмотрен пример создания модели данных и её загрузки в TDG.
Для выполнения примера требуется настроенный кластер TDG.
Модель данных включает в себя:
структуру объектов для заданной предметной области;
описание связей между объектами;
ограничения, которые накладываются на объекты.
В TDG для описания модели данных используются язык Avro Schema,
а также расширения, разработанные специально для системы TDG.
Схема в стандарте Avro Schema – это JSON-файл с расширением .avsc, содержащий описание типов данных для объектов и для их полей.
Приложение использует схему в качестве формата и понимает ее, как массив типов объектов:
[
{"name": "TypeA", "type": "record", ...},
{"name": "TypeB", "type": "record", ...}
]
Все типы объектов соответствуют стандарту Avro Schema, за исключением расширений для системы TDG.
Расширения обратно совместимы, а модель, описанная с их помощью, успешно преобразуется
стандартными парсерами (синтаксическими анализаторами).
Для начала зададим модель данных с двумя типами объектов – Country (страна) и City (город).
В качестве примера возьмем следующую диаграмму объектов:
Теперь представим модель с диаграммы в виде схемы данных Avro:
[
{
"name": "Country",
"type": "record",
"doc": "Страна",
"fields": [
{"name": "title", "type": "string"},
{"name": "phone_code", "type": ["null", "string"]}
],
"indexes": ["title"],
"relations": [
{ "name": "city_relation", "to": "City", "count": "many", "from_fields": "title", "to_fields": "country" }
]
},
{
"name": "City",
"type": "record",
"doc": "Город",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"},
{"name": "postcodes", "type": {"type":"array", "items":"int"}}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population",
"postcodes"
]
}
]
где
name – название типа объекта;
type – вид схемы;
doc – текстовое описание для типа объекта;
fields – поля для типа объекта вместе с соответствующими им типами данных.
Примечание
Если в модели данных есть опциональное поле, его тип данных описывают с помощью объединяющего массива union.
Такой массив содержит основной тип данных для этого поля и тип null.
Пример:
{"name": "phone_code", "type": ["null", "string"]}
indexes – индексы, которые используются при выполнении операций.
Первый по счету индекс в списке является первичным.
Поле indexes – расширение TDG для задания ключей;
relations – вид связи между объектами.
В этой модели данных типы объектов Country и City имеют связь один ко многим, так как в одной стране обычно
расположено много городов. Поле relations – расширение TDG для задания отношений между объектами.
Описания всех доступных расширений TDG приведены в разделе Расширения модели данных.
Чтобы применить модель данных и делать запросы к данным, нужно загрузить модель данных
в TDG. Основные способы загрузки данных:
через веб-интерфейс на вкладке Model;
в файле .avsc, который будет запакован в архив вместе с файлом конфигурации.
Загрузка через веб-интерфейс
Чтобы загрузить модель данных через веб-интерфейс TDG, выполните следующие шаги:
Откройте веб-интерфейс на экземпляре, входящем в набор реплик
с кластерной ролью runner. Если вы используете уже
развернутый TDG-кластер, URL экземпляра
будет следующий: http://172.19.0.2:8082.
В веб-интерфейсе выберите вкладку Model.
Вставьте созданную модель данных в поле Request.
Нажмите Submit. Если модель данных загружена успешно, в окне Response появится ответ OK.
Загрузка в составе zip-архива
Загрузить модель данных можно также в составе zip-архива вместе с файлом конфигурации. Для этого:
Упакуйте в zip-архив:
модель данных в файле с расширением .avsc, например, model.avsc;
файл конфигурации config.yml.
Загрузите архив в TDG согласно инструкции.
Расширения для системы TDG дополняют спецификацию Avro Schema.
Эти расширения позволяют:
Задание отношений между объектами
Явно задавать связи между объектами нужно:
Чтобы указать такую связь, используется поле relations в теле описания типа объекта.
Это поле игнорируется существующими парсерами Avro Schema.
Связываемые поля (внешние ключи в терминологии SQL) должны быть объявлены на уровне типов объектов.
Например, чтобы задать связь между страной и ее городами, требуются следующие поля:
Пример поля relations из заданной ранее модели данных:
{
"relations": [
{
"name": "city_relation",
"to": "City",
"count": "many",
"from_fields": "title",
"to_fields": "country"
},
...
]
}
где:
name – название поля, через которое можно получить связанные объекты в GraphQL-запросах;
to – тип объекта, с которым устанавливается связь;
count – вид связи. Возможные значения:
from_fields – название поля или индекса, содержащего первичный ключ. Возможные значения:
название индекса ("from_fields": "title");
название поля ("from_fields": "field_name");
список названий полей ("from_fields": ["field_name1", "field_name2"]);
to_fields – название поля или индекса, содержащего внешний ключ. Возможные значения:
название индекса ("to_fields": "country");
название поля ("to_fields": "field_name");
список названий полей ("to_fields": ["field_name1", "field_name2"]).
Все параметры поля обязательные.
Поле relations можно задать как с одной стороны отношения, так и с обеих.
Поле указывается только в одном типе объекта, когда запрашивать данные в обратном направлении не требуется.
Дополним модель данных еще одним полем relations (City), чтобы можно было запрашивать данные в обоих направлениях.
Полный пример может выглядеть так:
[
{
"name": "Country",
"type": "record",
"doc": "Страна",
"fields": [
{"name": "title", "type": "string"},
{"name": "phone_code", "type": ["null", "string"]}
],
"indexes": ["title"],
"relations": [
{"name": "city_relation", "to": "City", "count": "many", "from_fields": "title", "to_fields": "country"}
]
},
{
"name": "City",
"type": "record",
"doc": "Город",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"},
{"name": "postcodes", "type": {"type":"array", "items":"int"}}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population",
"postcodes"
],
"relations": [
{"name": "country_relation", "to": "Country", "count": "one", "from_fields": "country", "to_fields": "title"}
]
}
]
Задание индексов (ключей)
Для задания индексов используется поле indexes в описании типа объекта.
Поле не меняет поведение, регулируемое стандартом Avro Schema, а добавляет дополнительные
ограничения на хранение и запросы.
Если для типа объекта указаны индексы, TDG создает спейсы под этот тип.
Примечание
Если поле indexes содержит список индексов, первичным индексом считается первый индекс в списке.
Синтаксис поля indexes:
{
"indexes": ["<index1>", <"index2">, <"index3">, ...]
}
Каждый индекс в поле indexes может быть задан в виде:
строки с названием поля, по которому будет построен индекс ("indexes": ["title"]);
словаря, на основе которого строятся составной индекс или индекс по полю вложенного объекта.
Такой индекс указывается в следующем формате:
{
"name": "<index_name>",
"parts": [
{"path": "<field_name>", "collation": "<collation_type>"},
{"path": "<field_name>", "collation": "<collation_type>"},
...
]
}
где:
name – название индекса, не совпадающее с именами существующих полей;
parts – части индекса. Включает в себя:
path – названия полей, по которым строится индекс;
collation (опционально) – способ сравнения строк. Возможные значения:
binary (по умолчанию) – бинарное сравнение ('A' < 'B' < 'a');
case_sensitivity – сравнение, зависящее от регистра ('a' < 'A' < 'B');
case_insensitivity – сравнение, не зависящее от регистра (('a' = 'A') < 'B' и 'a' = 'A' = 'á' = 'Á').
Примечание
Существуют ограничения при использовании в поле indexes мультиключевого индекса – индекса по полю, содержащему массив.
Подробная информация об этих ограничениях приведена в разделе Запросы по мультиключевому индексу.
Пример составного индекса
{
"name": "City",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"},
{"name": "postcodes", "type": {"type":"array", "items":"int"}}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population",
"postcodes"
]
}
Пример индексации по полю вложенного объекта
Иногда требуется построить индекс по полю не из самого объекта, а из его вложенного объекта.
Вложенный объект при этом создается, чтобы сгруппировать логически набор стандартных полей.
Примечание
Тип объекта можно использовать как вложенный только в случае, если у этого типа не задано поле indexes.
Например, представьте, что каждая страна (Country) в примере содержит дополнительный блок информации для туристов.
Создадим новый тип объекта Info и сложный индекс в типе объекта Country.
Тип объекта Info включается здесь непосредственно в тип объекта Country, поэтому индекс может сослаться на поле из Info:
[
{
"name": "Info",
"type": "record",
"doc": "Информация для туристов",
"fields": [
{"name": "id", "type": "long"},
{"name": "info_text", "type": "string"}
]
},
{
"name": "Country",
"type": "record",
"doc": "Страна",
"fields": [
{"name": "title", "type": "string"},
{"name": "info", "type": "Info"},
{"name": "phone_code", "type": ["null", "string"]}
],
"indexes": [
"title",
{"name": "info_id", "parts": ["info.id"]}
]
}
]
Распределение объектов по хранилищам
В случае распределенного хранилища данных объекты распределяются с
использованием хеш-функции от первичного ключа объекта.
Указать такой индекс можно в поле affinity.
Примечание
Поле affinity может содержать только те поля, которые входят в первичный ключ (в том числе составной).
Пример
Перед загрузкой модели с новым полем affinity удалите старую модель данных.
Кроме того, проверьте список спейсов во вкладке Settings > Unlinked spaces в веб-интерфейсе TDG.
Если в списке есть спейсы с типом объекта City, удалите их, чтобы избежать ошибки при загрузке новой модели.
Теперь дополните модель данных новым полем и загрузите модель в TDG:
{
"name": "City",
"type": "record",
"doc": "Город",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"},
{"name": "postcodes", "type": {"type":"array", "items":"int"}}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population",
"postcodes"
],
"affinity": ["country"]
}
В примере города одной и той же страны размещены физически на одном хранилище.
Поле affinity при этом содержит индекс из составного первичного ключа.
Атрибуты полей
Расширение для TDG дополняет список стандартных атрибутов полей Avro Schema:
default_function (function) – задает для поля динамическое значение по умолчанию.
Значение атрибута – это функция, файл с которой хранится в директории src в корне проекта.
При вставке в спейс новой записи вызывается указанная функция, и результат функции становится значением для данного поля.
Атрибут не стоит путать со стандартным атрибутом default, который задает для поля статическое значение;
auto_increment (boolean) – значение true делает поле автоинкрементным. По умолчанию: false.
Может использоваться в качестве числового идентификатора, уникального для объектов данного типа, даже при
шардировании базы данных.
Автоинкрементное поле обязательно должно иметь тип long.
Атрибут несовместим с атрибутами default и default_function.
Пример
Расширьте тип объекта City этими атрибутами:
Обновленные поля объекта могут выглядеть так:
{
"name": "City",
"type": "record",
"fields": [
{"name": "city_id", "type": "long", "auto_increment": true},
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int", "default" : "count_population.call"}},
...
],
...
}
Логический тип – это простой или составной тип данных Avro, содержащий дополнительные атрибуты для представления
нового типа данных для поля.
Чтобы объявить в модели поле с логическим типом, используется атрибут logicalType.
Поля этих типов можно использовать при построении любых индексов,
кроме мультиключевых.
По умолчанию для логических типов задается строковый тип данных.
TDG поддерживает следующие логические типы:
Date – дата. Хранится в виде int. Формат записи: YYYY-MM-DDZ;
Time – время. Хранится в виде int. Формат записи: HH:MM:SSZ;
Datetime – дата и время. Хранится в виде int. Форматы записи:
дата и время с миллисекундами: YYYY-MM-DDTHH:MM:SS.sssZ;
дата и время с микросекундами: YYYY-MM-DDTHH:MM:SS.ssssssZ;
дата и время с наносекундами: YYYY-MM-DDTHH:MM:SS.sssssssssZ.
Примечание
Начиная с версии TDG 2.7, тип DateTime объявлен устаревшим,
используйте вместо него тип Timestamp.
Timestamp – тип для работы с датой и временем на основе Tarantool-модуля datetime;
Decimal – вычисления с точными числами. Пример записи: 10.001. Тип использует Tarantool-модуль decimal;
UUID – уникальный идентификатор. Формат записи: 00000000-0000-0000-0000-000000000000.
Тип использует Tarantool-модуль uuid.
Примеры объявления полей с логическими типами:
[
{
"name": "LogicalTypes",
"type": "record",
"fields": [
{"name": "id", "type": {"type": "string", "logicalType": "Timestamp"}},
{"name": "datetime", "type": ["null", {"type": "string", "logicalType": "DateTime"}]},
{"name": "time", "type": ["null", {"type": "string", "logicalType": "Time"}]},
{"name": "date", "type": ["null", {"type": "string", "logicalType": "Date"}]},
{"name": "decimal", "type": ["null", {"type": "string", "logicalType": "Decimal"}]},
{"name": "uuid", "type": ["null", {"type": "string", "logicalType": "UUID"}]}
],
"indexes": ["id", "datetime", "time", "date", "decimal", "uuid"]
}
]
Авторизация
Авторизация и отправка HTTP-запроса
Чтобы HTTP-запрос был обработан, он должен пройти авторизацию по токену приложений.
Заранее сгенерированный (например, в веб-интерфейсе TDG) токен приложений
необходимо передать в HTTP-заголовке запроса по схеме Authorization: Bearer <token>, где:
Пример
Authorization: Bearer 2fc136cf-8cae-4655-a431-7c318967263d
Важно
Токен должен быть сформирован в кластере TDG, к которому осуществляется доступ,
иначе он не пройдет авторизацию. Кроме того, ему должны быть выданы соответствующие права
для выполнения операций чтения и записи с объектами модели данных.
В HTTP-запросе в заголовке указывается один из двух вариантов схемы данных:
схема default (по умолчанию) – работа с пользовательскими данными.
Если схема данных в заголовке пропущена, для запроса используется схема default.
схема admin – управление настройками TDG.
Для выполнения запросов в примерах ниже используется утилита curl.
Пример запроса на добавление данных в схеме default:
curl --request POST \
--url http://172.19.0.2:8080/graphql \
--header 'Authorization: Bearer 2fc136cf-8cae-4655-a431-7c318967263d' \
--data '{"query":"mutation{ Country(insert: { title: \"Poland\", phone_code:\"+48\"}) {title phone_code}}"}'
Пример запроса в схеме admin:
curl --request POST \
--url http://172.19.0.2:8080/graphql \
--header 'Authorization: Bearer 2fc136cf-8cae-4655-a431-7c318967263d' \
--header 'schema: admin' \
--header 'Content-Type: application/json' \
--data '{"query":"mutation{ token{ add(name:\"App01\", role:\"user\") { name, token, created_at role } } } "}'
В запросе внешнее приложение авторизуется, используя свой заранее созданный токен,
и выпускает (генерирует) новый токен App01.
Подробнее о генерации токена приложений через GraphQL API рассказывается в разделе
Добавление токена Руководства администратора.
Авторизация коннекторов с использованием токена приложений
Приложения, использующие для доступа к данным в TDG
коннекторы для языков программирования,
авторизуются по токенам приложений.
Подробнее о настройке таких коннекторов, запросах к данным и вызове сервисов рассказано
в главе Использование бинарного протокола iproto.
Чтобы авторизовать коннектор, нужно указать токен приложения непосредственно в вызываемой функции в дополнительном
аргументе credentials. Например, запрос на вставку объекта через интерфейс репозитория
будет выглядеть следующим образом:
repository.put(type_name, obj, options, context, credentials)
где:
type_name – тип объекта;
object – объект для вставки;
options – параметры для управления запросом;
context – контекст выполнения запроса;
credentials – таблица с данными токена приложения. Единственный обязательный параметр в таблице –
это ключ токена.
Пример авторизации с использованием токена приложений на языке Python:
from tarantool.connection import Connection
conn = Connection(server.host, server.binary_port, user='tdg_service_user', password='')
admin_token = {'token': '2fc136cf-8cae-4655-a431-7c318967263d'}
obj = {'id': '12567', 'name': 'John'}
conn.call('repository.put', 'Users', obj, {}, {}, admin_token)
Запрос из примера добавит новый объект Users с первичным ключом id, равным 12567,
если такой ещё не существует.
Запросы данных
Глава посвящена запросам данных в TDG.
В ней описаны логика и синтаксис запросов, а также представлено несколько сценариев использования.
В качестве среды для выполнения запросов вы будете использовать уже
развернутый TDG-кластер.
Чтобы загрузить данные в TDG, а затем получать к ним доступ через запросы
GraphQL, нужно сначала определить модель данных.
В этом руководстве используется модель из раздела по настройке модели данных:
Определение модели данных.
Загрузка модели данных.
Модель данных загружена. Теперь можно добавлять, выбирать и удалять данные.
Загрузить данные в TDG можно с помощью мутации GraphQL:
В меню слева выберите вкладку GraphQL.
Выберите default в качестве нужной схемы и очистите поле запроса.
В поле слева вставьте следующий запрос:
mutation all {
russia:Country(insert: {
title: "Russia",
phone_code: "+7"}) {
title
phone_code
}
germany:Country(insert: {
title: "Germany",
phone_code: "+49"}) {
title
}
moscow:City(insert: {
title: "Moscow",
country: "Russia",
population: 12655050,
capital: true,
postcodes: [101000, 119021, 115035, 109028, 109004]}) {
title
country
population
capital
postcodes
}
spb:City(insert: {
title: "Saint Petersburg",
country: "Russia",
population: 5384342,
capital: false,
postcodes: [191193, 191040, 195275, 983002, 983015]}) {
title
country
population
capital
postcodes
}
tver:City(insert: {
title: "Tver",
country: "Russia",
population: 424969,
capital: false,
postcodes: [170006, 170100, 170037, 170028]}) {
title
country
population
capital
postcodes
}
berlin:City(insert: {
title: "Berlin",
country: "Germany",
population: 3520031,
capital: true,
postcodes: [10115, 110117, 10245, 10367]}) {
title
country
population
capital
postcodes
}
munich:City(insert: {
title: "Munich",
country: "Germany",
population: 1450381,
capital: false,
postcodes: [80339, 80336, 80639, 80798]}) {
title
country
population
capital
postcodes
}
dresden:City(insert: {
title: "Dresden",
country: "Germany",
population: 547172,
capital: false,
postcodes: [40210, 40212, 40595, 40627]}) {
title
country
population
capital
postcodes
}
}
Выполните мутацию, нажав кнопку Execute Query (Выполнить запрос):
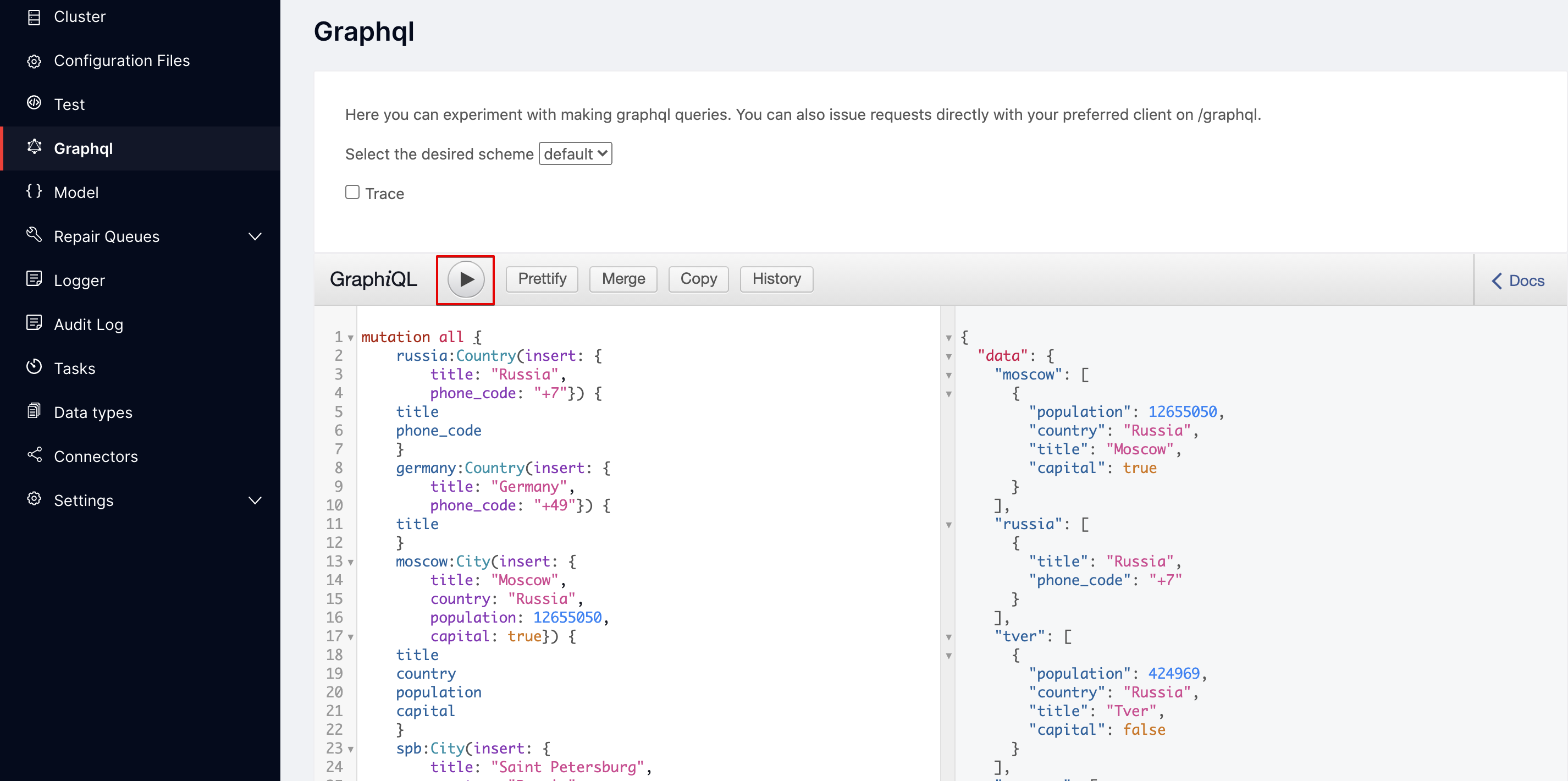
Данные загружены, как видно по ответу системы в поле справа.
Вот типичные сценарии использования, связанные с запросами данных:
Примеры запросов GraphQL, приведенные ниже, проще всего запустить через
встроенный клиент GraphiQL в веб-интерфейсе TDG. Отправляя запросы на доступ
к данным, используйте схему по умолчанию (default):
В меню слева выберите вкладку GraphQL.
Выберите default в качестве нужной схемы, очистите поле запроса и вставьте код примера.
Общий запрос объектов по типу
Чтобы выбрать объекты определенного типа, укажите имя типа, а также нужные
вам поля, значения которых требуется получить. Не обязательно указывать все
поля объекта, определенные в модели данных. Пример:
query {
Country {
title
}
}
Ответ – объект JSON, содержащий массив со всеми записями типа Country.
Для каждой записи ответ включает только указанные в запросе поля.
{
"data": {
"Country": [
{
"title": "Russia"
},
{
"title": "Germany"
}
]
}
}
Запросы по первичному индексу
С помощью первичного индекса можно выбрать отдельный объект:
query {
Country(title: "Germany") {
title
phone_code
}
}
Запросы по вторичному индексу
У запросов по вторичному индексу такой же синтаксис:
query {
City(country: "Russia") {
title
country
population
}
}
Запросы по составному индексу
Чтобы выполнить запрос по составному индексу, укажите массив значений полей:
query {
City(primary: ["Saint Petersburg", "Russia"]) {
title
country
population
}
}
Запросы по мультиключевому индексу
Мультиключевой индекс (multikey index) – это индекс по полю, которое содержит массив.
Если под условие запроса по мультиключевому индексу подходят несколько элементов массива, будет несколько ключей,
указывающих на один и тот же объект.
Такой объект вернется несколько раз, и это нужно
учитывать при составлении запросов и при обработке полученных результатов.
Кроме того, есть ряд ограничений при работе с мультиключевыми индексами:
Примечание
Мультиключевой индекс не может быть первичным.
Мультиключевой индекс не может быть составным.
Мультиключевой индекс невозможно построить по полю, содержащему сложные типы, например, DateTime, Date,
Time и Decimal.
Пример:
{
City(postcodes_gt: 983000) {
title
postcodes
}
}
Запрос вернет объект дважды:
{
"data": {
"City": [
{
"title": "Saint Petersburg",
"postcodes": [
191193,
191040,
195275,
983002,
983015
]
},
{
"title": "Saint Petersburg",
"postcodes": [
191193,
191040,
195275,
983002,
983015
]
}
]
}
}
Операторы сравнения
Операторы сравнения представлены суффиксами, которые добавляются к именам индексов.
Поддерживаются следующие операторы:
_gt (больше)
_ge (больше или равно)
_lt (меньше)
_le (меньше или равно)
Пример:
query {
City(population_ge: 1000000) {
title
country
population
}
}
При поиске по строковому индексу поддерживаются операторы:
В шаблонах можно использовать подстановочный символ %.
query {
City(title_like: "M%") {
title
country
}
}
Множественные условия
В одном запросе можно сочетать несколько условий. Тогда TDG будет искать
объекты, удовлетворяющие всем условиям одновременно (логическое И).
Указывайте в условиях только индексированные поля.
query {
City(country: "Russia", population_lt: 1000000) {
title
country
population
}
}
Запросы по отношениям
Чтобы выбрать объекты по отношениям, используйте тот же синтаксис, что и в общем запросе объектов по типу.
В примере модели между объектами Country
и City есть связь один ко многим. Поэтому вы можете одним запросом
получить данные как о стране, так и о городах.
query {
Country(title: "Russia") {
title
city {
title
population
}
}
}
Пример ответа:
{
"data": {
"Country": [
{
"title": "Russia",
"city": [
{
"title": "Moscow",
"population": 12655050
},
{
"title": "Saint Petersburg",
"population": 5384342
},
{
"title": "Tver",
"population": 424969
}
]
}
]
}
}
Запросы по версии
В TDG реализовано версионирование объектов, поэтому в условие запроса можно
включать версии. Подробности вы найдете на этой странице: Версионирование.
Выбор экземпляров для выполнения запросов
В TDG можно определить, на каких узлах будет выполняться запрос.
Поддерживаются следующие параметры:
mode – установка целевого экземпляра для выполнения запроса.
Тип: string. Значения:
prefer_replica – установка реплики в качестве целевого экземпляра для выполнения запроса.
Тип: boolean. Значения:
true – предпочитаемой целью будет одна из реплик.
Если доступной реплики нет, то запрос будет выполнен на мастере.
false (по умолчанию) – запрос будет выполнен на мастер-узле.
Параметр полезен для ресурсозатратных функций, чтобы избежать снижения скорости работы мастер-узлов;
balance – управление балансировкой нагрузки.
Тип: boolean. Значения:
true (по умолчанию) – запросы будут распределяться по всем экземплярам набора реплик по кругу.
При этом, если prefer_replica = true, предпочтение отдается репликам.
false – балансировка отключена.
Чтобы установить эти параметры, используйте в запросе GraphQL-директиву @options:
query {
City @options(mode: read, balance: true) {
title
country
population
}
}
Эти параметры также можно определить в некоторых функциях программного интерфейса репозитория.
Подробности вы найдете на странице Repository API.
Запросы к данным через REST API
В этом разделе описано взаимодействие с хранилищем TDG через REST API.
Здесь вы найдёте примеры HTTP-запросов для распространённых сценариев работы с данными.
Полное описание REST API TDG приведено в
справочнике по REST API.
Для работы с данными через REST API TDG предоставляет HTTP-адреса (endpoints)
вида /data/<TypeName> для типов, объявленных в модели данных.
Например, http://localhost:8081/data/City.
Для получения данных определённого типа через REST API используются GET-запросы.
Через REST API можно выбирать данные по индексам со условиями поиска:
совпадение;
сравнение: больше, больше или равно, меньше, меньше или равно;
совпадение строки с шаблоном (учётом или без учёта регистра);
условие выбора версий для типов, поддерживающих версионирование.
Условия выбора объектов по индексам передаются в HTTP параметрах запроса вида:
<index_name>=<value> для поиска по полному совпадению;
<index_name>_<condition>=<value> для поиска по условию. Здесь <condition> –
постфикс, определяющий оператор сравнения, например,
_ge для условия «больше или равно», like для проверки соответствия строки шаблону.
Полный список доступных параметров приведён в справочнике по REST API.
Рассмотрим реализацию некоторых популярных сценариев доступа к данным через REST API.
Точечный запрос объекта
Точечные запросы предполагают получение одного объекта по уникальному
индексу. Для выполнения точечного запроса по полному совпадению достаточно
выполнить один GET-запрос с параметром <index_name>=<value>, например,
title_index=Berlin:
curl http://localhost:8081/data/City?title_index=Berlin
Примечание
Использование имён индексов, отличных от имён полей, позволяет точно
знать, по какому индексу выполняется запрос и оптимизировать работу
с данными за счёт этого.
Пакетная обработка
В случае выполнения запросов с неизвестным количеством результатов необходимо
учитывать пагинацию – постраничную разбивку
возвращаемых объектов. По умолчанию размер одной страницы равен 10.
Это значит, что ответ на один запрос с условиями будет содержать максимум 10
записей, даже если подходящих объектов больше.
Если вы заранее знаете, сколько объектов хотите получить, вы можете изменить объём
страницы с помощью параметра first. Например, получить 25 объектов, подходящих
под условие выбора:
curl http://localhost:8081/data/City?population_ge=100000&first=25
Если количество результатов заранее неизвестно, нужно реализовать пакетную обработку
(batching) с использованием курсоров. Курсоры позволяют задать начальный объект
страницы.
Например, для получения всех объектов типа необходимо выполнять запросы в цикле
с указанием параметра after - курсора последнего элемента, полученного в предыдущем запросе.
Скрипт для выполнения такого цикла может выглядеть следующим образом:
while true; do
url="http://127.0.0.1:8181/data/City?first=25"
if [[ -n "$cursor" ]]; then
url=$url"&after=$cursor"
fi
res=$(curl -s --url $url)
if [[ $res == "[]" ]]; then break; fi
len=$(echo $res | jq length)
echo $len
cursor=$(echo $res | jq ".[$len - 1].cursor")
done
Порядок возврата результатов
Порядок возврата результатов определяется индексом, используемым для выбора объектов,
и условием выбора:
Если индекс не указан (в запросе нет условий выбора), используется первичный индекс.
Объекты можно запросить в порядке возрастания любого из доступных индексов.
Для этого используется параметр indexed_by=<index_name>:
curl http://localhost:8081/data/City?indexed_by=population&first=25
Примечание
Параметр indexed_by работает только при отсутствии условий выбора объектов.
Если в запросе используется другой индекс для выбора объектов, условие
indexed_by игнорируется.
Использование составных индексов
Если необходима фильтрация объектов по одному полю и сортировка по другому,
рекомендуется использовать составной индекс, содержащий оба этих поля.
Пример: есть тип данных с полями типа string и datetime. Например, «событие»:
у него есть дата и время (datetime) и идентификатор объекта, с которым произошло
событие (string).
Допустим, нужно получить все события, произошедшие с выбранным объектом, по убыванию даты.
Для этого нужен составной индекс, включающий оба поля (object_datetime_index).
Использовать этот индекс для поиска по полному совпадению не получится, поскольку
изначально известен только идентификатор объекта, но не дата.
Поэтому нужно выполнять поиск по условию «меньше или равно» с указанием только
идентификатора объекта:
curl http://localhost:8081/data/Events?object_datetime_index_le="object_id"
Примечание
При необходимости используйте параметры first, after и пакетную обработку
для получения нужного количества объектов.
В этом случае объекты будут фильтроваться только по идентификатору, без условий выбора даты.
Но оператор сравнения «меньше или равно» применяется и к дате, поэтому результаты будут упорядочены
по её убыванию.
При этом результат будет содержать лишние объекты с идентификаторами меньше указанного.
Такие объекты нужно отсеять, отфильтровав массив полученных результатов в коде приложения.
Для вставки данных определённого типа через REST API используются POST-запросы.
Тело POST-запроса должно содержать добавляемый объект в формате JSON.
Пример вызова curl для вставки объекта:
curl --request POST \
--url 'http://localhost:8081/data/City' \
--data '{"title": "Stuttgart","population": 623738,"country":"Germany","capital":false}'
В результате такого запроса возвращается вставленный объект в формате JSON.
Для ускорения работы можно добавить параметр skip_result=true: в этом случае
тело ответа будет пустым.
curl --request POST \
--url 'http://localhost:8081/data/City?skip_result=true' \
--data '{"title": "Stuttgart","population": 623738,"country":"Germany","capital":false}'
Для модификации данных определённого типа через REST API используются PUT-запросы.
В запросах на модификацию данных используются те же параметры для поиска объектов по индексу,
что и в запросах на чтение: <index_name>, <index_name>_ge,
<index_name>_lt и так далее.
Для изменения объекта выполните PUT-запрос с параметром <index_name>=<value>,
однозначно идентифицирущим объект. Например, title=Berlin:
В теле запроса должны содержаться новые значения изменяемых полей объектов в формате JSON.
curl --request PUT \
--url 'http://localhost:8081/data/City?title=Berlin' \
--data '{"population": 3520032}'
Параметр skip_result (пустой ответ) также может применяться в запросах на
изменение данных:
curl --request PUT \
--url 'http://localhost:8081/data/City?title=Berlin&skip_result=true' \
--data '{"population": 3520032}'
Для удаления данных определённого типа через REST API используются DELETE-запросы.
В запросах на модификацию данных используются те же параметры для поиска объектов по индексу,
что и в запросах на чтение: <index_name>, <index_name>_ge,
<index_name>_lt и так далее.
Для удаления объекта выполните DELETE-запрос с параметром <index_name>=<value>,
однозначно идентифицирущим объект. Например, title=Berlin:
curl --request DELETE \
--url 'http://localhost:8081/data/City?title=Berlin'
Массовое удаление
Для массового удаления объектов можно использовать точечные DELETE-запросы
с прохождением по списку объектов, например, полученному с помощью GET-запроса.
Однако, лучшим решением будет реализация массового удаления с помощью
сервис-функций. Этот способ позволяет реализовать удаление с учётом
особенностей схемы данных и в общем случае имеет лучшую производительность.
Разработка бизнес-логики
В этой главе описывается реализация бизнес-логики в TDG.
Бизнес-логика реализуется в TDG с помощью пользовательского кода
на Lua – скриптовом языке, который нативно
поддерживается в Tarantool. Единица бизнес-логики – исполняемая Lua-функция,
загруженная в TDG – является аналогом хранимой процедуры в СУБД.
TDG расширяет возможности Tarantool по работе с пользовательским кодом,
упрощая разработку бизнес-логики. В частности, доступны следующие возможности:
загрузка пользовательского кода как части конфигурации TDG;
исполнение пользовательского кода на узлах TDG с ролью Runner –
отдельно от хранилища данных.
автоматическая генерация API для вызова пользовательских функций извне;
автоматическая обработка входящих и исходящих данных с помощью input- и
output-процессоров;
выполнение задач по расписанию.
собственные Lua-модули для работы с хранилищем TDG, доступа к базам
данных (ODBC), работы с JSON и другие;
Lua-код, реализующий бизнес-логику решения TDG, можно разделить на
следующие виды:
Сервис-функции (services) предназначены
для вызова внешними системами или пользователями через API: GraphQL, REST API
или iproto.
Процессоры входящих и исходящих данных (input processor и output processor)
автоматически выполняют пользовательский код при поступлении нового объекта
через выбранный коннектор или отправке в него.
Задачи (tasks) вызываются изнутри TDG
вручную, либо автоматически с заданным интервалом, либо по расписанию.
Подробнее о возможностях реализации бизнес-логики рассказывается на страницах
этого раздела.
Сервис-функции
Сервис-функции (services) – это хранимые процедуры, реализующие бизнес-логику решения
и доступные для вызова извне. В TDG такие процедуры представляют
собой функции на языке Lua.
Чтобы добавить в TDG вызываемый сервис, нужно:
Задать конфигурацию сервиса в формате YAML: его имя, аргументы вызова,
возвращаемое значение.
Реализовать необходимую логику на языке Lua с использованием Lua API TDG.
Загрузить файлы с исходным кодом и конфигурацией сервиса в TDG.
После этого TDG автоматически сгенерирует API для вызова сервиса
через GraphQL, REST API и iproto (бинарный протокол Tarantool).
В этом руководстве рассмотрим пример создания нового сервиса в TDG
и способы его вызова.
Для выполнения примера требуются:
настроенный кластер TDG;
модель данных, сохраненная в файле model.avsc.
В примере используется модель из раздела по настройке модели данных;
HTTP-клиент, например, curl.
Пример сервиса будет возвращать список всех городов страны, загруженных в хранилище,
по её имени.
Руководство включает в себя следующие шаги:
Чтобы добавить в TDG сервис, необходимо добавить соответствующую
секцию в конфигурацию TDG. Сервисы можно описывать
либо в общем конфигурационном файле (секция services в файле config.yml),
либо в отдельном файле services.yml.
Конфигурация сервиса включает такие параметры, как его уникальное имя, вызываемая
функция, аргументы вызова, тип возвращаемого значения и другие. Полная информация
о параметрах конфигурации сервисов приведена в справочнике по конфигурации
бизнес-логики.
Пример минимальной конфигурации сервиса без аргументов:
# config.yml
services:
hello_world:
doc: "Hello World script"
function: hello.hello
return_type: string
Создадим конфигурацию сервиса для получения всех городов по названию страны:
# config.yml
services:
get_cities:
doc: "Get cities by country name"
function: cities.get_cities
return_type: {"type":"array", "items":"City"}
args:
country: string
types:
__file: model.avsc
Эта конфигурация задаёт следующее поведение:
Сервис будет доступен для вызова через GraphQL по имени get_cities
и через REST API по адресу http://localhost:8081/service/get_cities;
При вызове будет выполняться функция get_cities из файла cities.lua;
Сервис будет возвращать массив объектов пользовательского типа City;
Сервис будет принимать один строковый аргумент – название страны.
Как указано в конфигурации сервиса, его код должен храниться в файле cities.lua
в функции get_cities. Этот файл может выглядеть следующим образом:
-- cities.lua
local repository = require('repository')
local log = require('log')
local json = require('json')
function get_cities(arg)
log.info('Getting cities of: %s', json.encode(arg))
local result = repository.find("City", {{'country', '==', arg["country"]}})
return result
end
return {
get_cities = get_cities
}
Использование аргументов сервиса
Все аргументы сервиса передаются в первый аргумент функции в виде
Lua-таблицы. Ключами в этой таблице являются имена аргументов, объявленные
в конфигурации сервиса. Таким образом, для обращения к конкретному аргументу
необходимо получить элемент таблицы по имени из конфигурации
сервиса, например, arg["country"].
Использование модулей
TDG предоставляет набор Lua-модулей для реализации бизнес-логики.
Набор включает как модули для работы с хранилищем Tarantool и подсистемами TDG,
так и модули для работы с распространёнными технологиями, такими как различные
СУБД или JSON.
В этом примере используются модули:
repository – интерфейс репозитория TDG. Содержит функции для
работы с данными в хранилище Tarantool. В примере используется repository.find
для поиска подходящих объектов типа City.
log – запись в журнал TDG. В примере используется log.info
для записи в журнал информации о вызовах сервиса.
json – работа с JSON. В примере используется json.encode для формирования
строкового JSON представления переданного аргумента.
Чтобы выполнить пример, нужно загрузить архив с моделью данных, файлом конфигурации
и функцией сервиса в TDG:
Поместите Lua-файл с кодом сервиса в папку src.
Упакуйте в zip-архив:
папку src, внутри которой лежит файл с кодом сервиса;
модель данных model.avsc;
файл конфигурации config.yml.
Загрузите архив в TDG согласно инструкции.
GraphQL
Чтобы вызвать сервис через GraphQL, укажите в запросе имя сервиса и аргументы
в формате name:value:
query {
get_cities(country: "Germany")
}
Как и в случае запросов к данным, GraphQL позволяет получать отдельные поля
возвращаемых объектов:
query {
get_cities(country: "Germany") {
title,
capital
}
}
Ответ:
{
"data": {
"get_cities": [
{
"title": "Berlin",
"capital": true
},
{
"title": "Dresden",
"capital": false
},
{
"title": "Munich",
"capital": false
}
]
}
}
REST API
Сервисы доступны для вызова через REST API на HTTP-адресах (endpoint) вида
/service/<service_name>. Для вызова сервисов используются POST-запросы.
Для вызова сервиса без аргументов отправьте POST-запрос на соответствующий адрес,
например:
curl -X POST http://localhost:8081/service/hello_world
Если у сервиса есть аргументы, передайте их одним из двух способов:
Ответ:
{
"result": [
{
"cursor": "gaRzY2FukqZSdXNzaWGmTW9zY293",
"country": "Russia",
"title": "Moscow",
"population": 12655050,
"postcodes": [
101000,
119021,
115035,
109028,
109004
],
"capital": true
},
{
"cursor": "gaRzY2FukqZSdXNzaWGwU2FpbnQgUGV0ZXJzYnVyZw",
"country": "Russia",
"title": "Saint Petersburg",
"population": 5384342,
"postcodes": [
191193,
191040,
195275,
983002,
983015
],
"capital": false
},
{
"cursor": "gaRzY2FukqZSdXNzaWGkVHZlcg",
"country": "Russia",
"title": "Tver",
"population": 424969,
"postcodes": [
170006,
170100,
170037,
170028
],
"capital": false
}
]
}
Полная информация о REST API сервисов TDG приведена в справочнике
по REST API.
Процессоры входящих и исходящих данных
Процессор (processor) – это подсистема, которая задает в TDG логику обработки объектов
и автоматически выполняет пользовательский код при поступлении нового объекта или при его отправке через заданный
коннектор.
Для исполнения пользовательского кода используются обработчики.
Обработчик (handler) – это пользовательская функция, которая вызывается процессором и
обрабатывает входящие или исходящие данные. В TDG такие функции представляют
собой функции на языке Lua.
Существует два вида процессоров, оба они выполняются на экземплярах TDG с ролью runner:
input-процессор (input processor) – процессор входящих данных. Этот процессор обрабатывает объект,
поступивший на вход через коннектор, настраивает для него маршрутизацию и правила хранения полученных объектов.
output-процессор (output processor) – процессор исходящих данных.
Этот процессор готовит объект к отправке во внешнюю систему и передает его в коннектор.
В этом руководстве рассмотрим пример создания input-процессора и обработчика в TDG.
В примере на HTTP-коннектор придет новый объект в формате JSON, который после преобразования в Lua-объект будет
обработан input-процессором, а затем сохранен в хранилище – на экземплярах с ролью storage.
Для выполнения примера требуются:
Руководство включает в себя следующие шаги:
Указать конфигурацию входящего коннектора можно:
Задайте конфигурацию входящего HTTP-коннектора:
# config.yml
connector:
input:
- name: http
type: http
routing_key: input_key
При получении нового объекта в формате JSON через HTTP-коннектор:
JSON-объект преобразовывается в Lua-таблицу (объект Lua).
Для объекта генерируется UUID, по которому можно проследить дальнейший путь объекта (например, найти его в
ремонтной очереди).
Объектам, пришедшим на коннектор, присваивается определенный ключ маршрутизации (секция routing_key
в конфигурации коннектора).
Ключ маршрутизации – это строковый ключ, который задается объекту и определяет для него процесс дальнейшей обработки.
На коннекторе такой ключ определяет, в какой обработчик на input-процессоре будет передан объект.
Если ключ маршрутизации не задан, объект обрабатывается функцией по умолчанию, которая превращает объект вида
{ "obj_type": { "field_1": 1 } } в объект вида { "field_1": 1 } и задает значение ключа маршрутизации как
routing_key = obj_type.
После получения ключа маршрутизации объект передается на input-процессор.
Выше в конфигурации определены имя коннектора http, его тип http и ключ маршрутизации input_key,
с которым объект отправится в обработчик, заданный в файле конфигурации в секции input_processor.
Подробная информация о параметрах конфигурации коннектора приведена в
справочнике по конфигурации бизнес-логики.
Как указано в конфигурации процессора, код обработчика должен храниться в файле handle_band.lua.
Создайте обработчик с функцией newband(obj), которая принимает на вход новый Lua-объект с музыкальной группой:
-- handle_band.lua
local log = require('log')
local json = require('json')
log.info('Starting handle_band.lua')
function newband(obj)
log.info('Received new object from the HTTP connector: %s', json.encode(obj))
obj.routing_key = "band"
log.info('The routing key is set to "%s" value', obj.routing_key)
return obj
end
return {
newband = newband
}
Здесь функция newband(obj) выводит информацию об объекте obj, пришедшем из HTTP-коннектора, в логах
TDG в формате JSON.
После этого функция присваивает объекту новый ключ маршрутизации band, а затем возвращает этот объект.
Чтобы выполнить пример, нужно загрузить архив с файлом конфигурации, моделью данных
и функциями обработчиков в TDG. Для этого:
Поместите Lua-файл с кодом обработчика в папку src.
Упакуйте в zip-архив:
папку src, внутри которой лежит файл с кодом обработчика handle_band.lua;
модель данных model.avsc;
файл конфигурации config.yml.
Загрузите архив в TDG согласно инструкции.
Чтобы проверить добавленную конфигурацию, добавьте новую музыкальную группу в TDG через HTTP-коннектор.
Для этого переключитесь на вкладку Test и выберите для запроса формат JSON.
Введите в поле запрос в формате JSON и затем нажмите Submit:
{
"name":"Beatles",
"genre":["Rock-n-roll"],
"wasformed": 1965
}
При успешном добавлении объекта в поле Response вернется ответ «OK».
Проверить добавленные данные можно на вкладке Graphql. Убедитесь, что выбрана схема
default, и напишите запрос на выборку всех музыкальных групп:
query {
MusicBand {
name
wasformed
genre
}
}
Так как добавлена всего одна группа, ответ будет выглядеть следующим образом:
{
"data": {
"MusicBand": [
{
"genre": [
"Rock-n-roll"
],
"name": "Beatles",
"wasformed": 1965
}
]
}
}
Также информацию о добавленном объекте можно проверить в логах TDG.
В логах TDG видно, что сначала HTTP-коннектор получил на вход новый объект, а затем был
запущен обработчик handle_band.lua.
Задачи
Задачи (tasks) – это загруженные в TDG пользовательские функции,
которые исполняются автоматически (в том числе по расписанию) или вызываются
вручную изнутри TDG.
Задачи используются для реализации внутренней бизнес-логики решения. Примеры:
построение регулярных отчётов или инвалидация кэшей. Для реализации логики,
доступной для вызова извне, используется механизм сервис-функций.
Технически, задачи реализуются в виде функций на языке Lua. Возвращаемое значение
функции является результатом выполнения соответствующей задачи.
Существует три вида задач:
единоразовые (single-shot) – выполняются один раз после каждого вызова
вручную из интерфейса TDG.
непрерывно выполняемые (continuous) – выполняются циклически с заданным
интервалом времени. Например, если TDG используется как кэш горячих
данных, такая задача может автоматически обновлять этот кэш на основе
изменений в данных раз в несколько минут.
по расписанию (periodical) – выполняются по расписанию, заданному в
расширенном формате cron с добавлением секунд; подробнее в
справочнике по конфигурации бизнес-логики.
Например, в конце каждого дня можно строить отчёты по хранимым в кластере данным.
В этом руководстве рассмотрим пример создания задач в TDG и инструменты
управления задачами.
Для выполнения примера требуется настроенный кластер TDG.
Руководство включает в себя следующие шаги:
Чтобы добавить в TDG задачу, необходимо добавить соответствующую
секцию в конфигурацию TDG. Задачи можно описывать
либо в общем конфигурационном файле (секция tasks в файле config.yml),
либо в отдельном файле tasks.yml.
Конфигурация задачи включает такие параметры, как её уникальное имя, вызываемая
функция, вид задачи и другие. Полная информация о параметрах конфигурации задач
приведена в справочнике по конфигурации бизнес-логики.
Пример конфигурации трёх задач разных видов:
# config.yml
tasks:
report_now:
kind: single_shot
function: tasks.build_report
update_caches:
kind: continuous
function: tasks.update_caches
pause_sec: 3600
weekly_report:
kind: periodical
function: tasks.build_report
schedule: "0 0 19 * * 5"
Здесь:
report_now – единоразовая задача. Вызывается вручную.
update_caches – задача, которая выполняется автоматически с периодом в
1 час (3600 секунд).
weekly_report – задача, которая исполняется по расписанию каждую
пятницу в 19:00:00. Использует ту же функцию, что и задача report_now.
Если вызываемая функция имеет аргументы, их значения можно передать в параметре
args:
# config.yml
tasks:
task_with_args:
kind: single_shot
function: tasks.function_with_args
args: [1, "hello"]
Если в TDG включен режим обязательной аутентификации,
необходимо добавить параметр run_as для указания пользователя, от имени которого
будут выполняться задачи по расписанию и периодические задачи:
# config.yml
update_caches:
kind: continuous
function: tasks.update_caches
pause_sec: 3600
run_as:
user: username
weekly_report:
kind: periodical
function: tasks.build_report
schedule: "0 0 19 * * 5"
run_as:
user: username
Как указано в конфигурации задач, соответствующие им функции должны храниться в файле
tasks.lua.
Для упрощения демонстрации реализуем функции-заглушки:
-- tasks.lua
local function build_report()
return 'Report is ready'
end
local function update_caches()
return 'Caches updated'
end
return {
build_report = build_report
update_caches = update_caches
}
Чтобы выполнить пример, нужно загрузить архив с файлом конфигурации
и функциями задач в TDG. Для этого:
Поместите Lua-файл с кодом задач в папку src.
Упакуйте в zip-архив:
Загрузите архив в TDG согласно инструкции.
Инструменты для управления задачами и отслеживания их выполнения расположены на
вкладке Tasks веб-интерфейса TDG. Полная информация об
управлении задачами через веб-интерфейс приведена в разделе Задачи
руководства администратора.
Взаимодействие с Kafka
Протокол Kafka – один из доступных форматов для запросов к данным в TDG.
Формат позволяет как читать данные с сервера (брокера), а затем обрабатывать их, так и отправлять данные во внешние
системы.
В терминологии Kafka TDG при работе с запросами можно настроить как в качестве consumer (получение объектов),
так и в качестве producer (отправка объектов).
Для взаимодействия с шиной данных Apache Kafka в TDG используется коннектор
типа Kafka.
Документация охватывает следующие темы, связанные с Kafka:
Запросы к данным через Kafka-коннектор
В руководстве пошагово демонстрируется пример работы TDG c Kafka – от настройки коннектора до
выполнения обмена данными. Пример реализует следующую логику:
получение объекта из топика (topic) Kafka;
изменение обработчиком объекта, полученного в TDG;
сохранение измененного объекта в хранилище;
отправка измененного объекта в тот же топик.
Для выполнения примера требуются:
Руководство включает в себя следующие шаги:
Коннектор в TDG можно настроить двумя способами:
указать параметры коннектора в файле конфигурации .yml;
добавить или изменить коннектор, используя веб-интерфейс (только для input-коннекторов).
Чтобы узнать больше, обратитесь к разделу Вкладка Connectors.
Зададим настройки первым способом, в файле .yml.
Создайте файл конфигурации config.yml со следующими настройками:
types:
__file: model.avsc
connector:
input:
- name: from_kafka
type: kafka
brokers:
- localhost:9092
topics:
- cities
group_id: kafka
routing_key: add_kafka
output:
- name: to_kafka
type: kafka
brokers:
- localhost:9092
topic: cities
input_processor:
handlers:
- key: add_kafka
function: kafka_input_handler.call
storage:
- key: input_key
type: City
output_processor:
input_key:
handlers:
- function: kafka_output_handler.call
outputs:
- to_kafka
В файле указываются:
используемая модель данных;
секция connector – настройки input- и output-коннекторов.
Разделу input соответствует функция consumer, разделу output – функция producer.
Настройки включают в себя имя коннектора, адрес сервера (брокера), а также название топика (cities), к которому
будет обращаться TDG. В разделе input также определен ключ маршрутизации routing_key со значением
add_kafka;
секция input_processor – обработка входящих данных.
Здесь заданы ключ для хранилища (input_key), в котором будет сохранен объект City, а также
определен обработчик (kafka_input_handler) для ключа маршрутизации add_kafka.
Узнать больше про настройку input_processor
можно в соответствующем разделе справочника;
секция output_processor – обработка исходящих данных.
Здесь определены имя хранилища (input_key) и функция-обработчик (kafka_output_handler).
Кроме того, задан параметр outputs (to_kafka) – это означает, что объект будет отправлен обратно
в топик Kafka.
Узнать больше про настройку output_processor
можно в соответствующем разделе справочника.
Чтобы ознакомиться со всеми доступными параметрами конфигурации для коннектора Kafka, обратитесь
к справочнику по настройке коннектора.
Обработка исходящих данных
В разделе output указывается, как объект будет изменен в обработчике перед отправкой во внешние системы.
Обработка выполняется после успешного сохранения объектов на экземплярах с ролью storage.
Чтобы обработать объект в output_processor, в файле конфигурации укажите название хранилища (input_key),
в котором был сохранен объект, а затем определите обработчик для него (секция handlers).
Создайте файл kafka_output_handler.lua. В нем будет записана функция, вызываемая output-обработчиком.
Функция вернет объект City:
#!/usr/bin/env tarantool
return {
call = function(params)
return {obj = params.obj}
end
}
Чтобы выполнить пример, нужно загрузить архив с моделью данных, файлом конфигурации и функциями обработчиков (handlers) в
TDG:
Поместите файлы со скриптами обработчиков (kafka_input_handler.lua и kafka_output_handler.lua)
в папку src.
Упакуйте в zip-архив:
папку src, внутри которой лежат файлы со скриптами обработчиков;
модель данных model.avsc;
файл конфигурации config.yml.
Загрузите архив в TDG согласно инструкции.
На сервере (брокере) Kafka создайте новый топик
с именем cities.
Для демонстрации работы примера и просмотра переданных в топик сообщений напишем простой скрипт на языке Python.
Скрипт сыграет роль consumer Kafka, который получает сообщения из топика cities на брокере localhost:9092.
Чтобы работать с Kafka средствами Python, установите модуль kafka-python:
Для запуска чтения сообщений, приходящих из топика cities, подготовьте следующий скрипт на языке Python:
from kafka import KafkaConsumer
consumer = KafkaConsumer('cities')
for message in consumer:
print (message)
Чтобы выполнить скрипт, используйте интерактивный режим интерпретатора или сохраните функцию в файл consumer.py,
а затем запустите ее командой python consumer.py.
Оставьте работать запущенный consumer.py, а затем переключитесь на новую вкладку консоли.
Чтобы запустить отправку сообщений, отправьте в Kafka JSON-объект типа City с полем population.
Для этого подготовьте следующий скрипт на языке Python:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
headers = [("Header Key", b"Header Value")]
producer.send('cities', value='{"title": "Moscow", "population": 12655050}'.encode('ascii'), headers=headers)
producer.flush()
Скрипт содержит подключение к Kafka в качестве producer и отправку простого JSON-объекта:
{"title": "Moscow", "population": 12655050}.
Чтобы выполнить скрипт, используйте интерактивный режим интерпретатора или сохраните функцию в файл producer.py,
а затем запустите ее командой python producer.py.
В результате TDG получит объект City из топика cities, обработает его (увеличится значение поля
population) и сохранит, а затем отправит объект в тот же топик Kafka.
Это вызовет повторное получение, обработку и отправку.
Пока пример запущен, во вкладке терминала consumer будут появляться все новые сообщения с постоянно возрастающим
значением поля population.
Чтобы остановить обработку объектов, выполните одно из действий ниже:
Решение проблем при работе с Kafka
При использовании Kafka проблемы могут возникнуть как на этапе подключения к брокеру, так и во время работы с данными.
В статье рассматриваются распространенные ошибки и приводятся способы их устранения.
Чтобы облегчить решение возникших проблем
Обратитесь к разделу Инструменты для проверки ошибок, чтобы узнать больше.
Статья включает в себя следующие ошибки:
Проблема |
Пример сообщения об ошибке |
|---|
Неверно указан брокер |
Failed to resolve 'kafka-broker:9091': Name or service not known
|
Неизвестный топик или раздел |
kafka_error: consumer "kafka": Broker: Unknown topic or partition
|
Неверно заданы SSL-сертификаты |
ip:port/bootstrap: Disconnected while requesting ApiVersion: might be caused by incorrect security.protocol configuration (connecting to a SSL listener?) or broker version is < 0.10 (see api.version.request)
|
Возможные ошибки
Неверно указан брокер
Пример вывода
Failed to resolve 'kafka-broker:9091': Name or service not known
Возможные причины
В файле конфигурации config.yml неверно указаны номер порта для брокера Kafka или название Docker-контейнера.
Решение
Проверьте адрес брокера (параметр brokers) в секции connector в файле конфигурации config.yml.
Сравните это значение с параметрами брокера Kafka.
Например, если брокер Kafka запущен с помощью Docker Compose, проверьте параметры брокера ports и container_name
в файле конфигурации Docker-контейнеров (docker-compose.yml).
Неизвестный топик или раздел
Пример вывода
kafka_error: consumer "kafka": Broker: Unknown topic or partition
Возможные причины
Запрос на запись был отправлен в несуществующий топик или раздел.
Ошибка возникает, если на момент отправки данных на брокер указанный топик еще не был создан, и в Kafka отключено
автоматическое создание топиков.
Решение
Убедитесь, что указанный топик существует.
Если топика еще не существует, попробуйте создать его в Offset Explorer.
Если при создании топика возникли проблемы, обратитесь к администратору Kafka.
Проверьте, что в настройках Kafka разрешено автоматическое создание топиков при отправке данных – по умолчанию
такое поведение отключено.
Если создание топиков разрешено, в Offset Explorer новый топик появится после обновления в папке Topics.
При этом данные о новой записи не будут потеряны – запись будет добавлена в топик.
При последующей отправке данных в этот топик ошибка возникать не будет.
Неверно заданы SSL-сертификаты
Пример вывода
ip:port/bootstrap: Disconnected while requesting ApiVersion: might be caused by incorrect security.protocol configuration (connecting to a SSL listener?) or broker version is < 0.10 (see api.version.request) (after 2ms in state APIVERSION_QUERY, 3 identical error(s) suppressed)
Возможные причины
Решение
Если соединение недоступно, запустите приложение Offset Explorer и попытайтесь
подключиться к Kafka.
Если подключиться с помощью Offset Explorer не удалось, проверьте, что параметры брокера Kafka настроены корректно.
Проверьте значение параметра security.protocol в секции коннектора input
(раздел options) в файле конфигурации config.yml.
Использование бинарного протокола iproto
TDG поддерживает работу с хранилищем данных и пользовательскими сервисами
через бинарный протокол Tarantool
(iproto). В частности, бинарный протокол используется коннекторами к Tarantool
из разных языков программирования, таких как Python, Java, Go и другие. Полный
список доступных коннекторов и примеры их использования приведены в
документации Tarantool.
Бинарный протокол Tarantool обеспечивает лучшее быстродействие по сравнению с HTTP
и таким образом позволяет наиболее эффективно создавать промежуточные слои бизнес-логики
перед TDG. При этом выбор языка для реализации этой логики предоставляется разработчику.
В этом руководстве демонстрируется работа с данными и сервисами TDG
через бинарный протокол Tarantool. Руководство включает следующие шаги:
В примерах используется:
Для вызовов используется язык Python и коннектор tarantool-python.
Чтобы узнать, как делать аналогичные вызовы из других языков, обратитесь к документации
соответствующего коннектора.
Настройка коннектора
Для возможности подключения к TDG через бинарный протокол используется
коннектор типа tarantool_protocol. Настроить коннектор можно двумя способами:
Пример YAML-конфигурации входящего коннектора iproto:
input:
- routing_key: null
type: tarantool_protocol
is_async: true
name: iproto
Подробнее о параметрах коннектора рассказывается в справочнике по настройке коннекторов.
Подключение
Клиенты, которые подключаются к TDG через бинарный протокол, используют
подключение напрямую к экземпляру Tarantool, имеющему кластерную роль connector.
В связи с этим для подключения используется учетная запись пользователя Tarantool.
Пример подключения через Python-коннектор:
from tarantool.connection import Connection
conn = Connection(server.host, server.binary_port, user='tdg_service_user', password='')
По умолчанию для подключения доступны пользователи:
При необходимости вы можете добавить других пользователей Tarantool c нужными
привилегиями. Инструкции по управлению пользователями в Tarantool приведены в документации по
контролю доступа в Tarantool.
После того, как подключение установлено, TDG проверяет права клиента
на выполнение каждого входящего вызова с помощью токенов приложений.
Токен передается непосредственно в вызовах функций через iproto-соединение
в аргументе credentials. Пример:
conn.call('repository.put', 'Users', obj, {}, {}, {'token': token})
Подробнее об использовании токенов приложений рассказывается в главе Авторизация.
Запросы GraphQL
Для отправки запросов GraphQL через бинарный протокол используется функция execute_graphql.
Её основные аргументы:
query – строка, содержащая GraphQL-запрос;
variables – значения переменных, если они используются в запросе;
schema – схема данных: default (пользовательские данные) или admin.
Пример отправки GraphQL-запроса через бинарный протокол без переменных:
resp, _ = conn.call('execute_graphql', {
"query": '''
query {
Country {
title
}
}
''',
"schema": "default",
})
Пример отправки GraphQL-запроса через бинарный протокол с переменными:
resp, _ = conn.call('execute_graphql', {
"query": '''
query ($title: String!) {
Country(title: $title) {
title,
phone_code
}
}
''',
"variables": {
"title": "Russia"
},
"schema": "default",
})
Пример GraphQL-вызова сервиса через бинарный протокол:
resp, _ = conn.call('execute_graphql', {
"query": '''
query {
hello_world
}
''',
"schema": "default",
})
Пример GraphQL-вызова сервиса ` с аргументами через бинарный протокол:
resp, _ = conn.call('execute_graphql', {
"query": '''
query ($title: String!) {
Country(title: $title) {
title,
phone_code
}
}
''',
"variables": {
"title": "Russia"
},
"schema": "default",
})
Примечание
Вызов сервисов через бинарный протокол напрямую описан в разделе
Вызов сервисов.
Подробнее о доступе к данным в TDG через GraphQL рассказываeтся в главе
Запросы данных.
Использование интерфейса репозитория
Функции Repository API доступны для вызова через бинарный
протокол напрямую. Для вызова необходимо указать вызываемую функцию (например,
repository.get) и передать её аргументы.
Пример запроса объекта по ключу через интерфейс репозитория:
resp, _ = conn.call('repository.get', ( 'Country', ['Russia']))
Пример вставки объекта через интерфейс репозитория:
resp, _ = conn.call('repository.put', ( 'Country', {'title': 'China', 'phone_code': '+86'}))
Вызов сервисов
Для вызова сервисов через бинарный протокол используется функция call_service.
Её основной аргумент - имя вызываемого сервиса. Если у него есть аргументы, они
передаются в виде таблицы в следующем аргументе.
Пример вызова сервиса без аргументов через бинарный протокол:
resp, _ = conn.call('call_service', 'hello_world')
Пример вызова сервиса с аргументами через бинарный протокол:
resp, _ = conn.call('call_service', 'get_cities', {'country': 'Russia'})
Загрузка данных из файлов
В этой главе описывается загрузка данных в TDG из файлов.
TDG предоставляет возможность загрузки данных в хранилища из файлов
с помощью файловых коннекторов. Поддерживается загрузка из двух форматов:
comma-separated values
(csv) и JSON Lines (jsonl).
В момент своего создания файловый коннектор обрабатывает все входящие данные из
указанного в конфигурации файла и затем удаляет его. После этого коннектор
периодически проверяет существование файла и при его наличии загружает содержимое.
Таким образом, для загрузки новых данных нужно помещать их в файл с тем же именем.
В этом руководстве рассмотрим пример загрузки данных из CSV-файла в TDG
с помощью файлового коннектора.
Для выполнения примера требуются:
Руководство включает в себя следующие шаги:
CSV-файл с данными для загрузки в TDG должен содержать в каждой строке
поля одного объекта данных. Файл может содержать данные только одного модельного типа.
Первая строка должна описывать формат строк с данными: в ней указывается порядок
полей объекта.
CSV-файл countries.csv для загрузки нескольких объектов типа Country может
выглядеть следующим образом:
"title","phone_code"
"Argentina","+54"
"Australia","+61"
"Austria","+43"
Примечание
Значения обнуляемых полей могут быть пропущены. В этом случае они получат значение null.
Файл с данными необходимо загрузить в место, откуда его сможет вычитать TDG.
У пользователя, под которым работает процесс TDG, должны быть права
на чтение и запись в директорию с этим файлом.
Для выполнения примера загрузите файл на сервер, на котором работает узел кластера
с ролью connector, в директорию /tmp/csv/.
Файловый коннектор в TDG можно настроить в файле конфигурации .yml.
Создайте файл конфигурации config.yml со следующими настройками:
types:
__file: model.avsc
connector:
input:
- name: csv_importer
type: file
format: csv
workdir: /tmp/csv/
filename: countries.csv
routing_key: input_key
input_processor:
handlers:
- key: input_key
function: classifier.call
storage:
- key: country
type: Country
В файле указываются:
используемая модель данных;
секция connector – настройки файлового коннектора.
Настройки включают в себя имя и тип коннектора, формат файла для загрузки (csv),
его имя (countries.csv) и расположение (/tmp/csv/). Также определен ключ
маршрутизации routing_key со значением input_key;
секция input_processor – обработка входящих данных.
Здесь заданы ключ для хранилища (country), в котором будет сохранен объект Country,
а также определен обработчик (classifier.call) для ключа маршрутизации input_key.
Узнать больше про настройку input_processor
можно в соответствующем разделе справочника;
Чтобы ознакомиться со всеми доступными параметрами конфигурации файлового коннектора,
обратитесь к справочнику по настройке коннектора.
Данные из файла попадают через коннектор в обработчики (handlers), заданные в файле
конфигурации в секции input_processor.
В функции обработчика можно модифицировать поступившую информации, а также определить
ключ routing_key для дальнейшей обработки. В данном случае следующим этапом
будет сохранение в хранилище объектов Country.
В файле classifier.lua укажите функцию, которая будет запускаться в input-обработчике.
Функция задаст ключу routing_key значение country:
return {
call = function(param)
param.routing_key = 'country'
return param
end
}
Чтобы выполнить пример, нужно загрузить архив с моделью данных, файлом конфигурации
и функцией обработчика в TDG:
Поместите файл с функцией обработчика classifier.lua в папку src.
Упакуйте в zip-архив:
папку src, внутри которой лежит файл classifier.lua;
модель данных model.avsc;
файл конфигурации config.yml.
Загрузите архив в TDG согласно инструкции.
Файловый коннектор выполнит загрузку данных в соответствии со своей конфигурацией
немедленно после добавления.
Предупреждение
В результате срабатывания файлового коннектора файл, из которого выполнялась загрузка,
будет удалён.
В случае ошибки при работе файлового коннектора в директории workdir будет создан
файл с расширением .error с информацией об ошибке.
В результате работы файлового коннектора:
Корректно форматированные объекты из файла будут загружены в соответствующее
хранилище;
Объекты, которые не удалось загрузить автоматически, попадут в
ремонтную очередь;
Для проверки добавления новых объектов отправьте GraphQL-запрос на чтение объектов
типа Country (например, на вкладке GraphQL веб-интерфейса TDG):
{
Country {
phone_code
title
}
}
В результате вы получите список объектов, которые были описаны в CSV-файле:
{
"data": {
"Country": [
{
"title": "Argentina",
"phone_code": "+54"
},
{
"title": "Australia",
"phone_code": "+61"
},
{
"title": "Austria",
"phone_code": "+43"
}
]
}
}
Версионирование
Этот раздел объясняет, как управлять данными в Tarantool Data Grid (TDG).
Управление версиями данных в TDG
Управление версиями данных (версионирование) – это возможность сохранять, извлекать и
восстанавливать разные версии объектов, а также отслеживать когда и какие
изменения в них были внесены.
В TDG для управления версиями используется параметр versioning, который задается в
файле конфигурации config.yml.
Когда параметр включен, в определенные моменты времени для всех созданных или модифицированных
объектов сохраняются новые версии.
Например, у нас есть модель данных и тип объекта Country, для которого
включено версионирование. Спейс, где хранятся объекты данного типа, имеет первичный ключ. Если
выполняется операция по сохранению в спейс нового объекта с таким же значением первичного ключа, то
новый объект не заменит предыдущий, а будет сохранен как новый кортеж, но с уникальным значением timestamp,
которое фиксируется каждый раз при сохранении объекта. Это время является идентификатором версии объекта и
также сохраняется в кортеже, в котором хранится информация об объекте.
Сочетание первичного ключа и уникального времени сохранения объекта позволяет иметь
несколько версий одного и того же объекта. Это может быть полезно, если необходимо
хранить историю изменения параметров объекта.
По умолчанию на хранение версий установлено ограничение – не более пяти версий для одного объекта,
но вы можете выставить другое значение в config.yml.
Примечание
Старайтесь ограничивать количество хранимых версий, чтобы сохранять высокую производительность
TDG.
Почему версионирование важно?
Версионирование может быть полезно во многих случаях. Например:
В последней версии объекта вы случайно удалили важное поле.
Вы можете использовать предыдущую версию этого объекта, в котором
удаление не произведено.
Это будет быстрее, чем повторное создание поля.
Вы хотите просмотреть изменения, которые были внесены в объект.
Вы можете получить эту информацию, делая запросы к нескольким
сохраненным версиям объекта.
Таким образом, версионирование помогает свести к минимуму
стоимость ошибок и отследить изменение данных с течением времени.
Это также способ увеличить скорость разработки.
Запросы к данным по версии
Запросы к данным по версии выполняются путем указания поля version в теле
HTTP-запроса или запроса
GraphQL.
В TDG есть две категории таких запросов:
Исторические данные – данные объектов, которые имеют более раннюю версию, чем
указанная, или ту же версию, что и указанная в запросе.
Исторические модификации – данные об изменениях объектов, которые имеют более раннюю версию,
чем указанная, или ту же версию, что и указанная в запросе.
Исторические данные
Запросы на чтение исторических данных полезны, например, когда
часть информации была удалена в последней версии объекта.
Вспомним пример модели данных и рассмотрим
запрос на чтение исторических данных Country.
Пример. У нас есть тип объекта Country с информацией о телефонном коде страны.
Но в последней версии Country правильная информация о телефонном коде была изменена.
Чтобы получить правильную информацию о телефонном коде, нужно посмотреть
предыдущую версию Country.
Сделать это можно в два этапа:
Узнайте последнюю версию Country
Сделайте запрос на чтение данных предыдущий версии Country
Чтобы проверить последнюю версию, добавьте поле version в параметры запроса GraphQL:
{
Country(title: "Russia") {
title
phone_code
version
}
}
Пример ответа:
{
"data": {
"Country": [
{
"version": "1515",
"title": "Russia",
"phone_code": "+8"
}
]
}
}
Примечание
Ответ возвращает указанную или более раннюю версию, если запрошенная версия не существует.
Если поле version не было указано, ответ вернет последнюю версию объекта.
Скопируйте из ответа значение version, вычтите из него единицу
и выполните запрос GraphQL на предыдущую версию:
{
Country(title: "Russia", version: "1514") {
title
phone_code
version
}
}
Пример ответа:
{
"data": {
"Country": [
{
"version": "1514",
"title": "Russia",
"phone_code": "+7"
}
]
}
}
Вы можете перебирать предыдущие версии, пока не обнаружите версию с нужной информацией.
Примечание
Если запрошенная версия меньше существующего минимального значения, ответ вернет
пустой объект.
Вы также можете запросить все версии объекта, используя поле all_versions, и ограничить
результат ответа при помощи пагинации:
{
Country(title: "Russia", all_versions: true, first: 5) {
title
phone_code
}
}
Исторические модификации
Запросы на исторические модификации данных полезны, например,
когда нужно изменить или удалить данные в конкретной версии объекта.
TDG поддерживает следующие запросы на изменение данных (mutations):
Для осуществления запросов на изменение данных вы можете использовать
HTTP-запросы
или запросы GraphQL.
Примечание
Выполнение HTTP-запросов потребует токен приложений.
В примерах используется уже сгенерированный токен Authorization: Test f0d4d72b-2232-42ff-a1ee-1127a93df0d3.
Вам необходимо сгенерировать свой токен с правами на запись и чтение в кластере TDG,
к которому будет осуществляться доступ,
иначе авторизация не пройдет.
Ниже приведены примеры обоих вариантов запросов.
Вставка объекта
Когда вы добавляете объект, поле version определяет, какая версия
объекта добавляется или заменяется.
Пример. Добавьте объект типа Country с title: "Poland" и phone_code: "+48".
Пример запроса GraphQL:
mutation {
Country(
insert: {
version: "1515"
title: "Poland"
phone_code: "+48"})
{
version
title
phone_code
}
}
Пример HTTP-запроса с использованием утилиты curl:
curl --request POST \
--url 'http://172.19.0.2:8080/graphql?=' \
--header 'Authorization: Test f0d4d72b-2232-42ff-a1ee-1127a93df0d3' \
--data '{"query":"mutation {Country(insert: {version: "1515", title: \"Poland\", phone_code:\"+48\"}) {version title phone_code}}"}'
Ответ в обоих случаях будет одинаковым:
{
"data": {
"Country": [
{
"version": "1515",
"title": "Poland",
"phone_code": "+48"
}
]
}
}
Примечание
Если указанного параметра version нет, то вставка данных будет выполнена
в ближайшую предыдущую версию этого объекта.
Если необходимо вставить данные во все версии объекта, используйте поле all_versions.
Обновление объекта
При обновлении данных в поле version указывается версия объекта,
подлежащая изменению.
Пример. Вернемся к типу объекта Country.
В запросе укажем версию 1515 и обновим поле phone_code на значение +7.
Пример запроса GraphQL:
mutation {
Country(title: "Russia", version: "1515" update:[["set", "phone_code", "+7"]]) {
version
title
phone_code
}
}
Пример HTTP-запроса с использованием утилиты curl:
curl --request POST \
--url 'http://172.19.0.2:8080/graphql?=' \
--header 'Authorization: Test f0d4d72b-2232-42ff-a1ee-1127a93df0d3' \
--data '{"query":"mutation {Country(update: {title: "Russia", version: "1515" [[\"set\", \"phone_code\", \"+7\"]]) {title version phone_code}}"}'
Ответ в обоих случаях будет одинаковым:
{
"data": {
"Country": [
{
"version": "1515"
"title": "Russia"
"phone_code": "+7"
}
]
}
}
Примечание
Если указанного параметра version нет, то обновление данных объекта будет выполнено
в ближайшую предыдущую версию этого объекта.
Удаление объекта
При удалении данных в поле version указывается версия объекта,
подлежащая удалению.
Примечание
Чтобы все версии объекта были полностью удалены,
установите значение true параметру all_versions.
Пример. Удалите объект Country с версией 1514.
Пример запроса GraphQL:
mutation {
Country(delete: true, title: "Russia", version: "1514") {
title
version
phone_code
}
}
Пример ответа:
{
"data": {
"Country": [
{
"version": "1514"
"phone_code": "+7",
"title": "Russia"
}
]
}
}
Примечание
Если параметр version не задан, то будет удалена последняя версия объекта.
Ограничения запросов
Использование дополнительных параметров блока hard-limits в
config.yml помогает контролировать нагрузку на сервер.
Вы можете задать следующие параметры:
scanned – ограничивает прохождение запроса в спейсах. По умолчанию: 2000
returned – ограничивает возвращаемые объекты в ответе. По умолчанию: 100.
При превышении одного из ограничений выполнение запроса прекращается и возвращается ошибка
Пример заполнения параметров:
hard-limits:
scanned: 1500
returned: 200
Практический пример использования
Воспользуемся примером аналитики, чтобы получить более четкое представление
о пользе версионирования в различных сферах.
Основной процесс аналитики заключается в создании метрик, содержащих логику для
оценки бизнеса и поведения пользователей.
Вспомним пример модели данных и добавим новый тип объекта Tourists:
[
{
"name": "Country",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "phone_code", "type": ["null", "string"]}
],
"indexes": ["title"],
"relations": [
{ "name": "city_relation", "to": "City", "count": "many", "from_fields": "title", "to_fields": "country" }
]
},
{
"name": "City",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"},
{"name": "postcodes", "type": {"type":"array", "items":"int"}}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population",
"postcodes"
]
},
{
"name": "Tourists",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "name", "type": "string"},
{"name": "number_of_visits", "type": "int"}
],
"indexes": ["title"],
"relations": [
{ "name": "city", "to": "City", "count": "many", "from_fields": "title", "to_fields": "сity" }
]
},
]
Tourists уже имеет 12 версий, и сегодня нам нужно сделать очередную выборку о
количестве посещений туристами определенного города.
Для этого всегда использовался запрос на чтение Tourists:
{
Tourists(title: "Moscow") {
title
country
number_of_visits
}
}
Но сегодня запрос, который отлично работал день назад, вызывает ошибки из-за
измененных данных.
Самый эффективный способ выяснить, что вызывает проблему – выполнить тот же запрос к предыдущей версии,
в которой не было ошибки.
В нашем случае – это версия 11:
{
Tourists(title: "Moscow", version: "11") {
title
country
number_of_visits
}
}
Но ответ снова возвращает ошибку.
В этом случае необходимо сделать новый запрос к 10 версии объекта и продолжать делать запросы к
предыдущим версиям, пока не будет найдена та, в которой нет ошибки.
Обнаружив такую версию, вы можете передать эти данные команде разработке. Сведения о том,
с какой версии появилась ошибка, позволит им решить проблему гораздо быстрее.
Вы же сможете временно использовать рабочую версию объекта, если она содержит необходимые
данные для решения вашей задачи.
Таким образом, если вы используете версионирование, это упрощает отладку и приводит к
быстрому исправлению ошибок данных.
Рекомендации
Каким должен быть срок хранения старых версий?
Вы должны определить точный период хранения версий, исходя из потребностей компании.
Рекомендованный период хранения – не менее 30 дней. Но не более
одного года, так как это может повлиять на производительность TDG.
Справочник
Этот документ посвящен функциям API и параметрам конфигурации Tarantool Data Grid (TDG).
Конфигурация кластера
В конфигурацию кластера
можно добавить параметры топологии и
авторизации, а также
настройку времени ожидания сетевых вызовов при шардировании.
Параметры топологии
Топология кластера настраивается при помощи секций topology и
vshard_groups.
Примечание
Рекомендуется создать и настроить эти секции в отдельных файлах:
topology.yml и vshard_groups.yml, поместив эти файлы в папку config в корне проекта.
Секция topology
Секция topology содержит три главных подраздела:
replicasets – содержит информацию о том, как экземпляры Tarantool организованы в наборы реплик,
какие у узлов кластерные роли и
веса
при шардировании;
servers – список всех экземпляров Tarantool;
failover – настройки восстановления после сбоев.
replicasets
Этот подраздел содержит информацию о том, как экземпляры организованы в
наборы реплик.
Каждый набор реплик идентифицируется по своему номеру
UUID.
Для каждого приводятся следующие параметры:
weight – вес набора реплик. По умолчанию: 0 (подключен, но пока не принимает данные).
При указанном весе 0 попытки шардирования будут приводить к ошибке на роутере (vshard-router).
master – UUID экземпляра-мастера в этом наборе реплик.
alias – человекопонятное имя набора реплик.
vshard_group – группа шардирования, к которой относится набор реплик. По умолчанию: default.
roles – список кластерных ролей,
включенных (true) или выключенных (false) для набора реплик.
all_rw – являются ли все узлы в наборе реплик мастерами. По умолчанию: false.
Пример для одного набора реплик:
replicasets:
5e47bf8e-57f5-4166-96ba-e16f964fb82b: # UUID набора реплик
weight: 1
master:
- dee26aab-0190-461d-9121-56b96b881a59
alias: unnamed
vshard_group: default
roles:
tracing: true
ddl-manager: true
maintenance: true
watchdog: true
account_provider: true
metrics: true
common: true
core: true
failover-coordinator: true
storage: true
runner: true
vshard-router: true
connector: true
vshard-storage: true
all_rw: false
servers
В этом подразделе приведен список всех экземпляров Tarantool.
Каждый из них идентифицируется по своему номеру
UUID.
Для каждого указаны следующие параметры:
uri – внутренний URI-адрес экземпляра.
disabled – выключен ли экземпляр. По умолчанию: false.
replicaset_uuid – UUID набора реплик, в котором состоит экземпляр.
Пример для одного экземпляра:
servers:
dee26aab-0190-461d-9121-56b96b881a59:
uri: localhost:3301
disabled: false
replicaset_uuid: 5e47bf8e-57f5-4166-96ba-e16f964fb82b
failover
В этом подразделе указываются настройки восстановления после сбоев,
аналогичные соответствующим настройкам Cartridge.
Пример:
failover:
fencing_enabled: true
failover_timeout: 20
fencing_pause: 2
mode: eventual
fencing_timeout: 10
По умолчанию подраздел отключен:
Секция vshard_groups
В этой секции указываются группы шардирования, или vshard-группы, к каждой из которых может принадлежать
один или несколько наборов реплик. Внутри такой группы данные шардируются между входящими в нее наборами реплик.
В vshard-группе могут состоять только наборы реплик с ролью storage.
Один набор реплик не может состоять в двух разных vshard-группах.
Параметры групп шардирования указываются
так же, как при работе с Tarantool.
Значения по умолчанию:
default:
rebalancer_max_receiving: 100
bootstrapped: true
collect_lua_garbage: false
sync_timeout: 1
rebalancer_max_sending: 1
sched_ref_quota: 300
rebalancer_disbalance_threshold: 1
bucket_count: 30000
sched_move_quota: 1
См. также настройку времени ожидания сетевых вызовов при шардировании.
Параметры авторизации
Авторизация настраивается при помощи секций
auth/auth_external,
ldap.
Секция auth позволяет настроить существующую систему авторизации аналогично тому, как это
делается в Tarantool Cartridge.
Вместо этого можно в секции auth_external указать путь к файлу с Lua-кодом, где задана нестандартная логика для авторизации входящих запросов.
Кроме того, ниже рассматривается секция pepper, где можно задать
переменную, с помощью которой будут хешироваться пароли.
Секция auth_external
В этой секции можно указать путь к файлу с Lua-кодом, где
пользователь может самостоятельно задать логику для авторизации входящих запросов.
Код должен вернуть таблицу с параметром auth, в котором лежит функция для проверки
входящих запросов в формате HTTP.
Функция вернет либо nil, если доступ запрещен, либо объект, содержащий аутентификационную информацию.
Пример. Укажем путь к файлу auth.lua с логикой для авторизации входящих запросов:
auth_external: {__file: auth.lua}
Содержание auth.lua определяется пользователем самостоятельно.
Например, в файле может быть указана такая логика обработки:
-- Функция авторизует пользователя по HTTP-заголовку
local function auth(request)
local header = request.headers['custom_token']
if header == nil then
return nil, "no header"
end
if header == 'error-injection' then
error('error-injection')
end
if header == 'invalid-answer' then
return 'invalid-answer'
end
if header == 'invalid-decision' then
return {
decision = 'invalid-decision',
}
end
if header == 'invalid-token' then
return {
decision = 'reject',
reason = 'invalid token',
}
end
if header == 'fallback-token' then
return {
decision = 'fallback',
}
end
if header == 'custom-response' then
return {
decision = 'reject',
status_code = 418,
reason = 'Hello, world!',
headers = {
['custom'] = 'header',
}
}
end
return {
decision = 'accept',
account = {
is_user = true,
email = 'example@tarantool.org',
role_id = 1,
},
}
end
return {
auth = auth,
}
Секция ldap
В этой секции указываются параметры авторизации внешних пользователей и систем через LDAP:
domain – доменное имя, которое используется в доменном логине пользователя (user@domain).
organizational_units – названия организационных подразделений или групп пользователей.
Параметр опциональный и будет пропущен, если для него не задано значение.
hosts – адрес подключения к серверу LDAP.
use_active_directory – параметр, определяющий использование Active Directory
(служба каталогов Microsoft).
Значение по умолчанию: false.
Если установлено значение true, используйте адрес электронной почты для входа в систему и атрибут
Active Directory userprincipalname=email в качестве фильтра,
где email – адрес электронной почты пользователя.
Часть с именем пользователя в email будет распознана одинаково независимо от регистра
(aBc@mail.ru и AbC@mail.ru – это один и тот же пользователь).
use_tls – параметр, определяющий использование TLS.
Значение по умолчанию: false.
search_timeout – время ожидания ответа от сервера LDAP в секундах.
Значение по умолчанию: 2.
options – настройки LDAP. Параметр опционален.
Доступные настройки:
LDAP_OPT_DEBUG_LEVEL – уровень отладки клиентской библиотеки.
LDAP_OPT_PROTOCOL_VERSION – версия протокола LDAP.
LDAP_OPT_X_TLS_CACERTDIR– путь к директории с корневыми сертификатами.
LDAP_OPT_X_TLS_CACERTFILE – полный путь к файлу корневого сертификата.
LDAP_OPT_X_TLS_NEWCTX – создание нового контекста библиотеки TLS.
LDAP_OPT_X_TLS_REQUIRE_CERT – стратегия проверки сертификатов. Принимает целое значение от 0 до 4, где:
0 – LDAP_OPT_X_TLS_NEVER,
1 – LDAP_OPT_X_TLS_HARD,
2 – LDAP_OPT_X_TLS_DEMAND,
3 – LDAP_OPT_X_TLS_ALLOW,
4 – LDAP_OPT_X_TLS_TRY.
Подробное описание этих настроек LDAP приведено на странице ldap_get_option().
roles – описание ролей, которые будут назначаться пользователю в зависимости от групп LDAP, в которых он
состоит. Вложенные параметры:
role – роль, назначенная пользователю или внешнему приложению для авторизованного доступа и действий в
системе (читать подробнее про роли).
domain_groups – LDAP-группы, которые соответствуют указанной выше роли.
В параметрах групп указываются:
cn (common name) – общее имя.
ou (organization unit name) – организационное подразделение или группа пользователей.
dc (domain component) – компонент домена.
Если пользователь состоит сразу в нескольких LDAP-группах, он получает разрешения на действия из всех ролей,
назначенных для этих групп.
Пример
В примере заданы настройки для:
Для них указаны основные параметры авторизации, отключен Active Directory и отключен TLS:
ldap:
- domain: 'my.domain.ru'
organizational_units: ['tarantool']
hosts:
- server.my.domain.ru:389
use_tls: false
use_active_directory: false
search_timeout: 2
options:
- LDAP_OPT_DEBUG_LEVEL: 3
roles:
- domain_groups:
- 'cn=tarantool,ou=groups,dc=my,dc=domain,dc=ru'
role: 'admin'
- domain: 'my.domain.ru'
organizational_units: ['svcaccts']
hosts:
- server.my.domain.ru:389
use_tls: false
use_active_directory: false
search_timeout: 2
roles:
- domain_groups:
- 'cn=svcaccts,ou=groups,dc=my,dc=domain,dc=ru'
role: 'supervisor'
Секция pepper
В этой секции указывается строка символов, которая в целях усиления безопасности добавляется к паролю
перед его хешированием.
Если данный параметр не указан в конфигурации, добавляется строка по умолчанию, определенная в коде системы.
Пример:
pepper: 2d60ec7f-e9f0-4018-b354-c54907b9423d
Настройка времени ожидания сетевых вызовов при шардировании
vshard-timeout – отдельная секция, где указывается время, в течение которого
модуль vshard ожидает сетевые запросы.
Это время в секундах передается в функциях
vshard.router.callro()
и vshard.router.callrw().
Значение по умолчанию – 2 секунды:
Конфигурация бизнес-логики
В конфигурацию бизнес-логики можно добавить параметры модели данных,
мониторинга,
сервисов GraphQL, подсистем и
коннекторов.
Примечание
Для простоты эксплуатации рекомендуется хранить различные параметры конфигурации
в разных YAML-файлах.
Параметры модели данных
Настроить модель данных можно, используя следующие секции:
types – описание типов объектов в модели данных.
versioning – настройка параметров времени жизни объектов
и ограничения количества версий объектов.
archivation – настройка параметров архивации объектов.
welcome-message – текст приветственного сообщения.
tdg-version – проверка версии TDG при применении конфигурации.
Секция types
В этой секции настраивается модель данных – указываются типы объектов, которые будут сохраняться в TDG.
В качестве языка описания модели данных TDG используется Apache Avro Schema.
По умолчанию указывается путь к файлу, где определена модель данных:
types: {__file: model.avsc}
Содержание model.avcs определяется пользователем самостоятельно.
Например, в файле может быть указана такая модель данных:
[
{
"name": "Country",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "phone_code", "type": ["null", "string"]}
],
"indexes": ["title"],
"relations": [
{ "name": "city", "to": "City", "count": "many", "from_fields": "title", "to_fields": "country" }
]
},
{
"name": "City",
"type": "record",
"fields": [
{"name": "title", "type": "string"},
{"name": "country", "type": "string"},
{"name": "population", "type": "int"},
{"name": "capital", "type": "boolean"}
],
"indexes": [
{"name":"primary", "parts":["title", "country"]},
"title",
"country",
"population"
]
}
]
Секция versioning
В этой секции настраивается версионирование – сохранение разных версий объектов для последующего извлечения,
просмотра и восстановления объектов.
По умолчанию версионирование отключено.
Чтобы его включить, укажите enabled: true для нужного типа объекта.
Пример. Включить версионирование для объекта типа Tourists можно так:
versioning:
- type: Tourists
enabled: true
Вы также можете настроить следующие параметры:
keep_version_count – количество хранимых версий. По умолчанию: 5. Минимальное значение: 1.
Если вы не хотите ограничивать количество хранимых версий, удалите этот параметр.
Если параметр задан, старые версии будут удаляться.
Только новые версии, количество которых меньше или равно заданному значению параметра, будут сохранены.
Каждый раз, когда добавляется новая версия, система проводит проверку и удаляет старые версии при необходимости.
delay_sec – интервал в секундах, через который запускается новая проверка устаревших объектов.
Найденные устаревшие объекты удаляются. Минимальное значение: 1.
lifetime_hours – время жизни версии в часах, также может быть задано в днях (lifetime_days)
или годах (lifetime_years).
По умолчанию не задано, поэтому версии хранятся неограниченное время. Минимальное значение: 1.
Если параметр задан, версии, существующие дольше заданного значения параметра, будут удалены.
strategy – стратегия удаления предыдущих версий из хранилища (архивирование).
Варианты стратегии:
dir – вывод в файл;
permanent – постоянное удаление версий;
cold_storage – хранение на диске с расчетом на то, что данные будут запрашиваться редко.
Примечание
Когда включена стратегия cold_storage, данные сохраняются в спейсе на vinyl.
Получить доступ к таким данным можно только вручную, с помощью запросов space_object:select().
Значение по умолчанию: permanent.
Если параметр strategy задан на вывод в файл или хранение на диске, необходимо
указать schedule – расписание запуска задачи на архивацию в формате cron
с поддержкой секунд.
При выводе в файл также необходимо указать максимальный размер файла, используя параметр file_size_threshold.
schedule – расписание в формате cron,
по которому проверяется наличие изменений в объектах.
Обязательный параметр, если задана стратегия strategy: cold_storage или strategy: file.
dir – директория, где в JSON-файлах хранятся прежние версии объектов.
file_size_threshold – предельный размер JSON-файла, в котором хранятся прежние версии объектов.
Когда предельное значение достигнуто, версии начинают сохраняться в новый файл.
Обязательный параметр, если задана стратегия strategy: file.
Пример
Укажем параметры версионирования для типов объектов Country и City.
Country: хранить 7 версий, ограничить время жизни 4 часами, запускать проверку через 1 секунду,
использовать холодное хранение (хранить на диске).
City: хранить 3 версии, ограничить время жизни 2 днями, запускать проверку через 1 секунду,
архивировать версии в файл.
versioning:
- type: Country
enabled: true
keep_version_count: 7
lifetime_hours: 4
delay_sec: 1
strategy: cold_storage
schedule: "0 0 0 */1"
- type: City
enabled: true
keep_version_count: 3
lifetime_days: 2
delay_sec: 1
strategy: file
schedule: "0 0 0 */1 * *"
dir: "/var/data"
file_size_threshold: 100001
Секция archivation
В этой секции настраивается архивация – выгрузка объектов из TDG и сохранение их отдельно на жестком диске в
файлах формата .jsonl (формат имени – YYYY-MM-DDTHH:MM:SS.jsonl).
Объекты записываются в файл построчно: один объект – одна строка вида {"TypeName": {... data ...}},
где TypeName – тип сохраняемого объекта.
Определенные типы объектов могут поступать в TDG в большом количестве, но при
этом иметь короткое время активного использования, после чего потребность в обращении к ним возникает редко.
Именно для таких объектов полезно настраивать архивацию.
По умолчанию архивация не настроена.
Чтобы ее настроить, задайте в секции archivation следующие параметры:
type – тип объекта.
lifetime_days – время жизни объекта в TDG, указывается в днях. Объекты старше этой величины архивируется.
schedule – расписание запуска задачи на архивацию в формате cron
с поддержкой секунд.
dir – директория для хранения файлов с архивными данными.
file_size_threshold – максимальный размер файла с архивными данными, указывается в байтах.
При достижении этого размера запись архивируемых данных начинается в новый файл.
По умолчанию: 104857600 (100 Мб).
Пример
Укажем настройки архивации для типа объекта Quotation, чтобы повысить производительность
TDG за счёт архивирования редко используемых цитат.
archivation:
- type: Quotation
lifetime_days: 7
schedule: "0 0 0 */1 * *"
dir: "/var/data"
file_size_threshold: 104857600
Секция welcome-message
В этой секции настраивается текст приветственного сообщения, которое будет появляться при входе в систему.
Ограничения на количество символов в сообщении нет.
Полезно изменять секцию welcome-message, например, если вы хотите облегчить работу с TDG новым сотрудникам, дописав им
полезные подсказки, или решили оставить важную информацию для опытных коллег.
Пример
Изменим текст приветственного сообщения, чтобы сообщить коллегам о планируемом обновлении сервиса.
welcome-message: |
Коллеги, сервис может быть недоступен в четверг с 12.00 до 14.00 в связи с плановым обновлением.
Секция tdg-version
В этой секции настраивается проверка версии TDG на совместимость при применении конфигурации.
Для параметра указывается условие проверки, и с ним сравнивается текущая версия TDG.
Если условие не выполняется, применение конфигурации останавливается.
Примеры
Проверим версию 1.6.0 на совместимость.
В примере:
==, <=, <, >, >= – оператор.
1.7.0 – версия major.minor.patch (семантическое версионирование) или scm-<число>.
Примечание
Чтобы избежать возможных ошибок при чтении, всегда заключайте выражение из оператора и версии в кавычки.
Обязательного помещения в кавычки не требует только выражение с ==.
Синтаксис YAML позволяет указывать многостроковые значения
с помощью операторов >, <, >=, >= в первой строке.
Чтобы задать версию больше, чем выбранное значение, нужно поместить оператор > и версию в кавычки.
Пример неправильного заполнения, когда версия будет прочитана как 1.6.0:
Пример правильного заполнения, когда версия будет прочитана как больше чем 1.6.0:
Параметры мониторинга
Настроить параметры мониторинга и изменить логику обработки объектов,
при необходимости передавая функциональную нагрузку на резервный компонент, можно
при помощи секций jobs,
tracing, repair_queue,
maintenance
и metrics.
Секция jobs
В этой секции при помощи параметра max_jobs_in_parallel настраивается максимальное количество
отложенных задач (jobs), которые могут выполняться одновременно.
Если вы используете отложенные задачи, рекомендуется настроить данную секцию и ограничить
количество отложенных задач, чтобы сохранить высокую производительность TDG.
При достижении установленного ограничения отложенные задачи сверх лимита будут поставлены в очередь
и будут выполняться последовательно.
Значение по умолчанию – 50:
jobs:
max_jobs_in_parallel: 50
Секция tracing
В этой секции настраиваются параметры для взаимодействия с системой трассировки, которая позволяет
анализировать производительность выполнения кода TDG:
lbase_url – адрес API-ресурса (endpoint), куда отсылаются собранные для анализа участки кода (spans).
lapi_method – тип HTTP-запроса для обращения к base_url.
Для систем трассировки, поддерживающих протокол OpenZipkin, используется POST.
lreport_interval – интервал в секундах, через который в систему трассировки
отсылаются накопленные участки кода.
lspans_limit – максимальное количество участков кода, которое может накапливаться в буфере
перед отправкой в систему трассировки.
Пример
Укажем локальный адрес для отправки участков кода с максимальным размером буфера = 100.
tracing:
base_url: localhost:8080/api/v2/spans
api_method: POST
report_interval: 0
spans_limit: 100
Секция repair_queue
При стандартном поведении TDG, когда объект поступает в систему на обработку, он сразу помещается
в ремонтную очередь.
Если объект удалось обработать и сохранить, он удаляется из ремонтной очереди.
В случае ошибки объекты остаются в ремонтной очереди, и администратор имеет возможность просматривать их, а
после устранения источника проблемы – отправлять на повторную обработку.
В этой секции можно изменить порядок обработки объектов, которые попали в ремонтную очередь.
Пример. Настроим репликацию во внешнюю систему для всех объектов ремонтной очереди, которые получили
специальное значение ключа __unclassified__, используемое для определения неклассифицированных объектов.
При попадании такого объекта в ремонтную очередь, согласно настройкам postprocess_with_routing_key: unclassified,
объекту присваивается другой ключ маршрутизации unclassified, и с этим ключом он направляется
в подсистему output_processor.
Дальнейшая обработка объекта будет выполняться в соответствии с параметрами
секции output_processor.
repair_queue:
on_object_added:
__unclassified__:
postprocess_with_routing_key: unclassified
Секция maintenance
В этой секции устанавливаются следующие параметры, сигнализирующие об ошибках системы:
clock_delta_threshold_sec – порог рассинхронизации истинного времени (CLOCK_REALTIME) на разных
экземплярах Tarantool. Значение указывается в секундах.
fragmentation_threshold_critical – порог, при превышении которого система покажет критическое
сообщение о фрагментации данных. Принимает относительные значения от 0 до 1.
fragmentation_threshold_warning – порог, при превышении которого система покажет предупреждение
о фрагментации данных. Принимает относительные значения от 0 до 1.
Если тот или иной параметр в секции maintenance выходит за указанные рамки,
об этом появляется сообщение в веб-интерфейсе TDG на вкладке Cluster.
Значения по умолчанию:
maintenance:
clock_delta_threshold_sec: 5
fragmentation_threshold_critical: 0.9
fragmentation_threshold_warning: 0.6
Секция metrics
В этой секции настраиваются параметры, задающие формат и возможность просмотра метрик
по нескольким адресам ресурсов (endpoints) для мониторинга работы TDG.
Эти параметры указываются внутри подраздела export:
metrics:
export:
- path: '/path_for_json_metrics'
format: 'json'
- path: '/path_for_prometheus_metrics'
format: 'prometheus'
- path: '/health'
format: 'health'
Параметры:
path – путь, по которому будут доступны метрики.
format – формат, в котором будут доступны метрики. Может принимать следующие значения:
При необходимости можно добавить несколько адресов ресурсов одного формата по разным путям.
Это полезно, когда есть несколько систем хранения метрик.
По умолчанию значения метрик в формате Prometheus доступны по адресу http://<IP_адрес_экземпляра>/metrics.
После заполнения секции metrics в файле конфигурации метрики по умолчанию в формате
Prometheus по адресу http://<IP_адрес_экземпляра>/metrics перестанут быть доступными.
Чтобы сделать их доступными, также укажите path: '/metrics' и format: 'prometheus' в секции metrics.
Параметры сервисов GraphQL
Настроить сервисы GraphQL можно, используя следующие секции:
Секция services
В этой секции настраивается конфигурация сервисов.
Для примера настроим сервис получения цены со следующими параметрами:
get_price – имя сервиса. Оно всегда должно начинаться с латинской буквы и может содержать латинские буквы,
цифры и символ подчеркивания (_).
type – тип запроса GraphQL для вызова сервиса: query или mutation.
Если тип – query, параметр можно не указывать.
doc – произвольное описание сервиса.
function – ссылка на Lua-файл с сервис-функцией.
return_type – тип данных, который возвращается в результате выполнения сервиса.
args – описание аргументов, передаваемых на вход при выполнении сервиса,
в формате имя_аргумента: тип_данных.
services:
get_price:
doc: "Get the item price by ID"
function: {__file: get_price_by_id.lua}
return_type: ItemPrice
args:
item_id: string
Секция hard-limits
В этой секции устанавливаются ограничения для запросов GraphQL.
Такие настройки для планировщика запросов позволяют контролировать нагрузку на кластер
и предотвращают полное сканирование спейса в TDG.
Также данные ограничения учитываются при работе функций
Repository API и Sandbox API.
Параметры:
scanned – максимальное количество кортежей, которое TDG будет сканировать при выполнении запроса.
Значение по умолчанию: 2000.
Примечание
Начиная с версии 2.7.0, вместо ограничения scanned для hard-limits
TDG использует механизм fiber.slice.
returned – максимальное количество кортежей, которое может вернуть одно хранилище.
Значение по умолчанию: 100. Например, returned = 100,
а в настройках пагинации параметр first равен 5.
Тогда запрос вернет 5 кортежей, а остальной массив данных можно обойти
с помощью параметра after.
Настройка данных параметров возможна при конфигурации системы или с помощью специальных запросов и мутаций GraphQL.
Пример настроек подраздела hard-limits в файле конфигурации:
hard-limits:
scanned: 2000
returned: 100
Во встроенном клиенте GraphiQL в веб-интерфейсе TDG для установки данных ограничений используется схема admin.
Пример запроса:
mutation {
config {
hard_limits(scanned:5000 returned:400) {
scanned
returned
}
}
}
Данные настройки превентивно требуют качественного написания запросов.
Если одно из ограничений превышается, выполнение запроса прекращается и возвращается ошибка.
Всего существует два вида ошибок – для параметров scanned и returned соответственно.
Кроме того, ошибка возникает, если:
для параметра returned верно first > returned;
для параметра scanned верно, что количество записей больше значения scanned, при этом first > scanned.
Пример ошибки: Hard limit for scan rows reached 2000 for space \"storage_MusicBand\"
Такая ошибка при сканировании означает, что при поиске по индексу в спейсе MusicBand было просмотрено более
2000 записей. Для устранения ошибки необходимо добавить индекс, который сократит выборку для данного запроса.
Примечание
Появление данной ошибки сканирования также возможно, когда используются функции repository.find(),
repository.update() и repository.delete() из раздела Repository API.
Ошибка может возникнуть
независимо от значения параметра first, если не используется индекс.
Например, есть запрос repository.find("ModelName", {{'key', '==', 'a'}}.
Значение параметра scanned = 5000.
Первые 5000 записей при этом не подходят по запросу.
Такой запрос вызовет ошибку.
Решение: добавить индекс – "indexes": [..., "key"];
если в запросе используются два или больше фильтров.
Например, есть запрос с несколькими фильтрами, где scanned = 5000.
Под первый фильтр подходит 10000 записей.
При этом первые 5000 записей не подходят под второй фильтр.
Такой запрос вызовет ошибку.
Секция force_yield_limits
В этой секции устанавливается ограничение на количество сканирований записей в спейсе.
При достижении порога управление потоком переходит от текущего файбера к другому (выполняется yield).
Актуально при выполнении map_reduce, чтобы избежать зависаний на экземплярах с ролью storage.
Также учитывается при работе функций Repository API.
Значение по умолчанию – 1000:
Секция graphql_query_cache_size
В этой секции устанавливается размер кэша для уникальных GraphQL-запросов.
Значение по умолчанию – 3000:
graphql_query_cache_size: 3000
Секция test-soap-data
В этой секции можно задать текст, который будет по умолчанию отображаться на вкладке
Test в веб-интерфейсе TDG. Это может также быть путь к файлу, содержащему
структуру тестового объекта в формате XML или JSON для имитации входящего запроса.
Пример. Укажем путь к файлу.
test-soap-data: {__file: test_object.json}
Параметры подсистем
Каждая подсистема – это набор определенных функциональных возможностей, входящих в ту или иную
кластерную роль.
Управляющие подсистемы объединяет в себе роль core.
Обрабатывающие подсистемы объединяет в себе роль runner.
Принимающие подсистемы объединяет в себе роль connector.
Хранящие подсистемы объединяет в себе роль storage.
Ниже рассматриваются параметры, связанные со следующими подсистемами:
input_processor – настраивает логику обработки,
маршрутизацию и правила хранения объектов. Относится к роли runner.
output_processor – настраивает логику обработки объектов,
которые будут реплицироваться во внешние системы. Относится к роли runner.
account_manager – настраивает работу ролевой модели доступа
и связанные с ней функции безопасности. Относится к роли core.
notifier – настраивает отправку уведомлений при попадании объекта
в ремонтную очередь. Относится к роли core.
gc – принудительно запускает сборку мусора в коде Lua.
Запускается на экземплярах с любой ролью.
sequence_generator – генерирует последовательность случайных чисел.
Относится к роли core.
logger – настраивает ведение журнала.
Запускается на экземплярах с любой ролью.
tasks – настраивает задачи, выполняемые при помощи ролей
scheduler и task_runner.
task_runner – настраивает порог количества выполняемых пайплайнов
для задач (tasks) и отложенных задач (jobs). Относится к роли runner.
audit_log – настраивает ведение журнала аудита.
Запускается на экземплярах с любой ролью.
output_processor
В этой секции задается логика обработки объектов, которые будут реплицироваться во внешние системы.
Выполняется после успешного сохранения объектов на экземплярах с ролью storage.
Для каждого ключа маршрутизации, присвоенного объекту, определяются следующие подразделы:
Пример:
output_processor:
estate_key:
handlers:
- function: output.estate_output.call
outputs:
- dummy
account_manager
В этой секции настраивается подсистема account_manager, которая обеспечивает работу
ролевой модели доступа и связанные с ней функций безопасности.
Параметры:
only_one_time_passwords – флаг (true/false). По умолчанию: false. Если указано значение true,
нет возможности вручную задавать пароль при создании или импорте профиля пользователя.
Вместо этого TDG автоматически генерирует одноразовый пароль и высылает его на адрес электронной почты пользователя.
Для отсылки пароля также необходимо иметь работающий сервер SMTP,
описание его конфигурации в секции connector (output: type: smtp)
и указание на этот output в секции account_manager.
Опционально можно указать заголовок письма, в котором высылается одноразовый пароль (options: subject:).
Если указано значение only_one_time_passwords: false, то пароль будет генерироваться
и отправляться пользователю, даже если поле Password при создании профиля пользователя оставлено пустым.
password_change_timeout_seconds – минимальное время, которое должно пройти до следующей смены пароля.
Указывается в секундах. Действует только в отношении смены собственного пароля.
block_after_n_failed_attempts – количество неудачных попыток входа в систему,
после которых пользователь будет заблокирован (получит статус blocked).
ban_inactive_more_seconds – максимальное время, в течение которого пользователь может быть
неактивен в системе. Указывается в секундах. По истечении этого времени пользователь будет заблокирован.
Максимально возможное значение параметра – 45 дней. Если значение превышает 45 дней или параметр не задан,
устанавливается значение по умолчанию, равное 45 дням.
password_policy – настройки политики в отношении паролей.
Эти настройки также можно задать через веб-интерфейс TDG.
min_length – минимально допустимая длина пароля. По умолчанию: 8.
include – флаги (true/false), определяющие, какие категории символов должны
обязательно входить в пароль.
Допустимые значения:
lower – латинские буквы в нижнем регистре. По умолчанию: true.
upper – латинские буквы в верхнем регистре. По умолчанию: true.
digits – цифры от 0 до 9 включительно. По умолчанию: true.
symbols– дополнительные символы !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~. По умолчанию: false.
Пример. Настроим возможность получать одноразовый пароль по электронной почте.
account_manager:
only_one_time_passwords: true
output:
name: to_smtp
options:
subject: "Registration"
password_change_timeout_seconds: 10
block_after_n_failed_attempts: 5
ban_inactive_more_seconds: 86400
password_policy:
min_length: 8
include:
lower: true
upper: true
digits: true
symbols: false
notifier
В этой секции настраивается подсистема notifier для отправки уведомлений:
mail_server – секция настроек сервера SMTP, который используется для отправки уведомлений
при попадании объекта в ремонтную очередь. Данные параметры также можно задать через веб-интерфейс TDG.
Вложенные параметры:
url – URL сервера SMTP.
from – имя отправителя, которое будет показываться в поле «From» при получении уведомления.
username – имя пользователя сервера SMTP.
password – пароль пользователя сервера SMTP.
timeout – тайм-аут запроса к серверу SMTP. Указывается в секундах.
skip_verify_host – флаг (true/false): пропустить проверку хоста по протоколу TLS.
users – секция, где задаются данные подписчиков (subscribers), которые будут получать уведомления.
Подписчиков также можно создать через веб-интерфейс TDG.
Вложенные параметры:
Пример:
notifier:
mail_server:
url: 127.0.0.1:2525
from: TDG_repair_queue
username: user
password: passpass
timeout: 5
skip_verify_host: true
users:
- id: 1
name: Petrov
addr: petrov@mailserver.com
gc
В этой секции настраивается подсистема garbage_collector, которая принудительно запускает сборку мусора в Lua.
Подсистема включается неявно на всех экземплярах:
forced – включение (true) или отключение (false) принудительной сборки мусора. По умолчанию: false.
period_sec – интервал, через который происходит запуск нового цикла сборки мусора. Указывается в секундах.
steps – размер шага сборщика мусора.
Пример. Настроим принудительную сборку мусора так, чтобы она происходила каждые три секунды.
gc:
forced: true
period_sec: 3
steps: 20
sequence_generator
В этой секции указываются настройки, используемые при генерации последовательностей уникальных чисел:
starts_with – число, с которого начинается последовательность. По умолчанию: 1.
range_width – диапазон последовательности. По умолчанию: 100.
Пример. Зададим генерацию последовательности уникальных чисел с 5 при диапазоне 15.
sequence_generator:
starts_with: 5
range_width: 15
logger
В этой секции определяются параметры подсистемы логирования logger. Все параметры обязательные:
rotate_log – флаг (true/false), осуществлять ли ротацию лога.
max_msg_in_log – максимальное количество сообщений, сохраняемых в логе.
max_log_size – максимальный размер файла лога, в байтах.
delete_by_n_msg – количество одновременно удаляемых сообщений при ротации лога.
При превышении значений параметров max_msg_in_log или max_msg_log_size
наиболее старые n сообщений в логе удаляются за раз, что повышает производительность
по сравнению с режимом, когда старые сообщения удаляются по одному.
logger:
rotate_log: true
max_msg_in_log: 500000
max_log_size: 10485760
delete_by_n_msg: 1000
tasks
В этом разделе определяется, какие задачи и в какое время будут запускаться в системе.
Пример:
tasks:
task_1:
kind: single_shot
function: single_task
keep: 5
task_2:
kind: continuous
function: long_task
pause_sec: 10
run_as:
user: username
task_3:
kind: periodical
function: long_task
schedule: "0 */5 * * * *"
run_as:
user: username
В этом примере:
task_N – имя задачи.
kind – вид задачи: single_shot (однократная), continuous (постоянная)
или periodical (периодическая).
function – функция, определяющая, что именно делается в рамках задачи.
keep – количество завершенных экземпляров задачи, которые сохраняются в истории. По умолчанию: 10.
pause_sec – пауза в выполнении задачи вида continuous. Указывается в секундах.
schedule – расписание выполнения для задач вида periodical.
Задается в формате cron c расширенным синтаксисом,
в котором минимальной величиной является секунда:
* * * * * *
| | | | | |
| | | | | ----- День недели (0-6) (Воскресенье = 0)
| | | | ------- Месяц (1-12)
| | | --------- День (1-31)
| | ----------- Час (0-23)
| ------------- Минута (0-59)
--------------- Секунда (0-59)
Например, schedule: "0 */5 * * * *" означает, что задача будет запускаться
периодически каждые 5 минут.
run_as – пользователь, от имени которого выполняется задача. Применяется
только для задач видов continuous или periodical.
Указанный пользователь должен иметь достаточно прав для выполнения действий задачи.
Если режим обязательной аутентификации
выключен, параметр run_as не обязателен. Внутри блока run_as передается параметр:
task_runner
В этой секции настраивается running_count_threshold – порог количества функций, выполняемых в рамках
задач (tasks) и отложенных задач (jobs).
Значение по умолчанию:
task_runner:
running_count_threshold: 100
audit_log
В этой секции задаются параметры журнала аудита.
Все параметры опциональные:
enabled – включить (true) или выключить (false) запись событий в журнал аудита.
По умолчанию: false.
severity – уровень важности событий, которые будут записываться в журнал аудита.
Возможные значения по возрастанию важности: VERBOSE, INFO, WARNING, ALARM.
По умолчанию: INFO.
При указании определенного уровня в журнал аудита будут записываться события этого уровня и выше.
Например, если задано INFO, будут записываться события,
соответствующие уровням INFO, WARNING и ALARM.
remove_older_than_n_hours – максимальное время хранения записей в журнале аудита. Указывается в часах.
Записи старше указанного времени удаляются.
Пример. Включим запись событий уровня INFO и более высоких.
audit_log:
enabled: true
severity: INFO
remove_older_than_n_hours: 5
По умолчанию журнал аудита выключен:
audit_log:
enabled: false
Параметры коннекторов
В этой секции настраиваются параметры коннекторов TDG:
input – получение и первоначальная обработка (парсинг) входящих запросов;
output – отправка запросов во внешние системы;
routing – маршрутизация объектов.
Настройка output
output – параметры коннекторов для отправки исходящих запросов.
У всех типов коннекторов есть общие параметры:
name – имя коннектора (произвольное).
type – тип коннектора. Поддерживаемые типы:
input_processor – для отправки объекта в подсистему input_processor;
http – для отправки объекта в формате JSON во внешнюю систему по HTTP;
soap – для отправки объекта в формате XML (SOAP) во внешнюю систему по HTTP;
kafka – для интеграции с шиной данных Apache Kafka;
smtp – для отправки запросов через SMTP-сервер;
dummy – для игнорирования объектов: пришедший объект никуда не отправляется.
headers – заголовки HTTP, которые при необходимости может установить пользователь
при отправке данных во внешнюю систему.
is_async – режим работы TDG в качестве producer:
true (по умолчанию) – асинхронный режим: подтверждение о доставке сообщения отправляется
сразу после того, как сообщение добавлено в очередь на отправку.
false – синхронный режим: подтверждение о доставке сообщения отправляется только после того,
как сообщение было доставлено.
Помимо этих параметров, у некоторых типов коннекторов есть параметры, специфические только для них.
Особые параметры коннектора типа http
url – URL внешней системы, куда отправляется объект.
format – формат, в котором отправляется объект. Для коннектора типа http формат – всегда JSON.
options – опции параметра opts из встроенного модуля Tarantool http).
Пример. Укажем коннектор типа http.
connector:
output:
- name: to_external_http_service
type: http
url: http://localhost:8021
format: json
options:
timeout: 5
keepalive_idle: 60
keepalive_interval: 60
verify_host: true
verify_peer: true
headers:
hello: world
Особые параметры коннектора типа soap
Пример. Укажем коннектор типа soap.
connector:
output:
- name: to_external_soap_service
type: soap
url: http://localhost:8020/test_soap_endpoint
headers:
config_header: header_for_soap
Особые параметры коннектора типа kafka
brokers – адреса (URL) брокеров сообщений.
topic – топик (topic) в терминологии Kafka.
format – формат, в котором отправляется сообщение в Kafka.
Возможные значения: json и plain.
Значение plain может применяться для случая, когда необходимо отправить в Kafka сообщение в формате XML.
Значение по умолчанию: json.
options – опции библиотеки
librdkafka:
queue.buffering.max.ms (integer) – задержка в миллисекундах.
Используется, чтобы дождаться, пока накопятся сообщения в очереди продюсера, прежде чем будут созданы пакеты
сообщений для отправки брокерам.
Значение по умолчанию: 5.
statistics.interval.ms (integer) – интервал обновления метрик в миллисекундах.
Значение по умолчанию: 15000.
Диапазон доступных значений: 0–86400000.
Значение 0 отключает сбор статистики.
debug – выбор режима отладки.
Возможные значения: generic, metadata, broker, topic, msg, all.
Значение по умолчанию: all.
logger – выбор режима для журнала событий:
stderr (по умолчанию) – в логи TDG выводятся только сообщения об ошибках.
tdg – в TDG отправляются все логи Kafka, включая сообщения об ошибках.
set_key – генерация ключа UUID для отправляемого сообщения.
Значение по умолчанию: true.
При значении false ключ в исходящем сообщении будет пустым.
Примечание
При подключении к Kafka в логах TDG выводятся output-параметры, с которым был создан producer Kafka.
В логах указаны значения для всех опций библиотеки librdkafka, в том числе выставленные по умолчанию.
Отключить вывод логов нельзя.
Пример вывода:
tdg2 | 2023-03-02 16:17:19.821 [1] main/304/main I> [dcb31ae4-ca99-4b1c-995f-a0dd05194fa9] Kafka producer for "to_kafka" output configuration: ---
tdg2 | ssl.engine.id: dynamic
tdg2 | socket.blocking.max.ms: '1000'
tdg2 | message.max.bytes: '1000000'
tdg2 | connections.max.idle.ms: '0'
tdg2 | enable_sasl_queue: 'false'
tdg2 | batch.size: '1000000'
...
Пример. Укажем коннектор типа kafka.
connector:
output:
- name: to_kafka
type: kafka
brokers:
- localhost:9092
topic: objects
options:
debug: "all"
queue.buffering.max.ms: 1
is_async: true
Особые параметры коннектора типа smtp
url – URL сервера SMTP.
from – имя отправителя, которое будет показываться в поле From при получении сообщения.
subject – тема отправляемого сообщения.
timeout – тайм-аут запроса к серверу SMTP. Указывается в секундах.
ssl_cert – путь к SSL-сертификату.
ssl_key – путь к приватному ключу для SSL-сертификата.
Пример. Укажем коннектор типа smtp.
connector:
output:
- name: to_smtp
type: smtp
url: localhost:2525
from: tdg@localhost
subject: TDG_Objects
timeout: 5
ssl_cert: ssl.crt
ssl_key: ssl.pem
Настройка routing
routing – маршрутизация объекта для отправки в систему, которая определяется в поле output
в зависимости от ключа маршрутизации key.
Ключ маршрутизации объект получает в результате обработки функцией, указанной в input.
Если в input функция не указана, объект обрабатывается функцией по умолчанию, которая превращает объект
вида { "obj_type": { "field_1": 1 } } в объект вида { "field_1": 1 }
и задает значение ключа маршрутизации как routing_key = obj_type.
Пример конфигурации:
connector:
routing:
- key: input_processor
output: to_input_processor
- key: external_http_service
output: to_external_http_service
- key: external_soap_service
output: to_external_soap_service
Пример настройки бизнес-логики
connector:
input:
- name: http
type: http
routing_key: input_key
output:
- name: http_output
type: http
url: http://localhost:{HTTP_PORT}
format: json
headers:
hello: world
- name: invalid_http_output
type: http
url: http://localhost:8085
format: json
- name: soap_output
type: soap
url: http://localhost:{HTTP_PORT}
headers:
config_header: header_for_soap
input_processor:
handlers:
- key: input_key
function: classifier.call
storage:
- key: test_object_1
type: TestObject
- key: test_object_2
type: TestObject
- key: test_object_3
type: TestObject
- key: soap_object
type: TestObject
- key: updatable_object
type: UpdatableObject
- key: object_with_entity
type: ObjectWithEntity
- key: bad_object
type: BadObject
repair_queue:
on_object_added:
bad_object:
postprocess_with_routing_key: bad_object_failed
__unclassified__:
postprocess_with_routing_key: unclassified
output_processor:
test_object_1:
handlers:
- function: output_processor_handler.call
outputs:
- http_output
test_object_2:
handlers:
- function: output_processor_handler.call
outputs:
- invalid_http_output
test_object_3:
handlers:
- function: bad_output_processor_handler.call
outputs:
- invalid_http_output
updatable_object:
handlers:
- function: output_processor_handler.call
outputs:
- http_output
bad_object_failed:
handlers:
- function: output_processor_handler.call
outputs:
- http_output
object_with_entity:
handlers:
- function: output_processor_handler.call
outputs:
- http_output
soap_object:
handlers:
- function: soap_processor.call
outputs:
- soap_output
unclassified:
handlers:
- function: output_processor_handler.call
outputs:
- http_output
Права доступа
В Tarantool Data Grid используется основанная на ролях модель доступа к
системным функциям и данным, хранящимся в системе. В этой главе подробно
описываются профили доступа, которые можно назначать для создаваемых ролей,
и связанные с этими профилями действия.
Access provider
Работа с настройками доступа:
Audit Logs
Работа с журналом аудита:
Clear the audit log — очистка журнала аудита.
Enable the audit log — включение журнала аудита.
Set the lowest severity level for audit log messages — возможность установки минимального уровня важности событий для журнала аудита.
Show the audit log — просмотр журнала аудита.
Cartridge Actions
Работа с Cartridge:
Allow to bootstrap vshard — разрешить включение шардирования.
Allow to disable listed servers — разрешить отключение серверов из списка.
Allow to edit cluster topology server — разрешить изменять топологию кластера.
Allow to edit vshard options — разрешить изменять настройки шардирования.
Allow to modify auth parameters — разрешить изменять настройки аутентификации.
Allow to modify failover parameters — разрешить изменять настройки восстановления после сбоев.
Allow to probe server — разрешить проверять работоспособность сервера.
Allow to promote instance to the leader of replica set — разрешить повышать уровень экземпляра до лидера набора реплик.
Allow to reapply config on the specified nodes — разрешить повторное применение конфигурации к заданным узлам.
Allow to restart replication — разрешить перезапуск репликации.
Show cluster compression status — просмотр статуса сжатия для кластера.
Show cluster management suggestions — просмотр подсказок по управлению кластером.
Show cluster problems — просмотр проблемы возникших в кластере.
Show cluster servers — просмотр серверов входящих в кластер.
Show replica sets information — просмотр информации о наборах реплик.
Checks
Работа с различными проверками:
Configuration
Работа с конфигурацией:
Apply configuration — применение конфигурации.
Change current configuration — изменение текущей конфигурации.
Change the settings of the password generator — изменение настроек создания паролей.
Check the input section in config — проверка входных данных в секции конфигурации.
Delete stored configurations from space — удаление сохраненных конфигураций из спейса.
Load sample configuration — загрузка примеров конфигурации.
Read default keep_version_count parameter for versioning — чтение значения по умолчанию параметра keep_version_count, используемого для версионирования.
Read TDG configuration — чтение конфигурации TDG.
Read the cache size for GraphQL queries — чтение размера кэша для запросов GraphQL.
Read the force yield limit — чтение лимита времени принудительной отдача контекста (yield).
Read the hard limits — чтение жестких лимитов (hard limits).
Read the input section in config — чтение входных данных в секции конфигурации.
Read the locked sections in config — чтение заблокированных секций в конфигурации.
Read the timeout for vshard requests — чтение таймаута для запросов шардирования.
Read time limit for inactive users and tokens in config — чтение лимита времени для неактивных пользователей и токенов в конфигурации.
Save TDG configuration — сохранение конфигурации TDG.
Set default keep_version_count parameter for versioning — установка значения по умолчанию параметра keep_version_count, используемого для версионирования.
Set the cache size for GraphQL queries — установка размера кэша для запросов GraphQL.
Set the force yield limit — установка лимита времени принудительной отдача контекста (yield).
Set the hard limits — установка жестких лимитов (hard limits).
Set the timeout for vshard requests — установка таймаута для запросов шардирования.
Show metrics configuration — просмотр конфигурации метрик.
Update metrics configuration — изменение конфигурации метрик.
Update the input section in config — изменение входных данных в секции конфигурации.
Update time limit for inactive users and tokens in config — изменение лимита времени для неактивных пользователей и токенов в конфигурации.
Write the locked sections in config — изменение заблокированных секций в конфигурации.
Data Actions Management
Управление профилями доступа:
Allow to create new data action — возможность создания нового профиля доступа.
Allow to delete data action — возможность удаления профиля доступа.
Allow to read data actions — возможность чтения профиля доступа.
Allow to update data action — возможность изменения профиля доступа.
Data Type Management
Работа с типами данных:
Allow to modify model and versioning configuration — возможность изменения модели и конфигурации версионирования.
Allow to read model and versioning configuration — возможность чтения модели и конфигурации версионирования.
Clean up expired data — удаление устаревших данных.
Jobs List
Работа с отложенными задачами:
Delete the job — удаление отложенной задачи.
Show all jobs — просмотр всех отложенных задач.
Try executing the job again — повторная попытка запуска отложенной задачи.
Logs
Работа с общим журналом событий:
Change configuration of logging — изменение конфигурации журнала событий.
Clear logs — очистка журнала событий.
Show logs — просмотр журнала событий.
Notifier
Управление уведомлениями:
Delete users subscribed to notifications — удаление пользователей подписанных на уведомления.
Show all users subscribed to notifications — просмотр пользователей подписанных на уведомления.
Show the mail servers for sending notifications — просмотр почтовых серверов для отправки уведомлений.
Specify a user subscribed to notifications — подписка пользователя на уведомления.
Specify the mail server for sending notifications — задание почтового сервера для отправки уведомлений.
Output Processor List
Управление обработчиком исходящих данных (output processor):
Delete tasks in the output processor — удаление задач из обработчика исходящих данных.
Restart post processing in the output processor — перезапуск постобработки обработчика исходящих данных.
Show all tasks sent to the output processor (state + history) — просмотр всех задач отправленных в обработчик исходящих данных.
Pages Access
Управление доступом к интерфейсу:
Show audit_log page — доступ к странице Audit log.
Show cluster page — доступ к странице Cluster.
Show configuration page — доступ к странице Configuration Files.
Show connectors configuration page — доступ к странице Connectors.
Show data types page — доступ к странице Data types.
Show doc page — доступ к странице Doc.
Show graphql page — доступ к странице Graphql.
Show logger page — доступ к странице Logger.
Show model page — доступ к странице Model.
Show repair pages — доступ к странице Repair Queues.
Show settings page — доступ к странице Settings.
Show tasks page — доступ к странице Tasks.
Show test page — доступ к странице Test.
Repair Queue
Работа с ремонтной очередью:
Delete objects in the repair queue — удаление объектов из ремонтной очереди.
Retry processing objects in the repair queue — повторение попытки обработки объектов из ремонтной очереди.
Show all objects in the repair queue — показать все объекты из ремонтной очереди.
Roles
Управление ролями доступа:
Change access-related roles — изменение ролей доступа.
Change settings for access-related roles — изменение настроек ролей доступа.
Create access-related roles — создание ролей доступа.
Delete access-related roles — удаление ролей доступа.
Read the role information — просмотр информации о роли доступа.
Show access-related actions — просмотр действий для роли доступа.
Show all access roles — просмотр всех доступных ролей доступа.
Show all actions allowed for the access-related role — просмотр всех действий доступных для роли доступа.
Services
Работа с сервисами:
Storage
Работа с хранилищем:
Delete spaces not linked from anywhere — удаление неиспользуемых спейсов.
Drop all spaces — удаление всех спейсов.
Remove data from spaces not linked from anywhere — удаление данных из неиспользуемых спейсов.
Show all aggregates — показывать все типы данных.
Show all spaces not linked from anywhere — просмотр всех неиспользуемых спейсов.
Show length of all storage spaces — просмотр размера всех спейсов в хранилище.
Tasks
Работа с задачами:
Delete the result of a task — удаление результата выполнения задачи.
Edit tasks config — изменение конфигурации задач.
Run the task — запуск задачи.
Show tasks config — просмотр конфигурации задач.
Show the tasks with statuses — просмотр задач с их статусами.
Stop the task — остановка задачи.
Tokens
Работа с токенами:
Change the token state — изменение состояния токена.
Create a new token — создание нового токена.
Delete the token — удаление токена.
Get the token — получение токена.
Import a token — импорт токена.
Show all tokens — просмотр всех токенов.
Update the token — обновление токена.
Users
Работа с пользователями:
Change the user's state — изменение состояния пользователя.
Create a new user — создание нового пользователя.
Delete the user — удаление пользователя.
Import a user — импорт пользователя.
Set user password — задание пользовательского пароля.
Show all users — просмотр всех пользователей.
Update user information — обновление информации о пользователе.
Sandbox API
В TDG пользовательский код выполняется в окружении sandbox, отдельно от собственного кода TDG.
sandbox – изолированная среда (песочница) для исполнения кода, где используется JIT-компилятор LuaJIT.
Sandbox API включает в себя:
модули и функции Lua и Tarantool;
функции, специфичные для TDG, предназначенные для доступа к
данным, их обработке и других действий.
Кроме того, к песочнице можно подключать новые функции.
Чтобы узнать больше, обратитесь к разделу Расширения.
В sandbox недоступны некоторые функции или интерфейсы (например, библиотека ffi).
Все доступные модули и функции Sandbox API в этом справочнике разделены на группы по своей функциональности:
Repository API
Sandbox API включает в себя модуль repository – интерфейс репозитория TDG.
Этот модуль предоставляет функции для работы с шардированным хранилищем.
Функции позволяют выполнять следующие действия с данными:
операции выбора, вставки, изменения и удаления данных;
управление процессом обработки данных.
Все запросы к данным в TDG от внешних информационных систем, включая
GraphQL-запросы (а также запросы, выполняемые во вкладке GraphQL), реализованы на основе
функций программного интерфейса репозитория.
Доступные функции:
Функции find(), update(), update-batch(), delete и count() поддерживают
порядковую нумерацию страниц (пагинацию).
Для этого используются параметры:
first и after – в функциях find() и count();
first_n_on_storage и after – в функциях update(), update_batch() и delete().
Все функции модуля, кроме call_on_storage() и push_job(), поддерживают версионирование – получение
или обработку объектов, которые предшествуют или равны определённой версии.
Фильтрация объектов
Для выбора нужных объектов запросы применяют условия-предикаты, или фильтры.
Предикаты указываются в параметре filter в формате булевых выражений.
Синтаксис предикатов
В запросах предикаты (filter) записываются в виде:
{{left, comparator, right}, ...}
где:
left – левая часть выражения. Содержит один из двух вариантов:
comparator – оператор сравнения: ">", ">=", "==", "<=", "<";
right – правая часть выражения. Содержит один из двух вариантов:
полный путь к полю объекта (Customer.first_name);
строковое значение, численное значение, булево значение или таблица.
Если в предикате несколько условий, по умолчанию они объединяются логической операцией and (конъюнкцией).
Примеры предикатов:
{{"id", ">", 10}}
{{"id", ">", 10}, {"id", "<", 100}}
{{"Customer.first_name", "==", "Ivan"}, {"birth_year", "==", 1990}}
{{"Customer.first_name", "==", "Ivan"}, {"reg_date", "==", {1990, 04, 23}}}
Как работают фильтры
Все условия-предикаты в параметре filter проверяются по очереди, чтобы
определить основной фильтр для сканирования.
Остальные фильтры используются как дополнительные условия при прохождении по индексу.
При выборе основного фильтра соблюдается следующий порядок:
Если в списке условий есть фильтр по индексу, он используется в качестве основного и задает индекс для сканирования;
Если в запросе нет фильтра по индексу, проверяются фильтры по полю.
Если при этом какое-то поле является первым в составном индексе,
используется этот составной индекс.
Если нет ни одного подходящего индекса, идет полное сканирование спейса по первичному ключу.
При этом в версиях до 2.7.0 TDG использует ограничение на полное сканирование спейса
(параметр scanned в секции hard-limits конфигурации).
По умолчанию при выполнении запроса сканируются 2000 кортежей.
Начиная с версии 2.7.0, вместо ограничения scanned для hard-limits
TDG использует механизм fiber.slice;
Если условие содержит операторы like или ilike, такое условие не может задавать
индекс для сканирования.
Для примера определим модель данных с двумя типами объектов: Client и Passport:
[
{
"name": "Passport",
"type": "record",
"fields": [
{"name": "id", "type": "long"},
{"name": "passport_series", "type": "string"},
{"name": "passport_number", "type": "string"},
{"name": "expired_flag", "type": "boolean"}
],
"indexes": [
"id",
{
"name": "passport",
"parts": ["passport_series", "passport_number"]
}
]
},
{
"name": "Client",
"type": "record",
"fields": [
{"name": "id", "type": "long"},
{"name": "first_name", "type": "string"},
{"name": "last_name", "type": "string"},
{"name": "passports", "type": {"type": "array", "items": "Passport"}}
],
"indexes": ["id"]
}
]
Пример 1
Запрос возвращает клиентов по имени Ivan с id больше 40:
repository.find(
"Client",
{{"first_name", "==", "Ivan"},
{"id", ">", 40}})
В запросе указаны:
фильтр по индексу id – первичный ключ, по которому ведется сканирование;
фильтр по полю first_name – дополнительное условие поиска.
Пример 2
Запрос возвращает клиентов по имени Ivan, у которых первый паспорт имеет указанную серию:
repository.find(
"Client",
{{"first_name", "==", "Ivan"},
{"passports.1.passport_series", "==", "012345"}})
В запросе указаны два фильтра по полю. При этом поле passport_series – часть составного индекса passport.
Сканирование идет по индексу passport.
Пример 3
Запрос возвращает клиентов, у которых истек срок действия первого паспорта:
repository.find(
"Client",
{{"first_name", "==", "Ivan"}
{"last_name", "==", "Petrov"},
{"passports.1.expired_flag", "==", "false"}})
Среди условий нет подходящего индекса (в том числе составного), так что начинается полное сканирование по первичному ключу.
Оптимистичные блокировки
Внесение параллельных изменений из разных обработчиков в один и тот же объект может вызвать конфликты.
Чтобы избежать конфликта, задайте один из двух параметров в аргументе запроса options:
only_if_version – механизм оптимистичных блокировок, основанный на версиях объектов.
Запрос выполнится, только если данная версия объекта является последней и совпадает с заданной в запросе.
repository.put(
"Client",
{id = "42", first_name = "Ivan", last_name = "Petrov"},
{version = 6, only_if_version = 5})
Запрос в примере выполняет поиск по первичному ключу id.
Если объект с таким id найден, он обновляется, только если версия объекта в системе
на момент исполнения совпадает со значением в параметре only_if_version.
После успешного исполнения запроса последняя версия объекта станет равна 6.
if_not_exists – проверка на наличие дубликата объекта перед вставкой.
Параметр доступен при вставке новых объектов (repository.put()) или массивов
(repository.put_batch()), а также при подсчете количества объектов (repository.count()).
Если задано значение true, система проверяет, существует ли уже такой объект.
Если такого объекта еще нет, новый объект добавляется в хранилище.
Примечание
Параметры only_if_version и if_not_exists взаимоисключающие.
При использовании параметров вместе в одном запросе система выдаст ошибку.
Справочник по Repository API
-
repository.find(type_name, filter[, options])
Возвращает объекты, соответствующие заданным условиям.
Если тип объекта поддерживает версионирование, метод возвращает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество возвращаемых элементов.
Значение по умолчанию: 10;
after – курсор пагинации на первый элемент;
all_versions – поиск по всем версиям объекта, если задано значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false;
version – версия объекта, которая будет возвращена.
Параметр применяется только при включенном версионировании.
Если параметр задан, возвращается указанная версия объекта.
Если такой версии не существует, возвращается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия.
Если вместе с этим параметром задан параметр all_versions, то обрабатываются все
версии меньше или равные заданной;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
Возможные значения: true и false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
Возможные значения: true и false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам.
- Результат
таблица объектов, соответствующих заданным условиям
- Тип результата
table
Пример
repository.find(
"Client",
{{"first_name", "==", "Ivan"},
{"last_name", "==", "Petrov"}})
-
repository.get(type_name, pkey[, options])
Получает объект по первичному ключу.
Если тип объекта поддерживает версионирование, метод возвращает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
pkey (any) – первичный ключ
options (table) –
параметры для управления запросом. Доступные параметры:
version – версия объекта, которая будет получена.
Параметр применяется только при включенном версионировании.
Если параметр задан, возвращается указанная версия объекта.
Если такой версии не существует, возвращается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
По умолчанию: false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
По умолчанию: false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам.
- Результат
объект
- Тип результата
table
Пример
repository.get("Client", 42)
-
repository.put(type_name, object[, options])
Вставляет новый или заменяет существующий объект.
Поддерживает оптимистичные блокировки.
Если тип объекта поддерживает версионирование, метод вставляет новую версию объекта или заменяет существующую.
- Параметры
type_name (string) – тип объекта
object (table) – объект для вставки
options (table) –
параметры для управления запросом. Доступные параметры:
version – версия объекта, которая будет добавлена или заменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, заменяется указанная версия объекта.
Если такой версии не существует, заменяется ближайшая предшествующая версия.
Объект при этом сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и вставляет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед вставкой.
Параметр применяется только при включенном версионировании.
При указанном параметре запрос добавляет или заменяет объект, только если последняя версия
объекта совпадает с указанной;
if_not_exists – проверка имеющегося объекта перед вставкой. По умолчанию: false.
Если задано значение true, система проверяет, существует ли уже такой объект в хранилище.
Новый объект будет добавлен, если его еще нет в хранилище;
skip_result – при значении true возвращает пустой массив, а не сами измененные объекты.
По умолчанию: false.
- Результат
измененный объект
- Тип результата
table
Пример
Запрос добавляет объект с первичным ключом id:
repository.put("Client", {id = "42", first_name = "Ivan", last_name = "Petrov"})
Если версионирование отключено:
Если версионирование включено:
новый объект добавляется в хранилище, version равно последней версии;
для объекта c уже существующим id добавляется новая версия объекта.
-
repository.put_batch(type_name, array[, options])
Вставляет массив из новых объектов или заменяет существующие.
Поддерживает оптимистичные блокировки.
Если тип объекта поддерживает версионирование, метод вставляет новую версию объекта или заменяет существующую.
- Параметры
type_name (string) – тип объекта
array (table) – массив объектов для вставки
options (table) –
параметры для управления запросом. Доступные параметры:
version – версия объекта, которая будет добавлена или заменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, заменяется указанная версия объекта.
Если такой версии не существует, заменяется ближайшая предшествующая версия.
Объект при этом сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и вставляет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед вставкой.
Параметр применяется только при включенном версионировании.
При указанном параметре запрос добавляет или заменяет объект, только если последняя версия
объекта совпадает с указанной;
if_not_exists – проверка имеющегося массива объектов перед вставкой.
По умолчанию: false.
Если задано значение true, система проверяет, существуют ли уже такие объекты в хранилище.
Новые объекты будет добавлены, если их еще нет в хранилище;
skip_result – при значении true возвращает пустой массив, а не сами измененные объекты.
По умолчанию: false.
- Результат
таблица с измененными объектами
- Тип результата
table
Пример
Запрос вставляет массив объектов:
array = {}
batch_count = 1000
for i = 1, batch_count do
array[i] = {id = tostring(i), old_field = tostring(i)}
end
repository.put_batch("Client", array)
Если версионирование отключено:
Если версионирование включено:
новые объекты добавляются в хранилище, version равно последней версии;
для объектов c уже существующими id добавляются новые версии объектов.
-
repository.update(type_name, filter, updaters[, options])
Обновляет объекты, соответствующие заданным условиям.
Запрос выполняется в две стадии:
исполнение запроса на каждом хранилище, которое может содержать объекты по условию в аргументе filter;
сбор результатов на роутере.
Если тип объекта поддерживает версионирование, метод сохраняет новую версию объекта или обновляет существующую.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
updaters (table) –
список обновлений для объекта, состоящий из списка мутаторов
{{mutator, path, new_value}, ...}, где:
mutator – имя мутатора, например:
set – устанавливает значение;
add – увеличивает значение на указанное число;
sub – уменьшает значение на указанное число;
path – строковый путь до поля объекта с точкой-разделителем (.). Путь
до объекта(ов) массива должен включать индекс массива или символ * для захвата
всех вложенных объектов;
new_value – новое значение;
options (table) –
параметры для управления запросом. Доступные параметры:
first_n_on_storage – количество возвращаемых элементов;
after – курсор пагинации на первый элемент;
version – версия объекта, которая будет изменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, обновляется указанная версия объекта.
Если такой версии не существует, обновляется ближайшая предшествующая версия.
Объект обновляется, и результат сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и сохраняет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед обновлением.
Параметр применяется только при включенном версионировании.
При указанном параметре объект обновляется, только если последняя версия объекта совпадает с указанной;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс;
skip_result – при значении true возвращает пустой массив, а не сами обновленные объекты.
По умолчанию: false.
- Результат
таблица с обновленными объектами
- Тип результата
table
Примеры
Запрос обновляет имя клиента с id = 42:
repository.update(
"Client",
{{"id", "==", 42}},
{{"set", "first_name", "Ivan"},
{"set", "last_name", "Petrov"}})
Если у клиента истек срок действия первого паспорта и необходимо обновить
соответствующее поле expired_flag, можно использовать следующий запрос:
repository.update(
"Client",
{{"id", "==", 42}},
{{"set", "passports.1.expired_flag", "true"}})
где .1. – индекс массива, содержащего экземпляры сущности Passport объекта Client, то есть первый
паспорт клиента.
-
repository.update_batch(type_name, updates_list[, options])
Обновляет объекты, соответствующие заданным условиям.
Вызывает несколько обновлений в одном запросе.
Если тип объекта поддерживает версионирование, метод сохраняет новую версию объекта или обновляет существующую.
- Параметры
type_name (string) – тип объекта
updates_list (table) –
список обновлений, которые необходимо применить. Для каждого обновления в списке задаются вложенные элементы:
таблица, содержащая список условий-предикатов
для выбора (фильтрации) объектов указанного типа;
список мутаторов {{mutator, path, new_value}, ...} (список обновлений для объекта), где:
mutator – имя мутатора, например:
set – устанавливает значение;
add – увеличивает значение на указанное число;
sub – уменьшает значение на указанное число;
path – строковый путь до поля объекта с точкой-разделителем (.). Путь
до объекта(ов) массива должен включать индекс массива или символ * для захвата
всех вложенных объектов;
new_value – новое значение;
options (table) –
параметры для управления запросом. Доступные параметры:
first_n_on_storage – количество возвращаемых элементов;
after – курсор пагинации на первый элемент;
version – версия объекта, которая будет изменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, обновляется указанная версия объекта.
Если такой версии не существует, обновляется ближайшая предшествующая версия.
Объект обновляется, и результат сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и сохраняет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед обновлением.
Параметр применяется только при включенном версионировании.
При указанном параметре объект обновляется, только если последняя версия объекта совпадает с указанной;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс;
skip_result – при значении true возвращает пустой массив, а не сами обновленные объекты.
По умолчанию: false.
- Результат
таблица с обновленными объектами
- Тип результата
table
Пример
Запрос обновляет имена клиентов с id = 40 и id = 41:
repository.update_batch(
"Client", { {
{{"id", "==", 40}},
{{"set", "first_name", "Maria"},
{"set", "last_name", "Ivanova"}},
}, {
{{"id", "==", 41}},
{{"set", "first_name", "Anna"},
{"set", "last_name", "Ivanova"}}
} })
-
repository.delete(type_name, filter[, options])
Удаляет объекты, соответствующие заданным условиям.
Поддерживает оптимистичные блокировки.
Если тип объекта поддерживает версионирование, метод удаляет указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first_n_on_storage – количество возвращаемых элементов;
after – курсор пагинации на первый элемент;
version – версия объекта для удаления.
Параметр применяется только при включенном версионировании.
Если параметр задан, удаляется указанная версия объекта.
Если такой версии не существует, удаляется ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия;
only_if_version – проверка имеющейся версии перед удалением.
Параметр применяется только при включенном версионировании.
При указанном параметре объект удаляется, только если последняя версия объекта совпадает с указанной;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс;
skip_result – при значении true возвращает пустой массив, а не сами удаленные объекты.
По умолчанию: false.
- Результат
таблица с удаленными объектами
- Тип результата
table
Пример
Запрос удаляет клиентов с заданной фамилией:
repository.delete(
"Client",
{{"last_name", "==", "Petrov"}})
В результате запроса все объекты, удовлетворяющие условию, дополняются новой версией (используется значение по умолчанию).
-
repository.count(type_name, filter[, options])
Вычисляет количество объектов, соответствующих заданным условиям.
Если тип объекта поддерживает версионирование, метод обрабатывает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество элементов.
Значение по умолчанию: 10;
after – курсор пагинации на первый элемент;
version – версия объекта.
Параметр применяется только при включенном версионировании.
Если параметр задан, обрабатывается указанная версия объекта.
Если такой версии не существует, обрабатывается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия.
Если вместе с этим параметром задан параметр all_versions, то обрабатываются все
версии меньше или равные заданной;
all_versions – поиск по всем версиям объекта, если задано значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false;
only_if_version – проверка имеющейся версии перед обработкой.
Параметр применяется только при включенном версионировании.
При указанном параметре объект обрабатывается, только если последняя версия объекта совпадает с указанной;
if_not_exists – проверка имеющегося объекта перед обработкой.
По умолчанию: false.
Если задано значение true, система проверяет, существует ли уже такой объект в хранилище;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс;
skip_result – при значении true возвращает пустой массив, а не сами обновленные объекты.
По умолчанию: false.
- Результат
количество объектов, соответствующих фильтру
- Тип результата
number
-
repository.pairs(type_name, filter[, options])
Создает итератор.
Используется для чтения большого объема данных.
Сигнатура функции аналогична repository.find(), но в pairs() нет
параметра first, пагинация применяется автоматически.
Если тип объекта поддерживает версионирование, метод обрабатывает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
after – курсор пагинации на первый элемент;
version – версия объекта.
Параметр применяется только при включенном версионировании.
Если параметр задан, обрабатывается указанная версия объекта.
Если такой версии не существует, обрабатывается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия.
Если вместе с этим параметром задан параметр all_versions, то обрабатываются все
версии меньше или равные заданной;
all_versions – поиск по всем версиям объекта, если задано значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
По умолчанию: false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
По умолчанию: false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам;
timeout – время ожидания выполнения запроса, секунды.
Значение не должно быть больше, чем значение параметра конфигурации
vshard_timeout.
- Результат
итератор
Пример
В примере таблица заполняется результатами вызова repository.pairs() и затем печатается:
local res = {}
for _, object in repository.pairs("Client",{{"first_name", "==", "Ivan"}}) do
table.insert(res, object)
end
print(res)
-
repository.call_on_storage(type_name, index_name, value, func_name[, func_args, options])
Вызывает функцию на экземпляре с ролью storage.
Файл с функцией должен храниться в директории src в корневой директории TDG.
- Параметры
type_name (string) – тип объекта
index_name (string) – имя индекса
value (any) – значение ключа поиска
func_name (string) – имя вызываемой функции
func_args (table) – аргументы, которые передаются в вызываемую функцию
options (table) –
параметры для управления запросом. Доступные параметры:
timeout – время ожидания выполнения запроса, секунды.
Значение не должно быть больше, чем значение параметра конфигурации
vshard_timeout;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
По умолчанию: false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
По умолчанию: false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам.
- Результат
результат выполнения функции
- Тип результата
any
Пример
Запрос вызывает функцию on_storage.call для объекта с id = 42, в функцию переданы аргументы 2 и 4:
repository.call_on_storage('Data', 'id', '42', 'on_storage.call', {2, 4}, { timeout = 0.1 })
-
repository.call_on_storage_batch(type_name, arguments_list[, options])
Группирует и вызывает несколько функций на экземплярах с ролью storage.
Файлы с функциями должны храниться в директории src в корневой директории TDG.
- Параметры
type_name (string) – тип объекта
arguments_list (table) –
список (map) c парами key-value, где key – ключ с идентификатором вызова,
а value – таблица из следующих элементов:
options (table) –
параметры для управления запросом. Доступные параметры:
timeout – время ожидания выполнения запроса, секунды.
Значение не должно быть больше, чем значение параметра конфигурации
vshard_timeout;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
По умолчанию: false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
По умолчанию: false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам.
- Результат
результаты выполнения функций
- Тип результата
table
Пример
Запрос вызывает функцию on_storage.call для объектов с id от 1 до 3, в функцию переданы аргументы fn_arg1 и fn_arg2:
repository.call_on_storage_batch(
'Data', {
{on_storage1 = {'id', '1', 'on_storage.call', {'fn_arg1', 'fn_arg2'}}},
{on_storage2 = {'id', '2', 'on_storage.call', {'fn_arg1', 'fn_arg2'}}},
{on_storage3 = {'id', '3', 'on_storage.call', {'fn_arg1', 'fn_arg2'}}}
})
-
repository.push_job(name, args)
Асинхронный запуск задач и функций.
- Параметры
-
- Результат
true при успешном запуске задачи
- Тип результата
boolean
-
repository.map_reduce(type_name, filter, map_fn_name, combine_fn_name, reduce_fn_name, options)
Запрос на обработку всех данных кластером по модели MapReduce. Выполняется на всех экземплярах типа storage.
Состоит из трех этапов:
Map – выполняется на экземплярах с ролью storage;
Combine – выполняется на экземплярах с ролью storage;
Reduce — выполняется на экземпляре, где была вызвана функция map_reduce.
Если тип объекта поддерживает версионирование, метод обрабатывает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
map_fn_name (string) – указатель на функцию для этапа Map
combine_fn_name (string) – указатель на функцию для этапа Combine
reduce_fn_name (string) – указатель на функцию для этапа Reduce
options (table) –
параметры для управления запросом. Доступные параметры:
map_args – дополнительные аргументы для этапа Map;
combine_args – дополнительные аргументы для этапа Combine;
combine_initial_state – исходное состояние для этапа Combine;
reduce_args – дополнительные аргументы для этапа Reduce;
reduce_initial_state — исходное состояние для этапа Reduce;
version – версия объекта, которая будет обработана.
Параметр применяется только при включенном версионировании.
Если параметр задан, обрабатывается указанная версия объекта.
Если такой версии не существует, обрабатывается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия;
mode – целевой экземпляр для выполнения запроса. Возможные значения:
read и write. Если задано write, целью будет мастер;
prefer_replica – целевой экземпляр для выполнения запроса.
По умолчанию: false. Если задано true, то предпочитаемая цель
– одна из реплик. Если доступной реплики нет, то целью будет мастер. Опция полезна
для ресурсозатратных функций, чтобы избежать замедления работы мастера;
balance – управление балансировкой нагрузки.
По умолчанию: false. Если задано true, добавится балансировка
нагрузки – запросы на чтение распределяются по всем узлам набора реплик по кругу.
Если при этом параметр prefer_replica определен как true, предпочтение отдается репликам;
timeout – время ожидания выполнения запроса, секунды.
Значение не должно быть больше, чем значение параметра конфигурации
vshard_timeout.
- Результат
результат выполнения reduce_fn_name
- Тип результата
any
Этап Map
На каждом экземпляре c ролью storage вызывается функция map_fn_name.
Функция вызывается столько раз, сколько на этом экземпляре будет найдено объектов, соответствующих типу
type_name и условиям filter.
Функция map_fn_name применяется к каждому найденному кортежу.
local map_res, err = map_fn(tuple, options.map_args)
Функция может вернуть любые данные или nil. Если возвращены данные, на следующем этапе они будут использованы
для запуска функции combine_fn_name. combine_fn_name будет вызвана столько раз, сколько раз
вызовы Map вернут данные.
Этап Combine (опционально)
Нужен для уменьшения количества данных, полученных на стадии Map, перед их передачей по сети и
дальнейшей обработкой. Результат каждого вызова map_fn_name передаётся в combine_fn_name.
Далее каждый вызов combine_fn_name осуществляется с передачей исходного состояния,
равного результату предыдущего вызова combine_fn_name. Для первого вызова исходное
состояние равно combine_initial_state, либо равно пустой таблице, если этот параметр не задан.
local combine_res = options.combine_initial_state or {}
local combine_res, err = combine_fn_name(combine_res, map_res, options.combine_args)
Функция combine_fn также выполняется на роли storage.
Результат выполнения combine_fn накапливается в переменной combine_res
и передается на ту роль, откуда был вызван map_reduce – в функцию reduce_fn_name.
Этап Reduce
Этап предназначен для завершения обработки данных со всего кластера.
Данные передаются по сети на экземпляр, на котором была вызвана функция map_reduce.
Там вызывается функция reduce_fn_name. Функция будет вызвана столько
раз, сколько экземпляров типа storage в кластере найдут подходящие объекты и,
соответственно, вернут результат в combine_res.
Результат reduce_fn_name возвращается как результат всего map_reduce.
local reduce_res, err = reduce_fn_name(combine_res, options.reduce_initial_state, options.reduce_args)
Доступ к данным
Основные функции для доступа к данным в TDG входят в
программный интерфейс репозитория.
Кроме этого, для работы доступны следующие модули:
model_accessor
Модуль model_accessor содержит функции для доступа к данным на экземпляре с ролью storage.
CRUD
Примечание
Все запросы ниже, за исключением put(), поддерживают параметр filter, позволяющий задать условия фильтрации
объектов. Узнать больше об этом параметре можно в разделе Repository API.
-
model_accessor.count(type_name, filter[, options])
Вычисляет количество записей, соответствующих заданным условиям.
Если тип объекта поддерживает версионирование, метод обрабатывает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество элементов.
Значение по умолчанию: 10;
after – курсор пагинации на первый элемент;
version – версия объекта.
Параметр применяется только при включенном версионировании.
Если параметр задан, обрабатывается указанная версия объекта.
Если такой версии не существует, обрабатывается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия.
Если вместе с этим параметром задан параметр all_versions, то обрабатываются все
версии меньше или равные заданной;
all_versions – поиск по всем версиям объекта, если задано значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс.
- Результат
количество записей, соответствующих фильтру
- Тип результата
number
-
model_accessor.find(type_name, filter[, options])
Возвращает объекты, соответствующие заданным условиям.
Пагинация осуществляется аналогично операциям интерфейса репозитория TDG.
Если тип объекта поддерживает версионирование, метод возвращает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество возвращаемых элементов.
Значение по умолчанию: 10;
after – курсор пагинации на первый элемент;
all_versions – поиск по всем версиям объекта, если задано значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false;
version – версия объекта, которая будет возвращена.
Параметр применяется только при включенном версионировании.
Если параметр задан, возвращается указанная версия объекта.
Если такой версии не существует, возвращается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия.
Если вместе с этим параметром задан параметр all_versions, то обрабатываются все
версии меньше или равные заданной.
- Результат
таблица объектов, соответствующих заданным условиям
- Тип результата
table
-
model_accessor.get(type_name, filter[, options])
Получает объект по первичному ключу.
Если тип объекта поддерживает версионирование, метод возвращает указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – первичный ключ
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество возвращаемых элементов.
Значение по умолчанию: 10;
after – курсор пагинации на первый элемент;
version – версия объекта, которая будет получена.
Параметр применяется только при включенном версионировании.
Если параметр задан, возвращается указанная версия объекта.
Если такой версии не существует, возвращается ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия;
all_versions – указатель для поиска по всем версиям объекта, если задано
значение true.
Параметр применяется только при включенном версионировании.
По умолчанию: false.
- Результат
объект
- Тип результата
table
-
model_accessor.delete(type_name, filter[, options])
Удаляет объекты, соответствующие заданным условиям.
Поддерживает оптимистичные блокировки.
Если тип объекта поддерживает версионирование, метод удаляет указанную версию объекта.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество возвращаемых элементов.
Значение по умолчанию: 10;
version – версия объекта для удаления.
Параметр применяется только при включенном версионировании.
Если параметр задан, удаляется указанная версия объекта.
Если такой версии не существует, удаляется ближайшая предшествующая версия.
Значение по умолчанию: последняя хранимая версия;
only_if_version – проверка имеющейся версии перед удалением.
Параметр применяется только при включенном версионировании.
При указанном параметре объект удаляется, только если последняя версия объекта совпадает с указанной;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс.
- Результат
количество удаленных объектов
- Тип результата
number
-
model_accessor.put(type_name, object[, options])
Вставляет новый или заменяет существующий объект.
Поддерживает оптимистичные блокировки.
Если тип объекта поддерживает версионирование, метод вставляет новую версию объекта или заменяет существующую.
- Параметры
type_name (string) – тип объекта
object (table) – объект для вставки
options (table) –
параметры для управления запросом. Доступные параметры:
version – версия объекта, которая будет добавлена или заменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, заменяется указанная версия объекта.
Если такой версии не существует, заменяется ближайшая предшествующая версия.
Объект при этом сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и вставляет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед вставкой.
Параметр применяется только при включенном версионировании.
При указанном параметре запрос добавляет или заменяет объект, только если последняя версия
объекта совпадает с указанной;
if_not_exists – проверка имеющегося объекта перед вставкой. По умолчанию: false.
Если задано значение true, система проверяет, существует ли уже такой объект в хранилище.
Новый объект будет добавлен, если его еще нет в хранилище.
- Результат
количество измененных объектов
- Тип результата
number
-
model_accessor.update(type_name, filter, updaters[, options])
Обновляет объекты, соответствующие заданным условиям.
Если тип объекта поддерживает версионирование, метод сохраняет новую версию объекта или обновляет существующую.
- Параметры
type_name (string) – тип объекта
filter (table) – список условий-предикатов для выбора (фильтрации) объектов указанного типа
updaters (table) –
список обновлений для объекта, состоящий из списка мутаторов
{{mutator, path, new_value}, ...}, где:
mutator – имя мутатора, например:
set – устанавливает значение;
add – увеличивает значение на указанное число;
sub – уменьшает значение на указанное число;
path – строковый путь до поля объекта с точкой-разделителем (.). Путь
до объекта(ов) массива должен включать индекс массива или символ * для захвата
всех вложенных объектов;
new_value – новое значение;
options (table) –
параметры для управления запросом. Доступные параметры:
first – количество возвращаемых элементов.
Значение по умолчанию: 10;
version – версия объекта, которая будет изменена.
Параметр применяется только при включенном версионировании.
Если параметр задан, обновляется указанная версия объекта.
Если такой версии не существует, обновляется ближайшая предшествующая версия.
Объект обновляется, и результат сохраняется с той же версией.
Если параметр не задан, запрос получает последнюю версию объекта и сохраняет новую версию объекта.
Значение по умолчанию: целое монотонно возрастающее число;
only_if_version – проверка имеющейся версии перед обновлением.
Параметр применяется только при включенном версионировании.
При указанном параметре объект обновляется, только если последняя версия объекта совпадает с указанной;
indexed_by – индекс, по которому выполняется поиск. Используется, если необходимо
явным образом указать индекс.
- Результат
количество обновленных объектов
- Тип результата
number
Управление транзакциями
-
model_accessor.begin_transaction()
Начинает транзакцию. Аналог функции box.begin().
- Результат
none
-
model_accessor.commit_transaction()
Завершает транзакцию и сохраняет все изменения.
Аналог функции box.commit().
- Результат
none
-
model_accessor.rollback_transaction()
Завершает транзакцию без сохранения изменений.
Аналог функции box.rollback().
- Результат
none
-
model_accessor.is_in_transaction()
Проверяет наличие активной транзакции.
Аналог функции box.is_in_txn().
- Результат
true при наличии активной транзакции, иначе – false
- Тип результата
boolean
Утилиты
-
model_accessor.unflatten(type_name, tuple)
Преобразует плоский кортеж в Lua-таблицу.
- Параметры
-
- Результат
Lua-таблица
- Тип результата
table
-
model_accessor.is_read_only()
Возвращает значение параметра box.info.ro – true
или false.
- Результат
true, если экземпляр находится в режиме read-only или в статусе
orphan, иначе false.
- Тип результата
boolean
-
model_accessor.snapshot()
Создает снимок всех данных и сохраняет его.
Аналог функции box.snapshot
- Результат
результат выполнения операции – ok, если снимок создан успешно
- Тип результата
string
blob_storage
Модуль blob_storage содержит функции для работы с key-value хранилищем на базе
движка vinyl.
-
blob_storage.new(namespace)
Создает новое key-value хранилище.
- Параметры
namespace (string) – имя хранилища
- Результат
указатель на созданное хранилище
- Тип результата
table
local_cache
Модуль local_cache содержит функции для доступа к локальному кэшу.
Локальный кэш представляет собой Lua-таблицу, с которой можно работать (добавлять и получать данные) в рамках одного
экземпляра.
-
local_cache.set(key, val)
Задает в таблице пару ключ–значение.
- Параметры
key (string) – ключ
val (any) – значение
- Результат
none
-
local_cache.get(key)
Получает значение из таблицы по переданному ключу.
- Параметры
key (string) – ключ
- Результат
значение для переданного ключа
- Тип результата
any
shared_storage
Модуль shared_storage содержит функции для работы с распределенным кэшем.
Распределенный кэш можно использовать для передачи объектов между функциями и экземплярами TDG.
-
shared_storage.new(namespace)
Создает новый распределенный кэш.
- Параметры
namespace (string) – имя хранилища
- Результат
указатель на созданное хранилище
- Тип результата
table
Примечание
При создании распределенного кэша создаётся спейс, хранящийся на одном из наборов реплик с ролью storage.
Персистентность данных в распределенном кэше не гарантируется: данные из него могут быть потеряны,
например, при перезапуске кластера.
Пример
Чтобы подключить существующий распределенный кэш или создать новый, используйте следующую команду:
local shared_storage_object = shared_storage.new('some_namespace')
Данные в распределенный кэш помещаются в формате key, value, например:
shared_storage_object:set('abc', 123)
где 'abc' – это ключ (key), а 123 – значение (value).
Для получения данных из распределенного кэша выполните следующую команду:
shared_storage_object:get('abc')
connector
Модуль connector содержит функции для отправки данных из sandbox в коннектор.
-
connector.send(output_name, obj[, output_options])
Направляет объект в секцию output для отправки в смежную систему.
- Параметры
output_name (string) – имя коннектора
obj (object) – объект для отправки
output_options (table) – опции для отправки во внешнюю систему
- Результат
true в случае успешной отправки, false в случае возникновения ошибки
- Тип результата
boolean
odbc
Модуль odbc содержит функции для работы с API ODBC.
-
odbc.execute(connection_name, statement, params)
Выполняет запрос через ODBC c заданными параметрами.
- Параметры
connection_name (string) – название соединения
statement (string) – выполняемый запрос
params (table) – параметры запроса
- Результат
объект запроса
- Тип результата
object
-
odbc.prepare(connection_name, query)
Подготавливает запрос через ODBC.
- Параметры
-
- Результат
объект подготовленного запроса
- Тип результата
object
Преобразование данных
Доступные модули:
mapping_tools – работа со значениями объекта;
soap – конвертация XML-документов в объекты Lua и обратно;
json – конвертация JSON-строк в объект Lua и обратно;
yaml – конвертация YAML-строк в объект Lua и обратно;
msgpack – конвертация строк MsgPack в объекты Lua и обратно;
table – работа с таблицами в Lua;
decimal – вычисления с точными числами;
digest – кодирование и хеширование;
fun – библиотека Luafun для функционального программирования;
math – интерфейс стандартной математической библиотеки Lua;
string – работа со строками в Lua;
utf8 – обработка строк в кодировке UTF-8;
uuid – модуль для работы с UUID (универсальный уникальный
идентификатор).
Помимо модулей, для работы доступна константа box.NULL (нулевой указатель) из
встроенного Tarantool-модуля box.
soap
Модуль soap содержит функции для преобразования SOAP-запроса в формате XML в объекты Lua и обратно.
-
soap.encode(data)
Преобразует Lua-таблицу в строку с XML-документом.
- Параметры
data (table) – Lua-таблица
- Результат
XML-документ
- Тип результата
string
-
soap.decode(doc)
Преобразует строку с XML-документом в объекты Lua.
- Параметры
doc (string) – XML-документ
- Результат
объекты Lua, полученные в результате парсинга XML.
строка, содержащая указатель на пространство имен (namespace);
строка с именем метода, переданного в SOAP-запросе (method);
Lua-таблица, которая содержит значения, переданные в тегах SOAP-запроса (entries).
- Тип результата
string or table
json
Функции из модуля json для преобразования строки в формате JSON
в объект Lua и обратно.
-
json.encode(lua_value[, configuration])
Преобразует объект Lua в строку в формате JSON.
- Параметры
-
- Результат
JSON-строка
- Тип результата
string
-
json.decode(string[, configuration])
Преобразует JSON-строку в объект Lua.
- Параметры
-
- Результат
Lua-таблица
- Тип результата
table
yaml
Функция из модуля yaml для преобразования строки в формате YAML в объект Lua.
-
yaml.encode(lua_value)
Преобразует объект Lua в строку в формате YAML.
- Параметры
lua_value (table/scalar) – объект Lua
- Результат
YAML-строка
- Тип результата
string
table
Модуль table содержит функции для работы с таблицами в Lua.
Информация о модуле table и доступных функциях приведена в
справочнике по встроенным модулям.
Кроме того, модуль расширен двумя дополнительными функциями:
-
table.cmpdeeply(got, expected[, extra])
Сравнение двух таблиц с учетом вложенности.
- Параметры
got (lua-value) – фактический результат
expected (lua-value) – ожидаемый результат
extra (table) – таблица, в которой сохраняется путь для различающихся элементов
- Результат
результат сравнения, true или false
- Тип результата
boolean
-
table.append_table(where, from)
Копирует один массив в конец другого массива.
При этом используется неглубокое (shallow) копирование.
- Параметры
where (table) – целевая таблица, в которую вставляют значения из первой таблицы
from (table) – таблица, значения которой добавляют в целевую таблицу
- Результат
целевая таблица
- Тип результата
table
Константа box.NULL
Константа box.NULL представляет собой нулевой указатель (NULL pointer).
box.NULL позволяет хранить ключ без значения, в таблицах эта константа является местозаполнителем для значения nil.
Имеет тип cdata.
Чтобы узнать больше о box.NULL, обратитесь к
соответствующему разделу справочника> в документации Tarantool.
Управление обработкой
Доступные модули и функции:
spawn
Модуль spawn содержит функции для запуска файберов.
-
spawn.spawn(func_name, args, options)
Запускает один или несколько файберов для выполнения функции func_name с заданными аргументами.
- Параметры
func_name (string) – имя функции
args (table) – аргументы функции
options (table) – дополнительные параметры, в которых можно указать время ожидания.
Пример: spawn('my_func', {1, 2, 3}, {timeout = 30}).
- Тип результата
table
-
spawn.spawn_n(func_name, func_num, options)
Запускает func_num количество файберов для выполнения функции func_name без аргументов.
- Параметры
func_name (string) – имя функции
func_num (number) – количество запускаемых файберов
options (table) – дополнительные параметры, в которых можно указать время ожидания.
Пример: spawn_n('my_func', 2, {timeout = 30}).
- Результат
функция spawn()
fiber
Функция из модуля fiber.
-
fiber.sleep(time)
Передает управление другому файберу и переходит в режим ожидания на указанное количество секунд.
Перевести в режим ожидания можно только текущий файбер.
- Параметры
time (number) – количество секунд в режиме ожидания
- Результат
none
request_context
-
request_context.get()
- Результат
контекст запроса
- Тип результата
table
Мониторинг
Доступные модули:
log
Модуль log содержит функции для записи сообщений в журнал
(по аналогии с модулем Tarantool log).
-
log.error(message)
-
log.warn(message)
-
log.info(message)
-
log.verbose(message)
-
log.debug(message)
Записывает сообщение в журнал с указанным уровнем детализации.
Значение на выходе представляет собой строку в журнале, которая содержит:
текущую метку времени
название модуля
обозначения „E“, „W“, „I“, „V“ или „D“ – в зависимости от вызванной функции
содержимое аргумента message
- Параметры
message (any) –
Сообщение в журнале. Аргумент message может содержать:
- Результат
nil
tracing
Модуль tracing содержит функцию трассировки.
-
tracing.start_span(name, ...)
Начинает span (основной блок трассировки в распределенных системах) и возвращает специальный объект.
Для завершения трассировки выполнения функции используется метод finish возвращаемого объекта.
- Параметры
name (string) – имя для span
- Результат
object
metrics
Функции из модуля metrics.
Узнать больше о метриках в TDG можно из раздела Мониторинг в руководстве администратора.
-
metrics.counter(name[, help, metainfo])
Регистрирует новый монотонно возрастающий счетчик.
- Параметры
name (string) – имя счетчика
help (string) – описание счетчика
metainfo (table) – метаинформация счетчика
- Результат
объект счетчика
- Тип результата
counter_obj
-
metrics.gauge(name[, help, metainfo])
Регистрирует новую метрику для числовых значений.
Такие значения могут как возрастать, так и убывать.
- Параметры
name (string) – имя метрики типа gauge
help (string) – описание метрики типа gauge
metainfo (table) – метаинформация метрики типа gauge
- Результат
объект gauge
- Тип результата
gauge_obj
-
metrics.histogram(name[, help, metainfo])
Регистрирует новую гистограмму.
Гистограмма – выборка из некоторого количества значений. Тип histogram подсчитывает полученные значения
и объединяет их в настраиваемые бакеты (buckets).
- Параметры
name (string) – имя гистограммы
help (string) – описание гистограммы
buckets (table) – бакеты гистограммы (массив сортированных неотрицательных чисел)
metainfo (table) – метаинформация гистограммы
- Результат
объект гистограммы
- Тип результата
histogram_obj
Работа с датами и временем
Доступные модули:
datetime – работа с датой и временем;
timezone – работа с часовыми поясами;
clock – значения времени, полученные
из функции Posix / C CLOCK_GETTIME.
Для работы доступны все функции модуля, за исключением функции clock.bench().
datetime
Модуль datetime содержит функции для работы с датой и временем.
Помимо функций ниже, для работы также доступны функции из встроенного Tarantool-модуля
datetime.
-
datetime.now()
- Результат
текущее время по Гринвичу (GMT) в наносекундах
- Тип результата
cdata
-
datetime.sec_to_iso_8601_date(sec)
Преобразует число секунд в строковое представление даты.
- Параметры
sec (number) – число секунд
- Результат
дата в формате ISO 8601 вида yyyy-MM-dd
- Тип результата
string
-
datetime.nsec_to_iso_8601_date(nsec)
Преобразует число наносекунд в строковое представление даты.
- Параметры
nsec (cdata) – число наносекунд
- Результат
дата в формате ISO 8601 вида yyyy-MM-dd
- Тип результата
string
-
datetime.nsec_to_iso_8601_datetime(nsec)
Преобразует число наносекунд в строковое представление даты и времени.
- Параметры
nsec (cdata) – число наносекунд
- Результат
дата и время в формате ISO 8601 вида yyyy-MM-ddTHH:mm:ss.SSSZ
- Тип результата
string
-
datetime.nsec_to_iso_8601_time(nsec)
Преобразует заданную в наносекундах дату и время в строковое представление времени.
- Параметры
nsec (cdata) – число наносекунд
- Результат
время в формате ISO 8601 вида HH:mm:ss.SSS
- Тип результата
string
-
datetime.nsec_to_day_of_week(nsec)
Возвращает день недели для заданной в наносекундах даты и времени.
- Параметры
nsec (cdata) – число наносекунд
- Результат
день недели в формате числа от 1 до 7, где 1 – воскресенье, а 7 – суббота
- Тип результата
number
-
datetime.iso_8601_datetime_to_nsec(iso_8601_datetime)
Преобразует строковое представление даты и времени в наносекунды.
- Параметры
iso_8601_datetime (string) –
дата и время в формате ISO 8601. Доступные форматы строки:
yyyy-MM-dd'T'HH:mm:ss.SSSZZZZZ
yyyy-MM-dd'T'HH:mm:ssZZZZZ
yyyy-MM-dd'T'HH:mm:ss
yyyy-MM-dd'T'HHmmss.SZZZZZ
yyyy-MM-dd'T'HHmmssZZZZZ
yyyy-MM-dd'T'HHmmss.SSS
yyyy-MM-dd'T'HHmmss
- Результат
число наносекунд
- Тип результата
cdata
-
datetime.iso_8601_date_to_nsec(iso_8601_date)
Преобразует строковое представление даты в наносекунды.
- Параметры
iso_8601_date (string) – дата в формате ISO 8601 вида yyyy-MM-dd
- Результат
число наносекунд
- Тип результата
cdata
-
datetime.iso_8601_time_to_nsec(iso_8601_time)
Преобразует строковое представление времени в наносекунды.
- Параметры
iso_8601_time (string) – время в формате ISO 8601. Доступные форматы: HH:mm:ss.SSS, HH:mm:ss.
- Результат
число наносекунд
- Тип результата
cdata
-
datetime.iso_8601_day_of_week_to_number(iso_8601_day_of_week)
Преобразует строковое представление дня недели в число от 1 до 7, где 1 – воскресенье, а 7 – суббота.
- Параметры
iso_8601_day_of_week (string) – день недели в формате ISO 8601 (например, «Sunday», «Sun»)
- Результат
число от 1 до 7
- Тип результата
number
-
datetime.custom_datetime_str_to_nsec(date_str, format_str)
Преобразует заданное шаблоном строковое представление даты или даты и времени в наносекунды.
- Параметры
-
- Результат
число наносекунд
- Тип результата
cdata
-
datetime.millisec_to_formatted_datetime(datetime_millisec, datetime_format_str)
Преобразует миллисекунды в заданное шаблоном строковое представление даты и времени.
- Параметры
-
- Результат
дата и время, заданные шаблоном
- Тип результата
string
-
datetime.to_sec(nsec)
Преобразует наносекунды в секунды и приводит к типу number.
- Параметры
nsec (cdata) – число наносекунд
- Результат
число секунд
- Тип результата
number
-
datetime.to_millisec(nsec)
Преобразует наносекунды в миллисекунды и приводит к типу number.
- Параметры
nsec (cdata) – число наносекунд
- Результат
число миллисекунд
- Тип результата
number
-
datetime.seconds_since_midnight()
- Результат
число секунд с начала суток по Гринвичу (GMT)
- Тип результата
number
-
datetime.curr_date_nsec()
Метка времени (Unix timestamp) в наносекундах, соответствующая началу текущих суток UTC.
Например, для времени и даты 01.01.2023 15:42 вернется метка, соответствующая 01.01.2023 00:00.
- Результат
Unix timestamp в наносекундах
- Тип результата
cdata
Набор констант, которые используются для работы со временем:
NSEC_IN_SEC – число наносекунд в секунде;
NSEC_IN_MILLISEC – число наносекунд в миллисекунде;
NSEC_IN_DAY – число наносекунд в сутках.
timezone
Модуль timezone содержит функции для работы с часовыми поясами.
-
timezone.now()
- Результат
текущее время по Гринвичу (GMT) в наносекундах
- Тип результата
cdata
-
timezone.seconds_since_midnight(timezone_id)
- Параметры
timezone_id (string) – ID часового пояса
- Результат
число секунд с начала текущих суток для указанного часового пояса
- Тип результата
number
-
timezone.curr_date_nsec(timezone_id)
Метка времени (Unix timestamp) в наносекундах, соответствующая началу текущих местных суток
для указанного часового пояса.
- Параметры
timezone_id (string) – ID часового пояса
- Результат
Unix timestamp в наносекундах
- Тип результата
cdata
Работа с последовательностями
sequence – генератор уникальных возрастающих целых чисел.
Уникальность чисел гарантируется в пределах отдельной последовательности с заданным именем даже при вызове
из разных файберов или на разных экземплярах.
Чтобы обеспечить уникальность при вызовах из разных экземпляров, используется роль core.
Эта роль выделяет доступные диапазоны чисел.
Новый диапазон чисел выделяется:
По умолчанию для экземпляров или файберов выделяются диапазоны по 100 номеров.
sequence
-
sequence.get(sequence_name)
Возвращает ссылку на объект заданной последовательности.
Если последовательность с таким именем отсутствует, создаёт новую последовательность.
Объект последовательности имеет единственный метод next, который возвращает следующий элемент
последовательности.
Пример использования
На двух разных экземплярах один раз вызывается обработчик, заполняющий поле объекта уникальным номером
с помощью метода next.
Тогда на первом экземпляре номер объекта будет 1, а на втором – 101.
Если после этого каждый обработчик вызывать еще 99 раз, то номера объектов будут 2–100 и 102–200
соответственно.
При повторном запуске обработчика на первом экземпляре объекту будет присвоен номер 201.
- Параметры
sequence_name – имя последовательности
- Результат
ссылка на объект последовательности
- Тип результата
table
Встроенные функции Lua
Помимо модулей, для работы доступны отдельные функции из библиотеки Lua:
assert() – вызов исключения, если значение аргумента содержит false;
error() – вызов исключения;
next() – вывод следующего элемента таблицы по индексу;
pairs() – итерации по парам ключ-значение (key-value) таблицы;
ipairs() – итерации по парам ключ-значение для числовых ключей;
pcall() – вызов функции в защищенном режиме;
xpcall() – вызов функции в защищенном режиме с указанием обработчика ошибки;
print() – печать в stdout;
select() – выборка аргументов функции или общее число переданных аргументов;
tonumber() – конвертация в число;
tonumber64() – конвертация в 64-битное число;
tostring() – конвертация в строку;
type() – определение типа данных у переданного аргумента;
unpack() – вывод элементов переданной таблицы.
-
assert(v[, message])
Вызывает исключение, если аргумент v содержит nil или false.
- Параметры
v (boolean) – аргумент или условие, значение которого проверяется
message (string) – сообщение об ошибке. Значение по умолчанию: assertion failed!.
- Результат
v, если аргумент содержит true;
сообщение об ошибке, если аргумент содержит false.
-
error(message[, level])
Завершает последнюю вызванную защищенную функцию и вызывает исключение.
Обычно при этом в начало сообщения добавляется информация о месте возникновения ошибки.
- Параметры
-
- Результат
none
-
next(t[, index])
Позволяет проходить по всем полям таблицы t.
Функцию можно использовать, чтобы проверить, пустая ли таблица.
- Параметры
t (table) – таблица
index (number) – индекс элемента в таблице. Если аргумент t – таблица, а index – индекс элемента в
в таблице, то next() возвращает индекс следующего после него элемента и связанное с ним
значение. Если аргумент пропущен, он интерпретируется как nil. Если в
аргументе index передан nil, функция возвращает начальный индекс и значение для него.
Если передан индекс последнего элемента таблицы или таблица пустая, возвращается nil.
- Результат
индекс элемента таблицы + связанное с ним значение или nil
-
pairs(t)
Позволяет выполнять итерации по парам ключ-значение (key-value) таблицы t.
- Параметры
t (table) – таблица, по которой производится итерация
- Результат
-
-
ipairs(t)
Позволяет выполнять итерации по парам ключ-значение (key-value) таблицы t.
Использует числовые ключи, другие ключи игнорируются.
- Параметры
t (table) – таблица, по которой производится итерация
- Результат
функция итерации
таблица t
nil
-
pcall(function_name, arg1, ···)
Вызывает функцию в защищенном режиме с заданными аргументами.
pcall обрабатывает функцию и возвращает код состояния – true или false (boolean).
- Параметры
-
- Результат
true, если вызов функции был успешным;
false, если возникла ошибка.
Если ошибок нет, помимо статуса возвращаются все результаты вызова.
Если ошибки есть, помимо статуса возвращается результат выполнения err.
-
xpcall(function_name, err, arg1, ...)
Как и pcall(), вызывает функцию в защищенном режиме с заданными аргументами,
но еще позволяет установить новый обработчик ошибок err.
xpcall обрабатывает функцию и возвращает код состояния – true или false (boolean).
В случае возникновения ошибки вызывается обработчик err с исходным объектом ошибки и возвращает код состояния
(boolean).
- Параметры
function_name (string) – имя вызываемой функции
err (string) – обработчик ошибок
arg1 (any) – аргумент функции
- Результат
true, если вызов функции был успешным;
false, если возникла ошибка.
-
print(...)
Принимает любое количество аргументов и печатает их значения в stdout.
Для конвертации значений аргументов в строки используется функция tostring().
- Результат
none
-
select(index, ...)
Возвращает значения аргументов функции или общее число переданных аргументов.
- Параметры
index (string/number) – индекс, который содержит число или строку #
arg (any) – аргумент, переданный в функцию
- Результат
все аргументы после аргумента с заданным индексом, если index – число;
общее количество переданных аргументов, если index – строка #.
-
tonumber(value)
Конвертирует заданное значение в число.
- Параметры
value (string/number) – строка или Lua-число
- Результат
конвертированное значение
- Тип результата
number
-
tonumber64(value)
Конвертирует заданное значение в 64-битное целое число.
Подробнее о функции tonumber64() можно прочитать в
справочнике по встроенным модулям.
- Параметры
value (string/number) – строка или Lua-число. На вход принимаются числа в десятичной, двоичной и
шестнадцатеричной системах счисления. Если передать число с дробной частью (например,
tonumber64('2.2')) в виде строки, функция вернет null.
- Результат
конвертированное значение
- Тип результата
number
-
tostring(value)
Конвертирует заданное значение в строку.
- Параметры
value (any) – строка или Lua-число
- Результат
конвертированное значение
- Тип результата
string
-
type(value)
Определяет тип данных у переданного аргумента.
- Параметры
value (any) – аргумент, тип которого требуется определить
- Результат
тип данных в формате строки
- Тип результата
string
-
unpack(list[, i, j])
Возвращает элементы для переданной таблицы.
Если индексы элементов i и j пропущены, возвращает все элементы таблицы list.
- Параметры
list (table) – таблица
i (number) – индекс первого возвращаемого элемента. Значение по умолчанию: 1.
j (number) – индекс последнего возвращаемого элемента. По умолчанию, j – общее количество элементов
таблицы list (длина списка).
- Результат
элементы таблицы
Расширения
Вы можете загрузить подключаемые функции, или расширения, в TDG вместе с конфигурацией приложения.
Для этого поместите расширения в корень проекта в директорию extensions.
При применении конфигурации в TDG:
Расширение global.lua
Модуль global.lua используется, чтобы задать в TDG глобальные изменения поведения,
например, для настройки пользовательского HTTP-маршрута или функции IPROTO.
Код из файла модуля запускается при обновлении конфигурации на всех экземплярах и выполняется вне окружения sandbox.
Чтобы добавить это расширение, выполните следующие действия:
В корневой директории TDG создайте директорию extensions.
Создайте файл модуля global.lua, напишите в нем необходимый код, а затем разместите файл в директории
extensions.
Модуль должен возвращать функцию init(), которая вызывается при применении конфигурации.
Упакуйте в zip-архив:
Загрузите архив в TDG согласно инструкции.
Подключение новых функций
Предупреждение
Подключение новых функций в TDG может приводить к проблемам с безопасностью.
Чтобы предупредить эти проблемы, рекомендуется:
Чтобы подключить новые функции (расширения) к Sandbox API, выполните следующие действия:
В корневой директории TDG создайте директорию extensions/sandbox.
На следующем шаге в нее будет добавлен модуль с подключаемыми функциями.
Также нужно проследить, чтобы у пользователей были необходимые права для чтения данной директории.
Разместите в директории sandbox файл Lua-модуля, который вы хотите подключить.
Модуль при этом должен возвращать объект с определяемыми модулем функциями.
Кроме того, в добавленном модуле все используемые встроенные библиотеки должны быть явно подключены
с использованием require(). Пример файла с Lua-модулем:
-- ./extensions/sandbox/csv.lua
-- По умолчанию в TDG не доступен модуль ``csv``
return require('csv')
Упакуйте в zip-архив:
Загрузите архив в TDG согласно инструкции.
REST API
В этом справочнике содержатся сведения об адресах HTTP-ресурсов (endpoints) и параметрах
запросов и ответов REST API TDG.
Выполняя запросы к REST API, можно совершать операции с данными, вызывать сервисы и получать
метрики для мониторинга.
Операции с данными
TDG предоставляет следующие возможности работы с данными через REST API:
Чтение данных
Для чтения данных из TDG используются GET-запросы на адреса вида data/<TypeName>.
В параметрах запроса передаются условия выборки объектов.
Такие запросы эквивалентны вызовам repository.find() c аналогичными аргументами.
Запрос
GET /data/<TypeName>?<arguments>
Запрос может содержать следующие параметры (все они являются опциональными):
<index_name>
|
Выборка по индексу <index_name> по полному совпадению с указанным значением.
Например: id=10.
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index=0,10,true,null.
|
<index_name_gt>
|
Выборка по индексу <index_name> с условием «больше указанного значения».
Например: population_gt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_gt=0,10
|
<index_name_ge>
|
Выборка по индексу <index_name> с условием «больше или равно указанного значения».
Например: population_ge=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_ge=0,10
|
<index_name_lt>
|
Выборка по индексу <index_name> с условием «меньше указанного значения».
Например: population_lt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_lt=0,10
|
<index_name_le>
|
Выборка по индексу <index_name> с условием «меньше или равно указанного значения».
Например: population_le=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_le=0,10
|
<index_name_like>
|
Выборка по строковому индексу <index_name> по шаблону.
Например: name=Abc% |
<index_name_ilike>
|
Выборка по строковому индексу <index_name> по шаблону
без учёта регистра.
Например: name=abc% |
indexed_by
|
Имя индекса для упорядочивания объектов выборки. При передаче этого параметра
объекты будут упорядочены по возрастанию значений указанного индекса.
Обратите внимание, что параметр indexed_by применяется на этапе выборки объектов.
Таким образом, запросы, отличающиеся только значением indexed_by, могут возвращать
разные наборы объектов. Например, запрос с indexed_by=price&first=5 вернёт 5 объектов
с наименьшими значениями price, а запрос c indexed_by=name&first=5 – 5 объектов с
первыми значениями name в лексикографическом порядке.
|
first
|
Количество возвращаемых объектов. Значение по умолчанию: 10. |
after
|
Значение курсора первого возвращаемого объекта (поле cursor в возвращаемых объектах JSON).
Значение по умолчанию: курсор первого добавленного объекта. |
version
|
Запрашиваемая версия объектов для типов, поддерживающих версионирование.
Значение по умолчанию: последняя хранимая версия.
Номер версии также можно передать в HTTP-заголовке version.
|
all_versions
|
Флаг получения всех доступных версий объектов для типов, поддерживающих
версионирование. Значение по умолчанию: false. |
Тело запроса для получения данных должно быть пустым.
Ответ
Набор объектов, удовлетворяющих заданным условиям, в формате JSON.
Пример
Запрос:
GET http://localhost:8081/data/City?population_ge=300000&indexed_by=title&first=3
Ответ:
[
{
"cursor": "gaRzY2FukqZCZXJsaW6nR2VybWFueQ",
"country": "Germany",
"title": "Berlin",
"population": 3520031,
"capital": true
},
{
"cursor": "gaRzY2FukqdEcmVzZGVup0dlcm1hbnk",
"country": "Germany",
"title": "Dresden",
"population": 547172,
"capital": false
},
{
"cursor": "gaRzY2FukqZNb3Njb3emUnVzc2lh",
"country": "Russia",
"title": "Moscow",
"population": 12655050,
"capital": true
}
]
Вставка данных
Для вставки данных в TDG используются POST-запросы на адреса вида data/<TypeName>.
Такие запросы эквивалентны вызовам repository.put c аналогичными аргументами.
Запрос
POST /data/<TypeName>?<arguments>
Запрос может содержать следующие параметры (все они являются опциональными):
version
|
Номер версии объекта для типов, поддерживающих версионирование.
Значение по умолчанию: текущее значение временной метки Unix (Unix timestamp).
Номер версии также можно передать в HTTP-заголовке version.
|
only_if_version
|
Для типов, поддерживающих версионирование: выполнить
вставку, только если в хранилище есть переданный объект и номер его актуальной версии равен
указанному значению.
Значение по умолчанию: последняя хранимая версия. |
skip_result
|
Флаг выполнения запроса без возврата вставленного объекта.
Значение по умолчанию: false. |
Тело запроса для вставки объекта должно содержать описание этого объекта в формате JSON.
Если в хранилище уже существует объект с аналогичными значениями полей первичного индекса,
в результате выполнения запроса он будет перезаписан.
Пример
Запрос:
POST http://localhost:8081/data/City
{
"population": 3520031,
"title": "Berlin",
"capital": true,
"country":"Germany"
}
Ответ:
{
"population": 3520031,
"title": "Berlin",
"capital": true,
"country":"Germany"
}
Изменение данных
Для изменения данных в TDG используются PUT-запросы на адреса вида data/<TypeName>.
В параметрах запроса передаются условия выборки объектов для изменения, а в теле –
новые значения изменяемых полей.
Такие запросы эквивалентны вызовам repository.update c аналогичными аргументами.
Запрос
PUT /data/<TypeName>?<arguments>
Предупреждение
Если в PUT-запросе нет ни одного условия выбора объектов (<index_name> или <index_name_*>),
его результатом будет изменение всех объектов типа.
Запрос может содержать следующие параметры (все они являются опциональными):
<index_name>
|
Выборка по индексу <index_name> по полному совпадению с указанным значением.
Например: id=10.
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index=0,10,true,null.
|
<index_name_gt>
|
Выборка по индексу <index_name> с условием «больше указанного значения».
Например: population_gt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_gt=0,10
|
<index_name_ge>
|
Выборка по индексу <index_name> с условием «больше или равно указанного значения».
Например: population_ge=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_ge=0,10
|
<index_name_lt>
|
Выборка по индексу <index_name> с условием «меньше указанного значения».
Например: population_lt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_lt=0,10
|
<index_name_le>
|
Выборка по индексу <index_name> с условием «меньше или равно указанного значения».
Например: population_le=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_le=0,10
|
<index_name_like>
|
Выборка по строковому индексу <index_name> по шаблону.
Например: name=Abc% |
<index_name_ilike>
|
Выборка по строковому индексу <index_name> по шаблону
без учёта регистра.
Например: name=abc% |
indexed_by
|
Имя индекса для упорядочивания объектов выборки. При передаче этого параметра
объекты будут упорядочены по возрастанию значений указанного индекса. |
version
|
Номер версии объекта для типов, поддерживающих версионирование.
Значение по умолчанию: текущее значение временной метки Unix (Unix timestamp).
Номер версии также можно передать в HTTP-заголовке version.
|
only_if_version
|
Для типов, поддерживающих версионирование: выполнить
изменение, только если номер актуальной версии объекта равен указанному значению.
Значение по умолчанию: последняя хранимая версия. |
skip_result
|
Флаг выполнения запроса без возврата списка изменённых объектов.
Значение по умолчанию: false. |
Тело запроса для изменения данных должно содержать новые значения изменяемых полей в формате JSON.
Пример
Запрос:
POST http://localhost:8081/data/City?population_le=500000
Ответ:
[
{
"country": "Germany",
"title": "Bonn",
"population": 318809,
"capital": false
},
{
"country": "Germany",
"title": "Karlsruhe",
"population": 307755,
"capital": false
},
{
"country": "Russia",
"title": "Tver",
"population": 424969,
"capital": false
}
]
Удаление данных
Для удаления данных из TDG используются DELETE-запросы на адреса вида data/<TypeName>.
В параметрах запроса передаются условия выборки объектов для удаления.
Такие запросы эквивалентны вызовам repository.delete c аналогичными аргументами.
Запрос
DELETE /data/<TypeName>?<arguments>
Предупреждение
Если в DELETE-запросе нет ни одного условия выбора объектов (<index_name> или <index_name_*>),
его результатом будет удаление всех объектов типа.
Запрос может содержать следующие параметры (все они являются опциональными):
<index_name>
|
Выборка по индексу <index_name> по полному совпадению с указанным значением.
Например: id=10.
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index=0,10,true,null.
|
<index_name_gt>
|
Выборка по индексу <index_name> с условием «больше указанного значения».
Например: population_gt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_gt=0,10
|
<index_name_ge>
|
Выборка по индексу <index_name> с условием «больше или равно указанного значения».
Например: population_ge=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_ge=0,10
|
<index_name_lt>
|
Выборка по индексу <index_name> с условием «меньше указанного значения».
Например: population_lt=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_lt=0,10
|
<index_name_le>
|
Выборка по индексу <index_name> с условием «меньше или равно указанного значения».
Например: population_le=100000
При использовании составных индексов указывайте значения полей через запятую.
Например: multipart_index_le=0,10
|
<index_name_like>
|
Выборка по строковому индексу <index_name> по шаблону.
Например: name=Abc% |
<index_name_ilike>
|
Выборка по строковому индексу <index_name> по шаблону
без учёта регистра.
Например: name=abc% |
indexed_by
|
Имя индекса для упорядочивания объектов выборки. При передаче этого параметра
объекты будут упорядочены по возрастанию значений указанного индекса. |
version
|
Удаляемая версия объектов для типов, поддерживающих версионирование.
Значение по умолчанию: последняя хранимая версия. |
all_versions
|
Флаг удаления всех доступных версий объектов для типов, поддерживающих
версионирование. Значение по умолчанию: false. |
skip_result
|
Флаг выполнения запроса без возврата списка удаляемых объектов.
Значение по умолчанию: false. |
Тело запроса для удаления данных должно быть пустым.
Ответ
Если skip_result=false (по умолчанию): набор объектов, удалённых из хранилища в результате
выполнения запроса, в формате JSON.
Если skip_result=true: пустое тело ответа.
Пример
Запрос:
DELETE http://localhost:8081/data/City?population_ge=300000
Ответ:
[
{
"cursor": "gaRzY2FukqZCZXJsaW6nR2VybWFueQ",
"country": "Germany",
"title": "Berlin",
"population": 3520031,
"capital": true
},
{
"cursor": "gaRzY2FukqdEcmVzZGVup0dlcm1hbnk",
"country": "Germany",
"title": "Dresden",
"population": 547172,
"capital": false
},
{
"cursor": "gaRzY2FukqZNb3Njb3emUnVzc2lh",
"country": "Russia",
"title": "Moscow",
"population": 12655050,
"capital": true
}
]
Вызов сервисов
TDG предоставляет REST API для вызова сервисов, развёрнутых в кластере.
Для вызова сервисов используются POST-запросы на адреса вида /service/<service_name>.
Аргументы для вызова передаются в параметрах запроса или в виде JSON в теле запроса.
Запрос
POST /service/<service_name>?<arguments>
Аргументы вызова сервиса можно передавать двумя способами:
Аргументы, переданные в параметрах запроса, имеют более высокий приоритет.
Все аргументы должны быть переданы одним способом. Нельзя передать часть аргументов в
параметрах запроса, а другую часть – в теле.
Если аргумент может принимать значение null, его можно не передавать.
Ответ
Возвращаемое значение сервиса в формате JSON.
Пример
Запрос:
POST http://localhost:8081/service/say_hello?name=world×=2
Ответ:
{
"result": "Hello, world! Hello, world!"
}
Получение метрик кластера
Для получения метрик кластера TDG используются GET-запросы на адрес metrics.
TDG возвращает метрики в формате Prometheus. Это
позволяет в дальнейшем использовать их, например, для визуализации в Grafana.
Запрос
Тело запроса для получения метрик должно быть пустым.
Ответ
Текущие значения метрик кластера TDG в формате Prometheus.
Пример
Запрос:
GET http://localhost:8081/metrics
Фрагмент ответа:
# HELP tdg_kafka_broker_int_latency_min Kafka: Smallest value of internal producer queue latency in microseconds
# TYPE tdg_kafka_broker_int_latency_min gauge
# HELP lj_gc_freed Total amount of freed memory
# TYPE lj_gc_freed counter
lj_gc_freed{alias="app-01"} 96399741997
# HELP tdg_kafka_eos_producer_id Kafka: The currently assigned Producer ID (or -1)
# TYPE tdg_kafka_eos_producer_id gauge
# HELP tdg_kafka_simple_cnt Kafka: Internal tracking of legacy vs new consumer API state
# TYPE tdg_kafka_simple_cnt gauge
# HELP tnt_cpu_user_time CPU user time usage
# TYPE tnt_cpu_user_time gauge
tnt_cpu_user_time{alias="app-01"} 1868.676635
# HELP tnt_slab_quota_used_ratio Slab quota_used_ratio info
# TYPE tnt_slab_quota_used_ratio gauge
tnt_slab_quota_used_ratio{alias="app-01"} 12.5
# HELP tnt_cpu_number The number of processors
# TYPE tnt_cpu_number gauge
tnt_cpu_number{alias="app-01"} 1
...
Управление настройками через GraphQL API
Этот раздел посвящен различным запросам, позволяющим просматривать и изменять настройки
TDG.
Все запросы на просмотр и изменение настроек TDG передаются по протоколу HTTP в
формате GraphQL.
При этом они должны иметь соответствующий заголовок для авторизации.
Примечание
Для выполнения GraphQL-запросов можно использовать
встроенный веб-клиент GraphiQL (на вкладке Graphql веб-интерфейса) или любой
сторонний GraphQL-клиент, либо иное средство для отправки HTTP-запросов. При
этом специализированные GraphQL-клиенты, в отличие от средств отправки HTTP-запросов,
могут использовать функции автодополнения и проверки синтаксиса
запросов, а также автоматического формирования документации на GraphQL API.
Данные стандартные возможности GraphQL позволяют определять состав функций
API, а также состав аргументов функций, типы исходных данных и возвращаемых
результатов.
GraphQL-запросы от клиентов (за исключением встроенного веб клиента GraphiQL)
необходимо направлять на соответствующие адреса (endpoints):
/graphql (без указания схемы или с указанием в заголовке схемы
default) – используется для запросов к пользовательским данным,
хранящимся в TDG. Подробнее смотрите
Раздел про GraphQL-запросы к данным.
/graphql (с указанием в заголовке схемы admin) – используется для основных
настроек TDG.
/admin/api – используется для изменения топологии кластера и других
настроек Tarantool Cartridge.
Данные по аргументам вызова функций и возвращаемым результатам не приводятся,
исходя из того, что GraphQL обладает встроенными механизмами обмена этой
информацией с клиентским программным обеспечением, выполняющим запросы. Описания
параметров и аргументов приведены в исключительном порядке для отдельных
случаев, требующих пояснения.
Основные настройки TDG
Для выполнения запроса направьте его по протоколу HTTP на HTTP-порт экземпляра кластера с ролью connector с указанием адреса ресурса (endpoint) /graphql и
заголовком admin, а также данными авторизации.
Пример выполнения запроса при помощи утилиты curl:
curl --request POST \
--url http://172.19.0.2:8080/graphql \
--header 'Authorization: Bearer 2fc136cf-8cae-4655-a431-7c318967263d' \
--header 'schema: admin' \
--data '{"query":"query{ user{ list{ username } } } "}'
Далее приведены все типы запросов на чтение или изменение основных настроек
TDG. Для некоторых запросов дополнительно указаны возвращаемые
значения и пояснения к ним.
Запросы на получение информации по текущим настройкам и состоянию (query)
Пример запроса на получение названия роли по ее id (access_role.get):
query {
access_role {
get(id: 1) {
name
}
}
}
-
query.jobs
Чтение ремонтной очереди неудавшихся отложенных работ (попытка
выполнения которых закончилась неудачно, вкладка Failed jobs):
-
query.repair_list
Возвращает список объектов, находящихся в ремонтной очереди (вкладка Repair).
-
query.tasks
Чтение списка задач:
-
query.password_generator
Генерация и проверка валидности паролей, чтение
настроек требований к сложности паролей:
generate – возвращает сгенерированный пароль.
validate – выполняет проверку переданного пароля на соответствие
имеющимся требованиям к сложности пароля.
config – возвращает текущие настройки требований к сложности
пароля.
-
query.output_processor
Чтение данных ремонтной очереди объектов на отправку (вкладка Output Processor):
-
query.access_role
Чтение настроек ролевой модели:
actions_list – возвращает список всех возможных действий, доступ к
которым настраивается при помощи ролевой модели.
get_access_role_actions – возвращает список действий, доступных для роли по ее id.
list – возвращает список ролей.
get – возвращает данные о роли по ее id.
-
query.cartridge
Чтение данных из конфигурации:
-
query.data_access_action
Чтение информации о шаблонах доступа к действиям над данными:
-
query.user
Чтение информации о пользователях и настройке доступа анонимных пользователей:
is_anonymous_allowed – возвращает статус настройки, разрешающей доступ без авторизации.
self – возвращает информацию о текущем пользователе.
list – возвращает список пользователей.
-
query.notifier_get_users
Возвращает список подписчиков (вкладка Subscribers).
-
query.audit_log
Чтение данных о журнале событий безопасности:
get – возвращает журнал событий безопасности (аудит лог).
enabled – возвращает статус настройки, отвечающей за включение и отключение ведения журнала аудита.
-
query.maintenance
Чтение служебной информации:
clock_delta – данные по рассинхронизации времени на внутренних (системных)
часах экземпляров. Может возвращать следующие значения:
value – возвращает максимальное текущее значение отклонения часов между экземплярами кластера.
is_threshold_exceeded – отвечает на вопрос, превышено ли предельное
значение отклонения часов среди экземпляров кластера.
get_aggregates – возвращает список агрегатов модели данных.
current_tdg_version – проверяет версию TDG при применении конфигурации (только в схеме admin).
unlinked_space_list – возвращает список агрегатов, которые были удалены
из модели, но при этом в хранилище остались их сохраненные данные.
-
query.token
Чтение информации о токенах приложений:
-
query.get_mail_server
Возвращает настройки почтового сервера для отправки оповещений.
-
query.config
Чтение настроек кластера:
vshard-timeout – возвращает таймаут выполнения удаленного вызова для
операции модуля Tarantool vshard.
force_yield_limits – возвращает количество чтений записей спейса, после
которых происходит принудительная передача управления (yield)
для обеспечения кооперативной многозадачности.
hard_limits – возвращает текущие настройки ограничений при выполнении
GraphQL-запросов. Может возвращать следующие значения:
scanned – ограничение числа записей в спейсах, которые могут быть
прочитаны для выполнения запроса.
returned – ограничение числа записей, которые могут быть возвращены в ответе на запрос.
graphql_query_cache_size – возвращает ограничение количества кэшируемых
уникальных GraphQL-запросов. Кэшируется только текст запроса, но не переменные.
locked_sections_list – Список закрепленных секций.
Если в список закрепленных секций добавить любую секцию, например, секцию metrics, а потом загрузить новый
файл конфигурации, в котором секции metrics не будет, то эта секция не удалится – вместо нее будет
использована последняя загруженная версия секции metrics.
Прописать закрепленные секции в файле конфигурации явным образом нельзя.
-
query.account_provider
Управление доступом:
-
query.checks
Валидация различных настроек:
-
query.data_type
Доступ к текущей модели данных:
model – возвращает текущую модель данных.
expiration – возвращает настройки устаревания данных.
versioning – возвращает параметры версионирования модели данных.
-
query.logs
Доступ к общему журналу событий:
-
query.metrics
Доступа к метрикам:
-
query.migration
Управление миграцией данных:
-
query.settings
Настройки учетной записи:
Запросы на внесение изменений в настройки (mutation)
Пример запроса на изменение настроек требований к сложности паролей пользователей (password_generator.config):
mutation {
password_generator {
config(lower: true, digits: true, symbols: false, min_length: 6)
}
}
-
mutation.jobs
Работа с ремонтной очередью неудавшихся отложенных работ (попытка
выполнения которых закончилась неудачно, вкладка Failed jobs):
delete_all_jobs – удалить все отложенные работы из ремонтной очереди отложенных работ.
try_again_all – выполнить повторную попытку обработки всех
отложенных работ из ремонтной очереди отложенных работ.
try_again – выполнить повторную попытку обработки неудавшейся отложенной работы по ее id.
delete_job – удалить неудавшуюся отложенную работу по ее id.
-
mutation.token
Работа с токенами приложений:
remove – удалить токен приложения по его имени. В запрос передается единственный аргумент name – имя токена.
import – импортировать токен приложения. Возможные аргументы:
state_reason (опционально) – пояснение к присвоению текущего статуса.
expires_in – ограничение времени действия токена в секундах. Значение 0 означает неограниченный срок действия.
uid – внутренний ID токена.
role – имя роли из ролевой модели доступа.
state – статус (active/blocked).
created_at – дата и время создания в формате Unix time.
name – имя токена.
last_login (опционально) – дата и время последнего входа в формате Unix time.
unblocked_at (опционально) – дата и время последней разблокировки в формате Unix time.
add – добавить новый токен приложения. Возможные аргументы:
update – отредактировать данные токена приложения (срок действия или роль). Возможные аргументы:
set_state – изменить статус токена приложения (заблокировать или разблокировать). Возможные аргументы:
-
mutation.notifier_upsert_user
Добавление нового или редактирование существующего
адреса для оповещения (вкладка Subscribers). Возможные аргументы:
name – имя контакта для оповещения.
addr – адрес электронной почты.
id – внутренний идентификатор (строка).
-
mutation.clear_repair_queue
Очистить ремонтную очередь (вкладка Repair).
-
mutation.password_generator
Изменение настроек требований к сложности паролей пользователей.
-
mutation.output_processor
Работа с ремонтной очередью на отправку (вкладка Output processor):
clear_list – удалить все объекты на отправку из ремонтной очереди.
try_again_all – выполнить повторную попытку обработки всех объектов на отправку из ремонтной очереди.
try_again – выполнить повторную попытку обработки объекта на отправку из ремонтной очереди по его id.
delete_from_list – удалить объект на отправку из ремонтной очереди по его id.
-
mutation.access_role
Управление настройками ролевой модели:
delete – удаление роли пользователя по ее id.
create – создание новой роли пользователя. Возможные аргументы:
update – изменение имени или описания роли пользователя.
update_access_role_actions – изменение прав доступа для роли.
Возможные аргументы:
-
mutation.set_mail_server
Изменение настроек почтового сервера для отправки
оповещений (см. Подробнее про модуль SMTP).
Возможные аргументы:
username – имя учетной записи, с которой будет проводиться рассылка.
password – пароль от учетной записи.
url – адрес почтового сервера.
from – адрес, указываемый в поле отправителя сообщения.
skip_verify_host – при установке true позволяет пропускать проверку валидности сертификата хоста.
timeout – таймаут отправки.
-
mutation.cartridge
Изменение конфигурации:
-
mutation.data_access_action
Внесение изменений в шаблоны доступа к действиям над данным:
-
mutation.user
Управление пользователями:
import – импорт пользователя.
add – добавление нового пользователя.
remove – удаление существующего пользователя по его uid.
modify – редактирование существующего пользователя по его uid.
self_modify – редактирование пароля или имени учетной записи для текущего пользователя
(из-под которого выполняется GraphQL-запрос).
set_state – блокирование или разблокирование пользователя.
reset_password – сброс пароля пользователя по его uid.
-
mutation.tasks
Управление задачами:
start – запуск задачи по ее id.
stop – остановка задачи по ее id.
forget – удаляет один из результатов выполнения задачи по его id.
-
mutation.maintenance
Служебные функции:
drop_unlinked_spaces – удаление спейсов от агрегатов, которые были удалены
из модели, но при этом в хранилище остались их сохраненные данные.
truncate_unlinked_spaces – удаление данных из спейсов агрегатов, которые
были удалены из модели, но при этом в хранилище остались их сохраненные данные.
-
mutation.audit_log
Ведение журнала событий безопасности (аудит лог):
enabled – включение функции ведения журнала событий безопасности.
clear – очистка журнала событий безопасности.
severity – настройка уровня важности событий, которые будут записываться
в журнал событий безопасности.
-
mutation.notifier_delete_user
Удаляет запись из списка подписчиков (вкладка Subscribers) по ее id.
-
mutation.repair_all
Выполняет повторную попытку обработки всех объектов из ремонтной очереди (вкладка Repair).
-
mutation.repair
Выполняет повторную попытку обработки объекта из ремонтной очереди (вкладка Repair) по его id.
-
mutation.delete_from_repair_queue
Выполняет удаление объекта из ремонтной очереди (вкладка Repair) по его id.
-
mutation.config
Изменение настроек кластера:
vshard-timeout – таймаут выполнения удаленного вызова для
операции модуля Tarantool vshard.
force_yield_limits – количество чтений записей спейса, после
которых происходит принудительная передача управления (yield)
для обеспечения кооперативной многозадачности.
hard_limits – ограничения при выполнении GraphQL-запросов. Возможные аргументы:
scanned – ограничение числа записей в спейсах, которые могут быть
прочитаны для выполнения запроса.
returned – ограничение числа записей, которые могут быть возвращены в ответе на запрос.
graphql_query_cache_size – ограничение количества кэшируемых уникальных GraphQL-запросов.
-
mutation.account_provider
Управление доступом:
-
mutation.backup
Управление резервным копированием конфигураций:
config_apply – применяет конфигурацию заданной версии.
config_delete – удаляет конфигурацию заданной версии.
config_save_current – создает резервную копию конфигурации с заданным комментарием.
settings – изменяет настройки резервного копирования конфигураций.
-
mutation.connector
Управление коннекторами:
-
mutation.data_type
Доступ к текущей модели данных:
model – позволяет изменить текущую модель данных.
expiration – позволяет изменить настройки устаревания данных.
versioning – позволяет изменить версию модели данных.
-
mutation.expiration_cleanup
Очистка (сброс) настроек устаревания данных по имени агрегата.
-
mutation.logs
Управление общим журналом событий:
-
mutation.metrics
Управление метриками:
-
mutation.migration
Управление миграцией данных:
-
mutation.settings
Управление настройками учетной записи:







