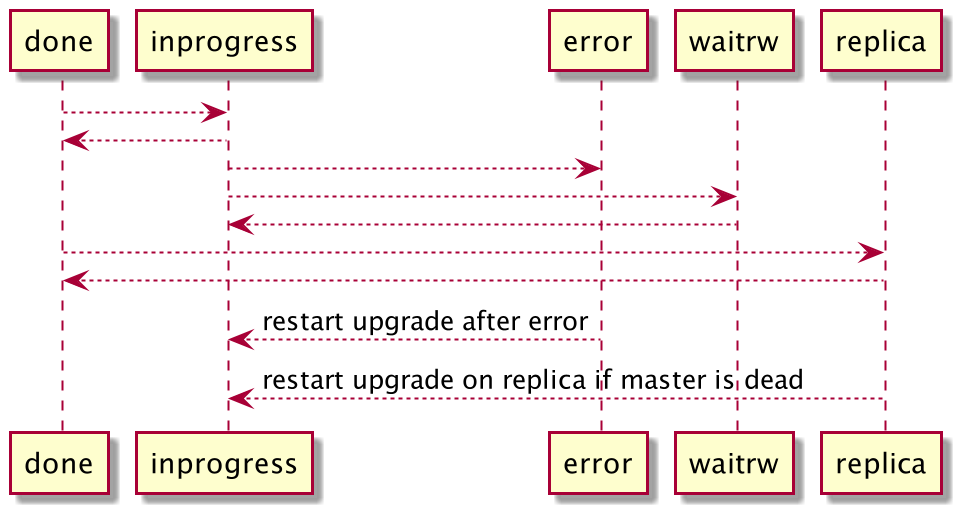
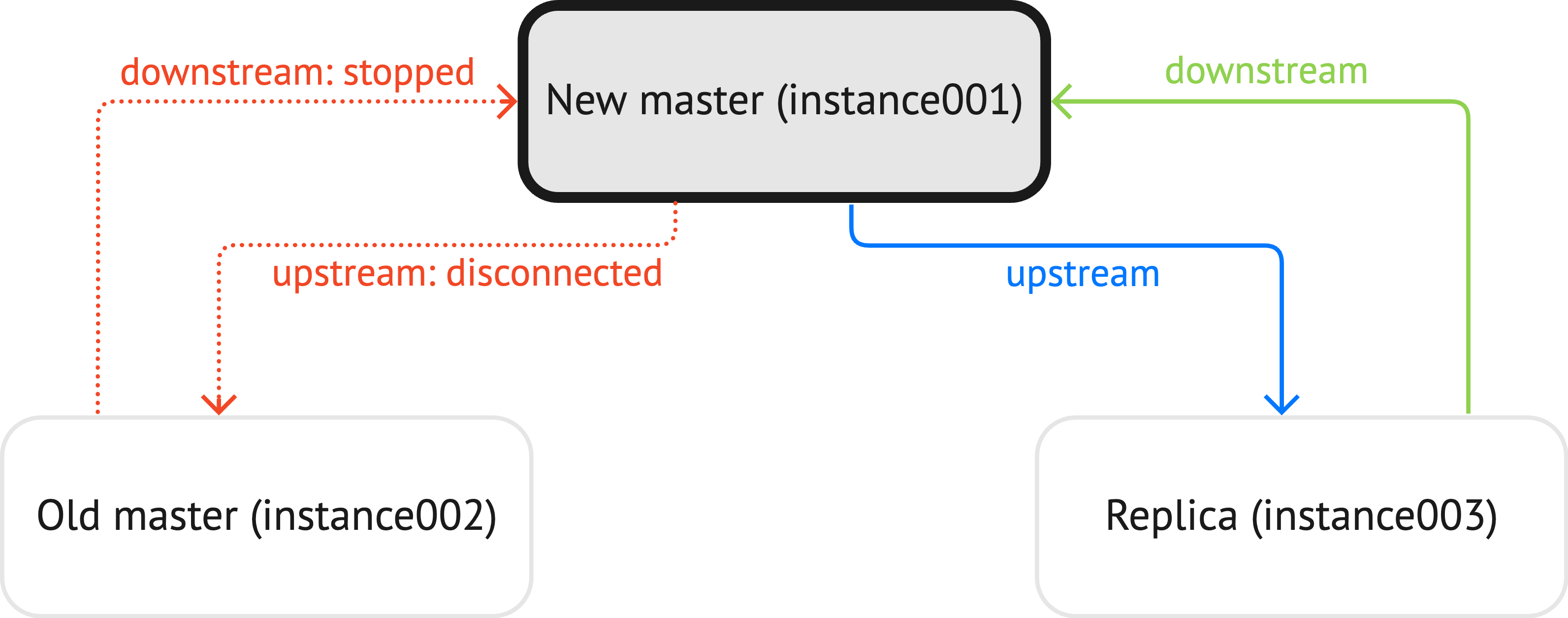
Tarantool combines an in-memory DBMS and a Lua server in a single platform
providing ACID-compliant storage. It comes in two editions:
Community and Enterprise.
The use cases for Tarantool vary from ultra-fast cache
to product data marts and smart queue services.
Here are some of Tarantool’s key characteristics:
Easy handling of OLTP workloads: processes hundreds of thousands RPS
Tarantool allows executing code alongside data, which helps increase the speed of operations.
Developers can implement any business logic with Lua,
and a single Tarantool instance can also receive SQL requests.
Tarantool has a variety of compatible modules (Lua rocks).
You can pick the ones that you need and install them manually.
Tarantool runs on Linux (x86_64, aarch64), macOS (x86_64, aarch64), and FreeBSD (x86_64).
You can use Tarantool with a programming language you’re familiar with.
For this purpose, a number of connectors are provided.
Editions
Tarantool comes in two editions: the open-source Community Edition (CE)
and the commercial Enterprise Edition (EE).
Tarantool Community Edition
Tarantool Community Edition lets you develop applications and speed up a system in operation.
It features synchronous replication, affords easy scalability,
and includes tools to develop efficient applications.
The Tarantool community helps with any practical questions
regarding the Community Edition.
Tarantool Enterprise Edition
Tarantool Enterprise Editionprovides advanced tools for
administration, deployment, and security management, along with premium support services.
This edition includes all the Community Edition features
and is more predictable in terms of solution cost and maintenance.
The Enterprise Edition is shipped as an SDK and includes a number of closed-source modules.
Note
In this documentation, topics related to Enterprise Edition features are marked with an EnterpriseEdition admonition.
The Enterprise Edition provides an extended feature set for developing
and managing clustered Tarantool applications, such as:
This section explains how to download and set up Tarantool Enterprise Edition and run
a sample application provided with it.
To learn how to download and install Tarantool Community Edition, see the Download page.
Note
The tt utility provides the ability to install and work with multiple Tarantool versions.
System requirements
The recommended system requirements for running Tarantool Enterprise are as
follows.
Hardware requirements
To fully ensure the fault tolerance of a distributed data storage system, at
least three physical computers or virtual servers are required.
For testing/development purposes, the system can be deployed using a smaller number of servers.
However, it is not recommended to use such configurations for production.
Software requirements
As host operating systems, Tarantool Enterprise Edition supports
Red Hat Enterprise Linux and CentOS versions 7.5 and higher.
Note
Tarantool Enterprise can run on other systemd-based Linux distributions
but it is not tested on them and may not work as expected.
glibc 2.17-260.el7_6.6 and higher is required. Take care to check and
update, if needed:
Hereinafter, “storage servers” or “Tarantool servers” are the computers
used to store and process data, and “administration server” is the computer
used by the system operator to install and configure the product.
The Tarantool cluster has a full mesh topology, therefore all Tarantool servers
should be able to communicate and send traffic from and to TCP/UDP ports
used by the cluster’s instances (see advertise_uri:<host>:<port> and
config:advertise_uri:'<host>:<port>' in /etc/tarantool/conf.d/*.yml
for each instance). For example:
# /etc/tarantool/conf.d/*.yml
myapp.s2-replica:
advertise_uri:localhost:3305# this is a TCP/UDP porthttp_port:8085
all:
...
hosts:
storage-1:
config:
advertise_uri:'vm1:3301'# this is a TCP/UDP porthttp_port:8081
To configure remote monitoring or to connect via the administrative console,
the administration server should be able to access the following TCP ports on
Tarantool servers:
22 to use the SSH protocol,
ports specified in instance configuration to monitor the HTTP-metrics.
Additionally, it is recommended to apply the following settings for sysctl
on all Tarantool servers:
This optional setup of the Linux network stack helps speed up the troubleshooting
of network connectivity when the server physically fails. To achieve maximum
performance, you may also need to configure other network stack parameters that
are not specific to the Tarantool DBMS. For more information, please refer to the
Network Performance Tuning Guide
section of the RHEL7 user documentation.
Package contents
The latest release packages of Tarantool Enterprise are available in the
customer zone
at Tarantool website. Please contact support@tarantool.io for access.
Each package is distributed as a tar+gzip archive and includes
the following components and features:
Static Tarantool binary for simplified deployment in Linux environments.
tt command-line utility that provides a unified command-line interface for
managing Tarantool-based applications. See tt CLI utility for details.
Tarantool Cluster Manager – a web-based interface for managing Tarantool EE clusters.
See Tarantool Cluster Manager for details.
Selection of open and closed source modules.
Sample application walking you through all included modules
Archive contents:
tarantool is the main executable of Tarantool.
tt command-line utility.
tcm is the Tarantool Cluster Manager executable.
examples/ is the directory containing sample applications:
pg_writethrough_cache/ is an application showcasing how Tarantool can
cache data written to, for example, a PostgreSQL database;
ora_writebehind_cache/ is an application showcasing how Tarantool can
cache writes and queue them to, for example, an Oracle database;
docker/ is an application designed to be easily packed into a Docker
container;
rocks/ is the directory containing a selection of additional open and
closed source modules included in the distribution as an offline rocks
repository. See the rocks reference for details.
templates/ is the directory containing template files for your application
development environment.
Installation
The delivered tar+gzip archive should be uploaded to a server and unpacked:
$ tarxvftarantool-enterprise-sdk-<version>.tar.gz
No further installation is required as the unpacked binaries are almost ready
to go. Go to the directory with the binaries (tarantool-enterprise) and
add them to the executable path by running the script provided by the distribution:
$ source./env.sh
Make sure you have enough privileges to run the script and that the file is executable.
Otherwise, try chmod and chown commands to adjust it.
The tt utility provides the ability to install Tarantool software using the tt install command.
Creating an application
The tt create command can be used to create an application from a predefined or custom template.
In this tutorial, the application layout is prepared manually:
Create a tt environment in the current directory using the tt init command.
Inside the instances.enabled directory of the created tt environment, create the create_db directory.
Inside instances.enabled/create_db, create the instances.yml and config.yaml files:
instances.yml specifies instances to run in the current environment. In this example, there is one instance:
Format the created space by specifying field names and types:
create_db:instance001> box.space.bands:format({ { name = 'id', type = 'unsigned' }, { name = 'band_name', type = 'string' }, { name = 'year', type = 'unsigned' } })---...
In this tutorial, you get a sharded cluster up and running on your local machine and learn how to manage the cluster using the tt utility.
This cluster uses the following external modules:
The tt utility provides the ability to install Tarantool software using the tt install command.
Creating a cluster application
The tt create command can be used to create an application from a predefined or custom template.
For example, the built-in vshard_cluster template enables you to create a ready-to-run sharded cluster application.
In this tutorial, the application layout is prepared manually:
Create a tt environment in the current directory by executing the tt init command.
Inside the empty instances.enabled directory of the created tt environment, create the sharded_cluster_crud directory.
Inside instances.enabled/sharded_cluster_crud, create the following files:
instances.yml specifies instances to run in the current environment.
sharded_cluster_crud-scm-1.rockspec specifies external dependencies required by the application.
The next Developing the application section shows how to configure the cluster and write code for routing read and write requests to different storages.
Developing the application
Configuring instances to run
Open the instances.yml file and add the following content:
In this section, two users with the specified passwords are created:
The replicator user with the replication role.
The storage user with the sharding role.
These users are intended to maintain replication and sharding in the cluster.
Important
It is not recommended to store passwords as plain text in a YAML configuration.
Learn how to load passwords from safe storage such as external files or environment variables from Loading secrets from safe storage.
In this section, the following options are configured:
iproto.advertise.peer specifies how to advertise the current instance to other cluster members.
In particular, this option informs other replica set members that the replicator user should be used to connect to the current instance.
iproto.advertise.sharding specifies how to advertise the current instance to a router and rebalancer.
The cluster topology defined in the following section also specifies the iproto.advertise.client option for each instance.
This option accepts a URI used to advertise the instance to clients.
For example, Tarantool Cluster Manager uses these URIs to connect to cluster instances.
roles: This option enables the roles.crud-storagerole provided by the CRUD module for all storage instances.
app: The app.module option specifies that code specific to storages should be loaded from the storage module. This is explained below in the Adding storage code section.
sharding: The sharding.roles option specifies that all instances inside this group act as storages.
A rebalancer is selected automatically from two master instances.
replication: The replication.failover option specifies that a leader in each replica set should be specified manually.
replicasets: This section configures two replica sets that constitute cluster storages.
To configure a router, add the following code inside the groups section:
roles: This option enables the roles.crud-routerrole provided by the CRUD module for a router instance.
app: The app.module option specifies that code specific to a router should be loaded from the router module. This is explained below in the Adding router code section.
sharding: The sharding.roles option specifies that an instance inside this group acts as a router.
replicasets: This section configures a replica set with one router instance.
Resulting configuration
The resulting config.yaml file should look as follows:
The box.schema.create_space() function creates a space.
Note that the created bands space includes the bucket_id field.
This field represents a sharding key used to partition a dataset across different storage instances.
replicasets: contains information about storages and their availability.
bucket: displays the total number of read-write and read-only buckets that are currently available for this router.
status: the number from 0 to 3 that indicates whether there are any issues with the cluster.
0 means that there are no issues.
alerts: might describe the exact issues related to bootstrapping a cluster, for example, connection issues, failover events, or unidentified buckets.
Writing and selecting data
To insert sample data, call crud.insert_many() on the router:
crud.insert_many('bands',{{1,box.NULL,'Roxette',1986},{2,box.NULL,'Scorpions',1965},{3,box.NULL,'Ace of Base',1987},{4,box.NULL,'The Beatles',1960},{5,box.NULL,'Pink Floyd',1965},{6,box.NULL,'The Rolling Stones',1962},{7,box.NULL,'The Doors',1965},{8,box.NULL,'Nirvana',1987},{9,box.NULL,'Led Zeppelin',1968},{10,box.NULL,'Queen',1970}})
Calling this function distributes data evenly across the cluster nodes.
To get a tuple by the specified ID, call the crud.get() function:
In this tutorial, you get Tarantool Cluster Manager up and running on your local system, deploy
a local Tarantool EE cluster, and learn to manage the cluster from the TCM web UI.
To complete this tutorial, you need:
A Linux machine with glibc 2.17 or later.
A web browser: Chromium-based (Chromium version 108 or later), Mozilla Firefox 101 or later, or another up-to-date browser.
The Tarantool Enterprise Edition SDK 3.0 or later in the tar.gz archive.
See Installing Tarantool for information about getting the archive.
During the development, it is also convenient to use the TCM-embedded etcd
as a configuration storage for Tarantool EE clusters connected to TCM.
Learn more in Centralized configuration storages.
Logging into TCM
Open a web browser and go to http://127.0.0.1:8080/.
Enter the username and the password you got from the TCM bootstrap log in the previous step.
Click Log in.
After a successful login, you see the TCM web UI:
Setting up a Tarantool EE cluster
To prepare a Tarantool EE cluster, complete the following steps:
Define the cluster connection settings in TCM.
Configure the cluster in TCM.
Start the cluster instances locally using the tt utility.
Defining the cluster’s connection settings in TCM
A freshly installed TCM has a predefined cluster named Default cluster. It
doesn’t have any configuration or topology out of the box. Its initial properties
include the etcd and Tarantool connection parameters. Check these properties
to find out where TCM sends the cluster configuration that you write.
To view the Default cluster’s properties:
Go to Clusters and click Edit in the Actions menu opposite the cluster name.
Click Next on the General tab.
Find the connection properties of the configuration storage that the cluster uses.
By default, it’s an etcd running on port 2379 (default etcd port) on the same host.
The key prefix used for the cluster configuration is /default. Click Next.
Check the Tarantool user that TCM uses to connect to the cluster instances.
It’s guest by default.
Configuring a cluster in TCM
TCM provides a web-based editor for writing cluster configurations. It is connected
to the configuration storage (etcd in this case): all changes you make in the browser
are sent to etcd in one click.
To write the cluster configuration and upload it to the etcd storage:
Go to Configuration.
Click + and provide an arbitrary name for the configuration file, for example, all.
Inside instances.enabled/cluster, create the instances.yml and config.yaml files:
instances.yml specifies instances to run in the current environment. In this example, there are three instances:
instance-001:instance-002:instance-003:
config.yaml instructs tt to load the cluster configuration from etcd.
The specified etcd location matches the configuration storage of the Default cluster in TCM:
To learn to interact with a cluster in TCM, complete typical database tasks such as:
Checking the cluster state.
Creating a space.
Writing data.
Viewing data.
Checking cluster state
To check the cluster state in TCM, go to Stateboard. Here you see the overview
of the cluster topology, health, memory consumption, and other information.
Connecting to an instance
To view detailed information about an instance, click its name in the instances list
on the Stateboard page.
To connect to the instance interactively and execute code on it, go to the Terminal tab.
Creating a space
Go to the terminal of instance-001 (the leader instance) and run the following code to
create a formatted space with a primary index in the cluster:
Since instance-001 is a read-write instance (its box.info.ro is false),
the write requests must be executed on it. Run the following code in the instance-001
terminal to write tuples in the space:
box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}
Reading data
Check the space’s tuples by running a read request on instance-001:
box.space.bands:select{3}
This is how it looks in TCM:
Checking replication
To check that the data is replicated across instances, run the read request on any
other instance – instance-002 or instance-003. The result is the same as on instance-001.
Note
If you try to execute a write request on any instance but instance-001,
you get an error because these instances are configured to be read-only.
Viewing data in TCM
TCM web UI includes a tool for viewing data stored in the cluster. To view
the space tuples in TCM:
Click an instance name on the Stateboard page.
Open the Actions menu in the top-right corner and click Explorer.
This opens the page that lists user-created spaces on the instance.
Click View in the Actions menu of the space you want to see. The page
shows all the tuples added previously.
Platform
This section contains documentation for the Tarantool platform consisting of a database and an application server.
Tarantool is a NoSQL database. It stores data in spaces,
which can be thought of as tables in a relational database, and tuples,
which are analogous to rows. There are six basic data operations in Tarantool.
Tarantool’s ACID-compliant transaction model lets the user choose
between two modes of transactions.
The default mode allows for fast monopolistic atomic transactions.
It doesn’t support interactive transactions, and in case of an error, all transaction changes are rolled back.
The MVCC mode relies on a multi-version concurrency control engine
that allows yielding within a longer transaction.
This mode only works with the default in-memory memtx storage engine.
Replication allows keeping the data in copies of the same database for better reliability.
Several Tarantool instances can be organized in a replica set.
They communicate and transfer data via the iproto binary protocol.
Learn more about Tarantool’s replication architecture.
By default, replication in Tarantool is asynchronous.
A transaction committed locally on the master node
may not get replicated onto other instances before the client receives a success response.
Thus, if the master reports success and then dies, the client might not see the result of the transaction.
With synchronous replication, transactions on the master node are not considered committed
or successful before they are replicated onto a number of instances. This is slower, but more reliable.
Synchronous replication in Tarantool is based on an implementation of the RAFT algorithm.
Tarantool implements database sharding via the vshard module.
For details, go to the Sharding page.
Triggers
Tarantool allows specifying callback functions that run upon certain database events.
They can be useful for resolving replication conflicts.
For details, go to the Triggers page.
Application server
Using Tarantool as an application server, you can write
applications in Lua, C, or C++. You can also create reusable modules.
To increase the speed of code execution, Tarantool has a Lua Just-In-Time compiler (LuaJIT) on board.
LuaJIT compiles hot paths in the code – paths that are used many times –
thus making the application work faster.
To enable developers to work with LuaJIT, Tarantool provides tools like the memory profiler
and the getmetrics module.
To learn how to use Tarantool as an application server, refer to the guides in the How-to section.
Storage engines
A storage engine is a set of low-level routines which actually store and
retrieve tuple values. Tarantool offers a choice of two storage engines:
memtx is the in-memory storage engine used by default.
The memtx storage engine is used in Tarantool by default.
The engine keeps all data in random-access memory (RAM), and therefore has a low read latency.
Tarantool prevents the data loss in case of emergency, such as outage or Tarantool instance failure, in the following ways:
Tarantool persists all data changes by writing requests to the write-ahead log (WAL)
that is stored on disk. Also, Tarantool periodically takes the entire
database snapshot and saves it on disk.
Learn more: Data persistence.
In case of a distributed application, a synchronous replication is used to ensure keeping the data consistent on a quorum of replicas.
Although replication is not directly a storage engine topic, it is a part of the answer regarding data safety.
Learn more: Replicating data.
In this section, the following topics are discussed in brief with the references to other sections that explain the
subject matter in details.
There is a fixed number of independent execution threads.
The threads don’t share state. Instead they exchange data using low-overhead message queues.
While this approach limits the number of cores that the instance uses,
it removes competition for the memory bus and ensures peak scalability of memory access and network throughput.
Only one thread, namely, the transaction processor thread (further, TX thread)
can access the database, and there is only one TX thread for each Tarantool instance.
In this thread, transactions are executed in a strictly consecutive order.
Multi-statement transactions exist to provide isolation:
each transaction sees a consistent database state and commits all its changes atomically.
At commit time, a yield happens and all transaction changes are written to WAL
in a single batch.
In case of errors during transaction execution, a transaction is rolled-back completely.
Read more in the following sections: Transaction model, Transaction mode: MVCC.
Within the TX thread, there is a memory area allocated for Tarantool to store data. It’s called Arena.
Data is stored in spaces. Spaces contain database records – tuples.
To access and manipulate the data stored in spaces and tuples, Tarantool builds indexes.
Special allocators manage memory allocations for spaces, tuples, and indexes within the Arena.
The slab allocator is the main allocator used to store tuples.
Tarantool has a built-in module called box.slab which provides the slab allocator statistics
that can be used to monitor the total memory usage and memory fragmentation.
For more details, see the box.slab module reference.
Also inside the TX thread, there is an event loop. Within the event loop, there are a number of fibers.
Fibers are cooperative primitives that allow interaction with spaces, that is, reading and writing the data.
Fibers can interact with the event loop and between each other directly or by using special primitives called channels.
Due to the usage of fibers and cooperative multitasking, the memtx engine is lock-free in typical situations.
To interact with external users, there is a separate network thread also called the iproto thread.
The iproto thread receives a request from the network, parses and checks the statement,
and transforms it into a special structure—a message containing an executable statement and its options.
Then the iproto thread ships this message to the TX thread and runs the user’s request in a separate fiber.
After executing data change requests in memory, Tarantool writes each such request to the write-ahead log (WAL) files (.xlog)
that are stored on disk. Tarantool does this via a separate thread called the WAL thread.
Tarantool periodically takes the entire database snapshot and saves it on disk.
It is necessary for accelerating instance’s restart because when there are too many WAL files, it can be difficult for Tarantool to restart quickly.
To save a snapshot, there is a special fiber called the snapshot daemon.
It reads the consistent content of the entire Arena and writes it on disk into a snapshot file (.snap).
Due of the cooperative multitasking, Tarantool cannot write directly on disk because it is a locking operation.
That is why Tarantool interacts with disk via a separate pool of threads from the fio library.
So, even in emergency situations such as an outage or a Tarantool instance failure,
when the in-memory database is lost, the data can be restored fully during Tarantool restart.
What happens during the restart:
Tarantool finds the latest snapshot file and reads it.
Tarantool finds all the WAL files created after that snapshot and reads them as well.
When the snapshot and WAL files have been read, there is a fully recovered in-memory data set
corresponding to the state when the Tarantool instance stopped.
While reading the snapshot and WAL files, Tarantool is building the primary indexes.
When all the data is in memory again, Tarantool is building the secondary indexes.
Tarantool runs the application.
Accessing data
To access and manipulate the data stored in memory, Tarantool builds indexes.
Indexes are also stored in memory within the Arena.
Tarantool supports a number of index types intended for different usage scenarios.
The possible types are TREE, HASH, BITSET, and RTREE.
Select query are possible against secondary index keys as well as primary keys.
Indexes can have multi-part keys.
For detailed information about indexes, refer to the Indexes page.
Replicating data
Although this topic is not directly related to the memtx engine, it completes the overall picture of how Tarantool works in case of a distributed application.
Replication allows multiple Tarantool instances to work on copies of the same database.
The copies are kept in sync because each instance can communicate its changes to all the other instances.
It is implemented via WAL replication.
To send data to a replica, Tarantool runs another thread called relay.
Its purpose is to read the WAL files and send them to replicas.
On a replica, the fiber called applier is run. It receives the changes from a remote node and applies them to the replica’s Arena.
All the changes are being written to WAL files via the replica’s WAL thread as if they are done locally.
By default, replication in Tarantool is asynchronous: if a transaction
is committed locally on a master node, it does not mean it is replicated onto any
replicas.
Synchronous replication exists to solve this problem. Synchronous transactions
are not considered committed and are not responded to a client until they are
replicated onto some number of replicas.
The main key points describing how the in-memory storage engine works can be summarized in the following way:
All data is in RAM.
Access to data is from one thread.
Tarantool writes all data change requests in WAL.
Data snapshots are taken periodically.
Indexes are build to access the data.
WAL can be replicated.
Storing data with vinyl
Tarantool is a transactional and persistent DBMS that maintains 100% of its data
in RAM. The greatest advantages of in-memory databases are their speed and ease
of use: they demonstrate consistently high performance, but you never need to
tune them.
A few years ago we decided to extend the product by implementing a classical
storage engine similar to those used by regular DBMSs: it uses RAM for caching,
while the bulk of its data is stored on disk. We decided to make it possible to
set a storage engine independently for each table in the database, which is the
same way that MySQL approaches it, but we also wanted to support transactions
from the very beginning.
The first question we needed to answer was whether to create our own storage
engine or use an existing library. The open-source community offered a few
viable solutions. The RocksDB library was the fastest growing open-source
library and is currently one of the most prominent out there. There were also
several lesser-known libraries to consider, such as WiredTiger, ForestDB,
NestDB, and LMDB.
Nevertheless, after studying the source code of existing libraries and
considering the pros and cons, we opted for our own storage engine. One reason
is that the existing third-party libraries expected requests to come from
multiple operating system threads and thus contained complex synchronization
primitives for controlling parallel data access. If we had decided to embed one
of these in Tarantool, we would have made our users bear the overhead of a
multithreaded application without getting anything in return. The thing is,
Tarantool has an actor-based architecture. The way it processes transactions in
a dedicated thread allows it to do away with the unnecessary locks, interprocess
communication, and other overhead that accounts for up to 80% of processor time
in multithreaded DBMSs.
The Tarantool process consists of a fixed number of “actor” threads
If you design a database engine with cooperative multitasking in mind right from
the start, it not only significantly speeds up the development process, but also
allows the implementation of certain optimization tricks that would be too
complex for multithreaded engines. In short, using a third-party solution
wouldn’t have yielded the best result.
Algorithm
Once the idea of using an existing library was off the table, we needed to pick
an architecture to build upon. There are two competing approaches to on-disk
data storage: the older one relies on B-trees and their variations; the newer
one advocates the use of log-structured merge-trees, or “LSM” trees. MySQL,
PostgreSQL, and Oracle use B-trees, while Cassandra, MongoDB, and CockroachDB
have adopted LSM trees.
B-trees are considered better suited for reads and LSM trees—for writes.
However, with SSDs becoming more widespread and the fact that SSDs have read
throughput that’s several times greater than write throughput, the advantages of
LSM trees in most scenarios was more obvious to us.
Before dissecting LSM trees in Tarantool, let’s take a look at how they work. To
do that, we’ll begin by analyzing a regular B-tree and the issues it faces. A
B-tree is a balanced tree made up of blocks, which contain sorted lists of key-
value pairs. (Topics such as filling and balancing a B-tree or splitting and
merging blocks are outside of the scope of this article and can easily be found
on Wikipedia). As a result, we get a container sorted by key, where the smallest
element is stored in the leftmost node and the largest one in the rightmost
node. Let’s have a look at how insertions and searches in a B-tree happen.
Classical B-tree
If you need to find an element or check its membership, the search starts at the
root, as usual. If the key is found in the root block, the search stops;
otherwise, the search visits the rightmost block holding the largest element
that’s not larger than the key being searched (recall that elements at each
level are sorted). If the first level yields no results, the search proceeds to
the next level. Finally, the search ends up in one of the leaves and probably
locates the needed key. Blocks are stored and read into RAM one by one, meaning
the algorithm reads blocks in a single search, where N is the number of
elements in the B-tree. In the simplest case, writes are done similarly: the
algorithm finds the block that holds the necessary element and updates (inserts)
its value.
To better understand the data structure, let’s consider a practical
example: say we have a B-tree with 100,000,000 nodes, a block size of 4096
bytes, and an element size of 100 bytes. Thus each block will hold up to 40
elements (all overhead considered), and the B-tree will consist of around
2,570,000 blocks and 5 levels: the first four will have a size of 256 Mb, while
the last one will grow up to 10 Gb. Obviously, any modern computer will be able
to store all of the levels except the last one in filesystem cache, so read
requests will require just a single I/O operation.
But if we change our
perspective —B-trees don’t look so good anymore. Suppose we need to update a
single element. Since working with B-trees involves reading and writing whole
blocks, we would have to read in one whole block, change our 100 bytes out of
4096, and then write the whole updated block to disk. In other words,we were
forced to write 40 times more data than we actually modified!
If you take into
account the fact that an SSD block has a size of 64 Kb+ and not every
modification changes a whole element, the extra disk workload can be greater
still.
Authors of specialized literature and blogs dedicated to on-disk data
storage have coined two terms for these phenomena: extra reads are referred to
as “read amplification” and writes as “write amplification”.
The amplification
factor (multiplication coefficient) is calculated as the ratio of the size of
actual read (or written) data to the size of data needed (or actually changed).
In our B-tree example, the amplification factor would be around 40 for both
reads and writes.
The huge number of extra I/O operations associated with
updating data is one of the main issues addressed by LSM trees. Let’s see how
they work.
The key difference between LSM trees and regular B-trees is that LSM
trees don’t just store data (keys and values), but also data operations:
insertions and deletions.
LSM tree:
Stores statements, not values:
REPLACE
DELETE
UPSERT
Every statement is marked by LSN
Append-only files, garbage is collected after a checkpoint
Transactional log of all filesystem changes: vylog
For example, an element corresponding to an insertion operation has, apart from
a key and a value, an extra byte with an operation code (“REPLACE” in the image
above). An element representing the deletion operation contains a key (since
storing a value is unnecessary) and the corresponding operation code—“DELETE”.
Also, each LSM tree element has a log sequence number (LSN), which is the value
of a monotonically increasing sequence that uniquely identifies each operation.
The whole tree is first ordered by key in ascending order, and then, within a
single key scope, by LSN in descending order.
A single level of an LSM tree
Filling an LSM tree
Unlike a B-tree, which is stored completely on disk and can be partly cached in
RAM, when using an LSM tree, memory is explicitly separated from disk right from
the start. The issue of volatile memory and data persistence is beyond the scope
of the storage algorithm and can be solved in various ways—for example, by
logging changes.
The part of an LSM tree that’s stored in RAM is called L0 (level zero). The size
of RAM is limited, so L0 is allocated a fixed amount of memory. For example, in
Tarantool, the L0 size is controlled by the vinyl_memory parameter. Initially,
when an LSM tree is empty, operations are written to L0. Recall that all
elements are ordered by key in ascending order, and then within a single key
scope, by LSN in descending order, so when a new value associated with a given
key gets inserted, it’s easy to locate the older value and delete it. L0 can be
structured as any container capable of storing a sorted sequence of elements.
For example, in Tarantool, L0 is implemented as a B+*-tree. Lookups and
insertions are standard operations for the data structure underlying L0, so I
won’t dwell on those.
Sooner or later the number of elements in an LSM tree exceeds the L0 size and
that’s when L0 gets written to a file on disk (called a “run”) and then cleared
for storing new elements. This operation is called a “dump”.
Dumps on disk form a sequence ordered by LSN: LSN ranges in different runs don’t
overlap, and the leftmost runs (at the head of the sequence) hold newer
operations. Think of these runs as a pyramid, with the newest ones closer to the
top. As runs keep getting dumped, the pyramid grows higher. Note that newer runs
may contain deletions or replacements for existing keys. To remove older data,
it’s necessary to perform garbage collection (this process is sometimes called
“merge” or “compaction”) by combining several older runs into a new one. If two
versions of the same key are encountered during a compaction, only the newer one
is retained; however, if a key insertion is followed by a deletion, then both
operations can be discarded.
The key choices determining an LSM tree’s efficiency are which runs to compact
and when to compact them. Suppose an LSM tree stores a monotonically increasing
sequence of keys (1, 2, 3, …,) with no deletions. In this case, compacting
runs would be useless: all of the elements are sorted, the tree doesn’t have any
garbage, and the location of any key can unequivocally be determined. On the
other hand, if an LSM tree contains many deletions, doing a compaction would
free up some disk space. However, even if there are no deletions, but key ranges
in different runs overlap a lot, compacting such runs could speed up lookups as
there would be fewer runs to scan. In this case, it might make sense to compact
runs after each dump. But keep in mind that a compaction causes all data stored
on disk to be overwritten, so with few reads it’s recommended to perform it less
often.
To ensure it’s optimally configurable for any of the scenarios above, an LSM
tree organizes all runs into a pyramid: the newer the data operations, the
higher up the pyramid they are located. During a compaction, the algorithm picks
two or more neighboring runs of approximately equal size, if possible.
Multi-level compaction can span any number of levels
A level can contain multiple runs
All of the neighboring runs of approximately equal size constitute an LSM tree
level on disk. The ratio of run sizes at different levels determines the
pyramid’s proportions, which allows optimizing the tree for write-intensive or
read-intensive scenarios.
Suppose the L0 size is 100 Mb, the ratio of run sizes at each level (the
vinyl_run_size_ratio parameter) is 5, and there can be no more than 2 runs per
level (the vinyl_run_count_per_level parameter). After the first 3 dumps, the
disk will contain 3 runs of 100 Mb each—which constitute L1 (level one). Since 3
> 2, the runs will be compacted into a single 300 Mb run, with the older ones
being deleted. After 2 more dumps, there will be another compaction, this time
of 2 runs of 100 Mb each and the 300 Mb run, which will produce one 500 Mb run.
It will be moved to L2 (recall that the run size ratio is 5), leaving L1 empty.
The next 10 dumps will result in L2 having 3 runs of 500 Mb each, which will be
compacted into a single 1500 Mb run. Over the course of 10 more dumps, the
following will happen: 3 runs of 100 Mb each will be compacted twice, as will
two 100 Mb runs and one 300 Mb run, which will yield 2 new 500 Mb runs in L2.
Since L2 now has 3 runs, they will also be compacted: two 500 Mb runs and one
1500 Mb run will produce a 2500 Mb run that will be moved to L3, given its size.
This can go on infinitely, but if an LSM tree contains lots of deletions, the
resulting compacted run can be moved not only down, but also up the pyramid due
to its size being smaller than the sizes of the original runs that were
compacted. In other words, it’s enough to logically track which level a certain
run belongs to, based on the run size and the smallest and greatest LSN among
all of its operations.
Controlling the form of an LSM tree
If it’s necessary to reduce the number of runs for lookups, then the run size
ratio can be increased, thus bringing the number of levels down. If, on the
other hand, you need to minimize the compaction-related overhead, then the run
size ratio can be decreased: the pyramid will grow higher, and even though runs
will be compacted more often, they will be smaller, which will reduce the total
amount of work done. In general, write amplification in an LSM tree is described
by this formula: or, alternatively,
, where N is
the total size of all tree elements, L0 is the level zero size, and x is the
level size ratio (the level_size_ratio parameter). At = 40 (the disk-to-
memory ratio), the plot would look something like this:
As for read amplification, it’s proportional to the number of levels. The lookup
cost at each level is no greater than that for a B-tree. Getting back to the
example of a tree with 100,000,000 elements: given 256 Mb of RAM and the default
values of vinyl_run_size_ratio and vinyl_run_count_per_level, write
amplification would come out to about 13, while read amplification could be as
high as 150. Let’s try to figure out why this happens.
Search
When doing a lookup in an LSM tree, what we need to find is not the element
itself, but the most recent operation associated with it. If it’s a deletion,
then the tree doesn’t contain this element. If it’s an insertion, we need to
grab the topmost value in the pyramid, and the search can be stopped after
finding the first matching key. In the worst-case scenario, that is if the tree
doesn’t hold the needed element, the algorithm will have to sequentially visit
all of the levels, starting from L0.
Unfortunately, this scenario is quite common in real life. For example, when
inserting a value into a tree, it’s necessary to make sure there are no
duplicates among primary/unique keys. So to speed up membership checks, LSM
trees use a probabilistic data structure called a “Bloom filter”, which will be
covered a bit later, in a section on how vinyl works under the hood.
Range searching
In the case of a single-key search, the algorithm stops after encountering the
first match. However, when searching within a certain key range (for example,
looking for all the users with the last name “Ivanov”), it’s necessary to scan
all tree levels.
Searching within a range of [24,30)
The required range is formed the same way as when compacting several runs: the
algorithm picks the key with the largest LSN out of all the sources, ignoring
the other associated operations, then moves on to the next key and repeats the
procedure.
Deletion
Why would one store deletions? And why doesn’t it lead to a tree overflow in the
case of for i=1,10000000 put(i) delete(i) end?
With regards to lookups, deletions signal the absence of a value being searched;
with compactions, they clear the tree of “garbage” records with older LSNs.
While the data is in RAM only, there’s no need to store deletions. Similarly,
you don’t need to keep them following a compaction if they affect, among other
things, the lowest tree level, which contains the oldest dump. Indeed, if a
value can’t be found at the lowest level, then it doesn’t exist in the tree.
We can’t delete from append-only files
Tombstones (delete markers) are inserted into L0 instead
Deletion, step 1: a tombstone is inserted into L0
Deletion, step 2: the tombstone passes through intermediate levels
Deletion, step 3: in the case of a major compaction, the tombstone is removed from the tree
If a deletion is known to come right after the insertion of a unique value,
which is often the case when modifying a value in a secondary index, then the
deletion can safely be filtered out while compacting intermediate tree levels.
This optimization is implemented in vinyl.
Advantages of an LSM tree
Apart from decreasing write amplification, the approach that involves
periodically dumping level L0 and compacting levels L1-Lk has a few advantages
over the approach to writes adopted by B-trees:
Dumps and compactions write relatively large files: typically, the L0 size
is 50-100 Mb, which is thousands of times larger than the size of a B-tree
block.
This large size allows efficiently compressing data before writing it.
Tarantool compresses data automatically, which further decreases write
amplification.
There is no fragmentation overhead, since there’s no
padding/empty space between the elements inside a run.
All operations create
new runs instead of modifying older data in place. This allows avoiding those
nasty locks that everyone hates so much. Several operations can run in
parallel without causing any conflicts. This also simplifies making backups
and moving data to replicas.
Storing older versions of data allows for the
efficient implementation of transaction support by using multiversion
concurrency control.
Disadvantages of an LSM tree and how to deal with them
One of the key advantages of the B-tree as a search data structure is its
predictability: all operations take no longer than to run.
Conversely, in a classical LSM tree, both read and write speeds can differ by a
factor of hundreds (best case scenario) or even thousands (worst case scenario).
For example, adding just one element to L0 can cause it to overflow, which can
trigger a chain reaction in levels L1, L2, and so on. Lookups may find the
needed element in L0 or may need to scan all of the tree levels. It’s also
necessary to optimize reads within a single level to achieve speeds comparable
to those of a B-tree. Fortunately, most disadvantages can be mitigated or even
eliminated with additional algorithms and data structures. Let’s take a closer
look at these disadvantages and how they’re dealt with in Tarantool.
Unpredictable write speed
In an LSM tree, insertions almost always affect L0 only. How do you avoid idle
time when the memory area allocated for L0 is full?
Clearing L0 involves two lengthy operations: writing to disk and memory
deallocation. To avoid idle time while L0 is being dumped, Tarantool uses
writeaheads. Suppose the L0 size is 256 Mb. The disk write speed is 10 Mbps.
Then it would take 26 seconds to dump L0. The insertion speed is 10,000 RPS,
with each key having a size of 100 bytes. While L0 is being dumped, it’s
necessary to reserve 26 Mb of RAM, effectively slicing the L0 size down to 230
Mb.
Tarantool does all of these calculations automatically, constantly updating the
rolling average of the DBMS workload and the histogram of the disk speed. This
allows using L0 as efficiently as possible and it prevents write requests from
timing out. But in the case of workload surges, some wait time is still
possible. That’s why we also introduced an insertion timeout (the
vinyl_timeout parameter), which is set to 60 seconds by default. The write
operation itself is executed in dedicated threads. The number of these threads
(4 by default) is controlled by the vinyl_write_threads parameter. The default
value of 2 allows doing dumps and compactions in parallel, which is also
necessary for ensuring system predictability.
In Tarantool, compactions are always performed independently of dumps, in a
separate execution thread. This is made possible by the append-only nature of an
LSM tree: after dumps runs are never changed, and compactions simply create new
runs.
Delays can also be caused by L0 rotation and the deallocation of memory dumped
to disk: during a dump, L0 memory is owned by two operating system threads, a
transaction processing thread and a write thread. Even though no elements are
being added to the rotated L0, it can still be used for lookups. To avoid read
locks when doing lookups, the write thread doesn’t deallocate the dumped memory,
instead delegating this task to the transaction processor thread. Following a
dump, memory deallocation itself happens instantaneously: to achieve this, L0
uses a special allocator that deallocates all of the memory with a single
operation.
anticipatory dump
throttling
The dump is performed from the so-called “shadow” L0 without blocking new
insertions and lookups
Unpredictable read speed
Optimizing reads is the most difficult optimization task with regards to LSM
trees. The main complexity factor here is the number of levels: any optimization
causes not only much slower lookups, but also tends to require significantly
larger RAM resources. Fortunately, the append-only nature of LSM trees allows us
to address these problems in ways that would be nontrivial for traditional data
structures.
page index
bloom filters
tuple range cache
multi-level compaction
Compression and page index
In B-trees, data compression is either the hardest problem to crack or a great
marketing tool—rather than something really useful. In LSM trees, compression
works as follows:
During a dump or compaction all of the data within a single run is split into
pages. The page size (in bytes) is controlled by the vinyl_page_size
parameter and can be set separately for each index. A page doesn’t have to be
exactly of vinyl_page_size size—depending on the data it holds, it can be a
little bit smaller or larger. Because of this, pages never have any empty space
inside.
Data is compressed by
Facebook’s streaming algorithm
called “zstd”. The first key of each page, along with the page offset, is added
to a “page index”, which is a separate file that allows the quick retrieval
of any page. After a dump or compaction, the page index of the created run is
also written to disk.
All .index files are cached in RAM, which allows finding the necessary page
with a single lookup in a .run file (in vinyl, this is the extension of files
resulting from a dump or compaction). Since data within a page is sorted, after
it’s read and decompressed, the needed key can be found using a regular binary
search. Decompression and reads are handled by separate threads, and are
controlled by the vinyl_read_threads parameter.
Tarantool uses a universal file format: for example, the format of a .run file
is no different from that of an .xlog file (log file). This simplifies backup
and recovery as well as the usage of external tools.
Bloom filters
Even though using a page index enables scanning fewer pages per run when doing a
lookup, it’s still necessary to traverse all of the tree levels. There’s a
special case, which involves checking if particular data is absent when scanning
all of the tree levels and it’s unavoidable: I’m talking about insertions into a
unique index. If the data being inserted already exists, then inserting the same
data into a unique index should lead to an error. The only way to throw an error
in an LSM tree before a transaction is committed is to do a search before
inserting the data. Such reads form a class of their own in the DBMS world and
are called “hidden” or “parasitic” reads.
Another operation leading to hidden reads is updating a value in a field on
which a secondary index is defined. Secondary keys are regular LSM trees that
store differently ordered data. In most cases, in order not to have to store all
of the data in all of the indexes, a value associated with a given key is kept
in whole only in the primary index (any index that stores both a key and a value
is called “covering” or “clustered”), whereas the secondary index only stores
the fields on which a secondary index is defined, and the values of the fields
that are part of the primary index. Thus, each time a change is made to a value
in a field on which a secondary index is defined, it’s necessary to first remove
the old key from the secondary index—and only then can the new key be inserted.
At update time, the old value is unknown, and it is this value that needs to be
read in from the primary key “under the hood”.
For example:
updatet1setcity=’Moscow’whereid=1
To minimize the number of disk reads, especially for nonexistent data, nearly
all LSM trees use probabilistic data structures, and Tarantool is no exception.
A classical Bloom filter is made up of several (usually 3-to-5) bit arrays. When
data is written, several hash functions are calculated for each key in order to
get corresponding array positions. The bits at these positions are then set to
1. Due to possible hash collisions, some bits might be set to 1 twice. We’re
most interested in the bits that remain 0 after all keys have been added. When
looking for an element within a run, the same hash functions are applied to
produce bit positions in the arrays. If any of the bits at these positions is 0,
then the element is definitely not in the run. The probability of a false
positive in a Bloom filter is calculated using Bayes’ theorem: each hash
function is an independent random variable, so the probability of a collision
simultaneously occurring in all of the bit arrays is infinitesimal.
The key advantage of Bloom filters in Tarantool is that they’re easily
configurable. The only parameter that can be specified separately for each index
is called vinyl_bloom_fpr (FPR stands for “false positive ratio”) and it has the
default value of 0.05, which translates to a 5% FPR. Based on this parameter,
Tarantool automatically creates Bloom filters of the optimal size for partial-
key and full-key searches. The Bloom filters are stored in the .index file,
along with the page index, and are cached in RAM.
Caching
A lot of people think that caching is a silver bullet that can help with any
performance issue. “When in doubt, add more cache”. In vinyl, caching is viewed
rather as a means of reducing the overall workload and consequently, of getting
a more stable response time for those requests that don’t hit the cache. vinyl
boasts a unique type of cache among transactional systems called a “range tuple
cache”. Unlike, say, RocksDB or MySQL, this cache doesn’t store pages, but
rather ranges of index values obtained from disk, after having performed a
compaction spanning all tree levels. This allows the use of caching for both
single-key and key-range searches. Since this method of caching stores only hot
data and not, say, pages (you may need only some data from a page), RAM is used
in the most efficient way possible. The cache size is controlled by the
vinyl_cache parameter.
Garbage collection control
Chances are that by now you’ve started losing focus and need a well-deserved
dopamine reward. Feel free to take a break, since working through the rest of
the article is going to take some serious mental effort.
An LSM tree in vinyl is just a small piece of the puzzle. Even with a single
table (or so-called “space”), vinyl creates and maintains several LSM trees, one
for each index. But even a single index can be comprised of dozens of LSM trees.
Let’s try to understand why this might be necessary.
Recall our example with a tree containing 100,000,000 records, 100 bytes each.
As time passes, the lowest LSM level may end up holding a 10 Gb run. During
compaction, a temporary run of approximately the same size will be created. Data
at intermediate levels takes up some space as well, since the tree may store
several operations associated with a single key. In total, storing 10 Gb of
actual data may require up to 30 Gb of free space: 10 Gb for the last tree
level, 10 Gb for a temporary run, and 10 Gb for the remaining data. But what if
the data size is not 10 Gb, but 1 Tb? Requiring that the available disk space
always be several times greater than the actual data size is financially
unpractical, not to mention that it may take dozens of hours to create a 1 Tb
run. And in the case of an emergency shutdown or system restart, the process
would have to be started from scratch.
Here’s another scenario. Suppose the primary key is a monotonically increasing
sequence—for example, a time series. In this case, most insertions will fall
into the right part of the key range, so it wouldn’t make much sense to do a
compaction just to append a few million more records to an already huge run.
But what if writes predominantly occur in a particular region of the key range,
whereas most reads take place in a different region? How do you optimize the
form of the LSM tree in this case? If it’s too high, read performance is
impacted; if it’s too low—write speed is reduced.
Tarantool “factorizes” this problem by creating multiple LSM trees for each
index. The approximate size of each subtree may be controlled by the
vinyl_range_size configuration parameter. We call such
subtrees “ranges”.
Factorizing large LSM trees via ranging
Ranges reflect a static layout of sorted runs
Slices connect a sorted run into a range
Initially, when the index has few elements, it consists of a single range. As more
elements are added, its total size may exceed
the maximum range size. In that case a
special operation called “split” divides the tree into two equal parts. The tree
is split at the middle element in the range of keys stored in the tree. For
example, if the tree initially stores the full range of -inf…+inf, then after
splitting it at the middle key X, we get two subtrees: one that stores the range
of -inf…X, and the other storing the range of X…+inf. With this approach, we
always know which subtree to use for writes and which one for reads. If the tree
contained deletions and each of the neighboring ranges grew smaller as a result,
the opposite operation called “coalesce” combines two neighboring trees into
one.
Split and coalesce don’t entail a compaction, the creation of new runs, or other
resource-intensive operations. An LSM tree is just a collection of runs. vinyl
has a special metadata log that helps keep track of which run belongs to which
subtree(s). This has the .vylog extension and its format is compatible with an
.xlog file. Similarly to an .xlog file, the metadata log gets rotated at each
checkpoint. To avoid the creation of extra runs with split and coalesce, we have
also introduced an auxiliary entity called “slice”. It’s a reference to a run
containing a key range and it’s stored only in the metadata log. Once the
reference counter drops to zero, the corresponding file gets removed. When it’s
necessary to perform a split or to coalesce, Tarantool creates slice objects for
each new tree, removes older slices, and writes these operations to the metadata
log, which literally stores records that look like this: <treeid,sliceid>
or <sliceid,runid,min,max>.
This way all of the heavy lifting associated with splitting a tree into two
subtrees is postponed until a compaction and then is performed automatically. A
huge advantage of dividing all of the keys into ranges is the ability to
independently control the L0 size as well as the dump and compaction processes
for each subtree, which makes these processes manageable and predictable. Having
a separate metadata log also simplifies the implementation of both “truncate”
and “drop”. In vinyl, they’re processed instantly, since they only work with the
metadata log, while garbage collection is done in the background.
Advanced features of vinyl
Upsert
In the previous sections, we mentioned only two operations stored by an
LSM tree: deletion and replacement. Let’s take a look at how all of the other
operations can be represented. An insertion can be represented via a
replacement—you just need to make sure there are no other elements with the
specified key. To perform an update, it’s necessary to read the older value from
the tree, so it’s easier to represent this operation as a replacement as
well—this speeds up future read requests by the key. Besides, an update must
return the new value, so there’s no avoiding hidden reads.
In B-trees, the cost
of hidden reads is negligible: to update a block, it first needs to be read from
disk anyway. Creating a special update operation for an LSM tree that doesn’t
cause any hidden reads is really tempting.
Such an operation must contain not
only a default value to be inserted if a key has no value yet, but also a list
of update operations to perform if a value does exist.
At transaction execution
time, Tarantool just saves the operation in an LSM tree, then “executes” it
later, during a compaction.
The upsert operation:
space:upsert(tuple,{{operator,field,value},...})
Non-reading update or insert
Delayed execution
Background upsert squashing prevents upserts from piling up
Unfortunately, postponing the operation execution until a
compaction doesn’t leave much leeway in terms of error handling. That’s why
Tarantool tries to validate upserts as fully as possible before writing them to
an LSM tree. However, some checks are only possible with older data on hand, for
example when the update operation is trying to add a number to a string or to
remove a field that doesn’t exist.
A semantically similar operation exists in
many products including PostgreSQL and MongoDB. But anywhere you look, it’s just
syntactic sugar that combines the update and replace operations without avoiding
hidden reads. Most probably, the reason is that LSM trees as data storage structures
are relatively new.
Even though an upsert is a very important optimization and
implementing it cost us a lot of blood, sweat, and tears, we must admit that it
has limited applicability. If a table contains secondary keys or triggers,
hidden reads can’t be avoided. But if you have a scenario where secondary keys
are not required and the update following the transaction completion will
certainly not cause any errors, then the operation is for you.
I’d like to tell
you a short story about an upsert. It takes place back when vinyl was only
beginning to “mature” and we were using an upsert in production for the first
time. We had what seemed like an ideal environment for it: we had tons of keys,
the current time was being used as values; update operations were inserting keys
or modifying the current time; and we had few reads. Load tests yielded great
results.
Nevertheless, after a couple of days, the Tarantool process started
eating up 100% of our CPU, and the system performance dropped close to zero.
We
started digging into the issue and found out that the distribution of requests
across keys was significantly different from what we had seen in the test
environment. It was…well, quite nonuniform. Most keys were updated once or
twice a day, so the database was idle for the most part, but there were much
hotter keys with tens of thousands of updates per day. Tarantool handled those
just fine. But in the case of lookups by key with tens of thousands of upserts,
things quickly went downhill. To return the most recent value, Tarantool had to
read and “replay” the whole history consisting of all of the upserts. When
designing upserts, we had hoped this would happen automatically during a
compaction, but the process never even got to that stage: the L0 size was more
than enough, so there were no dumps.
We solved the problem by adding a
background process that performed readaheads on any keys that had more than a
few dozen upserts piled up, so all those upserts were squashed and substituted
with the read value.
Secondary keys
Update is not the only operation where
optimizing hidden reads is critical. Even the replace operation, given secondary
keys, has to read the older value: it needs to be independently deleted from the
secondary indexes, and inserting a new element might not do this, leaving some
garbage behind.
If secondary indexes are not unique, then collecting “garbage” from them can be
put off until a compaction, which is what we do in Tarantool. The
append-only nature of LSM trees allowed us to implement full-blown serializable
transactions in vinyl. Read-only requests use older versions of data without
blocking any writes. The transaction manager itself is fairly simple for now: in
classical terms, it implements the MVTO (multiversion timestamp ordering) class,
whereby the winning transaction is the one that finished earlier. There are no
locks and associated deadlocks. Strange as it may seem, this is a drawback
rather than an advantage: with parallel execution, you can increase the number
of successful transactions by simply holding some of them on lock when
necessary. We’re planning to improve the transaction manager soon. In the
current release, we focused on making the algorithm behave 100% correctly and
predictably. For example, our transaction manager is one of the few on the NoSQL
market that supports so-called “gap locks”.
Difference between memtx and vinyl storage engines
The primary difference between memtx and vinyl is that memtx is an in-memory
engine while vinyl is an on-disk engine. An in-memory storage engine is
generally faster (each query is usually run under 1 ms), and the memtx engine
is justifiably the default for Tarantool. But on-disk engine such as vinyl is
preferable when the database is larger than the available memory, and adding more
memory is not a realistic option.
Does not yield on the select requests unless the
transaction is committed to WAL
Yields on the select requests or on its equivalents:
get() or pairs()
Configuration
Tarantool provides the ability to configure the full topology of a cluster and set parameters specific for concrete instances, such as connection settings, memory used to store data, logging, and snapshot settings.
Each instance uses this configuration during startup to organize the cluster.
There are two approaches to configuring Tarantool:
Since version 3.0: In the YAML format.
YAML configuration allows you to provide the full cluster topology and specify all configuration options.
You can use local configuration in a YAML file for each instance or store configuration data in a reliable centralized storage.
In version 2.11 and earlier: In code using the box.cfg API.
In this case, configuration is provided in a Lua initialization script.
Note
Starting with the 3.0 version, configuring Tarantool in code is considered a legacy approach.
Configuration overview
YAML configuration describes the full topology of a Tarantool cluster.
A cluster’s topology includes the following elements, starting from the lower level:
An instance represents a single running Tarantool instance.
It stores data or might act as a router for handling CRUD requests in a sharded cluster.
replicasets
A replica set is a pack of instances that operate on same data sets.
Replication provides redundancy and increases data availability.
groups
A group provides the ability to organize replica sets.
For example, in a sharded cluster, one group can contain storage instances and another group can contain routers used to handle CRUD requests.
You can flexibly configure a cluster’s settings on different levels: from global settings applied to all groups to parameters specific for concrete instances.
The instances section includes only one instance named instance001.
The iproto.listen.uri option sets an address used to listen for incoming requests.
The replicasets section contains one replica set named replicaset001.
The groups section contains one group named group001.
Configuration scopes
This section shows how to control a scope the specified configuration option is applied to.
Most of the configuration options can be applied to a specific instance, replica set, group, or to all instances globally.
Instance
To apply certain configuration options to a specific instance,
specify such options for this instance only.
In the example below, iproto.listen is applied to instance001 only.
Configuration scopes above are listed in the order of their precedence – from highest to lowest.
For example, if the same option is defined at the instance and global level, the instance’s value takes precedence over the global one.
Note
The Configuration reference contains information about scopes to which each configuration option can be applied.
Configuration scopes: Replica set example
The example below shows how specific configuration options work in different configuration scopes for a replica set with a manual failover.
You can learn more about configuring replication from Replication tutorials.
This section is used to create the replicator user and assign it the specified role.
These options are applied globally to all instances.
iproto (global, instance)
The iproto section is specified on both global and instance levels.
The iproto.advertise.peer option specifies the parameters used by an instance to connect to another instance as a replica, for example, a URI, a login and password, or SSL parameters .
In the example above, the option includes login only.
An URI is taken from iproto.listen that is set on the instance level.
replication (global)
The replication.failover global option sets a manual failover for all replica sets.
leader (replica set)
The <replicaset-name>.leader option sets a master instance for replicaset001.
Enabling and configuring roles
An application role is a Lua module that implements specific functions or logic.
You can turn on or off a particular role for certain instances in a configuration without restarting these instances.
There can be built-in Tarantool roles, roles provided by third-party Lua modules, or custom roles that are developed as a part of a cluster application.
This section describes how to enable and configure roles.
To learn how to develop custom roles, see Application roles.
Enabling a role
To turn on or off a role for a specific instance or a set of instances, use the roles configuration option.
The example below shows how to enable the roles.crud-router role provided by the CRUD module using the roles option:
roles:[roles.crud-router]
Similarly, you can enable the roles.crud-storage role to make instances act as CRUD storages:
The roles_cfg option allows you to specify the configuration for each role.
In this option, the role name is the key and the role configuration is the value.
The example below shows how to enable statistics on called operations by providing the roles.crud-router role’s configuration:
As the most of configuration options, roles and their configurations can be defined at different levels.
Given that the roles option has the array type and roles_cfg has the map type, there are some specifics of applying the configuration:
For roles, an instance’s role takes precedence over roles defined at another level.
In the example below, instance001 has only role3:
Learn more about the order of precedence for different configuration scopes in Configuration scopes.
For roles_cfg, the following rules are applied:
If a configuration for the same role is provided at different levels, an instance configuration takes precedence over the configuration defined at another level.
In the example below, role1.greeting is 'Hi':
If the configurations for different roles are provided at different levels, both configurations are applied at the instance level.
In the example below, instance001 has role1.greeting set to 'Hi' and role2.farewell set to 'Bye':
Labels allow adding custom attributes to your cluster configuration. A label is
an arbitrary key:value pair with a string key and value.
labels:dc:'east'production:'false'
Labels can be defined in any configuration scope. An instance receives labels from
all scopes it belongs to. The labels section in a group or a replica set scope
applies to all instances of the group or a replica set. To override these labels on
the instance level or add instance-specific labels, define another labels section in the instance scope.
Labels can be used to direct function calls to instances that match certain criteria
using the connpool module.
Predefined variables
In a configuration file, you can use the following predefined variables that are replaced with actual values at runtime:
instance_name
replicaset_name
group_name
To reference these variables in a configuration file, enclose them in double curly braces with whitespaces.
In the example below, {{instance_name}} is replaced with instance001.
A YAML configuration can include parts that apply only to instances that meet certain conditions.
This is useful for cluster upgrade scenarios: during an upgrade, instances can be running
different Tarantool versions and therefore require different configurations.
Conditional parts are defined in the conditional configuration section in the global scope.
It includes one or more if subsections. Each if subsection defines conditions
and configuration parts that apply to instances that meet these conditions.
The example below shows a conditional section for cluster upgrade from Tarantool 3.0.0
to Tarantool 3.1.0:
The user-defined labelupgraded is true
on instances that are running Tarantool 3.1.0 or later. On older versions, it is false.
Two compat options that were introduced in 3.1.0 are defined for Tarantool 3.1.0
instances. On older versions, they would cause an error.
if sections can use one variable – tarantool_version. It contains
a three-number Tarantool version and compares with values of the same format
using the comparison operators >, <, >=, <=, ==, and !=.
You can write complex conditions using the logical operators || (OR) and && (AND).
Parentheses () can be used to define the operators precedence.
If the same option is set in multiple if sections that are true for an instance,
this option receives the value from the section declared last in the configuration.
Example:
conditional:-if:tarantool_version >= 3.0.0labels:version:'3.0'# applies to versions >= 3.0.0 and < 3.1.0-if:tarantool_version >= 3.1.0labels:version:'3.1+'# applies to versions >= 3.1.0
Environment variables
For each configuration parameter, Tarantool provides two sets of predefined environment variables:
TT_<CONFIG_PARAMETER>. These variables are used to substitute parameters specified in a configuration file.
This means that these variables have a higher priority than the options specified in a configuration file.
TT_<CONFIG_PARAMETER>_DEFAULT. These variables are used to specify default values for parameters missing in a configuration file.
These variables have a lower priority than the options specified in a configuration file.
For example, TT_IPROTO_LISTEN and TT_IPROTO_LISTEN_DEFAULT correspond to the iproto.listen option.
TT_SNAPSHOT_DIR and TT_SNAPSHOT_DIR_DEFAULT correspond to the snapshot.dir option.
To see all the supported environment variables, execute the tarantool command with the --help-env-listoption.
$ tarantool--help-env-list
Note
There are also special TT_INSTANCE_NAME and TT_CONFIG environment variables that can be used to start the specified Tarantool instance with configuration from the given file.
Below are a few examples that show how to set environment variables of different types, like string, number, array, or map.
String
In this example, TT_LOG_LEVEL is used to set a logging level to CRITICAL:
$ exportTT_LOG_LEVEL='crit'
Number
In this example, a logging level is set to CRITICAL using a corresponding numeric value:
$ exportTT_LOG_LEVEL=3
Array
The examples below show how to set the TT_SHARDING_ROLES variable that accepts an array value.
Arrays can be passed in two ways: using a simple …
$ exportTT_SHARDING_ROLES=router,storage
… or JSON format:
$ exportTT_SHARDING_ROLES='["router", "storage"]'
The simple format is applicable only to arrays containing scalar values.
Map
To assign map values to environment variables, you can also use simple or JSON formats.
In the example below, TT_LOG_MODULES sets different logging levels for different modules using a simple format:
$ exportTT_LOG_MODULES=module1=info,module2=error
In the next example, TT_ROLES_CFG is used to specify the value of a custom configuration for a role using a JSON format:
Tarantool enables you to store a cluster’s configuration in one reliable place using a Tarantool or etcd-based storage:
A Tarantool-based configuration storage is a replica set that stores a cluster’s configuration in synchronous spaces.
etcd is a distributed key-value storage for any type of critical data used by distributed systems.
With a local YAML configuration, you need to make sure that all cluster instances use identical configuration files:
Using a centralized configuration storage, all instances get the actual configuration from one place:
This topic describes how to set up a configuration storage, publish a cluster configuration to this storage, and use this configuration for all cluster instances.
Setting up a configuration storage
Tarantool-based storage
To make a replica set act as a configuration storage, use the built-in config.storagerole.
Configuring a storage
To configure a Tarantool-based storage, follow the steps below:
Define a replica set topology and specify the following options at the replica set level:
Optionally, provide the role configuration in roles_cfg. In the example below, the status_check_interval option sets the interval (in seconds) of status checks.
To learn how to set up an etcd-based configuration storage, consult the etcd documentation.
The example script below demonstrates how to use the etcdctl utility to create a user that has read and write access to configurations stored by the /myapp/ prefix:
etcdctl user add root:topsecretetcdctl role add myapp_config_manageretcdctl role grant-permission myapp_config_manager --prefix=true readwrite /myapp/etcdctl user add sampleuser:123456etcdctl user grant-role sampleuser myapp_config_manageretcdctl auth enable
The credentials of this user should be specified when configuring a connection to the etcd cluster.
Publishing a cluster’s configuration
Publishing configuration using the tt utility
The tt utility provides the tt cluster command for managing centralized cluster configurations.
The ttclusterpublish command can be used to publish a cluster’s configuration to both Tarantool and etcd-based storages.
The example below shows how a tt environment and a layout of the application called myapp might look:
source.yaml contains a cluster’s configuration to be published.
config.yaml contains a local configuration used to connect to the centralized storage.
instances.yml specifies instances to run in the current environment.
The configured instances are used by tt when starting a cluster.
ttclusterpublish ignores this configuration file.
To publish a cluster’s configuration (source.yaml) to a centralized storage, execute ttclusterpublish as follows:
Executing this command publishes a cluster configuration by the /myapp/config/all path.
Note
You can see a cluster’s configuration using the ttclustershow command.
Publishing configuration using the ‘config’ module
The config module provides the API for interacting with a Tarantool-based configuration storage.
The example below shows how to read a configuration stored in the source.yaml file using the fio module API and put this configuration by the /myapp/config/all path:
The net.boxmodule provides the ability to monitor configuration updates by watching path or prefix changes. Learn more in conn:watch().
Publishing configuration using etcdctl
To publish a cluster’s configuration to etcd using the etcdctl utility, use the put command:
$ etcdctlput/myapp/config/all<source.yaml
Note
For etcd versions earlier than 3.4, you need to set the ETCDCTL_API environment variable to 3.
Configuring connection to a storage
To use a configuration from a centralized storage for your cluster, you need to provide connection settings in a local configuration file.
Configuring connection to a Tarantool storage
Connection options for a Tarantool-based storage should be specified in the config.storage section of the configuration file.
In the example below, the following options are specified:
endpoints specifies the list of configuration storage endpoints.
prefix sets a key prefix used to search a configuration. Tarantool searches keys by the following path: <prefix>/config/*. Note that <prefix> should start with a slash (/).
timeout specifies the interval (in seconds) to perform the status check of a configuration storage.
reconnect_after specifies how much time to wait (in seconds) before reconnecting to a configuration storage.
Connection options for etcd should be specified in the config.etcd section of the configuration file.
In the example below, the following options are specified:
prefix sets a key prefix used to search a configuration. Tarantool searches keys by the following path: <prefix>/config/*. Note that <prefix> should start with a slash (/).
username and password specify credentials used for authentication.
http.request.timeout configures a request timeout for an etcd server.
By default, Tarantool watches keys with the specified prefix for changes in a cluster’s configuration and reloads a changed configuration automatically.
If necessary, you can set the config.reload option to manual to turn off configuration reloading:
Starting with the 3.0 version, the recommended way of configuring Tarantool is using a configuration file.
Configuring Tarantool in code is considered a legacy approach.
This topic covers the specifics of configuring Tarantool in code using the box.cfg API.
In this case, a configuration is stored in an initialization file - a Lua script with the specified configuration options.
You can find all the available options in the Configuration reference.
Initialization file
If the command to start Tarantool includes an instance file, then
Tarantool begins by invoking the Lua program in the file, which may have the name init.lua.
The Lua program may get further arguments
from the command line or may use operating-system functions, such as getenv().
The Lua program almost always begins by invoking box.cfg(), if the database
server will be used or if ports need to be opened. For example, suppose
init.lua contains the lines
and suppose the environment variable LISTEN_URI contains 3301,
and suppose the command line is tarantoolinit.luaARG.
Then the screen might look like this:
$ exportLISTEN_URI=3301$ tarantoolinit.luaARG
... main/101/init.lua C> Tarantool 2.8.3-0-g01023dbc2... main/101/init.lua C> log level 5... main/101/init.lua I> mapping 33554432 bytes for memtx tuple arena...... main/101/init.lua I> recovery start... main/101/init.lua I> recovering from './00000000000000000000.snap'... main/101/init.lua I> set 'listen' configuration option to "3301"... main/102/leave_local_hot_standby I> ready to accept requestsStarting ARG... main C> entering the event loop
If you wish to start an interactive session on the same terminal after
initialization is complete, you can pass the -icommand-line option.
Environment variables
Starting from version 2.8.1, you can specify configuration parameters via special environment variables.
The name of a variable should have the following pattern: TT_<NAME>,
where <NAME> is the uppercase name of the corresponding box.cfg parameter.
An empty variable (TT_LISTEN=) has the same effect as an unset one, meaning that the corresponding configuration parameter won’t be set when calling box.cfg{}.
Configuration parameters
Configuration parameters have the form:
box.cfg{[key=value[,key=value...]]}
Configuration parameters can be set in a Lua initialization file,
which is specified on the Tarantool command line.
Most configuration parameters are for allocating resources, opening ports, and
specifying database behavior. All parameters are optional.
Most of the parameters are dynamic, that is, they can be changed at runtime by calling box.cfg{} a second time.
For example, the command below sets the listen port to 3301.
tarantool> box.cfg{listen=3301}2023-05-10 13:28:54.667 [31326] main/103/interactive I> tx_binary: stopped2023-05-10 13:28:54.667 [31326] main/103/interactive I> tx_binary: bound to [::]:33012023-05-10 13:28:54.667 [31326] main/103/interactive/box.load_cfg I> set 'listen' configuration option to 3301---...
To see all the non-null parameters, execute box.cfg (no parentheses).
tarantool> box.cfg----replication_skip_conflict:falsewal_queue_max_size:16777216feedback_host:https://feedback.tarantool.iomemtx_dir:.memtx_min_tuple_size:16-- other parameters --...
To see a particular parameter value, call a corresponding box.cfg option.
For example, box.cfg.listen shows the specified listen address.
tarantool> box.cfg.listen----3301...
Listen URI
Some configuration parameters and some functions depend on a URI (Universal Resource Identifier).
The URI string format is similar to the
generic syntax for a URI schema.
It may contain (in order):
user name for login
password
host name or host IP address
port number
query parameters
Only a port number is always mandatory. A password is mandatory if a user
name is specified unless the user name is ‘guest’.
Formally, the URI
syntax is [host:]port or [username:password@]host:port.
If a host is omitted, then “0.0.0.0” or “[::]” is assumed,
meaning respectively any IPv4 address or any IPv6 address
on the local machine.
If username:password is omitted, then the “guest” user is assumed. Some examples:
URI fragment
Example
port
3301
host:port
127.0.0.1:3301
username:password@host:port
notguest:sesame@mail.ru:3301
In code, the URI value can be passed as a number (if only a port is specified) or a string:
In certain circumstances, a Unix domain socket may be used
where a URI is expected, for example, unix/:/tmp/unix_domain_socket.sock or
simply /tmp/unix_domain_socket.sock.
The uri module provides functions that convert URI strings into their
components or turn components into URI strings.
Specifying several URIs
Starting from version 2.10.0, a user can open several listening iproto sockets on a Tarantool instance
and, consequently, can specify several URIs in the configuration parameters
such as box.cfg.listen and box.cfg.replication.
Using the params table: a URI is passed in a table with additional parameters in the “params” table.
Parameters in the “params” table overwrite the ones from a URI string (“value2” overwrites “value1” for p1 in the example below).
Using the default_params table for specifying default parameter values.
In the example below, two URIs are passed in a table.
The default value for the p3 parameter is defined in the default_params table
and used if this parameter is not specified in URIs.
Parameters in the default_params table are applicable to all the URIs passed in a table.
Since version 2.10.0, Tarantool Enterprise Edition has the built-in support for using SSL to encrypt the client-server communications over binary connections,
that is, between Tarantool instances in a cluster or connecting to an instance via connectors using net.box.
Tarantool uses the OpenSSL library that is included in the delivery package.
Note that SSL connections use only TLSv1.2.
Configuration
To configure traffic encryption, you need to set the special URI parameters for a particular connection.
The parameters can be set for the following box.cfg options and net.box method:
Below is the list of the parameters.
In the next section, you can find details and examples on what should be configured on both the server side and the client side.
transport – enables SSL encryption for a connection if set to ssl.
The default value is plain, which means the encryption is off. If the parameter is not set, the encryption is off too.
Other encryption-related parameters can be used only if the transport='ssl' is set.
ssl_key_file – a path to a private SSL key file.
Mandatory for a server.
For a client, it’s mandatory if the ssl_ca_file parameter is set for a server; otherwise, optional.
If the private key is encrypted, provide a password for it in the ssl_password or ssl_password_file parameter.
ssl_cert_file – a path to an SSL certificate file.
Mandatory for a server.
For a client, it’s mandatory if the ssl_ca_file parameter is set for a server; otherwise, optional.
ssl_ca_file – a path to a trusted certificate authorities (CA) file. Optional. If not set, the peer won’t be checked for authenticity.
Both a server and a client can use the ssl_ca_file parameter:
If it’s on the server side, the server verifies the client.
If it’s on the client side, the client verifies the server.
If both sides have the CA files, the server and the client verify each other.
ssl_ciphers – a colon-separated (:) list of SSL cipher suites the connection can use. See the Supported ciphers section for details. Optional.
Note that the list is not validated: if a cipher suite is unknown, Tarantool just ignores it, doesn’t establish the connection and writes to the log that no shared cipher found.
ssl_password – a password for an encrypted private SSL key. Optional. Alternatively, the password
can be provided in ssl_password_file.
ssl_password_file – a text file with one or more passwords for encrypted private SSL keys
(each on a separate line). Optional. Alternatively, the password can be provided in ssl_password.
Tarantool applies the ssl_password and ssl_password_file parameters in the following order:
If ssl_password is provided, Tarantool tries to decrypt the private key with it.
If ssl_password is incorrect or isn’t provided, Tarantool tries all passwords from ssl_password_file
one by one in the order they are written.
If ssl_password and all passwords from ssl_password_file are incorrect,
or none of them is provided, Tarantool treats the private key as unencrypted.
Tarantool Enterprise supports the following cipher suites:
ECDHE-ECDSA-AES256-GCM-SHA384
ECDHE-RSA-AES256-GCM-SHA384
DHE-RSA-AES256-GCM-SHA384
ECDHE-ECDSA-CHACHA20-POLY1305
ECDHE-RSA-CHACHA20-POLY1305
DHE-RSA-CHACHA20-POLY1305
ECDHE-ECDSA-AES128-GCM-SHA256
ECDHE-RSA-AES128-GCM-SHA256
DHE-RSA-AES128-GCM-SHA256
ECDHE-ECDSA-AES256-SHA384
ECDHE-RSA-AES256-SHA384
DHE-RSA-AES256-SHA256
ECDHE-ECDSA-AES128-SHA256
ECDHE-RSA-AES128-SHA256
DHE-RSA-AES128-SHA256
ECDHE-ECDSA-AES256-SHA
ECDHE-RSA-AES256-SHA
DHE-RSA-AES256-SHA
ECDHE-ECDSA-AES128-SHA
ECDHE-RSA-AES128-SHA
DHE-RSA-AES128-SHA
AES256-GCM-SHA384
AES128-GCM-SHA256
AES256-SHA256
AES128-SHA256
AES256-SHA
AES128-SHA
GOST2012-GOST8912-GOST8912
GOST2001-GOST89-GOST89
Tarantool Enterprise static build has the embedded engine to support the GOST cryptographic algorithms.
If you use these algorithms for traffic encryption, specify the corresponding cipher suite in the ssl_ciphers parameter, for example:
When configuring the traffic encryption, you need to specify the necessary parameters on both the server side and the client side.
Below you can find the summary on the options and parameters to be used and examples of configuration.
Server side
Is configured via the box.cfg.listen option.
Mandatory URI parameters: transport, ssl_key_file and ssl_cert_file.
Optional URI parameters: ssl_ca_file, ssl_ciphers, ssl_password, and ssl_password_file.
Client side
Is configured via the box.cfg.replication option (see details) or net_box_object.connect().
Parameters:
If the server side has only the transport, ssl_key_file and ssl_cert_file parameters set,
on the client side, you need to specify only transport=ssl as the mandatory parameter.
All other URI parameters are optional.
If the server side also has the ssl_ca_file parameter set,
on the client side, you need to specify transport, ssl_key_file and ssl_cert_file as the mandatory parameters.
Other parameters – ssl_ca_file, ssl_ciphers, ssl_password, and ssl_password_file – are optional.
Configuration examples
Suppose, there is a master-replica set with two Tarantool instances:
127.0.0.1:3301 – master (server)
127.0.0.1:3302 – replica (client).
Examples below show the configuration related to connection encryption for two cases:
when the trusted certificate authorities (CA) file is not set on the server side and when it does.
Only mandatory URI parameters are mentioned in these examples.
In Tarantool, all data is stored in random-access memory (RAM) by default.
For this purpose, the memtx storage engine is used.
This topic describes how to define basic settings related to in-memory storage in the
memtx section of a YAML configuration
– for example, memory size and maximum tuple size.
For the specific settings related to allocator or sorting threads,
check the corresponding memtx options in the Configuration reference.
Note
To estimate the required amount of memory, you can use the
sizing calculator.
Memory size
In Tarantool, data is stored in spaces.
Each space consists of tuples – the database records.
To specify the amount of memory that Tarantool allocates to store tuples, use the
memtx.memory configuration option.
In the example below, the memory size is set to 1 GB (1073741824 bytes):
memtx:memory:1073741824
The server does not exceed this limit to allocate tuples.
For indexes and connection information, additional memory is used.
When the memtx.memory limit is reached, INSERT or UPDATE requests fail with
ER_MEMORY_ISSUE.
Tuple size
You can configure the minimum and the maximum tuple sizes in bytes.
If the tuples are small, you can decrease the minimum size.
If the tuples are large, you can increase the maximum size.
To ensure data persistence, Tarantool provides the abilities to:
Record each data change request into a write-ahead log (WAL) file (.xlog files).
When a power outage occurs or the Tarantool instance is killed incidentally, the in-memory database is lost.
In such case, Tarantool restores the data from WAL files by reading them and redoing the requests.
This is called the “recovery process”.
Take internals-snapshot that contain an on-disk copy of the entire data set for a given moment
(.snap files).
During the recovery process, Tarantool can load the latest snapshot file and then read the requests from the WAL files, produced after this snapshot was made.
After creating a new snapshot, the earlier WAL files can be removed to free up space.
the recording to the write-ahead log in the wal section of a YAML configuration.
To learn more about the persistence mechanism in Tarantool, see the Persistence section.
The formats of WAL and snapshot files are described in detail in the File formats section.
A new snapshot is taken once the size of all WAL files created since the last snapshot exceeds a given limit
(see snapshot.by.wal_size).
The snapshot.by.interval option sets up the checkpoint daemon
that takes a new snapshot every snapshot.by.interval seconds.
If the snapshot.by.interval option is set to zero, the checkpoint daemon is disabled.
The snapshot.by.wal_size option defines the maximum size in bytes for all WAL files created since the last snapshot taken.
Once this size is exceeded, the checkpoint daemon takes a snapshot. Then, Tarantool garbage collector
deletes the old WAL files.
The example shows how to specify the snapshot.by.interval and the snapshot.by.wal_size options:
by:interval:7200wal_size:1000000000000000000
In the example, a new snapshot is created in two cases:
every 2 hours (every 7200 seconds)
when the size for all WAL files created since the last snapshot reaches the size of 1e18 (1000000000000000000) bytes.
Specify a directory for snapshot files
To configure a directory where the snapshot files are stored, use the snapshot.dir
configuration option.
The example below shows how to specify a snapshot directory for instance001 explicitly:
By default, WAL files and snapshot files are stored in the same directory var/lib/{{instance_name}}.
However, you can specify different directories for them.
For example, you can place snapshots and write-ahead logs on different hard drives for better reliability:
You can set a limit on the number of snapshots stored in the snapshot.dir
directory using the snapshot.count option.
Once the number of snapshots reaches the given limit, Tarantool garbage collector
deletes the oldest snapshot file and any associated WAL files after the new snapshot is taken.
In the example below, the snapshot is created every two hours (every 7200 seconds) until there are three snapshots in the
snapshot.dir directory.
After creating a new snapshot (the fourth one), the oldest snapshot and the corresponding WALs are deleted.
This section describes how to define WAL settings in the wal section of a YAML configuration.
Set the WAL mode
The recording to the write-ahead log is enabled by default.
It means that if an instance restart occurs, the data will be recovered.
The recording to the WAL can be configured using the wal.mode configuration option.
There are two modes that enable writing to the WAL:
write (default) – enable WAL and write the data without waiting for the data to be flushed to the storage device.
fsync – enable WAL and ensure that the record is written to the storage device.
The example below shows how to specify the write WAL mode:
mode:'write'
To turn the WAL writer off, set the wal.mode option to none.
Specify a directory for WAL files
To configure a directory where the WAL files are stored, use the wal.dir configuration option.
The example below shows how to specify a directory for instance001 explicitly:
In case of replication or hot standby mode,
Tarantool scans for changes in the WAL files every wal.dir_rescan_delay
seconds. The example below shows how to specify the interval between scans:
dir_rescan_delay:3
Set a maximum size for the WAL file
A new WAL file is created when the current one reaches the wal.max_size
size. The configuration for this option might look as follows:
max_size:268435456
Set a delay for the garbage collector
In Tarantool, the checkpoint daemon
takes new snapshots at the given interval (see snapshot.by.interval).
After an instance restart, the Tarantool garbage collector deletes the old WAL files.
To delay the immediate deletion of WAL files, use the wal.cleanup_delay
configuration option. The delay eliminates possible erroneous situations when the master deletes WALs
needed by replicas after restart.
As a consequence, replicas sync with the master faster after its restart and
don’t need to download all the data again.
In the example, the delay is set to 5 hours (18000 seconds):
cleanup_delay:18000
Specify the WAL extensions
In Tarantool Enterprise, you can store an old and new tuple for each CRUD operation performed.
A detailed description and examples of the WAL extensions are provided in the WAL extensions section.
The checkpoint daemon (snapshot daemon) is a constantly running fiber.
The checkpoint daemon creates a schedule for the periodic snapshot creation based on
the configuration options and the speed of file size growth.
If enabled, the daemon makes new snapshot (.snap) files according to this schedule.
The work of the checkpoint daemon is based on the following configuration options:
snapshot.by.wal_size – a new snapshot is taken once the size
of all WAL files created since the last snapshot exceeds a given limit.
If necessary, the checkpoint daemon also activates the Tarantool garbage collector
that deletes old snapshots and WAL files.
Note
The memtx engine takes only regular snapshots with the interval set in
the checkpoint daemon configuration.
The vinyl engine runs checkpointing in the background at all times.
Tarantool garbage collector
Tarantool garbage collector can be activated by the checkpoint daemon.
The garbage collector tracks the snapshots that are to be relayed to a replica or needed
by other consumers. When the files are no longer needed, Tarantool garbage collector deletes them.
Note
The garbage collector called by the checkpoint daemon is distinct from the Lua garbage collector
which is for Lua objects, and distinct from the Tarantool garbage collector that specializes in handling shard buckets.
This garbage collector is called as follows:
When the number of snapshots reaches the limit of snapshot.count size.
After a new snapshot is taken, Tarantool garbage collector deletes the oldest snapshot file and any associated WAL files.
When the size of all WAL files created since the last snapshot reaches the limit of snapshot.by.wal_size.
Once this size is exceeded, the checkpoint daemon takes a snapshot, then the garbage collector deletes the old WAL files.
If an old snapshot file is deleted, the Tarantool garbage collector also deletes
any write-ahead log (.xlog) files that meet the following conditions:
The WAL files are older than the snapshot file.
The WAL files contain information present in the snapshot file.
Tarantool garbage collector also deletes obsolete vinyl .run files.
Tarantool garbage collector doesn’t delete a file in the following cases:
A backup is running, and the file has not been backed up
(see Hot backup).
Replication is running, and the file has not been relayed to a replica
(see Replication architecture),
A replica is connecting.
A replica has fallen behind.
The progress of each replica is tracked; if a replica’s position is far
from being up to date, then the server stops to give it a chance to catch up.
If an administrator concludes that a replica is permanently down, then the
correct procedure is to restart the server, or (preferably) remove the replica from the cluster.
WAL extensions allow you to add auxiliary information to each write-ahead log record.
For example, you can enable storing an old and new tuple for each CRUD operation performed.
This information might be helpful for implementing a CDC (Change Data Capture) utility
that transforms a data replication stream.
WAL extensions are disabled by default.
To configure them, use the wal.ext.* configuration options.
Inside the wal.ext block, you can enable storing old and new tuples as follows:
To store old and new tuples in a write-ahead log for all spaces, set the
wal.ext.old and wal.ext.new
options to true:
ext:new:trueold:true
To adjust these options for specific spaces, specify the wal.ext.spaces option:
The configuration for specific spaces has priority over the configuration in the wal.ext.new and wal.ext.old
options.
It means that only new tuples are added to the log for space1 and only old tuples for space2.
Note that records with additional fields are replicated as follows:
If a replica doesn’t support the extended format configured on a master, auxiliary fields are skipped.
If a replica and master have different configurations for WAL records, the master’s configuration is ignored.
Example
The table below demonstrates how write-ahead log records might look
for the specific CRUD operations
if storing old and new tuples is enabled for the bands space.
Tarantool stores data in spaces, which can be thought of as tables in a relational database.
Every record or row in a space is called a tuple.
A tuple may have any number of fields, and the fields may be of different types.
String data in fields are compared based on the specified collation rules.
The user can provide hard limits for data values through constraints
and link related spaces with foreign keys.
Tarantool supports highly customizable indexes of various types.
In particular, indexes can be defined with generators like sequences.
There are six basic data operations in Tarantool:
SELECT, INSERT, UPDATE, UPSERT, REPLACE, and DELETE. A number of complexity factors
affects the resource usage of each function.
A tuple is a group of data values in Tarantool’s memory.
Think of it as a “database record” or a “row”.
The data values in the tuple are called fields.
When Tarantool returns a tuple value in the console,
by default, it uses YAML format,
for example: [3,'AceofBase',1993].
Internally, Tarantool stores tuples as
MsgPack arrays.
field
Fields are distinct data values, contained in a tuple.
They play the same role as “row columns” or “record fields” in relational databases,
with a few improvements:
fields can be composite structures, such as arrays or maps,
fields don’t need to have names.
A given tuple may have any number of fields, and the fields may be of
different types.
The field’s number is the identifier of the field.
Numbers are counted from base 1 in Lua and other 1-based languages,
or from base 0 in languages like PHP or C/C++.
So, 1 or 0 can be used in some contexts to refer to the first
field of a tuple.
Spaces
Tarantool stores tuples in containers called spaces.
space
In Tarantool, a space is a primary container that stores data.
It is analogous to tables in relational databases.
Spaces contain tuples – the Tarantool name for
database records.
The number of tuples in a space is unlimited.
At least one space is required to store data with Tarantool.
Each space has the following attributes:
a unique name specified by the user,
a unique numeric identifier which can be specified by
the user, but usually is assigned automatically by Tarantool,
an engine: memtx (default) — in-memory engine,
fast but limited in size, or vinyl — on-disk engine for huge data sets.
To be functional, a space also needs to have a primary index.
It can also have secondary indexes.
Data types
Tarantool is both a database manager and an application server.
Therefore a developer often deals with two type sets:
the types of the programming language (such as Lua) and
the types of the Tarantool storage format (MsgPack).
MsgPack values have variable lengths.
So, for example, the smallest number requires only one byte, but the largest number
requires nine bytes.
Note
The Lua nil type is encoded as MsgPack nil but
decoded as msgpack.NULL.
Field type details
nil
In Lua, the nil type has only one possible value, also called nil.
Tarantool displays it as null when using the default
YAML format.
Nil may be compared to values of any types with == (is-equal)
or ~= (is-not-equal), but other comparison operations will not work.
Nil may not be used in Lua tables; the workaround is to use
box.NULL because nil==box.NULL is true.
Example:nil.
boolean
A boolean is either true or false.
Example:true.
integer
The Tarantool integer type is for integers between
-9223372036854775808 and 18446744073709551615, which is about 18 quintillion.
This type corresponds to the number type in Lua and to the integer type in MsgPack.
Example:-2^63.
unsigned
The Tarantool unsigned type is for integers between
0 and 18446744073709551615. So it is a subset of integer.
Example:123456.
double
The double field type exists
mainly to be equivalent to Tarantool/SQL’s
DOUBLE data type.
In msgpuck.h (Tarantool’s interface to MsgPack),
the storage type is MP_DOUBLE and the size of the encoded value is always 9 bytes.
In Lua, fields of the double type can only contain non-integer numeric values and
cdata values with double floating-point numbers.
Examples:1.234, -44, 1.447e+44.
To avoid using the wrong kind of values inadvertently, use
ffi.cast() when searching or changing double fields.
For example, instead of
space_object:insert{value}
use
ffi=require('ffi')...space_object:insert({ffi.cast('double',value)}).
Arithmetic with cdata double will not work reliably, so
for Lua, it is better to use the number type.
This warning does not apply for Tarantool/SQL because
Tarantool/SQL does
implicit casting.
number
The Tarantool number field may have both
integer and floating-point values, although in Lua a number
is a double-precision floating-point.
Tarantool will try to store a Lua number as
floating-point if the value contains a decimal point or is very large
(greater than 100 trillion = 1e14), otherwise Tarantool will store it as an integer.
To ensure that even very large numbers are stored as integers, use the
tonumber64 function, or the LL (Long Long) suffix,
or the ULL (Unsigned Long Long) suffix.
Here are examples of numbers using regular notation, exponential notation,
the ULL suffix and the tonumber64 function:
-55, -2.7e+20, 100000000000000ULL, tonumber64('18446744073709551615').
You can also use the ffi module to specify a C type to cast the number to.
In this case, the number will be stored as cdata.
decimal
The Tarantool decimal type is stored as a MsgPack ext (Extension).
Values with the decimal type are not floating-point values although
they may contain decimal points.
They are exact with up to 38 digits of precision.
Example: a value returned by a function in the decimal module.
datetime
Introduced in v. 2.10.0.
The Tarantool datetime type facilitates operations with date and time,
accounting for leap years or the varying number of days in a month.
It is stored as a MsgPack ext (Extension).
Operations with this data type use code from c-dt, a third-party library.
The Tarantool interval type represents periods of time.
They can be added to or subtracted from datetime values or each other.
Operations with this data type use code from c-dt, a third-party library.
The type is stored as a MsgPack ext (Extension).
For more information, see Module datetime.
string
A string is a variable-length sequence of bytes, usually represented with
alphanumeric characters inside single quotes. In both Lua and MsgPack, strings
are treated as binary data, with no attempts to determine a string’s
character set or to perform any string conversion – unless there is an optional
collation.
So, usually, string sorting and comparison are done byte-by-byte, without any special
collation rules applied.
For example, numbers are ordered by their point on the number line, so 2345 is
greater than 500; meanwhile, strings are ordered by the encoding of the first
byte, then the encoding of the second byte, and so on, so '2345' is less than '500'.
Example:'A,B,C'.
bin
A bin (binary) value is not directly supported by Lua but there is
a Tarantool type varbinary. See the varbinary module reference
for details.
An array is represented in Lua with {...} (braces).
Examples: lists of numbers representing points in geometric figures:
{10,11}, {3,5,9,10}.
table
Lua tables with string keys are stored as MsgPack maps;
Lua tables with integer keys starting with 1 are stored as MsgPack arrays.
Nils may not be used in Lua tables; the workaround is to use
box.NULL.
Example: a box.space.tester:select() request will return a Lua table.
tuple
A tuple is a light reference to a MsgPack array stored in the database.
It is a special type (cdata) to avoid conversion to a Lua table on retrieval.
A few functions may return tables with multiple tuples. For tuple examples,
see box.tuple.
scalar
Values in a scalar field can be boolean, integer, unsigned, double,
number, decimal, string, uuid, or varbinary; but not array, map, or tuple.
Examples:true, 1, 'xxx'.
any
Values in a field of this type can be boolean, integer, unsigned, double,
number, decimal, string, uuid, varbinary, array, map, or tuple.
Examples:true, 1, 'xxx', {box.NULL,0}.
Examples
Examples of insert requests with different field types:
tarantool> box.space.K:insert{1,nil,true,'A B C',12345,1.2345}----[1,null,true,'ABC',12345,1.2345]...tarantool> box.space.K:insert{2,{['a']=5,['b']=6}}----[2,{'a':5,'b':6}]...tarantool> box.space.K:insert{3,{1,2,3,4,5}}----[3,[1,2,3,4,5]]...
Indexed field types
To learn more about what values can be stored in indexed fields, read the
Indexes section.
Collations
By default, when Tarantool compares strings, it uses the so-called
binary collation.
It only considers the numeric value of each byte in a string.
For example, the encoding of 'A' (what used to be called the “ASCII value”) is 65,
the encoding of 'B' is 66, and the encoding of 'a' is 98.
Therefore, if the string is encoded with ASCII or UTF-8, then 'A'<'B'<'a'.
Binary collation is the best choice for fast deterministic simple maintenance and searching
with Tarantool indexes.
But if you want the ordering that you see in phone books and dictionaries,
then you need Tarantool’s optional collations, such as unicode and
unicode_ci, which allow for 'a'<'A'<'B' and 'a'=='A'<'B'
respectively.
In all, collation involves much more than these simple examples of
upper case / lower case and accented / unaccented equivalence in alphabets.
We also consider variations of the same character, non-alphabetic writing systems,
and special rules that apply for combinations of characters.
For English, Russian, and most other languages and use cases, use the “unicode” and “unicode_ci” collations.
If you need Cyrillic letters ‘Е’ and ‘Ё’ to have the same level-1 weights,
try the Kyrgyz collation.
The tailored optional collations: for other languages, Tarantool supplies tailored collations for every
modern language that has more than a million native speakers, and
for specialized situations such as the difference between dictionary
order and telephone book order.
Run box.space._collation:select() to see the complete list.
The tailored collation names have the form
unicode_[languagecode]_[strength], where language code is a standard
2-character or 3-character language abbreviation, and strength is s1
for “primary strength” (level-1 weights), s2 for “secondary”, s3 for “tertiary”.
Tarantool uses the same language codes as the ones in the “list of tailorable locales” on man pages of
Ubuntu and
Fedora.
Charts explaining the precise differences from DUCET order are
in the
Common Language Data Repository.
Default values
Default values are assigned to tuple fields automatically if these fields are
skipped during the tuple insert or update.
You can specify a default value for a field in the space_object:format()
call that defines the space format. Default values apply regardless of the field nullability:
any tuple in which the field is skipped or set to nil receives
the default value.
Default values can be set in two ways: explicitly or using a function.
Explicit default values
Explicit default values are defined in the default parameter of the field declaration
in a space_object:format() call.
To use a default value for a field, skip it or assign nil:
books:insert{1,'Thinking in Java'}books:insert{2,'How to code in Go',nil}
Any Lua object that can be evaluated during the space_object.format() call
may be used as a default value, for example:
a constant: default=100
an initialized variable: default=default_size
an expression: default=10+default_size
a function return value: default=count_default()
Important
Explicit default values are evaluated only when setting the space format.
If you use a variable as a default value, its further assignments do not affect the default value.
To change the default values, call space_object:format() again.
A default value can be defined as a return value of a stored Lua function. To be
the default, a function must be created with box.schema.func.create()
with the function body and return one value of the field’s type. It also must not yield.
Default functions are set in the default_func parameter of the field declaration
in a space_object:format() call. To make a function with no arguments the default
for a field, specify its name:
A key difference between a default function (default_func='count_default')
and a function return value used as a field default value (default=count_default())
is the following:
A default function is called every time a default value must be produced,
that is, a tuple is inserted or updated without specifying the field.
A return value used a field default value: the function is called once
when setting the space format. Then, all tuples receive the result of
this exact call if the field is not specified.
For better control over stored data, Tarantool supports constraints – user-defined
limitations on the values of certain fields or entire tuples. Together with data types,
constraints allow limiting the ranges of available field values both syntactically and semantically.
For example, the field age typically has the number type, so it cannot store
strings or boolean values. However, it can still have values that don’t make sense,
such as negative numbers. This is where constraints come to help.
Constraint types
There are two types of constraints in Tarantool:
Field constraints check that the value being assigned to a field
satisfies a given condition. For example, age must be non-negative.
Tuple constraints check complex conditions that can involve all fields of
a tuple. For example, a tuple contains a date in three fields:
year, month, and day. You can validate day values based on
the month value (and even year if you consider leap years).
Field constraints work faster, while tuple constraints allow implementing
a wider range of limitations.
Constraint functions
Constraints use stored Lua functions or SQL expressions, which must return true when the constraint
is satisfied. Other return values (including nil) and exceptions make the
check fail and prevent tuple insertion or modification.
To create a constraint function, call box.schema.func.create() with the function definition specified in the body attribute.
Constraint functions take two parameters:
The tuple and the constraint name for tuple constraints.
-- Define a tuple constraint function --box.schema.func.create('check_person',{language='LUA',is_deterministic=true,body='function(t, c) return (t.age >= 0 and #(t.name) > 3) end'})
Warning
Tarantool doesn’t check field names used in tuple constraint functions.
If a field referenced in a tuple constraint gets renamed, this constraint will break
and prevent further insertions and modifications in the space.
The field value and the constraint name for field constraints.
-- Define a field constraint function --box.schema.func.create('check_age',{language='LUA',is_deterministic=true,body='function(f, c) return (f >= 0 and f < 150) end'})
Creating constraints
To create a constraint in a space, specify the corresponding function’s name
in the constraint parameter:
Tuple constraints: when creating or altering a space.
-- Create a space with a tuple constraint --customers=box.schema.space.create('customers',{constraint='check_person'})
Field constraints: when setting up the space format.
-- Specify format with a field constraint --box.space.customers:format({{name='id',type='number'},{name='name',type='string'},{name='age',type='number',constraint='check_age'},})
In both cases, constraint can contain multiple function names passed as a tuple.
Each constraint can have an optional name:
-- Create one more tuple constraint --box.schema.func.create('another_constraint',{language='LUA',is_deterministic=true,body='function(t, c) return true end'})-- Set two constraints with optional names --box.space.customers:alter{constraint={check1='check_person',check2='another_constraint'}}
Note
When adding a constraint to an existing space with data, Tarantool checks it
against the stored data. If there are fields or tuples that don’t satisfy
the constraint, it won’t be applied to the space.
Foreign keys
Foreign keys provide links between related fields, therefore maintaining the
referential integrity
of the database.
Fields can contain values that exist only in other fields. For example,
a shop order always belongs to a customer. Hence, all values of the customer
field of the orders space must also exist in the id field of the customers
space. In this case, customers is a parent space for orders (its child space).
When two spaces are linked with a foreign key, each time a tuple is inserted or
modified in the child space, Tarantool checks that a corresponding value is present
in the parent space.
Note
A foreign key can link a field to another field in the same space. In this case,
the child field must be nullable. Otherwise, it is impossible to insert
the first tuple in such a space because there is no parent tuple to which
it can link.
Foreign key types
There are two types of foreign keys in Tarantool:
Field foreign keys check that the value being assigned to a field
is present in a particular field of another space. For example, the customer
value in a tuple from the orders space must match an id stored in the customers space.
Tuple foreign keys check that multiple fields of a tuple have a match in
another space. For example, if the orders space has fields customer_id
and customer_name, a tuple foreign key can check that the customers space
contains a tuple with both these values in the corresponding fields.
Field foreign keys work faster while tuple foreign keys allow implementing
more strict references.
Creating foreign keys
Important
For each foreign key, there must exist a parent space index that includes
all its fields.
To create a foreign key in a space, specify the parent space and linked fields in the foreign_key parameter.
Parent spaces can be referenced by name or by id. When linking to the same space, the space can be omitted.
Fields can be referenced by name or by number:
Field foreign keys: when setting up the space format.
-- Create a space with a field foreign key --box.schema.space.create('orders')box.space.orders:format({{name='id',type='number'},{name='customer_id',foreign_key={space='customers',field='id'}},{name='price_total',type='number'},})
Tuple foreign keys: when creating or altering a space. Note that for foreign
keys with multiple fields there must exist an index that includes all these fields.
-- Create a space with a tuple foreign key --box.schema.space.create("orders",{foreign_key={space='customers',field={customer_id='id',customer_name='name'}}})box.space.orders:format({{name="id",type="number"},{name="customer_id"},{name="customer_name"},{name="price_total",type="number"},})
Note
Type can be omitted for foreign key fields because it’s
defined in the parent space.
Foreign keys can have an optional name.
-- Set a foreign key with an optional name --box.space.orders:alter{foreign_key={customer={space='customers',field={customer_id='id',customer_name='name'}}}}
A space can have multiple tuple foreign keys. In this case, they all must have names.
-- Set two foreign keys: names are mandatory --box.space.orders:alter{foreign_key={customer={space='customers',field={customer_id='id',customer_name='name'}},item={space='items',field={item_id='id'}}}}
Tarantool performs integrity checks upon data modifications in parent spaces.
If you try to remove a tuple referenced by a foreign key or an entire parent space,
you will get an error.
Important
Renaming parent spaces or referenced fields may break the corresponding foreign
keys and prevent further insertions or modifications in the child spaces.
Indexes
Basics
An index is a special data structure that stores a group of key values and
pointers. It is used for efficient manipulations with data.
As with spaces, you should specify the index name and let Tarantool
come up with a unique numeric identifier (“index id”).
An index always has a type. The default index type is TREE.
TREE indexes are provided by all Tarantool engines, can index unique and
non-unique values, support partial key searches, comparisons, and ordered results.
Additionally, the memtx engine supports HASH,
RTREE and BITSET indexes.
An index may be multi-part, that is, you can declare that an index key value
is composed of two or more fields in the tuple, in any order.
For example, for an ordinary TREE index, the maximum number of parts is 255.
An index may be unique, that is, you can declare that it would be illegal
to have the same key value twice.
The first index defined on a space is called the primary key index,
and it must be unique. All other indexes are called secondary indexes,
and they may be non-unique.
Indexes have certain limitations. See details on page Limitations.
To create a generator for indexes, you can use a sequence object.
Learn how to do it in the tutorial.
Indexed field types
Not to be confused with index types – the types of the data structure that is an index.
See more about index types below.
Indexes restrict values that Tarantool can store with MsgPack.
This is why, for example, 'unsigned' and 'integer' are different field types,
although in MsgPack they are both stored as integer values.
An 'unsigned' index contains only non-negative integer values,
while an ‘integer’ index contains any integer values.
The default field type is 'unsigned' and the default index type is TREE.
Although 'nil' is not a legal indexed field type, indexes may contain nilas a non-default option.
may include nil,
boolean,
integer,
unsigned,
number,
decimal,
string,
varbinary,
or uuid values |
When a scalar field contains values of
different underlying types, the key order
is: nils, then booleans, then numbers,
then strings, then varbinaries, then
uuids.
TREE or HASH
Index types
An index always has a type. Different types are intended for different
usage scenarios.
We give an overview of index features in the following table:
ALL, EQ, BITS_ALL_SET, BITS_ANY_SET, BITS_ALL_NOT_SET
Note
In 2.11.0, the GT index type is deprecated for HASH indexes.
TREE indexes
The default index type is ‘TREE’.
TREE indexes are provided by memtx and vinyl engines, can index unique and
non-unique values, support partial key searches, comparisons and ordered results.
This is a universal type of indexes, for most cases it will be the best choice.
Additionally, memtx engine supports HASH, RTREE and BITSET indexes.
HASH indexes
HASH indexes require unique fields and loses to TREE in almost all respects.
So we do not recommend to use it in the applications.
HASH is now present in Tarantool mainly because of backward compatibility.
Here are some tips. Do not use HASH index:
just if you want to
if you think that HASH is faster with no performance metering
if you want to iterate over the data
for primary key
as an only index
Use HASH index:
if it is a secondary key
if you 100% won’t need to make it non-unique
if you have taken measurements on your data and you see an accountable
increase in performance
if you save every byte on tuples (HASH is a little more compact)
RTREE indexes
RTREE is a multidimensional index supporting up to 20 dimensions.
It is used especially for indexing spatial information, such as geographical
objects. In this example we demonstrate spatial searches
via RTREE index.
RTREE index could not be primary, and could not be unique.
The option list of this type of index may contain dimension and distance options.
The parts definition must contain the one and only part with type array.
RTREE index can accept two types of distance functions: euclid and manhattan.
Warning
Currently, the isolation level of RTREE indexes
in MVCC transaction mode is read-committed (not serializable, as stated).
If a transaction uses these indexes, it can read committed or confirmed data (depending on the isolation level).
However, the indexes are subject to different anomalies that can make them unserializable.
Corresponding tuple field thus must be an array of 2 or 4 numbers.
2 numbers mean a point {x, y};
4 numbers mean a rectangle {x1, y1, x2, y2},
where (x1, y1) and (x2, y2) - diagonal point of the rectangle.
Selection results depend on a chosen iterator.
The default EQ iterator searches for an exact rectangle,
a point is treated as zero width and height rectangle:
3D, 4D and more dimensional RTREE indexes work in the same way as 2D except
that user must specify more coordinates in requests.
Here’s short example of using 4D tree:
Keep in mind that select NEIGHBOR iterator with unset limits extracts
the entire space in order of increasing distance. And there can be
tons of data, and this can affect the performance.
And another frequent mistake is to specify iterator type without quotes,
in such way: rtree_index:select(rect,{iterator=LE}).
This leads to silent EQ select, because LE is undefined variable and
treated as nil, so iterator is unset and default used.
BITSET indexes
Bitset is a bit mask. You should use it when you need to search by bit masks.
This can be, for example, storing a vector of attributes and searching by these
attributes.
Warning
Currently, the isolation level of BITSET indexes
in MVCC transaction mode is read-committed (not serializable, as stated).
If a transaction uses these indexes, it can read committed or confirmed data (depending on the isolation level).
However, the indexes are subject to different anomalies that can make them unserializable.
Example 1:
The following script shows creating and searching with a BITSET index.
Notice that BITSET cannot be unique, so first a primary-key index is created,
and bit values are entered as hexadecimal literals for easier reading.
tarantool> my_space=box.schema.space.create('space_with_bitset')tarantool> my_space:create_index('primary_index',{ > parts={1,'string'}, > unique=true, > type='TREE' > })tarantool> my_space:create_index('bitset_index',{ > parts={2,'unsigned'}, > unique=false, > type='BITSET' > })tarantool> my_space:insert{'Tuple with bit value = 01',0x01}tarantool> my_space:insert{'Tuple with bit value = 10',0x02}tarantool> my_space:insert{'Tuple with bit value = 11',0x03}tarantool> my_space.index.bitset_index:select(0x02,{ > iterator=box.index.EQ > })-----['Tuplewithbitvalue=10',2]...tarantool> my_space.index.bitset_index:select(0x02,{ > iterator=box.index.BITS_ANY_SET > })-----['Tuplewithbitvalue=10',2]-['Tuplewithbitvalue=11',3]...tarantool> my_space.index.bitset_index:select(0x02,{ > iterator=box.index.BITS_ALL_SET > })-----['Tuplewithbitvalue=10',2]-['Tuplewithbitvalue=11',3]...tarantool> my_space.index.bitset_index:select(0x02,{ > iterator=box.index.BITS_ALL_NOT_SET > })-----['Tuplewithbitvalue=01',1]...
because (7 AND 2) is not equal to 0, and (3 AND 2) is not equal to 0.
Additionally, there exist
index iterator operations.
They can only be used with code in Lua and C/C++. Index iterators are for
traversing indexes one key at a time, taking advantage of features that are
specific to an index type.
For example, they can be used for evaluating Boolean expressions when
traversing BITSET indexes, or for going in descending order when traversing TREE
indexes.
Using indexes
Creating an index
It is mandatory to create an index for a space before trying to insert
tuples into the space, or select tuples from the space.
This creates a unique TREE index on the first field
of all tuples (often called “Field#1”), which is assumed to be numeric.
A recommended design pattern for a data model is to base primary keys on the
first fields of a tuple. This speeds up tuple comparison due to the specifics of
data storage and the way comparisons are arranged in Tarantool.
This looks for a single tuple via the first index. Since the first index
is always unique, the maximum number of returned tuples will be 1.
You can call select() without arguments, and it will return all tuples.
Be careful! Using select() for huge spaces hangs your instance.
An index definition may also include identifiers of tuple fields
and their expected types. See allowed indexed field types in section
Details about indexed field types:
Space definitions and index definitions are stored permanently in Tarantool’s
system spaces _space and _index.
Tip
See full information about creating indexes, such as
how to create a multikey index, an index using the path option, or
how to create a functional index in our reference for
space_object:create_index().
Index operations
Index operations are automatic: if a data manipulation request changes a tuple,
then it also changes the index keys defined for the tuple.
Create a sample space named bands:
bands=box.schema.space.create('bands')
Format the created space by specifying field names and types:
box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}box.space.bands:insert{5,'Pink Floyd',1965}box.space.bands:insert{6,'The Rolling Stones',1962}box.space.bands:insert{7,'The Doors',1965}box.space.bands:insert{8,'Nirvana',1987}box.space.bands:insert{9,'Led Zeppelin',1968}box.space.bands:insert{10,'Queen',1970}
Create secondary indexes:
-- Create a unique secondary index --box.space.bands:create_index('band',{parts={'band_name'}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{'year'}},unique=false})
Value comparisons make sense if and only if the index type is TREE.
The iterator types for other types of indexes are slightly different and work
differently. See details in section Iterator types.
Note that we don’t use the name of the index, which means we use primary index here.
This type of search may return more than one tuple. The tuples will be sorted
in descending order by key if the comparison operator is LT or LE or REQ.
Otherwise they will be sorted in ascending order.
The search can use a secondary index.
-- Select a tuple by the specified secondary key value --select_secondary=bands.index.band:select{'The Doors'}--[[---- - [7, 'The Doors', 1965]...--]]
Partial key search: The search may be for some key parts starting with
the prefix of the key. Note that partial key searches are available
only in TREE indexes.
-- Select tuples by the specified partial key value --select_multipart_partial=bands.index.year_band:select{1965}--[[---- - [5, 'Pink Floyd', 1965] - [2, 'Scorpions', 1965] - [7, 'The Doors', 1965]...--]]
The search can be for all fields, using a table as the value:
-- Select a tuple by the specified multi-part secondary key value --select_multipart=bands.index.year_band:select{1960,'The Beatles'}--[[---- - [4, 'The Beatles', 1960]...--]]
Tip
You can also add, drop, or alter the definitions at runtime, with some
restrictions. Read more about index operations in reference for
box.index submodule.
Tuple compression, introduced in Tarantool Enterprise Edition 2.10.0, aims to save memory space.
Typically, it decreases the volume of stored data by 15%.
However, the exact volume saved depends on the type of data.
The following compression algorithms are supported:
Tarantool doesn’t compress tuples themselves, just the fields inside these tuples.
You can only compress non-indexed fields.
Compression works best when JSON is stored in the field.
Note
The compress module provides the API for compressing and decompressing data.
Enabling compression for a new space
First, create a space:
box.schema.space.create('bands')
Then, create an index for this space, for example:
Create a format to declare field names and types.
In the example below, the band_name and year fields have the zstd and lz4 compression formats, respectively.
The first field (id) has the index, so it cannot be compressed.
Now, the new tuples that you add to the space bands will be compressed.
When you read a compressed tuple, you do not need to decompress it back yourself.
Checking which fields are compressed
To check which fields in a space are compressed, run
space_object:format() on the space.
If a field is compressed, the format includes the compression algorithm, for example:
You can enable compression for existing fields.
All the tuples added after that will have this field compressed.
However, this doesn’t affect the tuples already stored in the space.
You need to make the snapshot and restart Tarantool to compress the existing tuples.
Here’s an example of how to compress existing fields:
Create a space without compression and add several tuples:
box.schema.space.create('bands')box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})box.space.bands:create_index('primary',{parts={'id'}})box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}
Suppose that you want fields 2 and 3 to be compressed from now on.
To enable compression, change the format as follows:
From now on, all the tuples that you add to the space have fields 2 and 3 compressed.
To finalize the change, create a snapshot by running
box.snapshot() and restart Tarantool.
As a result, all old tuples will also be compressed in memory during recovery.
Note
space:upgrade() provides the ability to enable compression
and update the existing tuples in the background.
To achieve this, you need to pass a new space format in the format argument of space:upgrade().
Tuple compression performance
Below are the results of a synthetic test that illustrate how tuple compression affects performance.
The test was carried out on a simple Tarantool space containing 100,000 tuples,
each having a field with a sample JSON roughly 600 bytes large.
The test compared the speed of running select and replace operations on uncompressed and compressed data
as well as the overall data size of the space.
Performance is measured in requests per second.
Compression type
select, RPS
replace, RPS
Space size, bytes
None
4,486k
1,109k
41,168,548
zstd
308k
26k
21,368,548
lz4
1,765k
672k
25,268,548
zlib
325k
107k
20,768,548
Data schema description
In Tarantool, the use of a data schema is optional.
When creating a space, you do not have to define a data schema. In this case,
the tuples store random data. This rule does not apply to indexed fields.
Such fields must contain data of the same type.
You can define a data schema when creating a space. Read more in the description of the
box.schema.space.create() function.
If you have already created a space without specifying a data schema, you can do it later using
space_object:format().
After the data schema is defined, all the data is validated by type. Before any insert or update,
you will get an error if the data types do not match.
We recommend using a data schema because it helps avoid mistakes.
In Tarantool, you can define a data schema in two different ways.
Data schema description in a code file
The code file is usually called init.lua and contains the following schema description:
This is quite simple: when you run tarantool, it executes this code and creates
a data schema. To run this file, use:
tarantoolinit.lua
However, it may seem complicated if you do not plan to dive deep into the Lua language and its syntax.
Possible difficulty: the snippet above has a function call with a colon: users:format.
It is used to pass the users variable as the first argument
of the format function.
This is similar to self in object-based languages.
So it might be more convenient for you to describe the data schema with YAML.
Data schema description using the DDL module
The DDL module allows you to describe a data schema
in the YAML format in a declarative way.
It is forbidden to modify the data schema in DDL after it has been applied.
For migration, there are different scenarios described in the Migrations section.
Operations
Data operations
The basic data operations supported in Tarantool are:
five data-manipulation operations (INSERT, UPDATE, UPSERT, DELETE, REPLACE), and
one data-retrieval operation (SELECT).
All of them are implemented as functions in box.space submodule.
The first field, field[1], will be 999 (MsgPack type is integer).
The second field, field[2], will be ‘Taranto’ (MsgPack type is string).
tarantool> box.space.tester:insert{999,'Taranto'}
UPDATE: Update the tuple, changing field field[2].
The clause “{999}”, which has the value to look up in the index of the tuple’s
primary-key field, is mandatory, because update() requests must always have
a clause that specifies a unique key, which in this case is field[1].
The clause “{{‘=’, 2, ‘Tarantino’}}” specifies that assignment will happen to
field[2] with the new value.
UPSERT: Upsert the tuple, changing field field[2]
again.
The syntax of upsert() is similar to the syntax of update(). However,
the execution logic of these two requests is different.
UPSERT is either UPDATE or INSERT, depending on the database’s state.
Also, UPSERT execution is postponed until after transaction commit, so, unlike
update(), upsert() doesn’t return data back.
In reference for box.space and
Submodule box.index
submodules, there are notes about which complexity factors might affect the
resource usage of each function.
Complexity factor
Effect
Index size
The number of index keys is the same as the number
of tuples in the data set. For a TREE index, if
there are more keys, then the lookup time will be
greater, although, of course, the effect is not
linear. For a HASH index, if there are more keys,
then there is more RAM used, but the number of
low-level steps tends to remain constant.
Index type
Typically, a HASH index is faster than a TREE index
if the number of tuples in the space is greater
than one.
Number of indexes accessed
Ordinarily, only one index is accessed to retrieve
one tuple. But to update the tuple, there must be N
accesses if the space has N different indexes.
Note regarding storage engine: Vinyl optimizes away such
accesses if secondary index fields are unchanged by
the update. So, this complexity factor applies only to
memtx, since it always makes a full-tuple copy on every
update.
Number of tuples accessed
A few requests, for example, SELECT, can retrieve
multiple tuples. This factor is usually less
important than the others.
WAL settings
The important setting for the write-ahead log is
wal.mode.
If the setting causes no writing or
delayed writing, this factor is unimportant. If the
setting causes every data-change request to wait
for writing to finish on a slow device, this factor
is more important than all the others.
CRUD operation examples
Using data operations
This section shows basic usage scenarios and typical errors for each
data operation in Tarantool:
INSERT,
DELETE,
UPDATE,
UPSERT,
REPLACE, and
SELECT.
Before trying out the examples, you need to bootstrap a Tarantool instance as shown below.
-- Create a space --bands=box.schema.space.create('bands')-- Specify field names and types --box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})-- Create a primary index --box.space.bands:create_index('primary',{parts={'id'}})-- Create a unique secondary index --box.space.bands:create_index('band',{parts={'band_name'}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{'year'}},unique=false})-- Create a multi-part index --box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})
-- Insert a tuple with a unique primary key --tarantool> bands:insert{1,'Scorpions',1965}----[1,'Scorpions',1965]...
insert also checks all the keys for duplicates.
-- Try to insert a tuple with a duplicate primary key --tarantool> bands:insert{1,'Scorpions',1965}----error:Duplicate key exists in unique index "primary" in space "bands" with oldtuple - [1, "Scorpions", 1965] and new tuple - [1, "Scorpions", 1965]...-- Try to insert a tuple with a duplicate secondary key --tarantool> bands:insert{2,'Scorpions',1965}----error:Duplicate key exists in unique index "band" in space "bands" with old tuple- [1, "Scorpions", 1965] and new tuple - [2, "Scorpions", 1965]...-- Insert a second tuple with unique primary and secondary keys --tarantool> bands:insert{2,'Pink Floyd',1965}----[2,'PinkFloyd',1965]...-- Delete all tuples --tarantool> bands:truncate()---...
DELETE
space_object.delete allows you to delete a tuple identified by the primary key.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960}-- Delete a tuple with an existing key --tarantool> bands:delete{4}----[4,'TheBeatles',1960]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'Scorpions',1965]-[3,'AceofBase',1987]...
You can also use index_object.delete to delete a tuple by the specified unique index.
-- Delete a tuple by the primary index --tarantool> bands.index.primary:delete{3}----[3,'AceofBase',1987]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'Scorpions',1965]...-- Delete a tuple by a unique secondary index --tarantool> bands.index.band:delete{'Scorpions'}----[2,'Scorpions',1965]...tarantool> bands:select()-----[1,'Roxette',1986]...-- Try to delete a tuple by a non-unique secondary index --tarantool> bands.index.year:delete(1986)----error:Get() doesn't support partial keys and non-unique indexes...tarantool> bands:select()-----[1,'Roxette',1986]...-- Try to delete a tuple by a partial key --tarantool> bands.index.year_band:delete('Roxette')----error:Invalid key part count in an exact match (expected 2, got 1)...-- Delete a tuple by a full key --tarantool> bands.index.year_band:delete{1986,'Roxette'}----[1,'Roxette',1986]...tarantool> bands:select()----[]...-- Delete all tuples --tarantool> bands:truncate()---...
UPDATE
space_object.update allows you to update a tuple identified by the primary key.
Similarly to delete, the update method accepts a full key and also an operation to execute.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960}-- Update a tuple with an existing key --tarantool> bands:update({2},{{'=',2,'Pink Floyd'}})----[2,'PinkFloyd',1965]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'PinkFloyd',1965]-[3,'AceofBase',1987]-[4,'TheBeatles',1960]...
index_object.update updates a tuple identified by the specified unique index.
-- Update a tuple by the primary index --tarantool> bands.index.primary:update({2},{{'=',2,'The Rolling Stones'}})----[2,'TheRollingStones',1965]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'TheRollingStones',1965]-[3,'AceofBase',1987]-[4,'TheBeatles',1960]...-- Update a tuple by a unique secondary index --tarantool> bands.index.band:update({'The Rolling Stones'},{{'=',2,'The Doors'}})----[2,'TheDoors',1965]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'TheDoors',1965]-[3,'AceofBase',1987]-[4,'TheBeatles',1960]...-- Try to update a tuple by a non-unique secondary index --tarantool> bands.index.year:update({1965},{{'=',2,'Scorpions'}})----error:Get() doesn't support partial keys and non-unique indexes...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'TheDoors',1965]-[3,'AceofBase',1987]-[4,'TheBeatles',1960]...-- Delete all tuples --tarantool> bands:truncate()---...
If the existing tuple is found by the primary key,
Tarantool applies the update operation to this tuple
and ignores the new tuple.
If no existing tuple is found,
Tarantool inserts the new tuple and ignores the update operation.
tarantool> bands:insert{1,'Scorpions',1965}----[1,'Scorpions',1965]...-- As the first argument, upsert accepts a tuple, not a key --tarantool> bands:upsert({2},{{'=',2,'Pink Floyd'}})----error:Tuple field 2 (band_name) required by space format is missing...tarantool> bands:select()-----[1,'Scorpions',1965]...tarantool> bands:delete(1)----[1,'Scorpions',1965]...
upsert acts as insert when no existing tuple is found by the primary key.
tarantool> bands:upsert({1,'Scorpions',1965},{{'=',2,'The Doors'}})---...-- As you can see, {1, 'Scorpions', 1965} is inserted, ---- and the update operation is not applied. --tarantool> bands:select()-----[1,'Scorpions',1965]...-- upsert with the same primary key but different values in other fields ---- applies the update operation and ignores the new tuple. --tarantool> bands:upsert({1,'Scorpions',1965},{{'=',2,'The Doors'}})---...tarantool> bands:select()-----[1,'TheDoors',1965]...
upsert searches for the existing tuple by the primary index,
not by the secondary index. This can lead to a duplication error
if the tuple violates a secondary index uniqueness.
tarantool> bands:upsert({2,'The Doors',1965},{{'=',2,'Pink Floyd'}})----error:Duplicate key exists in unique index "band" in space "bands" with old tuple- [1, "The Doors", 1965] and new tuple - [2, "The Doors", 1965]...tarantool> bands:select()-----[1,'TheDoors',1965]...-- This works if uniqueness is preserved. --tarantool> bands:upsert({2,'The Beatles',1960},{{'=',2,'Pink Floyd'}})---...tarantool> bands:select()-----[1,'TheDoors',1965]-[2,'TheBeatles',1960]...-- Delete all tuples --tarantool> bands:truncate()---...
REPLACE
space_object.replace accepts a well-formatted tuple and searches for the existing tuple
by the primary key of the new tuple:
If the existing tuple is found, Tarantool deletes it and inserts the new tuple.
If no existing tuple is found, Tarantool inserts the new tuple.
replace can violate unique constraints, like upsert does.
tarantool> bands:insert{1,'Scorpions',1965}- [1, 'Scorpions', 1965]...tarantool> bands:insert{2,'The Beatles',1960}----[2,'TheBeatles',1960]...tarantool> bands:replace{2,'Scorpions',1965}----error:Duplicate key exists in unique index "band" in space "bands" with old tuple- [1, "Scorpions", 1965] and new tuple - [2, "Scorpions", 1965]...tarantool> bands:truncate()---...
SELECT
The space_object.select request searches for a tuple or a set of tuples in the given space
by the primary key.
To search by the specified index, use index_object.select.
These methods work with any keys, including unique and non-unique, full and partial.
If a key is partial, select searches by all keys where the prefix matches the specified key part.
tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'The Doors', 1965} bands:insert{4, 'The Beatles', 1960}tarantool> bands:select(1)-----[1,'Roxette',1986]...tarantool> bands:select()-----[1,'Roxette',1986]-[2,'Scorpions',1965]-[3,'TheDoors',1965]-[4,'TheBeatles',1960]...tarantool> bands.index.primary:select(2)-----[2,'Scorpions',1965]...tarantool> bands.index.band:select('The Doors')-----[3,'TheDoors',1965]...tarantool> bands.index.year:select(1965)-----[2,'Scorpions',1965]-[3,'TheDoors',1965]...
Using box.space functions to read _space tuples
This example illustrates how to look at all the spaces, and for each
display: approximately how many tuples it contains, and the first field of
its first tuple. The function uses the Tarantool’s box.space functions len()
and pairs(). The iteration through the spaces is coded as a scan of the
_space system space, which contains metadata. The third field in
_space contains the space name, so the key instruction
space_name=v[3] means space_name is the space_name field in
the tuple of _space that we’ve just fetched with pairs(). The function
returns a table:
functionexample()localtuple_count,space_name,linelocalta={}fork,vinbox.space._space:pairs()dospace_name=v[3]ifbox.space[space_name].index[0]~=nilthentuple_count='1 or more'elsetuple_count='0'endline=space_name..' tuple_count ='..tuple_countiftuple_count=='1 or more'thenfork1,v1inbox.space[space_name]:pairs()doline=line..'. first field in first tuple = '..v1[1]breakendendtable.insert(ta,line)endreturntaend
The output below shows what happens if you invoke this function:
tarantool> example()-----_schema tuple_count =1 or more. first field in first tuple = cluster-_space tuple_count =1 or more. first field in first tuple = 272-_vspace tuple_count =1 or more. first field in first tuple = 272-_index tuple_count =1 or more. first field in first tuple = 272-_vindex tuple_count =1 or more. first field in first tuple = 272-_func tuple_count =1 or more. first field in first tuple = 1-_vfunc tuple_count =1 or more. first field in first tuple = 1-_user tuple_count =1 or more. first field in first tuple = 0-_vuser tuple_count =1 or more. first field in first tuple = 0-_priv tuple_count =1 or more. first field in first tuple = 1-_vpriv tuple_count =1 or more. first field in first tuple = 1-_cluster tuple_count =1 or more. first field in first tuple = 1...
Using box.space functions to organize a _space tuple
This examples shows how to display field names and field types of a system space –
using metadata to find metadata.
To begin: how can one select the _space tuple that describes _space?
A simple way is to look at the constants in box.schema,
which shows that there is an item named SPACE_ID == 288,
so these statements retrieve the correct tuple:
box.space._space:select{288}-- or --box.space._space:select{box.schema.SPACE_ID}
Another way is to look at the tuples in box.space._index,
which shows that there is a secondary index named ‘name’ for a space
number 288, so this statement also retrieve the correct tuple:
It looks disorganized because field number 7 has been formatted with recommended
names and data types. How can one get those specific sub-fields? Since it’s
visible that field number 7 is an array of maps, this for loop will do the
organizing:
tarantool> do > localtuple_of_space=box.space._space.index.name:get{'_space'} > for_,fieldinipairs(tuple_of_space[7])do > print(field.name..', '..field.type) > end > endid, numowner, numname, strengine, strfield_count, numflags, strformat, *---...
Using sequences
A sequence is a generator of ordered integer values.
As with spaces and indexes, you should specify the sequence name and let
Tarantool generate a unique numeric identifier (sequence ID).
As well, you can specify several options when creating a new sequence.
The options determine the values that are generated whenever the sequence is used.
Options for box.schema.sequence.create()
Option name
Type and meaning
Default
Examples
start
Integer. The value to generate the first time a sequence is used
1
start=0
min
Integer. Values smaller than this cannot be generated
1
min=-1000
max
Integer. Values larger than this cannot be generated
9223372036854775807
max=0
cycle
Boolean. Whether to start again when values cannot be generated
false
cycle=true
cache
Integer. The number of values to store in a cache
0
cache=0
step
Integer. What to add to the previous generated value, when generating a new value
1
step=-1
if_not_exists
Boolean. If this is true and a sequence with this name exists already,
ignore other options and use the existing values
false
if_not_exists=true
Once a sequence exists, it can be altered, dropped, reset, forced to generate
the next value, or associated with an index.
The result shows that the new sequence has all default values,
except for the two that were specified, min and start.
Get the next value from the sequence by calling the next() function:
-- Get the next item --box.sequence.id_seq:next()--[[---- 1000...--]]
The result is the same as the start value. The next call increases the value
by one (the default sequence step).
Create a space and specify that its primary key should be
generated from the sequence:
-- Create a space --box.schema.space.create('customers')-- Create an index that uses the sequence --box.space.customers:create_index('primary',{sequence='id_seq'})--[[---- parts: - type: unsigned is_nullable: false fieldno: 1 sequence_id: 1 id: 0 space_id: 513 unique: true hint: true type: TREE name: primary sequence_fieldno: 1...--]]
Insert a tuple without specifying a value for the primary key:
-- Insert a tuple without the primary key value --box.space.customers:insert{nil,'Adams'}--[[---- [1001, 'Adams']...--]]
The result is a new tuple where the first field is assigned the next value from
the sequence. This arrangement, where the system automatically generates the
values for a primary key, is sometimes called “auto-incrementing”
or “identity”.
For syntax and implementation details, see the reference for
box.schema.sequence.
Migrations
Migration refers to any change in a data schema: adding or removing a field,
creating or dropping an index, changing a field format, and so on. Space creation
is also a migration. Using migrations, you can track the evolution of your
data schema since its initial state. In Tarantool, migrations are presented as Lua
code that alters the data schema using the built-in Lua API.
There are two types of migrations:
simple migrations don’t require additional actions on existing data
complex migrations include both schema and data changes
Simple migrations
There are two types of schema migration that do not require data migration:
Creating an index. A new index can be created at any time. To learn more about
index creation, see Indexes and the space_object:create_index() reference.
Adding a field to the end of a space. To add a field, update the space format so
that it includes all its fields and also the new field. For example:
The field must have the is_nullable parameter. Otherwise, an error occurs
if the space contains tuples of old format.
Note
After creating a new field, you probably want to fill it with data.
The tarantool/moonwalker
module is useful for this task.
Complex migrations
Other types of migrations are more complex and require additional actions to
maintain data consistency.
Migrations are possible in two cases:
When Tarantool starts, and no client uses the database yet
During request processing, when active clients are already using the database
For the first case, it is enough to write and test the migration code.
The most difficult task is to migrate data when there are active clients.
You should keep it in mind when you initially design the data schema.
We identify the following problems if there are active clients:
Associated data can change atomically.
The system should be able to transfer data using both the new schema and the old one.
When data is being transferred to a new space, data access should consider
that the data might be in one space or another.
Write requests must not interfere with the migration.
A common approach is to write according to the new data schema.
These issues may or may not be relevant depending on your application and
its availability requirements.
Tarantool offers the following features that make migrations easier and safer:
Transaction mechanism. It is useful when writing a migration,
because it allows you to work with the data atomically. But before using
the transaction mechanism, you should explore its limitations.
For details, see the section about transactions.
space:upgrade()function (EE only). With the help of space:upgrade(),
you can enable compression and migrate, including already created tuples.
For details, check the Upgrading space schema section.
Centralized migration management mechanism (EE only). Implemented
in the Enterprise version of the tt utility and in Tarantool Cluster Manager,
this mechanism enables migration execution and tracking in the replication
clusters. For details, see Centralized migration management.
Applying migrations
The migration code is executed on a running Tarantool instance.
Important: no method guarantees you transactional application of migrations
on the whole cluster.
Method 1: include migrations in the application code
This is quite simple: when you reload the code, the data is migrated at the right moment,
and the database schema is updated.
However, this method may not work for everyone.
You may not be able to restart Tarantool or update the code using the hot-reload mechanism.
Connect to the necessary instance using ttconnect.
$ ttconnectadmin:password@localhost:3301
If your migration is written in a Lua file, you can execute it
using dofile(). Call this function and specify the path to the
migration file as the first argument. It looks like this:
tarantool> dofile('0001-delete-space.lua')---...
(or) Copy the migration script code,
paste it into the console, and run it.
You can also connect to the instance and execute the migration script in a single call:
Centralized migration management is available in the Enterprise Edition only.
Tarantool EE offers a mechanism for centralized migration management in replication
clusters that use etcd as a configuration storage.
The mechanism uses the same etcd storage to store migrations and applies them
across the entire Tarantool cluster. This ensures migration consistency
in the cluster and enables migration history tracking.
The centralized migration management mechanism is implemented in the Enterprise
version of the tt utility and in Tarantool Cluster Manager.
To learn how to manage migrations in Tarantool EE clusters from the command line,
see Centralized migrations with tt. To learn how to use the mechanism from the TCM
web interface, see the Performing migrations TCM documentation page.
In this tutorial, you learn to define the cluster data schema using the centralized
migration management mechanism implemented in the Enterprise Edition of the tt utility.
It creates an etcd user app_user with read and write permissions to the /myapp
prefix, in which the cluster configuration will be stored. The user’s password is config_pass.
Note
If you don’t enable etcd authentication, make ttmigrations calls without
the configuration storage credentials.
Creating a cluster
Initialize a tt environment:
$ ttinit
In the instances.enabled directory, create the myapp directory.
Go to the instances.enabled/myapp directory and create application files:
Create the source.yaml with a cluster configuration to publish to etcd:
Note
This configuration describes a typical CRUD-enabled sharded cluster with
one router and two storage replica sets, each including one master and one read-only replica.
The migration unit is a single file: its scenario is executed as a whole. An error
that happens in any step of the scenario causes the entire migration to fail.
Migrations are executed in the lexicographical order. Thus, it’s convenient to
use filenames that start with ordered numbers to define the migrations order, for example:
The default location where tt searches for migration files is /migrations/scenario.
Create this subdirectory inside the tt environment. Then, create two migration files:
000001_create_writers_space.lua: create a space, define its format, and
create a primary index.
Note the usage of the tt-migrations.helpers module.
In this example, its function register_sharding_key is used
to define a sharding key for the space.
000002_create_writers_index.lua: add one more index.
To publish migrations to the etcd configuration storage, run ttmigrationspublish:
$ ttmigrationspublish"http://app_user:config_pass@localhost:2379/myapp" • 000001_create_writes_space.lua: successfully published to key "000001_create_writes_space.lua" • 000002_create_writers_index.lua: successfully published to key "000002_create_writers_index.lua"
Applying migrations
To apply published migrations to the cluster, run ttmigrationsapply providing
a cluster user’s credentials:
In this tutorial, you learn to write migrations that include data migration using
the space.upgrade() function.
Prerequisites
Before starting this tutorial, complete the Basic tt migrations tutorial.
As a result, you have a sharded Tarantool EE cluster that uses an etcd-based configuration
storage. The cluster has a space with two indexes.
Writing a complex migration
Complex migrations require data migration along with schema migration. Connect to
the router instance and insert some tuples into the space before proceeding to the next steps.
$ ttconnectmyapp:router-001-a
myapp:router-001-a> require('crud').insert_object_many('writers', { {id = 1, name = 'Haruki Murakami', age = 75}, {id = 2, name = 'Douglas Adams', age = 49}, {id = 3, name = 'Eiji Mikage', age = 41},}, {noreturn = true})
The next migration changes the space format incompatibly: instead of one name
field, the new format includes two fields first_name and last_name.
To apply this migration, you need to change each tuple’s structure preserving the stored
data. The space.upgrade function helps with this task.
Create a new file 000003_alter_writers_space.lua in /migrations/scenario.
Prepare its initial structure the same way as in previous migrations:
box.space.writers.index.age:drop() drops an existing index. This is done
because indexes rely on field numbers and may break during this format change.
If you need the age field indexed, recreate the index after applying the
new format.
Next, create a stored function that transforms tuples to fit the new format.
In this case, the function extracts the first and the last name from the name field
and returns a tuple of the new format:
box.schema.func.create('_writers_split_name',{language='lua',is_deterministic=true,body=[[ function(t) local name = t[3] local split_data = {} local split_regex = '([^%s]+)' for v in string.gmatch(name, split_regex) do table.insert(split_data, v) end local first_name = split_data[1] assert(first_name ~= nil) local last_name = split_data[2] assert(last_name ~= nil) return {t[1], t[2], first_name, last_name, t[4]} end ]],})
Finally, call space:upgrade() with the new format and the transformation function
as its arguments. Here is the complete migration code:
localfunctionapply_scenario()localspace=box.space['writers']localnew_format={{name='id',type='number'},{name='bucket_id',type='number'},{name='first_name',type='string'},{name='last_name',type='string'},{name='age',type='number'},}box.space.writers.index.age:drop()box.schema.func.create('_writers_split_name',{language='lua',is_deterministic=true,body=[[ function(t) local name = t[3] local split_data = {} local split_regex = '([^%s]+)' for v in string.gmatch(name, split_regex) do table.insert(split_data, v) end local first_name = split_data[1] assert(first_name ~= nil) local last_name = split_data[2] assert(last_name ~= nil) return {t[1], t[2], first_name, last_name, t[4]} end ]],})localfuture=space:upgrade({func='_writers_split_name',format=new_format,})future:wait()endreturn{apply={scenario=apply_scenario,},}
You can also publish all migrations from the default location /migrations/scenario.
All other migrations stored in this directory are already published, so tt
skips them.
In this tutorial, you learn how to consistently define the data schema on newly
added cluster instances using the centralized migration management mechanism.
Prerequisites
Before starting this tutorial, complete the Basic tt migrations tutorial and Data migrations with space.upgrade().
As a result, you have a sharded Tarantool EE cluster that uses an etcd-based configuration
storage. The cluster has a space with two indexes.
Extending the cluster
Having all migrations in a centralized etcd storage, you can extend the cluster
and consistently define the data schema on new instances on the fly.
Add one more storage replica set to the cluster. To do this, edit the cluster files in instances.enabled/myapp:
$ ttstartmyapp
• The instance myapp:router-001-a (PID = 61631) is already running. • The instance myapp:storage-001-a (PID = 61632) is already running. • The instance myapp:storage-001-b (PID = 61634) is already running. • The instance myapp:storage-002-a (PID = 61639) is already running. • The instance myapp:storage-002-b (PID = 61640) is already running. • Starting an instance [myapp:storage-003-a]... • Starting an instance [myapp:storage-003-b]...
Now the cluster contains three storage replica sets.
Applying migrations to the new replica set
The new replica set – storage-003– is just started and has no data schema yet.
Apply all stored migrations to the cluster to load the same data schema to the new replica set:
You can also apply migrations without specifying the replica set. All published
migrations are already applied on other replica sets, so tt skips the
operation on them.
The centralized migrations mechanism allows troubleshooting migration issues using
dedicated ttmigration options. When troubleshooting migrations, remember that
any unfinished or failed migration can bring the data schema into to inconsistency.
Additional steps may be needed to fix this.
Warning
The options used for migration troubleshooting can cause migration inconsistency
in the cluster. Use them only for local development and testing purposes.
Incorrect migration published
If an incorrect migration was published to etcd but wasn’t applied yet,
fix the migration file and publish it again with the --overwrite option:
Any schema change that was made by an incorrect migration before its fail or
cancellation must be resolved manually on each replica set before reapply.
--force-reapply and other ttmigrations options affect only internal
status of the migration and don’t revert changes that it has made in the cluster.
If the migration is already applied, publish the fixed version and apply it with
the --force-reapply option:
If execution of the incorrect migration version has failed, you may also need to add
the --ignore-preceding-status option:
When you reapply a migration, tt checks the statuses of preceding migrations
to ensure consistency. To skip this check, add the --ignore-preceding-status option:
In Tarantool, migration refers to any change in a data schema, for example,
creating an index, adding a field, or changing a field format.
If you need to change a data schema, there are several possible cases:
Schema migration does not require data migration: adding a field with the is_nullable parameter to the end
of the space, creating an index.
Schema migration requires data migration. For example, it is necessary when you have to iterate
over the entire space to convert columns to a new format or remove the column completely.
The space:upgrade() feature allows users to upgrade the format of a space and the tuples stored in it without
blocking the database.
How to apply space upgrade
First, specify an upgrade function – a function that will convert the tuples in the space to a new format.
The requirements for this function are listed below.
The upgrade function takes two arguments. The first argument is a tuple to be upgraded.
The second one is optional. It contains some additional information stored in plain Lua object.
If omitted, the second argument is nil.
The function returns a new tuple or a Lua table. For example, it can add a new field to the tuple.
The new tuple must conform to the new space format set by the upgrade operation.
The function should be registered with
box.schema.func.create.
It should also be stored, deterministic, and written in Lua.
The function should not change the primary key of the tuple.
The function should be idempotent: f(f(t))=f(t). This is necessary because the function
is applied to all tuples returned to the user, and some of them may have already been upgraded in the background.
Then define a new space format. This step is optional.
However, it could be useful if, for example, you want to add a new column with data.
For details, check the Usage Example section.
The next optional step is to choose an upgrade mode.
There are three modes: upgrade, dryrun, and dryrun+upgrade.
The default value is upgrade.
To check an upgrade function without applying any changes, choose the dryrun mode.
To run a space upgrade without testing the function, pick the upgrade mode.
If you want to apply both the test and the actual upgrade, use the dryrun+upgrade option.
For details, see the Upgrade Modes section.
How the upgrade works
The user defines an upgrade function.
Each tuple of the chosen space is passed through the function.
The function converts the tuple from the old format to a new one.
The function is applied to all tuples stored in the space in the background.
Besides, the function is applied to all tuples returned to the user via the box API (for example, select, get).
Therefore, it appears that the space upgrades instantly.
Keep in mind that space:upgrade differs from
the space_object:format() in the following ways:
Difference
space:upgrade()
space:format()
Non-blocking
Yes. It returns tuples in the new format, whether or not they have already been converted.
Yes.
Set a format incompatible with the current one
Yes. Works for non-indexed field types only.
No, only expand the format in a compatible way.
Visibility of changes
Immediately. All changes are visible and replicated immediately.
New data should conform to the new format immediately after the call.
After data validation.
Data validation starts in the background, it does not block the database.
Inserting data incompatible with the new format is allowed before
validation is completed – in this case space.format fails.
Cancel (error/restart)
Writes the state to the system table.
Restart: the operation continues.
Error: the operation should be restarted manually, any other attempt to change the table fails.
Leaves no traces.
Set the upgrade function
Yes. The upgrade may take a while to traverse the space and transform tuples.
No.
Note
At the moment, the feature is not supported
for vinyl spaces.
User API
The space:upgrade() method is added to the space object:
space:upgrade({func[, arg, format, mode, is_async]}])¶
Parameters:
func (string/integer) – upgrade function name (string) or ID (integer). For details, see the
upgrade function requirements section.
arg – additional information passed to the upgrade function in the second argument.
The option accepts any Lua value that can be encoded in MsgPack, which means that
the msgpack.encode(arg) should succeed.
For example, one can pass a scalar or a Lua table.
The default value is nil.
format (map) – new space format. The requirements for this are the same as for any other
space:format().
If the field is omitted, the space format will remain the same as before the upgrade.
mode (string) – upgrade mode. Possible values: upgrade, dryrun,
dryrun+upgrade. The default value is upgrade.
is_async (boolean) – the flag indicates whether to wait until the upgrade operation is complete
before exiting the function.
The default value is false – the function is blocked
until the upgrade operation is finished.
Return:
object describing the status of the operation (also known as future).
The methods of the object are described below.
Shows information about the state of the upgrade operation.
Parameters:
dryrun (boolean) – dry run mode flag. Possible values:
true for a dry run, nil for an actual upgrade.
status (string) – upgrade status. Possible values:
inprogress, waitrw, error, replica, done.
func (string/integer) – name of the upgrade function.
It is the same as passed to the space:upgrade method.
The field is nil if the status is done.
arg – additional information passed to the upgrade function.
It is the same as for the space:upgrade method.
The field is nil if it is omitted in the space:upgrade.
owner (string) – UUID of the instance running the upgrade
(see box.info.uuid).
The field is nil if the status is done.
error (string) – error message if the status is error, otherwise nil.
progress (string) – completion percentage if the status is inprogress/waitrw,
otherwise nil.
Return:
a table with information about the state of the upgrade operation
If called without arguments, space:upgrade() returns a future object for the active upgrade operation.
If there is none, it returns nil.
Upgrade modes
There are three upgrade modes: dryrun, dryrun+upgrade, and upgrade.
Regardless of the mode selected, the upgrade does not block execution.
Once in a while, the background fiber commits the upgraded tuples and yields.
Calling space:upgrade without arguments always returns the current state of the space upgrade,
never the state of a dry run. If there is a dry run working in the background, space:upgrade will still return nil.
Unlike an actual space upgrade, the future object returned by a dry run upgrade can’t be recovered if it is lost.
So a dry run is aborted if it is garbage collected.
Warning
In dryrun+upgrade mode: if the future object is garbage collected by Lua
before the end of the dry run and the start of the upgrade,
then the dry run will be canceled, and no upgrade will be started.
Upgrade modes:
upgrade mode: the background fiber iterates over the
space, applies the upgrade function, checks that obtained tuples fit the new space format,
and updates the tuples. This mode prevents the space from being altered.
The mode can only be performed on the master instance.
dryrun mode: the dry-run mode is used to check the upgrade function. The mode does not apply any changes
to the target space. It starts a background fiber. The fiber:
Iterates over the target space.
Attempts to apply the upgrade function to each tuple stored in the space.
Checks if the returned tuple matches the new format.
Checks if the function is idempotent.
Checks that the function does not modify the primary key.
To start a dry run, pass mode='dryrun' to the space:upgrade method.
In this case, the future object has the dryrun field set to true.
The possible statuses are inprogress and dryrun. replica and waitrw states are never set
for a dry run future object.
The dryrun mode is not persisted. Restarting the instance does not restart a dry run.
A dry run only works on the original instance, never on replicas.
Unlike a real upgrade, a dry run does not prevent the space from being altered.
The space can even be dropped. In this case, the dry run will complete with an error.
dryrun+upgrade mode: it starts a dry run, which, if completed successfully, triggers an actual upgrade.
The future object returned by space:upgrade remains valid throughout the process.
It starts as the future object of the dry run. Then, under the hood, it is converted into an upgrade future object.
Waiting on it would wait for both the dry run and the upgrade to complete.
During the dry run, the future object has the dryrun field set to true.
When the actual upgrade starts, the dryrun field is set to nil.
The mode can only be performed on the master instance.
States
An upgrade operation has one of the following upgrade states:
inprogress – the upgrade operation is running in the background.
The function is applied to all tuples returned to the user.
waitrw – the instance was switched to the read-only mode
(for example, by using box.cfg.read_only), so the upgrade couldn’t proceed.
The upgrade process will resume as soon as the instance switches back to read-write mode.
Nevertheless, the upgrade function is applied to all tuples returned to the user.
error – the upgrade operation failed with an error. See the error field for the error message.
See the log for the tuple that caused the error. No alter operation is allowed, except for another upgrade,
supposed to fix the problem.
Nevertheless, the upgrade function is applied to all tuples returned to the user. The space is writable.
done – the upgrade operation is successfully completed. The upgrade function is not applied to tuples returned
to the user anymore. The function can be deleted.
replica – the upgrade operation is either running or completed with an error on another instance.
See the owner field for the UUID of the instance running the upgrade.
Nevertheless, the upgrade function is applied to all tuples returned to the user.
Interaction with alter
While a space upgrade is in progress, the space can’t be altered or dropped.
The attempt to do that will throw an exception.
Restarting an upgrade is allowed in case the currently running upgrade is canceled or completed with an error.
It means the manual restart is possible if the upgrade operation is in the error state.
If a space upgrade was canceled or failed with an error, the space can’t be altered or dropped.
The only option is to restart the upgrade using a different upgrade function or format.
Interaction with recovery
The space upgrade state is persisted. It is stored in the _space system table. If an instance with
a space upgrade in progress (inprogress state) is shut down, it restarts the space upgrade after recovery.
If a space upgrade fails (switches to the error state), it remains in the error state after recovery.
Interaction with replication
The changes made to a space by a space upgrade are replicated.
Just as on the instance where the upgrade is performed, the upgrade function is applied to all tuples returned
to the user on the replicas. However, the upgrade operation is not performed on the replicas in the background.
The replicas wait for the upgrade operation to complete on the master.
They can’t alter or drop the space. Normally, they can’t cancel or restart the upgrade operation either.
There is an emergency exception when the master is permanently dead.
It is possible to restart a space upgrade that started on another instance.
The restart is possible if the upgrade owner UUID (see the owner field) has been deleted
from the _cluster system table.
Note
Except the dryrun mode, the upgrade can only be performed on the master.
If the instance is no longer the master, the upgrade is suspended until the instance is master again.
Restarting the upgrade on a new master works only if the old one has been removed from the replica set
(_cluster system space).
Usage example
Suppose there are two columns in the space test – id (unsigned) and data (string).
The example shows how to upgrade the schema and add another column to the space using space:upgrade().
The new column contains the id values converted to string. Each step takes a while.
The test space is generated with the following script:
locallog=require('log')box.cfg{checkpoint_count=1,memtx_memory=5*1024*1024*1024,}box.schema.space.create('test')box.space.test:format{{name='id',type='unsigned'},{name='data',type='string'},}box.space.test:create_index('pk')localcount=20*1000*1000localprogress=0box.begin()fori=1,countdobox.space.test:insert{i,'data'..i}ifi%1000==0thenbox.commit()localp=math.floor(i/count*100)ifprogress~=pthenprogress=plog.info('Generating test data set... %d%% done',p)endbox.begin()endendbox.commit()box.snapshot()os.exit(0)
To upgrade the space, connect to the server and then run the commands below:
While the upgrade is in progress, you can track the state of the upgrade.
To check the status, connect to Tarantool from another console and run the following commands:
A read view is an in-memory snapshot of the entire database that isn’t
affected by future data modifications.
Read views provide access to database spaces and their indexes and enable you to
retrieve data using the same select and pairs operations.
Read views can be used to make complex analytical queries.
This reduces the load on the main database and improves RPS for a single Tarantool instance.
To improve memory consumption and performance,
Tarantool creates read views using the copy-on-write technique.
In this case, duplication of the entire data set is not required:
Tarantool duplicates only blocks modified after a read view is created.
Note
Tarantool Enterprise Edition supports read views starting from v2.11.0 and enables the ability
to work with them using both Lua and C API.
After creating a read view, you can access database spaces using the
read_view_object.space field.
This field provides access to a space object that exposes the
select, get,
and pairs methods with the same behavior
as corresponding box.space methods.
The example below shows how to select 4 records from the bands space:
Pagination is supported in read views in the same ways as in select requests
to spaces: using the fetch_pos and after arguments. To get the cursor position
after executing a request on a read view, set fetch_pos to true:
When a read view is no longer needed, close it using the
read_view_object:close() method
because a read view may consume a substantial amount of memory.
tarantool> read_view1:close()---...
Otherwise, a read view is closed implicitly when the read view object is collected by the Lua garbage collector.
After the read view is closed,
its status is set to closed.
On an attempt to use it, an error is raised.
Example
A Tarantool session below demonstrates how to open a read view,
get data from this view, and close it.
To repeat these steps, you need to bootstrap a Tarantool instance
as described in Using data operations
(you can skip creating secondary indexes).
Insert test data.
tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960}
Create a read view by calling the open function.
Then, make sure that the read view status is open.
The Beginners’ Guide describes how users can start up with SQL with Tarantool, and necessary concepts.
The SQL Beginners’ Guide is about databases in general, and about the relationship between
Tarantool’s NoSQL and SQL products.
Most of the matters in the Beginners’ Guide will already be familiar to people who have used relational databases before.
Start a Tarantool instance in the interactive mode by running tt run -i:
$ ttrun-i
Tarantool 3.0.0-0-g6ba34da7f8type 'help' for interactive helptarantool>
Initialize the instance and switch the input language to SQL:
tarantool> box.cfg{}
tarantool> \set language sql
tarantool> \set delimiter ;
Now you have a running Tarantool instance that accepts SQL input.
Sample table
In football training camp it is traditional for the trainer to begin by showing a football
and saying “this is a football”. In that spirit, this is a table:
But the labels are misleading – one usually doesn’t identify rows and columns by their ordinal positions,
one prefers to pick out specific items by their contents. In that spirit, this is a table:
So one does not use longitude/latitude navigation by talking about “Row#2 Column #2”,
one uses the contents of the Name column and the name of the Size column
by talking about “the size, where the name is ‘clock’”.
To be more exact, this is what one says:
SELECTsizeFROMmodulesWHEREname='clock';
If you’re familiar with Tarantool’s architecture – and ideally you read
about that before coming to this chapter – then you know that there is a NoSQL
way to get the same thing:
box.space.MODULES:select()[2][2]
Well, you can do that. One of the advantages of Tarantool is that if you can get
data via an SQL statement, then you can get the same data via a NoSQL request.
But the reverse is not true, because not all NoSQL tuple sets are definable
as SQL tables. These restrictions apply for SQL that do not apply for NoSQL:
1. Every column must have a name.
2. Every column should have a scalar type (Tarantool is relaxed about
which particular scalar type you can have, but there is no way to index and
search arrays, tables within tables, or what MessagePack calls “maps”.)
Tarantool/NoSQL’s “format” clause causes the same restrictions.
So an SQL “table” is a NoSQL “tuple set with format restrictions”,
an SQL “row” is a NoSQL “tuple”, an SQL “column” is a NoSQL “list of fields within a tuple set”.
The words that are IN CAPITAL LETTERS are “keywords” (although it is only a convention in
this manual that keywords are in capital letters, in practice many programmers prefer to avoid shouting).
A keyword has meaning for the SQL parser so many keywords are reserved, they cannot be used as names
unless they are enclosed inside quotation marks.
The word “modules” is a “table name”, and the words “name” and “size” and “purpose” are “column names”.
All tables and all columns must have names.
The words “STRING” and “INTEGER” are “data types”.
STRING means “the contents should be characters, the length is indefinite, the equivalent NoSQL type is ‘string’’”.
INTEGER means “the contents should be numbers without decimal points, the equivalent NoSQL type is ‘integer’”.
Tarantool supports other data types but this section’s example table has data types from the two main groups,
namely, data types for numbers and data types for strings.
The final clause, PRIMARY KEY (name), means that the name column is the main column used to identify the row.
Nulls
Frequently it is necessary, at least temporarily, that a column value should be NULL.
Typical situations are: the value is unknown, or the value is not applicable.
For example, you might make a module as a placeholder but you don’t want to say its size or purpose.
If such things are possible, the column is “nullable”.
The example table’s name column cannot contain nulls, and it could be defined explicitly as “name STRING NOT NULL”,
but in this case that’s unnecessary – a column defined as PRIMARY KEY is automatically NOT NULL.
Is a NULL in SQL the same thing as a nil in Lua?
No, but it is close enough that there will be confusion.
When nil means “unknown” or “inapplicable”, yes.
But when nil means “nonexistent” or “type is nil”, no.
NULL is a value, it has a data type because it is inside a column which is defined with that data type.
Creating an index
This is how to create indexes for the modules table:
There is no need to create an index on the name column,
because Tarantool creates an index automatically when it sees a PRIMARY KEY clause in the CREATE TABLE statement.
In fact there is no need to create indexes on the size or purpose columns
either – if indexes don’t exist, then it is still possible to use the columns for searches.
Typically people create non-primary indexes, also called secondary indexes,
when it becomes clear that the table will grow large and searches will be frequent,
because searching with an index is generally much faster than searching without an index.
Another use for indexes is to enforce uniqueness.
When an index is created with CREATE UNIQUE INDEX for the purpose column,
it is not possible to have duplicate values in that column.
Data change
Putting data into a table is called “inserting”.
Changing data is called “updating”.
Removing data is called “deleting”.
Together, the three SQL statements INSERT plus UPDATE plus DELETE are the three main “data-change” statements.
This is how to insert, update, and delete a row in the modules table:
INSERTINTOmodulesVALUES('json',14,'format functions for JSON');UPDATEmodulesSETsize=15WHEREname='json';DELETEFROMmodulesWHEREname='json';
The corresponding non-SQL Tarantool requests would be:
box.space.MODULES:insert{'json',14,'format functions for JSON'}box.space.MODULES:update('json',{{'=',2,15}})box.space.MODULES:delete{'json'}
This is how one would populate the table with the values that was shown earlier:
Some data-change statements are illegal due to something in the table’s definition.
This is called “constraining what can be done”. Some types of constraints have already been shown …
NOT NULL – if a column is defined with a NOT NULL clause, it is illegal to put NULL into it.
A primary-key column is automatically NOT NULL.
UNIQUE – if a column has a UNIQUE index, it is illegal to put a duplicate into it.
A primary-key column automatically has a UNIQUE index.
data domain – if a column is defined as having data type INTEGER, it is illegal to put a non-number into it.
More generally, if a value doesn’t correspond to the data type of the definition, it is illegal.
Some database management systems (DBMSs) are very forgiving and will try to
make allowances for bad values rather than reject them; Tarantool is a bit more strict than those DBMSs.
Now, here are other types of constraints …
CHECK – a table description can have a clause “CHECK (conditional expression)”.
For example, if the CREATE TABLE modules statement looked like this:
then this INSERT statement would be illegal: INSERTINTOmodulesVALUES('box',0,'TheDatabaseKernel');
because there is a CHECK constraint saying that the second column, the size column,
cannot contain a value which is less than or equal to zero. Try this instead: INSERTINTOmodulesVALUES('box',1,'TheDatabaseKernel');
FOREIGN KEY – a table description can have a clause
“FOREIGN KEY (column-list) REFERENCES table (column-list)”.
For example, if there is a new table “submodules” which in a way depends on the modules table,
it can be defined like this:
The insert will fail because the second column (module_name)
refers to the name column in the modules table, and the name
column in the modules table does not contain ‘Box’.
However, it does contain ‘box’.
By default searches in Tarantool’s SQL use a binary collation. This will work:
Now try to delete the corresponding row from the modules table:
DELETEFROMmodulesWHEREname='box';
The delete will fail because the second column (module_name) in the submodules
table refers to the name column in the modules table, and the name column
in the modules table would not contain ‘box’ if the delete succeeded.
So the FOREIGN KEY constraint affects both the table which contains
the FOREIGN KEY clause and the table that the FOREIGN KEY clause refers to.
The constraints in a table’s definition – NOT NULL, UNIQUE, data domain, CHECK,
and FOREIGN KEY – are guarantors of the database’s integrity.
It is important that they are fixed and well-defined parts of the definition,
and hard to bypass with SQL.
This is often seen as a difference between SQL and NoSQL – SQL emphasizes law and order,
NoSQL emphasizes freedom and making your own rules.
Table relationships
Think about the two tables that have been discussed so far:
Because of the FOREIGN KEYS clause in the submodules table, there is clearly a many-to-one relationship:
submodules –>> modules
that is, every submodules row must refer to one (and only one) modules row,
while every modules row can be referred to in zero or more submodules rows.
Table relationships are important, but beware:
do not trust anyone who tells you that databases made with SQL are relational
“because there are relationships between tables”.
That is wrong, as will be clear in the discussion about what makes a database relational, later.
Selecting with WHERE
Important
By default, Tarantool prohibits SELECT queries that scan table rows
instead of using indexes to avoid unwanted heavy load. For the purposes of
this tutorial, allow SQL scan queries in Tarantool by running the command:
SETSESSION"sql_seq_scan"=true;
Alternatively, you can allow a specific query to perform a table scan by adding
the SEQSCAN keyword before the table name. Learn more about using SEQSCAN
in SQL scan queries in the SQL FROM clause description.
We gave a simple example of a SELECT statement earlier:
SELECTsizeFROMmodulesWHEREname='clock';
The clause “WHERE name = ‘clock’” is legal in other statements – it
is in examples with UPDATE and DELETE – but here the only examples will be with SELECT.
The first variation is that the WHERE clause does not have to be specified at all,
it is optional. So this statement would return all rows:
SELECTsizeFROMmodules;
The second variation is that the comparison operator does not have to be ‘=’,
it can be anything that makes sense: ‘>’ or ‘>=’ or ‘<’ or ‘<=’,
or ‘LIKE’ which is an operator that works with strings that may
contain wildcard characters ‘_’ meaning ‘match any one character’
or ‘%’ meaning ‘match any zero or one or many characters’.
These are legal statements which return all rows:
The third variation is that IS [NOT] NULL is a special condition.
Remembering that the NULL value can mean “it is unknown what the value should be”,
and supposing that in some row the size is NULL,
then the condition “size > 10” is not certainly true and it is not certainly false,
so it is evaluated as “unknown”.
Ordinarily the application of a WHERE clause filters out both false and unknown results.
So when searching for NULL, say IS NULL;
when searching anything that is not NULL, say IS NOT NULL.
This statement will return all rows because (due to the definition) there are no NULLs in the name column:
SELECTsizeFROMmodulesWHEREnameISNOTNULL;
The fourth variation is that conditions can be combined with AND / OR, and negated with NOT.
So this statement would return all rows (the first condition is false
but the second condition is true, and OR means “return true if either condition is true”):
Yet again, here is a simple example of a SELECT statement:
SELECTsizeFROMmodulesWHEREname='clock';
The words between SELECT and FROM are the select list.
In this case, the select list is just one word: size.
Formally it means that the desire is to return the size values,
and technically the name for picking a particular column is called “projection”.
The first variation is that one can specify any column in any order:
SELECTname,purpose,sizeFROMmodules;
The second variation is that one can specify an expression,
it does not have to be a column name, it does not even have to include a column name.
The common expression operators for numbers are the arithmetic operators +-/*;
the common expression operator for strings is the concatenation operator ||.
For example this statement will return 8, ‘XY’:
SELECTsize*2,'X'||'Y'FROMmodulesWHEREsize=4;
The third variation is that one can add a clause [AS name] after every expression,
so that in the return the column titles will make sense.
This is especially important when a title might otherwise be ambiguous or meaningless.
For example this statement will return 8, ‘XY’ as before
Instead of listing columns in a select list, one can just say '*'. For example
SELECT*FROMmodules;
This is the same thing as
SELECTname,size,purposeFROMmodules;
Selecting with "*" saves time for the writer,
but it is unclear to a reader who has not memorized what the column names are.
Also it is unstable, because there is a way to change a table’s
definition (the ALTER statement, which is an advanced topic).
Nevertheless, although it might be bad to use it for production,
it is handy to use it for introduction, so "*" will appear in some following examples.
Select with subqueries
Remember that there is a modules table and there is a submodules table.
Suppose that there is a desire to list the submodules that refer to modules for which the purpose is X.
That is, this involves a search of one table using a value in another table.
This can be done by enclosing “(SELECT …)” within the WHERE clause. For example:
Subqueries are also useful in the select list, when one wishes to combine
information from more than one table.
For example this statement will display submodules rows but will include values that come from the modules table:
Whoa. What are “modules.name” and “submodules.name”?
Whenever you see “x . y” you are looking at a “qualified column name”,
and the first part is a table identifier, the second part is a column identifier.
It is always legal to use qualified column names, but until now it has not been necessary.
Now it is necessary, or at least it is a good idea, because both tables have a column named “name”.
The result will look like this:
+-------------------+------------------------+--------------------+
| SUBMODULES_NAME | MODULES_PURPOSE | SUBMODULES_PURPOSE |
+-------------------+------------------------+--------------------+
| space | Database Management | insert etc. |
+-------------------+------------------------+--------------------+
Perhaps you have read somewhere that SQL stands for “Structured Query Language”.
That is not true any more.
But it is true that the query syntax allows for a structural component,
namely the subquery, and that was the original idea.
However, there is a different way to combine tables – with joins instead of subqueries.
Select with Cartesian join
Until now only “FROM modules” or “FROM submodules” was used in SELECT statements.
What if there was more than one table in the FROM clause? For example
SELECT*FROMmodules,submodules;
or
SELECT*FROMmodulesJOINsubmodules;
That is legal. Usually it is not what you want, but it is a learning aid. The result will be:
{ columns from modules table } { columns from submodules table }
+--------+------+---------------------+-------+-------------+-------+-------------+
| NAME | SIZE | PURPOSE | NAME | MODULE_NAME | SIZE | PURPOSE |
+--------+------+---------------------+-------+-------------+-------+-------------+
| box | 1432 | Database Management | space | box | 10000 | insert etc. |
| clock | 188 | Seconds | space | box | 10000 | insert etc. |
| crypto | 4 | Cryptography | space | box | 10000 | insert etc. |
+--------+------+---------------------+-------+-------------+-------+-------------+
It is not an error. The meaning of this type of join is “combine every row in table-1 with every row in table-2”.
It did not specify what the relationship should be, so the result has everything,
even when the submodule has nothing to do with the module.
It is handy to look at the above result, called a “Cartesian join” result, to see what would really be desirable.
Probably for this case the row that actually makes sense is the one where the modules.name = submodules.module_name,
and it’s better to make that clear in both the select list and the WHERE clause, thus:
In other words, you can specify a Cartesian join in the FROM clause,
then you can filter out the irrelevant rows in the WHERE clause,
and then you can rename columns in the select list.
This is fine, and every SQL DBMS supports this.
But it is worrisome that the number of rows in a Cartesian join is always
(number of rows in first table multiplied by number of rows in second table),
which means that conceptually you are often filtering in a large set of rows.
It is good to start by looking at Cartesian joins because they show the concept.
Many people, though, prefer to use different syntaxes for joins because they
look better or clearer. So now those alternatives will be shown.
Select with join with ON clause
The ON clause would have the same comparisons as the WHERE clause that was illustrated
for the previous section, but the use of different syntax would be making it clear
“this is for the sake of the join”.
Readers can see at a glance that it is, in concept at least, an initial step before
the result rows are filtered. For example this
The USING clause would take advantage of names that are held in common between the two tables,
with the assumption that the intent is to match those columns with ‘=’ comparisons. For example,
If the table had been created with a plan in advance to use USING clauses,
that would save time. But that did not happen.
So, although the above example “works”, the results will not be sensible.
Select with natural join
A natural join would take advantage of names that are held in common between the two tables,
and would do the filtering automatically based on that knowledge, and throw away duplicate columns.
If the table had been created with a plan in advance to use natural joins, that would be very handy.
But that did not happen. So, although the following example “works”, the results won’t be sensible.
SELECT*FROMmodulesNATURALJOINsubmodules;
Result: nothing, because modules.name does not match submodules.name,
and so on And even if there had been a result, it would only have included
four columns: name, module_name, size, purpose.
Select with left join
Now what if there is a desire to join modules to submodules,
but it’s necessary to be sure that all the modules are found?
In other words, suppose the requirement is to get modules even if the condition submodules.module_name = modules.name
is not true, because the module has no submodules.
When that is the requirement, the type of join is an “outer join”
(as opposed to the type that has been used so far which is an “inner join”).
Specifically the format will be LEFT [OUTER] JOIN because the main table, modules, is on the left. For example:
Thus, for the submodules of the clock module and the submodules of the crypto
module – which do not exist – there are NULLs in every column.
Select with functions
A function can take any expression, including an expression that contains another function,
and return a scalar value. There are many such functions. Here will be a description of only one, SUBSTR,
which returns a substring of a string.
Format: SUBSTR(input-string,start-with[,length])
Description: SUBSTR takes input-string, eliminates any characters before start-with,
eliminates any characters after (start-with plus length), and returns the result.
Suppose that there is no need to know all the individual size values,
all that is important is their aggregation, that is, take the attributes of the collection.
SQL allows aggregation functions including: AVG (average), SUM, MIN (minimum), MAX (maximum), and COUNT.
For example
Suppose that the requirement is aggregations, but aggregations of rows that have some common characteristic.
Supposing further, the rows should be divided into two groups, the ones whose names
begin with ‘b’ and the ones whose names begin with ‘c’.
This can be done by adding a clause [GROUP BY expression]. For example,
So far, tor every search in the modules table, the rows have come out in alphabetical order by name:
‘box’, then ‘clock’, then ‘crypto’.
However, to really be sure about the order, or to ask for a different order,
it is necessary to be explicit and add a clause:
ORDERBYcolumn-name[ASC|DESC].
(ASC stands for ASCending, DESC stands for DESCending.)
For example:
SELECT*FROMmodulesORDERBYnameDESC;
The result will be the usual rows, in descending alphabetical order: ‘crypto’ then ‘clock’ then ‘box’.
After the ORDER BY clause there can be a clause LIMIT n, where n is the maximum number of rows to retrieve. For example:
SELECT*FROMmodulesORDERBYnameDESCLIMIT2;
The result will be the first two rows, ‘crypto’ and ‘clock’.
After the ORDER BY clause and the LIMIT clause there can be a clause OFFSET n,
where n is the row to start with. The first offset is 0. For example:
SELECT*FROMmodulesORDERBYnameDESCLIMIT2OFFSET2;
The result will be the third row, ‘box’.
Views
A view is a canned SELECT. If you have a complex SELECT that you want to run frequently, create a view and then do a simple SELECT on the view. For example:
Tarantool has a “Write Ahead Log” (WAL).
Effects of data-change statements are logged before they are permanently stored on disk.
This is a reason that, although entire databases can be stored in temporary memory,
they are not vulnerable in case of power failure.
Tarantool supports commits and rollbacks. In effect, asking for a commit means
asking for all the recent data-change statements,
since a transaction began, to become permanent.
In effect, asking for a rollback means asking for all the recent data-change statements,
since a transaction began, to be cancelled.
The result will be: one row, containing ‘A’. The ROLLBACK cancelled the second INSERT statement,
but did not cancel the first one, because it had already been committed.
Ordinarily every statement is automatically committed.
After START TRANSACTION, statements are not automatically committed – Tarantool considers
that a transaction is now “active”, until the transaction ends with a COMMIT statement or a ROLLBACK statement.
While a transaction is active, all statements are legal except another START TRANSACTION.
Implementing Tarantool’s SQL On Top of NoSQL
Tarantool’s SQL data is the same as Tarantool’s NoSQL data. When you create a table or an index with SQL,
you are creating a space or an index in NoSQL. For example:
Therefore you can take advantage of Tarantool’s NoSQL features even though your primary language is SQL.
Here are some possibilities.
(1) NoSQL applications written in one of the connector languages may be slightly faster than SQL applications
because SQL statements may require more parsing and may be translated to NoSQL requests.
(2) You can write stored procedures in Lua, combining Lua loop-control and Lua library-access statements with SQL statements.
These routines are executed on the server, which is the principal advantage of pure-SQL stored procedures.
(3) There are some options that are implemented in NoSQL that are not (yet) implemented in SQL.
For example you can use NoSQL to change an index option, and to deny access to users named ‘guest’.
(4) System spaces such as _space and _index can be accessed with SQL SELECT statements.
This is not quite the same as an information_schema, but it does mean that you can
use SQL to access the database’s metadata catalog.
Fields in NoSQL spaces can be accessed with SQL if and only if they are scalar and are defined
in format clauses. Indexes of NoSQL spaces will be used with SQL if and only if they are TREE indexes.
Relational databases
Edgar F. Codd, the person most responsible for researching and explaining relational database concepts,
listed the main criteria as
(Codd’s 12 rules).
Although Tarantool is not advertised as “relational”, Tarantool comes with a claim that it complies with these rules,
with the following caveats and exceptions …
The rules state that all data must be viewable as relations.
A Tarantool SQL table is a relation.
However, it is possible to have duplicate values in SQL tables and it is possible
to have an implicit ordering. Those characteristics are not allowed for true relations.
The rules state that there must be a dynamic online catalog. Tarantool has one but some metadata is missing from it.
The rules state that the data language must support authorization.
Tarantool’s SQL does not. Authorization occurs via NoSQL requests.
The rules require that data must be physically independent (from underlying storage changes)
and logically independent (from application program changes).
So far there is not enough experience to make this guarantee.
The rules require certain types of updatable views. Tarantool’s views are not updatable.
The rules state that it should be impossible to use a low-level language to bypass
integrity as defined in the relational-level language.
In Tarantool’s case, this is not true, for example one can execute a request
with Tarantool’s NoSQL to violate a foreign-key constraint that was defined with Tarantool’s SQL.
To learn more about SQL in Tarantool, check the reference.
SQL tutorial
This tutorial is a demonstration of the support for SQL in Tarantool.
It includes the functionality that you’d encounter in an “SQL-101” course.
This INSERT fails because of a primary-key violation: the row with the primary
key 1,'AB' already exists.
The SEQSCAN keyword
Sequential scan is the scan through all the table rows instead of using indexes.
In Tarantool, SELECT SQL queries that perform sequential scans are prohibited by default.
For example, this query leads to the error Scanningisnotallowedfor'table2':
SELECT*FROMtable2;
To execute a scan query, put the SEQSCAN keyword before the table name:
SELECT*FROMSEQSCANtable2;
Try to execute these queries that use indexed column1 in filters:
The second query fails with the error Scanningisnotallowedfor'TABLE2'.
Although column1 is indexed, the expression column1+1 is not calculated
from the index, which makes this SELECT a scan query.
Note
To enable SQL scan queries without SEQSCAN for the current session,
run this command:
The first statement uses the LIKE comparison operator which is asking
for “first character must be ‘A’, the next characters can be anything.”
The second statement uses logical operators and parentheses, so the AND expressions must be true, or the OR
expression must be true. Notice the columns don’t have to be indexed.
The first INSERT fails because NULL is not
permitted for a column that was defined with a
PRIMARYKEY clause.
The other INSERT statements succeed.
Indexes
Create a new index on column4.
There already is an index for the primary key. Indexes are useful for making queries
faster. In this case, the index also acts as a constraint, because it prevents
two rows from having the same values in column4. However, it is not an error
that column4 has multiple occurrences of NULLs.
CREATEUNIQUEINDEXiONtable2(column4);
The result is: rowcount:1.
Create a subset table
Create a table table3, which contains a subset of the table2 columns
and a subset of the table2 rows.
You can do this by combining INSERT with SELECT. Then select everything
from the result table.
The first INSERT statement succeeds because
table3 contains a row with [2,'AB','',12.34567].
The second INSERT statement, correctly, fails with the message
Foreignkeyconstraint''fk_unnamed_TABLE5_1''failed:foreigntuplewasnotfound.
UPDATE
Due to earlier INSERT statements, these values are in column4 of table2:
{0,NULL,NULL,5.5,10000,12.34567}. Add 5 to each of these values except 0.
Adding 5 to NULL results in NULL, as SQL arithmetic requires.
Use SELECT to see what happened to column4.
The first DELETE statement causes an error because
there’s a foreign-key constraint.
The second DELETE statement succeeds.
The SELECT statement shows that there are 5 rows remaining.
ALTER TABLE with a FOREIGN KEY clause
Create another constraint that there must not be any rows in table1
containing values that do not appear in table5. This was impossible
during the table1 creation because at that time table5 did not exist.
You can add constraints to existing tables with the ALTERTABLE statement.
Result: the ALTERTABLE statement fails the first time because there is a row
in table1, and ADDCONSTRAINT requires that the table be empty.
After the row is deleted, the ALTERTABLE statement completes successfully.
Now there is a chain of references, from table1 to table5 and from table5
to table2.
Triggers
The idea of a trigger is: if a change (INSERT or UPDATE or DELETE) happens,
then a further action – perhaps another INSERT or UPDATE or DELETE
– will happen.
Set up the following trigger: when a update to table3 is done, do an update
to table2. Specify this as FOREACHROW, so that the trigger activates 5
times (since there are 5 rows in table3).
Tarantool can handle statements like SELECT55; (select without FROM)
like some other popular DBMSs. But it also handles the more standard statement
VALUES(expression[,expression...]);.
SELECT55*55,'The rain in Spain';VALUES(55*55,'The rain in Spain');
The result of both these statements is:
- - [3025, 'The rain in Spain']
Metadata
To find out the internal structure of the Tarantool database with SQL,
select from the Tarantool system tables _space, _index, and _trigger:
To see how the SQL in Tarantool scales, create a bigger table.
The following Lua code generates one million rows with random data and
inserts them into a table. Copy this code into the Tarantool console and wait
a bit:
box.execute("CREATE TABLE tester (s1 INT PRIMARY KEY, s2 VARCHAR(10))");functionstring_function()localrandom_numberlocalrandom_stringrandom_string=""forx=1,10,1dorandom_number=math.random(65,90)random_string=random_string..string.char(random_number)endreturnrandom_stringend;functionmain_function()localstring_value,t,sql_statementfori=1,1000000,1dostring_value=string_function()sql_statement="INSERT INTO tester VALUES ("..i..",'"..string_value.."')"box.execute(sql_statement)endend;start_time=os.clock();main_function();end_time=os.clock();print('insert done in '..end_time-start_time..' seconds');
The result is: you now have a table with a million rows, with a message saying
insertdonein88.570578seconds.
Select from a million-row table
Check how SELECT works on the million-row table:
the first query goes by an index because s1 is the primary key
the second query does not go by an index
box.execute([[SELECT * FROM tester WHERE s1 = 73446;]]);box.execute([[SELECT * FROM SEQSCAN tester WHERE s2 LIKE 'QFML%';]]);
The result is:
the first statement completes instantaneously
the second statement completed noticeably slower
Cleanup and exit
To cleanup all the objects created in this tutorial, switch to the SQL input
language again. Then run the DROP statements for all created tables, views,
and triggers.
These statements must be entered separately.
sql_tutorial:instance001> \set language sqlsql_tutorial:instance001> DROP TABLE tester;sql_tutorial:instance001> DROP TABLE table1;sql_tutorial:instance001> DROP VIEW v3;sql_tutorial:instance001> DROP TRIGGER tr;sql_tutorial:instance001> DROP TABLE table5;sql_tutorial:instance001> DROP TABLE table4;sql_tutorial:instance001> DROP TABLE table3;sql_tutorial:instance001> DROP TABLE table2;sql_tutorial:instance001> DROP TABLE t6;sql_tutorial:instance001> \set language luasql_tutorial:instance001> os.exit();
Improving MySQL with Tarantool
Replicating MySQL is one of the Tarantool’s killer functions.
It allows you to keep your existing MySQL database while at the same time
accelerating it and scaling it out horizontally. Even if you aren’t interested
in extensive expansion, replacing existing replicas with Tarantool can
save you money, because Tarantool is more efficient per core than MySQL. To read
a testimonial of a company that implemented Tarantool replication on a large scale, see
the following article.
If you run into any trouble with regards to the basics of Tarantool, see the
Getting started guide or the Data model description.
A helpful log for troubleshooting during this tutorial is replicatord.log in /var/log.
You can also have a look at the instance’s log example.log in /var/log/tarantool.
The tutorial is intended for CentOS 7.5 and MySQL 5.7.
The tutorial requires that systemd and MySQL are installed.
Setting up MySQL
In this section, you configure MySQL and create a database.
$ cdmysql-tarantool-replication
$ gitsubmoduleupdate--init--recursive
$ cmake.
$ make
The replicator will run as a systemd daemon called replicatord, so, edit
its systemd service file (replicatord.service) in the
mysql-tarantool-replication repository:
The transaction model of Tarantool corresponds to the properties ACID
(atomicity, consistency, isolation, durability).
Tarantool has two modes of transaction behavior:
Default – suitable for fast monopolistic atomic transactions
MVCC – designed for long-running concurrent transactions
Each transaction in Tarantool is executed in a single fiber on a single thread, sees a consistent database state
and commits all changes atomically.
All transaction changes are written to the WAL (Write Ahead Log)
in a single batch in a specific order at the time of the
commit.
If needed, transaction changes can also be rolled back –
completely or to
a specified savepoint.
By default, the isolation level of Tarantool is serializable.
The exception is a failure during writing to the WAL, which can occur, for example, when the disk space is over.
In this case, the isolation level of the concurrent read transaction would be read-committed.
The MVСС mode provides several options that enable you to tune
the visibility behavior during transaction execution.
Read-committed
The read-committed isolation level makes visible all transactions that started commit (box.commit() was called).
Write transactions with reads
Manual usage of read-committed for write transactions with reads is completely safe, as this transaction will eventually result in a commit.
If a previous transactions fails, this transaction will inevitably fail as well due to the serializable isolation level.
Read transactions
Manual usage of read-committed for read transactions may be unsafe, as it may lead to phantom reads.
Read-confirmed
The read-confirmed isolation level makes visible all transactions that finished
the commit (box.commit() was returned).
This means that new data is already on disk or even on other replicas.
Read transactions
The use of read-confirmed is safe for read transactions given that data
is on disk (for asynchronous replication) or even in other replicas
(for synchronous replication).
Write transactions
To achieve serializable, any write transaction should read all data that has already been committed.
Otherwise, it may conflict when it reaches its commit.
Linearizable read
Linearizability of read operations implies that if a response for a write request arrived earlier than a read request was made, this read request should return the results of the write request.
When called with linearizable, box.begin() yields until the instance receives enough data from remote peers to be sure that the transaction is linearizable.
Linearizable transactions may only perform requests to the following memtx space types:
A linearizable transaction can fail with an error in the following cases:
If the node can’t contact enough remote peers to determine which data is committed.
If the data isn’t received during the timeout specified in box.begin().
Note
To start a linearizable transaction, the node should be the replication source for at least N-Q+1 remote replicas.
Here N is the count of registered nodes in the cluster and Q is replication_synchro_quorum.
So, for example, you can’t perform a linearizable transaction on anonymous replicas because they can’t be the source of replication for other nodes.
Best-effort (default)
To minimize the possibility of conflicts, MVCC uses what is called best-effort visibility:
This inevitably leads to the serializable isolation level.
Since there is no option for MVCC to analyze the whole transaction to make a decision, it makes the choice on
the first operation.
Note
If the serializable isolation level becomes unreachable, the transaction is marked as “conflicted”
and rolled back.
Thread model
Main threads
The thread model assumes that a query received by Tarantool via network
is processed with three operating system threads:
The network thread (or threads)
on the server side receives the query, parses
the statement, checks if it is correct, and then transforms it into a special
structure – a message containing an executable statement and its options.
The network thread sends this message to the instance’s
transaction processor thread (TX thread) via a lock-free message bus.
Lua programs are executed directly in the transaction processor thread,
and do not need to be parsed and prepared.
The TX thread either uses a space index to find and update the tuple,
or executes a stored function that performs a data operation.
The execution of the operation results in a message to the
write-ahead logging (WAL) thread used to commit
the transaction and the fiber executing the transaction is suspended.
When the transaction results in a COMMIT or ROLLBACK, the following actions are taken:
The WAL thread responds with a message to the TX thread.
The fiber executing the transaction is resumed to process the result of the transaction.
The result of the fiber execution is passed to the network thread,
and the network thread returns the result to the client.
Note
There is only one TX thread in Tarantool.
Some users are used to the idea that there can be multiple threads
working on the database. For example, thread #1 reads a row #x while
thread #2 writes a row #y. With Tarantool this does not happen.
Only the TX thread can access the database,
and there is only one TX thread for each Tarantool instance.
The TX thread can handle many fibers –
a set of computer instructions that can contain “yield” signals.
The TX thread executes all computer instructions up to a
yield signal, and then switches to execute the instructions of another fiber.
Yields must happen, otherwise the TX thread would
be permanently stuck on the same fiber.
Supplementary threads
There are also several supplementary threads that serve additional capabilities:
For replication, Tarantool creates a separate thread for each connected replica.
This thread reads a write-ahead log and sends it to the replica, following its position in the log.
Separate threads are required because each replica can point to a different position in the log and can run at different speeds.
There is a thread pool for ad hoc asynchronous tasks, such as a DNS resolver or fsync.
There is a thread pool that can be used for parallel sorting (hence, to parallelize building indexes).
To configure it, use the memtx.sort_threads configuration option.
The option sets the number of threads used to sort keys of secondary indexes on loading a memtx database.
Note
Since 3.0.0, this option replaces the approach when OpenMP threads are used to parallelize sorting.
For backward compatibility, the OMP_NUM_THREADS environment variable is taken into account to
set the number of sorting threads.
Transaction mode: default
By default, Tarantool does not allow “yielding” inside a memtx
transaction and the transaction manager is disabled. This allows fast
atomic transactions without conflicts, but brings some limitations:
To switch back to the default mode, disable the transaction manager:
box.cfg{memtx_use_mvcc_engine=false}
Transaction mode: MVCC
Since version 2.6.1,
Tarantool has another transaction behavior mode that
allows “yielding” inside a memtx transaction.
This is controlled by the transaction manager.
This mode allows concurrent transactions but may cause conflicts.
You can use this mode on the memtx storage engine.
The vinyl storage engine also supports MVCC mode,
but has a different implementation.
Note
Currently, you cannot use several different storage engines within one transaction.
Transaction manager
The transaction manager is designed to isolate concurrent transactions
and provides a serializabletransaction isolation level.
It consists of two parts:
MVCC – multi version concurrency control engine, which stores all change actions of all
transactions. It also creates the transaction view of the database state and a read view
(a fixed state of the database that is never changed by other transactions) when necessary.
Conflict manager – a manager that tracks changes to transactions and determines their correctness
in the serialization order. The conflict manager declares transactions to be in conflict
or sends transactions to read views when necessary.
Since version 2.10.1, the conflict manager detects conflicts right after
the first one of several conflicting transactions is committed. After this moment, any CRUD operations
in the conflicted transaction will result in errors until the transaction is
rolled back.
The transaction manager also provides a non-classical snapshot isolation level – this snapshot is not
necessarily tied to the start time of the transaction, like the classical snapshot where a transaction
can get a consistent snapshot of the database. The conflict manager decides if and when each transaction
gets which snapshot. This avoids some conflicts compared to the classic snapshot isolation approach.
Warning
Currently, the isolation level of BITSET and RTREE indexes
in MVCC transaction mode is read-committed (not serializable, as stated).
If a transaction uses these indexes, it can read committed or confirmed data (depending on the isolation level).
However, the indexes are subject to different anomalies that can make them unserializable.
Enabling the transaction manager
By default, the transaction manager is disabled. Use the memtx_use_mvcc_engine
option to enable it via box.cfg.
Using best-effort as the default option allows MVCC to consider the actions of transactions
independently and determine the best isolation level for them.
It increases the probability of successful completion of the transaction and helps to avoid possible conflicts.
To set another default isolation level, for example, read-committed, use the following command:
box.cfg{txn_isolation='read-committed'}
Note that the linearizable isolation level can’t be set as default and can be used for a specific transaction only.
You can set an isolation level for a specific transaction in its box.begin() call:
box.begin({txn_isolation='best-effort'})
In this case, you can also use the default option. It sets the transaction’s isolation level
to the one set in box.cfg.
Note
For autocommit transactions (actions with a statement without explicit box.begin/box.commit calls)
there is a rule:
Read-only transactions (for example, select) are performed with read-confirmed.
All other transactions (for example, replace) are performed with read-committed.
You can also set the isolation level in the net.box stream:begin() method
and IPROTO_BEGIN binary protocol request.
Choosing the better option depends on whether you have conflicts or not.
If you have many conflicts, you should set a different option or use
the default transaction mode.
Since v. 2.10.0, IPROTO implements streams and interactive
transactions that can be used when memtx_use_mvcc_engine
is enabled on the server.
Stream
A stream supports multiplexing several transactions over one connection.
Each stream has its own identifier, which is unique within the connection.
All requests with the same non-zero stream ID belong to the same stream.
All requests in a stream are executed strictly sequentially.
This allows the implementation of
interactive transactions.
If the stream ID of a request is 0, it does not belong to any stream and is
processed in the old way.
In net.box, a stream is an object above
the connection that has the same methods but allows sequential execution of requests.
The ID is automatically generated on the client side.
If a user writes their own connector and wants to use streams,
they must transmit the stream_id over the IPROTO protocol.
Unlike a thread, which involves multitasking and execution within a program,
a stream transfers data via the protocol between a client and a server.
Interactive transaction
An interactive transaction is one that does not need to be sent in a single request.
There are multiple ways to begin, commit, and roll back a transaction, and they can be mixed.
You can use stream:begin(), stream:commit(),
stream:rollback() or the appropriate stream methods
– call, eval, or execute – using the SQL transaction syntax.
Let’s create a Lua client (client.lua) and run it with Tarantool:
localnet_box=require'net.box'localconn=net_box.connect('127.0.0.1:3301')localconn_tickets=conn.space.ticketslocalyaml=require'yaml'localstream=conn:new_stream()localstream_tickets=stream.space.tickets-- Begin transaction over an iproto stream:stream:begin()print("Replaced in a stream\n"..yaml.encode(stream_tickets:replace({1,768})))-- Empty select, the transaction was not committed.-- You can't see it from the requests that do not belong to the-- transaction.print("Selected from outside of transaction\n"..yaml.encode(conn_tickets:select({},{limit=10})))-- Select returns the previously inserted tuple-- because this select belongs to the transaction:print("Selected from within transaction\n"..yaml.encode(stream_tickets:select({},{limit=10})))-- Commit transaction:stream:commit()-- Now this select also returns the tuple because the transaction has been committed:print("Selected again from outside of transaction\n"..yaml.encode(conn_tickets:select({},{limit=10})))os.exit()
Then call it and see the following output:
Replaced in a stream
--- [1, 768]
...
Selected from outside of transaction
---
- [1, 429]
- [2, 429]
...
Selected from within transaction
---
- [1, 768]
- [2, 429]
...
Selected again from outside of transaction
---
- [1, 768]
- [2, 429]
...```
Replication
Replication allows multiple Tarantool instances to work on copies of the same
databases. The databases are kept in sync because each instance can communicate
its changes to all the other instances.
For practical guides to replication, see Replication tutorials.
You can learn about bootstrapping a replica set, adding instances to the replica set, or removing them.
Replication architecture
Replication mechanism
Overview
A pack of instances that operate on copies of the same databases makes up a replica set.
Each instance in a replica set has a role: master or replica.
A replica gets all updates from the master by continuously fetching and applying
its write-ahead log (WAL). Each record in the WAL represents a single
Tarantool data-change request such as INSERT,
UPDATE, or DELETE, and is assigned
a monotonically growing log sequence number (LSN). In essence, Tarantool
replication is row-based: each data-change request is fully deterministic
and operates on a single tuple. However, unlike a classical row-based log, which
contains entire copies of the changed rows, Tarantool’s WAL contains copies of the requests.
For example, for UPDATE requests, Tarantool only stores the primary key of the row and
the update operations to save space.
Note
WAL extensions available in Tarantool Enterprise Edition enable you to add auxiliary information to each write-ahead log record.
This information might be helpful for implementing a CDC (Change Data Capture) utility that transforms a data replication stream.
The following are specifics of adding different types of information to the WAL:
Invocations of stored programs are not written to the WAL.
Instead, records of the actual data-change requests, performed by the Lua code, are written to the WAL.
This ensures that the possible non-determinism of Lua does not cause replication to go out of sync.
Data definition operations on temporary spaces (created with temporary=true), such as creating/dropping, adding indexes, and truncating, are written to the WAL, since information about temporary spaces is stored in non-temporary system spaces, such as box.space._space.
Data change operations on temporary spaces are not written to the WAL and are not replicated.
Data change operations on replication-local spaces (created with is_local=true) are written to the WAL but are not replicated.
To create a valid initial state, to which WAL changes can be applied, every instance of a replica set requires a start set of checkpoint files, such as .snap files for memtx and .run files for vinyl.
A replica goes through the following stages:
Bootstrap (optional)
When an entire replica set is bootstrapped for the first time, there is no master that could provide the initial checkpoint.
In such a case, replicas connect to each other and elect a master.
The master creates the starting set of checkpoint files and distributes them to all the other replicas.
This is called an automatic bootstrap of a replica set.
Join
At this stage, a replica downloads the initial state from the master.
The master register this replica in the box.space._cluster space.
If join fails with a non-critical error, for example, ER_READONLY, ER_ACCESS_DENIED, or a network-related issue, an instance tries to find a new master to join.
Note
On subsequent connections, a replica downloads all changes happened after the latest local LSN (there can be many LSNs – each master has its own LSN).
Follow
At this stage, a replica fetches and applies updates from the master’s write-ahead log.
Each replica set is identified by a globally unique identifier, called the replica set UUID.
The identifier is created by the master, which creates the very first checkpoint and is part of the checkpoint file. It is stored in the box.space._schema system space, for example:
Additionally, each instance in a replica set is assigned its own UUID, when it
joins the replica set. It is called an instance UUID and is a globally unique
identifier. The instance UUID is checked to ensure that instances do not join a different
replica set, e.g. because of a configuration error. A unique instance identifier
is also necessary to apply rows originating from different masters only once,
that is, to implement multi-master replication. This is why each row in the write-ahead log,
in addition to its log sequence number, stores the instance identifier
of the instance on which it was created. But using a UUID as such an identifier
would take too much space in the write-ahead log, thus a shorter integer number
is assigned to the instance when it joins a replica set. This number is then
used to refer to the instance in the write-ahead log. It is called
instance ID. All identifiers are stored in the system space
box.space._cluster, for example:
Here the instance ID is 1 (unique within the replica set), and the instance
UUID is 88580b5c-4474-43ab-bd2b-2409a9af80d2 (globally unique).
Using instance IDs is also handy for tracking the state of the entire
replica set. For example, box.info.vclock
describes the state of replication in regard to each connected peer.
tarantool> box.info.vclock----{1:827, 2:584}...
Here vclock contains log sequence numbers (827 and 584) for instances with
instance IDs 1 and 2.
If required, you can explicitly specify the instance and the replica set UUID values rather than letting Tarantool generate them.
To learn more, see the replicaset_uuid configuration parameter description.
Replication roles: master and replica
The replication role (master or replica) is set by the
read_only configuration parameter. The recommended
role is “read_only” (replica) for all but one instance in the replica set.
In a master-replica configuration, every change that happens on the master will
be visible on the replicas, but not vice versa.
A simple two-instance replica set with the master on one machine and the replica
on a different machine provides two benefits:
failover, because if the master goes down, then the replica can take over,
and
load balancing, because clients can connect to either the master or the
replica for read requests.
In a master-master configuration (also called “multi-master”), every change
that happens on either instance will be visible on the other one.
The failover benefit in this case is still present, and the load-balancing
benefit is enhanced, because any instance can handle both read and write
requests. Meanwhile, for multi-master configurations, it is necessary to
understand the replication guarantees provided by the asynchronous protocol
that Tarantool implements.
Tarantool multi-master replication guarantees that each change on each master is
propagated to all instances and is applied only once. Changes from the same
instance are applied in the same order as on the originating instance. Changes
from different instances, however, can be mixed and applied in a different order on
different instances. This may lead to replication going out of sync in certain
cases.
For example, assuming the database is only appended to (i.e. it contains only
insertions), a multi-master configuration is safe. If there are also
deletions, but it is not mission critical that deletion happens in the same
order on all replicas (e.g. the DELETE is used to prune expired data),
a master-master configuration is also safe.
UPDATE operations, however, can easily go out of sync. For example, assignment
and increment are not commutative and may yield different results if applied
in a different order on different instances.
More generally, it is only safe to use Tarantool master-master replication if
all database changes are commutative: the end result does not depend on the
order in which the changes are applied. You can start learning more about
conflict-free replicated data types
here.
Replication topologies: cascade, ring, and full mesh
Replication topology is set by the replication
configuration parameter. The recommended topology is a full mesh because it
makes potential failover easy.
Some database products offer cascading replication topologies: creating a
replica on a replica. Tarantool does not recommend such a setup.
The problem with a cascading replica set is that some instances have no
connection to other instances and may not receive changes from them. One
essential change that must be propagated across all instances in a replica set
is an entry in box.space._cluster system space with the replica set UUID.
Without knowing the replica set UUID, a master refuses to accept connections from
such instances when replication topology changes. Here is how this can happen:
We have a chain of three instances. Instance #1 contains entries for instances
#1 and #2 in its _cluster space. Instances #2 and #3 contain entries for
instances #1, #2, and #3 in their _cluster spaces.
Now instance #2 is faulty. Instance #3 tries connecting to instance #1 as its
new master, but the master refuses the connection since it has no entry, for
example, #3.
Ring replication topology is, however, supported:
So, if you need a cascading topology, you may first create a ring to ensure all
instances know each other’s UUID, and then disconnect the chain in the place you
desire.
A stock recommendation for a master-master replication topology, however, is a
full mesh:
You then can decide where to locate instances of the mesh – within the same
data center, or spread across a few data centers. Tarantool will automatically
ensure that each row is applied only once on each instance. To remove a degraded
instance from a mesh, simply change the replication configuration parameter.
This ensures full cluster availability in case of a local failure, e.g. one of
the instances failing in one of the data centers, as well as in case of an
entire data center failure.
The maximal number of replicas in a mesh is 32.
Orphan status
During box.cfg(), an instance tries to join all nodes listed
in box.cfg.replication.
If the instance does not succeed in connecting to the required number of nodes
(see bootstrap_strategy),
it switches to the orphan status.
Synchronous replication
Overview
By default, replication in Tarantool is asynchronous: if a transaction
is committed locally on a master node, it does not mean it is replicated onto any
replicas. If a master responds success to a client and then dies, after failover
to a replica, from the client’s point of view the transaction will disappear.
Synchronous replication exists to solve this problem. Synchronous transactions
are not considered committed and are not responded to a client until they are
replicated onto some number of replicas.
To enable synchronous replication, use the space_opts.is_sync option when creating or altering a space.
Synchronous and asynchronous transactions
A killer feature of Tarantool’s synchronous replication is its being per-space.
So, if you need it only rarely for some critical data changes, you won’t pay for
it in performance terms.
When there is more than one synchronous transaction, they all wait for being
replicated. Moreover, if an asynchronous transaction appears, it will
also be blocked by the existing synchronous transactions. This behavior is very
similar to a regular queue of asynchronous transactions because all the transactions
are committed in the same order as they make the box.commit() call.
So, here comes the commit rule:
transactions are committed in the same order as they make
the box.commit() call – regardless of being synchronous or asynchronous.
If one of the waiting synchronous transactions times out and is rolled back, it
will first roll back all the newer pending transactions. Again, just like how
asynchronous transactions are rolled back when WAL write fails.
So, here comes the rollback rule:
transactions are always rolled back in the order reversed from the one they
make the box.commit() call – regardless of being synchronous or asynchronous.
One more important thing is that if an asynchronous transaction is blocked by
a synchronous transaction, it does not become synchronous as well.
This just means it will wait for the synchronous transaction to be committed.
But once it is done, the asynchronous transaction will be committed
immediately – it won’t wait for being replicated itself.
Warning
Be careful when using synchronous and asynchronous transactions together.
Asynchronous transactions are considered committed even if there is no connection to other nodes.
Therefore, an old leader node (synchronous transaction queue owner) might have some
committed asynchronous transactions that no other replica set member has.
When the connection to such an old (previous) leader node is restored, it starts receiving data from the new leader.
At the same time, other replica set members receive the data from the previous leader that they don’t have yet.
The data from the previous leader contains some committed asynchronous transactions.
At this time, the integrity protection will throw
the ER_SPLIT_BRAIN error, which will force the user to rebootstrap the previous leader.
Limitations and known problems
Until version 2.5.2,
there was no way to enable synchronous replication for
existing spaces, but since 2.5.2 it can be enabled by
space_object:alter({is_sync = true}).
Synchronous transactions work only for master-slave topology. You can have multiple
replicas, anonymous replicas, but only one node can make synchronous transactions.
Since Tarantool 2.10.0, anonymous replicas do not participate in the quorum.
Leader election
Starting from version 2.6.1,
Tarantool has the built-in functionality
managing automated leader election in a replica set. For more information,
refer to the corresponding chapter.
Automated leader election
Starting from version 2.6.1,
Tarantool has the built-in functionality
managing automated leader election in a replica set.
This functionality increases the fault tolerance of the systems built
on the base of Tarantool and decreases
dependency on external tools for replica set management.
Leader election and synchronous replication are implemented in Tarantool as
a modification of the Raft
algorithm.
Raft is an algorithm of synchronous replication and automatic leader election.
Its complete description can be found in the corresponding document.
In Tarantool, synchronous replication and leader election
are supported as two separate subsystems.
So it is possible to get synchronous replication
but use an alternative algorithm for leader election.
And vice versa – elect a leader
in the cluster but don’t use synchronous spaces at all.
Synchronous replication has a separate documentation section.
Leader election is described below.
Note
The system behavior can be specified exactly according to the Raft algorithm. To do this:
In the replication.election_fencing_mode option, select either the soft mode (the default)
or the strict mode, which is more restrictive.
Leader election process
Automated leader election in Tarantool helps guarantee that
there is at most one leader at any given moment of time in a replica set.
A leader is a writable node, and all other nodes are non-writable –
they accept read-only requests exclusively.
When the election is enabled, the life cycle of
a replica set is divided into so-called
terms. Each term is described by a monotonically growing number.
After the first boot, each node has its term equal to 1. When a node sees that
it is not a leader and there is no leader available for some time in the replica
set, it increases the term and starts a new leader election round.
Leader election happens via votes. The node that started the election votes
for itself and sends vote requests to other nodes.
Upon receiving vote requests, a node votes for the first of them, and then cannot
do anything in the same term but wait for a leader to be elected.
The node that collected a quorum of votes defined by the replication.synchro_quorum parameter
becomes the leader
and notifies other nodes about that. Also, a split vote can happen
when no nodes received a quorum of votes. In this case,
after a random timeout,
each node increases its term and starts a new election round if no new vote
request with a greater term arrives during this time.
Eventually, a leader is elected.
If any unfinalized synchronous transactions are left from the previous leader,
the new leader finalizes them automatically.
All the non-leader nodes are called followers. The nodes that start a new
election round are called candidates. The elected leader sends heartbeats to
the non-leader nodes to let them know it is alive.
In case there are no heartbeats for the period of replication.timeout * 4,
a non-leader node starts a new election if the following conditions are met:
The node has a quorum of connections to other cluster members.
None of these cluster members can see the leader node.
Note
A cluster member considers the leader node to be alive if the member received heartbeats from the leader at least
once during the replication.timeout*4,
and there are no replication errors (the connection is not broken due to timeout or due to an error).
Terms and votes are persisted by each instance to preserve certain Raft guarantees.
During the election, the nodes prefer to vote for those ones that have the
newest data. So as if an old leader managed to send something before its death
to a quorum of replicas, that data wouldn’t be lost.
When election is enabled, there must be connections
between each node pair so as it would be the full mesh topology. This is needed
because election messages for voting and other internal things need a direct
connection between the nodes.
In the classic Raft algorithm, a leader doesn’t track its connectivity to the rest of the cluster.
Once the leader is elected, it considers itself in the leader position until receiving a new term from another cluster node.
This can lead to a split situation if the other nodes elect a new leader upon losing the connectivity to the previous one.
The issue is resolved in Tarantool version 2.10.0 by introducing the leader fencing mode.
The mode can be switched by the replication.election_fencing_mode configuration parameter.
When the fencing is set to soft or strict, the leader resigns its leadership if it has less than
replication.synchro_quorum of alive connections to the cluster nodes.
The resigning leader receives the status of a follower in the current election term and becomes read-only.
Leader fencing can be turned off by setting the replication.election_fencing_mode configuration parameter to off.
In soft mode, a connection is considered dead if there are no responses for
4 * replication.timeout seconds both on the current leader and the followers.
In strict mode, a connection is considered dead if there are no responses
for 2 * replication.timeout seconds on the current leader and for
4 * replication.timeout seconds on the followers.
This improves chances that there is only one leader at any time.
Fencing applies to the instances that have the replication.election_mode set to “candidate” or “manual”.
There can still be a situation when a replica set has two leaders working independently (so-called split-brain).
It can happen, for example, if a user mistakenly lowered the replication.synchro_quorum below N/2+1.
In this situation, to preserve the data integrity, if an instance detects the split-brain anomaly in the incoming replication data,
it breaks the connection with the instance sending the data and writes the ER_SPLIT_BRAIN error in the log.
Eventually, there will be two sets of nodes with the diverged data,
and any node from one set is disconnected from any node from the other set with the ER_SPLIT_BRAIN error.
Once noticing the error, a user can choose any representative from each of the sets and inspect the data on them.
To correlate the data, the user should remove it from the nodes of one set,
and reconnect them to the nodes from the other set that have the correct data.
Also, if election is enabled on the node, it doesn’t replicate from any nodes except
the newest leader. This is done to avoid the issue when a new leader is elected,
but the old leader has somehow survived and tries to send more changes
to the other nodes.
Term numbers also work as a kind of filter.
For example, if election is enabled on two nodes and node1 has the term number less than node2,
then node2 doesn’t accept any transactions from node1.
replication.election_timeout – specifies the timeout between election rounds if the
previous round ended up with a split vote.
replication.timeout – a time interval (in seconds) used by a master to send heartbeat requests to a replica when there are no updates to send to this replica.
It is important to know that being a leader is not the only requirement for a node to be writable.
The leader should also satisfy the following requirements:
Nothing prevents you from setting the database.mode option to ro,
but the leader won’t be writable then. The option doesn’t affect the
election process itself, so a read-only instance can still vote and become
a leader.
Monitoring
To monitor the current state of a node regarding the leader election, use the box.info.election function.
The Raft-based election implementation logs all its actions
with the RAFT: prefix. The actions are new Raft message handling,
node state changing, voting, and term bumping.
Important notes
Leader election doesn’t work correctly if the election quorum is set to less or equal
than <clustersize>/2. In that case, a split vote can lead to
a state when two leaders are elected at once.
For example, suppose there are five nodes. When the quorum is set to 2, node1
and node2 can both vote for node1. node3 and node4 can both vote
for node5. In this case, node1 and node5 both win the election.
When the quorum is set to the cluster majority, that is
(<clustersize>/2)+1 or greater, the split vote is impossible.
That should be considered when adding new nodes.
If the majority value is changing, it’s better to update the quorum on all the existing nodes
before adding a new one.
Also, the automated leader election doesn’t bring many benefits in terms of data
safety when used withoutsynchronous replication.
If the replication is asynchronous and a new leader gets elected,
the old leader is still active and considers itself the leader.
In such case, nothing stops
it from accepting requests from clients and making transactions.
Non-synchronous transactions are successfully committed because
they are not checked against the quorum of replicas.
Synchronous transactions fail because they are not able
to collect the quorum – most of the replicas reject
these old leader’s transactions since it is not a leader anymore.
Tarantool provides the ability to control leadership in a replica set using an external failover coordinator.
A failover coordinator reads a cluster configuration from a file or an etcd-based configuration storage, polls instances for their statuses, and appoints a leader for each replica set depending on the availability and health of instances.
To increase fault tolerance, you can run two or more failover coordinators.
In this case, an etcd cluster provides synchronization between coordinators.
Overview
The main steps of using an external failover coordinator for a newly configured cluster might look as follows:
Configure a cluster to work with an external coordinator.
The main step is setting the replication.failover option to supervised for all replica sets that should be managed by the external coordinator.
Start a configured cluster.
When an external coordinator is still not running, instances in a replica set start in the following modes:
If a replica set is already bootstrapped, all instances are started in read-only mode.
If a replica set is not bootstrapped, one instance is started in read-write mode.
Start a failover coordinator.
You can start two or more failover coordinators to increase fault tolerance.
In this case, one coordinator is active and others are passive.
Once a cluster and failover coordinators are up and running, a failover coordinator appoints one instance to be a master if there is no master instance in a replica set.
Then, the following events may occur:
If a master instance fails, a failover coordinator performs an automated failover.
If an active failover coordinator fails, another coordinator becomes active and performs an automated failover.
Note
Note that a failover coordinator doesn’t work with replica sets with two or more read-write instances.
In this case, a coordinator logs a warning to stdout and doesn’t perform any appointments.
Appointing a new master instance
After a master instance has been appointed, a failover coordinator monitors the statuses of all instances in a replica set by sending requests each probe_interval seconds.
For the master instance, the coordinator maintains a read-write mode deadline, which is renewed periodically each renew_interval seconds.
If all attempts to renew the deadline fail during the specified time interval (lease_interval), the master switches to read-only mode.
Then, the coordinator appoints a new instance as the master.
If a remote etcd-based storage is used to maintain the state of failover coordinators, you can also perform a manual failover.
Active and passive coordinators
To increase fault tolerance, you can run two or more failover coordinators.
In this case, only one coordinator is active and used to control leadership in a replica set.
Other coordinators are passive and don’t perform any read-write appointments.
To maintain the state of coordinators, Tarantool uses a stateboard – a remote etcd-based storage.
This storage uses the same connection settings as a centralized etcd-based configuration storage.
If a cluster configuration is stored in the <prefix>/config/* keys in etcd, the failover coordinator looks into <prefix>/failover/* for its state.
Here are a few examples of keys used for different purposes:
<prefix>/failover/info/by-uuid/<uuid>: contains a state of a failover coordinator identified by the specified uuid.
<prefix>/failover/active/lock: a unique identifier (UUID) of an active failover coordinator.
<prefix>/failover/active/term: a kind of fencing token allowing to have an order in which coordinators become active (took the lock) over time.
<prefix>/failover/command/<id>: a key used to perform a manual failover.
Configuring a cluster
To configure a cluster to work with an external failover coordinator, follow the steps below:
In Tarantool 3.0 and 3.1, the configuration is different and the function
must be created in the application code. See Tarantool 3.0 and 3.1 configuration for details.
(Optional) Configure options that control how a failover coordinator operates in the failover section:
Before version 3.2, Tarantool used another mechanism to grant execute access to Lua
functions. In Tarantool 3.0 and 3.1, the credentials configuration section
should look as follows:
# Tarantool 3.0 and 3.1credentials:users:replicator:password:'topsecret'roles:[replication]privileges:-permissions:[execute]functions:['failover.execute']
Additionally, you should create the failover.execute function in the application code.
For example, you can create a custom role for this purpose:
-- Tarantool 3.0 and 3.1 ---- supervised_instance.lua --return{validate=function()end,apply=function()ifbox.info.rothenreturnendlocalfunc_name='failover.execute'localopts={if_not_exists=true}box.schema.func.create(func_name,opts)end,stop=function()ifbox.info.rothenreturnendlocalfunc_name='failover.execute'ifnotbox.schema.func.exists(func_name)thenreturnendbox.schema.func.drop(func_name)end,}
Then, enable this role for all storage instances:
# Tarantool 3.0 and 3.1roles:['supervised_instance']
Starting a failover coordinator
To start a failover coordinator, you need to execute the tarantool command with the failover option.
This command accepts the path to a cluster configuration file:
You can run two or more failover coordinators to increase fault tolerance.
In this case, only one coordinator is active and used to control leadership in a replica set.
Learn more from Active and passive coordinators.
Performing manual failover
If an etcd-based storage is used to maintain the state of failover coordinators, you can perform a manual failover.
External tools can use the <prefix>/failover/command/<id> key to choose a new master.
For example, the tt utility provides the tt cluster failover command for managing a supervised failover.
Note that a vclock value might include the 0 component that is related to local space operations and might differ for different instances in a replica set.
Adding instances
This section describes how to add a new replica to a replica set.
Adding an instance to the configuration
Add instance003 to the instances.yml file:
instance001:instance002:instance003:
Add instance003 with the specified iproto.listen option to the config.yaml file:
After you added instance003 to the configuration and started it, you need to reload configurations on all instances.
This is required to allow instance001 and instance002 to get data from the new instance in case it becomes a master.
Connect to instance003 using ttconnect:
$ ttconnectmanual_leader:instance003
• Connecting to the instance... • Connected to manual_leader:instance001
Reload configurations on all three instances using the reload() function provided by the config module:
This section shows how to perform manual failover and change a replica set leader.
Switching instances to read-only mode
In the config.yaml file, change the replica set leader from instance001 to null:
replicaset001:leader:null
Reload configurations on all three instances using config:reload() and check that instances are in read-only mode.
The example below shows how to do this for instance001:
Define a replica set topology inside the groups section.
The iproto.listen option specifies an address used to listen for incoming requests and allows replicas to communicate with each other.
$ ttconnectauto_leader:instance001
• Connecting to the instance... • Connected to auto_leader:instance001
Check the instance state in regard to leader election using box.info.election.
The output below shows that instance001 is a follower while instance002 is a replica set leader.
Check that instance001 is in read-only mode using box.info.ro:
auto_leader:instance001> box.info.ro---- true...
Execute box.info.replication to check a replica set status.
Make sure that upstream.status and downstream.status are follow for instance002 and instance003.
Note that a vclock value might include the 0 component that is related to local space operations and might differ for different instances in a replica set.
Testing automated failover
To test how automated failover works if the current master is stopped, follow the steps below:
Stop the current master instance (instance002) using the ttstop command:
$ ttstopauto_leader:instance002
• The Instance auto_leader:instance002 (PID = 24769) has been terminated.
On instance001, check box.info.election.
In this example, a new replica set leader is instance001.
The process of adding instances to a replica set and removing them is similar for all failover modes.
Learn how to do this from the Master-replica: manual failover tutorial:
Before removing an instance from a replica set with replication.failover set to election, make sure this instance is in read-only mode.
If the instance is a master, choose a new leader manually.
To see the diagrams that illustrate how the upstream and downstream connections look,
refer to Monitoring a replica set.
Note
Note that a vclock value might include the 0 component that is related to local space operations and might differ for different instances in a replica set.
Adding data
To check that both instances get updates from each other, follow the steps below:
On instance001, create a space, format it, and create a primary index:
To insert conflicting records to instance001 and instance002, follow the steps below:
Stop instance001 using the ttstop command:
$ ttstopmaster_master:instance001
On instance002, insert a new record:
box.space.bands:insert{5,'incorrect data',0}
Stop instance002 using ttstop:
$ ttstopmaster_master:instance002
Start instance001 back:
$ ttstartmaster_master:instance001
Connect to instance001 and insert a record that should conflict with a record already inserted on instance002:
box.space.bands:insert{5,'Pink Floyd',1965}
Start instance002 back:
$ ttstartmaster_master:instance002
Then, check box.info.replication on instance001.
upstream.status should be stopped because of the Duplicatekeyexists error:
master_master:instance001> box.info.replication----1:id:1uuid:c3bfd89f-5a1c-4556-aa9f-461377713a2alsn:13name:instance0012:id:2uuid:dccf7485-8bff-47f6-bfc4-b311701e36eflsn:2upstream:peer:replicator@127.0.0.1:3302lag:115.99977827072status:stoppedidle:2.0342070000006message:Duplicate key exists in unique index "primary" in space "bands" withold tuple - [5, "Pink Floyd", 1965] and new tuple - [5, "incorrect data",0]name:instance002downstream:status:stoppedmessage:'unexpectedEOFwhenreadingfromsocket,calledonfd24,aka127.0.0.1:3301,peerof127.0.0.1:58478:Brokenpipe'system_message:Broken pipe...
The diagram below illustrates how the upstream and downstream connections look like:
Reseeding a replica
To resolve a replication conflict, instance002 should get the correct data from instance001 first.
To achieve this, instance002 should be rebootstrapped:
Select all the tuples in the box.space._cluster system space to get a UUID of instance002:
After reseeding a replica, you need to resolve a replication conflict that keeps replication stopped:
Execute box.info.replication on instance001.
upstream.status is still stopped:
master_master:instance001> box.info.replication----1:id:1uuid:c3bfd89f-5a1c-4556-aa9f-461377713a2alsn:13name:instance0012:id:2uuid:dccf7485-8bff-47f6-bfc4-b311701e36eflsn:2upstream:peer:replicator@127.0.0.1:3302lag:115.99977827072status:stoppedidle:1013.688243message:Duplicate key exists in unique index "primary" in space "bands" withold tuple - [5, "Pink Floyd", 1965] and new tuple - [5, "incorrect data",0]name:instance002downstream:status:followidle:0.69694700000036vclock:{2:2, 1:13}lag:0...
The diagram below illustrates how the upstream and downstream connections look like:
In the config.yaml file, clear the iproto option for instance001 by setting its value to {} to disconnect this instance from instance002.
Set database.mode to ro:
Change database.mode values back to rw for both instances and restore iproto.listen for instance001.
The database.instance_uuid option can be removed for instance002:
The process of adding instances to a replica set and removing them is similar for all failover modes.
Learn how to do this from the Master-replica: manual failover tutorial:
Before removing an instance from a replica set with replication.failover set to off, make sure this instance is in read-only mode.
Sharding
Scaling databases in a growing project is often considered one of the most
challenging issues. Once a single server cannot withstand the load, scaling
methods should be applied.
Sharding is a database architecture that allows for
horizontal scaling,
which implies that a dataset is partitioned and distributed over multiple servers.
With Tarantool’s vshard module,
the tuples of a dataset are distributed across
multiple nodes, with a Tarantool database server instance on each node. Each instance
handles only a subset of the total data, so larger loads can be handled by simply
adding more servers. The initial dataset is partitioned into multiple parts, so each
part is stored on a separate server.
The vshard module is based on the concept of
virtual buckets, where a tuple
set is partitioned into a large number of abstract virtual nodes (virtual buckets,
further just buckets) rather than into a smaller number of physical nodes.
The dataset is partitioned using sharding keys (bucket id numbers).
Hashing a sharding key into a large number of buckets allows seamlessly
changing the number of servers in the cluster. The rebalancing mechanism distributes
buckets evenly among all shards in case some servers were added or removed.
The buckets have states, so it is easy to monitor the server states. For example,
a server instance is active and available for all types of requests, or a failover
occurred and the instance accepts only read requests.
The vshard module provides router and storage API (public and internal) for sharding-aware applications.
Consider a distributed Tarantool cluster that consists of subclusters called
shards, each storing some part of data. Each shard, in its turn, constitutes
a replica set consisting of several replicas, one of which serves as a master
node that processes all read and write requests.
The whole dataset is logically partitioned into a predefined number of virtual
buckets (further just buckets), each assigned a unique number
ranging from 1 to N, where N is the total number of buckets.
The number of buckets is specifically chosen
to be several orders of magnitude larger than the potential number of cluster
nodes, even given future cluster scaling. For example, with M projected nodes
the dataset may be split into 100 * M or even 1,000 * M buckets. Care should
be taken when picking the number of buckets: if too large, it may require extra
memory for storing the routing information; if too small, it may decrease
the granularity of rebalancing.
Each shard stores a unique subset of buckets, which means that a bucket cannot
belong to several shards at once, as illustrated below:
This shard-to-bucket mapping is stored in a table in one of Tarantool’s system
spaces, with each shard holding only a specific part of the mapping that covers
those buckets that were assigned to this shard.
Apart from the mapping table, the bucket id is also stored in a special field of
every tuple of every table participating in sharding.
Once a shard receives any request (except for SELECT) from an
application, this shard checks the bucket id specified in the request
against the table of bucket ids that belong to a given node. If the
specified bucket id is invalid, the request gets terminated with the
following error: “wrong bucket”. Otherwise the request is executed, and
all the data created in the process is assigned the bucket id specified
in the request. Note that the request should only modify the data that
has the same bucket id as the request itself.
Storing bucket ids both in the data itself and the mapping table ensures data
consistency regardless of the application logic and makes rebalancing
transparent for the application. Storing the mapping table in a system space
ensures sharding is performed consistently in case of a failover, as all the
replicas in a shard share a common table state.
Virtual buckets
The sharded dataset is partitioned into a large number of abstract nodes called
virtual buckets (further just buckets).
The dataset is partitioned using the sharding key (or bucket id, in Tarantool
terminology). Bucket id is a number from 1 to N, where N is the total number of
buckets.
Each replica set stores a unique subset of buckets. One bucket cannot belong to
multiple replica sets at a time.
The total number of buckets is determined by the administrator who sets up the initial cluster configuration.
Every space you plan to shard must have a numeric field containing bucket id-s.
You can learn more from Data definition.
Structure
A sharded cluster in Tarantool consists of:
One or more replica sets.
Each replica set should contain at least two storage instances.
For redundancy, it is recommended to have 3 or more storage instances in a replica set.
One or more router instances.
The number of router instances is not limited and should be increased if the existing router instances become CPU or I/O bound.
Rebalancer.
Storage
Storage is a node storing a subset of the dataset. Multiple replicated (for
redundancy) storages comprise a replica set (also called shard).
Each storage in a replica set has a role, master or replica. A master
processes read and write requests. A replica processes read requests but cannot
process write requests.
Router
Router is a standalone software component that routes read and write requests
from the client application to shards.
All requests from the application come to the sharded cluster through a router.
The router keeps the topology of a sharded cluster transparent for the application,
thus keeping the application unaware of:
the number and location of shards,
data rebalancing process,
the fact and the process of a failover that occurred after a replica’s failure.
A router can also calculate a bucket id on its own provided that the application
clearly defines rules for calculating a bucket id based on the request data.
To do it, a router needs to be aware of the data schema.
The router does not have a persistent state, nor does it store the cluster topology
or balance the data. The router is a standalone software component that can run
in the storage layer or application layer depending on the application features.
A router maintains a constant pool of connections to all the storages that is
created at startup. Creating it this way helps avoid configuration errors. Once
a pool is created, a router caches the current state of the _vbucket table to
speed up the routing. In case a bucket id is moved to another storage as
a result of data rebalancing, or one of the shards fails over to a replica,
a router updates the routing table in a way that’s transparent for the application.
Sharding is not integrated into any centralized configuration storage system.
It is assumed that the application itself handles all the interactions with such
systems and passes sharding parameters. That said, the configuration can be
changed dynamically - for example, when adding or deleting one or several shards:
To add a new shard to the cluster, a system administrator first changes the
configuration of all the routers and then the configuration of all the storages.
The new shard becomes available to the storage layer for rebalancing.
As a result of rebalancing, one of the vbuckets is moved to the new shard.
When trying to access the vbucket, a router receives a special error code
that specifies the new vbucket location.
CRUD (create, read, update, delete) operations
CRUD operations can be:
executed in a stored procedure inside a storage, or
initialized by the application.
In any case, the application must include the operation bucket id in a request.
When executing an INSERT request, the operation bucket id is stored in a newly
created tuple. In other cases, it is checked if the specified operation
bucket id matches the bucket id of a tuple being modified.
SELECT requests
Since a storage is not aware of the mapping between a bucket id and a primary
key, all the SELECT requests executed in stored procedures inside a storage are
only executed locally. Those SELECT requests that were initialized by the
application are forwarded to a router. Then, if the application has passed
a bucket id, a router uses it for shard calculation.
Calling stored procedures
There are several ways of calling stored procedures in cluster replica sets.
Stored procedures can be called:
on a specific vbucket located in a replica set (in this case, it is necessary
to differentiate between read and write procedures, as write procedures are not
applicable to vbuckets that are being migrated), or
without specifying any particular vbucket.
All the routing validity checks performed for sharded DML operations hold true
for vbucket-bound stored procedures as well.
Rebalancer
Rebalancer is a background rebalancing process that ensures an even
distribution of buckets across the shards. During rebalancing, buckets are being
migrated among replica sets.
The rebalancer “wakes up” periodically and redistributes data from the most
loaded nodes to less loaded nodes. Rebalancing starts if the replicaset disbalance
of a replica set exceeds a disbalance threshold specified in the configuration.
The replicaset disbalance is calculated as follows:
A replica set from which the bucket is being migrated is called a source ; a
target replica set to which the bucket is being migrated is called a destination.
A replica set lock makes a replica set invisible to the rebalancer. A locked
replica set can neither receive new buckets nor migrate its own buckets.
While a bucket is being migrated, it can have different states:
ACTIVE – the bucket is available for read and write requests.
PINNED – the bucket is locked for migrating to another replica set. Otherwise
pinned buckets are similar to buckets in the ACTIVE state.
SENDING – the bucket is currently being copied to the destination replica set;
read requests to the source replica set are still processed.
RECEIVING – the bucket is currently being filled; all requests to it are rejected.
SENT – the bucket was migrated to the destination replica set. The router
uses the SENT state to calculate the new location of the bucket. A bucket in
the SENT state goes to the GARBAGE state automatically after 0.5 seconds.
GARBAGE – the bucket was already migrated to the destination replica set during
rebalancing; or the bucket was initially in the RECEIVING state, but some error
occurred during the migration.
Buckets in the GARBAGE state are deleted by the garbage collector.
Migration is performed as follows:
At the destination replica set, a new bucket is created and assigned the RECEIVING
state, the data copying starts, and the bucket rejects all requests.
The source bucket in the source replica set is assigned the SENDING state, and
the bucket continues to process read requests.
Once the data is copied, the bucket on the source replica set is assigned the SENT
and it starts rejecting all requests.
The bucket on the destination replica set is assigned the ACTIVE state and starts
accepting all requests.
Note
There is a specific error vshard.error.code.TRANSFER_IS_IN_PROGRESS that
returns in case a request tries to perform an action not applicable to a bucket
which is being relocated. You need to retry the request in this case.
The _bucket system space
The _bucket system space of each replica set stores the ids of buckets present
in the replica set. The space contains the following fields:
Once the bucket is migrated, the destination replica set identified by UUID is filled in the
table. While the bucket is still located on the source replica set, the value of
the destination replica set UUID is equal to NULL.
The routing table
А routing table on the router stores the map of all bucket ids to replica sets.
It ensures the consistency of sharding in case of failover.
The router keeps a persistent pool of connections to all the storages that
are created at startup. This helps prevent configuration errors. Once the connection
pool is created, the router caches the current state of the routing table in order
to speed up routing. If a bucket migrated to another storage after rebalancing,
or a failover occurred and caused one of the shards switching to another replica,
the discoveryfiber on the router updates the routing table automatically.
As the bucket id is explicitly indicated both in the data and in the mapping table
on the router, the data is consistent regardless of the application logic. It also
makes rebalancing transparent for the application.
Processing requests
Requests to the database can be performed by the application or using stored
procedures. Either way, the bucket id should be explicitly specified in the request.
All requests are forwarded to the router first. The only operation supported
by the router is call. The operation is performed via the vshard.router.call()
function:
The router uses the bucket id to search for a replica set with the
corresponding bucket in the routing table.
If the map of the bucket id to the replica set is not known to the router
(the discovery fiber hasn’t filled the table yet), the router makes requests
to all storages to find out where the bucket is located.
Once the bucket is located, the shard checks:
whether the bucket is stored in the _bucket system space of the replica set;
whether the bucket is ACTIVE or PINNED (for a read request, it can also be SENDING).
If all the checks succeed, the request is executed. Otherwise, it is terminated
with the error: “wrongbucket”.
Glossary
Vertical scaling
Adding more power to a single server: using a more powerful CPU, adding
more capacity to RAM, adding more storage space, etc.
Horizontal scaling
Adding more servers to the pool of resources, then partitioning and
distributing a dataset across the servers.
Sharding
A database architecture that allows partitioning a dataset using a sharding
key and distributing a dataset across multiple servers. Sharding is a
special case of horizontal scaling.
Node
A virtual or physical server instance.
Cluster
A set of nodes that make up a single group.
Storage
A node storing a subset of a dataset.
Replica set
A set of storage nodes storing copies of a dataset. Each storage in a
replica set has a role, master or replica.
Master
A storage in a replica set processing read and write requests.
Replica
A storage in a replica set processing only read requests.
Read requests
Read-only requests, that is, select requests.
Write requests
Data-change operations, that is create, read, update, delete requests.
Buckets (virtual buckets)
The abstract virtual nodes into which the dataset is partitioned by the
sharding key (bucket id).
Bucket id
A sharding key defining which bucket belongs to which replica set.
A bucket id may be calculated from a hash key.
Router
A proxy server responsible for routing requests from an application to
nodes in a cluster.
Sharding with vshard
Sharding in Tarantool is implemented in the vshard module.
For a quick start with vshard, refer to Creating a sharded cluster.
Note
Starting with the 3.0 version, the recommended way of configuring Tarantool is using a configuration file.
The sharding section defines configuration parameters related to sharding.
To learn how to configure vshard in code, see Configuration reference.
Installation
The vshard module is distributed separately from the main Tarantool package.
To install the module, execute the following command:
$ ttrocksinstallvshard
If you are developing a sharded cluster application, add the vshard module dependency to a *.rockspec file:
dependencies = {
'vshard == 0.1.27'
}
Note
The minimum required version of vshard is 0.1.25.
Configuration overview
Configuring settings related to sharding might include the following steps:
Configure connection settings to allow instances within a sharded cluster to communicate with each other.
Specify which role each replica set plays in a sharded cluster.
This section describes connection options that enable communication between instances within a sharded cluster.
For general information about connections, see the Connections topic.
Advertise URI
In a sharded cluster configuration, you need to specify how a router and rebalancer connect to storages using the iproto.advertise.sharding option.
In the example below, the storage user is used for this purpose:
The storage user should have the sharding role described in the next section.
Credentials
To allow a router and rebalancer to connect to storages, a user with the shardingrole should be used.
The example below shows how to grant the sharding role to the storage user:
The sharding role has different privileges depending on a replica set’s sharding role.
For replica sets with the storage sharding role, the sharding credential role has the following privileges:
You can use the sharding.roles option to assign a specific role to a replica set or group of replica sets.
In the example below, all replica sets in the storages group have the storage role while replica sets in the routers group have the router role.
Note that the rebalancer role is optional.
If it is not specified, a rebalancer is selected automatically from the master instances of replica sets.
To specify the rebalancer manually or turn it off, use the sharding.rebalancer_mode option.
Data partitioning
This section describes configuration settings related to data partitioning.
Learn how to define spaces to be sharded in Data definition.
Bucket count
To define the total number of buckets in a cluster, configure the sharding.bucket_count option at the global level.
In the example below, sharding.bucket_count is set to 1000:
sharding:bucket_count:1000
sharding.bucket_count should be several orders of magnitude larger than the potential number of cluster nodes considering potential scaling out in the future.
If the estimated number of nodes in a cluster is N, then the data set should be divided into 100N or even 1000N buckets depending on the planned scaling out.
This number is greater than the potential number of cluster nodes in the system being designed.
Keep in mind that too many buckets can cause a need to allocate more memory to store routing information.
On the other hand, an insufficient number of buckets can lead to decreased granularity when rebalancing.
Replica set weights
A replica set weight defines the storage capacity of the replica set: the larger the weight, the more buckets the replica set can store.
You can configure a replica set weight using the sharding.weight option.
This option can be used to store the prevailing amount of data on a replica set with more memory space.
You can also assign a zero weight to a replica set to initiate migration of its buckets to the remaining cluster nodes.
In the example below, the storage-a replica set can store twice as much data as storage-b:
There is an etalon number of buckets for a replica set.
(Etalon in this context means “ideal”.)
If there is no deviation
from this number in the whole replica set, then the buckets are distributed evenly.
The etalon number is calculated automatically considering the number of buckets
in the cluster and the weights of the replica sets.
Rebalancing starts if the disbalance threshold of a replica set
exceeds the disbalance threshold specified in the configuration
(the sharding.rebalancer_disbalance_threshold option).
The disbalance threshold of a replica set is calculated as follows:
In this case, the etalon numbers of buckets for the replica sets are:
1st replica set – 1000.
2nd replica set – 500.
3rd replica set – 1500.
You can set a replica set weight to zero to initiate migration of its buckets to the remaining cluster nodes.
You can also add a new replica set with a non-zero weight to initiate migration of the buckets from the existing replica sets.
When a new shard is added, a configuration should be reloaded on each instance to migrate buckets to a new shard:
If a local configuration file is used, you need to reload a configuration on all the routers first and then on all the storages.
Parallel rebalancing
Originally, vshard had quite a simple rebalancer –
one process on one node that calculated routes that should send buckets, how
many, and to whom. The nodes applied these routes one by
one sequentially.
Unfortunately, such a simple schema worked not fast enough,
especially for Vinyl, where costs of reading disk were comparable
with network costs. In fact, with Vinyl the rebalancer routes
applier was sleeping most of the time.
Now each node can send multiple buckets in parallel in a
round-robin manner to multiple destinations, or to just one.
Specifying sharding.rebalancer_max_sending=N probably won’t give N times
speed up. It depends on network, disk, number of other fibers in the system.
Example 1
You have 10 replica sets and a new one is added.
Now all the 10 replica sets will try to send buckets to the new one.
Assume that each replica set can send up to 5 buckets at once. In that case,
the new replica set will experience a rather big load of 50 buckets
being downloaded at once. If the node needs to do some other
work, perhaps such a big load is undesirable. Also too, many
parallel buckets can cause timeouts in the rebalancing process
itself.
To fix the problem, you can set a lower value for rebalancer_max_sending
for old replica sets, or decrease rebalancer_max_receiving for the new one.
In the latter case, some workers on old nodes will be throttled,
and you will see that in the logs.
rebalancer_max_sending is important, if you have restrictions for
the maximum number of buckets that can be read only at once in the cluster. As you
remember, when a bucket is being sent, it does not accept new
write requests.
Example 2
You have 100000 buckets and each
bucket stores ~0.001% of your data. The cluster has 10
replica sets. And you never can afford > 0.1% of data locked on
write. Then you should not set rebalancer_max_sending > 10 on
these nodes. It guarantees that the rebalancer won’t send more
than 100 buckets at once in the whole cluster.
If rebalancer_max_sending is too high and rebalancer_max_receiving is too low,
then some buckets will try to get relocated – and will fail with that.
This problem will consume network resources and time. It is important to
configure these parameters to not conflict with each other.
Replica set lock and bucket pin
A replica set lock (sharding.lock) makes a replica set invisible to the rebalancer: a locked
replica set can neither receive new buckets nor migrate its own buckets.
A bucket pin (vshard.storage.bucket_pin(bucket_id)) blocks a specific bucket from migrating: a pinned bucket stays on
the replica set to which it is pinned until it is unpinned.
Pinning all replica set buckets is not equivalent to locking a replica set. Even if
you pin all buckets, a non-locked replica set can still receive new buckets.
A replica set lock is helpful, for example, to separate a replica set from production
replica sets for testing, or to preserve some application metadata that must not
be sharded for a while. A bucket pin is used for similar cases but in a smaller
scope.
By both locking a replica set and pinning all buckets, you can
isolate an entire replica set.
Locked replica sets and pinned buckets affect the rebalancing algorithm as the
rebalancer must ignore locked replica sets and consider pinned buckets when
attempting to reach the best possible balance.
The issue is not trivial as a user can pin too many buckets to a replica set,
so a perfect balance becomes unreachable. For example, consider the following
cluster (assume all replica set weights are equal to 1).
The perfect balance would be 100-100-100, which is impossible since the
rs2 replica set has 120 pinned buckets. The best possible balance here is the
following:
The rebalancer moved as many buckets as possible from rs2 to decrease the
disbalance. At the same time, it respected equal weights of rs1 and rs3.
The algorithms for implementing locks and pins are completely different, although
they look similar in terms of functionality.
Replica set lock and rebalancing
Locked replica sets do not participate in rebalancing. This means that
even if the actual total number of buckets is not equal to the etalon number,
the disbalance cannot be fixed due to the lock. When the rebalancer detects that
one of the replica sets is locked, it recalculates the etalon number of buckets
of the non-locked replica sets as if the locked replica set and its buckets did
not exist at all.
Bucket pin and rebalancing
Rebalancing replica sets with pinned buckets requires a more complex algorithm.
Here pinned_count[o] is the number of pinned buckets, and etalon_count is
the etalon number of buckets for a replica set:
The rebalancer calculates the etalon number of buckets as if all buckets
were not pinned. Then the rebalancer checks each replica set and compares the
etalon number of buckets with the number of pinned buckets in a replica set.
If pinned_count<etalon_count, non-locked replica sets (at this point all
locked replica sets already are filtered out) with pinned buckets can receive
new buckets.
If pinned_count>etalon_count, the disbalance cannot be fixed, as the
rebalancer cannot move pinned buckets out of this replica set. In such a case
the etalon number is updated and set equal to the number of pinned buckets.
The replica sets with pinned_count>etalon_count are not processed by
the rebalancer, and the number of pinned buckets is subtracted from the
total number of buckets. The rebalancer tries to move out as many buckets as
possible from such replica sets.
This procedure is restarted from step 1 for replica sets with
pinned_count>=etalon_count until pinned_count<=etalon_count on
all replica sets. The procedure is also restarted when the total number of
buckets is changed.
Here is the pseudocode for the algorithm:
functioncluster_calculate_perfect_balance(replicasets,bucket_count)-- rebalance the buckets using weights of the still viable replica sets --end;cluster=<allofthenon-lockedreplicasets>;bucket_count=<thetotalnumberofbucketsinthecluster>;can_reach_balance=falsewhilenotcan_reach_balancedocan_reach_balance=truecluster_calculate_perfect_balance(cluster,bucket_count);foreachreplicasetinclusterdoifreplicaset.perfect_bucket_count<replicaset.pinned_bucket_countthencan_reach_balance=falsebucket_count-=replicaset.pinned_bucket_count;replicaset.perfect_bucket_count=replicaset.pinned_bucket_count;end;end;end;cluster_calculate_perfect_balance(cluster,bucket_count);
The complexity of the algorithm is O(N^2), where N is the number of replica sets.
On each step, the algorithm either finishes the calculation, or ignores at least
one new replica set overloaded with the pinned buckets, and updates the etalon
number of buckets on other replica sets.
Bucket ref
Bucket ref is an in-memory counter that is similar to the
bucket pin, but has the following differences:
Bucket ref is not persistent. Refs are intended for forbidding bucket transfer
during request execution, but on restart all requests are dropped.
There are two types of bucket refs: read-only (RO) and read-write (RW).
If a bucket has RW refs, it cannot be moved. However, when the rebalancer
needs it to be sent, it locks the bucket for new write requests, waits
until all current requests are finished, and then sends the bucket.
If a bucket has RO refs, it can be sent, but cannot be dropped. Such a
bucket can even enter GARBAGE or SENT state, but its data is kept until
the last reader is gone.
A single bucket can have both RO and RW refs.
Bucket ref is countable.
The vshard.storage.bucket_ref/unref() methods
are called automatically when vshard.router.call()
or vshard.storage.call() is used.
For raw API like r=vshard.router.route()r:callro/callrw, you should
explicitly call the bucket_ref() method inside the function. Also, make sure
that you call bucket_unref() after bucket_ref(), otherwise the bucket
cannot be moved from the storage until the instance is restarted.
Sharded spaces should be defined in a storage application inside box.once() and should have a field with bucket id values.
This field should meet the following requirements:
The field’s data type can be unsigned, number, or integer.
The field must be non-nullable.
The field must be indexed by the shard_index. The default name for this index is bucket_id.
In the example below, the bands space has the bucket_id field, which is used to partition a dataset across different storage instances:
All DML operations with data should be performed via a router using the vshard.router.call functions, such as vshard.router.callrw() or vshard.router.callro().
For example, a storage application has the insert_band function used to insert new tuples:
If a replica set master fails, it is recommended to:
Switch one of the replicas into the master mode. This allows the new master
to process all the incoming requests.
Update the configuration of all the cluster members. This forwards all the
requests to the new master.
Replica set crash
In case a whole replica set fails, some part of the dataset becomes inaccessible.
Meanwhile, the router tries to reconnect to the master of the failed replica set.
This way, once the replica set is up and running again, the cluster is automatically restored.
Master scheduled downtime
To perform a scheduled downtime of a replica set master, it is recommended to:
Update the configuration to use another instance as a master.
Reload the configuration on all the instances. All the requests then are forwarded to a new master.
Shut down the old master.
Replica set scheduled downtime
To perform a scheduled downtime of a replica set, it is recommended to:
Migrate all the buckets to the other cluster storages.
You can do this by assigning a zero weight to a replica set to initiate migration of its buckets to the remaining cluster nodes.
Update the configuration of all the nodes.
Shut down the replica set.
Fibers
Searches for buckets, buckets recovery, and buckets rebalancing are performed
automatically and do not require manual intervention.
Technically, there are multiple fibers responsible for different types of
operations:
a discovery fiber on the router searches for buckets in the background
a failover fiber on the router maintains replica connections
a garbage collector fiber on each master storage removes the contents
of buckets that were moved
a bucket recovery fiber on each master storage recovers buckets in the
SENDING and RECEIVING states in case of reboot
a rebalancer on a single master storage among all replica sets executes the rebalancing process.
A garbage collector fiber runs in the background on the master storages
of each replica set. It starts deleting the contents of the bucket in the GARBAGE
state part by part. Once the bucket is empty, its record is deleted from the
_bucket system space.
Bucket recovery
A bucket recovery fiber runs on the master storages. It helps to recover
buckets in the SENDING and RECEIVING states in case of reboot.
Buckets in the SENDING state are recovered as follows:
The system first searches for buckets in the SENDING state.
If such a bucket is found, the system sends a request to the destination
replica set.
If the bucket on the destination replica set is ACTIVE, the original bucket
is deleted from the source node.
Buckets in the RECEIVING state are deleted without extra checks.
Failover
A failover fiber runs on every router. If a master of a replica set
becomes unavailable, the failover fiber redirects read requests to the replicas.
Write requests are rejected with an error until the master becomes available.
Connections and authentication
This section contains guides on how to configure connections and authentication features.
To set up a Tarantool cluster, you need to enable communication between its instances, regardless of whether they running on one or different hosts.
This requires configuring connection settings that include:
One or several URIs used to listen for incoming requests.
An URI used to advertise an instance to other cluster members. This URI lets other cluster members know how to connect to the current Tarantool instance.
(Optional) SSL settings used to secure connections between instances.
Configuring connection settings is also required to enable communication of a Tarantool cluster to external systems.
For example, this might be administering cluster members using tt, managing clusters using Tarantool Cluster Manager, or using connectors for different languages.
This topic describes how to define connection settings in the iproto section of a YAML configuration.
Note
iproto is a binary protocol used to communicate between cluster instances and with external systems.
Listen URI
To configure URIs used to listen for incoming requests, use the iproto.listen configuration option.
One listen address
The example below shows how to set a listening IP address for instance001 to 127.0.0.1:3301:
instance001:iproto:listen:-uri:'127.0.0.1:3301'
Multiple listen addresses
In this example, instance001 listens on two IP addresses:
An advertise URI (iproto.advertise.*) lets other cluster members or clients know how to connect to the current Tarantool instance:
iproto.advertise.peer specifies how to advertise the instance to other cluster members.
iproto.advertise.sharding specifies how to advertise the instance to a router and rebalancer.
iproto.advertise.client accepts a URI used to advertise the instance to clients.
iproto.advertise.<peer_or_sharding> might include the credentials required to connect to this instance, a URI used to listen for incoming requests, and SSL settings.
If iproto.advertise.<peer_or_sharding>.uri is not specified explicitly, a listen URI of this instance is used.
In this case, you need at least to specify credentials for connecting to this instance.
Connection credentials
In the example below, the iproto.advertise.peer option is used to inform other replica set members that the replicator user should be used to connect to the current instance:
iproto:advertise:peer:login:replicator
In a sharded cluster, iproto.advertise.sharding specifies that a router and rebalancer should use the storage user to connect to storages:
If required, you can specify an advertise URI explicitly by setting up the iproto.advertise.<peer_or_sharding>.uri option.
In the example below, iproto.listen includes two URIs that can be used to connect to instance001 but only the second one is used to advertise this instance to other replica set peers:
Tarantool supports the use of SSL connections to encrypt client-server communications for increased security.
To enable SSL, use the <uri>.params.* options, which can be applied to both listen and advertise URIs.
Without CA
The example below demonstrates how to enable traffic encryption by using a self-signed server certificate.
The following parameters are specified for each instance:
The example below demonstrates how to enable traffic encryption by using a server certificate signed by a trusted certificate authority.
In this case, all replica set peers verify each other for authenticity.
The following parameters are specified for each instance:
ssl_ca_file: a path to a trusted certificate authorities (CA) file.
SSL parameters for an advertise URI should be set only if this advertise URI is specified explicitly.
Otherwise, SSL parameters of a listen URI are used and no additional configuration is required.
Configuring an advertise URI’s SSL options depends on whether a trusted certificate authorities (CA) file is set or not.
Without the CA file, you only need to set iproto.advertise.<peer_or_sharding>.params.transport to ssl as shown below:
To reload SSL certificate files specified in the configuration, open an admin console and reload the configuration using config.reload():
require('config'):reload()
New certificates will be used for new connections.
Existing connections will continue using old SSL certificates until reconnection is required.
For example, certificate expiry or a network issue causes reconnection.
Credentials
Tarantool enables flexible management of access to various database resources by providing specific privileges to users.
You can read more about the main concepts of Tarantool access control system in the Access control section.
This topic describes how to create users and grant them the specified privileges in the credentials section of a YAML configuration.
For example, you can define users with the replication and sharding roles to maintain replication and sharding in a Tarantool cluster.
Managing users and roles
Creating a user
You can create new or configure credentials of the existing users in the credentials.users section.
In the example below, a dbadmin user without a password is created:
To assign a role to a user, use the credentials.users.<username>.roles option.
In this example, the dbadmin user gets privileges granted to the super built-in role:
To create a new role, define it in the credentials.roles.* section.
In the example below, the writers_space_reader role gets privileges to select data in the writers space:
You can grant specific privileges directly using credentials.users.<username>.privileges.
In this example, sampleuser gets privileges to select and modify data in the books space:
Tarantool enables you to load secrets from safe storage such as external files or environment variables.
To do this, you need to define corresponding options in the config.context section.
In the examples below, context.dbadmin_password and context.sampleuser_password define how to load user passwords from *.txt files or environment variables:
This example shows how to load passwords from *.txt files:
Tarantool Enterprise Edition provides the ability to apply additional restrictions for user authentication.
For example, you can specify the minimum time between authentication attempts
or turn off access for guest users.
In the configuration below, security.auth_retries is set to 2,
which means that Tarantool lets a client try to authenticate with the same username three times.
At the fourth attempt, the authentication delay configured with security.auth_delay is enforced.
This means that a client should wait 10 seconds after the first failed attempt.
The disable_guest option turns off access over remote connections from unauthenticated or guest users.
Password policy
A password policy allows you to improve database security by enforcing the use
of strong passwords, setting up a maximum password age, and so on.
When you create a new user with
box.schema.user.create
or update the password of an existing user with
box.schema.user.passwd,
the password is checked against the configured password policy settings.
In the example below, the following options are specified:
password_min_length specifies that a password should be at least 16 characters.
By default, Tarantool uses the
CHAP
protocol to authenticate users and applies SHA-1 hashing to
passwords.
Note that CHAP stores password hashes in the _user space unsalted.
If an attacker gains access to the database, they may crack a password, for example, using a rainbow table.
In the Enterprise Edition, you can enable
PAP authentication
with the SHA256 hashing algorithm.
For PAP, a password is salted with a user-unique salt before saving it in the database,
which keeps the database protected from cracking using a rainbow table.
For new users, the box.schema.user.create method generates authentication data using PAP-SHA256.
For existing users, you need to reset a password using
box.schema.user.passwd
to use the new authentication protocol.
Warning
Given that PAP transmits a password as plain text,
Tarantool requires configuring SSL/TLS
for a connection.
The example below shows how to specify the authentication protocol using the auth_type parameter when connecting to an instance using net.box:
If the authentication protocol isn’t specified explicitly on the client side,
the client uses the protocol configured on the server via security.auth_type.
Security
This section contains guides related to security features.
The audit module allows you to record various events occurred in Tarantool.
Each event is an action related to authorization and authentication, data manipulation,
administrator activity, or system events.
The module provides detailed reports of these activities and helps you find and
fix breaches to protect your business. For example, you can see who created a new user
and when.
It is up to each company to decide exactly what activities to audit and what actions to take.
System administrators, security engineers, and people in charge of the company may want to
audit different events for different reasons. Tarantool provides such an option for each of them.
Configure audit log
The section describes how to enable and configure audit logging and write logs to a selected destination – a file, a pipe,
or a system logger.
In the configuration below, the audit_log.to option is set to file.
It means that the logs are written to a file.
By default, audit logs are saved in the var/log/{{instance_name}}/audit.log file.
To specify the path to an audit log file explicitly, use the audit_log.file option.
audit_log:to:filefile:'audit_tarantool.log'
If you log to a file, Tarantool reopens the audit log at SIGHUP.
To disable audit logging, set the audit_log.to option to devnull.
Filter the events
Tarantool’s extensive filtering options help you write only the events you need to the audit log.
To select the recorded events, use the audit_log.filter option.
Its value can be a list of events and event groups.
You can customize the filters and use different combinations of them for your purposes.
Possible filtering options:
Filter by event. You can set a list of events to be recorded. For example, select
password_change to monitor the users who have changed their passwords:
audit_log:filter:[password_change]
Filter by group. You can specify a list of event groups to be recorded. For example,
select auth and priv to see the events related to authorization and granted privileges:
audit_log:filter:[auth,priv]
Filter by group and event. You can specify a group and a certain event depending on the purpose.
In the configuration below, user_create, data_operations, ddl, and custom are selected to see the events related to:
user creation
space creation, altering, and dropping
data modification or selection from spaces
custom events (any events added manually using the audit module API)
filter:[user_create,data_operations,ddl,custom]
Set the format of audit log events
Use the audit_log.format option to choose the format of audit log events
– plain text, CSV, or JSON.
format:json
JSON is used by default. It is more convenient to receive log events, analyze them, and integrate them with other systems if needed.
The plain format can be efficiently compressed.
The CSV format allows you to view audit log events in tabular form.
Specify the spaces to be logged
The audit_log.spaces option is used to specify
a list of space names for which data operation events should be logged.
In the configuration below, only the events from the bands space are logged:
spaces:[bands]
Specify the logging mode in DML events
If set to true, the audit_log.extract_key option
forces the audit subsystem to log the primary key instead of a full tuple in DML operations.
extract_key:true
Examples of audit log entries
In this example, the following audit log configuration is used:
Create a space bands and check the logs in the file after the creation:
box.schema.space.create('bands')
The audit log entry for the space_create event might look as follows:
{"time":"2024-01-24T11:43:21.566+0300","uuid":"26af0a7d-1052-490a-9946-e19eacc822c9","severity":"INFO","remote":"unix/:(socket)","session_type":"console","module":"tarantool","user":"admin","type":"space_create","tag":"","description":"Create space Bands"}
Then insert one tuple to space:
box.space.bands:insert{1,'Roxette',1986}
If the extract_key option is set to true, the audit system prints the primary key instead of the full tuple:
{"time":"2024-01-24T11:45:42.358+0300","uuid":"b437934d-62a7-419a-8d59-e3b33c688d7a","severity":"VERBOSE","remote":"unix/:(socket)","session_type":"console","module":"tarantool","user":"admin","type":"space_insert","tag":"","description":"Insert key [2] into space bands"}
If the extract_key option is set to false, the audit system prints the full tuple like this:
{"time":"2024-01-24T11:45:42.358+0300","uuid":"b437934d-62a7-419a-8d59-e3b33c688d7a","severity":"VERBOSE","remote":"unix/:(socket)","session_type":"console","module":"tarantool","user":"admin","type":"space_insert","tag":"","description":"Insert tuple [1, \"Roxette\", 1986] into space bands"}
Audit log events
Events types
The Tarantool audit log module can record various events that you can monitor and
decide whether you need to take actions:
Administrator activity – events related to actions performed by the administrator.
For example, such logs record the creation of a user.
Access events – events related to authorization and authentication of users.
For example, such logs record failed attempts to access secure data.
Data access and modification – events of data manipulation in the storage.
System events – events related to modification or configuration of resources.
For example, such logs record the replacement of a space.
Custom events – any events added manually using
the audit module API.
The full list of available audit log events is provided in the table below:
Failed attempt to access secure data (for example, personal records, details, geolocation)
access_denied
ALARM
<ACCESS_TYPE>deniedto<OBJECT_TYPE><OBJECT_NAME>
Expressions with arguments evaluated in a string
eval
INFO
Evaluateexpression<EXPR>
Function called with arguments
call
VERBOSE
Callfunction<FUNCTION>witharguments<ARGS>
Iterator key selected from space.index
space_select
VERBOSE
Select<ITER_TYPE><KEY>from<SPACE>.<INDEX>
Space created
space_create
INFO
Createspace<SPACE>
Space altered
space_alter
INFO
Alterspace<SPACE>
Space dropped
space_drop
INFO
Dropspace<SPACE>
Tuple inserted into space
space_insert
VERBOSE
Inserttuple<TUPLE>intospace<SPACE>
Tuple replaced in space
space_replace
VERBOSE
Replacetuple<TUPLE>with<NEW_TUPLE>inspace<SPACE>
Tuple deleted from space
space_delete
VERBOSE
Deletetuple<TUPLE>fromspace<SPACE>
Note
The eval event displays data from the console module
and the eval function of the net.box module.
For more on how they work, see Module console
and Module net.box – eval.
To separate the data, specify console or binary in the session field.
Structure of audit log event
Each audit log event contains a number of fields that can be used to filter and aggregate the resulting logs.
An example of a Tarantool audit log entry in JSON:
{"time":"2024-01-15T13:39:36.046+0300","uuid":"cb44fb2b-5c1f-4c4b-8f93-1dd02a76cec0","severity":"VERBOSE","remote":"unix/:(socket)","session_type":"console","module":"tarantool","user":"admin","type":"auth_ok","tag":"","description":"Authenticate user Admin"}
Each event consists of the following fields:
Field
Description
Example
time
Time of the event
2024-01-15T16:33:12.368+0300
uuid
Since 3.0.0. A unique identifier of audit log event
cb44fb2b-5c1f-4c4b-8f93-1dd02a76cec0
severity
Since 3.0.0. A severity level. Each system audit event has a severity level determined by its importance.
Custom events have the INFO severity level by default.
VERBOSE
remote
Remote host that triggered the event
unix/:(socket)
session_type
Session type
console
module
Audit log module. Set to tarantool for system events;
can be overwritten for custom events
tarantool
user
User who triggered the event
admin
type
Audit event type
auth_ok
tag
A text field that can be overwritten by the user
description
Human-readable event description
AuthenticateuserAdmin
Event groups
Built-in event groups are used to filter the event types that you want to audit.
For example, you can set to record only authorization events or only events related to a space.
Events call and eval are included only in the all group.
audit – audit_enable event.
auth – authorization events: auth_ok, auth_fail.
priv – events related to authentication, authorization, users, and roles:
user_create, user_drop, role_create, role_drop, user_enable, user_disable,
user_grant_rights, user_revoke_rights, role_grant_rights, role_revoke_rights.
ddl – events of space creation, altering, and dropping:
space_create, space_alter, space_drop.
dml – events of data modification in spaces:
space_insert, space_replace, space_delete.
data_operations – events of data modification or selection from spaces:
space_select, space_insert, space_replace, space_delete.
compatibility – events available in Tarantool before the version 2.10.0.
auth_ok, auth_fail, disconnect, user_create, user_drop,
role_create, role_drop, user_enable, user_disable,
user_grant_rights, user_revoke_rights, role_grant_rights.
role_revoke_rights, password_change, access_denied.
This group enables the compatibility with earlier Tarantool versions.
Warning
Be careful when recording all and data_operations event groups.
The more events you record, the slower the requests are processed over time.
It is recommended that you select only those groups
whose events your company needs to monitor and analyze.
Custom events
Tarantool provides an API for writing custom audit log events.
To enable these events, specify the custom value in the audit_log.filter option:
filter:[user_create,data_operations,ddl,custom]
Log a custom event
To log an event, use the audit.log() function that takes one of the following values:
Message string. Printed to the audit log with type message:
audit.log('Hello, Alice!')
Format string and arguments. Passed to string format and then output to the audit log with type message:
audit.log('Hello, %s!','Bob')
Table with audit log field values. The table must contain at least one field – description.
Alternatively, you can use audit.new() to create a new log module.
This allows you to avoid passing all custom audit log fields each time audit.log() is called.
The audit.new() function takes a table of audit log field values (same as audit.log()).
The type of the log module for writing custom events must either be message or have the custom_ prefix.
It is possible to overwrite most of the custom audit log fields using audit.new() or audit.log().
The only audit log field that cannot be overwritten is time.
If omitted, the session_type is set to the current session type, remote is set to the remote peer address.
Note
To avoid confusion with system events, the value of the type field must either be message (default)
or begin with the custom_ prefix. Otherwise, you receive the error message.
Custom events are filtered out by default.
Severity level
By default, custom events have the INFOseverity level.
To override the level, you can:
If you write to a file, the size of the Tarantool audit log is limited by the disk space.
If you write to a system logger, the size of the Tarantool audit log is limited by the system logger.
If you write to a pipe, the size of the Tarantool audit message is limited by the system buffer.
If the audit_log.nonblock=false, if audit_log.nonblock = true, there is no limit.
How often should audit logs be reviewed?
Consider setting up a schedule in your company. It is recommended to review audit logs at least every 3 months.
How long should audit logs be stored?
It is recommended to store audit logs for at least one year.
What is the best way to process audit logs?
It is recommended to use SIEM systems for this issue.
Security audit
This document will help you audit the security of a Tarantool cluster.
It explains certain security aspects, their rationale, and the ways to check them.
For details on how to configure Tarantool Enterprise Edition and its infrastructure for each aspect,
refer to the security hardening guide.
Encryption of external iproto traffic
Tarantool uses the
iproto binary protocol
for replicating data between instances and also in the connector libraries.
Since version 2.10.0, the Enterprise Edition has the built-in support for using SSL to encrypt the client-server communications over binary connections.
For details on enabling SSL encryption, see the Securing connections with SSL section of this document.
In case the built-in encryption is not enabled, we recommend using VPN to secure data exchange between data centers.
Closed iproto ports
When a Tarantool cluster does not use iproto for external requests,
connections to the iproto ports should be allowed only between Tarantool instances.
For more details on configuring ports for iproto,
see the advertise_uri section in the Cartridge documentation.
HTTPS connection termination
A Tarantool instance can accept HTTP connections from external services
or access the administrative web UI.
All such connections must go through an HTTPS-providing web server,
running on the same host, such as nginx.
This requirement is for both virtual and physical hosts.
Running HTTP traffic through a few separate hosts with HTTPS termination
is not sufficiently secure.
Closed HTTP ports
Tarantool accepts HTTP connections on a specific port.
It must be only available on the same host for nginx to connect to it.
Check that the configured HTTP port is closed
and that the HTTPS port (443 by default) is open.
Restricted access to the administrative console
The console module provides
a way to connect to a running instance and run custom Lua code.
This can be useful for development and administration.
The following code examples open connections on a TCP port and on a UNIX socket.
Opening an administrative console through a TCP port is always unsafe.
Check that there are no calls like console.listen(<port_number>)
in the code.
Connecting through a socket requires having the write permission on the
/var/lib/tarantool directory.
Check that write permission to this directory is limited to the tarantool user.
Limiting the guest user
Connecting to the instance with ttconnect or tarantoolctlconnect without
user credentials (under the guest user) must be disabled.
There are two ways to check this vulnerability:
Check that the source code doesn’t grant access to the guest user.
The corresponding code can look like this:
Besides searching for the whole code pattern,
search for any entries of 'universe'.
Try connecting with ttconnect to each Tarantool node.
For more details, refer to the documentation on
access control.
Authorization in the web UI
Using the web interface must require logging in with a username and password.
Running under the tarantool user
All Tarantool instances should be running under the tarantool user.
Limiting access to the tarantool user
The tarantool user must be a non-privileged user without the sudo permission.
Also, it must not have a password set to prevent logging in via SSH or su.
Keeping two or more snapshots
In order to have a reliable backup, a Tarantool instance must keep
two or more latest snapshots.
This should be checked on each Tarantool instance.
The snapshot_count value
determines the number of kept snapshots.
Configuration values are primarily set in the configuration files
but can be overridden with environment variables and command-line arguments.
So, it’s best to check both the values in the configuration files and the actual values
using the console:
tarantool> box.cfg.checkpoint_count----2
Enabled write-ahead logging (WAL)
Tarantool records all incoming data in the write-ahead log (WAL).
The WAL must be enabled to ensure that data will be recovered in case of
a possible instance restart.
Secure values of the wal.mode configuration option are write and fsync:
An exclusion from this requirement is when the instance is processing data,
which can be freely rejected - for example, when Tarantool is used for caching.
In this case, WAL can be disabled to reduce i/o load.
The logging level is INFO or higher
The logging level should be set to 5 (INFO), 6 (VERBOSE), or 7 (DEBUG).
Application logs will then have enough information to research a possible security breach.
This guide explains how to enhance security in your Tarantool Enterprise Edition’s
cluster using built-in features and provides general recommendations on security
hardening.
If you need to perform a security audit of a Tarantool Enterprise cluster,
refer to the security checklist.
Tarantool Enterprise Edition does not provide a dedicated API for security control. All
the necessary configurations can be done via an administrative console or
initialization code.
Tarantool Enterprise Edition has the following built-in security features:
Over a binary port for read and write operations and procedure invocation.
For more information on authentication and connection types, see the
Security section in Administration.
In addition, Tarantool provides the following functionality:
Sessions
– states which associate connections with users and make Tarantool API available
to them after authentication.
Authentication triggers,
which execute actions on authentication events.
Third-party (external) authentication protocols and services such as LDAP or
Active Directory – supported in the web interface, but unavailable
on the binary-protocol level.
Access control
Tarantool Enterprise Edition provides the means for administrators to prevent
unauthorized access to the database and to certain functions.
Tarantool recognizes:
different users (guests and administrators)
privileges associated with users
roles (containers for privileges) granted to users
The following system spaces are used to store users and privileges:
The _user space to store usernames and hashed passwords for authentication.
The _priv space to store privileges for access control.
Users who create objects (spaces, indexes, users, roles, sequences, and
functions) in the database become their owners and automatically acquire
privileges for what they create. For more information, see the
Owners and privileges section.
Audit log
Tarantool Enterprise Edition has a built-in audit log that records events such as:
authentication successes and failures
connection closures
creation, removal, enabling, and disabling of users
changes of passwords, privileges, and roles
denials of access to database objects
The audit log contains:
timestamps
usernames of users who performed actions
event types (for example, user_create, user_enable, disconnect)
descriptions
You can configure the following audit log options:
audit_log.to – enable audit logging and define the log location (file, pipe, or syslog).
The option is similar to the log.
audit_log.nonblock – specify the logging behavior if the system is not ready to write.
The option is similar to the log_nonblock.
For more information on logging, see the following:
Access permissions to audit log files can be set up as to any other Unix file
system object – via chmod.
Recommendations on security hardening
This section lists recommendations that can help you harden the cluster’s security.
Encrypting traffic
Since version 2.10.0, Tarantool Enterprise Edition has built-in support for using SSL to encrypt the client-server communications over binary connections,
that is, between Tarantool instances in a cluster. For details on enabling SSL encryption, see the Securing connections with SSL section of this guide.
In case the built-in encryption is not set for particular connections, consider the following security recommendations:
setting up connection tunneling, or
encrypting the actual data stored in the database.
The HTTP server module provided by rocks
does not support the HTTPS protocol. To set up a secure connection for a client
(e.g., REST service), consider hiding the Tarantool instance (router if it is
a cluster of instances) behind an Nginx server and setting up an SSL certificate
for it.
To make sure that no information can be intercepted ‘from the wild’, run nginx
on the same physical server as the instance and set up their communication over
a Unix socket. For more information, see the
socket module reference.
Firewall configuration
To protect the cluster from any unwanted network activity ‘from the wild’,
configure the firewall on each server to allow traffic on ports listed in
Network requirements.
If you are using static IP addresses, whitelist them, again, on each server as
the cluster has a full mesh network topology. Consider blacklisting all the other
addresses on all servers except the router (running behind the Nginx server).
Tarantool Enterprise does not provide defense against DoS or DDoS attacks.
Consider using third-party software instead.
Data integrity
Tarantool Enterprise Edition does not keep checksums or provide the means to control
data integrity. However, it ensures data persistence using a write-ahead log,
regularly snapshots the entire data set to disk, and checks the data format
whenever it reads the data back from the disk. For more information, see the
Data persistence section.
Triggers
Triggers, also known as callbacks, are functions which the server
executes when certain events happen.
To associate an event with a callback,
pass the callback to the corresponding on_event function:
Triggers are stored in the Tarantool instance’s memory, not in the database.
Therefore triggers disappear when the instance is shut down.
To make them permanent, put function definitions and trigger settings
into Tarantool’s initialization script.
Triggers have low overhead. If a trigger is not defined, then the overhead
is minimal: merely a pointer dereference and check. If a trigger is defined,
then its overhead is equivalent to the overhead of calling a function.
There can be multiple triggers for one event. In this case, triggers are
executed in the reverse order that they were defined in.
Triggers must work within the event context, that is, operate variables passed
as the trigger function arguments. Triggers should not affect the global state
of the program or change things unrelated to the event. If a trigger performs
such calls as, for example, os.exit()
or box.rollback(), the result of
its execution is undefined.
Triggers are replaceable. The request to “redefine a trigger” implies
passing a new trigger function and an old trigger function
to one of the on_event functions.
The on_event functions all have parameters which are function
pointers, and they all return function pointers. Remember that a Lua
function definition such as functionf()x=x+1end is the same
as f=function()x=x+1end - in both cases f gets a function pointer.
And trigger=box.session.on_connect(f) is the same as
trigger=box.session.on_connect(function()x=x+1end) - in both cases
trigger gets the function pointer which was passed.
You can call any on_event function with no arguments to get a list
of its triggers. For example, use box.session.on_connect() to return
a table of all connect-trigger functions.
Here we log connect and disconnect events into Tarantool server log.
log=require('log')functionon_connect_impl()log.info("connected "..box.session.peer()..", sid "..box.session.id())endfunctionon_disconnect_impl()log.info("disconnected, sid "..box.session.id())endfunctionon_auth_impl(user)log.info("authenticated sid "..box.session.id().." as "..user)endfunctionon_connect()pcall(on_connect_impl)endfunctionon_disconnect()pcall(on_disconnect_impl)endfunctionon_auth(user)pcall(on_auth_impl,user)endbox.session.on_connect(on_connect)box.session.on_disconnect(on_disconnect)box.session.on_auth(on_auth)
Applications
Using Tarantool as an application server, you can write your own applications.
Tarantool’s native language for writing applications is
Lua, so a typical application would be
a file that contains your Lua script. But you can also write applications
in C or C++.
Using Tarantool as an application server, you can write your own applications.
Tarantool’s native language for writing applications is
Lua, so a typical application would be
a file that contains your Lua script. But you can also write applications
in C or C++.
Note
If you’re new to Lua, we recommend going over the interactive Tarantool
tutorial before proceeding with this chapter. To launch the tutorial, say
tutorial() in Tarantool console:
tarantool> tutorial()----|Tutorial -- Screen #1 -- Hello, Moon====================================Welcome to the Tarantool tutorial.It will introduce you to Tarantool’s Lua application serverand database server, which is what’s running what you’re seeing.This is INTERACTIVE -- you’re expected to enter requestsbased on the suggestions or examples in the screen’s text.<...>
Let’s create and launch our first Lua application for Tarantool.
Here’s a simplest Lua application, the good old “Hello, world!”:
#!/usr/bin/env tarantoolprint('Hello, world!')
We save it in a file. Let it be myapp.lua in the current directory.
Now let’s discuss how we can launch our application with Tarantool.
Launching in Docker
If we run Tarantool in a Docker container,
the following command will start Tarantool without any application:
$ # create a temporary container and run it in interactive mode$ dockerrun--rm-t-itarantool/tarantool:latest
To run Tarantool with our application, we can say:
$ # create a temporary container and$ # launch Tarantool with our application$ dockerrun--rm-t-i\-v`pwd`/myapp.lua:/opt/tarantool/myapp.lua\-v/data/dir/on/host:/var/lib/tarantool\tarantool/tarantool:latesttarantool/opt/tarantool/myapp.lua
Here two resources on the host get mounted in the container:
our application file (myapp.lua) and
Tarantool data directory (/data/dir/on/host).
By convention, the directory for Tarantool application code inside a container
is /opt/tarantool, and the directory for data is /var/lib/tarantool.
Launching a binary program
If we run Tarantool from a package or from a source build, we can launch our application:
in the script mode,
as a server application, or
as a daemon service.
The simplest way is to pass the filename to Tarantool at start:
$ tarantoolmyapp.lua
Hello, world!$
Tarantool starts, executes our script in the script mode and exits.
Now let’s turn this script into a server application. We use
box.cfg from Tarantool’s built-in
Lua module to:
launch the database (a database has a persistent on-disk state, which needs
to be restored after we start an application) and
configure Tarantool as a server that accepts requests over a TCP port.
We also add some simple database logic, using
space.create() and
create_index() to create a space with a primary
index. We use the function box.once() to make sure that our
logic will be executed only once when the database is initialized for the first
time, so we don’t try to create an existing space or index on each invocation
of the script:
This time, Tarantool executes our script and keeps working as a server,
accepting TCP requests on port 3301. We can see Tarantool in the current
session’s process list:
But the Tarantool instance will stop if we close the current terminal window.
To detach Tarantool and our application from the terminal window, we can launch
it in the daemon mode. To do so, we add some parameters to box.cfg{}:
background = true that actually tells
Tarantool to work as a daemon service,
log = 'dir-name' that tells the Tarantool
daemon where to store its log file (other log settings are available in
Tarantool log module), and
pid_file = 'file-name' that tells the
Tarantool daemon where to store its pid file.
We launch our application in the same manner as before:
$ tarantoolmyapp.lua
Hello, world!$
Tarantool executes our script, gets detached from the current shell session
(you won’t see it with ps|grep"tarantool") and continues working in the
background as a daemon attached to the global session (with SID = 0):
Now that we have discussed how to create and launch a Lua application for
Tarantool, let’s dive deeper into programming practices.
Application roles
An application role is a Lua module that implements specific functions or logic.
You can turn on or off a particular role for certain instances in a configuration without restarting these instances.
A role is run when a configuration is loaded or reloaded.
Roles can be divided into the following groups:
Tarantool’s built-in roles.
For example, the config.storage role can be used to make a Tarantool replica set act as a configuration storage.
Roles provided by third-party Lua modules.
For example, the CRUD module provides the roles.crud-storage and roles.crud-router roles that enable CRUD operations in a sharded cluster.
Custom roles that are developed as a part of a cluster application.
For example, you can create a custom role to define a stored procedure or implement a supplementary service, such as an email notifier or a replicator.
This section describes how to develop custom roles.
To learn how to enable and configure roles, see Enabling and configuring roles.
Note
Don’t confuse application roles with other role types:
A role is a container for privileges that can be granted to users. Learn more in Roles.
A role of a replica set in regard to sharding. Learn more in Sharding roles.
Providing a role configuration
A custom role can be configured in the same way as roles provided by Tarantool or third-party Lua modules.
You can learn more from Enabling and configuring roles.
This example shows how to enable and configure the greeter role, which is implemented in the next section:
The role configuration provided in roles_cfg can be accessed when validating and applying this configuration.
Tarantool includes the experimental.config.utils.schema
built-in module that provides tools for managing user-defined configurations
of applications (app.cfg) and roles (roles_cfg). The examples below show its
basic usage.
Given that a role is a Lua module, a role name is passed to require() to obtain the module.
When developing an application, you can place a file with the role code next to the cluster configuration file.
Creating a custom role
Overview
Creating a custom role includes the following steps:
(Optional) Define the role configuration schema.
Define a function that validates a role configuration.
Define a function that applies a validated configuration.
Define a function that stops a role.
(Optional) Define roles from which this custom role depends on.
As a result, a role module should return an object that has corresponding functions and fields specified:
If you don’t use the module, skip this step. In this case, use the cfg argument
of the role’s validate() and apply() functions to refer to its configuration
values, for example, cfg.greeting.
Validating a role configuration
To validate a role configuration, you need to define the validate([cfg]) function.
In the example below, the validate() function of the role configuration schema
is used to validate the greeting value:
If the configuration is not valid, validate() reports an unrecoverable error by throwing an error object.
Applying a role configuration
To apply the validated configuration, define the apply([cfg]) function.
As the validate() function, apply() provides access to a role’s configuration using the cfg argument.
In the example below, the apply() function uses the log module to write a value from the role configuration to the log:
localfunctionapply(cfg)log.info("%s from the 'greeter' role!",greeter_schema:get(cfg,'greeting'))end
In the example below, the stop() function uses the log module to indicate that a role is stopped:
localfunctionstop()log.info("The 'greeter' role is stopped")end
When you’ve defined all the role functions, you need to return an object that has corresponding functions specified:
return{validate=validate,apply=apply,stop=stop,}
Role dependencies
To define a role’s dependencies, use the dependencies field.
In this example, the byeer role has the greeter role as the dependency:
-- byeer.lua --locallog=require('log').new("byeer")return{dependencies={'greeter'},validate=function()end,apply=function()log.info("Bye from the 'byeer' role!")end,stop=function()end,}
A role cannot be started without its dependencies.
This means that all the dependencies of a role should be defined in the roles configuration parameter:
To create a space in a role, you need to make sure that the target instance is in read-write mode (its box.info.ro is false).
You can check an instance state by subscribing to the box.status event using box.watch():
box.watch('box.status',function()-- creating a space-- ...end)
Note
Given that a role may be enabled when an instance is already in read-write mode,
you also need to execute schema initialization code from apply().
To make sure a space is created only once, use the if_not_exists option.
Roles life cycle
A role’s life cycle includes the stages described below.
Loading roles
On each run, all roles are loaded in the order they are specified in the configuration.
This stage takes effect when a role is enabled or an instance with this role is restarted.
At this stage, a role executes the initialization code.
A role cannot be started if it has dependencies that are not specified in a configuration.
Note
Dependencies do not affect the order in which roles are loaded.
However, the validate(), apply(), and stop() functions are executed taking dependencies into account.
Learn more in Executing functions for dependent roles.
Stopping roles
This stage takes effect during a configuration reload when a role is removed from the configuration for a given instance.
Note that all stop() calls are performed before any validate() or apply() calls.
This means that old roles are stopped first, and only then new roles are started.
Validating a role’s configurations
At this stage, a configuration for each role is validated using the corresponding validate() function in the same order in which they are specified in the configuration.
Applying a role’s configurations
At this stage, a configuration for each role is applied using the corresponding apply() function in the same order in which they are specified in the configuration.
All role’s functions report an unrecoverable error by throwing an error object.
If an error is thrown in any phase, applying a configuration is stopped.
If starting or stopping a role throws an error, no roles are stopped or started afterward.
An error is caught and shown in config:info() in the alerts section.
Executing functions for dependent roles
For roles that depend on each other, their validate(), apply(), and stop() functions are executed taking into account the dependencies.
Suppose, there are three independent and two dependent roles:
role1
role2
role3
└─── role4
└─── role5
role1, role2, and role5 are independent roles.
role3 depends on role4, role4 depends on role5.
The roles are enabled in a configuration as follows:
roles:[role1,role2,role3,role4,role5]
In this case, validate() and apply() for these roles are executed in the following order:
role1 -> role2 -> role5 -> role4 -> role3
Roles removed from a configuration are stopped in the order reversed to the order they are specified in a configuration, taking into account the dependencies.
Suppose, all roles except role1 are removed from the configuration above:
roles:[role1]
After reloading a configuration, stop() functions for the removed roles are executed in the following order:
role3 -> role4 -> role5 -> role2
Example: Role without a configuration
The example below shows how to enable the custom greeter role for instance001:
instance001:roles:[greeter]
The implementation of this role looks as follows:
-- greeter.lua --return{validate=function()end,apply=function()require('log').info("Hi from the 'greeter' role!")end,stop=function()end,}
-- greeter.lua --locallog=require('log').new("greeter")localschema=require('experimental.config.utils.schema')localgreeter_schema=schema.new('greeter',schema.record({greeting=schema.scalar({type='string',allowed_values={'Hi','Hello'}})}))localfunctionvalidate(cfg)greeter_schema:validate(cfg)endlocalfunctionapply(cfg)log.info("%s from the 'greeter' role!",greeter_schema:get(cfg,'greeting'))endlocalfunctionstop()log.info("The 'greeter' role is stopped")endreturn{validate=validate,apply=apply,stop=stop,}
-- http-api.lua --localhttpdlocaljson=require('json')localschema=require('experimental.config.utils.schema')localfunctionvalidate_host(host,w)localhost_pattern="^(%d+)%.(%d+)%.(%d+)%.(%d+)$"ifnothost:match(host_pattern)thenw.error("'host' should be a string containing a valid IP address, got %q",host)endendlocalfunctionvalidate_port(port,w)ifport<=1orport>=65535thenw.error("'port' should be between 1 and 65535, got %d",port)endendlocallisten_address_schema=schema.new('listen_address',schema.record({host=schema.scalar({type='string',validate=validate_host,default='127.0.0.1',}),port=schema.scalar({type='integer',validate=validate_port,default=8080,}),}))localfunctionvalidate(cfg)listen_address_schema:validate(cfg)endlocalfunctionapply(cfg)ifhttpdthenhttpd:stop()endlocalcfg_with_defaults=listen_address_schema:apply_default(cfg)localhost=listen_address_schema:get(cfg_with_defaults,'host')localport=listen_address_schema:get(cfg_with_defaults,'port')httpd=require('http.server').new(host,port)localresponse_headers={['content-type']='application/json'}httpd:route({path='/band/:id',method='GET'},function(req)localid=req:stash('id')localband_tuple=box.space.bands:get(tonumber(id))ifnotband_tuplethenreturn{status=404,body='Band not found'}elselocalband={id=band_tuple['id'],band_name=band_tuple['band_name'],year=band_tuple['year']}return{status=200,headers=response_headers,body=json.encode(band)}endend)httpd:route({path='/band',method='GET'},function(req)locallimit=req:query_param('limit')ifnotlimitthenlimit=5endlocalband_tuples=box.space.bands:select({},{limit=tonumber(limit)})localbands={}for_,tupleinpairs(band_tuples)dolocalband={id=tuple['id'],band_name=tuple['band_name'],year=tuple['year']}table.insert(bands,band)endreturn{status=200,headers=response_headers,body=json.encode(bands)}end)httpd:start()endlocalfunctionstop()httpd:stop()endlocalfunctioninit()require('data'):add_sample_data()endinit()return{validate=validate,apply=apply,stop=stop,}
Validate a role’s configuration.
This function is called on instance startup or when the configuration is reloaded for the instance with this role.
Note that the validate() function is called regardless of whether the role’s configuration or any field in a cluster’s configuration is changed.
validate() should throw an error if the validation fails.
Parameters:
cfg – a role’s role configuration to be validated.
This parameter provides access to configuration options defined in roles_cfg.<role_name>.
To get values of configuration options placed outside roles_cfg.<role_name>, use config:get().
Apply a role’s configuration.
apply() is called after validate() is executed for all the enabled roles.
As the validate() function, apply() is called on instance startup or when the configuration is reloaded for the instance with this role.
apply() should throw an error if the specified configuration can’t be applied.
Note
Note that apply() is not invoked if an instance switches to read-write mode when replication.failover is set to election or supervised.
You can check an instance state by subscribing to the box.status event using box.watch().
Parameters:
cfg – a role’s role configuration to be applied.
This parameter provides access to configuration options defined in roles_cfg.<role_name>.
To get values of configuration options placed outside roles_cfg.<role_name>, use config:get().
Creating a fiber is the Tarantool way of making application logic work in the background at all times.
A fiber is a set of instructions that are executed with cooperative multitasking:
the instructions contain yield signals, upon which control is passed to another fiber.
Fibers
Fibers are similar to threads of execution in computing.
The key difference is that threads use
preemptive multitasking, while fibers use cooperative multitasking (see below).
This gives fibers the following two advantages over threads:
Better controllability. Threads often depend on the kernel’s thread scheduler
to preempt a busy thread and resume another thread, so preemption may occur
unpredictably. Fibers yield themselves to run another fiber while executing,
so yields are controlled by application logic.
Higher performance. Threads require more resources to preempt as they need to
address the system kernel. Fibers are lighter and faster as they don’t need to
address the kernel to yield.
Yet fibers have some limitations as compared with threads, the main limitation
being no multi-core mode. All fibers in an application belong to a single thread,
so they all use the same CPU core as the parent thread. Meanwhile, this
limitation is not really serious for Tarantool applications, because a typical
bottleneck for Tarantool is the HDD, not the CPU.
A fiber has all the features of a Lua
coroutine and all programming
concepts that apply for Lua coroutines will apply for fibers as well. However,
Tarantool has made some enhancements for fibers and has used fibers internally.
So, although the use of coroutines is possible and supported, the use of fibers is
recommended.
Any live fiber can be in one of three states: running, suspended, and
ready. After a fiber dies, the dead status returns.
To learn more about fibers, go to the fiber module documentation.
Yields
Yield is an action that occurs in a cooperative environment that
transfers control of the thread from the current fiber to another fiber that is ready to execute.
Any live fiber can be in one of three states: running, suspended, and
ready. After a fiber dies, the dead status is returned. By observing
fibers from the outside, you can only see running (for the current fiber)
and suspended for any other fiber waiting for an event from the event loop (ev)
for execution.
After a yield has occurred, the next ready fiber is taken from the queue and executed.
When there are no more ready fibers, execution is transferred to the event loop.
After a fiber has yielded and regained control, it immediately issues testcancel.
Explicit yields are clearly visible from the invoking code. There are only two
explicit yields: fiber.yield() and fiber.sleep(t).
fiber.yield() yields execution to another ready fiber while putting itself in the ready state, meaning that it will be executed again as soon as possible while being polite to other fibers waiting for execution.
fiber.sleep(t) yields execution to another ready fiber and puts itself in the suspended state for time t until time passes and the event loop wakes up this fiber to the ready state.
In general, it is good behavior for long-running cpu-intensive tasks to yield periodically to
be cooperative to other waiting fibers.
Implicit yields
On the other hand, there are many operations, such as operations with sockets, file system,
and disk I/O, which imply some waiting for the current fiber while others can be
executed. When such an operation occurs, a possible blocking operation would be passed into the
event loop and the fiber would be suspended until the resource is ready to
continue fiber execution.
Here is the list of implicitly yielding operations:
Please note that all operations of the os module are non-cooperative and
exclusively block the whole tx thread.
For memtx, since all data is in memory, there is no yielding for a read request
(like :select, :pairs, :get).
For vinyl, since some data may not be in memory, there may be disk I/O for a
read (to fetch data from disk) or write (because a stall may occur while waiting for memory to be freed).
For both memtx and vinyl, since data change requests
must be recorded in the WAL, there is normally a box.commit().
With the default autocommit mode the following operations are yielding:
box.commit (if there were some modifications within the transaction).
To provide atomicity for transactions in transaction mode, some changes are applied to the
modification operations for the memtx engine. After executing
box.begin or within a box.atomic
call, any modification operation will not yield, and yield will occur only on box.commit or upon return
from box.atomic. Meanwhile, box.rollback does not yield.
That is why executing separate commands like select(), insert(), update() in the console inside a
transaction without MVCC will cause it to an abort. This is due to implicit yield after each
chunk of code is executed in the console.
Example #1
Engine = memtx.
space:get()space:insert()
The sequence has one yield, at the end of the insert, caused by implicit commit;
get() has nothing to write to the WAL and so does not yield.
The sequence has one yield, at the end of the box.commit, none of the inserts are yielding.
Engine = vinyl.
space:get()space:insert()
The sequence has one to three yields, since get() may yield if the data is not in the cache,
insert() may yield if it waits for available memory, and there is an implicit yield
at commit.
If wal_mode = none, then
there is no implicit yielding at the commit time because there are
no writes to the WAL.
If a request if performed via network connector such as net.box and implies
sending requests to the server and receiving responses, then it involves network
I/O and thus implicit yielding. Even if the request that is sent to the server
has no implicit yield. Therefore, the following sequence causes yields
three times sequentially when sending requests to the network and awaiting the results.
Cooperative multitasking means that unless a running fiber deliberately yields
control, it is not preempted by some other fiber. But a running fiber will
deliberately yield when it encounters a “yield point”: a transaction commit,
an operating system call, or an explicit “yield” request.
Any system call which can block will be performed asynchronously, and any running
fiber which must wait for a system call will be preempted, so that another
ready-to-run fiber takes its place and becomes the new running fiber.
This model makes all programmatic locks unnecessary: cooperative multitasking
ensures that there will be no concurrency around a resource, no race conditions,
and no memory consistency issues. The way to achieve this is simple:
Use no yields, explicit or implicit in critical sections, and no one can
interfere with code execution.
For small requests, such as simple UPDATE or INSERT or DELETE or
SELECT, fiber scheduling is fair: it takes little time to process the
request, schedule a disk write, and yield to a fiber serving the next client.
However, a function may perform complex calculations or be written in
such a way that yields take a long time to occur. This can lead to
unfair scheduling when a single client throttles the rest of the system, or to
apparent stalls in processing requests. It is the responsibility of the function
author to avoid this situation. As a protective mechanism, a fiber slice can be used.
Lua cookbook recipes
Here are contributions of Lua programs for some frequent or tricky situations.
You can execute any of these programs by copying the code into a .lua file,
and then entering chmod+x./program-name.lua
and ./program-name.lua on the terminal.
The first line is a “hashbang”:
#!/usr/bin/env tarantool
This runs Tarantool Lua application server, which should be on the execution
path.
Use box.once() to initialize a database
(creating spaces) if this is the first time the server has been run.
Then use console.start() to start interactive mode.
Use the fio module to open, read, and close a file.
#!/usr/bin/env tarantoollocalfio=require('fio')localerrno=require('errno')localf=fio.open('/tmp/xxxx.txt',{'O_RDONLY'})ifnotfthenerror("Failed to open file: "..errno.strerror())endlocaldata=f:read(4096)f:close()print(data)
fio_write.lua
Use the fio module to open, write, and close a file.
#!/usr/bin/env tarantoollocalfio=require('fio')localerrno=require('errno')localf=fio.open('/tmp/xxxx.txt',{'O_CREAT','O_WRONLY','O_APPEND'},tonumber('0666',8))ifnotfthenerror("Failed to open file: "..errno.strerror())endf:write("Hello\n");f:close()
#!/usr/bin/env tarantoollocalffi=require('ffi')ffi.cdef[[ int printf(const char *format, ...);]]ffi.C.printf("Hello, %s\n",os.getenv("USER"));
ffi_gettimeofday.lua
Use the LuaJIT ffi library to call a C function: gettimeofday().
This delivers time with millisecond precision, unlike the time function in
Tarantool’s clock module.
#!/usr/bin/env tarantoollocalffi=require('ffi')ffi.cdef[[ typedef long time_t; typedef struct timeval { time_t tv_sec; time_t tv_usec;} timeval; int gettimeofday(struct timeval *t, void *tzp);]]localtimeval_buf=ffi.new("timeval")localnow=function()ffi.C.gettimeofday(timeval_buf,nil)returntonumber(timeval_buf.tv_sec*1000+(timeval_buf.tv_usec/1000))end
#!/usr/bin/env tarantoollocalffi=require("ffi")ffi.cdef[[ unsigned long compressBound(unsigned long sourceLen); int compress2(uint8_t *dest, unsigned long *destLen, const uint8_t *source, unsigned long sourceLen, int level); int uncompress(uint8_t *dest, unsigned long *destLen, const uint8_t *source, unsigned long sourceLen);]]localzlib=ffi.load(ffi.os=="Windows"and"zlib1"or"z")-- Lua wrapper for compress2()localfunctioncompress(txt)localn=zlib.compressBound(#txt)localbuf=ffi.new("uint8_t[?]",n)localbuflen=ffi.new("unsigned long[1]",n)localres=zlib.compress2(buf,buflen,txt,#txt,9)assert(res==0)returnffi.string(buf,buflen[0])end-- Lua wrapper for uncompresslocalfunctionuncompress(comp,n)localbuf=ffi.new("uint8_t[?]",n)localbuflen=ffi.new("unsigned long[1]",n)localres=zlib.uncompress(buf,buflen,comp,#comp)assert(res==0)returnffi.string(buf,buflen[0])end-- Simple test code.localtxt=string.rep("abcd",1000)print("Uncompressed size: ",#txt)localc=compress(txt)print("Compressed size: ",#c)localtxt2=uncompress(c,#txt)assert(txt2==txt)
ffi_meta.lua
Use the LuaJIT ffi library to
access a C object via a metamethod (a method which is defined with
a metatable).
Create Lua tables, and print them.
Notice that for the ‘array’ table the iterator function
is ipairs(), while for the ‘map’ table the iterator function
is pairs(). (ipairs() is faster than pairs(), but pairs()
is recommended for map-like tables or mixed tables.)
The display will look like:
“1 Apple | 2 Orange | 3 Grapefruit | 4 Banana | k3 v3 | k1 v1 | k2 v2”.
Missing elements in arrays, which Lua treats as “nil”s,
cause the simple “#” operator to deliver improper results.
The “print(#t)” instruction will print “4”;
the “print(counter)” instruction will print “3”;
the “print(max)” instruction will print “10”.
Other table functions, such as table.sort(), will
also misbehave when “nils” are present.
Use explicit NULL values to avoid the problems caused by Lua’s
nil == missing value behavior. Although json.NULL==nil is
true, all the print instructions in this program will print
the correct value: 10.
#!/usr/bin/env tarantool-- define class objectslocalmyclass_somemethod=function(self)print('test 1',self.data)endlocalmyclass_someothermethod=function(self)print('test 2',self.data)endlocalmyclass_tostring=function(self)return'MyClass <'..self.data..'>'endlocalmyclass_mt={__tostring=myclass_tostring;__index={somemethod=myclass_somemethod;someothermethod=myclass_someothermethod;}}-- create a new object of myclasslocalobject=setmetatable({data='data'},myclass_mt)print(object:somemethod())print(object.data)
Start one fiber for producer and one fiber for consumer.
Use fiber.channel() to exchange data and synchronize.
One can tweak the channel size (ch_size in the program code)
to control the number of simultaneous tasks waiting for processing.
#!/usr/bin/env tarantoollocalfiber=require('fiber')localfunctionconsumer_loop(ch,i)-- initialize consumer synchronously or raise an error()fiber.sleep(0)-- allow fiber.create() to continuewhiletruedolocaldata=ch:get()ifdata==nilthenbreakendprint('consumed',i,data)fiber.sleep(math.random())-- simulate some workendendlocalfunctionproducer_loop(ch,i)-- initialize consumer synchronously or raise an error()fiber.sleep(0)-- allow fiber.create() to continuewhiletruedolocaldata=math.random()ch:put(data)print('produced',i,data)endendlocalfunctionstart()localconsumer_n=5localproducer_n=3-- Create a channellocalch_size=math.max(consumer_n,producer_n)localch=fiber.channel(ch_size)-- Start consumersfori=1,consumer_n,1dofiber.create(consumer_loop,ch,i)end-- Start producersfori=1,producer_n,1dofiber.create(producer_loop,ch,i)endendstart()print('started')
socket_tcpconnect.lua
Use socket.tcp_connect()
to connect to a remote host via TCP.
Display the connection details and the result of a GET request.
Use socket.tcp_connect()
to set up a simple TCP server, by creating
a function that handles requests and echos them,
and passing the function to
socket.tcp_server().
This program has been used to test with 100,000 clients,
with each client getting a separate fiber.
#!/usr/bin/env tarantoollocalfunctionhandler(s,peer)s:write("Welcome to test server, "..peer.host.."\n")whiletruedolocalline=s:read('\n')ifline==nilthenbreak-- error or eofendifnots:write("pong: "..line)thenbreak-- error or eofendendendlocalserver,addr=require('socket').tcp_server('localhost',3311,handler)
getaddrinfo.lua
Use socket.getaddrinfo() to perform
non-blocking DNS resolution, getting both the AF_INET6 and AF_INET
information for ‘google.com’.
This technique is not always necessary for tcp connections because
socket.tcp_connect()
performs socket.getaddrinfo under the hood,
before trying to connect to the first available address.
Tarantool does not currently have a udp_server function,
therefore socket_udp_echo.lua is more complicated than
socket_tcp_echo.lua.
It can be implemented with sockets and fibers.
#!/usr/bin/env tarantoollocalsocket=require('socket')localerrno=require('errno')localfiber=require('fiber')localfunctionudp_server_loop(s,handler)fiber.name("udp_server")whiletruedo-- try to read a datagram firstlocalmsg,peer=s:recvfrom()ifmsg==""then-- socket was closed via s:close()breakelseifmsg~=nilthen-- got a new datagramhandler(s,peer,msg)elseifs:errno()==errno.EAGAINors:errno()==errno.EINTRthen-- socket is not readys:readable()-- yield, epoll will wake us when new data arriveselse-- socket errorlocalmsg=s:error()s:close()-- save resources and don't wait GCerror("Socket error: "..msg)endendendendlocalfunctionudp_server(host,port,handler)locals=socket('AF_INET','SOCK_DGRAM',0)ifnotsthenreturnnil-- check errno:strerror()endifnots:bind(host,port)thenlocale=s:errno()-- save errnos:close()errno(e)-- restore errnoreturnnil-- check errno:strerror()endfiber.create(udp_server_loop,s,handler)-- start a new background fiberreturnsend
A function for a client that connects to this server could
look something like this …
localfunctionhandler(s,peer,msg)-- You don't have to wait until socket is ready to send UDP-- s:writable()s:sendto(peer.host,peer.port,"Pong: "..msg)endlocalserver=udp_server('127.0.0.1',3548,handler)ifnotserverthenerror('Failed to bind: '..errno.strerror())endprint('Started')require('console').start()
#!/usr/bin/env tarantoollocalhttp_client=require('http.client')localjson=require('json')localr=http_client.get('https://api.frankfurter.app/latest?to=USD%2CRUB')ifr.status~=200thenprint('Failed to get currency ',r.reason)returnendlocaldata=json.decode(r.body)print(data.base,'rate of',data.date,'is',data.rates.RUB,'RUB or',data.rates.USD,'USD')
Use the httprock (which must first be installed)
to turn Tarantool into a web server.
#!/usr/bin/env tarantoollocalfunctionhandler(self)returnself:render{json={['Your-IP-Is']=self.peer.host}}endlocalserver=require('http.server').new(nil,8080,{charset="utf8"})-- listen *:8080server:route({path='/'},handler)server:start()-- connect to localhost:8080 and see json
http_generate_html.lua
Use the httprock (which must first be installed)
to generate HTML pages from templates.
The httprock has a fairly simple template engine which allows execution
of regular Lua code inside text blocks (like PHP). Therefore there is no need
to learn new languages in order to write templates.
#!/usr/bin/env tarantoollocalfunctionhandler(self)localfruits={'Apple','Orange','Grapefruit','Banana'}returnself:render{fruits=fruits}endlocalserver=require('http.server').new(nil,8080,{charset="utf8"})-- nil means '*'server:route({path='/',file='index.html.lua'},handler)server:start()
An “HTML” file for this server, including Lua, could look like this
(it would produce “1 Apple | 2 Orange | 3 Grapefruit | 4 Banana”).
Create a templates directory and put this file in it:
In Go, there is no one-liner to select all tuples from a Tarantool space.
Yet you can use a script like this one. Call it on the instance you want to
connect to.
packagemainimport("fmt""log""github.com/tarantool/go-tarantool")/*box.cfg{listen = 3301}box.schema.user.passwd('pass')s = box.schema.space.create('tester')s:format({ {name = 'id', type = 'unsigned'}, {name = 'band_name', type = 'string'}, {name = 'year', type = 'unsigned'}})s:create_index('primary', { type = 'hash', parts = {'id'} })s:create_index('scanner', { type = 'tree', parts = {'id', 'band_name'} })s:insert{1, 'Roxette', 1986}s:insert{2, 'Scorpions', 2015}s:insert{3, 'Ace of Base', 1993}*/funcmain(){conn,err:=tarantool.Connect("127.0.0.1:3301",tarantool.Opts{User:"admin",Pass:"pass",})iferr!=nil{log.Fatalf("Connection refused")}deferconn.Close()spaceName:="tester"indexName:="scanner"idFn:=conn.Schema.Spaces[spaceName].Fields["id"].IdbandNameFn:=conn.Schema.Spaces[spaceName].Fields["band_name"].IdvartuplesPerRequestuint32=2cursor:=[]interface{}{}for{resp,err:=conn.Select(spaceName,indexName,0,tuplesPerRequest,tarantool.IterGt,cursor)iferr!=nil{log.Fatalf("Failed to select: %s",err)}ifresp.Code!=tarantool.OkCode{log.Fatalf("Select failed: %s",resp.Error)}iflen(resp.Data)==0{break}fmt.Println("Iteration")tuples:=resp.Tuples()for_,tuple:=rangetuples{fmt.Printf("\t%v\n",tuple)}lastTuple:=tuples[len(tuples)-1]cursor=[]interface{}{lastTuple[idFn],lastTuple[bandNameFn]}}}
Lua tutorials
First steps
If you’re new to Lua, we recommend going over the interactive Tarantool
tutorial. To launch the tutorial, run the tutorial() command in the Tarantool console:
tarantool> tutorial()----|Tutorial -- Screen #1 -- Hello, Moon====================================Welcome to the Tarantool tutorial.It will introduce you to Tarantool’s Lua application serverand database server, which is what’s running what you’re seeing.This is INTERACTIVE -- you’re expected to enter requestsbased on the suggestions or examples in the screen’s text.<...>
Insert one million tuples with a Lua stored procedure
This is an exercise assignment: “Insert one million tuples. Each tuple should
have a constantly-increasing numeric primary-key field and a random alphabetic
10-character string field.”
The purpose of the exercise is to show what Lua functions look like inside
Tarantool. It will be necessary to employ the Lua math library, the Lua string
library, the Tarantool box library, the Tarantool box.tuple library, loops, and
concatenations. It should be easy to follow even for a person who has not used
either Lua or Tarantool before. The only requirement is a knowledge of how other
programming languages work and a memory of the first two chapters of this manual.
But for better understanding, follow the comments and the links, which point to
the Lua manual or to elsewhere in this Tarantool manual. To further enhance
learning, type the statements in with the tarantool client while reading along.
Configure
We are going to use the Tarantool sandbox that was created for our
“Getting started” exercises.
So there is a single space, and a numeric primary key,
and a running Tarantool server instance which also serves as a client.
Delimiter
In earlier versions of Tarantool, multi-line functions had to be
enclosed within “delimiters”. They are no longer necessary, and
so they will not be used in this tutorial. However, they are still
supported. Users who wish to use delimiters, or users of
older versions of Tarantool, should check the syntax description for
declaring a delimiter before proceeding.
Create a function that returns a string
We will start by making a function that returns a fixed string, “Hello world”.
functionstring_function()return"hello world"end
The word “function” is a Lua keyword – we’re about to go into Lua. The
function name is string_function. The function has one executable statement,
return"helloworld". The string “hello world” is enclosed in double quotes
here, although Lua doesn’t care – one could use single quotes instead. The
word “end” means “this is the end of the Lua function declaration.”
To confirm that the function works, we can say
string_function()
Sending function-name() means “invoke the Lua function.” The effect is
that the string which the function returns will end up on the screen.
We begin by declaring a variable “string_value”. The word “local”
means that string_value appears only in main_function. If we didn’t use
“local” then string_value would be visible everywhere - even by other
users using other clients connected to this server instance! Sometimes that’s a very
desirable feature for inter-client communication, but not this time.
Then we assign a value to string_value, namely, the result of
string_function(). Soon we will invoke main_function() to check that it
got the value.
Modify the function so it returns a one-letter random string
Now that it’s a bit clearer how to make a variable, we can change
string_function() so that, instead of returning a fixed literal
“Hello world”, it returns a random letter between ‘A’ and ‘Z’.
It is not necessary to destroy the old string_function() contents, they’re
simply overwritten. The first assignment invokes a random-number function
in Lua’s math library; the parameters mean “the number must be an integer
between 65 and 90.” The second assignment invokes an integer-to-character
function in Lua’s string library; the parameter is the code point of the
character. Luckily the ASCII value of ‘A’ is 65 and the ASCII value of ‘Z’
is 90 so the result will always be a letter between A and Z.
… Well, actually it won’t always look like this because math.random()
produces random numbers. But for the illustration purposes it won’t matter
what the random string values are.
Modify the function so it returns a ten-letter random string
Now that it’s clear how to produce one-letter random strings, we can reach our
goal of producing a ten-letter string by concatenating ten one-letter strings,
in a loop.
The words “for x = 1,10,1” mean “start with x equals 1, loop until x equals 10,
increment x by 1 for each iteration.” The symbol “..” means “concatenate”, that
is, add the string on the right of the “..” sign to the string on the left of
the “..” sign. Since we start by saying that random_string is “” (a blank
string), the end result is that random_string has 10 random letters. Once
again the string_function() can be invoked from main_function() which
can be invoked with main_function().
Now that it’s clear how to make a 10-letter random string, it’s possible to
make a tuple that contains a number and a 10-letter random string, by invoking
a function in Tarantool’s library of Lua functions.
Once this is done, t will be the value of a new tuple which has two fields.
The first field is numeric: 1. The second field is a random string. Once again
the string_function() can be invoked from main_function() which can be
invoked with main_function().
For more about Tarantool tuples see Tarantool manual section Submodule box.tuple.
Modify main_function to insert a tuple into the database
Now that it’s clear how to make a tuple that contains a number and a 10-letter
random string, the only trick remaining is putting that tuple into tester.
Remember that tester is the first space that was defined in the sandbox, so
it’s like a database table.
The new line here is box.space.tester:replace(t). The name contains
‘tester’ because the insertion is going to be to tester. The second parameter
is the tuple value. To be perfectly correct we could have said
box.space.tester:insert(t) here, rather than box.space.tester:replace(t),
but “replace” means “insert even if there is already a tuple whose primary-key
value is a duplicate”, and that makes it easier to re-run the exercise even if
the sandbox database isn’t empty. Once this is done, tester will contain a tuple
with two fields. The first field will be 1. The second field will be a random
10-letter string. Once again the string_function() can be invoked from
main_function() which can be invoked with main_function(). But
main_function() won’t tell the whole story, because it does not return t, it
only puts t into the database. To confirm that something got inserted, we’ll use
a SELECT request.
Modify main_function to insert a million tuples into the database
Now that it’s clear how to insert one tuple into the database, it’s no big deal
to figure out how to scale up: instead of inserting with a literal value = 1
for the primary key, insert with a variable value = between 1 and 1 million, in
a loop. Since we already saw how to loop, that’s a simple thing. The only extra
wrinkle that we add here is a timing function.
functionmain_function()localstring_value,tfori=1,1000000,1dostring_value=string_function()t=box.tuple.new({i,string_value})box.space.tester:replace(t)endendstart_time=os.clock()main_function()end_time=os.clock()'insert done in '..end_time-start_time..' seconds'
The standard Lua function
os.clock()
will return the number of CPU seconds since the
start. Therefore, by getting start_time = number of seconds just before the
inserting, and then getting end_time = number of seconds just after the
inserting, we can calculate (end_time - start_time) = elapsed time in seconds.
We will display that value by putting it in a request without any assignments,
which causes Tarantool to send the value to the client, which prints it. (Lua’s
answer to the C printf() function, which is print(), will also work.)
Since this is the grand finale, we will redo the final versions of all the
necessary requests: the request that
created string_function(), the request that created main_function(),
and the request that invokes main_function().
functionstring_function()localrandom_numberlocalrandom_stringrandom_string=""forx=1,10,1dorandom_number=math.random(65,90)random_string=random_string..string.char(random_number)endreturnrandom_stringendfunctionmain_function()localstring_value,tfori=1,1000000,1dostring_value=string_function()t=box.tuple.new({i,string_value})box.space.tester:replace(t)endendstart_time=os.clock()main_function()end_time=os.clock()'insert done in '..end_time-start_time..' seconds'
What has been shown is that Lua functions are quite expressive (in fact one can
do more with Tarantool’s Lua stored procedures than one can do with stored
procedures in some SQL DBMSs), and that it’s straightforward to combine
Lua-library functions and Tarantool-library functions.
What has also been shown is that inserting a million tuples took 37 seconds. The
host computer was a Linux laptop. By changing wal_mode to ‘none’ before
running the test, one can reduce the elapsed time to 4 seconds.
Sum a JSON field for all tuples
This is an exercise assignment: “Assume that inside every tuple there is a
string formatted as JSON. Inside that string there is a JSON numeric field.
For each tuple, find the numeric field’s value and add it to a ‘sum’ variable.
At end, return the ‘sum’ variable.” The purpose of the exercise is to get
experience in one way to read and process tuples.
LINE 3: WHY “LOCAL”. This line declares all the variables that will be used in
the function. Actually it’s not necessary to declare all variables at the start,
and in a long function it would be better to declare variables just before using
them. In fact it’s not even necessary to declare variables at all, but an
undeclared variable is “global”. That’s not desirable for any of the variables
that are declared in line 1, because all of them are for use only within the function.
LINE 5: WHY “PAIRS()”. Our job is to go through all the rows and there are two
ways to do it: with box.space.space_object:pairs() or with
variable=select(...) followed by fori,n,1dosome-function(variable[i])end.
We preferred pairs() for this example.
LINE 5: START THE MAIN LOOP. Everything inside this “for” loop will be
repeated as long as there is another index key. A tuple is fetched and can be
referenced with variable t.
LINE 6: WHY “PCALL”. If we simply said lua_table=json.decode(t[2])), then
the function would abort with an error if it encountered something wrong with the
JSON string - a missing colon, for example. By putting the function inside “pcall”
(protected call), we’re saying: we want to intercept that sort of error, so if
there’s a problem just set is_valid_json=false and we will know what to do
about it later.
LINE 6: MEANING. The function is json.decode which means decode a JSON
string, and the parameter is t[2] which is a reference to a JSON string. There’s
a bit of hard coding here, we’re assuming that the second field in the tuple is
where the JSON string was inserted. For example, we’re assuming a tuple looks like
meaning that the tuple’s first field, the primary key field, is a number while
the tuple’s second field, the JSON string, is a string. Thus the entire statement
means “decode t[2] (the tuple’s second field) as a JSON string; if there’s an
error set is_valid_json=false; if there’s no error set is_valid_json=true and
set lua_table= a Lua table which has the decoded string”.
LINE 8. At last we are ready to get the JSON field value from the Lua table that
came from the JSON string. The value in field_name, which is the parameter for the
whole function, must be a name of a JSON field. For example, inside the JSON string
'{"Hello":"world","Quantity":15}', there are two JSON fields: “Hello” and
“Quantity”. If the whole function is invoked with sum_json_field("Quantity"),
then field_value=lua_table[field_name] is effectively the same as
field_value=lua_table["Quantity"] or even field_value=lua_table.Quantity.
Those are just three different ways of saying: for the Quantity field in the Lua table,
get the value and put it in variable field_value.
LINE 9: WHY “IF”. Suppose that the JSON string is well formed but the JSON field
is not a number, or is missing. In that case, the function would be aborted when
there was an attempt to add it to the sum. By first checking
type(field_value)=="number", we avoid that abortion. Anyone who knows that
the database is in perfect shape can skip this kind of thing.
And the function is complete. Time to test it. Starting with an empty database,
defined the same way as the sandbox database in our
“Getting started” exercises,
-- if tester is left over from some previous test, destroy itbox.space.tester:drop()box.schema.space.create('tester')box.space.tester:create_index('primary',{parts={1,'unsigned'}})
then add some tuples where the first field is a number and the second
field is a string.
Since this is a test, there are deliberate errors. The “golf club” and the
“waffle iron” do not have numeric Quantity fields, so must be ignored.
Therefore the real sum of the Quantity field in the JSON strings should be:
15 + 7 = 22.
Invoke the function with sum_json_field("Quantity").
tarantool> sum_json_field("Quantity")----22...
It works. We’ll just leave, as exercises for future improvement, the possibility
that the “hard coding” assumptions could be removed, that there might have to be
an overflow check if some field values are huge, and that the function should
contain a yield instruction if the count of tuples is huge.
Indexed pattern search
Here is a generic function which takes a field identifier
and a search pattern, and returns all tuples that match.
* The field must be the first field of a TREE index.
* The function will use Lua pattern matching,
which allows “magic characters” in regular expressions.
* The initial characters in the pattern, as far as the
first magic character, will be used as an index search key.
For each tuple that is found via the index, there will be
a match of the whole pattern.
* To be cooperative,
the function should yield after every
10 tuples, unless there is a reason to delay yielding.
With this function, we can take advantage of Tarantool’s indexes
for speed, and take advantage of Lua’s pattern matching for flexibility.
It does everything that an SQL
LIKE search can do, and far more.
Read the following Lua code to see how it works.
The comments that begin with “SEE NOTE …” refer to long
explanations that follow the code.
functionindexed_pattern_search(space_name,field_no,pattern)-- SEE NOTE #1 "FIND AN APPROPRIATE INDEX"if(box.space[space_name]==nil)thenprint("Error: Failed to find the specified space")returnnilendlocalindex_no=-1fori=0,box.schema.INDEX_MAX,1doif(box.space[space_name].index[i]==nil)thenbreakendif(box.space[space_name].index[i].type=="TREE"andbox.space[space_name].index[i].parts[1].fieldno==field_noand(box.space[space_name].index[i].parts[1].type=="scalar"orbox.space[space_name].index[i].parts[1].type=="string"))thenindex_no=ibreakendendif(index_no==-1)thenprint("Error: Failed to find an appropriate index")returnnilend-- SEE NOTE #2 "DERIVE INDEX SEARCH KEY FROM PATTERN"localindex_search_key=""localindex_search_key_length=0locallast_character=""localc=""localc2=""fori=1,string.len(pattern),1doc=string.sub(pattern,i,i)if(last_character~="%")thenif(c=='^'orc=="$"orc=="("orc==")"orc=="."orc=="["orc=="]"orc=="*"orc=="+"orc=="-"orc=="?")thenbreakendif(c=="%")thenc2=string.sub(pattern,i+1,i+1)if(string.match(c2,"%p")==nil)thenbreakendindex_search_key=index_search_key..c2elseindex_search_key=index_search_key..cendendlast_character=cendindex_search_key_length=string.len(index_search_key)if(index_search_key_length<3)thenprint("Error: index search key "..index_search_key.." is too short")returnnilend-- SEE NOTE #3 "OUTER LOOP: INITIATE"localresult_set={}localnumber_of_tuples_in_result_set=0localprevious_tuple_field=""whiletruedolocalnumber_of_tuples_since_last_yield=0localis_time_for_a_yield=false-- SEE NOTE #4 "INNER LOOP: ITERATOR"for_,tupleinbox.space[space_name].index[index_no]:pairs(index_search_key,{iterator=box.index.GE})do-- SEE NOTE #5 "INNER LOOP: BREAK IF INDEX KEY IS TOO GREAT"if(string.sub(tuple[field_no],1,index_search_key_length)>index_search_key)thenbreakend-- SEE NOTE #6 "INNER LOOP: BREAK AFTER EVERY 10 TUPLES -- MAYBE"number_of_tuples_since_last_yield=number_of_tuples_since_last_yield+1if(number_of_tuples_since_last_yield>=10andtuple[field_no]~=previous_tuple_field)thenindex_search_key=tuple[field_no]is_time_for_a_yield=truebreakendprevious_tuple_field=tuple[field_no]-- SEE NOTE #7 "INNER LOOP: ADD TO RESULT SET IF PATTERN MATCHES"if(string.match(tuple[field_no],pattern)~=nil)thennumber_of_tuples_in_result_set=number_of_tuples_in_result_set+1result_set[number_of_tuples_in_result_set]=tupleendend-- SEE NOTE #8 "OUTER LOOP: BREAK, OR YIELD AND CONTINUE"if(is_time_for_a_yield~=true)thenbreakendrequire('fiber').yield()endreturnresult_setend
NOTE #1 “FIND AN APPROPRIATE INDEX”
The caller has passed space_name (a string) and field_no (a number).
The requirements are:
(a) index type must be “TREE” because for other index types
(HASH, BITSET, RTREE) a search with iterator=GE
will not return strings in order by string value;
(b) field_no must be the first index part;
(c) the field must contain strings, because for other data types
(such as “unsigned”) pattern searches are not possible;
If these requirements are not met by any index, then
print an error message and return nil.
NOTE #2 “DERIVE INDEX SEARCH KEY FROM PATTERN”
The caller has passed pattern (a string).
The index search key will be
the characters in the pattern as far as the first magic character.
Lua’s magic characters are % ^ $ ( ) . [ ] * + - ?.
For example, if the pattern is “ABC.E”, the period is a magic
character and therefore the index search key will be “ABC”.
But there is a complication … If we see “%” followed by a punctuation
character, that punctuation character is “escaped” so
remove the “%” when making the index search key. For example, if the
pattern is “AB%$E”, the dollar sign is escaped and therefore
the index search key will be “AB$E”.
Finally there is a check that the index search key length
must be at least three – this is an arbitrary number, and in
fact zero would be okay, but short index search keys will cause
long search times.
NOTE #3 – “OUTER LOOP: INITIATE”
The function’s job is to return a result set,
just as box.space...select<box_space-select> would. We will fill
it within an outer loop that contains an inner
loop. The outer loop’s job is to execute the inner
loop, and possibly yield, until the search ends.
The inner loop’s job is to find tuples via the index, and put
them in the result set if they match the pattern.
NOTE #4 “INNER LOOP: ITERATOR”
The for loop here is using pairs(), see the
explanation of what index iterators are.
Within the inner loop,
there will be a local variable named “tuple” which contains
the latest tuple found via the index search key.
NOTE #5 “INNER LOOP: BREAK IF INDEX KEY IS TOO GREAT”
The iterator is GE (Greater or Equal), and we must be
more specific: if the search index key has N characters,
then the leftmost N characters of the result’s index field
must not be greater than the search index key. For example,
if the search index key is ‘ABC’, then ‘ABCDE’ is
a potential match, but ‘ABD’ is a signal that
no more matches are possible.
NOTE #6 “INNER LOOP: BREAK AFTER EVERY 10 TUPLES – MAYBE”
This chunk of code is for cooperative multitasking.
The number 10 is arbitrary, and usually a larger number would be okay.
The simple rule would be “after checking 10 tuples, yield,
and then resume the search (that is, do the inner loop again)
starting after the last value that was found”. However, if
the index is non-unique or if there is more than one field
in the index, then we might have duplicates – for example
{“ABC”,1}, {“ABC”, 2}, {“ABC”, 3}” – and it would be difficult
to decide which “ABC” tuple to resume with. Therefore, if
the result’s index field is the same as the previous
result’s index field, there is no break.
NOTE #7 “INNER LOOP: ADD TO RESULT SET IF PATTERN MATCHES”
Compare the result’s index field to the entire pattern.
For example, suppose that the caller passed pattern “ABC.E”
and there is an indexed field containing “ABCDE”.
Therefore the initial index search key is “ABC”.
Therefore a tuple containing an indexed field with “ABCDE”
will be found by the iterator, because “ABCDE” > “ABC”.
In that case string.match will return a value which is not nil.
Therefore this tuple can be added to the result set.
NOTE #8 “OUTER LOOP: BREAK, OR YIELD AND CONTINUE”
There are three conditions which will cause a break from
the inner loop: (1) the for loop ends naturally because
there are no more index keys which are greater than or
equal to the index search key, (2) the index key is too
great as described in NOTE #5, (3) it is time for a yield
as described in NOTE #6. If condition (1) or condition (2)
is true, then there is nothing more to do, the outer loop
ends too. If and only if condition (3) is true, the
outer loop must yield and then continue. If it does
continue, then the inner loop – the iterator search –
will happen again with a new value for the index search key.
EXAMPLE:
Start Tarantool, cut and paste the code for function indexed_pattern_search(),
and try the following:
The Lua syntax for data-manipulation functions
can vary. Here are examples of the variations with select() requests.
The same rules exist for the other data-manipulation functions.
Every one of the examples does the same thing:
select a tuple set from a space named ‘tester’ where the primary-key field value
equals 1. For these examples, we assume that the numeric id of ‘tester’
is 512, which happens to be the case in our sandbox example only.
Object reference variations
First, there are three object reference variations:
-- #1 module . submodule . nametarantool> box.space.tester:select{1}-- #2 replace name with a literal in square bracketstarantool> box.space['tester']:select{1}-- #3 use a variable for the entire object referencetarantool> s=box.space.testertarantool> s:select{1}
Examples in this manual usually have the “box.space.tester:”
form (#1). However, this is a matter of user preference and all the variations
exist in the wild.
Also, descriptions in this manual use the syntax “space_object:”
for references to objects which are spaces, and
“index_object:” for references to objects which are indexes (for example
box.space.tester.index.primary:).
Lua allows to omit parentheses () when invoking a function if its only
argument is a Lua table, and we use it sometimes in our examples.
This is why select{1} is equivalent to select({1}).
Literal values such as 1 (a scalar value) or {1} (a Lua table value)
may be replaced by variable names, as in examples #6 and #7.
Although there are special cases where braces can be omitted, they are
preferable because they signal “Lua table”.
Examples and descriptions in this manual have the {1} form. However, this
too is a matter of user preference and all the variations exist in the wild.
Rules for object names
Database objects have loose rules for names:
the maximum length is 65000 bytes (not characters),
and almost any legal Unicode character is allowed,
including spaces, ideograms and punctuation.
In those cases, to prevent confusion with Lua operators and
separators, object references should have the literal-in-square-brackets
form (#2), or the variable form (#3). For example:
checks
is a type checker of functional arguments. This library that declares
a checks() function and checkers table that allow to check the
parameters passed to a Lua function in a fast and unobtrusive way.
http is an
on-board HTTP-server, which comes in addition to Tarantool’s out-of-the-box
HTTP client, and must be installed as described in the
installation section.
icu-date
is a date-and-time formatting library for Tarantool
based on International Components for Unicode;
kafka
is a full-featured high-performance kafka library for Tarantool
based on librdkafka;
luacheck is a static analyzer and
linter for Lua, preconfigured for Tarantool.
luatest is
a Tarantool test framework written in Lua.
membership
builds a mesh from multiple Tarantool instances based on gossip protocol.
The mesh monitors itself, helps members discover everyone else in the group
and get notified about their status changes with low latency. It is built
upon the ideas from Consul or, more precisely, the SWIM algorithm.
metrics is a collection
of useful monitoring metrics.
tracing
is a module for debugging performance issues.
vshard
is an automatic sharding system that enables horizontal scaling for Tarantool
DBMS instances.
Closed source modules
ldap allows you to authenticate in a LDAP server and perform searches.
odbc is an ODBC connector for Tarantool based on unixODBC.
oracle
is an Oracle connector for Lua applications through which they can send and
receive data to and from Oracle databases.
The advantage of the Tarantool-Oracle integration is that anyone can handle all
the tasks with Oracle DBMSs (control, manipulation, storage, access) with the
same high-level language (Lua) and with minimal delay.
task
is a module for managing background tasks in a Tarantool cluster.
Installing and using modules
To use a module, install the following:
All the necessary third-party software packages (if any). See the
module’s prerequisites for the list.
Further we walk you through key programming practices that will give you a good
start in writing Lua applications for Tarantool. We will implement a real microservice
based on Tarantool! It is a backend for a simplified version of
Pokémon Go, a location-based
augmented reality game launched in mid-2016.
In this game, players use the GPS capability of a mobile device to locate, catch,
battle, and train virtual monsters called “pokémon” that appear on the screen as
if they were in the same real-world location as the player.
To stay within the walk-through format, let’s narrow the original gameplay as
follows. We have a map with pokémon spawn locations. Next, we have multiple
players who can send catch-a-pokémon requests to the server (which runs our
Tarantool microservice). The server responds whether the
pokémon is caught or not, increases the player’s pokémon counter if yes,
and triggers the respawn-a-pokémon method that spawns a new pokémon at the same
location in a while.
We leave client-side applications outside the scope of this story. However, we
promise a mini-demo in the end to simulate real users and give us some fun.
To make our game logic available to other developers and Lua applications, let’s
put it into a Lua module.
A module (called “rock” in Lua) is an optional library which enhances
Tarantool functionality. So, we can install our logic as a module in Tarantool
and use it from any Tarantool application or module. Like applications, modules
in Tarantool can be written in Lua (rocks), C or C++.
Modules are good for two things:
easier code management (reuse, packaging, versioning), and
hot code reload without restarting the Tarantool instance.
Technically, a module is a file with source code that exports its functions in
an API. For example, here is a Lua module named mymodule.lua that exports
one function named myfun:
To launch the function myfun() – from another module, from a Lua application,
or from Tarantool itself, – we need to save this module as a file, then load
this module with the require() directive and call the exported function.
For example, here’s a Lua application that uses myfun() function from
mymodule.lua module:
-- loading the modulelocalmymodule=require('mymodule')-- calling myfun() from within test() functionlocaltest=function()mymodule.myfun()end
A thing to remember here is that the require() directive takes load paths
to Lua modules from the package.path variable. This is a semicolon-separated
string, where a question mark is used to interpolate the module name. By default,
this variable contains system-wide Lua paths and the working directory.
But if we put our modules inside a specific folder (e.g. scripts/), we need
to add this folder to package.path before any calls to require():
package.path='scripts/?.lua;'..package.path
For our microservice, a simple and convenient solution would be to put all
methods in a Lua module (say pokemon.lua) and to write a Lua application
(say game.lua) that initializes the gaming environment and starts the game
loop.
Now let’s get down to implementation details. In our game, we need three entities:
map, which is an array of pokémons with coordinates of respawn locations;
in this version of the game, let a location be a rectangle identified with two
points, upper-left and lower-right;
player, which has an ID, a name, and coordinates of the player’s location
point;
pokémon, which has the same fields as the player, plus a status
(active/inactive, that is present on the map or not) and a catch probability
(well, let’s give our pokémons a chance to escape :-) )
We’ll store these entities as tuples in Tarantool spaces. But to deliver our
backend application as a microservice, the good practice would be to send/receive
our data in the universal JSON format, thus using Tarantool as a document storage.
Avro schemas
To store JSON data as tuples, we will apply a savvy practice which reduces data
footprint and ensures all stored documents are valid. We will use Tarantool
module avro-schema which checks
the schema of a JSON document and converts it to a Tarantool tuple. The tuple
will contain only field values, and thus take a lot less space than the original
document. In avro-schema terms, converting JSON documents to tuples is
“flattening”, and restoring the original documents is “unflattening”.
First you need to install
the module with ttrocksinstallavro-schema.
Further usage is quite straightforward:
For each entity, we need to define a schema in
Apache Avro schema syntax,
where we list the entity’s fields with their names and
Avro data types.
At initialization, we call avro-schema.create() that creates objects
in memory for all schema entities, and compile() that generates
flatten/unflatten methods for each entity.
Further on, we just call flatten/unflatten methods for a respective entity
on receiving/sending the entity’s data.
Here’s what our schema definitions for the player and pokémon entities look like:
And here’s how we create and compile our entities at initialization:
-- load avro-schema module with require()localavro=require('avro_schema')-- create modelslocalok_m,pokemon=avro.create(schema.pokemon)localok_p,player=avro.create(schema.player)ifok_mandok_pthen-- compile modelslocalok_cm,compiled_pokemon=avro.compile(pokemon)localok_cp,compiled_player=avro.compile(player)ifok_cmandok_cpthen-- start the game<...>elselog.error('Schema compilation failed')endelselog.info('Schema creation failed')endreturnfalse
As for the map entity, it would be an overkill to introduce a schema for it,
because we have only one map in the game, it has very few fields, and – which
is most important – we use the map only inside our logic, never exposing it
to external users.
Next, we need methods to implement the game logic. To simulate object-oriented
programming in our Lua code, let’s store all Lua functions and shared variables
in a single local variable (let’s name it as game). This will allow us to
address functions or variables from within our module as self.func_name or
self.var_name. Like this:
localgame={-- a local variablenum_players=0,-- a method that prints a local variablehello=function(self)print('Hello! Your player number is '..self.num_players..'.')end,-- a method that calls another method and returns a local variablesign_in=function(self)self.num_players=self.num_players+1self:hello()returnself.num_playersend}
In OOP terms, we can now regard local variables inside game as object fields,
and local functions as object methods.
Note
In this manual, Lua examples use local variables. Use global
variables with caution, since the module’s users may be unaware of them.
To enable/disable the use of undeclared global variables in your Lua code,
use Tarantool’s strict module.
So, our game module will have the following methods:
catch() to calculate whether the pokémon was caught (besides the
coordinates of both the player and pokémon, this method will apply
a probability factor, so not every pokémon within the player’s reach
will be caught);
respawn() to add missing pokémons to the map, say, every 60 seconds
(we assume that a frightened pokémon runs away, so we remove a pokémon from
the map on any catch attempt and add it back to the map in a while);
notify() to log information about caught pokémons (like
“Player 1 caught pokémon A”);
start() to initialize the game (it will create database spaces, create
and compile avro schemas, and launch respawn()).
Besides, it would be convenient to have methods for working with Tarantool
storage. For example:
add_pokemon() to add a pokémon to the database, and
map() to populate the map with all pokémons stored in Tarantool.
We’ll need these two methods primarily when initializing our game, but we can
also call them later, for example to test our code.
Bootstrapping a database
Let’s discuss game initialization. In start() method, we need to populate
Tarantool spaces with pokémon data. Why not keep all game data in memory?
Why use a database? The answer is: persistence.
Without a database, we risk losing data on power outage, for example.
But if we store our data in an in-memory database, Tarantool takes care to
persist it on disk whenever it’s changed. This gives us one more benefit:
quick startup in case of failure.
Tarantool has a smart algorithm that quickly
loads all data from disk into memory on startup, so the warm-up takes little time.
We’ll be using functions from Tarantool built-in box module:
box.schema.create_space('pokemons') to create a space named pokemon for
storing information about pokémons (we don’t create a similar space for players,
because we intend to only send/receive player information via API calls, so we
needn’t store it);
box.space.pokemons:create_index('primary',{type='hash',parts={1,'unsigned'}})
to create a primary HASH index by pokémon ID;
box.space.pokemons:create_index('status',{type='tree',parts={2,'str'}})
to create a secondary TREE index by pokémon status.
Notice the parts= argument in the index specification. The pokémon ID is
the first field in a Tarantool tuple since it’s the first member of the respective
Avro type. So does the pokémon status. The actual JSON document may have ID or
status fields at any position of the JSON map.
The implementation of start() method looks like this:
-- create game objectstart=function(self)-- create spaces and indexesbox.once('init',function()box.schema.create_space('pokemons')box.space.pokemons:create_index("primary",{type='hash',parts={1,'unsigned'}})box.space.pokemons:create_index("status",{type="tree",parts={2,'str'}})end)-- create modelslocalok_m,pokemon=avro.create(schema.pokemon)localok_p,player=avro.create(schema.player)ifok_mandok_pthen-- compile modelslocalok_cm,compiled_pokemon=avro.compile(pokemon)localok_cp,compiled_player=avro.compile(player)ifok_cmandok_cpthen-- start the game<...>elselog.error('Schema compilation failed')endelselog.info('Schema creation failed')endreturnfalseend
GIS
Now let’s discuss catch(), which is the main method in our gaming logic.
Here we receive the player’s coordinates and the target pokémon’s ID number,
and we need to answer whether the player has actually caught the pokémon or not
(remember that each pokémon has a chance to escape).
First thing, we validate the received player data against its
Avro schema. And we check whether such a pokémon
exists in our database and is displayed on the map (the pokémon must have the
active status):
catch=function(self,pokemon_id,player)-- check player datalocalok,tuple=self.player_model.flatten(player)ifnotokthenreturnfalseend-- get pokemon datalocalp_tuple=box.space.pokemons:get(pokemon_id)ifp_tuple==nilthenreturnfalseendlocalok,pokemon=self.pokemon_model.unflatten(p_tuple)ifnotokthenreturnfalseendifpokemon.status~=self.state.ACTIVEthenreturnfalseend-- more catch logic to follow<...>end
Next, we calculate the answer: caught or not.
To work with geographical coordinates, we use Tarantool
gis module.
To keep things simple, we don’t load any specific map, assuming that we deal with
a world map. And we do not validate incoming coordinates, assuming again that all
received locations are within the planet Earth.
We use two geo-specific variables:
wgs84, which stands for the latest revision of the World Geodetic System
standard, WGS84.
Basically, it comprises a standard coordinate system for the Earth and
represents the Earth as an ellipsoid.
nationalmap, which stands for the
US National Atlas Equal Area. This is a projected
coordinates system based on WGS84. It gives us a zero base for location
projection and allows positioning our players and pokémons in meters.
Both these systems are listed in the EPSG Geodetic Parameter Registry, where each
system has a unique number. In our code, we assign these listing numbers to
respective variables:
wgs84=4326,nationalmap=2163,
For our game logic, we need one more variable, catch_distance, which defines
how close a player must get to a pokémon before trying to catch it. Let’s set
the distance to 100 meters.
catch_distance=100,
Now we’re ready to calculate the answer. We need to project the current location
of both player (p_pos) and pokémon (m_pos) on the map, check whether the
player is close enough to the pokémon (using catch_distance), and calculate
whether the player has caught the pokémon (here we generate some random value and
let the pokémon escape if the random value happens to be less than 100 minus
pokémon’s chance value):
-- project locationslocalm_pos=gis.Point({pokemon.location.x,pokemon.location.y},self.wgs84):transform(self.nationalmap)localp_pos=gis.Point({player.location.x,player.location.y},self.wgs84):transform(self.nationalmap)-- check catch distance conditionifp_pos:distance(m_pos)>self.catch_distancethenreturnfalseend-- try to catch pokemonlocalcaught=math.random(100)>=100-pokemon.chanceifcaughtthen-- update and notify on successbox.space.pokemons:update(pokemon_id,{{'=',self.STATUS,self.state.CAUGHT}})self:notify(player,pokemon)endreturncaught
Index iterators
By our gameplay, all caught pokémons are returned back to the map. We do this
for all pokémons on the map every 60 seconds using respawn() method.
We iterate through pokémons by status using Tarantool index iterator function
index_object:pairs() and reset the statuses of all
“caught” pokémons back to “active” using box.space.pokemons:update().
The complete implementation of start() now looks like this:
-- create game objectstart=function(self)-- create spaces and indexesbox.once('init',function()box.schema.create_space('pokemons')box.space.pokemons:create_index("primary",{type='hash',parts={1,'unsigned'}})box.space.pokemons:create_index("status",{type="tree",parts={2,'str'}})end)-- create modelslocalok_m,pokemon=avro.create(schema.pokemon)localok_p,player=avro.create(schema.player)ifok_mandok_pthen-- compile modelslocalok_cm,compiled_pokemon=avro.compile(pokemon)localok_cp,compiled_player=avro.compile(player)ifok_cmandok_cpthen-- start the gameself.pokemon_model=compiled_pokemonself.player_model=compiled_playerself.respawn()log.info('Started')returntrueelselog.error('Schema compilation failed')endelselog.info('Schema creation failed')endreturnfalseend
Fibers, yields and cooperative multitasking
But wait! If we launch it as shown above – self.respawn() – the function
will be executed only once, just like all the other methods. But we need to
execute respawn() every 60 seconds. Creating a fiber
is the Tarantool way of making application logic work in the background at all
times.
A fiber is a set of instructions that are executed with
cooperative multitasking:
the instructions contain yield signals, upon which control is passed to another fiber.
Let’s launch respawn() in a fiber to make it work in the background all the time.
To do so, we’ll need to amend respawn():
respawn=function(self)-- let's give our fiber a name;-- this will produce neat output in fiber.info()fiber.name('Respawn fiber')whiletruedofor_,tupleinbox.space.pokemons.index.status:pairs(self.state.CAUGHT)dobox.space.pokemons:update(tuple[self.ID],{{'=',self.STATUS,self.state.ACTIVE}})endfiber.sleep(self.respawn_time)endend
and call it as a fiber in start():
start=function(self)-- create spaces and indexes<...>-- create models<...>-- compile models<...>-- start the gameself.pokemon_model=compiled_pokemonself.player_model=compiled_playerfiber.create(self.respawn,self)log.info('Started')-- errors if schema creation or compilation fails<...>end
Logging
One more helpful function that we used in start() was log.infо() from
Tarantool log module. We also need this function in
notify() to add a record to the log file on every successful catch:
We use default Tarantool log settings, so we’ll see the log
output in console when we launch our application in script mode.
Great! We’ve discussed all programming practices used in our Lua module (see
pokemon.lua).
Now let’s prepare the test environment. As planned, we write a Lua application
(see game.lua) to
initialize Tarantool’s database module, initialize our game, call the game loop
and simulate a couple of player requests.
To launch our microservice, we put both the pokemon.lua module and the game.lua
application in the current directory, install all external modules, and launch
the Tarantool instance running our game.lua application (this example is for
Ubuntu):
$ ls
game.lua pokemon.lua$ sudoapt-getinstalltarantool-gis
$ sudoapt-getinstalltarantool-avro-schema
$ tarantoolgame.lua
Tarantool starts and initializes the database. Then Tarantool executes the demo
logic from game.lua: adds a pokémon named Pikachu (its chance to be caught
is very high, 99.1), displays the current map (it contains one active pokémon,
Pikachu) and processes catch requests from two players. Player1 is located just
near the lonely Pikachu pokémon and Player2 is located far away from it.
As expected, the catch results in this output are “true” for Player1 and “false”
for Player2. Finally, Tarantool displays the current map which is empty, because
Pikachu is caught and temporarily inactive:
In the real life, this microservice would work over HTTP. Let’s add
nginx web server to our environment and make a similar
demo. But how do we make Tarantool methods callable via REST API? We use nginx
with Tarantool nginx upstream
module and create one more Lua script
(app.lua) that
exports three of our game methods – add_pokemon(), map() and catch()
– as REST endpoints of the nginx upstream module:
localgame=require('pokemon')box.cfg{listen=3301}game:start()-- add, map and catch functions exposed to REST APIfunctionadd(request,pokemon)return{result=game:add_pokemon(pokemon)}endfunctionmap(request)return{map=game:map()}endfunctioncatch(request,pid,player)localid=tonumber(pid)ifid==nilthenreturn{result=false}endreturn{result=game:catch(id,player)}end
An easy way to configure and launch nginx would be to create a Docker container
based on a Docker image
with nginx and the upstream module already installed (see
http/Dockerfile).
We take a standard
nginx.conf,
where we define an upstream with our Tarantool backend running (this is another
Docker container, see details below):
Likewise, we put Tarantool server and all our game logic in a second Docker
container based on the
official Tarantool 1.9 image (see
src/Dockerfile)
and set the container’s default command to tarantoolapp.lua.
This is the backend.
Non-blocking IO
To test the REST API, we create a new script
(client.lua),
which is similar to our game.lua application, but makes HTTP POST and GET
requests rather than calling Lua functions:
localhttp=require('curl').http()localjson=require('json')localURI=os.getenv('SERVER_URI')localfiber=require('fiber')localplayer1={name="Player1",id=1,location={x=1.0001,y=2.0003}}localplayer2={name="Player2",id=2,location={x=30.123,y=40.456}}localpokemon={name="Pikachu",chance=99.1,id=1,status="active",location={x=1,y=2}}functionrequest(method,body,id)localresp=http:request(method,URI,body)ifid~=nilthenprint(string.format('Player %d result: %s',id,resp.body))elseprint(resp.body)endendlocalplayers={}functioncatch(player)fiber.sleep(math.random(5))print('Catch pokemon by player '..tostring(player.id))request('POST','{"method": "catch", "params": [1, '..json.encode(player)..']}',tostring(player.id))table.insert(players,player.id)endprint('Create pokemon')request('POST','{"method": "add", "params": ['..json.encode(pokemon)..']}')request('GET','')fiber.create(catch,player1)fiber.create(catch,player2)-- wait for playerswhile#players~=2dofiber.sleep(0.001)endrequest('GET','')os.exit()
When you run this script, you’ll notice that both players have equal chances to
make the first attempt at catching the pokémon. In a classical Lua script,
a networked call blocks the script until it’s finished, so the first catch
attempt can only be done by the player who entered the game first. In Tarantool,
both players play concurrently, since all modules are integrated with Tarantool
cooperative multitasking and use
non-blocking I/O.
Indeed, when Player1 makes its first REST call, the script doesn’t block.
The fiber running catch() function on behalf of Player1 issues a non-blocking
call to the operating system and yields control to the next fiber, which happens
to be the fiber of Player2. Player2’s fiber does the same. When the network
response is received, Player1’s fiber is activated by Tarantool cooperative
scheduler, and resumes its work. All Tarantool modules
use non-blocking I/O and are integrated with Tarantool cooperative scheduler.
For module developers, Tarantool provides an API.
To run this test locally, download our pokemon
project from GitHub and say:
$ docker-composebuild
$ docker-composeup
Docker Compose builds and runs all the three containers: pserver (Tarantool
backend), phttp (nginx) and pclient (demo client). You can see log
messages from all these containers in the console, pclient saying that it made
an HTTP request to create a pokémon, made two catch requests, requested the map
(empty since the pokémon is caught and temporarily inactive) and exited:
pclient_1 | Create pokemon<...>pclient_1 | {"result":true}pclient_1 | {"map":[{"id":1,"status":"active","location":{"y":2,"x":1},"name":"Pikachu","chance":99.100000}]}pclient_1 | Catch pokemon by player 2pclient_1 | Catch pokemon by player 1pclient_1 | Player 1 result: {"result":true}pclient_1 | Player 2 result: {"result":false}pclient_1 | {"map":[]}pokemon_pclient_1 exited with code 0
Congratulations! Here’s the end point of our walk-through. As further reading,
see more about installing and
contributing a module.
Tarantool can call C code with modules,
or with ffi,
or with C stored procedures.
This tutorial only is about the third option, C stored procedures.
In fact the routines are always “C functions” but the phrase
“stored procedure” is commonly used for historical reasons.
In this tutorial, which can be followed by anyone with a Tarantool
development package and a C compiler, there are five tasks:
After following the instructions, and seeing that the results
are what is described here, users should feel confident about
writing their own stored procedures.
Preparation
Check that these items exist on the computer:
Tarantool 2.1 or later
A gcc compiler, any modern version should work
module.h and files #included in it
msgpuck.h
libmsgpuck.a (only for some recent msgpuck versions)
The module.h file will exist if Tarantool was installed from source.
Otherwise Tarantool’s “developer” package must be installed.
For example on Ubuntu say:
$ sudoapt-getinstalltarantool-dev
or on Fedora say:
$ dnf-yinstalltarantool-devel
The msgpuck.h file will exist if Tarantool was installed from source.
Otherwise the “msgpuck” package must be installed from
https://github.com/tarantool/msgpuck.
Both module.h and msgpuck.h must be on the include path for the
C compiler to see them.
For example, if module.h address is /usr/local/include/tarantool/module.h,
and msgpuck.h address is /usr/local/include/msgpuck/msgpuck.h,
and they are not currently on the include path, say:
The libmsgpuck.a static library is necessary with msgpuck versions
produced after February 2017. If and only if you encounter linking
problems when using the gcc statements in the examples for this tutorial, you should
put libmsgpuck.a on the path (libmsgpuck.a is produced from both msgpuck
and Tarantool source downloads so it should be easy to find). For
example, instead of “gcc-shared-oharder.so-fPICharder.c”
for the second example below, you will need to say
“gcc-shared-oharder.so-fPICharder.clibmsgpuck.a”.
Requests will be done using Tarantool as a
client.
Start Tarantool, and enter these requests.
In plainer language: create a space named capi_test,
and make a connection to self named capi_connection.
Leave the client running. It will be necessary to enter more requests later.
easy.c
Start another shell. Change directory (cd) so that it is
the same as the directory that the client is running on.
Create a file. Name it easy.c. Put the following code in it:
#include"module.h"inteasy(box_function_ctx_t*ctx,constchar*args,constchar*args_end){printf("hello world\n");return0;}inteasy2(box_function_ctx_t*ctx,constchar*args,constchar*args_end){printf("hello world -- easy2\n");return0;}
Compile the program, producing a library file named easy.so:
$ gcc-shared-oeasy.so-fPICeasy.c
Now go back to the client and execute these requests:
The function that matters is capi_connection:call('easy').
Its first job is to find the ‘easy’ function, which should
be easy because by default Tarantool looks on the current
directory for a file named easy.so.
Its second job is to call the ‘easy’ function.
Since the easy() function in easy.c begins with printf("helloworld\n"),
the words “hello world” will appear on the screen.
Its third job is to check that the call was successful.
Since the easy() function in easy.c ends with return0,
there is no error message to display and the request is over.
Now let’s call the other function in easy.c – easy2().
This is almost the same as the easy() function, but there’s a detail:
when the file name is not the same as the function name,
then we have to specify
file-name.function-name.
This time the call is passing a Lua table (passable_table)
to the harder() function. The harder() function will see it,
it’s in the char*args parameter.
At this point the harder() function will start using functions
defined in msgpuck.h.
The routines that begin with “mp” are msgpuck functions that
handle data formatted according to the MsgPack specification.
Passes and returns are always done with this format so
one must become acquainted with msgpuck
to become proficient with the C API.
For now, though, it’s enough to know that mp_decode_array()
returns the number of elements in an array, and mp_decode_uint
returns an unsigned integer, from args. And there’s a side
effect: when the decoding finishes, args has changed
and is now pointing to the next element.
Therefore the first displayed line will be “arg_count = 1”
because there was only one item passed: passable_table.
The second displayed line will be “field_count = 3”
because there are three items in the table.
The next three lines will be “1” and “2” and “3”
because those are the values in the items in the table.
Conclusion: decoding parameter values passed to a
C function is not easy at first, but there are routines
to do the job, and they’re documented, and there aren’t
very many of them.
hardest.c
Go back to the shell where the easy.c
and the harder.c programs were created.
Create a file. Name it hardest.c. Put these 13 lines in it:
#include"module.h"#include"msgpuck.h"inthardest(box_function_ctx_t*ctx,constchar*args,constchar*args_end){uint32_tspace_id=box_space_id_by_name("capi_test",strlen("capi_test"));chartuple[1024];/* Must be big enough for mp_encode results */char*tuple_pointer=tuple;tuple_pointer=mp_encode_array(tuple_pointer,2);tuple_pointer=mp_encode_uint(tuple_pointer,10000);tuple_pointer=mp_encode_str(tuple_pointer,"String 2",8);intn=box_insert(space_id,tuple,tuple_pointer,NULL);returnn;}
Compile the program, producing a library file named hardest.so:
$ gcc-shared-ohardest.so-fPIChardest.c
Now go back to the client and execute these requests:
finding the numeric identifier of the capi_test space
by calling box_space_id_by_name();
formatting a tuple using more msgpuck.h functions;
inserting a tuple using box_insert().
Warning
chartuple[1024]; is used here as just a quick way
of saying “allocate more than enough bytes”. For serious
programs the developer must be careful to allow enough space for
all the bytes that the mp_encode routines will use up.
Go back to the shell where the easy.c
and the harder.c and the hardest.c programs were created.
Create a file. Name it read.c. Put these 43 lines in it:
#include"module.h"#include<msgpuck.h>intread(box_function_ctx_t*ctx,constchar*args,constchar*args_end){chartuple_buf[1024];/* where the raw MsgPack tuple will be stored */uint32_tspace_id=box_space_id_by_name("capi_test",strlen("capi_test"));uint32_tindex_id=0;/* The number of the space's first index */uint32_tkey=10000;/* The key value that box_insert() used */mp_encode_array(tuple_buf,0);/* clear */box_tuple_format_t*fmt=box_tuple_format_default();box_tuple_t*tuple=NULL;charkey_buf[16];/* Pass key_buf = encoded key = 1000 */char*key_end=key_buf;key_end=mp_encode_array(key_end,1);key_end=mp_encode_uint(key_end,key);assert(key_end<=key_buf+sizeof(key_buf));/* Get the tuple. There's no box_select() but there's this. */intr=box_index_get(space_id,index_id,key_buf,key_end,&tuple);assert(r==0);assert(tuple!=NULL);/* Get each field of the tuple + display what you get. */intfield_no;/* The first field number is 0. */for(field_no=0;field_no<2;++field_no){constchar*field=box_tuple_field(tuple,field_no);assert(field!=NULL);assert(mp_typeof(*field)==MP_STR||mp_typeof(*field)==MP_UINT);if(mp_typeof(*field)==MP_UINT){uint32_tuint_value=mp_decode_uint(&field);printf("uint value=%u.\n",uint_value);}else/* if (mp_typeof(*field) == MP_STR) */{constchar*str_value;uint32_tstr_value_length;str_value=mp_decode_str(&field,&str_value_length);printf("string value=%.*s.\n",str_value_length,str_value);}}return0;}
Compile the program, producing a library file named read.so:
$ gcc-shared-oread.so-fPICread.c
Now go back to the client and execute these requests:
once again, finding the numeric identifier of the capi_test space
by calling box_space_id_by_name();
formatting a search key = 10000 using more msgpuck.h functions;
getting a tuple using box_index_get();
going through the tuple’s fields with box_tuple_get() and then
decoding each field depending on its type. In this case, since
what we are getting is the tuple that we inserted with hardest.c,
we know in advance that the type is either MP_UINT or MP_STR;
however, it’s very common to have a case statement here with one
option for each possible type.
The result of capi_connection:call('read') should look like this:
This proves that the read() function succeeded.
Once again the important functions that start with box
– box_index_get() and
box_tuple_field() –
came from the C API.
write.c
Go back to the shell where the programs easy.c, harder.c, hardest.c
and read.c were created.
Create a file. Name it write.c. Put these 24 lines in it:
#include"module.h"#include<msgpuck.h>intwrite(box_function_ctx_t*ctx,constchar*args,constchar*args_end){staticconstchar*space="capi_test";chartuple_buf[1024];/* Must be big enough for mp_encode results */uint32_tspace_id=box_space_id_by_name(space,strlen(space));if(space_id==BOX_ID_NIL){returnbox_error_set(__FILE__,__LINE__,ER_PROC_C,"Can't find space %s","capi_test");}char*tuple_end=tuple_buf;tuple_end=mp_encode_array(tuple_end,2);tuple_end=mp_encode_uint(tuple_end,1);tuple_end=mp_encode_uint(tuple_end,22);box_txn_begin();if(box_replace(space_id,tuple_buf,tuple_end,NULL)!=0)return-1;box_txn_commit();fiber_sleep(0.001);structtuple*tuple=box_tuple_new(box_tuple_format_default(),tuple_buf,tuple_end);returnbox_return_tuple(ctx,tuple);}
Compile the program, producing a library file named write.so:
$ gcc-shared-owrite.so-fPICwrite.c
Now go back to the client and execute these requests:
once again, finding the numeric identifier of the capi_test space
by calling box_space_id_by_name();
making a new tuple;
starting a transaction;
replacing a tuple in box.space.capi_test
ending a transaction;
the final line is a replacement for the loop in read.c –
instead of getting each field and printing it, use the
box_return_tuple(...) function to return the entire tuple
to the caller and let the caller display it.
The result of capi_connection:call('write') should look like this:
Conclusion: the long description of the whole C API is
there for a good reason.
All of the functions in it can be called from C functions
which are called from Lua.
So C “stored procedures” have full access to the database.
Remove the .c and .so files that were created for this
tutorial.
An example in the test suite
Download the source code of Tarantool. Look in a subdirectory
test/box. Notice that there is a file named
tuple_bench.test.lua and another file named
tuple_bench.c. Examine the Lua file and observe
that it is calling a function in the C file, using the
same techniques that this tutorial has shown.
Conclusion: parts of the standard test suite
use C stored procedures, and they must work,
because releases don’t happen if Tarantool doesn’t pass the tests.
Developing with an IDE
You can use IntelliJ IDEA as an IDE to develop and debug Lua applications for
Tarantool.
JetBrains provides specialized editions for particular languages:
IntelliJ IDEA (Java), PHPStorm (PHP), PyCharm (Python), RubyMine (Ruby),
CLion (C/C++), WebStorm (Web) and others.
So, download a version that suits your primary programming language.
Tarantool integration is supported for all editions.
Configure the IDE:
Start IntelliJ IDEA.
Click Configure button and select Plugins.
Click Browserepositories.
Install EmmyLua plugin.
Note
Please don’t be confused with Lua plugin, which is less powerful
than EmmyLua.
Restart IntelliJ IDEA.
Click Configure, select ProjectDefaults and then
RunConfigurations.
Find LuaApplication in the sidebar at the left.
In Program, type a path to an installed tarantool binary.
By default, this is tarantool or /usr/bin/tarantool on most
platforms.
If you installed tarantool from sources to a custom directory,
please specify the proper path here.
Now IntelliJ IDEA is ready to use with Tarantool.
Create a new Lua project.
Add a new Lua file, for example init.lua.
Write your code, save the file.
To run you application, click Run->Run in the main menu and select
your source file in the list.
Or click Run->Debug to start debugging.
Note
To use Lua debugger, please upgrade Tarantool to version
1.7.5-29-gbb6170e4b or later.
Tooling
This section describes the tools that enable developers and administrators
to work with Tarantool.
tt is a utility that provides a unified command-line interface for managing
Tarantool-based applications. It covers a wide range of tasks – from installing
a specific Tarantool version to managing remote instances and developing applications.
tt is developed in its own GitHub repository.
Here you can find its source code, changelog, and releases information.
For a complete list of releases, see the Releases section on GitHub.
There is also the Enterprise version of tt available in a
Tarantool Enterprise Edition’s release package.
The Enterprise version provides additional features, for example, importing and exporting data.
This section provides instructions on tt installation and configuration,
concept explanation, and the tt command reference.
The key aspect of the tt usage is an environment. A tt environment
is a directory that includes a tt configuration, Tarantool installations,
application files, and other resources. If you’re familiar with Python virtual
environments,
you can think of tt environments as their analog.
tt environments enable independent management of multiple Tarantool applications,
each running on its own Tarantool version and configuration, on a single host in
an isolated manner.
To create a tt environment in a directory, run tt init in it.
Multi-instance applications
tt supports Tarantool applications that run on multiple instances. For example,
you can write an application that includes different source files for storage and router
instances. With tt, you can start and stop them in a single call, or manage
each instance independently.
A multi-purpose tool for working with Tarantool from the command line, tt has
come to replace the deprecated utilities tarantoolctl
and Cartridge CLI command-line utilities.
The instructions on migration to tt are provided in Migration from tarantoolctl to tt.
Installation
To install the tt command-line utility, use a package manager – Yum or
APT on Linux, or Homebrew on macOS. If you need a specific build, you can build
tt from sources.
Note
A Tarantool Enterprise Edition’s release package includes the tt utility extended with additional features like importing and exporting data.
Using Linux package managers
On Linux systems, you can install tt with yum or apt package managers
from the tarantool/modules repository. Learn how to add this repository.
The installation command looks like this:
On Ubuntu:
$ sudoapt-getinstalltt
On CentOS:
$ sudoyuminstalltt
Using Homebrew on macOS
On macOS, use Homebrew to install tt:
$ brewinstalltt
Building from sources
To build tt from sources:
Install third-party software required for building tt:
(Optional) Checkout a release tag to build a specific version:
gitcheckouttags/v1.0.0
Build tt using mage:
magebuild
tt will appear in the current directory.
Enabling shell completion
To enable the completion for tt commands, run the following command specifying
the shell (bash or zsh):
.<(ttcompletionbash)
Configuration
Configuration file
The key artifact that defines the tt environment and various aspects of its
execution is its configuration file. You can generate it with a tt init call.
In the default launch mode, the file is generated
in the current directory, making it the environment root.
Name and location
By default, the configuration file is called tt.yaml and located in the tt
environment root directory. It depends on the launch mode.
It is also possible to pass the configuration file name and location explicitly using
the following ways:
The tt configuration format and application layout have been changed in version
2.0. Learn how to upgrade from earlier versions in Migrating from tt 1.* to 2.0 or later.
env section
Note
The paths specified in env.* parameters are relative to the current tt
environment’s root.
instances_enabled – the directory where instances
are stored. Default: instances.enabled.
bin_dir – the directory where binary files are stored. Default: bin.
inc_dir – the base directory for storing header files. They will
be placed in the include subdirectory inside the specified directory.
Default: include.
Note
The header files directory path can also be passed using the TT_CLI_TARANTOOL_PREFIX
environment variable. If it is set, ttrocks and ttbuild commands use the
include/tarantool directory inside TT_CLI_TARANTOOL_PREFIX as the
header files directory.
restart_on_failure – restart the instance on failure: true or false.
Default: false.
tarantoolctl_layout – use a layout compatible with the deprecated tarantoolctl
utility for artifact files: control sockets, .pid files, log files.
Default: false.
The paths specified in app.*_dir parameters are relative to the application
location inside the instances.enabled directory specified in the env
configuration section. For example, the default location of the myapp
application’s logs is instances.enabled/myapp/var/log.
Inside this location, tt creates separate directories for each application
instance that runs in the current environment.
run_dir– the directory for instance runtime artifacts, such as console
sockets or PID files. Default: var/run.
log_dir – the directory where log files are stored. Default: var/log.
wal_dir – the directory where write-ahead log (.xlog) files are stored.
Default: var/lib.
memtx_dir – the directory where memtx stores snapshot (.snap) files.
Default: var/lib.
vinyl_dir – the directory where vinyl files or subdirectories are stored.
Default: var/lib.
repo section
rocks – the directory where rocks files are stored.
Note
The rocks directory path can be passed in the TT_CLI_REPO_ROCKS
environment variable instead. The variable is also used if the directory
specified in repo.rocks does not include a repository manifest.
distfiles – the directory where installation files are stored.
ee section
credential_path – a path to the file with credentials used for
downloading Tarantool Enterprise Edition (Tarantool customer zone credentials).
The file should contain a username and a password, each on a separate line.
Find an example in the tt install command
reference.
Note
The customer zone credentials can also be passed in the
TT_CLI_EE_USERNAME and TT_CLI_EE_PASSWORD environment variables.
templates section
path – a path to application templates used for creating applications with
tt create. May be specified more than once.
Launch modes
tt launch mode defines its working directory and the way it searches for the
configuration file. There are three launch modes:
default
system
local
Default launch
Global option: none
Configuration file: searched from the current directory to the root.
Taken from /etc/tarantool if the file is not found.
Working directory: The directory where the configuration file is found.
System launch
Global option: --system or -S
Configuration file: Taken from /etc/tarantool.
Working directory: Current directory.
Local launch
Global option: --local=DIRECTORY or -L=DIRECTORY
Configuration file: Searched from the specified directory to the root.
Taken from /etc/tarantool if the file is not found.
Working directory: The specified directory. If tarantool or tt
executable files are found in the working directory, they will be used.
Migrating from tt 1.* to 2.0 or later
The tt configuration and application layout were changed in version 2.0.
If you are using tt 1.*, complete the following steps to migrate to tt 2.0 or later:
Update the tt configuration file.
In tt 2.0, the following changes were made to the configuration file:
The root section tt was removed. Its child sections – app, repo,
modules, and other – have been moved to the top level.
Environment configuration parameters were moved from the app section
to the new section env. These parameters are instances.enabled,
bin_dir, inc_dir, and restart_on_failure.
The paths in the app section are now relative to the app directory in instances.enabled
instead of the environment root.
You can use tt init to generate a configuration file with
the new structure and default parameter values.
Move application artifacts.
With tt 1.*, application artifacts (logs, snapshots, pid, and other files)
were created in the var directory inside the environment root. Starting from
tt 2.0, these artifacts are created in the var directory inside the
application directory, which is instances.enabled/<app-name>. This is
how an application directory looks:
To continue using existing application artifacts after migration from tt 1.*:
Create the var directory inside the application directory.
Create the lib, log, and run directories inside var.
Move directories with instance artifacts from the old var directory
to the new var directories in applications’ directories.
Move the files accessed from the application code.
The working directory of instance processes was changed from the tt working
directory to the application directory inside instances.enabled. If the
application accesses files using relative paths, move the files accordingly
or adjust the application code.
Global options
Important
Global options of tt must be passed before its commands and other options.
For example:
This section provides a high-level overview on how to prepare a Tarantool application for deployment
and how the application’s environment and layout might look.
This information is helpful for understanding how to administer Tarantool instances using tt CLI in both development and production environments.
The main steps of creating and preparing the application for deployment are:
In this section, a sharded_cluster_crud application is used as an example.
This cluster includes 5 instances: one router and 4 storages, which constitute two replica sets.
Initializing a local environment
Before creating an application, you need to set up a local environment for tt:
Create a home directory for the environment.
Run ttinit in this directory:
~/myapp$ tt init • Environment config is written to 'tt.yaml'
This command creates a default tt configuration file tt.yaml for a local
environment and the directories for applications, control sockets, logs, and other
artifacts:
~/myapp$ lsbin distfiles include instances.enabled modules templates tt.yaml
Find detailed information about the tt configuration parameters and launch modes
on the tt configuration page.
Creating and developing an application
You can create an application in two ways:
Manually by preparing its layout in a directory inside instances_enabled.
The directory name is used as the application identifier.
The sharded_cluster_crud directory contains the following files:
config.yaml: contains the configuration of the cluster. This file might include the entire cluster topology or provide connection settings to a centralized configuration storage.
instances.yml: specifies instances to run in the current environment. For example, on the developer’s machine, this file might include all the instances defined in the cluster configuration. In the production environment, this file includes instances to run on the specific machine.
The application’s layout looks similar to the one defined when developing the application with some differences:
bin: contains the tarantool and tt binaries packed with the application bundle.
instances.enabled: contains a symlink to the packed sharded_cluster application.
sharded_cluster_crud: a packed application. In addition to files created during the application development, includes the .rocks directory containing application dependencies (for example, vshard and crud).
tt.yaml: a tt configuration file.
Note
In DEB/PRM packages generated by tt pack, there are also .service
unit files for each packaged application.
Deploying the application
Instances to run
When deploying a distributed cluster application from a .tar.gz archive, you can
define instances to run on each machine by changing the content of the instances.yaml file.
On the developer’s machine, this file might include all the instances defined in the cluster configuration.
Tarantool applications installed from DEB and RPM packages built with tt pack
can run as systemd services. They run on behalf of the tarantool system user.
It is created automatically during the package installation.
By default, the application artifacts are placed in the following directories:
/var/lib/tarantool/sys_env – application data
/var/log/tarantool/sys_env – logs
/var/run/tarantool/sys_env – runtime artifacts
If you want to change these directories, make sure that the tarantool user
has enough permissions on the directories you use.
Starting and stopping instances
This section describes how to manage instances in a Tarantool cluster using the tt utility.
A cluster can include multiple instances that run different code.
A typical example is a cluster application that includes router and storage instances.
Particularly, you can perform the following actions:
start all instances in a cluster or only specific ones
check the status of instances
connect to a specific instance
stop all instances or only specific ones
To get more context on how the application’s environment might look, refer to Application environment.
Note
In this section, a sharded_cluster_crud application is used to demonstrate how to start, stop, and manage instances in a cluster.
Starting Tarantool instances
To start Tarantool instances use the tt start command:
$ ttstartsharded_cluster_crud
• Starting an instance [sharded_cluster_crud:storage-a-001]... • Starting an instance [sharded_cluster_crud:storage-a-002]... • Starting an instance [sharded_cluster_crud:storage-b-001]... • Starting an instance [sharded_cluster_crud:storage-b-002]... • Starting an instance [sharded_cluster_crud:router-a-001]...
After the cluster has started and worked for some time, you can find its artifacts
in the directories specified in the tt configuration. These are the default
locations in the local launch mode:
sharded_cluster_crud/var/run/<instance_name>/ – control sockets and PID files.
In the system launch mode, artifacts are created in these locations:
/var/log/tarantool/<instance_name>/
/var/lib/tarantool/<instance_name>/
/var/run/tarantool/<instance_name>/
Basic instance management
Most of the commands described in this section can be called with or without an instance name.
Without the instance name, they are executed for all instances defined in instances.yaml.
Checking an instance’s status
To check the status of instances, execute tt status:
To connect to the instance, use the tt connect command:
$ ttconnectsharded_cluster_crud:storage-a-001
• Connecting to the instance... • Connected to sharded_cluster_crud:storage-a-001sharded_cluster_crud:storage-a-001>
In the instance’s console, you can execute commands provided by the box module.
For example, box.info can be used to get various information about a running instance:
After executing ttrestart, you need to confirm this operation:
Confirm restart of 'sharded_cluster_crud:storage-a-002' [y/n]: y • The Instance sharded_cluster_crud:storage-a-002 (PID = 2026) has been terminated. • Starting an instance [sharded_cluster_crud:storage-a-002]...
Stopping instances
To stop the specific instance, use tt stop as follows:
$ ttstopsharded_cluster_crud:storage-a-002
You can also stop all the instances at once as follows:
$ ttstopsharded_cluster_crud
• The Instance sharded_cluster_crud:storage-b-001 (PID = 2020) has been terminated. • The Instance sharded_cluster_crud:storage-b-002 (PID = 2021) has been terminated. • The Instance sharded_cluster_crud:router-a-001 (PID = 2022) has been terminated. • The Instance sharded_cluster_crud:storage-a-001 (PID = 2023) has been terminated. • can't "stat" the PID file. Error: "stat /home/testuser/myapp/instances.enabled/sharded_cluster_crud/var/run/storage-a-002/tt.pid: no such file or directory"
Note
The error message indicates that storage-a-002 is already not running.
Removing instance artifacts
The tt clean command removes instance artifacts (such as logs or snapshots):
$ ttcleansharded_cluster_crud
• List of files to delete: • /home/testuser/myapp/instances.enabled/sharded_cluster_crud/var/log/storage-a-001/tt.log • /home/testuser/myapp/instances.enabled/sharded_cluster_crud/var/lib/storage-a-001/00000000000000001062.snap • /home/testuser/myapp/instances.enabled/sharded_cluster_crud/var/lib/storage-a-001/00000000000000001062.xlog • ...Confirm [y/n]:
Enter y and press Enter to confirm removing of artifacts for each instance.
Note
The -f option of the ttclean command can be used to remove the files without confirmation.
Preloading Lua scripts and modules
Tarantool supports loading and running chunks of Lua code before starting instances.
To load or run Lua code immediately upon Tarantool startup, specify the TT_PRELOAD
environment variable. Its value can be either a path to a Lua script or a Lua module name:
To run the Lua script preload_script.lua from the sharded_cluster_crud directory, set TT_PRELOAD as follows:
Path to a .rockspec file to use for the current build
Details
The PATH argument should contain the path to the application directory
(that is, to the build source). The default path is . (current directory).
The application directory must contain a .rockspec file to use for the build.
If there is more than one .rockspec file in the application directory, specify
the one to use in the --spec argument.
ttbuild builds an application with the ttrocksmake command.
It downloads the application dependencies into the .rocks directory,
making the application ready to run locally.
Pre-build and post-build scripts
In addition to building the application with LuaRocks, ttbuild
can execute pre-build and post-build scripts. These scripts should
contain steps to execute right before and after building the application.
These files must be named tt.pre-build and tt.post-build correspondingly
and located in the application directory.
Note
For compatibility with Cartridge applications,
the pre-build and post-build scripts can also have names cartridge.pre-build
and cartridge.post-build.
tt.pre-build is helpful when your application depends on closed-source rocks,
or if the build should contain rocks from a project added as a submodule.
You can install these dependencies using the pre-build script before building.
Example:
#!/bin/sh# The main purpose of this script is to build non-standard rocks modules.# The script will run before `tt rocks make` during application build.
ttrocksmake--chdir./third_party/proj
tt.post-build is a script that runs after ttrocksmake. The main purpose
of this script is to remove build artifacts from the final package. Example:
#!/bin/sh# The main purpose of this script is to remove build artifacts from the resulting package.# The script will run after `tt rocks make` during application build.
rm-rfthird_party
rm-rfnode_modules
rm-rfdoc
Examples
Build the application app1 from its directory:
$ ttbuild
Build the application app1 from the simple_app directory inside the current directory:
$ ttbuildsimple_app
Build the application app1 from its directory explicitly specifying the rockspec file to use:
$ ttbuild--specapp1-scm-1.rockspec
Managing a Cartridge application
Important
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
$ ttcartridgeCOMMAND{[OPTION...]|SUBCOMMAND}
ttcartridge manages a Cartridge application.
COMMAND is one of the following:
Join the instance to a cluster.
If a replica set with the specified alias isn’t found in the cluster, it is created.
Otherwise, instances are joined to an existing replica set.
Filter the output by replica ID. Can be passed more than once.
When calling ttcat with filters by LSN (--from and --to flags) and
replica ID (--replica), remember that LSNs differ across replicas.
Thus, if you pass more than one replica ID via --from or --to,
the result may not reflect the actual sequence of operations.
-r, --raw: Print a raw content of the tt.yaml configuration file.
Examples
Print the current tt environment configuration:
$ ttcfgdump
Checking an application file
$ ttcheck{FILEPATH|APPLICATION[:APP_INSTANCE]}
ttcheck checks the syntax correctness of Lua files within Tarantool applications
or separate Lua scripts. The files must be stored inside the instances_enabled
directory specified in the tt configuration file.
Examples
To check all Lua files in an application directory at once, specify the directory name:
$ ttcheckapp
To check a single Lua file from an application directory, add the path to this file:
$ ttcheckapp/router
# or
$ ttcheckapp/router.lua
Note
The .lua extension can be omitted.
Cleaning instance files
$ ttcleanAPPLICATION[:APP_INSTANCE][OPTION...]
ttclean cleans stored files of Tarantool instances: logs, snapshots, and
other files. To avoid accidental deletion of files, ttclean shows
the files it is going to delete and asks for confirmation.
When called without arguments, cleans files of all applications in the current environment.
Clean the files of all instances of the app application:
$ ttcleanapp
Clean the files of the master instance of the app application:
$ ttcleanapp:master
Managing cluster configurations
$ ttclusterCOMMAND[COMMAND_OPTION...]
ttcluster manages configurations of Tarantool applications.
This command works both with local YAML files in application directories
and with centralized configuration storages (etcd or Tarantool-based).
ttclusterpublish publishes a cluster configuration using an arbitrary YAML file as a source.
Publishing local configurations
ttclusterpublish can modify local cluster configurations stored in
config.yaml files inside application directories.
To write a configuration to a local config.yaml, run ttclusterpublish
with two arguments:
the application name.
the path to a YAML file from which the configuration should be taken.
$ ttclusterpublishmyappsource.yaml
Publishing configurations in centralized storages
ttclusterpublish can modify centralized cluster configurations
in storages of both supported types: etcd or a Tarantool-based configuration storage.
To publish a configuration from a file to a centralized configuration storage,
run ttclusterpublish with a URI of this storage’s
instance as the target. For example, the command below publishes a configuration from source.yaml
to a local etcd instance running on the default port 2379:
A URI must include a prefix that is unique for the application. It can also include
credentials and other connection parameters. Find the detailed description of the
URI format in URI format.
Publishing configurations of specific instances
In addition to whole cluster configurations, ttclusterpublish can manage
configurations of specific instances within applications: rewrite configurations
of existing instances and add new instance configurations.
In this case, it operates with YAML fragments that describe a single instance configuration section.
For example, the following YAML file can be a source when publishing an instance configuration:
If the instance already exists, this call overwrites its configuration with the one
from the file.
To add a new instance configuration from a YAML fragment, specify the name to assign to
the new instance and its location in the cluster topology – replica set and group –
in the --replicaset and --group options.
Note
The --group option can be omitted if the configuration contains only one group.
To add a new instance instance-003 to the replicaset-001 replica set:
ttclusterpublish validates configurations against the Tarantool configuration schema
and aborts in case of an error. To skip the validation, add the --force option:
$ ttclusterpublishmyappsource.yaml--force
Publishing configurations with integrity check
Enterprise Edition
The integrity check functionality is supported by the Enterprise Edition only.
When called with the --with-integrity-check option, ttclusterpublish
generates a checksum of the configurations it publishes. It signs the checksum using
the private key passed as the option argument, and writes it into the configuration store.
ttclustershow can read local cluster configurations stored in config.yaml
files inside application directories.
To print a local configuration from an application’s config.yaml, specify the
application name as an argument:
$ ttclustershowmyapp
Displaying configurations from centralized storages
ttclustershow can display centralized cluster configurations
from configuration storages of both supported types: etcd or a Tarantool-based configuration storage.
To print a cluster configuration from a centralized storage, run ttclustershow
with a storage URI including the prefix identifying the application. For example, to print
myapp’s configuration from a local etcd storage:
$ ttclustershow"http://localhost:2379/myapp"
Displaying configurations of specific instances
In addition to whole cluster configurations, ttclustershow can display
configurations of specific instances within applications. In this case, it prints
YAML fragments that describe a single instance configuration section.
To print an instance configuration from a local config.yaml, use the application:instance
argument:
$ ttclustershowmyapp:instance-002
To print an instance configuration from a centralized configuration storage, specify
the instance name in the name argument of the URI:
ttclusterreplicaset works only with centralized cluster configurations.
To manage replica sets in clusters with local YAML configurations,
use tt replicaset.
ttclusterreplicasetpromote promotes the specified instance,
making it a leader of its replica set.
This command works on Tarantool clusters with centralized configuration and
with failover modesoff and manual. It updates the centralized configuration according to
the specified arguments and reloads it:
off failover mode: the command sets database.mode
to rw on the specified instance.
Important
If failover is off, the command doesn’t consider the modes of other
replica set members, so there can be any number of read-write instances in one replica set.
manual failover mode: the command updates the leader
option of the replica set configuration. Other instances of this replica set become read-only.
ttclusterreplicasetdemote demotes an instance in a replica set.
This command works on Tarantool clusters with centralized configuration and
with failover modeoff.
Note
In clusters with manual failover mode, you can demote a read-write instance
by promoting a read-only instance from the same replica set with ttclusterreplicasetpromote.
The command sets the instance’s database.mode
to ro and reloads the configuration.
Important
If failover is off, the command doesn’t consider the modes of other
replica set members, so there can be any number of read-write instances in one replica set.
ttclusterreplicasetroles manages application roles
in the configuration scope specified in the command options. It has two subcommands:
add adds a role
remove removes a role
Use the --global, --group, --replicaset, --instance options to specify
the configuration scope to add or remove roles. For example, to add a role to
all instances in a replica set:
The changes that ttclusterreplicaset makes to the configuration storage
occur transactionally. Each call creates a new revision. In case of a revision mismatch,
an error is raised.
If the cluster configuration is distributed over multiple keys in the configuration
storage (for example, in two paths /myapp/config/k1 and /myapp/config/k2),
the affected instance configuration can be present in more that one of them.
If it is found under several different keys, the command prompts the user to choose
a key for patching. You can skip the selection by adding the -f/--force option:
In this case, the command selects the key for patching automatically. A key’s priority
is determined by the detail level of the instance or replica set configuration stored
under this key. For example, when failover is off, a key with
instance.database options takes precedence over a key with the only instance field.
In case of equal priority, the first key in the lexicographical order is patched.
In the example below, ttclusterfailoverswitch appoints storage-a-002 to be a master:
$ ttclusterfailoverswitchhttp://localhost:2379/myappstorage-a-002
To check the switching status, run:tt cluster failover switch-status http://localhost:2379/myapp b1e938dd-2867-46ab-acc4-3232c2ef7ffe
Note that the command output includes an identifier of the task responsible for switching a master.
You can use this identifier to see the status of switching a master instance using ttclusterfailoverswitch-status.
switch-status
$ ttclusterfailoverswitch-statusCONFIG_URITASK_ID
ttclusterfailoverswitch-status shows the status of switching a master instance.
This command accepts the following arguments:
CONFIG_URI: A URI of the cluster configuration storage.
TASK_ID: An identifier of the task used to switch a master instance. You can find the task identifier in the ttclusterfailoverswitch command output.
There are three ways to pass the credentials for connecting to the centralized configuration storage.
They all apply to both etcd and Tarantool-based storages. The following list
shows these ways ordered by precedence, from highest to lowest:
Credentials specified in the storage URI: https://username:password@host:port/prefix:
The list of SSL cipher suites used for encrypted connections, separated by colons (:).
Details
To connect to an instance, tt typically needs its URI – the host name or IP address
and the port.
You can also connect to instances in the same tt environment
(that is, those that use the same configuration file and Tarantool installation)
by their instance names.
Authentication
When connecting to an instance by its URI, ttconnect establishes a remote connection
for which authentication is required. Use one of the following ways to pass the
username and the password:
The -u (--username) and -p (--password) options:
$ ttconnect192.168.10.10:3301-umyuser-pp4$$w0rD
The connection string:
$ ttconnectmyuser:p4$$w0rD@192.168.10.10:3301
Environment variables TT_CLI_USERNAME and TT_CLI_PASSWORD:
If no credentials are provided for a remote connection, the user is automatically guest.
Note
Local connections (by instance name instead of the URI) don’t require authentication.
Encrypted connection
To connect to instances that use SSL encryption,
provide the SSL certificate and SSL key files in the --sslcertfile and --sslkeyfile options.
If necessary, add other SSL parameters – --sslcafile and --sslciphers.
Script evaluation
By default, ttconnect opens an interactive tt console.
Alternatively, you can open a connection to evaluate a Lua script from a file or stdin.
To do this, pass the file path in the -f (--file) option or use -f-
to take the script from stdin.
$ ttconnectapp-ftest.lua
Examples
Connect to the app instance in the same environment:
$ ttconnectapp
Connect to the master instance of the app application in the same environment:
$ ttconnectapp:master
Connect to the 192.168.10.10 host on port 3301 with authentication:
$ ttconnect192.168.10.10:3301-umyuser-pp4$$w0rD
Connect to the app instance and evaluate the code from the test.lua file:
$ ttconnectapp-ftest.lua
Connect to the app instance and evaluate the code from stdin:
$ echo"function test() return 1 end"|ttconnectapp-f-# Create the test() function$ echo"test()"|ttconnectapp-f-# Call this function
Manipulating Tarantool core dumps
$ ttcoredumpCOMMAND[COMMAND_OPTION...]
ttcoredump provides commands for manipulating Tarantool core dumps.
Pack a tar.gz file with a Tarantool core dump and supporting data:
$ ttcoredumppackname.core
unpack
$ ttcoredumpunpackARCHIVE
Unpack a Tarantool core dump archive created with ttcoredumppack into a new directory:
$ ttcoredumpunpacktarantool-core-dump.tar.gz
inspect
$ ttcoredumpinspect[ARCHIVE|DIRECTORY][-s]
Inspect a Tarantool core dump with the GNU debugger (gdb).
The command argument can be either an archive file produced with ttcoredumppack
or directory where such an archive is extracted.
Inspect the core dump archive with gdb:
$ ttcoredumpinspecttarantool-core-dump.tar.gz
Inspect the unpacked core dump directory with gdb:
ttcreate creates a new Tarantool application from a template.
Application templates speed up the development of Tarantool applications by
defining their initial structure and content. A template can include application
code, configuration, build scripts, and other resources.
tt comes with built-in templates for popular use cases. You can also create
custom templates for specific purposes.
Built-in templates
There are the following built-in templates:
vshard_cluster: a sharded cluster application for Tarantool 3.0 or later.
single_instance: a single-instance application for Tarantool 3.0 or later.
cartridge: a Cartridge cluster application for Tarantool 2.x.
Important
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later.
To create the app1 application in the current tt environment from the built-in
vshard_cluster template:
The command requests cluster topology parameters, such as the number of shards
or routers, interactively during the execution.
To create the application in the /opt/tt/apps directory with default cluster
topology and force rewrite the application directory if it already exists:
pre-hook and post-hook – paths to executables to run before and after the template
instantiation.
include – a list of files to keep in the application directory after
instantiation. If this section is omitted, the application will contain all template files
and directories.
Files and directories of a template are copied to the application directory
according to the include section of the manifest (or its absence).
Note
Don’t include the .rocks directory in application templates.
To specify application dependencies, use the .rockspec files.
There is a special file type *.tt.template. The content of such files is
adjusted for each application with the help of template variables.
During the instantiation, the variables in these files are replaced with provided
values and the *.tt.template extension is removed.
Variables
Templates variables are replaced with their values provided upon the instantiation.
All templates have the name variable. Its value is taken from the --name option.
To add other variables, define them in the vars section of the template manifest.
A variable can have the following attributes:
prompt: a line of text inviting to enter the variable value in the interactive mode. Required.
name: the variable name. Required.
default: the default value. Optional.
re: a regular expression that the value must match. Optional.
Variables can be used in all file names and the content of *.tttemplate files.
Note
Variables don’t work in directory names.
To use a variable, enclose its name with a period in the beginning in double curly braces:
{{.var_name}} (as in the Golang text templates
syntax).
Examples:
init.lua.tt.template file:
localapp_name={{.name}}locallogin={{.user_name}}
A file name {{.user_name}}.txt
Variables receive their values during the template instantiation. By default, ttcreate
asks you to provide the values interactively. You can use the -s (or --non-interactive)
option to disable the interactive input. In this case, the values are searched in the following order:
In the --var option. Pass a string of the var=value format after the --var
option. You can pass multiple variables, each after a separate --var option:
$ ttcreatetemplateapp--varuser_name=admin
In a file. Specify var=value pairs in a plain text file, each on a new line, and
pass it as the value of the --vars-file option:
$ ttcreatetemplateapp--vars-filevariables.txt
variables.txt can look like this:
user_name=admin
password=p4$$w0rd
version=2
If a variable isn’t initialized in any of these ways, the default value
from the manifest is used.
You can combine different ways of passing variables in a single call of ttcreate.
Application directory
By default, the application appears in the directory named after the provided
application name (--name value).
To change the application location, use the -dst option.
ttcrud enables the interaction with a cluster using the CRUD module.
COMMAND is one of the following:
export: export a cluster’s data to a file. Learn more at Exporting data.
import: import data from a file. Learn more at Importing data.
Downloading Tarantool Enterprise SDK
$ ttdownloadVERSION[OPTION...]
ttdownload downloads Tarantool Enterprise SDK from the customer zone.
The VERSION is a part of the SDK archive name between tarantool-enterprise-sdk-
and the platform identifier. For example, to download tarantool-enterprise-sdk-gc64-3.0.0-0-gf58f7d82a-r23.linux.x86_64.tar.gz,
run:
$ ttdownloadgc64-3.0.0-0-gf58f7d82a-r23
tt automatically chooses the bundle for the current platform.
Authentication
To download the Tarantool Enterprise SDK using ttdownload, you need to provide
access credentials for the Tarantool customer zone. Use one of the following ways to pass
the username and the password:
In the CSV format, tt exports empty values by default for fields containing compound data such as arrays or maps.
To export compound values in a specific format, use the --compound-value-format option.
For example, the command below exports compound values to CSV serialized in JSON:
Object fields that contain maps with non-string keys are converted to maps with string keys.
TDG2 sets a limit on the number of objects transferred from each storage during a query execution
(the hard-limits.returned
TDG2 configuration parameter). If an export batch size (--batch-size parameter)
is greater than this limit, it is possible that more than hard-limits.returned objects
will be requested from one storage and export will fail.
To make sure that hard-limits.returned is never exceeded during an export operation,
set the export batch size less or equal to this limit.
For example, if your TDG2 cluster has a 1000 objects hard-limits.returned limit:
# tdg2 config.yaml# ...hard-limits.returned:1000
Set the tttdg2export batch size less or equal to 1000:
To connect to instances that use SSL encryption,
provide the SSL certificate and SSL key files in the --sslcertfile and --sslkeyfile options.
If necessary, add other SSL parameters in the --ssl* options.
The maximum number of tuple batches in a queue between a fetch and write threads (the default is 32).
tt exports data using two threads:
A fetch thread makes requests and receives data from a Tarantool instance.
A write thread encodes received data and writes it to the output.
The fetch thread uses a queue to pass received tuple batches to the write thread.
If a queue is full, the fetch thread waits until the write thread takes a batch from the queue.
In this case, fields in the input file and the target space are matched automatically.
You can also match fields manually if field names in the input file and the target space differ.
Note that if you’re importing data into a cluster, you don’t need to specify the bucket_id field.
The CRUD module generates bucket_id values automatically.
Manual matching
The --match option enables importing data by matching field names in the input file and the target space manually.
Suppose that you have the following customers.csv file with four fields:
Below are the rules if some fields are missing in input data or space:
If a space has fields that are not specified in input data, tt[crud]import tries to insert null values.
If input data contains fields missing in a target space, these fields are ignored.
Importing bucket_id into sharded clusters
When importing data into a CRUD-enabled sharded cluster, ttcrudimport ignores
the bucket_id field values from the input file. This allows CRUD to automatically
manage data distribution in the cluster by generating new bucket_id for tuples
during import.
If you need to preserve the original bucket_id values, use the --keep-bucket-id option:
The --on-exist option enables you to control data import when a duplicate primary key error occurs.
In the example below, values already existing in the space are replaced with new ones:
Since JSON describes objects in maps with string keys, there is no way to
import a field value that is a map with a non-string key.
In case of an error during TDG2 import, tttdg2import rolls back the changes made
within the current batch on the storage where the error has happened (per-storage rollback)
and reports an error. On other storages, objects from the same batch can be successfully
imported. So, the rollback process of tttdg2import
is the same as the one of ttcrudimport with the --rollback-on-error option.
Since object batches can be imported partially (per-storage rollback), the absence
of error matching complicates the debugging in case of errors. To minimize this
effect, the default batch size (--batch-size) for tttdg2import is 1.
This makes the debugging straightforward: you always know which object caused the error.
On the other hand, this decreases the performance in comparison to import in larger batches.
If you increase the batch size, tt informs you about the possible issues and
asks for an explicit confirmation to proceed.
To automatically confirm a batch import operation, add the --force option:
To connect to instances that use SSL encryption,
provide the SSL certificate and SSL key files in the --sslcertfile and --sslkeyfile options.
If necessary, add other SSL parameters in the --ssl* options.
A symbol that defines a field value delimiter.
For CSV, the default delimiter is a comma (,).
To use a tab character as a delimiter, set this value as tab:
The name of a log file containing information about import errors (the default is import).
If the log file already exists, new data is written to this file.
A value to be interpreted as null when importing data.
By default, an empty value is interpreted as null.
For example, a tuple imported from the following row …
1,477,Andrew,,38
… should look as follows: [1,477,'Andrew',null,38].
The name of a progress file that stores the following information:
The positions of lines that were not imported at the last launch.
The last position that was processed at the last launch.
If a file with the specified name exists, it is taken into account when importing data.
ttimport tries to insert lines that were not imported and then continues importing from the last position.
At each launch, the content of a progress file with the specified name is overwritten.
If the file with the specified name does not exist, a progress file is created with the results of this run.
Note
If the option is not set, then this mechanism is not used.
A symbol that defines a quote.
For CSV, double quotes are used by default (").
The double symbol of this option acts as the escaping symbol within input data.
The string of symbols that define thousand separators for numeric data.
The default value includes a space and a backtick `.
This means that 1000000 and 1`000`000 are both imported as 1000000.
Note
Symbols specified in this option cannot intersect with --dec-sep.
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
ttinit checks the existence of configuration files for Cartridge (cartridge.yml)
or the tarantoolctl utility (.tarantoolctl) in the current directory.
If such files are found, tt generates an environment that uses the same
directories:
cartridge.yml – the directories specified in the file.
.tarantoolctl – the directories specified in the default_cfg table.
Note
init is the only tt command that invokes .tarantoolctl files.
Thus, variables defined in this script will not be available in
applications launched by a ttstart call.
If there is no cartridge.yml or .tarantoolctl files in the current directory,
ttinit creates a default environment in it. This includes creating the
following directories and files:
bin – the directory for storing binary files.
include – the directory for storing header files.
distfiles – the directory for storing installation files.
instances.enabled – the directory for storing running applications or symlinks.
modules – the directory for storing external modules.
tt.yaml – the configuration file.
templates – the directory for storing application templates.
For tarantool-ee, account credentials are required. Specify them in a file
(see the ee section of the configuration file) or
provide them interactively.
Additionally, ttinstall can build open source programs tarantool and tt
from a specific commit or a pull request on their GitHub repositories.
To uninstall a Tarantool or tt version, use tt uninstall.
Build Tarantool in an Ubuntu 18.04 Docker container.
Details
When called without an explicitly specified version, ttinstall installs the
latest available version. If the version is specified in the incomplete format <MAJOR>.<MINOR>,
the command installs the latest available patch version in the series.
To check versions available for installation, use tt search.
By default, available versions of Tarantool Community Edition and tt are taken from their git repositories.
Their installation includes building from sources, which requires some tools and
dependencies, such as a C compiler. Make sure they are available in the system.
Tarantool Enterprise Edition is installed from prebuilt packages.
Authentication
To install Tarantool EE using ttinstall, you need to provide access credentials
for the Tarantool customer zone. Use one of the following ways to pass the username and the password:
ttinstall can be used to build custom Tarantool and tt versions for
development purposes from commits and pull requests on their GitHub repositories.
To build Tarantool or tt from a specific commit on their GitHub repository,
pass the commit hash (7 or more characters) after the program name. If you want to use
a PR as a source, provide a pr/<PR_ID> argument:
$ ttinstalltarantool03c184d
$ ttinstallttpr/50
If you build Tarantool from sources, you can install
local builds to the current tt environment by running ttinstall with
the tarantool-dev program name and the path to the build:
$ ttinstalltarantool-dev~/src/tarantool/build
Local repositories
You can also set up a local repository with installation files you need.
To use it, specify its location in the repo section
of the tt configuration file and run ttinstall with the --local-repo flag.
Example
Install the latest available version of Tarantool CE:
$ ttinstalltarantool
Install the latest available patch version of Tarantool CE 3.2 release series:
$ ttinstalltarantool3.2
Install Tarantool 2.11.1 from the local repository:
$ ttinstalltarantool2.11.1--local-repo
Reinstall Tarantool 2.10.8:
$ ttinstalltarantool2.10.8--reinstall
Install Tarantool from a PR #1234 on the tarantool/tarantool GitHub repository:
$ ttinstalltarantoolpr/1234
Install tt from a commit with a hash 40e696e on the tarantool/tt GitHub repository:
ttinstances shows the list of enabled applications and their instances
in the current environment.
Note
Enabled applications are applications that are stored inside the instances_enabled
directory specified in the tt configuration file.
They can be either running or not. To check if an application is running,
use tt status.
Example
Show the list of enabled applications and their instances:
$ ttinstances
Terminating Tarantool instances
$ ttkillAPPLICATION[:APP_INSTANCE]
ttkill terminates instances with SIGQUIT and SIGKILL signals.
To terminate all instances of the app application:
$ ttkillapp
To terminate the storage-001-r instance of the app application without confirmation:
$ ttkillapp:storage-001-r--force
To terminate the storage-001-r instance of the app application and generate its core dump:
ttlogrotate rotates logs of a Tarantool application or specific instances,
and the tt log. For example, you need to call this function to continue logging
after a log rotation program renames or moves instances’ logs.
Learn more about rotating logs.
Calling ttlogrotate on an application has the same effect as executing the
built-in log.rotate() function on all its instances.
When publishing migrations, tt performs checks for:
Syntax errors in migration files. To skip syntax check, add the --skip-syntax-check option.
Existence of migrations with same names. To overwrite an existing migration with
the same name, add the --overwirte option.
Migration names order. By default, ttmigrations only adds new migrations
to the end of the migrations list ordered lexicographically. For example, if
migrations 001.lua and 003.lua are already published, an attempt to publish
002.lua will fail. To force publishing migrations disregarding the order,
add the --ignore-order-violation option.
Warning
Using the options that ignore checks when publishing migration may cause
migration inconsistency in the cluster.
apply
$ ttmigrationsapplyETCD_URI[OPTION...]
ttmigrationsapply applies published migrations
to the cluster. It executes all migrations from the cluster’s centralized
configuration storage on all its read-write instances (replica set leaders).
The command also provides options for migration troubleshooting: --ignore-order-violation,
--force-reapply, and --ignore-preceding-status. Learn to use them in
Troubleshooting migrations.
Warning
The use of migration troubleshooting options may lead to migration inconsistency
in the cluster. Use them only for local development and testing purposes.
status
$ ttmigrationsstatusETCD_URI[OPTION...]
ttmigrationsstatus prints the list of migrations published to the centralized
storage and the result of their execution on the cluster instances.
Possible migration statuses are:
APPLY_STARTED – the migration execution has started but not completed yet
or has been interrupted with tt migrations stop <tt-migrations-stop>`
APPLIED – the migration is successfully applied on the instance
FAILED – there were errors during the migration execution on the instance
To get the list of migrations stored in the given etcd storage and information about
their execution on the cluster, run:
ttmigrationsstop interrupts a single migration. If you call it to interrupt
the process that applies multiple migrations, the ones completed before the call
receive the APPLIED status. The migration is interrupted by the call remains in
APPLY_STARTED.
remove
$ ttmigrationsremoveETCD_URI[OPTION...]
ttmigrationsremove removes published migrations from the centralized storage.
With additional options, it can also remove the information about the migration execution
on the cluster instances.
To remove all migrations from a specified centralized storage:
Before removing migrations, the command checks their status
on the cluster. To ignore the status and remove migrations anyway, add the
--force-remove-on=config-storage option:
Since ttmigrations operates migrations via a centralizes etcd storage, it
needs credentials to access this storage. There are two ways to pass etcd credentials:
command-line options --config-storage-username and --config-storage-password
the etcd URI, for example, https://user:pass@localhost:2379/myapp
Credentials specified in the URI have a higher priority.
For commands that connect to the cluster (that is, all except publish), Tarantool
credentials are also required. The are passed in the --tarantool-username and
--tarantool-password options.
If the cluster uses SSL traffic encryption, provide the necessary connection
parameters in the --tarantool-ssl* options: --tarantool-sslcertfile,
--tarantool-sslkeyfile, and other. All options are listed in Options.
A username for connecting to the Tarantool cluster instances.
Packaging the application
$ ttpackTYPE[OPTION...]..
ttpack packages an application into a distributable bundle of the specified TYPE:
tgz: create a .tgz archive.
deb: create a DEB package.
rpm: create an RPM package.
Example: a DEB package
The command below creates a DEB package with all applications from the current tt
environment:
$ ttpackdeb
This command generates a .deb file whose name depends on the environment directory name and the operating system architecture, for example, test-env_0.1.0.0-1_x86_64.deb.
The package contains the following files:
The content of the application directories: source files, resources, dependencies.
.service unit files that allow running applications as systemd services
(a separate file for each application).
You can also pass various options to the ttpack command to adjust generation properties, for example, customize a bundle name, choose which artifacts should be included, specify the required application dependencies.
systemd unit parameters
You can customize your application’s systemd unit file generated by ttpack.
To add parameters to the unit file, define them in a YAML file named systemd-unit-params.yml
in the application directory.
$ ttpackrpm# unit file with parameters from systemd-unit-params.yml if it exists
You can also pass unit parameters from an arbitrary file by adding the --unit-params-file
option to the ttpack call:
$ ttpackrpm--unit-params-filemy-params.yml# unit file with parameters from my-params.yml
Important
The systemd-unit-params.yml file has a higher priority than the --unit-params-file option.
If this file exists, it overrides parameters from the file passed in the option.
ttpack supports the following systemd unit parameters:
FdLimit – the number of open file descriptors (LimitNOFile in the unit file).
instance-env – a list of environment variables in the <VAR_NAME>:<VALUE> format.
Each list item adds an Environment=<VAR_NAME>=<VALUE> line to the unit file.
The integrity check functionality is supported by the Enterprise Edition only.
ttpack can generate checksums and signatures to use for integrity checks
when running the application. These files are:
hashes.json and hashes.json.sig in each application directory.
hashes.json contains SHA256 checksums of executable files that the application uses
and its configuration file. hashes.json.sig contains a digital signature
for hashes.json.
env_hashes.json and env_hashes.json.sig in the environment root are
similar files for the tt environment. They contain checksums for
Tarantool and tt executables, and for the tt.yaml configuration file.
To generate checksums and signatures for integrity check, use the --with-integrity-check
option. Its argument must be an RSA private key.
Note
You can generate a key pair using OpenSSL 3 as follows:
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
Specify the path to a file containing dependencies included in RPM and DEB packages.
For example, the package-deps.txt file below contains several dependencies and their versions:
unzip==6.0
neofetch>=6,<7
gcc>8
If this file is placed in the current directory, a ttpack command might look like this:
Filter the operations by replica ID. Can be passed more than once.
When calling ttcat with filters by LSN (--from and --to flags) and
replica ID (--replica), remember that LSNs differ across replicas.
Thus, if you pass more than one replica ID via --from or --to,
the result may not reflect the actual sequence of operations.
ttplay plays operations from .xlog and .snap files to the destination
instance one by one. All data changes happen the same way as if they were performed
on this instance. This means that:
All affected spaces must exist on the destination instance. They must have the same structure
and space_id as on the instance that created the snapshot or WAL file.
To play a snapshot or a WAL to a clean instance, include the operations on system spaces
by adding the --show-system flag. With this flag, tt plays the operations that
create and configure user-defined spaces.
The operations’ LSNs change unless you play all operations that took place since the instance startup.
Replica IDs change in accordance with the destination instance configuration.
Authentication
Use one of the following ways to pass the username and the password when connecting
to the instance:
Learn about other ways to provide user credentials in Authentication.
promote
$ ttreplicasetpromote{APPLICATION:APP_INSTANCE|URI}[OPTIONS...]# or
$ ttrspromote{APPLICATION:APP_INSTANCE|URI}[OPTIONS...]
ttreplicasetpromote (ttrspromote) promotes the specified instance,
making it a leader of its replica set.
This command works on Tarantool clusters with a local YAML
configuration and Cartridge clusters.
Promoting in clusters with local YAML configurations
ttreplicasetpromote works on Tarantool clusters with local YAML configurations
with failover modesoff, manual, and election.
In failover modes off or manual, this command updates the cluster
configuration file according to the specified arguments and reloads it:
off failover mode: the command sets database.mode
to rw on the specified instance.
Important
If failover is off, the command doesn’t consider the modes of other
replica set members, so there can be any number of read-write instances in one replica set.
manual failover mode: the command updates the leader
option of the replica set configuration. Other instances of this replica set become read-only.
Example:
$ ttreplicasetpromotemy-app:storage-001-a
If some members of the affected replica set are running outside the current tt
environment, ttreplicasetpromote can’t ensure the configuration reload on
them and reports an error. You can skip this check by adding the -f/--force option:
$ ttreplicasetpromotemy-app:storage-001-a--force
In the election failover mode, ttreplicasetpromote initiates the new leader
election by calling box.ctl.promote() on the specified instance. The
--timeout option can be used to specify the election completion timeout:
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
ttreplicasetpromote promotes instances in Cartridge clusters as follows:
disabled or eventual failover mode: the command changes the instance failover priority.
Important
In these cases, consistency is not guaranteed and replication conflicts may occur.
eventual or raft failover mode: the command calls cartridge.failover_promote()
and waits until the instance transitions to the read-write mode. If the -f/--force
option is specified, the force_inconsistency option of cartridge.failover_promote
is set to true.
Demoting in clusters with local YAML configurations
ttreplicasetdemote can demote instances in Tarantool clusters with local
YAML configurations with failover modesoff and election.
Note
In clusters with manual failover mode, you can demote a read-write instance
by promoting a read-only instance from the same replica set with ttreplicasetpromote.
In the off failover mode, ttreplicasetdemote sets the instance’s database.mode
to ro and reloads the configuration.
Important
If failover is off, the command doesn’t consider the modes of other
replica set members, so there can be any number of read-write instances in one replica set.
If some members of the affected replica set are running outside the current tt
environment, ttreplicasetdemote can’t ensure the configuration reload on
them and reports an error. You can skip this check by adding the -f/--force option:
$ ttreplicasetdemotemy-app:storage-001-a--force
In the election failover mode, ttreplicasetdemote initiates a leader
election in the replica set. The specified instance’s replication.election_mode
is changed to voter for this election, which guarantees that another instance
is elected as a new replica set leader.
The --timeout option can be used to specify the election completion timeout:
$ ttreplicasetvshardCOMMAND{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]# or
$ ttrsvshardCOMMAND{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]# or
$ ttrsvsCOMMAND{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]
ttreplicasetvshard (ttrsvs) manages vshard in the cluster.
$ ttreplicasetvshardbootstrap{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]# or
$ ttrsvshardbootstrap{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]# or
$ ttrsvsbootstrap{APPLICATION[:APP_INSTANCE]|URI}[OPTIONS...]
ttreplicasetvshardbootstrap (ttrsvsbootstrap) bootstraps vshard
in the cluster.
You can specify the application name or the name of any cluster instance. The command
automatically finds a vshard router in the cluster and calls vshard.router.bootstrap() on it.
The command supports the --config, --cartridge, and --customoptions
that force the use of a specific orchestrator.
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
$ ttreplicasetbootstrapAPPLICATION[:APP_INSTANCE][OPTIONS...]# or
$ ttrsbootstrapAPPLICATION[:APP_INSTANCE][OPTIONS...]
ttreplicasetbootstrap (ttrsbootstrap) bootstraps a Cartridge cluster or
an instance. The command works within the current tt environment and uses
application and instance names.
Note
ttreplicasetsbootstrap effectively duplicates two other commands:
$ ttreplicasetrebootstrapAPPLICATION:APP_INSTANCE[-y|--yes]# or
$ ttrsrebootstrapAPPLICATION:APP_INSTANCE[-y|--yes]
ttreplicasetrebootstrap (ttrsrebootstrap) rebootstraps an instance:
stops it, removes instance artifacts, starts it again.
To rebootstrap the storage-001 instance of the myapp application:
$ ttreplicasetrebootstrapmyapp:storage-001
To automatically confirm reboostrap, add the -y/--yes option:
$ ttreplicasetrebootstrapmyapp:storage-001-y
roles
$ ttreplicasetroles[add|remove]APPLICATION[:APP_INSTANCE]ROLE_NAME[OPTIONS...]# or
$ ttrsroles[add|remove]APPLICATION[:APP_INSTANCE]ROLE_NAME[OPTIONS...]
ttreplicasetroles (ttrsroles) manages application roles
in the cluster.
This command works on Tarantool clusters with a local YAML
configuration and Cartridge clusters. It has two subcommands:
Managing roles in clusters with local YAML configurations
When called on clusters with local YAML configurations, ttreplicasetroles
subcommands add or remove the corresponding lines from the configuration file
and reload the configuration.
Use the --global, --group, --replicaset, --instance options to specify
the configuration scope to add or remove roles. For example, to add a role to
all instances in a replica set:
If some instances of the affected scope are running outside the current tt
environment, ttreplicasetroles can’t ensure the configuration reload on
them and reports an error. You can skip this check by adding the -f/--force option:
The Tarantool Cartridge framework is deprecated and is not compatible with
Tarantool 3.0 and later. This command is added for backward compatibility with
earlier versions.
When called on Cartridge clusters, ttreplicasetroles subcommands add or remove
Cartridge cluster roles.
Cartridge cluster roles are defined per replica set. Thus, you can use the
--replicaset and --group options to define a role’s scope. In this case,
a group is a vshard group.
Restart all instances of the application stored in the app directory inside
instances_enabled in accordance with the instances configuration:
$ ttrestartapp
Note
This call starts all application instances specified in its instances.yml,
even those that were not running before the call.
Restart only the master instance of the app application with automatic confirmation:
$ ttrestartapp:master-y
Using the LuaRocks package manager
$ ttrocks[OPTION...][VAR=VALUE]COMMAND[ARGUMENT]
ttrocks provides means to manage Lua modules (rocks) via the
LuaRocks package manager. tt uses its own
LuaRocks installation connected to the Tarantool rocks repository.
Below are lists of supported LuaRocks flags and commands. For detailed information on
their usage, refer to LuaRocks documentation.
Print the Tarantool version that is used for script execution.
Details
ttrun executes arbitrary Lua code in a Tarantool instance. The code can be
provided either in a Lua file, or in a string passed after the -e/--evaluate
flag. When called without arguments or flags, ttrun opens the Tarantool console.
If libraries are required for execution, pass their names after the -l/--library
flag.
By default, a Tarantool instance started by ttrun shuts down after code
execution completes. To leave this instance running and continue working in its
console, add the -i/--interactive flag.
Examples
Execute the app.lua file in a Tarantool instance:
$ ttrunapp.lua
Execute an expression in a Tarantool instance:
$ ttrun-e"print('hi there')"
Execute the app.lua file in a Tarantool instance and leave it running:
$ ttrun-iapp.lua
Listing available Tarantool versions
$ ttsearchPROGRAM_NAME[OPTION...]
ttsearch lists versions of Tarantool and tt that are available for
installation. The possible values of PROGRAM_NAME are:
tarantool
tarantool-ee
tt
Note
For tarantool-ee, account credentials are required. Specify them in a file
(see the ee section of the configuration file) or
provide interactively.
To start all instances of the application stored in the app directory inside
instances_enabled in accordance with its instances.yml:
$ ttstartapp
To start all instances of the app application appending their logs to stdout
(in the interactive mode):
$ ttstart-iapp
To start the router instance of the app application:
$ ttstartapp:router
When called without arguments, starts all enabled applications in the current environment:
$ ttstart
Application layout
ttstart can start entire Tarantool clusters based on their YAML configurations.
A cluster application directory inside instances_enabled must contain the following files:
config.yaml – a YAML configuration that defines
the cluster topology and settings.
It can either contain an explicit configuration in the YAML format or point
to a centralized configuration storage (for Enterprise Edition).
instances.yml – a file that defines the list of cluster instances to run
in the current environment.
(Optionally) *.lua files with code to load and run in the cluster.
tt also supports Tarantool applications with configuration in code,
which is considered a legacy approach since Tarantool 3.0. For information
about using tt with such applications, refer to the Tarantool 2.11 documentation.
Running in the background
ttstart runs Tarantool applications in the background and uses its own watchdog
process for status checks (tt status) and application stopping (tt stop).
Important
Do not switch on the background mode using the cluster configuration
(process.background:true in the YAML configuration) or code (box.cfg.background=true)
in applications that you run with tt.
If you start such an application with ttstart, tt won’t be able to check
the application status or stop it using the corresponding commands.
Integrity check
Enterprise Edition
The integrity check functionality is supported by the Enterprise Edition only.
ttstart can perform initial and periodical integrity checks of the environment,
application, and centralized configuration.
To enable integrity checks of environment and application files, you need to pack
the application using ttpack with the --with-integrity-check option.
This option generates and signs checksums of executables and configuration files in the current tt
environment. Learn more in Generating files for integrity checks.
To enable integrity check of the configuration at the centralized storage,
publish the configuration to this storage using ttclusterpublish with the --with-integrity-check option.
This option generates and signs configuration checksums and saves them to the storage.
Learn more in Publishing configurations with integrity check.
To perform the integrity checks when running the application, start it with the
--integrity-checkglobal option.
Its argument must be a public key matching the private key that was used for
generating checksums.
$ tt--integrity-checkpublic.pemstartmyapp
After such a call, tt checks the environment, application, and configuration integrity
using the checksums and starts the application in case of the success. Then, integrity
checks are performed periodically while the application is running. By default,
they are performed once every 24 hours. You can adjust the integrity check period
by adding the --integrity-check-period option:
tttdg2 enables the interaction with Tarantool Data Grid 2 clusters.
COMMAND is one of the following:
export: export a TDG2 cluster’s data to a file. Learn more at Exporting data.
import: import data to a TDG2 cluster from a file. Learn more at Importing data.
Uninstalling Tarantool software
$ ttuninstallPROGRAM_NAME[VERSION]
ttuninstall uninstalls a previously installed Tarantool version.
Example
Uninstall Tarantool 2.10.4:
$ ttuninstalltarantool2.10.4
Displaying the tt version
$ ttversion
ttversion shows the version of the tt utility being used.
Extending the tt functionality
The tt utility implements a modular architecture: its commands
are, in fact, separate modules. When you run tt with a command, the
corresponding module is executed with the given arguments.
The modular architecture enables the option to extend the tt functionality with
external modules (as opposed to internal modules that implement built-in
commands). Simply said, you can write any code you want to execute
from tt, pack it into an executable, and run it with a tt command:
ttmy-module-namemy-args
The name of the command that executes a module is the same as the name of the module’s executable.
Module description and help
Executables that implement external tt modules must have two flags:
--description – print a short description of the module. The description is shown alongside
the command in the tt help.
--help – display help. The help message is shown when tthelp<module_name> is called.
Location
External modules must be located in the modules directory specified in the
configuration file:
tt:modules:directory:path/to/modules/dir
To check if a module is available in tt, call tthelp.
It will show the available external modules in the EXTERNALCOMMANDS section together
with their descriptions.
Overloading built-in commands
External modules can overload built-in tt commands.
If you want to change the behavior of a built-in command, create an external
module with the same name and your own implementation.
When tt sees two modules – an external and an internal one – with the same
name, it will use the external module by default.
For example, if you want tt to show the information about your Tarantool
application, write the external module version that outputs the information
you need. The ttversion call will execute this module instead of the built-in one:
ttversion# Calls the external module if it's available
You can force the use of the internal module by running tt with the --internal or -Ioption. The following call will execute the built-in version
even if there is an external module with the same name:
ttversion-I# Calls the internal module
tt interactive console
The tt utility features a command-line console that allows executing requests
and Lua code interactively on the connected Tarantool instances.
It is similar to the Tarantool interactive console with
one key difference: the tt console allows connecting to any available instance,
both local and remote. Additionally, it offers more flexible output formatting capabilities.
Entering the console
To connect to a Tarantool instance using the tt console, run tt connect.
Specify the instance URI and the user credentials in the corresponding options:
$ ttconnect192.168.10.10:3301-umyuser-pp4$$w0rD
• Connecting to the instance... • Connected to 192.168.10.10:3301192.168.10.10:3301>
If a user is not specified, the connection is established on behalf of the guest user.
If the instance runs in the same tt environment, you can establish a local
connection with it by specifying the <application>:<instance> string instead of the URI:
$ ttconnectapp:storage001
• Connecting to the instance... • Connected to app:storage001 app:storage001>
Local connections are established on behalf of the admin user.
To get the list of supported console commands, enter \help or ?.
To quit the console, enter \quit or \q.
Console input
Similarly to the Tarantool interactive console, the
tt console can handle Lua or SQL input. The default is Lua. For Lua input,
the tab-based autocompletion works automatically for loaded modules.
To change the input language to SQL, run \setlanguagesql:
app:storage001> \set language sqlapp:storage001> select * from bands where id = 1---- metadata: - name: id type: unsigned - name: band_name type: string - name: year type: unsigned rows: - [1, 'Roxette', 1986]...
To change the input language back to Lua, run \setlanguagelua:
yaml (default) – each output item is a YAML object. Example: [1,'Roxette',1986].
Shorthand: \xy.
lua – each output tuple is a separate Lua table. Example: {{1,"Roxette",1986}};.
Shorthand: \xl.
table – the output is a table where tuples are rows.
Shorthand: \xt.
ttable – the output is a transposed table where tuples are columns.
Shorthand: \xT.
Note
The \x command switches the output format cyclically in the order
yaml > lua > table > ttable.
The format of table and ttable output can be adjusted using the \settable_format,
\setgraphics, and \settable_colum_width commands.
An analog of the tt connect option -x/--outputformat.
\set table_format
Set the table format if the output format is table or ttable.
Possible values:
default – a pseudographics (ASCII) table.
markdown – a table in the Markdown format.
jira – a Jira-compatible table.
\set graphics {true|false}, \x{g|G}
Whether to print pseudographics for table cells if the output format is table or ttable.
Possible values: true (default) and false.
The shorthands are:
\xG for true
\xg for false
\set table_colum_width WIDTH, \xw WIDTH
Set the maximum printed width of a table cell content. If the length exceeds this value,
it continues on the next line starting from the + (plus) sign.
Shorthand: \xw
Migration from tarantoolctl to tt
tt is a command-line utility for managing Tarantool applications
that comes to replace tarantoolctl. Starting from version 3.0, tarantoolctl
is no longer shipped as a part of Tarantool distribution; tt is the only
recommended tool for managing Tarantool applications from the command line.
tarantoolctl remains fully compatible with Tarantool 2.* versions. However,
it doesn’t receive major updates anymore.
We recommend that you migrate from tarantoolctl to tt to ensure the full
support and timely updates and fixes.
System-wide configuration
tt supports system-wide environment configuration by default. If you have
Tarantool instances managed by tarantoolctl in such an environment, you can
switch to tt without additional migration steps or use tt along with tarantoolctl.
If you have a local tarantoolctl configuration, create a tt environment
based on the existing .tarantoolctl configuration file. To do this, run
ttinit in the directory where the file is located.
Most tarantoolctl commands look the same in tt: tarantoolctlstart and
ttstart, tarantoolctlplay and ttplay, and so on. To migrate such
calls, it is usually enough to replace the utility name. There can be slight differences
in command flags and format. For details on tt commands, see the
tt commands reference.
The following commands are different in tt:
tarantoolctl command
tt command
tarantoolctlenter
ttconnect
tarantoolctleval
ttconnect with -f flag
Note
ttconnect also covers tarantoolctlconnect with the same syntax.
Tarantool Cluster Manager (TCM) is a web-based visual tool for configuring, managing, and
monitoring Tarantool EE clusters. It provides a GUI for working with clusters
and individual instances, from monitoring their state to executing commands interactively
in an instance’s console.
TCM is a standalone application included in the Tarantool Enterprise Edition
distribution package. It is shipped as ready-to-run
executable for Linux platforms.
TCM works only with Tarantool EE clusters that use centralized configuration in
etcd or a Tarantool-based configuration storage.
When you create or edit a cluster’s configuration in TCM, it publishes the saved
configuration to the storage. This ensures consistent and reliable configuration storage.
A single TCM installation can connect to multiple Tarantool EE clusters and
switch between them in one click.
To provide enterprise-grade security, TCM features its own role-based access control.
You can create users and assign them roles that include required permissions.
For example, a user can be an administrator of a specific cluster or only have the right
to read data. LDAP authorization is supported as well.
The Tarantool Cluster Manager web interface is available on the hostname and port defined by the
http.host and http.portconfiguration options.
If TLS is enabled, it uses the https protocol, otherwise the protocol is http.
When started locally with the default configuration, TCM is available at http://127.0.0.1:8080.
Logging into TCM
To log into TCM after bootstrap, use the following credentials:
Username: admin
Password: the initial password is shown in the TCM boot log in
a message like this:
Jun 11 11:24:08.900 WRN Generated super admin credentials login=admin password=jS9PsdkEJBYNhdMtSswMlxDR1vdbfc1N
After logging in with the default password:
Adjust the password policy
in accordance to the security requirements that apply in your organization.
Change the admin user’s password on the User settings page.
To log out of TCM, click the user’s name in the header and click Log out.
Page structure
The TCM web interface consists of three parts:
Navigation page on the left shows the list of pages available to the user.
The navigation pane can be collapsed by clicking the cross icon at its top.
Header at the top provides access to notifications and user settings.
Working area displays the contents of the selected page.
Onboarding
The Onboarding item of the navigation pane starts the interactive onboarding
tutorial. Use it to get familiar with main TCM features directly in the web interface.
Page visibility
This overview describes most TCM pages. The exact set of pages and controls available
to a particular user is determined by the user’s permissions.
Some features, such as data schema editing, are available only in the development mode.
You can switch to it in the user settings of the Default Admin user.
To learn more about the development mode, see Development mode.
Page groups
For easier navigation, TCM pages are grouped in the navigation pane by their content.
There are the following page groups:
Cluster: interaction with the selected cluster.
Clusters: interaction with all connected clusters in general.
Users: access management.
Tools: TCM administration.
Settings: runtime management of TCM settings.
Read on to learn what you can do on pages of these groups.
Cluster
The Cluster group includes pages used for interaction with a particular cluster.
To switch between clusters, click the Cluster group name and select a connected
cluster from the drop-down list.
Stateboard
The cluster Stateboard is a main page for monitoring the cluster state
and interacting with its instances.
On this page, you can:
view and edit the cluster topology
group and filter instances based on various criteria
view memory statistics and Tarantool versions running on instances
navigate to instance pages
by clicking instance names in the cluster topology list
start and stop instances (in the development mode).
The cluster Configuration page provides an interactive editor for the cluster
configuration. It is connected to the centralized configuration
storage that the cluster uses. All changes you make and apply on this page are
sent to this centralized storage.
The TCM metrics page provides access to the TCM metrics.
Settings
The Settings group includes service pages where you can configure various TCM features.
Password policy
On the Password policy page, you can configure the requirements to user passwords,
such as minimal length, required symbols, expiration, and other settings.
Learn more in Password policy.
Audit settings
On the Audit settings page, you can configure how TCM records events to its
audit log: whether audit log is enabled, which events are recorded, and so on.
Learn more in Audit log.
LDAP
On the LDAP page, you can manage TCM LDAP configurations.
User settings
The user settings dialog opens when you click Settings under the user’s name
in the header.
A single TCM installation can have multiple connected clusters. A connection to
TCM doesn’t affect the cluster’s functioning. You can connect clusters to TCM
and disconnect them on the fly.
There are two scenarios of cluster connection to TCM:
In both cases, you need to deploy Tarantool and start the cluster instances using
the tt CLI utility or another suitable way.
To add a cluster to TCM, you can use two ways:
Use the TCM web interface as described on this page.
Specify the initial-settings.clusters section of the TCM configuration.
To learn more, see Initial settings.
Connection parameters
When connecting a cluster to TCM, you need to provide two sets of connection parameters:
for the cluster instances and for the centralized configuration storage.
Configuration storage connection
The cluster configuration can be stored in either an etcd
cluster or a separate Tarantool-based storage. In both cases, the following connection
parameters are required:
A key prefix used to identify the cluster in the configuration storage.
A prefix must be unique for each cluster in storage.
URIs of all instances of the configuration storage.
Additionally, if SSL or TLS encryption is enabled for the configuration storage,
provide the corresponding encryption configuration: keys, certificates, and other
parameters. For the complete list of parameters, consult the etcd documentation
or Tarantool Securing connections with SSL.
Cluster connection
For interaction with the cluster instances, TCM needs the following access parameters:
A Tarantool user that exists in the cluster and their password.
TCM connects to the cluster on behalf of this user.
An SSL configuration if the traffic encryption
is enabled on the cluster.
Managing connected clusters
Administrators can add new clusters, edit, and remove existing ones from TCM.
Connected clusters are listed on the Clusters page.
Connecting a pre-configured cluster
If you already have a cluster and want to connect it to TCM,
follow these steps:
Go to Clusters and click Add.
Fill in the general cluster information:
Specify an arbitrary name.
Optionally, provide a description and select a color to mark this cluster in TCM.
Optionally, enter the URLs of additional services for the cluster. For example,
a Grafana dashboard that monitors the cluster metrics, or a syslog server
for viewing the cluster logs. TCM provides quick access to these URLs on
the cluster Stateboard page.
Provide the details of the cluster configuration storage:
Storage type: etcd or tarantool.
The Prefix specified in the cluster configuration.
The URIs of the configuration storage instances.
The credentials for accessing the configuration storage.
The SSL/TLS parameters if the connection encryption is enabled on the storage.
Provide the credentials for accessing the cluster: a Tarantool user’s name, their password,
and SSL parameters in case traffic encryption
is enabled on the cluster.
Adding a new cluster
If you don’t have a cluster yet, you can add one in TCM and write its configuration
from scratch using the built-in configuration editor.
Important
When adding a new cluster, you need to have a storage for its configuration up
and running so that TCM can connect to it. Cluster instances can be deployed later.
To add a new cluster:
Go to Clusters and click Add.
Fill in the general cluster information:
Specify an arbitrary name.
Optionally, provide a description and select a color to mark this cluster in TCM.
Optionally, enter the URLs of additional services for the cluster. For example,
a Grafana dashboard that monitors the cluster metrics, or a syslog server
for viewing the cluster logs. TCM provides quick access to these URLs on
the cluster Stateboard page.
Select the type of the cluster configuration storage: etcd or tarantool.
Define a unique Prefix for identifying this cluster in the configuration storage.
Provide the connection details for the cluster configuration storage:
The URIs of configuration storage instances.
The credentials for accessing the configuration storage.
The SSL/TLS parameters if the connection encryption is enabled on the storage.
Provide the cluster credentials: a username, a password, and SSL parameters in
case traffic encryption is enabled on
the cluster.
Deploy Tarantool on the cluster nodes using the tt CLI utility or other suitable tools.
Start the cluster using the tt CLI utility or other suitable tools.
Editing a connected cluster
To edit a connected cluster, go to Clusters and click Edit in the Actions
menu of the corresponding table row.
Disconnecting a cluster
To disconnect a cluster from TCM, go to Clusters and click Disconnect
in the Actions menu of the corresponding table row.
Note
Disconnecting a cluster does not affect its functioning. The only
thing that changes is that it’s no longer shown in TCM.
You can connect this cluster again at any time.
The main goal of Tarantool Cluster Manager is to provide visual tools for managing
various aspects of Tarantool clusters from the browser. See the pages of this section
to learn how to perform various management operations on Tarantool clusters from TCM.
Tarantool Cluster Manager provides a visual interface for checking various aspects of connected clusters,
such as:
topology
instance state
memory usage
data distribution
Tarantool versions
Cluster state information is available on the Cluster > Stateboard page.
Cluster topology
The cluster topology is displayed on the Stateboard page in one of two forms:
a list or a graph.
List view
The list view of the cluster topology is used by default. In this view, each row contains
the general information about an instance: its current state, memory usage and limit,
and other parameters.
In the list view, TCM additionally displays the Tarantool version information
and instance states on circle diagrams. You can click the sectors of these diagrams
to filter the instances with the selected versions and states.
To switch to the list view, click the list button on the right of the search bar on the Stateboard page.
Graph view
The graph view of the cluster topology is shown in a tree-like structure where
leafs are the cluster’s instances. Each instance’s state is shown by its color.
You can move the graph vertices to arrange them as you like, and zoom in and out,
which is helpful for larger clusters.
To switch to the graph view, click the graph button on the right of the search bar on the Stateboard page.
Instance grouping
By default, the cluster topology is shown hierarchically as it’s defined in the configuration:
instances are grouped by their replica set, and replica sets are grouped by
their configuration group.
For better navigation across the cluster, you can adjust the instance grouping.
For example, you can group instances by their roles or custom tags defined in the configuration.
A typical case for such tags is adding a geographical markers to instances. In this case,
you see if issues happen in a specific data center or server.
To change the instance grouping, click Group by in the Actions menu on the Stateboard page.
Then add or remove grouping criteria.
Filtering
You can filter the instances shown on the Stateboard page using the search bar
at the top. It has predefined filters that select:
instances with errors or warnings
leader or read-only instances
instances with no issues
stale instances
To display all instances, delete the filter applied in the search bar.
Instance details
The general information about the state of cluster instances is shown in the
list view of the cluster topology. Each row contains the information about the instance
status, used and available memory, read-only status, and virtual buckets for sharded
clusters.
To view the detailed information about an instance or connect to it, click the corresponding
row in the instances list or a vertex of the graph. On the instance page, you can
find:
the instance configuration overview
current state (with warning and error messages if any)
the detailed Tarantool information returned by the instance introspection functions
from box.info, box.stat,
and other built-in modules
The page also provides Lua and SQL terminals to execute built-in functions
and requests on the instance. You can choose between two Lua terminals: the
tt interactive console with code completion and highlighting or
the default Tarantool console.
Linked external services
When you connect a cluster to TCM, you can specify
URLs of external services linked to this cluster. For example, this can be a Grafana
server that monitors the cluster metrics.
All the URLs added for a cluster are available for quick access in the Actions
menu on the Stateboard page.
Tarantool Cluster Manager features a built-in text editor for Tarantool EE cluster configurations.
When you connect a cluster to TCM, it gains access
to the cluster’s centralized configuration storage: an etcd or a Tarantool cluster.
TCM has both read and write access to the cluster configuration. This enables
the configuration editor to work in two ways:
If a configuration already exists, the editor shows its current state.
When you change the configuration in the editor and apply changes, they
are sent to the configuration storage.
To learn how to write Tarantool cluster configurations, see Configuration.
Managing a cluster’s configuration
The configuration editor is available on the Cluster > Configuration page.
To start managing a cluster’s configuration, select this cluster in the Cluster
drop-down and go to the Configuration page.
A cluster configuration in TCM can consist of one or multiple YAML files.
When there are multiple files, they are all considered parts of a single cluster
configuration. You can use this for structuring big cluster configurations.
All files that form the configuration of a cluster are listed on the left side
of the Cluster configuration page.
To add a cluster configuration file, click the plus icon (+) below the page title.
To open a configuration file in the editor, click its name in the file list.
To delete a cluster configuration file, click the Delete button beside the filename.
To download a cluster configuration file, click the Download button beside the filename.
Warning
All configuration changes are discarded when you leave the Cluster configuration page.
Save the configuration if you want to continue
editing it later or apply it
to start using it on the cluster.
Saving a configuration draft
TCM can store configurations drafts. If you want to leave an unfinished configuration
and return to it later, save it in TCM. Saving applies to whole cluster configurations:
it records the edits of all files, file additions, and file deletions.
To save a cluster configuration draft after editing, click Save in the Cluster configuration page.
All unsaved changes are discarded when you leave the Cluster configuration page.
If you have a saved configuration draft, you can reset the changes for each of its
files individually. A reset returns the file into the state that is currently used
by a cluster (that is, saved in the configuration storage). If you reset a newly
added file, it is deleted.
To reset a saved configuration file, click the Reset button beside the filename.
Applying a configuration
When you finish editing a configuration and it’s ready to use, apply the updated
configuration to the cluster. To apply a cluster configuration, click Apply
on the Cluster configuration page. This sends the new configuration to the cluster
configuration storage, and it comes into effect upon the cluster configuration reload.
The Tarantool access model defines user access to entities
inside a single instance. Thus, to create or alter a cluster-wide user or role, you need to
do this on all cluster instances. In replication clusters, changes in access model
are possible only on read-write instances (replica set leaders). Changes made on
a leader instance are propagated to all instances of its replica set automatically.
Operations on the cluster access model are possible only if the user
that TCM uses to connect to the cluster has the privileges to manage users and roles.
You can also manage Tarantool users and roles from TCM using the Lua API
as described in Access control. To do this, connect to instance consoles
from the Terminal tab of the instance page.
Managing cluster users
The tools for managing cluster users are located on the Users tab
of the instance page.
Important
To ensure the access model consistency across the cluster, repeat all user
management operations on all read-write instances of the cluster.
To create a user on a cluster:
Go to Stateboard.
Find a replica set leader in the instances list and click it to open the instance page.
Go to the Users tab and click Add user.
To edit or delete a user, click the Edit or Delete button against the username
in the Users table.
To edit a user’s privileges:
Click the lock icon against the username in the Users table.
In the privileges dialog:
Click Add to grant privileges
Click Revoke (the trash bin icon) to revoke a privilege
Managing cluster roles
The tools for managing cluster roles are located on the Users tab
of the instance page.
Important
To ensure the access model consistency across the cluster, repeat all role
management operations on all read-write instances of the cluster.
To create a role on a cluster:
Go to Stateboard.
Find a replica set leader in the instances list and click it to open the instance page.
Go to the Users tab and click Add role.
To delete a role, click the Delete button against the role name in the Roles table.
To edit a role’s privileges:
Click the lock icon against the role name in the Roles table.
In the privileges dialog:
Click Add to grant privileges
Click Revoke (the trash bin icon) to revoke a privilege
Tarantool Cluster Manager includes a web interface for managing security settings of connected
clusters. It is available on the Cluster > Security page. On this page,
you can manage the following security features in the cluster:
Authentication settings: protocol (CHAP or PAP), number of retries, and
the delay after a failed authentication attempt (security.auth_*
configuration options). To learn more about Tarantool authentication settings, see Authentication.
Password policy: minimal password length, required characters, expiration
period, and other settings (security.password_*
configuration options). To learn more about Tarantool password policy, see Password policy.
Guest access: whether unauthenticated or guest
users can connect to cluster (security.disable_guest
configuration option).
Secure erasing: whether to delete data files securely so that they cannot be restored
(security.secure_erasing configuration option).
Audit log: configure audit logging in the cluster
(audit_log.* configuration options).
To learn how to manage audit logging in the cluster, see Audit module.
In Tarantool Cluster Manager, you can view metrics of connected clusters in real time on the
Cluster > Cluster metrics page. The list of metrics that Tarantool exposes
is provided in the Metrics reference.
Metrics are displayed one by one. To view a metric, select it in the drop-down list
at the top of the page. Then, choose a way to visualize it:
Chart: a time series chart with the metric values displayed as lines.
Table: a table where the metric values are displayed as numbers in table cells.
Once you select a metric, TCM starts visualizing its current values, updating them
once per second. To pause the visualization, click the button on the left from
the metrics selector. To stop the visualization, clear the metric selection.
Viewing instance metrics
To view metrics of a specific instance, find this instance on the Stateboard,
click its name, and go to the Metrics tab of the instance page.
Monitoring metrics with Prometheus
To allow collecting cluster metrics with external systems, such as Prometheus,
TCM provides HTTP endpoints at /api/metrics/<clusterId>.
Note
Cluster IDs are shown in the cluster selection dialog that opens when you click
Cluster at the top of the left navigation pane.
To access such an endpoint, a request must be authorized with an API token
that has a cluster.metrics permission on the target cluster.
Below is an example of a Prometheus scrape configuration that collects metrics of
a Tarantool cluster from TCM:
For Tarantool clusters that use supervised failover,
Tarantool Cluster Manager offers tools for interaction with external failover coordinators from its web interface.
The tools for using supervised failover are located on the Failovers page
available from the Actions menu on the cluster stateboard.
Note
TCM can interact with failover coordinators that are already running.
There is no way to start or stop coordinators from TCM.
Viewing failover coordinators
To view failover coordinators running on the cluster, go to the Failovers tab.
On this tab, you can see the information about all Tarantool instances that the cluster
uses as failover coordinators. The information includes:
Current coordinator status – Active or Notactive
PID – process ID
Hostname – the host on which the coordinator is running
UUID – the coordinator ID
Term – a value that defines the order in which coordinators become active
(take the lock) over time.
Executing failover commands
To send a failover command to a coordinator, go to the Commands tab and click Add.
Then, provide the command description in the YAML format. It can include the following
fields:
command – the command name. Possible value: switch – switch master
in a replica set.
new_master – the name of the instance to make the new master.
timeout – the command execution timeout.
Example:
command:switchnew_master:instance-002timeout:30
After entering the command, click Save to send the command for execution.
Tarantool assigns an id to the command and waits for the active coordinator to process the command.
All failover commands executed on the cluster are shown on the Commands tab with
their ids and statuses. A command can have the following statuses:
taken – a failover coordinator has started the command execution.
success – the command has completed successfully.
failed – an error occurred during the command execution.
A short error description is shown in the Reason field.
To see the command execution details, click this command in the list.
Tarantool Cluster Manager provides a web interface for managing and performing migrations
in connected clusters. To learn more about migrations in Tarantool, see Migrations.
Migrations are named Lua files with code that alters the cluster data schema, for example,
creates a space, changes its format, or adds indexes. In TCM, there is a dedicated
page where you can organize migrations, edit their code, and apply them to the cluster.
Managing migrations
The tools for managing migrations from TCM are located on the Cluster > Migrations page.
To create a migration:
Click Add (the + icon) on the Migrations page.
Enter the migration name.
Important
When naming migrations, remember that they are applied in the lexicographical order.
Use ordered numbers as filename prefixes to define the migrations order.
For example, 001_create_table, 002_add_column, 003_create_index.
Write the migration code in the editor window. Use the box.schema module reference
to learn how to work with Tarantool data schema.
Once you complete writing the migration, save it by clicking Save.
This saves the migration that is currently opened in the editor.
Appliyng migrations
After you prepare a set of migrations, apply it to the cluster.
To apply all saved migrations to the cluster at once, click Apply.
Important
Applying all saved migrations at once, in the lexicographical order is the
only way to apply migrations in TCM. There is no way to select a single or
several migrations to apply.
The migrations that are already applied are skipped. To learn how to check
a migration status, see Checking migrations status.
Migrations that were created but not saved yet are not applied when you click Apply.
Checking migrations status
To check the migration results on the cluster, use the Migrated widget on the
cluster stateboard. It reflects the general result
of the last applied migration set:
If all saved migration are applied successfully,
the widget is green.
If any migration from this set fails on certain instances, the widget color changes to yellow.
If there are saved migrations that are not applied yet, the widget becomes gray.
Hovering a cursor over the widget shows the number of instances on which the currently
saved migration set is successfully applied.
You can also check the status of each particular migration on the Migrations page.
The migrations that are successfully applied are marked with green check marks.
Failed migrations are marked with exclamation mark icons (!). Hover the cursor over
the icon to see the information about the error. To reapply a failed migration,
click Force apply in the pop-up with the error information.
Migration file example
The following migration code creates a formatted space with two indexes in a
sharded cluster:
Tarantool Cluster Manager provides a web interface for clusters that run within Tarantool Clusters Federation.
It is available on the Cluster > TCF page. If a connected cluster is
configured to run in a TCF installation, this page shows information about both
clusters in this installation: their ID’s, names, and statuses. To switch cluster
states in TCF, click Toggle on the TCF page.
To learn more about Tarantool Clusters Federation, see its documentation.
Tarantool Cluster Manager provides access to data stored in connected clusters through its
web interface. You can view, add, edit, and delete tuples from spaces.
Data access is implemented in TCM on a per-instance basis: you can access
data stored on one cluster instance at a time. For sharded clusters that use the
CRUD module,
it’s also possible to access data throughout the whole cluster.
Instance data
There are the following ways to access data stored on a cluster instance from TCM:
Instance explorer displays the instance’s spaces as tables in the web interface
SQL terminal allows executing SQL statements on the instance
Tarantool and tt consoles allow accessing the data using the Lua API
Important
Data modification is possible only on instances in the read-write mode (replica set leaders).
Changes are applied to read-only replicas in accordance with the cluster topology.
Instance explorer
The instance explorer provides access to all spaces that exist on the instances
in the web interface. This includes both system and user spaces.
To open the instance explorer:
Go to Stateboard.
Click the instance row in the instances list or its graph vertex in the graph view.
Click Explorer in the Actions menu of the instance details page.
To view tuples of a space, click its row in the spaces list.
To add a new tuple, click + on the space page and provide tuple field values
in the Lua format, for example, [1,1000,true,"test"].
To edit a tuple, click it in the table and then click Edit.
To delete a tuple, select it in the table and click Delete (the trash bin button).
In the development mode, you can also create, edit, truncate, and delete spaces
in the instance explorer. To create a space, click Add and follow the wizard steps.
To edit, truncate, or remove a space, click the corresponding button in the Actions
menu of the space row in the table.
SQL terminal
TCM features an SQL terminal that you can use to access stored data. It is located
on the SQL tab of the instance details page. In the SQL terminal, you can execute
any supported SQL expressions on the selected instance.
For select SQL queries, you can also download the query result set in the CSV format.
To learn more about using SQL in Tarantool, see the SQL tutorial.
Lua API: Tarantool and tt consoles
TCM provides interactive access to instances’ consoles on the Terminal tab
of the instance details page. You can choose between the tt console
(TT Connect tab) and Tarantool interactive console (Direct tab).
In these consoles, you can access the stored data using the Tarantool Lua API.
Sharded cluster data
For sharded clusters that use the CRUD module,
it’s possible to access stored data throughout the cluster on the Cluster > Tuples page.
This page displays only user spaces.
To view all tuples of a space in a sharded cluster, click the space row in the list.
To add a new tuple, click + on the space page and provide tuple field values
in the Lua format, for example [1,1000,true,"test"]. When you add a tuple
in a sharded cluster, it is distributed to a replica set based on the sharding key
(the bucket_id field) value.
To edit a tuple, click it in the table and then click Edit.
To delete a tuple, select it in the table and click Delete (the trash bin button).
Creating spaces in sharded clusters
To create a space in a sharded cluster, create it on all read-write cluster instances
on their Instance explorer pages.
Important
Sharded spaces must include the bucket_id field of the unsigned type
and a non-unique index by this field with the same name.
To edit, truncate, or delete spaces in a sharded cluster, perform the corresponding
action on all read-write cluster instances.
Tarantool Cluster Manager features a role-based access control system. It enables flexible
management of access to TCM functions, connected clusters, and stored data.
The TCM access system uses three main entities: permissions, roles,
and users (or user accounts). They work as follows:
Permissions correspond to specific functions or objects in
TCM (administrative permissions) or operations on clusters (cluster permissions).
Roles are predefined sets of administrative permissions to
assign to users.
Users have roles that define their access rights to TCM functions and objects, and
cluster permissions that are assigned for each cluster individually.
Note
TCM users, roles, and permissions are not to be confused with similar subjects
of the Tarantool access control system. To access Tarantool
instances directly, Tarantool users with corresponding roles are required.
Permissions
Permissions define access to specific actions that users can do in TCM. For example,
there are permissions to view connected clusters or to manage users.
There are two types of permissions in TCM: administrative and cluster permissions.
Administrative permissions provide access to TCM functions. They define which
pages and controls are available to users in the web UI. Typically, read permissions
define pages shown in the left menu. Write permissions define the availability
of controls for managing objects on the pages.
For example, users with read permission to clusters can view the Clusters page
but they don’t see Add, Edit, or Remove buttons unless they have the
write permission.
Administrative permissions are assigned to users through roles.
Cluster permissions enable actions with connected Tarantool clusters.
These permissions are granted to users on a per-cluster level: each user has a separate
set of permissions for each cluster.
Cluster permissions define which pages of the Cluster menu section users
see and what actions they can take on these pages.
For example, users with the read configuration permission to a cluster configuration
see the Configuration page when this cluster is selected.
Cluster permissions are assigned to users individually when creating or editing them.
For a fine-grained control over user access to particular spaces and functions stored
in clusters, there is the access control list.
Permissions are predefined in TCM, there is no way to change, add, or delete them.
The complete lists of administrative and cluster permissions in TCM are provided
in the Permissions reference.
The assigned roles define pages that users see in TCM and actions available
on these pages.
Note
Roles don’t include cluster permissions. Access to connected clusters
is configured for each user individually.
Default roles
TCM comes with default roles that cover three common usage scenarios:
Super Admin Role is a default role with all available
administrative permissions.
Additionally, the users with this role automatically gain all
cluster permissions
to all clusters.
Cluster Admin Role is a default role for cluster administration. It includes
administrative permissions for cluster management.
Default User Role is a default role for working with clusters. It includes
basic administrative read permissions that are required to log in to TCM
and navigate to a cluster.
Managing roles
Administrators can create new roles, edit, and delete existing ones.
Roles are listed on the Roles page.
To create a new role, click Add, enter the role name, and select the permissions
to include in the role.
To edit an existing role, click Edit in the Actions menu of the corresponding
table row.
To delete a role, click Delete in the Actions menu of the corresponding
table row.
Note
You can delete a role only if there are no users with this role.
A user can have any number of roles or none of them. Users without roles
have access only to clusters that are assigned to them.
TCM uses password authentication for users. For information on password management,
see the Passwords section below.
Default admin
There is one default user Default Admin. It has all the available permissions,
both administrative and cluster ones. When new clusters are added in TCM,
Default Admin automatically receives all cluster permissions for them as well.
Managing users
Administrators can create new users, edit, and delete existing ones.
The tools for managing users are located on the Users page.
To create a user:
Click Add.
Fill in the user information: username, full name, and description.
Generate or type in a password.
Select roles to assign to the user.
Add clusters to give the user access to, and select cluster permissions for
each of them.
To edit a user, click Edit in the Actions menu of the corresponding table row.
To delete a user, click Delete in the Actions menu of the corresponding table row.
Passwords
TCM uses the general term secret for user authentication keys. A secret is any
pair of a public and a private key that can be used for authentication. A password
combined with a username is a secret type used for TCM user authentication.
In this case, the public key is a username, and the private key is a password.
Users receive their first passwords during their account creation.
All passwords are governed by the password policy.
It can be flexibly configured to follow the security requirements of your organization.
Changing your password
To change your own password, click your name in the top-right corner and go to
Settings > Change password.
Changing users’ passwords
Administrators can manage a user’s password on this user’s Secrets page.
To open it, click Secrets in the Actions menu of the corresponding Users table row.
To change a user’s password, click Edit in the Actions menu of the corresponding
Secrets table row and enter the new password in the New secret key field.
Password expiry
Passwords expire automatically after the expiration period defined in the password policy.
When a user logs in to TCM with an expired password, the only action available to
them is a password change. All other TCM functions and objects are unavailable until
the new password is set.
Administrators can also set users’ passwords to expired manually.
To set a user’s password to expired, click Expire in the Actions
menu of the corresponding Secrets table row.
Important
Password expiration can’t be reverted.
Blocking passwords
To forbid users’ access to TCM, administrators can temporarily block their
passwords. A blocked password can’t be used to log into TCM until it’s
unblocked manually or the blocking period expires.
To block a user’s password, click Block in the Actions menu of the corresponding
Secrets table row. Then provide a blocking reason and enter the blocking period.
To unblock a blocked password, click Unblock in the Actions menu of the corresponding
Secrets table row.
Password policy
Password policy helps improve security and comply with security requirements that
can apply to your organization.
You can edit the TCM password policy on the Password policy page.
There are the following password policy settings:
Minimal password length.
Do not use last N passwords.
Password expiration in days. Users’ passwords expire
after this number of days since they were set. Users with expired passwords
lose access to any objects and functions except password change until they set
a new password.
Password expiration warning in days. After this number of days, the user
sees a warning that their password expires soon.
Block after N login attempts. Temporarily block users if they enter their
username or password incorrectly this number of times consecutively.
User lockout time in seconds. The time interval for which users can’t log
in after spending all failed login attempts.
Password must include. Characters and symbols that must be present in passwords:
Lowercase characters (a-z)
Uppercase characters (A-Z)
Digits (0-9)
Symbols (such as !@#$%^&*()_+№”’:,.;=][{}`?>/.)
Permissions reference
Administrative permissions
The following administrative permissions are available in TCM:
Permission
Description
admin.clusters.read
View connected clusters’ details
admin.clusters.write
Edit cluster details and add new clusters
admin.users.read
View users’ details
admin.users.write
Edit user details and add new users
admin.roles.read
View roles’ details
admin.roles.write
Edit roles and add new roles
admin.addons.read
View add-ons
admin.addons.write
Edit add-on flags
admin.addons.upload
Upload new add-ons
admin.auditlog.read
View audit log configuration and read audit log in TCM
In addition to its internal role-based access control model,
Tarantool Cluster Manager can use an external LDAP (Lightweight Directory Access Protocol)
directory server for user authentication and authorization.
When LDAP authentication is enabled, TCM uses a connected LDAP directory server
to authenticates users who submit the login form. TCM constructs requests to
the servers according to configuration parameters described on this page. Permissions
of LDAP users in TCM are defined by LDAP group mapping.
Both LDAP and secure LDAPS (LDAP over TLS) protocols are supported.
Enabling LDAP authentication
To allow LDAP user authentication in TCM, enable the ldap authentication method
in the security.auth configuration option before startup:
In the YAML TCM configuration:
security:auth:-ldap
In the command line:
$ tcm--security.auth="ldap"
Note
If both authentication methods – LDAP and local – are enabled, TCM tries them
for each login attempt in the order they are specified in the configuration.
LDAP configuration
To enable LDAP user access to TCM, create an LDAP configuration that connects
TCM to the LDAP server that stores the users. An LDAP configuration
defines how TCM connects to the server and queries user data. To create an LDAP
configuration, go to the LDAP page in the Settings group and click Add.
To edit an LDAP configuration, click Edit in the Actions menu of the corresponding row.
To delete an LDAP configuration, click Delete in the Actions menu of the corresponding row.
General settings
Define the general configuration settings:
Enabled. Defines if the configuration is used. Turn the toggle off to
stop using the configuration.
Note
If there are several enabled LDAP configurations, TCM attempts to use them
for user authentication in the order they are created.
Automatically add non-existent users. By default, TCM automatically saves
LDAP user information to its backend store
upon their first login. Turn the toggle off if you don’t want to save users from this LDAP server.
LDAP server connection
Enter the LDAP server connection parameters:
Endpoints. URLs of the LDAP server. Example: 127.0.0.1:5056.
Request timeout. The timeout for TCM requests to the LDAP server, in seconds.
Enabled TLS. If the server uses LDAPS, turn this toggle on and specify
TLS connection parameters, such as a certificate and a key file.
LDAP queries
To define how TCM queries the LDAP server for user authentication and authorization,
fill in the fields of the Queries step:
Query user and Query password. Credentials of the LDAP user on behalf
of which all LDAP queries are executed: a distinguished name (DN) and a password.
Example DN:
cn=admin,cn=users,dc=tarantool,dc=io
Base DN. The DN of a directory that serves as a root for making all LDAP requests.
Example: dc=tarantool,dc=io.
Username regex. A regular expression that defines a username template for
this LDAP configuration. When a user enters their username on the login page,
TCM matches it against username regular expressions of all enabled LDAP
configurations and selects the one to use for this user authentication.
Example: a regex to match employee email addresses within the specified domain.
^([\w\-\.]+)@tarantool.io$
(Optional) Template DN. A template for building a DN to send in an authentication bind request.
Use the numbers in curly braces as placeholders to replace with username regex parts:
{0}, {1}, and so on.
Example:
cn={0},cn=users,dc=tarantool,dc=io
When used with the Username regex shown above, it substitutes {0} with
the username part of the email address (before @) entered into the login form.
For example, the username user1@tarantool.io forms the following DN for bind request:
cn=user1,cn=users,dc=tarantool,dc=io
(Optional) Template query. A template for querying the LDAP server for the DN. This
way is used if Template DN is not provided.
Group query template. A template for querying groups to which a user belongs
for authorization purposes. Learn more in LDAP user permissions.
Example:
Permissions of LDAP users in TCM are defined by the groups to which they belong.
You can map TCM administrative and cluster permissions
to LDAP groups on the Groups step of the configuration creation.
To assign permissions to an LDAP group, click Add group. In the dialog that opens,
enter the group name, for example, CN=Admins,CN=Builtin,DC=tarantool,DC=io.
Then, select administrative permission to grant to this group in the Permissions list.
To grant cluster permissions, click Add cluster. Select a cluster and the cluster
permissions to grant to the group. Save the group.
Each user has permissions of all LDAP groups to which they belong.
Disabling LDAP configurations
To stop using an LDAP configuration, open its Edit page and turn off the Enabled toggle.
Tarantool Cluster Manager access control list (ACL) determines user access to particular data
and functions stored in clusters. You can use it to allow or deny access to specific
stored objects one by one.
Each ACL entry specifies privileges that a TCM user has on a particular
space or a function. There are three access privileges that can be granted in the ACL:
read, write, and execute (for stored functions only). The privileges work as follows:
Spaces:
Read: the user sees the space and its tuples on the Tuples and Explorer pages
Write: the user can add new and edit existing tuples of the space
Functions:
Read: the user sees the function on the Functions tab of the instance details page.
Write: the user can edit or delete the function
Execute: the user can call the function
Important
User access to space data and stored functions is primarily defined by the
cluster permissionscluster.space.data.* and cluster.func.*.
ACL only increases the access control granularity to particular objects.
Make sure that users have these permissions before enabling ACL for them.
Enabling ACL for a user
To granularly manage a user’s access to particular objects in a cluster, enable
the use of ACL in the user profile:
Go to Users and click Edit in the Actions menu of the corresponding table row.
In the user’s Clusters list, add a cluster on which you want to use ACL
or click the pencil icon if the cluster is already on the list.
Select the Use Access Control List (ACL) checkbox and save changes.
Repeat two previous steps for each cluster on which you want to use ACL for this user.
Click Update to save the user account.
If the user doesn’t exist yet, you can do the same when creating it.
Important
When ACL use is enabled for a user, this user loses access to all spaces and
functions of the selected cluster except the ones explicitly specified in the ACL.
Managing ACL
The tools for managing ACL are located on the ACL page.
To add an ACL entry:
Click Add.
Select a user to which you want to grant access.
Select a cluster that stores the target object: a space or a function.
Select the target object type and enter its name.
Select the privileges you want to grant.
To delete an ACL entry, click Delete in the Actions menu of the corresponding table row.
Tarantool Cluster Manager uses the Bearer HTTP authentication scheme with API tokens to authenticate
external applications’ requests to TCM. For example, these can be Prometheus
jobs that retrieve metrics of connected Tarantool clusters.
The API tokens functionality is disabled by default. To enable it, set the
feature.api-token configuration option to true.
feature:api-token:true
Each TCM API token belongs to the user that created it and has the same access permissions.
Thus, if a user has a permission to view a cluster’s metrics in TCM, this user’s
API tokens can be used to read this cluster’s metrics with Prometheus.
API tokens have expiration dates that are set during the token creation and cannot
be changed.
Managing API tokens
Note
Each user, including Default Admin and other administrators, can create only
their own tokens. There is no way to create a token for another user.
To create a TCM API token:
Open the user settings by clicking the user’s name in the top-right corner.
Go to the API tokens tab and click Add.
Specify the token expiration date and an optional description and click Add.
The created token is shown in a dialog.
Important
An API token is shown only once after its creation. There is no way to view
it again after you close the dialog. Make sure to copy the token in a safe place.
To delete an API token, click Delete in the actions menu of the corresponding
API tokens table row.
Administrators can also view information about users’ API tokens and delete them
on the Secrets page. To open a user’s secrets, click Secrets in the Actions
menu of the corresponding Users table row.
Tarantool Cluster Manager administrators can view and revoke user sessions in the web interface.
All active sessions are listed on the Sessions page. To revoke a session, click
Revoke in the Actions menu of the corresponding table row.
To revoke all sessions of a TCM user, go to Users and click Revoke all sessions
in the Actions menu of the corresponding table row.
Tarantool Cluster Manager provides the audit logging functionality for tracking user activity
and security-related events, such as:
Successful and failed login attempts.
Access to clusters, their configurations, data models, and stored data.
Changes in the access control system: users, roles, passwords, LDAP configurations.
The complete list of TCM audit events is provided in Event types.
Note
TCM audit log records only events that happen in TCM itself.
For information about Tarantool audit logging, see Audit module.
Audit logging is disabled in TCM by default. To start recording events, you need
to enable and configure it.
The audit log stores event details in the JSON format. Each log entry contains the
event type, description, time, impacted objects, and other information that
may be used for incident investigation. The complete list of fields is provided in
Structure of audit log events.
TCM also provides a built-in interface for reading and searching the audit log.
For details, see Viewing audit log.
Enabling audit logging
To enable audit logging in TCM, go to Audit settings and click Enable.
To additionally send audit log events to the standard output, click Send to stdout.
Audit log configuration
TCM audit events can be logged to a local file or sent to a
syslog server.
To configure audit logging, go to Audit settings.
Writing to a file
To write TCM audit logs to a file:
Go to Audit settings and select the file protocol.
Specify the name of the audit log file. The file appears in the TCM working directory.
Configure the log files rotation: the maximum file size and age, and the number
of files to store simultaneously.
(Optional) Enable compression of audit log files.
Configuration parameters:
Output file name. The name of the audit log file. Default: audit.log
Max size (in MB). The maximum size of the log file before it gets rotated, in megabytes. Default: 100.
Max backups. The maximum number of stored audit log files. Default: 10.
Max age (in days). The maximum age of audit log files in days. Default: 30.
Compress. Compress audit log files into gzip archives when rotating.
Sending to syslog
If you use a centralized log management system based on syslog,
you can configure TCM to send its audit log to your syslog server:
Go to Audit settings and select the syslog protocol.
Enter the syslog server URI and select the network protocol. Typically,
syslogd listens on port 514 and uses the UDP protocol.
Specify the syslog logging parameters: timeout, priority, and facility.
Configuration parameters:
Protocol. The network protocol used for connecting to the syslog server. Default: udp.
Output. The syslog server URI. Default: 127.0.0.1:514 (localhost).
Priority. The syslog severity level. Default: info.
Facility. The syslog facility. Default: local0.
Selecting audit events to record
When the audit log is enabled, TCM records all audit events listed in Event types.
To decrease load and make the audit log comply with specific security
requirements, you can record only selected events. For example, these can be events
of user account management or events of cluster data access.
To select events to record into the audit log, go to Audit settings and
enter their types into the Filters field
one-by-one, pressing the Enter key after each type.
To remove an event type from a filters list, click the cross icon beside it.
Viewing audit log
If the audit log is written to a file, you can view it in TCM on the Audit log page.
On this page, you can view or search for events.
To view the details of a logged audit event, click the corresponding line in the
table.
To search for an event, use the search bar at the top of the page. Note that the
search is case-sensitive. For example, to find events with the ALARM severity,
enter ALARM, not alarm.
Structure of audit log events
All entries of the TCM audit log include the mandatory fields listed in the table below.
Information about the client application and platform that was used to trigger the event
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
permission
The permission that was used to trigger the event
[“admin.users.write”]
result
Event result: ok or nok
ok
err
Human-readable error description for events with nok result
failed to login
fields
Additional fields for specific event types in the key-value format
Key examples:
clusterId in cluster-related events
payload in events that include sending data to the server
username in current.* or auth.* events
This is an example of an audit log entry on a successful login attempt:
{"time":"2023-11-23T12:01:27.247+07:00","severity":"INFO","description":"Login user","type":"current.login","uuid":"4b9c2dd1-d9a1-4b40-a448-6bef4a0e5c79","user":"","remote":"127.0.0.1:63370","user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36","host":"127.0.0.1:8080","permissions":[],"result":"ok","fields":[{"Key":"username","Value":"admin"},{"Key":"method","Value":"null"},{"Key":"output","Value":"true"}]}
Event types
The following table lists all possible values of the type field of TCM
audit log events.
Event type
Description
auth.fail
Authentication failed
auth.ok
Authentication successful
access.denied
An attempt to access an object without the required permission
user.add
User added
user.update
User updated
user.delete
User deleted
secret.add
User secret added
secret.update
User secret updated
secret.block
User secret blocked
secret.unblock
User secret unblocked
secret.delete
User secret deleted
secret.expire
User secret expired
session.revoke
Session revoked
session.revokeuser
All user’s sessions revoked
explorer.insert
Data inserted in a cluster
explorer.delete
Data deleted from a cluster
explorer.replace
Data replaced in a cluster
explorer.call
Stored function called on a cluster
explorer.evaluate
Code executed on a cluster
explorer.switchover
Master switched manually
test.devmode
Switched to development mode
auditlog.config
Audit log configuration changed
passwordpolicy.save
Password policy changed
passwordpolicy.resetpasswords
All passwords expired by an administrator
ddl.save
Cluster data model saved
ddl.apply
Cluster data model applied
cluster.config.save
Cluster configuration saved
cluster.config.reset
Saved cluster configuration reset
cluster.config.apply
Cluster configuration applied
current.logout
User logged out their own session
current.revoke
User revoked their own session
current.revokeall
User revoked all their active sessions
current.changepassword
User changed their password
role.add
Role added
role.update
Role updated
role.delete
Role deleted
cluster.add
Cluster added
cluster.update
Cluster updated
cluster.delete
Cluster removed
ldap.testlogin
Login test executed for a LDAP configuration
ldap.testconnection
Connection test executed for a LDAP configuration
ldap.add
LDAP configuration added
ldap.update
LDAP configuration updated
ldap.delete
LDAP configuration deleted
addon.enable
Add-on enabled
addon.disable
Add-on disabled
addon.delete
Add-on removed
tcmstate.save
Low-level information saved in the TCM storage (for debug purposes)
tcmstate.delete
Low-level information deleted from the TCM storage (for debug purposes)
This topic describes how to configure Tarantool Cluster Manager. For the complete
list of TCM configuration parameters, see the TCM configuration reference.
Note
To learn about Tarantool cluster configuration, see Configuration.
Configuration structure
Tarantool Cluster Manager configuration is a set of parameters that define various aspects
of TCM functioning. Parameters are grouped by the particular aspect that they
affect. There are the following groups:
HTTP
logging
configuration storage
security
add-ons
limits
TCM running mode
Parameter groups can be nested. For example, in the http group there are
tls and websession-cookie groups, which define TLS encryption and
cookie settings.
Parameter names are the full paths from the top-level group to the specific parameter.
For example:
http.host is the host parameter that is defined directly in the http group.
http.tls.enabled is the enabled parameter that is defined in the tls
nested group within http.
Ways to pass configuration parameters
There are three ways to pass TCM configuration parameters:
a YAML file
environment variables
command-line options of the TCM executable
YAML file
TCM configuration can be stored in a YAML file. Its structure must reflect the
configuration parameters hierarchy.
The example below shows a fragment of a TCM configuration file:
# a fragment of a YAML configuration filecluster:# top-level groupon-air-limit:4096connection-rate-limit:512tarantool-timeout:10starantool-ping-timeout:5shttp:# top-level groupbasic-auth:# nested groupenabled:falsenetwork:tcphost:127.0.0.1port:8080request-size:1572864websocket:# nested groupread-buffer-size:16384write-buffer-size:16384keepalive-ping-interval:20shandshake-timeout:10sinit-timeout:15s
To start TCM with a YAML configuration, pass the location of the configuration
file in the -c command-line option:
$ tcm-c=config.yml
Environment variables
TCM can take values of its configuration parameters from environment variables.
The variable names start with TCM_. Then goes the full path to the parameter,
converted to upper case. All delimiters are replaced with underscores (_).
Examples:
TCM_HTTP_HOST is a variable for the http.host parameter.
TCM_HTTP_WEBSESSION_COOKIE_NAME is a variable for the http.websession-cookie.name parameter.
The example below shows how to start TCM with configuration parameters passed in
environment variables:
The TCM executable has -- command-line options for each configuration parameter.
Their names reflect the full path to the parameter, with configuration levels separated by
periods (.). Examples:
--http.host is an option for http.host.
--http.websession-cookie.name is an option for http.websession-cookie.name.
The example below shows how to start TCM with configuration parameters passed in
command-line options:
TCM configuration options are applied from multiple sources with the following precedence,
from highest to lowest:
tcm executable arguments.
TCM_* environment variables.
Configuration from a YAML file.
If the same option is defined in two or more locations, the option with the highest
precedence is applied. For options that aren’t defined in any location, the default
values are used.
You can combine different ways of TCM configuration for efficient management of
multiple TCM installations:
A single YAML file for all installations can contain the common configuration parts.
For example, a single configuration storage that is used for all installations, or
TLS settings.
Environment variables that set specific parameters for each server, such as
local directories and paths.
Command-line options for parameters that must be unique for different TCM instances
running on a single server. For example, http.port.
Configuration parameter types
TCM configuration parameters have the Go language
types. Note that this is different from the Tarantool configuration parameters,
which have Lua types.
Most options have the Go’s basic types: int and other numeric types, bool, string.
In environment variables and command line options, such arrays are passed as
semicolon-separated strings of items.
Parameters that set timeouts, TTLs, and other duration values, have the Go’s time.Duration
type. Their values can be passed in time-formatted strings such as 4h30m25s.
Finally, there are parameters whose values are constants defined in Go packages.
For example, http.websession-cookie.same-site
values are constants from the Go’s http.SameSite
type. To find out the exact values available for such parameters, refer to the Go
packages documentation.
You can create a YAML configuration template for TCM with all parameters and
their default values using the generate-config option of the tcm executable.
To write a default TCM configuration to the tcm.example.yml file, run:
$ tcmgenerate-config>tcm.example.yml.
Initial settings
You can use YAML configuration files to create entities in TCM automatically
upon the first start. These entities are defined in the initial-settings
section of the configuration file.
Important
The initial settings are applied only once upon the first TCM start.
Further changes are not applied upon TCM restarts.
Clusters
To add clusters to TCM upon the first start, specify their settings in the
initial-settings.clusters
configuration section.
The initial-settings.clusters section is an array whose items describe separate clusters,
for example:
In this configuration, you can specify all cluster settings that you define
when connecting clusters through the TCM web interface.
This includes:
the cluster name
description
additional URLs
configuration storage connection
Tarantool instances connection
and other settings.
For the full list of cluster configuration parameters, see the initial-settings.clusters
reference. For example, this is how you add a cluster that uses an etcd configuration
storage:
By default, TCM contains a cluster named Default cluster with ID
00000000-0000-0000-0000-000000000000. You can use this ID to modify
the default cluster settings upon the first TCM start. For example, rename it
and add its connection settings:
Tarantool Cluster Manager uses an underlying data store (backend store) for its entities:
users, roles, cluster connections, settings, and other objects that you manipulate in TCM.
The backend store can be either an etcd or a Tarantool cluster.
For better reliability and scalability, the backend store works independently from TCM.
For example, it can be the same ectd or Tarantool cluster that you use as a centralized configuration storage.
This makes TCM stateless: all objects created or modified in its web UI are saved
to the backend store, and nothing is stored inside the TCM instances themselves.
Any number of instances can duplicate each other when connected to the same backend store.
If you stop all instances, the store still contains their objects. You can continue
working with them right after starting a new instance.
In addition to using an external backend store, you can run TCM with an embedded
etcd or Tarantool instance to use as the backend store.
On this page, you will learn to connect TCM to backend stores of both types,
or start TCM with an embedded backend store.
If you already have the centralized configuration store for your Tarantool clusters,
you can use it as a TCM backend store as well.
Configuring backend store connection
The TCM’s connection to its backend store is configured using the storage.*
configuration options. The storage.provider
option selects the store type. It can be either etcd or tarantool.
External etcd store
To use an etcd cluster as a TCM backend store, set the storage.provider option
to etcd and specify connection parameters in storage.etcd.* options.
A minimal etcd configuration includes the storage endpoints:
The TCM data is stored in etcd under the prefix specified in storage.etcd.prefix.
By default, the prefix is /tcm. If you want to change it or store data of
different TCM instances separately in one etcd cluster, set the prefix explicitly:
Other storage.etcd.* options configure various aspects of the etcd store connection,
such as network timeouts and limits or TLS parameters.
For the full list of the etcd TCM backend store options, see the
TCM configuration reference.
External Tarantool-based store
To use a Tarantool cluster as a TCM backend store, set the storage.provider option
to tarantool and specify connection parameters in storage.tarantool.* options.
A minimal configuration includes the one or more addresses of
the backend store instances:
The TCM data is stored in the Tarantool-based backend store under the prefix
specified in storage.tarantool.prefix.
By default, the prefix is /tcm. If you want to change it or store data of
different TCM instances separately in one Tarantool cluster, set the prefix explicitly:
Other storage.tarantool.* options configure various aspects of TCM connection
to the Tarantool-based backend store, such as network timeouts and limits or TLS parameters.
For the full list of the Tarantool-based TCM backend store options, see the
TCM configuration reference.
Embedded backend store
For development purposes, you can start TCM with an embedded backend store.
This is useful for local runs when you don’t have or don’t need an external backend store.
An embedded TCM backend store is a single instance of etcd or Tarantool that
is started automatically on the same host during the TCM startup. It runs
in the background until TCM is stopped. The embedded backend store is persistent:
if you start TCM again with the same backend store configuration, it restores
the TCM data from the previous runs.
Note
To start a clean instance of TCM, remove the working directory of the
embedded backend store specified in the storage.etcd.embed.workdir or
storage.tarantool.embed.workdir option.
The embedded backend store parameters are configured using the storage.etcd.embed.* options
for etcd or storage.tarantool.embed.* options for a Tarantool-based store.
To start TCM with an embedded etcd with default settings, set storage.etcd.embed.enabled to true
and leave other storage.* options default:
storage.etcd.embed.enabled:true
You can use the following call to get TCM running with embedded etcd without
a configuration file:
$ tcm--storage.etcd.embed.enabled
To start TCM with an embedded Tarantool storage with default settings:
You can tune the embedded backend store, for example, enable and configure TLS on it
or change its working directories or startup arguments. To set specific parameters,
specify the corresponding storage.etcd.embed.* or storage.tarantool.embed.*
options. For the full list of configuration options of embedded backend stores, see the
TCM configuration reference.
Setting up a cluster of embedded backend stores
To simulate the production environment, you can form a distributed multi-instance cluster
from embedded stores of multiple TCM instances. To do this, configure each TCM
instance’s embedded store to join each other.
For etcd, provide the embedded store clustering parameters storage.etcd.embed.*
and specify the endpoints in storage.etcd.endpoints. The options that configure
embedded etcd mostly match the etcd configuration options. For more information
about these options, see the etcd documentation.
Below are example configurations of three TCM instances that start with embedded etcd instances
and form an etcd cluster from them:
To set up a cluster from embedded Tarantool-based backend stores:
Specify the Tarantool cluster configuration in storage.tarantool.embed.config
(as a plain text) or storage.tarantool.embed.config-file (as a YAML file).
Assign an instance name from this configuration to each instance using storage.tarantool.embed.args
to each embedded store.
Below are example configurations of three TCM instances that start with embedded
Tarantool-based backend stores and form a cluster from them:
Tarantool Cluster Manager provides a special mode aimed to use during the development.
This mode extends the web interface with capabilities that can help in development
or testing environments, such as starting and stopping instances or instance promotion.
Enabling development mode
You can enable TCM development mode in different ways: in its web interface,
in the configuration file, using an environment variable, or using a command-line option.
Web interface
To enable development mode on the running TCM instance, use its web interface:
Open user settings: click Settings under the user name in the header.
Go to the About tab.
Click the toggle button beside tcm/mode.
Configuration file
To start TCM in the development mode, specify the mode:development option
in its configuration file:
# tcm_config.yamlmode:development
Command-line option
To start TCM in the development mode, specify the --mode=development command-line option:
$ tcm--mode=development
Environment variable
To make new TCM instances start in the development mode by default, set the
TCM_MODE environment variable to development:
Indicates whether the cookie can be sent only over the HTTPS protocol.
In this case, it’s never sent over the unencrypted HTTP, therefore preventing
man-in-the-middle attacks.
When true, the Secure attribute is added to the Set-Cookie
HTTP response header.
The network protocol used for connecting to the syslog server. Typically,
it’s tcp, udp, or unix. All possible values are listed in the Go’s
net.Dial documentation.
An array of log outputs that TCM uses in addition to the default one
that is defined by the log.default.* parameters. Each array item can include
the parameters of the log.default group. If a parameter is skipped, its
value is taken from log.default.
Type: []LogOuputConfig
Default: []
Environment variable: TCM_LOG_OUTPUTS
Command-line option: --log-outputs
storage
The storage section defines the parameters of the TCM backend store.
The storage.etcd.embed group defines the configuration of the embedded etcd
cluster to use as a TCM backend store.
This cluster can be used for development purposes when the production or testing
etcd cluster is not available or not needed.
A list of SSL cipher suites that can be used for connecting to the Tarantool TCM
configuration storage. Possible values are listed in <uri>.params.ssl_ciphers.
The storage.tarantool.embed group parameters define the configuration of the
embedded Tarantool cluster to use as a TCM backend store.
This cluster can be used for development purposes when the production or testing
cluster is not available or not needed.
The initial-settings.* configuration options can be set in the YAML
configuration file only. There are no environment variables nor
command-line options for them.
Cluster ID. Skip this option to generate an ID automatically.
Specify the value 00000000-0000-0000-0000-000000000000
to customize the default cluster upon TCM startup.
A list of SSL cipher suites that can be used for connecting to the cluster’s Tarantool-based
configuration storage. Possible values are listed in <uri>.params.ssl_ciphers.
Tarantool Cluster Manager 1.2 introduces new features that extend its
cluster management capabilities. Below is an overview of its key updates.
Managing Tarantool users
TCM 1.2 introduces the ability to manage Tarantool users on connected clusters.
Previously, you could manage Tarantool users only though the Lua API (box.schema submodule)
or cluster configuration.
Now you can create, edit, and delete users and roles on each instance of a Tarantool
cluster through the TCM web interface.
The tools for managing Tarantool users on a cluster instance are located on the
Users tab of the instance page.
Since version 1.2.0, TCM includes a page for editing and executing migrations
on connected clusters. The new page Migrations in the Cluster page group
provides a text editor where you can write migration scripts in Lua and apply them
to the cluster.
Learn more about migrations in Tarantool Migrations.
Cluster security settings
Since version 1.2.2, TCM provides a web interface for managing cluster security settings
on the Security page in the Cluster group.
Learn more about managing cluster security from TCM in Security settings.
Learn more about working with TCF in TCM in TCF integration.
Tarantool Cluster Manager 1.1
Release date: May 16, 2024
Latest release in series: 1.1.0
Tarantool Cluster Manager 1.1 introduces a number of new features that extend and improve its
cluster management capabilities. Below is an overview of its key updates.
Data access
An important update of TCM 1.1.0 is a set of features that enable access to clusters’
stored data.
The instance space explorer shows all spaces that exist on an instance, including
system spaces. On its pages, you can view and edit the stored data. To open the instance explorer,
find the instance on the cluster stateboard and click its name to open its details page.
Then click Explorer in the Actions menu in the top right corner.
In the development mode, the instance explorer also includes the schema editor.
It allows you to add new and edit existing spaces.
For clusters that use the CRUD module,
there is also the CRUD explorer that enables access to data in user spaces across
the entire cluster. The CRUD explorer is located on the Tuples page.
Access control list
TCM’s access control list (ACL) enables control over user access to particular spaces
and stored functions in the web interface.
For each user that has access to a cluster, you can enable the use of ACL on this cluster.
This restricts this user’s access to the cluster’s spaces and functions unless they
are explicitly specified in the ACL. The ACL must contain an entry for each such
space and function.
Users with ACL off have access to all spaces and functions on clusters according
to their cluster permissions.
The tools for managing ACL are located on the new ACL page.
API tokens
TCM 1.1 supports token authentication of external requests. Users can generate
API tokens in their user settings dialog. An API token has the same permissions
as its creator.
Stateboard improvements
TCM 1.1 extends the functionality of the cluster stateboard to improve the
cluster management experience. Here are the key updates of the stateboard:
More flexible instance grouping.
Stateful failover and switchover controls.
Runtime issues on the stateboard.
Instance interaction
The instance management dialog has been extended with new functions:
Starting from version 1.1.0, TCM displays metrics of connected clusters.
You can view metrics in TCM one by one, visualizing them as charts or tables.
The cluster metrics are shown on the new Cluster metrics page.
For more complex monitoring, you can use dedicated solutions, for example, Prometheus.
It can integrate with TCM using the API tokens.
Configuration validation
The cluster configuration editor now validates the configuration semantically.
Previously, TCM was able to highlight the syntax errors in configurations, for example,
incorrect spelling of option names or hierarchy. In TCM 1.1.0, the editor
checks and highlights possible semantic issues, such as:
Users without passwords.
Users with the super role.
Absence of leader instances in replica sets.
Onboarding tutorial
TCM 1.1.0 includes an interactive tutorial that takes new users through its
main features and pages. It opens automatically after the first start.
Tarantool Cluster Manager 1.0
Release date: December 26, 2023
Latest release in series: 1.0.4
1.0 is the first public release series of Tarantool Cluster Manager. It was introduced as a
part of the Tarantool EE 3.0 release.
Below is an overview of key features of TCM 1.0.
Multiple connected clusters
TCM works as a standalone application. You can connect any number of Tarantool EE
3.0+ clusters to a single TCM instance and switch between them on the fly.
To connect a cluster to TCM, you need to provide the endpoint URLs and connection
parameters of its centralized configuration storage (for example, etcd).
To learn more, see Connecting clusters.
Cluster stateboard
The cluster stateboard is a main TCM page that visualizes the information about
the selected cluster:
Cluster topology visualized as a table or a graph
Tarantool versions running on instances
Memory statistics
Errors and warnings that happen on instances
From the stateboard, you can navigate to specific instances to view their details
or connect to their interactive consoles.
TCM includes a visual editor for cluster configuration. It allows editing cluster
configurations as a YAML file in the browser. Once you’re done editing the configuration,
you can send the changes to the configuration storage in one click or save them locally
to continue editing them later.
TCM features its own role-based access control system. It defines users that can
log into TCM and their permissions to perform various actions or access clusters
in its web interface.
You can use built-in roles or create new ones with permissions you need. Users’
access can be limited to specific clusters and operations on them, for example,
editing the configuration or calling stored functions.
To learn more, see Access control.
TCM also supports LDAP authentication.
Audit logging
TCM has a built-in audit logging mechanism. When enabled, it records information
about events that occur in TCM and users’ actions to dedicated audit log files.
You can define events to write to the audit log and adjust logging parameters, such
as filename, log rotation, or compression.
The interactive console is Tarantool’s basic command-line interface for entering requests
and seeing results.
It is what users see when they start the server
without an instance file.
The interactive console is often called the Lua console to distinguish it from the administrative console,
but in fact it can handle both Lua and SQL input.
The majority of examples in this manual show what users see with the interactive console.
It includes:
tarantool> prompt
instruction (a Lua request or an SQL statement)
response (a display in either YAML or Lua format)
-- Interactive console example with Lua input and YAML output --tarantool> box.info().replication----1:id:1uuid:a5d22f66-2d28-4a35-b78f-5bf73baf6c8alsn:0...
Interactive console input and output
The input language can be either Lua (default) or SQL. To change the input
language, run \setlanguage<language>, for example:
-- Set input language to SQL --
tarantool> \set language sql
---
- true
...
The delimiter can be changed to any character with \setdelimiter<character>.
By default, the delimiter is empty, which means the input does not need to end
with a delimiter.
For example, a common recommendation for SQL input is to use the semicolon delimiter:
The output format can be either YAML (default) or Lua.
To change the output format, run \setoutput<format>, for example:
-- Set output format Lua --
tarantool> \set output lua
true
The default YAML output format is the following:
The output starts from a document-start line "---".
Each item begins on a separate line starting with "-".
Each sub-item in a nested structure is indented.
The output ends with a document-end line "...".
The alternative Lua format for console output is the following:
There are no lines for document-start or document-end.
Items are separated by commas.
Each sub-item in a nested structure is placed inside “{}” braces.
So, when an input is a Lua object description, the output in the Lua format equals it.
For the Lua output format, you can specify an end of statement symbol.
It is added to the end of each output statement in the current session and
can be used for parsing the output by scripts. By default, the end of statement
symbol is empty. You can change it to any character or character sequence.
To set an end of statement symbol for the current session, run \`setoutputlua,local_eos=<symbol>`,
for example:
-- Set output format Lua and '#' end of statement symbol --
tarantool> \set output lua,local_eos=#
true#
To switch back to the empty end of statement symbol:
-- Set output format Lua and empty end of statement symbol --
tarantool> \set output lua,local_eos=
true
The YAML output has better readability.
The Lua output can be reused in requests.
The table below shows output examples in these formats compared with the MsgPack
format, which is good for database storage.
Type
Lua input
Lua output
YAML output
MsgPack storage
scalar
1
1
---
-1
...
\x01
scalar sequence
1,2,3
1,2,3
---
-1
-2
-3
...
\x01\x02\x03
2-element table
{1,2}
{1,2}
---
--1
-2
...
0x920x010x02
map
{key=1}
{key=1}
---
-key:1
...
\x81\xa3\x6b\x65\x79\x01
The console parameters of a Tarantool instance can also be changed from another
instance using the console built-in module functions.
Discard current input with the SIGINT signal in the console mode and
jump to a new line with a default prompt.
CTRL+D
Quit Tarantool interactive console.
Important
Keep in mind that CTRL+C shortcut will shut Tarantool down if there is any currently running command
in the console.
The SIGINT signal stops the instance running in a daemon mode.
LuaJIT memory profiler
Since version 2.7.1, Tarantool
has a built‑in module called misc.memprof that implements a LuaJIT memory
profiler (further in this section we call it the profiler for short).
The profiler provides a memory allocation report that helps analyze Lua code
and find the places that put the most pressure on the Lua garbage collector (GC).
Collecting a binary profile of allocations,
reallocations, and deallocations in memory related to Lua
(further, binary memory profile or binary profile for short).
Parsing the collected binary profile to get
a human-readable profiling report.
Collecting a binary profile
To collect a binary profile for a particular part of the Lua code,
you need to place this part between two misc.memprof functions,
namely, misc.memprof.start() and misc.memprof.stop(), and then execute
the code in Tarantool.
Below is a chunk of Lua code named test.lua to illustrate this.
1-- Prevent allocations on traces. 2jit.off() 3localstr,err=misc.memprof.start("memprof_new.bin") 4-- Lua doesn't create a new frame to call string.rep, and all allocations 5-- are attributed not to the append() function but to the parent scope. 6localfunctionappend(str,rep) 7returnstring.rep(str,rep) 8end 910localt={}11fori=1,1e4do12-- table.insert is the built-in function and all corresponding13-- allocations are reported in the scope of the main chunk.14table.insert(t,15append('q',i)16)17end18localstr,err=misc.memprof.stop()
The Lua code for starting the profiler – as in line 3 in the test.lua example above – is:
localstr,err=misc.memprof.start(FILENAME)
where FILENAME is the name of the binary file where profiling events are written.
If the operation fails,
for example if it is not possible to open a file for writing or if the profiler is already running,
misc.memprof.start() returns nil as the first result,
an error-message string as the second result,
and a system-dependent error code number as the third result.
If the operation succeeds, misc.memprof.start() returns true.
The Lua code for stopping the profiler – as in line 18 in the test.lua example above – is:
localstr,err=misc.memprof.stop()
If the operation fails,
for example if there is an error when the file descriptor is being closed
or if there is a failure during reporting,
misc.memprof.stop() returns nil as the first result,
an error-message string as the second result,
and a system-dependent error code number as the third result.
If the operation succeeds, misc.memprof.stop() returns true.
To generate the file with memory profile in binary format
(in the test.lua code example above
the file name is memprof_new.bin), execute the code in Tarantool:
$ tarantooltest.lua
Tarantool collects the allocation events in memprof_new.bin, puts
the file in its working directory, and closes
the session.
The test.lua code example above also illustrates the memory
allocation logic in some cases that are important to understand for
reading and analyzing
a profiling report:
Line 2: It is recommended to switch the JIT compilation off by calling jit.off()
before the profiler start. Refer to the following
note about jitoff for more details.
Lines 6-8: Tail call optimization doesn’t create a new call frame, so all
allocations inside the function called via the CALLT/CALLMTbytecodes
are attributed to the function’s caller. See also the comments preceding these lines.
Lines 14-16: Usually the information about allocations inside Lua built‑ins
is not really
useful for developers. That’s why if a Lua built‑in function is called from
a Lua function, the profiler attributes all allocations to the Lua function.
Otherwise, this event is attributed to a C function.
See also the comments preceding these lines.
Parsing a binary profile and generating a profiling report
After getting the memory profile in binary format, the next step is
to parse it to get a human-readable profiling report. You can do this
via Tarantool by using the following command
(mind the hyphen - before the filename):
<filename> -— a name of the file containing Lua code.
<line_number> -— the line number where the event is detected.
<number_of_events> —- a number of events for this code line.
+<allocated>bytes —- amount of memory allocated during all the events on this line.
-<freed>bytes —- amount of memory freed during all the events on this line.
The Overrides label shows what allocation has been overridden.
See the test.lua chunk above
with the explanation in the comments for some examples.
The INTERNAL label indicates that this event is caused by internal LuaJIT
structures.
Note
Important note regarding the INTERNAL label and the recommendation
of switching the JIT compilation off (jit.off()): this version of the
profiler doesn’t support verbose reporting for allocations on
traces.
If memory allocations are made on a trace,
the profiler can’t associate the allocations with the part of Lua code
that generated the trace. In this case, the profiler labels such allocations
as INTERNAL.
So, if the JIT compilation is on,
new traces will be generated and there will be a mixture of events labeled
INTERNAL in the profiling report: some of them are really caused by
internal LuaJIT structures, but some of them are caused by allocations on
traces.
If you want to have a more definite report without JIT compiler allocations,
call jit.off() before starting the profiling.
And if you want to completely exclude the trace allocations from the report,
remove also the old traces by additionally calling jit.flush() after
jit.off().
Nevertheless, switching the JIT compilation off before the profiling is not
“a must”. It is rather a recommendation, and in some cases,
for example in a production environment, you may need to keep JIT compilation
on to see the full picture of all the memory allocations.
In this case, the majority of the INTERNAL events
are most probably caused by traces.
As for investigating the Lua code with the help of profiling reports,
it is always code-dependent and there can’t be hundred per cent definite
recommendations in this regard. Nevertheless, you can see some of the things
in the Profiling a report analysis example later.
Also, below is the FAQ section with the questions that
most probably can arise while using the profiler.
FAQ
In this section, some profiler-related points are discussed in
a Q&A format.
Question (Q): Is the profiler suitable for C allocations or allocations
inside C code?
Answer (A): The profiler reports only allocation events caused by the Lua
allocator. All Lua-related allocations, like table or string creation
are reported. But the profiler doesn’t report allocations made by malloc()
or other non-Lua allocators. You can use valgrind to debug them.
Q: Why are there so many INTERNAL allocations in my profiling report?
What does it mean?
A: INTERNAL means that these allocations/reallocations/deallocations are
related to the internal LuaJIT structures or are made on traces.
Currently, the profiler doesn’t verbosely report allocations of objects
that are made during trace execution. Try adding jit.off()
before the profiler start.
Q: Why are there some reallocations/deallocations without an Overrides
section?
A: These objects can be created before the profiler starts. Adding
collectgarbage() before the profiler’s start enables collecting all
previously allocated objects that are dead when the profiler starts.
Q: Why are some objects not collected during profiling? Is it
a memory leak?
A: LuaJIT uses incremental Garbage Collector (GC). A GC cycle may not be
finished at the moment the profiler stops. Add collectgarbage() before
stopping the profiler to collect all the dead objects for sure.
Q: Can I profile not just a current chunk but the entire running application?
Can I start the profiler when the application is already running?
A: Yes. Here is an example of code that can be inserted in the Tarantool
console for a running instance.
1localfiber=require"fiber" 2locallog=require"log" 3 4fiber.create(function() 5fiber.name("memprof") 6 7collectgarbage()-- Collect all objects already dead 8log.warn("start of profile") 910localst,err=misc.memprof.start(FILENAME)11ifnotstthen12log.error("failed to start profiler: %s",err)13end1415fiber.sleep(TIME)1617collectgarbage()18st,err=misc.memprof.stop()1920ifnotstthen21log.error("profiler on stop error: %s",err)22end2324log.warn("end of profile")25end)
where:
FILENAME—the name of the binary file where profiling events are written
TIME—duration of profiling, in seconds.
Also, you can directly call misc.memprof.start() and misc.memprof.stop()
from a console.
Profiling a report analysis example
In the example below, the following Lua code named format_concat.lua is
investigated with the help of the memory profiler reports.
1-- Prevent allocations on new traces. 2jit.off() 3 4localfunctionconcat(a) 5localnstr=a.."a" 6returnnstr 7end 8 9localfunctionformat(a)10localnstr=string.format("%sa",a)11returnnstr12end1314collectgarbage()1516localbinfile="/tmp/memprof_"..(arg[0]):match("([^/]*).lua")..".bin"1718localst,err=misc.memprof.start(binfile)19assert(st,err)2021-- Payload.22fori=1,10000do23localf=format(i)24localc=concat(i)25end26collectgarbage()2728localst,err=misc.memprof.stop()29assert(st,err)3031os.exit()
When you run this code in Tarantool and
then parse the binary memory profile
in /tmp/memprof_format_concat.bin,
you will get the following profiling report:
Why are there no allocations related to the concat() function?
Why is the number of allocations not a round number?
Why are there about 20K allocations instead of 10K?
First of all, LuaJIT doesn’t create a new string if the string with the same
payload exists (see details on lua-users.org/wiki).
This is called string interning.
So, when a string is
created via the format() function, there is no need to create the same
string via the concat() function, and LuaJIT just uses the previous one.
That is also the reason why the number of allocations is not a round number
as could be expected from the cycle operator fori=1,10000...:
Tarantool creates some
strings for internal needs and built‑in modules, so some strings already exist.
But why are there so many allocations? It’s almost twice as big as the expected
amount. This is because the string.format() built‑in function creates
another string necessary for the %s identifier, so there are two allocations
for each iteration: for tostring(i) and for string.format("%sa",string_i_value).
You can see the difference in behavior by adding the line
local_=tostring(i) between lines 22 and 23.
To profile only the concat() function, comment out line 23 (which is
localf=format(i)) and run the profiler. Now the output looks like this:
Q: But what will change if JIT compilation is enabled?
A: In the code, comment out line 2 (which is
jit.off()) and run the profiler.
Now there are only 56 allocations in the report, and all the other
allocations are JIT-related (see also the related
dev issue):
This happens because a trace has been compiled after 56 iterations (the default
value of the hotloop compiler parameter). Then, the
JIT-compiler removed the unused variable c from the trace, and, therefore,
the dead code of the concat() function is eliminated.
Next, let’s profile only the format() function with JIT enabled.
For that, comment out lines 2 and 24 (jit.off() and
localc=concat(i)), do not comment out line 23
(localf=format(i)), and run the profiler.
Now the output will look like this:
Q: Why are there so many allocations in comparison to the concat() function?
A: The answer is simple: the string.format() function with the %s
identifier is not yet compiled via LuaJIT. So, a trace can’t be recorded and
the compiler doesn’t perform the corresponding optimizations.
The end of each display is a HEAP SUMMARY section which looks like this:
@<filename>:<line number> holds <number of still reachable bytes> bytes:
<number of allocation events> allocs, <number of deallocation events> frees
Sometimes a program can cause many deallocations, so
the DEALLOCATION section can become large, so the display is not easy to read.
To minimize output, start the parsing with an extra flag: --leak-only,
for example
When --leak-only is used, only the HEAP SUMMARY section is displayed.
LuaJIT platform profiler
The default profiling options for LuaJIT are not fine enough to
get an understanding of performance. For example, perf is only
able to show the host stack, so all the Lua calls are displayed as a single
pcall(). Oppositely, the jit.p module provided with LuaJIT
is not able to give any information about the host stack.
Since version 2.10.0, Tarantool
has a built‑in module called misc.sysprof that implements a
LuaJIT sampling profiler (further in this section we call it the profiler
for short). The profiler can capture both guest and
host stacks simultaneously, along with virtual machine states, so
it can show the whole picture.
Three profiling modes are available:
Default: shows only virtual machine state counters.
Leaf: shows the last frame on the stack.
Callchain: performs a complete stack dump.
The profiler comes with a default parser, which produces output in
a flamegraph.pl-suitable format.
Collecting a binary profile of
stacks (further referred as binary sampling profile or binary profile
for short).
Parsing the collected binary
profile to get a human-readable profiling report.
Collecting a binary profile
To collect a binary profile for a particular part of the Lua and C code,
you need to place this part between two misc.sysprof functions –
namely, misc.sysprof.start() and misc.sysprof.stop() – and
then execute the code in Tarantool.
Below is a chunk of Lua code named test.lua to illustrate this.
sysprof.bin is the name of the binary file where profiling events are written.
If the operation fails, for example if it is not possible to open
a file for writing or if the profiler is already running,
misc.sysprof.start() returns nil as the first result,
an error-message string as the second result,
and a system-dependent error code number as the third result.
If the operation succeeds, misc.sysprof.start() returns true.
The Lua code for stopping the profiler – as in line 15 in the
test.lua example above – is:
localres,err=misc.sysprof.stop()
If the operation fails, for example if there is an error when the
file descriptor is being closed or if there is a failure during
reporting, misc.sysprof.stop() returns nil as the first
result, an error-message string as the second result,
and a system-dependent error code number as the third result.
If the operation succeeds, misc.sysprof.stop() returns true.
To generate a file with the memory profile in the binary format
(in the test.lua code example above
the file name is sysprof.bin), execute the code in Tarantool:
$ tarantooltest.lua
Tarantool collects allocation events in sysprof.bin, puts
the file in its working directory,
and closes the session.
Parsing a binary profile and generating a profiling report
After getting the platform profile in the binary format, the next step is
to parse it to get a human-readable profiling report. You can do this
via Tarantool with the following command
(mind the hyphen - before the filename):
where sysprof.bin is the binary profile
generated earlier by tarantooltest.lua.
Note
There is a slight behavior change here: the tarantool-e... command
was slightly different in Tarantool versions prior to Tarantool 2.8.1.
The resulting SVG image contains a flamegraph with collected stacks
and can be opened by a modern web-browser for analysis.
As for investigating the Lua code with the help of profiling reports,
it is always code-dependent and there are no definite recommendations
in this regard. Nevertheless, you can see some of the things
in the Profiling report analysis example below.
Profiler Lua API
The platform profiler provides a Lua interface:
misc.sysprof.start(opts)
misc.sysprof.stop()
misc.sysprof.report()
The first two functions return boolean res and err, which is
nil on success and contains an error message on failure.
misc.sysprof.report returns a Lua table containing the
following counters:
The opts argument of misc.sysprof.start can contain the
following parameters:
mode (required) – one of the supported profiling modes:
'D' = DEFAULT
'L' = LEAF
'C' = CALLGRAPH
interval (optional) – sampling interval in msec (default is 10 msec).
path (optional) – path to a file to store profile data
(default is sysprof.bin).
Profiler C API
The platform profiler provides a low-level C interface:
intluaM_sysprof_set_writer(sp_writerwriter) – sets a writer function
for sysprof.
intluaM_sysprof_set_on_stop(sp_on_stopon_stop) – sets
an on-stop callback for sysprof to clear resources.
intluaM_sysprof_set_backtracer(sp_backtracerbacktracer) – sets
a backtracing function. If the backtracer argument is NULL,
the default backtracer is set.
Note
There is no need to call the configuration functions multiple times
if you are starting and stopping the profiler several times
in a single program.
Also, it is not necessary to configure sysprof for the Default mode.
However, you MUST configure it for other modes.
intluaM_sysprof_start(lua_State*L,conststructluam_Sysprof_Options*opt) –
see Profiler options.
intluaM_sysprof_stop(lua_State*L)
intluaM_sysprof_report(structluam_Sysprof_Counters*counters) – writes
profiling counters for each vmstate.
All of the functions return 0 on success and an error code on failure.
Configuration C types
Profiler configuration settings include:
typedefsize_t(*sp_writer)(constvoid**data,size_tlen,void*ctx) –
a writer function for profile events.
Must be async-safe, see also man7signal-safety.
Should return the amount of written bytes on success, or zero in case of error.
Setting *data to NULL means end of profiling.
For details see lj_wbuf.h.
typedefint(*sp_on_stop)(void*ctx,uint8_t*buf) – a callback
on profiler stopping. Required for a correct cleanup at VM finalization
when the profiler is still running.
Returns zero on success.
typedefvoid(*sp_backtracer)(void*(*frame_writer)(intframe_no,void*addr)) –
a backtracing function for the host stack.
Should call frame_writer on each frame in the stack, in the order
from the stack top to the stack bottom.
The frame_writer function is implemented inside sysprof
and will be passed to the backtracer function.
If frame_writer returns NULL, backtracing should be stopped.
If frame_writer returns not NULL, the backtracing should be continued
if there are frames left.
Profiler options
The options structure for luaM_sysprof_start is as follows:
struct luam_Sysprof_Options { /* Profiling mode. */ uint8_t mode; /* Sampling interval in msec. */ uint64_t interval; /* Custom buffer to write data. */ uint8_t *buf; /* The buffer's size. */ size_t len; /* Context for the profile writer and final callback. */ void *ctx;};
Profiling modes
The platform profiler supports three profiling modes:
DEFAULT mode collects only data for luam_sysprof_counters,
which is stored in memory and can be collected with luaM_sysprof_report
after the profiler stops.
LEAF mode = DEFAULT + streams samples with only top frames of the host
and guests stacks in the format described in lj_sysprof.h.
CALLGRAPH mode = DEFAULT + streams samples with full callchains of the host
and guest stacks in the format described in lj_sysprof.h.
The metrics table contains 19 values.
All values have type = ‘number’ and are the result of a cast to double, so there may be a very slight precision loss.
Values whose names begin with gc_ are associated with the
LuaJIT garbage collector;
a fuller study of the garbage collector can be found at
a Lua-users wiki page
and
a slide from the creator of Lua.
Values whose names begin with jit_ are associated with the
“phases”
of the just-in-time compilation process; a fuller study of JIT phases can be found at
A masters thesis from cern.ch.
Values described as “monotonic” are cumulative, that is, they are “totals since
all operations began”, rather than “since the last getmetrics() call”.
Overflow is possible.
Because many values are monotonic,
a typical analysis involves calling getmetrics(), saving the table,
calling getmetrics() again and comparing the table to what was saved.
The difference is a “slope curve”.
An interesting slope curve is one that shows acceleration,
for example the difference between the latest value and the previous
value keeps increasing.
Some of the table members shown here are used in the examples that come later in this section.
Name
Content
Monotonic?
gc_allocated
number of bytes of allocated memory
yes
gc_cdatanum
number of allocated cdata objects
no
gc_freed
number of bytes of freed memory
yes
gc_steps_atomic
number of steps of garbage collector,
atomic phases, incremental
number of steps of garbage collector,
sweep phases for strings
yes
gc_strnum
number of allocated string objects
no
gc_tabnum
number of allocated table objects
no
gc_total
number of bytes of currently allocated memory
(normally equals gc_allocated minus gc_freed)
no
gc_udatanum
number of allocated udata objects
no
jit_mcode_size
total size of all allocated machine code areas
no
jit_snap_restore
overall number of snap restores, based on the
number of guard assertions leading to stopping
trace executions (see external Snap tutorial)
yes
jit_trace_abort
overall number of aborted traces
yes
jit_trace_num
number of JIT traces
no
strhash_hit
number of strings being interned because, if a
string with the same value is found via the
hash, a new one is not created / allocated
yes
strhash_miss
total number of strings allocations during
the platform lifetime
yes
Note: Although value names are similar to value names in
ujit.getmetrics()
the values are not the same, primarily because many ujit numbers are not monotonic.
Note: Although value names are similar to value names in LuaJIT metrics,
and the values are exactly the same, misc.getmetrics() is slightly easier
because there is no need to ‘require’ the misc module.
getmetrics C API
The Lua getmetrics() function is a wrapper for the C function luaM_metrics().
C programs may include a header named libmisclib.h.
The definitions in libmisclib.h include the following lines:
structluam_Metrics{/* the names described earlier for Lua */}LUAMISC_APIvoidluaM_metrics(lua_State*L,structluam_Metrics*metrics);
The names of structluam_Metrics members are the same as Lua’s
getmetrics table values names.
The data types of structluam_Metrics members are all size_t.
The luaM_metrics() function will fill the *metrics structure
with the metrics related to the Lua state anchored to the L coroutine.
Example with a C program
Go through the C stored procedures tutorial.
Replace the easy.c example with
Now when you go back to the client and execute the requests up to and including the line
capi_connection:call('easy')
you will see that the display is something like
“allocated memory = 4431950”
although the number will vary.
Example with gc_strnum, strhash_miss, and strhash_hit
The result will probably be:
“gc_strnum diff = 1100” because we added 1202 strings but 101 were duplicates,
“strhash_miss_diff = 1100” for the same reason,
“strhash_hit_diff = 101” plus some overhead, for the same reason.
(There is always a slight overhead amount for strhash_hit, which can be ignored.)
We say “probably” because there is a chance that the strings were already
allocated somewhere.
It is a good thing if the slope curve of
strhash_miss is less than the slope curve of strhash_hit.
The other gc_*num values – gc_cdatanum, gc_tabnum, gc_udatanum – can be accessed
in a similar way.
Any of the gc_*num values can be useful when looking for memory leaks – the total
number of these objects should not grow nonstop.
A more general way to look for memory leaks is to watch gc_total.
Also jit_mcode_size can be used to watch the amount of allocated memory for machine code traces.
Example with gc_allocated and gc_freed
To track an application’s effect on the garbage collector (less is better):
The result will be: gc_allocateddiff=800, gc_freeddiff=800.
This shows that local...=getmetrics() itself causes memory allocation
(because it is creating a table and assigning to it),
and shows that when the name of a variable (in this case the oldm variable)
is used again, that causes freeing.
Ordinarily the freeing would not occur immediately, but
collectgarbage("collect") forces it to happen so we can see the effect.
Example with gc_allocated and a space optimization
To test whether optimizing for space is possible with tables:
The result will show that diff equals approximately 6000.
gc_steps_atomic and gc_steps_propagate
The slope curves of gc_steps_* items can be used for tracking pressure on
the garbage collector too.
During long-running routines, gc_steps_* values will increase,
but long times between gc_steps_atomic increases are a good sign,
And, since gc_steps_atomic increases only once per garbage-collector cycle,
it shows how many garbage-collector cycles have occurred.
Also, increases in the gc_steps_propagate number can be used to
estimate indirectly how many objects there are. These values also correlate with the
garbage collector’s
step multiplier.
For example, the number of incremental steps can grow, but according to the
step multiplier configuration, one step can process only a small number of objects.
So these metrics should be considered when configuring the garbage collector.
The following function takes a casual look whether an SQL statement causes much pressure:
And the display will show that the gc_steps_* metrics are not significantly
different from what they would be if the box.execute() was absent.
Example with jit_trace_num and jit_trace_abort
Just-in-time compilers will “trace” code looking for opportunities to
compile. jit_trace_abort can show how often there was a failed attempt
(less is better), and jit_trace_num can show how many traces were
generated since the last flush (usually more is better).
The following function does not contain code that can cause trouble for LuaJIT:
The result is: trace_num = between 2 and 4, trace_abort = 1.
This means that up to four traces needed to be generated instead of one,
and this means that something made LuaJIT give up in despair.
Tracing more will reveal that the problem is
not the suspicious-looking statements within the function, it
is the jit.opt.start call.
(A look at a jit.dump file might help in examining the trace compilation process.)
Example with jit_snap_restore and a performance unoptimization
If the slope curves of the jit_snap_restore metric grow after
changes to old code, that can mean LuaJIT is stopping trace
execution more frequently, and that can mean performance is degraded.
Start with this code:
functionf()localfunctionfoo(i)returni<=5andiortostring(i)end-- minstitch option needs to emulate nonstitching behaviourjit.opt.start(0,"hotloop=2","hotexit=2","minstitch=15")localsum=0localoldm=misc.getmetrics()fori=1,10dosum=sum+foo(i)endlocalnewm=misc.getmetrics()localdiff=newm.jit_snap_restore-oldm.jit_snap_restoreprint("diff = "..diff)endf()
The result will be: diff = 3, because there is one side exit when the loop ends,
and there are two side exits to the interpreter before LuaJIT may decide that
the chunk of code is “hot”
(the default value of the hotloop parameter is 56 according to
Running LuaJIT).
And now change only one line within function localfoo, so now the code is:
functionf()localfunctionfoo(i)-- math.fmod is not yet compiled!returni<=5andiormath.fmod(i,11)end-- minstitch option needs to emulate nonstitching behaviourjit.opt.start(0,"hotloop=2","hotexit=2","minstitch=15")localsum=0localoldm=misc.getmetrics()fori=1,10dosum=sum+foo(i)endlocalnewm=misc.getmetrics()localdiff=newm.jit_snap_restore-oldm.jit_snap_restoreprint("diff = "..diff)endf()
The result will be: diff is larger, because there are more side exits.
So this test indicates that changing the code affected the performance.
Administration
Tarantool is designed to have multiple running instances on the same host.
Here we show how to administer Tarantool instances using any of the following
utilities:
systemd native utilities, or
tt, a command-line utility for managing Tarantool-based applications.
Note
Unlike the rest of this manual, here we use system-wide paths.
This section covers the installation and reloading of Tarantool modules.
To learn about writing your own module and contributing it,
check the Contributing a module section.
Installing a module
Modules in Lua and C that come from Tarantool developers and community
contributors are available in the following locations:
Install Tarantool as recommended on the
download page.
Install the module you need. Look up the module’s name on
Tarantool rocks page and put the prefix
“tarantool-” before the module name to avoid ambiguity:
$ # for Ubuntu/Debian:$ sudoapt-getinstalltarantool-<module-name>
$ # for RHEL/CentOS/Amazon:$ sudoyuminstalltarantool-<module-name>
For example, to install the module
vshard on Ubuntu, say:
$ sudoapt-getinstalltarantool-vshard
Once these steps are complete, you can:
load any module with
tarantool> name=require('module-name')
for example:
tarantool> vshard=require('vshard')
search locally for installed modules using package.path (Lua) or
package.cpath (C):
For example, a module in /usr/share/tarantool/app.lua:
localfunctionstart()-- initial versionbox.once("myapp:v1.0",function()box.schema.space.create("somedata")box.space.somedata:create_index("primary")...end)-- migration code from 1.0 to 1.1box.once("myapp:v1.1",function()box.space.somedata.index.primary:alter(...)...end)-- migration code from 1.1 to 1.2box.once("myapp:v1.2",function()box.space.somedata.index.primary:alter(...)box.space.somedata:insert(...)...end)end-- start some background fibers if you needlocalfunctionstop()-- stop all background fibers and clean up resourcesendlocalfunctionapi_for_call(xxx)-- do some businessendreturn{start=start,stop=stop,api_for_call=api_for_call}
For example, /etc/tarantool/instances.enabled/my_app.lua:
#!/usr/bin/env tarantool---- hot code reload example--box.cfg({listen=3302})-- ATTENTION: unload it all properly!localapp=package.loaded['app']ifapp~=nilthen-- stop the old application versionapp.stop()-- unload the applicationpackage.loaded['app']=nil-- unload all dependenciespackage.loaded['somedep']=nilend-- load the applicationlog.info('require app')app=require('app')-- start the applicationapp.start({someappoptionscontrolledbysysadmins})
The important thing here is to properly unload the application and its
dependencies.
After you compiled a new version of a C module (*.so shared library), call
box.schema.func.reload(‘module-name’)
from your Lua script to reload the module.
Logs
Each Tarantool instance logs important events to its own log file.
For instances started with tt, the log location is defined by
the log_dir parameter in the tt configuration.
By default, it’s /var/log/tarantool in the ttsystem mode,
and the var/log subdirectory of the tt working directory in the local mode.
In the specified location, tt creates separate directories for each instance’s logs.
To check how logging works, write something to the log using the log module:
$ ttconnectapplication
• Connecting to the instance... • Connected to applicationapplication> require('log').info("Hello for the manual readers")---...
Then check the logs:
$ tailinstances.enabled/application/var/log/instance001/tt.log
2024-04-09 17:34:29.489 [49502] main/106/gc I> wal/engine cleanup is resumed2024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'instance_name' configuration option to "instance001"2024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'custom_proc_title' configuration option to "tarantool - instance001"2024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'log_nonblock' configuration option to false2024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'replicaset_name' configuration option to "replicaset001"2024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'listen' configuration option to [{"uri":"127.0.0.1:3301"}]2024-04-09 17:34:29.489 [49502] main/107/checkpoint_daemon I> scheduled next checkpoint for Tue Apr 9 19:08:04 20242024-04-09 17:34:29.489 [49502] main/104/interactive/box.load_cfg I> set 'metrics' configuration option to {"labels":{"alias":"instance001"},"include":["all"],"exclude":[]}2024-04-09 17:34:29.489 [49502] main I> entering the event loop2024-04-09 17:34:38.905 [49502] main/116/console/unix/:/tarantool I> Hello for the manual readers
Log rotation
When logging to a file, the system administrator must ensure
logs are rotated timely and do not take up all the available disk space.
The recommended way to prevent log files from growing infinitely is using an external
log rotation program, for example, logrotate, which is pre-installed on most
mainstream Linux distributions.
A Tarantool log rotation configuration for logrotate can look like this:
# /var/log/tarantool/<env>/<app>/<instance>/*.log
/var/log/tarantool/*/*/*/*.log {
daily
size 512k
missingok
rotate 10
compress
delaycompress
sharedscripts # Run tt logrotate only once after all logs are rotated.
postrotate
/usr/bin/tt -S logrotate
endscript
}
In this configuration, tt logrotate is called after each log
rotation to reopen the instance log files after they are moved by the logrotate
program.
There is also the built-in function log.rotate(), which you
can call on an instance to reopen its log file after rotation.
Log destination
Tarantool can write its logs to a log file, to syslog, or to a specified program through a pipe.
For example, to send logs to syslog, specify the log.to parameter as follows:
log:to:syslogsyslog:server:'127.0.0.1:514'
Security
Tarantool allows for two types of connections:
With console.listen() function from console module,
you can set up a port which can be used to open an administrative console to
the server. This is for administrators to connect to a running instance and
make requests. tt invokes console.listen() to create a
control socket for each started instance.
With box.cfg{listen=…} parameter from box
module, you can set up a binary port for connections which read and write to
the database or invoke stored procedures.
When you connect to an admin console:
The client-server protocol is plain text.
No password is necessary.
The user is automatically ‘admin’.
Each command is fed directly to the built-in Lua interpreter.
Therefore you must set up ports for the admin console very cautiously. If it is
a TCP port, it should only be opened for a specific IP. Ideally, it should not
be a TCP port at all, it should be a Unix domain socket, so that access to the
server machine is required. Thus a typical port setup for admin console is:
if the listener has the privilege to write on /var/lib/tarantool and the
connector has the privilege to read on /var/lib/tarantool. Alternatively,
to connect to an admin console of an instance started with tt, use
tt connect.
To find out whether a TCP port is a port for admin console, use telnet.
For example:
$ telnet03303Trying 0.0.0.0...Connected to 0.Escape character is '^]'.Tarantool 2.1.0 (Lua console)type 'help' for interactive help
In this example, the response does not include the word “binary” and does
include the words “Lua console”. Therefore it is clear that this is a successful
connection to a port for admin console, and you can now enter admin requests on
this terminal.
To change the user, it’s necessary to authenticate.
For ease of use, ttconnect command automatically detects the type
of connection during handshake and uses EVAL
binary protocol command when it’s necessary to execute Lua commands over a binary
connection. To execute EVAL, the authenticated user must have global “EXECUTE”
privilege.
Therefore, when ssh access to the machine is not available, creating a
Tarantool user with global “EXECUTE” privilege and non-empty password can be
used to provide a system administrator remote access to an instance.
Access control
Tarantool enables flexible management of access to various database resources.
The main concepts of Tarantool access control system are as follows:
A user is a person or program that interacts with a Tarantool instance.
An object is an entity to which access can be granted, for example, a space, an index, or a function.
A privilege allows a user to perform certain operations on specific objects, for example, creating spaces, reading or updating data.
A role is a named collection of privileges that can be granted to a user.
Overview
Users
A user identifies a person or program that interacts with a Tarantool instance.
There might be different types of users, for example:
A database administrator responsible for the overall management and administration of a database.
An administrator can create other users and grant them specified privileges.
A user with limited access to certain data and stored functions.
Such users can get their privileges from the database administrator.
Users used in communications between Tarantool instances. For example, such users can be created to maintain replication and sharding in a Tarantool cluster.
There are two built-in users in Tarantool:
admin is a user with all available administrative privileges.
If the connection uses an admin-console port, the current user is admin.
For example, admin is used when connecting to an instance using tt connect locally using the instance name:
guest is a user with minimum privileges used by default for remote binary port connections.
For example, guest is used when connecting to an instance using tt connect using the IP address and port without specifying the name of a user:
$ ttconnect192.168.10.10:3301
Warning
Given that the guest user allows unauthenticated access to Tarantool instances, it is not recommended to grant additional privileges to this user.
For example, granting the execute access to universe allows remote code execution on instances.
Note
Information about users is stored in the _user space.
Passwords
Any user (except guest) may have a password.
If a password is not set, a user cannot connect to Tarantool instances.
Tarantool password hashes are stored in the _user system space.
By default, Tarantool uses the CHAP protocol to authenticate users and applies SHA-1 hashing to
passwords.
So, if the password is ‘123456’, the stored hash is a string like ‘a7SDfrdDKRBe5FaN2n3GftLKKtk=’.
In the Enterprise Edition, you can enable PAPauthentication with the SHA256 hashing algorithm.
Tarantool Enterprise Edition allows you to improve database security by enforcing the use of strong passwords, setting up a maximum password age, and so on.
Learn more from the Authentication topic.
Objects
An object is a securable entity to which access can be granted.
Tarantool has a number of objects that enable flexible management of access to data, stored functions, specific actions, and so on.
Below are a few examples of objects:
universe represents a database (box.schema) that contains database objects, including spaces, indexes, users, roles, sequences, and functions.
Granting privileges to universe gives a user access to any object in a database.
space enables granting privileges to user-created or system spaces.
function enables granting privileges to functions.
Note
The full list of object types is available in the Object types section.
Privileges
The privileges granted to a user determine which operations the user can perform, for example:
The read and write permissions granted to the spaceobject allow a user to read or modify data in the specified space.
The create permission granted to the space object allows a user to create new spaces.
The execute permission granted to the function object allows a user to execute the specified function.
The session permission granted to a user allows connecting to an instance over IPROTO.
Note that some privileges might require read and write access to certain system spaces.
For example, the create permission granted to the space object requires read and write permissions to the _space system space.
Similarly, granting the ability to create functions requires read and write access to the _func space.
Note
Information about privileges is stored in the _priv space.
Roles
A role is a container for privileges that can be granted to users.
Roles can also be assigned to other roles, creating a role hierarchy.
There are the following built-in roles in Tarantool:
super has all available administrative permissions.
public has certain read permissions. This role is automatically granted to new users when they are created.
replication can be granted to a user used to maintain replication in a cluster.
sharding can be granted to a user used to maintain sharding in a cluster.
Note
The sharding role is created only if an instance is managed using YAML configuration.
Below are a few diagrams that demonstrate how privileges can be granted to a user without and with using roles.
In this example, a user gets privileges directly without using roles.
Information about roles is stored in the _user space.
Object owners
An owner of a database object is the user who created it.
The owner of the database and the owner of objects that are created initially (the system spaces and the default users) is the adminuser.
Owners automatically have privileges for objects they create.
They can share these privileges with other users or roles using box.schema.user.grant() and box.schema.role.grant().
Note
Information about users who gave the specified privileges is stored in the _priv space.
Sessions
A session is the state of a connection to Tarantool.
The session contains:
A session’s local state, such as Lua variables and functions.
In Tarantool, a single session can execute multiple concurrent transactions.
Each transaction is identified by a unique integer ID, which can be queried
at the start of the transaction using box.session.sync().
To grant the specified privileges to a user, use the box.schema.user.grant() function.
In the example below, testuser gets read permissions to the writers space and read/write permissions to the books space:
For a binary port connection: using the
AUTH protocol command, supported by most clients.
For a binary-port connection invoking a stored function with the CALL command:
if the SETUID
property is enabled for the function,
Tarantool temporarily replaces the current user with the
function’s creator, with all the creator’s privileges, during function execution.
To grant the specified privileges to a role, use the box.schema.role.grant() function.
In the example below, the books_space_manager role gets read and write permissions to the books space:
Learn more about granting privileges to different types of objects from Granting privileges.
Note
Not all privileges can be granted to roles.
Learn more from Permissions.
Granting a role to a role
Roles can be assigned to other roles.
In the example below, the newly created all_spaces_manager role gets all privileges granted to books_space_manager and writers_space_reader:
To grant the specified role to a user, use the box.schema.user.grant() function.
In the example below, testuser gets privileges granted to the books_space_manager and writers_space_reader roles:
box.schema.role.info('books_space_manager')--[[- - - read,write - space - books--]]
If a role has the execute permission to other roles, this means that these roles are granted to this parent role:
box.schema.role.info('all_spaces_manager')--[[- - - execute - role - books_space_manager - - execute - role - writers_space_reader--]]
Revoking a role from a user
To revoke the specified role from a user, revoke the execute privilege for this role using the box.schema.user.revoke() function.
In the example below, the books_space_reader role is revoked from testuser:
To grant the specified privileges to a user or role, use the box.schema.user.grant() and box.schema.role.grant() functions,
which have similar signatures and accept the same set of arguments.
For example, the box.schema.user.grant() signature looks as follows:
username: the name of the user that gets the specified privileges.
permissions: a string value that represents permissions granted to the user. If there are several permissions, they should be separated by commas without a space.
object-type: a type of object to which permissions are granted.
object-name: the name of the object to which permissions are granted.
An empty string ("") or nil provided instead of object-name grants the specified permissions to all objects of the specified type.
Note
object-name is ignored for the following combinations of permissions and object types:
Any permission granted to universe.
The create and drop permissions for the following object types: user, role, space, function, sequence.
The execute permission for the following object types: lua_eval, lua_call, sql.
Any object
In the example below, testuser gets privileges allowing them to create any object of any type:
To allow testuser to alter indexes in the writers space, grant the privileges below.
This example assumes that indexes in the writers space are not created by testuser.
Similarly, executing an arbitrary SQL expression requires the execute privilege to the sql object:
box.schema.user.grant('testuser','execute','sql')
Example
In the example below, the created Lua function is executed on behalf of its
creator, even if called by another user.
First, the two spaces (space1 and space2) are created, and a no-password user (private_user)
is granted full access to them. Then read_and_modify is defined and private_user becomes this function’s creator.
Finally, another user (public_user) is granted access to execute Lua functions created by private_user.
Whenever public_user calls the function, it is executed on behalf of its creator, private_user.
All object types and permissions
Object types
Object type
Description
universe
A database (box.schema) that contains database objects, including spaces, indexes, users, roles, sequences, and functions. Granting privileges to universe gives a user access to any object in the database.
Allows reading data of the specified object.
For example, this permission can be used to allow a user to select data from the specified space.
write
All
Yes
Allows updating data of the specified object.
For example, this permission can be used to allow a user to modify data in the specified space.
create
All
Yes
Allows creating objects of the specified type.
For example, this permission can be used to allow a user to create new spaces.
Note that this permission requires read and write access to certain system spaces.
alter
All
Yes
Allows altering objects of the specified type.
Note that this permission requires read and write access to certain system spaces.
drop
All
Yes
Allows dropping objects of the specified type.
Note that this permission requires read and write access to certain system spaces.
execute
role, universe, function, lua_eval, lua_call, sql
Yes
For role, allows using the specified role.
For other object types, allows calling a function.
session
universe
No
Allows a user to connect to an instance over IPROTO.
usage
universe
No
Allows a user to use their privileges on database objects (for example, read, write, and alter spaces).
Object types and permissions
Object type
Details
universe
read: Allows reading any object types, including all spaces or sequence objects.
write: Allows modifying any object types, including all spaces or sequence objects.
execute: Allows execute functions, Lua code, or SQL expressions, including IPROTO calls.
session: Allows a user to connect to an instance over IPROTO.
usage: Allows a user to use their privileges on database objects (for example, read, write, and alter space).
create: Allows creating users, roles, functions, spaces, and sequences.
This permission requires read and write access to certain system spaces.
drop: Allows creating users, roles, functions, spaces, and sequences.
This permission requires read and write access to certain system spaces.
alter: Allows altering user settings or space objects.
user
alter: Allows modifying a user description, for example, change the password.
create: Allows creating new users.
This permission requires read and write access to the _user system space.
drop: Allows dropping users.
This permission requires read and write access to the _user system space.
role
execute: Indicates that a role is assigned to the user or another role.
create: Allows creating new roles.
This permission requires read and write access to the _user system space.
drop: Allows dropping roles.
This permission requires read and write access to the _user system space.
space
read: Allows selecting data from a space.
write: Allows modifying data in a space.
create: Allows creating new spaces.
This permission requires read and write access to the _space system space.
drop: Allows dropping spaces.
This permission requires read and write access to the _space system space.
alter: Allows modifying spaces.
This permission requires read and write access to the _space system space.
If a space is created by a user, they can read and write it without granting explicit permission.
function
execute: Allows calling a function.
create: Allows creating a function.
This permission requires read and write access to the _func system space.
If a function is created by a user, they can execute it without granting explicit permission.
drop: Allows dropping a function.
This permission requires read and write access to the _func system space.
sequence
read: Allows using sequences in space_obj:create_index().
write: Allows all operations for a sequence object.
seq_obj:drop() requires a write permission to the _priv system space.
create: Allows creating sequences.
This permission requires read and write access to the _sequence system space.
If a sequence is created by a user, they can read/write it without explicit permission.
drop: Allows dropping sequences.
This permission requires read and write access to the _sequence system space.
alter: Has no effect.
seq_obj:alter() and other methods require the write permission.
lua_eval
execute: Allows executing arbitrary Lua code using the IPROTO_EVAL request.
lua_call
execute: Allows executing any user-defined function using the IPROTO_CALL request.
This permission doesn’t allow a user to call built-in Lua functions (for example, loadstring() or box.session.su()) and functions defined in the _func system space.
sql
execute: Allows executing arbitrary SQL expression using the IPROTO_PREPARE and IPROTO_EXECUTE requests.
To learn what instances belong to the replica set and obtain statistics for all
these instances, execute a box.info.replication request.
The output below shows the replication status for a replica set containing one master and two replicas:
The following diagram illustrates the upstream and downstream connections if box.info.replication executed at the master instance (instance001):
If box.info.replication is executed on instance002, the upstream and downstream connections look as follows:
This means that statistics for replicas are given in regard to the instance on which box.info.replication is executed.
The primary indicators of replication health are:
idle: the time (in seconds) since
the instance received the last event from a master.
If the master has no updates to send to the replicas, it sends heartbeat messages
every replication_timeout seconds. The master
is programmed to disconnect if it does not see acknowledgments of the heartbeat messages
within replication_timeout * 4 seconds.
Therefore, in a healthy replication setup, idle should never exceed
replication_timeout: if it does, either the replication is lagging
seriously behind, because the master is running ahead of the replica, or the
network link between the instances is down.
lag: the time difference between
the local time at the instance, recorded when the event was received, and the
local time at another master recorded when the event was written to the
write-ahead log on that master.
Since the lag calculation uses the operating system clocks from two different
machines, do not be surprised if it’s negative: a time drift may lead to the
remote master clock being consistently behind the local instance’s clock.
Recovering from a degraded state
“Degraded state” is a situation when the master becomes unavailable – due to
hardware or network failure, or due to a programming bug.
In a master-replica set with manual failover, if a master disappears, error messages appear on the
replicas stating that the connection is lost:
2023-12-04 13:19:04.724 [16755] main/110/applier/replicator@127.0.0.1:3301 I> can't read row2023-12-04 13:19:04.724 [16755] main/110/applier/replicator@127.0.0.1:3301 coio.c:349 E> SocketError: unexpected EOF when reading from socket, called on fd 19, aka 127.0.0.1:55932, peer of 127.0.0.1:3301: Broken pipe2023-12-04 13:19:04.724 [16755] main/110/applier/replicator@127.0.0.1:3301 I> will retry every 1.00 second2023-12-04 13:19:04.724 [16755] relay/127.0.0.1:55940/101/main coio.c:349 E> SocketError: unexpected EOF when reading from socket, called on fd 23, aka 127.0.0.1:3302, peer of 127.0.0.1:55940: Broken pipe2023-12-04 13:19:04.724 [16755] relay/127.0.0.1:55940/101/main I> exiting the relay loop
In a master-replica set with automated failover, a log also includes Raft messages showing the process of a new master’s election:
2023-12-04 13:16:56.340 [16615] main/111/applier/replicator@127.0.0.1:3302 I> can't read row2023-12-04 13:16:56.340 [16615] main/111/applier/replicator@127.0.0.1:3302 coio.c:349 E> SocketError: unexpected EOF when reading from socket, called on fd 24, aka 127.0.0.1:55687, peer of 127.0.0.1:3302: Broken pipe2023-12-04 13:16:56.340 [16615] main/111/applier/replicator@127.0.0.1:3302 I> will retry every 1.00 second2023-12-04 13:16:56.340 [16615] relay/127.0.0.1:55695/101/main coio.c:349 E> SocketError: unexpected EOF when reading from socket, called on fd 25, aka 127.0.0.1:3301, peer of 127.0.0.1:55695: Broken pipe2023-12-04 13:16:56.340 [16615] relay/127.0.0.1:55695/101/main I> exiting the relay loop2023-12-04 13:16:59.690 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: message {term: 3, vote: 2, state: candidate, vclock: {1: 9}} from 22023-12-04 13:16:59.690 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: received a newer term from 22023-12-04 13:16:59.690 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: bump term to 3, follow2023-12-04 13:16:59.690 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: vote for 2, follow2023-12-04 13:16:59.691 [16615] main/119/raft_worker I> RAFT: persisted state {term: 3}2023-12-04 13:16:59.691 [16615] main/119/raft_worker I> RAFT: persisted state {term: 3, vote: 2}2023-12-04 13:16:59.691 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: message {term: 3, vote: 2, leader: 2, state: leader} from 22023-12-04 13:16:59.691 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: vote request is skipped - this is a notification about a vote for a third node, not a request2023-12-04 13:16:59.691 [16615] main/112/applier/replicator@127.0.0.1:3303 I> RAFT: leader is 2, follow
The master’s upstream status is reported as disconnected when executing box.info.replication on a replica:
To learn how to perform manual failover in a master-replica set, see the Performing manual failover section.
In a master-replica configuration with automated failover, a new master should be elected automatically.
Reseeding a replica
If any of a replica’s write-ahead log or snapshot files are corrupted or deleted, you can reseed the replica.
This procedure works only if the master’s write-ahead logs are present.
Delete write-ahead logs and snapshots stored in the var/lib/<instance_name> directory.
Note
var/lib is the default directory used by tt to store write-ahead logs and snapshots.
Learn more from Configuration.
Start the replica using the tt start command.
The replica should catch up with the master by retrieving all the master’s tuples.
(Optional) If you’re reseeding a replica after a replication conflict, you also need to restart replication.
Resolving replication conflicts
Tarantool guarantees that every update is applied only once on every replica.
However, due to the asynchronous nature of replication, the order of updates is not guaranteed.
This topic describes how to solve problems in master-master replication.
Replacing the same primary key
Case 1: You have two instances of Tarantool. For example, you try to make a
replace operation with the same primary key on both instances at the same time.
This causes a conflict over which tuple to save and which one to discard.
Tarantool trigger functions can help here to implement the
rules of conflict resolution on some condition. For example, if you have a
timestamp, you can declare saving the tuple with the bigger one.
First, you need a before_replace() trigger on
the space which may have conflicts. In this trigger, you can compare the old and new
replica records and choose which one to use (or skip the update entirely,
or merge two records together).
Then you need to set the trigger at the right time before the space starts
to receive any updates. The way you usually set the before_replace trigger
is right when the space is created, so you need a trigger to set another trigger
on the system space _space, to capture the moment when your space is created
and set the trigger there. This can be an on_replace()
trigger.
The difference between before_replace and on_replace is that on_replace
is called after a row is inserted into the space, and before_replace
is called before that.
To set a _space:on_replace() trigger correctly, you also need the right timing. The best
timing to use it is when _space is just created, which is
the box.ctl.on_schema_init() trigger.
You also need to utilize box.on_commit to get access to the space being
created. The resulting snippet would be the following:
localmy_space_name='my_space'localmy_trigger=function(old,new)...end-- your function resolving a conflictbox.ctl.on_schema_init(function()box.space._space:on_replace(function(old_space,new_space)ifnotold_spaceandnew_spaceandnew_space.name==my_space_namethenbox.on_commit(function()box.space[my_space_name]:before_replace(my_trigger)endendend)end)
Preventing duplicate insert
Case 2: In a replica set of two masters, both of them try to insert data by the same unique key:
tarantool> box.space.tester:insert{1,'data'}
This would cause an error saying Duplicatekeyexistsinuniqueindex'primary'inspace'tester' and the replication would be stopped.
(This is the behavior when the
replication_skip_conflict
configuration parameter has its default recommended value, false.)
$ # error messages from master #12017-06-26 21:17:03.233 [30444] main/104/applier/rep_user@100.96.166.1 I> can't read row2017-06-26 21:17:03.233 [30444] main/104/applier/rep_user@100.96.166.1 memtx_hash.cc:226 E> ER_TUPLE_FOUND:Duplicate key exists in unique index 'primary' in space 'tester'2017-06-26 21:17:03.233 [30444] relay/[::ffff:100.96.166.178]/101/main I> the replica has closed its socket, exiting2017-06-26 21:17:03.233 [30444] relay/[::ffff:100.96.166.178]/101/main C> exiting the relay loop$ # error messages from master #22017-06-26 21:17:03.233 [30445] main/104/applier/rep_user@100.96.166.1 I> can't read row2017-06-26 21:17:03.233 [30445] main/104/applier/rep_user@100.96.166.1 memtx_hash.cc:226 E> ER_TUPLE_FOUND:Duplicate key exists in unique index 'primary' in space 'tester'2017-06-26 21:17:03.234 [30445] relay/[::ffff:100.96.166.178]/101/main I> the replica has closed its socket, exiting2017-06-26 21:17:03.234 [30445] relay/[::ffff:100.96.166.178]/101/main C> exiting the relay loop
If we check replication statuses with box.info, we will see that replication
at master #1 is stopped (1.upstream.status=stopped). Additionally, no data
is replicated from that master (section 1.downstream is missing in the
report), because the downstream has encountered the same error:
# replication statuses (report from master #3)tarantool> box.info----version:1.7.4-52-g980d30092id:3ro:falsevclock:{1:9, 2:1000000, 3:3}uptime:557lsn:3vinyl:[]cluster:uuid:34d13b1a-f851-45bb-8f57-57489d3b3c8bpid:30445status:runningsignature:1000012replication:1:id:1uuid:7ab6dee7-dc0f-4477-af2b-0e63452573cflsn:9upstream:peer:replicator@192.168.0.101:3301lag:0.00050592422485352status:stoppedidle:445.8626639843message:Duplicate key exists in unique index 'primary' in space 'tester'2:id:2uuid:9afbe2d9-db84-4d05-9a7b-e0cbbf861e28lsn:1000000upstream:status:followidle:201.99915885925peer:replicator@192.168.0.102:3301lag:0.0015020370483398downstream:vclock:{1:8, 2:1000000, 3:3}3:id:3uuid:e826a667-eed7-48d5-a290-64299b159571lsn:3uuid:e826a667-eed7-48d5-a290-64299b159571...
When this operation is applied on both instances in the replica set:
# at master #1tarantool> box.space.tester:upsert({1},{{'=',2,box.info.uuid}})# at master #2tarantool> box.space.tester:upsert({1},{{'=',2,box.info.uuid}})
… we can have the following results, depending on the order of execution:
each master’s row contains the UUID from master #1,
each master’s row contains the UUID from master #2,
master #1 has the UUID of master #2, and vice versa.
Commutative changes
The cases described in the previous paragraphs represent examples of
non-commutative operations, that is operations whose result depends on the
execution order. On the contrary, for commutative operations, the
execution order does not matter.
This operation is commutative: we get the same result no matter in which order
the update is applied on the other masters.
Trigger usage
The logic and the snippet setting a trigger will be the same here as in case 1.
But the trigger function will differ.
Note that the trigger below assumes that tuple has a timestamp in the second field.
localmy_space_name='test'localmy_trigger=function(old,new,sp,op)-- op: ‘INSERT’, ‘DELETE’, ‘UPDATE’, or ‘REPLACE’ifnew==nilthenprint("No new during "..op,old)return-- deletes are okendifold==nilthenprint("Insert new, no old",new)returnnew-- insert without old value: okendprint(op.." duplicate",old,new)ifop=='INSERT'thenifnew[2]>old[2]then-- Creating new tuple will change op to ‘REPLACE’returnbox.tuple.new(new)endreturnoldendifnew[2]>old[2]thenreturnnewelsereturnoldendreturnendbox.ctl.on_schema_init(function()box.space._space:on_replace(function(old_space,new_space)ifnotold_spaceandnew_spaceandnew_space.name==my_space_namethenbox.on_commit(function()box.space[my_space_name]:before_replace(my_trigger)end)endend)end)
Tarantool displays a prompt (e.g. “tarantool>”) and you can enter requests.
When used this way, Tarantool can be a client for a remote server.
See basic examples in Getting started.
The interactive mode is used in the tt utility’s connect command.
Executing code on an instance
You can attach to an instance’s admin console and
execute some Lua code using tt:
$ # for local instances:$ ttconnectmy_app
• Connecting to the instance... • Connected to /var/run/tarantool/example.control/var/run/tarantool/my_app.control> 1 + 1---- 2.../var/run/tarantool/my_app.control>$ # for local and remote instances:$ ttconnectusername:password@127.0.0.1:3306
You can also use tt to execute Lua code on an instance without
attaching to its admin console. For example:
$ # executing commands directly from the command line$ <command>|ttconnectmy_app-f-
<...>$ # - OR -$ # executing commands from a script file$ ttconnectmy_app-fscript.lua
<...>
Note
Alternatively, you can use the console module or the
net.box module from a Tarantool server. Also, you can
write your client programs with any of the
connectors. However, most of the examples in
this manual illustrate usage with either ttconnect or
using the Tarantool server as a client.
Health checks
To check the instance status, run:
$ ttstatusmy_app
$ # - OR -$ systemctlstatustarantool@my_app
To check the boot log, on systems with systemd, run:
$ journalctl-utarantool@my_app-n5
For more specific checks, use the reports provided by functions in the following submodules:
Submodule box.cfg (check and specify all
configuration parameters for the Tarantool server)
Submodule box.slab (monitor the total use
and fragmentation of memory allocated for storing data in Tarantool)
Submodule box.info (introspect Tarantool
server variables, primarily those related to replication)
Submodule box.stat (introspect Tarantool
request and network statistics)
Finally, there is the metrics
library, which enables collecting metrics (such as memory usage or number
of requests) from Tarantool applications and expose them via various
protocols, including Prometheus. Check Monitoring for more details.
Example
A very popular administrator request is
box.slab.info(),
which displays detailed memory usage statistics for a Tarantool instance.
Tarantool takes memory from the operating system,
for example when a user does many insertions.
You can see how much it has taken by saying (on Linux):
ps -eo args,%mem | grep "tarantool"
Tarantool almost never releases this memory, even if the user
deletes everything that was inserted, or reduces
fragmentation by calling the Lua garbage collector via the
collectgarbage function.
Ordinarily this does not affect performance.
But, to force Tarantool to release memory, you can
call box.snapshot(), stop the server instance,
and restart it.
Inspect traffic
Inspecting binary traffic is a boring task. We offer a
Wireshark plugin to
simplify the analysis of Tarantool’s traffic.
Tarantool can at times work slower than usual. There can be multiple reasons,
such as disk issues, CPU-intensive Lua scripts or misconfiguration.
Tarantool’s log may lack details in such cases, so the only indications that
something goes wrong are log entries like this: W>toolongDELETE:8.546sec.
Here are tools and techniques that can help you collect Tarantool’s performance
profile, which is helpful in troubleshooting slowdowns.
Note
Most of these tools – except fiber.info() – are intended for
generic GNU/Linux distributions, but not FreeBSD or Mac OS.
fiber.info()
The simplest profiling method is to take advantage of Tarantool’s built-in
functionality. fiber.info() returns information about all
running fibers with their corresponding C stack traces. You can use this data
to see how many fibers are running and which C functions are executed more often
than others.
First, enter your instance’s interactive administrator console:
$ ttconnectNAME|URI
Once there, load the fiber module:
tarantool> fiber=require('fiber')
After that you can get the required information with fiber.info().
At this point, your console output should look something like this:
We highly recommend to assign meaningful names to fibers you create so that you
can find them in the fiber.info() list. In the example below, we create a
fiber named myworker:
tarantool> fiber=require('fiber')---...tarantool> f=fiber.create(function()whiletruedofiber.sleep(0.5)endend)---...tarantool> f:name('myworker')<!-- assigning the name to a fiber---...tarantool> fiber.info()----102:csw:14backtrace:-'#00x501a1ainfiber_yield_timeout+90'-'#10x4f2008inlbox_fiber_sleep+72'-'#20x5112a7inlj_BC_FUNCC+52'fid:102memory:total:57656used:0name:myworker <!-- newly created background fiber101:csw:284backtrace:[]fid:101memory:total:57656used:0name:interactive...
To get a table of all alive fibers you can use fiber.top().
If you want to dynamically obtain information with fiber.info(), the shell
script below may come in handy. It connects to a Tarantool instance specified by
NAME every 0.5 seconds, grabs the fiber.info() output and writes it to
the fiber-info.txt file:
$ rm-ffiber.info.txt
$ watch-n0.5"echo 'require(\"fiber\").info()' | tt connect NAME -f - | tee -a fiber-info.txt"
If you can’t understand which fiber causes performance issues, collect the
metrics of the fiber.info() output for 10-15 seconds using the script above
and contact the Tarantool team at support@tarantool.org.
Poor man’s profilers
pstack <pid>
To use this tool, first install it with a package manager that comes with your
Linux distribution. This command prints an execution stack trace of a running
process specified by the PID. You might want to run this command several times
in a row to pinpoint the bottleneck that causes the slowdown.
Once installed, say:
$ pstack$(pidoftarantoolINSTANCENAME.lua)
Next, say:
$ echo$(pidoftarantoolINSTANCENAME.lua)
to show the PID of the Tarantool instance that runs the INSTANCENAME.lua file.
You should get similar output:
Thread19(Thread0x7f09d1bff700(LWP24173)):
#0 0x00007f0a1a5423f2 in ?? () from /lib64/libgomp.so.1#1 0x00007f0a1a53fdc0 in ?? () from /lib64/libgomp.so.1#2 0x00007f0a1ad5adc5 in start_thread () from /lib64/libpthread.so.0#3 0x00007f0a1a050ced in clone () from /lib64/libc.so.6
Thread18(Thread0x7f09d13fe700(LWP24174)):
#0 0x00007f0a1a5423f2 in ?? () from /lib64/libgomp.so.1#1 0x00007f0a1a53fdc0 in ?? () from /lib64/libgomp.so.1#2 0x00007f0a1ad5adc5 in start_thread () from /lib64/libpthread.so.0#3 0x00007f0a1a050ced in clone () from /lib64/libc.so.6
<...>
Thread2(Thread0x7f09c8bfe700(LWP24191)):
#0 0x00007f0a1ad5e6d5 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0#1 0x000000000045d901 in wal_writer_pop(wal_writer*) ()#2 0x000000000045db01 in wal_writer_f(__va_list_tag*) ()#3 0x0000000000429abc in fiber_cxx_invoke(int (*)(__va_list_tag*), __va_list_tag*) ()#4 0x00000000004b52a0 in fiber_loop ()#5 0x00000000006099cf in coro_init ()
Thread1(Thread0x7f0a1c47fd80(LWP24172)):
#0 0x00007f0a1a0512c3 in epoll_wait () from /lib64/libc.so.6#1 0x00000000006051c8 in epoll_poll ()#2 0x0000000000607533 in ev_run ()#3 0x0000000000428e13 in main ()
gdb -ex “bt” -p <pid>
As with pstack, the GNU debugger (also known as gdb) needs to be installed
before you can start using it. Your Linux package manager can help you with that.
Once the debugger is installed, say:
$ gdb-ex"set pagination 0"-ex"thread apply all bt"--batch-p$(pidoftarantoolINSTANCENAME.lua)
Next, say:
$ echo$(pidoftarantoolINSTANCENAME.lua)
to show the PID of the Tarantool instance that runs the INSTANCENAME.lua file.
After using the debugger, your console output should look like this:
[Threaddebuggingusinglibthread_dbenabled]
Usinghostlibthread_dblibrary"/lib/x86_64-linux-gnu/libthread_db.so.1".
[CUT]
Thread1(Thread0x7f72289ba940(LWP20535)):
#0 _int_malloc (av=av@entry=0x7f7226e0eb20 <main_arena>, bytes=bytes@entry=504) at malloc.c:3697#1 0x00007f7226acf21a in __libc_calloc (n=<optimized out>, elem_size=<optimized out>) at malloc.c:3234#2 0x00000000004631f8 in vy_merge_iterator_reserve (capacity=3, itr=0x7f72264af9e0) at /usr/src/tarantool/src/box/vinyl.c:7629#3 vy_merge_iterator_add (itr=itr@entry=0x7f72264af9e0, is_mutable=is_mutable@entry=true, belong_range=belong_range@entry=false) at /usr/src/tarantool/src/box/vinyl.c:7660#4 0x00000000004703df in vy_read_iterator_add_mem (itr=0x7f72264af990) at /usr/src/tarantool/src/box/vinyl.c:8387#5 vy_read_iterator_use_range (itr=0x7f72264af990) at /usr/src/tarantool/src/box/vinyl.c:8453#6 0x000000000047657d in vy_read_iterator_start (itr=<optimized out>) at /usr/src/tarantool/src/box/vinyl.c:8501#7 0x00000000004766b5 in vy_read_iterator_next (itr=itr@entry=0x7f72264af990, result=result@entry=0x7f72264afad8) at /usr/src/tarantool/src/box/vinyl.c:8592#8 0x000000000047689d in vy_index_get (tx=tx@entry=0x7f7226468158, index=index@entry=0x2563860, key=<optimized out>, part_count=<optimized out>, result=result@entry=0x7f72264afad8) at /usr/src/tarantool/src/box/vinyl.c:5705#9 0x0000000000477601 in vy_replace_impl (request=<optimized out>, request=<optimized out>, stmt=0x7f72265a7150, space=0x2567ea0, tx=0x7f7226468158) at /usr/src/tarantool/src/box/vinyl.c:5920#10 vy_replace (tx=0x7f7226468158, stmt=stmt@entry=0x7f72265a7150, space=0x2567ea0, request=<optimized out>) at /usr/src/tarantool/src/box/vinyl.c:6608#11 0x00000000004615a9 in VinylSpace::executeReplace (this=<optimized out>, txn=<optimized out>, space=<optimized out>, request=<optimized out>) at /usr/src/tarantool/src/box/vinyl_space.cc:108#12 0x00000000004bd723 in process_rw (request=request@entry=0x7f72265a70f8, space=space@entry=0x2567ea0, result=result@entry=0x7f72264afbc8) at /usr/src/tarantool/src/box/box.cc:182#13 0x00000000004bed48 in box_process1 (request=0x7f72265a70f8, result=result@entry=0x7f72264afbc8) at /usr/src/tarantool/src/box/box.cc:700#14 0x00000000004bf389 in box_replace (space_id=space_id@entry=513, tuple=<optimized out>, tuple_end=<optimized out>, result=result@entry=0x7f72264afbc8) at /usr/src/tarantool/src/box/box.cc:754#15 0x00000000004d72f8 in lbox_replace (L=0x413c5780) at /usr/src/tarantool/src/box/lua/index.c:72#16 0x000000000050f317 in lj_BC_FUNCC ()#17 0x00000000004d37c7 in execute_lua_call (L=0x413c5780) at /usr/src/tarantool/src/box/lua/call.c:282#18 0x000000000050f317 in lj_BC_FUNCC ()#19 0x0000000000529c7b in lua_cpcall ()#20 0x00000000004f6aa3 in luaT_cpcall (L=L@entry=0x413c5780, func=func@entry=0x4d36d0 <execute_lua_call>, ud=ud@entry=0x7f72264afde0) at /usr/src/tarantool/src/lua/utils.c:962#21 0x00000000004d3fe7 in box_process_lua (handler=0x4d36d0 <execute_lua_call>, out=out@entry=0x7f7213020600, request=request@entry=0x413c5780) at /usr/src/tarantool/src/box/lua/call.c:382#22 box_lua_call (request=request@entry=0x7f72130401d8, out=out@entry=0x7f7213020600) at /usr/src/tarantool/src/box/lua/call.c:405#23 0x00000000004c0f27 in box_process_call (request=request@entry=0x7f72130401d8, out=out@entry=0x7f7213020600) at /usr/src/tarantool/src/box/box.cc:1074#24 0x000000000041326c in tx_process_misc (m=0x7f7213040170) at /usr/src/tarantool/src/box/iproto.cc:942#25 0x0000000000504554 in cmsg_deliver (msg=0x7f7213040170) at /usr/src/tarantool/src/cbus.c:302#26 0x0000000000504c2e in fiber_pool_f (ap=<error reading variable: value has been optimized out>) at /usr/src/tarantool/src/fiber_pool.c:64#27 0x000000000041122c in fiber_cxx_invoke(fiber_func, typedef __va_list_tag __va_list_tag *) (f=<optimized out>, ap=<optimized out>) at /usr/src/tarantool/src/fiber.h:645#28 0x00000000005011a0 in fiber_loop (data=<optimized out>) at /usr/src/tarantool/src/fiber.c:641#29 0x0000000000688fbf in coro_init () at /usr/src/tarantool/third_party/coro/coro.c:110
Run the debugger in a loop a few times to collect enough samples for making
conclusions about why Tarantool demonstrates suboptimal performance.
Use the following script:
$ rm-fstack-trace.txt
$ watch-n0.5"gdb -ex 'set pagination 0' -ex 'thread apply all bt' --batch -p $(pidoftarantoolINSTANCENAME.lua) | tee -a stack-trace.txt"
Structurally and functionally, this script is very similar to the one used with
fiber.info() above.
If you have any difficulties troubleshooting, let the script run for 10-15 seconds
and then send the resulting stack-trace.txt file to the Tarantool team at
support@tarantool.org.
Warning
Use the poor man’s profilers with caution: each time they attach to a running
process, this stops the process execution for about a second, which may leave
a serious footprint in high-load services.
gperftools
To use the CPU profiler from the Google Performance Tools suite with Tarantool,
first take care of the prerequisites:
For Debian/Ubuntu, run:
$ apt-getinstalllibgoogle-perftools4
For RHEL/CentOS/Fedora, run:
$ yuminstallgperftools-libs
Once you do this, install Lua bindings:
$ ttrocksinstallgperftools
Now you’re ready to go. Enter your instance’s interactive administrator console:
It takes at least a couple of minutes for the profiler to gather performance
metrics. After that, save the results to disk (you can do that as many times as
you need):
tarantool> cpuprof.flush()
To stop profiling, say:
tarantool> cpuprof.stop()
You can now analyze the output with the pprof utility that comes with the
gperftools package:
This tool for performance monitoring and analysis is installed separately via
your package manager. Try running the perf command in the terminal and
follow the prompts to install the necessary package(s).
Note
By default, some perf commands are restricted to root, so, to be on
the safe side, either run all commands as root or prepend them with
sudo.
To start gathering performance statistics, say:
$ perfrecord-g-p$(pidoftarantoolINSTANCENAME.lua)
This command saves the gathered data to a file named perf.data inside the
current working directory. To stop this process (usually, after 10-15 seconds),
press ctrl+C. In your console, you’ll see:
^C[ perf record: Woken up 1 times to write data ][ perf record: Captured and wrote 0.225 MB perf.data (1573 samples) ]
Now run the following command:
$ perfreport-n-g--stdio|teeperf-report.txt
It formats the statistical data in the perf.data file into a performance
report and writes it to the perf-report.txt file.
Unlike the poor man’s profilers, gperftools and perf have low overhead
(almost negligible as compared with pstack and gdb): they don’t result
in long delays when attaching to a process and therefore can be used without
serious consequences.
jit.p
The jit.p profiler comes with the Tarantool application server, to load it one
only needs to say require('jit.p') or require('jit.profile').
There are many options for sampling and display, they are described in
the documentation for the LuaJIT Profiler, available from the 2.1 branch of the git
repository in the file: doc/ext_profiler.html.
Example
Make a function that calls a function named f1 that
does 500,000 inserts and deletes in a Tarantool space.
Start the profiler, execute the function, stop the
profiler, and show what the profiler sampled.
Typically the result will show that the sampling happened
within f1() many times, but also within internal Tarantool
functions, whose names may change with each new version.
Daemon supervision
Server signals
Tarantool processes these signals during the event loop in the transaction
processor thread:
Signal
Effect
SIGHUP
May cause log file rotation. See the
example in
reference on Tarantool logging parameters.
May cause graceful shutdown (information will be
saved first).
SIGINT
(also known as
keyboard interrupt)
May cause graceful shutdown.
SIGKILL
Causes an immediate shutdown.
Other signals will result in behavior defined by the operating system. Signals
other than SIGKILL may be ignored, especially if Tarantool is executing a
long-running procedure which prevents return to the event loop in the
transaction processor thread.
Automatic instance restart
On systemd-enabled platforms, systemd automatically restarts all
Tarantool instances in case of failure. To demonstrate it, let’s try to destroy
an instance:
$ systemctlstatustarantool@my_app|grepPID
Main PID: 5885 (tarantool)$ ttconnectmy_app
• Connecting to the instance... • Connected to /var/run/tarantool/my_app.control/var/run/tarantool/my_app.control> os.exit(-1) ⨯ Connection was closed. Probably instance process isn't running anymore
Now let’s make sure that systemd has restarted the instance:
$ systemctlstatustarantool@my_app|grepPID
Main PID: 5914 (tarantool)
Additionally, you can find the information about the instance restart in the boot logs:
$ journalctl-utarantool@my_app-n8
Core dumps
Tarantool makes a core dump if it receives any of the following signals: SIGSEGV,
SIGFPE, SIGABRT or SIGQUIT. This is automatic if Tarantool crashes.
On systemd-enabled platforms, coredumpctl automatically saves core dumps
and stack traces in case of a crash. Here is a general “how to” for how to
enable core dumps on a Unix system:
Ensure session limits are configured to enable core dumps, i.e. say
ulimit-cunlimited. Check “man 5 core” for other reasons why a core
dump may not be produced.
Set a directory for writing core dumps to, and make sure that the directory
is writable. On Linux, the directory path is set in a kernel parameter
configurable via /proc/sys/kernel/core_pattern.
Make sure that core dumps include stack trace information. If you use a
binary Tarantool distribution, this is automatic. If you build Tarantool
from source, you will not get detailed information if you pass
-DCMAKE_BUILD_TYPE=Release to CMake.
To simulate a crash, you can execute an illegal command against a Tarantool
instance:
$ # !!! please never do this on a production system !!!$ ttconnectmy_app
• Connecting to the instance... • Connected to /var/run/tarantool/my_app.control/var/run/tarantool/my_app.control> require('ffi').cast('char *', 0)[0] = 48 ⨯ Connection was closed. Probably instance process isn't running anymore
Alternatively, if you know the process ID of the instance (here we refer to it
as $PID), you can abort a Tarantool instance by running gdb debugger:
$ gdb-batch-ex"generate-core-file"-p$PID
or manually sending a SIGABRT signal:
$ kill-SIGABRT$PID
Note
To find out the process id of the instance ($PID), you can:
Since Tarantool stores tuples in memory, core files may be large.
For investigation, you normally don’t need the whole file, but only a
“stack trace” or “backtrace”.
To save a stack trace into a file, say:
$ gdb-se"tarantool"-ex"bt full"-ex"thread apply all bt"--batch-ccore>/tmp/tarantool_trace.txt
where:
“tarantool” is the path to the Tarantool executable,
“core” is the path to the core file, and
“/tmp/tarantool_trace.txt” is a sample path to a file for saving the stack trace.
Symbolic names are present in stack traces even if you don’t have
tarantool-debuginfo package installed.
Disaster recovery
The minimal fault-tolerant Tarantool configuration would be a replica set
that includes a master and a replica, or two masters.
The basic recommendation is to configure all Tarantool instances in a replica set to create snapshot files on a regular basis.
Here are action plans for typical crash scenarios.
Problem: Some transactions are missing on a replica after the master has crashed.
Actions:
You lose a few transactions in the master
write-ahead log file, which may have not
transferred to the replica before the crash. If you were able to salvage the master
.xlog file, you may be able to recover these.
Find out instance UUID from the crashed master xlog:
Reload configurations on all instances using the reload() function provided by the config module.
Turn off deletion of expired checkpoints with box.backup.start().
This prevents the Tarantool garbage collector from removing files
made with older checkpoints until box.backup.stop() is called.
Get the latest valid .snap file and
use ttcat command to calculate at which LSN the data loss occurred.
Start a new instance and use tt play command to
play to it the contents of .snap and .xlog files up to the calculated LSN.
Bootstrap a new replica from the recovered master.
Note
The steps above are applicable only to data in the memtx storage engine.
Backups
Tarantool has an append-only storage architecture: it appends data to files but
it never overwrites earlier data. The
Tarantool garbage collector
removes old files after a
checkpoint. You can prevent or delay the garbage collector’s action
by configuring the
checkpoint daemon. Backups can be taken at
any time, with minimal overhead on database performance.
Two functions are helpful for backups in certain situations:
box.backup.start() informs
the server that activities related to the removal of outdated backups must
be suspended and returns a table with the names of snapshot and vinyl files
that should be copied.
box.backup.stop() later informs
the server that normal operations may resume.
Hot backup (memtx)
This is a special case when there are only in-memory tables.
The last snapshot file is a backup of the entire
database; and the WAL files
that are made after the last snapshot are incremental backups. Therefore taking
a backup is a matter of copying the snapshot and WAL files.
Use tar to make a (possibly compressed) copy of the latest .snap and .xlog
files on the snapshot.dir and
wal.dir directories.
If there is a security policy, encrypt the .tar file.
Copy the .tar file to a safe place.
Later, restoring the database is a matter of taking the .tar file and putting
its contents back in the snapshot.dir and wal.dir directories.
Hot backup (vinyl/memtx)
Vinyl stores its files in vinyl_dir, and creates a
folder for each database space. Dump and compaction processes are append-only and
create new files. The Tarantool garbage collector may remove old files after each
checkpoint.
To take a mixed backup:
Issue box.backup.start() on the
administrative console. This will return a list of
files to back up and suspend garbage collection for them till the next
box.backup.stop().
Copy the files from the list to a safe location. This will include memtx
snapshot files, vinyl run and index files, at a state consistent with the
last checkpoint.
Issue box.backup.stop() so the garbage
collector can continue as usual.
Continuous remote backup (memtx)
The replication feature is useful for backup as
well as for load balancing.
Therefore taking a backup is a matter of ensuring that any given replica is
up to date, and doing a cold backup on it. Since all the other replicas continue
to operate, this is not a cold backup from the end user’s point of view. This
could be done on a regular basis, with a cron job or with a Tarantool fiber.
Continuous backup (memtx)
The logged changes done since the last cold backup must be secured, while the
system is running.
For this purpose, you need a file copy utility that will do the copying
remotely and continuously, copying only the parts of a write ahead log file
that are changing.
One such utility is rsync.
Alternatively, you need an ordinary file copy utility, but there should be
frequent production of new snapshot files or new WAL files as changes occur,
so that only the new files need to be copied.
Upgrades
Important
This section contains instructions for upgrading Tarantool clusters to versions up to 2.11.x.
This section describes the general upgrade process for Tarantool. There are two
main upgrade scenarios for different use cases:
Live upgrade (without downtime) for replication clusters.
Upgrading from or to certain versions can involve specific steps or slightly differ
from the general upgrade procedure. Such version-specific cases are described on
the dedicated pages inside this section.
This page describes the process of upgrading a standalone Tarantool instance in production.
Note that this always implies a downtime because the application needs to be
stopped and restarted on the target version.
To upgrade without downtime, you need multiple Tarantool servers running in a
replication cluster. Find detailed instructions in Replication cluster upgrade.
Checking your application
Before upgrading, make sure your application is compatible with the target
Tarantool version:
Set up a development environment with the target Tarantool version installed.
See the installation instructions at the Tarantool download page
and in the tt install reference.
Deploy the application in this environment and check how it works. In case of
any issues, adjust the application code to ensure compatibility with the target version.
When your application is ready to run on the target Tarantool version, you can
start upgrading the production environment.
Upgrading a standalone instance
Stop the Tarantool instance.
Make a copy of all data and the package from which the current (old)
version was installed. You may need it for rollback purposes. Find the
backup instruction in the appropriate hot backup procedure in
Backups.
Install the target Tarantool version on the host. You can do this
using a package manager or the tt utility.
See the installation instructions at Tarantool download page
and in the tt install reference.
To check that the target Tarantool version is installed, run tarantool-v.
Start your application on the target version.
Run box.schema.upgrade().
This will update the Tarantool system spaces to match the currently installed version of Tarantool.
The rollback procedure for a standalone instance is almost the same as the upgrade.
The only difference is in the last step: you should call box.schema.downgrade()
to return the schema to the original version.
Replication cluster upgrade
Below are the general instructions for upgrading a Tarantool cluster with replication.
Upgrading from some versions can involve certain specifics. To find out if it is your case, check the version-specific topics of the Upgrades
section.
A replication cluster can be upgraded without downtime due to its redundancy.
When you disconnect a single instance for an upgrade, there is always another
instance that takes over its functionality: being a master storage for the same
data buckets or working as a router. This way, you can upgrade all the instances one by one.
The high-level steps of cluster upgrade are the following:
The only way to upgrade Tarantool from version 1.6, 1.7, or 1.9 to 2.x without downtime is
to take an intermediate step by upgrading to 1.10 and then to 2.x.
Before upgrading Tarantool from 1.6 to 2.x, please read about the associated
caveats.
Note
Some upgrade steps are moved to the separate section Procedures and checks
to avoid overloading the general instruction with details. Typically, these are
checks you should repeat during the upgrade to ensure it goes well.
If you experience issues during upgrade, you can roll back to the original version.
The rollback instructions are provided in the Rollback
section.
Checking your application
Before upgrading, make sure your application is compatible with the target
Tarantool version:
Set up a development environment with the target Tarantool version installed.
See the installation instructions at the Tarantool download page
and in the tt install reference.
Deploy the application in this environment and check how it works. In case of
any issues, adjust the application code to ensure compatibility with the target version.
When your application is ready to run on the target Tarantool version, you can
start upgrading the production environment.
Pre-upgrade checks
Perform these steps before the upgrade to ensure that your cluster is working correctly:
tarantool> box.info-- box.info.status == 'running'-- box.info.ro == 'false' on one instance in each replica set.-- box.info.replication[*].upstream.status == 'follow'-- box.info.replication[*].downstream.status == 'follow'-- box.info.replication[*].upstream.lag <= box.cfg.replication_timeout-- can also be moderately larger under a write load
If you’re running Cartridge, you can check the health of the cluster instances
on the Cluster tab of its web interface.
In case of any issues, make sure to fix them before starting the upgrade procedure.
Installing the target version
Install the target Tarantool version on all hosts of the cluster. You can do this
using a package manager or the tt utility.
See the installation instructions at the Tarantool download page
and in the tt install reference.
Check that the target Tarantool version is installed by running tarantool-v
on all hosts.
Upgrading a Tarantool cluster with no downtime
Upgrading routers
Upgrade router instances one by one:
Stop one router instance.
Start this instance on the target Tarantool version.
Repeat the previous steps for each router instance.
After completing the router instances upgrade, perform the vshard.router check
on each of them.
Upgrading storages
Before upgrading storage instances:
Disable Cartridge failover: run
ttcartridgefailoverdisable
or use the Cartridge web interface (Cluster tab, Failover: <Mode> button).
Make sure that the Cartridge upgrade_schema option is false.
Upgrade storage instances by performing the following steps for each replica set:
Note
To detect possible upgrade issues early, we recommend that you perform
a replication check on all instances of
the replica set after each step.
Pick a replica (a read-only instance) from the replica set. Stop this replica
and start it again on the target Tarantool version. Wait until it reaches the
running status (box.info.status==running).
Restart all other read-only instances of the replica set on the target
version one by one.
Make one of the updated replicas the new master using the applicable instruction
from Switching the master.
Restart the last instance of the replica set (the former master, now
a replica) on the target version.
Run box.schema.upgrade() on the new master.
This will update the Tarantool system spaces to match the currently installed
version of Tarantool. The changes will be propagated to other nodes via the
replication mechanism later.
Warning
This is the point of no return for upgrading from versions earlier than 2.8.2:
once you complete it, the schema is no longer compatible with the initial version.
When upgrading from version 2.8.2 or newer, you can undo the schema upgrade
using box.schema.downgrade().
Run box.snapshot() on every node in the replica set to make sure that the
replicas immediately see the upgraded database state in case of restart.
Once you complete the steps, enable failover or rebalancer back:
Enable Cartridge failover: run
ttcartridgefailoverset[mode]
or use the Cartridge web interface (Cluster tab, Failover: Disabled button).
tarantool> box.info-- box.info.status == 'running'-- box.info.ro == 'false' on one instance in each replica set.-- box.info.replication[*].upstream.status == 'follow'-- box.info.replication[*].downstream.status == 'follow'-- box.info.replication[*].upstream.lag <= box.cfg.replication_timeout-- can also be moderately larger under a write load
If you’re running Cartridge, you can check the health of the cluster instances
on the Cluster tab of its web interface.
Rollback
Rollback before the point of no return
If you decide to roll back before reaching the point of no return,
your data is fully compatible with the version you had before the upgrade.
In this case, you can roll back the same way: restart the nodes you’ve already
upgraded on the original version.
Rollback after the point of no return
If you’ve passed the point of no return (that is,
executed box.schema.upgrade()) during the upgrade, then a rollback requires
downgrading the schema to the original version.
To check if an automatic downgrade is available for your original version, use
box.schema.downgrade_versions(). If the version you need is on the list,
execute the following steps on each upgraded replica set to roll back:
Run box.schema.downgrade(<version>) on master specifying the original version.
Run box.snapshot() on every instance in the replica set to make sure that the
replicas immediately see the downgraded database state after restart.
Restart all read-only instances of the replica set on the initial
version one by one.
Make one of the updated replicas the new master using the applicable instruction
from Switching the master.
Restart the last instance of the replica set (the former master, now
a replica) on the original version.
Then enable failover or rebalancer back as described in the Upgrading storages.
Recovering from a failed upgrade
Warning
This section applies to cases when the upgrade procedure has failed and the
cluster is not functioning properly anymore. Thus, it implies a downtime and
a full cluster restart.
In case of an upgrade failure after passing the point of no return,
follow these steps to roll back to the original version:
Stop all cluster instances.
Save snapshot and xlog files from all instances whose data was modified
after the last backup procedure. These files will help apply these modifications
later.
Save the latest backups from all instances.
Restore the original Tarantool version on all hosts of the cluster.
Launch the cluster on the original Tarantool version.
Note
At this point, the application becomes fully functional and contains data
from the backups. However, the data modifications made after the backups
were taken must be restored manually.
Manually apply the latest data modifications from xlog files you saved on step 2
using the xlog module. On instances where such changes happened,
do the following:
Find out the vclock value of the latest operation in the original WAL.
Play the operations from the newer xlog starting from this vclock on the
instance.
Important
If the upgrade has failed after calling box.schema.upgrade(),
don’t apply the modifications of system spaces done by this call.
This can make the schema incompatible with the original Tarantool version.
Find more information about the Tarantool recovery in Disaster recovery.
Procedures and checks
Replication check
Run box.info:
tarantool> box.info
Check that the following conditions are satisfied:
box.info.status is running
box.info.replication[*].upstream.status and box.info.replication[*].downstream.status
are follow
box.info.replication[*].upstream.lag is less or equal than box.cfg.replication_timeout,
but it can also be moderately larger under a write load.
box.info.ro is false at least on one instance in each replica set.
If all instances have box.info.ro=true, this means there are no writable nodes.
On Tarantool v. 2.10.0 or later, you can find out
why this happened by running box.info.ro_reason.
If box.info.ro_reason or box.info.status has the value orphan,
the instance doesn’t see the rest of the replica set.
Then run box.info once more and check that box.info.replication[*].upstream.lag
values are updated.
vshard.storage check
Run vshard.storage.info():
tarantool> vshard.storage.info()
Check that the following conditions are satisfied:
there are no issues or alerts
replication.status is follow
vshard.router check
Run vshard.router.info():
tarantool> vshard.router.info()
Check that the following conditions are satisfied:
there are no issues or alerts
all buckets are available (the sum of bucket.available_rw on all replica
sets equals the total number of buckets)
Switching the master
Cartridge. If your cluster runs on Cartridge, you can switch the master in the web interface.
To do this, go to the Cluster tab, click Edit replica set, and drag an
instance to the top of Failover priority list to make it the master.
Pick a candidate – a read-only instance to become the new master.
Run box.ctl.promote() on the candidate. The operation will start and
wait for the election to happen.
Run box.cfg{election_mode="voter"} on the current master.
Check that the candidate became the new master: its box.info.ro
must be false.
Legacy. If your cluster neither works on Cartridge nor has automated leader election,
switch the master by following these steps:
Pick a candidate – a read-only instance to become the new master.
Run box.cfg{read_only=true} on the current master.
Check that the candidate’s vclock value matches the master’s:
The value of box.info.vclock[<master_id>] on the candidate must be equal
to box.info.lsn on the master. <master_id> here is the value of
box.info.id on the master.
If the vclock values don’t match, stop the switch procedure and restore
the replica set state by calling box.cfg{read_only==false} on the master.
Then pick another candidate and restart the procedure.
After switching the master, perform the replication check
on each instance of the replica set.
Live upgrade from Tarantool 1.6 to 1.10
This page includes explanations and solutions to some common issues
when upgrading a replica set from Tarantool 1.6 to 1.10.
Versions later that 1.6 have incompatible .snap and
.xlog file formats: 1.6 files are
supported during upgrade, but you won’t be able to return to 1.6 after running
under 1.10 or 2.x for a while. A few configuration parameters are also renamed.
To perform a live upgrade from Tarantool 1.6 to a more recent version,
like 2.8.4, 2.10.1 and such,
it is necessary to take an intermediate step by upgrading 1.6 -> 1.10 -> 2.x.
This is the only way to perform the upgrade without downtime.
However, a direct upgrade of a replica set from 1.6 to 2.x is also possible, but only
with downtime.
The procedure of live upgrade from 1.6 to 1.10 is similar to the general
cluster upgrade procedure,
but with slight differences in the Upgrading storages step.
Find below the general storage upgrade procedure and the 1.6-specific notes for its
steps.
General storage upgrade
Upgrade storage instances by performing the following steps for each replica set:
Note
To detect possible upgrade issues early, we recommend that you perform
a replication check on all instances of
the replica set after each step.
Pick a replica (a read-only instance) from the replica set. Stop this replica
and start it again on the target Tarantool version. Wait until it reaches the
running status (box.info.status==running).
Restart all other read-only instances of the replica set on the target
version one by one.
Make one of the updated replicas the new master using the applicable instruction
from Switching the master.
Restart the last instance of the replica set (the former master, now
a replica) on the target version.
Run box.schema.upgrade() on the new master.
This will update the Tarantool system spaces to match the currently installed
version of Tarantool. The changes will be propagated to other nodes via the
replication mechanism later.
Run box.snapshot() on every node in the replica set to make sure that the
replicas immediately see the upgraded database state in case of restart.
1.6 storage upgrade specifics
Replication check: New Tarantool nodes follow 1.6 nodes just fine,
but some 1.6 nodes might disconnect from new nodes with an ER_LOADING error.
This is not critical, the error goes away when replication on 1.6 is restarted:
Point of no return: When upgrading from Tarantool 1.6, the step 3 (switching
the master) is the point of no return. Оnce you complete it, the schema is no
longer compatible with the initial version.
Restarting on the target version (steps 1, 2, and 4): Tarantool 1.10+ fails to recover
from 1.6 xlogs, unless box.cfg{force_recovery=true} is set. There is a slight
difference between 1.6 and 1.10 xlogs, which makes 1.6 xlogs appear erroneous to 1.10+ instances.
In order to work around this, start the instance in force_recovery mode. To do so, add the line
force_recovery=true to the file where the instance is initialized – for example, to init.lua.
Running box.schema.upgrade() (step 5): There was a breaking change between 1.6 and 1.10 –
in 1.6, the field type num was an alias to number, and in 1.10, num is converted to unsigned.
This means that after box.schema.upgrade() is performed on the master,
the user might have some spaces with unsigned fields containing non-unsigned values:
double, int, and so on.
This will make the snapshot inconsistent, unless an extra action is performed after box.schema.upgrade().
Run this code in the Tarantool console on the new master:
-- First find all spaces containing unsigned fields with non-unsigned values in them.-- Say, we have one such space denoted problematic_space and the problem is in field problematic_field_no.a=box.space.problematic_space:format()a[problematic_field_no].type='number'box.space.problematic_space:format(a)
Taking snapshots (step 6): The user might be concerned with snapshot size in 1.10 –
it’s drastically smaller than the one created by 1.6 (for example, ~300 Mb vs. 6 Gb in some corner cases).
There is nothing to worry about.
Tarantool 1.6 didn’t compress snapshots, while Tarantool 1.10 and above does that.
Upgrade from 1.6 directly to 2.x with downtime
Versions later that 1.6 have incompatible .snap and
.xlog file formats: 1.6 files are
supported during upgrade, but you won’t be able to return to 1.6 after running
under 1.10 or 2.x for a while. A few configuration parameters are also renamed.
To perform a live upgrade from Tarantool 1.6 to a more recent version,
like 2.8.4, 2.10.1 and such,
it is necessary to take an intermediate step by upgrading 1.6 -> 1.10 -> 2.x.
This is the only way to perform the upgrade without downtime.
However, a direct upgrade of a replica set from 1.6 to 2.x is also possible, but only
with downtime.
Here is how to upgrade from Tarantool 1.6 directly to 2.x:
Stop all instances in the replica set.
Upgrade Tarantool version to 2.x on every instance.
Upgrade the corresponding instance files and applications, if needed.
Start all the instances with Tarantool 2.x.
Execute box.schema.upgrade() on the master.
Execute box.snapshot() on every node in the replica set.
Fix decimal values in vinyl spaces when upgrading to 2.10.1
This is an upgrade guide for fixing one specific problem which could happen with decimal values in vinyl spaces.
It’s only relevant when you’re upgrading from Tarantool version <= 2.10.0 to anything >= 2.10.1.
Before gh-6377 was fixed, decimal and double values in a scalar or number index
could end up in the wrong order after the update.
If such an index has been built for a space that uses the vinyl storage engine,
the index is persisted and is not rebuilt even after the upgrade.
If this is the case, the user has to rebuild the affected indexes manually.
Here are the rules to determine whether your installation was affected.
If all of the statements listed below are true, you have to rebuild indexes for the affected vinyl spaces manually.
You were running Tarantool version 2.10.0 and below.
You have spaces with the vinyl storage engine.
The vinyl spaces have number or scalar indexes.
The tuples in these spaces may contain both decimal and doubleInf or NaN values.
If this is the case for you, you can run the following script, which will find all the affected indices:
The indices requiring a rebuild will be stored in the require_rebuild table.
If the table is empty, you’re safe and can continue using Tarantool as before.
If the require_rebuild table contains some entries,
you can rebuild the affected indices with the following script.
Note
Please run the script below only on the master node
and only after all the nodes are upgraded to the new Tarantool version.
locallog=require('log')localfunctionrebuild_index(idx)localindex_name=idx[3]localspace_name=box.space[idx[1]].namelog.info("Rebuilding index %s on space %s",index_name,space_name)if(idx[2]==0)thenlog.error("Cannot rebuild primary index %s on space %s. Please, ".."recreate the space manually",index_name,space_name)returnendlog.info("Deleting index %s on space %s",index_name,space_name)localv=box.space._index:delete{idx[1],idx[2]}ifv==nilthenlog.error("Couldn't find index %s on space %s",index_name,space_name)returnendlog.info("Done")log.info("Creating index %s on space %s",index_name,space_name)box.space._index:insert(v)endfor_,idxinpairs(require_rebuild)dorebuild_index(idx)end
The script might fail on some of the indices with the following error:
“Cannot rebuild primary index index_name on space space_name. Please, recreate the space manually”.
If this happens, automatic index rebuild is impossible,
and you have to manually re-create the space to ensure data integrity:
Create a new space with the same format as the existing one.
Define the same indices on the freshly created space.
Iterate over the old space’s primary key and insert all the data into the new space.
Drop the old space.
Fix illegal type names when upgrading to 2.10.4
This is an upgrade guide for fixing one specific problem which could happen with field type names.
It’s only relevant when you’re upgrading from a Tarantool version <=2.10.3 to >=2.10.4.
Before gh-5940 was fixed, the empty string, n, nu, s,
and st (that is, leading parts of num and str) were accepted as valid field types.
Since 2.10.4, Tarantool doesn’t accept these strings and they must be replaced with
correct values num and str.
Check if your snapshots contain illegal type names
A snapshot can be validated against the issue using the following script:
#!/usr/bin/env tarantoollocalxlog=require('xlog')localjson=require('json')ifarg[1]==nilthenprint(('Usage: %s xxxxxxxxxxxxxxxxxxxx.snap'):format(arg[0]))os.exit(1)endlocalillegal_types={['']=true,['n']=true,['nu']=true,['s']=true,['st']=true,}localfunctionreport_field_def(name,field_def)localmsg='A field def in a _space entry %q contains an illegal type: %s'print(msg:format(name,json.encode(field_def)))endlocalhas_broken_format=falsefor_,recordinxlog.pairs(arg[1])do-- Filter inserts.ifrecord.HEADER==nilorrecord.HEADER.type~='INSERT'thengotocontinueend-- Filter _space records.ifrecord.BODY==nilorrecord.BODY.space_id~=280thengotocontinueendlocaltuple=record.BODY.tuplelocalname=tuple[3]localformat=tuple[7]localis_format_broken=falsefor_,field_definipairs(format)doifillegal_types[field_def.type]~=nilthenreport_field_def(name,field_def)is_format_broken=trueendifillegal_types[field_def[2]]~=nilthenreport_field_def(name,field_def)is_format_broken=trueendendifis_format_brokenthenhas_broken_format=truelocalmsg='The following _space entry contains illegal type(s): %s'print(msg:format(json.encode(record)))end::continue::endifhas_broken_formatthenprint('')print(('%s has an illegal type in a space format'):format(arg[1]))print('It is recommended to proceed with the upgrade instruction:')print('https://github.com/tarantool/tarantool/wiki/Fix-illegal-field-type-in-a-space-format-when-upgrading-to-2.10.4')elseprint('Everything looks nice!')endos.exit(has_broken_formatand2or0)
If the snapshot contains the values that aren’t valid in 2.10.4, you’ll get
an output like the following:
Fix an application file
To fix the application file that contains illegal type names, add the following code in it
before the box.cfg()/vshard.cfg()/cartridge.cfg() call.
Note
In Cartridge applications, the instance file is called init.lua.
-- Convert illegal type names in a space format that were-- allowed before tarantool 2.10.4.locallog=require('log')localjson=require('json')localtransforms={['']='num',['n']='num',['nu']='num',['s']='str',['st']='str',}-- The helper for before_replace().localfunctiontransform_field_def(name,field_def,field,new_type)localfield_def_old_str=json.encode(field_def)field_def[field]=new_typelocalfield_def_new_str=json.encode(field_def)localmsg='Transform a field def in a _space entry %q: %s -> %s'log.info(msg:format(name,field_def_old_str,field_def_new_str))end-- _space trigger.localfunctionbefore_replace(_,tuple)iftuple==nilthenreturntupleendlocalname=tuple[3]localformat=tuple[7]-- Update format if necessary.localis_format_changed=falsefori,field_definipairs(format)dolocalnew_type=transforms[field_def.type]ifnew_type~=nilthentransform_field_def(name,field_def,'type',new_type)is_format_changed=trueendlocalnew_type=transforms[field_def[2]]ifnew_type~=nilthentransform_field_def(name,field_def,2,new_type)is_format_changed=trueendend-- No changed: skip.ifnotis_format_changedthenreturntupleend-- Rebuild the tuple.localnew_tuple=tuple:transform(7,1,format)log.info(('Transformed _space entry %s to %s'):format(json.encode(tuple),json.encode(new_tuple)))returnnew_tupleend-- on_schema_init trigger to set before_replace().localfunctionon_schema_init()box.space._space:before_replace(before_replace)end-- Set the trigger on _space.box.ctl.on_schema_init(on_schema_init)
You can delete these triggers after the box.cfg()/vshard.cfg()/cartridge.cfg()
call.
An example for a Cartridge application:
The triggers will report the changes the make in the following form:
Recover from WALs with mixed transactions when upgrading to 2.11.0
This is a guide on fixing a specific problem that could happen when upgrading
from a Tarantool version between 2.1.2 and 2.2.0 to 2.8.1 or later. The described
solution is applicable since version 2.11.0.
The problem is described in the issue gh-7932. If two or more
transactions happened simultaneously in Tarantool 2.1.2-2.2.0, their operations
could be written to the write-ahead log mixed with each other. Starting from version
2.8.1, Tarantool recovers transactions atomically and expects all WAL entries
between a transaction’s begin and commit operations to belong to one transaction.
If there is an operation belonging to another transaction, Tarantool fails to recover
from such a WAL.
Starting from version 2.11.0, Tarantool can recover from
WALs with mixed transactions in the force_recovery mode.
Instances fail to start
If all instances or some of them fail to start after upgrading to 2.11 or a newer
version due to a recovery error:
Start these instances with the force_recovery
option to true.
Make new snapshots on the instances so that the old WALs with mixed transactions
aren’t used for recovery anymore. To do this, call box.snapshot().
Set force_recovery back to false.
Replication doesn’t work
After all the instances start successfully, WALs with mixed transactions
may still lead to replication issues. Some instances may fail to replicate from other
instances because they are sending incorrect WALs. To fix the replication issues,
rebootstrap the instances that fail to replicate.
Bug reports
If you found a bug in Tarantool, you’re doing us a favor by taking the time to
tell us about it.
Please create an issue at Tarantool repository at GitHub. We encourage you to
include the following information:
Steps needed to reproduce the bug, and an explanation why this differs from
the expected behavior according to our manual. Please provide specific unique
information. For example, instead of “I can’t get certain information”, say
“box.space.x:delete() didn’t report what was deleted”.
Your operating system name and version, the Tarantool name and version, and
any unusual details about your machine and its configuration.
The flight recorder is an event collection tool that gathers various information about a working Tarantool instance, such as:
logs
metrics
requests and responses
This information helps you investigate incidents related
to crashing a Tarantool instance.
Enable the flight recorder
The flight recorder is disabled by default and can be enabled and configured for
a specific Tarantool instance.
To enable the flight recorder, set the flightrec.enabled
configuration option to true.
flightrec:enabled:true
After flightrec.enabled is set to true, the flight recorder starts collecting data in the flight recording file current.ttfr.
This file is stored in the snapshot.dir directory.
By default, the directory is var/lib/{{instance_name}}/<file_name>.ttfr.
If the instance crashes and reboots, Tarantool rotates the flight recording:
current.ttfr is renamed to <timestamp>.ttfr (for example, 20230411T050721.ttfr)
and the new current.ttfr file is created for collecting data.
In the case of correct shutdown (for example, using os.exit()),
Tarantool continues writing to the existing current.ttfr file after restart.
Note
Note that old flight recordings should be removed manually.
Monitoring is the process of capturing runtime information about the instances of a Tarantool cluster using metrics.
Metrics can indicate various characteristics, such as memory usage, the number of records in spaces, replication status, and so on.
Typically, metrics are monitored in real time, allowing for the identification of current issues or the prediction of potential ones.
Tarantool allows you to configure and expose its metrics using a YAML configuration.
You can also use the built-in metrics module to create and collect custom metrics.
Configuring metrics
To configure metrics, use the metrics section in a cluster configuration.
The configuration below enables all metrics excluding vinyl-specific ones:
The metrics.labels option accepts the predefined {{ instance_name }} variable.
This adds an instance name as a label to every observation.
Third-party Lua modules, like crud or expirationd, offer their own metrics.
You can enable these metrics by configuring the corresponding role.
The example below shows how to enable statistics on called operations by providing the roles.crud-router role’s configuration:
To expose metrics in different formats, you can use a third-party metrics-export-role role.
In the following example, the metrics of storage-a-001 are provided on two endpoints:
/metrics/prometheus: exposes metrics in the Prometheus format.
/metrics/json: exposes metrics in the JSON format.
The metrics module provides a set of plugins that can be used to collect and expose metrics in different formats. Learn more in Collecting metrics using plugins.
Creating custom metrics
The metrics module allows you to create and collect custom metrics.
The example below shows how to collect the number of data operations performed on the specified space by increasing a counter value inside the on_replace() trigger function:
localmetrics=require('metrics')localbands_replace_count=metrics.counter('bands_replace_count','The number of data operations')localtrigger=require('trigger')trigger.set('box.space.bands.on_replace','update_bands_replace_count_metric',function(_,_,_,request_type)bands_replace_count:inc(1,{request_type=request_type})end)
When metrics are configured and exposed, you can use the desired third-party tool to collect them.
Below is the example of a Prometheus scrape configuration that collects metrics of multiple Tarantool instances:
The Tarantool Grafana dashboard is a ready for import template with basic memory,
space operations, and HTTP load panels, based on default metrics
package functionality.
Prepare a monitoring stack
Since there are Prometheus and InfluxDB data source Grafana dashboards,
you can use one of the following:
Telegraf
as a server agent for collecting metrics, InfluxDB
as a time series database for storing metrics, and Grafana
as a visualization platform.
Prometheus as both a server agent for collecting metrics
and a time series database for storing metrics, and Grafana
as a visualization platform.
For issues related to setting up Prometheus, Telegraf, InfluxDB, or Grafana instances, refer to the corresponding project’s documentation.
Collect metrics with server agents
Prometheus
To collect metrics for Prometheus, first set up metrics output with prometheus format.
You can use the roles.metrics-export configuration or set up the Prometheus plugin manually.
To start collecting metrics, add a job
to Prometheus configuration with each Tarantool instance URI as a target and
metrics path as it was configured on Tarantool instances:
To collect metrics for InfluxDB, use the Telegraf agent.
First off, configure Tarantool metrics output in json format
with roles.metrics-export configuration or corresponding JSON plugin.
To start collecting metrics, add http input
to Telegraf configuration including each Tarantool instance metrics URL:
Be sure to include each label key as label_pairs_<key> to extract it
with the plugin.
For example, if you use {state='ready'} labels somewhere in metric collectors, add label_pairs_state tag key.
Import the dashboard
Open Grafana import menu.
To import a specific dashboard, choose one of the following options:
paste the dashboard id (21474 for Prometheus dashboard, 21484 for InfluxDB dashboard)
You can choose the data source and data source variables after import.
Troubleshooting
If there are no data on the graphs, make sure that you picked datasource and job/measurement correctly.
If there are no data on the graphs, make sure that you have info group of Tarantool metrics
(in particular, tnt_info_uptime).
If some Prometheus graphs show no data because of parseerror:missingunitcharacterinduration,
ensure that you use Grafana 7.2 or newer.
If some Prometheus graphs display parseerror:baddurationsyntax"1m0" or similar error, you need
to update your Prometheus version. See
grafana/grafana#44542 for more details.
You can use internal Tarantool metrics to monitor detailed RAM consumption,
replication state, database engine status, track business logic issues (like
HTTP 4xx and 5xx responses or low request rate) and external modules statistics
(like CRUD errors). Evaluation timeouts, severity
levels and thresholds (especially ones for business logic) are placed here for
the sake of example: you may want to increase or decrease them for your
application. Also, don’t forget to set sane rate time ranges based on your
Prometheus configuration.
Lua memory
Monitoring tnt_info_memory_lua metric may prevent memory overflow and detect the presence of bad Lua code practices.
Note
The Lua memory is limited to 2 GB per instance if Tarantool doesn’t have the GC64 mode enabled for LuaJIT.
By monitoring slab allocation statistics you can see
how many free RAM is remaining to store memtx tuples and indexes for an
instance. If Tarantool hit the limits, the instance will become unavailable
for write operations, so this alert may help you see when it’s time to increase
your memtx_memory limit or to add a new storage to a vshard cluster.
-alert:LowMemtxArenaRemainingWarningexpr:(tnt_slab_quota_used_ratio >= 80) and (tnt_slab_arena_used_ratio >= 80)for:1mlabels:severity:warningannotations:summary:"Instance'{{$labels.alias}}'('{{$labels.job}}')lowarenamemoryremaining"description:"Lowarenamemory(tuplesandindexes)remainingfor'{{$labels.alias}}'instanceofjob'{{$labels.job}}'.Considerincreasingmemtx_memoryornumberofstoragesincaseofshardeddata."-alert:LowMemtxArenaRemainingexpr:(tnt_slab_quota_used_ratio >= 90) and (tnt_slab_arena_used_ratio >= 90)for:1mlabels:severity:pageannotations:summary:"Instance'{{$labels.alias}}'('{{$labels.job}}')lowarenamemoryremaining"description:"Lowarenamemory(tuplesandindexes)remainingfor'{{$labels.alias}}'instanceofjob'{{$labels.job}}'.Youarelikelytohitlimitsoon.Itisstronglyrecommendedtoincreasememtx_memoryornumberofstoragesincaseofshardeddata."-alert:LowMemtxItemsRemainingWarningexpr:(tnt_slab_quota_used_ratio >= 80) and (tnt_slab_items_used_ratio >= 80)for:1mlabels:severity:warningannotations:summary:"Instance'{{$labels.alias}}'('{{$labels.job}}')lowitemsmemoryremaining"description:"Lowitemsmemory(tuples)remainingfor'{{$labels.alias}}'instanceofjob'{{$labels.job}}'.Considerincreasingmemtx_memoryornumberofstoragesincaseofshardeddata."-alert:LowMemtxItemsRemainingexpr:(tnt_slab_quota_used_ratio >= 90) and (tnt_slab_items_used_ratio >= 90)for:1mlabels:severity:pageannotations:summary:"Instance'{{$labels.alias}}'('{{$labels.job}}')lowitemsmemoryremaining"description:"Lowitemsmemory(tuples)remainingfor'{{$labels.alias}}'instanceofjob'{{$labels.job}}'.Youarelikelytohitlimitsoon.Itisstronglyrecommendedtoincreasememtx_memoryornumberofstoragesincaseofshardeddata."
Vinyl engine status
You can monitor vinyl regulator
performance to track possible scheduler or disk issues.
If tnt_replication_status is equal to 0, instance replication
status is not equal to "follows": replication is either not ready yet or
has been stopped due to some reason.
Even if async replication is "follows", it could be considered malfunctioning
if the lag is too high. It also may affect Tarantool garbage collector work,
see box.info.gc().
High fiber event loop time leads to bad application
performance, timeouts and various warnings. The reason could be a high quantity
of working fibers or fibers that spend too much time without any yields or
sleeps.
Responding with high latency is a synonym of insufficient performance. It may
be a sign of application malfunction. Or maybe you need to add more routers to
your cluster.
If your application uses CRUD module
requests, monitoring module statistics may track internal errors caused by
invalid process of input and internal parameters.
Statistics could also monitor requests performance. Too high request latency
will lead to high latency of client responses. It may be caused by network
or disk issues. Read requests with bad (with respect to space indexes and
sharding schema) conditions may lead to full-scans or map reduces and also
could be the reason of high latency.
Do not forget to monitor your server’s CPU, disk and RAM from server side with
your favorite tools. For example, on some high CPU consumption cases Tarantool
instance may stop to send metrics, so you can track such breakdowns only from
the outside.
Metrics reference
This page provides a detailed description of metrics from the metrics module.
General metrics
General instance information:
tnt_cfg_current_time
Instance system time in the Unix timestamp format
tnt_info_uptime
Time in seconds since the instance has started
tnt_read_only
Indicates if the instance is in read-only mode (1 if true, 0 if false)
Memory general
The following metrics provide a picture of memory usage by the Tarantool process.
tnt_info_memory_cache
Number of bytes in the cache used to store
tuples with the vinyl storage engine.
tnt_info_memory_data
Number of bytes used to store user data (tuples)
with the memtx engine and with level 0 of the vinyl engine,
without regard for memory fragmentation.
tnt_info_memory_index
Number of bytes used for indexing user data.
Includes memtx and vinyl memory tree extents,
the vinyl page index, and the vinyl bloom filters.
tnt_info_memory_lua
Number of bytes used for the Lua runtime.
Monitoring this metric can prevent memory overflow.
tnt_info_memory_net
Number of bytes used for network input/output buffers.
tnt_info_memory_tx
Number of bytes in use by active transactions.
For the vinyl storage engine,
this is the total size of all allocated objects
(struct txv, struct vy_tx, struct vy_read_interval)
and tuples pinned for those objects.
Memory allocation
Provides a memory usage report for the slab allocator.
The slab allocator is the main allocator used to store tuples.
The following metrics help monitor the total memory usage and memory fragmentation.
To learn more about use cases, refer to the
box.slab submodule documentation.
Available memory, bytes:
tnt_slab_quota_size
Amount of memory available to store tuples and indexes.
Is equal to memtx_memory.
tnt_slab_arena_size
Total memory available to store both tuples and indexes.
Includes allocated but currently free slabs.
tnt_slab_items_size
Total amount of memory available to store only tuples and not indexes.
Includes allocated but currently free slabs.
Memory usage, bytes:
tnt_slab_quota_used
The amount of memory that is already reserved by the slab allocator.
tnt_slab_arena_used
The effective memory used to store both tuples and indexes.
Disregards allocated but currently free slabs.
tnt_slab_items_used
The effective memory used to store only tuples and not indexes.
Disregards allocated but currently free slabs.
Memory utilization, %:
tnt_slab_quota_used_ratio
tnt_slab_quota_used/tnt_slab_quota_size
tnt_slab_arena_used_ratio
tnt_slab_arena_used/tnt_slab_arena_size
tnt_slab_items_used_ratio
tnt_slab_items_used/tnt_slab_items_size
Spaces
The following metrics provide specific information
about each individual space in a Tarantool instance.
tnt_space_len
Number of records in the space.
This metric always has 2 labels: {name="test",engine="memtx"},
where name is the name of the space and
engine is the engine of the space.
tnt_space_bsize
Total number of bytes in all tuples.
This metric always has 2 labels: {name="test",engine="memtx"},
where name is the name of the space
and engine is the engine of the space.
tnt_space_index_bsize
Total number of bytes taken by the index.
This metric always has 2 labels: {name="test",index_name="pk"},
where name is the name of the space and
index_name is the name of the index.
tnt_space_total_bsize
Total size of tuples and all indexes in the space.
This metric always has 2 labels: {name="test",engine="memtx"},
where name is the name of the space and
engine is the engine of the space.
tnt_vinyl_tuples
Total tuple count for vinyl.
This metric always has 2 labels: {name="test",engine="vinyl"},
where name is the name of the space and
engine is the engine of the space. For vinyl this metric is disabled
by default and can be enabled only with global variable setup:
rawset(_G,'include_vinyl_count',true).
Network
Network activity stats.
These metrics can be used to monitor network load, usage peaks, and traffic drops.
Sent bytes:
tnt_net_sent_total
Bytes sent from the instance over the network since the instance’s start time
Received bytes:
tnt_net_received_total
Bytes received by the instance since start time
Connections:
tnt_net_connections_total
Number of incoming network connections since the instance’s start time
tnt_net_connections_current
Number of active network connections
Requests:
tnt_net_requests_total
Number of network requests the instance has handled since its start time
tnt_net_requests_current
Number of pending network requests
Requests in progress:
tnt_net_requests_in_progress_total
Total count of requests processed by tx thread
tnt_net_requests_in_progress_current
Count of requests currently being processed in the tx thread
Requests placed in queues of streams:
tnt_net_requests_in_stream_total
Total count of requests, which was placed in queues of streams
for all time
tnt_net_requests_in_stream_current
Count of requests currently waiting in queues of streams
Since Tarantool 2.10 in each network metric has the label thread, showing per-thread network statistics.
Fibers
Provides the statistics for fibers.
If your application creates a lot of fibers,
you can use the metrics below to monitor fiber count and memory usage.
tnt_fiber_amount
Number of fibers
tnt_fiber_csw
Overall number of fiber context switches
tnt_fiber_memalloc
Amount of memory reserved for fibers
tnt_fiber_memused
Amount of memory used by fibers
Operations
You can collect iproto requests an instance has processed
and aggregate them by request type.
This may help you find out what operations your clients perform most often.
tnt_stats_op_total
Total number of calls since server start
To distinguish between request types, this metric has the operation label.
For example, it can look as follows: {operation="select"}.
For the possible request types, check the table below.
LSN number in vclock.
This metric always has the label {id="id"},
where id is the instance’s number in the replica set.
tnt_replication_lsn
LSN of the tarantool instance.
This metric always has labels {id="id",type="type"}, where
id is the instance’s number in the replica set,
type is master or replica.
tnt_replication_lag
Replication lag value in seconds.
This metric always has labels {id="id",stream="stream"},
where id is the instance’s number in the replica set,
stream is downstream or upstream.
tnt_replication_status
This metrics equals 1 when replication status is “follow” and 0 otherwise.
This metric always has labels {id="id",stream="stream"},
where id is the instance’s number in the replica set,
stream is downstream or upstream.
Runtime
tnt_runtime_lua
Lua garbage collector size in bytes
tnt_runtime_used
Number of bytes used for the Lua runtime
tnt_runtime_tuple
Number of bytes used for the tuples (except tuples owned by memtx and vinyl)
LuaJIT metrics
LuaJIT metrics provide an insight into the work of the Lua garbage collector.
These metrics are available in Tarantool 2.6 and later.
General JIT metrics:
lj_jit_snap_restore_total
Overall number of snap restores
lj_jit_trace_num
Number of JIT traces
lj_jit_trace_abort_total
Overall number of abort traces
lj_jit_mcode_size
Total size of allocated machine code areas
JIT strings:
lj_strhash_hit_total
Number of strings being interned
lj_strhash_miss_total
Total number of string allocations
GC steps:
lj_gc_steps_atomic_total
Count of incremental GC steps (atomic state)
lj_gc_steps_sweepstring_total
Count of incremental GC steps (sweepstring state)
lj_gc_steps_finalize_total
Count of incremental GC steps (finalize state)
lj_gc_steps_sweep_total
Count of incremental GC steps (sweep state)
lj_gc_steps_propagate_total
Count of incremental GC steps (propagate state)
lj_gc_steps_pause_total
Count of incremental GC steps (pause state)
Allocations:
lj_gc_strnum
Number of allocated string objects
lj_gc_tabnum
Number of allocated table objects
lj_gc_cdatanum
Number of allocated cdata objects
lj_gc_udatanum
Number of allocated udata objects
lj_gc_freed_total
Total amount of freed memory
lj_gc_memory
Current allocated Lua memory
lj_gc_allocated_total
Total amount of allocated memory
CPU metrics
The following metrics provide CPU usage statistics.
They are only available on Linux.
tnt_cpu_number
Total number of processors configured by the operating system
tnt_cpu_time
Host CPU time
tnt_cpu_thread
Tarantool thread CPU time.
This metric always has the labels
{kind="user",thread_name="tarantool",thread_pid="pid",file_name="init.lua"},
where:
kind can be either user or system
thread_name is tarantool, wal, iproto, or coio
file_name is the entrypoint file name, for example, init.lua.
There are also two cross-platform metrics, which can be obtained with a getrusage() call.
The disk metrics are used to monitor overall data size on disk.
tnt_vinyl_disk_data_size
Amount of data in bytes stored in the .run files
located in vinyl_dir
tnt_vinyl_disk_index_size
Amount of data in bytes stored in the .index files
located in vinyl_dir
Regulator
The vinyl regulator decides when to commence disk IO actions.
It groups activities in batches so that they are more consistent and
efficient.
tnt_vinyl_regulator_dump_bandwidth
Estimated average dumping rate, bytes per second.
The rate value is initially 10485760 (10 megabytes per second).
It is recalculated depending on the the actual rate.
Only significant dumps that are larger than 1 MB are used for estimating.
tnt_vinyl_regulator_write_rate
Actual average rate of performing write operations, bytes per second.
The rate is calculated as a 5-second moving average.
If the metric value is gradually going down,
this can indicate disk issues.
tnt_vinyl_regulator_rate_limit
Write rate limit, bytes per second.
The regulator imposes the limit on transactions
based on the observed dump/compaction performance.
If the metric value is down to approximately 10^5,
this indicates issues with the disk
or the scheduler.
tnt_vinyl_regulator_dump_watermark
Maximum amount of memory in bytes used
for in-memory storing of a vinyl LSM tree.
When this maximum is accessed, a dump must occur.
For details, see Filling an LSM tree.
The value is slightly smaller
than the amount of memory allocated for vinyl trees,
reflected in the vinyl_memory parameter.
tnt_vinyl_regulator_blocked_writers
The number of fibers that are blocked waiting
for Vinyl level0 memory quota.
Transactional activity
tnt_vinyl_tx_commit
Counter of commits (successful transaction ends)
Includes implicit commits: for example, any insert operation causes a
commit unless it is within a
box.begin()–box.commit()
block.
tnt_vinyl_tx_rollback
Сounter of rollbacks (unsuccessful transaction ends).
This is not merely a count of explicit
box.rollback()
requests – it includes requests that ended with errors.
tnt_vinyl_tx_conflict
Counter of conflicts that caused transactions to roll back.
The ratio tnt_vinyl_tx_conflict/tnt_vinyl_tx_commit
above 5% indicates that vinyl is not healthy.
At that moment, you’ll probably see a lot of other problems with vinyl.
tnt_vinyl_tx_read_views
Current number of read views – that is, transactions
that entered the read-only state to avoid conflict temporarily.
Usually the value is 0.
If it stays non-zero for a long time, it is indicative of a memory leak.
Memory
The following metrics show state memory areas used by vinyl for caches and write buffers.
tnt_vinyl_memory_tuple_cache
Amount of memory in bytes currently used to store tuples (data)
tnt_vinyl_memory_level0
“Level 0” (L0) memory area, bytes.
L0 is the area that vinyl can use for in-memory storage of an LSM tree.
By monitoring this metric, you can see when L0 is getting close to its
maximum (tnt_vinyl_regulator_dump_watermark),
at which time a dump will occur.
You can expect L0 = 0 immediately after the dump operation is completed.
tnt_vinyl_memory_page_index
Amount of memory in bytes currently used to store indexes.
If the metric value is close to vinyl_memory,
this indicates that vinyl_page_size
was chosen incorrectly.
Total size of memory in bytes occupied by Vinyl tuples.
It includes cached tuples and tuples pinned by the Lua world.
Scheduler
The vinyl scheduler invokes the regulator and
updates the related variables. This happens once per second.
tnt_vinyl_scheduler_tasks
Number of scheduler dump/compaction tasks.
The metric always has label {status=<status_value>},
where <status_value> can be one of the following:
inprogress for currently running tasks
completed for successfully completed tasks
failed for tasks aborted due to errors.
tnt_vinyl_scheduler_dump_time
Total time in seconds spent by all worker threads performing dumps.
tnt_vinyl_scheduler_dump_total
Counter of dumps completed.
Event loop metrics
Event loop tx thread information:
tnt_ev_loop_time
Event loop time (ms)
tnt_ev_loop_prolog_time
Event loop prolog time (ms)
tnt_ev_loop_epilog_time
Event loop epilog time (ms)
Synchro
Shows the current state of a synchronous replication.
tnt_synchro_queue_owner
Instance ID of the current synchronous replication master.
tnt_synchro_queue_term
Current queue term.
tnt_synchro_queue_len
How many transactions are collecting confirmations now.
tnt_synchro_queue_busy
Whether the queue is processing any system entry (CONFIRM/ROLLBACK/PROMOTE/DEMOTE).
Election
Shows the current state of a replica set node in regards to leader election.
tnt_election_state
Election state (mode) of the node.
When election is enabled, the node is writable only in the leader state.
Possible values:
0 (follower): all the non-leader nodes are called followers
1 (candidate): the nodes that start a new election round are called candidates.
2 (leader): the node that collected a quorum of votes becomes the leader
tnt_election_vote
ID of a node the current node votes for.
If the value is 0, it means the node hasn’t voted in the current term yet.
tnt_election_leader
Leader node ID in the current term.
If the value is 0, it means the node doesn’t know which node is the leader in the current term.
tnt_election_term
Current election term.
tnt_election_leader_idle
Time in seconds since the last interaction with the known leader.
Memtx
Memtx mvcc memory statistics.
Transaction manager consists of two parts:
the transactions themselves (TXN section)
MVCC
TXN
tnt_memtx_tnx_statements are the transaction statements.
For example, the user started a transaction and made an action in it space:replace{0,1}.
Under the hood, this operation will turn into statement for the current transaction.
This metric always has the label {kind="..."},
which has the following possible values:
total: the number of bytes that are allocated for the statements of all current transactions.
average: average bytes used by transactions for statements
(txn.statements.total bytes / number of open transactions).
max: the maximum number of bytes used by one the current transaction for statements.
tnt_memtx_tnx_user
In Tarantool C API there is a function box_txn_alloc().
By using this function user can allocate memory for the current transaction.
This metric always has the label {kind="..."},
which has the following possible values:
total: memory allocated by the box_txn_alloc() function on all current transactions.
average: transaction average (total allocated bytes / number of all current transactions).
max: the maximum number of bytes allocated by box_txn_alloc() function per transaction.
tnt_memtx_tnx_system
There are internals: logs, savepoints.
This metric always has the label {kind="..."},
which has the following possible values:
total: memory allocated by internals on all current transactions.
average: average allocated memory by internals (total memory / number of all current transactions).
max: the maximum number of bytes allocated by internals per transaction.
MVCC
mvcc is responsible for the isolation of transactions.
It detects conflicts and makes sure that tuples that are no longer in the space, but read by some transaction
(or can be read) have not been deleted.
tnt_memtx_mvcc_trackers
Trackers that keep track of transaction reads.
This metric always has the label {kind="..."},
which has the following possible values:
total: trackers of all current transactions are allocated in total (in bytes).
average: average for all current transactions (total memory bytes / number of transactions).
max: maximum trackers allocated per transaction (in bytes).
tnt_memtx_mvcc_conflicts
Allocated in case of transaction conflicts.
This metric always has the label {kind="..."},
which has the following possible values:
total: bytes allocated for conflicts in total.
average: average for all current transactions (total memory bytes / number of transactions).
max: maximum bytes allocated for conflicts per transaction.
Tuples
Saved tuples are divided into 3 categories: used, read_view, tracking.
Each category has two metrics:
retained tuples - they are no longer in the index, but MVCC does not allow them to be removed.
stories - MVCC is based on the story mechanism, almost every tuple has a story.
This is a separate metric because even the tuples that are in the index can have a story.
So stories and retained need to be measured separately.
tnt_memtx_mvcc_tuples_used_stories
Tuples that are used by active read-write transactions.
This metric always has the label {kind="..."},
which has the following possible values:
count: number of used tuples / number of stories.
total: amount of bytes used by stories used tuples.
tnt_memtx_mvcc_tuples_used_retained
Tuples that are used by active read-write transactions.
But they are no longer in the index, but MVCC does not allow them to be removed.
This metric always has the label {kind="..."},
which has the following possible values:
count: number of retained used tuples / number of stories.
total: amount of bytes used by retained used tuples.
tnt_memtx_mvcc_tuples_read_view_stories
Tuples that are not used by active read-write transactions,
but are used by read-only transactions (i.e. in read view).
This metric always has the label {kind="..."},
which has the following possible values:
count: number of read_view tuples / number of stories.
total: amount of bytes used by stories read_view tuples.
tnt_memtx_mvcc_tuples_read_view_retained
Tuples that are not used by active read-write transactions,
but are used by read-only transactions (i.e. in read view).
This tuples are no longer in the index, but MVCC does not allow them to be removed.
This metric always has the label {kind="..."},
which has the following possible values:
count: number of retained read_view tuples / number of stories.
total: amount of bytes used by retained read_view tuples.
tnt_memtx_mvcc_tuples_tracking_stories
Tuples that are not directly used by any transactions, but are used by MVCC to track reads.
This metric always has the label {kind="..."},
which has the following possible values:
count: number of tracking tuples / number of tracking stories.
total: amount of bytes used by stories tracking tuples.
tnt_memtx_mvcc_tuples_tracking_retained
Tuples that are not directly used by any transactions, but are used by MVCC to track reads.
This tuples are no longer in the index, but MVCC does not allow them to be removed.
This metric always has the label {kind="..."},
which has the following possible values:
count: number of retained tracking tuples / number of stories.
total: amount of bytes used by retained tracking tuples.
Read view statistics
tnt_memtx_tuples_data_total
Total amount of memory (in bytes) allocated for data tuples.
This includes tnt_memtx_tuples_data_read_view and
tnt_memtx_tuples_data_garbage metric values plus tuples that
are actually stored in memtx spaces.
tnt_memtx_tuples_data_read_view
Memory (in bytes) held for read views.
tnt_memtx_tuples_data_garbage
Memory (in bytes) that is unused and scheduled to be freed
(freed lazily on memory allocation).
tnt_memtx_index_total
Total amount of memory (in bytes) allocated for indexing data.
This includes tnt_memtx_index_read_view metric value
plus memory used for indexing tuples
that are actually stored in memtx spaces.
Count of current instance configuration apply alerts.
{level="warn"} label covers warnings and
{level="error"} covers errors.
tnt_config_status
The status of current instance configuration apply.
status label contains possible status name.
Current status has metric value 1, inactive statuses have metric value 0.
# HELP tnt_config_status Tarantool 3 configuration status
# TYPE tnt_config_status gauge
tnt_config_status{status="reload_in_progress",alias="router-001-a"} 0
tnt_config_status{status="uninitialized",alias="router-001-a"} 0
tnt_config_status{status="check_warnings",alias="router-001-a"} 0
tnt_config_status{status="ready",alias="router-001-a"} 1
tnt_config_status{status="check_errors",alias="router-001-a"} 0
tnt_config_status{status="startup_in_progress",alias="router-001-a"} 0
For example, this set of metrics means that current configuration
for router-001-a status is ready.
Notes for operating systems
macOS
On macOS, no native system tools for administering Tarantool are supported.
The recommended way to administer Tarantool instances is using tt CLI.
Gentoo Linux
The section below is about a dev-db/tarantool package installed from the
official layman overlay (named tarantool).
The default instance directory is /etc/tarantool/instances.available, can be
redefined in /etc/default/tarantool.
Tarantool instances can be managed (start/stop/reload/status/…) using OpenRC.
Consider the example how to create an OpenRC-managed instance:
In versions of Tarantool before 1.10, the server needs to be restarted
to change this parameter. The Tarantool
server will be unavailable while restarting from .xlog files, unless
you restart it using hot standby mode.
In the latter case, nearly 100% server availability is guaranteed.
In case of heavy memory fragmentation (quota_used_ratio is getting close
to 100%, items_used_ratio is about 50%), we recommend restarting Tarantool
in the hot standby mode.
Attach to the Tarantool instance with tt utility,
analyze the query statistics with box.stat()
and spot the CPU consumption leader. The following commands can help:
$ # attaching to a Tarantool instance$ ttconnect<instance_name|URI>
-- checking the RPS of calling stored procedurestarantool> box.stat().CALL.rps
The critical RPS value is 75 000, boiling down to 10 000 - 20 000 for a rich
Lua application (a Lua module of 200+ lines).
-- checking RPS per query typetarantool> box.stat().<query_type>.rps
The critical RPS value for SELECT/INSERT/UPDATE/DELETE requests is 100 000.
If the load is mostly generated by SELECT requests, we recommend adding a
slave server and let it process part of the
queries.
If the load is mostly generated by INSERT/UPDATE/DELETE requests, we recommend
sharding the database.
Problem: Query processing times out
Possible reasons
Note
All reasons that we discuss here can be identified by messages
in Tarantool’s log file, all starting with the words 'Toolong...'.
Both fast and slow queries are processed within a single connection, so the
readahead buffer is cluttered with slow queries.
This parameter can be changed on the fly, so you don’t need to restart
Tarantool. Attach to the Tarantool instance with
tt utility and call box.cfg{} with a
new readahead value:
$ # attaching to a Tarantool instance$ ttconnect<instance_name|URI>
-- changing the readahead valuetarantool> box.cfg{readahead=10*1024*1024}
Example: Given 1000 RPS, 1 Кbyte of query size, and 10 seconds of
maximal query processing time, the minimal readahead buffer size must be
10 Mbytes.
On the business logic level, split fast and slow queries processing by
different connections.
Slow disks.
Solution
Check disk performance (use iostat,
iotop or
strace utility to
check iowait parameter) and try to put .xlog files and snapshot files on
different physical disks (i.e. use different locations for
wal_dir and memtx_dir).
Problem: Replication “lag” and “idle” contain negative values
This is about box.info.replication.(upstream.)lag and
box.info.replication.(upstream.)idle values in
box.info.replication section.
Possible reasons
Operating system clock on the hosts is not synchronized, or the NTP server is
faulty.
Solution
Check NTP server settings.
If you found no problems with the NTP server, just do nothing then.
Lag calculation uses operating system clock from two different machines.
If they get out of sync, the remote master clock can get consistently behind
the local instance’s clock.
Problem: Replication “idle” keeps growing, but no related log messages appear
This is about box.info.replication.(upstream.)idle value in
box.info.replication section.
Possible reasons
Some server was assigned different IP addresses, or some server was specified
twice in box.cfg{}, so duplicate connections were established.
Solution
Upgrade Tarantool 1.6 to 1.7, where this error
is fixed: in case of duplicate connections, replication is stopped and the
following message is added to the log:
'Incorrectvalueforoption''replication_source'':duplicateconnectionwiththesamereplicaUUID'.
Problem: Replication statistics differ on replicas within a replica set
This is about a replica set that consists of one master and several replicas.
In a replica set of this type, values in
box.info.replication section, like
box.info.replication.lsn, come from the master and must be the same on all
replicas within the replica set. The problem is that they get different.
In a master-master replica set of two Tarantool instances, one of the masters
has tried to perform an action already performed by the other server,
for example re-insert a tuple with the same unique key. This would cause an
error message like
'Duplicatekeyexistsinuniqueindex'primary'inspace<space_name>'.
Solution
This issue can be fixed in two ways:
Manually: reseed one master from another by removing write-ahead logs and snapshots.
$ # attaching to a Tarantool instance$ ttconnect<instance_name|URI>
-- loading Tarantool's "clock" module with time-related routinestarantool> clock=require'clock'-- starting the timertarantool> b=clock.proc()-- launching garbage collectiontarantool> c=collectgarbage('count')-- stopping the timer after garbage collection is completedtarantool> returnc,clock.proc()-b
If the returned clock.proc() value is greater than 0.001, this may be an
indicator of inefficient memory usage (no active measures are required, but we
recommend to optimize your Tarantool application code).
If the value is greater than 0.01, your application definitely needs thorough
code analysis aimed at optimizing memory usage.
Problem: Fiber switch is forbidden in ‘__gc’ metamethod
Problem description
Fiber switch is forbidden in __gc metamethod since this change
to avoid unexpected Lua OOM.
However, one may need to use a yielding function to finalize resources,
for example, to close a socket.
Below are examples of proper implementing such a procedure.
Solution
First, there come two simple examples illustrating the logic of the
solution:
Next comes the Example 3 illustrating
the usage of the sched.lua module that is the recommended method.
All the explanations are given in the comments in the code listing.
--> indicates the output in console.
Example 1
Implementing a valid finalizer for a particular FFI type (custom_t).
localffi=require('ffi')localfiber=require('fiber')ffi.cdef('struct custom { int a; };')localfunction__custom_gc(self)print(("Entered custom GC finalizer for %s... (before yield)"):format(self.a))fiber.yield()print(("Leaving custom GC finalizer for %s... (after yield)"):format(self.a))endlocalcustom_t=ffi.metatype('struct custom',{__gc=function(self)-- XXX: Do not invoke yielding functions in __gc metamethod.-- Create a new fiber to run after the execution leaves-- this routine.fiber.new(__custom_gc,self)print(("Finalization is scheduled for %s..."):format(self.a))end})-- Create a cdata object of <custom_t> type.localc=custom_t(42)-- Remove a single reference to that object to make it subject-- for GC.c=nil-- Run full GC cycle to purge the unreferenced object.collectgarbage('collect')-- > Finalization is scheduled for 42...-- XXX: There is no finalization made until the running fiber-- yields its execution. Let's do it now.fiber.yield()-- > Entered custom GC finalizer for 42... (before yield)-- > Leaving custom GC finalizer for 42... (after yield)
Example 2
Implementing a valid finalizer for a particular user type (structcustom).
custom.c
#include<lauxlib.h>#include<lua.h>#include<module.h>#include<stdio.h>structcustom{inta;};constchar*CUSTOM_MTNAME="CUSTOM_MTNAME";/* * XXX: Do not invoke yielding functions in __gc metamethod. * Create a new fiber to be run after the execution leaves * this routine. Unfortunately we can't pass the parameters to the * routine to be executed by the created fiber via <fiber_new_ex>. * So there is a workaround to load the Lua code below to create * __gc metamethod passing the object for finalization via Lua * stack to the spawned fiber. */constchar*gc_wrapper_constructor=" local fiber = require('fiber') "" print('constructor is initialized') "" return function(__custom_gc) "" print('constructor is called') "" return function(self) "" print('__gc is called') "" fiber.new(__custom_gc, self) "" print('Finalization is scheduled') "" end "" end ";intcustom_gc(lua_State*L){structcustom*self=luaL_checkudata(L,1,CUSTOM_MTNAME);printf("Entered custom_gc for %d... (before yield)\n",self->a);fiber_sleep(0);printf("Leaving custom_gc for %d... (after yield)\n",self->a);return0;}intcustom_new(lua_State*L){structcustom*self=lua_newuserdata(L,sizeof(structcustom));luaL_getmetatable(L,CUSTOM_MTNAME);lua_setmetatable(L,-2);self->a=lua_tonumber(L,1);return1;}staticconststructluaL_Reglibcustom_methods[]={{"new",custom_new},{NULL,NULL}};intluaopen_custom(lua_State*L){intrc;/* Create metatable for struct custom type */luaL_newmetatable(L,CUSTOM_MTNAME);/* * Run the constructor initializer for GC finalizer: * - load fiber module as an upvalue for GC finalizer * constructor * - return GC finalizer constructor on the top of the * Lua stack */rc=luaL_dostring(L,gc_wrapper_constructor);/* * Check whether constructor is initialized (i.e. neither * syntax nor runtime error is raised). */if(rc!=LUA_OK)luaL_error(L,"test module loading failed: constructor init");/* * Create GC object for <custom_gc> function to be called * in scope of the GC finalizer and push it on top of the * constructor returned before. */lua_pushcfunction(L,custom_gc);/* * Run the constructor with <custom_gc> GCfunc object as * a single argument. As a result GC finalizer is returned * on the top of the Lua stack. */rc=lua_pcall(L,1,1,0);/* * Check whether GC finalizer is created (i.e. neither * syntax nor runtime error is raised). */if(rc!=LUA_OK)luaL_error(L,"test module loading failed: __gc init");/* * Assign the returned function as a __gc metamethod to * custom type metatable. */lua_setfield(L,-2,"__gc");/* * Initialize Lua table for custom module and fill it * with the custom methods. */lua_newtable(L);luaL_register(L,NULL,libcustom_methods);return1;}
custom_c.lua
-- Load custom Lua C extension.localcustom=require('custom')-- > constructor is initialized-- > constructor is called-- Create a userdata object of <struct custom> type.localc=custom.new(9)-- Remove a single reference to that object to make it subject-- for GC.c=nil-- Run full GC cycle to purge the unreferenced object.collectgarbage('collect')-- > __gc is called-- > Finalization is scheduled-- XXX: There is no finalization made until the running fiber-- yields its execution. Let's do it now.require('fiber').yield()-- > Entered custom_gc for 9... (before yield)-- XXX: Finalizer yields the execution, so now we are here.print('We are here')-- > We are here-- XXX: This fiber finishes its execution, so yield to the-- remaining fiber to finish the postponed finalization.-- > Leaving custom_gc for 9... (after yield)
Example 3
It is important to note that the finalizer implementations in the examples above
increase pressure on the platform performance by creating a new fiber on each
__gc call. To prevent such an excessive fibers spawning, it’s better to start
a single “scheduler” fiber and provide the interface to postpone the required
asynchronous action.
For this purpose, the module called sched.lua is implemented (see the
listing below). It is a part of Tarantool and should be made required in your
custom code. The usage example is given in the init.lua file below.
sched.lua
localfiber=require('fiber')localworker_next_task=nillocalworker_last_tasklocalworker_fiberlocalworker_cv=fiber.cond()-- XXX: the module is not ready for reloading, so worker_fiber is-- respawned when sched.lua is purged from package.loaded.---- Worker is a singleton fiber for not urgent delayed execution of-- functions. Main purpose - schedule execution of a function,-- which is going to yield, from a context, where a yield is not-- allowed. Such as an FFI object's GC callback.--localfunctionworker_f()whiletruedolocaltaskwhiletruedotask=worker_next_taskiftaskthenbreakend-- XXX: Make the fiber wait until the task is added.worker_cv:wait()endworker_next_task=task.nexttask.f(task.arg)fiber.yield()endendlocalfunctionworker_safe_f()pcall(worker_f)-- The function <worker_f> never returns. If the execution is-- here, this fiber is probably canceled and now is not able to-- sleep. Create a new one.worker_fiber=fiber.new(worker_safe_f)endworker_fiber=fiber.new(worker_safe_f)localfunctionworker_schedule_task(f,arg)localtask={f=f,arg=arg}ifnotworker_next_taskthenworker_next_task=taskelseworker_last_task.next=taskendworker_last_task=taskworker_cv:signal()endreturn{postpone=worker_schedule_task}
init.lua
localffi=require('ffi')localfiber=require('fiber')localsched=require('sched')localfunction__custom_gc(self)print(("Entered custom GC finalizer for %s... (before yield)"):format(self.a))fiber.yield()print(("Leaving custom GC finalizer for %s... (after yield)"):format(self.a))endffi.cdef('struct custom { int a; };')localcustom_t=ffi.metatype('struct custom',{__gc=function(self)-- XXX: Do not invoke yielding functions in __gc metamethod.-- Schedule __custom_gc call via sched.postpone to be run-- after the execution leaves this routine.sched.postpone(__custom_gc,self)print(("Finalization is scheduled for %s..."):format(self.a))end})-- Create several <custom_t> objects to be finalized later.localt={}fori=1,10dot[i]=custom_t(i)end-- Run full GC cycle to collect the existing garbage. Nothing is-- going to be printed, since the table <t> is still "alive".collectgarbage('collect')-- Remove the reference to the table and, ergo, all references to-- the objects.t=nil-- Run full GC cycle to collect the table and objects inside it.-- As a result all <custom_t> objects are scheduled for further-- finalization, but the finalizer itself (i.e. __custom_gc-- functions) is not called.collectgarbage('collect')-- > Finalization is scheduled for 10...-- > Finalization is scheduled for 9...-- > ...-- > Finalization is scheduled for 2...-- > Finalization is scheduled for 1...-- XXX: There is no finalization made until the running fiber-- yields its execution. Let's do it now.fiber.yield()-- > Entered custom GC finalizer for 10... (before yield)-- XXX: Oops, we are here now, since the scheduler fiber yielded-- the execution to this one. Check this out.print("We're here now. Let's continue the scheduled finalization.")-- > We're here now. Let's continue the finalization-- OK, wait a second to allow the scheduler to cleanup the-- remaining garbage.fiber.sleep(1)-- > Leaving custom GC finalizer for 10... (after yield)-- > Entered custom GC finalizer for 9... (before yield)-- > Leaving custom GC finalizer for 9... (after yield)-- > ...-- > Entered custom GC finalizer for 1... (before yield)-- > Leaving custom GC finalizer for 1... (after yield)print("Did we finish? I guess so.")-- > Did we finish? I guess so.-- Stop the instance.os.exit(0)
Connectors
Connectors are APIs that allow using Tarantool with various programming languages.
Connectors can be divided into two groups – those maintained by the Tarantool team
and those supported by the community.
The Tarantool team maintains the following connectors:
All other connectors are community-supported, which means that support for new Tarantool features may be delayed.
Find all the available connectors on the Connectors page.
Protocol
Tarantool’s binary protocol was designed with a focus on asynchronous I/O and
easy integration with proxies. Each client request starts with a variable-length
binary header, containing request id, request type, instance id, log sequence
number, and so on.
The mandatory length, present in request header simplifies client or proxy I/O.
A response to a request is sent to the client as soon as it is ready. It always
carries in its header the same type and id as in the request. The id makes it
possible to match a request to a response, even if the latter arrived out of
order.
Unless implementing a client driver, you needn’t concern yourself with the
complications of the binary protocol. Language-specific drivers provide a
friendly way to store domain language data structures in Tarantool. A complete
description of the binary protocol is maintained in annotated Backus-Naur form
in the source tree. For detailed examples and diagrams of all binary-protocol
requests and responses, see
Tarantool’s binary protocol.
Packet example
The Tarantool API exists so that a client program can send a request packet to
a server instance, and receive a response. Here is an example of a what the client
would send for box.space[513]:insert{'A','BB'}. The BNF description of
the components is on the page about
Tarantool’s binary protocol.
Component
Byte #0
Byte #1
Byte #2
Byte #3
code for insert
02
rest of header
…
…
…
…
2-digit number: space id
cd
02
01
code for tuple
21
1-digit number: field count = 2
92
1-character string: field[1]
a1
41
2-character string: field[2]
a2
42
42
Now, you could send that packet to the Tarantool instance, and interpret the
response (the page about
Tarantool’s binary protocol has a
description of the packet format for responses as well as requests). But it
would be easier, and less error-prone, if you could invoke a routine that
formats the packet according to typed parameters. Something like
response=tarantool_routine("insert",513,"A","B");. And that is why APIs
exist for drivers for Perl, Python, PHP, and so on.
Setting up the server for connector examples
This chapter has examples that show how to connect to a Tarantool instance via
the Perl, PHP, Python, node.js, and C connectors. The examples contain hard code that
will work if and only if the following conditions are met:
the Tarantool instance (tarantool) is running on localhost (127.0.0.1) and is listening on
port 3301 (box.cfg.listen='3301'),
space examples has id = 999 (box.space.examples.id=999) and has
a primary-key index for a numeric field
(box.space[999].index[0].parts[1].type="unsigned"),
user ‘guest’ has privileges for reading and writing.
It is easy to meet all the conditions by starting the instance and executing this
script:
For all connectors, calling a function via Tarantool causes a return in the
MsgPack format. If the function is called using the connector’s API, some
conversions may occur. All scalar values are returned as tuples (with a MsgPack
type-identifier followed by a value); all non-scalar values are returned as a
group of tuples (with a MsgPack array-identifier followed by the scalar values).
If the function is called via the binary protocol command layer – “eval” –
rather than via the connector’s API, no conversions occur.
In the following example, a Lua function will be created. Since it will be
accessed externally by a ‘guest’ user, a
grant of an execute privilege will
be necessary. The function returns an empty array, a scalar string, two booleans,
and a short integer. The values are the ones described in the table
Common Types and MsgPack Encodings.
Here is a C program which calls the function. Although C is being used for the
example, the result would be precisely the same if the calling program was
written in Perl, PHP, Python, Go, or Java.
#include<stdio.h>#include<stdlib.h>#include<tarantool/tarantool.h>#include<tarantool/tnt_net.h>#include<tarantool/tnt_opt.h>voidmain(){structtnt_stream*tnt=tnt_net(NULL);/* SETUP */tnt_set(tnt,TNT_OPT_URI,"localhost:3301");if(tnt_connect(tnt)<0){/* CONNECT */printf("Connection refused\n");exit(-1);}structtnt_stream*arg;arg=tnt_object(NULL);/* MAKE REQUEST */tnt_object_add_array(arg,0);structtnt_request*req1=tnt_request_call(NULL);/* CALL function f() */tnt_request_set_funcz(req1,"f");uint64_tsync1=tnt_request_compile(tnt,req1);tnt_flush(tnt);/* SEND REQUEST */structtnt_replyreply;tnt_reply_init(&reply);/* GET REPLY */tnt->read_reply(tnt,&reply);if(reply.code!=0){printf("Call failed %lu.\n",reply.code);exit(-1);}constunsignedchar*p=(unsignedchar*)reply.data;/* PRINT REPLY */while(p<(unsignedchar*)reply.data_end){printf("%x ",*p);++p;}printf("\n");tnt_close(tnt);/* TEARDOWN */tnt_stream_free(arg);tnt_stream_free(tnt);}
go-tarantool is the official Go connector for Tarantool.
It is not supplied as part of the Tarantool repository and should be installed separately.
This tutorial shows how to use the go-tarantool 2.x library to create a Go application that connects to a remote Tarantool instance, performs CRUD operations, and executes a stored procedure.
You can find the full package documentation here: Client in Go for Tarantool.
Note
This tutorial shows how to make CRUD requests to a single-instance Tarantool database.
To make requests to a sharded Tarantool cluster with the CRUD module, use the crud package’s API.
Sample database configuration
This section describes the configuration of a sample database that allows remote connections:
The configuration contains one instance that listens for incoming requests on the 127.0.0.1:3301 address.
sampleuser has privileges to select and modify data in the bands space and execute the get_bands_older_than stored function. This user can be used to connect to the instance remotely.
myapp.lua defines the data model and a stored function.
The myapp.lua file looks as follows:
-- Create a space --box.schema.space.create('bands')-- Specify field names and types --box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})-- Create indexes --box.space.bands:create_index('primary',{parts={'id'}})box.space.bands:create_index('band',{parts={'band_name'}})box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})-- Create a stored function --box.schema.func.create('get_bands_older_than',{body=[[ function(year) return box.space.bands.index.year_band:select({ year }, { iterator = 'LT', limit = 10 }) end ]]})
You can find the full example on GitHub: sample_db.
Starting a sample database application
Before creating and starting a client Go application, you need to run the sample_db application using tt start:
$ ttstartsample_db
Now you can create a client Go application that makes requests to this database.
Developing a client application
Before you start, make sure you have Go installed on your computer.
Creating an application
Create the hello directory for your application and go to this directory:
$ mkdirhello
$ cdhello
Initialize a new Go module:
$ gomodinitexample/hello
Inside the hello directory, create the hello.go file for application code.
Importing ‘go-tarantool’ packages
In the hello.go file, declare a main package and import the following packages:
The packages for external MsgPack types, such as datetime, decimal, or uuid, are required to parse these types in a response.
Connecting to the database
Declare the main() function:
funcmain(){}
Inside the main() function, add the following code:
// Connect to the databasectx,cancel:=context.WithTimeout(context.Background(),time.Second)defercancel()dialer:=tarantool.NetDialer{Address:"127.0.0.1:3301",User:"sampleuser",Password:"123456",}opts:=tarantool.Opts{Timeout:time.Second,}conn,err:=tarantool.Connect(ctx,dialer,opts)iferr!=nil{fmt.Println("Connection refused:",err)return}// Interact with the database// ...
This code establishes a connection to a running Tarantool instance on behalf of sampleuser.
The conn object can be used to make CRUD requests and execute stored procedures.
Manipulating data
Inserting data
Add the following code to insert four tuples into the bands space:
// Insert datatuples:=[][]interface{}{{1,"Roxette",1986},{2,"Scorpions",1965},{3,"Ace of Base",1987},{4,"The Beatles",1960},}varfutures[]*tarantool.Futurefor_,tuple:=rangetuples{request:=tarantool.NewInsertRequest("bands").Tuple(tuple)futures=append(futures,conn.Do(request))}fmt.Println("Inserted tuples:")for_,future:=rangefutures{result,err:=future.Get()iferr!=nil{fmt.Println("Got an error:",err)}else{fmt.Println(result)}}
This code makes insert requests asynchronously:
The Future structure is used as a handle for asynchronous requests.
The NewInsertRequest() method creates an insert request object that is executed by the connection.
Note
Making requests asynchronously is the recommended way to perform data operations.
Further requests in this tutorial are made synchronously.
Querying data
To get a tuple by the specified primary key value, use NewSelectRequest() to create an insert request object:
// Select by primary keydata,err:=conn.Do(tarantool.NewSelectRequest("bands").Limit(10).Iterator(tarantool.IterEq).Key([]interface{}{uint(1)}),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Tuple selected by the primary key value:",data)
You can also get a tuple by the value of the specified index by using Index():
// Select by secondary keydata,err=conn.Do(tarantool.NewSelectRequest("bands").Index("band").Limit(10).Iterator(tarantool.IterEq).Key([]interface{}{"The Beatles"}),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Tuple selected by the secondary key value:",data)
Updating data
NewUpdateRequest() can be used to update a tuple identified by the primary key as follows:
// Updatedata,err=conn.Do(tarantool.NewUpdateRequest("bands").Key(tarantool.IntKey{2}).Operations(tarantool.NewOperations().Assign(1,"Pink Floyd")),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Updated tuple:",data)
NewUpsertRequest() can be used to update an existing tuple or insert a new one.
In the example below, a new tuple is inserted:
// Upsertdata,err=conn.Do(tarantool.NewUpsertRequest("bands").Tuple([]interface{}{uint(5),"The Rolling Stones",1962}).Operations(tarantool.NewOperations().Assign(1,"The Doors")),).Get()iferr!=nil{fmt.Println("Got an error:",err)}
In this example, NewReplaceRequest() is used to delete the existing tuple and insert a new one:
// Replacedata,err=conn.Do(tarantool.NewReplaceRequest("bands").Tuple([]interface{}{1,"Queen",1970}),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Replaced tuple:",data)
Deleting data
NewDeleteRequest() in the example below is used to delete a tuple whose primary key value is 5:
// Deletedata,err=conn.Do(tarantool.NewDeleteRequest("bands").Key([]interface{}{uint(5)}),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Deleted tuple:",data)
Executing stored procedures
To execute a stored procedure, use NewCallRequest():
// Calldata,err=conn.Do(tarantool.NewCallRequest("get_bands_older_than").Args([]interface{}{1966}),).Get()iferr!=nil{fmt.Println("Got an error:",err)}fmt.Println("Stored procedure result:",data)
Closing the connection
The CloseGraceful() method can be used to close the connection when it is no longer needed:
// Close connectionconn.CloseGraceful()fmt.Println("Connection is closed")
Note
You can find the example with all the requests above on GitHub: go.
Starting a client application
Execute the following goget commands to update dependencies in the go.mod file:
Can mimic a Tarantool instance (also as replica). Provides instrumentation for reading snapshot and xlog files
via snapio module.
Implements unpacking of query structs if you want to implement your own iproto proxy
API is experimental and breaking changes may happen
Java
There are two Java connectors available:
cartridge-java
supports both single Tarantool nodes and clusters,
as well as applications built using the
Cartridge framework and its modules.
The Tarantool team actively updates this module with the newest Tarantool features.
tarantool-java
works with early Tarantool versions (1.6 and later)
and offers JDBC interface support for single Tarantool nodes.
This module isn’t currently maintained and
does not support the newest 2.x Tarantool features or Tarantool clusters.
The following modules support Java libraries and frameworks:
Here follow two examples of using Tarantool’s high-level C API.
Example 1
Here is a complete C program that inserts [99999,'B'] into
space examples via the high-level C API.
#include<stdio.h>#include<stdlib.h>#include<tarantool/tarantool.h>#include<tarantool/tnt_net.h>#include<tarantool/tnt_opt.h>voidmain(){structtnt_stream*tnt=tnt_net(NULL);/* See note = SETUP */tnt_set(tnt,TNT_OPT_URI,"localhost:3301");if(tnt_connect(tnt)<0){/* See note = CONNECT */printf("Connection refused\n");exit(-1);}structtnt_stream*tuple=tnt_object(NULL);/* See note = MAKE REQUEST */tnt_object_format(tuple,"[%d%s]",99999,"B");tnt_insert(tnt,999,tuple);/* See note = SEND REQUEST */tnt_flush(tnt);structtnt_replyreply;tnt_reply_init(&reply);/* See note = GET REPLY */tnt->read_reply(tnt,&reply);if(reply.code!=0){printf("Insert failed %lu.\n",reply.code);}tnt_close(tnt);/* See below = TEARDOWN */tnt_stream_free(tuple);tnt_stream_free(tnt);}
Paste the code into a file named example.c and install tarantool-c.
One way to install tarantool-c (using Ubuntu) is:
$ # sometimes this is necessary:$ exportLD_LIBRARY_PATH=/usr/local/lib
$ gcc-oexampleexample.c-ltarantool
Before trying to run,
check that a server instance is listening at localhost:3301 and that the space
examples exists, as
described earlier.
To run the program, say ./example. The program will connect
to the Tarantool instance, and will send the request.
If Tarantool is not running on localhost with listen address = 3301, the program
will print “Connection refused”.
If the insert fails, the program will print “Insert failed” and an error number
(see all error codes in the source file
/src/box/errcode.h).
Here are notes corresponding to comments in the example program.
In this program, the stream will be named tnt.
Before connecting on the tnt stream, some options may have to be set.
The most important option is TNT_OPT_URI.
In this program, the URI is localhost:3301, since that is where the
Tarantool instance is supposed to be listening.
Function description:
struct tnt_stream *tnt_net(struct tnt_stream *s)
int tnt_set(struct tnt_stream *s, int option, variant option-value)
CONNECT
Now that the stream named tnt exists and is associated with a
URI, this example program can connect to a server instance.
The connection might fail for a variety of reasons, such as:
the server is not running, or the URI contains an invalid password.
If the connection fails, the return value will be -1.
MAKE REQUEST
Most requests require passing a structured value, such as
the contents of a tuple.
In this program, the request will
be an INSERT, and the tuple contents will be an integer
and a string. This is a simple serial set of values, that
is, there are no sub-structures or arrays. Therefore it
is easy in this case to format what will be passed using
the same sort of arguments that one would use with a C
printf() function: %d for the integer, %s for the string,
then the integer value, then a pointer to the string value.
The database-manipulation requests are analogous to the
requests in the box library.
tnt_insert(tnt,999,tuple);tnt_flush(tnt);
In this program, the choice is to do an INSERT request, so
the program passes the tnt_stream that was used for connection
(tnt) and the tnt_stream that was set up with
tnt_object_format() (tuple).
When a session ends, the connection that was made with
tnt_connect() should be closed, and the objects that were
made in the setup should be destroyed.
Here is a complete C program that selects, using index key [99999], from
space examples via the high-level C API.
To display the results, the program uses functions in the
MsgPuck library which allow decoding of
MessagePack arrays.
#include<stdio.h>#include<stdlib.h>#include<tarantool/tarantool.h>#include<tarantool/tnt_net.h>#include<tarantool/tnt_opt.h>#define MP_SOURCE 1#include<msgpuck.h>voidmain(){structtnt_stream*tnt=tnt_net(NULL);tnt_set(tnt,TNT_OPT_URI,"localhost:3301");if(tnt_connect(tnt)<0){printf("Connection refused\n");exit(1);}structtnt_stream*tuple=tnt_object(NULL);tnt_object_format(tuple,"[%d]",99999);/* tuple = search key */tnt_select(tnt,999,0,UINT32_MAX,0,0,tuple);tnt_flush(tnt);structtnt_replyreply;tnt_reply_init(&reply);tnt->read_reply(tnt,&reply);if(reply.code!=0){printf("Select failed.\n");exit(1);}charfield_type;field_type=mp_typeof(*reply.data);if(field_type!=MP_ARRAY){printf("no tuple array\n");exit(1);}longunsignedintrow_count;uint32_ttuple_count=mp_decode_array(&reply.data);printf("tuple count=%u\n",tuple_count);unsignedinti,j;for(i=0;i<tuple_count;++i){field_type=mp_typeof(*reply.data);if(field_type!=MP_ARRAY){printf("no field array\n");exit(1);}uint32_tfield_count=mp_decode_array(&reply.data);printf(" field count=%u\n",field_count);for(j=0;j<field_count;++j){field_type=mp_typeof(*reply.data);if(field_type==MP_UINT){uint64_tnum_value=mp_decode_uint(&reply.data);printf(" value=%lu.\n",num_value);}elseif(field_type==MP_STR){constchar*str_value;uint32_tstr_value_length;str_value=mp_decode_str(&reply.data,&str_value_length);printf(" value=%.*s.\n",str_value_length,str_value);}else{printf("wrong field type\n");exit(1);}}}tnt_close(tnt);tnt_stream_free(tuple);tnt_stream_free(tnt);}
Similarly to the first example, paste the code into a file named
example2.c.
To compile and link the program, say:
$ gcc-oexample2example2.c-ltarantool
To run the program, say ./example2.
The two example programs only show a few requests and do not show all that’s
necessary for good practice. See more in the
tarantool-c documentation at GitHub.
tarantool-python
is the official Python connector for Tarantool. It is not supplied as part
of the Tarantool repository and must be installed separately.
The tutorial shows how to use the tarantool-python library to create a Python script that connects to a remote Tarantool instance, performs CRUD operations, and executes a stored procedure.
You can find the full package documentation here: Python client library for Tarantool.
Note
This tutorial shows how to make CRUD requests to a single-instance Tarantool database.
To make requests to a sharded Tarantool cluster with the CRUD module, use the tarantool.crud module’s API.
Sample database configuration
This section describes the configuration of a sample database that allows remote connections:
The configuration contains one instance that listens for incoming requests on the 127.0.0.1:3301 address.
sampleuser has privileges to select and modify data in the bands space and execute the get_bands_older_than stored function. This user can be used to connect to the instance remotely.
myapp.lua defines the data model and a stored function.
The myapp.lua file looks as follows:
-- Create a space --box.schema.space.create('bands')-- Specify field names and types --box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})-- Create indexes --box.space.bands:create_index('primary',{parts={'id'}})box.space.bands:create_index('band',{parts={'band_name'}})box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})-- Create a stored function --box.schema.func.create('get_bands_older_than',{body=[[ function(year) return box.space.bands.index.year_band:select({ year }, { iterator = 'LT', limit = 10 }) end ]]})
You can find the full example on GitHub: sample_db.
Starting a sample database application
Before creating and starting a client Python application, you need to run the sample_db application using tt start:
$ ttstartsample_db
Now you can create a client Python application that makes requests to this database.
Developing a client application
Before you start, make sure you have Python installed on your computer.
Creating an application
Create the hello directory for your application and go to this directory:
$ mkdirhello
$ cdhello
Create and activate a Python virtual environment:
$ python-mvenv.venv
$ source.venv/bin/activate
Install the tarantool module:
$ pipinstalltarantool
Inside the hello directory, create the hello.py file for application code.
Importing ‘tarantool’
In the hello.py file, import the tarantool package:
importtarantool
Connecting to the database
Add the following code:
# Connect to the databaseconn=tarantool.Connection(host='127.0.0.1',port=3301,user='sampleuser',password='123456')
This code establishes a connection to a running Tarantool instance on behalf of sampleuser.
The conn object can be used to make CRUD requests and execute stored procedures.
Manipulating data
Inserting data
Add the following code to insert four tuples into the bands space:
# Insert datatuples=[(1,'Roxette',1986),(2,'Scorpions',1965),(3,'Ace of Base',1987),(4,'The Beatles',1960)]print("Inserted tuples:")fortupleintuples:response=conn.insert(space_name='bands',values=tuple)print(response[0])
Connection.insert() is used to insert a tuple to the space.
Querying data
To get a tuple by the specified primary key value, use Connection.select():
# Select by primary keyresponse=conn.select(space_name='bands',key=1)print('Tuple selected by the primary key value:',response[0])
You can also get a tuple by the value of the specified index using the index argument:
# Select by secondary keyresponse=conn.select(space_name='bands',key='The Beatles',index='band')print('Tuple selected by the secondary key value:',response[0])
Updating data
Connection.update() can be used to update a tuple identified by the primary key as follows:
To simplify the start of your working with the Tarantool C++ connector, we will
use the example application
from the connector repository. We will go step by step through the application
code and explain what each part does.
The following main topics are discussed in this manual:
The Tarantool C++ connector is currently supported for Linux only.
The connector itself is a header-only library, so, it doesn’t require
installation and building as such. All you need is to clone the connector
source code and embed it in your C++ project.
Also, make sure you have other necessary software and Tarantool installed.
Make sure you have the following third-party software. If you miss some of
the items, install them:
Do not close the terminal window where Tarantool is running.
You will need it later to connect to Tarantool from your C++ application.
Setting up access rights
To be able to execute the necessary operations in Tarantool, you need to grant
the guest user with the read-write rights. The simplest way is to grant
the user with the super role:
box.schema.user.grant('guest','super')
Connecting to Tarantool
There are three main parts of the C++ connector: the IO-zero-copy buffer,
the msgpack encoder/decoder, and the client that handles requests.
To set up connection to a Tarantool instance from a C++ application, you need
to do the following:
Embed the connector in your C++ application by including the main header:
#include"../src/Client/Connector.hpp"
Instantiating objects
First, we should create a connector client. It can handle many connections
to Tarantool instances asynchronously. To instantiate a client, you should specify
the buffer and the network provider implementations as template parameters.
The connector’s main class has the following signature:
The buffer is parametrized by allocator. It means that users can
choose which allocator will be used to provide memory for the buffer’s blocks.
Data is organized into a linked list of blocks of fixed size that is specified
as the template parameter of the buffer.
You can either implement your own buffer or network provider or use the default
ones as we do in our example. So, the default connector instantiation looks
as follows:
To use the BUFFER class, the buffer header should also be included:
#include"../src/Buffer/Buffer.hpp"
A client itself is not enough to work with Tarantool instances–we
also need to create connection objects. A connection also takes the buffer and
the network provider as template parameters. Note that they must be the same
as ones of the client:
Connection<Buf_t,Net_t>conn(client);
Connecting
Our Tarantool instance is listening to
the 3301 port on localhost.
Let’s define the corresponding variables as well as the WAIT_TIMEOUT variable
for connection timeout.
To connect to the Tarantool instance, we should invoke
the Connector::connect() method of the client object and
pass three arguments: connection instance, address, and port.
Implementation of the connector is exception free, so we rely on the return
codes: in case of fail, the connect() method returns rc<0. To get the
error message corresponding to the last error occured during
communication with the instance, we can invoke the Connection::getError()
method.
We will also go through the case of having several connections
and executing a number of requests from different connections simultaneously.
In our example C++ application, we execute the following types of requests:
ping
replace
select.
Note
Examples on other request types, namely, insert, delete, upsert,
and update, will be added to this manual later.
Each request method returns a request ID that is a sort of future.
This ID can be used to get the response message when it is ready.
Requests are queued in the output buffer of connection
until the Connector::wait() method is called.
Preparing requests
At this step, requests are encoded in the MessagePack
format and saved in the
output connection buffer. They are ready to be sent but the network
communication itself will be done later.
Let’s remind that for the requests manipulating with data we are dealing
with the Tarantool space tcreated earlier,
and the space has the following format:
Equals to Lua request <space_name>:replace(pk_value,"111",1).
uint32_tspace_id=512;intpk_value=666;std::tupledata=std::make_tuple(pk_value/* field 1*/,"111"/* field 2*/,1.01/* field 3*/);rid_treplace=conn.space[space_id].replace(data);
select
Equals to Lua request <space_name>.index[0]:select({pk_value},{limit=1}).
To send requests to the server side, invoke the client.wait()
method.
client.wait(conn,ping,WAIT_TIMEOUT);
The wait() method takes the connection to poll,
the request ID, and, optionally, the timeout as parameters. Once a response
for the specified request is ready, wait() terminates. It also
provides a negative return code in case of system related fails, for example,
a broken or timeouted connection. If wait() returns 0, then a response
has been received and expected to be parsed.
Now let’s send our requests to the Tarantool instance.
The futureIsReady() function checks availability of a future and returns
true or false.
while(!conn.futureIsReady(ping)){/* * wait() is the main function responsible for sending/receiving * requests and implements event-loop under the hood. It may * fail due to several reasons: * - connection is timed out; * - connection is broken (e.g. closed); * - epoll is failed. */if(client.wait(conn,ping,WAIT_TIMEOUT)!=0){std::cerr<<conn.getError().msg<<std::endl;conn.reset();}}
Receiving responses
To get the response when it is ready, use
the Connection::getResponse() method. It takes the request ID and returns
an optional object containing the response. If the response is not ready yet,
the method returns std::nullopt. Note that on each future,
getResponse() can be called only once: it erases the request ID from
the internal map once it is returned to a user.
A response consists of a header and a body (response.header and
response.body). Depending on success of the request execution on the server
side, body may contain either runtime error(s) accessible by
response.body.error_stack or data (tuples)–response.body.data.
In turn, data is a vector of tuples. However, tuples are not decoded and
come in the form of pointers to the start and the end of msgpacks.
See the “Decoding and reading the data” section to
understand how to decode tuples.
There are two options for single connection it regards to receiving responses:
we can either wait for one specific future or for all of them at once.
We’ll try both options in our example. For the ping request, let’s use the
first option.
std::optional<Response<Buf_t>>response=conn.getResponse(ping);/* * Since conn.futureIsReady(ping) returned <true>, then response * must be ready. */assert(response!=std::nullopt);/* * If request is successfully executed on server side, response * will contain data (i.e. tuple being replaced in case of :replace() * request or tuples satisfying search conditions in case of :select(); * responses for pings contain nothing - empty map). * To tell responses containing data from error responses, one can * rely on response code storing in the header or check * Response->body.data and Response->body.error_stack members. */printResponse<Buf_t>(*response);
For the replace and select requests, let’s examine the option of
waiting for both futures at once.
/* Let's wait for both futures at once. */std::vector<rid_t>futures(2);futures[0]=replace;futures[1]=select;/* No specified timeout means that we poll futures until they are ready.*/client.waitAll(conn,futures);for(size_ti=0;i<futures.size();++i){assert(conn.futureIsReady(futures[i]));response=conn.getResponse(futures[i]);assert(response!=std::nullopt);printResponse<Buf_t>(*response);}
Several connections at once
Now, let’s have a look at the case when we establish two connections
to Tarantool instance simultaneously.
/* Let's create another connection. */Connection<Buf_t,Net_t>another(client);if(client.connect(another,{.address=address,.service=std::to_string(port),/* .transport = STREAM_SSL, */})!=0){std::cerr<<conn.getError().msg<<std::endl;return-1;}/* Simultaneously execute two requests from different connections. */rid_tf1=conn.ping();rid_tf2=another.ping();/* * waitAny() returns the first connection received response. * All connections registered via :connect() call are participating. */std::optional<Connection<Buf_t,Net_t>>conn_opt=client.waitAny(WAIT_TIMEOUT);Connection<Buf_t,Net_t>first=*conn_opt;if(first==conn){assert(conn.futureIsReady(f1));(void)f1;}else{assert(another.futureIsReady(f2));(void)f2;}
Closing connections
Finally, a user is responsible for closing connections.
client.close(conn);client.close(another);
Building and launching C++ application
Now, we are going to build our example C++ application, launch it
to connect to the Tarantool instance and execute all the requests defined.
Make sure you are in the root directory of the cloned C++ connector repository.
To build the example application:
cdexamples
cmake.
make
Make sure the Tarantool session
you started earlier is running. Launch the application:
./Simple
As you can see from the execution log, all the connections to Tarantool
defined in our application have been established and all the requests
have been executed successfully.
Decoding and reading the data
Responses from a Tarantool instance contain raw data, that is, the data encoded
into the MessagePack tuples. To decode client’s data,
the user has to write their own
decoders (readers) based on the database schema and include them in one’s
application:
/** * Corresponds to tuples stored in user's space: * box.execute("CREATE TABLE t (id UNSIGNED PRIMARY KEY, a TEXT, d DOUBLE);") */structUserTuple{uint64_tfield1;std::stringfield2;doublefield3;staticconstexprautompp=std::make_tuple(&UserTuple::field1,&UserTuple::field2,&UserTuple::field3);};
Base reader prototype
Prototype of the base reader is given in src/mpp/Dec.hpp:
template<classBUFFER,TypeTYPE>structSimpleReaderBase:DefaultErrorHandler{usingBufferIterator_t=typenameBUFFER::iterator;/* Allowed type of values to be parsed. */staticconstexprTypeVALID_TYPES=TYPE;BufferIterator_t*StoreEndIterator(){returnnullptr;}};
Every new reader should inherit from it or directly from the
DefaultErrorHandler.
Parsing values
To parse a particular value, we should define the Value() method.
First two arguments of the method are common and unused as a rule,
but the third one defines the parsed value. In case of POD (Plain Old Data)
structures, it’s enough to provide a byte-to-byte copy. Since there are
fields of three different types in our schema, let’s define the corresponding
Value() functions:
Parsing array
It’s also important to understand that a tuple itself is wrapped in an array,
so, in fact, we should parse the array first. Let’s define another reader
for that purpose.
Setting reader
The SetReader() method sets the reader that is invoked while
each of the array’s entries is parsed. To make two readers defined above
work, we should create a decoder, set its iterator to the position of
the encoded tuple, and invoke the Read() method (the code block below is
from the example application).
C++ connector API
The official C++ connector for Tarantool is located in the
tanartool/tntcxx repository.
It is not supplied as part of the Tarantool repository and requires additional
actions for usage.
The connector itself is a header-only library and, as such, doesn’t require
installation and building. All you need is to clone the connector
source code and embed it in your C++ project. See the C++ connector Getting started
document for details and examples.
Below is the description of the connector public API.
The Connector class is a template class that defines a connector client
which can handle many connections to Tarantool instances asynchronously.
To instantiate a client, you should specify the buffer and the network provider
implementations as template parameters. You can either implement your own buffer
or network provider or use the default ones.
The default connector instantiation looks as follows:
Connects to a Tarantool instance that is listening on addr:port.
On successful connection, the method returns 0. If the host
doesn’t reply within the timeout period or another error occurs,
it returns -1. Then, Connection.getError()
gives the error message.
The main method responsible for sending a request and checking the response
readiness.
You should prepare a request beforehand by using the necessary
method of the Connection class, such as
ping()
and so on, which encodes the request
in the MessagePack format and saves it in
the output connection buffer.
wait() sends the request and is polling the future for the response
readiness. Once the response is ready, wait() returns 0.
If at timeout the response isn’t ready or another error occurs,
it returns -1. Then, Connection.getError()
gives the error message.
timeout=0 means the method is polling the future until the response
is ready.
future – request ID returned by a request method of
the Connection class, such as,
ping()
and so on.
timeout – waiting timeout, milliseconds. Optional. Defaults to 0.
Returns:
0 on receiving a response, or -1 otherwise.
Rtype:
int
Possible errors:
timeout exceeded
other possible errors depend on a network provider used.
If the EpollNetProvider is used, failing of the poll,
read, and write system calls leads to system errors,
such as, EBADF, ENOTSOCK, EFAULT, EINVAL, EPIPE,
and ENOTCONN (EWOULDBLOCK and EAGAIN don’t occur
in this case).
Similar to wait(), the method sends
the requests prepared and checks the response readiness, but can send
several different requests stored in the futures array.
Exceeding the timeout leads to an error; Connection.getError()
gives the error message.
timeout=0 means the method is polling the futures
until all the responses are ready.
futures – array with the request IDs returned by request
methods of the Connection
class, such as, ping()
and so on.
future_count – size of the futures array.
timeout – waiting timeout, milliseconds. Optional. Defaults to 0.
Returns:
none
Rtype:
none
Possible errors:
timeout exceeded
other possible errors depend on a network provider used.
If the EpollNetProvider is used, failing of the poll,
read, and write system calls leads to system errors,
such as, EBADF, ENOTSOCK, EFAULT, EINVAL, EPIPE,
and ENOTCONN (EWOULDBLOCK and EAGAIN don’t occur
in this case).
Sends all requests that are prepared at the moment and is waiting for
any first response to be ready. Upon the response readiness, waitAny()
returns the corresponding connection object.
If at timeout no response is ready or another error occurs, it returns
nullptr. Then, Connection.getError()
gives the error message.
timeout=0 means no time limitation while waiting for the response
readiness.
Parameters:
timeout – waiting timeout, milliseconds. Optional. Defaults to 0.
Returns:
object of the Connection class
on success, or nullptr on error.
Rtype:
Connection<BUFFER, NetProvider>*
Possible errors:
timeout exceeded
other possible errors depend on a network provider used.
If the EpollNetProvider is used, failing of the poll,
read, and write system calls leads to system errors,
such as, EBADF, ENOTSOCK, EFAULT, EINVAL, EPIPE,
and ENOTCONN (EWOULDBLOCK and EAGAIN don’t occur
in this case).
The Connection class is a template class that defines a connection objects
which is required to interact with a Tarantool instance. Each connection object
is bound to a single socket.
Similar to a connector client, a connection
object also takes the buffer and the network provider as template
parameters, and they must be the same as ones of the client. For example:
//Instantiating a connector clientusingBuf_t=tnt::Buffer<16*1024>;usingNet_t=EpollNetProvider<Buf_t>;Connector<Buf_t,Net_t>client;//Instantiating connection objectsConnection<Buf_t,Net_t>conn01(client);Connection<Buf_t,Net_t>conn02(client);
The Connection class has two nested classes, namely,
Space and Index
that implement the data-manipulation methods like select(),
replace(), and so on.
Executes a call of a remote stored-procedure similar to conn:call().
The method returns the request ID that is used to get the response by
getResponse().
Parameters:
func – a remote stored-procedure name.
args – procedure’s arguments.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
The following function is defined on the Tarantool instance you are
connected to:
box.execute("DROP TABLE IF EXISTS t;")box.execute("CREATE TABLE t(id INT PRIMARY KEY, a TEXT, b DOUBLE);")functionremote_replace(arg1,arg2,arg3)returnbox.space.T:replace({arg1,arg2,arg3})end
The method takes a request ID (future) as an argument and returns
an optional object containing a response. If the response is not ready,
the method returns std::nullopt.
Note that for each future the method can be called only once because it
erases the request ID from the internal map as soon as the response is
returned to a user.
A response consists of a header (response.header) and a body
(response.body). Depending on success of the request execution on
the server side, body may contain either runtime errors accessible by
response.body.error_stack or data (tuples) accessible by
response.body.data. Data is a vector of tuples. However,
tuples are not decoded and come in the form of pointers to the start and
the end of MessagePacks. For details on decoding the data received, refer to
“Decoding and reading the data”.
The method encodes the request in the MessagePack
format and queues it in the output connection buffer to be sent later
by one of Connector’s methods, namely,
wait(), waitAll(),
or waitAny().
Returns the request ID that is used to get the response by
the getResponce() method.
Space is a nested class of the Connection
class. It is a public wrapper to access the data-manipulation methods in the way
similar to the Tarantool submodule box.space,
like, space[space_id].select(), space[space_id].replace(), and so on.
All the Space class methods listed below work in the following way:
A method encodes the corresponding request in the MessagePack
format and queues it in the output connection buffer to be sent later
by one of Connector’s methods, namely,
wait(), waitAll(),
or waitAny().
A method returns the request ID. To get and read the actual data
requested, first you need to get the response object by using the
getResponce() method
and then decode the data.
Searches for a tuple or a set of tuples in the given space. The method works
similar to space_object:select() and performs the
search against the primary index (index_id=0) by default. In other
words, space[space_id].select() equals to
space[space_id].index[0].select().
Parameters:
key – value to be matched against the index key.
index_id – index ID. Optional. Defaults to 0.
limit – maximum number of tuples to select. Optional.
Defaults to UINT32_MAX.
offset – number of tuples to skip. Optional.
Defaults to 0.
iterator – the type of iterator. Optional.
Defaults to EQ.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:select({key_value}, {limit = 1}) in Tarantool*/uint32_tspace_id=512;intkey_value=5;uint32_tlimit=1;autoi=conn.space[space_id];rid_tselect=i.select(std::make_tuple(key_value),index_id,limit,offset,iter);
Inserts a tuple into the given space. If a tuple with the same primary key
already exists, replace() replaces the existing tuple with a new
one. The method works similar to space_object:replace() / put().
Parameters:
tuple – a tuple to insert.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:replace(key_value, "111", 1.01) in Tarantool*/uint32_tspace_id=512;intkey_value=5;std::tupledata=std::make_tuple(key_value,"111",1.01);rid_treplace=conn.space[space_id].replace(data);
Inserts a tuple into the given space.
The method works similar to space_object:insert().
Parameters:
tuple – a tuple to insert.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:insert(key_value, "112", 2.22) in Tarantool*/uint32_tspace_id=512;intkey_value=6;std::tupledata=std::make_tuple(key_value,"112",2.22);rid_tinsert=conn.space[space_id].insert(data);
Updates a tuple in the given space.
The method works similar to space_object:update()
and searches for the tuple to update against the primary index (index_id=0)
by default. In other words, space[space_id].update() equals to
space[space_id].index[0].update().
The tuple parameter specifies an update operation, an identifier of the
field to update, and a new field value. The set of available operations and
the format of specifying an operation and a field identifier is the same
as in Tarantool. Refer to the description of :doc:` </reference/reference_lua/box_space/update>`
and example below for details.
Parameters:
key – value to be matched against the index key.
tuple – parameters for the update operation, namely,
operator,field_identifier,value.
index_id – index ID. Optional. Defaults to 0.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:update(key, {{'=', 1, 'update' }, {'+', 2, 12}}) in Tarantool*/uint32_tspace_id=512;std::tuplekey=std::make_tuple(5);std::tupleop1=std::make_tuple("=",1,"update");std::tupleop2=std::make_tuple("+",2,12);rid_tf1=conn.space[space_id].update(key,std::make_tuple(op1,op2));
Updates or inserts a tuple in the given space.
The method works similar to space_object:upsert().
If there is an existing tuple that matches the key fields of tuple,
the request has the same effect as
update() and the ops parameter
is used.
If there is no existing tuple that matches the key fields of tuple,
the request has the same effect as
insert() and the tuple parameter
is used.
Parameters:
tuple – a tuple to insert.
ops – parameters for the update operation, namely,
operator,field_identifier,value.
index_base – starting number to count fields in a tuple:
0 or 1. Optional. Defaults to 0.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:upsert({333, "upsert-insert", 0.0}, {{'=', 1, 'upsert-update'}}) in Tarantool*/uint32_tspace_id=512;std::tupletuple=std::make_tuple(333,"upsert-insert",0.0);std::tupleop1=std::make_tuple("=",1,"upsert-update");rid_tf1=conn.space[space_id].upsert(tuple,std::make_tuple(op1));
Deletes a tuple in the given space.
The method works similar to space_object:delete()
and searches for the tuple to delete against the primary index (index_id=0)
by default. In other words, space[space_id].delete_() equals to
space[space_id].index[0].delete_().
Parameters:
key – value to be matched against the index key.
index_id – index ID. Optional. Defaults to 0.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to space_object:delete(123) in Tarantool*/uint32_tspace_id=512;std::tuplekey=std::make_tuple(123);rid_tf1=conn.space[space_id].delete_(key);
Index is a nested class of the Space
class. It is a public wrapper to access the data-manipulation methods in the way
similar to the Tarantool submodule box.index,
like, space[space_id].index[index_id].select() and so on.
All the Index class methods listed below work in the following way:
A method encodes the corresponding request in the MessagePack
format and queues it in the output connection buffer to be sent later
by one of Connector’s methods, namely,
wait(), waitAll(),
or waitAny().
A method returns the request ID that is used to get the response by
the getResponce() method.
Refer to the getResponce()
description to understand the response structure and how to read
the requested data.
This is an alternative to space.select().
The method searches for a tuple or a set of tuples in the given space against
a particular index and works similar to
index_object:select().
Parameters:
key – value to be matched against the index key.
limit – maximum number of tuples to select. Optional.
Defaults to UINT32_MAX.
offset – number of tuples to skip. Optional.
Defaults to 0.
iterator – the type of iterator. Optional.
Defaults to EQ.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to index_object:select({key}, {limit = 1}) in Tarantool*/uint32_tspace_id=512;uint32_tindex_id=1;intkey=10;uint32_tlimit=1;autoi=conn.space[space_id].index[index_id];rid_tselect=i.select(std::make_tuple(key),limit,offset,iter);
This is an alternative to space.update().
The method updates a tuple in the given space but searches for the tuple
against a particular index.
The method works similar to index_object:update().
The tuple parameter specifies an update operation, an identifier of the
field to update, and a new field value. The set of available operations and
the format of specifying an operation and a field identifier is the same
as in Tarantool. Refer to the description of :doc:` </reference/reference_lua/box_index/update>`
and example below for details.
Parameters:
key – value to be matched against the index key.
tuple – parameters for the update operation, namely,
operator,field_identifier,value.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to index_object:update(key, {{'=', 1, 'update' }, {'+', 2, 12}}) in Tarantool*/uint32_tspace_id=512;uint32_tindex_id=1;std::tuplekey=std::make_tuple(10);std::tupleop1=std::make_tuple("=",1,"update");std::tupleop2=std::make_tuple("+",2,12);rid_tf1=conn.space[space_id].index[index_id].update(key,std::make_tuple(op1,op2));
This is an alternative to space.delete_().
The method deletes a tuple in the given space but searches for the tuple
against a particular index.
The method works similar to index_object:delete().
Parameters:
key – value to be matched against the index key.
Returns:
a request ID
Rtype:
rid_t
Possible errors: none.
Example:
/* Equals to index_object:delete(123) in Tarantool*/uint32_tspace_id=512;uint32_tindex_id=1;std::tuplekey=std::make_tuple(123);rid_tf1=conn.space[space_id].index[index_id].delete_(key);
Community-supported connectors
This section provides information on several community-supported connectors.
Note that they may have limited support for new Tarantool features.
The most commonly used C# driver is
progaudi.tarantool,
previously named tarantool-csharp. It is not supplied as part of the
Tarantool repository; it must be installed separately. The makers recommend
cross-platform installation using Nuget.
To be consistent with the other instructions in this chapter, here is a way to
install the driver directly on Ubuntu 16.04.
Mono will not work, nor will .Net from xbuild. Only .net core supported on
Linux and Mac.
Read the Microsoft End User License Agreement first, because it is not an
ordinary open-source agreement and there will be a message during
installation saying “This software may collect information about you and
your use of the software, and send that to Microsoft.”
Still you can
set environment variables
to opt out from telemetry.
$ cat<<EOT>Program.cs
using System;using System.Threading.Tasks;using ProGaudi.Tarantool.Client;public class HelloWorld{ static public void Main () { Test().GetAwaiter().GetResult(); } static async Task Test() { var box = await Box.Connect("127.0.0.1:3301"); var schema = box.GetSchema(); var space = await schema.GetSpace("examples"); await space.Insert((99999, "BB")); }}EOT
Build and run your application.
Before trying to run, check that the server is listening at localhost:3301
and that the space examples exists, as
described earlier.
$ dotnetrestore
$ dotnetrun
The program will:
connect using an application-specific definition of the space,
open a socket connection with the Tarantool server at localhost:3301,
send an INSERT request, and — if all is well — end without saying anything.
If Tarantool is not running on localhost with listen port = 3301, or if user
‘guest’ does not have authorization to connect, or if the INSERT request
fails for any reason, the program will print an error message, among other
things (stacktrace, etc).
The example program only shows one request and does not show all that’s
necessary for good practice. For that, please see the
progaudi.tarantool driver repository.
Node.js
The most commonly used node.js driver is the Node Tarantool driver. It is not supplied as part
of the Tarantool repository; it must be installed separately. The most common
way to install it is with npm. For
example, on Ubuntu, the installation could look like this after npm has been
installed:
$ npminstalltarantool-driver--global
Here is a complete node.js program that inserts [99999,'BB'] into
space[999] via the node.js API. Before trying to run, check that the server instance
is listening at localhost:3301 and that the space examples exists, as
described earlier. To run, paste the code into
a file named example.rs and say nodeexample.rs. The program will
connect using an application-specific definition of the space. The program will
open a socket connection with the Tarantool instance at localhost:3301, then
send an INSERT request, then — if all is well — end after saying “Insert
succeeded”. If Tarantool is not running on localhost with listen port =
3301, the program will print “Connect failed”. If the ‘guest’ user does not have
authorization to connect, the program will print “Auth failed”. If the insert
request fails for any reason, for example because the tuple already exists,
the program will print “Insert failed”.
The example program only shows one request and does not show all that’s
necessary for good practice. For that, please see The node.js driver
repository.
Perl
The most commonly used Perl driver is
tarantool-perl. It is not
supplied as part of the Tarantool repository; it must be installed separately.
The most common way to install it is by cloning from GitHub.
To avoid minor warnings that may appear the first time tarantool-perl is
installed, start with installing some other modules that tarantool-perl uses,
with CPAN, the Comprehensive Perl Archive Network:
Here is a complete Perl program that inserts [99999,'BB'] into space[999]
via the Perl API. Before trying to run, check that the server instance is listening at
localhost:3301 and that the space examples exists, as
described earlier.
To run, paste the code into a file named example.pl and say
perlexample.pl. The program will connect using an application-specific
definition of the space. The program will open a socket connection with the
Tarantool instance at localhost:3301, then send an space_object:INSERT request, then — if
all is well — end without displaying any messages. If Tarantool is not running
on localhost with listen port = 3301, the program will print “Connection
refused”.
#!/usr/bin/perluseDR::Tarantool':constant','tarantool';useDR::Tarantool':all';useDR::Tarantool::MsgPack::SyncClient;my$tnt=DR::Tarantool::MsgPack::SyncClient->connect(host=>'127.0.0.1',# look for tarantool on localhostport=>3301,# on port 3301user=>'guest',# username. for 'guest' we do not also say 'password=>...'spaces=>{999=>{# definition of space[999] ...name=>'examples',# space[999] name = 'examples'default_type=>'STR',# space[999] field type is 'STR' if undefinedfields=>[{# definition of space[999].fields ...name=>'field1',type=>'NUM'}],# space[999].field[1] name='field1',type='NUM'indexes=>{# definition of space[999] indexes ...0=>{name=>'primary',fields=>['field1']}}}});$tnt->insert('examples'=>[99999,'BB']);
The example program uses field type names ‘STR’ and ‘NUM’
instead of ‘string’ and ‘unsigned’, due to a temporary Perl limitation.
The example program only shows one request and does not show all that’s
necessary for good practice. For that, please see the
tarantool-perl repository.
PHP
tarantool-php is the official
PHP connector for Tarantool.
It is not supplied as part of the Tarantool repository and must be installed
separately (see installation instructions
in the connector’s README file).
Here is a complete PHP program that inserts [99999,'BB'] into a space named
examples via the PHP API.
Before trying to run, check that the server instance is
listening at localhost:3301 and that the space
examples exists, as described earlier.
To run, paste the code into a file named example.php and say:
The program will open a socket connection with the Tarantool instance at
localhost:3301, then send an INSERT request,
then – if all is well – print “Insert succeeded”.
If the tuple already exists, the program will print
“Duplicate key exists in unique index ‘primary’ in space ‘examples’”.
The example program only shows one request and does not show all that’s
necessary for good practice. For that, please see
tarantool/tarantool-php
project at GitHub.
Most of the configuration options described in this reference can be applied to a specific instance, replica set, group, or to all instances globally.
To do so, you need to define the required option at the specified level.
app
Using Tarantool as an application server, you can run your own Lua applications.
In the app section, you can load the application and provide an application configuration in the app.cfg section.
The experimental.config.utils.schema
built-in module provides an API for managing user-defined configurations
of applications (app.cfg) and roles (roles_cfg).
The app section can be placed in any configuration scope.
As an example use case, you can provide different applications for storages and routers in a sharded cluster:
If set to true, the audit subsystem extracts and prints only the primary key instead of full
tuples in DML events (space_insert, space_replace, space_delete).
Otherwise, full tuples are logged.
The option may be useful in case tuples are big.
Specify a file for the audit log destination.
You can set the file type using the audit_log.to option.
If you write logs to a file, Tarantool reopens the audit log at SIGHUP.
Specify the logging behavior if the system is not ready to write.
If set to true, Tarantool does not block during logging if the system is non-writable and writes a message instead.
Using this value may improve logging performance at the cost of losing some log messages.
Note
The option only has an effect if the audit_log.to is set to syslog
or pipe.
Specify a pipe for the audit log destination.
You can set the pipe type using the audit_log.to option.
If log is a program, its pid is stored in the audit.pid field.
You need to send it a signal to rotate logs.
Example
This starts the cronolog program when the server starts
and sends all audit_log messages to cronolog standard input (stdin).
The array of space names for which data operation events (space_select, space_insert, space_replace,
space_delete) should be logged. The array accepts string values.
If set to box.NULL, the data operation events are logged for all spaces.
Example
In the example, only the events of bands and singers spaces are logged:
Set a location for the syslog server.
It can be a Unix socket path starting with ‘unix:’ or an ipv4 port number.
You can enable logging to a system logger using the audit_log.to option.
Above is an example of writing audit logs to a directory shared with the system logs.
Tarantool allows this option, but it is not recommended to do this to avoid difficulties
when working with audit logs. System and audit logs should be written separately.
To do this, create separate paths and specify them.
Type: string
Default: box.NULL
Environment variable: TT_AUDIT_LOG_SYSLOG_SERVER
compat
The compat section defines values of the compat module options.
Controls IPROTO_FEATURE_CALL_RET_TUPLE_EXTENSION and
IPROTO_FEATURE_CALL_ARG_TUPLE_EXTENSION feature bits that
define tuple encoding in iproto call and eval requests.
Specify a conditional section of the configuration. The configuration options
defined inside a conditional.if section apply only to instances on which
the specified condition is true.
Conditions can include one variable – tarantool_version: a three-number
Tarantool version running on the instance, for example, 3.1.0. It compares to
version literal values that include three numbers separated by periods (x.y.z).
The following operators are available in conditions:
comparison: >, <, >=, <=, ==, !=
logical operators || (OR) and && (AND)
parentheses ()
Example:
In this example, different configuration parts apply to instances running
Tarantool versions above and below 3.1.0:
On versions less than 3.1.0, the upgraded label is set to false.
On versions 3.1.0 or newer, the upgraded label is set to true.
Additionally, new compat options are defined. These options were introduced
in version 3.1.0, so on older versions they would cause an error.
Specify how to load settings from external storage.
For example, this option can be used to load passwords from safe storage.
You can find examples in the Loading secrets from safe storage section.
The name of an environment variable to load a configuration value from.
To load a configuration value from an environment variable, set config.context.<name>.from to env.
Example
In this example, passwords are loaded from the DBADMIN_PASSWORD and SAMPLEUSER_PASSWORD environment variables:
(Optional) Whether to strip whitespace characters and newlines from the end of data.
config.etcd.*
Enterprise Edition
Centralized configuration storages are supported by the Enterprise Edition only.
This section describes options related to providing connection settings to a centralized etcd-based storage.
If replication.failover is set to supervised, Tarantool also uses etcd to maintain the state of failover coordinators.
A key prefix used to search a configuration on an etcd server.
Tarantool searches keys by the following path: <prefix>/config/*.
Note that <prefix> should start with a slash (/).
A key prefix used to search a configuration in a centralized configuration storage.
Tarantool searches keys by the following path: <prefix>/config/*.
Note that <prefix> should start with a slash (/).
A list of global user-defined Lua functions that this user or a user with this role can call.
To allow calling all such functions, specify the all value.
This option should be configured together with the executepermission.
In particular, both instances use the same directory for storing write-ahead logs and snapshots.
When you start both cluster applications on the same machine, the instance from the first one will be the primary instance and the second will be the standby instance.
In the logs of the second cluster instance, you should see a notification:
main/104/interactive I> Entering hot standby mode
This means that the standby instance is ready to take over if the primary instance goes down.
The standby instance initializes and tries to take a lock on a directory for storing write-ahead logs
but fails because the primary instance has made a lock on this directory.
If the primary instance goes down for any reason, the lock is released.
In this case, the standby instance succeeds in taking the lock and becomes the primary instance.
If wal.dir_rescan_delay is set to a large value on macOS or FreeBSD. On these platforms, the hot standby mode is designed so that the loop repeats every wal.dir_rescan_delay seconds.
By default, instance UUIDs are generated automatically.
database.instance_uuid can be used to specify an instance identifier manually.
UUIDs should follow these rules:
The values must be true unique identifiers, not shared by other instances
or replica sets within the common infrastructure.
The values must be used consistently, not changed after the initial setup.
The initial values are stored in snapshot files
and are checked whenever the system is restarted.
The values must comply with RFC 4122.
The nil UUID is not allowed.
An instance’s operating mode.
This option is in effect if replication.failover is set to off.
The following modes are available:
rw: an instance is in read-write mode.
ro: an instance is in read-only mode.
If not specified explicitly, the default value depends on the number of instances in a replica set. For a single instance, the rw mode is used, while for multiple instances, the ro mode is used.
Example
You can set the database.mode option to rw on all instances in a replica set to make a master-master configuration.
In this case, replication.failover should be set to off.
A time interval (in seconds) that specifies how long an instance should be a leader without renew requests from a coordinator.
When this interval expires, the leader switches to read-only mode.
This action is performed by the instance itself and works even if there is no connectivity between the instance and the coordinator.
A time interval (in seconds) that specifies how often a failover coordinator sends read-write deadline renewals.
Type: number
Default: 10
Environment variable: TT_FAILOVER_RENEW_INTERVAL
failover.stateboard.*
failover.stateboard.* options define configuration parameters related to maintaining the state of failover coordinators in a remote etcd-based storage.
A time interval (in seconds) that specifies how long a transient state information is stored and how quickly a lock expires.
Note
failover.stateboard.keepalive_interval should be smaller than failover.lease_interval.
Otherwise, switching of a coordinator causes a replica set leader to go to read-only mode for some time.
A time interval (in seconds) that specifies how often a failover coordinator writes its state information to etcd.
This option also determines the frequency at which an active coordinator reads new commands from etcd.
The maximum size of memory (in bytes) used to store metrics before sending them to the feedback server.
If the size of collected metrics exceeds this value, earlier metrics are dropped.
The time period (in seconds) a fiber sleeps between
iterations of the event loop.
fiber.io_collect_interval can be used to reduce CPU load in deployments
where the number of client connections is large, but requests are not so frequent
(for example, each connection issues just a handful of requests per second).
Set a time period (in seconds) that specifies the error slice.
Type: number
Default: 1
Environment variable: TT_FIBER_SLICE_ERR
fiber.top.*
This section describes options related to configuring the
fiber.top() function, normally used for debug purposes.
fiber.top() shows all alive fibers and their CPU consumption.
Specify the level of detail the log has.
The default value is 6 (VERBOSE).
You can learn more about log levels from the log_level
option description.
Note that the flightrec.logs_log_level value might differ from log_level.
Specify the time period (in seconds) that defines how long metrics are stored from the moment of dump.
So, this value defines how much historical metrics data is collected up to the moment of crash.
The frequency of metric dumps is defined by flightrec.metrics_interval.
Specify the size (in bytes) of storage for the request and response data.
You can set this parameter to 0 to disable a storage of requests and responses.
An array of URIs used to listen for incoming requests.
If required, you can enable SSL for specific URIs by providing additional parameters (<uri>.params.*).
Note that a URI value can’t contain parameters, a login, or a password.
Example
In the example below, iproto.listen is set explicitly for each instance in a cluster:
To handle messages, Tarantool allocates fibers.
To prevent fiber overhead from affecting the whole system,
Tarantool restricts how many messages the fibers handle,
so that some pending requests are blocked.
On powerful systems, increase net_msg_max, and the scheduler
starts processing pending requests immediately.
On weaker systems, decrease net_msg_max, and the overhead
may decrease. However, this may take some time because the
scheduler must wait until already-running requests finish.
When net_msg_max is reached,
Tarantool suspends processing of incoming packages until it
has processed earlier messages. This is not a direct restriction of
the number of fibers that handle network messages, rather it
is a system-wide restriction of channel bandwidth.
This in turn restricts the number of incoming
network messages that the
transaction processor thread
handles, and therefore indirectly affects the fibers that handle
network messages.
Note
The number of fibers is smaller than the number of messages because
messages can be released as soon as they are delivered, while
incoming requests might not be processed until some time after delivery.
The size of the read-ahead buffer associated with a client connection.
The larger the buffer, the more memory an active connection consumes, and the
more requests can be read from the operating system buffer in a single
system call.
The recommendation is to make sure that the buffer can contain at least a few dozen requests.
Therefore, if a typical tuple in a request is large, e.g. a few kilobytes or even megabytes, the read-ahead buffer size should be increased.
If batched request processing is not used, it’s prudent to leave this setting at its default.
The number of network threads.
There can be unusual workloads where the network thread
is 100% loaded and the transaction processor thread is not, so the network
thread is a bottleneck.
In that case, set iproto_threads to 2 or more.
The operating system kernel determines which connection goes to
which thread.
A URI used to advertise the current instance to clients.
The iproto.advertise.client option accepts a URI in the following formats:
An address: host:port.
A Unix domain socket: unix/:.
Note that this option doesn’t allow to set a username and password.
If a remote client needs this information, it should be delivered outside of the cluster configuration.
Note
The host value cannot be 0.0.0.0/[::] and the port value cannot be 0.
Settings used to advertise the current instance to other cluster members.
The format of these settings is described in iproto.advertise.<peer_or_sharding>.*.
Example
In the example below, the following configuration options are specified:
In the credentials section, the replicator user with the replication role is created.
iproto.advertise.peer specifies that other instances should connect to an address defined in iproto.listen using the replicator user.
Settings used to advertise the current instance to a router and rebalancer.
The format of these settings is described in iproto.advertise.<peer_or_sharding>.*.
Note
If iproto.advertise.sharding is not specified, advertise settings from iproto.advertise.peer are used.
Example
In the example below, the following configuration options are specified:
In the credentials section, the replicator and storage users are created.
iproto.advertise.peer specifies that other instances should connect to an address defined in iproto.listen with the replicator user.
iproto.advertise.sharding specifies that a router should connect to storages using an address defined in iproto.listen with the storage user.
Allows you to enable traffic encryption for client-server communications over binary connections.
In a Tarantool cluster, one instance might act as the server that accepts connections from other instances and the client that connects to other instances.
<uri>.params.transport accepts one of the following values:
plain (default): turn off traffic encryption.
ssl: encrypt traffic by using the TLS 1.2 protocol (Enterprise Edition only).
Example
The example below demonstrates how to enable traffic encryption by using a self-signed server certificate.
The following parameters are specified for each instance:
(Optional) A colon-separated (:) list of SSL cipher suites the connection can use.
Note that the list is not validated: if a cipher suite is unknown, Tarantool ignores it, doesn’t establish the connection, and writes to the log that no shared cipher was found.
The supported cipher suites are:
ECDHE-ECDSA-AES256-GCM-SHA384
ECDHE-RSA-AES256-GCM-SHA384
DHE-RSA-AES256-GCM-SHA384
ECDHE-ECDSA-CHACHA20-POLY1305
ECDHE-RSA-CHACHA20-POLY1305
DHE-RSA-CHACHA20-POLY1305
ECDHE-ECDSA-AES128-GCM-SHA256
ECDHE-RSA-AES128-GCM-SHA256
DHE-RSA-AES128-GCM-SHA256
ECDHE-ECDSA-AES256-SHA384
ECDHE-RSA-AES256-SHA384
DHE-RSA-AES256-SHA256
ECDHE-ECDSA-AES128-SHA256
ECDHE-RSA-AES128-SHA256
DHE-RSA-AES128-SHA256
ECDHE-ECDSA-AES256-SHA
ECDHE-RSA-AES256-SHA
DHE-RSA-AES256-SHA
ECDHE-ECDSA-AES128-SHA
ECDHE-RSA-AES128-SHA
DHE-RSA-AES128-SHA
AES256-GCM-SHA384
AES128-GCM-SHA256
AES256-SHA256
AES128-SHA256
AES256-SHA
AES128-SHA
GOST2012-GOST8912-GOST8912
GOST2001-GOST89-GOST89
For detailed information on SSL ciphers and their syntax, refer to OpenSSL documentation.
(Optional) A text file with one or more passwords for encrypted private SSL keys provided using ssl_key_file (each on a separate line).
Alternatively, the password can be provided in ssl_password.
Any configuration parameter that can be defined in the group scope.
For example, iproto and database configuration parameters defined at the group level are applied to all instances in this group.
replicasets
Note
replicasets can be defined in the group scope only.
Any configuration parameter that can be defined in the replica set scope.
For example, iproto and database configuration parameters defined at the replica set level are applied to all instances in this replica set.
instances
Note
instances can be defined in the replica set scope only.
Any configuration parameter that can be defined in the instance scope.
For example, iproto and database configuration parameters defined at the instance level are applied to this instance only.
labels
The labels section allows adding custom attributes to the configuration.
Attributes must be key:value pairs with string keys and values.
The tarantool module that enables you to configure the logging level for Tarantool core messages.
Specifically, it configures the logging level for messages logged from non-Lua code, including C modules.
Example: Set a log level for C modules.
Example 1: Set log levels for files that use the default logger
Suppose you have two identical modules placed by the following paths: test/module1.lua and test/module2.lua.
These modules use the default logger and look as follows:
return{say_hello=function()locallog=require('log')log.info('Info message from module1')end}
To configure logging levels, you need to provide module names corresponding to paths to these modules:
Given that module1 has the verbose logging level and module2 has the error level, calling module1.say_hello() shows a message but module2.say_hello() is swallowed:
-- Prints 'info' messages --module1.say_hello()--[[[92617] main/103/interactive/test.logging.module1 I> Info message from module1---...--]]-- Swallows 'info' messages --module2.say_hello()--[[---...--]]
To create custom loggers in your application (app.lua), call the log.new() function:
-- Creates new loggers --module1_log=require('log').new('module1')module2_log=require('log').new('module2')
Given that module1 has the verbose logging level and module2 has the error level, calling module1_log.info() shows a message but module2_log.info() is swallowed:
-- Prints 'info' messages --module1_log.info('Info message from module1')--[[[16300] main/103/interactive/module1 I> Info message from module1---...--]]-- Swallows 'debug' messages --module1_log.debug('Debug message from module1')--[[---...--]]-- Swallows 'info' messages --module2_log.info('Info message from module2')--[[---...--]]
This example shows how to set the info level for the tarantool module:
log:modules:tarantool:'info'app:file:'app.lua'
The specified level affects messages logged from C modules:
ffi=require('ffi')-- Prints 'info' messages --ffi.C._say(ffi.C.S_INFO,nil,0,nil,'Info message from C module')--[[[6024] main/103/interactive I> Info message from C module---...--]]-- Swallows 'debug' messages --ffi.C._say(ffi.C.S_DEBUG,nil,0,nil,'Debug message from C module')--[[---...--]]
The example above uses the LuaJIT ffi library to call C functions provided by the say module.
Specify the logging behavior if the system is not ready to write.
If set to true, Tarantool does not block during logging if the system is non-writable and writes a message instead.
Using this value may improve logging performance at the cost of losing some log messages.
Note
The option only has an effect if the log.to is set to syslog
or pipe.
Specifies the maximum memory amount available to Lua scripts, measured in bytes.
When the specified value exceeds the current memory usage, the new limit takes effect immediately without a restart.
However, when the specified value is lower than the current memory usage, a restart of the instance is required for the change to take effect.
Example to set the Lua memory limit to 4 GB:
lua:memory:4294967296
Type: integer
Default: 2147483648 (2GB)
Environment variable: TT_LUA_MEMORY
memtx
The memtx section is used to configure parameters related to the memtx engine.
Specify the allocator that manages memory for memtx tuples.
Possible values:
system – the memory is allocated as needed, checking that the quota is not exceeded.
THe allocator is based on the malloc function.
small – a slab allocator.
The allocator repeatedly uses a memory block to allocate objects of the same type.
Note that this allocator is prone to unresolvable fragmentation on specific workloads,
so you can switch to system in such cases.
The amount of memory in bytes that Tarantool allocates to store tuples.
When the limit is reached, INSERT and
UPDATE requests fail with the ER_MEMORY_ISSUE error.
The server does not go beyond the memtx.memory limit to allocate tuples, but there is additional memory
used to store indexes and connection information.
Example
In the example below, the memory size is set to 1 GB (1073741824 bytes).
The multiplier for computing the sizes of memory
chunks that tuples are stored in.
A lower value may result in less wasted
memory depending on the total amount of memory available and the
distribution of item sizes.
Specify the granularity in bytes of memory allocation in the small allocator.
The memtx.slab_alloc_granularity value should meet the following conditions:
The value is a power of two.
The value is greater than or equal to 4.
Below are few recommendations on how to adjust the memtx.slab_alloc_granularity option:
If the tuples in space are small and have about the same size, set the option to 4 bytes to save memory.
If the tuples are different-sized, increase the option value to allocate tuples from the same mempool (memory pool).
The number of threads from the thread pool used to sort keys of secondary indexes on loading a memtx database.
The minimum value is 1, the maximum value is 256.
The default is to use all available cores.
Note
Since 3.0.0, this option replaces the approach when OpenMP threads are used to parallelize sorting.
For backward compatibility, the OMP_NUM_THREADS environment variable is taken into account to
set the number of sorting threads.
Type: integer
Default: box.NULL
Environment variable: TT_MEMTX_SORT_THREADS
metrics
The metrics section defines configuration parameters for metrics.
If this option is set to true, Tarantool log location defined by the
log.to option should be set to
file, pipe, or syslog – anything other than stderr,
the default, because a daemon process is detached from a terminal
and it can’t write to the terminal’s stderr.
Important
Do not enable the background mode for applications intended to run by the
tt utility. For more information, see the tt start reference.
Usually, an administrator needs to call ulimit-cunlimited
(or set corresponding options in systemd’s unit file)
before running a Tarantool process to get core dumps.
If process.coredump is enabled, Tarantool sets the corresponding
resource limit by itself
and the administrator doesn’t need to call ulimit-cunlimited
(see man 3 setrlimit).
This option also sets the state of the dumpable attribute,
which is enabled by default,
but may be dropped in some circumstances (according to
man 2 prctl, see PR_SET_DUMPABLE).
Whether coredump files should not include memory allocated for tuples –
this memory can be large if Tarantool runs under heavy load.
Setting to true means “do not include”.
A directory where Tarantool working files will be stored
(database files, logs, a PID file, a console Unix socket, and other files
if an application generates them in the current directory).
The server instance switches to process.work_dir with
chdir(2) after start.
If set as a relative file path, it is relative to the current
working directory, from where Tarantool is started.
If not specified, defaults to the current working directory.
Other directory and file parameters, if set as relative paths,
are interpreted as relative to process.work_dir, for example, directories for storing
snapshots and write-ahead logs.
Type: string
Default: box.NULL
Environment variable: TT_PROCESS_WORK_DIR
replication
The replication section defines configuration parameters related to replication.
While anonymous replicas are read-only, you can write data to replication-local and temporary spaces (created with is_local=true and temporary=true, respectively).
Given that changes to replication-local spaces are allowed, an anonymous replica might increase the 0 component of the vclock value.
Here are the limitations of having anonymous replicas in a replica set:
A replica set must contain at least one non-anonymous instance.
An anonymous replica can’t be configured as a writable instance by setting database.mode to rw or making it a leader using <replicaset_name>.leader.
If replication.failover is set to supervised, an external failover coordinator doesn’t consider anonymous replicas when selecting a bootstrap or replica set leader.
Note
Anonymous replicas are not registered in the _cluster space.
This means that there is no limitation on the number of anonymous replicas in a replica set.
The replication.autoexpel option designed for managing dynamic clusters using YAML-based configurations.
It enables the automatic expulsion of instances that are removed from the YAML configuration.
Only instances with names that match the specified prefix are considered for expulsion; all others are excluded.
Additionally, instances without a persistent name are ignored.
If an instance is in read-write mode and has the latest database schema, it initiates the expulsion of instances that:
Match the specified prefix
Absent from the updated YAML configuration
The expulsion process follows the standard procedure, involving the removal of the instance from the _cluster system space.
autoexpel does not take any actions on newly joined instances unless one of the triggering events occurs.
This means that an instance meeting the autoexpel criterion can still join the cluster, but it may be removed
later during reconfiguration or on subsequent triggering events.
Note
The replication.autoexpel option governs the expelling process and is configurable at the replicaset, group, and
global levels. It is not applicable at the instance level.
Configuration fields
by (string, default: nil): specifies the autoexpel criterion. Currently, only prefix is supported and must be explicitly set.
enabled (boolean, default: false): enables or disables the autoexpel logic.
prefix (string, default: nil): defines the pattern for instance names that are considered part of the cluster.
replication.autoexpel.by
replication.autoexpel_by purpose is to define the criterion used for determining which instances in a cluster are
subject to the autoexpel process.
The by field helps differentiate between:
Instances that are part of the cluster and should adhere to the YAML configuration.
Instances or tools (e.g., CDC tools) that use the replication channel but are not part of the cluster configuration.
The default value of by is nil, meaning no autoexpel criterion is applied unless explicitly set.
Currently, the only supported value for by is prefix. The prefix value instructs the system to identify instances
based on their names, matching them against a prefix pattern defined in the configuration.
If the autoexpel feature is enabled, the by field must be explicitly set to prefix.
The absence of this field or an unsupported value will result in configuration errors.
The replication.autoexpel_enabled field is a boolean configuration option that determines whether the autoexpel logic is active for the cluster.
This feature is designed to automatically manage dynamic cluster configurations by removing instances that are no longer present in the YAML configuration.
Note
By default, the enabled field is set to false, meaning the autoexpel logic is turned off. This ensures that no instances are automatically removed unless explicitly configured.
Enabling ``autoexpel`` logic
To enable autoexpel, you should set enabled to true in the replication.autoexpel section of your YAML configuration:
The prefix field filters instances for expulsion by differentiating cluster instances (from the YAML configuration) from external services (e.g., CDC tools). Only instances matching the prefix are considered.
A consistent naming pattern ensures the _cluster system space automatically aligns with the YAML configuration.
If the prefix field is not set (nil), the autoexpel logic cannot identify instances for expulsion, and the feature will not function.
This field is mandatory when replication.autoexpel_enabled is set to true.
How it works:
The prefix filters instance names (e.g., {{replicaset_name}} for replicaset-specific names or i- for names starting with i-).
Instances matching the prefix and removed from the YAML configuration are expelled.
Unnamed instances or those not matching the prefix are ignored.
Specifies a strategy used to bootstrap a replica set.
The following strategies are available:
auto: a node doesn’t boot if half or more of the other nodes in a replica set are not connected.
For example, if a replica set contains 2 or 3 nodes, a node requires 2 connected instances.
In the case of 4 or 5 nodes, at least 3 connected instances are required.
Moreover, a bootstrap leader fails to boot unless every connected node has chosen it as a bootstrap leader.
config: use the specified node to bootstrap a replica set.
To specify the bootstrap leader, use the <replicaset_name>.bootstrap_leader option.
supervised: a bootstrap leader isn’t chosen automatically but should be appointed using box.ctl.make_bootstrap_leader() on the desired node.
legacy (deprecated since 2.11.0): a node requires the replication_connect_quorum number of other nodes to be connected.
This option is added to keep the compatibility with the current versions of Cartridge and might be removed in the future.
A timeout (in seconds) a replica waits when trying to connect to a master in a cluster.
See orphan status for details.
This parameter is different from
replication.timeout,
which a master uses to disconnect a replica when the master
receives no acknowledgments of heartbeat messages.
off: a node doesn’t participate in the election activities.
voter: a node can participate in the election process but can’t be a leader.
candidate: a node should be able to become a leader.
manual: allow to control which instance is the leader explicitly instead of relying on automated leader election.
By default, the instance acts like a voter – it is read-only and may vote for other candidate instances.
Once box.ctl.promote() is called, the instance becomes a candidate and starts a new election round.
If the instance wins the elections, it becomes a leader but won’t participate in any new elections.
Note
You can set replication.election_mode to a value other than off if the replication.failover mode is election.
Specifies the timeout (in seconds) between election rounds in the
leader election process if the previous round
ended up with a split vote.
It is quite big, and for most of the cases, it can be lowered to
300-400 ms.
To avoid the split vote repeat, the timeout is randomized on each node
during every new election, from 100% to 110% of the original timeout value.
For example, if the timeout is 300 ms and there are 3 nodes started
the election simultaneously in the same term,
they can set their election timeouts to 300, 310, and 320 respectively,
or to 305, 302, and 324, and so on. In that way, the votes will never be split
because the election on different nodes won’t be restarted simultaneously.
Specifies the leader fencing mode that
affects the leader election process. When the parameter is set to soft
or strict, the leader resigns its leadership if it has less than
replication.synchro_quorum
of alive connections to the cluster nodes.
The resigning leader receives the status of a follower in the current election term and becomes
read-only.
In soft mode, a connection is considered dead if there are no responses for
4 * replication.timeout seconds both on the current leader and the followers.
In strict mode, a connection is considered dead if there are no responses
for 2 * replication.timeout seconds on the
current leader and
4 * replication.timeout seconds on the
followers. This improves the chances that there is only one leader at any time.
Fencing applies to the instances that have the
replication.election_mode set to candidate or manual.
To turn off leader fencing, set election_fencing_mode to off.
A failover mode used to take over a master role when the current master instance fails.
The following modes are available:
off
Leadership in a replica set is controlled using the database.mode option.
In this case, you can set the database.mode option to rw on all instances in a replica set to make a master-master configuration.
The default database.mode is determined as follows: rw if there is one instance in a replica set; ro if there are several instances.
In the manual mode, the database.mode option cannot be set explicitly.
The leader is configured in the read-write mode, all the other instances are read-only.
By default, if a replica adds a unique key that another replica has
added, replication stops
with the ER_TUPLE_FOUNDerror.
If replication.skip_conflict is set to true, such errors are ignored.
Note
Instead of saving the broken transaction to the write-ahead log, it is written as NOP (No operation).
The maximum delay (in seconds) between the time when data is written to the master and the time when it is written to a replica.
If replication.sync_lag is set to nil or 365 * 100 * 86400 (TIMEOUT_INFINITY),
a replica is always considered to be “synced”.
Note
This parameter is ignored during bootstrap.
See orphan status for details.
The timeout (in seconds) that a node waits when trying to sync with
other nodes in a replica set after connecting or during a configuration update.
This could fail indefinitely if replication.sync_lag is smaller than network latency, or if the replica cannot keep pace with master updates.
If replication.sync_timeout expires, the replica enters orphan status.
A number of replicas that should confirm the receipt of a synchronous transaction before it can finish its commit.
This option supports dynamic evaluation of the quorum number.
For example, the default value is N/2+1 where N is the current number of replicas registered in a cluster.
Once any replicas are added or removed, the expression is re-evaluated automatically.
Note that the default value (atleast50%oftheclustersize+1) guarantees data reliability.
Using a value less than the canonical one might lead to unexpected results,
including a split-brain.
replication.synchro_quorum is not used on replicas. If the master fails, the pending synchronous
transactions will be kept waiting on the replicas until a new master is elected.
Note
replication.synchro_quorum does not account for anonymous replicas.
For synchronous replication only.
Specify how many seconds to wait for a synchronous transaction quorum
replication until it is declared failed and is rolled back.
It is not used on replicas, so if the master fails, the pending synchronous
transactions will be kept waiting on the replicas until a new master is
elected.
The number of threads spawned to decode the incoming replication data.
In most cases, one thread is enough for all incoming data.
Possible values range from 1 to 1000.
If there are multiple replication threads, connections to serve are distributed evenly between the threads.
A time interval (in seconds) used by a master to send heartbeat requests to a replica when there are no updates to send to this replica.
For each request, a replica should return a heartbeat acknowledgment.
If a master or replica gets no heartbeat message for 4*replication.timeout seconds, a connection is dropped and a replica tries to reconnect to the master.
Specify a role’s configuration.
This option accepts a role name as the key and a role’s configuration as the value.
To specify the roles of an instance, use the roles option.
The experimental.config.utils.schema
built-in module provides an API for managing user-defined configurations
of applications (app.cfg) and roles (roles_cfg).
Type: map
Default: nil
Environment variable: TT_ROLES_CFG
security
Enterprise Edition
Configuring security parameters is available in the Enterprise Edition only.
The security section defines configuration parameters related to various security settings.
Specify a period of time (in seconds) that a specific user should wait for the next attempt after failed authentication.
The security.auth_retries option lets a client try to authenticate the specified number of times before security.auth_delay is enforced.
In the configuration below, Tarantool lets a client try to authenticate with the same username three times.
At the fourth attempt, the authentication delay configured with security.auth_delay is enforced.
This means that a client should wait 10 seconds after the first failed attempt.
Specify the maximum number of authentication retries allowed before security.auth_delay is enforced.
The default value is 0, which means security.auth_delay is enforced after the first failed authentication attempt.
The retry counter is reset after security.auth_delay seconds since the first failed attempt.
For example, if a client tries to authenticate fewer than security.auth_retries times within security.auth_delay seconds, no authentication delay is enforced.
The retry counter is also reset after any successful authentication attempt.
Specify a protocol used to authenticate users.
The possible values are:
chap-sha1: use the CHAP protocol with SHA-1 hashing applied to passwords.
pap-sha256: use PAP authentication with the SHA256 hashing algorithm.
Note that CHAP stores password hashes in the _user space unsalted.
If an attacker gains access to the database, they may crack a password, for example, using a rainbow table.
For PAP, a password is salted with a user-unique salt before saving it in the database,
which keeps the database protected from cracking using a rainbow table.
To enable PAP, specify the security.auth_type option as follows:
If true, turn off access over remote connections from unauthenticated or guest users.
This option affects connections between cluster members and net.box connections.
Specify the maximum period of time (in days) a user can use the same password.
When this period ends, a user gets the “Password expired” error on a login attempt.
To restore access for such users, use box.schema.user.passwd.
Note
The default 0 value means that a password never expires.
If true, forces Tarantool to overwrite a data file a few times before deletion to render recovery of a deleted file impossible.
The option applies to both .xlog and .snap files as well as Vinyl data files.
Type: boolean
Default: false
Environment variable: TT_SECURITY_SECURE_ERASING
sharding
The sharding section defines configuration parameters related to sharding.
Note
Sharding support requires installing the vshard module.
The minimum required version of vshard is 0.1.25.
The timeout (in seconds) after which a node is considered unavailable if there are no responses during this period.
The failover fiber is used to detect if a node is down.
Note
This option should be defined at the global level.
The maximum number of buckets that can be received in parallel by a single replica set.
This number must be limited because the rebalancer sends a large number of buckets from the existing replica sets to the newly added one.
This produces a heavy load on the new replica set.
Note
This option should be defined at the global level.
Example
Suppose, rebalancer_max_receiving is equal to 100 and bucket_count is equal to 1000.
There are 3 replica sets with 333, 333, and 334 buckets on each respectively.
When a new replica set is added, each replica set’s etalon_bucket_count becomes
equal to 250. Rather than receiving all 250 buckets at once, the new replica set
receives 100, 100, and 50 buckets sequentially.
auto (default): if there are no replica sets with the rebalancer sharding role (sharding.roles), a replica set with the rebalancer is selected automatically among all replica sets.
manual: one of the replica sets should have the rebalancer sharding role. The rebalancer is in this replica set.
off: rebalancing is turned off regardless of whether a replica set with the rebalancer sharding role exists or not.
Note
This option should be defined at the global level.
A scheduler’s bucket move quota used by the rebalancer.
sched_move_quota defines how many bucket moves can be done in a row if there are pending storage refs.
Then, bucket moves are blocked and a router continues making map-reduce requests.
A scheduler’s storage ref quota used by a router’s map-reduce API.
For example, the vshard.router.map_callrw() function implements consistent map-reduce over the entire cluster.
sched_ref_quota defines how many storage refs, therefore map-reduce requests, can be executed on the storage in a row if there are pending bucket moves.
Then, storage refs are blocked and the rebalancer continues bucket moves.
The name or ID of a TREE index over the bucket id.
Spaces without this index do not participate in a sharded Tarantool
cluster and can be used as regular spaces if needed. It is necessary to
specify the first part of the index, other parts are optional.
Note
This option should be defined at the global level.
The timeout to wait for synchronization of the old master with replicas before demotion.
Used when switching a master or when manually calling the sync() function.
Note
This option should be defined at the global level.
A zone that can be set for routers and replicas.
This allows sending read-only requests not only to a master instance but to any available replica that is the nearest to the router.
The snapshot section defines configuration parameters related to the snapshot files.
To learn more about the snapshots’ configuration, check the Persistence page.
A directory where memtx stores snapshot (.snap) files.
A relative path in this option is interpreted as relative to process.work_dir.
By default, snapshots and WAL files are stored in the same directory.
However, you can set different values for the snapshot.dir and wal.dir options
to store them on different physical disks for performance matters.
Reduce the throttling effect of box.snapshot() on
INSERT/UPDATE/DELETE performance by setting a limit on how many
megabytes per second it can write to disk. The same can be
achieved by splitting wal.dir and
snapshot.dir
locations and moving snapshots to a separate disk.
The limit also affects what
box.stat.vinyl().regulator
may show for the write rate of dumps to .run and .index files.
The maximum number of snapshots that are stored in the
snapshot.dir directory.
If the number of snapshots after creating a new one exceeds this value,
the Tarantool garbage collector deletes old snapshots.
If snapshot.count is set to zero, the garbage collector
does not delete old snapshots.
Example
In the example, the checkpoint daemon creates a snapshot every two hours until
it has created three snapshots. After creating a new snapshot (the fourth one), the oldest snapshot
and any associated write-ahead-log files are deleted.
snapshot:by:interval:7200count:3
Note
Snapshots will not be deleted if replication is ongoing and the file has not been relayed to a replica.
Therefore, snapshot.count has no effect unless all replicas are alive.
The interval in seconds between actions by the checkpoint daemon.
If the option is set to a value greater than zero, and there is
activity that causes change to a database, then the checkpoint daemon calls
box.snapshot() every snapshot.by.interval
seconds, creating a new snapshot file each time.
If the option is set to zero, the checkpoint daemon is disabled.
Example
In the example, the checkpoint daemon creates a new database snapshot every two hours, if there is activity.
The threshold for the total size in bytes for all WAL files created since the last snapshot taken.
Once the configured threshold is exceeded, the WAL thread notifies the
checkpoint daemon that it must make a new snapshot and delete old WAL files.
Type: integer
Default: 10^18
Environment variable: TT_SNAPSHOT_BY_WAL_SIZE
sql
The sql section defines configuration parameters related to SQL.
A bloom filter’s false positive rate – the suitable probability of the
bloom filter
to give a wrong result.
The vinyl.bloom_fpr setting is a default value for the
bloom_fpr
option passed to space_object:create_index().
Enable the deferred DELETE optimization in vinyl. It was disabled by default
since Tarantool version 2.10 to avoid possible performance degradation
of secondary index reads.
The page size. A page is a read/write unit for vinyl disk operations.
The vinyl.page_size setting is a default value
for the page_size
option passed to space_object:create_index().
The default maximum range size for a vinyl index, in bytes.
The maximum range size affects the decision of whether to
split a range.
If vinyl.range_size is specified (but the value is not null or 0), then
it is used as the default value for the
range_size
option passed to space_object:create_index().
If vinyl.range_size is not specified (or is explicitly set to null or 0),
and range_size is not specified when the index is created,
then Tarantool sets a value later depending on performance considerations.
To see the actual value, use
index_object:stat().range_size.
Type: integer
Default: box.NULL (means that an effective default is determined in runtime)
The maximum number of runs per level in the vinyl LSM tree.
If this number is exceeded, a new level is created.
The vinyl.run_count_per_level setting is a default value for the
run_count_per_level
option passed to space_object:create_index().
The ratio between the sizes of different levels in the LSM tree.
The vinyl.run_size_ratio setting is a default value for the
run_size_ratio
option passed to space_object:create_index().
The vinyl storage engine has a scheduler that performs compaction.
When vinyl is low on available memory, the compaction scheduler
may be unable to keep up with incoming update requests.
In that situation, queries may time out after vinyl.timeout seconds.
This should rarely occur, since normally vinyl
throttles inserts when it is running low on compaction bandwidth.
Compaction can also be initiated manually with
index_object:compact().
The delay in seconds used to prevent the Tarantool garbage collector
from immediately removing write-ahead log files after a node restart.
This delay eliminates possible erroneous situations when the master deletes WALs
needed by replicas after restart.
As a consequence, replicas sync with the master faster after its restart and
don’t need to download all the data again.
Once all the nodes in the replica set are up and running, a scheduled garbage collection is started again
even if wal.cleanup_delay has not expired.
A directory where write-ahead log (.xlog) files are stored.
A relative path in this option is interpreted as relative to process.work_dir.
By default, WAL files and snapshots are stored in the same directory.
However, you can set different values for the wal.dir and snapshot.dir options
to store them on different physical disks for performance matters.
The time interval in seconds between periodic scans of the write-ahead-log
file directory, when checking for changes to write-ahead-log
files for the sake of replication or hot standby.
The maximum number of bytes in a single write-ahead log file.
When a request would cause an .xlog file to become larger than
wal.max_size, Tarantool creates a new WAL file.
The size of the queue in bytes used by a replica to submit
new transactions to a write-ahead log (WAL).
This option helps limit the rate at which a replica submits transactions to the WAL.
Limiting the queue size might be useful when a replica is trying to sync with a master and
reads new transactions faster than writing them to the WAL.
Note
You might consider increasing the wal.queue_max_size value in case of
large tuples (approximately one megabyte or larger).
The delay in seconds used to prevent the Tarantool garbage collector from removing a write-ahead log file after it has been closed.
If a node is restarted, wal.retention_period counts down from the last modification time of the write-ahead log file.
The garbage collector doesn’t track write-ahead logs that are to be relayed to anonymous replicas, such as:
Anonymous replicas added as a part of a cluster configuration (see replication.anon).
CDC (Change Data Capture) that retrieves data using anonymous replication.
In case of a replica or CDC downtime, the required write-ahead logs can be removed.
As a result, such a replica needs to be rebootstrapped.
You can use wal.retention_period to prevent such issues.
Note that wal.cleanup_delay option also sets the delay used to prevent the Tarantool garbage collector from removing write-ahead logs.
The difference is that the garbage collector doesn’t take into account wal.cleanup_delay if all the nodes in the replica set are up and running, which may lead to the removal of the required write-ahead logs.
Enable storing a new tuple for each CRUD operation performed.
The option is in effect for all spaces.
To adjust the option for specific spaces, use the wal.ext.spaces
option.
Enable storing an old tuple for each CRUD operation performed.
The option is in effect for all spaces.
To adjust the option for specific spaces, use the wal.ext.spaces
option.
Enable or disable storing an old and new tuple in the WAL record
for a given space explicitly.
The configuration for specific spaces has priority over the configuration in the
wal.ext.new and wal.ext.old
options.
The option is a key-value pair:
The key is a space name (string).
The value is a table that includes two optional boolean options: old and new.
The format and the default value of these options are described in wal.ext.old and wal.ext.new.
Example
In the example, only new tuples are added to the log for the bands space.
ext:new:trueold:truespaces:bands:old:false
Type: map
Default: nil
Environment variable: TT_WAL_EXT_SPACES
Configuration reference (box.cfg)
Note
Starting with the 3.0 version, the recommended way of configuring Tarantool is using a configuration file.
Configuring Tarantool in code is considered a legacy approach.
This topic describes all configuration parameters
that can be specified in code using the box.cfg API.
Usually, an administrator needs to call ulimit-cunlimited
(or set corresponding options in systemd’s unit file)
before running a Tarantool process to get core dumps.
If coredump is enabled, Tarantool sets the corresponding
resource limit by itself
and the administrator doesn’t need to call ulimit-cunlimited
(see man 3 setrlimit).
This option also sets the state of the dumpable attribute,
which is enabled by default,
but may be dropped in some circumstances (according to
man 2 prctl, see PR_SET_DUMPABLE).
The read/write data port number or URI (Universal
Resource Identifier) string. Has no default value, so must be specified
if connections occur from the remote clients that don’t use the
“admin port”. Connections made with
listen=URI are called “binary port” or “binary protocol”
connections.
A directory where memtx stores snapshot (.snap) files.
A relative path in this option is interpreted as relative to work_dir.
By default, snapshots and WAL files are stored in the same directory.
However, you can set different values for the memtx_dir and wal_dir options
to store them on different physical disks for performance matters.
Say box.cfg{read_only=true...} to put the server instance in read-only
mode. After this, any requests that try to change persistent data will fail with error
ER_READONLY. Read-only mode should be used for master-replica
replication. Read-only mode does not affect data-change
requests for spaces defined as
temporary.
Although read-only mode prevents the server from writing to the WAL,
it does not prevent writing diagnostics with the log module.
Type: boolean
Default: false
Environment variable: TT_READ_ONLY
Dynamic: yes
Setting read_only==true affects spaces differently depending on the
options that were used during
box.schema.space.create,
as summarized by this chart:
The vinyl storage engine has a scheduler which does compaction.
When vinyl is low on available memory, the compaction scheduler
may be unable to keep up with incoming update requests.
In that situation, queries may time out after vinyl_timeout seconds.
This should rarely occur, since normally vinyl
would throttle inserts when it is running low on compaction bandwidth.
Compaction can also be ordered manually with
index_object:compact().
A directory where write-ahead log (.xlog) files are stored.
A relative path in this option is interpreted as relative to work_dir.
By default, WAL files and snapshots are stored in the same directory.
However, you can set different values for the wal_dir and memtx_dir options
to store them on different physical disks for performance matters.
A directory where database working files will be stored. The server instance
switches to work_dir with chdir(2) after start. Can be
relative to the current directory. If not specified, defaults to
the current directory. Other directory parameters may be relative to
work_dir, for example:
Whether coredump files should include memory allocated for tuples.
(This can be large if Tarantool runs under heavy load.)
Setting to true means “do not include”.
In an older version of Tarantool the default value of this parameter was false.
How much memory Tarantool allocates to store tuples.
When the limit is reached, INSERT or
UPDATE requests begin failing with
error ER_MEMORY_ISSUE. The server does not go beyond the
memtx_memory limit to allocate tuples, but there is additional memory
used to store indexes and connection information.
Specify the allocator that manages memory for memtx tuples.
Possible values:
system – the memory is allocated as needed, checking that the quota is not exceeded.
THe allocator is based on the malloc function.
small – a slab allocator.
The allocator repeatedly uses a memory block to allocate objects of the same type.
Note that this allocator is prone to unresolvable fragmentation on specific workloads,
so you can switch to system in such cases.
The number of threads from the thread pool used to sort keys of secondary indexes on loading a memtx database.
The minimum value is 1, the maximum value is 256.
The default is to use all available cores.
Note
Since 3.0.0, this option replaces the approach when OpenMP threads are used to parallelize sorting.
For backward compatibility, the OMP_NUM_THREADS environment variable is taken into account to
set the number of sorting threads.
The multiplier for computing the sizes of memory
chunks that tuples are stored in. A lower value may result in less wasted
memory depending on the total amount of memory available and the
distribution of item sizes.
Specify the granularity (in bytes) of memory allocation in the small allocator.
The memtx.slab_alloc_granularity value should meet the following conditions:
The value is a power of two.
The value is greater than or equal to 4.
Below are few recommendations on how to adjust the memtx.slab_alloc_granularity option:
If the tuples in space are small and have about the same size, set the option to 4 bytes to save memory.
If the tuples are different-sized, increase the option value to allocate tuples from the same mempool (memory pool).
Bloom filter false positive rate – the suitable probability of the
bloom filter
to give a wrong result.
The vinyl_bloom_fpr setting is a default value for one of the
options in the Options for space_object:create_index() chart.
Size of the largest allocation unit,
for the vinyl storage engine. It can be increased if it
is necessary to store large tuples.
See also: memtx_max_tuple_size.
Page size. Page is a read/write unit for vinyl disk operations.
The vinyl_page_size setting is a default value for one of the
options in the Options for space_object:create_index() chart.
The default maximum range size for a vinyl index, in bytes.
The maximum range size affects the decision whether to
split a range.
If vinyl_range_size is not nil and not 0, then
it is used as the
default value for the range_size option in the
Options for space_object:create_index() chart.
If vinyl_range_size is nil or 0, and range_size is not specified
when the index is created, then Tarantool sets a value later depending on
performance considerations. To see the actual value, use
index_object:stat().range_size.
In Tarantool versions prior to 1.10.2, vinyl_range_size default value was 1073741824.
The maximal number of runs per level in vinyl LSM tree.
If this number is exceeded, a new level is created.
The vinyl_run_count_per_level setting is a default value for one of the
options in the Options for space_object:create_index() chart.
Ratio between the sizes of different levels in the LSM tree.
The vinyl_run_size_ratio setting is a default value for one of the
options in the Options for space_object:create_index() chart.
The checkpoint daemon (snapshot daemon) is a constantly running fiber.
The checkpoint daemon creates a schedule for the periodic snapshot creation based on
the configuration options and the speed of file size growth.
If enabled, the daemon makes new snapshot (.snap) files according to this schedule.
The work of the checkpoint daemon is based on the following configuration options:
checkpoint_wal_threshold – a new snapshot is taken once the size
of all WAL files created since the last snapshot exceeds a given limit.
If necessary, the checkpoint daemon also activates the Tarantool garbage collector
that deletes old snapshots and WAL files.
Tarantool garbage collector
Tarantool garbage collector can be activated by the checkpoint daemon.
The garbage collector tracks the snapshots that are to be relayed to a replica or needed
by other consumers. When the files are no longer needed, Tarantool garbage collector deletes them.
Note
The garbage collector called by the checkpoint daemon is distinct from the Lua garbage collector
which is for Lua objects, and distinct from the Tarantool garbage collector that specializes in handling shard buckets.
This garbage collector is called as follows:
When the number of snapshots reaches the limit of checkpoint_count size.
After a new snapshot is taken, Tarantool garbage collector deletes the oldest snapshot file and any associated WAL files.
When the size of all WAL files created since the last snapshot reaches the limit of checkpoint_wal_threshold.
Once this size is exceeded, the checkpoint daemon takes a snapshot, then the garbage collector deletes the old WAL files.
If an old snapshot file is deleted, the Tarantool garbage collector also deletes
any write-ahead log (.xlog) files that meet the following conditions:
The WAL files are older than the snapshot file.
The WAL files contain information present in the snapshot file.
Tarantool garbage collector also deletes obsolete vinyl .run files.
Tarantool garbage collector doesn’t delete a file in the following cases:
A backup is running, and the file has not been backed up
(see Hot backup).
Replication is running, and the file has not been relayed to a replica
(see Replication architecture),
A replica is connecting.
A replica has fallen behind.
The progress of each replica is tracked; if a replica’s position is far
from being up to date, then the server stops to give it a chance to catch up.
If an administrator concludes that a replica is permanently down, then the
correct procedure is to restart the server, or (preferably) remove the replica from the cluster.
The interval in seconds between actions by the checkpoint daemon.
If the option is set to a value greater than zero, and there is
activity that causes change to a database, then the checkpoint daemon
calls box.snapshot() every checkpoint_interval
seconds, creating a new snapshot file each time. If the option
is set to zero, the checkpoint daemon is disabled.
Example
box.cfg{checkpoint_interval=7200}
In the example, the checkpoint daemon creates a new database snapshot every two hours, if there is activity.
The maximum number of snapshots that are stored in the
memtx_dir directory.
If the number of snapshots after creating a new one exceeds this value,
the Tarantool garbage collector deletes old snapshots.
If the option is set to zero, the garbage collector
does not delete old snapshots.
In the example, the checkpoint daemon creates a new snapshot every two hours until
it has created three snapshots. After creating a new snapshot (the fourth one), the oldest snapshot
and any associated write-ahead-log files are deleted.
Note
Snapshots will not be deleted if replication is ongoing and the file has not been relayed to a replica.
Therefore, checkpoint_count has no effect unless all replicas are alive.
The threshold for the total size in bytes for all WAL files created since the last checkpoint.
Once the configured threshold is exceeded, the WAL thread notifies the
checkpoint daemon that it must make a new checkpoint and delete old WAL files.
This parameter enables administrators to handle a problem that could occur
with calculating how much disk space to allocate for a partition containing
WAL files.
Type: integer
Default: 10^18 (a large number so in effect there is no limit by default)
If force_recovery equals true, Tarantool tries to continue if there is
an error while reading a snapshot file
(at server instance start) or a write-ahead log file
(at server instance start or when applying an update at a replica): skips
invalid records, reads as much data as possible and lets the process finish
with a warning. Users can prevent the error from recurring by writing to
the database and executing box.snapshot().
Otherwise, Tarantool aborts recovery if there is an error while reading.
The maximum number of bytes in a single write-ahead log file.
When a request would cause an .xlog file to become larger than
wal_max_size, Tarantool creates a new WAL file.
Reduce the throttling effect of box.snapshot() on
INSERT/UPDATE/DELETE performance by setting a limit on how many
megabytes per second it can write to disk. The same can be
achieved by splitting wal_dir and
memtx_dir
locations and moving snapshots to a separate disk.
The limit also affects what
box.stat.vinyl().regulator
may show for the write rate of dumps to .run and .index files.
The time interval in seconds between periodic scans of the write-ahead-log
file directory, when checking for changes to write-ahead-log
files for the sake of replication or hot standby.
The size of the queue (in bytes) used by a replica to submit
new transactions to a write-ahead log (WAL).
This option helps limit the rate at which a replica submits transactions to the WAL.
Limiting the queue size might be useful when a replica is trying to sync with a master and
reads new transactions faster than writing them to the WAL.
Note
You might consider increasing the wal_queue_max_size value in case of
large tuples (approximately one megabyte or larger).
The delay in seconds used to prevent the Tarantool garbage collector
from immediately removing write-ahead log files after a node restart.
This delay eliminates possible erroneous situations when the master deletes WALs
needed by replicas after restart.
As a consequence, replicas sync with the master faster after its restart and
don’t need to download all the data again.
Once all the nodes in the replica set are up and running, a scheduled garbage collection is started again
even if wal_cleanup_delay has not expired.
Note
The wal_cleanup_delay option has no effect on nodes running as
anonymous replicas.
(Enterprise Edition only) Allows you to add auxiliary information to each write-ahead log record.
For example, you can enable storing an old and new tuple for each CRUD operation performed.
This information might be helpful for implementing a CDC (Change Data Capture) utility that transforms a data replication stream.
You can enable storing old and new tuples as follows:
Set the old and new options to true to store old and new tuples in a write-ahead log for all spaces.
box.cfg{wal_ext={old=true,new=true}}
To adjust these options for specific spaces, use the spaces option.
The configuration for specific spaces has priority over the global configuration,
so only new tuples are added to the log for space1 and only old tuples for space2.
Note that records with additional fields are replicated as follows:
If a replica doesn’t support the extended format configured on a master, auxiliary fields are skipped.
If a replica and master have different configurations for WAL records, the master’s configuration is ignored.
(Enterprise Edition only) If true, forces Tarantool to overwrite a data file a few times before deletion to render recovery of a deleted file impossible.
The option applies to both .xlog and .snap files as well as Vinyl data files.
Hot standby is a feature which provides a simple form of failover without
replication.
The expectation is that there will be two instances of the server using the
same configuration. The first one to start will be the “primary” instance.
The second one to start will be the “standby” instance.
To initiate the standby instance, start a second instance of the Tarantool
server on the same computer with the same
box.cfg configuration settings –
including the same directories and same non-null URIs – and with the
additional configuration setting hot_standby=true.
Expect to see a notification ending with the words
I>Enteringhotstandbymode.
This is fine. It means that the standby instance is ready to take over if the
primary instance goes down.
The standby instance will initialize and will try to take a lock on
wal_dir,
but will fail because the primary instance has made a lock on wal_dir.
So the standby instance goes into a loop, reading the write ahead log which
the primary instance is writing (so the two instances are always in sync),
and trying to take the lock.
If the primary instance goes down for any reason, the lock will be released.
In this case, the standby instance will succeed in taking the lock,
will connect on the listen address and will become
the primary instance.
Expect to see a notification ending with the words
I>readytoacceptrequests.
Thus there is no noticeable downtime if the primary instance goes down.
Hot standby feature has no effect:
if wal_dir_rescan_delay = a large number
(on Mac OS and FreeBSD);
on these platforms, it is designed so that the loop repeats every
wal_dir_rescan_delay seconds.
if wal_mode = ‘none’;
it is designed to work with wal_mode='write' or wal_mode='fsync'.
for spaces created with engine = ‘vinyl’;
it is designed to work for spaces created with engine='memtx'.
If replication is not an empty string, the instance is considered to be
a Tarantool replica. The replica will
try to connect to the master specified in replication with a
URI (Universal Resource Identifier), for example:
konstantin:secret_password@tarantool.org:3301
If there is more than one replication source in a replica set, specify an
array of URIs, for example (replace ‘uri’ and ‘uri2’ in this example with
valid URIs):
box.cfg{replication={'uri1','uri2'}}
Note
Starting from version 2.10.0, there is a number of other ways for specifying several URIs. See syntax examples.
If one of the URIs is “self” – that is, if one of the URIs is for the
instance where box.cfg{} is being executed – then it is ignored.
Thus, it is possible to use the same replication specification on
multiple server instances, as shown in
these examples.
The default user name is ‘guest’.
A read-only replica does not accept data-change requests on the
listen port.
The replication parameter is dynamic, that is, to enter master
mode, simply set replication to an empty string and issue:
A Tarantool replica can be anonymous. This type of replica
is read-only (but you still can write to temporary and
replica-local spaces), and it isn’t present in the _cluster space.
Since an anonymous replica isn’t registered in the _cluster table,
there is no limitation for anonymous replicas count in a replica set:
you can have as many of them as you want.
In order to make a replica anonymous, pass the option
replication_anon=true to box.cfg and set read_only
to true.
Let’s go through anonymous replica bootstrap.
Suppose we have got a master configured with
As mentioned above, replication_anon may be set to true only together
with read_only.
The instance will fetch the master’s snapshot and start following its
changes. It will receive no id, so its id value will remain zero.
Note that while the instance is anonymous, it will increase the 0-th
component of its vclock:
tarantool> box.info.vclock----{0:10, 1:4}...
Let’s now promote the anonymous replica to a regular one:
tarantool> box.cfg{replication_anon=false}2019-12-13 20:34:37.423 [71329] main I> assigned id 2 to replica 6a9c2ed2-b9e1-4c57-a0e8-51a46def76612019-12-13 20:34:37.424 [71329] main/102/interactive I> set 'replication_anon' configuration option to false---...tarantool> 2019-12-1320:34:37.424[71329]main/117/applier/I>subscribed2019-12-13 20:34:37.424 [71329] main/117/applier/ I> remote vclock {1: 5} local vclock {0: 10, 1: 5}2019-12-13 20:34:37.425 [71329] main/118/applierw/ C> leaving orphan mode
The replica has just received an id equal to 2. We can make it read-write now.
tarantool> box.cfg{read_only=false}2019-12-13 20:35:46.392 [71329] main/102/interactive I> set 'read_only' configuration option to false---...tarantool> box.schema.space.create('test')----engine:memtxbefore_replace:'function:0x01109f9dc8'on_replace:'function:0x01109f9d90'ck_constraint:[]field_count:0temporary:falseindex:[]is_local:falseenabled:falsename:testid:513-created...tarantool> box.info.vclock----{0:10, 1:5, 2:2}...
Now the replica tracks its changes in the 2nd vclock component,
as expected.
It can also become a replication master from now on.
Notes:
You cannot replicate from an anonymous instance.
To promote an anonymous instance to a regular one,
first start it as anonymous, and only
then issue box.cfg{replication_anon=false}
In order for the deanonymization to succeed, the
instance must replicate from some read-write instance,
otherwise it cannot be added to the _cluster table.
Specify a strategy used to bootstrap a replica set.
The following strategies are available:
auto: a node doesn’t boot if a half or more of other nodes in a replica set are not connected.
For example, if the replication parameter contains 2 or 3 nodes,
a node requires 2 connected instances.
In the case of 4 or 5 nodes, at least 3 connected instances are required.
Moreover, a bootstrap leader fails to boot unless every connected node has chosen it as a bootstrap leader.
config: use the specified node to bootstrap a replica set.
To specify the bootstrap leader, use the bootstrap_leader option.
supervised: a bootstrap leader isn’t chosen automatically but should be appointed using box.ctl.make_bootstrap_leader() on the desired node.
legacy (deprecated since 2.11.0): a node requires the replication_connect_quorum number of other nodes to be connected.
This option is added to keep the compatibility with the current versions of Cartridge and might be removed in the future.
The number of seconds that a replica will wait when trying to
connect to a master in a cluster.
See orphan status for details.
This parameter is different from
replication_timeout,
which a master uses to disconnect a replica when the master
receives no acknowledgments of heartbeat messages.
Specify the number of nodes to be up and running to start a replica set.
This parameter has effect during bootstrap or
configuration update.
Setting replication_connect_quorum to 0 makes Tarantool
require no immediate reconnect only in case of recovery.
See Orphan status for details.
By default, if a replica adds a unique key that another replica has
added, replication stops
with error = ER_TUPLE_FOUND.
However, by specifying replication_skip_conflict=true,
users can state that such errors may be ignored. So instead of saving
the broken transaction to the xlog, it will be written there as NOP (No operation).
The maximum lag allowed for a replica.
When a replica syncs
(gets updates from a master), it may not catch up completely.
The number of seconds that the replica is behind the master is called the “lag”.
Syncing is considered to be complete when the replica’s lag is less than
or equal to replication_sync_lag.
If a user sets replication_sync_lag to nil or to 365 * 100 * 86400 (TIMEOUT_INFINITY),
then lag does not matter – the replica is always considered to be “synced”.
Also, the lag is ignored (assumed to be infinite) in case the master is running
Tarantool older than 1.7.7, which does not send heartbeat messages.
This parameter is ignored during bootstrap.
See orphan status for details.
The number of seconds that a node waits when trying to sync with
other nodes in a replica set (see bootstrap_strategy),
after connecting or during configuration update.
This could fail indefinitely if replication_sync_lag is smaller
than network latency, or if the replica cannot keep pace with master
updates. If replication_sync_timeout expires, the replica
enters orphan status.
Type: float
Default: 300
Environment variable: TT_REPLICATION_SYNC_TIMEOUT
Dynamic: yes
Note
The default replication_sync_timeout value is going to be changed in future versions from 300 to 0.
You can learn the reasoning behind this decision from the Default value for replication_sync_timeout topic, which also describes how to try the new behavior in the current version.
If the master has no updates to send to the replicas, it sends heartbeat messages
every replication_timeout seconds, and each replica sends an ACK packet back.
Both master and replicas are programmed to drop the connection if they get no
response in four replication_timeout periods.
If the connection is dropped, a replica tries to reconnect to the master.
Ordinarily it is sufficient to let the system generate and format the UUID
strings which will be permanently stored.
However, some administrators may prefer to store Tarantool configuration
information in a central repository, for example
Apache ZooKeeper.
Such administrators can assign their own UUID values for either – or both –
instances (instance_uuid) and
replica set (replicaset_uuid), when starting up for the first time.
General rules:
The values must be true unique identifiers, not shared by other instances
or replica sets within the common infrastructure.
The values must be used consistently, not changed after initial setup
(the initial values are stored in snapshot files
and are checked whenever the system is restarted).
The values must comply with RFC 4122.
The nil UUID is not
allowed.
The UUID format includes sixteen octets represented as 32 hexadecimal
(base 16) digits, displayed in five groups separated by hyphens, in the form
8-4-4-4-12 for a total of 36 characters (32 alphanumeric characters and
four hyphens).
For replication administration purposes, it is possible to set the
universally unique identifiers
of the instance (instance_uuid) and the replica set
(replicaset_uuid), instead of having the system generate the values.
See the description of
replicaset_uuid parameter for details.
For synchronous replication only.
This option tells how many replicas should confirm the receipt of a
synchronous transaction before it can finish its commit.
Since version 2.5.3,
the option supports dynamic evaluation of the quorum number.
That is, the number of quorum can be specified not as a constant number, but as a function instead.
In this case, the option returns the formula evaluated.
The result is treated as an integer number.
Once any replicas are added or removed, the expression is re-evaluated automatically.
For example,
box.cfg{replication_synchro_quorum="N / 2 + 1"}
Where N is a current number of registered replicas in a cluster.
Keep in mind that the example above represents a canonical quorum definition.
The formula atleast50%oftheclustersize+1 guarantees data reliability.
Using a value less than the canonical one might lead to unexpected results,
including a split-brain.
Since version 2.10.0, this option
does not account for anonymous replicas.
The default value for this parameter is N/2+1.
It is not used on replicas, so if the master dies, the pending synchronous
transactions will be kept waiting on the replicas until a new master is elected.
If the value for this option is set to 1, the synchronous transactions work like asynchronous when not configured.
1 means that successful WAL write to the master is enough to commit.
Type: number
Default: N / 2 + 1 (before version 2.10.0, the default value was 1)
For synchronous replication only.
Tells how many seconds to wait for a synchronous transaction quorum
replication until it is declared failed and is rolled back.
It is not used on replicas, so if the master dies, the pending synchronous
transactions will be kept waiting on the replicas until a new master is
elected.
The number of threads spawned to decode the incoming replication data.
The default value is 1.
It means that a single separate thread handles all the incoming replication streams.
In most cases, one thread is enough for all incoming data.
Therefore, it is likely that the user will not need to set this configuration option.
Possible values range from 1 to 1000.
If there are multiple replication threads, connections to serve are distributed evenly between the threads.
Participation of a replica set node in the automated leader election can be
turned on and off by this option.
The default value is off. All nodes that have values other than off
run the Raft state machine internally talking to other nodes according
to the Raft leader election protocol. When the option is off, the node
accepts Raft messages
from other nodes, but it doesn’t participate in the election activities,
and this doesn’t affect the node’s state. So, for example, if a node is not
a leader but it has election_mode='off', it is writable anyway.
You can control which nodes can become a leader. If you want a node
to participate in the election process but don’t want that it becomes
a leaders, set the election_mode option to voter. In this case,
the election works as usual, this particular node will vote for other nodes,
but won’t become a leader.
If the node should be able to become a leader, use election_mode='candidate'.
Since version 2.8.2, the manual election mode is introduced.
It may be used when a user wants to control which instance is the leader explicitly instead of relying on
the Raft election algorithm.
When an instance is configured with the election_mode='manual', it behaves as follows:
By default, the instance acts like a voter – it is read-only and may vote for other instances that are candidates.
Once box.ctl.promote() is called, the instance becomes a candidate and starts a new election round.
If the instance wins the elections, it becomes a leader, but won’t participate in any new elections.
Specify the timeout between election rounds in the
leader election process if the previous round
ended up with a split-vote.
In the leader election process, there
can be an election timeout for the case of a split-vote.
The timeout can be configured using this option; the default value is
5 seconds.
It is quite big, and for most of the cases it can be freely lowered to
300-400 ms. It can be a floating point value (300 ms would be
box.cfg{election_timeout=0.3}).
To avoid the split vote repeat, the timeout is randomized on each node
during every new election, from 100% to 110% of the original timeout value.
For example, if the timeout is 300 ms and there are 3 nodes started
the election simultaneously in the same term,
they can set their election timeouts to 300, 310, and 320 respectively,
or to 305, 302, and 324, and so on. In that way, the votes will never be split
because the election on different nodes won’t be restarted simultaneously.
Specify the leader fencing mode that
affects the leader election process. When the parameter is set to soft
or strict, the leader resigns its leadership if it has less than
replication_synchro_quorum
of alive connections to the cluster nodes.
The resigning leader receives the status of a
follower in the current election term and becomes
read-only.
In soft mode, a connection is considered dead if there are no responses for
4*replication_timeout seconds both on the current leader and the followers.
In strict mode, a connection is considered dead if there are no responses
for 2*replication_timeout seconds on the
current leader and
4*replication_timeout seconds on the
followers. This improves chances that there is only one leader at any time.
Fencing applies to the instances that have the
election_mode set to candidate or manual.
To turn off leader fencing, set election_fencing_mode to off.
Specify the instance name.
This value must be unique in a replica set.
The following rules are applied to instance names:
The maximum number of symbols is 63.
Should start with a letter.
Can contain lowercase letters (a-z). If uppercase letters are used, they are converted to lowercase.
Can contain digits (0-9).
Can contain the following characters: -, _.
To change or remove the specified name, you should temporarily set the box.cfg.force_recovery configuration option to true.
When all the names are updated and all the instances synced, box.cfg.force_recovery can be set back to false.
The instance will sleep for io_collect_interval seconds between iterations
of the event loop. Can be used to reduce CPU load in deployments in which
the number of client connections is large, but requests are not so frequent
(for example, each connection issues just a handful of requests per second).
To handle messages, Tarantool allocates fibers.
To prevent fiber overhead from affecting the whole system,
Tarantool restricts how many messages the fibers handle,
so that some pending requests are blocked.
On powerful systems, increase net_msg_max and the scheduler
will immediately start processing pending requests.
On weaker systems, decrease net_msg_max and the overhead
may decrease although this may take some time because the
scheduler must wait until already-running requests finish.
When net_msg_max is reached,
Tarantool suspends processing of incoming packages until it
has processed earlier messages. This is not a direct restriction of
the number of fibers that handle network messages, rather it
is a system-wide restriction of channel bandwidth.
This in turn causes restriction of the number of incoming
network messages that the
transaction processor thread
handles, and therefore indirectly affects the fibers that handle
network messages.
(The number of fibers is smaller than the number of messages because
messages can be released as soon as they are delivered, while
incoming requests might not be processed until some time after delivery.)
On typical systems, the default value (768) is correct.
The size of the read-ahead buffer associated with a client connection. The
larger the buffer, the more memory an active connection consumes and the
more requests can be read from the operating system buffer in a single
system call. The rule of thumb is to make sure the buffer can contain at
least a few dozen requests. Therefore, if a typical tuple in a request is
large, e.g. a few kilobytes or even megabytes, the read-ahead buffer size
should be increased. If batched request processing is not used, it’s prudent
to leave this setting at its default.
The number of network threads.
There can be unusual workloads where the network thread
is 100% loaded and the transaction processor thread is not, so the network
thread is a bottleneck. In that case set iproto_threads to 2 or more.
The operating system kernel will determine which connection goes to
which thread.
On typical systems, the default value (1) is correct.
Type: integer
Default: 1
Environment variable: TT_IPROTO_THREADS
Dynamic: no
Logging
This section provides information on how to configure options related to logging.
You can also use the log module to configure logging in your
application.
Specify the level of detail the log has. There are the following levels:
0 – fatal
1 – syserror
2 – error
3 – crit
4 – warn
5 – info
6 – verbose
7 – debug
By setting log_level, you can enable logging of all events with severities above
or equal to the given level. Tarantool prints logs to the standard
error stream by default. This can be changed with the
log configuration parameter.
Type: integer, string
Default: 5
Environment variable: TT_LOG_LEVEL
Dynamic: yes
Note
Prior to Tarantool 1.7.5 there were only six levels and DEBUG was
level 6. Starting with Tarantool 1.7.5, VERBOSE is level 6 and DEBUG is level 7.
VERBOSE is a new level for monitoring repetitive events which would cause
too much log writing if INFO were used instead.
This opens the file tarantool.log for output on the server’s default
directory. If the log string has no prefix or has the prefix “file:”,
then the string is interpreted as a file path.
This starts the program cronolog when the server starts, and
sends all log messages to the standard input (stdin) of cronolog.
If the log string begins with ‘|’ or has the prefix “pipe:”,
then the string is interpreted as a Unix
pipeline.
If the log string begins with “syslog:”, then it is
interpreted as a message for the
syslogd program, which normally
is running in the background on any Unix-like platform.
The setting can be syslog:, syslog:facility=..., syslog:identity=...,
syslog:server=..., or a combination.
The syslog:identity setting is an arbitrary string, which is placed at
the beginning of all messages. The default value is “tarantool”.
The syslog:facility setting is currently ignored but will be used in the future.
The value must be one of the syslog
keywords, which tell syslogd where the message should go.
The possible values are: auth, authpriv, cron, daemon, ftp,
kern, lpr, mail, news, security, syslog, user, uucp, local0, local1, local2,
local3, local4, local5, local6, local7. The default value is: local7.
The syslog:server setting is the locator for the syslog server.
It can be a Unix socket path beginning with “unix:”, or an ipv4 port number.
The default socket value is: dev/log (on Linux) or /var/run/syslog (on macOS).
The default port value is: 514, the UDP port.
When logging to a file, Tarantool reopens the log on SIGHUP.
When log is a program, its PID is saved in the log.pid
variable. You need to send it a signal to rotate logs.
If log_nonblock equals true, Tarantool does not block during logging
when the system is not ready for writing, and drops the message
instead. If log_level is high, and many
messages go to the log, setting log_nonblock to true may improve
logging performance at the cost of some log messages getting lost.
This parameter has effect only if log is
configured to send logs to a pipe or system logger.
The default log_nonblock value is nil, which means that
blocking behavior corresponds to the logger type:
false for stderr and file loggers.
true for a pipe and system logger.
This is a behavior change: in earlier versions of the Tarantool
server, the default value was true.
If processing a request takes longer than the given value (in seconds),
warn about it in the log. Has effect only if log_level is greater than or equal to 4 (WARNING).
The tarantool module that enables you to configure the logging level for Tarantool core messages. Specifically, it configures the logging level for messages logged from non-Lua code, including C modules.
Example: Set a log level for C modules.
Type: table
Default: blank
Environment variable: TT_LOG_MODULES
Dynamic: yes
Example 1: Set log levels for files that use the default logger
Suppose you have two identical modules placed by the following paths: test/logging/module1.lua and test/logging/module2.lua.
These modules use the default logger and look as follows:
return{say_hello=function()locallog=require('log')log.info('Info message from module1')end}
To load these modules in your application, you need to add the corresponding require directives:
To configure logging levels, you need to provide module names corresponding to paths to these modules.
In the example below, the box_cfg variable contains logging settings that can be passed to the box.cfg() function:
Given that module1 has the verbose logging level and module2 has the error level, calling module1.say_hello() shows a message but module2.say_hello() is swallowed:
-- Prints 'info' messages --module1.say_hello()--[[[92617] main/103/interactive/test.logging.module1 I> Info message from module1---...--]]-- Swallows 'info' messages --module2.say_hello()--[[---...--]]
Example 2: Set log levels for modules that use custom loggers
In the example below, the box_cfg variable contains logging settings that can be passed to the box.cfg() function.
This example shows how to set the verbose level for module1 and the error level for module2:
To create custom loggers, call the log.new() function:
-- Creates new loggers --module1_log=require('log').new('module1')module2_log=require('log').new('module2')
Given that module1 has the verbose logging level and module2 has the error level, calling module1_log.info() shows a message but module2_log.info() is swallowed:
-- Prints 'info' messages --module1_log.info('Info message from module1')--[[[16300] main/103/interactive/module1 I> Info message from module1---...--]]-- Swallows 'debug' messages --module1_log.debug('Debug message from module1')--[[---...--]]-- Swallows 'info' messages --module2_log.info('Info message from module2')--[[---...--]]
Example 3: Set a log level for C modules
In the example below, the box_cfg variable contains logging settings that can be passed to the box.cfg() function.
This example shows how to set the info level for the tarantool module:
The specified level affects messages logged from C modules:
ffi=require('ffi')-- Prints 'info' messages --ffi.C._say(ffi.C.S_INFO,nil,0,nil,'Info message from C module')--[[[6024] main/103/interactive I> Info message from C module---...--]]-- Swallows 'debug' messages --ffi.C._say(ffi.C.S_DEBUG,nil,0,nil,'Debug message from C module')--[[---...--]]
The example above uses the LuaJIT ffi library to call C functions provided by the say module.
Logging example
This example illustrates how “rotation” works, that is, what happens when the server
instance is writing to a log and signals are used when archiving it.
Start with two terminal shells: Terminal #1 and Terminal #2.
In Terminal #1, start an interactive Tarantool session.
Then, use the log property to send logs to Log_file and
call log.info to put a message in the log file.
box.cfg{log='Log_file'}log=require('log')log.info('Log Line #1')
In Terminal #2, use the mv command to rename the log file to Log_file.bak.
mvLog_fileLog_file.bak
As a result, the next log message will go to Log_file.bak.
Go back to Terminal #1 and put a message “Log Line #2” in the log file.
log.info('Log Line #2')
In Terminal #2, use ps to find the process ID of the Tarantool instance.
ps-A|greptarantool
In Terminal #2, execute kill-HUP to send a SIGHUP signal to the Tarantool instance.
Tarantool will open Log_file again, and the next log message will go to Log_file.
kill -HUP process_id
The same effect could be accomplished by calling log.rotate.
In Terminal #1, put a message “Log Line #3” in the log file.
log.info('Log Line #3')
In Terminal #2, use less to examine files.
Log_file.bak will have the following lines …
If set to true, the audit subsystem extracts and prints only the primary key instead of full
tuples in DML events (space_insert, space_replace, space_delete).
Otherwise, full tuples are logged.
The option may be useful in case tuples are big.
This opens the audit_tarantool.log file for output in the server’s default directory.
If the audit_log string has no prefix or the prefix file:, the string is interpreted as a file path.
If you log to a file, Tarantool will reopen the audit log at SIGHUP.
This starts the cronolog program when the server starts
and sends all audit_log messages to cronolog’s standard input (stdin).
If the audit_log string starts with ‘|’ or contains the prefix pipe:,
the string is interpreted as a Unix pipeline.
If log is a program, check out its pid and send it a signal to rotate logs.
Example: Writing to a system log
Warning
Below is an example of writing audit logs to a directory shared with the system logs.
Tarantool allows this option, but it is not recommended to do this to avoid difficulties
when working with audit logs. System and audit logs should be written separately.
To do this, create separate paths and specify them.
This sample configuration sends the audit log to syslog:
If the audit_log string starts with “syslog:”,
it is interpreted as a message for the syslogd program,
which normally runs in the background of any Unix-like platform.
The setting can be ‘syslog:’, ‘syslog:facility=…’, ‘syslog:identity=…’, ‘syslog:server=…’ or a combination.
The syslog:identity setting is an arbitrary string that is placed at the beginning of all messages.
The default value is tarantool.
The syslog:facility setting is currently ignored, but will be used in the future.
The value must be one of the syslog keywords
that tell syslogd where to send the message.
The possible values are auth, authpriv, cron, daemon, ftp,
kern, lpr, mail, news, security, syslog, user, uucp,
local0, local1, local2, local3, local4, local5, local6, local7.
The default value is local7.
The syslog:server setting is the locator for the syslog server.
It can be a Unix socket path starting with “unix:” or an ipv4 port number.
The default socket value is /dev/log (on Linux) or /var/run/syslog (on Mac OS).
The default port value is 514, which is the UDP port.
An example of a Tarantool audit log entry in the syslog:
Specify the logging behavior if the system is not ready to write.
If set to true, Tarantool does not block during logging if the system is non-writable and writes a message instead.
Using this value may improve logging performance at the cost of losing some log messages.
Note
The option only has an effect if the audit_log is set to syslog
or pipe.
Setting audit_nonblock to true is not allowed if the output is to a file.
In this case, set audit_nonblock to false.
The array of space names for which data operation events (space_select, space_insert, space_replace,
space_delete) should be logged. The array accepts string values.
If set to box.NULL, the data operation events are logged for all spaces.
Example
In the example, only the events of bands and singers spaces are logged:
Specify the maximum number of authentication retries allowed before auth_delay is enforced.
The default value is 0, which means auth_delay is enforced after the first failed authentication attempt.
The retry counter is reset after auth_delay seconds since the first failed attempt.
For example, if a client tries to authenticate fewer than auth_retries times within auth_delay seconds, no authentication delay is enforced.
The retry counter is also reset after any successful authentication attempt.
‘chap-sha1’: use the CHAP protocol to authenticate users with SHA-1 hashing applied to passwords.
‘pap-sha256’: use PAP authentication with the SHA256 hashing algorithm.
For new users, the box.schema.user.create method
will generate authentication data using PAP-SHA256.
For existing users, you need to reset a password using
box.schema.user.passwd
to use the new authentication protocol.
If true, disables access over remote connections
from unauthenticated or guest access users.
This option affects both
net.box and
replication connections.
Specify the maximum period of time (in days) a user can use the same password.
When this period ends, a user gets the “Password expired” error on a login attempt.
To restore access for such users, use box.schema.user.passwd.
Note
The default 0 value means that a password never expires.
The example below shows how to set a maximum password age to 365 days.
Specify the level of detail the log has.
You can learn more about log levels from the log_level
option description.
Note that the flightrec_logs_log_level value might differ from log_level.
Specify the time period (in seconds) that defines how long metrics are stored from the moment of dump.
So, this value defines how much historical metrics data is collected up to the moment of crash.
The frequency of metric dumps is defined by flightrec_metrics_interval.
Specify the size (in bytes) of storage for the request and response data.
You can set this parameter to 0 to disable a storage of requests and responses.
By default, a Tarantool daemon sends a small packet
once per hour, to https://feedback.tarantool.io.
The packet contains three values from box.info:
box.info.version, box.info.uuid, and box.info.cluster_uuid.
By changing the feedback configuration parameters, users can
adjust or turn off this feature.
How much memory Tarantool allocates to actually store tuples, in gigabytes.
When the limit is reached, INSERT or UPDATE requests begin failing with
error ER_MEMORY_ISSUE. While the server does not go beyond the
defined limit to allocate tuples, there is additional memory used to store
indexes and connection information. Depending on actual configuration and
workload, Tarantool can consume up to 20% more than the limit set here.
The parameter does not allow using the strict fencing mode. Setting to true
is equivalent to setting the softelection_fencing_mode.
Setting to false is equivalent to setting the offelection_fencing_mode.
Type: boolean
Default: true
Environment variable: TT_ELECTION_FENCING_ENABLED
Dynamic: yes
tarantool command-line options
tarantool is the Tarantool database and application server.
This command can be used for different purposes, for example, running a single Tarantool instance or starting an external coordinator used for a supervised failover.
The tarantool command also provides additional options that might be helpful for development purposes.
Try to start an instance if there is an error while reading a corrupted snapshot or write-ahead log file during the recovery process:
For a corrupted snapshot file – at the instance start.
For a corrupted write-ahead log file – at the instance start or when applying an update at a replica.
With this option enabled, Tarantool skips invalid records, reads as much data as possible, and lets the process finish with a warning.
When the instance has started, call box.snapshot() to make a new snapshot so that the corrupted snapshots or write-ahead logs aren’t used for recovery anymore.
You can also enable force recovery using the TT_FORCE_RECOVERY environment variable.
TT_FORCE_RECOVERY has a lower priority than the --force-recovery option.
Tarantool’s SQL is a major new feature that was first introduced with Tarantool version 2.1.
The primary advantages are:
- a high level of SQL compatibility
- an easy way to switch from NoSQL to SQL and back
- the Tarantool brand.
The “high level of SQL compatibility” includes support for joins, subqueries, triggers,
indexes, groupings, transactions in a multi-user environment, and conformance with the
majority of the mandatory requirements of the SQL:2016 standard.
The “easy way to switch” consists of the fact that the same tables can be operated
on with SQL and with the long-established Tarantool-NoSQL product, meaning that
when you want standard Relational-DBMS jobs you can do them, and when you want NoSQL capability
you can have it (Tarantool-NoSQL outperforms other NoSQL products in public benchmarks).
The “Tarantool brand” comes from the support of a multi-billion-dollar internet / mail / social-network
provider, a dozens-of-professionals staff of programmers and support people, a community who believes
in open-source BSD licensing, and hundreds of corporations / government bodies using Tarantool products in production already.
The status of Tarantool’s SQL feature is “release”. So, it is working now and you can verify
that by downloading it and trying all the features, which will be explained in the rest of this document.
There is also a tutorial.
Differences from other products
Differences from other SQL products:
The Tarantool design requirement is that Tarantool’s SQL conforms to the majority of the listed
mandatory requirements of the core SQL:2016 standard, and this
will be shown in the specific conformance statements in the feature list
in a section about “compliance with the official SQL standard”.
Possibly the deviations which most people will find notable are:
type checking is less strict,
and some data definition options must be done with NoSQL syntax.
Differences from other NoSQL products:
By examining attempts by others to paste relatively smaller
subsets of SQL onto NoSQL products, it should be possible to conclude that Tarantool’s
SQL has demonstrably more features and capabilities.
The reason is that the Tarantool developers started with a complete code base of
a working SQL DBMS and made it work with Tarantool-NoSQL underneath,
rather than starting with a NoSQL DBMS and adding syntax to it.
What Tarantool’s SQL manual delivers
The following parts of this document are:
The SQL User Guide explains “How to get Started” and explains the terms and the syntax elements that
apply for all SQL statements.
The SQL Statements and Clauses guide explains, for each SQL statement, the format and the rules
and the exceptions and the examples and the limitations.
The SQL Plus Lua guide has the details about calling Lua from SQL, calling SQL from Lua,
and using the same database objects in both SQL and Lua.
The SQL Features list shows how the product conforms with the mandatory features of the SQL standard.
Users are expected to know what databases are, and experience with other SQL DBMSs would be an advantage.
To learn about the basics of relational database management and SQL in particular,
check the SQL Beginners’ Guide in the How-to guides section.
SQL user guide
The User Guide describes how users can start up with SQL with Tarantool, and necessary concepts.
Now you are ready to execute any SQL statements via the connection. For example
box.execute([[CREATE TABLE things (id INTEGER PRIMARY key, remark STRING);]])box.execute([[INSERT INTO things VALUES (55, 'Hello SQL world!');]])box.execute([[SELECT * FROM things WHERE id > 0;]])
And you will see the results of the SQL query.
For the rest of this chapter, the
box.execute([[…]]) enclosure will not be shown.
Examples will simply say what a piece of syntax looks like, such as
SELECT'hello';
and users should know that must be entered as box.execute([[SELECT'hello';]])
It is also legal to enclose SQL statements inside single or double quote marks instead of [[ … ]].
Supported Syntax
Keywords, for example CREATE or INSERT or VALUES, may be entered in either upper case or lower case.
Literal values, for example 55 or 'HelloSQLworld!', should be entered without single quote marks
if they are numeric, and should be entered with single quote marks if they are strings.
Object names, for example table1 or column1, should usually be entered without double quote marks
and are subject to some restrictions. They may be enclosed in double quote marks and in that case
they are subject to fewer restrictions.
Almost all keywords are reserved,
which means that they cannot be used as object names
unless they are enclosed in double quote marks.
Comments may be between /* and */ (bracketed)
or between -- and the end of a line (simple).
INSERT/* This is a bracketed comment */INTOtVALUES(5);INSERTINTOtVALUES(5);-- this is a simple comment
Expressions, for example a+b or a>bANDNOTa<=b, may have arithmetic operators
+-/*, may have comparison operators =><<=>=LIKE, and may be combined with
ANDORNOT, with optional parentheses.
Concepts
In the SQL beginners’ guide there was discussion of:
What are: relational databases, tables, views, rows, and columns?
What are: transactions, write-ahead logs, commits and rollbacks?
What are: security considerations?
How to: add, delete, or update rows in tables?
How to: work inside transactions with commits and/or rollbacks?
How to: select, join, filter, group, and sort rows?
Tarantool has a “schema”. A schema is a container for all database objects.
A schema may be called a “database” in other DBMS implementations
Tarantool allows four types of “database objects” to be created within
the schema: tables, triggers, indexes, and constraints.
Within tables, there are “columns”.
Almost all Tarantool SQL statements begin with a reserved-word “verb”
such as INSERT, and end optionally with a semicolon.
For example: INSERTINTOtVALUES(1);
A Tarantool SQL database and a Tarantool NoSQL database are the same thing.
However, some operations are only possible with SQL, and others are only
possible with NoSQL. Mixing SQL statements with NoSQL requests is allowed.
Tokens
The token is the minimum SQL-syntax unit that Tarantool understands.
These are the types of tokens:
Keywords – official words in the language, for example SELECT
Literals – constants for numerics or strings, for example 15.7 or 'Taranto'
Identifiers – for example column55 or table_of_accounts
Operators (strictly speaking “non-alphabetic operators”) – for example */+-(),;<=>=
Tokens can be separated from each other by one or more separators:
* White space characters: tab (U+0009), line feed (U+000A), vertical tab (U+000B), form feed (U+000C), carriage return (U+000D), space (U+0020), next line (U+0085), and all the rare characters in Unicode classes Zl and Zp and Zs. For a full list see https://github.com/tarantool/tarantool/issues/2371.
* Bracketed comments (beginning with /* and ending with */)
* Simple comments (beginning with -- and ending with line feed)
Separators are not necessary before or after operators.
Separators are necessary after keywords or numerics or ordinary identifiers, unless the following token is an operator.
Thus Tarantool can understand this series of six tokens: SELECT'a'FROM/**/t;
but for readability one would usually use spaces to separate tokens: SELECT'a'FROM/**/t;
Literals
There are eight kinds of literals: BOOLEAN INTEGER DOUBLE DECIMAL STRING VARBINARY MAP ARRAY.
BOOLEAN literals:
TRUE | FALSE | UNKNOWN
A literal has data type = BOOLEAN if it is the keyword TRUE or FALSE.
UNKNOWN is a synonym for NULL.
A literal may have type = BOOLEAN if it is the keyword NULL and there is no context to indicate a different data type.
INTEGER literals:
[plus-sign | minus-sign] digit [digit …]
or, for a hexadecimal integer literal,
[plus-sign | minus-sign] 0X | 0x hexadecimal-digit [hexadecimal-digit …]
Examples: 5, -5, +5, 55555, 0X55, 0x55
Hexadecimal 0X55 is equal to decimal 85.
A literal has data type = INTEGER if it contains only digits and is in
the range -9223372036854775808 to +18446744073709551615, integers outside that range are illegal.
DOUBLE literals:
[E|e [plus-sign | minus-sign] digit …]
Examples: 1E5, 1.1E5.
A literal has data type = DOUBLE if it contains “E”.
DOUBLE literals are also known as floating-point literals or approximate-numeric literals.
To represent “Inf” (infinity), write a real numeric outside the double-precision numeric range, for example 1E309.
To represent “nan” (not a number), write an expression that does not result in a real numeric,
for example 0/0, using Tarantool/NoSQL. This will appear as NULL in Tarantool/SQL.
In an earlier version literals containing periods were considered to be NUMBER literals.
In a future version “nan” may not appear as NULL.
Prior to Tarantool v. 2.10.0, digits with periods such as .0 were considered to be DOUBLE literals,
but now they are considered to be DECIMAL literals.
DECIMAL literals:
[plus-sign | minus-sign] [digit [digit …]] period [digit [digit …]]
Examples: .0, 1.0, 12345678901234567890.123456789012345678
A literal has data type = DECIMAL if it contains a period, and does not contain “E”.
DECIMAL literals may contain up to 38 digits; if there are more, then post-decimal digits may be subject to rounding.
In earlier Tarantool versions literals containing periods were considered to be
NUMBER or DECIMAL literals.
STRING literals:
[quote] [character …] [quote]
Examples: 'ABC', 'AB''C'
A literal has data type type = STRING
if it is a sequence of zero or more characters enclosed in single quotes.
The sequence '' (two single quotes in a row) is treated as ' (a single quote) when enclosed in quotes,
that is, 'A''B' is interpreted as A'B.
VARBINARY literals:
X|x [quote] [hexadecimal-digit-pair …] [quote]
Example: X'414243', which will be displayed as 'ABC'.
A literal has data type = VARBINARY
(“variable-length binary”) if it is the letter X followed by quotes containing pairs of hexadecimal digits, representing byte values.
MAP literals:
[left curly bracket] key [colon] value [right curly bracket]
Examples: {'a':1}, {1:'a'}
A map literal is a pair of curly brackets (also called “braces”)
enclosing a STRING or INTEGER or UUID literal (called the map “key”)
followed by a colon
followed by any type of literal (called the map “value”).
This is a minimal form of a MAP expression.
ARRAY literals:
[left square bracket] [literal] [right square bracket]
Examples: [1], ['a']
An ARRAY literal is a literal value which is enclosed inside square brackets.
This is a minimal form of an ARRAY expression.
Here are four ways to put non-ASCII characters,such as the Greek letter α alpha, in string literals:
First make sure that your shell program is set to accept characters as UTF-8. A simple way to check is SELECThex(cast('α'asVARBINARY));
If the result is CEB1 – which is the hexadecimal value for the UTF-8 representation of α – it is good.
(1) Simply enclose the character inside '...', 'α'
(2) Find out what is the hexadecimal code for the UTF-8 representation of α,
and enclose that inside X'...', then cast to STRING because X'...' literals are data type VARBINARY not STRING, CAST(X'CEB1'ASSTRING)
(3) Find out what is the Unicode code point for α, and pass that to the CHAR function. CHAR(945)/*rememberthatthisisαasdatatypeSTRINGnotVARBINARY*/
(4) Enclose statements inside double quotes and include Lua escapes, for example
box.execute("SELECT'\206\177';")
One can use the concatenation operator || to combine characters made with any of these methods.
Limitations: (Issue#2344)
* LENGTH('A''B')=3 which is correct, but on the Tarantool console the display from
SELECTA''B; is A''B, which is misleading.
* It is unfortunate that X'41' is a byte sequence which looks the same as 'A',
but it is not the same. box.execute("select'A'<X'41';") is not legal at the moment.
This happens because TYPEOF(X'41') yields 'varbinary'.
Also it is illegal to say UPDATE...SETstring_column=X'41',
one must say UPDATE...SETstring_column=CAST(X'41'ASSTRING);.
Identifiers
All database objects – tables, triggers, indexes, columns, constraints, functions, collations – have identifiers.
An identifier should begin with a letter or underscore ('_') and should contain
only letters, digits, dollar signs ('$'), or underscores.
The maximum number of bytes in an identifier is between 64982 and 65000.
For compatibility reasons, Tarantool recommends that an identifier should not have more than 30 characters.
Letters in identifiers do not have to come from the Latin alphabet,
for example the Japanese syllabic ひ and the Cyrillic letter д are legal.
But be aware that a Latin letter needs only one byte but a Cyrillic letter needs two bytes,
so Cyrillic identifiers consume a tiny amount more space.
Reserved words
Certain words are reserved and should not be used for identifiers.
The simple rule is: if a word means something in Tarantool SQL syntax,
do not try to use it for an identifier. The current list of reserved words is:
ALL ALTER ANALYZE AND ANY ARRAY AS ASC ASENSITIVE AUTOINCREMENT
BEGIN BETWEEN BINARY BLOB BOOL BOOLEAN BOTH BY CALL CASE
CAST CHAR CHARACTER CHECK COLLATE COLUMN COMMIT CONDITION
CONNECT CONSTRAINT CREATE CROSS CURRENT CURRENT_DATE
CURRENT_TIME CURRENT_TIMESTAMP CURRENT_USER CURSOR DATE
DATETIME DEC DECIMAL DECLARE DEFAULT DEFERRABLE DELETE DENSE_RANK
DESC DESCRIBE DETERMINISTIC DISTINCT DOUBLE DROP EACH ELSE
ELSEIF END ESCAPE EXCEPT EXISTS EXPLAIN FALSE FETCH FLOAT
FOR FOREIGN FROM FULL FUNCTION GET GRANT GROUP HAVING IF
IMMEDIATE IN INDEX INNER INOUT INSENSITIVE INSERT INT
INTEGER INTERSECT INTO IS ITERATE JOIN LEADING LEAVE LEFT
LIKE LIMIT LOCALTIME LOCALTIMESTAMP LOOP MAP MATCH NATURAL NOT
NULL NUM NUMBER NUMERIC OF ON OR ORDER OUT OUTER OVER PARTIAL
PARTITION PRAGMA PRECISION PRIMARY PROCEDURE RANGE RANK
READS REAL RECURSIVE REFERENCES REGEXP RELEASE RENAME
REPEAT REPLACE RESIGNAL RETURN REVOKE RIGHT ROLLBACK ROW
ROWS ROW_NUMBER SAVEPOINT SCALAR SELECT SENSITIVE SEQSCAN SESSION SET
SIGNAL SIMPLE SMALLINT SPECIFIC SQL START STRING SYSTEM TABLE
TEXT THEN TO TRAILING TRANSACTION TRIGGER TRIM TRUE
TRUNCATE UNION UNIQUE UNKNOWN UNSIGNED UPDATE USER USING UUID VALUES
VARBINARY VARCHAR VIEW WHEN WHENEVER WHERE WHILE WITH
Identifiers may be enclosed in double quotes.
These are called quoted identifiers or “delimited identifiers”
(unquoted identifiers may be called “regular identifiers”).
The double quotes are not part of the identifier.
A delimited identifier may be a reserved word and may contain
any printable character. Tarantool converts letters in regular
identifiers to upper case before it accesses the database,
so for statements like
CREATETABLEa(aINTEGERPRIMARYKEY);
or
SELECTaFROMa;
the table name is A and the column name is A.
However, Tarantool does not convert delimited identifiers
to upper case, so for statements like
CREATETABLE"a"("a"INTEGERPRIMARYKEY);
or
SELECT"a"FROM"a";
the table name is a and the column name is a.
The sequence "" is treated as " when enclosed in double quotes,
that is, "A""B" is interpreted as "A"B".
Inside certain statements, identifiers may have “qualifiers” to prevent ambiguity.
A qualifier is an identifier of a higher-level object, followed by a period.
For example column1 within table1 may be referred to as table1.column1.
The “name” of an object is the same as its identifier, or its qualified identifier.
For example, inside SELECTtable1.column1,table2.column1FROMtable1,table2; the qualifiers
make it clear that the first column is column1 from table1 and the second column
is column1 from table2.
The rules are sometimes relaxed for compatibility reasons, for example
some non-letter characters such as $ and « are legal in regular identifiers.
However, it is better to assume that rules are never relaxed.
The following are examples of legal and illegal identifiers.
_A1 -- legal, begins with underscore and contains underscore | letter | digit
1_A -- illegal, begins with digit
A$« -- legal, but not recommended, try to stick with digits and letters and underscores
+ -- illegal, operator token
grant -- illegal, GRANT is a reserved word
"grant" -- legal, delimited identifiers may be reserved words
"_space" -- legal, but Tarantool already uses this name for a system space
"A"."X" -- legal, for columns only, inside statements where qualifiers may be necessary
'a' -- illegal, single quotes are for literals not identifiers
A123456789012345678901234567890 -- legal, identifiers can be long
ддд -- legal, and will be converted to upper case in identifiers
The following example shows that conversion to upper case affects regular identifiers but not delimited identifiers.
CREATETABLE"q"("q"INTEGERPRIMARYKEY);SELECT*FROMq;-- Result = "error: 'no such table: Q'.
Operands
An operand is something that can be operated on. Literals and column identifiers are operands. So are NULL and DEFAULT.
NULL and DEFAULT are keywords which represent values whose data types are not known until they are assigned or compared,
so they are known by the technical term “contextually typed value specifications”.
(Exception: for the non-standard statement “SELECT NULL FROM table-name;” NULL has data type BOOLEAN.)
Operand data types
Every operand has a data type.
For literals, as seen earlier, the data type is usually determined by the format.
For identifiers, the data type is usually determined by the definition.
The usual determination may change because of context or because of
explicit casting.
For some SQL data type names there are aliases.
An alias may be used for data definition.
For example VARCHAR(5) and TEXT are aliases of STRING and may appear in
CREATETABLEtable_name(column_nameVARCHAR(5)PRIMARYKEY); but Tarantool,
if asked, will report that the data type of column_name is STRING.
For every SQL data type there is a corresponding NoSQL type, for example
an SQL STRING is stored in a NoSQL space as type = ‘string’.
To avoid confusion in this manual, all references to SQL data type names are
in upper case and all similar words which refer to NoSQL types or to other kinds
of object are in lower case, for example:
STRING is a data type name, but string is a general term;
NUMBER is a data type name, but numeric is a general term.
Although it is common to say that a VARBINARY value is a “binary string”,
this manual will not use that term and will instead say “byte sequence”.
Here are all the SQL data types, their corresponding NoSQL types, their aliases,
and minimum / maximum literal examples.
BOOLEAN values are FALSE, TRUE, and UNKNOWN (which is the same as NULL).
FALSE is less than TRUE.
INTEGER values are numerics that do not contain decimal points and are
not expressed with exponential notation. The range of possible values is
between -2^63 and +2^64, or NULL.
UNSIGNED values are numerics that do not contain decimal points and are not
expressed with exponential notation. The range of possible values is
between 0 and +2^64, or NULL.
DOUBLE values are numerics that do contain decimal points (for example 0.5) or
are expressed with exponential notation (for example 5E-1).
The range of possible values is the same as for the IEEE 754 floating-point
standard, or NULL. Numerics outside the range of DOUBLE literals may be displayed
as -inf or inf.
NUMBER values have the same range as DOUBLE values.
But NUMBER values may also be integers.
There is no literal format for NUMBER (literals like 1.5 or 1E555
are considered to be DOUBLEs), so use CAST
to insist that a numeric has data type NUMBER, but that is rarely necessary.
See the description of NoSQL type ‘number’.
Support for arithmetic and built-in arithmetic functions with NUMBERs was removed in Tarantool version 2.10.1.
DECIMAL values can contain up to 38 digits on either side of a decimal point.
and any arithmetic with DECIMAL values has exact results
(arithmetic with DOUBLE values could have approximate results instead of exact results).
Before Tarantool v. 2.10.0 there was no literal format for DECIMAL,
so it was necessary to use CAST to insist that a numeric
has data type DECIMAL, for example CAST(1.1ASDECIMAL) or
CAST('99999999999999999999999999999999999999'ASDECIMAL).
See the description of NoSQL type ‘decimal’.
DECIMAL support in SQL was added in Tarantool version 2.10.1.
STRING values are any sequence of zero or more characters encoded with UTF-8,
or NULL. The possible character values are the same as for the Unicode standard.
Byte sequences which are not valid UTF-8 characters are allowed but not recommended.
STRING literal values are enclosed within single quotes, for example 'literal'.
If the VARCHAR alias is used for column definition, it must include a maximum
length, for example column_1 VARCHAR(40). However, the maximum length is ignored.
The data-type may be followed by [COLLATE collation-name].
VARBINARY values are any sequence of zero or more octets (bytes), or NULL.
VARBINARY literal values are expressed as X followed by pairs of hexadecimal
digits enclosed within single quotes, for example X'0044'.
VARBINARY’s NoSQL equivalent is 'varbinary' but not character string – the
MessagePack storage is MP_BIN (MsgPack binary).
UUID (Universally unique identifier) values are 32 hexadecimal digits, or NULL.
The usual format is a string with five fields separated by hyphens, 8-4-4-4-12,
for example '000024ac-7ca6-4ab2-bd75-34742ac91213'.
The MessagePack storage is MP_EXT (MsgPack extension) with 16 bytes.
UUID values may be created with
Tarantool/NoSQL Module uuid,
or with the UUID() function,
or with the CAST() function.
UUID support in SQL was added in Tarantool version 2.9.1.
DATETIME. Introduced in v. 2.10.0.
A datetime table field can be created by using this type, which is semantically equivalent to the standard TIMESTAMP WITH TIME ZONE type.
There is no implicit cast available from a string expression to a datetime expression (unlike convention used by majority of SQL vendors).
In such cases, you need to use explicit cast from a string value to a datetime value (see the example above).
You can subtract datetime and datetime, datetime and interval, or add datetime and interval in any order (see examples of such arithmetic in the description of the INTERVAL type).
The built-in functions related to the DATETIME type are DATE_PART() and NOW()
INTERVAL. Introduced in v. 2.10.0.
Similarly to the DATETIME type, you can define a column of the INTERVAL type.
Unlike DATETIME, INTERVAL cannot be a part of an index.
There is no implicit cast available for conversions to an interval from a string or any other type.
But there is explicit cast allowed from maps (see examples below).
Intervals can be used in arithmetic operations like + or - only with the datetime expression or another interval:
SCALAR can be used for
column definitions and the individual column values have
type SCALAR. See
Column definition – the rules for the SCALAR data type.
The data-type may be followed by [COLLATE collation-name].
Prior to Tarantool version 2.10.1, individual column values had
one of the preceding types – BOOLEAN, INTEGER, DOUBLE, DECIMAL, STRING, VARBINARY, or UUID.
Starting in Tarantool version 2.10.1, all values have type SCALAR.
MAP values are key:value combinations which can be produced with
MAP expressions.
Maps cannot be used in arithmetic or comparison (except IS[NOT]NULL),
and the only
functions where they are allowed are CAST,
QUOTE,
TYPEOF, and functions involving NULL comparisons.
ARRAY values are lists which can be produced with
ARRAY expressions.
Arrays cannot be used in arithmetic or comparison (except IS[NOT]NULL), and the only
functions where they are allowed are CAST,
QUOTE,
TYPEOF, and functions involving NULL comparisons.
ANY can be used for
column definitions and the individual column values have
type ANY.
The difference between SCALAR and ANY is:
SCALAR columns may not contain MAP or ARRAY values, but ANY columns may contain them.
SCALAR values are comparable, while ANY values are not comparable.
Any value of any data type may be NULL. Ordinarily NULL will be cast to the
data type of any operand it is being compared to or to the data type of the
column it is in. If the data type of NULL cannot be determined from context,
it is BOOLEAN.
Most of the SQL data types correspond to
Tarantool/NoSQL types with the same name.
In Tarantool versions before v. 2.10.0,
There were also some Tarantool/NoSQL data types which had no corresponding SQL data types.
In those versions, if Tarantool/SQL reads a Tarantool/NoSQL value of a type that has no SQL equivalent,
Tarantool/SQL could treat it as NULL or INTEGER or VARBINARY.
For example, SELECT"flags"FROM"_vspace"; would return a column whose type is 'map'.
Such columns can only be manipulated in SQL by
invoking Lua functions.
Operators
An operator signifies what operation can be performed on operands.
Almost all operators are easy to recognize because they consist of one-character
or two-character non-alphabetic tokens, except for six keyword operators (AND IN IS LIKE NOT OR).
Almost all operators are “dyadic”, that is, they are performed on a pair of operands
– the only operators that are performed on a single operand are NOT and ~ and (sometimes) -.
The result of an operation is a new operand. If the operator is a comparison operator
then the result has data type BOOLEAN (TRUE or FALSE or UNKNOWN).
Otherwise the result has the same data type as the original operands, except that:
promotion to a broader type may occur to avoid overflow.
Arithmetic with NULL operands will result in a NULL operand.
In the following list of operators, the tag “(arithmetic)” indicates
that all operands are expected to be numerics (other than NUMBER) and should result in a numeric;
the tag “(comparison)” indicates that operands are expected to have similar
data types and should result in a BOOLEAN; the tag “(logic)”
indicates that operands are expected to be BOOLEAN and should result in a BOOLEAN.
Exceptions may occur where operations are not possible, but see the “special situations”
which are described after this list.
Although all examples show literals, they could just as easily show column identifiers.
Starting with Tarantool version 2.10.1, arithmetic operands cannot be NUMBERs.
+ addition (arithmetic)
Add two numerics according to standard arithmetic rules.
Example: 1+5, result = 6.
- subtraction (arithmetic)
Subtract second numeric from first numeric according to standard arithmetic rules.
Example: 1-5, result = -4.
* multiplication (arithmetic)
Multiply two numerics according to standard arithmetic rules.
Example: 2*5, result = 10.
/ division (arithmetic)
Divide second numeric into first numeric according to standard arithmetic rules.
Division by zero is not legal.
Division of integers always results in rounding toward zero,
use CAST to DOUBLE or to DECIMAL to get
non-integer results.
Example: 5/2, result = 2.
% modulus (arithmetic)
Divide second numeric into first numeric according to standard arithmetic rules.
The result is the remainder.
Starting with Tarantool version 2.10.1, operands must be INTEGER or UNSIGNED.
Examples: 17%5, result = 2; -123%4, result = -3.
<< shift left (arithmetic)
Shift the first numeric to the left N times, where N = the second numeric.
For positive numerics, each 1-bit shift to the left is equivalent to multiplying times 2.
Example: 5<<1, result = 10.
Note
Starting with Tarantool version 2.10.1, operands must be non-negative INTEGER or UNSIGNED.
>> shift right (arithmetic)
Shift the first numeric to the right N times, where N = the second numeric.
For positive numerics, each 1-bit shift to the right is equivalent to dividing by 2.
Example: 5>>1, result = 2.
Note
Starting with Tarantool version 2.10.1, operands must be non-negative INTEGER or UNSIGNED.
& and (arithmetic)
Combine the two numerics, with 1 bits in the result if and only if both original numerics have 1 bits.
Example: 5&4, result = 4.
Note
Starting with Tarantool version 2.10.1, operands must be non-negative INTEGER or UNSIGNED.
| or (arithmetic)
Combine the two numerics, with 1 bits in the result if either original numeric has a 1 bit.
Example: 5|2, result = 7.
Note
Starting with Tarantool version 2.10.1, operands must be non-negative INTEGER or UNSIGNED.
~ negate (arithmetic), sometimes called bit inversion
Change 0 bits to 1 bits, change 1 bits to 0 bits.
Example: ~5, result = -6.
Note
Starting with Tarantool version 2.10.1, the operand must be non-negative INTEGER or UNSIGNED.
< less than (comparison)
Return TRUE if the first operand is less than the second by arithmetic or collation rules.
Example for numerics: 5<2, result = FALSE
Example for strings: 'C'<'', result = FALSE
<= less than or equal (comparison)
Return TRUE if the first operand is less than or equal to the second by arithmetic or collation rules.
Example for numerics: 5<=5, result = TRUE
Example for strings: 'C'<='B', result = FALSE
> greater than (comparison)
Return TRUE if the first operand is greater than the second by arithmetic or collation rules.
Example for numerics: 5>-5, result = TRUE
Example for strings: 'C'>'!', result = TRUE
>= greater than or equal (comparison)
Return TRUE if the first operand is greater than or equal to the second by arithmetic or collation rules.
Example for numerics: 0>=0, result = TRUE
Example for strings: 'Z'>='Γ', result = FALSE
= equal (assignment or comparison)
After the word SET, “=” means the first operand gets the value from the second operand.
In other contexts, “=” returns TRUE if operands are equal.
For IS NULL: Return TRUE if the first operand is NULL, otherwise return FALSE.
Example: column1 IS NULL, result = TRUE if column1 contains NULL.
For IS NOT NULL: Return FALSE if the first operand is NULL, otherwise return TRUE.
Example: column1ISNOTNULL, result = FALSE if column1 contains NULL.
LIKE (comparison)
Perform a comparison of two string operands.
If the second operand contains '_', the '_' matches any single character in the first operand.
If the second operand contains '%', the '%' matches 0 or more characters in the first operand.
If it is necessary to search for either '_' or '%' within a string without treating it specially,
an optional clause can be added, ESCAPE single-character-operand, for example
'abc_'LIKE'abcX_'ESCAPE'X' is TRUE because X' means “following character is not
special”. Matching is also affected by the string’s collation.
BETWEEN (comparison)
xBETWEENyANDz is shorthand for x>=yANDx<=z.
NOT negation (logic)
Return TRUE if operand is FALSE return FALSE if operand is TRUE, else return UNKNOWN.
Example: NOT(1>1), result = TRUE.
IN is equal to one of a list of operands (comparison)
Return TRUE if first operand equals any of the operands in a parenthesized list.
Example: 1IN(2,3,4,1,7), result = TRUE.
AND and (logic)
Return TRUE if both operands are TRUE.
Return UNKNOWN if both operands are UNKNOWN.
Return UNKNOWN if one operand is TRUE and the other operand is UNKNOWN.
Return FALSE if one operand is FALSE and the other operand is (UNKNOWN or TRUE or FALSE).
OR or (logic)
Return TRUE if either operand is TRUE.
Return FALSE if both operands are FALSE.
Return UNKNOWN if one operand is UNKNOWN and the other operand is (UNKNOWN or FALSE).
|| concatenate (string manipulation)
Return the value of the first operand concatenated with the value of the second operand.
Example: 'A'||'B', result = 'AB'.
The precedence of dyadic operators is:
||
* / %
+ -
<< >> & |
< <= > >=
= == != <> IS IS NOT IN LIKE
AND
OR
To ensure a desired precedence, use () parentheses.
Special situations
If one of the operands has data type DOUBLE, Tarantool uses floating-point arithmetic.
This means that exact results are not guaranteed and rounding may occur without warning.
For example, 4.7777777777777778 = 4.7777777777777777 is TRUE.
The floating-point values inf and -inf are possible.
For example, SELECT1e318,-1e318; will return “inf, -inf”.
Arithmetic on infinite values may cause NULL results,
for example SELECT1e318-1e318; is NULL and SELECT1e318*0; is NULL.
SQL operations never return the floating-point value -nan,
although it may exist in data created by Tarantool’s NoSQL. In SQL, -nan is treated as NULL.
In older Tarantool versions,
a string would be converted to a numeric if it was used with an arithmetic operator and conversion was possible,
for example '7'+'7' = 14.
And for comparison, '7' = 7.
This is called implicit casting. It was applicable for STRINGs and all numeric data types.
Starting with Tarantool version 2.10, it is no longer supported.
Limitations: (Issue#2346)
* Some words, for example MATCH and REGEXP, are reserved but are not necessary for current or planned Tarantool versions
* 999999999999999 << 210 yields 0.
Expressions
An expression is a chunk of syntax that causes return of a value.
Expressions may contain literals, column-names, operators, and parentheses.
Therefore these are examples of expressions:
1, 1+1<<1, (1=2)OR4>3, 'x'||'y'||'z'.
Also there are two expressions that involve keywords:
valueIS[NOT]NULL: determine whether value is (not) NULL.
CASE...WHEN...THEN...ELSE...END: set a series of conditions.
An expression has data type = ARRAY if it is a sequence of zero or more values
enclosed in square brackets ([ and ]).
Often the values in the sequence are called “elements”.
The element data type may be anything, including ARRAY – that is, ARRAYs may be nested.
Different elements may have different types.
The Lua equivalent type is ‘array’.
An expression has data type = MAP if it is enclosed in curly brackets
(also called braces) { and } and contains a key for identification,
then a colon :, then a value for what the key identifies.
The key data type must be INTEGER or STRING or UUID.
The value data type may be anything, including MAP – that is, MAPs may be nested.
The Lua equivalent type is ‘map’ but the syntax is slightly different,
for example the SQL value {'a':1} is represented in Lua as {a=1}.
There are rules for determining whether value-1 is “less than”, “equal to”, or “greater than” value-2.
These rules are applied for searches, for sorting results in order by column values,
and for determining whether a column is unique.
The result of a comparison of two values can be TRUE, FALSE, or UNKNOWN (the three BOOLEAN values).
For any comparisons where neither operand is NULL, the operands are “distinct” if the comparison
result is FALSE.
For any set of operands where all operands are distinct from each other, the set is considered to be “unique”.
When comparing a numeric to a numeric:
* infinity = infinity is true
* regular numerics are compared according to usual arithmetic rules
When comparing any value to NULL:
(for examples in this paragraph assume that column1 in table T contains {NULL, NULL, 1, 2})
* value comparison-operator NULL is UNKNOWN (not TRUE and not FALSE), which affects “WHERE condition” because the condition must be TRUE, and does not affect “CHECK (condition)” because the condition must be either TRUE or UNKNOWN. Therefore SELECT * FROM T WHERE column1 > 0 OR column1 < 0 OR column1 = 0; returns only {1,2}, and the table can have been created with CREATE TABLE T (… column1 INTEGER, CHECK (column1 >= 0));
* for any operations that contain the keyword DISTINCT, NULLs are not distinct. Therefore SELECT DISTINCT column1 FROM T; will return {NULL,1,2}.
* for grouping, NULL values sort together. Therefore SELECT column1, COUNT(*) FROM T GROUP BY column1; will include a row {NULL, 2}.
* for ordering, NULL values sort together and are less than non-NULL values. Therefore SELECT column1 FROM T ORDER BY column1; returns {NULL, NULL, 1,2}.
* for evaluating a UNIQUE constraint or UNIQUE index, any number of NULLs is okay. Therefore CREATE UNIQUE INDEX i ON T (column1); will succeed.
When comparing any value (except an ARRAY or MAP or ANY) to a SCALAR:
* This is always legal, and the result depends on the underlying type of the value.
For example, if COLUMN1 is defined as SCALAR, and a value in the column is ‘a’, then
COLUMN1 < 5 is a legal comparison and the result is FALSE because numeric is less than STRING.
When comparing a numeric to a STRING:
* Comparison is legal if the STRING value can be converted to a numeric with an explicit cast.
When comparing a BOOLEAN to a BOOLEAN:
TRUE is greater than FALSE.
When comparing a VARBINARY to a VARBINARY:
* The numeric value of each pair of bytes is compared until the end of the byte sequences or until inequality. If two byte sequences are otherwise equal but one is longer, then the longer one is greater.
When comparing for the sake of eliminating duplicates:
* This is usually signalled by the word DISTINCT, so it applies to SELECT DISTINCT, to set operators such as UNION (where DISTINCT is implied), and to aggregate functions such as AVG(DISTINCT).
* Two operators are “not distinct” if they are equal to each other, or are both NULL
* If two values are equal but not identical, for example 1.0 and 1.00, they are non-distinct and there is no way to specify which one will be eliminated
* Values in primary-key or unique columns are distinct due to definition.
When comparing a STRING to a STRING:
* Ordinarily collation is “binary”, that is, comparison is done according to the numeric values of the bytes. This can be cancelled by adding a COLLATE clause at the end of either expression. So 'A'<'a' and 'a'<'Ä', but 'A'COLLATE"unicode_ci"='a' and 'a'COLLATE"unicode_ci"='Ä'.
* When comparing a column with a string literal, the column’s defined collation is used.
* Ordinarily trailing spaces matter. So 'a'='a' is not TRUE. This can be cancelled by using the TRIM(TRAILING …) function.
When comparing any value to an ARRAY or MAP or ANY:
* The result is an error.
Limitations:
* LIKE is not expected to work with VARBINARY.
Statements
A statement consists of SQL-language keywords and expressions that direct Tarantool to do something with a database.
Statements begin with one of the words
ALTER ANALYZE COMMIT CREATE DELETE DROP EXPLAIN INSERT PRAGMA RELEASE REPLACE ROLLBACK SAVEPOINT
SELECT SET START TRUNCATE UPDATE VALUES WITH.
Statements should end with ; semicolon although this is not mandatory.
A client sends a statement to the Tarantool server.
The Tarantool server parses the statement and executes it.
If there is an error, Tarantool returns an error message.
List of legal statements
In alphabetical order, the following statements are legal.
Data type conversion, also called casting, is necessary for any operation involving two operands X and Y,
when X and Y have different data types.
Or, casting is necessary for assignment operations
(when INSERT or UPDATE is putting a value of type X into a column defined as type Y).
Casting can be “explicit” when a user uses the CAST function, or “implicit” when Tarantool does a conversion automatically.
The general rules are fairly simple:
Assignments and operations involving NULL cause NULL or UNKNOWN results.
For arithmetic, convert to the data type which can contain both operands and the result.
For explicit casts, if a meaningful result is possible, the operation is allowed.
For implicit casts, if a meaningful result is possible and the data types on both sides
are either STRINGs or most numeric types (that is, are STRING or INTEGER or UNSIGNED or DOUBLE or DECIMAL but not NUMBER),
the operation is sometimes allowed.
The specific situations in this chart follow the general rules:
~ To BOOLEAN | To numeric | To STRING | To VARBINARY | To UUID
--------------- ---------- ---------- --------- ------------ -------
From BOOLEAN | AAA | --- | A-- | --- | ---
From numeric | --- | SSA | A-- | --- | ---
From STRING | S-- | S-- | AAA | A-- | S--
From VARBINARY | --- | --- | A-- | AAA | S--
From UUID | --- | --- | A-- | A-- | AAA
Where each entry in the chart has 3 characters:
Where A = Always allowed, S = Sometimes allowed, - = Never allowed.
The first character of an entry is for explicit casts,
the second character is for implicit casts for assignment,
the third character is for implicit cast for comparison.
So AAA = Always for explicit, Always for Implicit (assignment), Always for Implicit (comparison).
The S “Sometimes allowed” character applies for these special situations:
From STRING To BOOLEAN is allowed if UPPER(string-value) = 'TRUE' or 'FALSE'.
From numeric to INTEGER or UNSIGNED is allowed for cast and assignment only if the result is not out of range,
and the numeric has no post-decimal digits.
From STRING to INTEGER or UNSIGNED or DECIMAL is allowed only if the string has a representation of a numeric,
and the result is not out of range,
and the numeric has no post-decimal digits.
From STRING to DOUBLE or NUMBER is allowed only if the string has a representation of a numeric.
From STRING to UUID is allowed only if the value is
(8 hexadecimal digits) hyphen (4 hexadecimal digits) hyphen (4 hexadecimal digits) hyphen (4 hexadecimal digits) hyphen (12 hexadecimal digits),
such as '8e3b281b-78ad-4410-bfe9-54806a586a90'.
From VARBINARY to UUID is allowed only if the value is
16 bytes long,
as in X'8e3b281b78ad4410bfe954806a586a90'.
The chart does not show To|From SCALAR because the conversions depend on the type of the value,
not the type of the column definition. Explicit cast to SCALAR is always allowed.
The chart does not show To|From ARRAY or MAP or ANY because almost no conversions are possible.
Explicit cast to ANY, or casting any value to its original data type, is legal, but that is all.
This is a slight change: before Tarantool v. 2.10.0, it was legal to cast such values
as VARBINARY. It is still possible to use arguments with these types in
QUOTE functions, which is a way to convert them to STRINGs.
Note
Since version 2.4.1, the NUMBER type is processed
in the same way as the number type in
NoSQL Tarantool.
Starting with Tarantool 2.10.1, these conversions which used to be legal are now illegal:
Explicit cast from numeric to BOOLEAN,
Explicit cast from BOOLEAN to numeric,
Implicit cast from NUMBER to other numeric types for arithmetic or built-in functions.
Implicit cast from numeric to STRING.
Implicit cast from STRING to numeric.
Examples of casts, illustrating the situations in the chart:
CAST(TRUEASSTRING) is legal. The intersection of the “From BOOLEAN” row with the “To STRING”
column is A-- and the first letter of A-- is for explicit cast and A means Always Allowed.
The result is ‘TRUE’.
UPDATE...SETvarbinary_column='A' is illegal. The intersection of the “From STRING” row with the “To VARBINARY”
column is A-- and the second letter of A-- is for implicit cast (assignment) and - means not allowed.
The result is an error message.
1.7E-1>0 is legal. The intersection of the “From numeric” row with the “To numeric”
column is SSA, and the third letter of SSA is for implicit cast (comparison) and A means Always Allowed.
The result is TRUE.
11>'2' is illegal. The intersection of the “From numeric” row with the “To STRING”
column is A– and the third letter of A– is for implicit cast (comparison) and - means not allowed.
The result is an error message. For detailed explanation see the following section.
CAST('5'ASINTEGER) is legal. The intersection of the “From STRING” row with the “To numeric”
column is S– and the first letter of S– is for explicit cast and S means Sometimes Allowed.
However, CAST('5.5'ASINTEGER) is illegal because 5.5 is not an integer –
if the string contains post-decimal digits and the target is INTEGER or UNSIGNED,
the assignment will fail.
Implicit string/numeric cast
The examples in this section are true only for Tarantool versions before Tarantool 2.10.
Starting with Tarantool 2.10, implicit string/numeric cast is no longer allowed.
Special considerations may apply for casting STRINGs
to/from INTEGERs/DOUBLEs/NUMBERs/UNSIGNEDs (numerics) for comparison or assignment.
For comparisons, the cast is always from STRING to numeric.
Therefore 1e2='100' is TRUE, and 11>'2' is TRUE.
If the cast fails, then the numeric is less than the STRING.
Therefore 1e400<'' is TRUE.
Exception: for BETWEEN the cast is to the data type of the first and last operands.
Therefore '66'BETWEEN5AND'7' is TRUE.
For assignments, due to a change in behavior starting with Tarantool
2.5.1,
implicit casts from strings to numerics are not legal. Therefore
INSERTINTOt(integer_column)VALUES('5'); is an error.
Implicit cast does happen if STRINGS are used in arithmetic.
Therefore '5'/'5'=1. If the cast fails, then the result is an error.
Therefore '5'/'' is an error.
Implicit cast does NOT happen if numerics are used in concatenation, or in LIKE.
Therefore 5||'5' is illegal.
In the following examples, implicit cast does not happen for values in SCALAR columns: DROPTABLEscalars; CREATETABLEscalars(scalar_columnSCALARPRIMARYKEY); INSERTINTOscalarsVALUES(11),('2'); SELECT*FROMscalarsWHEREscalar_column>11;/*0rows.So11>'2'.*/ SELECT*FROMscalarsWHEREscalar_column<'2';/*1row.So11<'2'.*/ SELECTmax(scalar_column)FROMscalars;/*1row:'2'.So11<'2'.*/ SELECTsum(scalar_column)FROMscalars;/*1row:13.Socasthappened.*/
These results are not affected by indexing, or by reversing the operands.
Implicit cast does NOT happen for GREATEST()
or LEAST().
Therefore LEAST('5',6) is 6.
For function arguments:
If the function description says that a parameter has a specific data type,
and implicit assignment casts are allowed, then arguments which are not passed with that
data type will be converted before the function is applied.
For example, the LENGTH() function expects a
STRING or VARBINARY,
and INTEGER can be converted to STRING, therefore LENGTH(15) will return
the length of '15', that is, 2.
But implicit cast sometimes does NOT happen for parameters.
Therefore ABS('5') will cause an error message after
Issue#4159 is fixed.
However, TRIM(5) will still be legal.
Although it is not a requirement of the SQL standard, implicit cast is supposed to help compatibility
with other DBMSs. However, other DBMSs have different rules about what can be converted
(for example they may allow assignment of 'inf' but disallow comparison with '1e5').
And, of course, it is not possible to be compatible with other DBMSs and at the same
time support SCALAR, which other DBMSs do not have.
SQL statements and clauses
The Statements and Clauses guide shows all Tarantool/SQL statements’ syntax and use.
ALTER is used to change a table’s name or a table’s elements.
Examples:
For renaming a table with ALTER...RENAME, the old-table must exist, the new-table must not
exist. Example: --renamingatable:ALTERTABLEt1RENAMETOt2;
For adding a column with ADDCOLUMN,
the table must exist, the table must be empty,
the column name must be unique within the table.
Example with a STRING column that must start with X:
ALTERTABLEt1ADDCOLUMNs4STRINGCHECK(s4LIKE'X%');
ALTERTABLE...ADDCOLUMN support was added in version 2.7.1.
For adding a table constraint with ADDCONSTRAINT,
the table must exist, the table must be empty,
the constraint name must be unique within the table.
Example with a foreign-key constraint definition: ALTERTABLEt1ADDCONSTRAINTfk_s1_t1_1FOREIGNKEY(s1)REFERENCESt1;
It is not possible to say CREATETABLEtable_a...REFERENCEStable_b...
if table b does not exist yet. This is a situation where ALTERTABLE is
handy – users can CREATETABLEtable_a without the foreign key, then
CREATETABLEtable_b, then ALTERTABLEtable_a...REFERENCEStable_b....
-- adding a primary-key constraint definition:-- This is unusual because primary keys are created automatically-- and it is illegal to have two primary keys for the same table.-- However, it is possible to drop a primary-key index, and this-- is a way to restore the primary key if that happens.ALTERTABLEt1ADDCONSTRAINT"pk_unnamed_T1_1"PRIMARYKEY(s1);-- adding a unique-constraint definition:-- Alternatively, you can say CREATE UNIQUE INDEX unique_key ON t1 (s1);ALTERTABLEt1ADDCONSTRAINT"unique_unnamed_T1_2"UNIQUE(s1);-- Adding a check-constraint definition:ALTERTABLEt1ADDCONSTRAINT"ck_unnamed_T1_1"CHECK(s1>0);
For ALTER...DROPCONSTRAINT, it is only legal to drop a named constraint.
(Tarantool generates the
constraint names automatically if the user does not provide them.)
Since version 2.4.1, it is possible to drop
any of the named table constraints, namely, PRIMARY KEY, UNIQUE, FOREIGN KEY,
and CHECK.
To remove a unique constraint, use either ALTER...DROPCONSTRAINT or
DROP INDEX, which will drop the constraint
as well.
-- dropping a constraint:ALTERTABLEt1DROPCONSTRAINT"fk_unnamed_JJ2_1";
For ALTER...ENABLE|DISABLECHECKCONSTRAINT, it is only legal to enable or disable a named constraint,
and Tarantool only looks for names of check constraints.
By default a constraint is enabled.
If a constraint is disabled, then the check will not be performed.
-- disabling and re-enabling a constraint:ALTERTABLEt1DISABLECHECKCONSTRAINTc;ALTERTABLEt1ENABLECHECKCONSTRAINTc;
Limitations:
It is not possible to drop a column.
It is not possible to modify NOT NULL constraints or column properties DEFAULT
and data type.
However, it is possible to modify them with Tarantool/NOSQL, for example by
calling space_object:format() with a different
is_nullable value.
Create a new base table, usually called a “table”.
Note
A table is a base table if it is created with CREATE TABLE and contains
data in persistent storage.
A table is a viewed table, or just “view”, if it is created with
CREATE VIEW and gets its data from other views or from base tables.
The table-name must be an identifier which is valid according to the rules for
identifiers, and must not be the name of an already existing base table or view.
The column-definition or table-constraint list is a comma-separated list
of column definitions
or table constraint definitions.
Column definitions and table constraint definitions are sometimes called table elements.
Rules:
A primary key is necessary; it can be specified with a table constraint
PRIMARY KEY.
There must be at least one column.
When IF NOT EXISTS is specified, and there is already a table with the same
name, the statement is ignored.
When WITHENGINE=string is specified,
where string must be either ‘memtx’ or ‘vinyl’,
the table is created with that storage engine.
When this clause is not specified,
the table is created with the default engine,
which is ordinarily ‘memtx’ but may be changed
by updating the box.space._session_settings system table..
Actions:
Tarantool evaluates each column definition and table-constraint,
and returns an error if any of the rules is violated.
Tarantool makes a new definition in the schema.
Tarantool makes new indexes for PRIMARY KEY or UNIQUE constraints.
A unique index name is created automatically.
Usually Tarantool effectively executes a COMMIT statement.
Examples:
-- the simplest form, with one column and one constraint:CREATETABLEt1(s1INTEGER,PRIMARYKEY(s1));-- you can see the effect of the statement by querying-- Tarantool system spaces:SELECT*FROM"_space"WHERE"name"='T1';SELECT*FROM"_index"JOIN"_space"ON"_index"."id"="_space"."id"WHERE"_space"."name"='T1';-- variation of the simplest form, with delimited identifiers-- and a bracketed comment:CREATETABLE"T1"("S1"INT/* synonym of INTEGER */,PRIMARYKEY("S1"));-- two columns, one named constraintCREATETABLEt1(s1INTEGER,s2STRING,CONSTRAINTpk_s1s2_t1_1PRIMARYKEY(s1,s2));
Define a column, which is a table element used in a CREATE TABLE statement.
The column-name must be an identifier which is valid according to the rules
for identifiers.
Each column-name must be unique within a table.
Column definition – data type
Every column has a data type:
ANY or ARRAY or BOOLEAN or DECIMAL or DOUBLE or INTEGER or MAP or NUMBER
or SCALAR or STRING or UNSIGNED or UUID or VARBINARY.
The detailed description of data types is in the section
Operands.
Column definition – the rules for the SCALAR data type
The rules for the SCALAR data type were significantly changed in Tarantool version
v. 2.10.0.
SCALAR is a “complex” data type, unlike all the other data types which are “primitive”.
Two column values in a SCALAR column can have two different primitive data types.
Any item defined as SCALAR has an underlying primitive type. For example, here:
the underlying primitive type of the item in the first row is INTEGER
because literal 55 has data type INTEGER, and the underlying primitive type
in the second row is STRING (the data type of a literal is always clear from
its format).
An item’s primitive type is far less important than its defined type.
Incidentally Tarantool might find the primitive type by looking at the way
MsgPack stores it, but that is an implementation detail.
A SCALAR definition may not include a maximum length, as there is no suggested
restriction.
A SCALAR definition may include a COLLATE clause, which affects any items
whose primitive data type is STRING. The default collation is “binary”.
Some assignments are illegal when data types differ, but legal when the
target is a SCALAR item. For example UPDATE...SETcolumn1='a'
is illegal if column1 is defined as INTEGER, but is legal if column1
is defined as SCALAR – values which happen to be INTEGER will be changed
so their data type is SCALAR.
There is no literal syntax which implies data type SCALAR.
TYPEOF(x) is always ‘scalar’ or ‘NULL’, it is never the underlying data type.
In fact there is no function that is guaranteed to return the underlying data type.
For example, TYPEOF(CAST(1ASSCALAR)); returns ‘scalar’, not ‘integer’.
For any operation that requires implicit casting from an item defined as SCALAR,
the operation will fail at runtime.
For example, if a definition is:
CREATETABLEt(s1SCALARPRIMARYKEY,s2INTEGER);
and the only row in table T has s1 = 1, that is, its underlying primitive type is
INTEGER, then UPDATEtSETs2=s1; is illegal.
For any dyadic operation that requires implicit casting for comparison, the
syntax is legal and the operation will not fail at runtime.
Take this situation: comparison with a primitive type VARBINARY and
a primitive type STRING.
The comparison is valid, because Tarantool knows the ordering of X’41’ and ‘a’
in Tarantool/NoSQL ‘scalar’ – this is a case where the primitive type matters.
The result data type of min/max operation on a column defined as SCALAR
is SCALAR.
Users will need to know the underlying primitive type of the result in advance. For example:
That is only possible with Tarantool/NoSQL scalar rules, but SELECTSUM(s2)
would not be legal because addition would in this case require implicit casting
from VARBINARY to a numeric, which is not sensible.
The result data type of a primitive combination is sometimes SCALAR although Tarantool
in effect uses the primitive data type not the defined data type.
(Here the word “combination” is used in the way that the standard document
uses it for section “Result of data type combinations”.) Therefore for
greatest(1E308,'a',0,X'00') the result is X’00’ but
typeof(greatest(1E308,'a',0,X'00') is ‘scalar’.
The union of two SCALARs is sometimes the primitive type.
For example, SELECTTYPEOF((SELECTCAST('a'ASSCALAR)UNIONSELECTCAST('a'ASSCALAR)));
returns ‘string’.
Column definition – relation to NoSQL
All of the SQL data types except SCALAR correspond to
Tarantool/NoSQL types with the same name.
For example an SQL STRING is stored in a NoSQL space as type = ‘string’.
Therefore specifying an SQL data type X determines that the storage will be
in a space with a format column saying that the NoSQL type is ‘x’.
The rules for that NoSQL type are applicable to the SQL data type.
If two items have SQL data types that have the same underlying type, then they
are compatible for all assignment or comparison purposes.
If two items have SQL data types that have different underlying types, then the
rules for explicit casts, or implicit (assignment) casts, or implicit (comparison)
casts, apply.
There is one floating-point value which is not handled by SQL: -nan is seen as NULL
although its data type is ‘double’.
Before Tarantool v. 2.10.0, there were also some Tarantool/NoSQL data types which had no corresponding
SQL data types. For example, SELECT"flags"FROM"_vspace"; would return
a column whose SQL data type is VARBINARY rather than MAP. Such columns can only be manipulated in SQL
by invoking Lua functions.
Column definition – column-constraint or default clause
The column-constraint or default clause may be as follows:
Type
Comment
NOT NULL
means “it is illegal to assign a NULL to this column”
means
“if INSERT does not assign to this column
then assign expression result to this column” –
if there is no DEFAULT clause then DEFAULT NULL
is assumed
If column-constraint is PRIMARY KEY, this is a shorthand for a separate
table-constraint definition: “PRIMARY KEY (column-name)”.
If column-constraint is UNIQUE, this is a shorthand for a separate
table-constraint definition: “UNIQUE (column-name)”.
If column-constraint is CHECK, this is a shorthand for a separate
table-constraint definition: “CHECK (expression)”.
Columns defined with PRIMARY KEY are automatically NOT NULL.
To enforce some restrictions that Tarantool does not enforce automatically,
add CHECK clauses, like these:
These are shown within CREATE TABLE statements.
Data types may also appear in CAST functions.
-- the simple form with column-name and data-typeCREATETABLEt(column1INTEGER...);-- with column-name and data-type and column-constraintCREATETABLEt(column1STRINGPRIMARYKEY...);-- with column-name and data-type and collate-clauseCREATETABLEt(column1SCALARCOLLATE"unicode"...);
-- with all possible data types and aliasesCREATETABLEt(column1BOOLEAN,column2BOOL,column3INTPRIMARYKEY,column4INTEGER,column5DOUBLE,column6NUMBER,column7STRING,column8STRINGCOLLATE"unicode",column9TEXT,columnaTEXTCOLLATE"unicode_sv_s1",columnbVARCHAR(0),columncVARCHAR(100000)COLLATE"binary",columndUUID,columneVARBINARY,columnfSCALAR,columngSCALARCOLLATE"unicode_uk_s2",columnhDECIMAL,columniARRAY,columnjMAP,columnkANY);
-- with all possible column constraints and a default clauseCREATETABLEt(column1INTEGERNOTNULL,column2INTEGERPRIMARYKEY,column3INTEGERUNIQUE,column4INTEGERCHECK(column3>column2),column5INTEGERREFERENCESt,column6INTEGERDEFAULTNULL);
Table constraint definition
A table constraint restricts the data you can add to the table.
If you try to insert invalid data on a column, Tarantool throws an error.
Define a constraint, which is a table element used in a CREATE TABLE statement.
A constraint name must be an identifier that is valid according to the rules for identifiers.
A constraint name must be unique within the table for a specific constraint type.
For example, the CHECK and FOREIGN KEY constraints can have the same name.
PRIMARY KEY constraints
PRIMARY KEY constraints look like this:
PRIMARYKEY(column_name,...)
There is a shorthand: specifying PRIMARY KEY in a column definition.
Every table must have one and only one primary key.
Primary-key columns are automatically NOTNULL.
Primary-key columns are automatically indexed.
Primary-key columns are unique. That means it is illegal to have two rows with the same values for the columns specified in the constraint.
Example 1: one-column primary key
Create an author table with the id primary key column:
On an attempt to add an author with the existing id, the following error is raised:
INSERTINTOauthorVALUES(2,'Alexander Pushkin');/*- Duplicate key exists in unique index "pk_unnamed_author_1" in space "author" with old tuple - [2, "Fyodor Dostoevsky"] and new tuple - [2, "Alexander Pushkin"]*/
Example 2: two-column primary key
Create a book table with the primary key defined on two columns:
INSERTINTObookVALUES(1,'War and Peace'),(2,'Crime and Punishment');
On an attempt to add the existing book, the following error is raised:
INSERTINTObookVALUES(2,'Crime and Punishment');/*- Duplicate key exists in unique index "pk_unnamed_book_1" in space "BOOK" with old tuple - [2, "Crime and Punishment"] and new tuple - [2, "Crime and Punishment"]*/
PRIMARY KEY with the AUTOINCREMENT modifier may be specified in one of two ways:
In a column definition after the words PRIMARY KEY, as in CREATETABLEt(cINTEGERPRIMARYKEYAUTOINCREMENT);
In a PRIMARY KEY (column-list) after a column name, as in CREATETABLEt(cINTEGER,PRIMARYKEY(cAUTOINCREMENT));
When AUTOINCREMENT is specified, the column must be a primary-key column and it must be INTEGER or UNSIGNED.
Only one column in the table may be autoincrement.
However, it is legal to say PRIMARYKEY(a,b,cAUTOINCREMENT) – in that case, there
are three columns in the primary key but only the third column (c) is AUTOINCREMENT.
As the name suggests, values in an autoincrement column are automatically incremented.
That is: if a user inserts NULL in the column, then the stored value will be the smallest
non-negative integer that has not already been used.
This occurs because autoincrement columns are associated with sequences.
On an attempt to add an author with the same name, the following error is raised:
INSERTINTOauthorVALUES(3,'Leo Tolstoy');/*- Duplicate key exists in unique index "unique_unnamed_author_2" in space "author" with old tuple - [1, "Leo Tolstoy"] and new tuple - [3, "Leo Tolstoy"]*/
Example 2: two-column unique constraint
Create a book table with the unique constraint defined on two columns:
INSERTINTObookVALUES(1,'War and Peace',1),(2,'Crime and Punishment',2);
On an attempt to add a book with duplicated values, the following error is raised:
INSERTINTObookVALUES(3,'War and Peace',1);/*- Duplicate key exists in unique index "unique_unnamed_book_2" in space "book" with old tuple - [1, "War and Peace", 1] and new tuple - [3, "War and Peace", 1]*/
CHECK constraints
The CHECK constraint is used to limit the value range that a column can store.
CHECK constraints look like this:
The expression may be anything that returns a BOOLEAN result = TRUE or FALSE or UNKNOWN.
The expression may not contain a subquery.
If the expression contains a column name, the column must exist in the table.
If a CHECK constraint is specified, the table must not contain rows where the expression is FALSE.
(The table may contain rows where the expression is either TRUE or UNKNOWN.)
Constraint checking may be stopped with ALTER TABLE … DISABLE CHECK CONSTRAINT
and restarted with ALTER TABLE … ENABLE CHECK CONSTRAINT.
Example
Create an author table with the name column that should contain values longer than 4 characters:
On an attempt to add an author with a name shorter than 5 characters, the following error is raised:
INSERTINTOauthorVALUES(3,'Alex');/*- Check constraint 'check_name_length' failed for a tuple*/
Table constraint definition for foreign keys
A foreign key is a constraint that can be used to enforce data integrity across related tables.
A foreign key constraint is defined on the child table that references the parent table’s column values.
Since 2.11.0, the following referencing options aren’t supported anymore:
The ONUPDATE and ONDELETE triggers. The RESTRICT trigger action is used implicitly.
The MATCH subclause. MATCHFULL is used implicitly.
DEFERRABLE constraints. The INITIALLYIMMEDIATE constraint check time rule is used implicitly.
Note that a referenced column should meet one of the following requirements:
A referenced column is a PRIMARY KEY column.
A referenced column has a UNIQUE constraint.
A referenced column has a UNIQUE index.
Note that before the 2.11.0 version, an index existence for the referenced columns is checked when creating a constraint (for example, using CREATETABLE or ALTERTABLE).
Starting with 2.11.0, this check is weakened and the existence of an index is checked during data insertion.
Example
This example shows how to create a relation between the parent and child tables through a single-column foreign key:
INSERTINTObookVALUES(1,'War and Peace',1),(2,'Crime and Punishment',2);
Check how the created foreign key constraint enforces data integrity.
The following error is raised on an attempt to insert a new book with the author_id value that doesn’t exist in the parent author table:
INSERTINTObookVALUES(3,'Eugene Onegin',3);/*- 'Foreign key constraint ''fk_unnamed_book_1'' failed: foreign tuple was not found'*/
On an attempt to delete an author that already has books in the book table, the following error is raised:
DELETEFROMauthorWHEREid=2;/*- 'Foreign key ''fk_unnamed_book_1'' integrity check failed: tuple is referenced'*/
DROP TABLE
Syntax:
DROPTABLE[IFEXISTS]table-name;
Drop a table.
The table-name must identify a table that was created earlier with the
CREATE TABLE statement.
Rules:
If there is a view that references the table, the drop will fail.
Please drop the referencing view with DROP VIEW first.
If there is a foreign key that references the table, the drop will fail.
Please drop the referencing constraint with
ALTER TABLE … DROP first.
Actions:
Tarantool returns an error if the table does not exist and there is no IFEXISTS clause.
The table and all its data are dropped.
All indexes for the table are dropped.
All triggers for the table are dropped.
Usually Tarantool effectively executes a COMMIT statement.
Examples:
-- the simple case:DROPTABLEt31;-- with an IF EXISTS clause:DROPTABLEIFEXISTSt31;
The index-name must be valid according to the rules for identifiers.
The table-name must refer to an existing table.
The column-list must be a comma-separated list of names of columns in the
table.
Rules:
There must not already be, for the same table, an index with the same name as
index-name.
But there may already be, for a different table, an index with the same name as
index-name.
The maximum number of indexes per table is 128.
Actions:
Tarantool will throw an error if a rule is violated.
If the new index is UNIQUE, Tarantool will throw an error if any row exists
with columns that have duplicate values.
Tarantool will create a new index.
Usually Tarantool effectively executes a COMMIT statement.
Automatic indexes:
Indexes may be created automatically for columns mentioned in the PRIMARY KEY
or UNIQUE clauses of a CREATE TABLE statement.
If an index was created automatically, then the index-name has four parts:
pk if this is for a PRIMARY KEY clause, unique if this is for
a UNIQUE clause;
_unnamed_;
the name of the table;
_ and an ordinal number; the first index is 1, the second index is 2,
and so on.
For example, after CREATETABLEt(s1INTEGERPRIMARYKEY,s2INTEGER,UNIQUE(s2));
there are two indexes named pk_unnamed_T_1 and unique_unnamed_T_2.
You can confirm this by saying SELECT*FROM"_index"; which will list all
indexes on all tables.
There is no need to say CREATEINDEX for columns that already have
automatic indexes.
Examples:
-- the simple caseCREATEINDEXidx_column1_t_1ONt(column1);-- with IF NOT EXISTS clauseCREATEINDEXIFNOTEXISTSidx_column1_t_1ONt(column1);-- with UNIQUE specifier and more than one columnCREATEUNIQUEINDEXidx_unnamed_t_1ONt(column1,column2);
Dropping an automatic index created for a unique constraint will drop
the unique constraint as well.
DROP INDEX
Syntax:
DROPINDEX[IFEXISTS]index-nameONtable-name;
The index-name must be the name of an existing index, which was created with
CREATE INDEX.
Or, the index-name must be the name of an index that was created automatically
due to a PRIMARY KEY or UNIQUE clause in the CREATE TABLE statement.
To see what a table’s indexes are, use PRAGMA index_list(table-name);.
Rules: none
Actions:
Tarantool throws an error if the index does not exist, or is an automatically
created index.
Tarantool will drop the index.
Usually Tarantool effectively executes a COMMIT statement.
Example:
-- the simplest form:DROPINDEXidx_unnamed_t_1ONt;
CREATE TRIGGER
Syntax:
CREATETRIGGER[IFNOTEXISTS]trigger-name BEFORE|AFTER|INSTEADOF DELETE|INSERT|UPDATEONtable-name FOREACHROW [WHENsearch-condition] BEGIN delete-statement|insert-statement|replace-statement|select-statement|update-statement; [delete-statement|insert-statement|replace-statement|select-statement|update-statement;...] END;
The trigger-name must be valid according to the rules for identifiers.
If the trigger action time is BEFORE or AFTER, then the table-name must refer
to an existing base table.
If the trigger action time is INSTEAD OF, then the table-name must refer to an
existing view.
Rules:
There must not already be a trigger with the same name as trigger-name.
Triggers on different tables or views share the same namespace.
The statements between BEGIN and END should not refer to the table-name
mentioned in the ON clause.
The statements between BEGIN and END should not contain an
INDEXED BY clause.
SQL triggers are not activated by Tarantool/NoSQL requests.
This will change in a future version.
On a replica, effects of trigger execution are applied, and the SQL triggers
themselves are not activated upon replication events.
NoSQL triggers are activated both on replica and master, thus if you have a
NoSQL trigger on a replica, it is activated when applying effects of an SQL trigger.
Actions:
Tarantool will throw an error if a rule is violated.
Tarantool will create a new trigger.
Usually Tarantool effectively executes a COMMIT statement.
Examples:
-- the simple case:CREATETRIGGERstores_before_insertBEFOREINSERTONstoresFOREACHROWBEGINDELETEFROMwarehouses;END;-- with IF NOT EXISTS clause:CREATETRIGGERIFNOTEXISTSstores_before_insertBEFOREINSERTONstoresFOREACHROWBEGINDELETEFROMwarehouses;END;-- with FOR EACH ROW and WHEN clauses:CREATETRIGGERstores_before_insertBEFOREINSERTONstoresFOREACHROWWHENa=5BEGINDELETEFROMwarehouses;END;-- with multiple statements between BEGIN and END:CREATETRIGGERstores_before_insertBEFOREINSERTONstoresFOREACHROWBEGINDELETEFROMwarehouses;INSERTINTOinventoriesVALUES(1);END;
Trigger extra clauses
UPDATEOFcolumn-list
After BEFORE|AFTER UPDATE it is optional to add OFcolumn-list.
If any of the columns in column-list is affected at the time the row is
processed, then the trigger will be activated for that row. For example:
CREATETRIGGERtable1_before_updateBEFOREUPDATEOFcolumn1,column2ONtable1FOREACHROWBEGINUPDATEtable2SETcolumn1=column1+1;END;UPDATEtable1SETcolumn3=column3+1;-- Trigger will not be activatedUPDATEtable1SETcolumn2=column2+0;-- Trigger will be activated
WHEN
After table-name FOR EACH ROW it is optional to add [WHENexpression].
If the expression is true at the time the row is processed, only then will the
trigger will be activated for that row. For example:
At the beginning of the UPDATE for the single row of table1, the value in
column1 is ‘old value’ – so that is what is seen as old.column1.
At the end of the UPDATE for the single row of table1, the value in
column1 is ‘new value’ – so that is what is seen as new.column1.
(OLD and NEW are qualifiers for table1, not table2.)
OLD.column-name does not exist for an INSERT trigger.
NEW.column-name does not exist for a DELETE trigger.
OLD and NEW are read-only; you cannot change their values.
Deprecated or illegal statements:
It is illegal for the trigger action to include a qualified column reference
other than OLD.column-name or NEW.column-name. For example,
CREATETRIGGER...BEGINUPDATEtable1SETtable1.column1=5;END;
is illegal.
It is illegal for the trigger action to include statements that include a
WITH clause,
a DEFAULT VALUES clause, or an INDEXED BY clause.
It is usually not a good idea to have a trigger on table1 which causes
a change on table2, and at the same time have a trigger on table2
which causes a change on table1. For example:
Luckily UPDATEtable1... will not cause an infinite loop, because
Tarantool recognizes when it has already updated so it will stop.
However, not every DBMS acts this way.
Trigger activation
These are remarks concerning trigger activation.
Standard terminology:
“trigger action time” = BEFORE or AFTER or INSTEAD OF
“trigger event” = INSERT or DELETE or UPDATE
“triggered statement” = BEGIN … DELETE|INSERT|REPLACE|SELECT|UPDATE … END
“triggered when clause” = WHEN search-condition
“activate” = execute a triggered statement
some vendors use the word “fire” instead of “activate”
If there is more than one trigger for the same trigger event, Tarantool may
execute the triggers in any order.
It is possible for a triggered statement to cause activation of another
triggered statement. For example, this is legal:
Activation occurs FOR EACH ROW, not FOR EACH STATEMENT. Therefore, if no rows
are candidates for insert or update or delete, then no triggers are activated.
The BEFORE trigger is activated even if the trigger event fails.
If an UPDATE trigger event does not make a change, the trigger is activated
anyway. For example, if row 1 column1 contains 'a', and the trigger event
is UPDATE...SETcolumn1='a';, the trigger is activated.
The triggered statement may refer to a function:
RAISE(FAIL,error-message).
If a triggered statement invokes a RAISE(FAIL,error-message) function, or
if a triggered statement causes an error, then statement execution stops
immediately.
The triggered statement may refer to column values within the rows being changed.
in this case:
The row “as of before” the change is called the “old” row (which makes sense
only for UPDATE and DELETE statements).
The row “as of after” the change is called the “new” row (which makes sense
only for UPDATE and INSERT statements).
This example shows how an INSERT can be done to a view by referring to the
“new” row:
Ordinarily saying INSERTINTOview_name... is illegal in Tarantool,
so this is a workaround.
It is possible to generalize this so that all data-change statements
on views will change the base tables, provided that the view contains
all the columns of the base table, and provided that the triggers
refer to those columns when necessary, as in this example:
When INSERT or UPDATE or DELETE occurs for table X, Tarantool usually
operates in this order (a basic scheme):
For each row
Perform constraint checks
For each BEFORE trigger that refers to table X
Check that the trigger's WHEN condition is true.
Execute what is in the triggered statement.
Insert or update or delete the row in table X.
Perform more constraint checks
For each AFTER trigger that refers to table X
Check that the trigger's WHEN condition is true.
Execute what is in the triggered statement.
However, Tarantool does not guarantee execution order when there are multiple
constraints, or multiple triggers for the same event (including NoSQL
on_replace triggers
or SQL
INSTEAD OF triggers that affect a view of table
X).
The maximum number of trigger activations per statement is 32.
INSTEAD OF triggers
A trigger which is created with the clause INSTEADOFINSERT|UPDATE|DELETEONview-name
is an INSTEAD OF trigger. For each affected row, the trigger action is performed
“instead of” the INSERT or UPDATE or DELETE statement that causes trigger
activation.
For example, ordinarily it is illegal to INSERT rows in a view, but it is legal
to create a trigger which intercepts attempts to INSERT, and puts rows in the
underlying base table:
CREATETABLEt1(column1INTEGERPRIMARYKEY,column2INTEGER);CREATEVIEWv1ASSELECTcolumn1,column2FROMt1;CREATETRIGGERv1_instead_ofINSTEADOFINSERTONv1FOREACHROWBEGININSERTINTOt1VALUES(NEW.column1,NEW.column2);END;INSERTINTOv1VALUES(1,1);-- ... The result will be: table t1 will contain a new row.
INSTEAD OF triggers are only legal for views, while
BEFORE or AFTER triggers are only legal for base tables.
It is legal to create INSTEAD OF triggers with triggered WHEN clauses.
Limitations:
It is legal to create INSTEAD OF triggers with UPDATE OF column-list clauses,
but they are not standard SQL.
The table-name must be a name of a table defined earlier with CREATE TABLE.
The optional column-list must be a comma-separated list of names of columns
in the table.
The expression-list must be a comma-separated list of expressions; each
expression may contain literals and operators and subqueries and function invocations.
Rules:
The values in the expression-list are evaluated from left to right.
The order of the values in the expression-list must correspond to the order
of the columns in the table, or (if a column-list is specified) to the order
of the columns in the column-list.
The data type of the value should correspond to the
data type of the column,
that is, the data type that was specified with CREATE TABLE.
If a column-list is not specified, then the number of expressions must be
the same as the number of columns in the table.
If a column-list is specified, then some columns may be omitted; omitted
columns will get default values.
The parenthesized expression-list may be repeated –
(expression-list),(expression-list),... – for multiple rows.
Actions:
Tarantool evaluates each expression in expression-list, and returns an
error if any of the rules is violated.
Tarantool creates zero or more new rows containing values based on the values
in the VALUES list or based on the results of the select-expression or
based on the default values.
Tarantool executes constraint checks and trigger actions and the actual insertion.
Examples:
-- the simplest form:INSERTINTOtable1VALUES(1,'A');-- with a column list:INSERTINTOtable1(column1,column2)VALUES(2,'B');-- with an arithmetic operator in the first expression:INSERTINTOtable1VALUES(2+1,'C');-- put two rows in the table:INSERTINTOtable1VALUES(4,'D'),(5,'E');
The column-name must be an updatable column in the table.
The expression may contain literals and operators and subqueries and function
invocations and column names.
Rules:
The values in the SET clause are evaluated from left to right.
The data type of the value should correspond to the
data type of the column,
that is, the data type that was specified with CREATE TABLE.
If a search-condition is not specified, then all rows in the table will be
updated; otherwise only those rows which match the search-condition will be
updated.
Actions:
Tarantool evaluates each expression in the SET clause, and returns an error
if any of the rules is violated.
For each row that is found by the WHERE clause, a temporary new row is formed
based on the original contents and the modifications caused by the SET clause.
Tarantool executes constraint checks and trigger actions and the actual update.
Examples:
-- the simplest form:UPDATEtSETcolumn1=1;-- with more than one assignment in the SET clause:UPDATEtSETcolumn1=1,column2=2;-- with a WHERE clause:UPDATEtSETcolumn1=5WHEREcolumn2=6;
Special cases:
It is legal to say SET (list of columns) = (list of values). For example:
UPDATEtSET(column1,column2,column3)=(1,2,3);
It is not legal to assign to a column more than once. For example:
The search-condition may contain literals and operators and subqueries and
function invocations and column names.
Rules:
If a search-condition is not specified, then all rows in the table will be
deleted; otherwise only those rows which match the search-condition will be
deleted.
Actions:
Tarantool evaluates each expression in the search-condition, and returns
an error if any of the rules is violated.
Tarantool finds the set of rows that are to be deleted.
Tarantool executes constraint checks and trigger actions and the actual deletion.
Examples:
-- the simplest form:DELETEFROMt;-- with a WHERE clause:DELETEFROMtWHEREcolumn2=6;
Insert one or more new rows into a table, or update existing rows.
If a row already exists (as determined by the primary key or any unique key),
then the action is delete + insert, and the rules are the same as for a
DELETE statement followed by an INSERT statement.
Otherwise the action is insert, and the rules are the same as for the
INSERT statement.
Examples:
-- the simplest form:REPLACEINTOtable1VALUES(1,'A');-- with a column list:REPLACEINTOtable1(column1,column2)VALUES(2,'B');-- with an arithmetic operator in the first expression:REPLACEINTOtable1VALUES(2+1,'C');-- put two rows in the table:REPLACEINTOtable1VALUES(4,'D'),(5,'E');
The clauses of the SELECT statement are discussed in the following five sections.
Select list
Syntax:
select-list-column[,select-list-column...]
select-list-column:
Define what will be in a result set; this is a clause in a SELECT statement.
The select list is a comma-delimited list of expressions, or * (asterisk).
An expression can have an alias provided with an [[AS]column-name] clause.
The * “asterisk” shorthand is valid if and only if the SELECT statement also
contains a FROM clause which specifies the table or tables
(details about the FROM clause are in the next section). The simple form is
*
which means “all columns” – for example, if the select is done for a table
which contains three columns s1s2s3, then SELECT*...
is equivalent to SELECTs1,s2,s3....
The qualified form is table-name.* which means “all columns in the specified
table”, which again must be a result of the FROM clause – for example, if the
table is named table1, then table1.* is equivalent to a list of the
columns of table1.
The [[AS]column-name] clause determines the column name.
The column name is useful for two reasons:
in a tabular display, the column names are the headings
if the results of the SELECT are used when creating a new table (such as a view),
then
the column names in the new table will be the column names in the select list.
If [[AS]column-name] is missing, and the expression is not simply
the name of a column in the table, then Tarantool makes a name
COLUMN_n where n is the number of the non-simple
expression within the select list, for example
SELECT5.88,table1.x,'b'COLLATE"unicode_ci"FROMtable1;
will cause the column names to be COLUMN_1, X, COLUMN_2.
This is a behavior change since version 2.5.1.
In earlier versions, the name would be equal to the expression;
see Issue#3962.
It is still legal to define tables with column names like COLUMN_1 but not recommended.
Examples:
-- the simple form:SELECT5;-- with multiple expressions including operators:SELECT1,2*2,'Three'||'Four';-- with [[AS] column-name] clause:SELECT5AScolumn1;-- * which must be eventually followed by a FROM clause:SELECT*FROMtable1;-- as a list:SELECT1ASa,2ASb,table1.*FROMtable1;
FROM clause
Syntax:
FROM[SEQSCAN]table-reference[,table-reference...]
Specify the table or tables for the source of a SELECT statement.
The table-reference must be a name of an existing table, or a subquery, or
a joined table.
Parentheses are allowed, and [[AS]correlation-name] is allowed.
The maximum number of joins in a FROM clause is 64.
The SEQSCAN keyword (since 2.11) marks the queries that
perform sequential scans during the execution. It happens if the query can’t use indexes,
and goes through all the table rows one by one, sometimes causing a heavy load.
Such queries are called scan queries. If a scan query doesn’t have the
SEQSCAN keyword, Tarantool raises an error. SEQSCAN must precede all
names of the tables that the query scans.
To find out if a query performs a sequential scan, use EXPLAINQUERYPLAN.
For scan queries, the result contains SCANTABLEtable_name.
Note
For backward compatibility, the scan queries without the SEQSCAN keyword
are allowed in Tarantool 2.11. The errors on scan queries are the default
behavior starting from 3.0. You can change the default behavior of scan queries
using the compat option sql_seq_scan.
Examples:
-- the simplest form:SELECT*FROMSEQSCANt;-- with two tables, making a Cartesian join:SELECT*FROMSEQSCANt1,SEQSCANt2;-- with one table joined to itself, requiring correlation names:SELECTa.*,b.*FROMSEQSCANt1ASa,SEQSCANt1ASb;-- with a left outer join:SELECT*FROMSEQSCANt1LEFTJOINSEQSCANt2;
WHERE clause
Syntax:
WHEREcondition;
Specify the condition for filtering rows from a table; this is a clause in
a SELECT or UPDATE or DELETE statement.
The condition may contain any expression that returns a BOOLEAN
(TRUE or FALSE or UNKNOWN) value.
For each row in the table:
if the condition is true, then the row is kept;
if the condition is false or unknown, then the row is ignored.
In effect, WHERE condition takes a table with n rows and returns a table with
n or fewer rows.
Examples:
-- with a simple condition:SELECT1FROMtWHEREcolumn1=5;-- with a condition that contains AND and OR and parentheses:SELECT1FROMtWHEREcolumn1=5AND(x>1ORy<1);
The expressions should be column names in the table, and each column should be
specified only once.
In effect, the GROUP BY clause takes a table with rows that may have matching values,
combines rows that have matching values into single rows,
and returns a table which, because it is the result of GROUP BY,
is called a grouped table.
Thus, if the input is a table:
a b c
- - -
1 'a' 'b
1 'b' 'b'
2 'a' 'b'
3 'a' 'b'
1 'b' 'b'
then GROUPBYa,b will produce a grouped table:
a b c
- - -
1 'a' 'b'
1 'b' 'b'
2 'a' 'b'
3 'a' 'b'
The rows where column a and column b have the same value have been
merged; column c has been preserved but its value should not be depended
on – if the rows were not all ‘b’, Tarantool could pick any value.
It is useful to envisage a grouped table as having hidden extra columns for
the aggregation of the values, for example:
-- with a single column:SELECT1FROMtGROUPBYcolumn1;-- with two columns:SELECT1FROMtGROUPBYcolumn1,column2;
Limitations:
SELECTs1,s2FROMtGROUPBYs1; is legal.
SELECTs1ASqFROMtGROUPBYq; is legal.
SELECTs1FROMtGROUPby1; is legal.
Aggregate functions
Syntax:
function-name(oneormoreexpressions)
Apply a built-in aggregate function to one or more expressions and return
a scalar value.
Aggregate functions are only legal in certain clauses
of a SELECT statement for grouped tables. (A table is a grouped
table if a GROUP BY clause is present.) Also, if
an aggregate function is used in a select list and the
GROUP BY clause is omitted, then Tarantool assumes
SELECT...GROUPBY[allcolumns];.
NULLs are ignored for all aggregate functions except COUNT(*).
AVG([DISTINCT]expression)
Return the average value of expression.
Example: AVG(column1)
COUNT([DISTINCT]expression)
Return the number of occurrences of expression.
Example: COUNT(column1)
COUNT(*)
Return the number of occurrences of a row.
Example: COUNT(*)
GROUP_CONCAT(expression-1[,expression-2]) or GROUP_CONCAT(DISTINCTexpression-1)
Return a list of expression-1 values, separated
by commas if expression-2 is omitted, or separated
by the expression-2 value if expression-2 is not omitted.
Example: GROUP_CONCAT(column1)
MAX([DISTINCT]expression)
Return the maximum value of expression.
Example: MAX(column1)
MIN([DISTINCT]expression)
Return the minimum value of expression.
Example: MIN(column1)
SUM([DISTINCT]expression)
Return the sum of values of expression, or NULL if there are no rows.
Example: SUM(column1)
TOTAL([DISTINCT]expression)
Return the sum of values of expression, or zero if there are no rows.
Example: TOTAL(column1)
HAVING clause
Syntax:
HAVINGcondition;
Specify the condition for filtering rows from a grouped table;
this is a clause in a SELECT statement.
The clause preceding the HAVING clause may be a GROUP BY clause.
HAVING operates on the table that the GROUP BY produces,
which may contain grouped columns and aggregates.
If the preceding clause is not a GROUP BY clause,
then there is only one group and the HAVING clause may only contain
aggregate functions or literals.
For each row in the table:
if the condition is true, then the row is kept;
if the condition is false or unknown, then the row is ignored.
In effect, HAVING condition takes a table with n rows and returns a table
with n or fewer rows.
Examples:
-- with a simple condition:SELECT1FROMtGROUPBYcolumn1HAVINGcolumn2>5;-- with a more complicated condition:SELECT1FROMtGROUPBYcolumn1HAVINGcolumn2>5ORcolumn2<5;-- with an aggregate:SELECTx,SUM(y)FROMtGROUPBYxHAVINGSUM(y)>0;-- with no GROUP BY and an aggregate:SELECTSUM(y)FROMtGROUPBYxHAVINGMIN(y)<MAX(y);
Limitations:
HAVING without GROUP BY is not supported for multiple tables.
An ORDER BY expression has one of three types which are checked in order:
Expression is a positive integer, representing the ordinal position of the
column in the select list. For example, in the statement SELECTx,y,zFROMtORDERBY2; ORDERBY2 means “order by the second column in the select list”,
which is y.
Expression is a name of a column in the select list, which is determined
by an AS clause. For example, in the statement SELECTx,yASx,zFROMtORDERBYx; ORDERBYx means “order by the column explicitly named x in the
select list”, which is the second column.
Expression contains a name of a column in a table of the FROM clause.
For example, in the statement SELECTx,yFROMt1JOINt2ORDERBYz; ORDERBYz means “order by a column named z which is expected to be
in table t1 or table t2”.
If both tables contain a column named z, then Tarantool will choose
the first column that it finds.
The expression may also contain operators and function names and literals.
For example, in the statement SELECTx,yFROMtORDERBYUPPER(z); ORDERBYUPPER(z) means “order by the uppercase form of column t.z”,
which may be similar to doing ordering with one of Tarantool’s case-insensitive collations.
If an ORDER BY clause contains multiple expressions, then expressions on the
left are processed first and expressions on the right are processed only if
necessary for tie-breaking.
For example, in the statement SELECTx,yFROMtORDERBYx,y;
if there are two rows which both have the same values for column x,
then an additional check is made to see which row has a greater value
for column y.
In effect, ORDER BY clause takes a table with rows that may be out of order,
and returns a table with rows in order.
Sorting order:
The default order is ASC (ascending), the optional order is DESC (descending).
NULLs come first, then BOOLEANs, then numerics, then STRINGs, then VARBINARYs, then UUIDs.
Ordering does not matter for ARRAYs or MAPs or ANYs because they are not legal for comparisons.
Within STRINGs, ordering is according to collation.
Collation may be specified with a COLLATE clause within the ORDER BY column-list, or may be default.
Examples:
-- with a single column:SELECT1FROMtORDERBYcolumn1;-- with two columns:SELECT1FROMtORDERBYcolumn1,column2;-- with a variety of data:CREATETABLEh(s1NUMBERPRIMARYKEY,s2SCALAR);INSERTINTOhVALUES(7,'A'),(4,'a'),(-4,'AZ'),(17,17),(23,NULL);INSERTINTOhVALUES(17.5,'Д'),(1e+300,'A'),(0,''),(-1,'');SELECT*FROMhORDERBYs2COLLATE"unicode_ci",s1;-- The result of the above SELECT will be:--[23,null]-[17,17]-[-1,'']-[0,'']-[4,'a']-[7,'A']-[1e+300,'A']-[-4,'AZ']-[17.5,'Д']...
Limitations:
ORDER BY 1 is legal. This is common but is not standard SQL nowadays.
LIMIT clause
Syntax:
LIMITlimit-expression[OFFSEToffset-expression]
LIMIToffset-expression,limit-expression
Note
The above is not a typo: offset-expression and limit-expression are
in reverse order if a comma is used.
Specify a maximum number of rows and a start row; this is a clause in
a SELECT statement.
Expressions may contain integers and arithmetic operators or functions,
for example ABS(-3/1).
However, the result must be an integer value greater than or equal to zero.
Usually the LIMIT clause follows an ORDER BY clause, because otherwise
Tarantool does not guarantee that rows are in order.
Examples:
-- simple case:SELECT*FROMtLIMIT3;-- both limit and order:SELECT*FROMtLIMIT3OFFSET1;-- applied to a UNIONed result (LIMIT clause must be the final clause):SELECTcolumn1FROMtable1UNIONSELECTcolumn1FROMtable2ORDERBY1LIMIT1;
Limitations:
If ORDER BY … LIMIT is used, then all order-by columns must be
ASC or all must be DESC.
The SELECT and VALUES statements are called “queries” because they
return answers, in the form of result sets.
Subqueries may be the second part of INSERT statements. For example:
INSERTINTOt2SELECTa,b,cFROMt1;
Subqueries may be in the FROM clause of SELECT statements.
Subqueries may be expressions, or be inside expressions.
In this case they must be parenthesized, and usually the number of rows
must be 1. For example:
Subqueries may be expressions on the right side of certain comparison operators,
and in this unusual case the number of rows may be greater than 1.
The comparison operators are: [NOT] EXISTS and [NOT] IN. For example:
DELETEFROMtWHEREs1NOTIN(SELECTs2FROMt);
Subqueries may refer to values in the outer query.
In this case, the subquery is called a “correlated subquery”.
Subqueries may refer to rows which are being updated or deleted by the main query.
In that case, the subquery finds the matching rows first, before starting to
update or delete. For example, after:
WITH can only be used at the beginning of a statement, therefore it cannot
be used at the beginning of a subquery or after a set operator or inside
a CREATE statement.
A WITH-clause “view” is read-only because Tarantool does not support
updatable views.
WITH RECURSIVE
WITH RECURSIVE clause (iterative common table expression)
The real power of WITH lies in the WITH RECURSIVE clause, which is useful when
it is combined with UNION or UNION ALL:
In non-SQL this can be read as: starting with a seed value from
a non-recursive table, produce a recursive viewed table, UNION that with itself,
UNION that with itself, UNION that with itself … forever, or until a condition
in the WHERE clause says “stop”.
First, table w is seeded from t1, so it has one row: [1].
Then, UNIONALL(SELECTs1+1FROMw) takes the row from w – which
contains [1] – adds 1 because the select list says “s1+1”, and so it has
one row: [2].
Then, UNIONALL(SELECTs1+1FROMw) takes the row from w – which
contains [2] – adds 1 because the select list says “s1+1”, and so it has
one row: [3].
Then, UNIONALL(SELECTs1+1FROMw) takes the row from w – which
contains [3] – adds 1 because the select list says “s1+1”, and so it has
one row: [4].
Then, UNIONALL(SELECTs1+1FROMw) takes the row from w – which
contains [4] – and now the importance of the WHERE clause becomes evident,
because “s1 < 4” is false for this row, and therefore the
“stop” condition has been reached.
So, before the “stop”, table w got 4 rows – [1], [2], [3], [4] – and
the result of the statement looks like:
The UNION query returns 4 rows: NULL, ‘A’, ‘B’, ‘C’.
The UNION ALL query returns 6 rows: NULL, NULL, ‘A’, ‘A’, ‘B’, ‘C’.
The EXCEPT query returns 1 row: ‘B’.
The INTERSECT query returns 2 rows: NULL, ‘A’.
Limitations:
Parentheses are not allowed.
Evaluation is left to right, INTERSECT does not have precedence.
Example:
CREATETABLEt01(s1INTEGERPRIMARYKEY,s2STRING);CREATETABLEt02(s1INTEGERPRIMARYKEY,s2STRING);CREATETABLEt03(s1INTEGERPRIMARYKEY,s2STRING);INSERTINTOt01VALUES(1,'A');INSERTINTOt02VALUES(1,'B');INSERTINTOt03VALUES(1,'A');SELECTs2FROMt01INTERSECTSELECTs2FROMt03UNIONSELECTs2FROMt02;SELECTs2FROMt03UNIONSELECTs2FROMt02INTERSECTSELECTs2FROMt03;-- ... results are different.
INDEXED BY clause
Syntax:
INDEXEDBYindex-name
The INDEXED BY clause may be used in a
SELECT, DELETE, or UPDATE statement,
immediately after the table-name. For example:
DELETEFROMtable7INDEXEDBYindex7WHEREcolumn1='a';
In this case the search for ‘a’ will take place within index7. For example:
SELECT*FROMtable7NOTINDEXEDWHEREcolumn1='a';
In this case the search for ‘a’ will be done via a search of the whole table,
what is sometimes called a “full table scan”, even if there is an index for
column1.
Ordinarily Tarantool chooses the appropriate index or lookup method depending
on a complex set of “optimizer” rules; the INDEXED BY clause overrides the
optimizer choice. If the index was defined with the
exclude_null parts option,
it will only be used if the user specifies it.
Example:
Suppose a table has two columns:
The first column is the primary key and
therefore it has an automatic index named pk_unnamed_T_1.
The second column has an index created by the user.
The user selects with INDEXEDBYthe-index-on-column1,
then selects with INDEXEDBYthe-index-on-column-2.
CREATETABLEt(column1INTEGERPRIMARYKEY,column2INTEGER);CREATEINDEXidx_column2_t_1ONt(column2);INSERTINTOtVALUES(1,2),(2,1);SELECT*FROMtINDEXEDBY"pk_unnamed_T_1";SELECT*FROMtINDEXEDBYidx_column2_t_1;-- Result for the first select: (1, 2), (2, 1)-- Result for the second select: (2, 1), (1, 2).
Limitations:
Often INDEXED BY has no effect.
Often INDEXED BY affects a choice of covering index, but not a WHERE clause.
VALUES has the same effect as SELECT, that is, it returns a result set,
but VALUES statements may not have FROM or GROUP or ORDER BY or LIMIT clauses.
VALUES may be used wherever SELECT may be used, for example in subqueries.
Examples:
-- simple case:VALUES(1);-- equivalent to SELECT 1, 2, 3:VALUES(1,2,3);-- two rows:VALUES(1,2,3),(4,5,6);
PRAGMA
Syntax:
PRAGMApragma-name(pragma-value);
or PRAGMApragma-name;
PRAGMA statements will give rudimentary information about database ‘metadata’ or
server performance,
although it is better to get metadata via system tables.
For PRAGMA statements that include (pragma-value),
pragma values are strings and can be specified inside "" double quotes,
or without quotes.
When a string is used for searching, results must match according to a
binary collation. If the object being searched has a lower-case name,
use double quotes.
In an earlier version, there were some PRAGMA statements that determined behavior.
Now that does not happen. Behavior change is done by updating the
box.space._session_settings system table.
Pragma
Parameter
Effect
foreign_key_list
string table-name
Return a
result set
with one row for each foreign key of
“table-name”. Each row contains:
(INTEGER) id – identification number
(INTEGER) seq – sequential number
(STRING) table – name of table
(STRING) from – referencing key
(STRING) to – referenced key
(STRING) on_update – ON UPDATE clause
(STRING) on_delete – ON DELETE clause
(STRING) match – MATCH clause
The system table is "_fk_constraint".
collation_list
Return a result set with one row for each
supported collation. The first four collations
are 'none' and 'unicode' and
'unicode_ci' and 'binary', then come
about 270 predefined collations, the exact
count may vary because users can add their
own collations.
The system table is "_collation".
index_info
string table-name . index-name
Return a result set with one row for each
column in “table-name.index-name”.
Each row contains:
(INTEGER) seqno – the column’s ordinal
position in the index (first column is 0)
(INTEGER) cid – the column’s ordinal
position in the table (first column is 0)
(STRING) name – name of the column
(INTEGER) desc – 0 is ASC, 1 is DESC
(STRING) collation name
(STRING) type – data type
index_list
string table-name
Return a result set
with one row for each index of “table-name”.
Each row contains:
(INTEGER) seq – sequential number
(STRING) name – index name
(INTEGER) unique – whether the index is
unique, 0 is false, 1 is true
The system table is "_index".
stats
Return a result set with
one row for each index of each table.
Each row contains:
(STRING) table – name of the table
(STRING) index – name of the index
(INTEGER) width – arbitrary information
(INTEGER) height – arbitrary information
table_info
string table-name
Return a result set
with one row for each column
in “table-name”. Each row contains:
(INTEGER) cid – ordinal position in the table
(first column number is 0)
(STRING) name – column name
(STRING) type
(INTEGER) notnull – whether the column is
NOT NULL, 0 is
false, 1 is true.
(STRING) dflt_value – default value
(INTEGER) pk – whether the column is
a PRIMARY KEY column, 0 is false, 1 is true.
EXPLAIN will show what steps Tarantool would take if it executed explainable-statement.
This is primarily a debugging and optimization aid for the Tarantool team.
Variation: EXPLAINQUERYPLANstatement; shows the steps of a search.
Statements for transactions
START TRANSACTION
Syntax:
STARTTRANSACTION;
Start a transaction. After STARTTRANSACTION;, a transaction is “active”.
If a transaction is already active, then STARTTRANSACTION; is illegal.
Transactions should be active for fairly short periods of time, to avoid
concurrency issues. To end a transaction, say COMMIT; or ROLLBACK;.
Just as in NoSQL, transaction control statements are subject to limitations
set by the storage engine involved:
* For the memtx storage engine, if a yield happens within an active transaction, the transaction is rolled back.
* For the vinyl engine, yields are allowed.
Also, although CREATE AND DROP and ALTER statements are legal in transactions,
there are a few exceptions. For example, CREATEINDEXONtable_name... will fail within a
multi-statement transaction if the table is not empty.
However, transaction control statements still may not work as you expect when
run over a network connection:
a transaction is associated with a fiber, not a network connection, and
different transaction control statements sent via the same network connection
may be executed by different fibers from the fiber pool.
In order to ensure that all statements are part of the intended transaction,
put all of them between STARTTRANSACTION; and COMMIT; or ROLLBACK;
then send as a single batch. For example:
Enclose each separate SQL statement in a
box.execute() function.
Pass all the box.execute() functions to the server in a single message.
If you are using a console, you can do this by writing everything on a single
line.
If you are using net.box, you can do this by putting
all the function calls in a single string and calling
eval(string).
Example:
STARTTRANSACTION;
Example of a whole transaction sent to a server on localhost:3301 with
eval(string):
net_box=require('net.box')conn=net_box.new('localhost',3301)s='box.execute([[START TRANSACTION;]]) 's=s..'box.execute([[INSERT INTO t VALUES (1);]]) 's=s..'box.execute([[ROLLBACK;]]) 'conn:eval(s)
COMMIT
Syntax:
COMMIT;
Commit an active transaction, so all changes are made permanent
and the transaction ends.
COMMIT is illegal unless a transaction is active.
If a transaction is not active then SQL statements are committed automatically.
RELEASE is illegal unless a transaction is active.
Savepoints are released automatically when a transaction ends.
Example:
RELEASESAVEPOINTx;
ROLLBACK
Syntax:
ROLLBACK[TO[SAVEPOINT]savepoint-name];
If ROLLBACK does not specify a savepoint-name,
rollback an active transaction, so all changes
since START TRANSACTION are cancelled,
and the transaction ends.
If ROLLBACK does specify a savepoint-name,
rollback an active transaction, so all changes
since SAVEPOINT savepoint-name are cancelled,
and the transaction does not end.
ROLLBACK is illegal unless a transaction is active.
Examples:
-- the simple form:
ROLLBACK;
-- the form so changes before a savepoint are not cancelled:
ROLLBACK TO SAVEPOINT x;
-- An example of a Lua function that will do a transaction-- containing savepoint and rollback to savepoint.functionf()box.execute([[DROP TABLE IF EXISTS t;]])-- commits automaticallybox.execute([[CREATE TABLE t (s1 STRING PRIMARY KEY);]])-- commits automaticallybox.execute([[START TRANSACTION;]])-- after this succeeds, a transaction is activebox.execute([[INSERT INTO t VALUES ('Data change #1');]])box.execute([[SAVEPOINT "1";]])box.execute([[INSERT INTO t VALUES ('Data change #2');]])box.execute([[ROLLBACK TO SAVEPOINT "1";]])-- rollback Data change #2box.execute([[ROLLBACK TO SAVEPOINT "1";]])-- this is legal but does nothingbox.execute([[COMMIT;]])-- make Data change #1 permanent, end the transactionend
Functions
Explanation of functions
Syntax:
function-name(oneormoreexpressions)
Apply a built-in function to one or more expressions and return a scalar value.
Tarantool supports 33 built-in functions.
The maximum number of operands for any function is 127.
The required privileges for built-in functions will likely change in a future version.
List of functions
These are Tarantool/SQL’s built-in functions.
Starting with Tarantool 2.10, for functions that require numeric arguments,
function arguments with NUMBER data type are illegal.
ABS
Syntax:
ABS(numeric-expression)
Return the absolute value of numeric-expression, which can be any numeric type.
Example: ABS(-1) is 1.
CAST
Syntax:
CAST(expressionASdata-type)
Return the expression value after casting to the specified
data type.
CAST to/from UUID may change some components to/from little-endian.
The DATE_PART() function returns the requested information from a DATETIME value.
It takes two arguments: the first one tells us what information is requested, the second is a DATETIME value.
Below is a list of supported values of the first argument and what information is returned:
millennium – millennium
century – century
decade – decade
year – year
quarter – quarter of year
month – month of year
week – week of year
day – day of month
dow – day of week
doy – day of year
hour – hour of day
minute – minute of hour
second – second of minute
millisecond – millisecond of second
microsecond – microsecond of second
nanosecond – nanosecond of second
epoch – epoch
timezone_offset – time zone offset from the UTC, in minutes.
Return the greatest value of the supplied expressions, or, if any expression
is NULL, return NULL.
The reverse of GREATEST is LEAST.
Examples: GREATEST(7,44,-1) is 44;
GREATEST(1E308,'a',0,X'00') is ‘0’ = the nul character;
GREATEST(3,NULL,2) is NULL
HEX
Syntax:
HEX(expression)
Return the hexadecimal code for each byte in expression.
Starting with Tarantool version 2.10.0, the expression must be a byte sequence
(data type VARBINARY).
In earlier versions of Tarantool, the expression could be either a string or a byte sequence.
For ASCII characters, this
was straightforward because the encoding is
the same as the code point value. For
non-ASCII characters, since character strings
are usually encoded in UTF-8, each character
will require two or more bytes.
Examples:
HEX(X'41') will return 41.
HEX(CAST('Д'ASVARBINARY)) will return D094.
IFNULL
Syntax:
IFNULL(expression,expression)
Return the value of the first non-NULL expression, or, if both
expression values are NULL, return NULL. Thus
IFNULL(expression,expression) is the same as
COALESCE(expression, expression).
Return the least value of the supplied expressions, or, if any expression
is NULL, return NULL.
The reverse of LEAST is GREATEST.
Examples: LEAST(7,44,-1) is -1;
LEAST(1E308,'a',0,X'00') is 0;
LEAST(3,NULL,2) is NULL.
LENGTH
Syntax:
LENGTH(expression)
Return the number of characters in the expression,
or the number of bytes in the expression.
It depends on the data type:
strings with data type STRING are counted in characters,
byte sequences with data type VARBINARY
are counted in bytes and are not ended by the nul character.
There are two aliases for LENGTH(expression) – CHAR_LENGTH(expression)
and CHARACTER_LENGTH(expression) do the same thing.
Examples:
LENGTH('ДД') is 2, the string has 2 characters.
LENGTH(CAST('ДД'ASVARBINARY)) is 4, the string has 4 bytes.
LENGTH(CHAR(0,65)) is 2, ‘0’ does not mean ‘end of string’.
LENGTH(X'410041') is 3, X’…’ byte sequences have type VARBINARY.
LIKELIHOOD
Syntax:
LIKELIHOOD(expression,DOUBLEliteral)
Return the expression without change, provided that the numeric literal is between 0.0 and 1.0.
Example: LIKELIHOOD('a'='b',.0) is FALSE
LIKELY
Syntax:
LIKELY(expression)
Return TRUE if the expression is probably true.
Example: LIKELY('a'<='b') is TRUE
LOWER
Syntax:
LOWER(string-expression)
Return the expression, with upper-case characters converted to lower case.
The reverse of LOWER is UPPER.
The NOW() function returns the current date and time as a DATETIME
value.
If the function is called more than once in a query, it returns
the same result until the query completes, unless a yield has occurred.
On yield, the value returned by NOW() is changing.
Return expression-1 if expression-1 <> expression-2,
otherwise return NULL.
Examples:
NULLIF('a','A') is ‘a’.
NULLIF(1.00,1) is NULL.
Note
Before Tarantool 2.10.4, the type of the result was always SCALAR.
Since Tarantool 2.10.4, the result of NULLIF matches the type of the first argument.
If the first argument is the NULL literal, then the result has the SCALAR type.
POSITION
Syntax:
POSITION(expression-1,expression-2)
Return the position of expression-1 within expression-2,
or return 0 if expression-1 does not appear
within expression-2.
The data types of the expressions must be either STRING or VARBINARY.
If the expressions have data type STRING, then the result is the character position.
If the expressions have data type VARBINARY, then the result is the
byte position.
Short example:
POSITION('C','ABC') is 3
Long example: The UTF-8 encoding for the Latin letter A
is hexadecimal 41; the UTF-8 encoding for the
Cyrillic letter Д is hexadecimal D094 – you can confirm this
by saying SELECT HEX(‘ДA’); and seeing that the
result is ‘D09441’. If you now execute
SELECTPOSITION('A','ДA');
the result will be 2,
because ‘A’ is the second character in the string.
However, if you now execute
SELECTPOSITION(X'41',X'D09441');
the result will be 3,
because X’41’ is the third byte in the byte sequence.
PRINTF
Syntax:
PRINTF(string-expression[,expression...])
Return a string formatted according to the rules of the C
sprintf() function, where %d%s means the next two arguments
are a numeric and a string, and so on.
If an argument is missing or is NULL, it becomes:
‘0’ if the format requires an integer,
‘0.0’ if the format requires a numeric with a decimal point,
‘’ if the format requires a string.
Example: PRINTF('%da',5) is ‘5a’.
QUOTE
Syntax:
QUOTE(string-argument)
Return a string with enclosing quotes if necessary,
and with quotes inside the enclosing quotes if necessary.
This function is useful for creating strings
which are part of SQL statements, because of SQL’s rules that
string literals are enclosed by single quotes, and single quotes
inside such strings are shown as two single quotes in a row.
Starting with Tarantool version 2.10, arguments with numeric
data types are returned without change.
Example: QUOTE('a') is 'a'. QUOTE(5) is 5.
RAISE
Syntax:
RAISE(FAIL,error-message)
This may only be used within a triggered statement. See also Trigger Activation.
RANDOM
Syntax: RANDOM()
Return a 19-digit integer which is generated by a pseudo-random number generator,
Example: RANDOM() is 6832175749978026034, or it is any other integer
RANDOMBLOB
Syntax:
RANDOMBLOB(n)
Return a byte sequence, n bytes long, data type = VARBINARY, containing bytes generated by a
pseudo-random byte generator. The result can be translated to hexadecimal.
If n is less than 1 or is NULL or is infinity, then NULL is returned.
Example: HEX(RANDOMBLOB(3)) is ‘9EAAA8’, or it is the hex value for any other
three-byte string
REPLACE
Syntax:
REPLACE(expression-1,expression-2,expression-3)
Return expression-1, except that wherever expression-1
contains expression-2, replace expression-2 with
expression-3.
The expressions should all have data type STRING or VARBINARY.
Example: REPLACE('AAABCCCBD','B','!') is ‘AAA!CCC!D’
Return the rounded value of numeric-expression-1, always rounding
.5 upward for positive numerics or downward for negative numerics.
If numeric-expression-2 is supplied then rounding is to the nearest
numeric-expression-2 digits after the decimal point;
if numeric-expression-2 is not supplied then rounding is to the nearest integer.
Example: ROUND(-1.5) is -2, ROUND(1.7766E1,2) is 17.77.
ROW_COUNT
ROW_COUNT()
Return the number of rows that were inserted / updated / deleted
by the last INSERT or
UPDATE or
DELETE or
REPLACE statement.
Rows which were updated by an UPDATE statement are counted even if there was no change.
Rows which were inserted / updated / deleted due to foreign-key action are not counted.
Rows which were inserted / updated / deleted due to a view’s
INSTEAD OF triggers are not counted.
After a CREATE or DROP statement, ROW_COUNT() is 1.
After other statements, ROW_COUNT() is 0.
Example: ROW_COUNT() is 1 after a successful INSERT of a single row.
Special rule if there are BEFORE or AFTER triggers: In effect the ROW_COUNT()
counter is pushed at the beginning of a series of triggered statements,
and popped at the end. Therefore, after the following statements:
Return a four-character string which represents the sound
of string-expression. Often words and names which have
different spellings will have the same Soundex representation
if they are pronounced similarly,
so it is possible to search by what they sound like.
The algorithm works with characters in the Latin alphabet
and works best with English words.
Example: SOUNDEX('Crater') and SOUNDEX('Creature') both return C636.
If string-or-varbinary-value has data type STRING, then return the substring
which begins
at character position numeric-start-position and continues for
numeric-length characters (if numeric-length is
supplied), or continues till the end of string-or-varbinary-value
(if numeric-length is not supplied).
If numeric-start-position is less than 1, or if numeric-start-position
+ numeric-length is greater than the length of string-or-varbinary-value,
then the result is not an error, anything which would be before the start
or after the end is ignored. There are no symbols with index <= 0
or with index greater than the length of the first argument.
If numeric-length is less than 0, then the result is an error.
If string-or-varbinary-value has data type VARBINARY rather than data
type STRING, then positioning and counting is by bytes
rather than by characters.
Examples: SUBSTR('ABCDEF',3,2) is ‘CD’, SUBSTR('абвгде',-1,4) is ‘аб’
Return expression-2 after removing all leading and/or trailing characters or bytes.
The expressions should have data type STRING or VARBINARY.
If LEADING|TRAILING|BOTH is omitted, the default is BOTH.
If expression-1 is omitted, the default is ‘ ‘ (space) for data type STRING
or X’00’ (nul) for data type VARBINARY.
Examples:
TRIM('a'FROM'abaaaaa') is ‘b’ – all repetitions of ‘a’ are removed on both sides;
TRIM(TRAILING'ב'FROM'אב') is ‘א’ – if all characters are Hebrew, TRAILING means “left”;
TRIM(X'004400') is X’44’ – the default byte sequence to trim is X’00’ when data type is VARBINARY;
TRIM(LEADING'abc'FROM'abcd') is ‘d’ – expression-1 can have more than 1 character.
TYPEOF
Syntax:
TYPEOF(expression)
Return ‘NULL’ if the expression is NULL,
or return ‘scalar’ if the expression is the name of a column defined as SCALAR,
or return the data type of the expression.
Prior to Tarantool version 2.10, TYPEOF(expression) simply returned
the data type of the expression for all cases.
UNICODE
Syntax:
UNICODE(string-expression)
Return the Unicode code point value of the first character of string-expression.
If string-expression is empty, the return is NULL.
This is the reverse of CHAR(integer).
Example: UNICODE('Щ') is 1065 (hexadecimal 0429).
UNLIKELY
Syntax:
UNLIKELY(expression)
Return TRUE if the expression is probably false.
Limitation: in fact UNLIKELY may return the same thing as LIKELY.
Example: UNLIKELY('a'<='b') is TRUE.
UPPER
Syntax:
UPPER(string-expression)
Return the expression, with lower-case characters converted to upper case.
The reverse of UPPER is LOWER.
Example: UPPER('-4щl') is ‘-4ЩL’.
UUID
Syntax:
UUID([integer])
Return a Universal Unique Identifier, data type UUID.
Optionally one can specify a version number; however, at this time the
only allowed version is 4, which is the default.
UUID support in SQL was added in Tarantool version 2.9.1.
Example: UUID() or UUID(4)
VERSION
Syntax:
VERSION()
Return the Tarantool version.
Example: for a February 2020 build VERSION() is '2.4.0-35-g57f6fc932'.
ZEROBLOB
Syntax:
ZEROBLOB(n)
Return a byte sequence, data type = VARBINARY, n bytes long.
COLLATE clause
COLLATEcollation-name
The collation-name must identify an existing collation.
-- In CREATE INDEXCREATEINDEXidx_unicode_mb_1ONmb(s1COLLATE"unicode");-- In CREATE TABLECREATETABLEt1(s1INTEGERPRIMARYKEY,s2STRINGCOLLATE"unicode_ci");-- In CREATE TABLE ... UNIQUECREATETABLEmb(aSTRING,bSTRING,PRIMARYKEY(a),UNIQUE(bCOLLATE"unicode_ci"DESC));-- In string expressionsSELECT'a'='b'COLLATE"unicode"FROMtWHEREs1='b'COLLATE"unicode"ORDERBYs1COLLATE"unicode";
The collation rules comply completely with the Unicode Technical Standard #10
(“Unicode Collation Algorithm”)
and the default character order is as in the
Default Unicode Collation Element Table (DUCET).
There are many permanent collations; the commonly used ones include: "none" (not applicable) "unicode" (characters are in DUCET order with strength = ‘tertiary’) "unicode_ci" (characters are in DUCET order with strength = ‘primary’) "binary" (characters are in code point order)
These identifiers must be quoted and in lower case because they are in lower case in
Tarantool/NoSQL collations.
If one says COLLATE"binary", this is equivalent to asking for what is sometimes called
“code point order” because, if the contents are in the UTF-8 character set,
characters with larger code points will appear after characters with lower code points.
In an expression, COLLATE is an operator with higher precedence than anything except
~. This is fine because there are no other useful operators except || and comparison.
After ||, collation is preserved.
In an expression with more than one COLLATE clause, if the collation names differ,
there is an error: “Illegal mix of collations”.
In an expression with no COLLATE clauses, literals have collation "binary",
columns have the collation specified by CREATETABLE.
In other words, to pick a collation, Tarantool uses:
the first COLLATE clause in an expression if it was specified,
else the column’s COLLATE clause if it was specified,
else "binary".
However, for searches and sometimes for sorting, the collation may be an index’s collation,
so all non-index COLLATE clauses are ignored.
EXPLAIN will not show the name of what collation was used, but will show the collation’s characteristics.
Example with Swedish collation:
Knowing that “sv” is the two-letter code for Swedish,
and knowing that “s1” means strength = 1,
and seeing with PRAGMAcollation_list; that there is a collation named unicode_sv_s1,
check whether two strings are equal according to Swedish rules (yes they are): SELECT'ÄÄ'='ĘĘ'COLLATE"unicode_sv_s1";
Example with Russian and Ukrainian and Kyrgyz collations:
Knowing that Russian collation is practically the same as Unicode default,
and knowing that the two-letter codes for Ukrainian and Kyrgyz are ‘uk’ and ‘ky’,
and knowing that in Russian (but not Ukrainian) ‘Г’ = ‘Ґ’ with strength=primary,
and knowing that in Russian (but not Kyrgyz) ‘Е’ = ‘Ё’ with strength=primary,
the three SELECT statements here will return results in three different orders: CREATETABLEthings(remarkSTRINGPRIMARYKEY); INSERTINTOthingsVALUES('Е2'),('Ё1'); INSERTINTOthingsVALUES('Г2'),('Ґ1'); SELECTremarkFROMthingsORDERBYremarkCOLLATE"unicode"; SELECTremarkFROMthingsORDERBYremarkCOLLATE"unicode_uk_s1"; SELECTremarkFROMthingsORDERBYremarkCOLLATE"unicode_ky_s1";
Default function parameters
Starting in Tarantool 2.10, if a parameter for an aggregate function
or a built-in scalar SQL function is one of the extra-parameters
that can appear in box.execute(…[,extra-parameters])
requests,
default data type is calculated thus:
* When there is only one possible data type, it is default.
Example: box.execute([[SELECTTYPEOF(LOWER(?));]],{x}) is ‘string’.
* When possible data types are INTEGER or DOUBLE or DECIMAL, DECIMAL is default.
Example: box.execute([[SELECTTYPEOF(AVG(?));]],{x}) is ‘decimal’.
* When possible data types are STRING or VARBINARY, STRING is default.
Example: box.execute([[SELECTTYPEOF(LENGTH(?));]],{x}) is ‘string’.
* When possible data types are any other scalar data type, SCALAR is default.
Example: box.execute([[SELECTTYPEOF(GREATEST(?,5));]],{x}) is ‘scalar’.
* When possible data type is a non-scalar data type, such as ARRAY, result is undefined.
* Otherwise, there is no default.
Example: box.execute([[SELECTTYPEOF(LIKELY(?));]],{x}) is the name of one of the primitive data types.
SQL PLUS LUA – Adding Tarantool/NoSQL to Tarantool/SQL
The Adding Tarantool/NoSQL To Tarantool/SQL Guide contains descriptions of NoSQL
database objects that can be accessed from SQL, of SQL database objects that can
be accessed from NoSQL, of the way to call SQL from Lua, and of the way to call
Lua from SQL.
Making equivalents to standard-SQL information_schema tables
Lua Requests
A great deal of functionality is not specifically part of Tarantool’s SQL feature,
but is part of the Tarantool Lua application server and DBMS.
Here are some examples so it is clear where to look in other sections of the Tarantool manual.
NoSQL “spaces” can be accessed as SQL "tables", and vice versa.
For example, suppose a table has been created with CREATETABLEthings(idINTEGERPRIMARYKEY,remarkSCALAR);
This is viewable from Tarantool’s NoSQL feature as a memtx space named THINGS with a primary-key
TREE index …
The NoSQL basic data operation requests
select, insert, replace, upsert, update, delete will all work.
Particularly interesting are the requests that come only via NoSQL.
To create an index on things (remark) with a non-default option for example a special id, say: box.space.THINGS:create_index('idx_100_things_2',{id=100,parts={2,'scalar'}})
(If the SQL data type name is SCALAR, then the NoSQL type is ‘scalar’,
as described earlier. See the chart in section Operands.)
To grant
database-access privileges to user ‘guest’, say box.schema.user.grant('guest','execute','universe')
To grant SELECT privileges on table things to user ‘guest’, say box.schema.user.grant('guest','read','space','THINGS')
To grant UPDATE privileges on table things to user ‘guest’, say: box.schema.user.grant('guest','read,write','space','THINGS')
To grant DELETE or INSERT privileges on table things if no reading is involved, say: box.schema.user.grant('guest','write','space','THINGS')
To grant DELETE or INSERT privileges on table things if reading is involved, say: box.schema.user.grant('guest','read,write','space','THINGS')
To grant CREATE TABLE privilege to user ‘guest’, say box.schema.user.grant('guest','read,write','space','_schema') box.schema.user.grant('guest','read,write','space','_space') box.schema.user.grant('guest','read,write','space','_index') box.schema.user.grant('guest','create','space')
To grant CREATE TRIGGER privilege to user ‘guest’, say box.schema.user.grant('guest','read','space','_space') box.schema.user.grant('guest','read,write','space','_trigger')
To grant CREATE INDEX privilege to user ‘guest’, say box.schema.user.grant('guest','read,write','space','_index') box.schema.user.grant('guest','create','space')
To grant CREATE TABLE … INTEGER PRIMARY KEY AUTOINCREMENT to user ‘guest’, say box.schema.user.grant('guest','read,write','space','_schema') box.schema.user.grant('guest','read,write','space','_space') box.schema.user.grant('guest','read,write','space','_index') box.schema.user.grant('guest','create','space') box.schema.user.grant('guest','read,write','space','_space_sequence') box.schema.user.grant('guest','read,write','space','_sequence') box.schema.user.grant('guest','create','sequence')
To write a stored procedure that inserts 5 rows in things, say functionf()fori=3,7dobox.space.THINGS:insert{i,i}endend
For client-side API functions, see section “Connectors”.
To make spaces with field names that SQL can understand, use
space_object:format().
(Exception: in Tarantool/NoSQL it is legal for tuples to have more fields than are described by a format clause,
but in Tarantool/SQL such fields will be ignored.)
To handle replication and sharding of SQL data, see section
Sharding.
To enhance performance of SQL statements by preparing them in advance, see section
box.prepare().
Limitations: (Issue#2368)
* after box.schema.user.grant('guest','read,write,execute','universe'), user 'guest' can create tables. But this is a powerful set of privileges.
Limitations: (Issue#4659,
Issue#4757,
Issue#4758)
SELECT with * or ORDER BY or GROUP BY from spaces that have map fields
or array fields may cause errors. Any access to spaces that have hash
indexes may cause severe errors in Tarantool version 2.3 or earlier.
System Tables
There is a way to get some information about the database objects,
for example the names of all the tables and their indexes, using
SELECT statements.
This is done by looking at special read-only tables which Tarantool updates
automatically whenever objects are created or dropped.
See the submodule box.space overview section.
Names of system tables are in lower case so always enclose them in "quotes".
For example, the _space system table has these fields which are seen in SQL as columns:
id = numeric identifier
owner = for example, 1 if the object was made by the 'admin' user
name = the name that was used with CREATE TABLE
engine = usually 'memtx' (the 'vinyl' engine can be used but is not default)
field_count = sometimes 0, but usually a count of the table’s columns
flags = usually empty
format = what a Lua format() function or an SQL CREATE statement produced
Example selection: SELECT"id","name"FROM"_space";
SQL statements can invoke functions that are written in Lua.
This is Tarantool’s equivalent for the “stored procedure” feature found in other SQL DBMSs.
Tarantool server-side stored procedures are written in Lua rather than SQL/PSM dialect.
Functions can be invoked anywhere that the SQL syntax allows a literal or a column name for reading.
Function parameters can include any number of SQL values.
If a SELECT statement’s result set has a million rows, and the
select list invokes a non-deterministic function,
then the function is called a million times.
exports={'LUA','SQL'} – This indicates what languages can call the function.
The default is 'LUA'. Specify both: 'LUA','SQL'.
param_list={list} – This is the list of parameters.
Specify the Lua type names for each parameter of the function.
Remember that a Lua type name is
the same as an SQL data type name, in lower case.
The Lua type should not be an array.
Also it is good to specify {deterministic=true} if possible,
because that may allow Tarantool to generate more efficient SQL byte code.
For a useful example, here is a general function for decoding a single Lua 'map' field:
box.schema.func.create('_DECODE',{language='LUA',returns='string',body=[[function (field, key) -- If Tarantool version < 2.10.1, replace next line with -- return require('msgpack').decode(field)[key] return field[key] end]],is_sandboxed=false,-- If Tarantool version < 2.10.1, replace next line with-- param_list = {'string', 'string'},param_list={'map','string'},exports={'LUA','SQL'},is_deterministic=true})
See it work with, say, the _trigger space.
That space has a 'map' field named opts which has a key named sql.
By selecting from the space and passing the field and the key name to _DECODE,
you can get a list of all the trigger bodies.
box.execute([[SELECT _decode("opts", 'sql') FROM "_trigger";]])
Remember that SQL converts regular identifiers to upper case,
so this example works with a function named _DECODE.
If the function had been named _decode, then the SELECT statement would have to be: box.execute([[SELECT"_decode"("opts",'sql')FROM"_trigger";]])
Here is another example, which illustrates the way that Tarantool creates
a view which includes the table_name and table_type columns in the same
way that the standard-SQL information_schema.tables view contains them.
The difficulty is that, in order to discover whether table_type should
be 'BASETABLE' or should be 'VIEW', it is necessary to know the value of the
"flags" field in the Tarantool/NoSQL “_space” or "_vspace" space.
The "flags" field type is "map", which SQL does not understand well.
If there were no Lua functions, it would be necessary to treat the field as a VARBINARY
and look for POSITION(X'A476696577C3',"flags")>0 (A4 is a MsgPack signal
that a 4-byte string follows, 76696577 is UTF8 encoding for ‘view’,
C3 is a MsgPack code meaning true).
In any case, starting with Tarantool version 2.10, POSITION() does not work on VARBINARY operands.
But there is a more sophisticated way, namely, creating a function that
returns true if "flags".view is true.
So for this case the way to make the function looks like this:
box.schema.func.create('TABLES_IS_VIEW',{language='LUA',returns='boolean',body=[[function (flags) local view -- If Tarantool version < 2.10.1, replace next line with -- view = require('msgpack').decode(flags).view view = flags.view if view == nil then return false end return view end]],is_sandboxed=false,-- If Tarantool version < 2.10.1, replace next line with-- param_list = {'string'},param_list={'map'},exports={'LUA','SQL'},is_deterministic=true})
And this creates the view:
box.execute([[CREATE VIEW vtables AS SELECT"name" AS table_name,CASE WHEN tables_is_view("flags") == TRUE THEN 'VIEW' ELSE 'BASE TABLE' END AS table_type,"id" AS id,"engine" AS engine,(SELECT "name" FROM "_vuser" x WHERE x."id" = y."owner") AS owner,"field_count" AS field_countFROM "_vspace" y;]])
Remember that these Lua functions are persistent, so if the server has to be restarted then they do not have to be re-declared.
Executing Lua chunks
To execute Lua code without creating a function, use: LUA(Lua-code-string)
where Lua-code-string is any amount of Lua code.
The string should begin with 'return'.
For example this will show the number of seconds since the epoch: box.execute([[SELECTlua('returnos.time()');]])
For example this will show a database configuration member: box.execute([[SELECTlua('returnbox.cfg.memtx_memory');]])
For example this will return FALSE because Lua nil and box.NULL are the same as SQL NULL: box.execute([[SELECTlua('returnbox.NULL')ISNOTNULL;]])
Warning: the SQL statement must not invoke a Lua function, or execute a Lua chunk,
that accesses a space that underlies any SQL table that the SQL statement accesses.
For example, if function f() contains a request "box.space.TEST:insert{0}",
then the SQL statement "SELECTf()FROMtest;" will try to access the same space in two ways.
The results of such conflict may include a hang or an infinite loop.
Example Sessions
Example Session – Create, Insert, Select
Assume that the task is to create two tables, put some rows in each table,
create a view that is based on a join of the tables,
then select from the view all rows where the second column values
are not null, ordered by the first column.
That is, the way to populate the table is CREATETABLEt1(c1INTEGERPRIMARYKEY,c2STRING); CREATETABLEt2(c1INTEGERPRIMARYKEY,x2STRING); INSERTINTOt1VALUES(1,'A'),(2,'B'),(3,'C'); INSERTINTOt1VALUES(4,'D'),(5,'E'),(6,'F'); INSERTINTOt2VALUES(1,'C'),(4,'A'),(6,NULL); CREATEVIEWvASSELECT*FROMt1NATURALJOINt2; SELECT*FROMvWHEREc2ISNOTNULLORDERBYc1;
So the session looks like this: box.cfg{} box.execute([[CREATETABLEt1(c1INTEGERPRIMARYKEY,c2STRING);]]) box.execute([[CREATETABLEt2(c1INTEGERPRIMARYKEY,x2STRING);]]) box.execute([[INSERTINTOt1VALUES(1,'A'),(2,'B'),(3,'C');]]) box.execute([[INSERTINTOt1VALUES(4,'D'),(5,'E'),(6,'F');]]) box.execute([[INSERTINTOt2VALUES(1,'C'),(4,'A'),(6,NULL);]]) box.execute([[CREATEVIEWvASSELECT*FROMt1NATURALJOINt2;]]) box.execute([[SELECT*FROMvWHEREc2ISNOTNULLORDERBYc1;]])
If one executes the above requests with Tarantool as a client, provided the database
objects do not already exist, the execution will be successful and the final display will be
tarantool> box.execute([[SELECT * FROM v WHERE c2 IS NOT NULL ORDER BY c1;]])-----[1,'A','C']-[4,'D','A']-[6,'F',null]
Example Session – Get a List of Columns
Here is a function which will create a table that contains
a list of all the columns and their Lua types, for all tables.
It is not a necessary function because one can create a
_COLUMNS view instead.
It merely shows, with simpler Lua code, how to make a base table instead of a view.
If you now execute the function by saying create_information_schema_columns()
you will see that there is a table named information_schema_columns
containing table_name and column_name and ordinal_position and data_type for everything that was accessible.
box.execute([[CREATE TABLE tester (s1 INTEGER PRIMARY KEY, s2 STRING);]])functionstring_function()localrandom_numberlocalrandom_stringrandom_string=""forx=1,10,1dorandom_number=math.random(65,90)random_string=random_string..string.char(random_number)endreturnrandom_stringendfunctionmain_function()localstring_value,t,sql_statementfori=1,1000000,1dostring_value=string_function()sql_statement="INSERT INTO tester VALUES ("..i..",'"..string_value.."');"box.execute(sql_statement)endendstart_time=os.clock()main_function()end_time=os.clock()'insert done in '..end_time-start_time..' seconds'
Limitations:
The function takes more time than the original (Tarantool/NoSQL).
Lua functions to make views of metadata
Tarantool does not include all the standard-SQL
information_schema
views, which are for looking at metadata, that is, “data about the data”.
But here is the Lua code and SQL code for creating equivalents: _TABLES nearly equivalent to INFORMATION_SCHEMA.TABLES _COLUMNS nearly equivalent to INFORMATION_SCHEMA.COLUMNS _VIEWS nearly equivalent to INFORMATION_SCHEMA.VIEWS _TRIGGERS nearly equivalent to INFORMATION_SCHEMA.TRIGGERS _REFERENTIAL_CONSTRAINTS nearly equivalent to INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS _CHECK_CONSTRAINTS nearly equivalent to INFORMATION_SCHEMA.CHECK_CONSTRAINTS _TABLE_CONSTRAINTS nearly equivalent to INFORMATION_SCHEMA.TABLE_CONSTRAINTS.
For each view there will be an example of a SELECT from the view, and the code.
Users who want metadata can simply copy the code.
Use this code only with Tarantool version 2.3.0 or later.
With an earlier Tarantool version, a PRAGMA statement may be useful.
Definition of the function and the CREATE VIEW statement:
box.schema.func.drop('_TABLES_IS_VIEW',{if_exists=true})box.schema.func.create('_TABLES_IS_VIEW',{language='LUA',returns='boolean',body=[[function (flags) local view -- If Tarantool version < 2.10.1, replace next line with -- view = require('msgpack').decode(flags).view view = flags.view if view == nil then return false end return view end]],is_sandboxed=false,-- If Tarantool version < 2.10.1, replace next line with-- param_list = {'string'},param_list={'map'},exports={'LUA','SQL'},is_deterministic=true})box.schema.role.grant('public','execute','function','_TABLES_IS_VIEW')pcall(function()box.schema.role.revoke('public','read','space','_TABLES',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _tables;]])box.execute([[CREATE VIEW _tables AS SELECT CAST(NULL AS STRING) AS table_catalog, CAST(NULL AS STRING) AS table_schema, "name" AS table_name, CASE WHEN _tables_is_view("flags") = TRUE THEN 'VIEW' ELSE 'BASE TABLE' END AS table_type, "id" AS id, "engine" AS engine, (SELECT "name" FROM "_vuser" x WHERE x."id" = y."owner") AS owner, "field_count" AS field_countFROM "_vspace" y;]])box.schema.role.grant('public','read','space','_TABLES')
_COLUMNS view
This is also an example of how one can use recursive views to make temporary tables
with multiple rows for each tuple in the original "_vspace" space.
It requires a global variable, _G.box.FORMATS, as a temporary static variable.
Warning: Use this code only with Tarantool version 2.3.2 or later.
Use with earlier versions will cause an assertion.
See Issue#4504.
Definition of the function and the CREATE VIEW statement:
box.schema.func.drop('_COLUMNS_FORMATS',{if_exists=true})box.schema.func.create('_COLUMNS_FORMATS',{language='LUA',returns='scalar',body=[[ function (row_number_, ordinal_position) if row_number_ == 0 then _G.box.FORMATS = {} local vspace = box.space._vspace:select() for i = 1, #vspace do local format = vspace[i]["format"] for j = 1, #format do local is_nullable = 'YES' if format[j].is_nullable == false then is_nullable = 'NO' end table.insert(_G.box.FORMATS, {vspace[i].name, format[j].name, j, is_nullable, format[j].type, vspace[i].id}) end end return '' end if row_number_ > #_G.box.FORMATS then _G.box.FORMATS = {} return '' end return _G.box.FORMATS[row_number_][ordinal_position] end ]],param_list={'integer','integer'},exports={'LUA','SQL'},is_sandboxed=false,setuid=false,is_deterministic=false})box.schema.role.grant('public','execute','function','_COLUMNS_FORMATS')pcall(function()box.schema.role.revoke('public','read','space','_COLUMNS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _columns;]])box.execute([[CREATE VIEW _columns ASWITH RECURSIVE r_columns AS(SELECT 0 AS row_number_, '' AS table_name, '' AS column_name, 0 AS ordinal_position, '' AS is_nullable, '' AS data_type, 0 AS idUNION ALLSELECT row_number_ + 1 AS row_number_, _columns_formats(row_number_, 1) AS table_name, _columns_formats(row_number_, 2) AS column_name, _columns_formats(row_number_, 3) AS ordinal_position, _columns_formats(row_number_, 4) AS is_nullable, _columns_formats(row_number_, 5) AS data_type, _columns_formats(row_number_, 6) AS id FROM r_columns WHERE row_number_ == 0 OR row_number_ <= lua('return #_G.box.FORMATS + 1'))SELECT CAST(NULL AS STRING) AS catalog_name, CAST(NULL AS STRING) AS schema_name, table_name, column_name, ordinal_position, is_nullable, data_type, id FROM r_columns WHERE data_type <> '';]])box.schema.role.grant('public','read','space','_COLUMNS')
Definition of the function and the CREATE VIEW statement:
box.schema.func.drop('_VIEWS_DEFINITION',{if_exists=true})box.schema.func.create('_VIEWS_DEFINITION',{language='LUA',returns='string',body=[[function (flags) -- If Tarantool version < 2.10.1, replace next line with -- return require('msgpack').decode(flags).sql return flags.sql end]],-- If Tarantool version < 2.10.1, replace next line with-- param_list = {'string'},param_list={'map'},exports={'LUA','SQL'},is_sandboxed=false,setuid=false,is_deterministic=false})box.schema.role.grant('public','execute','function','_VIEWS_DEFINITION')pcall(function()box.schema.role.revoke('public','read','space','_VIEWS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _views;]])box.execute([[CREATE VIEW _views AS SELECT CAST(NULL AS STRING) AS table_catalog, CAST(NULL AS STRING) AS table_schema, "name" AS table_name, CAST(_views_definition("flags") AS STRING) AS VIEW_DEFINITION, "id" AS id, (SELECT "name" FROM "_vuser" x WHERE x."id" = y."owner") AS owner, "field_count" AS field_count FROM "_vspace" y WHERE _tables_is_view("flags") = TRUE;]])box.schema.role.grant('public','read','space','_VIEWS')
_TABLES_IS_VIEW() was described earlier, see _TABLES view.
_TRIGGERS view
Example:
tarantool>SELECT trigger_name, opts_sql FROM _triggers;
OK 2 rows selected (0.0 seconds)
+--------------+-------------------------------------------------------------------------------------------------+
| TRIGGER_NAME | OPTS_SQL |
+--------------+-------------------------------------------------------------------------------------------------+
| THINGS1_AD | CREATE TRIGGER things1_ad AFTER DELETE ON things1 FOR EACH ROW BEGIN DELETE FROM things2; END; |
| THINGS1_BI | CREATE TRIGGER things1_bi BEFORE INSERT ON things1 FOR EACH ROW BEGIN DELETE FROM things2; END; |
+--------------+-------------------------------------------------------------------------------------------------+
Definition of the function and the CREATE VIEW statement:
box.schema.func.drop('_TRIGGERS_OPTS_SQL',{if_exists=true})box.schema.func.create('_TRIGGERS_OPTS_SQL',{language='LUA',returns='string',body=[[function (opts) -- If Tarantool version < 2.10.1, replace next line with -- return require('msgpack').decode(opts).sql return opts.sql end]],-- If Tarantool version < 2.10.1, replace next line with-- param_list = {'string'},param_list={'map'},exports={'LUA','SQL'},is_sandboxed=false,setuid=false,is_deterministic=false})box.schema.role.grant('public','execute','function','_TRIGGERS_OPTS_SQL')pcall(function()box.schema.role.revoke('public','read','space','_TRIGGERS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _triggers;]])box.execute([[CREATE VIEW _triggers AS SELECT CAST(NULL AS STRING) AS trigger_catalog, CAST(NULL AS STRING) AS trigger_schema, "name" AS trigger_name, CAST(_triggers_opts_sql("opts") AS STRING) AS opts_sql, "space_id" AS space_id FROM "_trigger";]])box.schema.role.grant('public','read','space','_TRIGGERS')
Users who select from this view will need ‘read’ privilege on the _trigger space.
pcall(function()box.schema.role.revoke('public','read','space','_REFERENTIAL_CONSTRAINTS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _referential_constraints;]])box.execute([[CREATE VIEW _referential_constraints AS SELECT CAST(NULL AS STRING) AS constraint_catalog, CAST(NULL AS STRING) AS constraint_schema, "name" AS constraint_name, CAST(NULL AS STRING) AS unique_constraint_catalog, CAST(NULL AS STRING) AS unique_constraint_schema, '' AS unique_constraint_name, "on_update" AS update_rule, "on_delete" AS delete_rule, "match" AS match_option, (SELECT "name" FROM "_vspace" x WHERE x."id" = y."child_id") AS referencing, (SELECT "name" FROM "_vspace" x WHERE x."id" = y."parent_id") AS referenced, "is_deferred" AS is_deferred, "child_id" AS child_id, "parent_id" AS parent_id FROM "_fk_constraint" y;]])box.schema.role.grant('public','read','space','_REFERENTIAL_CONSTRAINTS')
In this example child_cols or parent_cols are not taken
from the _fk_constraint space because in standard SQL those
are in a separate table.
Users who select from this view will need ‘read’ privilege on the _fk_constraint space.
_CHECK_CONSTRAINTS view
Example:
tarantool>SELECT constraint_name, check_clause, space_name, language
> FROM _check_constraints;
OK 3 rows selected (0.0 seconds)
+------------------------+-------------------------+------------+----------+
| CONSTRAINT_NAME | CHECK_CLAUSE | SPACE_NAME | LANGUAGE |
+------------------------+-------------------------+------------+----------+
| ck_unnamed_Employees_1 | first_name LIKE 'Влад%' | Employees | SQL |
| ck_unnamed_Critics_1 | first_name LIKE 'Vlad%' | Critics | SQL |
| ck_unnamed_ACTORS_1 | salary > 0 | ACTORS | SQL |
+------------------------+-------------------------+------------+----------+
Definition of the CREATE VIEW statement:
pcall(function()box.schema.role.revoke('public','read','space','_CHECK_CONSTRAINTS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _check_constraints;]])box.execute([[CREATE VIEW _check_constraints AS SELECT CAST(NULL AS STRING) AS constraint_catalog, CAST(NULL AS STRING) AS constraint_schema, "name" AS constraint_name, "code" AS check_clause, (SELECT "name" FROM "_vspace" x WHERE x."id" = y."space_id") AS space_name, "language" AS language, "is_deferred" AS is_deferred, "space_id" AS space_id FROM "_ck_constraint" y;]])box.schema.role.grant('public','read','space','_CHECK_CONSTRAINTS')
Users who select from this view will need ‘read’ privilege on the _ck_constraint space.
_TABLE_CONSTRAINTS view
This has only the constraints (primary-key and unique-key) that can be found by looking at the
_index space.
It is not a list of indexes, that is, it is not equivalent to INFORMATION_SCHEMA.STATISTICS.
The columns of the index are not taken because in standard SQL they would be in a different table.
Example:
tarantool>SELECT constraint_name, constraint_type, table_name, id, iid, index_type
> FROM _table_constraints
> LIMIT 5;
OK 5 rows selected (0.0 seconds)
+-----------------+-----------------+-------------+-----+-----+------------+
| CONSTRAINT_NAME | CONSTRAINT_TYPE | TABLE_NAME | ID | IID | INDEX_TYPE |
+-----------------+-----------------+-------------+-----+-----+------------+
| primary | PRIMARY | _schema | 272 | 0 | tree |
| primary | PRIMARY | _collation | 276 | 0 | tree |
| name | UNIQUE | _collation | 276 | 1 | tree |
| primary | PRIMARY | _vcollation | 277 | 0 | tree |
| name | UNIQUE | _vcollation | 277 | 1 | tree |
+-----------------+-----------------+-------------+-----+-----+------------+
Definition of the function and the CREATE VIEW statement:
box.schema.func.drop('_TABLE_CONSTRAINTS_OPTS_UNIQUE',{if_exists=true})function_TABLE_CONSTRAINTS_OPTS_UNIQUE(opts)returnrequire('msgpack').decode(opts).uniqueendbox.schema.func.create('_TABLE_CONSTRAINTS_OPTS_UNIQUE',{language='LUA',returns='boolean',body=[[function (opts) return require('msgpack').decode(opts).unique end]],param_list={'string'},exports={'LUA','SQL'},is_sandboxed=false,setuid=false,is_deterministic=false})box.schema.role.grant('public','execute','function','_TABLE_CONSTRAINTS_OPTS_UNIQUE')pcall(function()box.schema.role.revoke('public','read','space','_TABLE_CONSTRAINTS',{if_exists=true})end)box.execute([[DROP VIEW IF EXISTS _table_constraints;]])box.execute([[CREATE VIEW _table_constraints AS SELECTCAST(NULL AS STRING) AS constraint_catalog,CAST(NULL AS STRING) AS constraint_schema,"name" AS constraint_name,(SELECT "name" FROM "_vspace" x WHERE x."id" = y."id") AS table_name,CASE WHEN "iid" = 0 THEN 'PRIMARY' ELSE 'UNIQUE' END AS constraint_type,CAST(NULL AS STRING) AS initially_deferrable,CAST(NULL AS STRING) AS deferred,CAST(NULL AS STRING) AS enforced,"id" AS id,"iid" AS iid,"type" AS index_typeFROM "_vindex" yWHERE _table_constraints_opts_unique("opts") = TRUE;]])box.schema.role.grant('public','read','space','_TABLE_CONSTRAINTS')
SQL features
This section compares Tarantool’s features with SQL:2016’s “Feature taxonomy and definition
for mandatory features”.
For each feature in that list, there will be a simple example SQL
statement.
If Tarantool appears to handle the example, it will be marked “Okay”,
else it will be marked “Fail”.
Since this is rough and arbitrary, the hope is that tests which are unfairly
marked “Okay” will probably be balanced by tests which are unfairly marked “Fail”.
Fail. Tarantool’s floating point data type is
DOUBLE.
Note: Floating point SQL types are not planned to
be compatible between 2.1 and 2.2 releases. The reason
is that in 2.1 we set ‘number’ format for columns of
these types, but will restrict it to ‘float32’ and
‘float64’ in 2.2. The format change requires data
migration and cannot be done automatically, because in
2.1 we have no information to distinguish ‘number’
columns (created from Lua) from FLOAT/DOUBLE/REAL ones
(created from SQL).
E011-03
DECIMAL and NUMERIC data types
CREATETABLEtd(s1NUMERICPRIMARYKEY);
Fail, NUMERIC data types are not supported,
although the DECIMAL data type is supported.
Implicit casting among the fixed-length and
variable-length character string types
SELECT*FROMtmWHEREchar_column>varchar_column;
Fail, there is no fixed-length character string type.
E021-11
POSITION function
SELECTposition(xINy)FROMz;
Fail. Tarantool’s POSITION function
requires ‘,’ rather than ‘IN’.
E021-12
Character comparison
SELECT*FROMtWHEREs1>'a';
Okay. We should note here that comparisons use a binary
collation by default, but it is easy to use a
COLLATE clause.
E031, Identifiers
Feature ID
Feature
Example
Tests
E031
Identifiers
CREATETABLErank(ceilINTPRIMARYKEY);
Fail. Tarantool’s list of
reserved words
differs from the standard’s list of reserved words.
E031-01
Delimited identifiers
CREATETABLE"t47"(s1INTPRIMARYKEY);
Okay.
Also, enclosing identifiers inside double quotes
means they won’t be converted to upper case or lower
case, this is the behavior that some other DBMSs lack.
Fail. Tarantool doesn’t have schemas or databases.
F311-02
CREATE TABLE for persistent base tables
Fail. Tarantool doesn’t have CREATE TABLE inside CREATE SCHEMA.
F311-03
CREATE VIEW
Fail. Tarantool doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-04
CREATE VIEW: WITH CHECK OPTION
Fail. Tarantool doesn’t have CREATE VIEW inside CREATE SCHEMA.
F311-05
GRANT statement
Fail. Tarantool doesn’t have GRANT inside CREATE SCHEMA.
F*, Other
Feature ID
Feature
Example
Tests
F471
Scalar subquery values
SELECTs1FROMtWHEREs1=(SELECTcount(*)FROMt);
Okay.
F481
Expanded NULL predicate
SELECT*FROMtWHERErow(s1,s1)ISNOTNULL;
Fail. Syntax error.
F812
Basic flagging
Fail. Tarantool doesn’t support any flagging.
S011, Distinct types
Feature ID
Feature
Example
Tests
S011
Distinct types
CREATETYPExASFLOAT;
Fail. Tarantool doesn’t support distinct types.
T321, Basic SQL-invoked routines
Feature ID
Feature
Example
Tests
T321-01
User-defined functions with no overloading
CREATEFUNCTIONf()RETURNSINTRETURN5;
Fail. User-defined functions for SQL are created in
Lua with a different syntax.
T321-02
User-defined procedures with no overloading
CREATEPROCEDUREp()BEGINEND;
Fail. User-defined functions for SQL are created in
Lua with a different syntax.
T321-03
Function invocation
SELECTf(1)FROMt;
Okay. Tarantool can invoke Lua user-defined functions.
T321-04
CALL statement
CALLp();
Fail. Tarantool doesn’t support CALL statements.
T321-05
RETURN statement
CREATEFUNCTIONf()RETURNSINTRETURN5;
Fail. Tarantool doesn’t support RETURN statements.
T*, Other
Feature ID
Feature
Example
Tests
T631
IN predicate with one list element
SELECT*FROMtWHERE1IN(1);
Okay.
Total number of items marked “Fail”: 67
Total number of items marked “Okay”: 79
Built-in modules reference
This reference covers Tarantool’s built-in Lua modules.
Note
Some functions in these modules are analogs to functions from
standard Lua libraries. For better results,
we recommend using functions from Tarantool’s built-in modules.
As well as executing Lua chunks or defining your own functions, you can exploit
Tarantool’s storage functionality with the box module and its submodules.
Every submodule contains one or more Lua functions. A few submodules contain
members as well as functions. The functions allow data definition (create
alter drop), data manipulation (insert delete update upsert select replace), and
introspection (inspecting contents of spaces, accessing server configuration).
To catch errors that functions in box submodules may throw, use pcall.
The contents of the box module can be inspected at runtime
with box, with no arguments. The box module contains:
Informs the server that activities related to the removal of outdated
backups must be suspended.
To guarantee an opportunity
to copy these files, Tarantool will not delete them. But there will be no
read-only mode and checkpoints will continue by schedule as usual.
Parameters:
n (number) – optional argument starting with Tarantool 1.10.1 that
indicates the checkpoint
to use relative to the latest checkpoint. For example n=0 means
“backup will be based on the latest checkpoint”, n=1 means “backup
will be based on the first checkpoint before the latest checkpoint (counting
backwards)”, and so on. The default value for n is zero.
Return: a table with the names of snapshot and vinyl files that should
be copied
To set particular parameters, use the following syntax: box.cfg{key=value[,key=value...]}
(further referred to as box.cfg{...} for short). For example:
tarantool> box.cfg{listen=3301}
Parameters that are not specified in the box.cfg{...} call explicitly will
be set to the default values.
If you say box.cfg{} with no parameters, Tarantool applies the following
default settings to all the parameters:
The first call to box.cfg{...} (with or without parameters) initiates
Tarantool’s database module box.
box.cfg{...} is also the command that reloads
persistent data files into RAM upon restart
once we have data.
Submodule box.ctl
The wait_ro (wait until read-only) and wait_rw (wait until read-write) functions
are useful during server initialization.
To see whether a function is already in read-only or read-write mode, check box.info.ro.
A particular use is for box.once().
For example, when a replica is initializing, it may call
a box.once() function while the server is still in
read-only mode, and fail to make changes that are necessary
only once before the replica is fully initialized.
This could cause conflicts between a master and a replica
if the master is in read-write mode and the replica is in
read-only mode.
Waiting until “read only mode = false” solves this problem.
Create a “schema_init trigger”.
The trigger-function will be executed
when box.cfg{} happens for the first time.
That is, the schema_init trigger is called before the server’s
configuration and recovery begins, and therefore box.ctl.on_schema_init
must be called before box.cfg is called.
Parameters:
trigger-function (function) – function which will become the
trigger function
old-trigger-function (function) – existing trigger function which
will be replaced by
trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function), then the old
trigger is deleted.
A common use is: make a schema_init trigger function which creates
a before_replace trigger function on a system space. Thus, since
system spaces are created when the server starts, the before_replace
triggers will be activated for each tuple in each system space.
For example, such a trigger could change the storage engine of a
given space, or make a given space replica-local
while a replica is being bootstrapped. Making such a change after box.cfg
is not reliable because other connections might use the database before
the change is made.
Details about trigger characteristics are in the triggers section.
Example:
Suppose that, before the server is fully up and ready
for connections, you want to make sure that the engine of
space space_name is vinyl. So you want to make a trigger
that will be activated when a tuple is inserted in the
_space system space. In this case you could end up with
a master that has space-name with engine='memtx' and a
replica that has space_name with engine='vinyl', with
the same contents.
Create a “shutdown trigger”.
The trigger-function will be executed
whenever os.exit() happens, or when the server is
shut down after receiving a SIGTERM or SIGINT or SIGHUP signal
(but not after SIGSEGV or SIGABORT or any signal that causes
immediate program termination).
Parameters:
trigger-function (function) – function which will become the
trigger function
old-trigger-function (function) – existing trigger function which
will be replaced by
trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function), then the old
trigger is deleted.
Create a trigger executed on different stages of a node recovery or initial configuration.
Note that you need to set the box.ctl.on_recovery_state trigger before the initial box.cfg call.
Parameters:
trigger-function (function) – a trigger function
Return:
nil or a function pointer
A registered trigger function is run on each of the supported recovery
state and receives the state name as a parameter:
snapshot_recovered: the node has recovered the snapshot files.
wal_recovered: the node has recovered the WAL files.
indexes_built: the node has built secondary indexes for memtx spaces.
This stage might come before any actual data is recovered. This means that the
indexes are available right after the first tuple is recovered.
synced: the node has synced with enough remote peers.
This means that the node changes the state from orphan to running.
All these states are passed during the initial box.cfg call when recovering
from the snapshot and WAL files.
Note that the synced state might be reached after the initial box.cfg call finishes.
For example, if replication_sync_timeout
is set to 0, the node finishes box.cfg without reaching synced and stays orphan.
Once the node is synced with enough remote peers, the synced state is reached.
Note
When bootstrapping a fresh cluster with no data, all the instances in this cluster
execute triggers on the same stages for consistency.
For example, snapshot_recovered and wal_recovered
run when the node finishes a cluster’s bootstrap or finishes joining to an existing cluster.
Example:
The example below shows how to log a specified message when each state is reached.
locallog=require('log')locallog_recovery_state=function(state)log.info(state..' state reached')endbox.ctl.on_recovery_state(log_recovery_state)
Create a trigger executed every time
the current state of a replica set node in regard to leader election changes.
The current state is available in the box.info.election table.
The trigger doesn’t accept any parameters.
You can see the changes in box.info.election and
box.info.synchro.
Set a timeout for the on_shutdown trigger.
If the timeout has expired, the server stops immediately
regardless of whether any on_shutdown triggers are left unexecuted.
Parameters:
timeout (double) – time to wait for the trigger to be completed. The default value is 3 seconds.
For synchronous transactions it is
possible that a new leader will be chosen but the transactions
of the old leader have not been completed. Therefore to
finalize the transaction, the function box.ctl.promote()
should be called, as mentioned in the notes for
leader election.
The old name for this function is box.ctl.clear_synchro_queue().
On synchronous transaction queue owner, the function works in the following way:
If box.cfg.election_mode is off,
the function writes a DEMOTE request to WAL.
The DEMOTE request clears the ownership of the synchronous transaction queue,
while the PROMOTE request assigns it to a new instance.
If box.cfg.election_mode is enabled in any mode, then the function
makes the instance start a new term and give up the leader role.
On instances that are not queue owners, the function does nothing and returns immediately.
Make the instance a bootstrap leader of a replica set.
To be able to make the instance a bootstrap leader manually, the replication.bootstrap_strategy configuration option should be set to supervised.
In this case, the instances do not choose a bootstrap leader automatically but wait for it to be appointed manually.
Configuration fails if no bootstrap leader is appointed during a replication.connect_timeout.
Note
When a new instance joins a replica set configured with the supervised bootstrap strategy,
this instance doesn’t choose the bootstrap leader automatically but joins to the instance on which
box.ctl.make_bootstrap_leader() was executed last time.
Submodule box.error
The box.error submodule can be used to work with errors in your application.
For example, you can get the information about the last error raised by Tarantool or
raise custom errors manually.
The difference between raising an error using box.error
and a Lua’s built-in error function
is that when the error reaches the client, its error code is preserved.
In contrast, a Lua error would always be presented to the client as
ER_PROC_LUA.
Note
To learn how to handle errors in your application, see the Handling errors section.
Creating an error
You can create an error object using the box.error.new() function.
The created object can be passed to box.error() to raise the error.
You can also raise the error using error_object:raise().
The example below shows how to create and raise the error with the specified code and reason.
localcustom_error=box.error.new({code=500,reason='Internal server error'})box.error(custom_error)--[[---- error: Internal server error...--]]
box.error.new() provides different overloads for creating an error object with different parameters.
These overloads are similar to the box.error() overloads described in the next section.
Raising an error
To raise an error, call the box.error() function.
This function can accept the specified error parameters or an error object created using box.error.new().
In both cases, you can use box.error() to raise the following error types:
A custom error with the specified reason, code, and type.
A predefined Tarantool error.
Custom error
The following box.error() overloads are available for raising a custom error:
In the example below, box.error() accepts a Lua table with the specified error code and reason:
box.error{code=500,reason='Custom server error'}--[[---- error: Custom server error...--]]
The next example shows how to specify a custom error type:
box.error{code=500,reason='Internal server error',type='CustomInternalError'}--[[---- error: Internal server error...--]]
When a custom type is specified, it is returned in the error_object.type attribute.
When it is not specified, error_object.type returns one of the built-in errors, such as
ClientError or OutOfMemory.
box.error(type, reason[, …])
This example shows how to raise an error with the type and reason specified in the box.error() arguments:
box.error('CustomConnectionError','cannot connect to the given port')--[[---- error: cannot connect to the given port...--]]
You can also use a format string to compose an error reason:
box.error('CustomConnectionError','%s cannot connect to the port %u','client',8080)--[[---- error: client cannot connect to the port 8080...--]]
Tarantool error
The box.error(code[, …]) overload raises a predefined
Tarantool error specified by its identifier.
The error code defines the error message format and the number of required arguments.
In the example below, no arguments are passed for the box.error.READONLY error code:
box.error(box.error.READONLY)--[[---- error: Can't modify data on a read-only instance...--]]
For the box.error.NO_SUCH_USER error code, you need to pass one argument:
box.error(box.error.NO_SUCH_USER,'John')--[[---- error: User 'John' is not found...--]]
box.error.CREATE_SPACE requires two arguments:
box.error(box.error.CREATE_SPACE,'my_space','the space already exists')--[[---- error: 'Failed to create space ''my_space'': the space already exists'...--]]
You can set the last error explicitly by calling box.error.set():
-- Create two errors --localerror1=box.error.new({code=500,reason='Custom error 1'})localerror2=box.error.new({code=505,reason='Custom error 2'})-- Raise the first error --box.error(error1)--[[---- error: Custom error 1...--]]-- Get the last error --box.error.last()--[[---- Custom error 1...--]]-- Set the second error as the last error --box.error.set(error2)--[[---...--]]-- Get the last error --box.error.last()--[[---- Custom error 2...--]]
box.error('CustomConnectionError','cannot connect to the given port')--[[---- error: cannot connect to the given port...--]]
Example 2: with arguments
box.error('CustomConnectionError','%s cannot connect to the port %u','client',8080)--[[---- error: client cannot connect to the port 8080...--]]
box.error(code[, ...])
Raise a predefined Tarantool error specified by its identifier.
You can see all Tarantool errors in the errcode.h file.
Parameters:
code (number) – a pre-defined error identifier; Lua constants that correspond to those Tarantool errors are defined as members of box.error, for example, box.error.NO_SUCH_USER==45
... – description arguments
Example 1: no arguments
box.error(box.error.READONLY)--[[---- error: Can't modify data on a read-only instance...--]]
Example 2: one argument
box.error(box.error.NO_SUCH_USER,'John')--[[---- error: User 'John' is not found...--]]
Example 3: two arguments
box.error(box.error.CREATE_SPACE,'my_space','the space already exists')--[[---- error: 'Failed to create space ''my_space'': the space already exists'...--]]
localcustom_error=box.error.new({code=500,reason='Internal server error'})box.error(custom_error)--[[---- error: Internal server error...--]]
Example 2: custom type
localcustom_error=box.error.new({code=500,reason='Internal server error',type='CustomInternalError'})box.error(custom_error)--[[---- error: Internal server error...--]]
box.error.new(type, reason[, ...])
Create an error object with the specified type and description.
localcustom_error=box.error.new('CustomInternalError','Internal server error')box.error(custom_error)--[[---- error: Internal server error...--]]
box.error.new(code[, ...])
Create a predefined Tarantool error specified by its identifier.
You can see all Tarantool errors in the errcode.h file.
Parameters:
code (number) – a pre-defined error identifier; Lua constants that correspond to those Tarantool errors are defined as members of box.error, for example, box.error.NO_SUCH_USER==45
... – description arguments
Example 1: one argument
localcustom_error=box.error.new(box.error.NO_SUCH_USER,'John')box.error(custom_error)--[[---- error: User 'John' is not found...--]]
Example 2: two arguments
localcustom_error=box.error.new(box.error.CREATE_SPACE,'my_space','the space already exists')box.error(custom_error)--[[---- error: 'Failed to create space ''my_space'': the space already exists'...--]]
-- Create two errors --localerror1=box.error.new({code=500,reason='Custom error 1'})localerror2=box.error.new({code=505,reason='Custom error 2'})-- Raise the first error --box.error(error1)--[[---- error: Custom error 1...--]]-- Get the last error --box.error.last()--[[---- Custom error 1...--]]-- Set the second error as the last error --box.error.set(error2)--[[---...--]]-- Get the last error --box.error.last()--[[---- Custom error 2...--]]
Returns the box.info.ro_reason value at the moment of throwing the box.error.READONLY error.
The following values may be returned:
election if the instance has box.cfg.election_mode set to a value other than off and this instance is not a leader.
In this case, error_object may include the following attributes: state, leader_id, leader_uuid, and term.
synchro if the synchronous queue has an owner that is not the given instance.
This error usually happens if synchronous replication is used and another instance is called box.ctl.promote().
In this case, error_object may include the queue_owner_id, queue_owner_uuid, and term attributes.
For the box.error.READONLY error, returns the current state of a replica set node in regards to leader election (see box.info.election.state).
This attribute presents if the error reason is election.
For the box.error.READONLY error, returns a numeric identifier (box.info.id) of the replica set leader.
This attribute may present if the error reason is election.
For the box.error.READONLY error, returns a globally unique identifier (box.info.uuid) of the replica set leader.
This attribute may present if the error reason is election.
For the box.error.READONLY error, returns a numeric identifier (box.info.id) of the synchronous queue owner.
This attribute may present if the error reason is synchro.
For the box.error.READONLY error, returns a globally unique identifier (box.info.uuid) of the synchronous queue owner.
This attribute may present if the error reason is synchro.
For the box.error.READONLY error, returns the current election term (see box.info.election.term).
This attribute may present if the error reason is election or synchro.
Submodule box.index
The box.index submodule provides read-only access for index definitions and
index keys. Indexes are contained in box.space.space-name.index array
within each space object. They provide an API for ordered iteration over tuples.
This API is a direct binding to corresponding methods of index objects of type
box.index in the storage engine.
Below is a list of all box.index functions and members.
This example will work with the sandbox configuration described in the preface.
That is, there is a space named tester with a numeric primary key. The example
function will:
select a tuple whose key value is 1000;
raise an error if the tuple already exists and already has 3 fields;
Insert or replace the tuple with:
field[1] = 1000
field[2] = a uuid
field[3] = number of seconds since 1970-01-01;
Get field[3] from what was replaced;
Format the value from field[3] as yyyy-mm-dd hh:mm:ss.ffff;
Here is an example that shows how to build one’s own iterator. The
paged_iter function is an “iterator function”, which will only be understood
by programmers who have read the Lua manual section Iterators and Closures. It does paginated retrievals, that is, it
returns 10 tuples at a time from a table named “t”, whose primary key was
defined with create_index('primary',{parts={1,'string'}}).
Programmers who use paged_iter do not need to know why it works, they only
need to know that, if they call it within a loop, they will get 10 tuples at a
time until there are no more tuples.
In this example the tuples are merely
printed, a page at a time. But it should be simple to change the functionality,
for example by yielding after each retrieval, or by breaking when the tuples
fail to match some additional criteria.
forpageinpaged_iter("X",10)doprint("New Page. Number Of Tuples = "..#page)fori=1,#page,1doprint(page[i])endend
Example showing submodule box.index
with index type = RTREE for spatial searches
This submodule may be used for spatial searches if
the index type is RTREE. There are operations for searching rectangles
(geometric objects with 4 corners and 4 sides) and boxes (geometric objects
with more than 4 corners and more than 4 sides, sometimes called
hyperrectangles). This manual uses the term rectangle-or-box for the whole
class of objects that includes both rectangles and boxes. Only rectangles will
be illustrated.
Rectangles are described according to their X-axis (horizontal axis) and Y-axis
(vertical axis) coordinates in a grid of arbitrary size. Here is a picture of
four rectangles on a grid with 11 horizontal points and 11 vertical points:
The rectangles are defined according to this scheme: {X-axis coordinate of top
left, Y-axis coordinate of top left, X-axis coordinate of bottom right, Y-axis
coordinate of bottom right} – or more succinctly: {x1,y1,x2,y2}. So in the
picture … Rectangle#1 starts at position 1 on the X axis and position 2 on
the Y axis, and ends at position 3 on the X axis and position 4 on the Y axis,
so its coordinates are {1,2,3,4}. Rectangle#2’s coordinates are {3,5,9,10}.
Rectangle#3’s coordinates are {4,7,5,9}. And finally Rectangle#4’s coordinates
are {10,11,10,11}. Rectangle#4 is actually a “point” since it has zero width
and zero height, so it could have been described with only two digits: {10,11}.
Some relationships between the rectangles are: “Rectangle#1’s nearest neighbor
is Rectangle#2”, and “Rectangle#3 is entirely inside Rectangle#2”.
Field#1 doesn’t matter, we just make it because we need a primary-key index.
(RTREE indexes cannot be unique and therefore cannot be primary-key indexes.)
The second field must be an “array”, which means its values must represent
{x,y} points or {x1,y1,x2,y2} rectangles. Now let us populate the table by
inserting two tuples, containing the coordinates of Rectangle#2 and Rectangle#4.
Request#1 returns 1 tuple because the point {10,11} is the same as the rectangle
{10,11,10,11} (“Rectangle#4” in the picture). Request#2 returns 1 tuple because
the rectangle {4,7,5,9}, which was “Rectangle#3” in the picture, is entirely
within{3,5,9,10} which was Rectangle#2. Request#3 returns 2 tuples, because the
NEIGHBOR iterator always returns all tuples, and the first returned tuple will
be {3,5,9,10} (“Rectangle#2” in the picture) because it is the closest neighbor
of {1,2,3,4} (“Rectangle#1” in the picture).
Now let us create a space and index for cuboids, which are rectangle-or-boxes
that have 6 corners and 6 sides.
The additional option here is dimension=3. The default dimension is 2, which
is why it didn’t need to be specified for the examples of rectangle. The maximum
dimension is 20. Now for insertions and selections there will usually be 6
coordinates. For example:
Now let us create a space and index for Manhattan-style spatial objects, which
are rectangle-or-boxes that have a different way to calculate neighbors.
The additional option here is distance='manhattan'. The default distance
calculator is ‘euclid’, which is the straightforward as-the-crow-flies method.
The optional distance calculator is ‘manhattan’, which can be a more appropriate
method if one is following the lines of a grid rather than traveling in a
straight line.
It is mandatory to create an index for a space before trying to insert
tuples into it or select tuples from it. The first created index
will be used as the primary-key index, so it must be unique.
Building or rebuilding a large index will cause occasional
yields
so that other requests will not be blocked.
If the other requests cause an illegal situation
such as a duplicate key in a unique index,
building or rebuilding such index will fail.
Example:
-- Create a space --bands=box.schema.space.create('bands')-- Specify field names and types --box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})-- Create a primary index --box.space.bands:create_index('primary',{parts={'id'}})-- Create a unique secondary index --box.space.bands:create_index('band',{parts={'band_name'}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{'year'}},unique=false})-- Create a multi-part index --box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})
Index options that include the index name, type, identifiers of key fields, and so on.
These options are passed to the space_object.create_index() method.
-- Create a primary index --box.space.bands:create_index('primary',{parts={'id'}})-- Create a unique secondary index --box.space.bands:create_index('band',{parts={'band_name'}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{'year'}},unique=false})-- Create a multi-part index --box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})
Note
Alternative way to declare index parts
Before version 2.7.1,
if an index consisted of a single part and had some options like
is_nullable or collation and its definition was written as
(with the only brackets) then options were ignored by Tarantool.
Since version 2.7.1 it is allowed to omit
extra braces in an index definition and use both ways:
-- with extra bracesmy_space:create_index('one_part_idx',{parts={{1,'unsigned',is_nullable=true}}})-- without extra bracesmy_space:create_index('one_part_idx',{parts={1,'unsigned',is_nullable=true}})
Specify the collation used to compare field values.
If the field collation is specified in space_object:format(),
key_part.collation inherits this value.
-- Create a space --box.schema.space.create('tester')-- Use the 'unicode' collation --box.space.tester:create_index('unicode',{parts={{field=1,type='string',collation='unicode'}}})-- Use the 'unicode_ci' collation --box.space.tester:create_index('unicode_ci',{parts={{field=1,type='string',collation='unicode_ci'}}})-- Insert test data --box.space.tester:insert{'ЕЛЕ'}box.space.tester:insert{'елейный'}box.space.tester:insert{'ёлка'}-- Returns nil --select_unicode=box.space.tester.index.unicode:select({'ЁлКа'})-- Returns 'ёлка' --select_unicode_ci=box.space.tester.index.unicode_ci:select({'ЁлКа'})
Specify whether nil (or its equivalent such as msgpack.NULL) can be used as a field value.
If the is_nullable option is specified in space_object:format(),
key_part.is_nullable inherits this value.
You can set this option to true if:
the index type is TREE
the index is not the primary index
It is also legal to insert nothing at all when using trailing nullable fields.
Within indexes, such null values are always treated as equal to other null
values and are always treated as less than non-null values.
Nulls may appear multiple times even in a unique index.
It is legal to create multiple indexes for the same field with different
is_nullable values or to call space_object:format()
with a different is_nullable value from what is used for an index.
When there is a contradiction, the rule is: null is illegal unless
is_nullable=true for every index and for the space format.
Specify whether an index can skip tuples with null at this key part.
You can set this option to true if:
the index type is TREE
the index is not the primary index
If exclude_null is set to true, is_nullable is set to true automatically.
Note that this option can be changed dynamically.
In this case, the index is rebuilt.
Such indexes do not store filtered tuples at all, so indexing can be done faster.
create_index() can use field names or field numbers to define key parts.
Example 1 (field names):
To create a key part by a field name, you need to specify space_object:format() first.
-- Create a primary index --box.space.bands:create_index('primary',{parts={'id'}})-- Create a unique secondary index --box.space.bands:create_index('band',{parts={'band_name'}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{'year'}},unique=false})-- Create a multi-part index --box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})
Example 2 (field numbers):
-- Create a primary index --box.space.bands:create_index('primary',{parts={1}})-- Create a unique secondary index --box.space.bands:create_index('band',{parts={2}})-- Create a non-unique secondary index --box.space.bands:create_index('year',{parts={{3}},unique=false})-- Create a multi-part index --box.space.bands:create_index('year_band',{parts={3,2}})
Creating an index using the path option for map fields (JSON-path indexes)
To create an index for a field that is a map (a path string and a scalar value),
specify the path string during index creation, like this:
parts={field-number,'data-type',path='path-name'}
The index type must be TREE or HASH and the contents of the field
must always be maps with the same path.
Creating a multikey index using the path option with [*]
The string in a path option can contain [*] which is called
an array index placeholder. Indexes defined with this are useful
for JSON documents that all have the same structure.
For example, when creating an index on field#2 for a string document
that will start with {'data':[{'name':'...'},{'name':'...'}],
the parts section in the create_index request could look like:
parts={{field=2,type='str',path='data[*].name'}}
Then tuples containing names can be retrieved quickly with
index_object:select({key-value}).
A single field can have multiple keys, as in this example
which retrieves the same tuple twice because there are two keys ‘A’ and ‘B’
which both match the request:
[*] must be alone or must be at the end of a name in the path.
[*] must not appear twice in the path.
If an index has a path with x[*], then no other index can have a path with
x.component.
[*] must not appear in the path of a primary key.
If an index has unique=true and has a path with [*],
then duplicate keys from different tuples are disallowed, but duplicate keys
for the same tuple are allowed.
The field’s value must have the same structure as in the path definition,
or be nil (nil is not indexed).
In a space with multikey indexes, any tuple cannot contain
more than ~8,000 elements indexed that way.
Creating a functional index
Functional indexes are indexes that call a user-defined function for forming
the index key, rather than depending entirely on the Tarantool default formation.
Functional indexes are useful for condensing or truncating or reversing or
any other way that users want to customize the index.
There are several recommendations for building functional indexes:
The function definition must expect a tuple, which has the contents of
fields at the time a data-change request happens, and must return a tuple,
which has the contents that will be put in the index.
The create_index definition must include the specification of all key parts,
and the custom function must return a table that has the same number of key
parts with the same types.
The function must access key-part values by index, not by field name.
Functional indexes must not be primary-key indexes.
Functional indexes cannot be altered and the function cannot be changed if
it is used for an index, so the only way to change them is to drop the index
and create it again.
Only sandboxed functions
are suitable for functional indexes.
Example:
A function could make a key using only the first letter of a string field.
Create a space. The space needs a primary-key field, which is not
the field that we will use for the functional index:
Create a function. The function expects a tuple. In this example, it will
work on tuple[2] because the key source is field number 2 in what we will
insert. Use string.sub() from the string module to get the first character:
Insert a few tuples. Select using only the first letter, it will work
because that is the key. Or, select using the same function as was used for
insertion:
Functions for functional indexes can return multiple keys. Such functions are
called “multikey” functions.
To create a multikey function, the options of box.schema.func.create() must include is_multikey=true.
The return value must be a table of tuples. If a multikey function returns
N tuples, then N keys will be added to the index.
Example:
tester=box.schema.space.create('withdata')tester:format({{name='name',type='string'},{name='address',type='string'}})name_index=tester:create_index('name',{parts={{field=1,type='string'}}})function_code=[[function(tuple) local address = string.split(tuple[2]) local ret = {} for _, v in pairs(address) do table.insert(ret, {utf8.upper(v)}) end return ret end]]box.schema.func.create('address',{body=function_code,is_deterministic=true,is_sandboxed=true,is_multikey=true})addr_index=tester:create_index('addr',{unique=false,func='address',parts={{field=1,type='string',collation='unicode_ci'}}})tester:insert({"James","SIS Building Lambeth London UK"})tester:insert({"Sherlock","221B Baker St Marylebone London NW1 6XE UK"})addr_index:select('Uk')
Search for a tuple or a set of tuples via the given index,
and allow iterating over one tuple at a time.
To search by the primary index in the specified space, use the space_object:pairs() method.
The key parameter specifies what must match within the index.
Note
key is only used to find the first match. Do not assume
all matched tuples will contain the key.
The iterator parameter specifies the rule for matching and
ordering. Different index types support different iterators. For
example, a TREE index maintains a strict order of keys and can return
all tuples in ascending or descending order, starting from the specified
key. Other index types, however, do not support ordering.
To understand consistency of tuples returned by an iterator, it’s
essential to know the principles of the Tarantool transaction processing
subsystem. An iterator in Tarantool does not own a consistent read view.
Instead, each procedure is granted exclusive access to all tuples and
spaces until there is a “context switch”: which may happen due to
the implicit yield rules, or by an
explicit call to fiber.yield. When the execution
flow returns to the yielded procedure, the data set could have changed
significantly. Iteration, resumed after a yield point, does not preserve
the read view, but continues with the new content of the database. The
tutorial Indexed pattern search shows one way that iterators
and yields can be used together.
For information about iterators’ internal structures, see the
“Lua Functional library”
documentation.
key (scalar/table) – value to be matched against the index key,
which may be multi-part.
iterator – as defined in tables below. The default iterator type is ‘EQ’.
after – a tuple or the position of a tuple (tuple_pos) after which pairs starts the search. You can pass an empty string or box.NULL to this option to start the search from the first tuple.
Return:
The iterator, which can be
used in a for/end loop or with totable().
Possible errors:
no such space
wrong type
selected iteration type is not supported for the index type
key is not supported for the iteration type
iterator position is invalid
Complexity factors: Index size, Index type; Number of tuples
accessed.
A search-key-value can be a number (for example 1234), a string
(for example 'abcd'), or a table of numbers and strings (for example
{1234,'abcd'}). Each part of a key will be compared to each part of
an index key.
The returned tuples will be in order by index key value, or by the hash of
the index key value if index type = ‘hash’. If the index is non-unique, then
duplicates will be secondarily in order by primary key value. The order
will be reversed if the iterator type is ‘LT’ or ‘LE’ or ‘REQ’.
Iterator types for TREE indexes
Iterator type
Arguments
Description
box.index.EQ
or ‘EQ’
search
value
The comparison operator is ‘==’ (equal to).
If an index key is equal to a search value,
it matches.
Tuples are returned in ascending order by
index key. This is the default.
box.index.REQ
or ‘REQ’
search
value
Matching is the same as for
box.index.EQ.
Tuples are returned in descending order by
index key.
box.index.GT
or ‘GT’
search
value
The comparison operator is ‘>’ (greater
than).
If an index key is greater than a search
value, it matches.
Tuples are returned in ascending order by
index key.
box.index.GE
or ‘GE’
search
value
The comparison operator is ‘>=’ (greater
than or equal to).
If an index key is greater than or equal to
a search value, it matches.
Tuples are returned in ascending order by
index key.
box.index.ALL
or ‘ALL’
search
value
Same as box.index.GE.
box.index.LT
or ‘LT’
search
value
The comparison operator is ‘<’ (less than).
If an index key is less than a search
value, it matches.
Tuples are returned in descending order by
index key.
box.index.LE
or ‘LE’
search
value
The comparison operator is ‘<=’ (less than
or equal to).
If an index key is less than or equal to a
search value, it matches.
Tuples are returned in descending order by
index key.
Informally, we can state that searches with TREE indexes are
generally what users will find is intuitive, provided that there
are no nils and no missing parts. Formally, the logic is as follows.
A search key has zero or more parts, for example {}, {1,2,3},{1,nil,3}.
An index key has one or more parts, for example {1}, {1,2,3},{1,2,3}.
A search key may contain nil (but not msgpack.NULL, which is the wrong type).
An index key may not contain nil or msgpack.NULL, although a later version
of Tarantool will have different rules – the behavior of searches with nil is subject to change.
Possible iterators are LT, LE, EQ, REQ, GE, GT.
A search key is said to “match” an index key if the following
statements, which are pseudocode for the comparison operation,
return TRUE.
All index keys match.
Tuples are returned in ascending order by
hash of index key, which will appear to be
random.
box.index.EQ
or ‘EQ’
search
value
The comparison operator is ‘==’ (equal to).
If an index key is equal to a search value,
it matches.
The number of returned tuples will be 0 or 1.
This is the default.
Iterator types for BITSET indexes
Type
Arguments
Description
box.index.ALL
or ‘ALL’
none
All index keys match.
Tuples are returned in their order within
the space.
box.index.EQ
or ‘EQ’
bitset
value
If an index key is equal to a bitset value,
it matches.
Tuples are returned in their order within
the space. This is the default.
box.index.BITS_ALL_SET
bitset
value
If all of the bits which are 1 in the bitset
value are 1 in the index key, it matches.
Tuples are returned in their order within
the space.
box.index.BITS_ANY_SET
bitset
value
If any of the bits which are 1 in the bitset
value are 1 in the index key, it matches.
Tuples are returned in their order within
the space.
box.index.BITS_ALL_NOT_SET
bitset
value
If all of the bits which are 1 in the bitset
value are 0 in the index key, it matches.
Tuples are returned in their order within
the space.
Iterator types for RTREE indexes
Type
Arguments
Description
box.index.ALL or ‘ALL’
none
All keys match. Tuples are returned in their order within the space.
box.index.EQ or ‘EQ’
search value
If all points of the rectangle-or-box defined by the search value are the same as the rectangle-or-box defined by the index key, it matches. Tuples are returned in their order within the space. “Rectangle-or-box” means “rectangle-or-box as explained in section about RTREE”. This is the default.
box.index.GT or ‘GT’
search value
If all points of the rectangle-or-box defined by the search value are within the rectangle-or-box defined by the index key, it matches. Tuples are returned in their order within the space.
box.index.GE or ‘GE’
search value
If all points of the rectangle-or-box defined by the search value are within, or at the side of, the rectangle-or-box defined by the index key, it matches. Tuples are returned in their order within the space.
box.index.LT or ‘LT’
search value
If all points of the rectangle-or-box defined by the index key are within the rectangle-or-box defined by the search key, it matches. Tuples are returned in their order within the space.
box.index.LE or ‘LE’
search value
If all points of the rectangle-or-box defined by the index key are within, or at the side of, the rectangle-or-box defined by the search key, it matches. Tuples are returned in their order within the space.
box.index.OVERLAPS or ‘OVERLAPS’
search value
If some points of the rectangle-or-box defined by the search value are within the rectangle-or-box defined by the index key, it matches. Tuples are returned in their order within the space.
box.index.NEIGHBOR or ‘NEIGHBOR’
search value
If some points of the rectangle-or-box defined by the defined by the key are within, or at the side of, defined by the index key, it matches. Tuples are returned in order: nearest neighbor first.
Examples:
Below are few examples of using pairs with different parameters.
To try out these examples, you need to bootstrap a Tarantool instance
as described in Using data operations.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960} bands:insert{5, 'Pink Floyd', 1965} bands:insert{6, 'The Rolling Stones', 1962} bands:insert{7, 'The Doors', 1965} bands:insert{8, 'Nirvana', 1987} bands:insert{9, 'Led Zeppelin', 1968} bands:insert{10, 'Queen', 1970}---...-- Select all tuples by the primary index --tarantool> for_,tupleinbands.index.primary:pairs()do print(tuple) end[1, 'Roxette', 1986][2, 'Scorpions', 1965][3, 'Ace of Base', 1987][4, 'The Beatles', 1960][5, 'Pink Floyd', 1965][6, 'The Rolling Stones', 1962][7, 'The Doors', 1965][8, 'Nirvana', 1987][9, 'Led Zeppelin', 1968][10, 'Queen', 1970]---...-- Select all tuples whose secondary key values start with the specified string --tarantool> for_,tupleinbands.index.band:pairs("The",{iterator="GE"})do if (string.sub(tuple[2], 1, 3) ~= "The") then break end print(tuple) end[4, 'The Beatles', 1960][7, 'The Doors', 1965][6, 'The Rolling Stones', 1962]---...-- Select all tuples whose secondary key values are between 1965 and 1970 --tarantool> for_,tupleinbands.index.year:pairs(1965,{iterator="GE"})do if (tuple[3] > 1970) then break end print(tuple) end[2, 'Scorpions', 1965][5, 'Pink Floyd', 1965][7, 'The Doors', 1965][9, 'Led Zeppelin', 1968][10, 'Queen', 1970]---...-- Select all tuples after the specified tuple --tarantool> for_,tupleinbands.index.primary:pairs({},{after={7,'The Doors',1965}})do print(tuple) end[8, 'Nirvana', 1987][9, 'Led Zeppelin', 1968][10, 'Queen', 1970]---...
Search for a tuple or a set of tuples by the current index.
To search by the primary index in the specified space, use the space_object:select() method.
key (scalar/table) – a value to be matched against the index key, which may be multi-part.
options (table/nil) –
none, any, or all of the following parameters:
iterator – the iterator type. The default iterator type is ‘EQ’.
limit – the maximum number of tuples.
offset – the number of tuples to skip (use this parameter carefully when scanning large data sets).
options.after – a tuple or the position of a tuple (tuple_pos) after which select starts the search. You can pass an empty string or box.NULL to this option to start the search from the first tuple.
options.fetch_pos – if true, the select method returns the position of the last selected tuple as the second value.
Note
The after and fetch_pos options are supported for the TREEindex only.
Return:
This function might return one or two values:
The tuples whose fields are equal to the fields of the passed key.
If the number of passed fields is less than the
number of fields in the current key, then only the passed
fields are compared, so select{1,2} matches a tuple
whose primary key is {1,2,3}.
(Optionally) If options.fetch_pos is set to true, returns a base64-encoded string representing the position of the last selected tuple as the second value.
If no tuples are fetched, returns nil.
Rtype:
array of tuples
(Optionally) string
Warning
Use the offset option carefully when scanning
large data sets as it linearly increases the number
of scanned tuples and leads to a full space scan.
Instead, you can use the after and fetch_pos options.
Examples:
Below are few examples of using select with different parameters.
To try out these examples, you need to bootstrap a Tarantool database
as described in Using data operations.
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}box.space.bands:insert{5,'Pink Floyd',1965}box.space.bands:insert{6,'The Rolling Stones',1962}box.space.bands:insert{7,'The Doors',1965}box.space.bands:insert{8,'Nirvana',1987}box.space.bands:insert{9,'Led Zeppelin',1968}box.space.bands:insert{10,'Queen',1970}-- Select a tuple by the specified primary key value --select_primary=bands.index.primary:select{1}--[[---- - [1, 'Roxette', 1986]...--]]-- Select a tuple by the specified secondary key value --select_secondary=bands.index.band:select{'The Doors'}--[[---- - [7, 'The Doors', 1965]...--]]-- Select a tuple by the specified multi-part secondary key value --select_multipart=bands.index.year_band:select{1960,'The Beatles'}--[[---- - [4, 'The Beatles', 1960]...--]]-- Select tuples by the specified partial key value --select_multipart_partial=bands.index.year_band:select{1965}--[[---- - [5, 'Pink Floyd', 1965] - [2, 'Scorpions', 1965] - [7, 'The Doors', 1965]...--]]-- Select maximum 3 tuples by the specified secondary index --select_limit=bands.index.band:select({},{limit=3})--[[---- - [3, 'Ace of Base', 1987] - [9, 'Led Zeppelin', 1968] - [8, 'Nirvana', 1987]...--]]-- Select maximum 3 tuples with the key value greater than 1965 --select_greater=bands.index.year:select({1965},{iterator='GT',limit=3})--[[---- - [9, 'Led Zeppelin', 1968] - [10, 'Queen', 1970] - [1, 'Roxette', 1986]...--]]-- Select maximum 3 tuples after the specified tuple --select_after_tuple=bands.index.primary:select({},{after={4,'The Beatles',1960},limit=3})--[[---- - [5, 'Pink Floyd', 1965] - [6, 'The Rolling Stones', 1962] - [7, 'The Doors', 1965]...--]]-- Select first 3 tuples and fetch a last tuple's position --result,position=bands.index.primary:select({},{limit=3,fetch_pos=true})-- Then, pass this position as the 'after' parameter --select_after_position=bands.index.primary:select({},{limit=3,after=position})--[[---- - [4, 'The Beatles', 1960] - [5, 'Pink Floyd', 1965] - [6, 'The Rolling Stones', 1962]...--]]
Note
box.space.space-name.index.index-name:select(...)[1]. can be
replaced by box.space.space-name.index.index-name:get(...).
That is, get can be used as a convenient shorthand to get the first
tuple in the tuple set that would be returned by select. However,
if there is more than one tuple in the tuple set, then get throws
an error.
key (scalar/table) – values to be matched against the index key
Return:
the tuple for the first key in the index. If the optional
key value is supplied, returns the first key that is greater than or equal to key.
Starting with Tarantool 2.0.4,
index_object:min(key) returns nothing
if key doesn’t match any value in the index.
Rtype:
tuple
Possible errors:
Index is not of type ‘TREE’.
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode.
Complexity factors: Index size, Index type.
Example:
Below are few examples of using min.
To try out these examples, you need to bootstrap a Tarantool database
as described in Using data operations.
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}box.space.bands:insert{5,'Pink Floyd',1965}box.space.bands:insert{6,'The Rolling Stones',1962}box.space.bands:insert{7,'The Doors',1965}box.space.bands:insert{8,'Nirvana',1987}box.space.bands:insert{9,'Led Zeppelin',1968}box.space.bands:insert{10,'Queen',1970}-- Find the minimum value in the specified indexmin=box.space.bands.index.year:min()--[[---- [4, 'The Beatles', 1960]...--]]-- Find the minimum value that matches the partial key valuemin_partial=box.space.bands.index.year_band:min(1965)--[[---- [5, 'Pink Floyd', 1965]...--]]
key (scalar/table) – values to be matched against the index key
Return:
the tuple for the last key in the index. If the optional key value
is supplied, returns the last key that is less than or equal to key.
Starting with Tarantool 2.0.4, index_object:max(key)
returns nothing if key doesn’t match any value in the index.
Rtype:
tuple
Possible errors:
Index is not of type ‘TREE’.
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode.
Complexity factors: index size, index type.
Example:
Below are few examples of using max.
To try out these examples, you need to bootstrap a Tarantool database
as described in Using data operations.
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}box.space.bands:insert{5,'Pink Floyd',1965}box.space.bands:insert{6,'The Rolling Stones',1962}box.space.bands:insert{7,'The Doors',1965}box.space.bands:insert{8,'Nirvana',1987}box.space.bands:insert{9,'Led Zeppelin',1968}box.space.bands:insert{10,'Queen',1970}-- Find the maximum value in the specified indexmax=box.space.bands.index.year:max()--[[---- [8, 'Nirvana', 1987]...--]]-- Find the maximum value that matches the partial key valuemax_partial=box.space.bands.index.year_band:max(1965)--[[---- [7, 'The Doors', 1965]...--]]
Find a random value in the specified index. This method is useful when
it’s important to get insight into data distribution in an index without
having to iterate over the entire data set.
key (scalar/table) – values to be matched against the index key
iterator – comparison method
Return:
the number of matching tuples.
Rtype:
number
Example:
Below are few examples of using count.
To try out these examples, you need to bootstrap a Tarantool database
as described in Using data operations.
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}box.space.bands:insert{4,'The Beatles',1960}box.space.bands:insert{5,'Pink Floyd',1965}box.space.bands:insert{6,'The Rolling Stones',1962}box.space.bands:insert{7,'The Doors',1965}box.space.bands:insert{8,'Nirvana',1987}box.space.bands:insert{9,'Led Zeppelin',1968}box.space.bands:insert{10,'Queen',1970}-- Count the number of tuples that match the full key valuecount=box.space.bands.index.year:count(1965)--[[---- 3...--]]-- Count the number of tuples that match the partial key valuecount_partial=box.space.bands.index.year_band:count(1965)--[[---- 3...--]]
key (scalar/table) – values to be matched against the index key
operator (string) – operation type represented in string
field_identifier (field-or-string) – what field the operation will apply to. The
field number can be negative, meaning the
position from the end of tuple.
(#tuple + negative field number + 1)
value (lua_value) – what value will be applied
Return:
the updated tuple
nil if the key is not found
Rtype:
tuple or nil
Since Tarantool 2.3 a tuple can also be updated via JSON paths.
Alter an index.
It is legal in some circumstances to change one or more of the
index characteristics, for example its type, its sequence options,
its parts, and whether it is unique. Usually this causes rebuilding
of the space, except for the simple case where a part’s is_nullable
flag is changed from false to true.
Remove unused index space. For the memtx storage engine this
method does nothing; index_object:compact() is only for the
vinyl storage engine. For example, with vinyl, if a tuple is
deleted, the space is not immediately reclaimed. There is a
scheduler for reclaiming space automatically based on factors
such as lsm shape and amplification as discussed in the section
Storing data with vinyl,
so calling index_object:compact() manually is not always necessary.
Return:
nil (Tarantool returns without waiting for compaction to complete)
tuple (scalar/table) – a tuple whose position should be found
Return:
a tuple’s position in a space
Rtype:
base64-encoded string
Example:
To try out this example, you need to bootstrap a Tarantool instance
as described in Using data operations.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960} bands:insert{5, 'Pink Floyd', 1965} bands:insert{6, 'The Rolling Stones', 1962}---...-- Get a tuple's position --tarantool> position=bands.index.primary:tuple_pos({3,'Ace of Base',1987})---...-- Pass the tuple's position as the 'after' parameter --tarantool> bands:select({},{limit=3,after=position})-----[4,'TheBeatles',1960]-[5,'PinkFloyd',1965]-[6,'TheRollingStones',1962]...
index_object extensions
You can extend index_object with custom functions as follows:
Create a Lua function.
Add the function name to a predefined global variable, which has the table type.
Call the function on the index_object: index_object:function-name([parameters]).
There are three predefined global variables:
Adding to box_schema.index_mt makes the function available for all indexes.
Adding to box_schema.memtx_index_mt makes the function available for all memtx indexes.
Adding to box_schema.vinyl_index_mt makes the function available for all vinyl indexes.
Alternatively, you can make a user-defined function available for only one index
by calling getmetatable(index_object) and then adding the function name to the
meta table.
Example 1:
The example below shows how to extend all memtx indexes with the custom function:
box.schema.space.create('tester1',{engine='memtx'})box.space.tester1:create_index('index1')global_counter=5-- Create a custom function.functionincrease_global_counter()global_counter=global_counter+1end-- Extend all memtx indexes with the created function.box.schema.memtx_index_mt.increase_global_counter=increase_global_counter-- Call the 'increase_global_counter' function on 'index1'-- to change the 'global_counter' value from 5 to 6.box.space.tester1.index.index1:increase_global_counter()
Example 2:
The example below shows how to extend the specified index with the custom function with parameters:
box.schema.space.create('tester2',{engine='memtx',id=1000})box.space.tester2:create_index('index2')local_counter=0-- Create a custom function.functionincrease_local_counter(i_arg,param)local_counter=local_counter+param+i_arg.space_idend-- Extend only the 'index2' index with the created function.box.schema.memtx_index_mt.increase_local_counter=increase_local_countermeta=getmetatable(box.space.tester2.index.index2)meta.increase_local_counter=increase_local_counter-- Call the 'increase_local_counter' function on 'index2'-- to change the 'local_counter' value from 0 to 1005.box.space.tester2.index.index2:increase_local_counter(5)
Submodule box.info
The box.info submodule provides access to information about a running Tarantool instance.
Below is a list of all box.info functions and members.
Get all keys and values provided by the box.info submodule.
Since box.info contents are dynamic, it’s not possible to iterate over
keys with the Lua pairs() function. For this purpose, box.info()
builds and returns a Lua table with all keys and values provided in the
submodule.
The current state of this replica set node in regard to leader election.
The following information is provided:
state – the election state (mode) of the node. Possible values are leader, follower, or candidate.
For more details, refer to description of the leader election process.
When replication.failover is set to election, the node is writable only in the leader state.
term – the current election term.
vote – the ID of a node the current node votes for. If the value is 0, it means the node hasn’t voted in the current term yet.
leader – a leader node ID in the current term. If the value is 0, it means the node doesn’t know which node is the leader in the current term.
leader_name – a leader name. Returns nil if there is no leader in a cluster or box.NULL if a leader does not have a name. Since version 3.0.0.
leader_idle – time in seconds since the last interaction with the known leader. Since version 2.10.0.
Note
IDs in the box.info.election output are the replica IDs visible in the box.info.id output on each node and in the _cluster space.
Get information about the Tarantool garbage collector.
The garbage collector compares vclock (vector clock)
values of users and checkpoints, so a look at box.info.gc() may show why the
garbage collector has not removed old WAL files, or show what it may soon remove.
consumers – a list of users whose requests might affect the garbage collector.
checkpoints – a list of preserved checkpoints.
checkpoints[n].references – a list of references to a checkpoint.
checkpoints[n].vclock – a checkpoint’s vclock value.
checkpoints[n].signature – a sum of a checkpoint’s vclock’s components.
checkpoint_is_in_progress – true if a checkpoint is in progress, otherwise false
vclock – the garbage collector’s vclock.
signature – the sum of the garbage collector’s checkpoint’s components.
wal_retention_vclock – a vclock value of the oldest write-ahead log file protected from removing by the garbage collector by using the wal.retention_period option.
A numeric identifier of the current instance within the replica set.
This value corresponds to replication[{n}].id.
Learn more in box.info.replication.
Get information about memory usage for the current instance.
Note
To get a picture of the vinyl subsystem, use
box.stat.vinyl() instead.
cache – the number of bytes used for caching user data. The
memtx storage engine does not require a cache, so in fact this is
the number of bytes in the cache for the tuples stored for the vinyl
storage engine.
data – the number of bytes used for storing user data
(the tuples) with the memtx engine and with level 0 of the vinyl engine,
without taking memory fragmentation into account.
index – the number of bytes used for indexing user data,
including memtx and vinyl memory tree extents, the vinyl page index,
and the vinyl bloom filters.
lua – the number of bytes used for Lua runtime.
net – the number of bytes used for network input/output buffers.
tx – the number of bytes in use by active transactions.
For the vinyl storage engine, this is the total size of all allocated
objects (struct txv, struct vy_tx, struct vy_read_interval)
and tuples pinned for those objects.
The replication section of box.info() is a table with statistics for all instances in the replica set that the current instance belongs to.
To see the example, refer to Monitoring a replica set.
In the following, n is the index number of one table item, for example,
replication[1], which has data about server instance number 1,
which may or may not be the same as the current instance
(the “current instance” is what is responding to box.info).
replication[n].id is a short numeric identifier of instance n
within the replica set.
This value is stored in the box.space._cluster
system space.
replication[n].uuid is a globally unique identifier of instance
n. This value is stored in the box.space._cluster
system space.
replication[n].name is the instance name. See also: box.info.name.
replication[n].upstream appears (is not nil)
if the current instance is following or intending to follow instance n,
which ordinarily means
replication[n].upstream.status = follow,
replication[n].upstream.peer = url of instance n which is
being followed, replication[n].lagandidle = the instance’s
speed, described later.
Another way to say this is: replication[n].upstream will appear
when replication[n].upstream.peer is not of the current instance,
and is not read-only, and was specified in box.cfg{replication={...}},
so it is shown in box.cfg.replication.
replication[n].upstream.status is the replication status of the
connection with the instance n:
wait_snapshot: an instance is receiving metadata from the master. If join fails with a non-critical error at this stage (for example, ER_READONLY, ER_ACCESS_DENIED, or a network-related issue), an instance tries to find a new master to join.
fetch_snapshot: an instance is receiving data from the master’s .snap files.
final_join: an instance is receiving new data added during fetch_snapshot.
sync: the master and replica are synchronizing to have the same data.
follow: the current instance’s role is replica.
This means that the instance is read-only or acts as a replica for this remote peer in master-master configuration.
The instance is receiving or able to receive data from the instance n’s (upstream) master.
stopped: replication is stopped due to a replication
error (for example, duplicate key).
disconnected: an instance is not connected to the replica set
(for example, due to network issues, not replication errors).
replication[n].upstream.idle is the time (in seconds) since
the last event was received.
This is the primary indicator of replication health.
Learn more from Monitoring a replica set.
replication[n].upstream.peer contains instance n’s
URI, for example, 127.0.0.1:3302.
Learn more from Monitoring a replica set.
replication[n].upstream.lag is the time difference between the
local time of instance n, recorded when the event was received, and
the local time at another master recorded when the event was written to
the write-ahead log on that master.
Learn more from Monitoring a replica set.
replication[n].upstream.message contains an error message in
case of a degraded state; otherwise, it is nil.
replication[n].downstream appears (is not nil)
with data about an instance that is following instance n
or is intending to follow it, which ordinarily means
replication[n].downstream.status = follow.
replication[n].downstream.vclock contains the
vector clock, which is a table of
‘id, lsn’ pairs, for example,
vclock:{1:3054773,4:8938827,3:285902018}.
(Notice that the table may have multiple pairs although vclock is
a singular name).
Even if instance n is removed,
its values will still appear here; however,
its values will be overridden if an instance joins later with the same UUID.
Vector clock pairs will only appear if lsn>0.
replication[n].downstream.vclock may be the same as the current
instance’s vclock (box.info.vclock) because this is for all known
vclock values of the cluster.
A master will know what is in a replica’s copy of vclock
because, when the master makes a data change, it sends
the change information to the replica (including the master’s
vector clock), and the replica replies with what is in its entire
vector clock table.
A replica also sends its entire vector clock table in response
to a master’s heartbeat message, see the heartbeat-message examples
in the section Binary protocol – replication.
replication[n].downstream.idle is the time (in seconds) since the
last time that instance n sent events through the downstream replication.
replication[n].downstream.status is the replication status for
downstream replications:
stopped means that downstream replication has stopped,
follow means that downstream replication is in progress (instance
n is ready to accept data from the master or is currently doing so).
replication[n].downstream.lag is the time difference between the
local time at the master node, recorded when a particular transaction was written to
the write-ahead log, and the local time recorded when it receives an acknowledgment
for this transaction from a replica.
Since version 2.10.0.
See more in Monitoring a replica set.
replication[n].downstream.message and
replication[n].downstream.system_message
will be nil unless a problem occurs with the connection.
For example, if instance n goes down, then one may see
status='stopped', message='unexpectedEOFwhenreadingfromsocket', and system_message='Brokenpipe'.
See also degraded state.
The output is similar to the one produced by box.info.replication with
an exception that anonymous replicas are indexed by their uuid strings
rather than server ids, since server ids have no meaning for anonymous
replicas.
Notice that when you issue a plain box.info.replication_anon, the only
info returned is the number of anonymous replicas following the current
instance. In order to see the full stats, you have to call
box.info.replication_anon(). This is done to not overload the box.info
output with excess info, since there may be lots of anonymous replicas.
Notice that anonymous replicas hide their lsn from the others, so an
anonymous replica lsn will always be reported as zero, even if an anonymous
replica performs some local space operations.
To find out the lsn of a specific anonymous replica, you have to issue box.info.lsn on
it.
The reason why the current instance is read-only.
To get whether the current instance is writable or read-only, use box.info.ro.
If the instance is in writable mode, box.info.ro_reason returns nil.
The possible values returned by ro_reason:
election – the instance is not the leader.
See box.info.election for details.
synchro – the instance is not the owner of the synchronous transaction queue.
For details, see box.info.synchro.
config – the instance is is configured to be read only.
The database schema version.
A schema version is a number that indicates whether the database schema is changed.
For example, the schema_version value grows if a space or index is added or deleted, or a space, index, or field name is changed.
In synchronous replication, transaction is considered committed only after achieving
the required quorum number.
While transactions are collecting confirmations from remote nodes, these transactions are waiting in the queue.
The following information is provided:
queue:
owner (since version 2.10.0) – ID of the replica that owns the synchronous
transaction queue. Once an owner instance appears, all other instances become read-only.
If the owner field is 0, then every instance may be writable,
but they can’t create any synchronous transactions.
To claim or reclaim the queue, use box.ctl.promote() on the instance that you want
to promote.
To clear the ownership, call box.ctl.demote() on the synchronous queue owner.
When Raft election is enabled and replication.election_mode
is set to candidate, the new Raft leader claims the queue automatically after winning the elections.
It means that the value of box.info.synchro.queue.owner becomes equal to box.info.election.leader.
When Raft is enabled, no manual intervention with box.ctl.promote() or box.ctl.demote() is required.
term (since version 2.10.0) – current queue term.
It contains the term of the last PROMOTE request.
Usually, it is equal to box.info.election.term.
However, the queue term value may be less than the election term.
It can happen when a new round of elections has started, but no instance has been promoted yet.
len – the number of entries that are currently waiting in the queue.
busy (since version 2.10.0) – the boolean value is true
when the instance is processing or writing some system request that modifies the queue
(for example, PROMOTE, CONFIRM, or ROLLBACK).
Until the request is complete, any other incoming synchronous transactions and system requests
will be delayed.
age (since version 3.2.0) – the time in seconds that the oldest entry currently
present in the queue has spent waiting for the quorum to collect.
confirm_lag (since version 3.2.0) – the time in seconds that the latest successfully
confirmed entry waited for the quorum to collect.
quorum – the resulting value of the
replication.synchro_quorum configuration option.
Since version 2.5.3, the option can be set as a dynamic formula.
In this case, the value of the quorum member depends on the current number of replicas.
Example 1:
In this example, the quorum field is equal to 1.
That is, synchronous transactions work like asynchronous ones.
1 means that a successful WAL writing to the master is enough to commit.
On the second instance, simulate failure like if this instance would crash or go out of the network:
box_info_synchro:instance002> os.exit(0) ⨯ Connection was closed. Probably instance process isn't running anymore
On the first instance, try to perform some synchronous transactions.
The transactions would hang, because the replication.synchro_quorum
option is set to 2, and the second instance is not available:
box_info_synchro:instance001> fiber = require('fiber')---...box_info_synchro:instance001> for i = 1, 3 do fiber.new(function() box.space.sync:replace{i} end) end---...
Call the box.info.synchro command on the first instance again:
The box.iproto submodule provides the ability to work with the network subsystem of Tarantool.
It allows you to extend the IPROTO functionality from Lua.
With this submodule, you can:
IPROTO constants in the box.iproto namespace are written in uppercase letters without the IPROTO_ prefix.
The constants are divided into several groups:
IPROTO protocol features with the corresponding code (box.iproto.feature)
Example
The example converts the feature names from box.iproto.protocol_features set into codes:
-- Features supported by the serverbox.iproto.protocol_features={streams=true,transactions=true,error_extension=true,watchers=true,pagination=true,}-- Convert the feature names into codesfeatures={}fornameinpairs(box.iproto.protocol_features)dotable.insert(features,box.iproto.feature[name])endreturnfeatures-- [0, 1, 2, 3, 4]
Handling the unknown IPROTO request types
Every IPROTO request has a static handler.
That is, before version 2.11.0, any unknown request raised an error.
Since 2.11.0, a new request type is introduced – IPROTO_UNKNOWN.
This type is used to override the handlers of the unknown IPROTO request types. For details, see
box.iproto.override() and box_iproto_override functions.
API reference
The table lists all available functions and data of the submodule:
Since version 2.11.0.
Set a new IPROTO request handler callback for the given request type.
Parameters:
request_type (number) –
a request type code. Possible values:
a type code from box.iproto.type (except
box.iproto.type.UNKNOWN) – override the existing request type handler.
box.iproto.type.UNKNOWN – override the handler of unknown request types.
handler (function) –
IPROTO request handler.
The signature of a handler function: function(sid,header,body), where
header (userdata): a request header encoded as a msgpack_object
body (userdata): a request body encoded as a msgpack_object
Returns true on success, otherwise false. On false, there is a fallback
to the default handler. Also, you can indicate an error by throwing an exception.
In this case, the return value is false, but this does not always mean a failure.
To reset the request handler, set the handler parameter to nil.
Return:
none
Possible errors:
If a Lua handler throws an exception, the behavior is similar to that of a remote procedure call.
The following errors are returned to the client over IPROTO (see src/lua/utils.h):
ER_PROC_LUA – an exception is thrown from a Lua handler, diagnostic is not set.
diagnostics from src/box/errcode.h – an exception is thrown, diagnostic is set.
When using box.iproto.override(), it is important that you follow the wire protocol.
That is, the server response should match the return value types of the corresponding request type.
Otherwise, it could lead to peer breakdown or undefined behavior.
Example:
Define a handler function for the box.iproto.type.SELECT request type:
Since version 2.11.0.
Send an IPROTO packet over the session’s socket with the given MsgPack header
and body.
The header and body contain exported IPROTO constants from the box.iproto() submodule.
Possible IPROTO constant formats:
a lowercase constant without the IPROTO_ prefix (schema_version, request_type)
a constant from the corresponding box.iproto subnamespace (box.iproto.SCHEMA_VERSION, box.iproto.REQUEST_TYPE)
The function works for binary sessions only. For details, see box.session.type().
Parameters:
sid (number) – the IPROTO session identifier (see box.session.id())
header (table|string) – a request header encoded as MsgPack
body (table|string|nil) – a request body encoded as MsgPack
Return:
0 on success, otherwise an error is raised
Rtype:
number
Possible errors:
ER_SESSION_CLOSED – the session is closed.
ER_NO_SUCH_SESSION – the session does not exist.
ER_MEMORY_ISSUE – out-of-memory limit has been reached.
ER_WRONG_SESSION_TYPE – the session type is not binary.
Return an array of all active database read views.
This array might include the following read view types:
read views created by application code (Enterprise Edition only)
system read views (used, for example, to make a checkpoint
or join a new replica)
Read views created by application code also have the space field.
The field lists all spaces available in a read view,
and may be used like a read view object returned by box.read_view.open().
Note
read_view.list() also contains read views created using the
C API (box_raw_read_view_new()).
Note that you cannot access database spaces included in such views from Lua.
opts (table) – (optional) configurations options for a read view.
For example, the name option specifies a read view name.
If name is not specified, a read view name is set to unknown.
Create a space.
You can use either syntax. For example,
s=box.schema.space.create('tester') has the same effect as
s=box.schema.create_space('tester').
There are three syntax variations
for object references targeting space objects, for example
box.schema.space.drop(space-id)
drops a space. However, the common approach is to use functions
attached to the space objects, for example
space_object:drop().
After a space is created, usually the next step is to
create an index for it, and then it is
available for insert, select, and all the other box.space
functions.
Space options that include the space id, format, field count, constraints and
foreign keys, and so on.
These options are passed to the box.schema.space.create() method.
Field names and types.
See the illustrations of format clauses in the space_object:format()
description and in the box.space._space
example. Optional and usually not specified.
-- Define a tuple constraint function --box.schema.func.create('check_person',{language='LUA',is_deterministic=true,body='function(t, c) return (t.age >= 0 and #(t.name) > 3) end'})-- Create a space with a tuple constraint --customers=box.schema.space.create('customers',{constraint='check_person'})
-- Create a space with a tuple foreign key --box.schema.space.create("orders",{foreign_key={space='customers',field={customer_id='id',customer_name='name'}}})box.space.orders:format({{name="id",type="number"},{name="customer_id"},{name="customer_name"},{name="price_total",type="number"},})
Saying box.cfg{read_only=true...} during configuration
affects spaces differently depending on the options that were used during
box.schema.space.create, as summarized by this chart:
If you created a database with an older Tarantool version and have now installed
a newer version, make the request box.schema.upgrade(). This updates
Tarantool system spaces to match the currently installed version of Tarantool.
You can learn about the general upgrade process from the Upgrades topic.
For example, here is what happens when you run box.schema.upgrade() with a
database created with Tarantool version 1.6.4 to version 1.7.2 (only a small
part of the output is shown):
tarantool> box.schema.upgrade()alter index primary on _space set options to {"unique":true}, parts to [[0,"unsigned"]]alter space _schema set options to {}create view _vindex...grant read access to 'public' role for _vindex viewset schema version to 1.7.0---...
You can also put the request box.schema.upgrade()
inside a box.once() function in your Tarantool
initialization file.
On startup, this will create new system spaces, update data type names (for example,
num -> unsigned, str -> string) and options in Tarantool system spaces.
Allows you to downgrade a database to the specified Tarantool version.
This might be useful if you need to run a database on older Tarantool versions.
To prepare a database for using it on an older Tarantool instance,
call box.schema.downgrade and pass the desired Tarantool version:
tarantool> box.schema.downgrade('2.8.4')
Note
The Tarantool’s downgrade procedure is similar to the upgrade process that is described in the Upgrades topic.
You need to run box.schema.downgrade() only on master and execute box.snapshot() on every instance in a replica set before restart to an older version.
To see Tarantool versions available for downgrade, call box.schema.downgrade_versions(). The oldest release available for downgrade is 2.8.2.
Note that the downgrade process might fail if the database enables specific features not supported
in the target Tarantool version.
You can see all such issues using the box.schema.downgrade_issues() method,
which accepts the target version.
For example, downgrade to the 2.8.4 version fails if you use tuple compression or field constraints in your database:
tarantool> box.schema.downgrade_issues('2.8.4')-----Tuple compression is found in space 'bands', field 'band_name'. It is supportedstarting from version 2.10.0.-Field constraint is found in space 'bands', field 'year'. It is supported startingfrom version 2.10.0....
Return a list of Tarantool versions available for downgrade.
To learn how to downgrade a database to the specified Tarantool version, see box.schema.downgrade().
Return a list of downgrade issues for the specified Tarantool version.
To learn how to downgrade a database to the specified Tarantool version, see box.schema.downgrade().
Create a user.
For explanation of how Tarantool maintains user data, see
section Users and reference on
_user space.
The possible options are:
if_not_exists = true|false (default = false) - boolean;
true means there should be no error if the user already exists,
password (default = ‘’) - string; the password = password
specification is good because in a URI
(Uniform Resource Identifier) it is usually illegal to include a
username without a password.
Return true if a user exists; return false if a user does not exist.
For explanation of how Tarantool maintains user data, see
section Users and reference on
_user space.
The user must exist, and the object must exist,
but if the option setting is {if_exists=true} then
it is not an error if the user does not have the privilege.
Variation: instead of object-type,object-name say ‘universe’
which means ‘all object-types and all objects’.
Variation: instead of permissions,object-type,object-name say
role-name (see section Roles).
Variation: instead of
box.schema.user.revoke('username','usage,session','universe',nil,{if_exists=true})
say box.schema.user.disable('username').
Return a hash of a user’s password. For explanation of how Tarantool maintains
passwords, see section Passwords and reference on
_user space.
Note
If a non-‘guest’ user has no password, it’s impossible to connect
to Tarantool using this user. The user is regarded as “internal” only,
not usable from a remote connection. Such users can be useful if they
have defined some procedures with the
SETUID option,
on which privileges are granted to externally-connectable users.
This way, external users cannot create/drop objects,
they can only invoke procedures.
For the ‘guest’ user, it’s impossible to set a password: that would be misleading,
since ‘guest’ is the default user on a newly-established connection over a
binary port, and Tarantool does not require
a password to establish a binary connection.
It is, however, possible to change the
current user to ‘guest’ by providing the
AUTH packet with no password at all or an
empty password. This feature is useful for connection pools, which want to reuse a
connection for a different user without re-establishing it.
username (string) – the name of the user.
This is optional; if it is not
supplied, then the information
will be for the user who is
currently logged in.
Using the body option, you can make a function persistent.
In this case, the function is “persistent” because its definition is stored in a snapshot (the box.space._func system space) and can be recovered if the server restarts.
The example below shows how to create a persistent Lua function,
show its definition using box.func.{func-name},
and call this function using box.func.{func-name}:call([parameters]):
tarantool> lua_code=[[function(a, b) return a + b end]]tarantool> box.schema.func.create('sum',{body=lua_code})tarantool> box.func.sum----is_sandboxed:falseis_deterministic:falseid:2setuid:falsebody:function(a, b) return a + b endname:sumlanguage:LUA...tarantool> box.func.sum:call({1,2})----3...
Make Tarantool treat the function’s caller as the function’s creator, with full privileges.
Note that setuid works only over binary ports.
setuid doesn’t work if you invoke a function using the
admin console or inside a Lua script.
Whether the function should be executed in an isolated environment.
This means that any operation that accesses the world outside the sandbox is forbidden or has no effect.
Therefore, a sandboxed function can only use modules and functions
that cannot affect isolation:
Also, a sandboxed function cannot refer to global variables – they
are treated as local variables because the sandbox is established
with setfenv.
So, a sandboxed function is stateless and deterministic.
If set to true for a Lua function and the function is called via net.box (conn:call()) or by box.func.<func-name>:call(),
the function arguments are passed being wrapped in a MsgPack object:
localmsgpack=require('msgpack')box.schema.func.create('my_func',{takes_raw_args=true})localmy_func=function(mp)assert(msgpack.is_object(mp))localargs=mp:decode()-- array of argumentsend
If a function forwards most of its arguments to another Tarantool instance or writes them to a database,
the usage of this option can improve performance because it skips the MsgPack data decoding in Lua.
Reload a C module with all its functions without restarting the server.
Under the hood, Tarantool loads a new copy of the module (*.so shared
library) and starts routing all new request to the new version.
The previous version remains active until all started calls are finished.
All shared libraries are loaded with RTLD_LOCAL (see “man 3 dlopen”),
therefore multiple copies can co-exist without any problems.
Note
Reload will fail if a module was loaded from Lua script with
ffi.load().
options (table) – see a quick overview in the
“Options for box.schema.sequence.create()”
chart
(in the Sequences
section of the “Data model” chapter),
and see more details below.
Return:
a reference to a new sequence object.
Options:
start – the STARTS WITH value. Type = integer, Default = 1.
min – the MINIMUM value. Type = integer, Default = 1.
max - the MAXIMUM value. Type = integer, Default = 9223372036854775807.
There is a rule: min <= start <= max.
For example it is illegal to say {start=0} because then the
specified start value (0) would be less than the default min value (1).
There is a rule: min <= next-value <= max.
For example, if the next generated value would be 1000,
but the maximum value is 999, then that would be considered
“overflow”.
There is a rule: start and min and max must all
be <= 9223372036854775807 which is 2^63 - 1 (not 2^64).
cycle – the CYCLE value. Type = bool. Default = false.
If the sequence generator’s next value is an overflow number,
it causes an error return – unless cycle==true.
But if cycle==true, the count is started again, at the
MINIMUM value or at the MAXIMUM value (not the STARTS WITH value).
cache – the CACHE value. Type = unsigned integer. Default = 0.
Currently Tarantool ignores this value, it is reserved for future use.
step – the INCREMENT BY value. Type = integer. Default = 1.
Ordinarily this is what is added to the previous value.
If this is the first time, then return the STARTS WITH value.
If the previous value plus the INCREMENT value is less than the
MINIMUM value or greater than the MAXIMUM value, that is “overflow”,
so either raise an error (if cycle = false) or return the
MAXIMUM value (if cycle = true and step < 0)
or return the MINIMUM value (if cycle = true and step > 0).
If there was no error, then save the returned result, it is now
the “previous value”.
For example, suppose sequence ‘S’ has:
min == -6,
max == -1,
step == -3,
start = -2,
cycle = true,
previous value = -2.
Then box.sequence.S:next() returns -5 because -2 + (-3) == -5.
Then box.sequence.S:next() again returns -1 because -5 + (-3) < -6,
which is overflow, causing cycle, and max == -1.
The alter() function can be used to change any of the sequence’s
options. Requirements and restrictions are the same as for
box.schema.sequence.create().
Options:
start – the STARTS WITH value. Type = integer, Default = 1.
min – the MINIMUM value. Type = integer, Default = 1.
max - the MAXIMUM value. Type = integer, Default = 9223372036854775807.
There is a rule: min <= start <= max.
For example it is illegal to say {start=0} because then the
specified start value (0) would be less than the default min value (1).
There is a rule: min <= next-value <= max.
For example, if the next generated value would be 1000,
but the maximum value is 999, then that would be considered
“overflow”.
cycle – the CYCLE value. Type = bool. Default = false.
If the sequence generator’s next value is an overflow number,
it causes an error return – unless cycle==true.
But if cycle==true, the count is started again, at the
MINIMUM value or at the MAXIMUM value (not the STARTS WITH value).
cache – the CACHE value. Type = unsigned integer. Default = 0.
Currently Tarantool ignores this value, it is reserved for future use.
step – the INCREMENT BY value. Type = integer. Default = 1.
Ordinarily this is what is added to the previous value.
Set the sequence back to its original state.
The effect is that a subsequent next() will return the start value.
This function requires a
‘write’ privilege
on the sequence.
Since version 2.4.1.
Return the last retrieved value of the specified sequence or throw an error
if no value has been generated yet (next() has not been called yet, or current() is called right
after reset() is called).
Example:
tarantool> sq=box.schema.sequence.create('test')---...tarantool> sq:current()----error:Sequence 'test' is not started...tarantool> sq:next()----1...tarantool> sq:current()----1...tarantool> sq:set(42)---...tarantool> sq:current()----42...tarantool> sq:reset()---...tarantool> sq:current()-- error----error:Sequence 'test' is not started...
You can use the sequence=sequence-name
(or sequence=sequence-id or sequence=true)
option when creating or
altering a primary-key index.
The sequence becomes associated with the index, so that the next
insert() will put the next generated number into the primary-key
field, if the field would otherwise be nil.
The syntax may be any of: sequence=sequenceidentifier
or
sequence={id=sequenceidentifier}
or
sequence={field=fieldnumber}
or
sequence={id=sequenceidentifier,field=fieldnumber}
or
sequence=true
or
sequence={}.
The sequence identifier may be either a number
(the sequence id) or a string (the sequence name).
The field number may be the ordinal number of any field
in the index; default = 1.
Examples of all possibilities:
sequence=1 or
sequence='sequence_name' or
sequence={id=1} or
sequence={id='sequence_name'} or
sequence={id=1,field=1} or
sequence={id='sequence_name',field=1} or
sequence={field=1} or
sequence=true or
sequence={}.
Notice that the sequence identifier can be omitted,
if it is omitted then a new sequence is created
automatically with default name = space-name_seq.
Notice that the field number does not have to be 1,
that is, the sequence can be associated with any
field in the primary-key index.
For example, if ‘Q’ is a sequence and ‘T’ is a new space, then this will
work:
The index key type may be either ‘integer’ or ‘unsigned’.
If any of the sequence options is a negative number, then
the index key type should be ‘integer’.
Users should not insert a value greater than 9223372036854775807,
which is 2^63 - 1, in the indexed field. The sequence generator
will ignore it.
A sequence cannot be dropped if it is associated with an index.
However, index_object:alter()
can be used to say that a sequence
is not associated with an index, for example
box.space.T.index.I:alter({sequence=false}).
If a sequence was created automatically because the
sequence identifier was omitted, then it will be dropped
automatically if the index is altered so that sequence=false,
or if the index is dropped.
index_object:alter() can also be used to associate a
sequence with an existing index, with the same syntax for options.
When a sequence is used with an index based on a JSON path,
inserted tuples must have all components of the path preceding
the autoincrement field, and the autoincrement field.
To achieve that use box.NULL rather than nil. Example:
s=box.schema.space.create('test')s:create_index('pk',{parts={{'[1].a.b[1]','unsigned'}},sequence=true})s:replace{}-- errors:replace{{c={}}}-- errors:replace{{a={c={}}}}-- errors:replace{{a={b={}}}}-- errors:replace{{a={b={nil}}}}-- errors:replace{{a={b={box.NULL}}}}-- ok
Submodule box.session
The box.session submodule allows querying the session state, writing to a
session-specific temporary Lua table, or sending out-of-band messages, or
setting up triggers which will fire when a session starts or ends.
A session is an object associated with each client connection.
Below is a list of all box.session functions and members.
This function works only if there is a peer, that is,
if a connection has been made to a separate Tarantool instance.
Return:
The host address and port of the session peer,
for example “127.0.0.1:55457”.
If the session exists but there is no connection to a
separate instance, the return is null.
The command is executed on the server instance,
so the “local name” is the server instance’s host
and port, and the “peer name” is the client’s host
and port.
the value of the sync integer constant used in the
binary protocol.
This value becomes invalid when the session is disconnected.
Rtype:
number
This function is local for the request, i.e. not global for the session. If
the connection behind the session is multiplexed, this function can be
safely used inside the request processor.
box.session.type() is useful for an
on_replace() trigger
on a replica – the value will be ‘applier’ if and only if
the trigger was activated because of a request that was done on
the master.
Change Tarantool’s current user –
this is analogous to the Unix command su.
Or, if function-to-execute is specified,
change Tarantool’s current user
temporarily while executing the function –
this is analogous to the Unix command sudo.
function-to-execute – name of a function, or definition of a function.
Additional parameters may be passed to
box.session.su, they will be interpreted
as parameters of function-to-execute.
Every user has a unique name (seen with
box.session.user())
and a unique ID (seen with box.session.uid()).
The values are stored together in the _user space.
The first case: if the call to box.session.euid() is within
a function invoked by
box.session.su(user-name, function-to-execute)
– in that case, box.session.euid() returns the ID of the changed user
(the user who is specified by the user-name parameter of the su
function) but box.session.uid() returns the ID of the original user
(the user who is calling the su function).
The second case: if the call to box.session.euid() is within
a function specified with
box.schema.func.create(function-name, {setuid= true})
and the binary protocol is in use
– in that case, box.session.euid() returns the ID of the user who
created “function-name” but box.session.uid() returns the ID of the
the user who is calling “function-name”.
A Lua table that can hold arbitrary unordered session-specific
names and values, which will last until the session ends.
For example, this table could be useful to store current tasks when working
with a Tarantool queue manager.
Example:
tarantool> box.session.peer(box.session.id())----127.0.0.1:45129...tarantool> box.session.storage.random_memorandum="Don't forget the eggs"---...tarantool> box.session.storage.radius_of_mars=3396---...tarantool> m=''---...tarantool> fork,vinpairs(box.session.storage)do > m=m..k..'='..v..' ' > end---...tarantool> m----'radius_of_mars=3396random_memorandum=Don't forget the eggs. '...
Define a trigger for execution when a new session is created due to an event
such as console.connect. The trigger function will
be the first thing executed after a new session is created. If the trigger
execution fails and raises an error, the error is sent to the client and
the connection is closed.
Parameters:
trigger-function (function) – function which will become the trigger
function
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function), then the old trigger
is deleted.
If both parameters are omitted, then the response is a list of existing
trigger functions.
Details about trigger characteristics are in the
triggers section.
Define a trigger for execution after a client has disconnected. If the
trigger function causes an error, the error is logged but otherwise is
ignored. The trigger is invoked while the session associated with the
client still exists and can access session properties, such as
box.session.id().
Since version 1.10, the trigger function is invoked immediately after the
disconnect, even if requests that were made during the session have not
finished.
Parameters:
trigger-function (function) – function which will become the trigger
function
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function),
then the old trigger is deleted.
If both parameters are omitted, then the response is a list of existing
trigger functions.
Details about trigger characteristics are in the
triggers section.
The on_auth trigger function is invoked in these circumstances:
The console.connect function includes an
authentication check for all users except ‘guest’. For this case, the
on_auth trigger function is invoked after the on_connect
trigger function, if and only if the connection has succeeded so far.
Unlike other trigger types, on_auth trigger functions are invoked
before the event. Therefore a trigger function like
functionauth_function()v=box.session.user();end
will set v to “guest”, the user name before the authentication is
done. To get the user name after the authentication is done, use the
special syntax: functionauth_function(user_name)v=user_name;end
If the trigger fails by raising an error, the error is sent to the client
and the connection is closed.
Parameters:
trigger-function (function) – function which will become the
trigger function
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function),
then the old trigger is deleted.
If both parameters are omitted, then the response is
a list of existing trigger functions.
Details about trigger characteristics are in the
triggers section.
This is a more complex example, with two server instances.
The first server instance listens on port 3301; its default
user name is ‘admin’.
There are three on_auth triggers:
The first trigger has a function with no arguments, it can only look
at box.session.user().
The second trigger has a function with a user_name argument,
it can look at both of: box.session.user() and user_name.
The third trigger has a function with a user_name argument
and a status argument,
it can look at all three of:
box.session.user() and user_name and status.
The second server instance will connect with
console.connect,
and then will cause a display of the variables that were set by the
trigger functions.
-- On the first server instance, which listens on port 3301box.cfg{listen=3301}functionfunction1()print('function 1, box.session.user()='..box.session.user())endfunctionfunction2(user_name)print('function 2, box.session.user()='..box.session.user())print('function 2, user_name='..user_name)endfunctionfunction3(user_name,status)print('function 3, box.session.user()='..box.session.user())print('function 3, user_name='..user_name)ifstatus==truethenprint('function 3, status = true, authorization succeeded')endendbox.session.on_auth(function1)box.session.on_auth(function2)box.session.on_auth(function3)box.schema.user.passwd('admin')
-- On the second server instance, that connects to port 3301console=require('console')console.connect('admin:admin@localhost:3301')
The result looks like this:
function 3, box.session.user()=guestfunction 3, user_name=adminfunction 3, status = true, authorization succeededfunction 2, box.session.user()=guestfunction 2, user_name=adminfunction 1, box.session.user()=guest
Define a trigger for reacting to user’s attempts to execute actions that are
not within the user’s privileges.
Parameters:
trigger-function (function) – function which will become the
trigger function
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function
Return:
nil or function pointer
If the parameters are (nil, old-trigger-function),
then the old trigger is deleted.
If both parameters are omitted, then the response is
a list of existing trigger functions.
Details about trigger characteristics are in the
triggers section.
Example:
For example, server administrator can log restricted actions like this:
tarantool> functionon_access_denied(op,type,name) > log.warn('User %s tried to %s %s %s without required privileges',box.session.user(),op,type,name) > end---...tarantool> box.session.on_access_denied(on_access_denied)----'function:0x011b41af38'...tarantool> functiontest()print('you shall not pass')end---...tarantool> box.schema.func.create('test')---...
Then, when some user without required privileges tries to call test()
and gets the error, the server will execute this trigger and write to log
“User *user_name* tried to Execute function test without required privileges”
Generate an out-of-band message. By “out-of-band” we mean an extra
message which supplements what is passed in a network via the usual
channels. Although box.session.push() can be called at any time, in
practice it is used with networks that are set up with
module net.box, and
it is invoked by the server (on the “remote database system” to use
our terminology for net.box), and the client has options for getting
such messages.
This function returns an error if the session is disconnected.
Parameters:
message (any-Lua-type) – what to send
sync (int) – an optional argument to indicate what the session is,
as taken from an earlier call to
box.session.sync().
If it is omitted, the default is the current box.session.sync() value.
In Tarantool version 2.4.2, sync
is deprecated and its use will cause a warning.
Since version 2.5.1, its use will cause an error.
Rtype:
{nil, error} or true:
If the result is an error, then the first part of the return is
nil and the second part is the error object.
If the result is not an error, then the return is the boolean value true.
When the return is true, the message has gone to the network
buffer as a packet
with a different header code
so the client can distinguish from an ordinary Okay response.
The server’s sole job is to call box.session.push(), there is no
automatic mechanism for showing that the message was received.
Situation 1: when the client calls synchronously with the default
{async=false} option. There are two optional additional options:
on_push=function-name, and on_push_ctx=function-argument.
When the client receives an out-of-band message for the session,
it invokes “function-name(function-argument)”. For example, with
options {on_push=table.insert,on_push_ctx=messages}, the client
will insert whatever it receives into a table named ‘messages’.
Situation 2: when the client calls asynchronously with the non-default
{async=true} option. Here on_push and on_push_ctx are not allowed, but
the messages can be seen by calling pairs() in a loop.
Situation 2 complication: pairs() is subject to timeout. So there
is an optional argument = timeout per iteration. If timeout occurs before
there is a new message or a final response, there is an error return.
To check for an error one can use the first loop parameter (if the loop
starts with “for i, message in future:pairs()” then the first loop parameter
is i). If it is box.NULL then the second parameter (in our example, “message”)
is the error object.
Example:
-- Make two shells. On Shell#1 set up a "server", and-- in it have a function that includes box.session.push:box.cfg{listen=3301}box.schema.user.grant('guest','read,write,execute','universe')x=0fiber=require('fiber')functionserver_function()x=x+1;fiber.sleep(1);box.session.push(x);end-- On Shell#2 connect to this server as a "client" that-- can handle Lua (such as another Tarantool server operating-- as a client), and initialize a table where we'll get messages:net_box=require('net.box')conn=net_box.connect(3301)messages_from_server={}-- On Shell#2 remotely call the server function and receive-- a SYNCHRONOUS out-of-band message:conn:call('server_function',{},{is_async=false,on_push=table.insert,on_push_ctx=messages_from_server})messages_from_server-- After a 1-second pause that is caused by the fiber.sleep()-- request inside server_function, the result in the-- messages_from_server table will be: 1. Like this:-- tarantool> messages_from_server-- ----- - - 1-- ...-- Good. That shows that box.session.push(x) worked,-- because we know that x was 1.-- On Shell#2 remotely call the same server function and-- get an ASYNCHRONOUS out-of-band message. For this we cannot-- use on_push and on_push_ctx options, but we can use pairs():future=conn:call('server_function',{},{is_async=true})messages={}keys={}fori,messageinfuture:pairs()dotable.insert(messages,message)table.insert(keys,i)endmessagesfuture:wait_result(1000)fori,messageinfuture:pairs()dotable.insert(messages,message)table.insert(keys,i)endmessages-- There is no pause because conn:call does not wait for-- server_function to finish. The first time that we go through-- the pairs() loop, we see the messages table is empty. Like this:-- tarantool> messages-- ----- - - 2-- - []-- ...-- That is okay because the server hasn't yet called-- box.session.push(). The second time that we go through-- the pairs() loop, we see the value of x at the time of-- the second call to box.session.push(). Like this:-- tarantool> messages-- ----- - - 2-- - &0 []-- - 2-- - *0-- ...-- Good. That shows that the message was asynchronous, and-- that box.session.push() did its job.
Submodule box.slab
The box.slab submodule provides access to slab allocator statistics. The
slab allocator is the main allocator used to store tuples.
This can be used to monitor the total memory usage and memory fragmentation.
The runtime memory encompasses internal Lua memory as well as the runtime arena.
The Lua memory stores Lua objects.
The runtime arena stores Tarantool-specific objects – for example, runtime tuples, network buffers
and other objects associated with the application server subsystem.
Return:
lua is the size of the Lua heap that is controlled by the Lua garbage collector.
maxalloc is the maximum size of the runtime memory.
used is the current number of bytes used by the runtime memory.
Show an aggregated memory usage report in bytes for the slab allocator.
This report is useful for assessing out-of-memory risks.
box.slab.info gives a few ratios:
items_used_ratio
arena_used_ratio
quota_used_ratio
Here are two possible cases for monitoring memtx memory usage:
Case 1: 0.5 < items_used_ratio < 0.9
Apparently your memory is highly fragmented. Check how many
slab classes you have by looking at box.slab.stats() and counting the number
of different classes. If there are many slab classes (more than a few
dozens), you may run out of memory even though memory utilization is not high.
While each slab may have few items used, whenever a tuple of a size different
from any existing slab class size is allocated, Tarantool may need to get a
new slab from the slab arena, and since the arena has few empty slabs left, it will
attempt to increase its quota usage, which, in turn, may end up with an out-of-memory
error due to the low remaining quota.
Case 2:items_used_ratio > 0.9
You are running out of memory. All memory utilization indicators
are high. Your memory is not fragmented, but there are few reserves left on
each slab allocator level. You should consider increasing Tarantool’s
memory limit (box.cfg.memtx_memory).
To sum up: your main out-of-memory indicator is quota_used_ratio.
However, there are lots of perfectly stable setups with a high quota_used_ratio,
so you only need to pay attention to it when both arena and item used ratio
are also high.
Return:
quota_size - memory limit for slab allocator (as configured in the
memtx_memory parameter,
the default is 2^28 bytes = 268,435,456 bytes)
quota_used - used by slab allocator
items_size - allocated only for tuples
items_used - used only for tuples
arena_size - allocated for both tuples and indexes
Show a detailed memory usage report (in bytes) for the slab allocator.
The report is broken down into groups by data item size as well as by
slab size (64-byte, 136-byte, etc). The report includes the memory
allocated for storing both tuples and indexes.
return:
mem_free is the allocated, but currently unused memory;
mem_used is the memory used for storing data items (tuples and indexes);
This report is saying that there are 2 data items (item_count = 2) stored
in one (slab_count = 1) 24-byte slab (item_size = 24), so
mem_used = 2 * 24 = 48 bytes. Also, slab_size is 16384 bytes, of
which 16384 - 48 = 16232 bytes are free (mem_free).
A complete report would show memory usage statistics for all groups:
The total mem_used for all groups in this report equals arena_used
in box.slab.info() report.
Submodule box.space
CRUD operations in Tarantool are implemented by the box.space submodule.
It has the data-manipulation functions select, insert, replace,
update, upsert, delete, get, put. It also has members,
such as id, and whether or not a space is enabled.
Below is a list of all box.space functions and members.
Since version 2.5.2.
Alter an existing space. This method changes certain space parameters.
Parameters:
options (table) – the space options such as field_count, user,
format, name, and other. The full list of
these options with descriptions parameters is provided in
box.schema.space.create()
Insert a new tuple using an auto-increment primary key. The space
specified by space_object must have an
‘unsigned’ or ‘integer’ or ‘number’
primary key index of type TREE. The primary-key field
will be incremented before the insert.
Since version 1.7.5 this method is deprecated – it is better to use a
sequence.
Number of bytes in the space. This number, which is stored
in Tarantool’s internal memory, represents the total number
of bytes in all tuples, not including index keys.
For a measure of index size,
see index_object:bsize().
format-clause (table) – a list of field names and types
Return:
nil, unless format-clause is omitted
Possible errors:
space_object does not exist
field names are duplicated
type is not legal
Note
If you need to make a schema migration, see section Migrations.
Ordinarily Tarantool allows unnamed untyped fields.
But with format users can, for example, document
that the Nth field is the surname field and must contain strings.
It is also possible to specify a format clause in
box.schema.space.create().
The format clause contains, for each field, a definition within braces:
{name='...',type='...'[,is_nullable=...]}, where:
The name value may be any string, provided that two fields do not
have the same name.
The type value may be any of allowed types: any | unsigned | string |
integer | number | varbinary | boolean | double | decimal | uuid | array |
map | scalar, but for creating an index use only
indexed fields;
(Optional) The is_nullable boolean value specifies whether nil can be used as a field value.
See also: key_part.is_nullable.
(Optional) The collation string value specifies the collation used to compare field values.
See also: key_part.collation.
(Optional) The constraint table specifies the constraints that the field value must satisfy.
(Optional) The foreign_key table specifies the foreign keys for the field.
(Optional) The default value specifies the explicit default value for the field
or the argument of the default function if default_func is specified.
(Optional) The default_func string value specifies the name of the field’s default function.
To pass the default function’s argument, add the default parameter.
It is not legal for tuples to contain values that have the wrong type.
The example below will cause an error:
--This example will cause an error.box.space.tester:format({{' ',type='number'}})box.space.tester:insert{'string-which-is-not-a-number'}
It is not legal for tuples to contain null values if is_nullable=false,
which is the default. The example below will cause an error:
--This example will cause an error.box.space.tester:format({{' ',type='number',is_nullable=false}})box.space.tester:insert{nil,2}
It is legal for tuples to have more fields than are described by a format
clause. The way to constrain the number of fields is to specify a space’s
field_count member.
It is legal for tuples to have fewer fields than are described by a format
clause, if the omitted trailing fields are described with is_nullable=true.
For example, the request below will not cause a format-related error:
It is legal to use format on a space that already has a format,
thus replacing any previous definitions,
provided that there is no conflict with existing data or index definitions.
It is legal to use format to change the is_nullable flag.
The example below will not cause an error – and will not cause
rebuilding of the space.
But going the other way and changing is_nullable from true
to false might cause rebuilding and might cause an error if there
are existing tuples with nulls.
If the format clause is omitted, then the returned value is the
table that was used in a previous space_object:format(format-clause)
invocation. For example, after box.space.tester:format({{'x','scalar'}}),
box.space.tester:format() will return [{'name':'x','type':'scalar'}].
Formatting or reformatting a large space will cause occasional
yields
so that other requests will not be blocked.
If the other requests cause an illegal situation such as a field value
of the wrong type, the formatting or reformatting will fail.
Note regarding storage engine: vinyl supports formatting of non-empty
spaces. Primary index definition cannot be formatted.
Convert a map to a tuple instance or to a table.
The map must consist of “field name = value” pairs.
The field names and the value types must match names and types
stated previously for the space, via
space_object:format().
map (field-value-pairs) – a series of “field = value” pairs, in any order.
option (boolean) – the only legal option is {table=true|false};
if the option is omitted or if {table=false},
then return type will be ‘cdata’ (i.e. tuple);
if {table=true}, then return type will be ‘table’.
Return:
a tuple instance or table.
Rtype:
tuple or table
Possible errors:space_object does not exist or has no format; “unknown field”.
Example:
-- Create a format with two fields named 'a' and 'b'.-- Create a space with that format.-- Create a tuple based on a map consistent with that space.-- Create a table based on a map consistent with that space.tarantool> format1={{name='a',type='unsigned'},{name='b',type='scalar'}}---...tarantool> s=box.schema.create_space('test',{format=format1})---...tarantool> s:frommap({b='x',a=123456})----[123456,'x']...tarantool> s:frommap({b='x',a=123456},{table=true})-----123456-x...
key (scalar/table) – value to be matched against the index
key, which may be multi-part.
Return:
the tuple whose index key matches key, or nil.
Rtype:
tuple
Possible errors:
space_object does not exist.
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode.
Complexity factors: Index size, Index type, Number of indexes
accessed, WAL settings.
The box.space...select function returns a set of tuples as a Lua
table; the box.space...get function returns at most a single tuple.
And it is possible to get the first tuple in a space by appending
[1]. Therefore box.space.tester:get{1} has the same effect as
box.space.tester:select{1}[1], if exactly one tuple is found.
Example:
box.space.tester:get{1}
Using field names instead of field numbers:get() can use field names
described by the optional space_object:format() clause.
This is true because the object returned by get() can be used with most of the
features described in the Submodule box.tuple description, including
tuple_object[field-name].
For example, we can format the tester space
with a field named x and use the name x in the index definition:
Return the number of tuples in the space.
If compared with count(),
this method works faster because len() does not scan the entire space
to count the tuples.
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode.
Example:
tarantool> box.space.tester:len()----2...
Note regarding storage engine: vinyl supports len() but the result may be approximate.
If an exact result is necessary then use count()
or pairs():length().
Create a “replace trigger”.
The trigger-function will be executed
whenever a replace() or insert() or update() or upsert()
or delete() happens to a tuple in <space-name>.
Parameters:
trigger-function (function) – function which will become the
trigger function; see Example 2
below for details about
trigger function parameters
old-trigger-function (function) – existing trigger function which
will be replaced by
trigger-function
Return:
nil or function pointer
If the parameters are (nil,old-trigger-function), then the old
trigger is deleted.
If both parameters are omitted, then the response is a list of existing
trigger functions.
If it is necessary to know whether the trigger activation
happened due to replication or on a specific connection type,
the function can refer to box.session.type().
Details about trigger characteristics are in the
triggers section.
The trigger-function can have up to four parameters:
(tuple) old value which has the contents before the request started,
(tuple) new value which has the contents after the request ended,
(string) space name,
(string) type of request which is INSERT, DELETE, UPDATE,
or REPLACE.
For example, the following code causes nil and INSERT
to be printed when the insert request is processed and causes
[1,'Hi'] and DELETE to be printed when the delete request
is processed:
The following series of requests will create a space, create an index,
create a function which increments a counter, create a trigger, do two
inserts, drop the space, and display the counter value - which is 2,
because the function is executed once after each insert.
actions that are not allowed to be used in transactions
(see rule #2).
Example:
tarantool> box.space.test:on_replace(fiber.yield)tarantool> box.space.test:replace{1,2,3}2020-02-02 21:22:03.073 [73185] main/102/init.lua txn.c:532 E> ER_TRANSACTION_YIELD: Transaction has been aborted by a fiber yield----error:Transaction has been aborted by a fiber yield...
Create a “replace trigger”.
The trigger-function will be executed
whenever a replace() or insert() or update() or upsert()
or delete() happens to a tuple in <space-name>.
Parameters:
trigger-function (function) – function which will become the
trigger function; for the trigger
function’s optional parameters see
the description of
on_replace.
old-trigger-function (function) – existing trigger function which
will be replaced by
trigger-function
Return:
nil or function pointer
If the parameters are (nil,old-trigger-function), then the old
trigger is deleted.
If both parameters are omitted, then the response is a list of existing trigger functions.
If it is necessary to know whether the trigger activation
happened due to replication or on a specific connection type,
the function can refer to box.session.type().
Details about trigger characteristics are in the
triggers section.
Administrators can make replace triggers with on_replace(),
or make triggers with before_replace().
If they make both types, then all before_replace triggers
are executed before all on_replace triggers.
The functions for both on_replace and before_replace
triggers can make changes to the database, but only the
functions for before_replace triggers can change the
tuple that is being replaced.
Since a before_replace trigger function has the extra
capability of making a change to the old tuple, it also can have
extra overhead, to fetch the old tuple before making the
change. Therefore an on_replace trigger is better if
there is no need to change the old tuple. However, this
only applies for the memtx engine – for the vinyl engine,
the fetch will happen for either kind of trigger.
(With memtx the tuple data is stored along with the
index key so no extra search is necessary;
with vinyl that is not the case so the extra search
is necessary.)
Where the extra capability is not needed,
on_replace should be used instead of before_replace.
Usually before_replace is used only for certain
replication scenarios – it is useful for conflict resolution.
The value that a before_replace trigger function can return
affects what will happen after the return. Specifically:
if there is no return value, then execution proceeds,
inserting|replacing the new value;
if the value is nil, then the tuple will be deleted;
if the value is the same as the old parameter, then no
on_replace function will be called and the data
change will be skipped. The return value will be absent.
if the value is the same as the new parameter, then it’s as if
the before_replace function wasn’t called;
if the value is some other tuple, then it is used for insert/replace.
However, if a trigger function returns an old tuple, or if a
trigger function calls
run_triggers(false),
that will not affect other triggers that are activated for the same
insert | update | replace request.
Example:
The following are before_replace functions that have no return
value, or that return nil, or the same as the old parameter, or the
same as the new parameter, or something else.
Search for a tuple or a set of tuples in the given space, and allow
iterating over one tuple at a time.
To search by the specific index, use the index_object:pairs() method.
key (scalar/table) – value to be matched against the index key,
which may be multi-part
iterator – the iterator type. The default iterator type is ‘EQ’
after – a tuple or the position of a tuple (tuple_pos) after which pairs starts the search. You can pass an empty string or box.NULL to this option to start the search from the first tuple.
Return:
The iterator, which can be
used in a for/end loop or with totable().
Possible errors:
no such space
wrong type
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode
iterator position is invalid
Complexity factors: Index size, Index type.
For information about iterators’ internal structures, see the
“Lua Functional library”
documentation.
Examples:
Below are few examples of using pairs with different parameters.
To try out these examples, you need to bootstrap a Tarantool instance
as described in Using data operations.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960} bands:insert{5, 'Pink Floyd', 1965} bands:insert{6, 'The Rolling Stones', 1962} bands:insert{7, 'The Doors', 1965} bands:insert{8, 'Nirvana', 1987} bands:insert{9, 'Led Zeppelin', 1968} bands:insert{10, 'Queen', 1970}---...-- Select all tuples by the primary index --tarantool> for_,tupleinbands:pairs()do print(tuple) end[1, 'Roxette', 1986][2, 'Scorpions', 1965][3, 'Ace of Base', 1987][4, 'The Beatles', 1960][5, 'Pink Floyd', 1965][6, 'The Rolling Stones', 1962][7, 'The Doors', 1965][8, 'Nirvana', 1987][9, 'Led Zeppelin', 1968][10, 'Queen', 1970]---...-- Select all tuples whose primary key values are between 3 and 6 --tarantool> for_,tupleinbands:pairs(3,{iterator="GE"})do if (tuple[1] > 6) then break end print(tuple) end[3, 'Ace of Base', 1987][4, 'The Beatles', 1960][5, 'Pink Floyd', 1965][6, 'The Rolling Stones', 1962]---...-- Select all tuples after the specified tuple --tarantool> for_,tupleinbands:pairs({},{after={7,'The Doors',1965}})do print(tuple) end[8, 'Nirvana', 1987][9, 'Led Zeppelin', 1968][10, 'Queen', 1970]---...
Insert a tuple into a space. If a tuple with the same primary key already
exists, box.space...:replace() replaces the existing tuple with a new
one. The syntax variants box.space...:replace() and
box.space...:put() have the same effect; the latter is sometimes used
to show that the effect is the converse of box.space...:get().
At the time that a trigger is defined, it is
automatically enabled - that is, it will be executed.
Replace triggers
can be disabled with box.space.space-name:run_triggers(false)
and re-enabled with box.space.space-name:run_triggers(true).
Return:
nil
Example:
The following series of requests will associate an existing function named F
with an existing space named T, associate the function a second time with the
same space (so it will be called twice), disable all triggers of T, and delete
each trigger by replacing with nil.
options.iterator – the iterator type. The default iterator type is ‘EQ’.
options.limit – the maximum number of tuples.
options.offset – the number of tuples to skip.
options.after – a tuple or the position of a tuple (tuple_pos) after which select starts the search. You can pass an empty string or box.NULL to this option to start the search from the first tuple.
options.fetch_pos – if true, the select method returns the position of the last selected tuple as the second value.
Note
The after and fetch_pos options are supported for the TREEindex only.
Return:
This function might return one or two values:
The tuples whose primary-key fields are equal to the fields of the passed key.
If the number of passed fields is less than the
number of fields in the primary key, then only the passed
fields are compared, so select{1,2} matches a tuple
whose primary key is {1,2,3}.
(Optionally) If options.fetch_pos is set to true, returns a base64-encoded string representing the position of the last selected tuple as the second value.
If no tuples are fetched, returns nil.
Rtype:
array of tuples
(Optionally) string
Possible errors:
no such space
wrong type
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode
iterator position is invalid
Complexity factors: Index size, Index type.
Examples:
Below are few examples of using select with different parameters.
To try out these examples, you need to bootstrap a Tarantool instance
as described in Using data operations.
-- Insert test data --tarantool> bands:insert{1,'Roxette',1986} bands:insert{2, 'Scorpions', 1965} bands:insert{3, 'Ace of Base', 1987} bands:insert{4, 'The Beatles', 1960} bands:insert{5, 'Pink Floyd', 1965} bands:insert{6, 'The Rolling Stones', 1962} bands:insert{7, 'The Doors', 1965} bands:insert{8, 'Nirvana', 1987} bands:insert{9, 'Led Zeppelin', 1968} bands:insert{10, 'Queen', 1970}---...-- Select a tuple by the specified primary key --tarantool> bands:select(4)-----[4,'TheBeatles',1960]...-- Select maximum 3 tuples with the primary key value greater than 3 --tarantool> bands:select({3},{iterator='GT',limit=3})-----[4,'TheBeatles',1960]-[5,'PinkFloyd',1965]-[6,'TheRollingStones',1962]...-- Select maximum 3 tuples after the specified tuple --tarantool> bands:select({},{after={4,'The Beatles',1960},limit=3})-----[5,'PinkFloyd',1965]-[6,'TheRollingStones',1962]-[7,'TheDoors',1965]...-- Select first 3 tuples and fetch a last tuple's position --tarantool> result,position=bands:select({},{limit=3,fetch_pos=true})---...-- Then, pass this position as the 'after' parameter --tarantool> bands:select({},{limit=3,after=position})-----[4,'TheBeatles',1960]-[5,'PinkFloyd',1965]-[6,'TheRollingStones',1962]...
Returns a table with the cumulative statistics on the memory usage by tuples in the space.
Statistics are grouped by arena types: memtx or malloc.
For each arena type, the return table includes tuple memory usage statistics
listed in the tuple_object.info() reference.
Note
Memory usage statistics are shown only for the memtx storage engine.
For other types of spaces, an empty table is returned.
Complexity factors: Index size, Index type, Number of tuples accessed.
Return:
nil
The truncate method can only be called by the user who created
the space, or from within a setuid function created by the user
who created the space.
Read more about setuid functions in the reference for
box.schema.func.create().
Note
Do not call this method within a transaction in
Tarantool older than v. 2.10.0. See gh-6123 for details.
The update function supports operations on fields — assignment,
arithmetic (if the field is numeric), cutting and pasting
fragments of a field, deleting or inserting a field. Multiple
operations can be combined in a single update request, and in this
case they are performed atomically and sequentially. Each operation
requires specification of a field identifier, which is usually a number. When multiple operations
are present, the field number for each operation is assumed to be
relative to the most recent state of the tuple, that is, as if all
previous operations in a multi-operation update have already been
applied. In other words, it is always safe to merge multiple update
invocations into a single invocation, with no change in semantics.
Possible operators are:
+ for addition. values must be numeric, e.g. unsigned or decimal
- for subtraction. values must be numeric
& for bitwise AND. values must be unsigned numeric
| for bitwise OR. values must be unsigned numeric
^ for bitwise XOR. values must be
unsigned numeric
: for string splice.
! for insertion of a new field.
# for deletion.
= for assignment.
Possible field_identifiers are:
Positive field number. The first field is 1, the second field is 2,
and so on.
Negative field number. The last field is -1, the second-last field
is -2, and so on. In other words: (#tuple + negative field number + 1).
Name. If the space was formatted with
space_object:format(), then this can
be a string for the field ‘name’.
key (scalar/table) – primary-key field values, must be passed as a
Lua table if key is multi-part
operator (string) – operation type represented in string
field_identifier (number-or-string) – what field the operation will apply to.
value (lua_value) – what value will be applied
Return:
the updated tuple
nil if the key is not found
Rtype:
tuple or nil
Possible errors:
It is illegal to modify a primary key field.
ER_TRANSACTION_CONFLICT if a transaction conflict is detected in the
MVCC transaction mode.
Complexity factors: Index size, Index type, number of indexes
accessed, WAL settings.
Thus, in the instruction:
s:update(44,{{'+',1,55},{'=',3,'x'}})
the primary-key value is 44, the operators are '+' and '='
meaning add a value to a field and then assign a value to a field, the
first affected field is field 1 and the value which will be added to
it is 55, the second affected field is field 3 and the value
which will be assigned to it is 'x'.
Example:
Assume that initially there is a space named tester with a
primary-key index whose type is unsigned. There is one tuple, with
field[1] = 999 and field[2] = 'A'.
In the update: box.space.tester:update(999,{{'=',2,'B'}})
The first argument is tester, that is, the affected space is tester.
The second argument is 999, that is, the affected tuple is identified by
primary key value = 999.
The third argument is =, that is, there is one operation —
assignment to a field.
The fourth argument is 2, that is, the affected field is field[2].
The fifth argument is 'B', that is, field[2] contents change to 'B'.
Therefore, after this update, field[1] = 999 and field[2] = 'B'.
In the update: box.space.tester:update({999},{{'=',2,'B'}})
the arguments are the same, except that the key is passed as a Lua table
(inside braces). This is unnecessary when the primary key has only one
field, but would be necessary if the primary key had more than one field.
Therefore, after this update, field[1] = 999 and field[2] = 'B' (no change).
In the update: box.space.tester:update({999},{{'=',3,1}})
the arguments are the same, except that the fourth argument is 3,
that is, the affected field is field[3]. It is okay that, until now,
field[3] has not existed. It gets added. Therefore, after this update,
field[1] = 999, field[2] = 'B', field[3] = 1.
In the update: box.space.tester:update({999},{{'+',3,1}})
the arguments are the same, except that the third argument is '+',
that is, the operation is addition rather than assignment. Since
field[3] previously contained 1, this means we’re adding 1
to 1. Therefore, after this update, field[1] = 999,
field[2] = 'B', field[3] = 2.
In the update: box.space.tester:update({999},{{'|',3,1},{'=',2,'C'}})
the idea is to modify two fields at once. The formats are '|' and
=, that is, there are two operations, OR and assignment. The fourth
and fifth arguments mean that field[3] gets OR’ed with 1. The
seventh and eighth arguments mean that field[2] gets assigned 'C'.
Therefore, after this update, field[1] = 999, field[2] = 'C',
field[3] = 3.
In the update: box.space.tester:update({999},{{'#',2,1},{'-',2,3}})
The idea is to delete field[2], then subtract 3 from field[3].
But after the delete, there is a renumbering, so field[3] becomes
field[2] before we subtract 3 from it, and that’s why the
seventh argument is 2, not 3. Therefore, after this update,
field[1] = 999, field[2] = 0.
In the update: box.space.tester:update({999},{{'=',2,'XYZ'}})
we’re making a long string so that splice will work in the next example.
Therefore, after this update, field[1] = 999, field[2] = 'XYZ'.
In the update: box.space.tester:update({999},{{':',2,2,1,'!!'}})
The third argument is ':', that is, this is the example of splice.
The fourth argument is 2 because the change will occur in field[2].
The fifth argument is 2 because deletion will begin with the second byte.
The sixth argument is 1 because the number of bytes to delete is 1.
The seventh argument is '!!', because '!!' is to be added at this position.
Therefore, after this update, field[1] = 999, field[2] = 'X!!Z'.
If there is an existing tuple which matches the key fields of tuple,
then the request has the same effect as
space_object:update() and the
{{operator,field_identifier,value},...} parameter is used.
If there is no existing tuple which matches the key fields of tuple,
then the request has the same effect as
space_object:insert() and the
{tuple} parameter is used. However, unlike insert or
update, upsert will not read a tuple and perform
error checks before returning – this is a design feature which
enhances throughput but requires more caution on the part of the user.
You can extend space_object with custom functions as follows:
Create a Lua function.
Add the function name to a predefined global variable box.schema.space_mt, which has the table type. Adding to box.schema.space_mt makes the function available for all spaces.
Call the function on the space_object: space_object:function-name([parameters]).
Alternatively, you can make a user-defined function available for only one space
by calling getmetatable(space_object) and then adding the function name to the
meta table.
-- Visible to any space, no parameters.-- After these requests, the value of global_variable will be 6.box.schema.space.create('t')box.space.t:create_index('i')global_variable=5functionf(space_arg)global_variable=global_variable+1endbox.schema.space_mt.counter=fbox.space.t:counter()
box.space.create_check_constraint()
Warning
This function was removed in 2.11.0.
The check constraint mechanism is replaced with the new tuple constraints.
Learn more about tuple constraints in Constraints.
Create a check constraint.
A check constraint is a requirement that must be met when a tuple
is inserted or updated in a space.
Check constraints created with space_object:create_check_constraint have
the same effect as check constraints created with an SQL CHECK() clause
in a CREATE TABLE statement.
expression (string) – SQL code of an expression which must return a boolean result
Return:
check constraint object
Rtype:
check_constraint_object
The space must be formatted with space_object:format()
so that the expression can contain field names.
The space must be empty. The space must not be a system space.
The expression must return true or false and should be deterministic.
The expression may be any SQL (not Lua) expression containing field names,
built-in function names, literals, and operators. Not subqueries.
If a field name contains lower case characters, it must be enclosed in “double quotes”.
Check constraints are checked before the request is performed,
at the same time as Lua
before_replace triggers.
If there is more than one check constraint or before_replace trigger,
then they are ordered according to time of creation.
(This is a change from the earlier behavior of check constraints,
which caused checking before the tuple was formed.)
Check constraints can be dropped with space_object.ck_constraint.check_constraint_name:drop().
Check constraints can be disabled with space_object.ck_constraint.check_constraint_name:enable(false)
or check_constraint_object:enable(false).
Check constraints can be enabled with space_object.ck_constraint.check_constraint_name:enable(true)
or check_constraint_object:enable(true).
By default a check constraint is ‘enabled’ which means that the check is performed
whenever the request is performed, but can be changed to ‘disabled’ which means that
the check is not performed.
During the recovery process, for example when the Tarantool server is starting,
the check is not performed unless
force_recovery
is specified.
Example:
box.schema.space.create('t')box.space.t:format({{name='f1',type='unsigned'},{name='f2',type='string'},{name='f3',type='string'}})box.space.t:create_index('i')box.space.t:create_check_constraint('c1',[["f2" > 'A']])box.space.t:create_check_constraint('c2',[["f2"=UPPER("f3") AND NOT "f2" LIKE '__']])-- This insert will fail, constraint c1 expression returns falsebox.space.t:insert{1,'A','A'}-- This insert will fail, constraint c2 expression returns falsebox.space.t:insert{1,'B','c'}-- This insert will succeed, both constraint expressions return truebox.space.t:insert{1,'B','b'}-- This update will fail, constraint c2 expression returns falsebox.space.t:update(1,{{'=',2,'xx'},{'=',3,'xx'}})
Ordinal space number. Spaces can be referenced by either name or
number. Thus, if space tester has id=800, then
box.space.tester:insert{0} and box.space[800]:insert{0}
are equivalent requests.
-- checking the number of indexes for space 'tester'tarantool> localcounter=0;fori=0,#box.space.tester.indexdo if box.space.tester.index[i]~=nil then counter=counter+1 end end; print(counter)1---...-- checking the type of index 'primary'tarantool> box.space.tester.index.primary.type----TREE...
A system space containing functions created using box.schema.func.create().
If a function’s definition is specified in the body option,
this function is persistent.
In this case, its definition is stored in a snapshot and can be recovered if the server restarts.
_priv is a system space where
privileges are stored.
Tuples in this space contain the following fields:
the numeric id of the user who gave the privilege (“grantor_id”),
the numeric id of the user who received the privilege (“grantee_id”),
the type of object: ‘space’, ‘index’, ‘function’, ‘sequence’, ‘user’, ‘role’, or ‘universe’,
the numeric id of the object,
the type of operation: “read” = 1, “write” = 2, “execute” = 4,
“create” = 32, “drop” = 64, “alter” = 128, or
a combination such as “read,write,execute”.
once...: tuples that correspond to specific
box.once() blocks from the instance’s
initialization file.
The first field in these tuples contains the key value from the
corresponding box.once() block prefixed with ‘once’ (for example, oncehello),
so you can easily find a tuple that corresponds to a specific
box.once() block.
Example:
In the example, the _schema space contains two box.once objects – oncebye and oncehello.
The following requests will create a space using
box.schema.space.create() with a format clause, then retrieve
the _space tuple for the new space. This illustrates the typical use of
the format clause, it shows the recommended names and data types for the
fields.
-- Create a sequence --box.schema.sequence.create('id_seq',{min=1000,start=1000})-- Create a space --box.schema.space.create('customers')-- Create an index that uses the sequence --box.space.customers:create_index('primary',{sequence='id_seq'})-- Create a space --box.schema.space.create('orders')-- Create an index that uses an auto sequence --box.space.orders:create_index('primary',{sequence=true})-- Check the connections between spaces and sequencesbox.space._space_sequence:select{}--[[---- - [512, 1, false, 0, ''] - [513, 2, true, 0, '']...--]]
_user is a system space where user names and password hashes are stored.
Learn more about Tarantool’s access control system from the Access control topic.
Tuples in this space contain the following fields:
a numeric id of the tuple (“id”)
a numeric id of the tuple’s creator
a name
a type: ‘user’ or ‘role’
(optional) a password hash
(optional) an array of previous authentication data
(optional) a timestamp of the last password update
There are five special tuples in the _user space: ‘guest’, ‘admin’,
‘public’, ‘replication’, and ‘super’.
Name
ID
Type
Description
guest
0
user
Default user when connecting remotely.
Usually, an untrusted user with few privileges.
admin
1
user
Default user when using Tarantool as a console.
Usually, an
administrative user
with all privileges.
public
2
role
Pre-defined role,
automatically granted to new users when they are
created with
box.schema.user.create(user-name).
Therefore a convenient way to grant ‘read’ on space
‘t’ to every user that will ever exist is with
box.schema.role.grant('public','read','space','t').
replication
3
role
Pre-defined role,
which the ‘admin’ user can grant to users who need to use
replication features.
super
31
role
Pre-defined role,
which the ‘admin’ user can grant to users who need all
privileges on all objects.
The ‘super’ role has these privileges on
‘universe’:
read, write, execute, create, drop, alter.
To select a tuple from the _user space, use box.space._user:select().
In the example below, select is executed for a user with id = 0.
This is the ‘guest’ user that has no password.
Explanation of the fields in the example: id = 239 i.e. Tarantool’s primary key is 239,
name = ‘unicode_uk_s2’ i.e. according to Tarantool’s naming convention this is a
Unicode collation + it is for the uk locale + it has secondary strength,
owner = 1 i.e. the admin user,
type = ‘ICU’ i.e. the rules are according to International Components for Unicode,
locale = ‘uk’ i.e. Ukrainian,
opts = ‘strength:secondary’ i.e. with this collation comparisons use both primary and secondary
weights.
A system space view, also called a ‘sysview’, is a restricted read-only copy of a system space.
The system space views and the system spaces that they are associated with are: _vcollation, a view of _collation, _vfunc, a view of _func, _vindex, a view of _index, _vpriv, a view of _priv, _vsequence, a view of _sequence, _vspace, a view of _space, _vspace_sequence, a view of _space_sequence, _vuser, a view of _user.
The structure of a system space view’s tuples is identical to the
structure of the associated space’s tuples. However, the privileges for a
system space view are usually different. By default, ordinary users do not have
any privileges for most system spaces, but have a ‘read’ privilege for system space views.
Typically this is the default situation:
* The ‘public’ role has ‘read’ privilege on all system space views
because that is the situation when the database is first created.
* All users have the ‘public’ role, because it is granted
to them automatically during box.schema.user.create().
* The system space view will contain the tuples in the associated system space,
if and only if the user has a privilege for the object named in the tuple.
Unless administrators change the privileges, the effect is that non-administrator
users cannot access the system space, but they can access the system space view, which shows
only the objects that they can access.
For example, typically, the ‘admin’ user can do anything with _space and _vspace
looks the same as _space. But the ‘guest’ user can only read _vspace, and
_vspace contains fewer tuples than _space. Therefore in most installations
the ‘guest’ user should select from _vspace to get a list of spaces.
Example:
This example shows the difference between _vuser and _user.
We have explained that:
If the user has the full set of privileges (like ‘admin’), the contents
of _vuser match the contents of _user. If the user has limited
access, _vuser contains only tuples accessible to this user.
To see how _vuser works,
connect to a Tarantool database remotely
via net.box and select all tuples from the _user
space, both when the ‘guest’ user is and is not allowed to read from the
database.
First, start Tarantool and grant read, write and execute
privileges to the guest user:
Switch to the other terminal, stop the session (to stop tarantool type Ctrl+C
or Ctrl+D), start again, connect again, and repeat the
conn.space._user:select{} request. The access is denied:
tarantool> conn.space._user:select{}----error:Read access to space '_user' is denied for user 'guest'...
However, if you select from _vuser instead, the users’ data available for the
‘guest’ user is displayed:
A temporary system space with settings that affect behavior, particularly SQL behavior,
for the current session. It uses a special engine named ‘service’.
Every ‘service’ tuple is created on the fly, that is, new tuples are made every
time _session_settings is accessed.
Every settings tuple has two fields: name (the primary key) and value.
The tuples’ names and default values are:
sql_default_engine: default storage engine for new SQL tables. Default: memtx.
sql_full_metadata: whether SQL result set metadata includes more than just name
and type. Default:false.
sql_parser_debug: show parser steps for following statements. Default: false.
sql_recursive_triggers: whether a triggered statement can activate a trigger.
Default: true.
sql_reverse_unordered_selects: return result rows in reverse order if there is no ORDER BY clause.
Default: false.
sql_select_debug: show execution steps during SELECT. Default:false.
sql_seq_scan: allow sequential scans in SQL SELECT. Default: true.
sql_vdbe_debug: for internal use. Default:false.
sql_defer_foreign_keys (removed in 2.11.0): whether foreign-key checks can wait till
commit. Default: false.
error_marshaling_enabled (removed in 2.10.0): whether error objects have
a special structure. Default: false.
Three requests are possible: select, get
and update.
For example, after s=box.space._session_settings,
s:select('sql_default_engine') probably returns {'sql_default_engine','memtx'}, and
s:update('sql_default_engine',{{'=','value','vinyl'}}) changes the default engine to ‘vinyl’.
Updating sql_parser_debug or sql_select_debug or sql_vdbe_debug has no effect unless
Tarantool was built with -DCMAKE_BUILD_TYPE=Debug. To check if this is so, look at
require('tarantool').build.target.
Submodule box.stat
The box.stat submodule provides access to request and network statistics.
Shows the total number of requests since startup and
the average number of requests per second,
broken down by request type.
Return:
in the tables that box.stat() returns:
total: total number of requests processed per second since the server started
rps: average number of requests per second in the last 5 seconds.
ERROR is the count of requests that resulted in an error.
Example:
tarantool> box.stat()-- return 15 tables----DELETE:total:0rps:0COMMIT:total:0rps:0SELECT:total:12rps:0ROLLBACK:total:0rps:0INSERT:total:6rps:0EVAL:total:0rps:0ERROR:total:0rps:0CALL:total:0rps:0BEGIN:total:0rps:0PREPARE:total:0rps:0REPLACE:total:0rps:0UPSERT:total:0rps:0AUTH:total:0rps:0EXECUTE:total:0rps:0UPDATE:total:2rps:0...tarantool> box.stat().DELETE-- total + requests per second from one table----total:0rps:0...
Shows network activity per network thread:
the number of bytes sent and received, the number of connections, streams,
and requests (current, average, and total).
When called with an index (box.stat.net.thread[1]), shows network statistics for
a single network thread.
Return:
Same network activity metrics as box.stat.net()
for each network thread
data shows how much memory (in bytes) is allocated for memtx tuples:
data.garbage is the amount of memory that is unused and scheduled to be freed
(freed lazily on memory allocation).
data.total is the total amount of memory allocated for data tuples.
This includes data.read_view and data.garbage plus tuples that are
actually stored in memtx spaces.
data.read_view is the amount of memory held for read views.
This includes memory allocated both for system read views (snapshot, replication)
and user read views (EE-only). This should be non-zero only if there are open read views.
index shows how much memory (in bytes) is allocated for indexing memtx tuples:
index.read_view is the amount of memory held for read views.
This includes memory allocated both for system read views (snapshot, replication)
and user read views (EE-only). This should be non-zero only if there are open read views.
index.total is the total amount of memory allocated for
indexing data. This includes index.read_view plus memory used for indexing
tuples that are actually stored in memtx spaces.
tx shows the statistics of the memtx transactional manager,
which is responsible for transactions (box.stat.memtx().tx.txn)
and multiversion concurrency control (box.stat.memtx().tx.mvcc).
box.stat.memtx().tx.txn shows memory allocation related to transactions.
It consists of the following sections:
statements are transaction statements.
As an example, consider a user starting a transaction with
space:replace{0,1} within this transaction. Under the hood,
this operation becomes a statement for this transaction.
user is the memory that a user allocated within
the current transaction using the Tarantool C API function
box_txn_alloc().
system is the memory allocated for internal needs
(for example, logs) and savepoints.
For each section, Tarantool reports the following statistics:
total is the number of bytes that are currently allocated in memtx
for all transactions within the section scope.
avg is the average number of bytes that a single transaction uses
(equals total / number of open transactions).
max is the maximal number of bytes that a single transaction uses.
box.stat.memtx().tx.mvcc shows memory allocation related to
multiversion concurrency control (MVCC).
MVCC is reponsible for isolating transactions.
It reveals conflicts and makes sure that tuples that do not belong to a particular
space but were (or could be) read by some transaction were not deleted.
It consists of the following sections:
trackers is the memory allocated for trackers of transaction reads.
Like in the previous sections,
Tarantool reports the total, average, and maximal number of bytes allocated
for trackers per a single transaction.
conflicts is the memory allocated for conflicts
which are entities created when transactional conflicts occur.
Like in the previous sections,
Tarantool reports the total, average, and maximal number of allocated bytes.
tuples is the memory allocated for storing tuples.
With MVCC, tuples are stored using the stories mechanism. Nearly every
tuple has its story. Even tuples in an index may have their stories, so
it may be useful to differentiate memory allocated for tuples and memory
allocated for stories.
All stored tuples fall into three categories, with memory statistics
reported for each category:
tracking is for tuples that are not used by any transactions directly,
but MVCC uses them for tracking transaction reads.
used is for tuples that are used by active read-write transactions.
See a detailed example below.
read_view is for tuples that are not used by active read-write transactions,
but are used by read-only transactions.
For each of the three categories, Tarantool reports two statistical blocks:
stories is for stories.
retained is for retained tuples which do not belong to any index,
but MVCC doesn’t allow to delete them yet.
For each block, Tarantool reports the following statistics:
count is the number of stories or retained tuples.
total is the number of bytes allocated for stories or retained tuples.
Example
This example illustrates memory statistics for used tuples in a transaction.
The cluster must be started with the database.use_mvcc_engine
parameter set to true. This enables MVCC so that
box.stat.memtx.tx().mvcc contains non-zero values.
The next step is to create a space with a primary index and to begin a transaction:
In the transaction above, three tuples are replaced by the 0 key:
{0,0}
{0,'aa...aa'}
{0,1}
MVCC considers all these tuples as used since they belong to the current transaction.
Also, MVCC considers tuples {0,0} and {0,'aa..aa'} as retained because
they don’t belong to any index (unlike {0,1}) but cannot be deleted yet.
Calling box.stat.memtx.tx() now returns the following result:
Shows vinyl-storage-engine activity, for example
box.stat.vinyl().tx has the number of commits and rollbacks.
Example:
tarantool> box.stat.vinyl().tx.commit-- one item of the vinyl table----1047632...
box.stat.vinyl().regulator
The vinyl regulator decides when to take or delay actions for
disk IO, grouping activity in batches so that it is
consistent and efficient. The regulator is invoked by
the vinyl scheduler, once per second, and updates
related variables whenever it is invoked.
box.stat.vinyl().regulator.dump_bandwidth is
the estimated average rate at which dumps are done.
Initially this will appear as 10485760 (10 megabytes per second).
Only significant dumps (larger than one megabyte) are used for estimating.
box.stat.vinyl().regulator.dump_watermark
is the point when dumping must occur.
The value is slightly smaller than the amount of memory
that is allocated for vinyl trees, which is the
vinyl_memory parameter.
box.stat.vinyl().regulator.write_rate
is the actual average rate at which recent writes to disk are done.
Averaging is done over a 5-second time window, so if there has
been no activity for 5 seconds then regulator.write_rate=0.
The write_rate may be slowed when a dump is in progress
or when the user has set
snap_io_rate_limit.
box.stat.vinyl().regulator.rate_limit is the write rate limit,
in bytes per second, imposed on transactions by
the regulator based on the observed dump/compaction performance.
box.stat.vinyl().regulator.blocked_writers is the number of fibers
currently blocked waiting for vinyl L0 memory
quota.
box.stat.vinyl().disk
Since vinyl is an on-disk storage engine
(unlike memtx which is an in-memory storage engine),
it can handle large databases – but if a database is
larger than the amount of memory that is allocated for vinyl,
then there will be more disk activity.
box.stat.vinyl().disk.data and box.stat.vinyl().disk.index
are the amount of data that has gone into files in a subdirectory
of vinyl_dir,
with names like {lsn}.run
and {lsn}.index. The size of the run will be
related to the output of scheduler.dump_*.
box.stat.vinyl().disk.data_compacted
Sum size of data stored at the last LSM tree level, in bytes,
without taking disk compression into account. It can be thought of as the
size of disk space that the user data would occupy if there were no compression,
indexing, or space increase caused by the LSM tree design.
box.stat.vinyl().memory
Although the vinyl storage engine is not “in-memory”, Tarantool does
need to have memory for write buffers and for caches:
box.stat.vinyl().memory.tuple_cache
is the number of bytes that are being used for tuples (data).
box.stat.vinyl().memory.tx
is transactional memory. This will usually be 0.
box.stat.vinyl().memory.level0
is the “level0” memory area, sometimes abbreviated “L0”, which is the
area that vinyl can use for in-memory storage of an LSM tree.
Therefore we can say that “L0 is becoming full” when the
amount in memory.level0 is close to the maximum, which is
regulator.dump_watermark.
We can expect that “L0 = 0” immediately after a dump.
box.stat.vinyl().memory.page_index and box.stat.vinyl().memory.bloom_filter
have the current amount being used for index-related structures.
The size is a function of the number and size of keys,
plus vinyl_page_size,
plus vinyl_bloom_fpr.
This is not a count of bloom filter “hits”
(the number of reads that could be avoided because the
bloom filter predicts their presence in a run file) –
that statistic can be found with
index_object:stat().
box.stat.vinyl().tx
This is about requests that affect transactional activity
(“tx” is used here as an abbreviation for “transaction”):
box.stat.vinyl().tx.conflict
counts conflicts that caused a transaction to roll back.
box.stat.vinyl().tx.commit
is the count of commits (successful transaction ends).
It includes implicit commits, for example any insert causes a commit unless
it is within a begin-end block.
box.stat.vinyl().tx.rollback
is the count of rollbacks (unsuccessful transaction ends).
This is not merely a count of explicit
box.rollback() requests –
it includes requests that ended in errors.
For example, after an attempted insert request that causes
a “Duplicate key exists in unique index” error, tx.rollback
is incremented.
box.stat.vinyl().tx.statements
will usually be 0.
box.stat.vinyl().tx.transactions
is the number of transactions that are currently running.
box.stat.vinyl().tx.gap_locks
is the number of gap locks that are outstanding during execution of a request.
For a low-level description of Tarantool’s implementation of gap locking, see
Gap locks in Vinyl transaction manager.
box.stat.vinyl().tx.read_views
shows whether a transaction has entered a read-only state
to avoid conflict temporarily. This will usually be 0.
box.stat.vinyl().scheduler
This primarily has counters related to tasks that the scheduler has arranged
for dumping or compaction:
(most of these items are reset to 0 when the server restarts or when
box.stat.reset() occurs):
box.stat.vinyl().scheduler.compaction_*
is the amount of data from recent changes that has been
compacted.
This is divided into scheduler.compaction_input (the amount that is being
compacted), scheduler.compaction_queue (the amount that is waiting to be
compacted),
scheduler.compaction_time (total time spent by all worker threads performing compaction, in seconds),
and scheduler.compaction_output (the amount that has been compacted,
which is presumably smaller than scheduler.compaction_input).
box.stat.vinyl().scheduler.tasks_*
is about dump/compaction tasks, in three categories,
scheduler.tasks_inprogress (currently running),
scheduler.tasks_completed (successfully completed)
scheduler.tasks_failed (aborted due to errors).
box.stat.vinyl().scheduler.dump_* has
the amount of data from recent changes that has been dumped,
including dump_time (total time spent by all worker threads performing dumps, in seconds),
and dump_count (the count of completed dumps),
dump_input and dump_output.
Sooner or later the number of elements in an LSM tree exceeds the L0 size and that is
when L0 gets written to a file on disk (called a ‘run’) and then cleared for storing new elements.
This operation is called a ‘dump’.
Thus it can be predicted that a dump will occur if the
size of L0
(which is memory.level0)
is approaching the
maximum
(which is regulator.dump_watermark)
and a
dump is not already in progress. In fact Tarantool will
try to arrange a dump before this hard limit is reached.
A dump will also occur during a
snapshot operation.
Resets the statistics of box.stat(), box.stat.net(),
box.stat.memtx(), box.stat.vinyl(), and
box.space.index.
Submodule box.tuple
The box.tuple submodule provides read-only access for the tuple
userdata type. It allows, for a single tuple: selective
retrieval of the field contents, retrieval of information about size, iteration
over all the fields, and conversion to a Lua table.
This function will illustrate how to convert tuples to/from Lua tables and lists
of scalars:
tuple=box.tuple.new({scalar1,scalar2,...scalar_n})-- scalars to tuplelua_table={tuple:unpack()}-- tuple to Lua tablelua_table=tuple:totable()-- tuple to Lua tablescalar1,scalar2,...scalar_n=tuple:unpack()-- tuple to scalarstuple=box.tuple.new(lua_table)-- Lua table to tuple
Then it will find the field that contains ‘b’, remove that field from the tuple,
and display how many bytes remain in the tuple. The function uses Tarantool
box.tuple functions new(), unpack(), find(), transform(),
bsize().
functionexample()localtuple1,tuple2,lua_table_1,scalar1,scalar2,scalar3,field_numberlocalluatable1={}tuple1=box.tuple.new({'a','b','c'})luatable1=tuple1:totable()scalar1,scalar2,scalar3=tuple1:unpack()tuple2=box.tuple.new(luatable1[1],luatable1[2],luatable1[3])field_number=tuple2:find('b')tuple2=tuple2:transform(field_number,1)return'tuple2 = ',tuple2,' # of bytes = ',tuple2:bsize()end
… And here is what happens when one invokes the function:
Construct a new tuple from either a scalar or a Lua table. Alternatively,
one can get new tuples from Tarantool’s select
or insert or replace
or update requests,
which can be regarded as statements that do
new() implicitly.
Parameters:
value (lua-value) – the value that will become the tuple contents.
Return:
a new tuple
Rtype:
tuple
In the following example, x will be a new table object containing one
tuple and t will be a new tuple object. Saying t returns the
entire tuple t.
If t is a tuple instance, t:bsize() will return the number of
bytes in the tuple. With both the memtx storage engine and the vinyl
storage engine the default maximum is one megabyte
(memtx_max_tuple_size or
vinyl_max_tuple_size). Every
field has one or more “length” bytes preceding the actual contents, so
bsize() returns a value which is slightly greater than the sum of
the lengths of the contents.
The value does not include the size of “struct tuple” (for the current
size of this structure look in the
tuple.h
file in Tarantool’s source code).
Return:
number of bytes
Rtype:
number
In the following example, a tuple named t is created which has
three fields, and for each field it takes one byte to store the length
and three bytes to store the contents, and then there is one more byte
to store a count of the number of fields, so bsize() returns
3*(1+3)+1. This is the same as the size of the string that
msgpack.encode({‘aaa’,’bbb’,’ccc’})
would return.
If t is a tuple instance, t['field-name'] will return the field
named ‘field-name’ in the tuple. Fields have names if the tuple has
been retrieved from a space that has an associated format.
t[lua-variable-name] will do the same thing if lua-variable-name
contains 'field-name'.
There is a variation which the
Lua manual
calls “syntactic sugar”:
use t.field-name as an equivalent of t['field-name'].
Return:
field value.
Rtype:
lua-value
In the following example, a tuple named t is returned from replace
and then the second field in t named ‘field2’ is returned.
If t is a tuple instance, t['path'] will return the field
or subset of fields that are in path. path must be a well
formed JSON specification. path may contain field names if the tuple has
been retrieved from a space that has an associated format.
To prevent ambiguity, Tarantool first tries to interpret the
request as tuple_object[field-number]
or tuple_object[field-name].
If and only if that fails, Tarantool tries to interpret the request
as tuple_object[field-path].
The path must be a well formed JSON specification, but it may be
preceded by ‘.’. The ‘.’ is a signal that the path acts as a suffix
for the tuple.
The advantage of specifying a path is that Tarantool will use it to
search through a tuple body and get only the tuple part, or parts,
that are actually necessary.
In the following example, a tuple named t is returned from replace
and then only the relevant part (in this case, matching a name)
of a relevant field is returned. Namely: the second field, its
third item, the value following ‘key=’.
If t is a tuple instance, t:find(search-value) will return the
number of the first field in t that matches the search value,
and t:findall(search-value[,search-value...]) will return numbers
of all fields in t that match the search value. Optionally one can
put a numeric argument field-number before the search-value to
indicate “start searching at field number field-number.”
Return:
the number of the field in the tuple.
Rtype:
number
In the following example, a tuple named t is created and then: the
number of the first field in t which matches ‘a’ is returned, then
the numbers of all the fields in t which match ‘a’ are returned,
then the numbers of all the fields in t which match ‘a’ and are at or
after the second field are returned.
Get the format of a tuple. The resulting table lists the fields of a tuple
(their names and types) if the format option was specified during the tuple
creation. Otherwise, the return value is empty.
An analogue of the Lua next() function, but for a tuple object.
When called without arguments, tuple:next() returns the first field
from a tuple. Otherwise, it returns the field next to the indicated position.
However tuple:next() is not really efficient, and it is better
to use
tuple:pairs()/ipairs().
In Lua, lua-table-value:pairs()
is a method which returns:
function, lua-table-value, nil. Tarantool has extended
this so that tuple-value:pairs() returns: function,
tuple-value, nil. It is useful for Lua iterators, because Lua
iterators traverse a value’s components until an end marker is reached.
tuple_object:ipairs() is the same as pairs(), because tuple
fields are always integers.
Return:
function, tuple-value, nil
Rtype:
function, lua-value, nil
In the following example, a tuple named t is created and then all
its fields are selected using a Lua for-end loop.
If t is a tuple instance, t:totable() will return all fields,
t:totable(1) will return all fields starting with field number 1,
t:totable(1,5) will return all fields between field number 1 and field number 5.
It is preferable to use t:totable() rather than t:unpack().
Return:
field(s) from the tuple
Rtype:
lua-table
In the following example, a tuple named t is created, then all
its fields are selected, then the result is returned.
A Lua table can have indexed values,
also called key:value pairs.
For example, here:
a={};a['field1']=10;a['field2']=20
a is a table with “field1: 10” and “field2: 20”.
The tuple_object:totable()
function only returns a table containing the values.
But the tuple_object:tomap() function returns a table containing
not only the values, but also the key:value pairs.
This only works if the tuple comes from a space that has
been formatted with a format clause.
If t is a tuple instance,
t:transform(start-field-number,fields-to-remove)
will return a tuple where, starting from field start-field-number,
a number of fields (fields-to-remove) are removed. Optionally one
can add more arguments after fields-to-remove to indicate new
values that will replace what was removed.
If the original tuple comes from a space that has been formatted with a
format clause, the formatting will not be
preserved for the result tuple.
Parameters:
start-field-number (integer) – base 1, may be negative
fields-to-remove (integer) –
field-value(s) (lua-value) –
Return:
tuple
Rtype:
tuple
In the following example, a tuple named t is created and then,
starting from the second field, two fields are removed but one new
one is added, then the result is returned.
If t is a tuple instance, t:unpack() will return all fields,
t:unpack(1) will return all fields starting with field number 1,
t:unpack(1,5) will return all fields between field number 1 and field number 5.
Return:
field(s) from the tuple.
Rtype:
lua-value(s)
In the following example, a tuple named t is created and then all
its fields are selected, then the result is returned.
This function updates a tuple which is not in a space. Compare the function
box.space.space-name:update(key,{{format,field_no,value},...})
which updates a tuple in a space.
If the original tuple comes from a space that has been formatted with a
format clause, the formatting will be
preserved for the result tuple.
Parameters:
operator (string) – operation type represented in string (e.g.
‘=’ for ‘assign new value’)
field_no (number) – what field the operation will apply to. The
field number can be negative, meaning the
position from the end of tuple.
(#tuple + negative field number + 1)
value (lua_value) – what value will be applied
Return:
new tuple
Rtype:
tuple
In the following example, a tuple named t is created and then its
second field is updated to equal ‘B’.
The same as tuple_object:update(), but ignores errors. In case
of an error the tuple is left intact, but an error message is
printed. Only client errors are ignored, such as a bad field type,
or wrong field index/name. System errors, such as OOM, are not
ignored and raised just like with a normal update(). Note that
only bad operations are ignored. All correct operations are
applied.
Parameters:
operator (string) – operation type represented as a string (e.g.
‘=’ for ‘assign new value’)
field_no (number) – the field to which the operation will be applied. The
field number can be negative, meaning the
position from the end of tuple.
(#tuple + negative field number + 1)
value (lua_value) – the value which will be applied
Return:
new tuple
Rtype:
tuple
See the following example where one operation is applied, and one is not.
tarantool> t=box.tuple.new({1,2,3})tarantool> t2=t:upsert({{'=',5,100}})UPSERT operation failed:ER_NO_SUCH_FIELD_NO: Field 5 was not found in the tuple---...tarantool> t----[1,2,3]...tarantool> t2----[1,2,3]...tarantool> t2=t:upsert({{'=',5,100},{'+',1,3}})UPSERT operation failed:ER_NO_SUCH_FIELD_NO: Field 5 was not found in the tuple---...tarantool> t----[1,2,3]...tarantool> t2----[4,2,3]...
Functions for transaction management
For general information and examples, see section
Transactions.
Observe the following rules when working with transactions:
Rule #1
The requests in a transaction must be sent to a server as a single block.
It is not enough to enclose them between begin and commit or rollback.
To ensure they are sent as a single block: put them in a function, or put
them all on one line, or use a delimiter so that multi-line requests
are handled together.
Rule #2
All database operations in a transaction should use the same storage engine.
It is not safe to access tuple sets that are defined with {engine='vinyl'}
and also access tuple sets that are defined with {engine='memtx'},
in the same transaction.
Rule #3
Requests which cause changes to the data definition
– create, alter, drop, truncate – are only allowed with
Tarantool version 2.1 or later.
Data-definition requests which change an index
or change a format, such as
space_object:create_index() and
space_object:format(),
are not allowed inside transactions except as the first request
after box.begin().
Below is a list of all functions for transaction management.
Begin the transaction. Disable implicit yields
until the transaction ends.
Signal that writes to the write-ahead log will be
deferred until the transaction ends.
In effect the fiber which executes box.begin() is starting an “active
multi-request transaction”, blocking all other fibers.
timeout – a timeout (in seconds), after which the transaction is rolled back
Possible errors:
error if this operation is not permitted because there is already an active transaction.
error if for some reason memory cannot be allocated.
error and abort the transaction if the timeout is exceeded.
Example
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Begin and commit the transaction explicitly --box.begin()box.space.bands:insert{4,'The Beatles',1960}box.space.bands:replace{1,'Pink Floyd',1965}box.commit()-- Begin the transaction with the specified isolation level --box.begin({txn_isolation='read-committed'})box.space.bands:insert{5,'The Rolling Stones',1962}box.space.bands:replace{1,'The Doors',1965}box.commit()
End the transaction, and make all its data-change operations permanent.
Possible errors:
error and abort the transaction in case of a conflict.
error if the operation fails to write to disk.
error if for some reason memory cannot be allocated.
Example
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Begin and commit the transaction explicitly --box.begin()box.space.bands:insert{4,'The Beatles',1960}box.space.bands:replace{1,'Pink Floyd',1965}box.commit()-- Begin the transaction with the specified isolation level --box.begin({txn_isolation='read-committed'})box.space.bands:insert{5,'The Rolling Stones',1962}box.space.bands:replace{1,'The Doors',1965}box.commit()
End the transaction, but cancel all its data-change operations.
An explicit call to functions outside box.space that always
yield, such as fiber.sleep() or
fiber.yield(), will have the same effect.
Example
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Rollback the transaction --box.begin()box.space.bands:insert{4,'The Beatles',1960}box.space.bands:replace{1,'Pink Floyd',1965}box.rollback()
Return a descriptor of a savepoint (type = table), which can be used later
by box.rollback_to_savepoint(savepoint).
Savepoints can only be created while a transaction is active, and they are
destroyed when a transaction ends.
Return:
savepoint table
Rtype:
Lua object
Return:
error if the savepoint cannot be set in absence of active
transaction.
Possible errors: error if for some reason memory cannot be allocated.
Example
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Rollback the transaction to a savepoint --box.begin()box.space.bands:insert{4,'The Beatles',1960}save1=box.savepoint()box.space.bands:replace{1,'Pink Floyd',1965}box.rollback_to_savepoint(save1)box.commit()
Do not end the transaction, but cancel all its data-change
and box.savepoint() operations that were done after
the specified savepoint.
Return:
error if the savepoint cannot be set in absence of active
transaction.
Possible errors: error if the savepoint does not exist.
Example
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Rollback the transaction to a savepoint --box.begin()box.space.bands:insert{4,'The Beatles',1960}save1=box.savepoint()box.space.bands:replace{1,'Pink Floyd',1965}box.rollback_to_savepoint(save1)box.commit()
Execute a function, acting as if the function starts with an implicit
box.begin() and ends with an implicit
box.commit() if successful, or ends with an implicit
box.rollback() if there is an error.
function-arguments – (optional) arguments passed to the function
Return:
the result of the function passed to atomic() as an argument
Possible errors:
error and abort the transaction in case of a conflict.
error and abort the transaction if the timeout is exceeded.
error if the operation fails to write to disk.
error if for some reason memory cannot be allocated.
Example
-- Create an index with the specified sequence --box.schema.sequence.create('id_sequence',{min=1})box.space.bands:create_index('primary',{parts={'id'},sequence='id_sequence'})-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Define a function --localfunctioninsert_band(band_name,year)box.space.bands:insert{nil,band_name,year}end-- Begin and commit the transaction implicitly --box.atomic(insert_band,'The Beatles',1960)-- Begin the transaction with the specified isolation level --box.atomic({txn_isolation='read-committed'},insert_band,'The Rolling Stones',1962)
Define a trigger for execution when a transaction ends due to an event
such as box.commit().
The trigger function may take an iterator parameter, as described in an
example for this section.
The trigger function should not access any database spaces.
If the trigger execution fails and raises an error, the effect is severe
and should be avoided – use Lua’s pcall() mechanism around code that
might fail.
box.on_commit() must be invoked within a transaction,
and the trigger ceases to exist when the transaction ends.
Parameters:
trigger-function (function) – function which will become the trigger
function
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function
Return:
nil or function pointer
If the parameters are (nil,old-trigger-function), then the old trigger
is deleted.
Details about trigger characteristics are in the
triggers section.
Example 1
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Define a function called on commit --functionprint_commit_result()print('Commit happened')end-- Commit the transaction --box.begin()box.space.bands:insert{4,'The Beatles',1960}box.on_commit(print_commit_result)box.commit()
Example 2
The function parameter can be an iterator.
The iterator goes through the effects of every request that changed a space
during the transaction.
The iterator has:
an ordinal request number
the old value of the tuple before the request
(nil for an insert request)
the new value of the tuple after the request
(nil for a delete request)
the ID of the space
The example below displays the effects of two replace requests:
-- Insert test data --box.space.bands:insert{1,'Roxette',1986}box.space.bands:insert{2,'Scorpions',1965}box.space.bands:insert{3,'Ace of Base',1987}-- Define a function called on commit --functionprint_replace_details(iterator)forrequest_number,old_tuple,new_tuple,space_idiniterator()doprint('request_number: '..tostring(request_number))print('old_tuple: '..tostring(old_tuple))print('new_tuple: '..tostring(new_tuple))print('space_id: '..tostring(space_id))endend-- Commit the transaction --box.begin()box.space.bands:replace{1,'The Beatles',1960}box.space.bands:replace{2,'The Rolling Stones',1965}box.on_commit(print_replace_details)box.commit()
The output might look like this:
request_number: 1old_tuple: [1, 'Roxette', 1986]new_tuple: [1, 'The Beatles', 1960]space_id: 512request_number: 2old_tuple: [2, 'Scorpions', 1965]new_tuple: [2, 'The Rolling Stones', 1965]space_id: 512
If a transaction is in progress (for example the user has called
box.begin() and has not yet
called either box.commit()
or box.rollback(),
return true. Otherwise return false.
Functions for SQL
The box module contains some functions related to SQL:
extra-parameters (table) – optional table for placeholders in the statement
Return:
depends on statement
There are two ways to pass extra parameters to box.execute():
The first way, which is the preferred way, is to put placeholders in the
string, and pass a second argument, an extra-parameters table. A
placeholder is either a question mark “?”, or a colon “:” followed by a
name. An extra parameter is any Lua expression.
If placeholders are question marks, then they are replaced by
extra-parameters values in corresponding positions. That is, the first ?
is replaced by the first extra parameter, the second ? is
replaced by the second extra parameter, and so on.
If placeholders are :names, then they are replaced by extra-parameters values with
corresponding names.
For example, this request that contains literal values 1 and 'x':
box.execute([[INSERT INTO tt VALUES (1, 'x');]]);
… is the same as the request below containing two question-mark placeholders
(? and ?) and a two-element extra-parameters table:
x={1,'x'}box.execute([[INSERT INTO tt VALUES (?, ?);]],x);
… and is the same as this request containing two :name placeholders
(:a and :b) and a two-element extra-parameters table with elements
named “a” and “b”:
box.execute([[INSERT INTO tt VALUES (:a, :b);]],{{[':a']=1},{[':b']='x'}})
The second way is to concatenate strings.
For example, the Lua script below inserts 10 rows with different primary-key
values into table t:
fori=1,10,1dobox.execute("insert into t values ("..i..")")end
When creating SQL statements based on user input, application developers
should beware of SQL injection.
Since box.execute() is an invocation of a Lua function,
it either causes an error message or returns a value.
For some statements the returned value contains a field named rowcount, for example:
tarantool> box.execute([[CREATE TABLE table1 (column1 INT PRIMARY key, column2 VARCHAR(10));]])----rowcount:1...tarantool> box.execute([[INSERT INTO table1 VALUES (55,'Hello SQL world!');]])----rowcount:1...
For statements that cause generation of values for PRIMARY KEY AUTOINCREMENT columns,
there is a field named autoincrement_id.
For SELECT or PRAGMA statements, the returned value is a result set,
containing a field named metadata (a table with column names and
Tarantool/NoSQL type names)
and a field named rows (a table with the contents of each row).
For example, for a statement SELECT"x"FROMtWHERE"x"=5;
where "x" is an INTEGER column and there is one row,
a display on the Tarantool client might look like this:
tarantool> box.execute([[SELECT "x" FROM t WHERE "x"=5;]])----metadata:-name:xtype:integerrows:-[5]...
The order of components within a map is not guaranteed.
If sql_full_metadata in the
_session_settings system table is TRUE,
then result set metadata may include these things in addition to name
and type:
collation (present only if COLLATE clause is specified for a STRING) =
“Collation”.
is_nullable (present only if the select list
specified a base table column and nothing else) = false if column was
defined as NOT NULL, otherwise true.
If this is not present, that implies that nullability is unknown.
is_autoincrement (present only if the select list specified a base
table column and nothing else) = true if column was defined as
PRIMARY KEY AUTOINCREMENT,
otherwise false.
span (always present) = the original expression in a select list,
which often is the same as name if the select list specifies a
column name and nothing else, but otherwise differs, for example, after
SELECTx+55ASxFROMt; the name is X and the span is x+55.
If span and name are the same then the content is MP_NIL.
Alternative: if you are using the Tarantool server as a client,
you can switch languages as follows:
\set language sql
\set delimiter ;
Afterwards, you can enter any SQL statement directly without needing
box.execute().
There is also an execute() function available in
module net.box.
For example, you can execute conn:execute(sql-statement]) after conn=net_box.connect(url-string).
box.prepare compiles an SQL statement into byte code and saves the byte
code in a cache. Since compiling takes a significant amount of time, preparing
a statement will enhance performance if the statement is executed many times.
If box.prepare succeeds, prepared_table contains:
stmt_id: integer – an identifier generated by a hash of the statement string
metadata: map [name : string, type : string] (This is present only for
SELECT or PRAGMA statements and has the same contents as the
result set metadata for box.execute)
The prepared statement cache (which is also called the prepared statement holder)
is “shared”, that is, there is one cache for
all sessions. However, session X cannot execute a statement prepared by session Y.
For monitoring the cache, see box.info().sql.
For changing the cache size, use sql.cache_size.
Prepared statements will “expire” (become invalid) if
any database object is dropped or created or altered –
even if the object is not mentioned in the SQL statement,
even if the create or drop or alter is rolled back,
even if the create or drop or alter is done in a different session.
There are two ways to execute: with the method or with the statement id.
That is, prepared_table:execute() and
box.execute(prepared_table.stmt_id) do the same thing.
Example: here is a test. This function inserts a million rows in a table
using a prepared INSERT statement.
functionf()localp,start_timebox.execute([[DROP TABLE IF EXISTS t;]])box.execute([[CREATE TABLE t (s1 INTEGER PRIMARY KEY);]])start_time=os.time()p=box.prepare([[INSERT INTO t VALUES (?);]])fori=1,1000000dop:execute({i})endp:unprepare()end_time=os.time()box.execute([[COMMIT;]])print(end_time-start_time)-- elapsed timeendf()
Take note of the elapsed time. Now change the line with the loop to: fori=1,1000000dobox.execute([[INSERTINTOtVALUES(?);]],{i})end
Run the function again, and take note of the elapsed time again.
The function which executes the prepared statement will be about 15% faster,
though of course this will vary depending on Tarantool version and
environment.
Undo the result of an earlier box.prepare()
request. This is equivalent to standard-SQL DEALLOCATE PREPARE.
Parameter prepared_table should be the result from box.prepare().
There are two ways to unprepare: with the method or with the statement id.
That is, prepared_table:unprepare() and
box.unprepare(prepared_table.stmt_id) do the same thing.
Tarantool strongly recommends using unprepare as soon as the immediate
objective (executing a prepared statement multiple times) is done, or
whenever a prepared statement expires.
There is no automatic eviction policy, although automatic unprepare
will happen when the session disconnects (the session’s prepared
statements will be removed from the prepared-statement cache).
The box module contains some features related to event subscriptions, also known as watchers.
The subscriptions are used to inform the client about server-side events.
Each event subscription is defined by a certain key.
Event
An event is a state change or a system update that triggers the action of other systems.
To read more about built-in events in Tarantool,
check the system events section.
State
A state is an internally stored key-value pair.
The key is a string.
The value is an arbitrary type that can be encoded as MsgPack.
To update a state, use the box.broadcast() function.
Watcher
A watcher is a callback that is invoked when a state change occurs.
To register a local watcher, use the box.watch() function.
To create a remote watcher, use the watch() function from the net.box module.
Note that it is possible to register more than one watcher for the same key.
How a watcher works
First, you register a watcher.
After that, the watcher callback is invoked for the first time.
In this case, the callback is triggered whether or not the key has already been broadcast.
All subsequent invocations are triggered with box.broadcast()
called on the remote host.
If a watcher is subscribed for a key that has not been broadcast yet, the callback is triggered only once,
after the registration of the watcher.
The watcher callback takes two arguments.
The first argument is the name of the key for which it was registered.
The second one contains current key data.
The callback is always invoked in a new fiber. It means that it is allowed to yield in it.
A watcher callback is never executed in parallel with itself.
If the key is updated while the watcher callback is running, the callback will be invoked again with the new
value as soon as it returns.
box.watch and box.broadcast functions can be used before box.cfg.
Below is a list of all functions and pages related to watchers or events.
Keep in mind that garbage collection of a watcher handle doesn’t lead to the watcher’s destruction.
In this case, the watcher remains registered.
It is okay to discard the result of watch function if the watcher will never be unregistered.
Example:
-- Broadcast value 42 for the 'foo' key.box.broadcast('foo',42)locallog=require('log')-- Subscribe to updates of the 'foo' key.localw=box.watch('foo',function(key,value)assert(key=='foo')log.info("The box.id value is '%d'",value)end)
If you don’t need the watcher anymore, you can unregister it using the command below:
Returns the current value of a given notification key.
The function can be used as an alternative to box.watch()
when the caller only needs the current value without subscribing to future changes.
To read more about watchers, see the Event watchers section.
Example:
-- Broadcast value 42 for the 'foo' key.box.broadcast('foo',42)-- Get the value of this keytarantool>box.watch_once('foo')----42...-- Non-existent keys' values are emptytarantool>box.watch_once('none')---...
Predefined events have a special naming schema – theirs names always start with the reserved box. prefix.
It means that you cannot create new events with it.
The system processes the following events:
box.id
box.status
box.election
box.schema
box.shutdown
In response to each event, the server sends back certain IPROTO fields.
The events are available from the beginning as non-MP_NIL.
If a watcher subscribes to a system event before it has been broadcast,
it receives an empty table for the event value.
The event is generated when there is a change in any of the values listed in the event.
For example, see the parameters in the box.id event below – id, instance_uuid, and replicaset_uuid.
Suppose the ìd value (box.info.id) has changed.
This triggers the box.info event, which states that the value of box.info.id has changed,
while box.info.uuid and box.info.cluster.uuid remain the same.
box.id
Contains identification of the instance.
Value changes are rare.
id: the numeric instance ID is unknown before the registration.
For anonymous replicas, the value is 0 until they are officially registered.
instance_uuid: the UUID of the instance never changes after the first
box.cfg.
The value is unknown before the box.cfg call.
replicaset_uuid: the value is unknown until the instance joins a replicaset or boots a new one.
Contains a boolean value which indicates whether there is an active shutdown request.
The event is generated when the server receives a shutdown request (os.exit() command or
SIGTERM signal).
The box.shutdown event is applied for the graceful shutdown protocol.
It is a feature which is available since 2.10.0.
This protocol is supposed to be used with connectors to signal a client about the upcoming server shutdown and
close active connections without broken requests.
For more information, refer to the graceful shutdown protocol section.
Usage example
localconn=net.box.connect(URI)locallog=require('log')-- Subscribe to updates of key 'box.id'localw=conn:watch('box.id',function(key,value)assert(key=='box.id')log.info("The box.id value is '%s'",value)end)
If you want to unregister the watcher when it’s no longer needed, use the following command:
Execute a function, provided it has not been executed before. A passed value
is checked to see whether the function has already been executed. If it has
been executed before, nothing happens. If it has not been executed before,
the function is invoked.
Warning: If an error occurs inside box.once() when initializing a
database, you can re-execute the failed box.once() block without
stopping the database. The solution is to delete the once object from
the system space _schema.
Say box.space._schema:select{}, find your once object there and
delete it.
When box.once() is used for initialization, it may be useful to
wait until the database is in an appropriate state (read-only or read-write).
In that case, see the functions in the Submodule box.ctl.
... – arguments that must be passed to the function
Note
The parameter key will be stored in the _schema
system space after box.once() is called in order to prevent a double
run. These keys are global per replica set. So a simultaneous call of
box.once() with the same key on two instances of the same replica set
may succeed on both of them, but it’ll lead to a transaction conflict.
Example
The example shows how to re-execute the box.once() block that contains the hello key.
First, check the _schema system space.
The _schema space in the example contains two box.once objects – oncebye and oncehello:
Take a snapshot of all data and store it in
snapshot.dir/<latest-lsn>.snap.
To take a snapshot, Tarantool first enters the delayed garbage collection
mode for all data. In this mode, the
Tarantool garbage collector
will not remove files which were created before the snapshot started, it will
not remove them until the snapshot has finished. To preserve consistency of
the primary key, used to iterate over tuples, a copy-on-write technique is
employed. If the master process changes part of a primary key, the
corresponding process page is split, and the snapshot process obtains an old
copy of the page.
In effect, the snapshot process uses multi-version concurrency control
in order to avoid copying changes which are superseded while it is running.
Since a snapshot is written sequentially, you can expect a very high write
performance (averaging to 80MB/second on modern disks), which means an average
database instance gets saved in a matter of minutes.
You may restrict the speed by changing
snapshot.snap_io_rate_limit.
Note
As long as there are any changes to the parent index memory through
concurrent updates, there are going to be page splits, and therefore you
need to have some extra free memory to run this command. 10% of
memtx_memory is, on average, sufficient.
This statement waits until a snapshot is taken and returns operation result.
Note
Change notice: Prior to Tarantool version 1.6.6, the snapshot process
caused a fork, which could cause occasional latency spikes. Starting with
Tarantool version 1.6.6, the snapshot process creates a consistent
read view and this view is written to the snapshot file by a separate thread
(the “Write Ahead Log” thread).
Although box.snapshot() does not cause a fork, there is a separate fiber
which may produce snapshots at regular intervals – see the discussion of
the checkpoint daemon.
Example:
tarantool> box.info.version----1.7.0-1216-g73f7154...tarantool> box.snapshot()----ok...tarantool> box.snapshot()----error:can't save snapshot, errno 17 (File exists)...
Taking a snapshot does not cause the server to start a new write-ahead log.
Once a snapshot is taken, old WALs can be deleted as long as all replicated
data is up to date. But the WAL which was current at the time box.snapshot()
started must be kept for recovery, since it still contains log records
written after the start of box.snapshot().
An alternative way to save a snapshot is to send a SIGUSR1 signal to the instance.
While this approach could be handy, it is not recommended for use
in automation: a signal provides no way to find out whether the snapshot
was taken successfully or not.
Vinyl
In vinyl, inserted data is stacked in memory until the limit, set in the
vinyl_memory parameter, is reached. Then
vinyl automatically dumps it to the disc. box.snapshot() forces
this dump in order to have the ability to recover from this checkpoint.
The snapshot files are stored in space_id/index_id/*.run.
Thus, strictly all the data that was written at the time of LSN of the
checkpoint is in the *.run files on the disk, and all operations that happened
after the checkpoint will be written in the *.xlog. All dump files created
by box.snapshot() are consistent and have the same LSN as checkpoint.
At the checkpoint vinyl also rotates the metadata log *.vylog, containing
data manipulation operations like “create file” and “delete file”. It goes
through the log, removes duplicating operations from the memory and creates
a new *.vylog file, giving it the name according to the
vclock of the new checkpoint, with
“create” operations only. This procedure cleans *.vylog and is useful for
recovery because the name of the log is the same as the checkpoint signature.
Constant box.NULL
There are some major problems with using Lua nil values in tables.
For example: you can’t correctly assess the length of a table that is not a sequence.
(Learn more about data types in Lua
and LuaJIT.)
The console output of t processes nil values in the middle and at
the end of the table differently. This is due to undefined behavior.
Note
Trying to find the length for sparse arrays in LuaJIT leads to another
scenario of
undefined behavior.
To avoid this problem, use Tarantool’s box.NULL constant instead of nil.
box.NULL is a placeholder for a nil value in tables to preserve a key
without a value.
Using box.NULL
box.NULL is a value of the cdata type representing a NULL pointer.
It is similar to msgpack.NULL, json.NULL and yaml.NULL. So it is
some not nil value, even if it is a pointer to NULL.
Use box.NULL only with capitalized NULL (box.null is incorrect).
Note
Technically speaking, box.NULL equals to ffi.cast('void*',0).
Notice that t[2] shows the same null output in both examples.
However in this example t[2] and t[5] are of the cdata type, while
in the previous example their type was nil.
Important
Avoid using implicit comparisons with nullable values when using box.NULL.
Due to Lua behavior,
returning anything except false or nil from a condition expression
is considered as true. And, as it was mentioned earlier, box.NULL is a
pointer by design.
That is why the expression box.NULL will always be considered true in case
it is used as a condition in a comparison. This means that the code
ifbox.NULLthenfunc()end
will always execute the function func() (because the condition box.NULL will
always be neither false nor nil).
Distinction of nil and box.NULL
Use the expression ifx==nil to check if the x is either a nil
or a box.NULL.
To check whether x is a nil but not a box.NULL, use the following
condition expression:
type(x)=='nil'
If it’s true, then x is a nil, but not a box.NULL.
You can use the following for box.NULL:
x==nilandtype(x)=='cdata'
If the expression above is true, then x is a box.NULL.
Note
By converting data to different formats (JSON, YAML, msgpack), you shall expect
that it is possible that nil in sparse arrays will be converted to
box.NULL. And it is worth mentioning that such conversion might be
unexpected (for example: by sending data via net.box
or by obtaining data from spaces etc.).
You must anticipate such behavior and use a proper condition expression.
Use the explicit comparison x==nil for checking for NULL in nullable values.
It will detect both nil and box.NULL.
Module buffer
The buffer module returns a dynamically resizable buffer which is solely
for optional use by methods of the net.box module
or the msgpack module.
Ordinarily the net.box methods return a Lua table.
If a buffer option is used, then the net.box methods return a
raw MsgPack string.
This saves time on the server, if the client application has
its own routine for decoding raw MsgPack strings.
The buffer uses four pointers to manage its capacity:
buf – a pointer to the beginning of the buffer
rpos – a pointer to the beginning of the range; available for reading data (“read position”)
wpos – a pointer to the end of the range; available for reading data, and to the
beginning of the range for writing new data (“write position”)
epos – a pointer to the end of the range; available for writing new data (“end position”)
In this example we will show that using buffer allows you to keep the data
in the format that you get from the server. So if you get the data only for
sending it somewhere else, buffer fastens this a lot.
Before Tarantool version 1.7.7, the function to use for
this case is msgpack.ibuf_decode(ibuf.rpos). Starting
with Tarantool version 1.7.7, ibuf_decode is deprecated.
Clear the memory slots used by buffer_object. This method allows to
keep the buffer but remove data from it. It is useful when you want to
use the buffer further.
Reserve memory for buffer_object. Check if there is enough memory to
write size bytes after wpos. If not, epos shifts until size
bytes will be available.
The result is still inside an array, as is clear from the fact that it is shown
inside square brackets. It is possible to skip the array header too, with
msgpack.decode_array_header().
The checks module provides the ability to check the types of arguments passed to a Lua function.
You need to call the checks(type_1, …) function inside the target Lua function and pass one or more type qualifiers to check the corresponding argument types.
There are two types of type qualifiers:
A string type qualifier checks whether a function’s argument conforms to the specified type. Example: 'string'.
A table type qualifier checks whether the values of a table passed as an argument conform to the specified types. Example: {'string','number'}.
In Tarantool 2.11.0 and later versions, the checks API is available in a script without loading the module.
For earlier versions, you need to install the checks module from the Tarantool rocks repository and load the module using the require() directive:
localchecks=require('checks')
Number of arguments to check
For each argument to check, you need to specify its own type qualifier in the checks(type_1, …) function.
One argument
In the example below, the checks function accepts a string type qualifier to verify that only a string value can be passed to the greet function.
Otherwise, an error is raised.
functiongreet(name)checks('string')return'Hello, '..nameend--[[greet('John')-- returns 'Hello, John'greet(123)-- raises an error: bad argument #1 to nil (string expected, got number)--]]
Multiple arguments
To check the types of several arguments, you need to pass the corresponding type qualifiers to the checks function.
In the example below, both arguments should be string values.
functiongreet_fullname(firstname,lastname)checks('string','string')return'Hello, '..firstname..' '..lastnameend--[[greet_fullname('John', 'Smith')-- returns 'Hello, John Smith'greet_fullname('John', 1)-- raises an error: bad argument #2 to nil (string expected, got number)--]]
To skip checking specific arguments, use the ? placeholder.
Variable number of arguments
You can check the types of explicitly specified arguments for functions that accept a variable number of arguments.
functionextra_arguments_num(a,b,...)checks('string','number')returnselect('#',...)end--[[extra_arguments_num('a', 2, 'c')-- returns 1extra_arguments_num('a', 'b', 'c')-- raises an error: bad argument #1 to nil (string expected, got number)--]]
String type qualifier
This section describes how to check a specific argument type using a string type qualifier:
The Supported types section describes all the types supported by the checks module.
If required, you can make a union type to allow an argument to accept several types.
To skip checking specific arguments, use the ? placeholder.
Supported types
Lua types
A string type qualifier can accept any of the Lua types, for example, string, number, table, or nil.
In the example below, the checks function accepts string to validate that only a string value can be passed to the greet function.
functiongreet(name)checks('string')return'Hello, '..nameend--[[greet('John')-- returns 'Hello, John'greet(123)-- raises an error: bad argument #1 to nil (string expected, got number)--]]
Tarantool types
You can use Tarantool-specific types in a string qualifier.
The example below shows how to check that a function argument is a decimal value.
localdecimal=require('decimal')functionsqrt(value)checks('decimal')returndecimal.sqrt(value)end--[[sqrt(decimal.new(16))-- returns 4sqrt(16)-- raises an error: bad argument #1 to nil (decimal expected, got number)--]]
This table lists all the checks available for Tarantool types:
A string type qualifier can accept the name of a custom function that performs arbitrary validations.
To achieve this, create a function returning true if the value is valid and add this function to the checkers table.
The example below shows how to use the positive function to check that an argument value is a positive number.
functioncheckers.positive(value)return(type(value)=='number')and(value>0)endfunctionget_doubled_number(value)checks('positive')returnvalue*2end--[[get_doubled_number(10)-- returns 20get_doubled_number(-5)-- raises an error: bad argument #1 to nil (positive expected, got number)--]]
Metatable type
A string qualifier can accept a value stored in the __type field of the argument metatable.
localblue=setmetatable({0,0,255},{__type='color'})functionget_blue_value(color)checks('color')returncolor[3]end--[[get_blue_value(blue)-- returns 255get_blue_value({0, 0, 255})-- raises an error: bad argument #1 to nil (color expected, got table)--]]
Union types
To allow an argument to accept several types (a union type), concatenate type names with a pipe (|).
In the example below, the argument can be both a number and string value.
functionget_argument_type(value)checks('number|string')returntype(value)end--[[get_argument_type(1)-- returns 'number'get_argument_type('key1')-- returns 'string'get_argument_type(true)-- raises an error: bad argument #1 to nil (number|string expected, got boolean)--]]
Optional types
To make any of the supported types optional, prefix its name with a question mark (?).
In the example below, the name argument is optional.
This means that the greet function can accept string and nil values.
functiongreet(name)checks('?string')ifname~=nilthenreturn'Hello, '..nameelsereturn'Hello from Tarantool'endend--[[greet('John')-- returns 'Hello, John'greet()-- returns 'Hello from Tarantool'greet(123)-- raises an error: bad argument #1 to nil (string expected, got number)--]]
As for a specific type, you can make a union type value optional: ?number|string.
Skipping argument checking
You can skip checking of the specified arguments using the question mark (?) placeholder.
In this case, the argument can be any type.
functiongreet_fullname_any(firstname,lastname)checks('string','?')return'Hello, '..firstname..' '..tostring(lastname)end--[[greet_fullname_any('John', 'Doe')-- returns 'Hello, John Doe'greet_fullname_any('John', 1)-- returns 'Hello, John 1'--]]
Table type qualifier
A table type qualifier checks whether the values of a table passed as an argument conform to the specified types.
In this case, the following checks are made:
The argument is checked to conform to the ?table type, and its content is validated.
When called inside a function, checks that the function’s arguments conform to the specified types.
Parameters:
type_1 (string/table) – a string or table type qualifier used to check the argument type
... – optional type qualifiers used to check the types of other arguments
checkers
The checkers global variable provides access to checkers for different types.
You can use this variable to add a custom checker that performs arbitrary validations.
Note
The checkers variable also provides access to checkers for Tarantool-specific types.
These checkers can be used in a custom checker.
The clock module returns time values derived from the Posix / C
CLOCK_GETTIME function or equivalent. Most functions in the module return a
number of seconds; functions whose names end in “64” return a 64-bit number of
nanoseconds.
The monotonic time. Derived from C function clock_gettime(CLOCK_MONOTONIC).
Monotonic time is similar to wall clock time but is not affected by changes
to or from daylight saving time, or by changes done by a user.
This is the best function to use with benchmarks that need to calculate
elapsed time.
Return:
seconds or nanoseconds since the last time that the computer was booted.
Rtype:
number or cdata (ctype<int64_t>)
Example:
-- This will print nanoseconds since the start.clock=require('clock')print(clock.monotonic64())
The processor time. Derived from C function
clock_gettime(CLOCK_PROCESS_CPUTIME_ID). This is the best function to
use with benchmarks that need to calculate how much time has been spent
within a CPU.
Return:
seconds or nanoseconds since processor start.
Rtype:
number or cdata (ctype<int64_t>)
Example:
-- This will print nanoseconds in the CPU since the start.clock=require('clock')print(clock.proc64())
The thread time. Derived from C function
clock_gettime(CLOCK_THREAD_CPUTIME_ID). This is the best function to use
with benchmarks that need to calculate how much time has been spent within a
thread within a CPU.
Return:
seconds or nanoseconds since the transaction processor thread started.
Rtype:
number or cdata (ctype<int64_t>)
Example:
-- This will print seconds in the thread since the start.clock=require('clock')print(clock.thread64())
The time that a function takes within a processor. This function uses
clock.proc(), therefore it calculates elapsed CPU time. Therefore it is
not useful for showing actual elapsed time.
Parameters:
function (function) – function or function reference
... – whatever values are required by the function.
Return:
table. first element – seconds of CPU time, second element –
whatever the function returns.
Example:
-- Benchmark a function which sleeps 10 seconds.-- NB: bench() will not calculate sleep time.-- So the returned value will be {a number less than 10, 88}.clock=require('clock')fiber=require('fiber')functionf(param)fiber.sleep(param)return88endclock.bench(f,10)
Module compat
The usual way to handle compatibility problems is to introduce an option for a new behavior and leave the old one by default.
It is not always the perfect way.
Sometimes developers want to keep the old behavior for existing applications and offer the new behavior by default for the new ones.
For example, the old behavior is known to be problematic, or less safe, or it doesn’t correspond to user expectations.
In contrast, the user doesn’t always read all the documentation and often assumes good defaults.
It was decided to introduce a compatibility module to provide a direct way to deprecate unwanted behavior.
The compat module is basically a global table of options with additional verbose interface and helper functions.
There are three stages of changing behavior:
Old behavior by default.
New behavior by default.
New behavior is frozen and the old behavior is removed.
During the first two stages, a user can toggle options via the interface and change the behavior according to one’s needs.
At the last stage, the old behavior is removed from the codebase, and the option is marked as obsolete.
Because compat is a global instance, options can be hardcoded into it or added in runtime, for example, by external module.
Options are switched to the next stage in major releases. In this way, developers are able to adapt to the new standard behavior and test it before switching to the next release.
If something is broken by a new Tarantool version, a developer can still have a way to fix it by a simple config change, that is, explicitly select the old behavior.
Consider example below:
The option json_esc_slash is introduced in the 2.11 minor release. Default is set to ‘old’, but a developer can utilize the new behavior or test the updated behavior by switching it manually to ‘new’.
In release 3.0, the next major release, json_esc_slash default is switched to ‘new’.
Now, developers who don’t manage to adapt to the new behavior, are able to switch the option to ‘old’ and fix their module in the future.
In release 4.0, json_esc_slash is marked as obsolete, and the old behavior is no longer accessible. Developers are forced to use the new behavior.
Basic usage
If you want to explicitly secure every behavior in compat, you can do it manually, and then call compat.dump() to get a Lua command that sets up the compat with all the options selected.
You should place this commands at the beginning of code in your init.lua file. In this way, you are guaranteed to get the same behavior on any other Tarantool version.
See a tutorial on using compat for more examples.
Configuration options
Another way to handle compatibility issues is setting the compat.*configuration options.
Similarly to the compat Lua module options, the configuration options can have
values new and old. The set of configuration options matches the set of
options available in the compat module.
Below is an example fragment of a YAML configuration file:
For some reason, in the upstream lua_cjson, the ‘/’ sign is escaped.
But according to the rfc4627 standard, it is unnecessary and questionably compatible with other implementations.
Old and new behavior
By toggling the json_escape_forward_slash compat option, you can chose either the json encoder escapes the ‘/’ sign or it does not:
The option affects both the global serializer instance and serializers created with json.new().
It also affects the way log messages are encoded when written to the log in the json format (the box.cfg.log_format option is set to ‘json’).
Known compatibility issues
At this point, no incompatible modules are known.
Detecting issues in your codebase
Both encoding styles are correct from the JSON standard standpoint, but if your module relies on encodings results bytewise, it may break with this change.
Be cautious if you do the following:
Hash results of json.encode().
Lua-YAML prettier multiline output
Option: yaml_pretty_multiline
The lua-yaml encoder selects the string style automatically, but in Tarantool context, it can be beneficial to enforce them, for example, for better readability.
The yaml_pretty_multiline compat option allows to encode multiline strings in a block style.
Old and new behavior
The compat module allows you to chose between the lua-yaml encodes multiline strings as usual or in the enforced block scalar style:
You can select the new/old behavior in compat. It affects the global YAML encoder.
Known compatibility issues
At this point, no incompatible modules are known.
Detecting issues in your codebase
Both encoding styles are correct from the YAML standard standpoint, but if your module relies on encodings results bytewise, it may break with this change.
Be cautious if you do the following:
Compare results of YAML encoding as strings.
Hash results of yaml encoding.
Fiber channel close mode
Option: fiber_channel_close_mode
Before the change, there was an unexpected behavior when using channel:close() because it closed the channel entirely and discarded all unread events.
Old and new behavior
The compat module allows you chose between the channel force and graceful closing. The latter is a new behavior.
You can select new/old behavior in compat. It will affect all existing channels and the future ones.
Known compatibility issues
At this point, no incompatible modules are known.
Detecting issues in your codebase
The new behavior is mostly backward compatible.
The only known problem that can appear is when the code relies on channel being entirely closed after ch:close() and ch:get() returning nil.
Default value for replication_sync_timeout
Option: box_cfg_replication_sync_timeout
Having a non-zero replication_sync_timeout gives a user the false assumption that the box.cfg{replication=...} call returns only when the configured node is synced with all the other nodes.
This is mostly true for the big replication_sync_timeout values, but it is not 100% guaranteed.
In other words, a user still has to check if the node is synced, or the sync just timed out.
Besides, while replication_sync_timeout is ticking, you cannot reconfigure box with another box.cfg call, which hardens reconfiguration.
It is decided to set the replication_sync_timeout to zero by default.
Old and new behavior
The compat module allows you to choose between
the old behavior: box.cfg.replication_sync_timeout is 300 seconds by default
and the new behavior:box.cfg.replication_sync_timeout is 0 by default.
It is important to set the desired behavior before the initial box.cfg{} call to take effect for it.
tarantool>compat.box_cfg_replication_sync_timeout='new'---...tarantool>box.cfg{}---...tarantool>box.cfg.replication_sync_timeout----0...tarantool>compat.box_cfg_replication_sync_timeout='old'----error:'builtin/box/load_cfg.lua:253: The compat option ''box_cfg_replication_sync_timeout'' takes effect only before the initial box.cfg() call'...
We expect issues with a user assuming that the node is not in the orphan state (box.info.status~="orphan") after the box.cfg{replication=...} call returns.
This is not true with the new behaviour. To simulate the old behavior, one may add a box.ctl.wait_rw() call after the box.cfg{} call.
box.ctl.wait_rw() returns only when the node becomes writable, and hence is not an orphan.
Default value for sql_seq_scan session setting
Option: sql_seq_scan_default
The default value for the sql_seq_scan session setting will be set to false starting with Tarantool 3.0.
To be able to return the behavior to the old default, a new compat option is introduced.
Old and new behavior
Old behavior: SELECT scan queries are always allowed.
New behavior: SELECT scan queries are only allowed if the SEQSCAN keyword is used correctly.
Note that the sql_seq_scan_default compat option only affects sessions during initialization.
It means that you should set sql_seq_scan_default before running box.cfg{} or creating a new session.
Also, a new session created before executing box.cfg{} will not be affected by the value of the compat option.
Examples of setting the option before execution of box.cfg{}:
We expect most SELECTs that do not use indexes to fail after the sql_seq_scan session setting is set to false.
The best way to avoid this is to refactor the query to use indexes.
To understand if SELECT uses indexes, you can use EXPLAIN QUERY PLAN.
If SEARCH TABLE is specified, the index is used. If it says SCAN TABLE, the index is not used.
You can use the SEQSCAN keyword to manually allow scanning queries. Or you can set the sql_seq_scan session setting to true to allow all scanning queries.
Default value for max fiber slice
Option: fiber_slice_default
The max fiber slice specifies the max fiber execution time without yield before a warning is logged or an error is raised.
It is set with the fiber.set_max_slice() function.
The new compat option – fiber_slice_default – controls the default value of the max fiber slice.
Old and new behavior
The old default value for the max fiber slice is infinity (no warnings or errors). The new default value is {warn=0.5,err=1.0}.
To use the new behavior, set fiber_slice_default to new as follows:
or the following error is raised unexpectedly by a box function
error:fibersliceisexceeded,
then your application has a fiber that may exceed its slice and fail.
First, make sure that fiber.yield() is used for this fiber to transfer control to another fiber.
You can also extend the fiber slice with the fiber.extend_slice(slice) function.
Decoding binary objects
Option: binary_data_decoding
Starting from version 3.0, Tarantool has the varbinary module
for handling binary objects of arbitrary lengths.
The binary_data_decoding compat option allows to define the format in which
varbinary field values are returned for handling in Lua: plain strings or varbinary
objects.
Old and new behavior
New behavior: varbinary field values are returned as varbinary objects.
String manipulation methods, such as string.sub() or string.match() are not
defined for varbinary objects. Thus, if you use such methods on results of
binary data decoding from MsgPack or YAML, convert them to strings
explicitly using the tostring() method.
tarantool>compat({>obsolete_set_explicitly='new',>option_set_old='old',>option_set_new='new'>})---...tarantool>compat-----option_set_old:old--option_set_new:new--option_default_old:default(old)--option_default_new:default(new)...#Obsoleteoptionsarenotreturnedinserialization,buthavethefollowingvalues:#-obsolete_option_default:default(new)#-obsolete_set_explicitly:new#nildoesoutputobsoleteunsetoptionsas'default'tarantool>compat.dump()----require('compat')({option_set_old='old',option_set_new='new',option_default_old='default',option_default_new='default',obsolete_option_default='default',-- obsolete since X.Yobsolete_set_explicitly='new',-- obsolete since X.Y})...#'current'isthesameasnilwithdefaultsettocurrentvaluestarantool>compat.dump('current')----require('compat')({option_set_old='old',option_set_new='new',option_default_old='old',option_default_new='new',obsolete_option_default='new',-- obsolete since X.Yobsolete_set_explicitly='new',-- obsolete since X.Y})...#'new'outputsobsoleteas'new'.tarantool>compat.dump('new')----require('compat')({option_set_old='new',option_set_new='new',option_default_old='new',option_default_new='new',obsolete_option_default='new',-- obsolete since X.Yobsolete_set_explicitly='new',-- obsolete since X.Y})...#'old'outputsobsoleteoptionsas'new'.tarantool>compat.dump('old')----require('compat')({option_set_old='old',option_set_new='old',option_default_old='old',option_default_new='old',obsolete_option_default='new',-- obsolete since X.Yobsolete_set_explicitly='new',-- obsolete since X.Y})...#'default'doesoutputobsoleteoptionsasdefault.tarantool>dump('default')----require('compat')({option_set_old='default',option_set_new='default',option_default_old='default',option_default_new='default',obsolete_option_default='default',-- obsoleted since X.Yobsolete_set_explicitly='default',-- obsoleted since X.Y})...
Setting all options to a specific value with compat.dump()
use compat.dump() to get a specific configuration
copy and paste it into console (or use loadstring())
brief (explanation of the option, can be multiline string)
obsolete (’X.Y’ / nil) — tarantool version that marked option as obsolete. When nil, option is treated as non-obsolete)
action function (argument - boolean is_new, changes the behavior accordingly)
run_action_now (true / false / nil) if add_options should run action afterwards, false by default
Option hot reload:
You can change an existing option in runtime using add_option(), it will update all the fields but keep currently selected behavior if any.
The new action will be called afterwards.
tarantool> compat.add_option{ name = 'option_4', default = 'new', brief = "<...>", obsolete = nil, -- you can explicitly mark the option as non-obsolete action = function(is_new) print(("option_4 action was called with is_new = %s!"):format(is_new)) end, run_action_now = true }option_4 postaction was called with is_new = true!---...tarantool> compat.add_option{-- hot reload of option_4 name = 'option_4', default = 'old', -- different default brief = "<...>", action = function(is_new) print(("new option_4 action was called with is_new = %s!"):format(is_new)) end }---...-- action is not called by default
A compressor instance that exposes the API for compressing and decompressing data using the zlib algorithm.
To create the zlib compressor, call compress.zlib.new().
Specifies the zlib compression level that enables you to adjust the compression ratio and speed.
The lower level improves the compression speed at the cost of compression ratio.
Specifies the compression strategy. The possible values:
default - for normal data.
huffman_only - forces Huffman encoding only (no string match). The fastest compression algorithm but not very effective in compression for most of the data.
filtered - for data produced by a filter or predictor. Filtered data consists mostly of small values with a somewhat random distribution. This compression algorithm is tuned to compress them better.
rle - limits match distances to one (run-length encoding). rle is designed to be almost as fast as huffman_only but gives better compression for PNG image data.
fixed - prevents the use of dynamic Huffman codes and provides a simpler decoder for special applications.
A compressor instance that exposes the API for compressing and decompressing data using the zstd algorithm.
To create the zstd compressor, call compress.zstd.new().
Specifies the zstd compression level that enables you to adjust the compression ratio and speed.
The lower level improves the compression speed at the cost of compression ratio.
For example, you can use level 1 if speed is most important and level 22 if size is most important.
Default: 3
Minimum: -131072
Maximum: 22
Note
Assigning 0 to level resets its value to the default (3).
A compressor instance that exposes the API for compressing and decompressing data using the lz4 algorithm.
To create the lz4 compressor, call compress.lz4.new().
Specifies the acceleration factor that enables you to adjust the compression ratio and speed.
The higher acceleration factor increases the compression speed but decreases the compression ratio.
Specifies the decompress buffer size (in bytes).
If the size of decompressed data is larger than this value, the compressor returns an error on decompression.
The config module provides the ability to work with an instance’s configuration.
For example, you can determine whether the current instance is up and running without errors after applying the cluster’s configuration.
By using the config.storagerole, you can set up a Tarantool-based centralized configuration storage and interact with this storage using the config module API.
Loading config
To load the config module, use the require() directive:
Get a configuration applied to the current or remote instance.
Note the following differences between getting a configuration for the current and remote instance:
For the current instance, get() returns its configuration considering environment variables.
For a remote instance, get() only considers a cluster configuration and ignores environment variables.
In the example below, the instance’s state is check_warnings.
The alerts section informs that privileges to the bands space for sampleuser cannot be granted because the bands space has not been created yet:
app:instance001> require('config'):info('v2')----status:check_warningsmeta:last:&0[]active:*0alerts:-type:warnmessage:box.schema.user.grant("sampleuser", "read,write", "space", "bands") hasfailed because either the object has not been created yet, a database schemaupgrade has not been performed, or the privilege write has failed (separatealert reported)timestamp:2024-07-03T18:09:18.826138+0300...
This warning is cleared when the bands space is created.
Example: configuration errors
In the example below, the instance’s state is check_errors.
The alerts section informs that the log.level configuration option has an incorrect value:
a table containing information about instances. The returned table uses instance names as the keys and contains the following information for each instance:
instance_name – an instance name
replicaset_name – the name of a replica set the instance belongs to
group_name – the name of a group the instance belongs to
Example
The example below shows how to use instances() to get the names of all instances in the cluster, create a connection to each instance using the connpool module, and log connection URIs using the log module:
localconfig=require('config')localconnpool=require('experimental.connpool')locallog=require('log')forinstance_nameinpairs(config:instances())dolocalconn=connpool.connect(instance_name)log.info("Connection URI for %q: %s:%s",instance_name,conn.host,conn.port)end
In this example, the same actions are performed for instances from the specified replica set:
localconfig=require('config')localconnpool=require('experimental.connpool')locallog=require('log')forinstance_name,definpairs(config:instances())doifdef.replicaset_name=='storage-b'thenlocalconn=connpool.connect(instance_name)log.info("Connection URI for %q: %s:%s",instance_name,conn.host,conn.port)endend
The example below shows how to read a configuration stored in the source.yaml file using the fio module API and put this configuration by the /myapp/config/all path:
The experimental.config.utils.schema module is used to validate and process
parts of cluster configurations that have arbitrary user-defined structures:
app.cfg for applications loaded using the app option
Define a schema – the root object that stores information about the role’s
configuration – using schema.new(). The example
below shows a schema that includes a single string option:
Use the validate() method of the schema object to
validate configuration values against the schema. In case of a role, call this
method inside the role’s validate() function:
A configuration schema stores information about a user-defined configuration structure
that can be passed inside an app.cfg
or a roles_cfg section. It includes
option names, types, hierarchy, and other aspects of a configuration.
To create a schema, use the schema.new() function.
It has the following arguments:
Schema name – an arbitrary string to use as an identifier.
Root schema node – a table describing the hierarchical schema structure
starting from the root.
(Optional) methods – user-defined functions that can be called on this schema object.
Schema nodes
Schema nodes describe the hierarchy of options within a schema. There are two types of schema nodes:
Scalar nodes hold a single value of a supported primitive type. For example,
a string configuration option of a role is a scalar node in its schema.
Composite nodes include multiple values in different forms: records, arrays, or maps.
A node can have annotations – named attributes that enable customization of
its behavior, for example, setting a default value.
Scalar nodes
Scalar nodes hold a single value of a primitive type, for example, a string or a number.
For the full list of supported scalar types, see Data types.
This configuration has one scalar node of the string type:
If a scalar node has a limited set of allowed values, you can also define it with
the schema.enum(). Pass the list of allowed values as
its argument:
scheme=schema.enum({'http','https'}),
Note
Another way to restrict possible option values is the allowed_values
built-in annotation.
Data types
Scalar nodes can have the following data types:
Scalar type
Lua type
Comment
string
string
number
number
integer
number
Only integer numbers
boolean
boolean
true or false
string,number
or
number,string
string or number
any
Arbitrary Lua value
May be used to declare an arbitrary value that doesn’t need validation.
Records
Record is a composite node that includes a predefined set of other nodes, scalar
or composite. In YAML, a record is represented as a node with nested fields.
For example, the following configuration has a record node http_api with
three scalar fields:
Records are also used to define nested schema nodes of non-primitive types. In the example
below, the http_api node includes another record listen_address.
Array is a composite node type that includes a collection of items of the same
type. The items can be either scalar or composite nodes.
In YAML, array items start with hyphens. For example, the following configuration
includes an array named http_api. Each its item is a record with three fields:
host, port, and scheme:
To create a map node in a schema, use schema.map().
If this node is declared as a map as shown below, the endpoints section can include
any number of options with arbitrary names and boolean values.
Node annotations are named attributes that define its various aspects. For example,
scalar nodes have a required annotation type that defines the node value type.
Other annotations can, for example, set a node’s default value and a validation function,
or store arbitrary user-provided data.
Annotations are passed in a table to the node creation function:
Built-in annotations are handled by the module. These are: type, validate, allowed_values, default and apply_default_if.
Note that validate and allowed_values are used for validation only. default and apply_default_if can transform the configuration.
User-defined annotations add named node attributes that can be used in the
application or role code.
Computed annotations allow access to annotations of other nodes throughout
the schema.
Built-in annotations
Built-in annotations are interpreted by the module itself. There are the following
built-in annotations:
type – the node value type.
The type must be explicitly specified for scalar nodes, except for those created with schema.enum().
For composite nodes and scalar enums, the corresponding constructors schema.record(), schema.map(), schema.array(),
schema.set(), and schema.enum() set the type automatically.
allowed_values – (optional) a list of possible node values.
validate – (optional) a validation function for the provided node value.
default – (optional) a value to use if the option is not specified in the configuration.
apply_default_if – (optional) a function that defines when to apply the default value.
The following schema uses built-in annotations default, allowed_values, and validate
to define default and allowed option values and validation functions:
localfunctionvalidate_host(host,w)localhost_pattern="^(%d+)%.(%d+)%.(%d+)%.(%d+)$"ifnothost:match(host_pattern)thenw.error("'host' should be a string containing a valid IP address, got %q",host)endendlocalfunctionvalidate_port(port,w)ifport<=1orport>=65535thenw.error("'port' should be between 1 and 65535, got %d",port)endend
User-defined annotations
A schema node can have user-defined annotations with arbitrary names. Such annotations
are used to implement custom behavior. You can get their names and values from
the schema and use in the role or application code.
Example: the env user-defined annotation is used to provide names
of environment variables from which the configuration values can be taken.
Computed annotations enable access from a node to annotations of its ancestor nodes.
In the example below, the listen_address record validation function refers to the
protocol annotation of its ancestor node:
locallisten_address=schema.record({scheme=schema.enum({'http','https'}),host=schema.scalar({type='string'}),port=schema.scalar({type='integer'})},{validate=function(data,w)localprotocol=w.schema.computed.annotations.protocolifprotocol=='iproto'anddata.scheme~=nilthenw.error("iproto doesn't support 'scheme'")endend,})
Note
If there are several ancestor nodes with this annotation, its value is taken
from the closest one to the current node.
The following schema with listen_address passes the validation:
The schema object’s validate() method performs all the necessary checks
on the provided configuration. It validates the configuration structure, node types, allowed values,
and other aspects of the schema.
To get configuration values, use the schema object’s get() method.
It takes the configuration and the full path to the node as arguments:
localfunctionapply(cfg)localscheme=listen_address_schema:get(cfg,'listen_address.scheme')localhost=listen_address_schema:get(cfg,'listen_address.host')localport=listen_address_schema:get(cfg,'listen_address.port')log.info("HTTP API endpoint: %s://%s:%d",scheme,host,port)end
Transforming configuration
The schema object has methods that transform configuration data based on the schema,
for example, apply_default(),
merge(), set().
The following sample shows how to apply default values from the schema to fill
missing configuration fields:
localfunctionapply(cfg)localcfg_with_defaults=listen_address_schema:apply_default(cfg)localscheme=listen_address_schema:get(cfg_with_defaults,'scheme')localhost=listen_address_schema:get(cfg_with_defaults,'host')localport=listen_address_schema:get(cfg_with_defaults,'port')log.info("HTTP API endpoint: %s://%s:%d",scheme,host,port)end
Parsing environment variables
The schema.fromenv() function allows getting
configuration values from environment variables. The example below shows how to do
this by adding a user-defined annotation env:
Parse an environment variable as a value of the given schema node.
The env_var_name parameter is used only for error messages.
The value (raw_value) should be received using os.getenv() or os.environ().
How the raw value is parsed depends on the schema_node type:
Scalar:
string: return the value as is
number or integer: parse the value as a number or an integer
string,number: attempt to parse as a number; in case of a failure
return the value as is
boolean: accept true and false (case-insensitively), or 1 and 0
for true and false values correspondingly
any: parse the value as a JSON
Map: parse either as JSON (if the raw value starts with {)
or as a comma-separated string of key=value pairs: key1=value1,key2=value2
Array: parse either as JSON (if the raw value starts with [)
or as a comma-separated string of items: item1,item2,item3
Note
Parsing records from environment variables is not supported.
Parameters:
env_var_name (string) – environment variable name to use for error messages
data is assumed to be validated against the given schema.
Apply default values to scalar nodes. The functions takes the default
built-in annotation values of the scalar nodes and applies them based
on the apply_default_if annotation. If there is no apply_default_if
annotation on a node, the default value is also applied.
Note
The method works for static defaults. To define a dynamic default value,
use the map() method.
data is assumed to be validated against the given schema.
Get nested configuration values at the given path. The path can be
either a dot-separated string (http.scheme) or an array-like table ({'http','scheme'}).
data is assumed to be validated against the given schema.
Transform data by the given function. The data fields are transformed
by the function passed in the second argument (f), while its structure remains unchanged.
The transformation function takes three arguments:
data – the configuration data
w – walkthrough node with the following fields:
w.schema – schema node
w.path – the path to the schema node
w.error() – a function for printing human-readable error messages
ctx – additional context for the transformation function. Can be
used to provide values for a specific call.
The map() method traverses all fields of the schema records,
even if they are nil or box.NULL in the provided configuration.
This allows using this method to set computed default values for missing
fields. Note that this is not the case for maps and arrays since the schema
doesn’t define their fields to traverse.
Parameters:
data (any) – configuration data
f (function) – transformation function
f_ctx (any) – user-provided context for the transformation function
data is assumed to be validated against the given schema.
value is validated by the method before the assignment.
Set a given value at the given path in a configuration.
The path can be either a dot-separated string (http.scheme) or
an array-like table ({'http','scheme'}).
Validate data against the schema. If the data doesn’t adhere to the schema,
an error is raised.
The method performs the following checks:
field type checks: field values are checked against the schema node types
allowed values: if a node has the allowed_values annotations of schema nodes,
the corresponding data field is checked against the allowed values list
validation functions: if a validation function is defined for a node
(the validate annotation), it is executed to check that the provided value is valid.
A boolean function that defines whether to apply the default value specified
using default. If this function returns true on a provided configuration data,
the node receives the default value upon the schema_object.apply_default()
method call.
The function takes two arguments:
data – the configuration data
w – walkthrough node with the following fields:
w.schema – schema node
w.path – the path to the schema node
w.error() – a function for printing human-readable error messages
A function used to validate node data. The function must raise an error to
fail the check. The function is called upon the schema_object:validate()
function calls.
The function takes two arguments:
data – the configuration data
w – walkthrough node with the following fields:
w.schema – schema node
w.path – the path to the schema node
w.error() – a function for printing human-readable error messages
Example:
A function that checks that a string is a valid IP address:
localfunctionvalidate_host(host,w)localhost_pattern="^(%d+)%.(%d+)%.(%d+)%.(%d+)$"ifnothost:match(host_pattern)thenw.error("'host' should be a string containing a valid IP address, got %q",host)endend
Node value validation function. The value
is taken from the validate annotation.
Module console
Overview
The console module allows one Tarantool instance to access another Tarantool
instance, and allows one Tarantool instance to start listening on an
admin port.
Connect to the instance at URI, change the prompt from
‘tarantool>’ to ‘uri>’, and act henceforth as a client
until the user ends the session or types control-D.
The console.connect function allows one Tarantool instance, in interactive
mode, to access another Tarantool instance. Subsequent requests will appear
to be handled locally, but in reality the requests are being sent to the
remote instance and the local instance is acting as a client. Once connection
is successful, the prompt will change and subsequent requests are sent to,
and executed on, the remote instance. Results are displayed on the local
instance. To return to local mode, enter control-D.
If the Tarantool instance at uri requires authentication, the
connection might look something like:
console.connect('admin:secretpassword@distanthost.com:3301').
There are no restrictions on the types of requests that can be entered,
except those which are due to privilege restrictions – by default the
login to the remote instance is done with user name = ‘guest’. The remote
instance could allow for this by granting at least one privilege:
box.schema.user.grant('guest','execute','universe').
Possible errors: the connection will fail if the target Tarantool instance
was not initiated with box.cfg{listen=...}.
Example:
tarantool> console=require('console')---...tarantool> console.connect('198.18.44.44:3301')---...198.18.44.44:3301> -- prompt is telling us that instance is remote
Listen on URI. The primary way of listening for incoming
requests is via the connection-information string, or URI, specified in
box.cfg{listen=...}. The alternative way of listening is via the URI
specified in console.listen(...). This alternative way is called
“administrative” or simply “admin port”.
The listening is usually over a local host with a Unix domain socket.
The “admin” address is the URI to listen on. It has no default value, so it
must be specified if connections will occur via an admin port. The parameter
is expressed with URI = Universal Resource Identifier format, for example
“/tmpdir/unix_domain_socket.sock”, or a numeric TCP port. Connections are
often made with telnet. A typical port value is 3313.
Start the console on the current interactive terminal.
Example:
A special use of console.start() is with initialization files. Normally, if one starts the Tarantool instance with
tarantoolinitializationfile there is no console. This can be
remedied by adding these lines at the end of the initialization file:
Set the auto-completion flag. If auto-completion is true, and the user is
using Tarantool as a client or the user is using Tarantool via
console.connect(), then hitting the TAB key may cause tarantool to
complete a word automatically. The default auto-completion value is true.
Set a custom end-of-request marker for Tarantool console.
The default end-of-request marker is a newline (line feed).
Custom markers are not necessary because Tarantool can tell when a multi-line
request has not ended (for example, if it sees that a function declaration
does not have an end keyword). Nonetheless for special needs, or for
entering multi-line requests in older Tarantool versions, you can change the
end-of-request marker. As a result, newline alone is not treated as
end of request.
To go back to normal mode, say: console.delimiter('')<marker>
Parameters:
marker (string) – a custom end-of-request marker for Tarantool console
Return the current default output format. The result will be
fmt="yaml", or it will be fmt="lua" if
the last set_default_output
call was console.set_default_output('lua').
Set the default output format.
The possible values are ‘yaml’ (the default default) or ‘lua’.
The output format can be changed within a session by executing
console.eval('\setoutputyaml|lua'); see the
description of output format in the
Interactive console section.
Set or access the end-of-output string if default output is ‘lua’.
This is the string that appears at the end of output in a response
to any Lua request.
The default value is ; semicolon.
Saying eos() will return the current value.
For example, after require('console').eos('!!') responses will end with ‘!!’.
Module crypto
Overview
“Crypto” is short for “Cryptography”, which generally refers to the production
of a digest value from a function (usually a
Cryptographic hash function),
applied against a string. Tarantool’s crypto module supports ten types of
cryptographic hash functions
(AES,
DES,
DSS,
MD4,
MD5,
MDC2,
RIPEMD,
SHA-1,
SHA-2).
Some of the crypto functionality is also present in the
Module digest module.
Suppose that a digest is done for a string ‘A’, then a new part ‘B’ is appended
to the string, then a new digest is required. The new digest could be recomputed
for the whole string ‘AB’, but it is faster to take what was computed before for
‘A’ and apply changes based on the new part ‘B’. This is called multi-step or
“incremental” digesting, which Tarantool supports for all crypto functions.
crypto=require('crypto')-- print aes-192 digest of 'AB', with one step, then incrementallykey='key/key/key/key/key/key/'iv='iviviviviviviviv'print(crypto.cipher.aes192.cbc.encrypt('AB',key,iv))c=crypto.cipher.aes192.cbc.encrypt.new(key)c:init(nil,iv)c:update('A')c:update('B')print(c:result())c:free()-- print sha-256 digest of 'AB', with one step, then incrementallyprint(crypto.digest.sha256('AB'))c=crypto.digest.sha256.new()c:init()c:update('A')c:update('B')print(c:result())c:free()
Getting the same results from digest and crypto modules
The following functions are equivalent. For example, the digest function and
the crypto function will both produce the same result.
The csv module handles records formatted according to Comma-Separated-Values
(CSV) rules.
The default formatting rules are:
Lua escape sequences such as \n or \10 are legal within strings but not
within files,
Commas designate end-of-field,
Line feeds, or line feeds plus carriage returns, designate end-of-record,
Leading or trailing spaces are ignored,
Quote marks may enclose fields or parts of fields,
When enclosed by quote marks, commas and line feeds and spaces are treated
as ordinary characters, and a pair of quote marks “” is treated as a single
quote mark.
The possible options which can be passed to csv functions are:
delimiter=string (default: comma) – single-byte character to
designate end-of-field
quote_char=string (default: quote mark) – single-byte character
to designate encloser of string
chunk_size=number (default: 4096) – number of characters to read
at once (usually for file-IO efficiency)
skip_head_lines=number (default: 0) – number of lines to skip at
the start (usually for a header)
Get CSV-formatted input from readable and return a table as output.
Usually readable is either a string or a file opened for reading.
Usually options is not specified.
Parameters:
readable (object) – a string, or any object which has a read() method,
formatted according to the CSV rules
Get table input from csv-table and return a CSV-formatted string as
output. Or, get table input from csv-table and put the output in
writable. Usually options is not specified. Usually
writable, if specified, is a file opened for writing. csv.dump() is the reverse of csv.load().
Parameters:
csv-table (table) – a table which can be formatted according to the CSV
rules.
Form a Lua iterator function for going through CSV records one field at a
time. Use of an iterator is strongly recommended if the amount of data is
large (ten or more megabytes).
Parameters:
csv-table (table) – a table which can be formatted according to the CSV
rules.
The datetime module provides support for the datetime data types.
It allows creating the date and time values either via the object interface
or via parsing string values conforming to the ISO-8601 standard.
API Reference
Below is a list of datetime functions, properties, and related objects.
units (table) – Table of time units.
If an empty table or no arguments are passed, the datetime object with the default values corresponding to Unix Epoch is created: 1970-01-01T00:00:00Z.
Fractional part of the last second. You can specify either nanoseconds (nsec), or microseconds (usec), or milliseconds (msec).
Specifying two of these units simultaneously or all three ones lead to an error.
number
0
sec
Seconds. Value range: 0 - 60. A leap second is supported, see a section leap second.
number
0
min
Minutes. Value range: 0 - 59.
number
0
hour
Hours. Value range: 0 - 23.
number
0
day
Day number. Value range: 1 - 31. The special value -1 generates the last day of a particular month (see example below).
number
1
month
Month number. Value range: 1 - 12.
number
1
year
Year.
number
1970
timestamp
Timestamp, in seconds. Similar to the Unix timestamp, but can have a fractional part that is converted in nanoseconds in the resulting datetime object.
If the fractional part for the last second is set via the nsec, usec, or msec units, the timestamp value should be integer otherwise an error occurs.
The timestamp is not allowed if you already set time and/or date via specific units, namely, sec, min, hour, day, month, and year.
number
0
tzoffset
A time zone offset from UTC, in minutes. Value range: -720 - 840 inclusive.
If both tzoffset and tz are specified, tz has the preference and the tzoffset
value is ignored. See a section timezone.
number
0
tz
A time zone name according to the Time Zone Database. See the Time zones section.
Convert an input string with the date and time information into a datetime object.
The input string should be formatted according to one of the following standards:
ISO 8601
RFC 3339
extended strftime – see description of the format() for details.
By default fields that are not specified are equal to appropriate values in a Unix time.
Leap second is supported, see a section leap second.
Parameters:
input_string (string) – string with the date and time information.
format (string) – indicator of the input_string format.
Possible values: ‘iso8601’, ‘rfc3339’, or strptime-like format string.
If no value is set, the default formatting is used ("%F%T%Z").
Note that only a part of possible ISO 8601 and RFC 3339 formats are supported.
To parse unsupported formats, you can specify a format string manually using
conversion specifications
and ordinary characters.
tzoffset (number) – time zone offset from UTC, in minutes.
input (table) – Table with time units and parameters. For all possible time units, the values are not restricted.
If an empty table or no arguments are passed, the interval object with the default value 0seconds is created.
Return:
interval_object
Rtype:
cdata
Possible input time units and parameters for datetime.interval.new()
Name
Description
Type
Default
nsec (usec, msec)
Fractional part of the last second. You can specify either nanoseconds (nsec), or microseconds (usec), or milliseconds (msec).
Specifying two of these units simultaneously or all three ones lead to an error.
number
0
sec
Seconds
number
0
min
Minutes
number
0
hour
Hours
number
0
day
Day number
number
0
week
Week number
number
0
month
Month number
number
0
year
Year
number
0
adjust
Defines how to round days in a month after an arithmetic operation.
string
‘none’
Examples:
tarantool> datetime.interval.new()----0 seconds...tarantool> datetime.interval.new{ month = 6, year = 1 }----+1 years, 6 months...tarantool> datetime.interval.new{ day = -1 }-----1 days...
A Lua table that maps timezone names (like Europe/Moscow) and
timezone abbreviations (like MSK) to its index and vice-versa.
See the Time zones section.
Modify an existing datetime object by adding values of the input argument.
See also: Datetime and interval arithmetic. The addition is performed taking tzdata
into account, when tzoffset or tz fields are set, see the Time zones.
adjust (string) – defines how to round days in a month after an arithmetic operation.
Possible values: none, last, excess (see Example #2). Defaults to none.
Return:
datetime_object
Rtype:
cdata
Example #1:
tarantool> dt=datetime.new{ day = 26, month = 8, year = 2021, tzoffset = 180 }---...tarantool> iv=datetime.interval.new{day=7}---...tarantool> dt,iv----2021-08-26T00:00:00+0300-+7 days...tarantool> dt:add(iv)----2021-09-02T00:00:00+0300...tarantool> dt:add{day=7}----2021-09-09T00:00:00+0300...
Example #2:
tarantool> dt=datetime.new{ day = 29, month = 2, year = 2020 }---...tarantool> dt:add{month=1,adjust='none'}----2020-03-29T00:00:00Z...tarantool> dt=datetime.new{ day = 29, month = 2, year = 2020 }---...tarantool> dt:add{month=1,adjust='last'}----2020-03-31T00:00:00Z...tarantool> dt=datetime.new{ day = 31, month = 1, year = 2020 }---...tarantool> dt:add{month=1,adjust='excess'}----2020-03-02T00:00:00Z...
Convert the standard datetime object presentation into a formatted string.
The conversion specifications are the same as in the strftime function.
Additional specification for nanoseconds is %f which also allows a modifier to control the output precision of fractional part: %5f (see the example below).
If no arguments are set for the method, the default conversions are used: '%FT%T.%f%z' (see the example below).
Parameters:
input_string (string) – string consisting of zero or more conversion specifications and ordinary characters
Return:
string with the formatted date and time information
Modify an existing datetime object by subtracting values of the input argument.
See also: Datetime and interval arithmetic. The subtraction is performed taking tzdata
into account, when tzoffset or tz fields are set, see the Time zones.
adjust (string) – defines how to round days in a month after an arithmetic operation.
Possible values: none, last, excess. Defaults to none.
The logic is similar to the one of the :add() method – see Example #2.
Return:
datetime_object
Rtype:
cdata
Example:
tarantool> dt=datetime.new{ day = 26, month = 8, year = 2021, tzoffset = 180 }---...tarantool> iv=datetime.interval.new{day=5}---...tarantool> dt,iv----2021-08-26T00:00:00+0300-+5 days...tarantool> dt:sub(iv)----2021-08-21T00:00:00+0300...tarantool> dt:sub{day=1}----2021-08-20T00:00:00+0300...
The datetime module enables creating of objects of two types: datetime and interval.
If you need to shift the datetime object values, you can use either the modifier methods, that is, the datetime_object:add() or datetime_object:sub() methods,
or apply interval arithmetic using overloaded + (__add) or - (__sub) methods.
datetime_object:add()/datetime_object:sub() modify the current object, but +/- create copy of the object as the operation result.
In the interval operation, each of the interval subcomponents is sequentially calculated starting from the largest (year) to the smallest (nsec):
year – years
month – months
week – weeks
day – days
hour – hours
min – minutes
sec – seconds
nsec – nanoseconds
If the results of the operation exceed the allowed range for any of the components, an exception is raised.
The datetime and interval objects can participate in arithmetic operations:
The sum of two intervals is an interval object, whose fields are the sum of each particular component of operands.
The result of subtraction of two intervals is similar: it’s an interval object where each subcomponent is the result of subtraction of particular fields in the original operands.
If you add datetime and interval objects, the result is a datetime object. The addition is performed in a determined order from the largest component (year) to the smallest (nsec).
Subtraction of two datetime objects produces an interval object. The difference of two time values is performed not as the difference of the epoch seconds,
but as difference of all the subcomponents, that is, years, months, days, hours, minutes, and seconds.
An untyped table object can be used in each context where the typed datetime or interval objects are used if the left operand is a typed object with an overloaded operation of + or -.
The matrix of the addition operands eligibility and their result types:
datetime
interval
table
datetime
unsupported
datetime
datetime
interval
datetime
interval
interval
The matrix of the subtraction operands eligibility and their result types:
datetime
interval
table
datetime
interval
datetime
datetime
interval
unsupported
interval
interval
The subtraction and addition of datetime objects are performed taking tzdata
into account tzoffset or tz fields are set:
If you need to compare the datetime and interval object values, you can use standard Lua relational operators: ==, ~=, >, <, >=, and <=. These operators use the overloaded __eq, __lt, and __le metamethods to compare values.
Support for relational operators for interval objects has been added since 2.11.0.
Leap seconds are a periodic
one-second adjustment of Coordinated Universal Time(UTC) in order to keep
a system’s time of day close to the mean solar time. However,
the Earth’s rotation speed varies in response to climatic and geological events,
and due to this, UTC leap seconds are irregularly spaced and unpredictable.
Tarantool includes the Time Zone Database
that besides the time zone description files also contains a leapseconds file.
You can use the Lua module tarantool to get a used
version of tzdata.
This section describes how the datetime module supports leap seconds:
The function datetime.parse() correctly parses
an input string with 60 seconds:
Tarantool uses the Time Zone Database
(also known as the Olson database and supported by IANA) for timezone support.
You can use the Lua module tarantool to get a used version of tzdata.
Every datetime object has three fields that represent timezone support:
tz, tzoffset, and isdst:
The field isdst is calculated using tzindex and attributes of the selected
timezone in the Olson DB timezone.
The field tz field can be set to a timezone name or abbreviation. A timezone name
is a human-readable name based on the Time Zone Database, for example, “Europe/Moscow”.
Timezone abbreviations represent time zones by alphabetic abbreviations
such as “EST”, “WST”, and “F”. Both timezone names and abbreviations are available
via the bidirectional array datetime.TZ.
The field tzoffset is calculated automatically using the current Olson rule.
This means that it takes into account summer time, leap year, and leap seconds information
when a timezone name is set. However, the tzoffset field can be set manually when
an appropriate timezone is not available.
The supported date range is from -5879610-06-22 to +5879611-07-11.
There were moments in past history when local mean time in some particular zone
used a timezone offset not representable in a whole minutes but rather in seconds.
For example, in Moscow before 1918 there used to be offset +2 hours 31 minutes and 19 seconds.
See an Olson dump for this period:
Modern tzdata rules do not use such a tiny fraction, and all timezones differ
from UTC in units measured in minutes, not seconds. Tarantool datetime module uses
minutes internally as units for tzoffset. So there might be some loss of precision
if you try to operate with such ancient timestamps.
The decimal module has functions for working with
exact numbers. This is important when numbers are large
or even the slightest inaccuracy is unacceptable.
For example Lua calculates 0.16666666666667*6
with floating-point so the result is 1.
But with the decimal module (using decimal.new
to convert the number to decimal type)
decimal.new('0.16666666666667')*6 is 1.00000000000002.
To construct a decimal number, bring in the module with
require('decimal') and then use decimal.new(n)
or any function in the decimal module:
where n can be a string or a non-decimal number or a decimal number.
If it is a string or a non-decimal number,
Tarantool converts it to a decimal number before
working with it.
It is best to construct from strings, and to convert
back to strings after calculations, because Lua numbers
have only 15 digits of precision. Decimal numbers have
38 digits of precision, that is, the total number of digits
before and after the decimal point can be 38.
Tarantool supports the usual arithmetic and comparison operators
+ - * / % ^ < > <= >= ~= ==.
If an operation has both decimal and non-decimal operands,
then the non-decimal operand is converted to decimal before
the operation happens.
Use tostring(decimal-number) to convert back to a string.
A decimal operation will fail if overflow happens (when a
number is greater than 10^38 - 1 or less than -10^38 - 1).
A decimal operation will fail if arithmetic is impossible
(such as division by zero or square root of minus 1).
A decimal operation will not fail if rounding of
post-decimal digits is necessary to get 38-digit precision.
Returns e raised to the power of a decimal number.
For example if a is 1 then decimal.exp(a) returns
2.7182818284590452353602874713526624978.
Compare math.exp(1) from the
Lua math library,
which returns 2.718281828459.
Returns true if the specified value is a decimal, and false otherwise.
For example if a is 123 then decimal.is_decimal(a) returns false.
if a is decimal.new(123) then decimal.is_decimal(a) returns true.
Returns the number after possible rounding or padding.
If the number of post-decimal digits is greater than new-scale,
then rounding occurs. The rounding rule is: round half away from zero.
If the number of post-decimal digits is less than new-scale,
then padding of zeros occurs.
For example if a is -123.4550 then decimal.rescale(a,2)
returns -123.46, and decimal.rescale(a,5) returns -123.45500.
Returns a decimal number after possible removing of trailing post-decimal zeros.
For example if a is 2.20200 then decimal.trim(a) returns 2.202.
Module digest
Overview
A “digest” is a value which is returned by a function (usually a
Cryptographic hash function),
applied against a string. Tarantool’s digest
module supports several types of cryptographic hash functions (
AES,
MD4,
MD5,
SHA-1,
SHA-2,
PBKDF2)
as well as a checksum function (CRC32), two
functions for base64, and two non-cryptographic hash functions
(guava,
murmur).
Some of the digest functionality is also present in the crypto.
Returns binary string = digest made with PBKDF2.
For effective encryption the iterations value should be
at least several thousand. The digest-length value
determines the length of the resulting binary string.
Note
digest.pbkdf2() yields and should not be used in a transaction (between
box.begin() and box.commit()/box.rollback()).
PBKDF2 is a time-consuming hash algorithm. It runs in a separate coio thread.
While calculations are performed, the fiber that calls digest.pbkdf2()
yields and another fiber continues working in the tx thread.
The crc32 and crc32_update functions use the
Cyclic Redundancy Check
polynomial value: 0x1EDC6F41 / 4812730177.
(Other settings are: input = reflected, output = reflected, initial value = 0xFFFFFFFF, final xor value = 0x0.)
If it is necessary to be
compatible with other checksum functions in other programming languages,
ensure that the other functions use the same polynomial value.
For example, in Python, install the crcmod package and say:
The guava function uses the Consistent Hashing
algorithm of the Google
guava library. The first parameter should be a hash code; the second
parameter should be the number of buckets; the returned value will be an
integer between 0 and the number of buckets. For example,
Initiates incremental MurmurHash.
See incremental methods notes.
For example:
murmur.new({seed=0})
Incremental methods in the digest
module
Suppose that a digest is done for a string ‘A’, then a new part ‘B’ is appended
to the string, then a new digest is required. The new digest could be recomputed
for the whole string ‘AB’, but it is faster to take what was computed before for
‘A’ and apply changes based on the new part ‘B’. This is called multi-step or
“incremental” digesting, which Tarantool supports with crc32 and with murmur…
digest=require('digest')-- print crc32 of 'AB', with one step, then incrementallyprint(digest.crc32('AB'))c=digest.crc32.new()c:update('A')c:update('B')print(c:result())-- print murmur hash of 'AB', with one step, then incrementallyprint(digest.murmur('AB'))m=digest.murmur.new()m:update('A')m:update('B')print(m:result())
Example
In the following example, the user creates two functions, password_insert()
which inserts a SHA-1 digest of the word “^S^e^c^ret Wordpass” into a tuple
set, and password_check() which requires input of a password.
tarantool> digest=require('digest')---...tarantool> functionpassword_insert() > box.space.tester:insert{1234,digest.sha1('^S^e^c^ret Wordpass')} > return'OK' > end---...tarantool> functionpassword_check(password) > localt=box.space.tester:select{12345} > ifdigest.sha1(password)==t[2]then > return'Password is valid' > else > return'Password is not valid' > end > end---...tarantool> password_insert()----'OK'...
If a later user calls the password_check() function and enters the wrong
password, the result is an error.
The errno module is typically used
within a function or within a Lua program, in association with a module whose
functions can return operating-system errors, such as fio.
Return a string, given an error number. The string will contain the
text of the conventional error message for the current operating system.
If code is not supplied, the error message will be for the last
operating-system-related function, or 0.
Parameters:
code (integer) – number of an operating-system error
This function displays the result of a call to fio.open()
which causes error 2 (errno.ENOENT). The display includes the
error number, the associated error string, and the error name.
tarantool> functionf() > localfio=require('fio') > localerrno=require('errno') > fio.open('no_such_file') > print('errno() = '..errno()) > print('errno.strerror() = '..errno.strerror()) > localt=getmetatable(errno).__index > fork,vinpairs(t)do > ifv==errno()then > print('errno() constant = '..k) > end > end > end---...tarantool> f()errno() = 2errno.strerror() = No such file or directoryerrno() constant = ENOENT---...
To see all possible error names stored in the errno metatable, say
getmetatable(errno) (output abridged):
experimental.connpool is an experimental module and is subject to changes.
The experimental.connpool module provides a set of features for connecting to remote cluster instances and for executing remote procedure calls on an instance that satisfies the specified criteria.
Note
Note that the execution time for experimental.connpool functions depends on the number of instances and the time required to connect to each instance.
Loading a module
To load the experimental.connpool module, use the require() directive:
Execute the specified function on a remote instance.
Note
The function is executed on behalf of the user that maintains replication in the cluster.
Ensure that this user has the executepermission for the function to execute.
Parameters:
func_name (string) – a name of the function to execute.
args (table/nil) – function arguments.
opts (table/nil) –
options used to select candidates on which the function should be executed:
Once you have a connection, you can execute requests on the remote instance, for example, select data from a space using conn.space.<space-name>:select().
Send and receive messages between different processes (i.e. different
connections, sessions, or fibers) via channels.
Use a synchronization mechanism for fibers,
similar to “condition variables” and similar to operating-system functions,
such as pthread_cond_wait() plus pthread_cond_signal().
Index
Below is a list of all fiber functions and members.
A fiber is a set of instructions that are executed with cooperative multitasking.
The fiber module enables you to create a fiber and
associate it with a user-supplied function called a fiber function.
A fiber has the following possible states: running, suspended, ready, or dead.
A program with fibers is, at any given time, running only one of its fibers.
This running fiber only suspends its execution when it explicitly
yields control to another fiber that is ready to execute.
When the fiber function ends, the fiber ends and becomes dead.
If required, you can cancel a running or suspended fiber.
Another useful capability is limiting
a fiber execution time for long-running operations.
Note
By default, each transaction in Tarantool is executed in
a single fiber on a single thread, sees a consistent database state, and commits all changes atomically.
Create a fiber
To create a fiber, call one of the following functions:
fiber.create() creates a fiber and runs it immediately.
The initial fiber state is running.
fiber.new() creates a fiber but does not start it.
The initial fiber state is ready.
You can join such fibers by calling the fiber_object:join() function
and get the result returned by the fiber’s function.
Yield control
Yield is an action that occurs in a cooperative environment that
transfers control of the thread from the current fiber to another fiber that is ready to execute.
The fiber module provides the following functions that yield control to another fiber explicitly:
fiber.sleep() yields control to the scheduler and sleeps for the specified number of seconds.
Cancel a fiber
To cancel a fiber, use the fiber_object.cancel function.
You can also call fiber.kill() to locate a fiber by its numeric ID and cancel it.
Limit execution time
If a fiber works too long without yielding control, you can use a fiber slice to limit its execution time.
The fiber_slice_defaultcompat option controls the default value of the maximum fiber slice.
There are two slice types: a warning and an error slice.
When a warning slice is over, a warning message is logged, for example:
fiber has not yielded for more than 0.500 seconds
When an error slice is over, the fiber is cancelled and the FiberSliceIsExceeded error is thrown:
FiberSliceIsExceeded: fiber slice is exceeded
Control is passed to another fiber that is ready to execute.
The fiber slice is checked by all functions operating on spaces and indexes, such as index_object.select(), space_object.replace(), and so on.
You can also use the fiber.check_slice() function in application code to check whether the slice for the current fiber is over.
The following functions override the the default value of the maximum fiber slice:
fiber.top() shows all alive fibers and their CPU consumption.
Garbage collection
Like all Lua objects, dead fibers are garbage collected. The Lua garbage collector
frees pool allocator memory owned by the fiber, resets all fiber data, and
returns the fiber (now called a fiber carcass) to the fiber pool. The carcass
can be reused when another fiber is created.
A fiber has all the features of a Lua
coroutine and all the programming
concepts that apply to Lua coroutines apply to fibers as well. However,
Tarantool has made some enhancements for fibers and has used fibers internally.
So, although the use of coroutines is possible and supported, the use of fibers is
recommended.
Create a fiber but do not start it.
The created fiber starts after the fiber creator
(that is, the job that is calling fiber.new()) yields.
The initial fiber state is ready.
Note
Note that fiber.status() returns the suspended state
for ready fibers because the ready state is not observable
using the fiber module API.
You can join fibers created using fiber.new by calling the
fiber_object:join() function and get the result returned by the fiber’s function.
To join the fiber, you need to make it joinable using fiber_object:set_joinable().
Parameters:
function – the function to be associated with the fiber
function-arguments – arguments to be passed to the function
Return:
created fiber object
Rtype:
userdata
Example:
The script below shows how to create a fiber using fiber.new:
-- app.lua --fiber=require('fiber')functiongreet(name)print('Hello, '..name)endgreet_fiber=fiber.new(greet,'John')print('Fiber not started yet')
The following output should be displayed after runningapp.lua:
$ tarantoolapp.lua
Fiber not started yetHello, John
The increment function below contains an infinite loop
that adds 1 to the counter global variable.
Then, the current fiber goes to sleep for period seconds.
sleep causes an implicit fiber.yield().
In the example below, two fibers are associated with the same function.
Each fiber yields control after printing a greeting.
-- app.lua --fiber=require('fiber')functiongreet()whiletruedoprint('Enter a name:')name=io.read()print('Hello, '..name..'. I am fiber '..fiber.id())fiber.yield()endendfori=1,2dofiber_object=fiber.create(greet)fiber_object:cancel()end
The output might look as follows:
$ tarantoolapp.lua
Enter a name:JohnHello, John. I am fiber 104Enter a name:JaneHello, Jane. I am fiber 105
backtrace (boolean) – show backtrace. Default: true.
Set to false to show less information (symbol resolving can be expensive).
bt (boolean) – same as backtrace, but with lower priority.
Return:
number of context switches (csw), backtrace, total memory, used
memory, fiber ID (fid), fiber name.
If fiber.top is enabled or Tarantool was built with ENABLE_FIBER_TOP,
processor time (time) is also returned.
backtrace, bt – each fiber’s stack trace, showing where it originated and what functions were called.
memory:
total – total memory occupied by the fiber as a C structure, its stack, etc.
used – actual memory used by the fiber.
time – duplicates the “time” entry from fiber.top().cpu for each fiber.
Only shown if fiber.top is enabled.
Example:
tarantool> fiber.info({bt=true})----101:csw:1backtrace:-C:'#00x5dd130inlbox_fiber_id+96'-C:'#10x5dd13dinlbox_fiber_stall+13'-L:stall in =[C] at line -1-L:(unnamed) in @builtin/fiber.lua at line 59-C:'#20x66371binlj_BC_FUNCC+52'-C:'#30x628f28inlua_pcall+120'-C:'#40x5e22a8inluaT_call+24'-C:'#50x5dd1a9inlua_fiber_run_f+89'-C:'#60x45b011infiber_cxx_invoke(int(*)(__va_list_tag*),__va_list_tag*)+17'-C:'#70x5ff3c0infiber_loop+48'-C:'#80x81ecf4incoro_init+68'memory:total:516472used:0time:0name:luafid:101102:csw:0backtrace:-C:'#0(nil)in+63'-C:'#1(nil)in+63'memory:total:516472used:0time:0name:on_shutdownfid:102...
cpu itself is a table whose keys are strings containing fiber ids and names.
The three metrics available for each fiber are:
instant (in percent), which indicates the share of time the fiber
was executing during the previous event loop iteration.
average (in percent), which is calculated as an exponential moving
average of instant values over all the previous event loop iterations.
time (in seconds), which estimates how much CPU time each fiber spent
processing during its lifetime.
The time entry is also added to each fiber’s output in fiber.info()
(it duplicates the time entry from fiber.top().cpu per fiber).
Note that time is only counted while fiber.top() is enabled.
cpu_misses indicates the number of times the TX thread detected it was
rescheduled on a different CPU core during the last event loop iteration.
fiber.top() uses the CPU timestamp counter to measure each fiber’s execution
time. However, each CPU core may have its own counter value (you can
only rely on counter deltas if both measurements were taken on the same
core, otherwise the delta may even get negative). When the TX thread is
rescheduled to a different CPU core, Tarantool just assumes the CPU delta was
zero for the latest measurement. This lowers the precision of our computations,
so the bigger cpumisses value the lower the precision of fiber.top() results.
Note
With 2.11.0, cpu_misses is deprecated and always returns 0.
Notice that by default new fibers created due to
fiber.create are named ‘lua’ so it is better to set
their names explicitly via fiber_object:name(‘name’).
There are several system fibers in fiber.top() output that might be useful:
sched is a special system fiber. It schedules tasks to other fibers,
if any, and also handles some libev events.
It can have high instant and average values in fiber.top()
output in two cases:
The instance has almost no load - then practically only
sched is executing, and the other fibers are sleeping.
So relative to the other fibers, sched may have almost 100% load.
sched handles a large number of system events.
This should not cause performance problems.
main fibers process requests that come over the network (iproto requests).
There are several such fibers, and new ones are created if needed.
When a new request comes in, a free fiber takes it and executes it.
The request can be a typical select/replace/delete/insert
or a function call. For example, conn:eval() or
conn:call().
Note
Enabling fiber.top() slows down fiber switching by about 15%,
so it is disabled by default. To enable it, use fiber.top_enable().
To disable it after you finished debugging, use fiber.top_disable().
Check if the current fiber has been cancelled
and throw an exception if this is the case.
Note
Even if you catch the exception, the fiber will remain cancelled.
Most types of calls will check fiber.testcancel().
However, some functions (id, status, join etc.) will return no error.
We recommend application developers to implement occasional checks with
fiber.testcancel() and to end fiber’s execution
as soon as possible in case it has been cancelled.
Example:
tarantool> fiber.testcancel()----error:fiber is cancelled...
Set the default maximum slice for all fibers.
A fiber slice limits the time period of executing a fiber without yielding control.
Parameters:
slice (number/table) –
a fiber slice, which can one of the following:
a time period (in seconds) that specifies the error slice. Example: fiber.set_max_slice(3).
a table that specifies the warning and error slices (in seconds). Example: fiber.set_max_slice({warn=1.5,err=3}).
Example:
The example below shows how to use set_max_slice to limit the slice for all fibers.
fiber.check_slice() is called inside a long-running operation to determine whether a slice for the current fiber is over.
Set a slice for the current fiber execution.
A fiber slice limits the time period of executing a fiber without yielding control.
Parameters:
slice (number/table) –
a fiber slice, which can one of the following:
a time period (in seconds) that specifies the error slice. Example: fiber.set_slice(3).
a table that specifies the warning and error slices (in seconds). Example: fiber.set_slice({warn=1.5,err=3}).
Example:
The example below shows how to use set_slice to limit the slice for the current fiber execution.
fiber.check_slice() is called inside a long-running operation to determine whether a slice for the current fiber is over.
Extend a slice for the current fiber execution.
For example, if the default error slice is set using fiber.set_max_slice()
to 3 seconds, extend_slice(1) extends the error slice to 4 seconds.
Parameters:
slice (number/table) –
a fiber slice, which can one of the following:
a time period (in seconds) that specifies the error slice. Example: fiber.extend_slice(1).
a table that specifies the warning and error slices (in seconds). Example: fiber.extend_slice({warn=0.5,err=1}).
Example:
The example below shows how to use extend_slice
to extend the slice for the current fiber execution.
The default fiber slice is set using set_max_slice.
current system time (in seconds since the epoch) as a Lua
number. The time is taken from the event loop clock,
which makes this call very cheap, but still useful for
constructing artificial tuple keys.
Get the monotonic time in seconds. It is better to use fiber.clock() for
calculating timeouts instead of fiber.time() because
fiber.time() reports real time so it is affected by system time changes.
Return:
a floating-point number of seconds, representing elapsed wall-clock
time since some time in the past that is guaranteed not to change
during the life of the process
a number of seconds as 64-bit integer, representing
elapsed wall-clock time since some time in the past that is
guaranteed not to change during the life of the process
fiber.self():name() can also be expressed as fiber.name().
Example:
tarantool> fiber.self():name()----interactive...
fiber_object:name(name[, options])
Change the fiber name. By default a Tarantool server’s
interactive-mode fiber is named ‘interactive’ and new
fibers created due to fiber.create are named ‘lua’.
Giving fibers distinct names makes it easier to
distinguish them when using fiber.info
and fiber.top().
Max length is 255.
truncate=true – truncates the name to the max length if it is
too long. If this option is false (the default),
fiber.name(new_name) fails with an exception if a new name is
too long. The name length limit is 255
(since version 2.4.1).
Send a cancellation request to the fiber. Running and suspended fibers can be cancelled.
After a fiber has been cancelled, attempts to operate on it
cause errors, for example, fiber_object:name()
causes error:thefiberisdead. But a dead fiber can still
report its ID and status.
Cancellation is asynchronous.
Use fiber_object:join() to wait for the cancellation to complete.
After fiber_object:cancel() is called, the fiber may or may not check whether it was cancelled.
If the fiber does not check it, it cannot ever be cancelled.
Set a fiber’s maximum slice.
A fiber slice limits the time period of executing a fiber without yielding control.
Parameters:
slice (number/table) –
a fiber slice, which can one of the following:
a time period (in seconds) that specifies the error slice. Example: long_operation_fiber.set_max_slice(3).
a table that specifies the warning and error slices (in seconds). Example: long_operation_fiber.set_max_slice({warn=1.5,err=3}).
Example:
The example below shows how to use set_max_slice to limit the fiber slice.
fiber.check_slice() is called inside a long-running operation to determine whether a slice for the fiber is over.
A local storage within the fiber. It is a Lua table created when it is
first accessed. The storage can contain any number of named values,
subject to memory limitations. Naming may be done with
fiber_object.storage.name or
fiber_object.storage['name']. or with a number
fiber_object.storage[number].
Values may be either numbers or strings.
fiber.storage is destroyed when the fiber is finished, regardless
of how is it finished – via fiber_object:cancel(),
or the fiber’s function did ‘return’. Moreover, the storage is cleaned
up even for pooled fibers used to serve IProto requests. Pooled fibers
never really die, but nonetheless their storage is cleaned up after each
request. That makes possible to use fiber.storage as a full featured
request-local storage. This behavior is implemented in versions
2.2.3, 2.3.2,
2.4.1, and all later versions.
This storage may be created for a fiber, no matter how the fiber
itself is created – from C or from Lua. For example, a fiber can
be created in C using fiber_new(), then it can insert into a
space, which has Lua on_replace triggers, and one of the triggers
can create fiber.storage. That storage is deleted when the
fiber is stopped.
Example:
The example below shows how to save the last entered name in a fiber storage
and get this value before cancelling a fiber.
-- app.lua --fiber=require('fiber')functiongreet()whiletruedoprint('Enter a name:')name=io.read()ifname~='bye'thenfiber.self().storage.name=nameprint('Hello, '..name)elseprint('Goodbye, '..fiber.self().storage['name'])fiber.self():cancel()endendendfiber_object=fiber.create(greet)
The output might look as follows:
$ tarantoolapp.lua
Enter a name:JohnHello, JohnEnter a name:JaneHello, JaneEnter a name:byeGoodbye, Jane
Make a fiber joinable.
A joinable fiber can be waited for using fiber_object:join().
The best practice is to call fiber_object:set_joinable() before the
fiber function begins to execute because otherwise the fiber could
become dead before fiber_object:set_joinable() takes effect.
The usual sequence could be:
Call fiber.new() instead of fiber.create() to create a new
fiber_object.
Do not yield at this point, because that will cause the fiber
function to begin.
Call fiber_object:set_joinable(true) to make the new
fiber_object joinable.
Now it is safe to yield.
Call fiber_object:join().
Usually fiber_object:join() should be called, otherwise the
fiber’s status may become ‘suspended’ when the fiber function ends,
instead of ‘dead’.
Parameters:
is_joinable (boolean) – the boolean value that specifies whether the fiber is joinable
Join a fiber.
Joining a fiber enables you to get the result returned by the fiber’s function.
Joining a fiber runs the fiber’s function and waits until the fiber’s status is dead.
Normally a status becomes dead when the function execution finishes.
Joining the fiber causes a yield, therefore, if the fiber is
currently in the suspended state, execution of its fiber function resumes.
timeout (number) – maximum number of seconds to wait for the completion of the fiber. Default: infinity.
Return:
The join method returns two values:
The boolean value that indicates whether the join is succeeded
because the fiber’s function ended normally.
The return value of the fiber’s function.
If the first value is false, then the join succeeded
because the fiber’s function ended abnormally and the
second result has the details about the error, which
one can unpack in the same way that one unpacks
a pcall result.
Rtype:
boolean + result type, or boolean + struct error
Possible errors: the fiber is already joined by concurrent fiber:join().
Example:
The example below shows how to get the result returned by the fiber’s function.
$ tarantoolapp.lua
Is successful: trueReturned value: 11
Example of yield failure
Warning: yield() and any function which implicitly yields
(such as sleep()) can fail (raise an exception).
For example, this function has a loop that repeats until
cancel() happens.
The last thing that it will print is ‘before yield’, which demonstrates
that yield() failed, the loop did not continue until
testcancel() failed.
Call fiber.channel() to create and get a new channel object.
Call the other routines, via channel, to send messages, receive messages, or
check channel status.
Message exchange is synchronous. The Lua garbage collector will mark or free the
channel when no one is
using it, as with any other Lua object. Use object-oriented syntax, for example,
channel:put(message) rather than fiber.channel.put(message).
Send a message using a channel. If the channel is full,
channel:put() waits until there is a free slot in the channel.
Note
The default channel capacity is 0.
With this default value, channel:put()waits infinitely
until channel:get() is called.
Parameters:
message (lua-value) – what will be sent, usually a string or number or table
timeout (number) – maximum number of seconds to wait for a slot to become free. Default: infinity.
Return:
If timeout is specified, and there is no free slot in the
channel for the duration of the timeout, then the return value
is false. If the channel is closed, then the return value is false.
Otherwise, the return value is true, indicating success.
Close the channel. All waiters in the channel will stop waiting. All
following channel:get() operations will return nil, and all
following channel:put() operations will return false.
Fetch and remove a message from a channel. If the channel is empty,
channel:get() waits for a message.
Parameters:
timeout (number) – maximum number of seconds to wait for a message. Default: infinity.
Return:
If timeout is specified, and there is no message in the
channel for the duration of the timeout, then the return
value is nil. If the channel is closed, then the
return value is nil. Otherwise, the return value is
the message placed on the channel by channel:put().
Rtype:
usually string or number or table, as determined by channel:put
true if the channel is already closed. Otherwise
false.
Rtype:
boolean
Example
This example should give a rough idea of what some functions for fibers should
look like. It’s assumed that the functions would be referenced in
fiber.create().
fiber=require('fiber')channel=fiber.channel(10)functionconsumer_fiber()whiletruedolocaltask=channel:get()...endendfunctionconsumer2_fiber()whiletruedo-- 10 secondslocaltask=channel:get(10)iftask~=nilthen...else-- timeoutendendendfunctionproducer_fiber()whiletruedotask=box.space...:select{...}...ifchannel:is_empty()then-- channel is emptyendifchannel:is_full()then-- channel is fullend...ifchannel:has_readers()then-- there are some fibers-- that are waiting for dataend...ifchannel:has_writers()then-- there are some fibers-- that are waiting for readersendchannel:put(task)endendfunctionproducer2_fiber()whiletruedotask=box.space...select{...}-- 10 secondsifchannel:put(task,10)then...else-- timeoutendendend
Condition variables
Call fiber.cond() to create a named condition variable, which will be called
‘cond’ for examples in this section.
Call cond:wait() to make a fiber wait for a signal via a condition variable.
Call cond:signal() to send a signal to wake up a single fiber that has
executed cond:wait().
Call cond:broadcast() to send a signal to all fibers that have executed
cond:wait().
Make the current fiber go to sleep, waiting until another fiber
invokes the signal() or broadcast() method on the cond object.
The sleep causes an implicit fiber.yield().
Parameters:
timeout – number of seconds to wait, default = forever.
Return:
If timeout is provided, and a signal doesn’t happen for the
duration of the timeout, wait() returns false. If a signal
or broadcast happens, wait() returns true.
Wake up all fibers that have executed wait() for the same variable.
Does not yield.
Rtype:
nil
Example
Assume that a Tarantool instance is running and listening for connections on
localhost port 3301. Assume that guest users have privileges to connect. We will
use the tt utility to start two clients.
Now look again at terminal #1. It will show that the waiting stopped, and the
cond:wait() function returned true.
This example depended on the use of a global conditional variable with the
arbitrary name cond. In real life, programmers would make sure to use
different conditional variable names for different applications.
Module fio
Overview
Tarantool supports file input/output with an API that is similar to POSIX
syscalls. All operations are performed asynchronously. Multiple fibers can
access the same file simultaneously.
(If no error) table of fields which describe the file’s block size,
creation time, size, and other attributes.
(If error) two return values: null, error message.
Rtype:
table.
Additionally, the result of fio.stat('file-name') will include methods
equivalent to POSIX macros:
is_blk() = POSIX macro S_ISBLK,
is_chr() = POSIX macro S_ISCHR,
is_dir() = POSIX macro S_ISDIR,
is_fifo() = POSIX macro S_ISFIFO,
is_link() = POSIX macro S_ISLINK,
is_reg() = POSIX macro S_ISREG,
is_sock() = POSIX macro S_ISSOCK.
For example, fio.stat('/'):is_dir() will return true.
mode (number) – Mode bits can be passed as a number or as string
constants, for example S_IWUSR. Mode bits can be
combined by enclosing them in braces.
Return:
(If no error) true.
(If error) two return values: false, error message.
Return a list of files that match an input string. The list is constructed
with a single flag that controls the behavior of the function:
GLOB_NOESCAPE. For details type man3glob.
Parameters:
path-name (string) – path-name, which may contain wildcard characters.
Return the name of a directory that can be used to store temporary files.
Example:
tarantool> fio.tempdir()----/tmp/lG31e7...
fio.tempdir() stores the created temporary directory into /tmp by
default. Since version 2.4.1, this can be changed
by setting the TMPDIR environment
variable. Before starting Tarantool, or at runtime by
os.setenv().
Copy everything in the from-path, including subdirectory
contents, to the to-path.
The result is similar to the cp-r shell command.
The to-path should not be empty.
(If no error) fio.link and fio.symlink and fio.unlink
return true, fio.readlink returns the link value.
(If error) two return values: false|null, error message.
Change the access time and possibly also change the update time of a file. For details type man2utime.
Times should be expressed as number of seconds since the epoch.
Open a file in preparation for reading or writing or seeking.
Parameters:
path-name (string) – Full path to the file to open.
flags (number) –
Flags can be passed as a number or as string
constants, for example ‘O_RDONLY’,
‘O_WRONLY’, ‘O_RDWR’. Flags can be
combined by enclosing them in braces.
On Linux the full set of flags
as described on the
Linux man page
is:
O_APPEND (start at end of file),
O_ASYNC (signal when IO is possible),
O_CLOEXEC (enable a flag related to closing),
O_CREAT (create file if it doesn’t exist),
O_DIRECT (do less caching or no caching),
O_DIRECTORY (fail if it’s not a directory),
O_EXCL (fail if file cannot be created),
O_LARGEFILE (allow 64-bit file offsets),
O_NOATIME (no access-time updating),
O_NOCTTY (no console tty),
O_NOFOLLOW (no following symbolic links),
O_NONBLOCK (no blocking),
O_PATH (get a path for low-level use),
O_SYNC (force writing if it’s possible),
O_TMPFILE (the file will be temporary and nameless),
O_TRUNC (truncate)
… and, always, one of:
O_RDONLY (read only),
O_WRONLY (write only), or
O_RDWR (either read or write).
mode (number) – Mode bits can be passed as a number or as string
constants, for example S_IWUSR. Mode bits
are significant if flags include O_CREAT or
O_TMPFILE. Mode bits can be
combined by enclosing them in braces.
Return:
(If no error) file handle (abbreviated as ‘fh’ in later
description).
(If error) two return values: null, error message.
Rtype:
userdata
Possible errors: nil.
Note that since version 2.4.1fio.open()
returns a descriptor which can be closed manually by
calling the :close() method, or it will be closed automatically when it has
no references, and the garbage collector deletes it.
Keep in mind that the number of file descriptors is limited, and
they can become exhausted earlier than the garbage collector will be triggered to collect not
used descriptors. It is always good practice to close them manually as soon as possible.
Example 1:
tarantool> fh=fio.open('/home/username/tmp.txt',{'O_RDWR','O_APPEND'})---...tarantool> fh-- display file handle returned by fio.open----fh:11...
Example 2:
Using fio.open() with tonumber('N',8) to set permissions
as an octal number:
Perform random-access write operation on a file, without affecting
the current seek position of the file.
For details type man2pwrite.
Parameters:
fh (userdata) – file-handle as returned by fio.open()
new-string (string) – value to write (if the format is pwrite(new-string,offset))
buffer (cdata) – value to write (if the format is pwrite(buffer,count,offset))
count (number) – number of bytes to write
offset (number) – offset within file where writing begins
Return:
true if success, false if failure.
Rtype:
boolean
If the format is pwrite(new-string,offset) then the returned string
is written to the file, as far as the end of the string.
If the format is pwrite(buffer,count,offset) then the buffer
contents are written to the file, for count bytes.
Buffers can be acquired with buffer.ibuf.
Perform non-random-access read on a file. For details type
man2read or man2write.
Note
fh:read and fh:write affect the seek position within the
file, and this must be taken into account when working on the same
file from multiple fibers. It is possible to limit or prevent file
access from other fibers with fiber.cond() or
fiber.channel().
Parameters:
fh (userdata) – file-handle as returned by fio.open().
buffer – where to read into (if the format is
read(buffer,count))
count (number) – number of bytes to read
Return:
If the format is read() – omitting count – then read all
bytes in the file.
If the format is read() or read([count]) then return a string
containing the data that was read from the file, or empty string if failure.
If the format is read(buffer,count) then return the data
to the buffer.
Buffers can be acquired with buffer.ibuf.
In case of an error the method returns nil,err and sets
the error to errno.
Perform non-random-access write on a file. For details type
man2write.
Note
fh:read and fh:write affect the seek position within the
file, and this must be taken into account when working on the same
file from multiple fibers. It is possible to limit or prevent file
access from other fibers with fiber.cond() or
fiber.channel().
Parameters:
fh (userdata) – file-handle as returned by fio.open()
new-string (string) – value to write (if the format is write(new-string))
buffer (cdata) – value to write (if the format is write(buffer,count))
count (number) – number of bytes to write
Return:
true if success, false if failure.
Rtype:
boolean
If the format is write(new-string) then the returned string
is written to the file, as far as the end of the string.
If the format is write(buffer,count) then the buffer contents
are written to the file, for count bytes.
Buffers can be acquired with buffer.ibuf.
Luafun, also known as the Lua Functional Library, takes advantage of the
features of LuaJIT to help users create complex functions. Inside the module are
“sequence processors” such as map, filter, reduce, zip – they
take a user-written function as an argument and run it against every element in
a sequence, which can be faster or more convenient than a user-written loop.
Inside the module are “generators” such as range, tabulate, and
rands – they return a bounded or boundless series of values. Within the
module are “reducers”, “filters”, “composers” … or, in short, all the
important features found in languages like Standard ML, Haskell, or Erlang.
The full documentation is On the luafun section of github.
However, the first chapter can be skipped because installation is already done, it’s inside
Tarantool. All that is needed is the usual require request. After that,
all the operations described in the Lua fun manual will work, provided they are
preceded by the name returned by the require request. For example:
The http module, specifically the http.client submodule,
provides the functionality of an HTTP client with support for HTTPS and keepalive.
The HTTP client uses the libcurl library under the hood and
takes into account the environment variables libcurl understands.
HTTP client instance
Default client
The http.client submodule provides the default HTTP client instance:
localhttp_client=require('http.client')
In this case, you need to make requests using the dot syntax, for example:
In addition to request, the HTTP client provides the API for particular HTTP methods:
get, post, put, and so on.
For example, you can replace the request above by calling get as follows:
To learn how to obtain cookies passed in the Set-Cookie response header, see Response cookies.
Body
Serialization
The HTTP client automatically serializes the content in a specific format when sending a request based on the specified Content-Type header.
By default, the client uses the application/json content type and sends data serialized as JSON:
Call the io_object.finish() method to finish writing data and make a request.
The example below shows how to upload data in two chunks:
localhttp_client=require('http.client').new()localjson=require('json')localio=http_client:post('https://httpbin.org/anything',nil,{chunked=true})io:write('Data part 1')io:write('Data part 2')io:finish()response=io:read('\r\n')decoded_data=json.decode(response)print('Posted data: '..decoded_data['data'])
Receiving responses
All methods that are used to make an HTTP request (request, get, post, etc.) receive response_object.
response_object exposes the API required to get a response body and obtain response parameters, such as a status code, headers, and so on.
To obtain response cookies, use response_object.cookies.
This option returns a Lua table where a cookie name is the key.
The value is an array of two elements where the first one is the cookie value and the second one is an array with the cookie’s options.
The example below shows how to obtain the session_id cookie value:
The HTTP client can deserialize response data to a Lua object based on the Content-Type response header value.
To deserialize data, call the response_object.decode() method.
In the example below, the JSON response is deserialized into a Lua object:
The following content types are supported out of the box:
application/json
application/msgpack
application/yaml
If the response doesn’t have the Content-Type header, the client uses application/json.
To deserialize other content types, you need to provide a custom deserializer
using the client_object.decoders property.
In the example below, application/xml responses are decoded using the
luarapidxml library:
The output for the code sample above should look as follows:
'title' value: Sample Slide Show
Decompressing
The HTTP client can automatically decompress a response body based on the Content-Encoding header value.
To enable this capability, pass the required formats using the
request_options.accept_encoding option:
The example below shows how to get chunks of a JSON response sequentially instead of waiting for the entire response:
localhttp_client=require('http.client').new()localjson=require('json')localio=http_client:get('https://httpbin.org/stream/5',{chunked=true})localchunk_ids=''whiledata~=''dolocaldata=io:read('\n')ifdata==''thenbreakendlocaldecoded_data=json.decode(data)chunk_ids=chunk_ids..decoded_data['id']..' 'endprint('IDs of received chunks: '..chunk_ids)io:finish()
Redirects
By default, the HTTP client redirects to a URL provided in the Location header of a 3xx response.
If required, you can disable redirection using the follow_location option:
Do not set max_connections to less than max_total_connections unless you are confident about your actions.
If max_connections is less than max_total_connections,
libcurl doesn’t reuse sockets in some cases for requests that go to the same host.
If the limit is reached and a new request occurs, then
libcurl creates a new socket first, sends the request, waits for the first connection
to be free, and closes it to avoid exceeding the max_connections cache size.
In the worst case, libcurl creates a new socket for every request,
even if all requests go to the same host.
You may want to control the maximum number of sockets that a particular HTTP client uses simultaneously.
If a system passes many requests to distinct hosts, then libcurl cannot reuse sockets.
In this case, setting max_total_connections may be useful
since it causes curl to avoid creating too many sockets, which would not be used anyway.
The interval (in seconds) the operating system waits between sending keepalive probes.
If both keepalive_idle and keepalive_interval are set,
then Tarantool also sets the HTTP keepalive headers: Connection:Keep-Alive and Keep-Alive:timeout=<keepalive_idle>.
Otherwise, Tarantool sends Connection:close.
The average transfer speed in bytes per second that the transfer should be below
during “low speed time” seconds for the library to consider it to be too slow and abort.
Specify whether the HTTP client follows redirect URLs provided in the Location header for 3xx responses.
When a non-3xx response is received, the client returns it as a result.
If you set this option to false, the client returns the first 3xx response.
A comma-separated list of hosts that do not require proxies, or *, or ''.
Set no_proxy=host[,host...] to specify
hosts that can be reached without requiring a proxy, even if proxy is
set to a non-blank value and/or if a proxy-related environment variable has been set.
Set no__proxy='*' to specify that all hosts can be reached
without requiring a proxy, which is equivalent to setting proxy=''.
Set no_proxy='' to specify that no hosts can be reached
without requiring a proxy, even if a proxy-related environment variable
(HTTP_PROXY) is used.
If no_proxy is not set, then a proxy-related environment variable
(HTTP_PROXY) may be used.
If proxy is a host or IP address, then it may begin with a scheme,
for example, https:// for an HTTPS proxy or http:// for an HTTP proxy.
If proxy is set to '' an empty string, then proxy use is disabled,
and no proxy-related environment variable is used.
If proxy is not set, then a proxy-related environment variable may be used, such as
HTTP_PROXY or HTTPS_PROXY or FTP_PROXY, or ALL_PROXY if the
protocol can be any protocol.
Response cookies.
The value is an array of two elements where the first one is the
cookie value and the second one is an array with the cookie’s options.
An IO object used to read or write data in chunks.
To get an IO object instead of the full response (response_object), you need to set the chunked request option to true.
The iconv module provides a way to convert a string with
one encoding to a string with another encoding, for example from ASCII
to UTF-8. It is based on the POSIX iconv routines.
An exact list of the available encodings may depend on environment.
Typically the list includes ASCII, BIG5, KOI8R, LATIN8, MS-GREEK, SJIS,
and about 100 others. For a complete list, type iconv--list on a
terminal.
the string that results from the conversion (the “to” string)
If anything in input-string cannot be converted, there will be an error message
and the result string will be unchanged.
Example:
We know that the Unicode code point for “Д” (CYRILLIC CAPITAL LETTER DE)
is hexadecimal 0414 according to the character database of
Unicode.
Therefore that is what it will look like in UTF-16.
We know that Tarantool typically uses the UTF-8 character set.
So make a from-UTF-8-to-UTF-16 converter,
use string.hex(‘Д’) to show what Д’s encoding looks like in the UTF-8 source,
and use string.hex(‘Д’-after-conversion) to show what it looks like in the UTF-16 target.
Since the result is 0414, we see that iconv conversion works.
(Different iconv implementations might use different names, for example UTF-16BE instead of UTF16BE.)
The jit module has functions for tracing the
LuaJIT Just-In-Time compiler’s
progress, showing the byte-code or assembler output that the compiler produces,
and in general providing information about what LuaJIT does with Lua code.
Prints the i386 assembler code of a string of bytes.
Example:
tarantool> -- Disassemble hexadecimal 97 which is the x86 code for xchg eax, edi---...tarantool> jit_dis_x86=require('jit.dis_x86')---...tarantool> jit_dis_86.disass('\x97')00000000 97 xchg eax, edi---...
Prints the x86-64 assembler code of a string of bytes.
Example:
tarantool> -- Disassemble hexadecimal 97 which is the x86-64 code for xchg eax, edi---...tarantool> jit_dis_x64=require('jit.dis_x64')---...tarantool> jit_dis_64.disass('\x97')00000000 97 xchg eax, edi---...
Prints a trace of LuaJIT’s progress compiling and interpreting code.
Example:
tarantool> -- Show what LuaJIT is doing for a Lua "for" looptarantool> jit_v=require('jit.v')tarantool> jit_v.on()tarantool> l=0tarantool> fori=1,1e6do > l=l+i > end[TRACE 3 "for i = 1, 1e6 do l = l + iend":1 loop]---...tarantool> print(l)500000500000---...tarantool> jit_v.off()---...
The values are all either integers or boolean true/false.
Option
Default
Use
cfg.encode_max_depth
128
Max recursion depth for encoding
cfg.encode_deep_as_nil
false
A flag saying whether to crop tables
with nesting level deeper than
cfg.encode_max_depth.
Not-encoded fields are replaced with
one null. If not set, too deep
nesting is considered an error.
cfg.encode_invalid_numbers
true
A flag saying whether to enable encoding
of NaN and Inf numbers
cfg.encode_number_precision
14
Precision of floating point numbers
cfg.encode_load_metatables
true
A flag saying whether the serializer will
follow __serialize
metatable field
cfg.encode_use_tostring
false
A flag saying whether to use
tostring() for unknown types
cfg.encode_invalid_as_nil
false
A flag saying whether use NULL for
non-recognized types
cfg.encode_sparse_convert
true
A flag saying whether to handle
excessively sparse arrays as maps.
See detailed description
below.
cfg.encode_sparse_ratio
2
1/encode_sparse_ratio is the
permissible percentage of missing values
in a sparse array.
cfg.encode_sparse_safe
10
A limit ensuring that small Lua arrays
are always encoded as sparse arrays
(instead of generating an error or
encoding as a map)
cfg.decode_invalid_numbers
true
A flag saying whether to enable decoding
of NaN and Inf numbers
cfg.decode_save_metatables
true
A flag saying whether to set metatables
for all arrays and maps
cfg.decode_max_depth
128
Max recursion depth for decoding
Sparse arrays features:
During encoding, the JSON encoder tries to classify a table into one of four kinds:
map - at least one table index is not unsigned integer
regular array - all array indexes are available
sparse array - at least one array index is missing
excessively sparse array - the number of values missing exceeds the configured ratio
An array is excessively sparse when all the following conditions are met:
encode_sparse_ratio > 0
max(table) > encode_sparse_safe
max(table) > count(table) * encode_sparse_ratio
The JSON encoder will never consider an array to be excessively sparse
when encode_sparse_ratio=0. The encode_sparse_safe limit ensures
that small Lua arrays are always encoded as sparse arrays.
By default, attempting to encode an excessively sparse array will
generate an error. If encode_sparse_convert is set to true,
excessively sparse arrays will be handled as maps.
json.cfg() example 1:
The following code will encode 0/0 as NaN (“not a number”)
and 1/0 as Inf (“infinity”), rather than returning nil or an error message:
To avoid generating errors on attempts to encode unknown data types as
userdata/cdata, you can use this code:
tarantool> httpc=require('http.client').new()---...tarantool> json.encode(httpc.curl)----error:unsupported Lua type 'userdata'...tarantool> json.encode(httpc.curl,{encode_use_tostring=true})----'"userdata:0x010a4ef2a0"'...
Note
To achieve the same effect for only one call to json.encode() (i.e.
without changing the configuration permanently), you can use
json.encode({1,x,y,2},{encode_invalid_numbers=true}).
Similar configuration settings exist for MsgPack
and YAML.
A value comparable to Lua “nil” which may be useful as a placeholder in a
tuple.
Example:
-- When nil is assigned to a Lua-table field, the field is nulltarantool> {nil,'a','b'}-----null-a-b...-- When json.NULL is assigned to a Lua-table field, the field is json.NULLtarantool> {json.NULL,'a','b'}-----null-a-b...-- When json.NULL is assigned to a JSON field, the field is nulltarantool> json.encode({field2=json.NULL,field1='a',field3='c'})----'{"field2":null,"field1":"a","field3":"c"}'...
Module key_def
The key_def module has a function for defining the field numbers and types of a tuple.
The definition is usually used with an index definition
to extract or compare the index key values.
parts (table) – field numbers and types.
There must be at least one part.
Every part must contain the attributes type and fieldno/field.
Other attributes are optional.
Return a tuple containing only the fields of the key_def object.
Parameters:
tuple (table) – tuple or Lua table with field contents
Return:
the fields defined for the key_def object
Example #1:
-- Suppose an item has five fields-- 1, 99.5, 'X', nil, 99.5-- and the fields that we care about are-- #3 (a string) and #1 (an integer).-- We can define those fields with k = key_def.new-- and extract the values with k:extract_key.tarantool> key_def=require('key_def')---...tarantool> k=key_def.new({{type='string',fieldno=3},> {type = 'unsigned', fieldno = 1}})---...tarantool> k:extract_key({1,99.5,'X',nil,99.5})----['X',1]...
Example #2
-- Now suppose the item is a tuple in a space with-- an index on field #3 plus field #1.-- We can use key_def.new with the index definition-- instead of filling it out (Example #1).-- The result will be the same.key_def=require('key_def')box.schema.space.create('T')i=box.space.T:create_index('I',{parts={3,'string',1,'unsigned'}})box.space.T:insert{1,99.5,'X',nil,99.5}k=key_def.new(i.parts)k:extract_key(box.space.T:get({'X',1}))
Example #3
-- Iterate through the tuples in a secondary non-unique index-- extracting the tuples' primary-key values, so they could be deleted-- using a unique index. This code should be a part of a Lua function.localkey_def_lib=require('key_def')locals=box.schema.space.create('test')localpk=s:create_index('pk')localsk=s:create_index('test',{unique=false,parts={{2,'number',path='a'},{2,'number',path='b'}}})s:insert{1,{a=1,b=1}}s:insert{2,{a=1,b=2}}localkey_def=key_def_lib.new(pk.parts)for_,tupleinsk:pairs({1}))dolocalkey=key_def:extract_key(tuple)pk:delete(key)end
Compare the key fields of tuple_1 with the key fields of tuple_2.
It is a tuple-by-tuple comparison so users do not have to
write code that compares one field at a time.
Each field’s type and collation will be taken into account.
In effect it is a comparison of extract_key(tuple_1) with extract_key(tuple_2).
Parameters:
tuple1 (table) – tuple or Lua table with field contents
tuple2 (table) – tuple or Lua table with field contents
Return:
> 0 if tuple_1 key fields > tuple_2 key fields,
= 0 if tuple_1 key fields = tuple_2 key fields,
< 0 if tuple_1 key fields < tuple_2 key fields
Example:
-- This will return 0key_def=require('key_def')k=key_def.new({{type='string',fieldno=3,collation='unicode_ci'},{type='unsigned',fieldno=1}})k:compare({1,99.5,'X',nil,99.5},{1,99.5,'x',nil,99.5})
Compare the key fields of tuple_1 with all the fields of tuple_2.
This is the same as key_def_object:compare()
except that tuple_2 contains only the key fields.
In effect it is a comparison of extract_key(tuple_1) with tuple_2.
Parameters:
tuple1 (table) – tuple or Lua table with field contents
tuple2 (table) – tuple or Lua table with field contents
Return:
> 0 if tuple_1 key fields > tuple_2 fields,
= 0 if tuple_1 key fields = tuple_2 fields,
< 0 if tuple_1 key fields < tuple_2 fields
Combine the main key_def_object with other_key_def_object.
The return value is a new key_def_object containing all the fields of
the main key_def_object, then all the fields of other_key_def_object which
are not in the main key_def_object.
Parameters:
other_key_def_object (key_def_object) – definition of fields to add
Return:
key_def_object
Example:
-- Returns a key definition with fieldno = 3 and fieldno = 1.key_def=require('key_def')k=key_def.new({{type='string',fieldno=3}})k2=key_def.new({{type='unsigned',fieldno=1},{type='string',fieldno=3}})k:merge(k2)
Returns a table containing the fields of the key_def_object.
This is the reverse of key_def.new():
key_def.new() takes a table and returns a key_def object,
key_def_object:totable() takes a key_def object and returns a table.
This is useful for input to _serialize methods.
Return:
table
Example:
-- Returns a table with type = 'string', fieldno = 3key_def=require('key_def')k=key_def.new({{type='string',fieldno=3}})k:totable()
Module log
Overview
Tarantool provides a set of options used to configure logging
in various ways: you can set a level of logging, specify where to send the log’s output,
configure a log format, and so on.
The log module allows you to configure logging in your application and
provides additional capabilities, for example, logging custom messages and
rotating log files.
Rotate the log.
For example, you need to call this function to continue logging after a log rotation program
renames or moves a file with the latest logs.
To create the module1 and module2 loggers in your application (app.lua), call the new() function:
-- Creates new loggers --module1_log=require('log').new('module1')module2_log=require('log').new('module2')
Then, you can call functions corresponding to different logging levels to make sure
that events with severities above or equal to the given levels are shown:
-- Prints 'info' messages --module1_log.info('Info message from module1')--[[[16300] main/103/interactive/module1 I> Info message from module1---...--]]-- Swallows 'debug' messages --module1_log.debug('Debug message from module1')--[[---...--]]-- Swallows 'info' messages --module2_log.info('Info message from module2')--[[---...--]]
At the same time, the events with severities below the specified levels are swallowed.
Create a new merger instance from a merger source.
A merger source is created from a
key_def
object and a set of (tuple or buffer or table or merger)
sources. It performs a kind of merge sort.
It chooses a source with a minimal / maximal tuple on each step,
consumes a tuple from this source, and repeats.
Parameters:
key_def – object created with key_def
source – parameter for the gen() function
options – reverse=true if descending, false or nil if ascending
The pairs() method (or the equivalent ipairs()alias method)
returns a luafun iterator. It is a Lua
iterator, but also provides a set of handy methods to operate in
functional style.
Parameters:
tuple (table) – tuple or Lua table with field contents
Return:
the tuples that can be found with a standard pairs() function
Example with new_tuple_source():
-- Source via new_tuple_source, from a space of tables-- The result will look like this:-- tarantool> so:pairs():totable()-- ----- - - [100]-- - [200]-- ...merger=require('merger')box.schema.space.create('s')box.space.s:create_index('i')box.space.s:insert({100})box.space.s:insert({200})so=merger.new_tuple_source(box.space.s:pairs())so:pairs():totable()
Example with two mergers:
-- Source via key_def, and table data-- Create the key_def objectmerger=require('merger')key_def_lib=require('key_def')key_def=key_def_lib.new({{fieldno=1,type='string',}})-- Create the table sourcedata={{'a'},{'b'},{'c'}}source=merger.new_source_fromtable(data)i1=merger.new(key_def,{source}):pairs()i2=merger.new(key_def,{source}):pairs()-- t1 will be 'a' (tuple 1 from merger 1)t1=i1:head():totable()-- t3 will be 'c' (tuple 3 from merger 2)t3=i2:head():totable()-- t2 will be 'b' (tuple 2 from merger 1)t2=i1:head():totable()-- i1:is_null() will be true (merger 1 ends)i1:is_null()-- i2:is_null() will be true (merger 2 ends)i2:is_null()
The metrics module provides the ability to collect and expose Tarantool metrics.
Note
If you use a Tarantool version below 2.11.1,
it is necessary to install the latest version of metrics first.
For Tarantool 2.11.1 and above, you can also use the external metrics module.
In this case, the external metrics module takes priority over the built-in one.
Overview
Collectors
Tarantool provides the following metric collectors:
A collector is a representation of one or more observations that change over time.
counter
A counter is a cumulative metric that denotes a single monotonically increasing counter. Its value might only
increase or be reset to zero on restart. For example, you can use the counter to represent the number of requests
served, tasks completed, or errors.
A gauge is a metric that denotes a single numerical value that can arbitrarily increase and decrease.
The gauge type is typically used for measured values like temperature or current memory usage.
It could also be used for values that can increase or decrease, such as the number of concurrent requests.
A histogram metric is used to collect and analyze
statistical data about the distribution of values within the application.
Unlike metrics that track the average value or quantity of events, a histogram provides detailed visibility into the distribution of values and can uncover hidden dependencies.
A summary metric is used to collect statistical data
about the distribution of values within the application.
Each summary provides several measurements:
total count of measurements
sum of measured values
values at specific quantiles
Similar to histograms, the summary also operates with value ranges. However, unlike histograms,
it uses quantiles (defined by a number between 0 and 1) for this purpose. In this case,
it is not required to define fixed boundaries. For summary type, the ranges depend
on the measured values and the number of measurements.
A label is a piece of metainfo that you associate with a metric in the key-value format.
For details, see labels in Prometheus and tags in Graphite.
Labels are used to differentiate between the characteristics of a thing being
measured. For example, in a metric associated with the total number of HTTP
requests, you can represent methods and statuses as label pairs:
The example above allows extracting the following time series:
The total number of requests over time with method="POST" (and any status).
The total number of requests over time with status=500 (and any method).
Configuring metrics
To configure metrics, use metrics.cfg().
This function can be used to turn on or off the specified metrics or to configure labels applied to all collectors.
Moreover, you can use the following shortcut functions to set-up metrics or labels:
Starting from version 3.0, metrics can be configured using a configuration file in the metrics section.
Custom metrics
Creating custom metrics
To create a custom metric, follow the steps below:
Create a metric
To create a new metric, you need to call a function corresponding to the desired collector type. For example, call metrics.counter() or metrics.gauge() to create a new counter or gauge, respectively.
In the example below, a new counter is created:
localmetrics=require('metrics')localbands_replace_count=metrics.counter('bands_replace_count','The number of data operations')
This counter is intended to collect the number of data operations performed on the specified space.
In the next example, a gauge is created:
localmetrics=require('metrics')localbands_waste_size=metrics.gauge('bands_waste_size','The size of memory wasted due to internal fragmentation')
Observe a value
You can observe a value in two ways:
At the appropriate place, for example, in an API request handler or trigger.
In this example below, the counter value is increased any time a data operation is performed on the bands space.
To increase a counter value, counter_obj:inc() is called.
localmetrics=require('metrics')localbands_replace_count=metrics.counter('bands_replace_count','The number of data operations')localtrigger=require('trigger')trigger.set('box.space.bands.on_replace','update_bands_replace_count_metric',function(_,_,_,request_type)bands_replace_count:inc(1,{request_type=request_type})end)
At the time of requesting the data collected by metrics.
In this case, you need to collect the required metric inside metrics.register_callback().
The example below shows how to use a gauge collector to measure the size of memory wasted due to internal fragmentation:
localmetrics=require('metrics')localbands_waste_size=metrics.gauge('bands_waste_size','The size of memory wasted due to internal fragmentation')metrics.register_callback(function()bands_waste_size:set(box.space.bands:stat()['tuple']['memtx']['waste_size'])end)
The module allows to add your own metrics, but there are some subtleties when working with specific tools.
When adding your custom metric, it’s important to ensure that the number of label value combinations is kept to a minimum.
Otherwise, combinatorial explosion may happen in the timeseries database with metrics values stored.
Examples of data labels:
For example, if your company uses InfluxDB for metric collection, you can potentially disrupt the entire
monitoring setup, both for your application and for all other systems within the company. As a result,
monitoring data is likely to be lost.
Example:
localsome_metric=metrics.counter('some','Some metric')-- THIS IS POSSIBLElocalfunctionon_value_update(instance_alias)some_metric:inc(1,{alias=instance_alias})end-- THIS IS NOT ALLOWEDlocalfunctionon_value_update(customer_id)some_metric:inc(1,{customer_id=customer_id})end
In the example, there are two versions of the function on_value_update. The top version labels
the data with the cluster instance’s alias. Since there’s a relatively small number of nodes, using
them as labels is feasible. In the second case, an identifier of a record is used. If there are many
records, it’s recommended to avoid such situations.
The same principle applies to URLs. Using the entire URL with parameters is not recommended.
Use a URL template or the name of the command instead.
In essence, when designing custom metrics and selecting labels or tags, it’s crucial to opt for a minimal
set of values that can uniquely identify the data without introducing unnecessary complexity or potential
conflicts with existing metrics and systems.
Collecting HTTP metrics
The metrics module provides middleware for monitoring HTTP latency statistics for endpoints that are created using the http module.
The latency collector observes both latency information and the number of invocations.
The metrics collected by HTTP middleware are separated by a set of labels:
a route (path)
a method (method)
an HTTP status code (status)
For each route that you want to track, you must specify the middleware explicitly.
The example below shows how to collect statistics for requests made to the /metrics/hello endpoint.
httpd=require('http.server').new('127.0.0.1',8080)localmetrics=require('metrics')metrics.http_middleware.configure_default_collector('summary')httpd:route({method='GET',path='/metrics/hello'},metrics.http_middleware.v1(function()return{status=200,headers={['content-type']='text/plain'},body='Hello from http_middleware!'}end))httpd:start()
Note
The middleware does not cover the 404 errors.
Collecting metrics using plugins
The metrics module provides a set of plugins that let you collect metrics through a unified interface:
For example, you can obtain an HTTP response object containing metrics in the Prometheus format by calling the metrics.plugins.prometheus.collect_http() function:
To create a plugin, you need to include the following in your main export function:
-- Invoke all callbacks registered via `metrics.register_callback(<callback-function>)`metrics.invoke_callbacks()-- Loop over collectorsfor_,cinpairs(metrics.collectors())do...-- Loop over instant observations in the collectorfor_,obsinpairs(c:collect())do-- Export observation `obs`...endend
cfg.include (string/table, default all): all to enable all
supported default metrics, none to disable all default metrics,
table with names of the default metrics to enable a specific set of metrics.
cfg.exclude (table, default {}): a table containing the names of
the default metrics that you want to disable. Has higher priority
than cfg.include.
cfg.labels (table, default {}): a table containing label names as
string keys, label values as values. See also: Labels.
You can work with metrics.cfg as a table to read values, but you must call
metrics.cfg{} as a function to update them.
Supported default metric names (for cfg.include and cfg.exclude tables):
all (metasection including all metrics)
network
operations
system
replicas
info
slab
runtime
memory
spaces
fibers
cpu
vinyl
memtx
luajit
clock
event_loop
config
See metrics reference for details.
All metric collectors from the collection have metainfo.default=true.
cfg.labels are the global labels to be added to every observation.
Global labels are applied only to metric collection. They have no effect
on how observations are stored.
Global labels can be changed on the fly.
label_pairs from observation objects have priority over global labels.
If you pass label_pairs to an observation method with the same key as
some global label, the method argument value will be used.
Note that both label names and values in label_pairs are treated as strings.
name.."_sum" – a counter holding the sum of added observations.
name.."_count" – a counter holding the number of added observations.
name.."_bucket" – a counter holding all bucket sizes under the label
le (less or equal). To access a specific bucket – x (where x is a number),
specify the value x for the label le.
Invoke all registered callbacks. Has to be called before each collect().
You can also use collect{invoke_callbacks=true} instead.
If you’re using one of the default exporters,
invoke_callbacks() will be called by the exporter.
Register a function named callback, which will be called right before metric
collection on plugin export.
Parameters:
callback (function) – a function that takes no parameters.
This method is most often used for gauge metrics updates.
Example:
localmetrics=require('metrics')localbands_waste_size=metrics.gauge('bands_waste_size','The size of memory wasted due to internal fragmentation')metrics.register_callback(function()bands_waste_size:set(box.space.bands:stat()['tuple']['memtx']['waste_size'])end)
objectives (table) – a list of “targeted” φ-quantiles in the {quantile=error,...} form.
Example: {[0.5]=0.01,[0.9]=0.01,[0.99]=0.01}.
The targeted φ-quantile is specified in the form of a φ-quantile and the tolerated
error. For example, {[0.5]=0.1} means that the median (= 50th
percentile) is to be returned with a 10-percent error. Note that
percentiles and quantiles are the same concept, except that percentiles are
expressed as percentages. The φ-quantile must be in the interval [0,1].
A lower tolerated error for a φ-quantile results in higher memory and CPU
usage during summary calculation.
params (table) – table of the summary parameters used to configuring the sliding
time window. This window consists of several buckets to store observations.
New observations are added to each bucket. After a time period, the head bucket
(from which observations are collected) is reset, and the next bucket becomes the
new head. This way, each bucket stores observations for
max_age_time*age_buckets_count seconds before it is reset.
max_age_time sets the duration of each bucket’s lifetime – that is, how
many seconds the observations are kept before they are discarded.
age_buckets_count sets the number of buckets in the sliding time window.
This variable determines the number of buckets used to exclude observations
older than max_age_time from the summary. The value is
a trade-off between resources (memory and CPU for maintaining the bucket)
and how smooth the time window moves.
Default value: {max_age_time=math.huge,age_buckets_count=1}.
name.."_sum" – a counter holding the sum of added observations.
name.."_count" – a counter holding the number of added observations.
name holds all the quantiles under observation that find themselves
under the label quantile (less or equal).
To access bucket x (where x is a number),
specify the value x for the label quantile.
Unregister a function named callback that is called right before metric
collection on plugin export.
Parameters:
callback (function) – a function that takes no parameters.
Example:
localcpu_callback=function()localcpu_metrics=require('metrics.psutils.cpu')cpu_metrics.update()endmetrics.register_callback(cpu_callback)-- after a while, we don't need that callback function anymoremetrics.unregister_callback(cpu_callback)
Return the default collector.
If the default collector hasn’t been set yet, register it
(with default http_middleware.build_default_collector() parameters)
and set it as default.
A concatenation of observation objects across all created collectors.
{label_pairs:table,-- `label_pairs` key-value tabletimestamp:ctype<uint64_t>,-- current system time (in microseconds)value:number,-- current valuemetric_name:string,-- collector}
label_pairs (table) – table containing label names as keys,
label values as values. Note that both
label names and values in label_pairs
are treated as strings.
{label_pairs:table,-- `label_pairs` key-value tabletimestamp:ctype<uint64_t>,-- current system time (in microseconds)value:number,-- current valuemetric_name:string,-- collector}
label_pairs (table) – table containing label names as keys,
label values as values. Note that both
label names and values in label_pairs
are treated as strings.
Record a new value in a histogram.
This increments all bucket sizes under the labels le >= num
and the labels that match label_pairs.
Parameters:
num (number) – value to put in the histogram.
label_pairs (table) – table containing label names as keys,
label values as values.
All internal counters that have these labels specified
observe new counter values.
Note that both label names and values in label_pairs
are treated as strings.
See also: Labels.
Return a concatenation of counter_obj:collect() across all internal
counters of histogram_obj. For the description of observation,
see counter_obj:collect().
label_pairs (table) – a table containing label names as keys,
label values as values.
All internal counters that have these labels specified
observe new counter values.
You can’t add the "quantile" label to a summary.
It is added automatically.
If max_age_time and age_buckets_count are set,
the observed value is added to each bucket.
Note that both label names and values in label_pairs
are treated as strings.
See also: Labels.
Return a concatenation of counter_obj:collect() across all internal
counters of summary_obj. For the description of observation,
see counter_obj:collect().
If max_age_time and age_buckets_count are set, quantile observations
are collected only from the head bucket in the sliding time window,
not from every bucket. If no observations were recorded,
the method will return NaN in the values.
The msgpack module decodes raw MsgPack strings by converting them to Lua objects,
and encodes Lua objects by converting them to raw MsgPack strings.
Tarantool makes heavy internal use of MsgPack because tuples in Tarantool
are stored as MsgPack arrays.
Besides, starting from version 2.10.0, the msgpack module enables creating a specific userdata Lua object – MsgPack object.
The MsgPack object stores arbitrary MsgPack data, and can be created from any Lua object including another MsgPack object
and from a raw MsgPack string. The MsgPack object has its own set of methods and iterators.
A “raw MsgPack string” is a byte array formatted according to the MsgPack specification including type bytes and sizes.
The type bytes and sizes can be made displayable with string.hex(),
or the raw MsgPack strings can be converted to Lua objects by using the msgpack module methods.
API Reference
Below is a list of msgpack members and related objects.
lua_value – either a scalar value or a Lua table value.
Return:
the original contents formatted as a raw MsgPack string;
Rtype:
raw MsgPack string
msgpack.encode(lua_value, ibuf)
Convert a Lua object to a raw MsgPack string in an ibuf,
which is a buffer such as buffer.ibuf() creates.
As with encode(lua_value),
the result is a raw MsgPack string,
but it goes to the ibuf output instead of being returned.
Parameters:
lua_value (lua-object) – either a scalar value or a Lua table value.
ibuf (buffer) – (output parameter) where the result raw MsgPack string goes
Return:
number of bytes in the output
Rtype:
raw MsgPack string
Example using buffer.ibuf()
and ffi.string()
and string.hex():
The result will be ‘91a161’ because 91 is the MessagePack encoding of “fixarray size 1”,
a1 is the MessagePack encoding of “fixstr size 1”,
and 61 is the UTF-8 encoding of ‘a’:
start_position (integer) – where to start, minimum = 1,
maximum = string length, default = 1.
Return:
(if msgpack_string is a valid raw MsgPack string) the original contents
of msgpack_string, formatted as a Lua object, usually a Lua table,
(otherwise) a scalar value, such as a string or a number;
“next_start_position”. If decode stops after parsing as far as
byte N in msgpack_string, then “next_start_position” will equal N + 1,
and decode(msgpack_string,next_start_position)
will continue parsing from where the previous decode stopped, plus 1.
Normally decode parses all of msgpack_string, so
“next_start_position” will equal string.len(msgpack_string) + 1.
Convert a raw MsgPack string, whose address is supplied as a C-style string pointer
such as the rpos pointer which is inside an ibuf such as
buffer.ibuf() creates, to a Lua object.
A C-style string pointer may be described as cdata<char*> or cdata<constchar*>.
Parameters:
C_style_string_pointer (buffer) – a pointer to a raw MsgPack string.
size (integer) – number of bytes in the raw MsgPack string
Return:
(if C_style_string_pointer points to a valid raw MsgPack string) the original contents
of msgpack_string, formatted as a Lua object, usually a Lua table,
(otherwise) a scalar value, such as a string or a number;
returned_pointer = a C-style pointer to the byte after
what was passed, so that C_style_string_pointer + size = returned_pointer
Rtype:
table and C-style pointer to after what was passed
Example using buffer.ibuf
and pointer arithmetic:
The result will be [‘a’] and 3 and true:
Input and output are the same as for
decode(C_style_string_pointer),
except that size is not needed.
Some checking is skipped, and decode_unchecked(C_style_string_pointer) can operate with
string pointers to buffers which decode(C_style_string_pointer) cannot handle.
For an example see the buffer module.
Call the MsgPuck’s mp_decode_array function
and return the array size and a pointer to the first array component.
A subsequent call to msgpack_decode can decode the component instead of the whole array.
Parameters:
byte-array – a pointer to a raw MsgPack string.
size – a number greater than or equal to the string’s length
Return:
the size of the array;
a pointer to after the array header.
Example:
-- Example of decode_array_header-- Suppose we have the raw data '\x93\x01\x02\x03'.-- \x93 is MsgPack encoding for a header of a three-item array.-- We want to skip it and decode the next three items.msgpack=require('msgpack');ffi=require('ffi');x,y=msgpack.decode_array_header(ffi.cast('char*','\x93\x01\x02\x03'),4)a=msgpack.decode(y,1);b=msgpack.decode(y+1,1);c=msgpack.decode(y+2,1);a,b,c-- The result is: 1,2,3.
Call the MsgPuck’s mp_decode_map function
and return the map size and a pointer to the first map component.
A subsequent call to msgpack_decode can decode the component instead of the whole map.
Parameters:
byte-array – a pointer to a raw MsgPack string.
size – a number greater than or equal to the raw MsgPack string’s length
Return:
the size of the map;
a pointer to after the map header.
Example:
-- Example of decode_map_header-- Suppose we have the raw data '\x81\xa2\x41\x41\xc3'.-- '\x81' is MsgPack encoding for a header of a one-item map.-- We want to skip it and decode the next map item.msgpack=require('msgpack');ffi=require('ffi')x,y=msgpack.decode_map_header(ffi.cast('char*','\x81\xa2\x41\x41\xc3'),5)a=msgpack.decode(y,3);b=msgpack.decode(y+3,1)x,a,b-- The result is: 1,"AA", true.
__serialize parameter
The MsgPack output structure can be specified with the __serialize parameter:
‘seq’, ‘sequence’, ‘array’ – table encoded as an array
‘map’, ‘mappping’ – table encoded as a map
function – the meta-method called to unpack the serializable representation
of table, cdata, or userdata objects
Serializing ‘A’ and ‘B’ with different __serialize values brings different
results. To show this, here is a routine which encodes {'A','B'} both as an
array and as a map, then displays each result in hexadecimal.
The values are all either integers or boolean true/false.
Option
Default
Use
cfg.encode_max_depth
128
The maximum recursion depth for encoding
cfg.encode_deep_as_nil
false
Specify whether to crop tables
with nesting level deeper than
cfg.encode_max_depth.
Not-encoded fields are replaced with
one null. If not set, too high
nesting is considered an error.
cfg.encode_invalid_numbers
true
Specify whether to enable encoding of
NaN and Inf numbers
cfg.encode_load_metatables
true
Specify whether the serializer will
follow __serialize
metatable field
cfg.encode_use_tostring
false
Specify whether to use tostring()
for unknown types
cfg.encode_invalid_as_nil
false
Specify whether to use NULL for
non-recognized types
cfg.encode_sparse_convert
true
Specify whether to handle excessively
sparse arrays as maps.
See detailed description
below
cfg.encode_sparse_ratio
2
1/encode_sparse_ratio is the permissible
percentage of missing values in a sparse
array
cfg.encode_sparse_safe
10
A limit ensuring that small Lua arrays
are always encoded as sparse arrays
(instead of generating an error or encoding
as a map)
cfg.encode_error_as_ext
true
Specify how error objects
(box.error.new())
are encoded in the MsgPack format:
if true, errors are encoded as the
the MP_ERROR
MsgPack extension.
if false, the encoding format depends
on other configuration options
(encode_load_metatables,
encode_use_tostring,
encode_invalid_as_nil).
cfg.decode_invalid_numbers
true
Specify whether to enable decoding of
NaN and Inf numbers
cfg.decode_save_metatables
true
Specify whether to set metatables for
all arrays and maps
Sparse arrays features
During encoding, the MsgPack encoder tries to classify tables into one of four kinds:
map - at least one table index is not unsigned integer
regular array - all array indexes are available
sparse array - at least one array index is missing
excessively sparse array - the number of values missing exceeds the configured ratio
An array is excessively sparse when all the following conditions are met:
encode_sparse_ratio > 0
max(table) > encode_sparse_safe
max(table) > count(table) * encode_sparse_ratio
MsgPack encoder never considers an array to be excessively sparse
when encode_sparse_ratio=0. The encode_sparse_safe limit ensures
that small Lua arrays are always encoded as sparse arrays.
By default, attempting to encode an excessively sparse array
generates an error. If encode_sparse_convert is set to true,
excessively sparse arrays will be handled as maps.
msgpack.cfg() example 1:
If msgpack.cfg.encode_invalid_numbers=true (the default),
then NaN and Inf are legal values. If that is not desirable, then
ensure that msgpack.encode() does not accept them, by saying
msgpack.cfg{encode_invalid_numbers=false}, thus:
tarantool> msgpack=require('msgpack');msgpack.cfg{encode_invalid_numbers=true}---...tarantool> msgpack.decode(msgpack.encode{1,0/0,1/0,false})----[1,-nan,inf,false]-22...tarantool> msgpack.cfg{encode_invalid_numbers=false}---...tarantool> msgpack.decode(msgpack.encode{1,0/0,1/0,false})----error:... number must not be NaN or Inf'...
msgpack.cfg() example 2:
To avoid generating errors on attempts to encode unknown data types as
userdata/cdata, you can use this code:
tarantool> httpc=require('http.client').new()---...tarantool> msgpack.encode(httpc.curl)----error:unsupported Lua type 'userdata'...tarantool> msgpack.cfg{encode_use_tostring=true}---...tarantool> msgpack.encode(httpc.curl)----!!binarytnVzZXJkYXRhOiAweDAxMDU5NDQ2Mzg=...
Note
To achieve the same effect for only one call to msgpack.encode()
(that is without changing the configuration permanently), you can use
msgpack.new({encode_invalid_numbers=true}).encode({1,2}).
Similar configuration settings exist for JSON
and YAML.
Encode an arbitrary Lua object into the MsgPack format.
Parameters:
lua_value (lua-object) – a Lua object of any type.
Return:
encoded MsgPack data encapsulated in a MsgPack object.
Rtype:
userdata
Example:
localmsgpack=require('msgpack')-- Create a MsgPack object from a Lua object of any typelocalmp_from_number=msgpack.object(123)localmp_from_string=msgpack.object('hello world')localmp_from_array=msgpack.object({10,20,30})localmp_from_table=msgpack.object({band_name='The Beatles',year=1960})localmp_from_tuple=msgpack.object(box.tuple.new{1,'The Beatles',1960})
localmsgpack=require('msgpack')-- Create a MsgPack object from a raw MsgPack stringlocalraw_mp_string=msgpack.encode({10,20,30})localmp_from_mp_string=msgpack.object_from_raw(raw_mp_string)
Create a MsgPack object from a raw MsgPack string. The address of the MsgPack string is supplied as a C-style string pointer
such as the rpos pointer inside an ibuf that the buffer.ibuf() creates.
A C-style string pointer may be described as cdata<char*> or cdata<constchar*>.
Parameters:
C_style_string_pointer (buffer) – a pointer to a raw MsgPack string.
size (integer) – number of bytes in the raw MsgPack string.
Return:
a MsgPack object
Rtype:
userdata
Example:
localmsgpack=require('msgpack')-- Create a MsgPack object from a raw MsgPack string using bufferlocalbuffer=require('buffer')localibuf=buffer.ibuf()msgpack.encode({10,20,30},ibuf)localmp_from_mp_string_pt=msgpack.object_from_raw(ibuf.buf,ibuf:size())
true if the argument is a MsgPack object; otherwise, false
Rtype:
boolean
Example:
localmsgpack=require('msgpack')localmp_from_string=msgpack.object('hello world')-- Check if the given argument is a MsgPack objectlocalmp_is_object=msgpack.is_object(mp_from_string)-- Returns truelocalstring_is_object=msgpack.is_object('hello world')-- Returns false
Get an element of the MsgPack array by the specified index key.
You can also use the get(key) method to get an array element.
The index key used to get the array element might be one of the following:
if a MsgPack object is an array, the key is an integer value (starting with 1) that specifies the element index.
if a MsgPack object is an associative array, key is the string value that specifies the element key. In this case, you can also access the array element using dot notation (msgpack_object.<key>).
If the specified key is missing in the array, msgpack_object[key] returns nil.
Example
localmsgpack=require('msgpack')localmp_from_array=msgpack.object({10,20,30})localmp_from_table=msgpack.object({band_name='The Beatles',year=1960})localmp_from_tuple=msgpack.object(box.tuple.new{1,'The Beatles',1960})-- Get MsgPack data by the specified index or keylocalmp_array_get_by_index=mp_from_array[1]-- Returns 10localmp_table_get_by_key=mp_from_table['band_name']-- Returns 'The Beatles'localmp_table_get_by_nonexistent_key=mp_from_table['rating']-- Returns nillocalmp_tuple_get_by_index=mp_from_tuple[3]-- Returns 1960
Note
Note that if the key for an associative array coincides with any
msgpack_object’s method name,
for example, ‘iterator’, mp_from_table['iterator'] returns
the iterator method function instead of a value corresponding to the
‘iterator’ key.
Decode a MsgPack array header under the iterator cursor and advance the cursor.
After calling this function, the iterator points to the first element of the array
or to the value following the array if the array is empty.
Return:
number of elements in the array
Rtype:
number
Possible errors: raise an error if the type of the value under the iterator cursor is not MP_ARRAY.
Decode a MsgPack map header under the iterator cursor and advance the cursor.
After calling this function, the iterator points to the first key stored in
the map or to the value following the map if the map is empty.
Return:
number of key-value pairs in the map
Rtype:
number
Possible errors: raise an error if the type of the value under the iterator cursor is not MP_MAP.
Return a MsgPack value under the iterator cursor as a MsgPack object without decoding and advance the cursor.
The method doesn’t copy MsgPack data. Instead, it takes a reference to the original object.
Possible errors: raise a Lua error if there’s no data to decode.
The net.box module contains connectors to remote database systems. One
variant is for connecting to MySQL or MariaDB or PostgreSQL
(see SQL DBMS modules reference). The other variant, which
is discussed in this section, is for connecting to Tarantool server instances via a
network.
The tutorial shows how to use net.box to connect to a remote Tarantool instance, perform CRUD operations, and execute stored procedures.
For more information about the net.box module API, check Module net.box.
Note
This tutorial shows how to make CRUD requests to a single-instance Tarantool database.
To make requests to a sharded Tarantool cluster with the CRUD module, use its API for CRUD operations.
Sample database configuration
This section describes the configuration of a sample database that allows remote connections:
The configuration contains one instance that listens for incoming requests on the 127.0.0.1:3301 address.
sampleuser has privileges to select and modify data in the bands space and execute the get_bands_older_than stored function. This user can be used to connect to the instance remotely.
myapp.lua defines the data model and a stored function.
The myapp.lua file looks as follows:
-- Create a space --box.schema.space.create('bands')-- Specify field names and types --box.space.bands:format({{name='id',type='unsigned'},{name='band_name',type='string'},{name='year',type='unsigned'}})-- Create indexes --box.space.bands:create_index('primary',{parts={'id'}})box.space.bands:create_index('band',{parts={'band_name'}})box.space.bands:create_index('year_band',{parts={{'year'},{'band_name'}}})-- Create a stored function --box.schema.func.create('get_bands_older_than',{body=[[ function(year) return box.space.bands.index.year_band:select({ year }, { iterator = 'LT', limit = 10 }) end ]]})
You can find the full example on GitHub: sample_db.
Making net.box requests interactively
To try out net.box requests in the interactive console, start the sample_db application using ttstart:
$ ttstartsample_db
Then, use the tt run -i command to start an interactive console:
$ ttrun-i
Tarantool 3.0.0-entrypoint-1144-geaff238d9type 'help' for interactive helptarantool>
In the console, you can create a net.box connection and try out data operations.
Creating a net.box connection
To load the net.box module, use the require() directive:
net_box=require('net.box')--[[---...]]
To create a connection, pass a database URI to the net_box.connect() method:
The connection:close() method can be used to close the connection when it is no longer needed:
conn:close()--[[---...]]
Note
You can find the example with all the requests above on GitHub: net_box.
Overview
You can call the following methods:
require('net.box') – to get a net.box object
(named net_box for examples in this section)
net_box.connect() – to connect and get a connection object
(named conn for examples in this section)
other net.box() routines, passing conn:, to execute requests on
the remote database system
conn:close – to disconnect
All net.box methods are fiber-safe, that is, it is safe to share and use the
same connection object across multiple concurrent fibers. In fact that is perhaps
the best programming practice with Tarantool. When multiple fibers use the same
connection, all requests are pipelined through the same network socket, but each
fiber gets back a correct response. Reducing the number of active sockets lowers
the overhead of system calls and increases the overall server performance. However
for some cases a single connection is not enough – for example, when
it is necessary to prioritize requests or to use different authentication IDs.
Most net.box methods accept the last {options} argument, which can be:
{timeout=...}. For example, a method whose last argument is
{timeout=1.5} will stop after 1.5 seconds on the local node, although this
does not guarantee that execution will stop on the remote server node.
{buffer=...}. For an example, see the buffer module.
{is_async=...}. For example, a method whose last argument is
{is_async=true} will not wait for the result of a request. See the
is_async description.
{on_push=...on_push_ctx=...}. For receiving out-of-band messages.
See the box.session.push() description.
{return_raw=...} (since version 2.10.0).
If set to true, net.box returns response data wrapped
in a MsgPack object instead of decoding it to Lua.
The default value is false.
For an example, see option description below.
The diagram below shows possible connection states and transitions:
On this diagram:
net_box.connect() method spawns a worker fiber, which will establish the connection and start the state machine.
The state machine goes to the initial state.
Authentication and schema upload.
It is possible later on to re-enter the fetch_schema state from active to trigger schema reload.
The state changes to the graceful_shutdown state when the state machine
receives a box.shutdown event from the remote host
(see conn:on_shutdown()).
Once all pending requests are completed, the state machine switches to the error (error_reconnect) state.
The transport goes to the error state in case of an error.
It can happen, for example, if the server closed the connection.
If the reconnect_after option is set, instead of the ‘error’ state,
the transport goes to the error_reconnect state.
conn.close() method sets the state to closed and kills the worker.
If the transport is already in the error state, close() does nothing.
Create a new connection. The connection is established on demand, at the
time of the first request. It can be re-established automatically after a
disconnect (see reconnect_after option below).
The returned conn object supports methods for making remote requests,
such as select, update or delete.
Parameters:
URI (string) – the URI of the target for the connection
options –
the supported options are shown below:
user/password: two options to connect to a remote host other than through
URI. For example, instead of connect('username:userpassword@localhost:3301')
you can write connect('localhost:3301',{user='username',password='userpassword'}).
wait_connected: a connection timeout. By default, the connection is blocked until the connection
is established, but if you specify wait_connected=false, the connection returns immediately.
If you specify this timeout, it will wait before returning (wait_connected=1.5 makes it wait at most 1.5 seconds).
Note
If reconnect_after is greater than zero, then wait_connected ignores transient failures.
The wait completes once the connection is established or is closed explicitly.
reconnect_after: a number of seconds to wait before reconnecting.
The default value, as with the other connect options, is nil. If reconnect_after
is greater than zero, then a net.box instance will attempt to reconnect if a connection
is lost or a connection attempt fails. This makes transient network failures transparent to the application.
Reconnection happens automatically in the background, so requests that initially fail due to connection drops
fail, are transparently retried. The number of retries is unlimited, connection retries are made after
any specified interval (for example, reconnect_after=5 means that reconnect attempts are made every 5 seconds).
When a connection is explicitly closed or when the Lua garbage collector removes it, then reconnect attempts stop.
connect_timeout: a number of seconds to wait before returning “error: Connection timed out”.
fetch_schema: a boolean option that controls fetching schema changes from the server. Default: true.
If you don’t operate with remote spaces, for example, run only call or eval, set fetch_schema to
false to avoid fetching schema changes which is not needed in this case.
Important
In connections with fetch_schema==false, remote spaces are unavailable
and the on_schema_reload triggers don’t work.
required_protocol_version: a minimum version of the IPROTO protocol
supported by the server. If the version of the IPROTO protocol supported
by the server is lower than specified, the connection will fail with an error message.
With required_protocol_version=1, all connections fail where the IPROTO protocol
version is lower than 1.
required_protocol_features: specified IPROTO protocol features supported by the server.
You can specify one or more net.box features from the table below. If the server does not
support the specified features, the connection will fail with an error message.
With required_protocol_features={'transactions'}, all connections fail where the
server has transactions:false.
net.box feature
Use
IPROTO feature ID
IPROTO versions supporting the feature
streams
Requires streams support on the server
IPROTO_FEATURE_STREAMS
1 and newer
transactions
Requires transactions support on the server
IPROTO_FEATURE_TRANSACTIONS
1 and newer
error_extension
Requires support for MP_ERROR MsgPack extension on the server
For a local Tarantool server, there is a pre-created always-established
connection object named net_box.self. Its purpose is to make
polymorphic use of the net_box API easier. Therefore
conn=net_box.connect('localhost:3301')
can be replaced by conn=net_box.self.
However, there is an important difference between the embedded connection
and a remote one:
With the embedded connection, requests which do not modify data do not yield.
When using a remote connection, due to
the implicit rules
any request can yield, and the database state may have changed by the
time it regains control.
All the options passed to a request (as is_async, on_push, timeout)
will be ignored.
true when a target state is reached, false on timeout or connection closure
Rtype:
boolean
Examples:
-- wait infinitely for 'active' state:conn:wait_state('active')-- wait for 1.5 secs at most:conn:wait_state('active',1.5)-- wait infinitely for either `active` or `fetch_schema` state:conn:wait_state({active=true,fetch_schema=true})
Connection objects are destroyed by the Lua garbage collector, just like any other objects in Lua, so
an explicit destruction is not mandatory. However, since close() is a system
call, it is good programming practice to close a connection explicitly when it
is no longer needed, to avoid lengthy stalls of the garbage collector.
conn.space.space-name:select({...}) is the remote-call equivalent
of the local call box.space.space-name:select{...} (see details).
For an additional option see Module buffer and skip-header.
Example:
conn.space.testspace:select({1,'B'},{timeout=1})
Note
Due to the implicit yield rules
a local box.space.space-name:select{...} does
not yield, but a remote conn.space.space-name:select{...}
call does yield, so global variables or database tuples data may
change when a remote conn.space.space-name:select{...}
occurs.
conn.space.space-name:insert(...) is the remote-call equivalent
of the local call box.space.space-name:insert(...) (see details).
For an additional option see Module buffer and skip-header.
conn.space.space-name:replace(...) is the remote-call equivalent
of the local call box.space.space-name:replace(...) (see details).
For an additional option see Module buffer and skip-header.
conn.space.space-name:update(...) is the remote-call equivalent
of the local call box.space.space-name:update(...) (see details).
For an additional option see Module buffer and skip-header.
conn.space.space-name:upsert(...) is the remote-call equivalent
of the local call box.space.space-name:upsert(...). (see details).
For an additional option see Module buffer and skip-header.
conn.space.space-name:delete(...) is the remote-call equivalent
of the local call box.space.space-name:delete(...) (see details).
For an additional option see Module buffer and skip-header.
conn:eval(Lua-string) evaluates and executes the expression
in Lua-string, which may be any statement or series of statements.
An execute privilege is required;
if the user does not have it, an administrator may grant it with
box.schema.user.grant(username,'execute','universe').
To ensure that the return from conn:eval is whatever the Lua expression returns,
begin the Lua-string with the word “return”.
conn:call('func',{'1','2','3'}) is the remote-call equivalent of
func('1','2','3'). That is, conn:call is a remote
stored-procedure call. The return from conn:call is whatever the function returns.
Limitation: the called function cannot return a function, for example
if func2 is defined as functionfunc2()returnfuncend then
conn:call(func2) will return “error: unsupported Lua type ‘function’”.
Examples:
tarantool>-- create 2 functions with conn:eval()tarantool>conn:eval('function f1() return 5+5 end;')tarantool>conn:eval('function f2(x,y) return x,y end;')tarantool>-- call first function with no parameters and no optionstarantool>conn:call('f1')----10...tarantool>-- call second function with two parameters and one optiontarantool>conn:call('f2',{1,'B'},{timeout=99})----1-B...
The method has the same syntax as the box.watch()
function, which is used for subscribing to events locally.
Watchers survive reconnection (see the reconnect_after connection option).
All registered watchers are automatically resubscribed when the
connection is reestablished.
If a remote host supports watchers, the watchers key will be set in the
connection peer_protocol_features.
For details, check the net.box features table.
Note
Keep in mind that garbage collection of a watcher handle doesn’t lead to the watcher’s destruction.
In this case, the watcher remains registered.
It is okay to discard the result of watch function if the watcher will never be unregistered.
Example 1:
Server:
-- Broadcast value 42 for the 'foo' key.box.broadcast('foo',42)
Client:
conn=net.box.connect(URI)locallog=require('log')-- Subscribe to updates of the 'foo' key.w=conn:watch('foo',function(key,value)assert(key=='foo')log.info("The box.id value is '%d'",value)end)
If you don’t need the watcher anymore, you can unregister it using the command below:
w:unregister()
Example 2:
The net.boxmodule provides the ability to monitor updates of a configuration stored in a Tarantool-based configuration storage by watching path or prefix changes.
In the example below, conn:watch() is used to monitor updates of a configuration stored by the /myapp/config/all path:
net_box=require('net.box')localconn=net_box.connect('127.0.0.1:4401')locallog=require('log')conn:watch('config.storage:/myapp/config/all',function(key,value)log.info("Configuration stored by the '/myapp/config/all' key is changed")end)
{is_async=true|false} is an option which is applicable for all
net_box requests including conn:call, conn:eval, and the
conn.space.space-name requests.
The default is is_async=false, meaning requests are synchronous
for the fiber. The fiber is blocked, waiting until there is a
reply to the request or until timeout expires. Before Tarantool
version 1.10, the only way to make asynchronous requests was to
put them in separate fibers.
The non-default is is_async=true, meaning requests are asynchronous
for the fiber. The request causes a yield but there is no waiting.
The immediate return is not the result of the request, instead it is
an object that the calling program can use later to get the result of the
request.
This immediately-returned object, which we’ll call “future”,
has its own methods:
future:is_ready() which will return true
when the result of the request is available,
future:result() to get the result of the request (returns the
response or nil in case it’s not ready yet or there has been an error),
future:wait_result(timeout) to
wait until the result of the request is available and then get it, or
throw an error if there is no result after the timeout exceeded,
future:discard() to abandon the object.
Typically a user would say future=request-name(...{is_async=true}),
then either loop checking future:is_ready() until it is true and
then say request_result=future:result(),
or say request_result=future:wait_result(...).
Alternatively the client could check for “out-of-band” messages from the server
by calling pairs() in a loop – see box.session.push().
A user would say future:discard() to make a connection forget about the response –
if a response for a discarded object is received then it will be ignored, so that
the size of the requests table will be reduced and other requests will be faster.
Examples:
-- Insert a tuple asynchronously --tarantool> future=conn.space.bands:insert({10,'Queen',1970},{is_async=true})---...tarantool> future:is_ready()----true...tarantool> future:result()----[10,'Queen',1970]...-- Iterate through a space with 10 records to get data in chunks of 3 records --tarantool> whiletruedo future = conn.space.bands:select({}, {limit=3, after=position, fetch_pos=true, is_async=true}) result = future:wait_result() tuples = result[1] position = result[2] if position == nil then break end print('Chunk size: '..#tuples) endChunk size: 3Chunk size: 3Chunk size: 3Chunk size: 1---...
Typically {is_async=true} is used only if the load is
large (more than 100,000 requests per second) and latency
is large (more than 1 second), or when it is necessary to
send multiple requests in parallel then collect responses
(sometimes called a “map-reduce” scenario).
Note
Although the final result of an async request is the same as
the result of a sync request, it is structured differently: as a
table, instead of as the unpacked values.
conn:request(...{return_raw=...})
{return_raw=true} is ignored for:
Methods that return nil:
begin, commit, rollback, upsert, prepare.
index.count (returns number).
For execute, the option is applied only to data (rows). Metadata is decoded even if {return_raw=true}.
The option can be useful if you want to pass a response through without decoding or with partial decoding.
The usage of MsgPack object can reduce pressure on the Lua garbage collector.
-- Start a server to create a new streamlocalconn=net_box.connect('localhost:3301')localconn_space=conn.space.testlocalstream=conn:new_stream()localstream_space=stream.space.test
Commit a stream transaction. Instead of the direct method, you can also use the call, eval or execute methods with SQL transaction.
Examples:
-- Begin stream transactionstream:begin()-- In the previously created ``accounts`` space with the primary key ``test``, modify the fields 2 and 3stream.space.accounts:update(test_1,{{'-',2,370},{'+',3,100}})-- Commit stream transactionstream:commit()
Rollback a stream transaction. Instead of the direct method, you can also use the call, eval or execute methods with SQL transaction.
Example:
-- Test rollback for memtx spacespace:replace({1})-- Select return tuple that was previously inserted, because this select belongs to stream transactionspace:select({})stream:rollback()-- Select is empty, stream transaction rollbackspace:select({})
Triggers
With the net.box module, you can use the following
triggers:
Define a trigger for execution when a new connection is established, and authentication
and schema fetch are completed due to an event such as net_box.connect.
If a trigger function issues net_box requests, they must be asynchronous
({is_async=true}). An attempt to wait for request completion with future:pairs()
or future:wait_result() in the trigger function will result in an error.
If the trigger execution fails and an exception happens, the connection’s
state changes to ‘error’. In this case, the connection is terminated, regardless of the
reconnect_after option’s value. Can be called as many times as
reconnection happens, if reconnect_after is greater than zero.
Parameters:
trigger-function (function) – the trigger function. Takes the conn
object as the first argument.
old-trigger-function (function) – an existing trigger function to replace
with trigger-function
Define a trigger for execution after a connection is closed. If the trigger
function causes an error, the error is logged but otherwise is ignored.
Execution stops after a connection is explicitly closed, or once the Lua
garbage collector removes it.
Parameters:
trigger-function (function) – the trigger
function. Takes the conn
object as the first argument
old-trigger-function (function) – an existing trigger function to replace
with trigger-function
Define a trigger for shutdown when a box.shutdown event is received.
The trigger starts in a new fiber.
While the on_shutdown() trigger is running, the connection stays active.
It means that the trigger callback is allowed to send new requests.
After the trigger return, the net.box connection goes to the graceful_shutdown state
(check the state diagram for details).
In this state, no new requests are allowed.
The connection waits for all pending requests to be completed.
Once all in-progress requests have been processed, the connection is closed.
The state changes to error or error_reconnect
(if the reconnect_after option is defined).
Servers that do not support the box.shutdown event or IPROTO_WATCH
just close the connection abruptly.
In this case, the on_shutdown() trigger is not executed.
Parameters:
trigger-function (function) – the trigger function. Takes the conn
object as the first argument
old-trigger-function (function) – an existing trigger function to replace
with trigger-function
Define a trigger executed when some operation has been performed on the remote
server after schema has been updated. So, if a server request fails due to a
schema version mismatch error, schema reload is triggered.
If a trigger function issues net_box requests, they must be asynchronous
({is_async=true}). An attempt to wait for request completion with future:pairs()
or future:wait_result() in the trigger function will result in an error.
Parameters:
trigger-function (function) – the trigger function. Takes the conn
object as the first argument
old-trigger-function (function) – an existing trigger function to replace
with trigger-function
Return:
nil or function pointer
Note
If the parameters are (nil,old-trigger-function),
then the old trigger is deleted.
If both parameters are omitted, then the response is a list of
existing trigger functions.
Find the detailed information about triggers in the
triggers section.
Parameters: (string) format-string = instructions; (string) time-since-epoch =
number of seconds since 1970-01-01. If time-since-epoch is omitted, it is assumed to be the current time.
Example:
tarantool> os.date("%A %B %d")----Sunday April 24...
To use Tarantool binary protocol primitives from Lua, it’s necessary to
convert Lua variables to binary format. The pickle.pack() helper
function is prototyped after Perl pack.
Format specifiers
b, B
converts Lua scalar value to a 1-byte integer,
and stores the integer in the resulting string
s, S
converts Lua scalar value to a 2-byte integer, and
stores the integer in the resulting string,
low byte first
i, I
converts Lua scalar value to a 4-byte integer, and
stores the integer in the resulting string, low
byte first
l, L
converts Lua scalar value to an 8-byte integer, and
stores the integer in the resulting string, low
byte first
n
converts Lua scalar value to a 2-byte integer, and
stores the integer in the resulting string, big
endian,
N
converts Lua scalar value to a 4-byte integer, and
stores the integer in the resulting string, big
q, Q
converts Lua scalar value to an 8-byte integer, and
stores the integer in the resulting string, big
endian,
f
converts Lua scalar value to a 4-byte float, and
stores the float in the resulting string
d
converts Lua scalar value to a 8-byte double, and
stores the double in the resulting string
a, A
converts Lua scalar value to a sequence of bytes,
and stores the sequence in the resulting string
Parameters:
format (string) – string containing format specifiers
argument(s) (scalar-value) – scalar values to be formatted
Return:
a binary string containing all arguments,
packed according to the format specifiers.
Since version 2.4.1, Tarantool has the popen
built-in module that supports execution of external programs.
It is similar to Python’s
subprocess()
or Ruby’s Open3.
However, Tarantool’s popen module does not have all the helpers that
those languages provide, it provides only basic functions.
popen uses the
vfork()
system call to create an object, so the caller thread is
blocked until execution of a child process begins.
The popen module provides two functions to create the popen
object:
(if success) a popen handle, which we will call
popen_handle or ph
(if failure) nil,err
Possible errors: if a parameter is incorrect, the result is
IllegalParams: incorrect type or value of a parameter.
For other possible errors, see popen.new().
'nil' which means inherit parent’s std* file descriptors
Several mode characters can be set together, for example 'rw', 'rRw'.
The shell function is just a shortcut for popen.new({command}, opts)
with opts.shell.setsid and opts.shell.group_signal both set to true, and with
opts.stdin and opts.stdout and opts.stderr all set based on the mode parameter.
All std* streams are inherited from the parent by default unless it is
changed using mode: 'r' for stdout, 'R' for stderr, or 'w' for
stdin.
Example:
This is the equivalent of the sh-cdate command.
It starts a process, runs 'date', reads the output,
and closes the popen object (ph).
localpopen=require('popen')-- Run the program and save its handle.localph=popen.shell('date','r')-- Read program's output, strip trailing newline.localdate=ph:read():rstrip()-- Free resources. The process is killed (but 'date'-- exits itself anyway).ph:close()print(date)
Unix defines a text file as a sequence of lines. Each line
is terminated by a newline (\\n) symbol. The same convention is usually
applied for text output of a command. So, when it is
redirected to a file, the file will be correct.
However, internally an application usually operates on
strings, which are not terminated by newline (for example literals
for error messages). The newline is usually added just
before a string is written for the outside world (stdout,
console or log). That is why the example above contains rstrip().
argv (array) – an array of a program to run with command line options,
mandatory; absolute path to the program is required when
opts.shell is false (default)
(if success) a popen handle, which we will call
popen_handle or ph
(if failure) nil,err
Possible raised errors are:
IllegalParams: incorrect type or value of a parameter
IllegalParams: group signal is set, while setsid is not
Possible error reasons when nil,err is returned are:
SystemError: dup(), fcntl(), pipe(), vfork() or close() fails in the
parent process
SystemError: (temporary restriction) the parent process has closed stdin,
stdout or stderr
OutOfMemory: unable to allocate the handle or a temporary buffer
Possible opts items are:
opts.stdin (action on STDIN_FILENO)
opts.stdout (action on STDOUT_FILENO)
opts.stderr (action on STDERR_FILENO)
The opts table file descriptor actions may be:
popen.opts.INHERIT (== 'inherit') [default] inherit the fd from the parent
popen.opts.DEVNULL (== 'devnull') open /dev/null on the fd
popen.opts.CLOSE (== 'close') close the fd
popen.opts.PIPE (== 'pipe') feed data from fd to parent,
or from parent to fd, using a pipe
The opts table may contain an env table of environment variables to
be used inside a process. Each opts.env item may be a key-value pair
(key is a variable name, value is a variable value).
If opts.env is not set then the current environment is inherited.
If opts.env is an empty table, then the environment will be dropped.
If opts.env is set to a non-empty table, then the environment will be replaced.
The opts table may contain these boolean items:
Name
Default
Use
opts.shell
false
If true, then run a child process
via sh-c"${opts.argv}".
If false, then call the executable
directly.
opts.setsid
false
If true, then run the program in a
new session.
If false, then run the program in
the Tarantool instance’s session
and process group.
opts.close_fds
true
If true, then close all inherited
fds from the parent.
If false, then do not close all
inherited fds from the parent.
opts.restore_signals
true
If true, then reset all signal
actions modified in the parent’s
process.
If false, then inherit all signal
actions modified in the parent’s
process.
opts.group_signal
false
If true, then send signal to a
child process group, if and only if
opts.setsid is enabled.
If false, then send signal to a
child process only.
opts.keep_child
false
If true, then do not send SIGKILL
to a child process (or to a
process group if opts.group_signal
true).
If false, then do send SIGKILL
to a child process (or to a
process group if opts.group_signal
is true) at
popen_handle:close()
or when Lua GC collects the handle.
The returned ph handle provides a
popen_handle:close() method for explicitly
releasing all occupied resources, including the child process
itself if opts.keep_child is not set). However, if the close()
method is not called for a handle during its lifetime, the
Lua GC will trigger the same freeing actions.
Tarantool recommends using opts.setsid plus opts.group_signal
if a child process may spawn its own children and if they should all
be killed together.
A signal will not be sent if the child process is
already dead. Otherwise we might kill another process that
occupies the same PID later. This means that if the child
process dies before its own children die, then the function will not
send a signal to the process group even when opts.setsid and
opts.group_signal are set.
Use os.environ() to pass a copy of the current
environment with several replacements (see example 2 below).
Example 1
This is the equivalent of the sh-cdate command.
It starts a process, runs ‘date’, reads the output,
and closes the popen object (ph).
localpopen=require('popen')localph=popen.new({'/bin/date'},{stdout=popen.opts.PIPE,})localdate=ph:read():rstrip()ph:close()print(date)-- e.g. Thu 16 Apr 2020 01:40:56 AM MSK
Example 2
Example 2 is quite similar to Example 1, but sets an
environment variable and uses the shell builtin 'echo' to
show it.
localpopen=require('popen')localenv=os.environ()env['FOO']='bar'localph=popen.new({'echo "${FOO}"'},{stdout=popen.opts.PIPE,shell=true,env=env,})localres=ph:read():rstrip()ph:close()print(res)-- bar
Example 3
Example 3 demonstrates how to capture a child’s stderr.
Example 4 demonstrates how to run a stream program (like grep, sed
and so on), write to its stdin and read from its stdout.
The example assumes that input data are small enough to fit in
a pipe buffer (typically 64 KiB, but this depends on the platform
and its configuration).
If a process writes lengthy data, it will get stuck in
popen_handle:write().
To handle this case: call popen_handle:read() in a loop in
another fiber (start it before the first :write()).
If a process writes lengthy text to stderr, it may get stick in write()
because the stderr pipe buffer becomes full.
To handle this case: read stderr in a separate fiber.
localfunctioncall_jq(input,filter)-- Start jq process, connect to stdin, stdout and stderr.localjq_argv={'/usr/bin/jq','-M','--unbuffered',filter}localph,err=popen.new(jq_argv,{stdin=popen.opts.PIPE,stdout=popen.opts.PIPE,stderr=popen.opts.PIPE,})ifph==nilthenreturnnil,errend-- Write input data to child's stdin and send EOF.localok,err=ph:write(input)ifnotokthenreturnnil,errendph:shutdown({stdin=true})-- Read everything until EOF.localchunks={}whiletruedolocalchunk,err=ph:read()ifchunk==nilthenph:close()returnnil,errendifchunk==''thenbreakend-- EOFtable.insert(chunks,chunk)end-- Read diagnostics from stderr if any.localerr=ph:read({stderr=true})iferr~=''thenph:close()returnnil,errend-- Glue all chunks, strip trailing newline.returntable.concat(chunks):rstrip()end
opts.stdout (boolean, default true, if true then read from stdout)
opts.stderr (boolean, default false, if true then read from stderr)
opts.timeout (number, default 100 years, time quota in seconds)
In other words: by default read() reads from stdout, but reads from
stderr if one sets opts.stderr to true. It is not legal to set both
opts.stdout and opts.stderr to true.
Return:
(if success) string with read value, empty string if EOF
(if failure) nil,err
Possible errors
These errors are raised on incorrect parameters or when the fiber is cancelled:
IllegalParams: incorrect type or value of a parameter
IllegalParams: called on a closed handle
IllegalParams: opts.stdout and opts.stderr are both set
IllegalParams: a requested IO operation is not supported by
the handle (stdout / stderr is not piped)
IllegalParams: attempt to operate on a closed file descriptor
FiberIsCancelled: cancelled by external code
nil,err is returned on following failures:
SocketError: an IO error occurs at read()
TimedOut: exceeded the opts.timeout quota
OutOfMemory: no memory space for a buffer to read into
LuajitError: (“not enough memory”): no memory space for the Lua string
Possible opts items are:
opts.timeout (number, default 100 years, time quota in seconds).
Possible raised errors are:
IllegalParams: incorrect type or value of a parameter
IllegalParams: called on a closed handle
IllegalParams: string length is greater then SSIZE_MAX
IllegalParams: a requested IO operation is not supported by the
handle (stdin is not piped)
IllegalParams: attempt to operate on a closed file descriptor
FiberIsCancelled: cancelled by an outside code
Possible error reasons when nil,err is returned are:
SocketError: an IO error occurs at write()
TimedOut: exceeded opts.timeout quota
write() may yield forever if the child process does
not read data from stdin and a pipe buffer becomes full.
The size of this pipe buffer depends on the platform. Set
opts.timeout when unsure.
When opts.timeout is not set, the write() blocks
(yields the fiber) until all data is written or an error
happens.
opts.stdout (boolean) close parent’s end of stdout
opts.stderr (boolean) close parent’s end of stderr
We may use the term std* to mean any one of these items.
Possible raised errors are:
IllegalParams: an incorrect handle parameter
IllegalParams: called on a closed handle
IllegalParams: neither stdin, stdout nor stderr is chosen
IllegalParams: a requested IO operation is not supported by
the handle (one of std* is not piped)
The main reason to use shutdown() is to send EOF to a
child’s stdin. However the parent’s end of stdout / stderr
may be closed too.
shutdown() does not fail on already closed fds (idempotence).
However, it fails on an attempt to close the end of a pipe that
never existed. In other words, only those std* options that
were set to popen.opts.PIPE during handle creation may be used
here (for popen.shell(): 'r' corresponds to stdout,
'R' to stderr and 'w' to stdin).
shutdown() does not close any fds on a failure: either all
requested fds are closed or none of them.
Example:
localpopen=require('popen')localph=popen.shell('sed s/foo/bar/','rw')ph:write('lorem foo ipsum')ph:shutdown({stdin=true})localres=ph:read()ph:close()print(res)-- lorem bar ipsum
SystemError: a process does not exists any more
(this may also be returned for a zombie process or when all
processes in a group are zombies (but see note re Mac OS below)
SystemError: invalid signal number
SystemError: no permission to send a signal to a process or
a process group
(this is returned on Mac OS when a signal is
sent to a process group, where a group leader
is a zombie (or when all processes in it
are zombies, details re uncertain)
(this may also appear due to other reasons, details are uncertain)
If opts.setsid and opts.group_signal are set for the handle,
the signal is sent to the process group rather than to the
process. See popen.new() for details about group
signaling. Warning: On Mac OS it is possible that a process in the group
will not receive the signal, particularly if the process has just been
forked (this may be due to a race condition).
Note: The module offers popen.signal.SIG* constants, because
some signals have different numbers on different platforms.
pid is a process id of the process when it is alive,
otherwise pid is nil.
command is a concatenation of space-separated arguments
that were passed to execve(). Multiword arguments are quoted.
Quotes inside arguments are not escaped.
opts is a table of handle options as in the
popen.new()opts parameter. opts.env is not shown here,
because the environment variables map is not stored in a
handle.
status is a table that represents a process status in the
following format:
{
state = one-of(
popen.state.ALIVE (== 'alive'),
popen.state.EXITED (== 'exited'),
popen.state.SIGNALED (== 'signaled'),
)
-- Present when `state` is 'exited'.
exit_code = <number>,
-- Present when `state` is 'signaled'.
signo = <number>,
signame = <string>,
}
stdin, stdout, and stderr reflect the status of the parent’s end
of a piped stream. If a stream is not piped, the field is
not present (nil). If it is piped, the status may be
either popen.stream.OPEN (== 'open') or popen.stream.CLOSED (== 'closed').
The status may be changed from 'open' to 'closed'
by a popen_handle:shutdown({std… = true}) call.
Possible diagnostics when nil,err is returned
(do not consider them as errors):
SystemError: no permission to send a signal to a process or a process group
(This diagnostic may appear due to Mac OS behavior on zombies when
opts.group_signal is set, see popen_handle:signal().
It may appear for other reasons, details are unclear.)
The return is always true when a process is known to be dead (for example,
after popen_handle:wait() no signal will be sent, so no ‘failure’
may appear).
close() kills a process using SIGKILL and releases all
resources associated with the popen handle.
Details about signaling:
The signal is sent only when opts.keep_child is not set.
The signal is sent only when a process is alive according
to the information available on current event loop iteration.
(There is a gap here: a zombie may be signaled; it is
harmless.)
The signal is sent to a process or a process group depending
on opts.group_signal. (See popen.new()
for details of group signaling).
Resources are released regardless whether or not a signal
sending succeeds: fds are closed, memory is released,
the handle is marked as closed.
No operation is possible on a closed handle except
close(), which is always successful on a closed handle
(idempotence).
close() may return true or nil,err, but it always
frees the handle resources. So any return value usually
means success for a caller. The return values are purely
informational: they are for logging or some kind of reporting.
The socket module allows exchanging data via BSD sockets with a local or
remote host in connection-oriented (TCP) or datagram-oriented (UDP) mode.
Semantics of the calls in the socket API closely follow semantics of the
corresponding POSIX calls.
The functions for setting up and connecting are socket, sysconnect,
tcp_connect. The functions for sending data are send, sendto,
write, syswrite. The functions for receiving data are recv,
recvfrom, read. The functions for waiting before sending/receiving
data are wait, readable, writable. The functions for setting
flags are nonblock, setsockopt. The functions for stopping and
disconnecting are shutdown, close. The functions for error checking
are errno, error.
Typically a socket session will begin with the setup functions, will set one
or more flags, will have a loop with sending and receiving functions, will
end with the teardown functions – as an example at the end of this section
will show. Throughout, there may be error-checking and waiting functions for
synchronization. To prevent a fiber containing socket functions from “blocking”
other fibers, the implicit yield rules
will cause a yield so that other processes
may take over, as is the norm for cooperative multitasking.
For all examples in this section the socket name will be sock and
the function invocations will look like sock:function_name(...).
The socket.getaddrinfo() function is useful for finding information
about a remote site so that the correct arguments for
sock:sysconnect() can be passed.
This function may use the worker_pool_threads
configuration parameter.
tarantool> socket.getaddrinfo('tarantool.org','http')-----host:188.93.56.70family:AF_INETtype:SOCK_STREAMprotocol:tcpport:80-host:188.93.56.70family:AF_INETtype:SOCK_DGRAMprotocol:udpport:80...-- To find the available values for the options use the following:tarantool> socket.internal.AI_FLAGS-- or SO_TYPE, or DOMAIN----AI_ALL:256AI_PASSIVE:1AI_NUMERICSERV:4096AI_NUMERICHOST:4AI_V4MAPPED:2048AI_ADDRCONFIG:1024AI_CANONNAME:2...
The socket.tcp_server() function makes Tarantool act as a server that
can accept connections. Usually the same objective
is accomplished with box.cfg{listen=…}.
handler-function-or-table (function/table) – what to execute when a
connection occurs
timeout (number) – host resolving timeout in seconds
Return:
(if error) {nil, error-message-string}. (if no error) a new socket object.
Rtype:
socket object, which may be viewed as a table
The handler-function-or-table parameter may be simply a function name
/ function declaration:
handler_function. Or it may be a table:
{handler=handler_function[,prepare=prepare_function][,name=name]}.
handler_function is mandatory; it may have a
parameter = the socket;
it is executed once after accept() happens (once per connection);
it is for continuous
operation after the connection is made.
prepare_function is optional;
it may have parameters = the socket object and a table with client information;
it should return either a backlog value or nothing;
it is executed only once before bind() on the listening socket
(not once per connection).
Examples:
socket.tcp_server('localhost', 3302, function (s) loop_loop() end)
socket.tcp_server('localhost', 3302, {handler=hfunc, name='name'})
socket.tcp_server('localhost', 3302, {handler=hfunc, prepare=pfunc})
Bind a socket to the given host/port.
This is equivalent to socket_object:bind(),
but is done on the result of require('socket'), rather than on the
socket object.
Possible errors: On error, returns an empty string, followed by status,
errno, errstr. In case the writing side has closed its
end, returns the remainder read from the socket (possibly
an empty string), followed by “eof” status.
Read from a connected socket until some condition is true, and return
the bytes that were read.
Reading goes on until limit bytes have been read, or a delimiter
has been read, or a timeout has expired.
Unlike socket_object:recv (which uses an internal read-ahead buffer),
socket_object:read depends on the socket’s buffer.
Parameters:
limit (integer) – maximum number of bytes to read, for
example 50 means “stop after 50 bytes”
delimiter (string) – separator for example
? means “stop after a question mark”; this parameter can accept a table of separators, for example, delimiter={"\n","\r"}
timeout (number) – maximum number of seconds to wait, for
example 50 means “stop after 50 seconds”.
options (table) – chunk=limit and/or
delimiter=delimiter,
for example {chunk=5,delimiter='x'}.
Return:
an empty string if there is nothing more to read, or a nil
value if error, or a string up to limit bytes long,
which may include the bytes that matched the delimiter
expression.
Return data from the socket buffer if non-blocking.
In case the socket is blocking, sysread() can block the calling process.
Rarely used. For details, see also
this description.
Parameters:
size (integer) – maximum number of bytes to read, for
example 50 means “stop after 50 bytes”
Return:
an empty string if there is nothing more to read, or a nil
value if error, or a string up to size bytes long.
Bind a socket to the given host/port. A UDP socket after binding
can be used to receive data (see socket_object.recvfrom).
A TCP socket can be used to accept new connections, after it has
been put in listen mode.
size (integer) – maximum number of bytes to receive. See Recommended size.
Return:
message, a table containing “host”, “family” and “port” fields.
Rtype:
string, table
Possible errors: on error, returns status, errno, errstr.
Example:
After message_content,message_sender=recvfrom(1)
the value of message_content might be a string containing ‘X’ and
the value of message_sender might be a table containing
Close (destroy) a socket. A closed socket should not be used any more.
A socket is closed automatically when the Lua garbage collector removes
its user data.
Return:
true on success, false on error. For example, if
sock is already closed, sock:close() returns false.
Retrieve information about the last error that occurred on a socket, if any.
Errors do not cause throwing of exceptions so these functions are usually necessary.
Return:
result for sock:errno(), result for sock:error().
If there is no error, then sock:errno() will return 0 and sock:error().
Wait until something is either readable or writable, or until a timeout value expires.
Return:
‘R’ if the socket is now readable, ‘W’ if the socket is now writable, ‘RW’ if the socket is now both readable and writable, ‘’ (empty string) if timeout expired;
The sock:name() function is used to get information about the
near side of the connection. If a socket was bound to xyz.com:45,
then sock:name will return information about [host:xyz.com,port:45].
The equivalent POSIX function is getsockname().
Return:
A table containing these fields: “host”, “family”, “type”, “protocol”, “port”.
The sock:peer() function is used to get information about the far side of a connection.
If a TCP connection has been made to a distant host tarantool.org:80, sock:peer()
will return information about [host:tarantool.org,port:80].
The equivalent POSIX function is getpeername().
Return:
A table containing these fields: “host”, “family”, “type”, “protocol”, “port”.
The socket.iowait() function is used to wait until read-or-write activity
occurs for a file descriptor.
Parameters:
fd – file descriptor
read-or-write-flags – ‘R’ or 1 = read, ‘W’ or 2 = write, ‘RW’ or 3 = read|write.
timeout – number of seconds to wait
If the fd parameter is nil, then there will be a sleep until the timeout.
If the timeout parameter is nil or unspecified, then timeout is infinite.
Ordinarily the return value is the activity that occurred (‘R’ or ‘W’ or ‘RW’ or 1 or 2 or 3).
If the timeout period goes by without any reading or writing, the
return is an error = ETIMEDOUT.
Example: socket.iowait(sock:fd(),'r',1.11)
LuaSocket wrapper functions
The LuaSocket API has functions that are equivalent to the ones described above,
with different names and parameters, for example connect()
rather than tcp_connect(). Tarantool supports these functions so that
third-party packages which depend on them will work.
The LuaSocket project is on
github.
The API description is in the
LuaSocket manual
(click the “introduction” and “reference” links at the
bottom of the manual’s main page).
For recv and recvfrom: use the
optional size parameter to limit the number of bytes to
receive. A fixed size such as 512 is often reasonable;
a pre-calculated size that depends on context – such as the
message format or the state of the network – is often better.
For recvfrom, be aware that a size greater than the
Maximum Transmission Unit
can cause inefficient transport.
For Mac OS X, be aware that the size can be tuned by
changing sysctlnet.inet.udp.maxdgram.
If size is not stated: Tarantool will make an extra
call to calculate how many bytes are necessary. This extra call
takes time, therefore not stating size may be inefficient.
If size is stated: on a UDP socket, excess bytes are discarded.
On a TCP socket, excess bytes are not discarded and can be
received by the next call.
Examples
Use of a TCP socket over the Internet
In this example a connection is made over the internet between a Tarantool
instance and tarantool.org, then an HTTP “head” message is sent, and a response
is received: “HTTP/1.1200OK” or something else if the site has moved.
This is not a useful way to communicate
with this particular site, but shows that the system works.
This is a variation of the earlier example
“Use of a TCP socket over the Internet”.
It uses LuaSocket wrapper functions,
with a too-short timeout so that a “Connection timed out” error is likely.
The more common way to specify timeout is with an option of
tcp_connect().
Here is an example with datagrams. Set up two connections on 127.0.0.1
(localhost): sock_1 and sock_2. Using sock_2, send a message
to sock_1. Using sock_1, receive a message. Display the received
message. Close both connections. This is not a useful way for a
computer to communicate with itself, but shows that the system works.
Use tcp_server to accept file contents sent with socat
Here is an example of the tcp_server function, reading
strings from the client and printing them. On the client
side, the Linux socat utility will be used to ship a
whole file for the tcp_server function to read.
Start two shells. The first shell will be a server instance.
The second shell will be the client.
Use tcp_server() to wait for a connection from any host on port 3302.
When it happens, enter a loop that reads on the socket and prints what it
reads. The “delimiter” for the read function is “\n” so each read()
will read a string as far as the next line feed, including the line feed.
On the second shell, create a file that contains a few lines. The contents don’t
matter. Suppose the first line contains A, the second line contains B, the third
line contains C. Call this file “tmp.txt”.
On the second shell, use the socat utility to ship the
tmp.txt file to the server instance’s host and port:
$ socatTCP:localhost:3302./tmp.txt
Now watch what happens on the first shell.
The strings “A”, “B”, “C” are printed.
Use tcp_server with handler and prepare
Here is an example of the tcp_server function
using handler and prepare.
Start two shells. The first shell will be a server instance.
The second shell will be the client.
Use tcp_server() to wait for a connection from any host on port 3302.
Specify that there will be an initial call to prepare which displays
something about the server, then calls setsockopt(...'SO_REUSEADDR'...)
(this is the same option that Tarantool would set if there was no prepare),
and then returns 5 (this is a rather low backlog queue size).
Specify that there will be per-connection calls to handler which display
something about the client.
Now watch what happens on the first shell. The display will include something
like ‘listening on socket 12’.
Now watch what happens on the first shell.
The display will include something like
‘accepted connection from
host: 127.0.0.1 family: AF_INET port: 37186’.
Module strict
The strict module has functions for turning “strict mode” on or off.
When strict mode is on, an attempt to use an undeclared global variable will
cause an error. A global variable is considered “undeclared” if it has never
had a value assigned to it. Often this is an indication of a programming error.
By default strict mode is off, unless tarantool was built with the
-DCMAKE_BUILD_TYPE=Debug option – see the description of build options
in section building-from-source.
Example:
tarantool> strict=require('strict')---...tarantool> strict.on()---...tarantool> a=b-- strict mode is on so this will cause an error----error:... variable ''b'' is not declared'...tarantool> strict.off()---...tarantool> a=b-- strict mode is off so this will not cause an error---...
Given a string containing pairs of hexadecimal digits, return a string with one byte
for each pair. This is the reverse of string.hex().
The hexadecimal-input-string must contain an even number of hexadecimal digits.
Parameters:
hexadecimal-input-string (string) – string with pairs of hexadecimal digits
Return:
string with one byte for each pair of hexadecimal digits
Return the value of the input string, after removing characters on the left.
The optional list-of-characters parameter is a set not a sequence, so
string.lstrip(...,'ABC') does not mean strip 'ABC', it means strip 'A' or 'B' or 'C'.
Return the value of the input string, after removing characters on the right.
The optional list-of-characters parameter is a set not a sequence, so
string.rstrip(...,'ABC') does not mean strip 'ABC', it means strip 'A' or 'B' or 'C'.
Return the value of the input string, after removing characters on the left and the right.
The optional list-of-characters parameter is a set not a sequence, so
string.strip(...,'ABC') does not mean strip 'ABC', it means strip 'A' or 'B' or 'C'.
The swim module contains Tarantool’s implementation of
SWIM – Scalable Weakly-consistent Infection-style Process Group Membership
Protocol. It is recommended for any type of Tarantool cluster where the
number of nodes can be large. Its job is to discover and monitor
the other members in the cluster and keep their information in a “member table”.
It works by sending and receiving, in a background event loop, periodically,
via UDP, messages.
Each message has several parts, including:
the ping such as “I am checking whether you are alive”,
the event such as “I am joining”,
the anti-entropy such as “I know that another member exists”,
the payload such as “I or another member could have user-generated data”.
The maximum message size is about 1500 bytes.
SWIM sends messages periodically to a random subset of the member table.
SWIM processes replies from those members asynchronously.
Each entry in the member table has:
a UUID,
a status (“alive”, “suspected”, “dead”, or “left”).
When a member fails to acknowledge a certain number of pings,
its status is changed from “alive” to “suspected”, that is, suspected of being
dead. But SWIM tries to avoid false positives (misidentifying members as dead)
which could happen when a member is overloaded and responds to pings too slowly,
or when there is network trouble and packets can not go through some channels.
When a member is suspected, SWIM randomly chooses other members and sends
requests to them: “please ping this suspected member”.
This is called an indirect ping.
Thus via different routes and additional hops the suspected member gets
additional chances to reply, and thus “refute” the suspicion.
Because selection is random there is an even network load of about one message
per member per protocol step, regardless of the cluster size. This is a major
feature of SWIM. Because the protocol depends on members passing information on,
also known as “gossiping”, members do not need to broadcast messages to every
member, which would cause a network load of N messages per member per protocol step,
where N is the number of members in the cluster. However, selection is not
entirely random, there is a preference for selecting least-recently-pinged
members, like a round-robin.
Regarding the anti-entropy part of a message: this is necessary for maintaining
the status in entries of the member table.
Consider an example where two members, #1 and #2, are both alive.
No events happen so only pings are being sent periodically.
Then a third member, #3 appears.
It knows about one of the existing members, #2.
How can it discover the other member?
Certainly #1 could notify #2 and #2 could notify #3, but messages go via UDP,
so any notification event can be lost.
However, regular messages containing “ping” and/or “event” also can contain
an “anti-entropy” section,
which is taken from a randomly-chosen part of the member table.
So for this example, #2 will eventually randomly add to a regular message
the anti-entropy note that #1 is alive, and thus #3 will discover #1
even though it did not receive a direct “I am alive” event message from #1.
Regarding the UUID part of an entry in the member table:
this is necessary for stable identification, because UUID changes more
rarely than URI (a combination of IP and port number).
But if the UUID does change,
SWIM will include both the new and old UUID in messages,
so all other members will eventually learn about the new UUID
and change the member table accordingly.
Regarding the payload part of a message:
this is not always necessary, it is a feature
which allows passing user-generated information via SWIM
instead of via node-to-node communication.
The swim module has methods for specifying a “payload”, which is arbitrary
user data with a maximum size of about 1.2 KB.
The payload can be anything, and it will be eventually
disseminated over the cluster and available at other members.
Each member can have its own payload.
Messages can be encrypted. Encryption may not be necessary in a closed
network but is necessary for safety if the cluster is on the public Internet.
Users can specify an encryption algorithm, an encryption mode, and a private key.
All parts of all messages (including ping, acknowledgment, event, payload,
URI, and UUID) will be encrypted
with that private key, as well as a random public key generated for each message to
prevent pattern attacks.
In theory the event dissemination speed (the number of hops to pass information
throughout the cluster) is O(log(cluster_size)). For that and other theoretical
information see the Cornell University
paper
which originally described SWIM.
Create a new SWIM instance. A SWIM instance maintains a member
table and interacts with other members.
Multiple SWIM instances can be created in a single Tarantool process.
If cfg is not specified or is nil, then
the new SWIM instance is not bound to a socket
and has nil attributes, so it cannot interact with other
members and only a few methods are valid
until swim_object:cfg() is called.
If cfg is specified, then the effect is the same as
calling s=swim.new()s:cfg(), except for
generation.
For configuration description see
swim_object:cfg().
The generation part of cfg can only be specified during new(),
it cannot be specified later during cfg().
Generation is part of incarnation.
Usually generation is not specified because the default value
(a timestamp) is sufficient, but if there is reason to mistrust
timestamps (because the time is changed or because the instance
is started on a different machine), then users may say
swim.new({generation=<number>}). In that case the latest
value should be persisted somehow (for example in a file, or in a space,
or in a global service), and the new value must be greater than
any previous value of generation.
cfg (table) – the options to describe instance behavior
The cfg table may have these components:
heartbeat_rate (double) – rate of sending round messages, in seconds.
Setting heartbeat_rate to X does not mean that every member
will be checked every X seconds, instead X is the protocol speed.
Protocol period depends on member count and heartbeat_rate.
Default = 1.
ack_timeout (double) – time in seconds after which a ping is
considered to be unacknowledged. Default = 30.
gc_mode (enum) – dead member collection mode.
If gc_mode=='off' then SWIM never removes dead
members from the member table (though users may remove them
with swim_object:remove_member()), and
SWIM will continue to ping them as if they were alive.
If gc_mode=='on' then SWIM removes dead members
from the member table after one round.
Default = 'on'.
uri (string or number) – either an 'ip:port' address,
or just a port number (if ip is omitted then 127.0.0.1 is
assumed). If port==0, then the kernel will select any free
port for the IP address.
uuid (string or cdata struct tt_uuid) – a value which should
be unique among SWIM instances. Users may choose any value
but the recommendation is: use
box.cfg.instance_uuid,
the Tarantool instance’s UUID.
All the cfg components are dynamic – swim_object:cfg()
may be called more than once. If it is not being called for
the first time and a component is not specified, then the
component retains its previous value. If it is being called
for the first time then uri and uuid are mandatory, since
a SWIM instance cannot operate without URI and UUID.
swim_object:cfg() is atomic – if there is an error,
then nothing changes.
Return:
true if configuration succeeds
Return:
nil, err if an error occurred. err is an error object
Example:
swim_object:cfg({heartbeat_rate=0.5})
After swim_object:cfg(), all other swim_object methods are callable.
.cfg
Expose all non-nil components of the read-only table which was set up
or changed by swim_object:cfg().
Delete a SWIM instance immediately. Its memory is freed,
its member table entry is deleted,
and it can no longer be used.
Other members will treat this member as ‘dead’.
After swim_object:delete() any attempt to use the
deleted instance will cause an exception to be thrown.
Return false if
a SWIM instance was created via
swim.new() without an optional cfg argument,
and was not configured with swim_object:cfg().
Otherwise return true.
Return:
boolean result, true if configured, otherwise false
This is a graceful equivalent of
swim_object:delete() – the instance is
deleted, but before deletion it sends to each member in its
member table a message, that this instance has left the cluster, and
should not be considered dead.
Other instances will mark such a member
in their tables as ‘left’, and drop it after one round of
dissemination.
Consequences to the caller are the same as after
swim_object:delete() – the instance is no longer usable,
and an error will be thrown if there is an attempt to use it.
This method is useful when a new member is joining
the cluster and does not yet know what members already exist.
In that case it can start interaction explicitly by
adding the details about an already-existing member
into its member table.
Subsequently SWIM will discover other members automatically
via messages from the already-existing member.
Send a ping request to the specified uri address. If another member
is listening at that address, it will receive the ping, and respond with
an ACK (acknowledgment) message containing information such as UUID.
That information will be added to the
member table.
swim_object:probe_member() is similar to
swim_object:add_member(), but it
does not require UUID, and it is not reliable because it uses UDP.
Parameters:
uri (string-or-number) – URI. Format is the same as for uri
in swim_object:cfg().
Return:
true if member is pinged
Return:
nil, err if an error occurred. err is an error object.
Payload is arbitrary user defined data up to 1200 bytes in size
and disseminated over the cluster. So each cluster member
will eventually learn what is the payload of other members in
the cluster, because it is stored in the member table and can be
queried with swim_member_object:payload().
Different members may have different payloads.
Parameters:
payload (object) – Arbitrary Lua object to disseminate. Set to nil
to remove the payload, in which case it will be eventually removed
on other instances. The object is serialized in
MessagePack.
Return:
true if payload is set
Return:
nil, err if an error occurred. err is an error object
Sometimes a payload does not need to be a Lua object.
For example, a user may already have a well formatted
MessagePack object and just wants to set it as a payload.
Or cdata needs to be exposed.
set_payload_raw allows setting
a payload as is, without MessagePack serialization.
Parameters:
payload (string-or-cdata) – any value
size (number) – Payload size in bytes. If payload is string then size is
optional, and if specified, then should not be larger
than actual payload size. If size is less than
actual payload size, then only the first size
bytes of payload are used. If payload is cdata then
size is mandatory.
Return:
true if payload is set
Return:
nil, err if an error occurred. err is an error object
algo (string) – encryption algorithm name.
All the names in module crypto are supported:
‘aes128’, ‘aes192’, ‘aes256’, ‘des’.
Specify ‘none’ to disable encryption.
mode (string) – encryption algorithm mode. All the modes in
module crypto are supported: ‘ecb’, ‘cbc’, ‘cfb’, ‘ofb’.
Default = ‘cbc’.
key (cdata or string) – a private secret key which is kept
secret and should never be stored hard-coded in source code.
key_size (integer) – size of the key in bytes.
key_size is mandatory if key is cdata.
key_size is optional if key is
string, and if key_size is shorter than than actual key size
then the key is truncated.
All of algo, mode, key, and key_size should be
the same for all SWIM instances, so that members can understand
each others’ messages.
Return a swim member object (of self) from the member table,
or from a cache containing earlier results of swim_object:self() or
swim_object:member_by_uuid() or swim_object:pairs().
Return a swim member object (given UUID) from the member table,
or from a cache containing earlier results of swim_object:self() or
swim_object:member_by_uuid() or swim_object:pairs().
Set up an iterator for returning
swim member objects from the member table,
or from a cache containing earlier results of swim_object:self() or
swim_object:member_by_uuid() or swim_object:pairs().
swim_object:pairs() should be in a ‘for’ loop, and
there should only be one iterator in operation
at one time. (The iterator is implemented in an extra light fashion so only
one iterator object is available per SWIM instance.)
Parameters:
generator+object+key (varies) – as for any Lua pairs() iterators.
generator function, iterator
object (a swim member object),
and initial key (a UUID).
Example:
tarantool> fiber=require('fiber')---...tarantool> swim=require('swim')---...tarantool> s1=swim.new({uri=0,uuid='00000000-0000-1000-8000-000000000001',heartbeat_rate=0.1})---...tarantool> s2=swim.new({uri=0,uuid='00000000-0000-1000-8000-000000000002',heartbeat_rate=0.1})---...tarantool> s1:add_member({uri=s2:self():uri(),uuid=s2:self():uuid()})----true...tarantool> fiber.sleep(0.2)---...tarantool> s1:self()----uri:127.0.0.1:55845status:aliveincarnation:cdata {generation = 1569353431853325ULL, version = 1ULL}uuid:00000000-0000-1000-8000-000000000001payload_size:0...tarantool> s1:member_by_uuid(s1:self():uuid())----uri:127.0.0.1:55845status:aliveincarnation:cdata {generation = 1569353431853325ULL, version = 1ULL}uuid:00000000-0000-1000-8000-000000000001payload_size:0...tarantool> s1:member_by_uuid(s2:self():uuid())----uri:127.0.0.1:53666status:aliveincarnation:cdata {generation = 1569353431865138ULL, version = 1ULL}uuid:00000000-0000-1000-8000-000000000002payload_size:0...tarantool> t={}---...tarantool> fork,vins1:pairs()dotable.insert(t,{k,v})end---...tarantool> t------00000000-0000-1000-8000-000000000002-uri:127.0.0.1:53666status:aliveincarnation:cdata {generation = 1569353431865138ULL, version = 1ULL}uuid:00000000-0000-1000-8000-000000000002payload_size:0--00000000-0000-1000-8000-000000000001-uri:127.0.0.1:55845status:aliveincarnation:cdata {generation = 1569353431853325ULL, version = 1ULL}uuid:00000000-0000-1000-8000-000000000001payload_size:0...
Return payload as a string object. Payload is not decoded. It
is just returned as a string instead of cdata. If payload was
not specified
by swim_object:set_payload() or
by swim_object:set_payload_raw(),
then its size is 0 and nil is returned.
Return:
string-object payload, or nil if there is no payload
Since the swim module is a Lua module, a user is likely to use Lua objects
as a payload – tables, numbers, strings etc. And it is natural
to expect that
swim_member_object:payload()
should return the same object
which was passed into
swim_object:set_payload()
by another instance.
swim_member_object:payload() tries to interpret payload as MessagePack,
and if that fails then it returns the payload as a string.
swim_member_object:payload() caches its result. Therefore only the first call
actually decodes cdata payload. All following calls return a
pointer to the same result, unless payload is changed with a new
incarnation. If payload was not specified (its size is 0), then nil is
returned.
Create an “on_member trigger”.
The trigger-function will be executed when a member in the member table is updated.
Parameters:
trigger-function (function) – this will become the trigger function
ctx (cdata) – (optional) this will be passed to trigger-function
Return:
nil or function pointer.
The trigger-function should have three parameter declarations
(Tarantool will pass values for them when it invokes the function):
the member which is having the member event,
the event object,
the ctx which will be the same value as what is passed to
swim_object:on_member_event.
A member event is any of:
appearance of a new member,
drop of an existing member, or
update of an existing member.
An event object is an object which the trigger-function
can use for determining what type of member event has happened.
The object’s methods – such as is_new_status(), is_new_uri(),
is_new_incarnation(), is_new_payload(), is_drop() –
return boolean values.
A member event may have more than one associated trigger.
Triggers are executed sequentially.
Therefore if a trigger function causes yields or sleeps,
other triggers may be forced to wait.
However, since trigger execution is done in a separate fiber,
SWIM itself is not forced to wait.
Example of an on-member trigger function:
tarantool> swim = require('swim')
local function on_event(member, event, ctx)
if event:is_new() then
...
elseif event:is_drop() then
...
end
if event:is_update() then
-- All next conditions can be
-- true simultaneously.
if event:is_new_status() then
...
end
if event:is_new_uri() then
...
end
if event:is_new_incarnation() then
...
end
if event:is_new_payload() then
...
end
end
end
Notice in the above example that the function is ready
for the possibility that multiple events can happen
simultaneously for a single trigger activation.
is_new() and is_drop() can not both be true,
but is_new() and is_update() can both be true,
or is_drop() and is_update() can both be true.
Multiple simultaneous events are especially likely if
there are many events and trigger functions are slow –
in that case, for example, a member might be added
and then updated after a while, and then after a while
there will be a single trigger activation.
Also: is_new() and is_new_payload() can both be true.
This case is not due to trigger functions that are slow.
It occurs because “omitted payload” and “size-zero payload”
are not the same thing. For example: when a ping is received,
a new member might be added, but ping messages do not include
payload. The payload will appear later in a different message.
If that is important for the application, then the function
should not assume when is_new() is true that the member
already has a payload, and should not assume that payload size
says something about the payload’s presence or absence.
Also: functions should not assume that is_new() and is_drop()
will always be seen.
If a new member appears but then is dropped before its appearance has
caused a trigger activation, then there will be no trigger
activation.
is_new_generation() will be true if the generation part
of incarnation changes.
is_new_version() will be true if the version part
of incarnation changes.
is_new_incarnation() will be true if either the generation part
or the version part of incarnation changes.
For example a combination of these methods can be used within a
user-defined trigger to check whether a process has restarted,
or a member has changed …
swim = require('swim')
s = swim.new()
s:on_member_event(function(m, e)
...
if e:is_new_incarnation() then
if e:is_new_generation() then
-- Process restart.
end
if e:is_new_version() then
-- Process version update. It means
-- the member is somehow changed.
end
end
end
This is a variation of on_member_event(new-trigger,[,ctx]).
The additional parameter is old-trigger.
Instead of adding the new-trigger at the end of a
list of triggers, this function will replace the entry in
the list of triggers that matches old-trigger.
The position within a list may be important because
triggers are activated sequentially starting
with the first trigger in the list.
The old-trigger value should be the value returned by
on_member_event(trigger-function[,ctx]).
swim_member_object:on_member_event()
Return the list of on-member triggers.
SWIM internals
The SWIM internals section is not necessary for programmers who wish to use the SWIM module,
it is for programmers who wish to change or replace the SWIM module.
The SWIM wire protocol is open, will be backward compatible in case of
any changes, and can be implemented by users who wish to simulate their
own SWIM cluster members because they use another language than Lua,
or another environment unrelated to Tarantool.
The protocol is encoded as
MsgPack.
The Initial vector section appears only when encryption
is enabled. This section contains a public key. For example,
for AES algorithms it is a 16-byte initial vector stored as is. When
no encryption is used, the section size is 0.
The later sections (Meta and Protocol Logic) are encrypted as one
big data chunk if encryption is enabled.
The Meta section handles routing and protocol versions compatibility. It
works at the ‘transport’ level of the SWIM protocol, and is always present.
Keys in the meta section are:
SWIM_META_TARANTOOL_VERSION – mandatory field. Tarantool sets
here its version as a 3 byte integer:
1 byte for major,
1 byte for minor,
1 byte for patch.
For example, Tarantool version 2.1.3 would
be encoded like this: (((2<<8)|1)<<8)|3;. This field
will be used to support multiple versions of the protocol.
SWIM_META_SRC_ADDRESS and SWIM_META_SRC_PORT – mandatory.
source IP address and port. IP is encoded as 4 bytes.
“xxx.xxx.xxx.xxx” where each ‘xxx’ is encoding of one byte. Port is encoded
as an integer. Example of how to encode “127.0.0.1:3313”:
SWIM_META_ROUTING subsection – not mandatory.
Responsible for packet forwarding. Used by SWIM
suspicion mechanism. Read about suspicion in the SWIM paper.
If this subsection is present then the following fields are
mandatory:
SWIM_ROUTE_SRC_ADDRESS and SWIM_ROUTE_SRC_PORT (source
IP address and port) (should be an address of the
message originator (can differ from
SWIM_META_SRC_ADDRESS and from SWIM_META_SRC_ADDRESS_PORT);
SWIM_ROUTE_DST_ADDRESS and SWIM_ROUTE_DST_PORT (destination
IP address and port, for the message’s final destination).
If a message was sent indirectly with the help of SWIM_META_ROUTING,
then the reply should be sent back by the same route.
For an example of how SWIM uses routing for indirect pings …
Assume there are 3 nodes: S1, S2, S3. S1 sends a message to
S3 via S2. The following steps are executed in order to
deliver the message:
S2 receives the message and sees that routing.dst is not equal to S2,
so it is a foreign packet. S2 forwards the packet to S3 preserving all the
data including body and routing sections.
S2 -> S3
S3 receives the message and sees that routing.dst is equal to S3,
so the message is delivered. If S3 wants to answer, it sends a
response via the same proxy. It knows that the message was
delivered from S2, so it sends an answer via S2.
The Protocol logic section handles SWIM logical protocol steps and actions.
SWIM_SRC_UUID – mandatory field. SWIM uses UUID as a unique
identifier of a member, not IP/port. This field stores UUID of
sender. Its type is MP_BIN. Size is always 16 bytes. UUID is
encoded in host byte order, no bswaps are needed.
Following SWIM_SRC_UUID there are four possible subsections:
SWIM_FAILURE_DETECTION, SWIM_DISSEMINATION, SWIM_ANTI_ENTROPY, SWIM_QUIT.
Any or all of these subsections may be present.
A connector should be ready to handle any combination.
SWIM_FAILURE_DETECTION subsection – describes a ping or ACK.
In the SWIM_FAILURE_DETECTION subsection are:
SWIM_FD_MSG_TYPE (0 is ping, 1 is ack);
SWIM_FD_GENERATION + SWIM_FD_VERSION (the incarnation).
SWIM_DISSEMINATION subsection – a list of
changed cluster members. It may include only a subset of changed
cluster members if there are too many changes to fit into one UDP packet.
SWIM_MEMBER_ADDRESS and SWIM_MEMBER_PORT (mandatory) member IP and port;
SWIM_MEMBER_UUID (mandatory) (member UUID);
SWIM_MEMBER_GENERATION + SWIM_MEMBER_VERSION (mandatory) (the member incarnation);
SWIM_MEMBER_PAYLOAD (not mandatory) (member payload)
(MessagePack type is MP_BIN).
Note that absence of SWIM_MEMBER_PAYLOAD means nothing -
it is not the same as a payload with zero size.
SWIM_ANTI_ENTROPY subsection – a helper for the
dissemination. It contains all the same fields as the
dissemination sub, but all of them are mandatory, including
payload even when payload size is 0. Anti-entropy eventually
spreads changes which for any reason are not spread by the dissemination.
SWIM_QUIT subsection – statement that the sender has left the
cluster gracefully, for example via swim_object:quit(),
and should not be considered dead. Sender
status should be changed to ‘left’.
In the SWIM_QUIT subsection are:
SWIM_QUIT_GENERATION + SWIM_QUIT_VERSION (the sender incarnation).
The incarnation is a 128-bit cdata value which is part of
each member’s configuration and is present in most messages.
It has two parts: generation and version.
Generation is persistent. By default it has the number of
microseconds since the epoch (compare the value returned by
clock_realtime64()). Optionally a user
can set generation during new().
Version is volatile. It is initially 0.
It is incremented automatically every time that a change occurs.
The incarnation, or sometimes the version alone,
is useful for deciding to ignore obsolete messages,
for updating a member’s attributes on remote nodes,
and for refuting messages that say a member is dead.
If the member’s incarnation is less than the locally stored incarnation,
then the message is obsolete.
This can happen because UDP allows reordering and duplication.
If the member’s incarnation in a message is greater than the locally stored incarnation,
then most of its attributes (IP,
port, status) should be updated with the values received in the message.
However, the payload attribute should not be updated
unless it is present in the message. Because of its relatively large size,
payload is not always included in every message.
Refutation usually happens when a false-positive failure
detection has happened. In such a case the member thought to be
dead receives that information from other members, increases its own
incarnation, and spreads a message saying the member is
alive (a “refutation”).
Note: in the original version of Tarantool SWIM, and in the original
SWIM specification, there is no generation and the incarnation consists
of only the version. Generation was added because it is useful for
detecting obsolete messages left over from a previous life of an instance
that has restarted.
The basic Lua table.sort
has a default comparison function: function(a,b)returna<bend.
That is efficient and standard. However, sometimes Tarantool users
will want an equivalent to table.sort which has any of these features:
If the table contains nils, except nils at the end, the results must still be correct.
That is not the case with the default tarantool_sort, and it cannot
be fixed by making a comparison that checks whether a and b are nil.
(Before trying certain Internet suggestions, test with
{1,nil,2,-1,44,1e308,nil,2,nil,nil,0}.
If strings are to be sorted in a language-aware way, there must be a
parameter for collation.
If the table has a mix of types, then they must be sorted as
booleans, then numbers, then strings, then byte arrays.
Since all those features are available in Tarantool spaces,
the solution for Tarantool is simple: make a temporary Tarantool
space, put the table contents into it, retrieve the tuples from it
in order, and overwrite the table.
Here then is tarantool_sort() which does the same thing as
table.sort but has those extra features. It is not fast and
it requires a database privilege, so it should only be used if the
extra features are necessary.
For example, suppose tablet={1,'A',-88.3,nil,true,'b','B',nil,'À'}.
After tarantool_sort(t,'unicode_ci')t contains {nil,nil,true,-88.3,1,'A','À','b','B'}.
Module tap
Overview
The tap module streamlines the testing of other modules. It allows writing
of tests in the TAP protocol.
The results from the tests can be parsed by standard TAP-analyzers so they can be passed to utilities such as
prove.
Thus, one can run tests and then use the results for statistics, decision-making, and
so on.
The result of tap.test is an object, which will be called taptest
in the rest of this discussion, which is necessary for taptest:plan()
and all the other methods.
Parameters:
test-name (string) – an arbitrary name to give for the test outputs.
The result will be a display saying #badplan:... if the number
of completed tests is not equal to the number of tests specified by
taptest:plan(...). (This is a purely Tarantool feature: “bad plan”
messages are out of the TAP13 standard.)
This check should only be done after all planned tests are complete,
so ordinarily taptest:check() will only appear at the end of a script.
However, as a Tarantool extension, taptest:check() may appear at the
end of any subtest. Therefore there are three ways to cause the check:
by calling taptest:check() at the end of a script,
by calling a function which ends with a call to taptest:check(),
or by calling taptest:test(‘…’, subtest-function-name) where
subtest-function-name does not need to end with taptest:check()
because it can be called after the subtest is complete.
This is a basic function which is used by other functions. Depending
on the value of condition, print ‘ok’ or ‘not ok’ along with
debugging information. Displays the message.
Parameters:
condition (boolean) – an expression which is true or false
Set taptest.strict=true if taptest:is()
and taptest:isnt()
and taptest:is_deeply()
must be compared strictly with nil.
Set taptest.strict=false if nil and box.NULL both have the same effect.
The default is false.
For example, if and only if taptest.strict=true has happened,
then taptest:is_deeply({a=box.NULL},{})
will return false.
Since v. 2.8.3, taptest.strict is inherited in all subtests:
t=require('tap').test('123')t.strict=truet:is_deeply({a=box.NULL},{})-- falset:test('subtest',function(t)t:is_deeply({a=box.NULL},{})-- also falseend)
Example
To run this example: put the script in a file named ./tap.lua, then make
tap.lua executable by saying chmoda+x./tap.lua, then execute using
Tarantool as a script processor by saying ./tap.lua.
#!/usr/bin/tarantoollocaltap=require('tap')test=tap.test("my test name")test:plan(2)test:ok(2*2==4,"2 * 2 is 4")test:test("some subtests for test2",function(test)test:plan(2)test:is(2+2,4,"2 + 2 is 4")test:isnt(2+3,4,"2 + 3 is not 4")end)test:check()
The output from the above script will look approximately like this:
TAP version 131..2ok - 2 * 2 is 4
# Some subtests for test2
1..2
ok - 2 + 2 is 4,
ok - 2 + 3 is not 4
# Some subtests for test2: end
ok - some subtests for test2
Module tarantool
By saying require('tarantool'), one can answer some questions about how the
tarantool server was built, such as “what flags were used”, or “what was the
version of the compiler”.
Additionally one can see the uptime and the server version and the process id.
Those information items can also be accessed with box.info() but use of
the tarantool module is recommended.
Encode a string using the specified encoding options.
By default, uri.escape() uses encoding options defined by the uri.RFC3986 table.
If required, you can customize encoding options using the uri_encoding_opts optional parameter, for example:
Pass the predefined set of options targeted for encoding a specific URI part (for example, uri.PATH or uri.QUERY).
Decode a string using the specified encoding options.
By default, uri.escape() uses encoding options defined by the uri.RFC3986 table.
If required, you can customize encoding options using the uri_encoding_opts optional parameter, for example:
Pass the predefined set of options targeted for encoding a specific URI part (for example, uri.PATH or uri.QUERY).
Encoding options that use unreserved symbols defined in RFC 3986.
These are default options used to encode and decode using the uri.escape()
and uri.unescape() functions, respectively.
Specify a Lua pattern defining unreserved symbols that are not encoded.
Rtype:
table
Example:'a-zA-Z0-9%-._~'
Module utf8
Overview
utf8 is Tarantool’s module for handling UTF-8 strings.
It includes some functions which are compatible with ones in
Lua 5.3
but Tarantool has much more. For example, because internally
Tarantool contains a complete copy of the
“International Components For Unicode” library,
there are comparison functions which understand the default ordering
for Cyrillic (Capital Letter Zhe Ж = Small Letter Zhe ж)
and Japanese (Hiragana A = Katakana A).
string (UTF8-string) – a string encoded with UTF-8
Return:
-1 meaning “less”, 0 meaning “equal”, +1 meaning “greater”
Rtype:
number
Compare two strings with the Default Unicode Collation Element Table
(DUCET) for the
Unicode Collation Algorithm.
Thus ‘å’ is less than ‘B’, even though the code-point value of å (229) is greater
than the code-point value of B (66), because the algorithm depends on
the values in the Collation Element Table, not the code-point values.
The comparison is done with primary weights. Therefore the
elements which affect secondary or later weights (such as “case”
in Latin or Cyrillic alphabets, or “kana differentiation” in Japanese)
are ignored. If asked “is this like a Microsoft case-insensitive
accent-insensitive collation” we tend to answer “yes”, though the
Unicode Collation Algorithm is far more sophisticated than those
terms imply.
The code-point number is the value that corresponds to a character
in the
Unicode Character Database
This is not the same as the byte values of the encoded character,
because the UTF-8 encoding scheme is more complex than a simple
copy of the code-point number.
Another way to construct a string with Unicode characters is
with the \u{hex-digits} escape mechanism, for example
‘\u{41}\u{42}’ and utf8.char(65,66) both produce the string ‘AB’.
string (UTF8-string) – a string encoded with UTF-8
Return:
-1 meaning “less”, 0 meaning “equal”, +1 meaning “greater”
Rtype:
number
Compare two strings with the Default Unicode Collation Element Table
(DUCET) for the
Unicode Collation Algorithm.
Thus ‘å’ is less than ‘B’, even though the code-point value of å (229) is greater
than the code-point value of B (66), because the algorithm depends on
the values in the Collation Element Table, not the code values.
The comparison is done with at least three weights. Therefore the
elements which affect secondary or later weights (such as “case”
in Latin or Cyrillic alphabets, or “kana differentiation” in Japanese)
are not ignored. and upper case comes after lower case.
string-or-number (UTF8-character) – a single UTF8 character, expressed
as a one-byte string or a code point value
Return:
true or false
Rtype:
boolean
Return true if the input character is an “alphabetic-like” character, otherwise return false.
Generally speaking a character will be considered alphabetic-like provided it
is typically used within a word, as opposed to a digit or punctuation.
It does not have to be a character in an alphabet.
string (UTF8-string) – a string encoded with UTF-8
integer (end-byte) – byte position of the first character
integer – byte position where to stop
Return:
the number of characters in the string, or between start and end
Rtype:
number
Byte positions for start and end can be negative, which indicates
“calculate from end of string” rather than “calculate from start of string”.
If the string contains a byte sequence which is not valid in UTF-8,
each byte in the invalid byte sequence will be counted as one character.
UTF-8 is a variable-size encoding scheme. Typically
a simple Latin letter takes one byte, a Cyrillic letter
takes two bytes, a Chinese/Japanese character takes three
bytes, and the maximum is four bytes.
The next function is often used in a loop to get one character
at a time from a UTF-8 string.
Example:
In the string ‘åa’ the first character is ‘å’, it starts
at position 1, it takes two bytes to store so the
character after it will be at position 3, its Unicode
code point value is (decimal) 229.
tarantool> -- show next-character position + first-character codepointtarantool> utf8.next('åa',1)----3-229...tarantool> -- (loop) show codepoint of every charactertarantool> forposition,codepointinutf8.next,'åa'doprint(codepoint)end22997...
Character positions for start and end can be negative, which indicates
“calculate from end of string” rather than “calculate from start of string”.
The default value
for end-character is the length of the input string. Therefore, saying
utf8.sub(1,'abc') will return ‘abc’, the same as the input string.
A “UUID” is a Universally unique identifier.
If an application requires that
a value be unique only within a single computer or on a single database, then a
simple counter is better than a UUID, because getting a UUID is time-consuming
(it requires a syscall). For clusters of computers, or widely distributed
applications, UUIDs are better.
Tarantool generates UUIDs following the rules for RFC 4122
version 4 variant 1.
Since version 2.4.1.
Create a UUID sequence. You can use it in an index over a
UUID field.
For example, to create such index for a space named test, say:
The all-zero UUID value can be expressed as uuid.NULL, or as
uuid.fromstr('00000000-0000-0000-0000-000000000000').
The comparison with an all-zero value can also be expressed as
uuid_with_type_cdata==uuid.NULL.
The varbinary module provides functions for operating variable-length binary
objects in Lua. It provides functions for creating varbinary objects, checking their type,
and also defines basic operators on such objects.
For example:
localvarbinary=require('varbinary')-- Create a varbinary objectlocalbin=varbinary.new('data')localbin_hex=varbinary.new('\xFF\xFE')-- Check whether a value is a varbinary objectvarbinary.is(bin)-- truevarbinary.is(bin_hex)-- truevarbinary.is(100)-- falsevarbinary.is('data')-- false-- Check varbinary objects equalityprint(bin==varbinary.new('data'))-- trueprint(bin=='data')-- trueprint(bin~='data1')-- trueprint(bin_hex~='\xFF\xFE')-- false-- Check varbinary objects lengthprint(#bin)-- 4print(#bin_hex)-- 2-- Print string representationprint(tostring(bin))-- data
Encoding varbinary objects
varbinary objects preserve their binary type when encoded by the built-in MsgPack
and YAML encoders. See the difference with strings:
The built-in decoders also decode binary data fields (fields with the
binary tag in YAML and the MP_BIN type in MsgPack) to varbinary
objects by default:
This behavior is different from what it was before Tarantool 3.0.
In earlier versions, such fields were decoded to plain strings.
To return to this behavior, use the compat option
binary_data_decoding.
API Reference
Below is a list of varbinary functions, properties, and related objects.
Check that the given object is a varbinary object.
Parameters:
object (object) – an object to check
Return:
Whether the given object is of varbinary type
Rtype:
boolean
Example:
localbin=varbinary.new('data')localbin_hex=varbinary.new('\xFF\xFE')-- Check whether a value is a varbinary objectvarbinary.is(bin)-- truevarbinary.is(bin_hex)-- truevarbinary.is(100)-- falsevarbinary.is('data')-- false
Checks the equality of two varbinary objects or a varbinary object and a string.
A varbinary object equals to another varbinary object or a string if it
contains the same data.
Defines the == and ~= operators for varbinary objects.
Set values affecting the behavior of encode and decode functions.
The values are all either integers or boolean true/false.
Option
Default
Use
cfg.encode_invalid_numbers
true
A flag saying whether to enable encoding
of NaN and Inf numbers
cfg.encode_number_precision
14
Precision of floating point numbers
cfg.encode_load_metatables
true
A flag saying whether the serializer will
follow __serialize
metatable field
cfg.encode_use_tostring
false
A flag saying whether to use
tostring() for unknown types
cfg.encode_invalid_as_nil
false
A flag saying whether to use NULL for
non-recognized types
cfg.encode_sparse_convert
true
A flag saying whether to handle
excessively sparse arrays as maps.
See detailed description
below
cfg.encode_sparse_ratio
2
1/encode_sparse_ratio is the
permissible percentage of missing values
in a sparse array
cfg.encode_sparse_safe
10
A limit ensuring that small Lua arrays
are always encoded as sparse arrays
(instead of generating an error or
encoding as map)
cfg.decode_invalid_numbers
true
A flag saying whether to enable decoding
of NaN and Inf numbers
cfg.decode_save_metatables
true
A flag saying whether to set metatables
for all arrays and maps
Sparse arrays features:
During encoding, The YAML encoder tries to classify table into one of four kinds:
Map: at least one table index is not unsigned integer.
Regular array: all array indexes are available.
Sparse array: at least one array index is missing.
Excessively sparse array: the number of values missing exceeds the configured ratio.
An array is excessively sparse when all the following conditions are met:
encode_sparse_ratio > 0
max(table) > encode_sparse_safe
max(table) > count(table) * encode_sparse_ratio
The YAML encoder will never consider an array to be excessively sparse
when encode_sparse_ratio=0. The encode_sparse_safe limit ensures
that small Lua arrays are always encoded as sparse arrays.
By default, attempting to encode an excessively sparse array will
generate an error. If encode_sparse_convert is set to true,
excessively sparse arrays will be handled as maps.
yaml.cfg() example 1:
The following code will encode 0/0 as NaN (“not a number”)
and 1/0 as Inf (“infinity”), rather than returning nil or an error message:
To avoid generating errors on attempts to encode unknown data types as
userdata/cdata, you can use this code:
tarantool> httpc=require('http.client').new()---...tarantool> yaml.encode(httpc.curl)----error:unsupported Lua type 'userdata'...tarantool> yaml.encode(httpc.curl,{encode_use_tostring=true})----'"userdata:0x010a4ef2a0"'...
Note
To achieve the same effect for only one call to yaml.encode()
(i.e. without changing the configuration permanently), you can use
yaml.encode({1,x,y,2},{encode_invalid_numbers=true}).
Similar configuration settings exist for JSON and MsgPack.
All the Tarantool modules are, at some level, inside a package which,
appropriately, is named package. There are also miscellaneous functions
and variables which are outside all modules.
Convert a string or a Lua number to a 64-bit integer.
The input value can be expressed in decimal, binary (for example 0b1010),
or hexadecimal (for example -0xffff). The result can be
used in arithmetic, and the arithmetic will be 64-bit integer arithmetic
rather than floating-point arithmetic. (Operations on an unconverted Lua
number use floating-point arithmetic.) The tonumber64() function is
added by Tarantool; the name is global.
Warning:
There is an underlying LuaJIT
library that operates with C rules.
Therefore you should expect odd results
if you compare unsigned and signed (for example 0ULL > -1LL is false),
or if you use numbers outside the 64-bit integer range
(for example 9223372036854775808LL is negative).
Also you should be aware that type(number-literal-ending-in-ULL)
is cdata, not a Lua arithmetic type, which prevents
direct use with some functions in Lua libraries such as math.
See the LuaJIT reference
and look for the phrase “64 bit integer arithmetic”.
and the phrase “64 bit integer comparison”.
Or see the comments on
Issue#4089.
Parse and execute an arbitrary chunk of Lua code. This function is mainly
useful to define and run Lua code without having to introduce changes to
the global Lua environment.
lua-chunk-string-argument (lua-value) – zero or more scalar values
which will be appended to, or substitute for,
items in the Lua chunk.
Return:
whatever is returned by the Lua code chunk.
Possible errors: If there is a compilation error, it is raised as a Lua
error.
Example:
tarantool> dostring('abc')---error:'[string"abc"]:1:''=''expectednear''<eof>'''...tarantool> dostring('return 1')----1...tarantool> dostring('return ...','hello','world')----hello-world...tarantool> dostring([[ > local f = function(key) > local t = box.space.tester:select{key} > if t ~= nil then > return t[1] > else > return nil > end > end > return f(...)]],1)----null...
Show Lua or C modules loaded by Tarantool, so that their functions and members are available.
loaded shows both pre-loaded modules and modules added using the require() directive.
Return the current search root, which defines the path to the root directory from which dependencies are loaded.
By default, the search root is the current directory.
In this case, modules are placed in the same directory as the application initialization file.
If you run the application using the tarantool command from the myapp directory, …
/home/testuser/myapp$ tarantool init.lua
… the search root is /home/testuser/myapp and Tarantool finds all modules in this directory automatically.
This means that to load the foo and modules.bar modules in init.lua, you only need to add the corresponding require directives:
Set the search root, which defines the path to the root directory from which dependencies are loaded.
By default, the search root is the current directory (see package.searchroot()).
Parameters:
search-root (string) – a relative or absolute path to the search root. If search-root is a relative path, it is expanded to an absolute path. You can omit this argument or set it to box.NULL to reset the search root to the current directory.
Example
Suppose external modules are stored outside the application directory, for example:
The table below lists some popular errors that can be raised by Tarantool in case of various issues.
You can find a complete list of errors in the
errcode.h file.
Note
The box.error module provides the ability to get the information about the last error raised by Tarantool or raise custom errors manually.
Code
box.error value
Description
ER_NONMASTER
box.error.NONMASTER
(In replication) A server instance cannot modify data unless it is a master.
ER_ILLEGAL_PARAMS
box.error.ILLEGAL_PARAMS
Illegal parameters. Malformed protocol message.
ER_MEMORY_ISSUE
box.error.MEMORY_ISSUE
Out of memory: memtx_memory limit has been reached.
ER_WAL_IO
box.error.WAL_IO
Failed to write to disk. May mean: failed to record a change in the write-ahead log.
ER_READONLY
box.error.READONLY
Can’t modify data on a read-only instance.
ER_KEY_PART_COUNT
box.error.KEY_PART_COUNT
Key part count is not the same as index part count.
ER_NO_SUCH_SPACE
box.error.NO_SUCH_SPACE
The specified space does not exist.
ER_NO_SUCH_INDEX
box.error.NO_SUCH_INDEX
The specified index in the specified space does not exist.
ER_PROC_LUA
box.error.PROC_LUA
An error occurred inside a Lua procedure.
ER_FIBER_STACK
box.error.FIBER_STACK
The recursion limit was reached when creating a new fiber. This usually indicates that a stored procedure is recursively invoking itself too often.
ER_UPDATE_FIELD
box.error.UPDATE_FIELD
An error occurred during update of a field.
ER_TUPLE_FOUND
box.error.TUPLE_FOUND
A duplicate key exists in a unique index.
Handling errors
Here are some procedures that can make Lua functions more robust when there are
errors, particularly database errors.
Invoke a function using pcall.
Take advantage of Lua’s mechanisms for Error handling and exceptions, particularly pcall.
That is, instead of invoking with …
box.space.{space-name}:{function-name}()
… call the function as follows:
if pcall(box.space.{space-name}.{function-name}, box.space.{space-name}) ...
For some Tarantool box functions, pcall also returns error details,
including a file-name and line-number within Tarantool’s source code.
This can be seen by unpacking, for example:
Examine errors and raise new errors using box.error.
To make a new error and pass it on, the box.error module provides
box.error().
To find the last error, the box.error submodule provides
box.error.last().
There is also a way to find
the text of the last operating-system error for certain functions –
errno.strerror([code]).
Filter automatically generated messages using the
log configuration parameter.
Generally, for Tarantool built-in functions which are designed to return objects:
the result is an object, or nil, or a Lua error.
For example consider the fio_read.lua program in a cookbook:
#!/usr/bin/env tarantoollocalfio=require('fio')localerrno=require('errno')localf=fio.open('/tmp/xxxx.txt',{'O_RDONLY'})ifnotfthenerror("Failed to open file: "..errno.strerror())endlocaldata=f:read(4096)f:close()print(data)
After a function call that might fail, like fio.open() above,
it is common to see syntax like ifnotfthen...
or iff==nilthen..., which check
for common failures. But if there had been a syntax
error, for example fio.opex instead of fio.open, then
there would have been a Lua error and f would not have
been changed. If checking for such an obvious error
had been a concern, the programmer would probably have
used pcall().
All functions in Tarantool modules should work this way,
unless the manual explicitly says otherwise.
Debug facilities
Overview
Tarantool users can benefit from built-in debug facilities that are part of:
The debug library provides an interface for debugging Lua programs. All
functions in this library reside in the debug table. Those functions that
operate on a thread have an optional first parameter that specifies the thread
to operate on. The default is always the current thread.
Note
This library should be used only for debugging and profiling and not as a
regular programming tool, as the functions provided here can take too long
to run. Besides, several of these functions can compromise otherwise
secure code.
Enters an interactive mode and runs each string that the user types in. The
user can, among other things, inspect global and local variables, change
their values and evaluate expressions.
Enter cont to exit this function, so that the caller can continue
its execution.
Note
Commands for debug.debug() are not lexically nested within any
function and so have no direct access to local variables.
what (string) – what information on the function to return
Return:
a table with information about the function
You can pass in a function directly, or you can give a number that
specifies a function running at level function of the call stack of
the given thread: level 0 is the current function (getinfo() itself),
level 1 is the function that called getinfo(), and so on. If function
is a number larger than the number of active functions, getinfo() returns
nil.
The default for what is to get all information available, except the table
of valid lines. If present, the option f adds a field named func with
the function itself. If present, the option L adds a field named
activelines with the table of valid lines.
the name and the value of the local variable with the index local
of the function at level level of the stack or nil if there
is no local variable with the given index; raises an error if
level is out of range
Note
You can call debug.getinfo() to check whether the level is valid.
level (number) – the level of the call stack which should contain the path
(default is 2)
Return:
a string with the relative path to the source file directory
Instead of debug.sourcedir() one can say debug.__dir__ which means the same thing.
Determining the real path to a directory is only possible
if the function was defined in a Lua file (this restriction
may not apply for loadstring()
since Lua will store the entire string in debug info).
If debug.sourcedir() is part of a return argument,
then it should be inside parentheses: return(debug.sourcedir()).
level (number) – the level of the call stack which should contain the path
(default is 2)
Return:
a string with the relative path to the source file
Instead of debug.sourcefile() one can say debug.__file__ which means the same thing.
Determining the real path to a file is only possible
if the function was defined in a Lua file (this restriction
may not apply to loadstring() since Lua will store the
entire string in debug info).
If debug.sourcefile() is part of a return argument,
then it should be inside parentheses: return(debug.sourcefile()).
message (string) – an optional message prepended to the traceback
level (number) – specifies at which level to start the traceback
(default is 1)
Return:
a string with a traceback of the call stack
Debug example:
Make a file in the /tmp directory named example.lua, containing:
function w()
print(debug.sourcedir())
print(debug.sourcefile())
print(debug.traceback())
print(debug.getinfo(1)['currentline'])
end
w()
Execute tarantool/tmp/example.lua. Expect to see this:
/tmp
/tmp/example.lua
stack traceback:
/tmp/example.lua:4: in function 'w'
/tmp/example.lua:7: in main chunk
5
JSON paths
Overview
Since version 2.3, Tarantool supports JSON path updates.
You can update or upsert formatted tuple /
space /
index
fields by name (not only by field number). Updates of nested structures are also supported.
Notice that field names that look like JSON paths are processed similarly to
accessing tuple fields by JSON:
first, the whole path is interpreted as a field name; if such a name does not exist,
then it is treated as a path.
For example, for a field name field.name.like.json, this update
will update this field instead of keys field -> name ->
like -> json. If you need such a name as part of a bigger
path, then you should wrap it in quotes "" and brackets []:
Operation '!' can’t be used to create all intermediate nodes of
a path. For example, {'!','field1[1].field3',...} can’t
create fields 'field1' and '[1]', they should exist.
Operation '#', when applied to maps, can’t delete more than one
key at once. That is, its argument should be always 1 for maps.
{'#','field1.field2',1} is allowed;
{'#','field1.field2',10} is not.
This limitation originates from the problem that keys in a map
are not ordered anyhow, and '#' with more than 1 key would lead
to undefined behavior.
Operation '!' on maps can’t create a key, if it exists already.
If a map contains non-string keys (booleans, numbers, maps,
arrays - anything), then these keys can’t be updated via JSON
paths. But it is still allowed to update string keys in such a
map.
Why JSON updates are good, and should be preferred when only a part of a tuple
needs to be updated:
They consume less space in WAL, because for an update only its
keys, operations, and arguments are stored. It is cheaper to
store an update of one deep field than of the whole tuple.
They are faster. Firstly, this is because they are implemented
in C, and have no problems with Lua GC and dynamic typing.
Secondly, some cases of JSON paths are highly optimized. For
example, an update with a single JSON path costs O(1) memory
regardless of how deep that path goes (not counting update
arguments).
They are available from remote clients, as well as any other DML. Before JSON
updates became available in Tarantool, to update one deep part of a tuple, it
was necessary to download that tuple, update it in memory, and send it back –
2 network hops. With JSON paths, it can be 1 hop when the update can be described in paths.
Rocks reference
This reference covers third-party Lua modules for Tarantool.
For Tarantool Enterprise modules, see the
Tarantool EE documentation.
Module membership
This module is a membership library for Tarantool based on a gossip protocol.
This library builds a mesh from multiple Tarantool instances. The mesh monitors
itself, helps members discover everyone else in the group and get notified about
their status changes with low latency. It is built upon the ideas from Consul or,
more precisely, the SWIM algorithm.
The membership module works over UDP protocol and can operate even before
the box.cfg initialization.
Member data structure
A member is represented by the table with the following fields:
uri (string) is a Uniform Resource Identifier.
status (string) is a string that takes one of the values below.
alive: a member that replies to ping-messages is alive and well.
suspect: if any member in the group cannot get a reply from any other
member, the first member asks three other alive members to send a
ping-message to the member in question. If there is no response, the latter
becomes a suspect.
dead: a suspect becomes dead after a timeout.
left: a member gets the left status after executing the
leave() function.
Note
The gossip protocol guarantees that every member in the group
becomes aware of any status change in two communication cycles.
incarnation (number) is a value incremented every time the instance
becomes a suspect, dead, or updates its payload.
payload (table) is auxiliary data that can be used by various modules.
timestamp (number) is a value of fiber.time64() which:
corresponds to the last update of status or incarnation;
Initialize the membership module. This binds a UDP socket to 0.0.0.0:<port>,
sets the advertise_uri parameter to <advertise_host>:<port>, and
incarnation to 1.
The init() function can be called several times, the old socket will be
closed and a new one opened.
If the advertise_uri changes during the next init(), the old URI is
considered DEAD. In order to leave the group gracefully, use the
leave() function.
Parameters:
advertise_host (string) – a hostname or IP address to advertise to other members
Add a member with the given URI to the group and propagate this event to other
members. Adding a member to a single instance is enough as everybody else
in the group will receive the update with time. It does not matter who adds
whom.
Parameters:
uri (string) – the advertise_uri of the member to add
Send a message to a member to make sure it is in the group. If the member is alive
but not in the group, it is added. If it already is in the group, nothing happens.
Parameters:
uri (string) – the advertise_uri of the member to ping
Return:
true if the member responds within 0.2 seconds, otherwise noresponse
Rtype:
boolean
Raises:
pingwasnotsent if the hostname could not be resolved
Set the key used for low-level message encryption.
The key is either trimmed or padded automatically to be exactly 32 bytes.
If the key value is nil, the encryption is disabled.
The encryption is handled by the crypto.cipher.aes256.cbc Tarantool
module.
For proper communication, all members must be configured to use the
same encryption key. Otherwise, members report either dead or
non-decryptable in their status.
Tarantool (it requires tarantool-specific fio module and ffi from LuaJIT).
Installation
ttrocksinstallluatest
.rocks/bin/luatest--help# list available options
Usage
Define tests.
-- test/feature_test.lualocalt=require('luatest')localg=t.group('feature')-- Default name is inferred from caller filename when possible.-- For `test/a/b/c_d_test.lua` it will be `a.b.c_d`.-- So `local g = t.group()` works the same way.-- Tests. All properties with name staring with `test` are treated as test cases.g.test_example_1=function()...endg.test_example_n=function()...end-- Define suite hookst.before_suite(function()...end)t.before_suite(function()...end)-- Hooks to run once for tests groupg.before_all(function()...end)g.after_all(function()...end)-- Hooks to run for each test in groupg.before_each(function()...end)g.after_each(function()...end)-- Hooks to run for a specified test in groupg.before_test('test_example_1',function()...end)g.after_test('test_example_2',function()...end)-- before_test runs after before_each-- after_test runs before after_each-- test/other_test.lualocalt=require('luatest')localg=t.group('other')-- ...g.test_example_2=function()...endg.test_example_m=function()...end-- Define parametrized groupslocalpg=t.group('pgroup',{{engine='memtx'},{engine='vinyl'}})pg.test_example_3=function(cg)-- Use cg.params herebox.schema.space.create('test',{engine=cg.params.engine,})end-- Hooks can be specified for one parameterpg.before_all({engine='memtx'},function()...end)pg.before_each({engine='memtx'},function()...end)pg.before_test('test_example_3',{engine='vinyl'},function()...end)
Run tests from a path.
luatest# run all tests from the ./test directory
luatesttest/integration# run all tests from the specified directory
luatesttest/feature_test.lua# run all tests from the specified file
Run tests from a group.
luatestfeature# run all tests from the specified group
luatestother.test_example_2# run one test from the specified group
luatestfeatureother.test_example_2# run tests by group and test name
Note that luatest recognizes an input parameter as a path only if it contains /, otherwise, it will be considered
as a group name.
luatestfeature# considered as a group name
luatest./feature# considered as a path
luatestfeature/# considered as a path
You can also use -p option in combination with the examples above for running tests matching to some name pattern.
luatestfeature-ptest_example# run all tests from the specified group matching to the specified pattern
Luatest automatically requires test/helper.lua file if it’s present.
You can configure luatest or run any bootstrap code there.
Use the --shuffle option to tell luatest how to order the tests.
The available ordering schemes are group, all and none.
group shuffles tests within the groups.
all randomizes execution order across all available tests.
Be careful: before_all/after_all hooks run always when test group is changed,
so it may run multiple time.
none is the default, which executes examples within the group in the order they
are defined (eventually they are ordered by functions line numbers).
With group and all you can also specify a seed to reproduce specific order.
--shufflenone
--shufflegroup
--shuffleall--seed123
--shuffleall:123# same as above
Stops a test due to a failure if condition
is met.
xfail(message)
Mark test as xfail.
xfail_if(condition,message)
Mark test as xfail if condition is met.
skip(message)
Skip a running test.
skip_if(condition,message)
Skip a running test if condition is met.
success()
Stops a test with a success.
success_if(condition)
Stops a test with a success if condition
is met.
Suite and groups
after_suite(fn)
Add after suite hook.
before_suite(fn)
Add before suite hook.
group(name)
Create group of tests.
XFail
The xfail mark makes test results to be interpreted vice versa: it’s
threated as passed when an assertion fails, and it fails if no errors are
raised. It allows one to mark a test as temporarily broken due to a bug in some
other component which can’t be fixed immediately. It’s also a good practice to
keep xfail tests in sync with an issue tracker.
localg=t.group()g.test_fail=function()t.xfail('Must fail no matter what')t.assert_equals(3,4)end
XFail only applies to the errors raised by the luatest assertions. Regular Lua
errors still cause the test failure.
Capturing output
By default runner captures all stdout/stderr output and shows it only for failed tests.
Capturing can be disabled with -c flag.
Tests repeating
Runners can repeat tests with flags -r / --repeat (to repeat all the tests) or
-R / --repeat-group (to repeat all the tests within the group).
Group can be parametrized with a matrix of parameters using luatest.helpers:
localg=t.group('pgroup',t.helpers.matrix({a={1,2},b={3,4}}))-- Will run:-- * a = 1, b = 3-- * a = 1, b = 4-- * a = 2, b = 3-- * a = 2, b = 4
Each test will be performed for every params combination. Hooks will work as usual
unless there are specified params. The order of execution in the hook group is
determined by the order of declaration.
-- called before every testg.before_each(function(cg)...end)-- called before tests when a == 1g.before_each({a=1},function(cg)...end)-- called only before the test when a == 1 and b == 3g.before_each({a=1,b=3},function(cg)...end)-- called before test named 'test_something' when a == 1g.before_test('test_something',{a=1},function(cg)...end)--etc
Test from a parameterized group can be called from the command line in such a way:
Note that values for a and b have to match to defined group params. The command below will give you an error
because such params are not defined for the group.
luatestpgroup.a:2.b:2.test_params# will raise an error
Test helpers
There are helpers to run tarantool applications and perform basic interaction with it.
If application follows configuration conventions it is possible to use
options to configure server instance and helpers at the same time. For example
http_port is used to perform http request in tests and passed in TARANTOOL_HTTP_PORT
to server process.
localserver=luatest.Server:new({command='/path/to/executable.lua',-- arguments for processargs={'--no-bugs','--fast'},-- additional envars to pass to processenv={SOME_FIELD='value'},-- passed as TARANTOOL_WORKDIRworkdir='/path/to/test/workdir',-- passed as TARANTOOL_HTTP_PORT, used in http_requesthttp_port=8080,-- passed as TARANTOOL_LISTEN, used in connect_net_boxnet_box_port=3030,-- passed to net_box.connect in connect_net_boxnet_box_credentials={user='username',password='secret'},})server:start()-- Wait until server is ready to accept connections.-- This may vary from app to app: for one server:connect_net_box() is enough,-- for another more complex checks are required.luatest.helpers.retrying({},function()server:http_request('get','/ping')end)-- http requestsserver:http_request('get','/path')server:http_request('post','/path',{body='text'})server:http_request('post','/path',{json={field=value},http={-- http client optionsheaders={Authorization='Basic '..credentials},timeout=1,}})-- This method throws error when response status is outside of then range 200..299.-- To change this behaviour, path `raise = false`:t.assert_equals(server:http_request('get','/not_found',{raise=false}).status,404)t.assert_error(function()server:http_request('get','/not_found')end)-- using net_boxserver:connect_net_box()server:eval('return do_something(...)',{arg1,arg2})server:call('function_name',{arg1,arg2})server:exec(function()returnbox.info()end)server:stop()
luatest.Process:start(path,args,env) provides low-level interface to run any other application.
There are several small helpers for common actions:
luatest.helpers.uuid('ab',2,1)=='abababab-0002-0000-0000-000000000001'luatest.helpers.retrying({timeout=1,delay=0.1},failing_function,arg1,arg2)-- wait until server is upluatest.helpers.retrying({},function()server:http_request('get','/status')end)
Show summary with grep-A999'^Summary'luacov.report.out
When running integration tests with coverage collector enabled, luatest
automatically starts new tarantool instances with luacov enabled.
So coverage is collected from all the instances.
However this has some limitations:
It works only for instances started with Server helper.
Process command should be executable lua file or tarantool with script argument.
Instance must be stopped with server:stop(), because this is the point where stats are saved.
Don’t save stats concurrently to prevent corruption.
Keep calling fn until it returns without error.
Throws last error if config.timeout is elapsed.
Default options are taken from helpers.RETRYING_TIMEOUT and helpers.RETRYING_DELAY.
Generates uuids from its 5 parts.
Strings are repeated and numbers are padded to match required part length.
If number of arguments is less than 5 then first and last arguments are used
for corresponding parts, missing parts are set to 0.
Sometimes it is necessary to run tarantool with particular arguments and
verify its output. luatest.server provides a supervisor like
interface: an instance is started, calls box.cfg() and we can
communicate with it using net.box. Another helper in tarantool/tarantool,
test.interactive_tarantool , aims to solve all the problems around
readline console and also provides ability to communicate with the
instance interactively.
However, there is nothing like ‘just run tarantool with given args and
give me its output’.
Functions
tarantool (dir, env, args[, opts])
Run tarantool in given directory with given environment and
command line arguments and catch its output.
Expects JSON lines as the output and parses it into an array
(it can be disabled using nojson option).
Options:
nojson (boolean, default: false)
Don’t attempt to decode stdout as a stream of JSON lines,
return as is.
stderr (boolean, default: false)
Collect stderr and place it into the stderr field of the
return value
quote_args (boolean, default: false)
Quote CLI arguments before concatenating them into a shell
command.
Parameters:
dir: (string) Directory where the process will run.
env: (table) Environment variables for the process.
args: (table) Options that will be passed when the process starts.
opts: (table) Custom options: nojson, stderr and quote_args. (optional)
The helper is used to automatically collect a set of
instances from the provided configuration and automatically
set up servers per each configured instance.
Ensure cluster startup error Starts a all instance of a cluster from the given config and
ensure that all the instances fails to start and reports the
given error message.
Build a listen URI based on the given server alias and extra path.
The resulting URI: <Server.vardir>/[<extra_path>/]<server_alias>.sock.
Provide a unique alias or extra path to avoid collisions with other sockets.
For now, only UNIX sockets are supported.
extra_path: (string) Extra path relative to the Server.vardir directory. (optional)
Returns:
string
Server:assert_follows_upstream (server_id)
Assert that the server follows the source node with the given ID.
Meaning that it replicates from the remote node normally, and has already
joined and subscribed.
Establish net.box connection.
It’s available in net_box field.
Server:copy_datadir ()
Copy contents of the data directory into the server’s working directory.
Invoked on the server’s start.
Server:drop ()
Stop the server and save its artifacts if the test fails.
This function should be used only at the end of the test (after_test,
after_each, after_all hooks) to terminate the server process.
Besides process termination, it saves the contents of the server
working directory to the <vardir>/artifacts directory for further
analysis if the test fails.
Much like Server:eval , but takes a function instead of a string.
The executed function must have no upvalues (closures). Though it
may use global functions and modules (like box , os , etc.)
Parameters:
fn: (function)
args: (tab) (optional)
options: (tab) (optional)
Usage:
localvclock=server:exec(function()returnbox.info.vclockend)localsum=server:exec(function(a,b)returna+bend,{1,2})-- sum == 3localt=require('luatest')server:exec(function()-- luatest is available via `t` upvaluet.assert_equals(math.pi,3)end)-- mytest.lua:12: expected: 3, actual: 3.1415926535898
Server:get_box_cfg ()
A simple wrapper around the Server:exec() method
to get the box.cfg value from the server.
Returns:
table
Server:get_downstream_vclock (server_id)
Get vclock acknowledged by another node to the current server.
Parameters:
server_id: (number) Server ID.
Returns:
table
Server:get_election_term ()
Get the election term as seen by the server.
Returns:
number
Server:get_instance_id ()
Get ID of the server instance.
Returns:
number
Server:get_instance_uuid ()
Get UUID of the server instance.
Returns:
string
Server:get_synchro_queue_term ()
Get the synchro term as seen by the server.
Returns:
number
Server:get_vclock ()
Get the server’s own vclock, including the local component.
Returns:
table
Server:grep_log (pattern[, bytes_num[, opts]])
Search a string pattern in the server’s log file.
If the server has crashed, opts.filename is required.
Parameters:
pattern: (string) String pattern to search in the server’s log file.
bytes_num: (number) Number of bytes to read from the server’s log file. (optional)
opts:
reset: (bool) Reset the result when Tarantool%d+.%d+.%d+-.*%d+-g.* pattern is found, which means that the server was restarted.Defaults to true . (optional)
filename: (string) Path to the server’s log file.Defaults to box.cfg.log . (optional)
json: data to encode as JSON into request body (optional)
http: (tab) other options for HTTP-client (optional)
raise: (bool) raise error when status is not in 200..299. Default to true. (optional)
Returns:
response object from HTTP client with helper methods.
Raises:
HTTPRequest error when response status is not 200.
See also:
luatest.http_response
Server:make_socketdir ()
Make directory for the server’s Unix socket.
Invoked on the server’s start.
Server:make_workdir ()
Make the server’s working directory.
Invoked on the server’s start.
Server:new ([object[, extra]])
Build a server object.
Parameters:
object: Table with the entries listed below. (optional)
command: (string) Executable path to run a server process with.Defaults to the internal server_instance.lua script. If a custom pathis provided, it should correctly process all env variables listed belowto make constructor parameters work. (optional)
args: (tab) Arbitrary args to run object.command with. (optional)
env: (tab) Pass the given env variables into the server process. (optional)
chdir: (string) Change to the given directory before runningthe server process. (optional)
alias: (string) Alias for the new server and the value of the.. code-block:: lua TARANTOOL_ALIAS env variable which is passed into the server process.Defaults to ‘server’. (optional)
workdir: (string) Working directory for the new server and thevalue of the TARANTOOL_WORKDIR env variable which is passed into theserver process. The directory path will be created on the server start.Defaults to <vardir>/<alias>-<randomid>. (optional)
datadir: (string) Directory path whose contents will be recursivelycopied into object.workdir on the server start. (optional)
http_port: (number) Port for HTTP connection to the new server andthe value of the TARANTOOL_HTTP_PORT env variable which is passed intothe server process.Not supported in the default server_instance.lua script. (optional)
net_box_port: (number) Port for the net.box connection to the newserver and the value of the TARANTOOL_LISTEN env variable which is passedinto the server process. (optional)
net_box_uri: (string) URI for the net.box connection to the newserver and the value of the TARANTOOL_LISTEN env variable which is passedinto the server process. If it is a Unix socket, the corresponding socketdirectory path will be created on the server start. (optional)
net_box_credentials: (tab) Override the default credentials for the.. code-block:: lua net.box connection to the new server. (optional)
box_cfg: (tab) Extra options for box.cfg() and the value of the.. code-block:: lua TARANTOOL_BOX_CFG env variable which is passed into the server process. (optional)
config_file: (string) Declarative YAML configuration for a serverinstance. Used to deduce advertise URI to connect net.box to the instance.The special value ‘’ means running without --config<...> CLI option(but still passes --name<alias>). (optional)
remote_config: (tab) If config_file is not passed, this configvalue is used to deduce advertise URI to connect net.box to the instance. (optional)
extra: (tab) Table with extra properties for the server object. (optional)
Returns:
table
Server:play_wal_until_synchro_queue_is_busy ()
Play WAL until the synchro queue becomes busy.
WAL records go one by one. The function is needed, because during
box.ctl.promote() it is not known for sure which WAL record is PROMOTE -
first, second, third? Even if known, it might change in the future. WAL delay
should already be started before the function is called.
Server:restart ([params[, opts]])
Restart the server with the given parameters.
Optionally waits until the server is ready.
Parameters:
params: (tab) Parameters to restart the server with.Like command , args , env , etc. (optional)
opts:
wait_until_ready: (bool) Wait until the server is ready.Defaults to true unless a custom executable path was provided whilebuilding the server object. (optional)
See also:
luatest.server.Server:new
Server:start ([opts])
Start a server.
Optionally waits until the server is ready.
Parameters:
opts:
wait_until_ready: (bool) Wait until the server is ready.Defaults to true unless a custom executable was provided while buildingthe server object. (optional)
Server:stop ()
Stop the server.
Waits until the server process is terminated.
Server:update_box_cfg (cfg)
A simple wrapper around the Server:exec() method
to update the box.cfg value on the server.
Parameters:
cfg: (tab) Box configuration settings.
Server:wait_for_downstream_to (server)
Wait for the given server to reach at least the same vclock as the local
server. Not including the local component, of course.
Parameters:
server: (tab) Server’s object.
Server:wait_for_election_leader ()
Wait for the server to become a writable election leader.
Server:wait_for_election_state (state)
Wait for the server to enter the given election state.
Note that if it becomes a leader, it does not mean it is already writable.
Stop all servers in the replica set and save their artifacts if the test fails.
This function should be used only at the end of the test (after_test,
after_each, after_all hooks) to terminate all server processes in
the replica set. Besides process termination, it saves the contents of
each server working directory to the <vardir>/artifacts directory
for further analysis if the test fails.
ReplicaSet:get_leader ()
Get a server which is a writable node in the replica set.
Returns:
table
ReplicaSet:get_server (alias)
Get the server object from the replica set by the given server alias.
Start all servers in the replica set.
Optionally waits until all servers are ready.
Parameters:
opts: Table with the entries listed below. (optional)
wait_until_ready: (bool) Wait until all servers are ready.Defaults to true . (optional)
ReplicaSet:stop ()
Stop all servers in the replica set.
ReplicaSet:wait_for_fullmesh ([opts])
Wait until every node is connected to every other node in the replica set.
Parameters:
opts: Table with the entries listed below. (optional)
timeout: (number) Timeout in seconds to wait for full mesh.Defaults to 60. (optional)
delay: (number) Delay in seconds between attempts to check full mesh.Defaults to 0.1. (optional)
Class luatest.cbuilder
Configuration builder.
It allows to construct a declarative configuration for a test case using
less boilerplace code/options, especially when a replicaset is to be
tested, not a single instance. All the methods support chaining (return
the builder object back).
Usage:
localconfig=Builder:new():add_instance('instance-001',{database={mode='rw',},}):add_instance('instance-002',{}):add_instance('instance-003',{}):config()Bydefault,allinstancesareaddedtoreplicaset-001ingroup-001,butit's possible to select a different replicaset and/or group:local config = Builder:new() :use_group('group-001') :use_replicaset('replicaset-001') :add_instance(<...>) :add_instance(<...>) :add_instance(<...>) :use_group('group-002') :use_replicaset('replicaset-002') :add_instance(<...>) :add_instance(<...>) :add_instance(<...>) :config()The default credentials and iproto options are added tosetup replication and to allow a test to connect to theinstances.There is a few other methods:* :set_replicaset_option('foo.bar', value)* :set_instance_option('instance-001', 'foo.bar', value)
Functions
Builder:add_instance (instance_name, iconfig)
Add an instance with the given options to the selected replicaset.
Parameters:
instance_name: (string) Instance where the config will be saved.
iconfig: (tab) Declarative config for the instance.
Builder:config ()
Return the resulting configuration.
Builder:new ([config])
Build a config builder object.
Parameters:
config: (tab) Table with declarative configuration. (optional)
Starting with the 3.0 version, the recommended way of configuring Tarantool is using a configuration file.
Configuring Tarantool in code is considered a legacy approach.
Name or id of a TREE index over the bucket id.
Spaces without this index do not participate in a sharded Tarantool
cluster and can be used as regular spaces if needed. It is necessary to
specify the first part of the index, other parts are optional.
This number should be several orders of magnitude larger than the potential number
of cluster nodes, considering potential scaling out in the foreseeable future.
Example:
If the estimated number of nodes is M, then the data set should be divided into
100M or even 1000M buckets, depending on the planned scaling out. This number is
certainly greater than the potential number of cluster nodes in the system being
designed.
Keep in mind that too many buckets can cause a need to allocate more memory to store
routing information. On the other hand, an insufficient number of buckets can lead to
decreased granularity when rebalancing.
Timeout to wait for synchronization of the old master with replicas before
demotion. Used when switching a master or when manually calling the
sync() function.
The maximum number of buckets that can be received in parallel by a single
replica set. This number must be limited, because when a new replica set is added to
a cluster, the rebalancer sends a very large amount of buckets from the existing
replica sets to the new replica set. This produces a heavy load on the new replica set.
Example:
Suppose rebalancer_max_receiving is equal to 100, bucket_count is equal to 1000.
There are 3 replica sets with 333, 333 and 334 buckets on each respectively.
When a new replica set is added, each replica set’s etalon_bucket_count becomes
equal to 250. Rather than receiving all 250 buckets at once, the new replica set
receives 100, 100 and 50 buckets sequentially.
A scheduler’s bucket move quota used by the rebalancer.
sched_move_quota defines how many bucket moves can be done in a row if there are pending storage refs.
Then, bucket moves are blocked and a router continues making map-reduce requests.
A scheduler’s storage ref quota used by a router’s map-reduce API.
For example, the vshard.router.map_callrw() function implements consistent map-reduce over the entire cluster.
sched_ref_quota defines how many storage refs, therefore map-reduce requests, can be executed on the storage in a row if there are pending bucket moves.
Then, storage refs are blocked and the rebalancer continues bucket moves.
Turns on automated master discovery in a replica set if set to auto.
Applicable only to the configuration of a router; the storage configuration ignores this parameter.
The parameter should be specified per replica set.
The configuration is not compatible with a manual master selection.
If the configuration is incorrect, it is not applied, and the vshard.router.cfg() call throws an error.
If the master parameter is set to auto for some replica sets, the router goes to these replica sets,
discovers the master in each of them, and periodically checks if the master instance still has its master status.
When the master in the replica set stops being a master, the router goes around all the nodes of the replica set
to find out which one is the new master.
Without this setting, the router cannot detect master nodes in the configured replica sets on its own.
It relies only on how they are specified in the configuration.
This becomes a problem when the master changes, and the change is not delivered to the router’s configuration:
for instance, in case the router doesn’t rely on a central configuration provider
or the provider cannot deliver a new configuration due to some reason.
Type: string
Default: nil
Dynamic: yes
API Reference
This section represents public and internal API for the router
and the storage.
Perform the initial cluster bootstrap and distribute all buckets across the
replica sets.
Parameters:
timeout – a number of seconds before ending a bootstrap attempt as
unsuccessful.
Recreate the cluster in case of bootstrap timeout.
if_not_bootstrapped – by default is set to false that means raise
an error, when the cluster is already
bootstrapped. True means consider an already
bootstrapped cluster a success.
To detect whether a cluster is bootstrapped, vshard looks for at least
one bucket in the whole cluster. If the cluster was bootstrapped only
partially (for example, due to an error during the first bootstrap), then
it will be considered a bootstrapped cluster on a next bootstrap call
with if_not_bootstrapped. So this is still a bad practice. Avoid
calling bootstrap() multiple times.
Create a new router instance. vshard supports multiple routers in a
single Tarantool instance. Each router can be connected to any vshard
cluster, and multiple routers can be connected to the same cluster.
A router created via vshard.router.new() works in the same way as
a static router, but the method name is preceded by a colon
(vshard.router:method_name(...)), while for a static router
the method name is preceded by a period (vshard.router.method_name(...)).
A static router can be obtained via the vshard.router.static() method
and then used like a router created via the vshard.router.new()
method.
Note
box.cfg is shared among all the routers of a single instance.
Parameters:
name – a router instance name. This name is used as a prefix in logs of
the router and must be unique within the instance
cfg – a configuration table
Return:
a router instance, if created successfully; otherwise, nil and an
error object
Call the function identified by function-name on the shard storing the bucket
identified by bucket_id.
See the Processing requests section
for details on function operation.
Parameters:
bucket_id – a bucket identifier
mode – either a string = ‘read’|’write’, or a map with mode=’read’|’write’ and/or prefer_replica=true|false and/or balance=true|false.
function_name – a function to execute
argument_list – an array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
The mode parameter has two possible forms: a string or a map. Examples of the string form are:
'read', 'write'. Examples of the map form are: {mode='read'}, {mode='write'},
{mode='read',prefer_replica=true}, {mode='read',balance=true},
{mode='read',prefer_replica=true,balance=true}.
If 'write' is specified then the target is the master.
If prefer_replica=true is specified then the preferred target is one of the replicas, but
the target is the master if there is no conveniently available replica.
It may be good to specify prefer_replica=true for functions which are expensive in terms
of resource use, to avoid slowing down the master.
If balance=true then there is load balancing—reads are distributed over all the nodes
in the replica set in round-robin fashion, with a preference for replicas if
prefer_replica=true is also set.
Return:
The original return value of the executed function, or nil and
error object. The error object has a type attribute equal to
ShardingError or one of the regular Tarantool errors
(ClientError, OutOfMemory, SocketError, etc.).
ShardingError is returned on errors specific for sharding:
the master is missing, wrong bucket id, etc. It has an attribute code
containing one of the values from the vshard.error.code.* LUA table, an
optional attribute containing a message with the human-readable error description,
and other attributes specific for the error code.
Examples:
To call customer_add function from vshard/example, say:
vshard.router.call(100,'write','customer_add',{{customer_id=2,bucket_id=100,name='name2',accounts={}}},{timeout=5})-- or, the same thing but with a map for the second argumentvshard.router.call(100,{mode='write'},'customer_add',{{customer_id=2,bucket_id=100,name='name2',accounts={}}},{timeout=5})
Call the function identified by function-name on the shard storing the bucket identified by bucket_id,
in read-only mode (similar to calling vshard.router.call
with mode=’read’). See the
Processing requests section for details on
function operation.
Parameters:
bucket_id – a bucket identifier
function_name – a function to execute
argument_list – an array of the function’s arguments
options –
timeout — a request timeout, in seconds.If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Return:
The original return value of the executed function, or nil and
error object. The error object has a type attribute equal to ShardingError
or one of the regular Tarantool errors (ClientError, OutOfMemory,
SocketError, etc.).
ShardingError is returned on errors specific for sharding: the replica
set is not available, the master is missing, wrong bucket id, etc. It has an
attribute code containing one of the values from the vshard.error.code.* LUA table, an
optional attribute containing a message with the human-readable error description,
and other attributes specific for this error code.
Call the function identified by function-name on the shard storing the bucket identified by bucket_id,
in read-write mode (similar to calling vshard.router.call
with mode=’write’). See the Processing requests section
for details on function operation.
Parameters:
bucket_id – a bucket identifier
function_name – a function to execute
argument_list – an array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Return:
The original return value of the executed function, or nil and
error object. The error object has a type attribute equal to ShardingError
or one of the regular Tarantool errors (ClientError, OutOfMemory,
SocketError, etc.).
ShardingError is returned on errors specific for sharding: the replica
set is not available, the master is missing, wrong bucket id, etc. It has an
attribute code containing one of the values from the vshard.error.code.* LUA table, an
optional attribute containing a message with the human-readable error description,
and other attributes specific for this error code.
Call the function identified by function-name on the shard storing the bucket identified by bucket_id,
in read-only mode (similar to calling vshard.router.call
with mode='read'), with preference for a replica rather than a master
(similar to calling vshard.router.call with prefer_replica=true). See the
Processing requests section for details on
function operation.
Parameters:
bucket_id – a bucket identifier
function_name – a function to execute
argument_list – an array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Return:
The original return value of the executed function, or nil and
error object. The error object has a type attribute equal to ShardingError
or one of the regular Tarantool errors (ClientError, OutOfMemory,
SocketError, etc.).
ShardingError is returned on errors specific for sharding: the replica
set is not available, the master is missing, wrong bucket id, etc. It has an
attribute code containing one of the values from the vshard.error.code.* LUA table, an
optional attribute containing a message with the human-readable error description,
and other attributes specific for this error code.
The function implements consistent map-reduce over the entire cluster.
Consistency means:
All the data was accessible.
The data was not migrated between physical storages during the map requests execution.
The function can be helpful if you need to access:
all the data in the cluster
a vast number of buckets scattered over the instances
in case their individual vshard.router.call() takes up too much time.
The function is called on the master node of each replica set with the given arguments.
Parameters:
function_name – a function to call on the storages (masters of all replica sets)
argument_list – an array of the function’s arguments
options –
timeout – a request timeout, in seconds. The timeout is for the entire map_callrw(), including all its stages.
return_raw – the net.box option implemented in Tarantool since version 2.10.0.
If set to true, net.box returns the response data wrapped in a MessagePack object instead of decoding it to Lua.
For more details, see the Return section below.
Important
Do not use a big timeout (longer than 1 minute, for instance). The router tries to block the bucket moves
to another storage for the given timeout on all storages. On failure, the block remains for the entire timeout.
Return:
On success: a map with replica set UUIDs (keys) and results of the function_name (values).
{uuid1={res1},uuid2={res2},...}
If the function returns nil or box.NULL from one of the storages,
it will not be present in the resulting map.
If the return_raw option is used,
the result is a map of the following format: {[replicaset_uuid]=msgpack.object}
where msgpack.object is an object that stores a MessagePack array with the results returned from the storage map function.
The option use case is the same as in using net.box: to avoid decoding of the call results into Lua.
The option can be helpful if a router is used as a proxy and results received from a storage are big.
Example:
localres=vshard.router.map_callrw('my_func',args,{...,return_raw=true})forreplicaset_uuid,msgpack_valueinpairs(res)dolog.info('Replicaset %s returned %s',replicaset_uuid,msgpack_value:decode())end
This is an illustration of the option usage.
Normally, you don’t need to use return_raw if you call the decode() function.
On failure: nil, error object, and optional replica set UUID where the error occurred.
UUID will not be returned if the error is not related to a particular replica set.
For instance, the method fails if not all buckets were found, even if all replica sets were scanned successfully.
Handling the result looks like this:
res,err,uuid=vshard.router.map_callrw(...)ifnotresthen-- Error.-- 'err' - error object. 'uuid' - optional UUID of replica set-- where the error happened....else-- Success.foruuid,valueinpairs(res)do...endend
If the return_raw option is used, the result on failure is the same as described above.
Map-Reduce in vshard can be divided into three stages: Ref, Map, and Reduce.
Ref and Map. map_callrw() combines both the Ref and the Map stages.
The Ref stage ensures data consistency while executing the user’s function (function_name) on all nodes.
Keep in mind that consistency is incompatible with rebalancing (it breaks data consistency).
Map-reduce and rebalancing are mutually exclusive, they compete for the cluster time.
Any bucket move makes the sender and receiver nodes inconsistent,
so it is impossible to call a function on them to access all the data
without vshard.storage.bucket_ref().
It makes the Ref stage intricate, as it should work together with the rebalancer to ensure
they do not block each other.
For this, the storage has a special scheduler for bucket moves and storage refs.
Storage ref is a volatile counter defined on each instance.
It is incremented when a map-reduce request comes and decremented when it ends.
Storage ref pins the entire instance with all its buckets, not just a single bucket (like bucket ref).
The scheduler shares storage time between bucket moves and storage refs fairly.
The distribution depends on how long and frequent the moves and refs are.
It can be configured using the storage options sched_move_quota and sched_ref_quota.
Keep in mind that the scheduler configuration may affect map-reduce requests if used during rebalancing.
During the Map stage, map_callrw() sends map requests one by one to many servers.
On success, the function returns a map. The map is a set of “key—value” pairs.
The keys are replica set UUIDs, and the values are the results of the user’s function—function_name.
Reduce. The Reduce stage is not performed by vshard.
It is what the user’s code does with the results of map_callrw().
Note
map_callrw() works only on masters.
Therefore, you can’t use it if at least one replica set has its master node down.
Deprecated. Logs a warning when used because it is not consistent
for cdata numbers.
In particular, it returns 3 different values for normal Lua numbers
like 123, for unsigned long long cdata (like 123ULL, or
ffi.cast('unsignedlonglong',123)), and for signed long long cdata
(like 123LL, or ffi.cast('longlong',123)). And it is important.
For float and double cdata
(ffi.cast('float',number), ffi.cast('double',number)) these functions
return different values even for the same numbers of the same floating point
type. This is because tostring() on a floating point cdata number returns not
the number, but a pointer at it. Different on each call.
vshard.router.bucket_id_strcrc32() behaves exactly the same, but
does not log a warning. In case you need that behavior.
This function is safer than bucket_id_strcrc32. It takes a CRC32 from
a MessagePack encoded value. That is, bucket id of integers does not
depend on their Lua type. In case of a string key, it does not encode it into
MessagePack, but takes a hash right from the string.
Parameters:
key – a hash key. This can be any Lua object (number, table, string).
Return:
a bucket identifier
Rtype:
number
However it still may return different values for not equal floating point
types. That is, ffi.cast('float',number) may be reflected into a bucket id
not equal to ffi.cast('double',number). This can’t be fixed, because a
float value, even being casted to double, may have a garbage tail in its fraction.
Floating point keys should not be used to calculate a bucket id,
usually.
Be very careful in case you store floating point types in a space. When data
is returned from a space, it is cast to Lua number. And if that value had
an empty fraction part, it will be treated as an integer by bucket_id_mpcrc32().
So you need to do explicit casts in such cases. Here is an example of the problem:
tarantool> s=box.schema.create_space('test',{format={{'id','double'}}});_=s:create_index('pk')---...tarantool> inserted=ffi.cast('double',1)---...-- Value is stored as doubletarantool> s:replace({inserted})----[1]...-- But when returned to Lua, stored as Lua number, not cdata.tarantool> returned=s:get({inserted}).id---...tarantool> type(returned),returned----number-1...tarantool> vshard.router.bucket_id_mpcrc32(inserted)----1411...tarantool> vshard.router.bucket_id_mpcrc32(returned)----1614...
Turn on/off the background discovery fiber used by the router to
find buckets.
Parameters:
mode – working mode of a discovery fiber. There are three modes: on,
off and once
When the mode is on (default), the discovery fiber works during all the lifetime
of the router. Even after all buckets are discovered, it will
still come to storages and download their buckets with some big
period (DISCOVERY_IDLE_INTERVAL).
This is useful if the bucket topology changes often and the number of
buckets is not big. The router will keep its route table up to
date even when no requests are processed.
When the mode is off, discovery is disabled completely.
When the mode is once, discovery starts and finds the locations of
all buckets, and then the discovery fiber is terminated. This
is good for a large bucket count and for clusters, where rebalancing is rare.
The method is good to enable/disable discovery after the router is
already started, but discovery is enabled by default. You may want
to never enable it even for a short time—then specify the
discovery_mode option in the configuration.
It takes the same values as vshard.router.discovery_set(mode).
You may decide to turn off discovery or make it once if you have
many routers, or tons of buckets (hundreds of thousands and more),
and you see that the discovery process consumes notable CPU % on
routers and storages. In that case it may be wise to turn off the
discovery when there is no rebalancing in the cluster. And turn it
on for new routers, as well as for all routers when rebalancing is
started.
Return information about each instance. Since vshard v.0.1.22, the
function also accepts options, which can be used to get additional
information.
Parameters:
options –
with_services — a bool value. If set to true, the
function returns information about the background services
(such as discovery, master search, or failover) that are
working on the current instance.
Return:
Replica set parameters:
replica set uuid
master instance parameters
replica instance parameters
Instance parameters:
uri—URI of the instance
uuid—UUID of the instance
status—status of the instance (available, unreachable, missing)
network_timeout—a timeout for the request. The value is updated automatically
on each 10th successful request and each 2nd failed request.
Bucket parameters:
available_ro – the number of buckets known to the router and available for read requests
available_rw – the number of buckets known to the router and available for read and write requests
unreachable – the number of buckets known to the router but unavailable for any requests
unknown – the number of buckets whose replica sets are not known to the router
Service parameters:
name – service name. Possible values: discovery, failover, master_search.
status – service status. Possible values: ok, error.
error – error message that appears on the error status.
activity – service state. It shows what the service is currently doing
(for example, updatingreplicas).
status_idx – incrementing counter of the status changes.
The ok status is updated on every successful iteration of the service.
The error status is updated only when it is fixed.
Example:
tarantool> vshard.router.info()----replicasets:ac522f65-aa94-4134-9f64-51ee384f1a54:replica:&0network_timeout:0.5status:availableuri:storage@127.0.0.1:3303uuid:1e02ae8a-afc0-4e91-ba34-843a356b8ed7uuid:ac522f65-aa94-4134-9f64-51ee384f1a54master:*0cbf06940-0790-498b-948d-042b62cf3d29:replica:&1network_timeout:0.5status:availableuri:storage@127.0.0.1:3301uuid:8a274925-a26d-47fc-9e1b-af88ce939412uuid:cbf06940-0790-498b-948d-042b62cf3d29master:*1bucket:unreachable:0available_ro:0unknown:0available_rw:3000status:0alerts:[]...tarantool> vshard.router.info({with_services=true})---<all info from vshard.router.info()>services:failover:status_idx:2error:activity:idlingname:failoverstatus:okdiscovery:status_idx:2error: Error during discovery:TimedOutactivity:idlingname:discoverystatus:error...
The router is enabled by default. However, it is automatically and
forcefully disabled until the configuration is finished, as accessing the
router’s methods at that time is not safe.
Manual disabling can be used, for example, if some preparatory work needs
to be done after calling vshard.router.cfg() but
before the router’s methods are available. It will look like this:
vshard.router.disable()vshard.router.cfg(...)-- Some preparatory work here ...vshard.router.enable()-- vshard.router's methods are available now
Call a function on a nearest available master (distances are defined using
replica.zone and cfg.weights matrix) with specified
arguments.
Note
The replicaset_object:call method is similar to replicaset_object:callrw.
Parameters:
function_name – function to execute
argument_list – array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Call a function on a nearest available master (distances are defined using
replica.zone and cfg.weights matrix) with a specified
arguments.
Note
The replicaset_object:callrw method is similar to replicaset_object:call.
Parameters:
function_name – function to execute
argument_list – array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Return:
result of function_name on success
nil, err otherwise
tarantool>localbucket=1;returnvshard.router.callrw(>bucket,>'box.space.actors:insert',>{{>1,bucket,'Renata Litvinova',>{theatre="Moscow Art Theatre"}>}},>{timeout=5}>)
Call a function on the nearest available replica (distances are defined
using replica.zone and cfg.weights matrix) with specified
arguments. It is recommended to use
replicaset_object:callro() for calling only read-only functions, as the called functions can be executed not only
on a master, but also on replicas.
Parameters:
function_name – function to execute
argument_list – array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Call a function on the nearest available replica (distances are defined using
replica.zone and cfg.weights matrix) with specified
arguments,
with preference for a replica rather than a master
(similar to calling vshard.router.call with prefer_replica=true).
It is recommended to use
replicaset_object:callre() for calling only read-only functions, as the called function can be executed not
only on a master, but also on replicas.
Parameters:
function_name – function to execute
argument_list – array of the function’s arguments
options –
timeout — a request timeout, in seconds. If the router cannot identify a
shard with the specified bucket_id, it will retry until the timeout is reached.
other net.box options, such as is_async,
buffer, on_push are also supported.
Automated master discovery works in its own fiber on a router,
which is activated only if at least one replica set is configured to look for the master (the master parameter is set to auto).
The fiber wakes up within a certain period. But it is possible to wake it up on demand by using this function.
Manual fiber wakeup can help speed up tests for master change.
Another use case is performing some actions with a router in the router console.
The function does nothing if master search is not configured for any replica set.
Search for the bucket in the whole cluster. If the bucket is not
found, it is likely that it does not exist. The bucket might also be
moved during rebalancing and currently is in the RECEIVING state.
Return information about the storage instance. Since vshard v.0.1.22, the
function also accepts options, which can be used to get additional
information.
Parameters:
options –
with_services — a bool value. If set to true, the
function returns information about the background services
(such as garbage collector, rebalancer, recovery, or applier
of the routes) that are working on the current instance. See
vshard.router.info for detailed
reference.
Return a flag indicating whether rebalancing is in progress. The result is true
if the node is currently applying routes received from a rebalancer node in
the special fiber.
Since vshard v.0.1.22. Define a trigger for execution when the data from
the user spaces is changed (deleted or inserted) due to the rebalancing
process. The trigger is invoked each time the data batch changes.
Parameters:
trigger-function (function) – function which will become the trigger function.
old-trigger-function (function) – existing trigger function which will
be replaced by trigger-function.
Return:
nil or function pointer
The trigger-function can have up to three parameters:
event_type (string) – in order to distinguish event, you can compare
this argument with the supported event types, bucket_data_recv_txn
and bucket_data_gc_txn.
bucket_id (unsigned) – bucket id.
data (table) – additional information about data change transaction.
Currently it only includes an array of all spaces (data.spaces),
affected by a transaction in which trigger-function is executed.
As everything executed inside triggers is already in a transaction,
you shouldn’t use transactions, yield-operations (explicit
or not), changes to different space engines (see rule #2).
If the parameters are (nil,old-trigger-function), then the old trigger
is deleted. If both parameters are omitted, then the response is a list of
existing trigger functions.
Details about trigger characteristics are in the
triggers section.
Receive a bucket identified by bucket id from a remote replica set.
Parameters:
bucket_id – a bucket identifier
from – UUID of source replica set
data – data logically stored in a bucket identified by bucket_id, in the same format as
the return value from bucket_collect()<storage_api-bucket_collect>
Collect an array of active bucket identifiers for discovery.
SQL DBMS Modules
The discussion here in the reference is about incorporating and using two
modules that have already been created: the “SQL DBMS rocks” for MySQL and
PostgreSQL.
To call another DBMS from Tarantool, the essential requirements are: another
DBMS, and Tarantool. The module which connects Tarantool to another DBMS may
be called a “connector”. Within the module there is a shared library which
may be called a “driver”.
Tarantool supplies DBMS connector modules with the module manager for Lua,
LuaRocks. So the connector modules may be called “rocks”.
The Tarantool rocks allow for connecting to SQL servers and executing SQL
statements the same way that a MySQL or PostgreSQL client does. The SQL
statements are visible as Lua methods. Thus Tarantool can serve as a “MySQL Lua
Connector” or “PostgreSQL Lua Connector”, which would be useful even if that was
all Tarantool could do. But of course Tarantool is also a DBMS, so the module
also is useful for any operations, such as database copying and accelerating,
which work best when the application can work on both SQL and Tarantool inside
the same Lua routine.
The methods for connect/select/insert/etc. are similar to the ones in the
net.box module.
From a user’s point of view the MySQL and PostgreSQL rocks are very similar, so
the following sections – “MySQL Example” and “PostgreSQL Example” – contain
some redundancy.
MySQL Example
This example assumes that MySQL 5.5 or MySQL 5.6 or MySQL 5.7 has been installed.
Recent MariaDB versions will also work, the MariaDB C connector is used. The
package that matters most is the MySQL client developer package, typically named
something like libmysqlclient-dev. The file that matters most from this package
is libmysqlclient.so or a similar name. One can use find or whereis to
see what directories these files are installed in.
It will be necessary to install Tarantool’s MySQL driver shared library, load
it, and use it to connect to a MySQL server instance. After that, one can pass any MySQL
statement to the server instance and receive results, including multiple result sets.
Installation
Check the instructions for
downloading and installing a binary package
that apply for the environment where Tarantool was installed. In addition to
installing tarantool, install tarantool-dev. For example, on Ubuntu, add
the line:
$ sudoapt-getinstalltarantool-dev
Now, for the MySQL driver shared library, there are two ways to install:
With LuaRocks
Begin by installing luarocks and making sure that tarantool is among the
upstream servers, as in the instructions on rocks.tarantool.org, the
Tarantool luarocks page. Now execute this:
luarocks install mysql [MYSQL_LIBDIR = path]
[MYSQL_INCDIR = path]
[--local]
$ gitclonehttps://github.com/tarantool/mysql.git
$ cdmysql&&cmake.-DCMAKE_BUILD_TYPE=RelWithDebInfo
$ make
$ makeinstall
At this point it is a good idea to check that the installation produced a file
named driver.so, and to check that this file is on a directory that is
searched by the require request.
Connecting
Begin by making a require request for the mysql driver. We will assume that
the name is mysql in further examples.
The connection-options parameter is a table. Possible options are:
host=host-name - string, default value = ‘localhost’
port=port-number - number, default value = 3306
user=user-name - string, default value is operating-system user name
password=password - string, default value is blank
db=database-name - string, default value is blank
raise=true|false - boolean, default value is false
The option names, except for raise, are similar to the names that MySQL’s
mysql client uses, for details see the MySQL manual at
dev.mysql.com/doc/refman/5.6/en/connecting.html.
The raise option should be set to true if errors should be
raised when encountered. To connect with a Unix socket rather than with TCP,
specify host='unix/' and port=socket-name.
Example, using a table literal enclosed in {braces}:
where sql-statement is a string, and the optional parameters are extra
values that can be plugged in to replace any question marks (“?”s) in the SQL
statement.
Example:
tarantool> conn:execute('select table_name from information_schema.tables')-----table_name:ALL_PLUGINS-table_name:APPLICABLE_ROLES-table_name:CHARACTER_SETS<...>-78...
Closing connection
To end a session that began with mysql.connect, the request is:
connection-name:close()
Example:
tarantool> conn:close()---...
For further information, including examples of rarely-used requests, see the
README.md file at github.com/tarantool/mysql.
Example
The example was run on an Ubuntu 12.04 (“precise”) machine where tarantool had
been installed in a /usr subdirectory, and a copy of MySQL had been installed
on ~/mysql-5.5. The mysqld server instance is already running on the local host 127.0.0.1.
$ exportTMDIR=~/mysql-5.5
$ # Check that the include subdirectory exists by looking$ # for .../include/mysql.h. (If this fails, there's a chance$ # that it's in .../include/mysql/mysql.h instead.)$ [-f$TMDIR/include/mysql.h]&&echo"OK"||echo"Error"OK$ # Check that the library subdirectory exists and has the$ # necessary .so file.$ [-f$TMDIR/lib/libmysqlclient.so]&&echo"OK"||echo"Error"OK$ # Check that the mysql client can connect using some factory$ # defaults: port = 3306, user = 'root', user password = '',$ # database = 'test'. These can be changed, provided one uses$ # the changed values in all places.$ $TMDIR/bin/mysql--port=3306-h127.0.0.1--user=root\--password=--database=testWelcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 25Server version: 5.5.35 MySQL Community Server (GPL)...Type 'help;' or '\h' for help. Type '\c' to clear ...$ # Insert a row in database test, and quit.mysql> CREATE TABLE IF NOT EXISTS test (s1 INT, s2 VARCHAR(50));Query OK, 0 rows affected (0.13 sec)mysql> INSERT INTO test.test VALUES (1,'MySQL row');Query OK, 1 row affected (0.02 sec)mysql> QUITBye$ # Install luarocks$ sudoapt-get-yinstallluarocks|grep-E"Setting up|already"Setting up luarocks (2.0.8-2) ...$ # Set up the Tarantool rock list in ~/.luarocks,$ # following instructions at rocks.tarantool.org$ mkdir~/.luarocks
$ echo"rocks_servers = {[[http://rocks.tarantool.org/]]}">>\~/.luarocks/config.lua
$ # Ensure that the next "install" will get files from Tarantool$ # master repository. The resultant display is normal for Ubuntu$ # 12.04 precise$ cat/etc/apt/sources.list.d/tarantool.list
deb http://tarantool.org/dist/2.1/ubuntu/ precise maindeb-src http://tarantool.org/dist/2.1/ubuntu/ precise main$ # Install tarantool-dev. The displayed line should show version = 2.1$ sudoapt-get-yinstalltarantool-dev|grep-E"Setting up|already"Setting up tarantool-dev (2.1.0.222.g48b98bb~precise-1) ...$$ # Use luarocks to install locally, that is, relative to $HOME$ luarocksinstallmysqlMYSQL_LIBDIR=/usr/local/mysql/lib--local
Installing http://rocks.tarantool.org/mysql-scm-1.rockspec...... (more info about building the Tarantool/MySQL driver appears here)mysql scm-1 is now built and installed in ~/.luarocks/$ # Ensure driver.so now has been created in a place$ # tarantool will look at$ find~/.luarocks-name"driver.so"~/.luarocks/lib/lua/5.1/mysql/driver.so$ # Change directory to a directory which can be used for$ # temporary tests. For this example we assume that the name$ # of this directory is /home/pgulutzan/tarantool_sandbox.$ # (Change "/home/pgulutzan" to whatever is the user's actual$ # home directory for the machine that's used for this test.)$ cd/home/pgulutzan/tarantool_sandbox
$ # Start the Tarantool server instance. Do not use a Lua initialization file.$ tarantool
tarantool: version 2.1.0-222-g48b98bbtype 'help' for interactive helptarantool>
Configure tarantool and load mysql module. Make sure that tarantool doesn’t
reply “error” for the call to “require()”.
Create a Lua function that will connect to the MySQL server instance, (using some factory
default values for the port and user and password), retrieve one row, and
display the row. For explanations of the statement types used here, read the
Lua tutorial earlier in the Tarantool user manual.
tarantool> functionmysql_select() > localconn=mysql.connect({ > host='127.0.0.1', > port=3306, > user='root', > db='test' > }) > localtest=conn:execute('SELECT * FROM test WHERE s1 = 1') > localrow='' > fori,cardinpairs(test)do > row=row..card.s2..' ' > end > conn:close() > returnrow > end---...tarantool> mysql_select()----'MySQLrow'...
Observe the result. It contains “MySQL row”. So this is the row that was inserted
into the MySQL database. And now it’s been selected with the Tarantool client.
PostgreSQL Example
This example assumes that PostgreSQL 8 or PostgreSQL 9 has been installed. More
recent versions should also work. The package that matters most is the
PostgreSQL developer package, typically named something like libpq-dev. On
Ubuntu this can be installed with:
$ sudoapt-getinstalllibpq-dev
However, because not all platforms are alike, for this example the assumption
is that the user must check that the appropriate PostgreSQL files are present
and must explicitly state where they are when building the Tarantool/PostgreSQL
driver. One can use find or whereis to see what directories
PostgreSQL files are installed in.
It will be necessary to install Tarantool’s PostgreSQL driver shared library,
load it, and use it to connect to a PostgreSQL server instance. After that, one can pass
any PostgreSQL statement to the server instance and receive results.
Installation
Check the instructions for
downloading and installing a binary package
that apply for the environment where Tarantool was installed. In addition to
installing tarantool, install tarantool-dev. For example, on Ubuntu, add
the line:
$ sudoapt-getinstalltarantool-dev
Now, for the PostgreSQL driver shared library, there are two ways to install:
With LuaRocks
Begin by installing luarocks and making sure that tarantool is among the upstream
servers, as in the instructions on rocks.tarantool.org, the Tarantool luarocks
page. Now execute this:
$ gitclonehttps://github.com/tarantool/pg.git
$ cdpg&&cmake.-DCMAKE_BUILD_TYPE=RelWithDebInfo
$ make
$ makeinstall
At this point it is a good idea to check that the installation produced a file
named driver.so, and to check that this file is on a directory that is
searched by the require request.
Connecting
Begin by making a require request for the pg driver. We will assume that the
name is pg in further examples.
pg=require('pg')
Now, say:
connection_name = pg.connect(connection options)
The connection-options parameter is a table. Possible options are:
host=host-name - string, default value = ‘localhost’
port=port-number - number, default value = 5432
user=user-name - string, default value is operating-system user name
pass=password or password=password - string, default value is blank
db=database-name - string, default value is blank
The names are similar to the names that PostgreSQL itself uses.
Example, using a table literal enclosed in {braces}:
where sql-statement is a string, and the optional parameters
are extra values that can be plugged in to replace any placeholders
($1 $2 $3 etc.) in the SQL statement.
Example:
tarantool> conn:execute('select tablename from pg_tables')-----tablename:pg_statistic-tablename:pg_type-tablename:pg_authid<...>...
Closing connection
To end a session that began with pg.connect, the request is:
connection-name:close()
Example:
tarantool> conn:close()---...
For further information, including examples of rarely-used requests, see the
README.md file at github.com/tarantool/pg.
Example
The example was run on an Ubuntu 12.04 (“precise”) machine where tarantool had
been installed in a /usr subdirectory, and a copy of PostgreSQL had been installed
on /usr. The PostgreSQL server instance is already running on the local host 127.0.0.1.
$ # Check that the include subdirectory exists$ # by looking for /usr/include/postgresql/libpq-fe-h.$ [-f/usr/include/postgresql/libpq-fe.h]&&echo"OK"||echo"Error"OK$ # Check that the library subdirectory exists and has the necessary .so file.$ [-f/usr/lib/x86_64-linux-gnu/libpq.so]&&echo"OK"||echo"Error"OK$ # Check that the psql client can connect using some factory defaults:$ # port = 5432, user = 'postgres', user password = 'postgres',$ # database = 'postgres'. These can be changed, provided one changes$ # them in all places. Insert a row in database postgres, and quit.$ psql-h127.0.0.1-p5432-Upostgres-dpostgres
Password for user postgres:psql (9.3.10)SSL connection (cipher: DHE-RSA-AES256-SHA, bits: 256)Type "help" for help.postgres=# CREATE TABLE test (s1 INT, s2 VARCHAR(50));CREATE TABLEpostgres=# INSERT INTO test VALUES (1,'PostgreSQL row');INSERT 0 1postgres=# \q$$ # Install luarocks$ sudoapt-get-yinstallluarocks|grep-E"Setting up|already"Setting up luarocks (2.0.8-2) ...$ # Set up the Tarantool rock list in ~/.luarocks,$ # following instructions at rocks.tarantool.org$ mkdir~/.luarocks
$ echo"rocks_servers = {[[http://rocks.tarantool.org/]]}">>\~/.luarocks/config.lua
$ # Ensure that the next "install" will get files from Tarantool master$ # repository. The resultant display is normal for Ubuntu 12.04 precise$ cat/etc/apt/sources.list.d/tarantool.list
deb http://tarantool.org/dist/2.0/ubuntu/ precise maindeb-src http://tarantool.org/dist/2.0/ubuntu/ precise main$ # Install tarantool-dev. The displayed line should show version = 2.0$ sudoapt-get-yinstalltarantool-dev|grep-E"Setting up|already"Setting up tarantool-dev (2.0.4.222.g48b98bb~precise-1) ...$$ # Use luarocks to install locally, that is, relative to $HOME$ luarocksinstallpgPOSTGRESQL_LIBDIR=/usr/lib/x86_64-linux-gnu--local
Installing http://rocks.tarantool.org/pg-scm-1.rockspec...... (more info about building the Tarantool/PostgreSQL driver appears here)pg scm-1 is now built and installed in ~/.luarocks/$ # Ensure driver.so now has been created in a place$ # tarantool will look at$ find~/.luarocks-name"driver.so"~/.luarocks/lib/lua/5.1/pg/driver.so$ # Change directory to a directory which can be used for$ # temporary tests. For this example we assume that the$ # name of this directory is $HOME/tarantool_sandbox.$ # (Change "$HOME" to whatever is the user's actual$ # home directory for the machine that's used for this test.)cd $HOME/tarantool_sandbox$ # Start the Tarantool server instance. Do not use a Lua initialization file.$ tarantool
tarantool: version 2.0.4-412-g803b15ctype 'help' for interactive helptarantool>
Configure tarantool and load pg module. Make sure that tarantool doesn’t
reply “error” for the call to “require()”.
Create a Lua function that will connect to a PostgreSQL server, (using some
factory default values for the port and user and password), retrieve one row,
and display the row. For explanations of the statement types used here, read the
Lua tutorial earlier in the Tarantool user manual.
Observe the result. It contains “PostgreSQL row”. So this is the row that was
inserted into the PostgreSQL database. And now it’s been selected with the
Tarantool client.
Other rocks
This page features a list of links to third-party Tarantool module documentation
that is hosted externally – mostly on GitHub pages or in READMEs:
Return a pointer to a series of bytes in MessagePack format.
This can be used instead of box_return_tuple() –
it can send the same value, but as MessagePack instead of as a tuple object.
It may be simpler than box_return_tuple() when the result is small, for
example a number or a boolean or a short string.
It will also be faster than box_return_tuple(), if the result is that
users save time by not creating a tuple every time they want to return
something from a C function.
On the other hand, if an already-existing tuple was obtained from
an iterator, then it would be faster to return the tuple via box_return_tuple()
rather than extracting its parts and sending them via box_return_mp().
Parameters:
ctx (box_function_ctx_t*) – an opaque structure passed to the C stored
procedure by Tarantool
For example, if mp is a buffer, and mp_end is a return value
produced by encoding a single MP_UINT scalar value with
mp_end=mp_encode_uint(mp,1);, then
box_return_mp(ctx,mp,mp_end); should return 0.
Since version 2.4.1. Push MessagePack data into
a session data channel – socket, console or
whatever is behind the session. Behaves just like Lua
box.session.push().
Parameters:
data (constchar*) – begin of MessagePack to push
data_end (constchar*) – end of MessagePack to push
Since version 2.11.0.
Return the database schema version.
A schema version is a number that indicates whether the database schema is changed.
For example, the schema_version value grows if a space or index
is added or deleted, or a space, index, or field name is changed.
Since version 2.11.0.
Send an IPROTO packet over the session’s socket with the given MsgPack header
and body.
The function yields.
The function works for binary sessions only. For details, see box.session.type().
Parameters:
sid (uint32_t) – the IPROTO session identifier (see box_session_id())
header (char*) – a MsgPack-encoded header
header_end (char*) – end of a header encoded as MsgPack
body (char*) – a MsgPack-encoded body. If the body and body_end parameters are omitted, the packet
consists of the header only.
body_end (char*) – end of a body encoded as MsgPack
/* IPROTO constants are not exported to C.* That is, the user encodes them by himself.*/#define IPROTO_REQUEST_TYPE 0x00#define IPROTO_OK 0x00#define IPROTO_SYNC 0x01#define IPROTO_SCHEMA_VERSION 0x05#define IPROTO_DATA 0x30charbuf[256]={};char*header=buf;char*header_end=header;header_end=mp_encode_map(header_end,3);header_end=mp_encode_uint(header_end,IPROTO_REQUEST_TYPE);header_end=mp_encode_uint(header_end,IPROTO_OK);header_end=mp_encode_uint(header_end,IPROTO_SYNC);header_end=mp_encode_uint(header_end,10);header_end=mp_encode_uint(header_end,IPROTO_SCHEMA_VERSION);header_end=mp_encode_uint(header_end,box_schema_version());char*body=header_end;char*body_end=body;body_end=mp_encode_map(body_end,1);body_end=mp_encode_uint(body_end,IPROTO_DATA);body_end=mp_encode_uint(body_end,1);/* The packet contains both the header and body. */box_iproto_send(box_session_id(),header,header_end,body,body_end);/* The packet contains the header only. */box_iproto_send(box_session_id(),header,header_end,NULL,NULL);
To override the handler of unknown request types, use the IPROTO_UNKNOWN type code.
handler (iproto_handler_t) – IPROTO request handler. To reset the request handler, set the handler parameter to NULL.
See the full parameter description in the Handler function section.
destroy (iproto_handler_destroy_t) – IPROTO request handler destructor. The destructor is called when the
corresponding handler is removed. See the full parameter description
in the Handler destructor function section.
ctx (void*) – a context passed to the handler and destroy callbacks
If a Lua handler throws an exception, the behavior is similar to that of a remote procedure call.
The following errors are returned to the client over IPROTO (see src/lua/utils.h):
ER_PROC_LUA – an exception is thrown from a Lua handler, diagnostic is not set.
diagnostics from src/box/errcode.h – an exception is thrown, diagnostic is set.
Create new eio task with specified function and arguments. Yield and wait
until the task is complete.
This function may use the worker_pool_threads
configuration parameter.
To avoid double error checking, this function does not throw exceptions.
In most cases it is also necessary to check the return value of the called
function and perform necessary actions. If func sets errno, the errno is
preserved across the call.
Get the information about the last API call error.
The Tarantool error handling works most like libc’s errno. All API calls
return -1 or NULL in the event of error. An internal pointer to box_error_t
type is set by API functions to indicate what went wrong. This value is only
significant if API call failed (returned -1 or NULL).
Successful function can also touch the last error in some cases. You don’t
have to clear the last error before calling API functions. The returned
object is valid only until next call to any API function.
You must set the last error using box_error_set() in your stored C procedures
if you want to return a custom error message. You can re-throw the last API
error to IPROTO client by keeping the current value and returning -1 to
Tarantool from your stored procedure.
A conditional variable: a synchronization primitive that allow fibers in
Tarantool’s cooperative multitasking
environment to yield until some predicate is satisfied.
Fiber conditions have two basic operations – “wait” and “signal”, – where
“wait” suspends the execution of a fiber (i.e. yields) until “signal” is
called.
Suspend the execution of the current fiber (i.e. yield) until
fiber_cond_signal() is called.
Like pthread_cond, fiber_cond can issue spurious wake ups caused by
explicit fiber_wakeup() or
fiber_cancel() calls. It is highly
recommended to wrap calls to this function into a loop and check the actual
predicate and fiber_is_cancelled()
on every iteration.
Controls how to iterate over tuples in an index. Different index types
support different iterator types. For example, one can start iteration
from a particular value (request key) and then retrieve all tuples where
keys are greater or equal (= GE) to this key.
If iterator type is not supported by the selected index type, iterator
constructor must fail with ER_UNSUPPORTED. To be selectable for primary
key, an index must support at least ITER_EQ and ITER_GE types.
NULL value of request key corresponds to the first or last key in the index,
depending on iteration direction. (first key for GE and GT types, and last
key for LE and LT). Therefore, to iterate over all tuples in an index, one
can use ITER_GE or ITER_LE iteration types with start key equal to NULL.
For ITER_EQ, the key must not be NULL.
Lock a latch. Waits indefinitely until the current fiber can gain access to
the latch. Since version 2.11.0, locks are acquired
exactly in the order in which they were requested.
Register and/or deregister an on_shutdown function.
Parameters:
arg (void*) – Pointer to an area that the new handler can use
new_handler (function*) – Pointer to a function which will be registered, or NULL
old_handler (function*) – Pointer to a function which will be deregistered, or NULL
Returns:
status of operation. 0 - success, -1 - failure
Return type:
int
A function which is registered will be called when the Tarantool instance shuts down.
This is functionally similar to what box.ctl.on_shutdown does.
If there are several on_shutdown functions, the Tarantool instance will call them
in reverse order of registration, that is, it will call the last-registered function first.
Typically a module developer will register an on_shutdown function that does whatever
cleanup work the module requires, and then returns control to the Tarantool instance.
Such an on_shutdown function should be fast, or should use an
asynchronous waiting mechanism (for example coio_wait).
Possible errors:
old_handler does not exist (errno = EINVAL),
new_handler and old_handler are both NULL (errno = EINVAL),
memory allocation fails (errno = ENOMEM).
Example: if the C API .c program contains a function
inton_shutdown_function(void*arg){printf("Bye!\n");return0;}
and later, in the function which the instance calls, contains a line
box_on_shutdown(NULL,on_shutdown_function,NULL);
then, if all goes well, when the instance shuts down, it will display “Bye!”.
When working with tuples, it is the developer’s responsibility
to ensure that enough space is allocated, taking especial caution
when writing to them with msgpuck functions such as
mp_encode_array().
Tuples are reference counted. All functions that return tuples guarantee
that the last returned tuple is reference counted internally until the next
call to API function that yields or returns another tuple.
You should increase the reference counter before taking tuples for long
processing in your code. The Lua garbage collector will not destroy a
tuple that has references, even
if another fiber removes them from a space. After processing,
decrement the reference counter using
box_tuple_unref(),
otherwise the tuple will leak.
Dump raw MsgPack data to the memory buffer buf of size size.
Store tuple fields in the memory buffer.
Upon successful return, the function returns the number of bytes written.
If buffer size is not enough then the return value is the number of bytes
which would have been written if enough space had been available.
Return the raw tuple field in MsgPack format.
The result is a pointer to raw MessagePack data which can be
decoded with mp_decode functions, for an example see the tutorial
program read.c.
The buffer is valid until the next call to a box_tuple_* function.
One cannot use STRS/ENUM macros for types because
there is a mismatch between enum name (STRING) and type
name literal (“STR”). STR is already used as a type in Objective C.
Allocate and initialize a new tuple iterator. The tuple iterator allows
iterating over fields at the root level of a MsgPack array.
Example:
box_tuple_iterator_t*it=box_tuple_iterator(tuple);if(it==NULL){// error handling using box_error_last()}constchar*field;while(field=box_tuple_next(it)){// process raw MsgPack data}// rewind the iterator to the first positionbox_tuple_rewind(it)assert(box_tuple_position(it)==0);// rewind three fieldsfield=box_tuple_seek(it,3);assert(box_tuple_position(it)==4);box_iterator_free(it);
Return zero-based next position in iterator. That is, this function
returnы the field id of the field that will be returned by the next call
to box_tuple_next().
Returned value is zero after initialization
or rewind and box_tuple_field_count()
after the end of iteration.
The result is a pointer to raw MessagePack data which can be
decoded with mp_decode functions, for an example see the tutorial
program read.c.
The returned buffer is valid until the next call to box_tuple_* API.
The requested field_no is returned by the next call to
box_tuple_next(it).
The result is a pointer to raw MessagePack data which can be
decoded with mp_decode functions, for an example see the tutorial
program read.c.
The returned buffer is valid until next call to box_tuple_* API.
This topic describes the C API for working with read views.
The C API is MT-safe and provides the ability to use a read view from any thread,
not only from the main (TX) thread.
The C API has the following specifics:
The space.upgrade function is not applied to retrieved tuples even if a space upgrade is in progress.
You can learn how to call C code using stored procedures in the
C tutorial.
Data types
The opaque data types below represent raw read views and an iterator over data in a raw read view.
Note that there is no special data type for tuples retrieved from a read view.
Tuples are returned as raw MessagePack data (constchar*).
Open a raw read view with the specified name and get a pointer to this read view.
In the case of error, returns NULL and sets box_error_last().
This function may be called from the main (TX) thread only.
Parameters:
*name (constchar) –
(optional) a read view name; if name is not specified, a read view name is set to unknown
To fetch data from a read view, you need to specify an index to fetch the data from.
The following functions are available for looking up spaces and indexes in a read view object.
The functions below provide the ability to look up a tuple by the key or create an iterator over a read view index.
Note
Methods of the read view iterator are safe to call from any thread, but they may be used in one thread at the same time. This means that an iterator should be thread-local.
Look up a tuple in a read view’s index.
If found, the data and size out arguments return a pointer to and the size of tuple data.
If not found, *data is set to NULL and *size is set to 0.
Create an iterator over a raw read view index.
The initialized iterator object returned by this function remains valid and may be safely used until it’s destroyed or the read view is closed.
When the iterator object is no longer needed, it should be destroyed using
box_raw_read_view_iterator_destroy().
Retrieve the current tuple and advance the given iterator over a raw read view index.
The pointer to and the size of tuple data are returned in the data and the size out arguments.
The data returned by this function remains valid and may be safely used until the read view is closed.
Destroy an iterator over a raw read view index.
The iterator object should not be used after calling this function,
but the data returned by the iterator may be safely dereferenced until the read view is closed.
Get the name of a field defined in the format of a read view space.
If the field number is greater than the total number of fields defined in the format, NULL is returned.
The string returned by this function is guaranteed to remain valid until the read view is closed.
Get the type of a field defined in the format of a read view space.
If the field number is greater than the total number of fields defined in the format, NULL is returned.
The string returned by this function is guaranteed to remain valid until the read view is closed.
This section provides information on the Tarantool binary protocol, iproto.
The protocol is called “binary” because the database is most frequently accessed
via binary code instead of Lua request text. Tarantool experts use it:
to write their own connectors
to understand network messages
to support new features that their favorite connector doesn’t support yet
to avoid repetitive parsing by the server
The binary protocol provides complete access to Tarantool functionality, including:
request multiplexing, for example ability to issue multiple requests
asynchronously via the same connection
response format that supports zero-copy writes
Note
Since version 2.11.0, you can use the box.iproto submodule to access
IPROTO constants and features from Lua. The submodule enables to send arbitrary IPROTO packets
over the session’s socket and override the behavior for all IPROTO
request types. Also, IPROTO_UNKNOWN constant is introduced. The constant is used for the
box.iproto.override() API, which allows setting a handler for incoming requests with an unknown type.
Now look at what tcpdump shows for the job connecting to 3302 – the “request”.
After the words “length 32” is a packet that ends with these 32 bytes
(we have added indented comments):
ce 00 00 00 1b MP_UINT = decimal 27 = number of bytes after this
82 MP_MAP, size 2 (we'll call this "Main-Map")
01 IPROTO_SYNC (Main-Map Item#1)
04 MP_INT = 4 = number that gets incremented with each request
00 IPROTO_REQUEST_TYPE (Main-Map Item#2)
01 IPROTO_SELECT
86 MP_MAP, size 6 (we'll call this "Select-Map")
10 IPROTO_SPACE_ID (Select-Map Item#1)
cd 02 00 MP_UINT = decimal 512 = id of tspace (could be larger)
11 IPROTO_INDEX_ID (Select-Map Item#2)
00 MP_INT = 0 = id of index within tspace
14 IPROTO_ITERATOR (Select-Map Item#3)
00 MP_INT = 0 = Tarantool iterator_type.h constant ITER_EQ
13 IPROTO_OFFSET (Select-Map Item#4)
00 MP_INT = 0 = amount to offset
12 IPROTO_LIMIT (Select-Map Item#5)
ce ff ff ff ff MP_UINT = 4294967295 = biggest possible limit
20 IPROTO_KEY (Select-Map Item#6)
91 MP_ARRAY, size 1 (we'll call this "Key-Array")
cd 01 18 MP_UINT = 280 (Select-Map Item#6, Key-Array Item#1)
-- 280 is the key value that we are searching for
Now read the source code file
net_box.c
and skip to the line netbox_encode_select(lua_State*L).
From the comments and from simple function calls like
mpstream_encode_uint(&stream,IPROTO_SPACE_ID);
you will be able to see how net_box put together the packet contents that you
have just observed with tcpdump.
There are libraries for reading and writing MessagePack objects.
C programmers sometimes include msgpuck.h.
Now you know how Tarantool itself makes requests with the binary protocol.
When in doubt about a detail, consult net_box.c – it has routines for each
request. Some connectors have similar code.
IPROTO_UPDATE
For an IPROTO_UPDATE example, suppose a user changes field #2 in tuple #2
in space #256 to 'BBBB'. The body will look like this:
(notice that in this case there is an extra map item
IPROTO_INDEX_BASE, to emphasize that field numbers
start with 1, which is optional and can be omitted):
04 IPROTO_UPDATE
85 IPROTO_MAP, size 5
10 IPROTO_SPACE_ID, Map Item#1
cd 02 00 MP_UINT 256
11 IPROTO_INDEX_ID, Map Item#2
00 MP_INT 0 = primary-key index number
15 IPROTO_INDEX_BASE, Map Item#3
01 MP_INT = 1 i.e. field numbers start at 1
21 IPROTO_TUPLE, Map Item#4
91 MP_ARRAY, size 1, for array of operations
93 MP_ARRAY, size 3
a1 3d MP_STR = OPERATOR = '='
02 MP_INT = FIELD_NO = 2
a5 42 42 42 42 42 MP_STR = VALUE = 'BBBB'
20 IPROTO_KEY, Map Item#5
91 MP_ARRAY, size 1, for array of key values
02 MP_UINT = primary-key value = 2
0b IPROTO_EXECUTE
83 MP_MAP, size 3
43 IPROTO_STMT_ID Map Item#1
ce d7 aa 74 1b MP_UINT value of n.stmt_id
41 IPROTO_SQL_BIND Map Item#2
92 MP_ARRAY, size 2
01 MP_INT = 1 = value for first parameter
a1 61 MP_STR = 'a' = value for second parameter
2b IPROTO_OPTIONS Map Item#3
90 MP_ARRAY, size 0 (there are no options)
IPROTO_INSERT
Byte codes for the response to the box.space.space-name:insert{6}
example:
ce 00 00 00 20 MP_UINT = HEADER AND BODY SIZE
83 MP_MAP, size 3
00 IPROTO_REQUEST_TYPE
ce 00 00 00 00 MP_UINT = IPROTO_OK
01 IPROTO_SYNC
cf 00 00 00 00 00 00 00 53 MP_UINT = sync value
05 IPROTO_SCHEMA_VERSION
ce 00 00 00 68 MP_UINT = schema version
81 MP_MAP, size 1
30 IPROTO_DATA
dd 00 00 00 01 MP_ARRAY, size 1 (row count)
91 MP_ARRAY, size 1 (field count)
06 MP_INT = 6 = the value that was inserted
IPROTO_EVAL
Byte codes for the response to the conn:eval([[box.schema.space.create('_space');]])
example:
ce 00 00 00 3b MP_UINT = HEADER AND BODY SIZE
83 MP_MAP, size 3 (i.e. 3 items in header)
00 IPROTO_REQUEST_TYPE
ce 00 00 80 0a MP_UINT = hexadecimal 800a
01 IPROTO_SYNC
cf 00 00 00 00 00 00 00 26 MP_UINT = sync value
05 IPROTO_SCHEMA_VERSION
ce 00 00 00 78 MP_UINT = schema version value
81 MP_MAP, size 1
31 IPROTO_ERROR_24
db 00 00 00 1d 53 70 61 63 etc. MP_STR = "Space '_space' already exists"
Creating a table with IPROTO_EXECUTE
Byte codes, if we use the same net.box connection that
we used in the beginning
and we say conn:execute([[CREATETABLEt1(ddINTPRIMARYKEYAUTOINCREMENT,ддSTRINGCOLLATE"unicode");]]) conn:execute([[INSERTINTOt1VALUES(NULL,'a'),(NULL,'b');]])
and we watch what tcpdump displays, we will see two noticeable things:
(1) the CREATE statement caused a schema change so the response has
a new IPROTO_SCHEMA_VERSION value and the body includes
the new contents of some system tables (caused by requests from net.box which users will not see);
(2) the final bytes of the response to the INSERT will be:
81 MP_MAP, size 1
42 IPROTO_SQL_INFO
82 MP_MAP, size 2
00 Tarantool constant (not in iproto_constants.h) = SQL_INFO_ROW_COUNT
02 1 = row count
01 Tarantool constant (not in iproto_constants.h) = SQL_INFO_AUTOINCREMENT_ID
92 MP_ARRAY, size 2
01 first autoincrement number
02 second autoincrement number
SELECT with SQL
Byte codes for the SQL SELECT example,
if we ask for full metadata by saying conn.space._session_settings:update('sql_full_metadata',{{'=','value',true}})
and we select the two rows from the table that we just created conn:execute([[SELECTdd,ддASдFROMt1;]])
then tcpdump will show this response, after the header:
82 MP_MAP, size 2 (i.e. metadata and rows)
32 IPROTO_METADATA
92 MP_ARRAY, size 2 (i.e. 2 columns)
85 MP_MAP, size 5 (i.e. 5 items for column#1)
00 a2 44 44 IPROTO_FIELD_NAME and 'DD'
01 a7 69 6e 74 65 67 65 72 IPROTO_FIELD_TYPE and 'integer'
03 c2 IPROTO_FIELD_IS_NULLABLE and false
04 c3 IPROTO_FIELD_IS_AUTOINCREMENT and true
05 c0 PROTO_FIELD_SPAN and nil
85 MP_MAP, size 5 (i.e. 5 items for column#2)
00 a2 d0 94 IPROTO_FIELD_NAME and 'Д' upper case
01 a6 73 74 72 69 6e 67 IPROTO_FIELD_TYPE and 'string'
02 a7 75 6e 69 63 6f 64 65 IPROTO_FIELD_COLL and 'unicode'
03 c3 IPROTO_FIELD_IS_NULLABLE and true
05 a4 d0 b4 d0 b4 IPROTO_FIELD_SPAN and 'дд' lower case
30 IPROTO_DATA
92 MP_ARRAY, size 2
92 MP_ARRAY, size 2
01 MP_INT = 1 i.e. contents of row#1 column#1
a1 61 MP_STR = 'a' i.e. contents of row#1 column#2
92 MP_ARRAY, size 2
02 MP_INT = 2 i.e. contents of row#2 column#1
a1 62 MP_STR = 'b' i.e. contents of row#2 column#2
IPROTO_PREPARE
Byte code for the SQL PREPARE example. If we said conn:prepare([[SELECTdd,ддASдFROMt1;]])
then tcpdump would show almost the same response, but there would
be no IPROTO_DATA. Instead, additional items will appear:
The binary protocol handles data in the MessagePack format.
Short descriptions of the basic MessagePack data types
are on MessagePack’s specification page.
Tarantool also introduces several MessagePack type extensions.
In this document, MessagePack types are described by words that start with MP_.
See this table:
Requests and responses have similar structure. They contain three sections: size, header, and body.
It is legal to put more than one request in a packet.
Size
The size is an MP_UINT – unsigned integer, usually 32-bit.
It is the size of the header plus the size of the body.
It may be useful to compare it with the number of bytes remaining in the packet.
Header
The header is an MP_MAP. It may contain, in any order:
Both the request and response use the IPROTO_REQUEST_TYPE key.
It denotes the type of the packet.
The request and the matching response have the same sync number (IPROTO_SYNC).
IPROTO_SCHEMA_VERSION is an optional key that indicates
whether there was a major change in the schema.
To see how Tarantool encodes the header, have a look at file
xrow.c,
function xrow_header_encode.
To see how Tarantool decodes the header, have a look at file
net_box.c,
function netbox_decode_data.
For example, in a successful response to box.space:select(),
the IPROTO_REQUEST_TYPE value is 0 = IPROTO_OK and the
array has all the tuples of the result.
Read the source code file net_box.c
where the function decode_metadata_optional is an example of how Tarantool
itself decodes extra items.
Body
The body is an MP_MAP. Maximal iproto package body length is 2 GiB.
The body has the details of the request or response. In a request, it can also
be absent or be an empty map. Both these states are interpreted equally.
Responses contain the body anyway even for an
IPROTO_PING request, where it is an empty MP_MAP.
A lot of responses contain the IPROTO_DATA map:
For most data-access requests (IPROTO_SELECT,
IPROTO_INSERT, IPROTO_DELETE, etc.)
the body is an IPROTO_DATA map with an array of tuples that contain an array of fields.
IPROTO_DATA is what we get with net_box and Module buffer
so if we were using net_box we could decode with
msgpack.decode_unchecked(),
or we could convert to a string with ffi.string(pointer,length).
The pickle.unpack() function might also be helpful.
Note
For SQL-specific requests and responses, the body is a bit different.
Learn more about this type of packets.
Error responses
Instead of IPROTO_OK, an error response header
has IPROTO_REQUEST_TYPE = IPROTO_TYPE_ERROR.
Its code is 0x8XXX, where XXX is the error code – a value in
src/box/errcode.h.
src/box/errcode.h also has some convenience macros which define hexadecimal
constants for return codes.
The error response body is a map that contains two keys: IPROTO_ERROR
and IPROTO_ERROR_24.
While IPROTO_ERROR contains an MP_MAP value, IPROTO_ERROR_24 contains a string.
The two keys are provided to accommodate clients with older and newer Tarantool versions.
Error responses before 2.4.1
Before Tarantool v. 2.4.1, the key IPROTO_ERROR contained a string
and was identical to the current IPROTO_ERROR_24 key.
Let’s consider an example. This is the fifth message, and the request was to create a duplicate
space with conn:eval([[box.schema.space.create('_space');]]).
The unsuccessful response looks like this:
Looking in errcode.h,
we find that the error code 0x0a (decimal 10) is
ER_SPACE_EXISTS, and the string associated with ER_SPACE_EXISTS is
“Space ‘%s’ already exists”.
Since version 2.4.1, responses for errors have extra information
following what was described above. This extra information is given via the
MP_ERROR extension type. See details in the MessagePack extensions section.
Keys used in requests and responses
This section describes iproto keys contained in requests and responses.
The keys are Tarantool constants that are either defined or mentioned in the
iproto_constants.h file.
While the keys themselves are unsigned 8-bit integers, their values can have different types.
Parameter values to match ? placeholders or :name placeholders
IPROTO_SQL_INFO
0x42 MP_MAP
Additional SQL-related parameters
SQL_INFO_ROW_COUNT
0x00 MP_UINT
Number of changed rows. Is 0 for statements that do not change rows. Nested in IPROTO_SQL_INFO
SQL_INFO_AUTO_INCREMENT_IDS
0x01 MP_ARRAY of MP_UINT items
New primary key value (or values) for an INSERT in a table
defined with PRIMARY KEY AUTOINCREMENT.
Nested in IPROTO_SQL_INFO
Details on individual keys
IPROTO_VERSION
Code: 0x54.
IPROTO_VERSION is an integer number reflecting the version of protocol that the
client supports. The latest IPROTO_VERSION is 3.
IPROTO_FEATURES
Code: 0x55.
Available IPROTO_FEATURES are the following:
IPROTO_FEATURE_STREAMS=0 – streams support: IPROTO_STREAM_ID
in the request header.
IPROTO_FEATURE_TRANSACTIONS=1 – transaction support: IPROTO_BEGIN,
IPROTO_COMMIT, and IPROTO_ROLLBACK commands (with IPROTO_STREAM_ID
in the request header). Learn more about sending transaction commands.
IPROTO_FEATURE_ERROR_EXTENSION=2 – MP_ERROR
MsgPack extension support. Clients that don’t support this feature receive
error responses for IPROTO_EVAL and
IPROTO_CALL encoded to string error messages.
Only used in streams.
This is an unsigned number that should be unique in every stream.
In requests, IPROTO_STREAM_ID is useful for two things:
ensuring that requests within transactions are done in separate groups,
and ensuring strictly consistent execution of requests (whether or not they are within transactions).
IPROTO_ERROR_24 is used in Tarantool versions before 2.4.1.
The key contains the error in the string format.
Since Tarantool 2.4.1,
Tarantool packs errors as the MP_ERROR MessagePack extension,
which includes extra information. Two keys are passed in the error response body: IPROTO_ERROR and IPROTO_ERROR_24.
When it comes to replicating synchronous transactions, the IPROTO_FLAGS key is included in the header.
The key contains an MP_UINT value of one or more bits:
IPROTO_FLAG_COMMIT (0x01) is set if this is the last message for a transaction.
IPROTO_FLAG_WAIT_SYNC (0x02) is set if this is the last message
for a transaction which cannot be completed immediately.
IPROTO_FLAG_WAIT_ACK (0x04) is set if this is the last message for a synchronous transaction.
Since version 2.11, the key is included in response to a heartbeat message.
The term corresponds to the value of box.info.synchro.queue.term on the sender instance.
Vclock keys
The vclock (vector clock) is a log sequence number map that defines the version of the dataset stored on the node.
In fact, it represents the number of logical operations executed on a specific node. A vclock looks like this:
There are five keys that correspond to vector clocks in different contexts of replication.
They all have the MP_MAP type:
IPROTO_VCLOCK_SYNC (0x5a) is used by replication heartbeats.
The master sends its heartbeats, including this monotonically growing key, to a replica.
Once the replica receives a heartbeat with a non-zero IPROTO_VCLOCK_SYNC value,
it starts responding with the same value in all its acknowledgements.
This key was introduced in version 2.11.
IPROTO_BALLOT_VCLOCK (0x02) is included in the IPROTO_BALLOT message.
IPROTO_BALLOT is sent in response to the IPROTO_VOTE request.
This key was introduced in Tarantool 2.6.1.
IPROTO_BALLOT_GC_VCLOCK (0x03) is also included in the IPROTO_BALLOT message.
IPROTO_BALLOT is sent in response to the IPROTO_VOTE request.
It is the vclock of the oldest WAL entry on the instance.
Corresponds to box.info.gc().vclock.
This key was introduced in Tarantool 2.6.1.
IPROTO_RAFT_VCLOCK (0x03) is included in the IPROTO_RAFT message.
It is present only on the instances in the “candidate” state
(IPROTO_RAFT_STATE == 2).
The key contains an array of column maps, with each column map containing
at least IPROTO_FIELD_NAME (0x00) and MP_STR, and IPROTO_FIELD_TYPE (0x01) and MP_STR.
Additionally, if sql_full_metadata in the
_session_settings system space
is TRUE, then the array has these additional column maps
which correspond to components described in the box.execute() section.
This request/response type is contained in the header and signifies success. Here is an example:
IPROTO_CHUNK
Code: 0x80.
If the response is out-of-band, due to use of box.session.push(),
then IPROTO_REQUEST_TYPE is IPROTO_CHUNK instead of IPROTO_OK.
IPROTO_TYPE_ERROR
Code: 0x8XXX (see below).
Instead of IPROTO_OK, an error response header
has 0x8XXX for IPROTO_REQUEST_TYPE. XXX is the error code – a value in
src/box/errcode.h.
src/box/errcode.h also has some convenience macros which define hexadecimal
constants for return codes.
An unknown request type. The constant is used to override the handler of unknown IPROTO request types.
Learn more: box.iproto.override() and box_iproto_override.
If the ID of tspace is 512 and this is the fifth message, conn.space.tspace:select({0},{iterator='GT',offset=1,limit=2}) will cause the following request packet:
In the examples,
you can find actual byte codes of an IPROTO_SELECT message.
For example, if the request is
INSERTINTOtable-nameVALUES(1),(2),(3), then the response body
contains an IPROTO_SQL_INFO map with SQL_INFO_ROW_COUNT=3.
SQL_INFO_ROW_COUNT can be 0 for statements that do not change rows,
but can be 1 for statements that create new objects.
Example
If the ID of tspace is 512 and this is the fifth message, conn.space.tspace:insert{1,'AAA'} will produce the following request and response packets:
See conn:eval().
Since the argument is a Lua expression, this is
Tarantool’s way to handle non-binary with the
binary protocol. Any request that does not have
its own code, for example box.space.space-name:drop(),
will be handled either with IPROTO_CALL
or IPROTO_EVAL.
The tt administrative utility
makes extensive use of eval.
The body is a 2-item map:
For IPROTO_EVAL and IPROTO_CALL
the response body will usually be an array but, since Lua requests can result in a wide variety
of structures, bodies can have a wide variety of structures.
Note
For SQL-specific responses, the body is a bit different.
Learn more about this type of packets.
Example
If this is the fifth message, conn:eval('return5;') will cause:
IPROTO_CALL
Code: 0x0a.
See conn:call().
This is a remote stored-procedure call.
Tarantool 1.6 and earlier made use of the IPROTO_CALL_16 request (code: 0x06). It is now deprecated
and superseded by IPROTO_CALL.
The body is a 2-item map. The response will be a list of values, similar to the
IPROTO_EVAL response. The return from conn:call is whatever the function returns.
Note
For SQL-specific responses, the body is a bit different.
Learn more about this type of packets.
IPROTO_AUTH
Code: 0x07.
For general information, see the Access control section in the administrator’s guide.
For more on how authentication is handled in the binary protocol,
see the Authentication section of this document.
The client sends an authentication packet as an IPROTO_AUTH message:
IPROTO_USERNAME holds the user name. IPROTO_TUPLE must be an array of 2 fields:
authentication mechanism
and scramble, encrypted according to the specified mechanism.
The server instance responds to an authentication packet with a standard response with 0 tuples.
To see how Tarantool handles this, look at
net_box.c
function netbox_encode_auth.
IPROTO_NOP
Code: 0x0c.
There is no Lua request exactly equivalent to IPROTO_NOP.
It causes the LSN to be incremented.
It could be sometimes used for updates where the old and new values
are the same, but the LSN must be increased because a data-change
must be recorded.
The body is: nothing.
IPROTO_PING
Code: 0x40.
See conn:ping(). The body will be an empty map because IPROTO_PING
in the header contains all the information that the server instance needs.
IPROTO_ID
Code: 0x49.
Clients send this message to inform the server about the protocol version and
features they support. Based on this information, the server can enable or
disable certain features in interacting with these clients.
The body is a 2-item map:
The response body has the same structure as
the request body. It informs the client about the protocol version, features
supported by the server, and a protocol used to generate user authentication data.
IPROTO_ID requests can be processed without authentication.
Session start and authentication
Every iproto session begins with a greeting and optional authentication.
Greeting message
When a client connects to the server instance, the instance responds with
a 128-byte text greeting message, not in MsgPack format:
The greeting contains two 64-byte lines of ASCII text.
Each line ends with a newline character (\n). If the line content is less than 64 bytes long,
the rest of the line is filled up with symbols with an ASCII code of 0 that aren’t displayed in the console.
The first line contains
the instance version and protocol type. The second line contains the session salt –
a base64-encoded random string, which is usually 44 bytes long.
The salt is used in the authentication packet – the IPROTO_AUTH message.
Authentication
If authentication is skipped, then the session user is 'guest'
(the 'guest' user does not need a password).
If authentication is not skipped, then at any time an authentication packet
can be prepared using the greeting, the user’s name and password,
and sha-1 functions, as follows.
PREPARE SCRAMBLE:
size_of_encoded_salt_in_greeting = 44;
size_of_salt_after_base64_decode = 32;
/* sha1() will only use the first 20 bytes */
size_of_any_sha1_digest = 20;
size_of_scramble = 20;
prepare 'chap-sha1' scramble:
salt = base64_decode(encoded_salt);
step_1 = sha1(password);
step_2 = sha1(step_1);
step_3 = sha1(first_20_bytes_of_salt, step_2);
scramble = xor(step_1, step_3);
return scramble;
Sequential processing:
With streams there is a guarantee that the server instance will not
handle the next request in a stream until it has completed the previous one.
Interleaving:
For example, a series of requests can include
“begin for stream #1”, “begin for stream #2”,
“insert for stream #1”, “insert for stream #2”, “delete
for stream #1”, “commit for stream #1”, “rollback for stream #2”.
To work with stream transactions using iproto, the following is required:
The client is responsible for ensuring that the stream identifier,
unsigned integer IPROTO_STREAM_ID, is in the request header.
IPROTO_STREAM_ID can be any positive 64-bit number, and should be unique for the connection.
If IPROTO_STREAM_ID equals zero, the server instance will ignore it.
At this point the stream object will look like a duplicate of
the conn object, with just one additional member: stream_id.
Now, using stream instead of conn, the client sends two requests:
stream.space.T:insert{1}stream.space.T:insert{2}
The header and body of these requests will be the same as in
non-stream IPROTO_INSERT requests, except
that the header will contain an additional item: IPROTO_STREAM_ID=0x0a
with MP_UINT=0x01. It happens to equal 1 for this example because
each call to conn:new_stream() assigns a new number, starting with 1.
The client makes stream transactions by sending, in order:
IPROTO_BEGIN with an optional transaction timeout in the IPROTO_TIMEOUT field of the request body.
The transaction data-change and query requests.
IPROTO_COMMIT or IPROTO_ROLLBACK.
All these requests must contain the same IPROTO_STREAM_ID value.
A rollback will happen automatically if
a disconnect occurs or the transaction timeout expires before the commit is possible.
Thus there are now multiple ways to do transactions:
with net_boxstream:begin() and stream:commit() or stream:rollback()
which cause IPROTO_BEGIN and IPROTO_COMMIT or IPROTO_ROLLBACK with
the current value of stream.stream_id;
with box.begin() and box.commit() or box.rollback();
with SQL and START TRANSACTION and COMMIT or ROLLBACK.
An application can use any or all of these ways.
Events and subscriptions
The commands below support asynchronous server-client notifications signalled
with box.broadcast().
Servers that support the new feature set the IPROTO_FEATURE_WATCHERS feature in reply to the IPROTO_ID command.
When the connection is closed, all watchers registered for it are unregistered.
The remote watcher (event subscription) protocol works in the following way:
The client sends an IPROTO_WATCH packet to subscribe to the updates of a specified key defined on the server.
The server sends an IPROTO_EVENT packet to the subscribed client after registration.
The packet contains the key name and its current value.
After that, the packet is sent every time the key value is updated with
box.broadcast(), provided that the last notification was acknowledged (see below).
After receiving the notification, the client sends an IPROTO_WATCH packet to acknowledge the notification.
If the client doesn’t want to receive any more notifications, it unsubscribes by sending
an IPROTO_UNWATCH packet.
All the three request types are asynchronous – the receiving end doesn’t send a packet in reply to any of them.
Therefore, neither of them has a sync number.
IPROTO_WATCH
Code: 0x4a.
Register a new watcher for the given notification key or confirms a notification if the watcher is
already subscribed.
The watcher is notified after registration.
After that, the notification is sent every time the key is updated.
The server doesn’t reply to the request unless it fails to parse the packet.
IPROTO_UNWATCH
Code: 0x4b.
Unregister a watcher subscribed to the given notification key.
The server doesn’t reply to the request unless it fails to parse the packet.
IPROTO_EVENT
Code: 0x4c.
Sent by the server to notify a client about an update of a key.
IPROTO_EVENT_DATA contains data sent to a remote watcher.
The parameter is optional, the default value is MP_NIL.
The graceful shutdown protocol is a mechanism that helps to prevent data loss in requests in case of a shutdown command.
According to the protocol, when a server receives an os.exit() command or a SIGTERM signal,
it does not exit immediately.
Instead of that, first, the server stops listening for new connections.
Then, the server sends the shutdown packets to all connections that support the graceful shutdown protocol.
When a client is notified about the upcoming server exit, it stops serving any new requests and
waits for active requests to complete before closing the connections.
Once all connections are terminated, the server will be shut down.
From now on, the server waits until all subscribed connections are terminated.
At the same time, the client gets the box.shutdown event and shuts the connection down gracefully.
After all connections are closed, the server will be stopped.
Otherwise, a timeout occurs, and the Tarantool exits immediately.
You can set up the required timeout with the
set_on_shutdown_timeout() function.
Use IPROTO_STMT_ID (0x43) and statement-id (MP_INT) if executing a prepared statement.
Use IPROTO_SQL_TEXT (0x40) and statement-text (MP_STR) if executing an SQL string.
IPROTO_SQL_BIND (0x41) corresponds to the array of parameter values to match ? placeholders or
:name placeholders.
IPROTO_OPTIONS (0x2b) corresponds to the array of options. It is usually empty.
Example 1
Suppose we prepare a statement
with two ? placeholders, and execute with two parameters, thus:
To call a prepared statement with named parameters from a connector pass the
parameters within an array of maps. A client should wrap each element into a map,
where the key holds a name of the parameter (with a colon) and the value holds
an actual value. So, to bind foo and bar to 42 and 43, a client should send
IPROTO_SQL_TEXT:<...>,IPROTO_SQL_BIND:[{"foo":42},{"bar":43}].
If a statement has both named and non-named parameters, wrap only named ones
into a map. The rest of the parameters are positional and will be substituted in order.
Example 2
Let’s ask for full metadata and then
select the two rows from a table named t1 that has columns named DD and Д:
conn.space._session_settings:update('sql_full_metadata',{{'=','value',true}})conn:prepare([[SELECT dd, дд AS д FROM t1;]])
In the iproto request, there would be no IPROTO_DATA and there would be two additional items:
3400=IPROTO_BIND_COUNTandMP_UINT=0 (there are no parameters to bind).
3390=IPROTO_BIND_METADATAandMP_ARRAY,size0 (there are no parameters to bind).
Here is what the request body looks like:
IPROTO_PREPARE
Code: 0x0d.
The body is a 1-item map:
The IPROTO_PREPARE map item is the same as the first item of the
IPROTO_EXECUTE body for an SQL string.
Responses for SQL
After the header, for a response to an SQL statement,
there will be a body that is slightly different from the body for non-SQL requests/responses.
Responses to SELECT, VALUES, or PRAGMA
If the SQL statement is SELECT or VALUES or PRAGMA, the response contains:
Example
Let’s ask for full metadata
and then select the two rows from a table named t1 that has columns named DD and Д:
conn.space._session_settings:update('sql_full_metadata',{{'=','value',true}})conn:execute([[SELECT dd, дд AS д FROM t1;]])
If the SQL request is not SELECT or VALUES or PRAGMA, then the response body
contains only IPROTO_SQL_INFO (0x42). Usually IPROTO_SQL_INFO is a map with only
one item – SQL_INFO_ROW_COUNT (0x00) – which is the number of changed rows.
For example, if the request is INSERTINTOtable-nameVALUES(1),(2),(3), then the response body
contains an IPROTO_SQL_INFO map with SQL_INFO_ROW_COUNT=3.
The IPROTO_SQL_INFO map may contain a second item – SQL_INFO_AUTO_INCREMENT_IDS(0x01) –
which is the new primary-key value (or values) for an INSERT in a table
defined with PRIMARY KEY AUTOINCREMENT. In this case the MP_MAP will have two
keys, and one of the two keys will be 0x01: SQL_INFO_AUTO_INCREMENT_IDS, which
is an array of unsigned integers.
Replication requests and responses
This section describes internal requests and responses that happen during replication.
Each of them is distinguished by the header,
containing a unique IPROTO_REQUEST_TYPE value.
These values and the corresponding packet body structures are considered below.
Connectors and clients do not need to send replication packets.
A request sent in response to IPROTO_JOIN or IPROTO_FETCH_SNAPSHOT
after the instance initialization information
The master also sends heartbeat messages to the replicas.
The heartbeat message’s IPROTO_REQUEST_TYPE is 0.
Below are details on individual replication requests.
For synchronous replication requests, see Synchronous.
Heartbeats
Once in replication_timeout seconds,
a master sends a heartbeat message to a replica,
and the replica sends a response.
Both messages’ IPROTO_REQUEST_TYPE is IPROTO_OK.
IPROTO_TIMESTAMP is a float-64 MP_DOUBLE 8-byte timestamp.
Since version 2.11, both messages have an optional field in the body that contains
the IPROTO_VCLOCK_SYNC key.
The master’s heartbeat has no body if the IPROTO_VCLOCK_SYNC key is omitted.
This step applies if the IPROTO_SERVER_VERSION specified in the request is 2.10 or later.
A number of INSERT requests (with additional LSN and ServerID).
This way, the data is updated on the instance that sent the IPROTO_JOIN request.
The instance should not reply to these INSERT requests.
The new vclock’s MP_MAP in a response similar to the one above.
A number of INSERT, REPLACE,
UPDATE, UPSERT,
and DELETE requests. This way, the instance
that is joining the replica set receives data updates that happened during
the join stage.
The new vclock’s MP_MAP in a response similar to the one above.
IPROTO_SUBSCRIBE
Code: 0x42.
If IPROTO_JOIN was successful,
the initiator instance must send an IPROTO_SUBSCRIBE request
to all the nodes listed in its box.cfg.replication:
After a successful IPROTO_SUBSCRIBE request,
the instance must process every request that could come from other masters.
Each master’s request includes a vclock pair corresponding to that master –
its instance ID and its LSN, independent from other masters.
IPROTO_ID_FILTER (0x51)
is an optional key used in the SUBSCRIBE request followed by an array
of ids of instances whose rows won’t be relayed to the replica.
The field is encoded only when the ID list is not empty.
IPROTO_FETCH_SNAPSHOT
Code: 0x45.
To join a replica set as an anonymous replica, an instance must send an initial
IPROTO_FETCH_SNAPSHOT request to the master instance of the replica set:
This step applies if the IPROTO_SERVER_VERSION specified in the request is 2.10 or later.
A number of INSERT requests (with additional LSN and ServerID).
This way, the data is updated on the instance that sent the IPROTO_JOIN request.
The instance should not reply to these INSERT requests.
The new vclock’s MP_MAP in a response similar to the one above.
IPROTO_REGISTER
Code: 0x46.
To register an anonymous replica in a replica set so that it’s not anonymous anymore,
it must send an IPROTO_REGISTER request to a master node of the replica set:
The instance that receives the request sends the following messages in response:
A number of INSERT, REPLACE,
UPDATE, UPSERT,
and DELETE requests. This way, the instance
that is registering in the replica set receives data updates that happened
since the time it fetched the snapshot.
The new vclock’s MP_MAP.
Technically, subsequent IPROTO_FETCH_SNAPSHOT and IPROTO_REGISTER requests are equivalent
to IPROTO_JOIN.
IPROTO_JOIN_META
Code: 0x47.
When an instance receives an IPOTO_JOIN or IPROTO_FETCH_SNAPSHOT request, its responses
include the information required for the instance initialization: current Raft term,
current state of synchronous transaction queue. Before sending this information,
the instance sends an IPROTO_JOIN_META request with an empty body:
An instance that has received an IPROTO_JOIN or IPROTO_FETCH_SNAPSHOT request
sends an IPROTO_JOIN_SNAPSHOT request with an empty body after it completes sending
the instance initialization information.
Roll back the RAFT transactions because they haven’t achieved quorum
IPROTO_RAFT
Code: 0x1e.
A node broadcasts the IPROTO_RAFT request to all the replicas connected to it
when the RAFT state of the node changes.
It can be any actions changing the state, like starting a new election, bumping the term,
voting for another node, becoming the leader, and so on.
If there should be a response, for example, in case of a vote request to other nodes,
the response will also be an IPROTO_RAFT message.
In this case, the node should be connected as a replica to another node from which the response is expected
because the response is sent via the replication channel.
In other words, there should be a full-mesh connection between the nodes.
IPROTO_REPLICA_ID is the ID of the replica from which the request came.
IPROTO_REPLICA_ID is the replica ID of the node that sent the request.
IPROTO_LSN is the actual LSN of the promote operation as recorded in the WAL.
In the body:
IPROTO_REPLICA_ID is the replica ID of the previous synchronous queue owner.
IPROTO_LSN is the LSN of the last operation on the previous synchronous queue owner.
IPROTO_TERM is the term in which the node that sent the request becomes the synchronous queue owner.
This term corresponds to the value of box.info.synchro.queue.term on the instance.
IPROTO_REPLICA_ID is the replica ID of the node that sent the request.
IPROTO_LSN is the actual LSN of the demote operation as recorded in the WAL.
In the body:
IPROTO_REPLICA_ID is the replica ID of the node that sent the request
(same as the value in the header).
IPROTO_LSN is the LSN of the last synchronous transaction recorded in the node’s WAL.
IPROTO_TERM is the term in which the queue becomes empty.
IPROTO_RAFT_CONFIRM
Code: 0x28.
This message is used in replication connections between
Tarantool nodes in synchronous replication.
It is not supposed to be used by any client applications in their
regular connections.
This message confirms that the transactions that originated from the instance
with id = IPROTO_REPLICA_ID (body) have achieved quorum and can be committed,
up to and including LSN = IPROTO_LSN (body).
The body is a 2-item map:
In the header:
IPROTO_REPLICA_ID is the ID of the replica that sends the confirm message.
IPROTO_LSN is the LSN of the confirmation action.
In the body:
IPROTO_REPLICA_ID is the ID of the instance from which the transactions originated.
IPROTO_LSN is the LSN up to which the transactions should be confirmed.
Prior to Tarantool v. 2.10.0, IPROTO_RAFT_CONFIRM was called IPROTO_CONFIRM.
IPROTO_RAFT_ROLLBACK
Code: 0x29.
This message is used in replication connections between
Tarantool nodes in synchronous replication.
It is not supposed to be used by any client applications in their
regular connections.
This message says that the transactions that originated from the instance
with id = IPROTO_REPLICA_ID (body) couldn’t achieve quorum for some reason
and should be rolled back, down to LSN = IPROTO_LSN (body) and including it.
The body is a 2-item map:
In the header:
IPROTO_REPLICA_ID is the ID of the replica that sends the rollback message.
IPROTO_LSN is the LSN of the rollback action.
In the body:
IPROTO_REPLICA_ID is the ID of the instance from which the transactions originated.
IPROTO_LSN is the LSN starting with which all pending synchronous transactions should be rolled back.
Prior to Tarantool v. 2.10.0, IPROTO_RAFT_ROLLBACK was called IPROTO_ROLLBACK.
MessagePack extensions
Tarantool uses predefined MessagePack extension types to represent some
of the special values. Extension types include MP_DECIMAL, MP_UUID,
MP_ERROR, MP_DATETIME, and MP_INTERVAL.
These types require special attention from the connector developers,
as they must be treated separately from the default MessagePack types,
and correctly mapped to programming language types.
The DECIMAL type
The MessagePack EXT type MP_EXT together with the extension type
MP_DECIMAL is a header for values of the DECIMAL type.
Here scale is either MP_INT or MP_UINT. scale = number of digits after the decimal point
BCD is a sequence of bytes representing decimal digits of the encoded number
(each byte has two decimal digits each encoded using 4-bit nibbles),
so byte>>4 is the first digit and byte&0x0f is the second digit.
The leftmost digit in the array is the most significant.
The rightmost digit in the array is the least significant.
The first byte of the BCD array contains the first digit of the number,
represented as follows:
| 4 bits | 4 bits |
= 0x = the 1st digit
(The first nibble contains 0 if the decimal number has an even number of digits.)
The last byte of the BCD array contains the last digit of the number and the
final nibble, represented as follows:
| 4 bits | 4 bits |
= the last digit = nibble
The final nibble represents the number’s sign:
0x0a, 0x0c, 0x0e, 0x0f stand for plus,
0x0b and 0x0d stand for minus.
Examples
The decimal -12.34 will be encoded as 0xd6,0x01,0x02,0x01,0x23,0x4d:
The MessagePack EXT type MP_EXT together with the extension type
MP_UUID for values of the UUID type. Since version 2.4.1.
MP_UUID type is 2.
The MessagePack specification
defines d8 to mean fixext with size 16, and a UUID’s size is always 16.
So the UUID MessagePack representation looks like this:
The 16-byte value has 2 digits per byte.
Typically, it consists of 11 fields, which are encoded as big-endian
unsigned integers in the following order:
time_low (4 bytes)
time_mid (2 bytes)
time_hi_and_version (2 bytes)
clock_seq_hi_and_reserved (1 byte)
clock_seq_low (1 byte)
node[0], …, node[5] (1 byte each)
Some of the functions in Module uuid can produce values
which are compatible with the UUID data type.
For example, after
a peek at the server response packet will show that it contains
d8 02 f6 42 3b df b4 9e 49 13 b3 61 07 40 c9 70 2e 4b
The ERROR type
Since version 2.4.1, responses for errors have extra information
following what was described in
Box protocol – responses for errors.
This is a “compatible” enhancement, because clients that expect old-style
server responses should ignore map components that they do not recognize.
Notice, however, that there has been a renaming of a constant:
formerly IPROTO_ERROR in ./box/iproto_constants.h was 0x31,
now IPROTO_ERROR is 0x52 and IPROTO_ERROR_24 is 0x31.
The extra information, most of which is also in
error object fields, is:
MP_ERROR_TYPE (0x00) (MP_STR) Type that implies source, as in error_object.base_type, for example “ClientError”.
MP_ERROR_FILE (0x01) (MP_STR) Source code file where error was caught, as in error_object.trace.
MP_ERROR_LINE (0x02) (MP_UINT) Line number in source code file, as in error_object.trace.
MP_ERROR_MESSAGE (0x03) (MP_STR) Text of reason, as in error_object.message.
The value here will be the same as in the IPROTO_ERROR_24 value.
MP_ERROR_ERRNO (0x04) (MP_UINT) Ordinal number of the error, as in error_object.errno.
Not to be confused with MP_ERROR_ERRCODE.
MP_ERROR_ERRCODE (0x05) (MP_UINT) Number of the error as defined in errcode.h, as in error_object.code,
which can also be retrieved with the C function box_error_code().
The value here will be the same as the lower part of the Response-Code-Indicator value.
MP_ERROR_FIELDS (0x06) (MP_MAPs) Additional fields depending on error
type. For example, if MP_ERROR_TYPE is “AccessDeniedError”, then MP_ERROR_FIELDS
will include “object_type”, “object_name”, “access_type”. This field will be
omitted from the response body if there are no additional fields available.
Client and connector programmers should ensure that unknown map keys are ignored,
and should check for addition of new keys in the Tarantool
source code file where error object creation is defined.
In version 2.4.1 the name of this source code file is mp_error.cc.
For example, in version 2.4.1 or later, if we try to create a duplicate space with conn:eval([[box.schema.space.create('_space');]])
the server response will look like this:
ce 00 00 00 88 MP_UINT = HEADER + BODY SIZE
83 MP_MAP, size 3 (i.e. 3 items in header)
00 Response-Code-Indicator
ce 00 00 80 0a MP_UINT = hexadecimal 800a
01 IPROTO_SYNC
cf 00 00 00 00 00 00 00 05 MP_UINT = sync value
05 IPROTO_SCHEMA_VERSION
ce 00 00 00 4e MP_UINT = schema version value
82 MP_MAP, size 2
31 IPROTO_ERROR_24
bd 53 70 61 63 etc. MP_STR = "Space '_space' already exists"
52 IPROTO_ERROR
81 MP_MAP, size 1
00 MP_ERROR_STACK
91 MP_ARRAY, size 1
86 MP_MAP, size 6
00 MP_ERROR_TYPE
ab 43 6c 69 65 6e 74 etc. MP_STR = "ClientError"
02 MP_ERROR_LINE
cd MP_UINT = line number
01 MP_ERROR_FILE
aa 01 b6 62 75 69 6c etc. MP_STR "builtin/box/schema.lua"
03 MP_ERROR_MESSAGE
bd 53 70 61 63 65 20 etc. MP_STR = Space.'_space'.already.exists"
04 MP_ERROR_ERRNO
00 MP_UINT = error number
05 MP_ERROR_ERRCODE
0a MP_UINT = error code ER_SPACE_EXISTS
The DATETIME type
Since version 2.10.0.
The MessagePack EXT type MP_EXT together with the extension type
MP_DATETIME is a header for values of the DATETIME type.
It creates a container with a payload of 8 or 16 bytes.
MP_DATETIME type is 4.
The MessagePack specification
defines d7 to mean fixext with size 8 or d8 to mean fixext with size 16.
So the datetime MessagePack representation looks like this:
Since version 2.10.0.
The MessagePack EXT type MP_EXT together with the extension type
MP_INTERVAL is a header for values of the INTERVAL type.
MP_INTERVAL type is 6.
The interval is saved as a variant of a map with a predefined number of known attribute names.
If some attributes are undefined, they are omitted from the generated payload.
The interval MessagePack representation looks like this:
To maintain data persistence, Tarantool writes each data change request (insert,
update, delete, replace, upsert) to a write-ahead log (WAL) file in the
wal.dir directory.
Each data change request is assigned a continuously growing 64-bit log sequence
number. The name of the WAL file is based on the log sequence number of the first
record in the file, plus an extension .xlog.
A new WAL file is created
when the current one reaches the wal_max_size size.
To see the hexadecimal bytes of the given WAL file, use the hexdump command:
$ hexdump00000000000000000000.xlog
For example, the WAL file after the first INSERT request might look the following way:
Hex dump of WAL file Comment
-------------------- -------
58 4c 4f 47 0a "XLOG\n"
30 2e 31 33 0a "0.13\n" = version
53 65 72 76 65 72 3a 20 "Server: "
38 62 66 32 32 33 65 30 2d [Server UUID]\n
36 39 31 34 2d 34 62 35 35
2d 39 34 64 32 2d 64 32 62
36 64 30 39 62 30 31 39 36
0a
56 43 6c 6f 63 6b 3a 20 "Vclock: "
7b 7d "{}" = vclock value, initially blank
... (not shown = tuples for system spaces)
d5 ba 0b ab Magic row marker always = 0xab0bbad5
19 Length, not including length of header, = 25 bytes
00 Record header: previous crc32
ce 8c 3e d6 70 Record header: current crc32
a7 cc 73 7f 00 00 66 39 Record header: padding
84 msgpack code meaning "Map of 4 elements" follows
00 02 element#1: tag=request type, value=0x02=IPROTO_INSERT
02 01 element#2: tag=server id, value=0x01
03 04 element#3: tag=lsn, value=0x04
04 cb 41 d4 e2 2f 62 fd d5 d4 element#4: tag=timestamp, value=an 8-byte "Float64"
82 msgpack code meaning "map of 2 elements" follows
10 cd 02 00 element#1: tag=space id, value=512, big byte first
21 91 01 element#2: tag=tuple, value=1-element fixed array={1}
Tarantool processes requests atomically: a change is either accepted and recorded
in the WAL, or discarded completely. To clarify how this happens, see the example with the REPLACE request below:
The server instance attempts to locate the original tuple by primary key. If found, a
reference to the tuple is retained for later use.
The new tuple is validated. If for example it does not contain an indexed
field, or it has an indexed field whose type does not match the type
according to the index definition, the change is aborted.
The new tuple replaces the old tuple in all existing indexes.
A message is sent to the WAL writer running in a separate thread, requesting that
the change be recorded in the WAL. The instance switches to work on the next
request until the write is acknowledged.
On success, a confirmation is sent to the client. On failure, a rollback
procedure begins. During the rollback procedure, the transaction processor
rolls back all changes to the database which occurred after the first failed
change, from latest to oldest, up to the first failed change. All rolled back
requests are aborted with ER_WAL_IO error. No new
change is applied while rollback is in progress. When the rollback procedure
is finished, the server restarts the processing pipeline.
One advantage of the described algorithm is that complete request pipelining is
achieved, even for requests on the same value of the primary key. As a result,
database performance doesn’t degrade even if all requests refer to the same
key in the same space.
The transaction processor thread communicates with the WAL writer thread using
asynchronous (yet reliable) messaging.
The transaction processor thread, not being blocked on WAL tasks, continues to handle requests quickly even at high
volumes of disk I/O. A response to a request is sent as soon as it is ready,
even if there were earlier incomplete requests on the same connection. In
particular, SELECT performance, even for SELECTs running on a connection packed
with UPDATEs and DELETEs, remains unaffected by disk load.
The WAL writer employs a number of durability modes, as defined in configuration
variable wal.mode.
It is possible to turn the write-ahead log completely off, by setting the wal_mode option to none.
Even without the write-ahead log it’s still possible to take a persistent copy of the
entire data set with the box.snapshot() request.
An .xlog file always contains changes based on the primary key.
Even if the client requested an update or delete using
a secondary key, the record in the .xlog file contains the primary key.
The snapshot file format
The format of a snapshot (.snap) file is the following:
The snapshot header contains the instance’s global unique identifier
and the snapshot file’s position in history, relative to earlier snapshot files.
The snapshot content contains the records of inserts to memtx spaces.
That differs from the content of an .xlog file that may contain records for any data-change requests
(inserts, updates, upserts, and deletes).
Primarily, the records in the snapshot file have the following order:
System spaces (id >= 256 && id <= 511), ordered by ID.
Non-system spaces, ordered by ID.
Secondarily, the .snap file’s records are ordered by primary key within space ID.
Example
The header of a .snap or .xlog file might look in the following way:
<type>\n SNAP\n or XLOG\n
<version>\n currently 0.13\n
Server: <server_uuid>\n where UUID is a 36-byte string
VClock: <vclock_map>\n e.g. {1: 0}\n
\n
After the file header come the data tuples.
Tuples begin with a row marker 0xd5ba0bab and
the last tuple may be followed by an EOF marker
0xd510aded.
Thus, between the file header and the EOF marker, there
may be data tuples that have this form:
The recovery process begins when box.cfg{} happens for the
first time after the Tarantool server instance starts.
The recovery process must recover the databases
as of the moment when the instance was last shut down. For this it may
use the latest snapshot file and any WAL files that were written
after the snapshot. One complicating factor is that Tarantool
has two engines – the memtx data must be reconstructed entirely
from the snapshot and the WAL files, while the vinyl data will
be on disk but might require updating around the time of a checkpoint.
(When a snapshot happens, Tarantool tells the vinyl engine to
make a checkpoint, and the snapshot operation is rolled back if
anything goes wrong, so vinyl’s checkpoint is at least as fresh
as the snapshot file.)
Find the latest snapshot file. Use its data to reconstruct the in-memory
databases. Instruct the vinyl engine to recover to the latest checkpoint.
There are actually two variations of the reconstruction procedure for memtx
databases, depending on whether the recovery process is “default”.
If the recovery process is default (force_recovery is false),
memtx can read data in the snapshot with all indexes disabled.
First, all tuples are read into memory. Then, primary keys are built in bulk,
taking advantage of the fact that the data is already sorted by primary key
within each space.
If the recovery process is non-default (force_recovery is true),
Tarantool performs additional checking. Indexes are enabled at
the start, and tuples are added one by one. This means that any unique-key
constraint violations will be caught, and any duplicates will be skipped.
Normally there will be no constraint violations or duplicates, so these checks
are only made if an error has occurred.
Step 3
Find the WAL file that was made at the time of, or after, the snapshot file.
Read its log entries until the log-entry LSN is greater than the LSN of the
snapshot, or greater than the LSN of the vinyl checkpoint. This is the
recovery process’s “start position”; it matches the current state of the
engines.
Step 4
Redo the log entries, from the start position to the end of the WAL. The
engine skips a redo instruction if it is older than the engine’s checkpoint.
Step 5
For the memtx engine, re-create all secondary indexes.
In addition to the recovery process described in the
section Recovery process, the server must take
additional steps and precautions if replication is enabled.
Once again the startup procedure is initiated by the box.cfg{} request.
One of the box.cfg parameters may be
replication which specifies replication
source(-s). We will refer to this replica, which is starting up due to box.cfg,
as the “local” replica to distinguish it from the other replicas in a replica set,
which we will refer to as “distant” replicas.
If there is no snapshot .snap file and thereplicationparameter is empty andcfg.read_only=false:
then the local replica assumes it is an unreplicated “standalone” instance, or is
the first replica of a new replica set. It will generate new UUIDs for
itself and for the replica set. The replica UUID is stored in the _cluster space; the
replica set UUID is stored in the _schema space. Since a snapshot contains all the
data in all the spaces, that means the local replica’s snapshot will contain the
replica UUID and the replica set UUID. Therefore, when the local replica restarts on
later occasions, it will be able to recover these UUIDs when it reads the .snap
file.
If there is no snapshot .snap file and thereplicationparameter is empty
andcfg.read_only=true:
it cannot be the first replica of a new replica set because the first replica
must be a master. Therefore an error message will occur: ER_BOOTSTRAP_READONLY.
To avoid this, change the setting for this (local) instance to read_only=false,
or ensure that another (distant) instance starts first and has the local instance’s
UUID in its _cluster space. In the latter case, if ER_BOOTSTRAP_READONLY still
occurs, set the local instance’s
box.replication_connect_timeout
to a larger value.
If there is no snapshot .snap file and thereplicationparameter is not empty
and the_clusterspace contains no other replica UUIDs:
then the local replica assumes it is not a standalone instance, but is not yet part
of a replica set. It must now join the replica set. It will send its replica UUID to the
first distant replica which is listed in replication and which will act as a
master. This is called the “join request”. When a distant replica receives a join
request, it will send back:
the distant replica’s replica set UUID,
the contents of the distant replica’s .snap file.
When the local replica receives this information, it puts the replica set UUID in
its _schema space, puts the distant replica’s UUID and connection information
in its _cluster space, and makes a snapshot containing all the data sent by
the distant replica. Then, if the local replica has data in its WAL .xlog
files, it sends that data to the distant replica. The distant replica will
receive this and update its own copy of the data, and add the local replica’s
UUID to its _cluster space.
If there is no snapshot .snap file and thereplicationparameter is not empty
and the_clusterspace contains other replica UUIDs:
then the local replica assumes it is not a standalone instance, and is already part
of a replica set. It will send its replica UUID and replica set UUID to all the distant
replicas which are listed in replication. This is called the “on-connect
handshake”. When a distant replica receives an on-connect handshake:
the distant replica compares its own copy of the replica set UUID to the one in
the on-connect handshake. If there is no match, then the handshake fails and
the local replica will display an error.
the distant replica looks for a record of the connecting instance in its
_cluster space. If there is none, then the handshake fails.
Otherwise the handshake is successful. The distant replica will read any new
information from its own .snap and .xlog files, and send the new requests to
the local replica.
In the end, the local replica knows what replica set it belongs to, the distant
replica knows that the local replica is a member of the replica set, and both
replicas have the same database contents.
If there is a snapshot file and replication source is not empty:
first the local replica goes through the recovery process described in the
previous section, using its own .snap and .xlog files. Then it sends a
“subscribe” request to all the other replicas of the replica set. The subscribe
request contains the server vector clock. The vector clock has a collection of
pairs ‘server id, lsn’ for every replica in the _cluster system space. Each
distant replica, upon receiving a subscribe request, will read its .xlog files’
requests and send them to the local replica if (lsn of .xlog file request) is
greater than (lsn of the vector clock in the subscribe request). After all the
other replicas of the replica set have responded to the local replica’s subscribe
request, the replica startup is complete.
The following temporary limitations applied for Tarantool versions earlier than
1.7.7:
The URIs in the replication parameter should all be in the same order on all replicas.
This is not mandatory but is an aid to consistency.
The replicas of a replica set should be started up at slightly different times.
This is not mandatory but prevents a situation where each replica is waiting
for the other replica to be ready.
The following limitation still applies for the current Tarantool version:
The maximum number of entries in the _cluster space is
32. Tuples for
out-of-date replicas are not automatically re-used, so if this 32-replica
limit is reached, users may have to reorganize the _cluster space manually.
Orphan status
Starting with Tarantool version 1.9, there is a change to the
procedure when an instance joins a replica set.
During box.cfg() the instance tries to join all nodes listed
in box.cfg.replication.
If the instance does not succeed with connecting to the required number of nodes
(see bootstrap_strategy),
it switches to the orphan status.
While an instance is in orphan status, it is read-only.
To “join” a master, a replica instance must “connect” to the
master node and then “sync”.
“Connect” means contact the master over the physical network
and receive acknowledgment. If there is no acknowledgment after
box.replication_connect_timeout
seconds (usually 4 seconds), and retries fail, then the connect step fails.
“Sync” means receive updates
from the master in order to make a local database copy.
Syncing is complete when the replica has received all the
updates, or at least has received enough updates that the replica’s lag
(see
replication.upstream.lag
in box.info())
is less than or equal to the number of seconds specified in
box.cfg.replication_sync_lag.
If replication_sync_lag is unset (nil) or set to TIMEOUT_INFINITY, then
the replica skips the “sync” state and switches to “follow” immediately.
In order to leave orphan mode, you need to sync with a sufficient number of
instances (bootstrap_strategy).
To do so, you may either:
Reset box.cfg.replication to exclude instances that cannot be reached
or synced with.
Set box.cfg.replication to "" (empty string).
The following situations are possible.
Situation 1: bootstrap
Here box.cfg{} is being called for the first time.
A replica is joining but no replica set exists yet.
Set the status to ‘orphan’.
Try to connect to all nodes from box.cfg.replication.
The replica tries to connect for the
replication_connect_timeout
number of seconds and retries each
replication_timeout seconds if needed.
Abort and throw an error if a replica is not connected to the majority of nodes in box.cfg.replication.
This instance might be elected as the replica set ‘leader’.
Criteria for electing a leader include vclock value (largest is best),
and whether it is read-only or read-write (read-write is best unless there is no other choice).
The leader is the master that other instances must join.
The leader is the master that executes
box.once() functions.
If this instance is elected as the replica set leader,
then
perform an “automatic bootstrap”:
Set status to ‘running’.
Return from box.cfg{}.
Otherwise this instance will be a replica joining an existing replica set,
so:
In background, sync with all the other nodes in the replication set.
Situation 2: recovery
Here box.cfg{} is not being called for the first time.
It is being called again in order to perform recovery.
Perform recovery from the last local
snapshot and the WAL files.
Try to establish connections to all other nodes for the
replication_connect_timeout number of seconds.
Once replication_connect_timeout is expired or all the connections are established, proceed to the “sync” state with all the established connections.
If connected, sync with all connected nodes, until the difference is not more than
replication_sync_lag seconds.
Situation 3: configuration update
Here box.cfg{} is not being called for the first time.
It is being called again because some replication parameter
or something in the replica set has changed.
Try to connect to all nodes from box.cfg.replication,
within the time period specified in
replication_connect_timeout.
Try to sync with the connected nodes,
within the time period specified in
replication_sync_timeout.
If earlier steps fail, change status to ‘orphan’.
(Attempts to sync will continue in the background and when/if they succeed
then ‘orphan’ status will end.)
If earlier steps succeed, set status to ‘running’ (master) or ‘follow’ (replica).
Situation 4: rebootstrap
Here box.cfg{} is not being called. The replica connected successfully
at some point in the past, and is now ready for an update from the master.
But the master cannot provide an update.
This can happen by accident, or more likely can happen because the replica
is slow (its lag is large),
and the WAL (.xlog) files containing the
updates have been deleted. This is not crippling. The replica can discard
what it received earlier, and then ask for the master’s latest snapshot
(.snap) file contents. Since it is effectively going through the bootstrap
process a second time, this is called “rebootstrapping”. However, there has
to be one difference from an ordinary bootstrap – the replica’s
replica id will remain the same.
If it changed, then the master would think that the replica is a
new addition to the cluster, and would maintain a record of an
instance ID of a replica that has ceased to exist. Rebootstrapping was
introduced in Tarantool version 1.10.2 and is completely automatic.
Limitations
Number of parts in an index
For TREE or HASH indexes, the maximum
is 255 (box.schema.INDEX_PART_MAX). For RTREE indexes, the
maximum is 1 but the field is an ARRAY of up to 20 dimensions.
For BITSET indexes, the maximum is 1.
Number of tuples in a hash index
4,294,967,288 (232-8).
Number of indexes in a space
128 (box.schema.INDEX_MAX).
Number of fields in a tuple
The theoretical maximum is 2,147,483,647 (box.schema.FIELD_MAX). The
practical maximum is whatever is specified by the space’s
field_count
member, or the maximal tuple length.
Number of bytes in a tuple
The maximal number of bytes in a tuple is roughly equal to
memtx.max_tuple_size or
vinyl.max_tuple_size
(with a metadata
overhead of about 20 bytes per tuple, which is added on top of useful bytes).
By default, the value of either memtx.max_tuple_size or
vinyl.max_tuple_size is 1,048,576.
Number of bytes in an index key
If a field in a tuple can contain a million bytes, then the index key
can contain a million bytes, so the maximum is determined by factors
such as Number of bytes in a tuple,
not by the index support.
Number of elements in array fields in a space with a multikey index
In a Tarantool space that has multikey indexes,
any tuple cannot contain more than ~8,000 elements in a field indexed with that multikey index.
This is because every element has 4 bytes of metadata, and the tuple’s metadata,
which includes multikey metadata, cannot exceed 2^16 bytes.
Number of spaces
The theoretical maximum is 2,147,483,646 (box.schema.SPACE_MAX)
but the practical maximum is around 65,000.
Number of connections
The practical limit is the number of file descriptors that one can set
with the operating system.
Space size
The total maximum size for all spaces is in effect set by
memtx.memory, which in turn
is limited by the total available memory.
Update operations count
The maximum number of operations per tuple that can be in a single update
is 4,000 (BOX_UPDATE_OP_CNT_MAX).
Number of users and roles
32 (BOX_USER_MAX).
Length of an index name or space name or user name
65,000 (box.schema.NAME_MAX).
Number of replicas in a replica set
32 (vclock.VCLOCK_MAX).
Releases
This section contains information about Tarantool releases: release notes, lifecycle
information, release policy, and other documents.
To download Tarantool releases, check the Download page.
All currently supported versions are listed on this page below.
The information about earlier versions is provided in EOL versions.
The Enterprise Edition of Tarantool is distributed in the form of an SDK that has
its own versioning. See the Enterprise SDK changelog to learn about
SDK version numbering and changes.
The detailed information about Tarantool version numbering and release lifecycle
is available in Tarantool release policy.
Backward compatibility is guaranteed between all versions in the same release series.
It is also appreciated but not guaranteed between different release series (major number changes).
To learn more, read the Compatibility guarantees article.
Supported versions
Every Tarantool release series has the same lifecycle
defined by the release policy. The following diagram visualizes the lifecycle of currently
supported Tarantool versions:
The table below provides information about supported versions with links to their
What’s new pages in the documentation and detailed changelogs on GitHub.
For information about earlier versions, see EOL versions.
Note
End of life (EOL) means the release series will no longer receive any patches,
updates, or feature improvements after the specified date. Versions that haven’t
reached their end of life yet are shown in bold.
End of support (EOS) means that we won’t provide technical support to product
versions after the specified date.
The 3.3 release of Tarantool adds the following main product features and improvements for the Community and Enterprise editions:
Community Edition (CE)
Improvements around queries with offsets.
Improvement in Raft implementation.
Persistent replication state.
New C API for sending work to the TX thread from user threads.
JSON cluster configuration schema.
New on_event callback in application roles.
API for user-defined alerts.
Isolated instance mode.
Automatic instance expulsion.
New configuration option for Lua memory size.
Enterprise Edition (EE)
Offset-related improvements in read views.
Supervised failover improvements.
Developing applications
Improved offset processing
Tarantool 3.3 brings a number of improvements around queries with offsets.
The performance of tree index select() with offset and
count() methods was improved.
Previously, the algorithm complexity had a linear dependency on the
provided offset size (O(offset)) or the number of tuples to count. Now,
the new algorithm complexity is O(log(size)) where size is the number of tuples
in the index. This change also eliminates the dependency on the offset value or
the number of tuples to count.
The index and space entities get a new
offset_of method that returns the position relative to the given iterator
direction of the tuple that matches the given key.
The offset parameter has been added to the index:pairs() method,
allowing to skip the first tuples in the iterator.
Same improvements are also introduced to read views in the Enterprise Edition.
Improved performance of the tree index read view select() with offset.
A new offset_of() method of index read views.
A new offset parameter in the index_read_view:pairs() method.
No rollback on timeout for synchronous transactions
To better match the canonical Raft algorithm design, Tarantool no longer rolls
back synchronous transactions on timeout (upon reaching replication.synchro_timeout).
In the new implementation, transactions can only be rolled back by a new leader after it is elected.
Otherwise, they can wait for a quorum infinitely.
Given this change in behavior, a new replication_synchro_timeoutcompat option is introduced.
To try the new behavior, set this option to new:
There is also a new replication.synchro_queue_max_size configuration option
that limits the total size of transactions in the master synchronous queue. The default
value is 16 megabytes.
C API for sending work to TX thread
New public C API functions tnt_tx_push() and tnt_tx_flush()
allow to send work to the TX thread from any other thread:
tnt_tx_push() schedules the given callback to be executed with the provided
arguments.
tnt_tx_flush() sends all pending callbacks for execution in the TX thread.
Execution is started in the same order as the callbacks were pushed.
JSON schema of the cluster configuration
Tarantool cluster configuration schema is now available in the JSON format.
A schema lists configuration options of a certain Tarantool version with descriptions.
As of Tarantool 3.3 release date, the following versions are available:
Additionally, there is the latest
schema that reflects the latest configuration schema in development (master branch).
Use these schemas to add code completion for YAML configuration files and get
hints with option descriptions in your IDE, or validate your configurations,
for example, with check-jsonschema:
There is also a new API for generating the JSON configuration schema as a Lua table –
the config:jsonschema() function.
on_event callbacks in roles
Now application roles can have on_event callbacks.
They are executed every time a box.statussystem event is
broadcast or the configuration is updated. The callback has three arguments:
config – the current configuration.
key – an event that has triggered the callback: config.apply or box.status.
return{name='my_role',validate=function()end,apply=function()end,stop=function()end,on_event=function(config,key,value)locallog=require('log')log.info('on_event is triggered by '..key)log.info('is_ro: '..value.is_ro)log.info('roles_cfg.my_role.foo: '..config.foo)end,}
API for raising alerts
Now developers can raise their own alerts from their application or application roles.
For this purpose, a new API is introduced into the config module.
The config:new_alerts_namespace() function creates a new
alerts namespace – a named container for user-defined alerts:
Alerts namespaces provide methods for managing alerts within them. All user-defined
alerts raised in all namespaces are shown in box.info.config.alerts.
To raise an alert, use the namespace methods add() or set():
The difference between them is that set() accepts a key to refer to the alert
later: overwrite or discard it. An alert is a table with one mandatory field message
(its value is logged) and arbitrary used-defined fields.
-- Raise a new alert.alerts:add({message='Test alert',my_field='my_value',})-- Raise a new alert with a key.alerts:set("my_alert",{message='Test alert',my_field='my_value',})
You can discard alerts individually by keys using the unset() method, or
all at once using clear():
alerts:unset("my_alert")alerts:clear()
Administration and maintenance
DDL before upgrade
Since version 3.3, Tarantool allows DDL operations before calling box.schema.upgrade()
during an upgrade if the source schema version is 2.11.1 or later. This allows,
for example, granting execute access to user-defined functions in the cluster configuration
before the schema is upgraded.
Isolated instances
A new instance-level configuration option isolated puts an instance into the
isolated mode. In this mode, an instance doesn’t accept updates from other members
of its replica set and other iproto requests. It also performs no background
data modifications and remains in read-only mode.
enabled: whether automatic expulsion logic is enabled in the cluster.
by: a criterion for selecting instances that can be expelled automatically.
In version 3.3, the only available criterion is prefix.
prefix: a prefix with which an instance name should start to make automatic expulsion possible.
Lua memory size
A new configuration option lua.memory specifies the maximum amount of memory
for Lua scripts execution, in bytes. For example, this configuration sets the Lua memory
limit to 4 GB:
lua:memory:4294967296
The default limit is 2 GB.
Supervised failover improvements
Tarantool 3.3 is receiving a number of supervised failover improvements:
Support for Tarantool-based stateboard
as an alternative to etcd.
Instance priority configuration: new failover.priority configuration section.
This section specify the instances’ relative order of being appointed by a coordinator:
bigger values mean higher priority.
Tarantool persistence mechanism uses
two types of files: snapshots and write-ahead log (WAL) files. These files are also used
for replication: read-only replicas receive data changes from the replica set leader
by reading these files.
The garbage collector
cleans up obsolete snapshots and WAL files, but it doesn’t remove the files while they
are in use for replication. To make such a check possible, the replica set leaders
store the replication state in connection with files. However, this information
was not persisted, which could lead to issues in case of the leader restart.
The garbage collector could delete WAL files after the restart even if there were
replicas that still read these files. The wal.cleanup_delay
configuration option was used to prevent such situations.
Since version 3.3, leader instances persist the information about WAL files in use
in a new system space _gc_consumers. After a restart, the replication state
is restored, and WAL files needed for replication are protected from garbage collection.
This eliminates the need to keep all WAL files after a restart, so the wal.cleanup_delay
option is now deprecated.
The 3.2 release of Tarantool adds the following main product features and improvements for the Community and Enterprise editions:
Community Edition (CE)
A new experimental module for validating role configurations.
Initial support for encoding structured data using Protobuf.
Next and Previous prefix iterators.
Support for all UUID versions.
Automatic loading of the most often used built-in modules into the console environment.
Enterprise Edition (EE)
Time-to-live (TTL) for keys in a Tarantool-based configuration storage.
Developing applications
Configuration validation
Tarantool 3.2 includes a new experimental module for validating role configurations using a declarative schema.
For example, you can validate the type of configuration values, provide an array of allowed values, or specify a custom validation function.
Suppose, a sample ‘http-api’ custom role can accept the host and port configuration values:
This release adds two new iterators for TREE indexes: np (next prefix) and pp (previous prefix).
If a key is a string value, a prefix is a common starting substring shared by multiple keys.
Suppose, the products space contains the following values:
Note that new iterators work only for the memtx engine.
Tarantool configuration storage: TTL support for keys (EE)
The Enterprise Edition now includes a time-to-live (TTL) for keys in a Tarantool-based configuration storage.
You can specify a TTL value in the config.storage.put() call as follows:
A new config.storage.info.features.ttl field allows you to check whether the current version of the configuration storage supports requests with TTL.
In the example below, the conn:call() method is used to make a remote call to get the ttl field value:
Before the 3.2 version, Tarantool supported only UUIDs following the rules for RFC 4122 version 4.
With v3.2, UUID values of all versions (including new 6, 7, and 8) can be parsed using the uuid module.
This improves interoperability with third-party data sources whose data is processed by Tarantool.
Administration and maintenance
Interactive console
With this release, both the Tarantool and tt interactive consoles automatically add the most often used built-in modules into the environment.
This means that you can start using a module without loading it with the require directive.
In the interactive session below, the config module is used to get the instance’s configuration state right after connecting to this instance:
The 3.1 release of Tarantool continues the development of a new cluster configuration approach introduced in the 3.0 version and adds the following main product features and improvements for the Community and Enterprise editions:
Community Edition (CE)
Improved developer experience for handling errors using the box.error module.
Introduced fixed-size numeric field types: uint8, int8, uint16, and more.
Added RPC functionality for accessing custom roles from the configuration.
Made the tt utility used to manage instances fully compatible with the latest Tarantool version.
Enterprise Edition (EE)
Introduced an external coordinator for automatic and manual failover.
Improved the stability of work with the centralized configuration stored in etcd.
Developing applications
Error handling
This release improves the developer experience for handling errors using the box.error module.
Below are listed the most notable features and changes.
Error payload fields
With the 3.1 release, you can add a custom payload to an error.
The payload is passed as key-value pairs where a key is a string and a value is any Lua object.
In the example below, the description key is used to keep the custom payload.
custom_error=box.error.new({type='CustomInternalError',message='Internal server error',description='Some error details'-- payload})
A payload field value can be accessed using the dot syntax:
The 3.1 release simplifies creating error chains.
In the earlier versions, you need to set an error cause using the set_prev(error_object) method, for example:
Using this approach, you need to construct a new error without raising it, then set its cause using set_prev(), and only then raise it.
Starting with the 3.1 version, you can use a new prev argument when constructing an error:
The 3.1 release allows you to increase the verbosity of error serialization.
Before the 3.1 release, a serialized error representation included only an error message:
tarantool> box.error.new({type='CustomInternalError',message='Internal server error'})----Internal server error...
Starting with the 3.1 version, a serialized error also includes other fields that might be useful for analyzing errors:
tarantool>box.error.new({type='CustomInternalError',message='Internal server error'})----code:0base_type:CustomErrortype:CustomInternalErrorcustom_type:CustomInternalErrormessage:Internalservererrortrace:-file:'[C]'line:4294967295...
Logging an error using a built-in logging module prints an error message followed by a tab space (\t) and all the payload fields serialized as a JSON map, for example:
main/104/app.lua/tarantool I> Internal server error {"code":0,"base_type":"CustomError","type":"CustomInternalError", ... }
Given that this change may change the behavior of existing code, a new box_error_serialize_verbosecompat option is introduced.
To try out an increased verbosity of error serialization, set this option to new:
The 3.1 release introduces fixed-size numeric types that might be useful to store data unencoded in an array for effective scanning.
The following numeric types are added:
uint8: an integer in a range [0..255].
int8: an integer in a range [-128..127].
uint16: an integer in a range [0..65,535].
int16: an integer in a range [-32,768..32,767].
uint32: an integer in a range [0..4,294,967,295].
int32: an integer in a range [-2,147,483,648..2,147,483,647].
uint64: an integer in a range [0..18,446,744,073,709,551,615].
int64: an integer in a range [-9,223,372,036,854,775,808..9,223,372,036,854,775,807].
float32: a 32-bit floating point number.
float64: a 64-bit floating point number.
Experimental ‘connpool’ module
A new experimental.connpoolmodule provides a set of features for remote connections to any cluster instance or executing remote procedure calls on an instance that meets the specified criteria.
To load the experimental.connpool module, use the require() directive:
The filter() function returns the names of instances that match the specified conditions.
In the example below, this function returns a list of instances with the storage role and specified
label value:
The call() function can be used to execute a function on a remote instance.
In the example below, the following conditions are specified to choose an instance to execute the vshard.storage.buckets_count function on:
In Tarantool 3.0, the config module provides the ability to work with a current instance’s configuration only.
Starting with the 3.1 version, you can get all the instances that constitute a cluster and obtain the configuration of any instance of this cluster.
The config:instances() function lists all instances of the cluster:
Tarantool Enterprise Edition 3.1 introduces an external failover coordinator that monitors a Tarantool cluster and performs automatic leadership change if a current replica set leader is inaccessible.
A failover coordinator requires the replication.failover configuration option to be set to supervised:
replication:failover:supervised# ...
To start a failover coordinator, execute the tarantool command with the failover option and pass a path to a YAML configuration file:
$ tarantool--failover--config/path/to/config
A failover coordinator connects to all the instances, polls them for their status, and controls that each replica set with replication.failover set to supervised has only one writable instance.
Optionally, you can configure failover timeouts and other parameters in the failover section at the global level:
The 3.1 release includes new sharding options that provide additional flexibility for configuring a sharded cluster.
A new sharding.weight specifies the relative amount of data that a replica set can store.
In the example below, the storage-a replica set can store twice as much data as storage-b:
The sharding.rebalancer_mode option configures whether a rebalancer is selected manually or automatically.
This option can have one of three values:
auto (default): if there are no replica sets with the rebalancer sharding role (sharding.roles), a replica set with the rebalancer will be selected automatically among all replica sets.
manual: one of the replica sets should have the rebalancer sharding role. The rebalancer will be in this replica set.
off: rebalancing is turned off regardless of whether a replica set with the rebalancer sharding role exists or not.
Compatibility with the tt utility
With this release, the tarantoolctl utility used to administer Tarantool instances is completely removed from Tarantool packages.
The latest version of the tt utility is fully compatible with Tarantool 3.1 and covers all the required functionality:
Setting up a development environment: initializing the environment and installing different Tarantool versions.
Various capabilities for developing cluster applications: creating applications from templates, managing modules, and building and packaging applications.
Managing cluster instances: starting and stopping instances, connecting to remote instances for administration, and so on.
Importing and exporting data (Enterprise Edition only).
The 3.0 release of Tarantool introduces a new declarative approach for configuring a cluster,
a new visual tool – Tarantool Cluster Manager,
and many other new features and fixes.
This document provides an overview of the most important features for the Community and Enterprise editions.
Starting with the 3.0 version, Tarantool provides the ability to configure the full topology of a cluster using a declarative YAML configuration instead of configuring each instance using a dedicated Lua script.
With a new approach, you can write a local configuration in a YAML file for each instance or store configuration data in one reliable place, for example, a Tarantool or an etcd cluster.
The example below shows how a configuration of a small sharded cluster might look.
In the diagram below, the cluster includes 5 instances: one router and 4 storages, which constitute two replica sets.
For each replica set, the master instance is specified manually.
The example below demonstrates how a topology of such a cluster might look in a YAML configuration file:
You can find the full sample in the GitHub documentation repository: sharded_cluster.
The latest version of the tt utility provides the ability to manage Tarantool instances configured using a new approach.
You can start all instances in a cluster by executing one command, check the status of instances, or stop them:
$ ttstartsharded_cluster
• Starting an instance [sharded_cluster:storage-a-001]... • Starting an instance [sharded_cluster:storage-a-002]... • Starting an instance [sharded_cluster:storage-b-001]... • Starting an instance [sharded_cluster:storage-b-002]... • Starting an instance [sharded_cluster:router-a-001]...
Centralized configuration (EE)
Tarantool Enterprise Edition enables you to store configuration data in one reliable place, for example, an etcd cluster. To achieve this, you need to configure connection options in the config.etcd section of the configuration file, for example:
Using the configuration above, a Tarantool instance searches for a cluster configuration by the following path:
http://localhost:2379/myapp/config/*
Tarantool Cluster Manager (EE)
Tarantool 3.0 Enterprise Edition comes with a brand new visual tool – Tarantool Cluster Manager (TCM).
It provides a web-based user interface for managing, configuring, and monitoring Tarantool EE clusters that use centralized configuration storage.
TCM can manage multiple clusters and covers a wide range of tasks, from writing a cluster’s configuration to executing commands interactively on specific instances.
TCM’s role-based access control system lets you manage users’ access to clusters, their configurations, and stored data.
The built-in customizable audit logging mechanism and LDAP authentication make TCM a suitable solution for different enterprise security requirements.
Administration and maintenance
Database statistics
Starting with 3.0, Tarantool provides extended statistics about memory consumption for the given space or specific tuples.
Usually, the space_object:bsize() method is used to get the size of memory occupied by the specified space:
In addition to the actual data, the space requires additional memory to store supplementary information.
You can see the total memory usage using box.slab.info():
The new version includes the capability to choose a bootstrap leader for a replica set manually.
The bootstrap leader is a node that creates an initial snapshot and registers all the replicas in a replica set.
First, you need to set replication.bootstrap_strategy to config.
Then, use the <replicaset_name>.bootstrap_leader option to specify a bootstrap leader.
Note that in 3.0, the replication_connect_quorum option is removed.
This option was used to specify the number of nodes to be up and running for starting a replica set.
Security (EE)
With the 3.0 version, Tarantool Enterprise Edition provides a set of new features that enhance security in your cluster:
Introduced the secure_erasing configuration option that forces Tarantool to overwrite a data file a few times before deletion to render recovery of a deleted file impossible.
With the new configuration approach, you can enable this capability as follows:
security:secure_erasing:true
This option can be also set using the TT_SECURITY_SECURE_ERASING environment variable.
Added the auth_retries option that configures the maximum number of authentication retries before throttling is enabled.
You can configure this option as follows:
security:auth_retries:3
Added the capability to use the new SSL certificate with the same name by reloading the configuration.
To do this, use the reload() function provided by the new config module:
app:instance001> require('config'):reload()---...
Audit logging (EE)
Tarantool Enterprise Edition includes the following new features for audit logging:
Added a unique identifier (UUID) to each audit log entry.
Introduced audit log severity levels.
Each system audit event now has a severity level determined by its importance.
Added the audit_log.audit_spaces option that configures the list of spaces for which data operation events should be logged.
Added the audit_log.audit_extract_key option that forces the audit subsystem to log the primary key instead of a full tuple in DML operations.
This might be useful for reducing audit log size in the case of large tuples.
The sample audit log configuration in the 3.0 version might look as follows, including new audit_spaces and audit_extract_key options:
With this configuration, an audit log entry for a DELETE operation may look like below:
{"time":"2023-12-19T10:09:44.664+0000","uuid":"65901190-f8a6-45c1-b3a4-1a11cf5c7355","severity":"VERBOSE","remote":"unix/:(socket)","session_type":"console","module":"tarantool","user":"admin","type":"space_delete","tag":"","description":"Delete key [\"0671623249\"] from space books"}
The entry includes the new uuid and severity fields.
The last description field gives only the information about the key of the deleted tuple.
Reading flight recordings (EE)
The flight recorder available in the Enterprise Edition is an event collection tool that gathers various information about a working Tarantool instance.
With the 3.0 version, you can read flight recordings using the API provided by the flightrec module.
To enable the flight recorder in a YAML file, set flightrec.enabled to true:
flightrec:enabled:true
Then, you can use the Lua API to open and read *.ttfr files:
app:instance001> flightrec = require('flightrec')---...app:instance001> flightrec_file = flightrec.open('var/lib/instance001/20231225T085435.ttfr')---...app:instance001> flightrec_file----sections:&0requests:size:10485760metrics:size:368640logs:size:10485760was_closed:falseversion:0pid:1350...app:instance001> for i, r in flightrec_file.sections.logs:pairs() do record = r; break end---...app:instance001> record----level:INFOfiber_name:interactivefiber_id:103cord_name:mainfile:./src/box/flightrec.ctime:2023-12-25 08:50:12.275message:'Flightrecorder:configurationhasbeendone'line:727...app:instance001> flightrec_file:close()---...
New DEB and RPM packages
With this release, the approach to delivering Tarantool to end users in DEB and RPM packages is slightly revised.
In the previous versions, Tarantool was built for the most popular Linux distributions and their latest version.
Starting with this release, only two sets of DEB and RPM packages are delivered.
The difference is that these packages include a statically compiled Tarantool binary.
This approach provides the ability to install DEB and RPM packages on any Linux distributions that are based on СentOS and Debian.
To ensure that Tarantool works for a wide range of different distributions and their versions, RPM and DEB packages are prepared on CentOS 7 with glibc 2.17.
Developing applications
varbinary in Lua
In the previous versions, Tarantool already supported the varbinary type for storing data.
But working with varbinary database fields required workarounds, such as using C to process such data.
The 3.0 version includes a new varbinary module for working with varbinary objects.
The module implements the following functions:
varbinary.new() - constructs a varbinary object from a plain string.
varbinary.is() - returns true if the argument is a varbinary object.
In the example below, an object is created from a string:
This also implies that the data stored in the database under the varbinary field type is now returned to Lua not as a plain string but as a varbinary object.
It’s possible to revert to the old behavior by toggling the new binary_data_decodingcompat option because this change may break backward compatibility:
compat:binary_data_decoding:old
Default field values
You can now assign the default values for specific fields
when defining a space format.
In this example, the isbn and title fields have the specified default values:
In the 3.0 version, the API for creating triggers is completely reworked.
A new trigger module is introduced, allowing you to set handlers on both predefined and custom events.
To create the trigger, you need to:
Provide an event name used to associate the trigger with.
Define the trigger name.
Provide a trigger handler function.
The code snippet below shows how to subscribe to changes in the books space:
With the 3.0 release, a read view object supports the after and fetch_pos arguments for the select and pairs methods:
-- Select first 3 tuples and fetch a last tuple's position --app:instance001> result, position = read_view1.space.bands:select({}, { limit = 3, fetch_pos = true })---...app:instance001> result-----[1,'Roxette',1986]-[2,'Scorpions',1965]-[3,'AceofBase',1987]...app:instance001> position----kQM...-- Then, you can pass this position as the 'after' parameter --app:instance001> read_view1.space.bands:select({}, { limit = 3, after = position })-----[4,'TheBeatles',1960]-[5,'PinkFloyd',1965]-[6,'TheRollingStones',1962]...
IPROTO tuple format
Starting with the 3.0 version, the IPROTO protocol is extended to support for sending names of tuple fields in the IPROTO_CALL and other IPROTO responses.
This simplifies the development of Tarantool connectors and also simplifies handling tuples received from remote procedure calls or from routers.
It’s possible to revert to the old behavior by toggling the box_tuple_extensioncompat option:
compat:box_tuple_extension:old
SQL: case-sensitive names
Starting with 3.0, names in SQL, for example, table, column, or constraint names are case-sensitive.
Before the 3.0 version, the query below created a MYTABLE table:
CREATETABLEMyTable(iINTPRIMARYKEY);
To create the MyTable table, you needed to enclose the name into double quotes:
CREATETABLE"MyTable"(iINTPRIMARYKEY);
Starting with 3.0, names are case-sensitive, and double quotes are no longer needed:
CREATETABLEMyTable(iINTPRIMARYKEY);
For backward compatibility, the new version also supports a second lookup using an uppercase name.
This means that the query below tries to find the MyTable table and then MYTABLE:
SELECT*FROMMyTable;
Stability
Handling LuaJIT compiler errors
The 3.0 release includes a fix for the gh-562 LuaJIT issue related to the inability to handle internal compiler on-trace errors using pcall.
The examples of such errors are:
An Outofmemory error might occur for select queries returning a large amount of data.
A Tableoverflow error is raised when exceeding the maximum number of keys in a table.
The script below tries to fill a Lua table with a large number of keys:
The 2.11 release of Tarantool includes many new features and fixes.
This document provides an overview of the most important features for the Enterprise and Community editions.
2.11 is the long-term support (LTS) release with two years of maintenance.
This means that you will receive all the necessary security fixes and bug fixes throughout this period, and
be able to get technical support afterward.
You can learn more about the Tarantool release policy from the corresponding document.
Tarantool provides the live upgrade mechanism that enables cluster upgrade without
downtime. In case of upgrade issues, you can roll back to the original state
without downtime as well.
To learn how to upgrade to Tarantool 2.11, see Upgrades.
Enterprise Edition
Security enhancements
Encrypted SSL/TLS keys
Tarantool Enterprise Edition now supports encrypted SSL/TLS private key files protected with a password.
Given that most certificate authorities generate encrypted keys, this feature simplifies the maintenance of Tarantool instances.
A password can be provided using either the new ssl_password URI parameter or in a text file specified using ssl_password_file, for example:
With 2.11, Tarantool Enterprise Edition includes new security enforcement options.
These options enable you to enforce the use of strong passwords, set up a maximum password age, and so on.
For example, the password_min_length configuration option specifies the minimum number of characters for a password:
box.cfg{password_min_length=10}
To specify the maximum period of time (in days) a user can use the same password, you can use the password_lifetime_days option, which uses the system clock under the hood:
box.cfg{password_lifetime_days=365}
Note that by default, new options are not specified.
You can learn more about all the available options from the
Authentication restrictions and
Password policy sections.
PAP-SHA256 authentication method
By default, Tarantool uses the CHAP protocol to authenticate users and applies SHA-1 hashing to passwords.
In this case, password hashes are stored in the _user space unsalted.
If an attacker gains access to the database, they may crack a password, for example, using a rainbow table.
With the Enterprise Edition, you can enable PAP authentication with the SHA256 hashing algorithm.
For PAP, a password is salted with a user-unique salt before saving it in the database.
Given that PAP transmits a password as plain text, Tarantool requires configuring
SSL/TLS.
Then, you need to specify the box.cfg.auth_type option as follows:
Starting with 2.11, Tarantool Enterprise Edition provides the ability to create read views - in-memory snapshots of the entire database that aren’t affected by future data modifications.
Read views can be used to make complex analytical queries.
This reduces the load on the main database and improves RPS for a single Tarantool instance.
Working with read views consists of three main steps:
To create a read view, call the box.read_view.open() function:
After creating a read view, you can access database spaces and their indexes and get data using the familiar select and pairs data-retrieval operations, for example:
Tarantool Enterprise Edition now includes the zlib algorithm for tuple compression.
This algorithm shows good performance in data decompression,
which reduces CPU usage if the volume of read operations significantly exceeds the volume of write operations.
To use the new algorithm, set the compression option to zlib when formatting a space:
The new compress module provides an API for compressing and decompressing arbitrary data strings using the same algorithms available for tuple compression:
compressor=require('compress.zlib').new()data=compressor:compress('Hello world!')-- returns a binary stringcompressor:decompress(data)-- returns 'Hello world!'
WAL extensions
Tarantool can use a write-ahead log not only to maintain data persistence and replication.
Another use case is implementing a CDC (Change Data Capture) utility that transforms a data replication stream and provides the ability to replicate data from Tarantool to an external storage.
With 2.11, Tarantool Enterprise Edition provides WAL extensions that add auxiliary information to each write-ahead log record.
For example, you can enable storing old and new tuples for each write-ahead log record.
This is especially useful for the update operation because a write-ahead log record contains only a key value.
See the WAL extensions topic to learn how to enable and configure WAL extensions.
Community Edition
Pagination
With the 2.11 version, Tarantool supports pagination and enables the ability to get data in chunks.
The index_object:select() and index_object:pairs() methods now provide the after option that specifies a tuple or a tuple’s position after which select starts the search.
In the example below, the select operation gets maximum 3 tuples after the specified tuple:
The after option also accepts the position of the tuple represented by the base64 string.
For example, you can set the fetch_pos boolean option to true to return the position of the last selected tuple as the second value:
The new after and fetch_pos options are also implemented by the built-in net.box connector.
For example, you can use these options to get data asynchronously.
Downgrading a database
The 2.11 version provides the ability to downgrade a database to the specified Tarantool version using the box.schema.downgrade() method.
This might be useful in the case of a failed upgrade.
To prepare a database for using it on an older Tarantool instance, call box.schema.downgrade and pass the desired Tarantool version:
tarantool> box.schema.downgrade('2.8.4')
To see Tarantool versions available for downgrade, call box.schema.downgrade_versions().
The earliest release available for downgrade is 2.8.2.
New bootstrap strategy
In previous Tarantool versions, the replication_connect_quorum option was used to specify the number of running nodes to start a replica set.
This option was designed to simplify a replica set bootstrap.
But in fact, this behavior brought some issues during a cluster lifetime and maintenance operations, for example:
Users who didn’t change this option encountered problems with the partial cluster bootstrap.
Users who changed the option encountered problems during the instance restart.
With 2.11, replication_connect_quorum is deprecated in favor of bootstrap_strategy.
This option works during a replica set bootstrap and implies sensible default values for other parameters based on the replica set configuration.
Currently, bootstrap_strategy accepts two values:
auto: a node doesn’t boot if half or more of the other nodes in a replica set are not connected.
For example, if the replication parameter contains 2 or 3 nodes, a node requires 2 connected instances.
In the case of 4 or 5 nodes, at least 3 connected instances are required.
Moreover, a bootstrap leader fails to boot unless every connected node has chosen it as a bootstrap leader.
legacy: a node requires the replication_connect_quorum number of other nodes to be connected.
This option is added to keep the compatibility with the current versions of Cartridge and might be removed in the future.
Limitation of fiber execution time
Starting with 2.11, if a fiber works too long without yielding control, you can use a fiber slice to limit its execution time.
The fiber_slice_defaultcompat option controls the default value of the maximum fiber slice.
In future versions, this option will be set to true by default.
There are two slice types - a warning and an error slice:
When a warning slice is over, a warning message is logged, for example:
fiber has not yielded for more than 0.500 seconds
When an error slice is over, the fiber is cancelled and the FiberSliceIsExceeded error is thrown:
FiberSliceIsExceeded: fiber slice is exceeded
Note that these messages can point at issues in the existing application code.
These issues can cause potential problems in production.
The fiber slice is checked by all functions operating on spaces and indexes,
such as index_object.select(), space_object.replace(), and so on.
You can also use the fiber.check_slice() function in application code to check whether the slice for the current fiber is over.
The example below shows how to use fiber.set_max_slice() to limit the slice for all fibers.
fiber.check_slice() is called inside a long-running operation to determine whether a slice for the current fiber is over.
Tarantool 2.11 adds support for modules in the logging subsystem.
You can configure different log levels for each module using the box.cfg.log_modules configuration option.
The example below shows how to set the info level for module1 and the error level for module2:
Given that module1_log has the info logging level, calling module1_log.info shows a message but module1_log.debug is swallowed:
tarantool> module1_log.info('Hello from module1!')2023-05-12 15:10:13.691 [39202] main/103/interactive/module1 I> Hello from module1!---...tarantool> module1_log.debug('Hello from module1!')---...
Similarly, module2_log swallows all events with severities below the error level:
tarantool> module2_log.info('Hello from module2!')---...
HTTP client enhancements
Content serialization
The HTTP client now automatically serializes the content in a specific format when sending a request based on the specified Content-Type header and supports all the Tarantool built-in types.
By default, the client uses the application/json content type and sends data serialized as JSON:
You can now encode query and form parameters using the new params request option.
In the example below, the requested URL is https://httpbin.org/get?page=1.
The HTTP client now supports chunked writing and reading of request and response data, respectively.
The example below shows how to get chunks of a JSON response sequentially instead of waiting for the entire response:
localhttp_client=require('http.client').new()localjson=require('json')localtimeout=1localio=http_client:get(url,nil,{chunked=true})fori=1,3dolocaldata=io:read('\r\n',timeout)iflen(data)==0then-- End of the response.breakendlocaldecoded=json.decode(data)-- <..process decoded data..>endio:finish(timeout)
Streaming can also be useful to upload a large file to a server or to subscribe to changes in etcd using the gRPC-JSON gateway.
The example below demonstrates communication with the etcd stream interface.
The request data is written line-by-line, and each line represents an etcd command.
localhttp_client=require('http.client').new()localio=http_client:post('http://localhost:2379/v3/watch',nil,{chunked=true})io:write('{"create_request":{"key":"Zm9v"}}')localres=io:read('\n')print(res)-- <..you can feed more commands here..>io:finish()
Linearizable read
Linearizability of read operations implies that if a response for a write request arrived earlier than a read request was made, this read request should return the results of the write request.
Tarantool 2.11 introduces the new linearizable isolation level for box.begin():
When called with linearizable, box.begin() yields until the instance receives enough data from remote peers to be sure that the transaction is linearizable.
There are several prerequisites for linearizable transactions:
Linearizable transactions may only perform requests to synchronous, local, or temporary memtx spaces.
The node is the replication source for at least N-Q+1 remote replicas.
Here N is the count of registered nodes in the cluster and Q is replication_synchro_quorum.
So, for example, you can’t perform a linearizable transaction on anonymous replicas.
Explicit sequential scanning in SQL
Tarantool is primarily designed for OLTP workloads.
This means that data reads are supposed to be relatively small.
However, a suboptimal SQL query can cause a heavy load on a database.
The new sql_seq_scansession setting is added to explicitly cancel full table scanning.
The request below should fail with the Scanningisnotallowedfor'T' error:
In future versions, SEQSCAN will be required for scanning queries with the ability to disable the check using the sql_seq_scan session setting.
The new behavior can be enabled using a corresponding compat option.
Strict fencing in RAFT
Leader election is implemented in Tarantool as a modification of the Raft algorithm.
The 2.11 release adds the ability to specify the leader fencing mode that affects the leader election process.
Note
Currently, Cartridge does not support leader election using Raft.
You can control the fencing mode using the election_fencing_mode property, which accepts the following values:
In soft mode, a connection is considered dead if there are no responses for 4*replication_timeout seconds both on the current leader and the followers.
In strict mode, a connection is considered dead if there are no responses for 2*replication_timeout seconds on the current leader and 4*replication_timeout seconds on the followers.
This improves the chances that there is only one leader at any time.
EOL versions
This section contains information about Tarantool versions that have reached
their end of life in accordance with the Tarantool release policy. This
means that these versions don’t receive updates and fixes anymore. However, we still
provide technical support for certain time after a version’s EOL. The current support
status is reflected by the End of support column of the table below.
For information about major changes between EOL versions, see Major features.
The table below lists major changes in Tarantool versions up to 2.11.0.
For overviews of changes in newer versions, see their What’s new pages inside Releases.
Every released version of Tarantool brings some notable features and fixes, which are all listed in
the release notes.
To keep track of the major features in Tarantool versions, you can use the table below.
Later versions inherit features from earlier ones in the same release series.
Note that versions before 2.10.* are numbered according to the legacy release policy,
while versions 2.10.0 and later adhere to the current release policy.
Versions that only include bug fixes are not listed in this table.
Introduced the _vspace_sequence system space view of the _space_sequence
system space (gh-7858).
The log produced during box.cfg{} now contains the build target
triplet (for example, Linux-x86_64-RelWithDebInfo).
2.10.4
The JSON log format can now be used with the syslog logger (gh-7860).
SQL improvements: CASE (gh-6990) and NULLIF() (gh-6989).
Diagnostics now provide relative file paths instead of absolute ones (gh-7808).
2.10.3
RedOS 7.3 is now supported.
Added the -DENABLE_HARDENING=ON/OFF CMake option that enables
hardening against memory corruption attacks (gh-7536).
2.10.2
Internal fibers cannot be cancelled from the Lua public API anymore (gh-7473)
2.10.1
Interactive transactions are now possible in remote binary consoles (gh-7413)
Improved string representation of datetime intervals (gh-7045)
A Tarantool release is identified by three digits, for example, 2.6.2 or 1.10.9:
The first digit stands for a MAJOR release series that introduces
some major changes. Up to now, there has been only one major release jump
when we delivered the 2.x release series with the SQL support.
The second digit stands for a MINOR release series that is used for
introducing new features.
Backward incompatible changes
are possible between these release series.
The third digit is for PATCH releases by which we reflect how stable
the MINOR release series is:
0 meaning alpha
1 meaning beta
2 and above meaning release (earlier known as stable).
So, each MINOR release series goes through a development-maturity life cycle
as follows:
Alpha. Once a quarter, we start off with a new alpha version,
such as 2.3.0, 2.4.0, and so on. This is not what an alpha release usually
means in the typical software release life cycle but rather the current trunk
version which is under heavy development and can be unstable.
The current alpha version always lives in the master branch.
Beta. When all the features planned are implemented, we fork a new branch
from the master branch and tag it as a new beta version.
It contains 1 for the PATCH digit, e.g., 2.3.1, 2.4.1, and so on.
This version cannot be called stable yet (feature freeze has just been done)
although there are no known critical regressions in it since
the last stable release.
Release (earlier known as stable).
Finally, after we see our beta version runs successfully in
a production or development environment during another quarter while we fix
incoming bugs, we declare this version stable. It is tagged with 2 for
the PATCH digit, e.g., 2.3.2, 2.4.2, and so on.
We support such version for 3 months while making another stable release
by fixing all bugs found. We release it in a quarter. This last tag
contains 3 for the PATCH digit, e.g., 2.3.3, 2.4.3, and so on.
After the tag is set, no new changes are allowed to the release branch,
and it is declared deprecated and superseded by a newer MINOR version.
Release versions don’t receive any new features and only get backward
compatible fixes.
Like Ubuntu, in terms of support, we distinguish between two kinds of stable
release series:
LTS (Long Term Support) is a release series that is supported
for 3 years (community) and up to 5 years (paying customers).
Current LTS release series is 1.10, and it receives only PATCH level
releases.
Standard is a release series that is supported only for a few months
until the next release series enters the stable state.
Below is a diagram that illustrates the release sequence issuing described above
by an example of some latest releases and release series:
1.10 series -- 1.10.4 -- 1.10.5 -- 1.10.6 -- 1.10.7
(LTS)
....
2.2 series --- 2.2.1 --- 2.2.2 --- 2.2.3 (end of support)
|
V
2.3 series ... 2.3.0 --- 2.3.1 --- 2.3.2 --- 2.3.3 (end of support)
|
V
2.4 series ............. 2.4.0 --- 2.4.1 --- 2.4.2
|
V
2.5 series ....................... 2.5.0 --- 2.5.1
|
V
2.6 series ................................. 2.6.0
-----------------|---------|---------|---------|------> (time)
1/4 yr. 1/4 yr. 1/4 yr.
Support means that we continue fixing bugs. We add bug fixes simultaneously
into the following release series: LTS, last stable, beta, and alpha.
If we look at the release diagram above, it means that the bug fixes are to be
added into 1.10, 2.4, 2.5, and 2.6 release series.
To sum it up, once a quarter we release (see the release diagram above for
reference):
next LTS release, e.g., 1.10.9
two stable releases, e.g., 2.5.3 and 2.6.2
beta version of the next release series, e.g., 2.7.1.
In all supported releases, when we find and fix an outstanding CVE/vulnerability,
we deliver a patch for that but do not tag a new PATCH level version.
Users will be informed about such critical patches via the official Tarantool news
channel (tarantool_news).
We also publish nightly builds, and use the fourth slot in the version
identifier to designate the nightly build number.
Note
A release series may introduce backward incompatible changes in a sense that
existing Lua, SQL or C code that are run on a current release series
may not be run with the same effect on a future series.
However, we don’t exploit this rule and don’t make incompatible changes
without appropriate reason. We usually deliver information how mature
a functionality is via release notes.
Please note that binary data layout
is always compatible with the previous series as well as with the LTS series
(an instance of X.Y version can be started on top of X.(Y+1)
or 1.10.z data); binary protocol is compatible too
(client-server as well as replication protocol).
2.10.8 is the ninth
stable version of the 2.10 release series.
It introduces 5 improvements and resolves 28 bugs since 2.10.7.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Box
The maximum length of box.cfg{} string parameters is now 512
instead of 256.
Test
Fuzz
LuaJIT now can be fuzzed using grammar-based fuzzer (gh-4823).
Build
Hardening against memory corruption attacks is now enabled by default
on FreeBSD (gh-7536).
Added the CMake option FIBER_STACK_SIZE to set the default fiber
stack size.
Updated libcurl to version 8.3.0.
Bugs fixed
Core
Fixed a bug when Tarantool failed to decode a request containing an
unknown IPROTO key. The bug resulted in broken connectivity between
Tarantool 2.10 and 2.11 (gh-8745).
Fixed a bug causing the ER_CURSOR_NO_TRANSACTION failure for
transactions on synchronous spaces when the on_commit/on_rollback
triggers are set (gh-8505).
Fixed a bug causing the effective session and user are not propagated
to box.on_commit and box.on_rollback trigger callbacks when
transaction is synchronous (gh-8742).
Fixed a crash that could happen when Tarantool is started in the
background mode (gh-6128).
Fixed a bug when MVCC sometimes lost gap record (gh-8326).
Fixed a bug when MVCC rollback of prepared statement could break
internal invariants (gh-8648).
Now MVCC engine automatically aborts a transaction if it reads
changes of a prepared transaction and this transaction is aborted
(gh-8654).
Fixed a bug that caused writing incorrect values into the
stream_id field of xlog headers (gh-8783).
Fixed a bug when a space that is referenced by a foreign key could
not be truncated even if the referring space was empty (gh-8946).
Fixed a crash that could happen when Tarantool is compiled by
clang version 15 and above with enabled AddressSanitizer
(tarantool/tarantool-qa#321).
Fixed a use-after-free bug in iproto server code (gh-9037).
Fixed a heap-buffer-overflow bug in fiber creation code (gh-9026).
Memtx
Fixed a heap-use-after-free bug in the transaction manager, which
could occur when performing a DDL operation concurrently with a
transaction on the same space (gh-8781).
Vinyl
Fixed a heap-use-after-free bug in the Vinyl read iterator caused by
a race between a disk read and a memory dump task. The bug could lead
to a crash or an invalid query result (gh-8852).
Replication
Fixed a possible failure to promote the desired node by
box.ctl.promote() on a cluster with nodes configured with
election_mode="candidate" (gh-8497).
Fixed nodes configured with election_mode='candidate'
spuriously detecting a split-vote when another candidate should win
with exactly a quorum of votes for it (gh-8698).
LuaJIT
Backported patches from the vanilla LuaJIT trunk (gh-8516, gh-8825).
The following issues were fixed as part of this activity:
Fixed canonicalization of +-0.0 keys for IR_NEWREF.
Fixed result truncation for bit.rol on x86_64 platforms.
Fixed lua_yield() invocation inside C hooks.
Fixed memory chunk allocation beyond the memory limit.
Fixed TNEW load forwarding with instable types.
Fixed use-def analysis for BC_VARG, BC_FUNCV.
Fixed BC_UCLO insertion for returns.
Fixed recording of BC_VARG with unused vararg values.
Initialization instructions on trace are now emitted only for the
first member of a union.
Prevent integer overflow while parsing long strings.
Fixed various ^ operator and math.pow() function
inconsistencies.
Fixed parsing with predicting next() and pairs().
Fixed binary number literal parsing. Parsing of binary number with a
zero fractional part raises error too now.
Fixed load forwarding optimization applied after table rehashing.
Fixed recording of the BC_TSETM.
Lua
Fixed the xlog reader Lua module to show unknown row header fields.
Before this change the xlog reader silently skipped them.
Netbox
Fixed a heap-use-after-free bug in the function creating a tuple
format Lua object for net.box (gh-8889).
Box
Fixed the memory leaks caused by the multi-statement transaction
errors in the space index building and the space format checking
operations (gh-8773).
Fixed a bug in the box console implementation because of which the
language parameter was shared between connected clients
(gh-8817).
Fixed an invalid memory access in a corner case of a specialized
comparison function (gh-8899).
Console
Fixed console ignoring -i flag in case stdin is not a tty
(gh-5064).
Datetime
Fixed a bug raising a false positive error when creating new
intervals with range boundary values (gh-8878).
Fixed a bug with buffer overflow in tnt_strptime (gh-8502).
Http
Fixed a streaming connection stuck if etcd is stopped unexpectedly
(gh-9086).
Msgpack
Fixed decoding datetime intervals with fields larger than possible
int32 values (gh-8887).
2.10.7 is the 8th
stable version of the 2.10 release series.
It resolves 17 bugs since 2.10.6.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Bugs fixed
Core
Fixed a crash that could happen when preparing a crash report on macOS
(gh-8445).
Fixed an integer overflow issue in net.box (ghs-121).
An IPROTO_EVENT packet now has the same sync number as the last
corresponding IPROTO_WATCH request (gh-8393).
Fixed a bug because of which a dirty (not committed to WAL) DDL record could
be written to a snapshot and cause a recovery failure (gh-8530).
Replication
Fixed a bug that occurred on applier failure: a node could start an election
without having a quorum to do this (gh-8433).
Now if a join fails with some non-critical error, such as ER_READONLY,
ER_ACCESS_DENIED, or something network-related, the instance tries
to find a new master to join off and tries again (gh-6126,
gh-8681).
States when joining a replica are renamed. Now the value of
box.info.replication[id].upstream.status during join can be either
wait_snapshot or fetch_snapshot instead of initial_join (gh-6126).
Fixed replicaset bootstrap getting stuck on some nodes with ER_READONLY when
there are connectivity problems (gh-7737, gh-8681).
Fixed a bug when a replicaset state machine that is tracking the number
of appliers according to their states could become inconsistent during
reconfiguration (gh-7590).
LuaJIT
Backported patches from the vanilla LuaJIT trunk (gh-8069, gh-8516).
The following issues were fixed as part of this activity:
Fixed emit_rma() for x64/GC64 mode for non-mov instructions.
Limited Lua C library path with the default PATH_MAX value of 4096 bytes.
Fixed assembling of IR_LREF assembling for GC64 mode on x86_64.
SQL
Fixed an assertion when selecting tuples with incomplete internal
format (gh-8418).
Fixed integer overflow issues in built-in functions (ghs-119).
Fixed a possible assertion or segmentation fault when optimizing
INSERTINTO...SELECTFROM (gh-8661).
Fixed an integer overflow issue and added check for the printf() failure due
to too large size (ghs-122).
Datetime
Fixed an error in datetime.set when timestamp is passed along with nsec,
usec, or msec (gh-8583).
Fixed errors when the string representation of a datetime object had
a negative nanosecond part (gh-8570).
Build
Enabled compiler optimizations for static build dependencies, which were
erroneously disabled in version 2.10.3 (gh-8606).
2.10.6 is the 7th
stable version of the 2.10 release series.
It resolves 3 bugs since 2.10.5.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Bugs fixed
Core
Fixed various bugs related to unsafe (i.e., coming from an unknown
source) decoding and validating of MsgPack extensions (ghs-73).
LuaJIT
Backported patches from the vanilla LuaJIT trunk (gh-8069).
The following issues were fixed as part of this activity:
Fixed successful math.min/math.max call with no args (gh-6163).
Fixed inconsistencies in math.min/math.max calls with a NaN arg
(gh-6163).
Fixed pcall() call without arguments on arm64.
Fixed assembling of IR_{AHUV}LOAD specialized to boolean for
aarch64.
Fixed constant rematerialization on arm64.
Box
Fixed a bug where box.cfg.force_recovery doesn’t work when there
is no user spaces in a snapshot (gh-7974).
2.10.5 is the sixth
stable version of the 2.10 release series.
It introduces 5 improvements and resolves 44 bugs since 2.10.4.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
Introduced the _vspace_sequence system space view of the
_space_sequence system space (gh-7858).
The log produced during box.cfg{} now contains the build target
triplet (for example, Linux-x86_64-RelWithDebInfo).
Fixed a bug in fiber switching that could lead to a segmentation
fault error on AArch64 systems (gh-7523, gh-7985).
Fixed wrong CPU architecture reported in tarantool.build.target
on M1/M2 Macs (gh-7495).
Fixed a bug when fields could be removed from a table stored in a
variable when a logging function was called on this variable (for
example, log.info(a)) (gh-3853).
Fixed a logging bug: when logging tables with fields that have
reserved internal names (such as pid) in the plain log format,
such fields weren’t logged (gh-3853).
Added the message field when logging tables without such field in
the JSON log format (gh-3853).
Fixed an assertion on malformed JSON message written to the log
(gh-7955).
Fixed the bug because of which box.session.on_auth triggers were
not invoked if the authenticated user didn’t exist (gh-8017).
Eliminated the possibility of user enumeration by analyzing errors
sent in reply to malformed authentication requests (ghs-21).
Fixed a bug when Tarantool could execute random bytes as a Lua code
after fork on systems with a glibc version earlier than 2.29
(gh-7886).
A referenced space or a function being used in a constraint can now
be dropped in the same transaction with the referencing constraint or
space (gh-7339).
Fixed Tarantool being stuck during a crash on macOS (gh-8023).
Fixed a bug that prevented collection of crash reports (gh-8083).
Fixed a crash in net.box that happened if the error message
raised by the server contained printf formatting specifiers, such
as %d or %s (gh-8043).
Fixed read-only statements executing successfully in transactions
that were aborted by yield or timeout. Now, read-only statements fail
in this case, just like write statements (gh-8123).
Fixed a transaction conflict reported mistakenly when a key was
deleted twice with MVCC engine enabled (gh-8122).
net.box connections now contain information about sequences used
by remote spaces (gh-7858).
Fixed a crash that happened if a transaction was aborted (for
example, by fiber yield with MVCC off) while the space’s
on_replace or before_replace trigger was running (gh-8027).
Fixed a possible crash when attempting to update the same field in
tuple/space/index:update() more than once (gh-8216).
Fixed empty BITSET indexes crashing on len calls (gh-5809).
Fixed a crash when functional indexes were used with very specific
chunk size (gh-6786).
Memtx
Fixed a possible repeatable read violation with reverse iterators
(gh-7755).
Fixed a crash on series of transactions in memtx (gh-7756).
Fixed a phantom read that could happen after reads from different
indexes followed by a rollback (gh-7828).
Fixed an assertion failure in MVCC during statement preparation
(gh-8104).
Fixed possible loss of a committed tuple after rollback of a prepared
transaction (gh-7930).
Vinyl
Fixed a bug that could result in select() skipping an existing
tuple after a rolled back delete() (gh-7947).
Replication
Fixed local space writes failing with error Founduncommittedsynctransactionsfromotherinstancewithid1 when synchronous
transaction queue belongs to another instance and isn’t empty
(gh-7592).
Fixed an assertion failure on master when a replica resubscribes with
a smaller vclock than previously seen (gh-5158).
A warning is now raised when replica_id is changed by a
before_replace trigger while adding a new replica. Previously,
there was an assertion checking this (gh-7846).
Fixed a segmentation fault that happened when a before_replace
trigger set on space _cluster returned nil (gh-7846).
Fixed possible transaction conflict errors on applying a replication
stream (gh-8121).
Raft
Fixed an assertion failure in case when an election candidate is
reconfigured to a voter during an ongoning WAL write (gh-8169).
Fixed nodes configured with election_mode="manual" sometimes
increasing the election term excessively after their promotion
(gh-8168).
LuaJIT
Backported patches from vanilla LuaJIT trunk (gh-7230). In the scope of
this activity, the following issues have been resolved:
Fix io.close() for already closed standard output.
Fix trace execution and stitching inside vmevent handler (gh-6782).
Fixed emit_loadi() on x86/x64 emitting xor between condition
check and jump instructions.
Fix stack top for error message when raising the OOM error (gh-3840).
Enabled external unwinding on several LuaJIT platforms. Now it is
possible to handle ABI exceptions from Lua code (gh-6096).
Disabled math.modf compilation due to its rare usage and difficulties
with proper implementation of the corresponding JIT machinery.
Fixed inconsistent behaviour on signed zeros for JIT-compiled unary
minus (gh-6976).
Fixed IR_HREF hash calculations for non-string GC objects for
GC64.
Fixed assembling of type-check-only variant of IR_SLOAD.
Enabled the platform profiler for Tarantool built with GC64 mode
(gh-7919).
Added full-range lightuserdata support to the luajit-gdb.py
extension (gh-6481).
Backported patches from vanilla LuaJIT trunk (gh-8069). In the scope of
this activity, the following issues have been resolved:
Fixed loop realigment for dual-number mode
Fixed os.date() for wider libc strftime() compatibility.
Fix interval parsing for sysprof for dual-number mode.
Lua
Fixed alias detection in the YAML serializer in case the input
contains objects that implement the __serialize meta method
(gh-8240).
SQL
Fixed a bug when collation could change the type of a built-in
function argument (gh-7992).
Fixed several bugs happening because of improper handling of
malloc() failures (ghs-65, ghs-66,
ghs-67, ghs-68).
Box
Fixed a possible error during rollback of read-only transaction
statements (gh-5501).
Fixed a bug in space_object:create_index() when collation
option is not set. Now it is inherited from the space format
(gh-5104).
Eliminated a code injection vulnerability in the processing of the
replication_synchro_quorumbox.cfg() option (ghs-20,
GHSA-74jr-2fq7-vp42).
Datetime
Fixed a segmentation fault that happened when the value passed to the
%f modifier of datetime_object:format() was too big (ghs-31).
Fiber
Fixed the assertion fail in cord_on_yield (gh-6647).
Log
Fixed an incorrect facility value in syslog on Alpine and OpenBSD
(gh-8269).
2.10.4 is the fifth
stable version of the 2.10 release series.
It introduces 5 improvements and resolves 28 bugs since 2.10.3.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Note
Now the empty string, n, nu, s, and st (that is, leading parts of
num and str) are not accepted as valid field types (gh-5940).
This instruction will help you upgrade
to Tarantool 2.10.4 and newer if you’ve previously used these values in field types.
Functionality added or changed
Core
The JSON log format can now be used with the syslog logger (gh-7860).
SQL
New rules are applied to determine the type of CASE operation
(gh-6990).
Now NULLIF() call results have the same type as its first
argument (gh-6989).
Build
Diagnostics now provide relative file paths instead of absolute ones
(gh-7808).
Now the compiler info displayed in tarantool.build.compiler and
tarantool--version shows the ID and the version of the compiler
that was used to build Tarantool. The output has the format
${CMAKE_C_COMPILER_ID}-${CMAKE_C_COMPILER_VERSION}, for example,
Clang-14.0.0.14000029 (gh-7888).
Bugs fixed
Core
Fixed creation of spaces with a constraint and a foreign key on the
same field (gh-7645).
Now the same error is returned when a password or a username provided
during authorization is incorrect. This prevents user enumeration
(ghs-16).
Added boundary checking for getenv() return values. Also, for
security reasons, Tarantool code now copies these values instead of
using them directly (gh-7797).
os.getenv() now always returns values of sane size (gh-7797).
Fixed the BEGIN, COMMIT, and ROLLBACK counters in the
box.stat() output. Now they show the number of started,
committed, and rolled back transactions (gh-7583).
Fixed a crash that could occur during log rotation and application
exit (gh-4450).
Fixed a possible buffer overflow in mp_decode_decimal() and
decimal_unpack() when an input string was too long (ghs-17).
Fixed a bug in the MsgPack library that could lead to a failure to
detect invalid MsgPack input and, as a result, an out-of-bounds read
(ghs-18).
If an error occurs during a snapshot recovery, its log now contains
information about the row that caused the error (gh-7917).
Memtx
Fixed possible loss of committed tuples in secondary indexes with
MVCC transaction manager (gh-7712).
Fixed an assertion being triggered on space:drop (gh-7757).
Fixed possible violation of the secondary index uniqueness with the
transaction manager enabled (gh-7761).
LuaJIT
Backported patches from vanilla LuaJIT trunk (gh-7230). In the scope
of this activity, the following issues have been resolved:
Fix overflow check in unpack() optimized by a compiler.
Fix recording of tonumber() with cdata argument for failed
conversions (gh-7655).
Fix concatenation operation on cdata. It always raises an error
now.
Fixed the Lua stack dump command (lj-stack) to support Python 2:
unpacking arguments within the list initialization is not supported
in it (gh-7458).
Lua
Fixed a crash in msgpack.decode in case the input string contains
an invalid MsgPack header 0xc1 (gh-7818).
SQL
Fixed an assertion when INDEXEDBY was used with an index that
was at least third in a space (gh-5976).
Fixed a crash that could occur when selecting tuples with more fields
than specified in the space format (gh-5310, gh-4666).
Fixed an assertion in JOIN when using an unsupported index
(gh-5678).
Creating indexes on newly added fields no longer leads to assertions
in SELECT queries (gh-5183).
Re-running a prepared statement that generates new auto-increment IDs
no longer causes an error (gh-6422).
An error is now thrown if too many indexes were created in SQL
(gh-5526).
Box
Revoked execute access rights to the LUA function from the public
role (ghs-14).
Now the empty string, n, nu, s, and
st (that is, leading parts of num and str) are not
accepted as valid field types (gh-5940).
This instruction will help you upgrade
to Tarantool 2.10.4 and newer if you’ve previously used these values in field types.
Fixed a bug when type=box.NULL in key_def.new() resulted in
type='unsigned' (gh-5222).
The _vfunc system space now has the same format as _func
(gh-7822).
Fixed a crash on recovery from snapshots that don’t include system
spaces (gh-7800).
Fixed a bug that occurred when a foreign key was created together
with fields that participate in that foreign key (gh-7652).
Datetime
Fixed interval arithmetic for boundaries crossing DST (gh-7700).
Results of datetime arithmetic operations could get a different
timezone if the DST boundary has been crossed during the operation:
2.10.3 is the fourth
stable version of the 2.10 release series.
It introduces 2 improvements and resolves 19 bugs since 2.10.2.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Build
RedOS 7.3 is now supported.
Added the -DENABLE_HARDENING=ON/OFF CMake option that enables
hardening against memory corruption attacks (gh-7536).
Bugs fixed
Core
Fixed a bug introduced in Tarantool 2.10.2: log messages could be
written to data files thus causing data corruption. The issue was
fixed by reverting the fix for gh-4450.
Switched from MT-Unsafe strerror() to MT-Safe strerror_r().
The usage of the unsafe function could result in corrupted error
messages.
Fixed a bug when a single JSON update couldn’t insert and update a
field of a map or an array in two sequential calls. It would either
crash or return an error (gh-7705).
Memtx
Fixed incorrect handling of transaction conflicts in full scans by
HASH indexes (gh-7493).
Fixed useafterfree that could occur in the transaction manager
in certain states (gh-7449).
Fixed possible phantom reads with get on TREE indexes containing
nullable parts (gh-7685).
Fixed an inconsistency in index:random in the context of
transaction management (gh-7670).
Fixed unserializable reads tracked incorrectly after transaction
rollbacks (gh-7343).
Replication
Fixed a bug when a fiber committing a synchronous transaction could
hang if the instance got a term bump during that or its synchro-queue
was fenced in any other way (gh-7253).
Fixed master occasionally deleting xlogs needed by replicas even
without a restart (gh-7584).
Raft
Fixed a bug when box.ctl.promote() could hang and bump thousands
of terms in a row if called on more than one node at the same time
(part of gh-7253).
Fixed a bug when a node with election_mode='voter' could hang in
box.ctl.promote() or become a leader (part of gh-7253).
Fixed a bug when a replicaset could be split into parts if a node
voted for another instance while having local WAL writes unfinished
(part of gh-7253).
Lua
Merger
Fixed useafterfree that could occur during iteration over
merge_source:pairs() or merger:pairs() (gh-7657).
Popen
Fixed a race condition in <popenhandle>:signal() on Mac OS 12
and newer (gh-7658).
Box
Fixed a bug when fiber.yield() might break the execution of a
shutdown trigger (gh-7434).
Fixed a possible high CPU usage caused by shutdown triggers
(gh-6801).
Synchro
Fixed assertions in debug builds and undefined behaviour in release
builds when simultaneous elections started or another instance was
promoted while an instance was acquiring or releasing the synchro
queue (gh-7086).
Uri
Fixed a bug in the URI parser: tarantoolctl could not connect when
the host name was skipped (gh-7479).
2.10.2 is the third
stable version of the 2.10 release series.
It introduces 1 improvement and resolves 8 bugs since 2.10.1.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
Certain internal fibers, such as the connection’s worker fiber, vinyl
fibers, and some other fibers, cannot be cancelled from the Lua
public API anymore (gh-7473).
Bugs fixed
Core
Fixed a crash of secondary indexes without hints (a critical regression found in 2.10.1)
(gh-7605).
Fixed a possible crash on concurrent fiber_object:join()
(gh-7489).
Fixed a potential nil dereference and a crash in case of an active
log rotation during the program exit stage (gh-4450).
Fixed crashes and undefined behaviour of triggers clearing other
triggers (gh-4264).
Replication
Fixed box.info.replication[id].downstream.lag growing
indefinitely on a server when it’s not writing any new transactions
(gh-7581).
Box
Fixed multiline commands being saved to ~/.tarantool_history as
separate lines (gh-7320).
Fixed inheritance of field options in indexes when index parts are
specified the old Tarantool 1.6 style: {<field>,<type>,...}
(gh-7614).
Fixed unauthorized inserts into the _truncate space (ghs-5).
It is highly recommended to use Tarantool v. 2.10.2 instead.
The 2.10.1 release introduced a severe regression (gh-7605),
which may pass testing with a low amount of data but impact a production server heavily.
It may crash the process and, that is worse, feed incorrect data.
The Tarantool development team has decided
to remove all the packages associated with this release.
2.10.1 is the second
stable version of the 2.10 release series.
It introduces 17 improvements and resolves 52 bugs since 2.10.0.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Notable changes are:
Interactive transactions are now possible in remote binary consoles.
Improved the string representation of datetime intervals.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
[Breaking change] Conflicted transactions now throw the
Transactionhasbeenabortedbyconflict error on any CRUD
operations until they are either rolled back (which will return no
error) or committed (which will return the same error) (gh-7240).
Read-view transactions now become conflicted on attempts to perform
DML statements immediately. Previously, this was detected only on the
transaction preparation stage, that is, when calling box.commit
(gh-7240).
Interactive transactions are now possible in remote binary consoles
(gh-7413).
It is now possible to omit space in declarations of foreign keys
that refer to the same space (gh-7200).
Datetime
Improved the string representation of datetime intervals. Now
nanoseconds aren’t converted and attached to seconds; the intervals
are displayed “as is”. Example:
Added Lua/C accessors for decimals into the module API (gh-7228).
Tuple
Added the box_tuple_field_by_path() function into the module API.
It allow the access to tuple fields from C code using a JSON path
(gh-7228).
Build
Fedora 30, 31, 32, and 33 are no longer supported.
Ubuntu 20.10 (Groovy Gorilla) and 21.04 (Hirsute Hippo) are no longer
supported.
Updated libcurl to version 7.84.0.
Updated OpenSSL used for static builds to version 1.1.1q.
Ubuntu 21.10 (Impish Indri) is no longer supported.
Updated Ncurses used for static builds to version 6.3-20220716 .
Updated Readline used for static builds to version 8.0p1.
Updated libyaml to the version with fixed stack overflows.
Updated zstd to version 1.5.2.
Updated zlib used for static builds to version 1.2.12.
Bugs fixed
Core
Improved validation of incoming tuples. Now tuples coming over the
network can’t contain malformed decimals, uuids, or datetime values
(gh-6857).
Fixed a bug in the net.box connector because of which a client could
fail to close its connection when receiving a shutdown request from
the server. This could lead to the server hanging on exit (gh-7225).
Fixed a crash and possible undefined behaviour when using scalar
and number indexes over fields containing both decimals and
double Inf or NaN.
For vinyl spaces, the above conditions could lead to wrong ordering
of indexed values. To fix the issue, recreate the indexes on such
spaces following this
guide
(gh-6377).
Fixed a bug because of which a net.box connection was not properly
terminated when the process had a child (for example, started with
popen) sharing the connection socket fd. The bug could lead to a
server hanging on exit while executing the graceful shutdown protocol
(gh-7256).
Removed an assertion on fiber_wakeup() calls with dead fibers in
debug builds. Such behavior was inconsistent with release builds, in
which the same calls were allowed (gh-5843).
Fixed the exclude_null index option not working for multikey and
JSON indexes (gh-5861).
Fixed the performance degradation of fiber backtrace collection after
the backtrace rework (gh-7207).
Fixed a hang when a synchronous request was issued from a net.box
on_connect or on_schema_reload trigger. Now an error is
raised instead (gh-5358).
Fixed a crash that could happen on x86 systems without the RDTSCP
instruction (gh-5869).
Fixed a bug that allowed to access indexed fields of nested tuples
with [*] in Lua (gh-5226).
Fixed the behavior of space_object:fselect() on binary data
(gh-7040).
Fixed Tarantool not being able to recover from old snapshots when
box.cfg.work_dir and box.cfg.memtx_dir were both set
(gh-7232).
Fixed Tarantool terminations on error messages with invalid UTF-8
sequences (gh-6781 and gh-6934).
Fixed a bug when the Transactionisactiveatreturnfromfunction
error was overwriting expression evaluation errors in case the
expression begins a transaction (gh-7288).
Added type checking for options in net.box’s remote queries and
connect method. Now graceful errors are thrown in case of incorrect
options (gh-6063, gh-6530).
Fixed space_object:format() and space_object.foreign_key
returning incorrect numbers of foreign key fields (gh-7350).
Fixed the foreign key check on space_object:truncate() calls
(gh-7309).
Fixed a crash when box.stat.net.thread[i] is called with invalid
i values (gh-7196).
Fixed a low-probability stack overflow bug in the qsort
implementation.
Memtx
Fixed the ability to perform read-only operations in conflicting
transactions in memtx, which led to spurious results (gh-7238).
Fixed false assertion on repeatable replace with the memtx
transaction manager enabled (gh-7214).
Fixed false transaction conflict on repeatable insert/upsert
with the memtx transaction manager enabled (gh-7217).
Fixed dirty reads in the GT iterator of HASH indexes (gh-7477).
Fixed phantom reads in reverse iterators (gh-7409).
Fixed select with LE iterator in memtxTREE index
returning deleted tuple (gh-7432).
Fixed incorrect handling of corner cases gap tracking in transaction
manager (gh-7375).
Fixed a bug in the memtx hash index implementation that could lead to
uncommitted data written to a snapshot file (gh-7539).
Vinyl
Fixed a bug in the vinyl upsert squashing optimization that could
lead to a segmentation fault error (gh-5080).
Fixed a bug in the vinyl garbage collector. It could skip stale
tuples stored in a secondary index if upsert operations were used on
the space before the index was created (gh-3638).
Fixed a bug in the vinyl read iterator that could result in a
significant performance degradation of range select requests in the
presence of an intensive write workload (gh-5700).
Explicitly disabled the hot standby mode for vinyl. Now an attempt to
enable the hot standby mode in case the master instance has vinyl
spaces results in an error. Before this change, the behavior was
undefined (gh-6565).
Replication
Added the logging of the error reason on a replica in case when the
master didn’t send a greeting message (gh-7204).
Fixed replication being stuck occasionally for no obvious reasons.
Fixed a possible split-brain when the old synchro queue owner might
finalize the transactions in the presence of the new owner (gh-5295).
Improved the detection of possible split-brain situations, for
example, when multiple leaders were working independently due to
manually lowered quorum. Once a node discovers that it received some
foreign data, it immediately stops replication from such a node with
an ER_SPLIT_BRAIN error (gh-5295).
Fixed a false positive split-brain error after box.ctl.demote()
(gh-7286).
Fixed a bug when followers with box.cfg.election_mode turned on
did not notice the leader hang due to a long request, such as a
select{} from a large space or a pairs iteration without
yields between loop cycles (gh-7512).
LuaJIT
Backported patches from vanilla LuaJIT trunk (gh-6548 and gh-7230).
In the scope of this activity, the following issues have been resolved:
Now initialization of zero-filled struct is compiled (gh-4630,
gh-5885).
Actually implemented maxirconst option for tuning JIT compiler.
Fixed JIT stack of Lua slots overflow during recording for metamethod
calls.
Fixed bytecode dump unpatching for JLOOP in up-recursion compiled
functions.
Fixed FOLD rule for strength reduction of widening in cdata indexing.
Fixed string.char() recording without arguments.
Fixed print() behaviour with the reloaded default metatable for
numbers.
tonumber("-0") now saves the sign of number for conversion.
tonumber() now gives predictable results for negative non-base-10
numbers.
Fixed write barrier for debug.setupvalue() and
lua_setupvalue().
Fixed conflict between 64 bit lightuserdata and ITERN key for ARM64.
Fixed emitting assembly for HREFK on ARM64.
Fixed pass-by-value struct in FFI calls on ARM64.
jit.p now flushes and closes output file after run, not at
program exit.
Fixed jit.p profiler interaction with GC finalizers.
Fixed the case for partial recording of vararg function body with the
fixed number of result values in with LJ_GC64 (i.e. LJ_FR2
enabled) (gh-7172).
Added /proc/self/exe symlink resolution to the symtab module to
obtain the .symtab section for the Tarantool executable.
Introduced stack sandwich support to sysprof’s parser (gh-7244).
Disabled proto and trace information dumpers in sysprof’s default
mode. Attempts to use them lead to a segmentation fault due to an
uninitialized buffer (gh-7264).
Fixed handling of errors during trace snapshot restore.
Lua
The fiber_obj:info() now correctly handles its options (gh-7210).
Fixed a bug when Ctrl+C doesn’t discard the multiline input
(gh-7109).
SQL
Fixed the creation of ephemeral space format in ORDERBY
(gh-7043).
The result type of arithmetic operations between two unsigned values
is now INTEGER (gh-7295).
Fixed a bug with the ANY type in the ephemeral space format in
ORDERBY (gh-7043).
Truncation of a space no longer corrupts prepared statements
(gh-7358).
Datetime
Fixed a bug when date:set{hour=nil,min=XXX} did not retain the
original hour value (gh-7298).
Introduced the validation of incoming data at the moment messagepack
is converted to datetime (gh-6723).
HTTP client
Enabled the automatic detection of system CA certificates in the
runtime (gh-7372). It was disabled in 2.10.0, which led to the
inability to use HTTPS without the verify_peer=false option.
Build
Fixed a build failure with gcc if libpbf is installed (gh-7292).
Fixed the static build on Mac OS 11 and newer (gh-7459).
2.10.0 is the first
stable version of the 2.10 release series.
It introduces 107 improvements and resolves 131 bugs since version 2.8.1.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Notable changes are:
HTTP client now supports HTTP/2.
Support of the new DATETIME type.
Improved type consistency in SQL.
Added transaction isolation levels.
Implemented fencing and pre-voting in RAFT.
Introduced foreign keys and constraints.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Some changes are labeled as [Breaking change].
It means that the old behavior was considered error-prone
and therefore changed to protect users from unintended mistakes.
However, there is a small probability that someone can rely on the old behavior,
and this label is to bring attention to the things that have been changed.
The changes that break backward compatibility are listed below:
fiber.wakeup() in Lua and fiber_wakeup() in C became NOP on the
currently running fiber.
The timeout() method of net.box connection was dropped.
The net.box console support was dropped.
The return value type for all time64 functions was changed from uint64_t to
int64_t.
Functionality added or changed
Core
The UUID field type is now part of the SCALAR field type
(gh-6042).
The UUID field type is now available in SQL. A new UUID can
be generated using the new SQL built-in UUID() function
(gh-5886).
[Breaking change] The timeout() method of net.box connection,
marked deprecated more than four years ago (in 1.7.4), has been dropped.
It negatively affected the performance of hot net.box methods,
such as call() and select() if they were called without
specifying a timeout (gh-6242).
Improved net.box performance by up to 70% by rewriting hot code
paths in C (gh-6241).
Introduced compact tuples that allow saving 4 bytes per tuple in case
of small user data (gh-5385).
Now streams and interactive transactions over streams are implemented in iproto.
Every stream is associated with its ID, which is unique within one connection.
All requests with the same non-zero stream ID belong to the same stream.
All requests in the stream are processed synchronously.
The next request will not start executing until the previous one is completed.
If a request’s stream ID is 0, it does not belong to a stream
and is processed in the old way.
In net.box, a stream is an object above the connection that has
the same methods but allows executing requests sequentially. The ID is
generated on the client-side automatically.
If a user writes his own connector and wants to use streams,
they must transmit the stream_id over the iproto protocol.
The primary purpose of streams is transactions via iproto.
As each stream can start a transaction, several transactions can be multiplexed over one connection.
There are multiple ways to begin, commit, and rollback a transaction.
One can do that using the appropriate stream methods, call, eval,
or execute with the SQL transaction syntax. Users can mix these methods.
For example, one might start a transaction using stream:begin(),
and commit it with stream:call('box.commit') or stream:execute('COMMIT').
If any request fails during the transaction, it will not affect the other requests in the transaction.
If a disconnect occurs while there is an active transaction in the stream,
that transaction will be rolled back if it hasn’t been committed before the connection failure
(gh-5860).
Added the new memtx_allocator option to box.cfg{}.
It allows selecting the appropriate allocator for memtx tuples if necessary.
The possible values are system for malloc allocator and small for
the default small allocator.
Implemented the system allocator based on malloc. The slab allocator, which is used for tuple allocation,
has a particular disadvantage – it is prone to unresolvable fragmentation on specific workloads (size migration).
In this case, the user should be able to choose another allocator.
The system allocator is based on the malloc function but restricted by the same quota as the slab allocator.
The system allocator does not alloc all the memory at the start. Instead, it allocates memory as needed,
checking that the quota is not exceeded
(gh-5419).
Added box.stat.net.thread() for reporting per thread net
statistics (gh-6293).
Added the new STREAMS metric to box.stat.net. It contains
statistics for iproto streams. The STREAMS contains the same counters
as the CONNECTIONS metric in box.stat.net: current, RPS, and
total (gh-6293).
Extended the network protocol (IPROTO) with a new request type
(IPROTO_ID). It is supposed to be used for exchanging sets of
supported features between the server and client (gh-6253).
Added required_protocol_version and required_protocol_features
to net.box connection options. The new options allow specifying
the IPROTO protocol version and features that must be supported by the server
for the connection to pass (gh-6253).
[Breaking change] Added the msgpack.cfg.encode_error_as_ext
configuration option to enable/disable encoding errors as
MP_ERROR MsgPack extension. The option is enabled by default
(gh-6433).
[Breaking change] Removed box.session.setting.error_marshaling_enabled.
Error marshalling is now enabled automatically if the connector supports it
(gh-6428).
Added the new REQUESTS_IN_PROGRESS and REQUESTS_IN_STREAM_QUEUE
metrics to box.stat.net that contains detailed statistics for iproto requests.
These metrics contain the same counters as other metrics in box.stat.net:
current, RPS, and total (gh-6293).
Implemented a timeout for fiber:join in Lua (gh-6203).
Added the new box.txn_id() function. It returns the ID of the
current transaction if called within a transaction, nil otherwise.
Previously, if a yield occurs for a transaction that does not support
it, all its statements are rolled back but still its new
statements are processed (they will roll back with each yield). Also, the
transaction will be rolled back when a commit is attempted. Now we
stop processing any new statements right after the first yield if a
transaction does not support it.
Implemented a timeout for transactions after which they are rolled
back (gh-6177).
Implemented the new C API box_txn_set_timeout function to set a
timeout for transactions.
Implemented a timeout for iproto transactions after which they are
rolled back (gh-6177).
Implemented the new IPROTO_TIMEOUT0x56 key, which is used to set a
timeout for transactions over iproto streams. It is stored in the
body of IPROTO_BEGIN request.
Introduced box.broadcast and box.watch functions to
signal/watch user-defined state changes (gh-6257).
Added watchers support to the network protocol (gh-6257).
Added watchers support to the net.box connector (gh-6257).
Now error objects with the code box.error.READONLY now have
the additional fields explaining why the error happened.
Also, there is a new field box.info.ro_reason. It is nil on a
writable instance, but reports a reason when box.info.ro is true
(gh-5568).
Implemented the ability to open several listening sockets. In
addition to the ability to pass uri as a number or string, added the
ability to pass uri as a table of numbers or strings (gh-3554).
[Breaking change]net.box console support, which was marked
deprecated in 1.10, has been dropped. Use require('console').connect()
instead.
Added the takes_raw_args Lua function option for wrapping arguments
in msgpack.object to skip decoding (gh-3349).
Implemented the graceful shutdown protocol for IPROTO connections
(gh-5924).
Added fetch_schema flag to netbox.connect to control schema
fetching from remote instance (gh-4789).
Added linking type (dynamic or static) to Tarantool build info.
Changed log level of some information messages from critical to info
(gh-4675).
Added predefined system events: box.status, box.id,
box.election, and box.schema (gh-6260).
Introduced transaction isolation levels in Lua and IPROTO (gh-6930).
Added support for backtrace feature on AARCH64 architecture
(gh-6060).
Implemented collection of parent backtrace for the newly created
fibers. To enable the feature, call fiber.parent_backtrace_enable. To disable it, call
fiber.parent_backtrace_disable: disabled by default (gh-4302).
Disabled the deferred DELETE optimization in Vinyl to avoid
possible performance degradation of secondary index reads. Now, to
enable the optimization, one has to set the defer_deletes flag in
space options (gh-4501).
Replication
Introduced box.info.replication[n].downstream.lag field to
monitor the state of replication. This member represents a lag between
the main node writing a certain transaction to its own WAL and the
moment it receives an ack for this transaction from a replica
(gh-5447).
Introduced on_election triggers. The triggers may be registered via
box.ctl.on_election() interface and are run asynchronously each
time box.info.election changes (gh-5819).
It is now possible to decode incoming replication data in a separate
thread. Added the replication_threads configuration option that
controls how many threads may be spawned to do the task (default is 1)
(gh-6329).
Raft
Added the term field to box.info.synchro.queue. It contains a
term of the last PROMOTE. It is usually equal to
box.info.election.term but may be less than the election term
when the new round of elections started, but no one promoted yet.
Servers with elections enabled won’t start new elections as long as
at least one of their peers sees the current leader. They also won’t
start the elections when they don’t have a quorum of connected peers.
This should reduce cases when a server that has lost connectivity to
the leader disrupts the whole cluster by starting new elections
(gh-6654).
Added the leader_idle field to box.info.election table. The
value shows time in seconds since the last communication with a known
leader (gh-6654).
LuaJIT
Introduced support for LJ_DUALNUM mode in luajit-gdb.py
(gh-6224).
Introduced preliminary support of GNU/Linux ARM64 and macOS M1. In
the scope of this activity, the following issues have been resolved:
Introduced support for a full 64-bit range of lightuserdata values
(gh-2712).
Fixed memory remapping issue when the page leaves 47-bit segments.
Fixed variadic arguments handling in FFI on M1 (gh-6066).
Fixed table.move misbehavior when table reallocation occurs
(gh-6084).
Fixed Lua stack inconsistency when xpcall is called with an
invalid second argument on ARM64 (gh-6093).
Fixed BC_USETS bytecode semantics for closed upvalues and gray
strings.
Fixed side exit jump target patching considering the range values
of the particular instruction (gh-6098).
Fixed current Lua coroutine restoring on an exceptional path on
ARM64 (gh-6189).
Now memory profiler records allocations from traces grouping them by
the trace number (gh-5814). The memory profiler parser can display
the new type of allocation sources in the following format:
| TRACE [<trace-no>] <trace-addr> started at @<sym-chunk>:<sym-line>
Now the memory profiler reports allocations made by the JIT engine while
compiling the trace as INTERNAL (gh-5679).
Now the memory profiler emits events of the new type when a function
or a trace is created. As a result, the memory profiler parser can
enrich its symbol table with the new functions and traces (gh-5815).
Furthermore, there are symbol generations introduced within the
internal parser structure to handle possible collisions of function
addresses and trace numbers.
Now the memory profiler dumps symbol table for C functions. As a result,
memory profiler parser can enrich its symbol table with C symbols
(gh-5813). Furthermore, now memory profiler dumps special events for symbol
table when it encounters a new C symbol, that has not been dumped yet.
Introduced the LuaJIT platform profiler (gh-781) and the profile
parser. This profiler is able to capture both host and VM stacks, so
it can show the whole picture. Both C and Lua API’s are available for
the profiler. Profiler comes with the default parser, which produces
output in a flamegraph.pl-suitable format. The following profiling
modes are available:
Default: only virtual machine state counters.
Leaf: shows the last frame on the stack.
Callchain: performs a complete stack dump.
Lua
Introduced the new method table.equals. It compares two tables by value and
respects the __eq metamethod.
Added support of console autocompletion for net.box objects
stream and future (gh-6305).
Added the box.runtime.info().tuple metric to track the amount of
memory occupied by tuples allocated on runtime arena (gh-5872).
It does not count tuples that arrive from memtx or vinyl but counts
tuples created on-the-fly: say, using box.tuple.new(<...>).
Datetime
Added a new built-in module datetime.lua that allows operating
timestamps and intervals values (gh-5941).
Added the method to allow converting string literals in extended
iso-8601 or rfc3339 formats (gh-6731).
Extended the range of supported years in all parsers to cover fully
-5879610-06-22..5879611-07-11 (gh-6731).
Datetime interval support has been reimplemented in C to make
possible future Olson/tzdata and SQL extensions (gh-6923).
Now all components of the interval values are kept and operated
separately (years, months, weeks, days, hours, seconds, and
nanoseconds). This allows applying date/time arithmetic correctly
when we add/subtract intervals to datetime values.
Extended datetime literal parser with the ability to handle known
timezone abbreviations (‘MSK’, ‘CET’, etc.) which are
deterministically translated to their offset
(gh-5941, gh-6751).
Timezone abbreviations can be used in addition to the timezone offset
in the datetime literals. For example, these literals produce equivalent
datetime values:
Parser fails if one uses ambiguous names (for example, ‘AT’) which could not
be directly translated into timezone offsets.
Enabled support for timezone names in the constructor and
date:set{} modifier via tz attribute. Currently, only
timezone name abbreviations are supported (gh-7076).
Timezone abbreviations can be used in addition to the timezone
offset. They can be used during constructing or modifying a date
object, or while parsing datetime literals. Numeric time offsets and
named abbreviations produce equivalent datetime values:
Note that the timezone name parser fails if one uses ambiguous names,
which could not be translated into timezone offsets directly (for
example, ‘AT’).
Digest
Introduced new hash types in digest module – xxhash32 and
xxhash64 (gh-2003).
Fiber
Introduced fiber_object:info() to get info from fiber. Works
as require('fiber').info() but only for one fiber.
Introduced fiber_object:csw() to get csw from fiber
(gh-5799).
Changed fiber.info() to hide backtraces of idle fibers (gh-4235).
Improved fiber fiber.self(), fiber.id() and fiber.find()
performance by 2-3 times.
Log
Implemented support of symbolic log levels representation in log
module (gh-5882). Now it is possible to specify levels the same way
as in box.cfg{} call.
Added the return_raw net.box option for returning msgpack.object
instead of decoding the response (gh-4861).
Schema
is_multikey option may now be passed to
box.schema.func.create directly, without opts sub-table.
SQL
Descriptions of type mismatch error and inconsistent type error
became more informative (gh-6176).
Removed explicit cast from BOOLEAN to numeric types and vice
versa (gh-4770).
Removed explicit cast from VARBINARY to numeric types and vice
versa (gh-4772, gh-5852).
Fixed a bug due to which a string that is not NULL-terminated
could not be cast to BOOLEAN, even if the conversion should be
successful according to the rules.
Now a numeric value can be cast to another numeric type only if the
cast is precise. In addition, a UUID value cannot be implicitly
cast to STRING/VARBINARY. Also, a STRING/VARBINARY
value cannot be implicitly cast to a UUID (gh-4470).
Now any number can be compared to any other number, and values of any
scalar type can be compared to any other value of the same type. A
value of a non-numeric scalar type cannot be compared with a value of
any other scalar type (gh-4230).
SQL built-in functions were removed from the _func system space
(gh-6106).
Functions are now looked up first in SQL built-in functions and then
in user-defined functions.
Fixed incorrect error message in case of misuse of the function used
to set the default value.
The typeof() function with NULL as an argument now returns
NULL (gh-5956).
The SCALAR and NUMBER types have been reworked in SQL. Now
SCALAR values cannot be implicitly cast to any other scalar type,
and NUMBER values cannot be implicitly cast to any other numeric
type. This means that arithmetic and bitwise operations and
concatenation are no longer allowed for SCALAR and NUMBER
values. In addition, any SCALAR value can now be compared with
values of any other scalar type using the SCALAR rules (gh-6221).
The DECIMAL field type is now available in SQL. Decimal can be
implicitly cast to and from INTEGER and DOUBLE, it can
participate in arithmetic operations and comparison between
DECIMAL, and all other numeric types are defined (gh-4415).
The argument types of SQL built-in functions are now checked in most
cases during parsing. In addition, the number of arguments is now
always checked during parsing (gh-6105).
A value consisting of digits and a decimal point is now parsed as
DECIMAL (gh-6456).
The ANY field type is now available in SQL (gh-3174).
Built-in SQL functions now work correctly with DECIMAL values
(gh-6355).
The default type is now defined in case the argument type of an SQL
built-in function cannot be determined during parsing (gh-4415).
The ARRAY field type is now available in SQL. The syntax has also
been implemented to allow the creation of ARRAY values (gh-4762).
User-defined aggregate functions are now available in SQL (gh-2579).
Introduced SQL built-in functions NOW() and DATE_PART()
(gh-6773).
The left operand is now checked before the right operand in an
arithmetic operation. (gh-6773).
The INTERVAL field type is introduced in SQL (gh-6773).
Bitwise operations can now only accept UNSIGNED and positive
INTEGER values (gh-5364).
The MAP field type is now available in SQL. Also, the syntax has been
implemented to allow the creation of MAP values (gh-4763).
Introduced [] operator for MAP and ARRAY values
(gh-6251).
Box
Public role now has read, write access on _session_settings space
(gh-6310).
The INTERVAL field type is introduced to BOX (gh-6773).
The behavior of empty or nil select calls on user spaces was
changed. A critical log entry containing the current stack traceback
is created upon such function calls. The user can explicitly request
a full scan though by passing fullscan=true to select ’s
options table argument, in which case a log entry will not be
created (gh-6539).
Improved checking for dangerous select calls. The calls with
offset+limit<=1000 are now considered safe, which means a
warning is not issued. The ‘ALL’, ‘GE’, ‘GT’, ‘LE’, ‘LT’ iterators
are now considered dangerous by default even with the key present
(gh-7129).
Datetime
Allowed using human-readable timezone names (for example,
‘Europe/Moscow’) in datetime strings. Use IANA tzdata (Olson DB)
for timezone-related operations, such as DST-based timezone offset
calculations (gh-6751).
The isdst field in the datetime object is now calculated
correctly, according to the IANA tzdata (aka Olson DB) rules for
the given date/time moment (gh-6751).
The datetime module exports the bidirectional TZ array, which
can be used to translate the timezone index (tzindex) into
timezone names, and vice versa (gh-6751).
Fiber
Previously csw (Context SWitch) of a new fiber could be more than 0,
now it is always 0 (gh-5799).
Luarocks
Set FORCE_CONFIG=false for luarocks config to allow loading
project-side .rocks/config-5.1.lua.
Added bundling of GNU libunwind to support backtrace feature on
AARCH64 architecture and distributives that don’t provide
libunwind package.
Re-enabled backtrace feature for all RHEL distributions by default,
except for AARCH64 architecture and ancient GCC versions, which
lack compiler features required for backtrace (gh-4611).
Updated libicu version to 71.1 for static build.
Bumped OpenSSL from 1.1.1f to 1.1.1n for static build (gh-6947).
[Breaking change]fiber.wakeup() in Lua and
fiber_wakeup() in C became NOP on the currently running fiber.
Previously they allowed ignoring the next yield or sleep, which
resulted in unexpected erroneous wake-ups. Calling these functions
right before fiber.create() in Lua or fiber_start() in C
could lead to a crash (in debug build) or undefined behaviour (in
release build) (gh-6043).
There was a single use case for that—reschedule in the same event
loop iteration which is not the same as fiber.sleep(0) in Lua and
fiber_sleep(0) in C. It could be done in the following way:
in C:
fiber_wakeup(fiber_self());fiber_yield();
in Lua:
fiber.self():wakeup()fiber.yield()
To get the same effect in C, one can use fiber_reschedule(). In Lua, it
is now impossible to reschedule the current fiber directly in the same
event loop iteration. One can reschedule self through a second fiber,
but it is strongly discouraged:
Fixed memory leak on each box.on_commit() and
box.on_rollback() (gh-6025).
Fixed the lack of testing for non-joinable fibers in fiber_join()
call. This could lead to unpredictable results. Note the issue
affects C level only, in Lua interface fiber:join() the
protection is turned on already.
Now Tarantool yields when scanning .xlog files for the latest
applied vclock and when finding the right place in .xlogs to
start recovering. This means that the instance is responsive right
after box.cfg call even when an empty .xlog was not created
on the previous exit. Also, this prevents the relay from timing out
when a freshly subscribed replica needs rows from the end of a
relatively long (hundreds of MBs) .xlog (gh-5979).
The counter in x.yMrowsprocessed log messages does not reset on
each new recovered xlog anymore.
Fixed wrong type specification when printing fiber state change which
led to negative fiber’s ID logging (gh-5846).
For example,
main/-244760339/cartridge.failover.task I> Instance state changed
instead of proper
main/4050206957/cartridge.failover.task I> Instance state changed
Fiber IDs were switched to monotonically increasing unsigned 8-byte
integers so that there would not be IDs wrapping anymore. This allows
detecting fiber’s precedence by their IDs if needed (gh-5846).
Fixed a crash in JSON update on tuple/space when it had more than one
operation, they accessed fields in reversed order, and these fields
did not exist. Example: box.tuple.new({1}):update({{'=',4,4},{'=',3,3}})
(gh-6069).
Fixed invalid results produced by the json module’s encode
function when it was used from Lua’s garbage collector. For instance,
in functions used as ffi.gc() (gh-6050).
Added check for user input of the number of iproto threads—value must
be > 0 and less than or equal to 1000 (gh-6005).
Fixed error related to the fact that if a user changed the listen
address, all iproto threads closed the same socket multiple times.
Fixed error related to Tarantool not deleting the unix socket path
when the work is finished.
Fixed a crash in MVCC during simultaneous update of a key in
different transactions (gh-6131).
Fixed a bug when memtx MVCC crashed during reading uncommitted DDL
(gh-5515).
Fixed a bug when memtx MVCC crashed if an index was created in the
transaction (gh-6137).
Fixed segmentation fault with MVCC when an entire space was updated
concurrently (gh-5892).
Fixed a bug with failed assertion after stress update of the same key
(gh-6193).
Fixed a crash that happened when a user called box.snapshot
during an incomplete transaction (gh-6229).
Fixed console client connection breakage if request times out
(gh-6249).
Added missing broadcast to net.box.future:discard(). Now
fibers waiting for a request result are woken up when the request is
discarded (gh-6250).
box.info.uuid, box.info.cluster.uuid, and
tostring(decimal) with any decimal number in Lua sometimes could
return garbage if __gc handlers were used in the user’s code
(gh-6259).
Fixed the error message that happened in a very specific case during
MVCC operation (gh-6247).
Fixed a repeatable read violation after delete (gh-6206).
Fixed a bug when hash select{} was not tracked by MVCC engine
(gh-6040).
Fixed a crash in MVCC after the drop of a space with several indexes
(gh-6274).
Fixed a bug when GC at some state could leave tuples in secondary
indexes (gh-6234).
Disallowed yields after DDL operations in MVCC mode. It fixes a crash
which takes place in case several transactions refer to system spaces
(gh-5998).
Fixed a bug in MVCC connected which happened on a rollback after DDL
operation (gh-5998).
Fixed a bug when rollback resulted in unserializable behaviour
(gh-6325).
At the moment, when a net.box connection is closed, all requests
that have not been sent will be discarded. This patch fixes this
behavior: all requests queued for sending before the connection is
closed are guaranteed to be sent (gh-6338).
Fixed a crash during replace of malformed tuple into _schema system
space (gh-6332).
Fixed dropping incoming messages when the connection is closed or
SHUT_RDWR received and net_msg_max or readahead limit is
reached (gh-6292).
Fixed memory leak in case of replace during background alter of the
primary index (gh-6290).
Fixed a bug when rolled back changes appear in the
built-in-background index (gh-5958).
Fixed a crash while encoding an error object in the MsgPack format
(gh-6431).
Fixed a bug when an index was inconsistent after background build in
case the primary index was hash (gh-5977).
Now inserting a tuple with the wrong id` field into the _priv
space returns the correct error (gh-6295).
Fixed dirty read in MVCC after space alter (gh-6263, gh-6318).
Fixed a crash in case the fiber changing box.cfg.listen is woken up
(gh-6480).
Fixed box.cfg.listen not reverted to the old address in case the
new one is invalid (gh-6092).
Fixed a crash caused by a race between box.session.push() and
closing connection (gh-6520).
Fixed a bug because of which the garbage collector could remove an
xlog file that was still in use (gh-6554).
Fixed crash during granting privileges from guest (gh-5389).
Fixed an error in listening when the user passed uri in numerical
form after listening unix socket (gh-6535).
Fixed a crash that could happen in case a tuple is deleted from a
functional index while there is an iterator pointing to it (gh-6786).
Fixed memory leak in interactive console (gh-6817).
Fixed an assertion fail when passing a tuple without primary key
fields to before_replace trigger. Now tuple format is checked
before execution of before_replace triggers and after each one
(gh-6780).
Banned DDL operations in space on_replace triggers, since they
could lead to a crash (gh-6920).
Implemented constraints and foreign keys. Now users can create
function constraints and foreign key relations (gh-6436).
Fixed a bug due to which all fibers created with
fiber_attr_setstacksize() leaked until the thread exit. Their
stacks also leaked except when fiber_set_joinable(...,true) was used.
Fixed a crash in MVCC related to a secondary index conflict
(gh-6452).
Fixed a bug which resulted in wrong space count (gh-6421).
SELECT in RO transaction now reads confirmed data, like a
standalone (autocommit) SELECT does (gh-6452).
Fixed a crash when Tarantool was launched with multiple -e or
-l options without a space between the option and the value
(gh-5747).
Fixed effective session and user not propagated to box.on_commit
and box.on_rollback trigger callbacks (gh-7005).
Fixed usage of box.session.peer() in box.session.on_disconnect()
trigger. Now it’s safe to assume that box.session.peer() returns
the address of the disconnected peer, not nil, as it used to (gh-7014).
Fixed creation of a space with a foreign key pointing to the same
space (gh-6961).
Fixed a bug when MVCC failed to track nothing-found range select
(gh-7025).
Allowed complex foreign keys with NULL fields (gh-7046).
Added decoding of election messages: RAFT and PROMOTE to
xlog Lua module (gh-6088). Otherwise tarantoolctl shows plain
number in type
[Breaking change] Return value signedness of 64-bit time
functions in clock and fiber was changed from uint64_t to
int64_t both in Lua and C (gh-5989).
Fixed reversed iterators gap tracking. Instead of tracking gaps for
the successors of keys, gaps for tuples shifted by one to the left of
the successor were tracked (gh-7113).
Memtx
Now memtx raises an error if the “clear” dictionary is passed to
s:select() (gh-6167).
Fixed MVCC transaction manager story garbage collection breaking
memtx TREE index iterator (gh-6344).
Vinyl
Fixed possible keys divergence during secondary index build, which
might lead to missing tuples (gh-6045).
Fixed the race between Vinyl garbage collection and compaction
that resulted in a broken vylog and recovery failure (gh-5436).
Immediate removal of compacted run files created after the last
checkpoint optimization now works for replica’s initial JOIN stage
(gh-6568).
Fixed crash during recovery of a secondary index in case the primary
index contains incompatible phantom tuples (gh-6778).
Replication
Fixed the use after free in the relay thread when using elections (gh-6031).
Fixed a possible crash when a synchronous transaction was followed by
an asynchronous transaction right when its confirmation was being
written (gh-6057).
Fixed an error where a replica, while attempting to subscribe to a foreign
cluster with a different replicaset UUID, did not notice it is impossible
and instead became stuck in an infinite retry loop printing
a TOO_EARLY_SUBSCRIBE error (gh-6094).
Fixed an error where a replica, while attempting to join a cluster with
exclusively read-only replicas available, just booted its own replicaset,
instead of failing or retrying. Now it fails with
an error about the other nodes being read-only so they can’t register
the new replica (gh-5613).
Fixed error reporting associated with transactions
received from remote instances via replication.
Any error raised while such a transaction was being applied was always reported as
Failedtowritetodisk regardless of what really happened. Now the
correct error is shown. For example, Outofmemory, or
Transactionhasbeenabortedbyconflict, and so on (gh-6027).
Fixed replication stopping occasionally with ER_INVALID_MSGPACK
when replica is under high load (gh-4040).
Fixed a cluster that sometimes could not bootstrap if it contained
nodes with election_modemanual or voter (gh-6018).
Fixed a possible crash when box.ctl.promote() was called in a
cluster with >= 3 instances, happened in debug build. In release
build, it could lead to undefined behavior. It was likely to happen
if a new node was added shortly before the promotion (gh-5430).
Fixed a rare error appearing when MVCC (box.cfg.memtx_use_mvcc_engine)
was enabled and more than one replica was joined to a cluster.
The join could fail with the error
"ER_TUPLE_FOUND:Duplicatekeyexistsinuniqueindex'primary'inspace'_cluster'".
The same could happen at the bootstrap of a cluster having >= 3 nodes
(gh-5601).
Fixed replica reconnecting to a living master on any
box.cfg{replication=...} change. Such reconnects could lead to
replica failing to restore connection for replication_timeout
seconds (gh-4669).
Fixed potential obsolete data write in synchronous replication due
to race in accessing terms while disk write operation is in progress
and not yet completed.
Fixed replicas failing to bootstrap when the master has just
restarted (gh-6966).
Fixed a bug when replication was broken on the master side with
ER_INVALID_MSGPACK (gh-7089).
Raft
Fixed box.ctl.promote() entering an infinite election loop when a
node does not have enough peers to win the elections (gh-6654).
Servers with elections enabled will resign the leadership and become
read-only when the number of connected replicas becomes less than a
quorum. This should prevent split-brain in some situations (gh-6661).
Fixed a rare crash with the leader election enabled (any mode except
off), which could happen if a leader resigned from its role at
the same time as some other node was writing something related to the
elections to WAL. The crash was in debug build. In the release
build, it would lead to undefined behavior (gh-6129).
Fixed an error when a new replica in a Raft cluster could try to join
from a follower instead of a leader and failed with an error
ER_READONLY (gh-6127).
Reconfiguration of box.cfg.election_timeout could lead to a crash
or undefined behavior if done during an ongoing election with a
special WAL write in progress.
Fixed several crashes and/or undefined behaviors (assertions in debug
build) which could appear when new synchronous transactions were made
during ongoing elections (gh-6842).
LuaJIT
Fixed optimization for single-char strings in the IR_BUFPUT
assembly routine.
Fixed slots alignment in lj-stack command output when LJ_GC64
is enabled (gh-5876).
Fixed dummy frame unwinding in lj-stack command.
Fixed top part of Lua stack (red zone, free slots, top slot)
unwinding in lj-stack command.
Added the value of g->gc.mmudata field to lj-gc output.
Fixed detection of inconsistent renames even in the presence of sunk
values (gh-4252, gh-5049, gh-5118).
Fixed the order VM registers are allocated by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Fixed inconsistency while searching for an error function when
unwinding a C-protected frame to handle a runtime error (an error
in __gc handler).
string.char() builtin recording is fixed in case when no
arguments are given (gh-6371, gh-6548).
Actually made JIT respect maxirconst trace limit while recording
(gh-6548).
Lua
Fixed a bug when multibyte characters broke space:fselect()
output.
When an error is raised during encoding call results, the auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Prior to the fix, it leads to undefined behavior during the next
usage of this Lua coroutine (gh-4617).
Fixed Lua C API misuse, when the error is raised during call results
encoding on unprotected coroutine and expected to be caught on the
different one that is protected (gh-6248).
Fixed net.box error in case connections are frequently opened and
closed (gh-6217).
Fixed incorrect handling of variable number of arguments in
box.func:call() (gh-6405).
Fixed table.equals result when booleans compared (gh-6386).
Tap subtests inherit strict mode from parent (gh-6868).
Fixed the behavior of Tarantool console on SIGINT. Now Ctrl+C
discards the current input and prints the new prompt (gh-2717).
Triggers
Fixed the possibility of a crash in case when trigger removes itself.
Fixed the possibility of a crash in case someone destroys trigger
when it’s yielding (gh-6266).
SQL
User-defined functions can now return VARBINARY to SQL as a
result (gh-6024).
Fixed assert on a cast of DOUBLE value greater than -1.0 and less
than 0.0 to INTEGER and UNSIGNED (gh-6255).
Removed spontaneous conversion from INTEGER to DOUBLE in a
field of type NUMBER (gh-5335).
All arithmetic operations can now only accept numeric values
(gh-5756).
Now function quote() returns an argument in case the argument
is DOUBLE. The same for all other numeric types. For types other
than numeric, STRING is returned (gh-6239).
The TRIM() function now does not lose collation when executed
with the keywords BOTH, LEADING, or TRAILING (gh-6299).
Now getting unsupported msgpack extension in SQL throws the correct error (gh-6375).
Now, when copying an empty string, an error will not be set
unnecessarily (gh-6157, gh-6399).
Fixed wrong comparison between DECIMAL and large DOUBLE
values (gh-6376).
Fixed truncation of DECIMAL during implicit cast to INTEGER
in LIMIT and OFFSET.
Fixed truncation of DECIMAL during implicit cast to INTEGER
when value is used in an index.
Fixed assert on a cast of DECIMAL value that is greater than -1.0
and less than 0.0 to INTEGER (gh-6485).
The HEX() SQL built-in function no longer throws an assert when
its argument consists of zero-bytes (gh-6113).
LIMIT is now allowed in ORDERBY where sort order is in both
directions (gh-6664).
Fixed a memory leak in SQL during calling of user-defined function
(gh-6789).
Fixed assertion or segmentation fault when MP_EXT received via net.box
(gh-6766).
Now the ROUND() function properly supports INTEGER and
DECIMAL as the first argument (gh-6988).
Fixed a crash when a table inserted data into itself with an
incorrect number of columns (gh-7132).
Box
Fixed log.cfg getting updated on box.cfg error (gh-6086).
Fixed the error message in an attempt to insert into a tuple the size
of which equals to box.schema.FIELD_MAX (gh-6198).
We now check that all privileges passed to box.schema.grant are
resolved (gh-6199).
Added iterator type checking and allow passing iterator as a
box.index.{ALL,GT,...} directly (gh-6501).
Datetime
Intervals received after datetime arithmetic operations may be
improperly normalized if the result was negative
It means that two immediately called date.now() produce very close values,
which difference should be close to 0, not 1 second (gh-6882).
Fixed a bug in datetime module when date:set{tzoffset=XXX} did
not produce the same result with date.new{tzoffset=XXX} for the
same set of attributes passed (gh-6793).
Fixed MVCC interaction with ephemeral spaces: TX manager now ignores
such spaces (gh-6095).
Fixed a loss of tuple after a conflict exception (gh-6132).
Fixed a segmentation fault in update/delete of the same tuple (gh-6021).
Net.box
Changed the type of the error returned by net.box on timeout from
ClientError to TimedOut (gh-6144).
Recovery
When force_recovery cfg option is set, Tarantool is able to boot
from snap/xlog combinations where xlog covers changes
committed both before and after snap creation. For example,
0...0.xlog, covering everything up to vclock{1:15} and
0...09.snap, corresponding to vclock{1:9} (gh-6794).
Tarantoolctl
Fixed the missing rocks keyword in tarantoolctlrocks help
messages.
Build
Bumped Debian packages tarantool-common dependency to use luarocks 3
(gh-5429).
Fixed an error when it was possible to have new Tarantool package
(version >= 2.2.1) installed with pre-luarocks 3 tarantool-common
package (version << 2.2.1), which caused rocks install to fail.
The Debian package does not depend on binutils anymore (gh-6699).
2.8.4 is the third
stable version of the 2.8 release series.
It introduces 1 improvement and resolves 16 bugs since version 2.8.3.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Fixed a crash that could happen in case a tuple is deleted from a
functional index while there is an iterator pointing to it (gh-6786).
Fixed memory leak in interactive console (gh-6817).
Fixed an assertion fail when passing tuple without primary key fields
to before_replace trigger. Now tuple format is checked before
execution of before_replace triggers and after each one (gh-6780).
Banned DDL operations in space on_replace triggers, since they could
lead to a crash (gh-6920).
Fixed a bug due to which all fibers created with
fiber_attr_setstacksize() leaked until the thread exit. Their
stacks also leaked except when fiber_set_joinable(...,true) was
used.
Vinyl
Immediate removal of compacted run files created after the last
checkpoint optimization now works for replica’s initial JOIN stage
(gh-6568).
Fixed crash during recovery of a secondary index in case the primary
index contains incompatible phantom tuples (gh-6778).
Raft
Reconfiguration of box.cfg.election_timeout could lead to a crash
or undefined behaviour if done during an ongoing election with a
special WAL write in progress.
LuaJIT
Fixed top part of Lua stack (red zone, free slots, top slot)
unwinding in lj-stack command.
Added the value of g->gc.mmudata field to lj-gc output.
string.char() builtin recording is fixed in case when no
arguments are given (gh-6371, gh-6548).
Actually made JIT respect maxirconst trace limit while recording
(gh-6548).
Lua
Fixed table.equals result when booleans compared (gh-6386).
Tap subtests inherit strict mode from parent (gh-6868).
Box
Added iterator type checking and allow to pass iterator as a
box.index.{ALL,GT,…} directly (gh-6501).
When force_recovery cfg option is set, Tarantool is able to boot
from snap/xlog combinations where xlog covers changes
committed both before and after snap creation. For example,
0...0.xlog, covering everything up to vclock{1:15} and
0...09.snap, corresponding to vclock{1:9} (gh-6794).
2.8.3 is the third
stable
version of the 2.8 release series. It introduces 3 improvements and
resolves 24 bugs since version 2.8.2.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
LuaJIT
Introduced support for LJ_DUALNUM mode in luajit-gdb.py
(gh-6224).
Bump debian package compatibility level to 10 (gh-5429). Bump minimal
required debhelper to version 10 (except for Ubuntu Xenial).
Bugs fixed
Core
Disallow yields after DDL operations in MVCC mode. It fixes crash
which takes place in case several transactions refer to system spaces
(gh-5998).
Fixed bug in MVCC connected which happens on rollback after DDL
operation (gh-5998).
Fix a bug when rollback resulted in unserializable behaviour
(gh-6325)
Fixed a crash during replace of malformed tuple into _schema system
space (gh-6332).
Fix memory leak in case of replace during background alter of primary
index (gh-6290)
Fix a bug when rollbacked changes appears in built-in-background
index (gh-5958)
Fix a bug when index was inconsistent after background build in case
when the primary index is hash (gh-5977)
Now inserting a tuple with the wrong “id” field into the _priv space
will return the correct error (gh-6295).
Fixed dirty read in MVCC after space alter (gh-6263, gh-6318).
Fixed a crash caused by a race between box.session.push() and closing
connection (gh-6520).
Fixed crash in case a fiber changing box.cfg.listen is woken up
(gh-6480).
Fixed box.cfg.listen not reverted to the old address in case the new
one is invalid (gh-6092).
Fixed a bug because of which the garbage collector could remove an
xlog file that is still in use (gh-6554).
Fix crash during granting priveleges from guest (gh-5389).
Replication
Fixed replica reconnecting to a living master on any
box.cfg{replication=...} change. Such reconnects could lead to
replica failing to restore connection for replication_timeout
seconds (gh-4669).
LuaJIT
Fixed the order VM registers are allocated by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Fixed inconsistency while searching for an error function when
unwinding a C protected frame to handle a runtime error (e.g. an
error in __gc handler).
Lua
When error is raised during encoding call results, auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Prior to the fix it leads to undefined behaviour during the next
usage of this Lua coroutine (gh-4617).
Fixed Lua C API misuse, when the error is raised during call results
encoding on unprotected coroutine and expected to be catched on the
different one, that is protected (gh-6248).
Fixed net.box error in case connections are frequently opened and
closed (gh-6217).
Fixed incorrect handling of variable number of arguments in
box.func:call() (gh-6405).
Triggers
Fixed possibility crash in case when trigger removes itself. Fixed
possibility crash in case when someone destroy trigger, when it’s
yield (gh-6266).
SQL
Now, when copying an empty string, an error will not be set
unnecessarily (gh-6157, gh-6399).
Build
The Debian package does not depend on binutils anymore (gh-6699).
2.8.2 is the second
stable
version of the 2.8 release series. It introduces 6 improvements and
resolves 51 bugs since version 2.8.1.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
LuaJIT
Introduced support for LJ_DUALNUM mode in luajit-gdb.py
(gh-6224).
Lua
Introduced the new method table.equals. It compares two tables by value with
respect to the __eq metamethod.
Logging
The log module now supports symbolic representation of log levels.
Now it is possible to specify levels the same way as in
the box.cfg{} call
(gh-5882).
For example, instead of
require('log').cfg{level=6}
it is possible to use
require('log').cfg{level='verbose'}
SQL
Descriptions of type mismatch error and inconsistent type error have
become more informative
(gh-6176).
Removed explicit cast from BOOLEAN to numeric types and vice
versa
(gh-4770).
For example, CAST(FALSEASINTEGER) was 0 in version 2.8.
Now it causes an error.
Removed explicit cast from VARBINARY to numeric types and vice
versa
(gh-4772, gh-5852).
Fixed a bug where a string that is not NULL-terminated
could not be cast to BOOLEAN, even if the conversion would be
successful according to the rules.
[Breaking change]fiber.wakeup() in Lua and
fiber_wakeup() in C became NOP on the currently running fiber.
Previously they allowed “ignoring” the next yield or sleep, which
resulted in unexpected erroneous wake-ups. Calling these functions
right before fiber.create() in Lua or fiber_start() in C
could lead to a crash (in debug build) or undefined behaviour (in
release build) (gh-6043).
There was a single use case for the previous behaviour: rescheduling
in the same event loop iteration, which is not the same as
fiber.sleep(0) in Lua and fiber_sleep(0) in C. It could be
done in the following way:
in C:
fiber_wakeup(fiber_self());fiber_yield();
and in Lua:
fiber.self():wakeup()fiber.yield()
To get the same effect in C, one can now use fiber_reschedule().
In Lua, it is now impossible to reschedule the current fiber directly
in the same event loop iteration. One can reschedule self
through a second fiber, but it is strongly discouraged:
-- do not use this codelocalself=fiber.self()fiber.new(function()self:wakeup()end)fiber.sleep(0)
Fixed memory leak on box.on_commit() and
box.on_rollback() (gh-6025).
fiber_join() now checks if the argument is a joinable fiber.
The absence of this check could lead to unpredictable results. Note that
the change affects the C level only; in the Lua interface, fiber:join()
protection is already enabled.
Now Tarantool yields when it scans .xlog files for the latest
applied vclock and finds the right place to
start recovering from. It means that the instance becomes responsive
right after the box.cfg call even if an empty .xlog was not
created on the previous exit.
This fix also prevents the relay from timing out when a freshly subscribed
replica needs rows from the end of a relatively long (hundreds of
MBs) .xlog file
(gh-5979).
The counter in Nrowsprocessed log messages no longer
resets on each newly recovered xlog.
Fixed a crash in JSON update on tuple/space, where the update included
two or more operations that accessed fields in reversed order and
these fields didn’t exist. Example:
box.tuple.new({1}):update({{'=',4,4},{'=',3,3}})
(gh-6069).
Fixed invalid results of the json module’s encode
function when it was used from the Lua garbage collector. For
example, this could happen in functions used as ffi.gc()
(gh-6050).
Added a check for user input of the number of iproto threads: value
must be greater than zero and less than or equal to 1000
(gh-6005).
Changing a listed address can no longer cause iproto threads to close
the same socket several times.
Tarantool now always removes the Unix socket correctly when it exits.
Simultaneously updating a key in different transactions
does not longer result in a MVCC crash
(gh-6131).
Fixed a bug where memtx MVCC crashed during reading uncommitted DDL
(gh-5515).
Fixed a bug where memtx MVCC crashed if an index was created in the
transaction thread
(gh-6137).
Fixed a MVCC segmentation fault that arose
when updating the entire space concurrently
(gh-5892).
Fixed a bug with failed assertion after a stress update of the same
key
(gh-6193).
Fixed a crash where box.snapshot could be called during an incomplete
transaction
(gh-6229).
Fixed console client connection failure in case of request timeout
(gh-6249).
Added a missing broadcast to net.box.future:discard() so that now
fibers waiting for a request result wake up when the request is
discarded (gh-6250).
box.info.uuid, box.info.cluster.uuid, and
tostring(decimal) with any decimal number in Lua could sometimes
return garbage if there were __gc handlers in the user’s code
(gh-6259).
Fixed an error message that appeared in a particular case during
MVCC operation (gh-6247).
Fixed a repeatable read violation after delete
(gh-6206).
Fixed a bug where the MVCC engine didn’t track the select{} hash
(gh-6040).
Fixed a crash in MVCC after a drop of space with several indexes
(gh-6274).
Fixed a bug where the GC could leave tuples in secondary indexes
(gh-6234).
Disallow yields after DDL operations in MVCC mode. It fixes a crash
that took place when several transactions referred to system spaces
(gh-5998).
Fixed a bug in MVCC that happened on rollback after a DDL operation
(gh-5998).
Fixed a bug where rollback resulted in unserializable behavior
(gh-6325).
Vinyl
Fixed possible keys divergence during secondary index build, which
might lead to missing tuples
(gh-6045).
Fixed the race between Vinyl garbage collection and compaction that
resulted in a broken vylog and recovery failure
(gh-5436).
Replication
Fixed the use after free in the relay thread when using elections
(gh-6031).
Fixed a possible crash when a synchronous transaction was followed by
an asynchronous transaction right when its confirmation was being
written
(gh-6057).
Fixed an error where a replica, while attempting to subscribe to a foreign
cluster with a different replicaset UUID, didn’t notice it is impossible
and instead became stuck in an infinite retry loop printing
a TOO_EARLY_SUBSCRIBE error
(gh-6094).
Fixed an error where a replica, while attempting to join a cluster with
exclusively read-only replicas available, just booted its own replicaset,
instead of failing or retrying. Now it fails with
an error about the other nodes being read-only so they can’t register
the new replica
(gh-5613).
Fixed error reporting associated with transactions
received from remote instances via replication.
Any error raised while such a transaction was being applied was always reported as
Failedtowritetodisk regardless of what really happened. Now the
correct error is shown. For example, Outofmemory, or
Transactionhasbeenabortedbyconflict, and so on
(gh-6027).
Fixed replication occasionally stopping with ER_INVALID_MSGPACK
when the replica is under high load (gh-4040).
Fixed a cluster sometimes being unable to bootstrap if it contains
nodes with election_mode set to manual or voter
(gh-6018).
Fixed a possible crash when box.ctl.promote() was called in a
cluster with more than three instances. The crash happened in the debug build.
In the release build, it could lead to undefined behaviour. It was likely to happen
if a new node was added shortly before the promotion
(gh-5430).
Fixed a rare error appearing when MVCC
(box.cfg.memtx_use_mvcc_engine) was enabled and more than one
replica joined the cluster. The join could fail with the error
"ER_TUPLE_FOUND:Duplicatekeyexistsinuniqueindex'primary'inspace'_cluster'".
The same could happen at the bootstrap of a cluster having more than three nodes
(gh-5601).
Raft
Fixed a rare crash with leader election enabled (any mode except
off), which could happen if a leader resigned from its role while
another node was writing something elections-related to WAL.
The crash was in the debug build, and in the release
build it would lead to undefined behaviour
(gh-6129).
Fixed an error where a new replica in a Raft cluster tried to join
from a follower instead of a leader and failed with the error
ER_READONLY (gh-6127).
LuaJIT
Fixed optimization for single-char strings in the IR_BUFPUT assembly
routine.
Fixed slots alignment in the lj-stack command output when LJ_GC64
is enabled (gh-5876).
Fixed dummy frame unwinding in the lj-stack command.
Fixed detection of inconsistent renames even in the presence of sunk
values (gh-4252, gh-5049, gh-5118).
Fixed the VM register allocation order provided by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Lua
When an error occurs during encoding call results, the auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Before the fix, it led to undefined behaviour during the next
usage of this Lua coroutine (gh-4617).
Fixed a Lua C API misuse when the error is raised during call results
encoding in an unprotected coroutine and expected to be caught in a
different, protected coroutine (gh-6248).
Triggers
Fixed a possible crash in case trigger removes itself. Fixed a
possible crash in case someone destroys a trigger when it
yields (gh-6266).
SQL
User-defined functions can now return a VARBINARY result to SQL
(gh-6024).
Fixed assert when a DOUBLE value greater than -1.0 and less
than 0.0 is cast to INTEGER and UNSIGNED
(gh-6225).
Removed spontaneous conversion from INTEGER to DOUBLE in a field of the
NUMBER type
(gh-5335).
All arithmetic operations can now accept numeric values only
(gh-5756).
MVCC
Fixed MVCC interaction with ephemeral spaces: TX manager now ignores them
(gh-6095).
Fixed loss of tuples after a conflict exception
(gh-6132).
Fixed a segfault during update/delete of the same tuple
(gh-6021).
2.8.1 is the beta
version of the 2.8 release series.
This release introduces 28 new features and resolves 31 bugs since version 2.7.2.
There can be bugs in less common areas.
If you find any, feel free to report an
issue on GitHub.
Notable changes are:
Tarantool is now able to set multiple iproto threads.
The new box.ctl.promote() function and the concept of manual elections.
Enhancements in the Lua memory profiler.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
The exclude_null option can now be used in the index part definition.
With this option, the index filters and doesn’t store tuples with “null” value
of the corresponding part (gh-4480).
For example, an index created with
s:create_index('sk',{parts={{2,'number',exclude_null=true}}})
will ignore tuples {1,null} and {2,null},
but will not ignore {null,1} or {1,1}.
Added a slab_alloc_granularity option to box.cfg{}. This option allows
user to set multiplicity of memory allocation in a small allocator.
The value of slab_alloc_granularity must be exponent of two and >= 4
(gh-5518).
Previously, Lua on_shutdown triggers started sequentially.
Now each trigger starts in a separate fiber.
By default, Tarantool waits for the triggers to finish for 3.0 seconds.
User has the option to change this value using the new
box.ctl.set_on_shutdown_timeout function.
When the timeout expires, Tarantool stops immediately
without waiting for the other triggers to finish.
Tarantool module developers can now register functions to call when Tarantool stops
with the new on_shutdown API, (gh-5723).
Read more: on_shutdown.
Introduced the concept of WAL queue and the new configuration option
wal_queue_max_size, measured in bytes.
The default value is 16 Mb.
The option helps limit the pace at which replica submits new transactions to the WAL.
The limit is checked every time a transaction from the master is
submitted to the replica’s WAL.
The space taken by the transaction is considered empty once it’s successfully written
(gh-5536).
The information about the state of synchronous replication is now available via the
box.info.synchro interface (gh-5191).
Tarantool can now run multiple iproto threads.
It is useful in some specific workloads where iproto thread is the bottleneck of
throughput (gh-5645).
Update operations can’t insert with gaps. This patch changes the
behavior so that the update operation fills the missing fields with
nulls (gh-3378).
The new box.lib module allows loading and executing C
stored procedures on read-only nodes (gh-4642).
The priority of sources of configuration options is the following, from higher to lower:
box.cfg{},
environment variables,
tarantoolctl options,
default values,
Replication
Introduced the box.ctl.promote() function and the concept of manual elections
(enabled with election_mode='manual') (gh-3055).
Once the instance is in the manual election mode,
it acts like a voter most of the time,
but may trigger elections and become a leader when box.ctl.promote() is called.
When election_mode~='manual',
box.ctl.promote() replaces box.ctl.clear_synchro_queue(),
which is now deprecated.
LuaJIT
The output of LuaJIT memory profiler parser has become more user-friendly
(gh-5811). Now the source line definition where the event occurs is
much clearer: it only shows the source file name and allocation-related line,
and omits the line number of the function definition.
Moreover, event-related statistics are now indicated with units.
Breaking change: Line info of the line function definition is now saved in
symbol info table by field linedefined.
The field name has been renamed to source with respect to the Lua Debug API.
A number of improvements in the memory profiler parser:
The parser now reports heap difference which occurs during
the measurement interval (gh-5812).
Use the option --leak-only to show only the heap difference.
New built-in module memprof.process performs post-processing and aggregation of
memory events.
Run the memory profiler with the following command:
New tooling for collecting crash artefacts and postmortem analysis
(gh-5569).
Build
Tarantool build infrastructure now requires CMake version 3.2 or later.
Binary packages for Fedora 33 are now available (gh-5502).
Binary packages for CentOS 6 and Debian Jessie won’t be published since this version.
RPM and DEB packages no longer have the autotools dependency (follows up
gh-4968).
Regular testing on MacOS 10.13 has been disabled, effectively stopping
the support of this version.
The built-in zstd is upgraded from v1.3.3 to v1.4.8
(part of gh-5502).
SMTP and SMTPS protocols are now enabled in the bundled libcurl (gh-4559).
The libcurl headers are now shipped to system path ${PREFIX}/include/tarantool
when libcurl is included as a bundled library or in a static build
(gh-4559).
Testing
Tarantool CI/CD has migrated to GitHub Actions (gh-5662).
Single node Jepsen testing now runs on per-push basis (gh-5736).
Fuzzing tests now continuously run on per-push basis (gh-1809).
A self-sufficient LuaJIT testing environment has been implemented.
As a result, LuaJIT build system is now partially ported to CMake and all testing
machinery is enclosed within the tarantool/luajit
repository (gh-4862, gh-5470).
Python 3 is now the default in the test infrastructure (gh-5652).
Bugs fixed
Core
The index part options are no longer skipped when the field type is not specified
(gh-5674).
The lbox_ctl_is_recovery_finished() function no longer returns true
when recovery is still in progress.
A memory corruption bug has been fixed in netbox.
The memory of a struct error which is still used will no longer be freed prematurely
because of the wrong order of ffi.gc and ffi.cast calls.
Relay can no longer time out while a replica is joining or syncing with the master.
(gh-5762).
An issue with missing “path” value of index schema fetched by netbox has been fixed
(gh-5451).
Extensive usage of uri and uuid modules with debug log level
no longer leads to crashes or corrupted results of the functions from these
modules.
Same problem is resolved for using these modules from the callbacks passed to ffi.gc(),
and for some functions from the modules fio, box.tuple, and iconv
(gh-5632).
The new wal_cleanup_delay option can prevent early cleanup of
*.xlog files, needed by replicas.
Such cleanup used to result in a XlogGapError (gh-5806).
Appliers will no longer cause errors with Unknownrequesttype40 during
a final join when the master has synchronous spaces (gh-5566).
Fixed a crash which occurred when reloading a compiled module when the new module
lacked some of the functions which were present in the former code.
This event triggered a fallback procedure where Tarantool restored old
functions, but instead of restoring each function it only processed a sole
entry, leading to a crash later when these restored functions were called
(gh-5968).
Added memtx MVCC tracking of read gaps which fixes the problem of phantom reads
(gh-5628).
Fixed the wrong result of using space:count() with memtx MVCC (gh-5972).
Fixed the dirty read after restart while using MVCC with synchronous
replication (gh-5973).
Replication
Fixed an issue with an applier hanging on a replica after failing to process
a CONFIRM or ROLLBACK message coming from a master.
Fixed the issue where master did not send some rows to an anonymous replica
which had fallen behind and was trying to register.
Fixed the bug when a synchronous transaction could be confirmed and
visible on a replica, but then not confirmed or invisible again after
restart. It was more likely to happen on memtx spaces with
memtx_use_mvcc_engine enabled (gh-5213).
Fixed the recovery of a rolled back multi-statement synchronous transaction
which could lead to the transaction being applied partially, and to
recovery errors. It happened in case the transaction worked with
non-sync spaces (gh-5874).
Fixed a bug in synchronous replication when rolled back transactions
could reappear after reconnecting a sufficiently old instance
(gh-5445).
Swim
Fixed an issue where <swim_instance>:broadcast() did not work on non-local
addresses and spammed “Permission denied” errors to the log.
After instance termination it could return a non-0 exit code even if there
were no errors in the script, and then spam the same error again
(gh-5864).
Fixed the crash on attempts to call swim:member_by_uuid() with no
arguments or with nil/box.NULL (gh-5951).
Fixed the crash on attempts to pass an object of a wrong type to
__serialize method of a swim member in Lua (gh-5952).
LuaJIT
Lua stack resizing no longer results in a wrong behaviour of the memory profiler
(gh-5842).
Fixed a double gc_cdatanum decrementing in LuaJIT platform metrics
which occurred when a finalizer was set for a GCсdata object (gh-5820).
Lua
Fixed the -e option, when tarantool used to enter the interactive mode when
stdin is a TTY. Now, tarantool-e"print('Hello')") doesn’t enter the
interactive mode, but just prints “Hello” and exits
(gh-5040).
Fixed a leak of a tuple object in key_def:compare_with_key(tuple,key),
which had occurred when the serialization of the key failed (gh-5388).
SQL
The string received by a user-defined C or Lua function will no longer be
different from the string passed to the function. This could happen
when the string passed from SQL had contained \\0
(gh-5938).
SQLSELECT or SQLUPDATE on UUID or DECIMAL field will not cause a
SEGMENTATION FAULT anymore (gh-5011,
gh-5704, gh-5913).
Fixed an issue with wrong results of SELECT with GROUPBY which occurred
when one of the selected values was VARBINARY and not directly obtained from the space
(gh-5890).
Build
Fix building on FreeBSD (incomplete definition of type structsockaddr)
(gh-5748).
The already downloaded static build dependencies will not be fetched repeatedly
(gh-5761).
Recovering with force_recovery option now deletes vylog files which are newer than the snapshot.
It helps an instance recover after incidents during a checkpoint (gh-5823).
Fixed the libcurl configuring when Tarantool itself has been configured with
cmake3 command and there was no cmake command in the PATH
(gh-5955).
This affects building Tarantool from sources with bundled libcurl (it
is the default mode).
2.7.3 is the second stable
version of the 2.7 release series. It introduces 6 improvements and
resolves 49 bugs since version 2.7.2.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Some changes are labeled as [Breaking change].
It means that the old behavior was considered error-prone
and therefore changed to protect users from unintended mistakes.
However, there is a small probability that someone can rely on the old behavior,
and this label is to bring attention to the things that have been changed.
Functionality added or changed
Core
The information about the state of synchronous replication is now available via the
box.info.synchro interface
(gh-5191).
LuaJIT
Introduced support for LJ_DUALNUM mode in luajit-gdb.py
(gh-6224).
Lua
Introduced the new method table.equals. It compares two tables by value with
respect to the __eq metamethod.
SQL
Descriptions of type mismatch error and inconsistent type error have
become more informative
(gh-6176).
Removed explicit cast from BOOLEAN to numeric types and vice
versa
(gh-4770).
For example, CAST(FALSEASINTEGER) was 0 in version 2.8.
Now it causes an error.
Removed explicit cast from VARBINARY to numeric types and vice
versa
(gh-4772, gh-5852).
Fixed a bug where a string that is not NULL-terminated
could not be cast to BOOLEAN, even if the conversion would be
successful according to the rules.
[Breaking change]fiber.wakeup() in Lua and
fiber_wakeup() in C became NOP on the currently running fiber.
Previously they allowed “ignoring” the next yield or sleep, which
resulted in unexpected erroneous wake-ups. Calling these functions
right before fiber.create() in Lua or fiber_start() in C
could lead to a crash (in debug build) or undefined behaviour (in
release build) (gh-6043).
There was a single use case for the previous behaviour: rescheduling
in the same event loop iteration, which is not the same as
fiber.sleep(0) in Lua and fiber_sleep(0) in C. It could be
done in the following way:
in C:
fiber_wakeup(fiber_self());fiber_yield();
and in Lua:
fiber.self():wakeup()fiber.yield()
To get the same effect in C, one can now use fiber_reschedule().
In Lua, it is now impossible to reschedule the current fiber directly
in the same event loop iteration. One can reschedule self
through a second fiber, but it is strongly discouraged:
-- do not use this codelocalself=fiber.self()fiber.new(function()self:wakeup()end)fiber.sleep(0)
Fixed memory leak on box.on_commit() and
box.on_rollback() (gh-6025).
fiber_join() now checks if the argument is a joinable fiber.
The absence of this check could lead to unpredictable results. Note that
the change affects the C level only; in the Lua interface, fiber:join()
protection is already enabled.
Now Tarantool yields when it scans .xlog files for the latest
applied vclock and finds the right place to
start recovering from. It means that the instance becomes responsive
right after the box.cfg call even if an empty .xlog was not
created on the previous exit.
This fix also prevents the relay from timing out when a freshly subscribed
replica needs rows from the end of a relatively long (hundreds of
MBs) .xlog file
(gh-5979).
The counter in Nrowsprocessed log messages no longer
resets on each newly recovered xlog.
Fixed invalid results of the json module’s encode
function when it was used from the Lua garbage collector. For
example, this could happen in functions used as ffi.gc()
(gh-6050).
Simultaneously updating a key in different transactions
does not longer result in a MVCC crash
(gh-6131).
Fixed a bug where memtx MVCC crashed during reading uncommitted DDL
(gh-5515).
Fixed a bug where memtx MVCC crashed if an index was created in the
transaction thread
(gh-6137).
Fixed a MVCC segmentation fault that arose
when updating the entire space concurrently
(gh-5892).
Fixed crash in case of reloading a compiled module when the new module lacks some functions
present in the former code. In turn, this event triggers a fallback procedure where we restore old functions,
but instead of restoring each function, we process a sole entry only, leading to the crash later
when these restored functions are called
(gh-5968).
Fixed a bug with failed assertion after a stress update of the same
key
(gh-6193).
Fixed a crash where box.snapshot could be called during an incomplete
transaction
(gh-6229).
Fixed console client connection failure in case of request timeout
(gh-6249).
Added a missing broadcast to net.box.future:discard() so that now
fibers waiting for a request result wake up when the request is
discarded (gh-6250).
box.info.uuid, box.info.cluster.uuid, and
tostring(decimal) with any decimal number in Lua could sometimes
return garbage if there were __gc handlers in the user’s code
(gh-6259).
Fixed an error message that appeared in a particular case during
MVCC operation (gh-6247).
Fixed a repeatable read violation after delete
(:gh-6206).
Fixed a bug where the MVCC engine didn’t track the select{} hash
(gh-6040).
Fixed a crash in MVCC after a drop of space with several indexes
(gh-6274).
Fixed a bug where the GC could leave tuples in secondary indexes
(gh-6234).
Disallow yields after DDL operations in MVCC mode. It fixes a crash
that took place when several transactions referred to system spaces
(gh-5998).
Fixed a bug in MVCC that happened on rollback after a DDL operation
(gh-5998).
Fixed a bug where rollback resulted in unserializable behavior
(gh-6325).
Vinyl
Fixed possible keys divergence during secondary index build, which
might lead to missing tuples
(gh-6045).
Fixed the race between Vinyl garbage collection and compaction that
resulted in a broken vylog and recovery failure
(gh-5436).
Replication
Fixed the use after free in the relay thread when using elections
(gh-6031).
Fixed a possible crash when a synchronous transaction was followed by
an asynchronous transaction right when its confirmation was being
written
(gh-6057).
Fixed an error where a replica, while attempting to subscribe to a foreign
cluster with a different replicaset UUID, didn’t notice it is impossible
and instead became stuck in an infinite retry loop printing
a TOO_EARLY_SUBSCRIBE error
(gh-6094).
Fixed an error where a replica, while attempting to join a cluster with
exclusively read-only replicas available, just booted its own replicaset,
instead of failing or retrying. Now it fails with
an error about the other nodes being read-only so they can’t register
the new replica
(gh-5613).
Fixed error reporting associated with transactions
received from remote instances via replication.
Any error raised while such a transaction was being applied was always reported as
Failedtowritetodisk regardless of what really happened. Now the
correct error is shown. For example, Outofmemory, or
Transactionhasbeenabortedbyconflict, and so on
(gh-6027).
Fixed replication occasionally stopping with ER_INVALID_MSGPACK
when the replica is under high load (gh-4040).
Fixed a cluster sometimes being unable to bootstrap if it contains
nodes with election_mode set to manual or voter
(gh-6018).
Fixed a possible crash when box.ctl.promote() was called in a
cluster with more than three instances. The crash happened in the debug build.
In the release build, it could lead to undefined behaviour. It was likely to happen
if a new node was added shortly before the promotion
(gh-5430).
Fixed a rare error appearing when MVCC
(box.cfg.memtx_use_mvcc_engine) was enabled and more than one
replica joined the cluster. The join could fail with the error
"ER_TUPLE_FOUND:Duplicatekeyexistsinuniqueindex'primary'inspace'_cluster'".
The same could happen at the bootstrap of a cluster having more than three nodes
(gh-5601).
Raft
Fixed a rare crash with leader election enabled (any mode except
off), which could happen if a leader resigned from its role while
another node was writing something elections-related to WAL.
The crash was in the debug build, and in the release
build it would lead to undefined behaviour
(gh-6129).
Fixed an error where a new replica in a Raft cluster tried to join
from a follower instead of a leader and failed with the error
ER_READONLY (gh-6127).
LuaJIT
Fixed optimization for single-char strings in the IR_BUFPUT assembly
routine.
Fixed slots alignment in the lj-stack command output when LJ_GC64
is enabled (gh-5876).
Fixed dummy frame unwinding in the lj-stack command.
Fixed detection of inconsistent renames even in the presence of sunk
values (gh-4252, gh-5049, gh-5118).
Fixed the VM register allocation order provided by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Lua
When an error occurs during encoding call results, the auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Before the fix, it led to undefined behaviour during the next
usage of this Lua coroutine (gh-4617).
Fixed a Lua C API misuse when the error is raised during call results
encoding in an unprotected coroutine and expected to be caught in a
different, protected coroutine (gh-6248).
Triggers
Fixed a possible crash in case trigger removes itself. Fixed a
possible crash in case someone destroys a trigger when it
yields (gh-6266).
SQL
User-defined functions can now return a VARBINARY result to SQL
(gh-6024).
Fixed assert when a DOUBLE value greater than -1.0 and less
than 0.0 is cast to INTEGER and UNSIGNED
(gh-6225).
Removed spontaneous conversion from INTEGER to DOUBLE in a field of the
NUMBER type
(:gh-5335).
All arithmetic operations can now accept numeric values only
(gh-5756).
MVCC
Fixed MVCC interaction with ephemeral spaces: TX manager now ignores them
(gh-6095).
Fixed loss of tuples after a conflict exception
(gh-6132).
Fixed a segfault during update/delete of the same tuple
(gh-6021).
2.7.2 is the first stable
version of the 2.7 release series. It introduces 15 improvements and
resolves 30 bugs since version 2.7.1.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
Introduced the concept of WAL queue and the new configuration option
wal_queue_max_size, measured in bytes.
The default value is 16 Mb.
The option helps limit the pace at which replica submits new transactions to the WAL.
The limit is checked every time a transaction from the master is
submitted to the replica’s WAL.
The space taken by the transaction is considered empty once it’s successfully written
(gh-5536).
Replication
Introduced the box.ctl.promote() function and the concept of manual elections
(enabled with election_mode='manual') (gh-3055).
Once the instance is in the manual election mode,
it acts like a voter most of the time,
but may trigger elections and become a leader when box.ctl.promote() is called.
When election_mode~='manual',
box.ctl.promote() replaces box.ctl.clear_synchro_queue(),
which is now deprecated.
Build
Tarantool build infrastructure now requires CMake version 3.1 or later.
Binary packages for Fedora 33 are now available (gh-5502) .
Binary packages for CentOS 6 and Debian Jessie won’t be published since this version.
RPM and DEB packages no longer have the autotools dependency (follows up
gh-4968).
Regular testing on MacOS 10.13 has been disabled, effectively stopping
the support of this version.
The built-in zstd is upgraded from v1.3.3 to v1.4.8
(part of gh-5502).
SMTP and SMTPS protocols are now enabled in the bundled libcurl (gh-4559).
The libcurl headers are now shipped to system path ${PREFIX}/include/tarantool
when libcurl is included as a bundled library or in a static build
(gh-4559).
Testing
Tarantool CI/CD has migrated to GitHub Actions (gh-5662).
Single node Jepsen testing now runs on per-push basis (gh-5736).
A self-sufficient LuaJIT testing environment has been implemented.
As a result, LuaJIT build system is now partially ported to CMake and all testing
machinery is enclosed within the tarantool/luajit
repository (gh-4862, gh-5470).
Python 3 is now the default in the test infrastructure (gh-5652).
Bugs fixed
Core
The index part options are no longer skipped when the field type is not specified
(gh-5674).
The lbox_ctl_is_recovery_finished() function no longer returns true
when recovery is still in progress.
A memory corruption bug has been fixed in netbox.
The memory of a struct error which is still used will no longer be freed prematurely
because of the wrong order of ffi.gc and ffi.cast calls.
Relay can no longer time out while a replica is joining or syncing with the master.
(gh-5762).
An issue with missing “path” value of index schema fetched by netbox has been fixed
(gh-5451).
Extensive usage of uri and uuid modules with debug log level
no longer leads to crashes or corrupted results of the functions from these
modules.
Same problem is resolved for using these modules from the callbacks passed to ffi.gc(),
and for some functions from the modules fio, box.tuple, and iconv
(gh-5632).
The new wal_cleanup_delay option can prevent early cleanup of
*.xlog files, needed by replicas.
Such cleanup used to result in a XlogGapError (gh-5806).
Appliers will no longer cause errors with Unknownrequesttype40 during
a final join when the master has synchronous spaces (gh-5566).
Added memtx MVCC tracking of read gaps which fixes the problem of phantom reads
(gh-5628).
Fixed the wrong result of using space:count() with memtx MVCC (gh-5972).
Fixed the dirty read after restart while using MVCC with synchronous
replication (gh-5973).
Replication
Fixed an issue with an applier hanging on a replica after failing to process
a CONFIRM or ROLLBACK message coming from a master.
Fixed the issue where master did not send some rows to an anonymous replica
which had fallen behind and was trying to register.
Fixed the bug when a synchronous transaction could be confirmed and
visible on a replica, but then not confirmed or invisible again after
restart. It was more likely to happen on memtx spaces with
memtx_use_mvcc_engine enabled (gh-5213).
Fixed the recovery of a rolled back multi-statement synchronous transaction
which could lead to the transaction being applied partially, and to
recovery errors. It happened in case the transaction worked with
non-sync spaces (gh-5874).
Fixed a bug in synchronous replication when rolled back transactions
could reappear after reconnecting a sufficiently old instance
(gh-5445).
Module swim
Fixed an issue where <swim_instance>:broadcast() did not work on non-local
addresses and spammed “Permission denied” errors to the log.
After instance termination it could return a non-0 exit code even if there
were no errors in the script, and then spam the same error again
(gh-5864).
Fixed the crash on attempts to call swim:member_by_uuid() with no
arguments or with nil/box.NULL (gh-5951).
Fixed the crash on attempts to pass an object of a wrong type to
__serialize method of a swim member in Lua (gh-5952).
LuaJIT
Lua stack resizing no longer results in a wrong behaviour of the memory profiler
(gh-5842).
Fixed a double gc_cdatanum decrementing in LuaJIT platform metrics
which occurred when a finalizer was set for a GCсdata object (gh-5820).
Lua
Fixed the -e option, when tarantool used to enter the interactive mode when
stdin is a TTY. Now, tarantool-e'print"Hello"' doesn’t enter the
interactive mode, but just prints “Hello” and exits
(gh-5040).
Fixed a leak of a tuple object in key_def:compare_with_key(tuple,key),
which had occurred when the serialization of the key failed (gh-5388).
SQL
The string received by a user-defined C or Lua function will no longer be
different from the string passed to the function. This could happen
when the string passed from SQL had contained \\0
(gh-5938).
SQLSELECT or SQLUPDATE on UUID or DECIMAL field will not cause a
SEGMENTATION FAULT anymore (gh-5011,
gh-5704, gh-5913).
Fixed an issue with wrong results of SELECT with GROUPBY which occurred
when one of the selected values was VARBINARY and not directly obtained from the space
(gh-5890).
Build
Fix building on FreeBSD (incomplete definition of type structsockaddr)
(gh-5748).
The already downloaded static build dependencies will not be fetched repeatedly
(gh-5761).
Recovering with force_recovery option now deletes vylog files which are newer than the snapshot.
It helps an instance recover after incidents during a checkpoint (gh-5823).
Fixed the libcurl configuring when Tarantool itself has been configured with
cmake3 command and there was no cmake command in the PATH
(gh-5955).
This affects building Tarantool from sources with bundled libcurl (it
is the default mode).
Tarantool 2.7.1
Release: v. 2.7.1
Date: 2020-12-30 Tag: 2.7.1-0-g3ac498c9f
Overview
2.7.1 is the beta
version of the 2.7 release series.
This release introduces 12 new features and resolves 21 bugs since the
2.6.1 version. There can be bugs in less common areas. If you find any,
feel free to report an
issue on GitHub.
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
Now it is allowed to define an index without extra braces when there
is only one part: parts={field1,type1,...} (gh-2866). Read more in
the note about index parts declaration.
Index-related options now can’t be specified in their definition due
to a more pedantic key-parts verification (gh-5473).
A warning is now logged when schema version is older than last
available schema version (gh-4574).
UUID values created via uuid Lua module (require('uuid')) can
now be compared using the comparison operators like <, >=,
and others (gh-5511).
The new box.ctl.is_recovery_finished() function allows user to
determine whether memtx recovery is finished.
The force_recovery option now ignores errors during snapshot
recovery (gh-5422).
Feedback daemon now reports box.stat().*.total,
box.stat.net().*.total, and box.stat.net().*.current together
with the time of report generation. The added fields reside in
feedback.stats.box, feedback.stats.net, and
feedback.stats.time (gh-5589).
It is now possible to specify synchro quorum as a function of a
number N of registered replicas instead of a const number,
for example:
box.cfg{replication_synchro_quorum="N/2 + 1"}
Only the non-anonymous bootstrapped replicas amount to N. The
expression should respect synchro guarantees: at least 50% of the
cluster size + 1. The expression value is re-evaluated automatically
inside of Tarantool when new replicas appear or old ones are removed
(gh-5446).
If Tarantool crashes, it will now send a crash dump report to the
feedback server. This report contains some fields from uname
output, build information, crash reason, and a stack trace. You can
disable crash reporting with box.cfg{feedback_crashinfo=false}
(gh-5261).
Bugs fixed
Core
fiber.cond:wait() now correctly throws an error when a fiber is
cancelled, instead of ignoring the timeout and returning without any
signs of an error (gh-5013).
Fixed a memory corruption issue, which was most visible on macOS, but
could affect any system (gh-5312).
A dynamic module now gets correctly unloaded from memory in case of
an attempt to load a non-existing function from it (gh-5475).
A swim:quit() call now can’t result in a crash (gh-4570).
Snapshot recovery with no JSONPath or multikey indices involved now
has normal performance (gh-4774).
Replication
A false-positive “too long WAL write” message no longer appears for
synchronous transactions (gh-5139).
A box.ctl.wait_rw() call could return when the instance was not
in fact writable due to having foreign synchronous transactions. As a
result, there was no proper way to wait until the automatically
elected leader would become writable. Now box.ctl.wait_rw() works
correctly (gh-5440).
Fixed a couple of crashes on various tweaks of election mode
(gh-5506).
Now box.ctl.clear_synchro_queue tries to commit everything that
is present on the node. In order to do so it waits for other
instances to replicate the data for replication_synchro_quorum
seconds. In case timeout passes and quorum wasn’t reached, nothing is
rolled back (gh-5435).
SQL
Data changes in read-only mode are now forbidden (gh-5231).
Query execution now does not occasionally raise an unrelated error
“Space ‘0’ does not exist” (gh-5592).
Coinciding names of temporary files (used to store data during
execution) having two instances running on the same machine no longer
cause a segfault (gh-5537).
The return value of ifnull() built-in function is now of a
correct type.
SQL calling Lua functions with box calls inside can no longer result
in a memory corruption (gh-5427).
LuaJIT
Dispatching __call metamethod no longer causes address clashing
(gh-4518, gh-4649).
Fixed a false positive panic when yielding in debug hook (gh-5649).
Lua
An attempt to use a net.box connection which is not established
yet now results in a correctly reported error (gh-4787).
Fixed a NULL dereference on error paths in merger which usually
happened on a ‘wrong’ key_def (gh-5450).
Calling key_def.compare_with_key() with an invalid key no longer
causes a segfault (gh-5307).
Fixed a hang which occured when tarantool ran a user script with
the -e option and this script exited with an error (like with
tarantool-e'assert(false)') (gh-4983).
Memtx
The on_schema_init triggers now can’t cause duplicates in primary
key (gh-5304).
2.6.3 is the second stable
version of the 2.6 release series. It introduces 15 improvements and
resolves 28 bugs since version 2.6.2.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
Introduced the concept of WAL queue and the new configuration option
wal_queue_max_size, measured in bytes.
The default value is 16 Mb.
The option helps limit the pace at which replica submits new transactions to the WAL.
The limit is checked every time a transaction from the master is
submitted to the replica’s WAL.
The space taken by the transaction is considered empty once it’s successfully written
(gh-5536).
Replication
Introduced the box.ctl.promote() function and the concept of manual elections
(enabled with election_mode='manual') (gh-3055).
Once the instance is in the manual election mode,
it acts like a voter most of the time,
but may trigger elections and become a leader when box.ctl.promote() is called.
When election_mode~='manual',
box.ctl.promote() replaces box.ctl.clear_synchro_queue(),
which is now deprecated.
Build
Tarantool build infrastructure now requires CMake version 3.1 or later.
Binary packages for Fedora 33 are now available (gh-5502) .
Binary packages for CentOS 6 and Debian Jessie won’t be published since this version.
RPM and DEB packages no longer have the autotools dependency (follows up
gh-4968).
Regular testing on MacOS 10.13 has been disabled, effectively stopping
the support of this version.
The built-in zstd is upgraded from v1.3.3 to v1.4.8
(part of gh-5502).
SMTP and SMTPS protocols are now enabled in the bundled libcurl (gh-4559).
The libcurl headers are now shipped to system path ${PREFIX}/include/tarantool
when libcurl is included as a bundled library or in a static build
(gh-4559).
Testing
Tarantool CI/CD has migrated to GitHub Actions (gh-5662).
Single node Jepsen testing now runs on per-push basis (gh-5736).
A self-sufficient LuaJIT testing environment has been implemented.
As a result, LuaJIT build system is now partially ported to CMake and all testing
machinery is enclosed within the tarantool/luajit
repository (gh-4862, gh-5470).
Python 3 is now the default in the test infrastructure (gh-5652).
Bugs fixed
Core
The lbox_ctl_is_recovery_finished() function no longer returns true
when recovery is still in progress.
A memory corruption bug has been fixed in netbox.
The memory of a struct error which is still used will no longer be freed prematurely
because of the wrong order of ffi.gc and ffi.cast calls.
Relay can no longer time out while a replica is joining or syncing with the master.
(gh-5762).
An issue with missing “path” value of index schema fetched by netbox has been fixed
(gh-5451).
Extensive usage of uri and uuid modules with debug log level
no longer leads to crashes or corrupted results of the functions from these
modules.
Same problem is resolved for using these modules from the callbacks passed to ffi.gc(),
and for some functions from the modules fio, box.tuple, and iconv
(gh-5632).
The new wal_cleanup_delay option can prevent early cleanup of
*.xlog files, needed by replicas.
Such cleanup used to result in a XlogGapError (gh-5806).
Appliers will no longer cause errors with Unknownrequesttype40 during
a final join when the master has synchronous spaces (gh-5566).
Added memtx MVCC tracking of read gaps which fixes the problem of phantom reads
(gh-5628).
Fixed the wrong result of using space:count() with memtx MVCC (gh-5972).
Fixed the dirty read after restart while using MVCC with synchronous
replication (gh-5973).
Replication
Fixed an issue with an applier hanging on a replica after failing to process
a CONFIRM or ROLLBACK message coming from a master.
Fixed the issue where master did not send some rows to an anonymous replica
which had fallen behind and was trying to register.
Fixed the bug when a synchronous transaction could be confirmed and
visible on a replica, but then not confirmed or invisible again after
restart. It was more likely to happen on memtx spaces with
memtx_use_mvcc_engine enabled (gh-5213).
Fixed the recovery of a rolled back multi-statement synchronous transaction
which could lead to the transaction being applied partially, and to
recovery errors. It happened in case the transaction worked with
non-sync spaces (gh-5874).
Fixed a bug in synchronous replication when rolled back transactions
could reappear after reconnecting a sufficiently old instance
(gh-5445).
Swim
Fixed an issue where <swim_instance>:broadcast() did not work on non-local
addresses and spammed “Permission denied” errors to the log.
After instance termination it could return a non-0 exit code even if there
were no errors in the script, and then spam the same error again
(gh-5864).
Fixed the crash on attempts to call swim:member_by_uuid() with no
arguments or with nil/box.NULL (gh-5951).
Fixed the crash on attempts to pass an object of a wrong type to
__serialize method of a swim member in Lua (gh-5952).
Lua
Fixed the -e option, when tarantool used to enter the interactive mode when
stdin is a TTY. Now, tarantool-e'print"Hello"' doesn’t enter the
interactive mode, but just prints “Hello” and exits
(gh-5040).
Fixed a leak of a tuple object in key_def:compare_with_key(tuple,key),
which had occurred when the serialization of the key failed (gh-5388).
SQL
The string received by a user-defined C or Lua function will no longer be
different from the string passed to the function. This could happen
when the string passed from SQL had contained \\0
(gh-5938).
SQLSELECT or SQLUPDATE on UUID or DECIMAL field will not cause a
SEGMENTATION FAULT anymore (gh-5011,
gh-5704, gh-5913).
Fixed an issue with wrong results of SELECT with GROUPBY which occurred
when one of the selected values was VARBINARY and not directly obtained from the space
(gh-5890).
LuaJIT
Fixed a double gc_cdatanum decrementing in LuaJIT platform metrics
which occurred when a finalizer was set for a GCсdata object (gh-5820).
Build
Fix building on FreeBSD (incomplete definition of type structsockaddr)
(gh-5748).
The already downloaded static build dependencies will not be fetched repeatedly
(gh-5761).
Recovering with force_recovery option now deletes vylog files which are newer than the snapshot.
It helps an instance recover after incidents during a checkpoint (gh-5823).
Fixed the libcurl configuring when Tarantool itself has been configured with
cmake3 command and there was no cmake command in the PATH
(gh-5955).
This affects building Tarantool from sources with bundled libcurl (it
is the default mode).
Tarantool 2.6.2
Release: v. 2.6.2
Date: 2020-12-30 Tag: 2.6.2-0-g34d504d
Overview
2.6.2 is the first stable
version of the 2.6 release series. It introduces one improvement and
resolves 21 bugs since 2.6.1.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Replication
It is now possible to specify synchro quorum as a function of a
number N of registered replicas instead of a const number,
for example:
box.cfg{replication_synchro_quorum="N/2 + 1"}
Only the non-anonymous bootstrapped replicas amount to N. The
expression should respect synchro guarantees: at least 50% of the
cluster size + 1. The expression value is re-evaluated automatically
inside of Tarantool when new replicas appear or old ones are removed
(gh-5446).
Lua
Show JSON tokens themselves instead of token names T_* in the
JSON decoder error messages (gh-4339).
Show a decoding context in the JSON decoder error messages (gh-4339).
fiber.cond:wait() now correctly throws an error when a fiber is
cancelled, instead of ignoring the timeout and returning without any
signs of an error (gh-5013).
Fixed a memory corruption issue, which was most visible on macOS, but
could affect any system (gh-5312).
A dynamic module now gets correctly unloaded from memory in case of
an attempt to load a non-existing function from it (gh-5475).
A swim:quit() call now can’t result in a crash (gh-4570).
Snapshot recovery with no JSONPath or multikey indices involved now
has normal performance (gh-4774).
Replication
A false-positive “too long WAL write” message no longer appears for
synchronous transactions (gh-5139).
A box.ctl.wait_rw() call could return when the instance was not
in fact writable due to having foreign synchronous transactions. As a
result, there was no proper way to wait until the automatically
elected leader would become writable. Now box.ctl.wait_rw() works
correctly (gh-5440).
Fixed a couple of crashes on various tweaks of election mode
(gh-5506).
Now box.ctl.clear_synchro_queue tries to commit everything that
is present on the node. In order to do so it waits for other
instances to replicate the data for replication_synchro_quorum
seconds. In case timeout passes and quorum was not reached, nothing is
rolled back (gh-5435).
SQL
Data changes in read-only mode are now forbidden (gh-5231).
Query execution now does not occasionally raise an unrelated error
“Space ‘0’ does not exist” (gh-5592).
Coinciding names of temporary files (used to store data during
execution) having two instances running on the same machine no longer
cause a segfault (gh-5537).
The return value of ifnull() built-in function is now of a
correct type.
SQL calling Lua functions with box calls inside can no longer result
in a memory corruption (gh-5427).
LuaJIT
Dispatching __call metamethod no longer causes address clashing
(gh-4518, gh-4649).
Fixed a false positive panic when yielding in debug hook (gh-5649).
Lua
An attempt to use a net.box connection which is not established
yet now results in a correctly reported error (gh-4787).
Fixed a NULL dereference on error paths in merger which usually
happened on a ‘wrong’ key_def (gh-5450).
Calling key_def.compare_with_key() with an invalid key no longer
causes a segfault (gh-5307).
Fixed a hang which occured when tarantool ran a user script with
the -e option and this script exited with an error (like with
tarantool-e'assert(false)') (gh-4983).
Memtx
The on_schema_init triggers now can’t cause duplicates in primary
key (gh-5304).
Tarantool 2.6.1
Release: v. 2.6.1
Date: 2020-10-22 Tag: 2.6.1-0-gcfe0d1a
Overview
2.6.1 is the beta version of the 2.6 release series.
This release introduces roughly 17 features and resolves 22 bugs since
the 2.5.1 version. There may be bugs in less common areas. If you find
any, feel free to report an issue at
GitHub.
Notable changes are:
Transactional manager for the memtx engine that
allows yielding in transactions. It also guarantees the data consistency
for synchronous replication, eliminating dirty reads for unconfirmed
transactions.
Raft-based automated failover mechanism for a
single-leader replica set. Replica set can be configured to provide
automated leader election and failover. Accompanied with synchronous
replication it brings data safety and service reliability on a new
level.
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
There are changes labeled with [Breaking change]. It means that the
old behavior was considered error-prone and therefore changed to protect
users from unintended mistakes. However, there is a little probability
that someone can lean on the old behavior, and this label is to bring
attention to the things that have been changed.
Functionality added or changed
Core
Introduce a function to check that the specified value is of UUID
type (gh-5171). Read more: uuid.is_uuid().
A new function space:alter(options) to change some space settings
without recreation nor touching _space space.
Read more: space_object:alter().
Composite types extraction is now supported in key_def (gh-4538).
Rework upsert operation in vinyl so that now (gh-5107):
if upsert can’t be applied it is skipped and corresponding error
is logged (gh-1622);
upserts now follow associative property: the result of several
upserts does not depend on the order of their application
(gh-5105);
upserts referring to -1 fieldno are handled correctly now
(gh-5087).
there’s no more upserts squash procedure: upserts referring to the
same field with arithmetic operations are not merged into one
operation since resulting upsert might not be applied - as a
result both upserts would be ignored (meanwhile only one should
be).
This change introduces new builtin library “misc” that may
conflict with user’s modules.
SQL
SQL views are not alterable anymore. Beforehand it led to the
undefined behaviour.
Introduce “automatic index” optimization. Ephemeral space with single
index can be created to store and speed-up intermediate results
access during query execution (gh-4933).
When election is enabled, a newly elected leader will automatically
finish all the synchronous transactions, created by the old leader
(gh-5339).
Build
Tarantool static build is enhanced in scope of gh-5095. It can be
built on the host machine with no Docker at all. As a result it can
be built using the OSX environment.
Misc
Add all exported symbols from bundled libcurl library (gh-5223)
Add fselect method that is similar to select, but formats results
like mysql would (gh-5161).
Module API
Exposed the box region, key_def and several other functions in order
to implement external tuple.keydef and tuple.merger modules on top of
them (gh-5273, gh-5384).
Bugs fixed
Core
Fixed a bug related to ignoring internal getaddrinfo errors on macOS
in logger (gh-4138).
Fixed a crash when JSON tuple field access was used to get a multikey
indexed field, and when a JSON contained [*] in the beginning
(gh-5224).
Dropped restrictions on nullable multikey index root. They were
introduced due to inaccuracy in multikey index realization. It is now
fixed. Also all fields are now nullable by default as it was before
2.2.1 (gh-5192).
Fixed fibers switch-over to prevent JIT machinery misbehavior. Trace
recording is aborted when fiber yields the execution. The yield
occurring while the compiled code is being run (it’s likely a
function with a yield underneath called via LuaJIT FFI) leads to the
platform panic (gh-1700, gh-4491).
Fixed fibers switch-over to prevent implicit GC disabling. The yield
occurring while user-defined __gc metamethod is running leads to the
platform panic.
Replication
Fixed a bug when a rolled back synchronous transaction could become
committed after restart (gh-5140).
Fixed crash in synchronous replication when master’s local WAL write
fails (gh-5146).
Instance will terminate if a synchronous transaction confirmation or
rollback fail. Before it was undefined behavior (gh-5159).
Snapshot could contain changes from a rolled back synchronous
transaction (gh-5167).
Fixed a crash when synchronous transaction’s rollback and confirm
could be written simultaneously for the same LSN (gh-5185).
Fixed a crash when replica cleared synchronous transaction queue,
while it was not empty on master (gh-5195).
During recovery of synchronous changes from snapshot the instance
could crash (gh-5288).
Having synchronous rows in the snapshot could make the instance hang
on recovery (gh-5298).
Anonymous replica could be registered and could prevent WAL files
removal (gh-5287).
XlogGapError is not a critical error anymore. It means,
box.info.replication will show upstream status as ‘loading’ if the
error was found. The upstream will be restarted until the error is
resolved automatically with a help of another instance, or until the
replica is removed from box.cfg.replication (gh-5287).
LuaJIT
Fixed the error occurring on loading luajit-gdb.py with Python 2
(gh-4828).
Lua
Fixed a bug related to ignoring internal getaddrinfo errors. Now they
can be thrown out by Lua socket functions (gh-4138).
Fixed: import of table.clear() method (gh-5210). Affected versions:
all 2.6.* until 2.6.0-53-g09aa813 (exclusive).
Fixed unhandled Lua error that may lead to memory leaks and
inconsistencies in <space_object>:frommap(),
<key_def_object>:compare(), <merge_source>:select()
(gh-5382).
Get rid of typedef redefinitions for compatibility with C99
(gh-5313).
Tarantool 2.5.3
Release: v. 2.5.3
Date: 2020-12-30 Tag: 2.5.3-0-gf93e480
Overview
2.5.3 is the second stable
version of the 2.5 release series. It introduces one improvement and
resolves 19 bugs since 2.5.2.
The “stable” label means that we have all planned features implemented
and we see no high-impact issues. However, if you encounter an issue,
feel free to report
it on GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Replication
It is now possible to specify synchro quorum as a function of a
number N of registered replicas instead of a const number,
for example:
box.cfg{replication_synchro_quorum="N/2 + 1"}
Only the non-anonymous bootstrapped replicas amount to N. The
expression should respect synchro guarantees: at least 50% of the
cluster size + 1. The expression value is re-evaluated automatically
inside of Tarantool when new replicas appear or old ones are removed
(gh-5446).
Lua
Show JSON tokens themselves instead of token names T_* in the
JSON decoder error messages (gh-4339).
Show a decoding context in the JSON decoder error messages (gh-4339).
fiber.cond:wait() now correctly throws an error when a fiber is
cancelled, instead of ignoring the timeout and returning without any
signs of an error (gh-5013).
Fixed a memory corruption issue, which was most visible on macOS, but
could affect any system (gh-5312).
A dynamic module now gets correctly unloaded from memory in case of
an attempt to load a non-existing function from it (gh-5475).
A swim:quit() call now can’t result in a crash (gh-4570).
Snapshot recovery with no JSONPath or multikey indices involved now
has normal performance (gh-4774).
Replication
A false-positive “too long WAL write” message no longer appears for
synchronous transactions (gh-5139).
A box.ctl.wait_rw() call could return when the instance was not
in fact writable due to having foreign synchronous transactions. As a
result, there was no proper way to wait until the automatically
elected leader would become writable. Now box.ctl.wait_rw() works
correctly (gh-5440).
SQL
Data changes in read-only mode are now forbidden (gh-5231).
Query execution now does not occasionally raise an unrelated error
“Space ‘0’ does not exist” (gh-5592).
Coinciding names of temporary files (used to store data during
execution) having two instances running on the same machine no longer
cause a segfault (gh-5537).
The return value of ifnull() built-in function is now of a
correct type.
SQL calling Lua functions with box calls inside can no longer result
in a memory corruption (gh-5427).
LuaJIT
Dispatching __call metamethod no longer causes address clashing
(gh-4518, gh-4649).
Fixed a false positive panic when yielding in debug hook (gh-5649).
Lua
An attempt to use a net.box connection which is not established
yet now results in a correctly reported error (gh-4787).
Fixed a NULL dereference on error paths in merger which usually
happened on a ‘wrong’ key_def (gh-5450).
Calling key_def.compare_with_key() with an invalid key no longer
causes a segfault (gh-5307).
Fixed a hang which occured when tarantool ran a user script with
the -e option and this script exited with an error (like with
tarantool-e'assert(false)') (gh-4983).
Release: v. 2.5.2
Date: 2020-10-22 Tag: 2.5.2-1-gf63c43b
Overview
This release resolves roughly 25 issues since the 2.5.2 version. There
may be bugs in less common areas. If you find any, feel free to report
an issue at GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Core
New function space:alter(options) to change some space settings
without recreation nor touching _space space.
Read more.
Module API
Exposed the box region, key_def and several other functions in order
to implement external tuple.keydef and tuple.merger modules on top of
them (gh-5273, gh-5384).
Bugs fixed
Core
Fixed a bug related to ignoring internal getaddrinfo errors on macOS
in logger (gh-4138).
Fixed a crash when JSON tuple field access was used to get a multikey
indexed field, and when a JSON contained [*] in the beginning
(gh-5224).
Dropped restrictions on nullable multikey index root. They were
introduced due to inaccuracy in multikey index realization. It is now
fixed. Also all fields are now nullable by default as it was before
2.2.1 (gh-5192).
Fixed fibers switch-over to prevent JIT machinery misbehavior. Trace
recording is aborted when fiber yields the execution. The yield
occurring while the compiled code is being run (it’s likely a
function with a yield underneath called via LuaJIT FFI) leads to the
platform panic (gh-1700, gh-4491).
Fixed fibers switch-over to prevent implicit GC disabling. The yield
occurring while user-defined __gc metamethod is running leads to the
platform panic.
Replication
Fixed a bug when a rolled back synchronous transaction could become
committed after restart (gh-5140).
Fixed crash in synchronous replication when master’s local WAL write
fails (gh-5146).
Instance will terminate if a synchronous transaction confirmation or
rollback fail. Before it was undefined behavior (gh-5159).
Snapshot could contain changes from a rolled back synchronous
transaction (gh-5167).
Fixed a crash when synchronous transaction’s rollback and confirm
could be written simultaneously for the same LSN (gh-5185).
Fixed a crash when replica cleared synchronous transaction queue,
while it was not empty on master (gh-5195).
During recovery of synchronous changes from snapshot the instance
could crash (gh-5288).
Having synchronous rows in the snapshot could make the instance hang
on recovery (gh-5298).
Anonymous replica could be registered and could prevent WAL files
removal (gh-5287).
XlogGapError is not a critical error anymore. It means,
box.info.replication will show upstream status as ‘loading’ if the
error was found. The upstream will be restarted until the error is
resolved automatically with a help of another instance, or until the
replica is removed from box.cfg.replication (gh-5287).
LuaJIT
Fixed the error occurring on loading luajit-gdb.py with Python 2
(gh-4828).
Lua
Fixed a bug related to ignoring internal getaddrinfo errors. Now they
can be thrown out by Lua socket functions (gh-4138).
Fixed: import of table.clear() method (gh-5210). Affected versions:
2.5.0-265-g3af79e70b (inclusive) to 2.5.1-52-ged9a156 (exclusive).
Fixed unhandled Lua error that may lead to memory leaks and
inconsistencies in <space_object>:frommap(),
<key_def_object>:compare(), <merge_source>:select()
(gh-5382).
SQL
SQL view are not alterable anymore. Beforehand it led to undefined
behavior.
Misc
Fixed potential lag on boot up procedure when system’s password
database is slow in access (gh-5034).
Module API
Get rid of typedef redefinitions for compatibility with C99
(gh-5313).
Tarantool 2.5.1
Release: v. 2.5.1
Date: 2020-07-17 Tag: 2.5.1-1-g635f6e5
Overview
2.5.1 is the beta version of the 2.5 release series.
This release introduces roughly 11 features and resolves 34 bugs since
the 2.4.1 version. There may be bugs in less common areas. If you find
any, feel free to report an issue at
GitHub.
Notable changes are:
Synchronous replication (beta).
Allow an anonymous replica follow another anonymous replica.
Fixed numerous crashes in Vinyl.
Make implicit cast rules for assignment operation more strict in SQL.
Updated curl version to 7.71.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
There are changes labeled with [Breaking change]. It means that the
old behavior was considered error-prone and therefore changed to protect
users from unintended mistakes. However, there is a little probability
that someone can lean on the old behavior, and this label is to bring
attention to the things that have been changed.
Functionality added or changed
Core
[Breaking change]box.session.push()
parameter sync is deprecated and deleted. It does not work anymore, and
a usage attempt leads to an error (gh-4689).
Symbols of the Tarantool executable are not masked anymore. Some
private symbols may become visible and available for FFI and
dlopen() + dlsym() (gh-2971).
Add ability to set up logging early without configuring the box
engine (gh-689).
box.snapshot() now ignores throttling of the scheduler and forces
the dump process immediately (gh-3519).
SQL
Use naming pattern “COLUMN_N” for automatically generated column’s
names (gh-3962). Read more: Select list.
Replication
Add box.info.replication_anon().
When called, it lists anonymous
replicas in the same format as box.info.replication, the only
exception is that anonymous replicas are indexed by their uuid
strings (gh-4900).
Allow anonymous replicas to be followed by other ones (gh-4696).
Before this release, the Tarantool package for Debian and Ubuntu
automatically enable and start the ‘example’ instance, which listens
on the TCP port 3301. Starting from this release, the instance file
is installed to /etc/tarantool/instances.available/example.lua,
but is not enabled by default and not started anymore. One may
perform the following actions to enable and start it:
The existing configuration will not be updated automatically at
package update, so manual actions are required to stop and disable
the instance (if it is not needed, of course):
Fixed confusing implicit requirements for tuple fields (gh-5027).
Added needed key validation to space_before_replace (gh-5017).
Fixed check of index field map size which led to crash (gh-5084).
Fixed NULL pointer dereference when merger is called via the binary
protocol (say, via net.box) (gh-4954).
Fix wrong mpsgpack extension type in an error message at decoding
(gh-5017).
Fixed crash when invalid JSON was used in update() (gh-5135).
Replication
Fixed possible ER_TUPLE_FOUND error when bootstrapping replicas in an
1.10/2.1.1 cluster (gh-4924).
Fixed tx boundary check for half-applied txns (gh-5125).
Fixed replication tx boundaries after local space rework (gh-4928).
Lua
Added format string usage to form a CustomError message (gh-4903).
Read more: Custom error.
Fixed error while closing socket.tcp_server socket (gh-4087).
Extended box.error objects reference counter to 64 bit to prevent
possible overflow (gh-4902).
Refactored Lua table encoding: removed excess Lua function object and
left protected Lua frame only for the case __serialize is a function
to improve msgpack.encode() performance (no GH issue).
Improved Lua call procedure for the case of built-in functions.
Prepared GCfunc object is used instead of temporary one, resulting in
3-6% garbage collection reduction.
Enabled luacheck in continuous integration (no GH issue).
Fixed warnings (two of them were real bugs!) found by luacheck in a
source code (no GH issue).
SQL
Fixed wrong order of rows as a result of query containing column of
SCALAR type in ORDER BY clause (gh-4697).
Fixed bug with the display of collation for scalar fields in <SELECT>
result, when sql_full_metadata is enabled (gh-4755).
Block using HASH indexes in SQL since scheduler is unable to use it
properly (gh-4659).
Fixed races and corner cases in box (re)configuration (gh-4231).
Vinyl
Fixed crash during compaction due to tuples with size exceeding
vinyl_max_tuple_size setting (gh-4864).
Fixed crash during recovery of vinyl index due to the lack of file
descriptors (gh-4805).
Fixed crash during executing upsert changing primary key in debug
mode (gh-5005).
Fixed crash due to triggered dump process during secondary index
creation (gh-5042).
Fixed crash/deadlock (depending on build type) during dump process
scheduling and concurrent DDL operation (gh-4821).
Fixed crash during read of prepared but still not yet not committed
statement (gh-3395).
Fixed squashing set and arithmetic upsert operations (gh-5106).
Created missing folders for vinyl spaces and indexes if needed to
avoid confusing fails of tarantool started from backup (gh-5090).
Fixed crash during squash of many (more than 4000) upserts modifying
the same key (gh-4957).
Memtx
Fixed concurrent replaces on index building. Tuples are now
referenced on all needed execution paths (gh-4973).
Misc
Fixed a possible stacked diagnostics crash due to incorrect reference
count (gh-4887).
Tarantool 2.4.3
Release: v. 2.4.3
Date: 2020-10-22 Tag: 2.4.3-1-g986fab7
Overview
This release resolves roughly 13 issues since the 2.4.2 version. There
may be bugs in less common areas. If you find any, feel free to report
an issue at GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in the binary
data layout, client-server protocol, and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
Module API
Exposed the box region, key_def and several other functions in order
to implement external tuple.keydef and tuple.merger modules on top of
them (gh-5273, gh-5384).
Bugs fixed
Core
Fixed a crash when JSON tuple field access was used to get a multikey
indexed field, and when a JSON contained [*] in the beginning
(gh-5224).
Dropped restrictions on nullable multikey index root. They were
introduced due to inaccuracy in multikey index realization. It is now
fixed. Also all fields are now nullable by default as it was before
2.2.1 (gh-5192).
Fixed fibers switch-over to prevent JIT machinery misbehavior. Trace
recording is aborted when fiber yields the execution. The yield
occurring while the compiled code is being run (it’s likely a
function with a yield underneath called via LuaJIT FFI) leads to the
platform panic (gh-1700, gh-4491).
Fixed fibers switch-over to prevent implicit GC disabling. The yield
occurring while user-defined __gc metamethod is running leads to the
platform panic.
Replication
Anonymous replica could be registered and could prevent WAL files
removal (gh-5287).
XlogGapError is not a critical error anymore. It means,
box.info.replication will show upstream status as ‘loading’ if the
error was found. The upstream will be restarted until the error is
resolved automatically with a help of another instance, or until the
replica is removed from box.cfg.replication (gh-5287).
LuaJIT
Fixed the error occurring on loading luajit-gdb.py with Python2
(gh-4828).
Lua
Fixed unhandled Lua error that may lead to memory leaks and
inconsistencies in <space_object>:frommap(),
<key_def_object>:compare(), <merge_source>:select()
(gh-5382).
SQL
SQL view are not alterable anymore. Beforehand it led to undefined
behavior.
Misc
Fixed potential lag on boot up procedure when system’s password
database is slow in access (gh-5034).
Module API
Get rid of typedef redefinitions for compatibility with C99
(gh-5313).
Tarantool 2.4.2
Release: v. 2.4.2
Date: 2020-07-17 Tag: 2.4.2-1-g3f00d29
Overview
2.4.2 is the first stable version of the 2.4 release series. The label
stable means we have all planned features implemented and we see no
high-impact issues.
This release resolves roughly 32 issues since the latest beta version.
There may be bugs in less common areas, please feel free to file an
issue at GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new features
of the 2.x series.
Functionality added or changed
Core
box.session.push() parameter sync
is deprecated. A warning is printed when the sync is used, but it still works.
It is removed in the next version (gh-4689).
Before this release tarantool package for Debian and Ubuntu
automatically enable and start ‘example’ instance, which listens on
the TCP port 3301. Starting from this release the instance file is
installed to /etc/tarantool/instances.available/example.lua, but is
not enabled by default and not started anymore. One may perform the
following actions to enable and start it:
Existing configuration will not be updated automatically at package
update, so manual actions are required to stop and disable the
instance (if it is not needed, of course):
Fixed assert outdated due to multikey index arrival (gh-5132).
Fixed confusing implicit requirements for tuple fields (gh-5027).
Added needed key validation to space_before_replace (gh-5017).
Fixed check of index field map size which led to crash (gh-5084).
Fixed NULL pointer dereference when merger is called via the binary
protocol (say, via net.box) (gh-4954).
Fix wrong mpsgpack extension type in an error message at decoding
(gh-5017).
Fixed crash when invalid JSON was used in update() (gh-5135).
Replication
Fixed possible ER_TUPLE_FOUND error when bootstrapping replicas in an
1.10/2.1.1 cluster (gh-4924).
Fixed tx boundary check for half-applied txns (gh-5125).
Fixed replication tx boundaries after local space rework (gh-4928).
Lua
Added format string usage to form a CustomError message (gh-4903).
Read more: Custom error.
Fixed error while closing socket.tcp_server socket (gh-4087).
Extended box.error objects reference counter to 64 bit to prevent
possible overflow (gh-4902).
SQL
Fix wrong order of rows as a result of query containing column of
SCALAR type in ORDER BY clause (gh-4697).
Fix bug with the display of collation for scalar fields in <SELECT>
result, when sql_full_metadata is enabled (gh-4755).
Block using HASH indexes in SQL since scheduler is unable to use it
properly (gh-4659).
Fixed races and corner cases in box (re)configuration (gh-4231).
Vinyl
Fixed crash during compaction due to tuples with size exceeding
vinyl_max_tuple_size setting (gh-4864).
Fixed crash during recovery of vinyl index due to the lack of file
descriptors (gh-4805).
Fixed crash during executing upsert changing primary key in debug
mode (gh-5005).
Fixed crash due to triggered dump process during secondary index
creation (gh-5042).
Fixed crash/deadlock (depending on build type) during dump process
scheduling and concurrent DDL operation (gh-4821).
Fixed crash during read of prepared but not committed statement
(gh-3395).
Fixed squashing set and arithmetic upsert operations (gh-5106).
Create missing folders for vinyl spaces and indexes if needed to
avoid confusing fails of tarantool started from backup (gh-5090).
Fixed crash during squash of many (more than 4000) upserts modifying
the same key (gh-4957).
Memtx
Fixed concurrent replaces on index building. Tuples are now
referenced on all needed execution paths (gh-4973).
Tarantool 2.4.1
Release: v. 2.4.1
Date: 2020-04-20 Tag: 2.4.1-1-g6c75f80
Overview
2.4.1 is the beta version of the 2.4 release series.
This release introduces roughly 20 features and resolves 92 bugs since
the 2.3.1 version. There may be bugs in less common areas. If you find
any, feel free to report an issue at
GitHub.
Notable changes are:
UUID type was introduced
It is now possible to report stack of errors
Added popen built-in module
Create errors of custom type and transparent marshaling over net.box
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new features
of the 2.x series.
Functionality added or changed
Core
Possibility to create errors of a custom user type (gh-4398). Read more:
box_session_push(): a new public C API function. It takes
constchar*MessagePack and returns it to the client out of
order, just like the Lua box.session.push() does (gh-4734). Read more:
box_session_push().
Introduce a new field type and a new index type: UUID (gh-4268,
gh-2916). Read more:
Introduce stacked diagnostic area: now each Lua table representing an
error object features the .prev member and the :set_prev()
method so that errors can be organized into lists. IProto protocol is
extended with new command keys to support this feature as well
(gh-1148). For details, refer to error_object.
The module provides popen implementation that is integrated with
tarantool’s event loop (like built-in fio and socket
modules).
It support bidirectional communication with a process: the module can
feed input to a process and capture its output. This way it allows to
run streaming programs (like grep) and even work interactively
with outside REPL (say, python-i).
A key feature of the implementation is that it uses vfork() under
hood and so does not copy virtual memory tables. Copying of them may
be quite time consuming: os.execute() takes ~2.5 seconds when 80 GiB
is allocated for memtx. Moreover, when memory overcommit is disabled
(which is default) it would be not possible to fork a process when
more then half of available physical memory is mapped to tarantool’s
process.
The API should be considered as beta: it is quite basic and will be
extended with convenience features. On the other hand, it may be
changed in a backward-incompatible manner in the future releases if
it will be valuable enough.
For more details, refer to the popen module documentation.
fio descriptors are closed on garbage collection (gh-4727). Read more
in description of fio.open().
fio.tempdir() uses the $TMPDIR environment variable
as a path indication to create temporary directories (gh-4794).
Add tarantoolctlrocks commands: build, config,
download, init, lint, new_version, purge,
which, write_rockspec (gh-4629). Read more in tarantoolctl-module_management.
Misc
box.info.listen: a new variable in the box.info. Shows the
real port when bound to the port 0. For example, if the
listen parameter of box.cfg is set to 127.0.0.1:0, the
box.info.listen shows 127.0.0.1:<real_port> (gh-4620).
Read more: box.info.listen.
sequence:current(): a new function to get the current sequence
value without changing it (gh-4752). Read more: sequence_object:current().
Bugs fixed
Core
fiber.storage is cleaned between requests,
and can be used as a
request-local storage. Previously fiber.storage could contain
some old values in the beginning of an iproto request execution, and
it needed to be nullified manually. Now the cleanup is unneeded
(gh-4662).
tuple/space/index:update()/upsert() were fixed
not to turn a value into an infinity when a float value was added to
or subtracted from a float column and exceeded the float value range
(gh-4701).
Fix potential execution abort when operating the system runs under
heavy memory load (gh-4722).
Make RTREE indexes handle the out of memory error: before this fix,
OOM during the recovery of an RTREE index resulted in segmentation
fault (gh-4619).
Fix the error message returned on using an already dropped sequence
(gh-4753).
Add cancellation guard to avoid WAL thread stuck (gh-4127).
Fix execution abort when memtx_memory and vinyl_memory are
set to more than 4398046510080 bytes. Now an error message is
returned (gh-4705).
box.error.new() does not add a created error to the Tarantool’s
diagnostic area anymore (gh-4778). Read more:
Add Lua output format support for box.session.push() (gh-4686).
Replication
Fix rebootstrap procedure not working in case replica itself is
listed in box.cfg.replication (gh-4759).
Fix possible user password leaking via replication logs (gh-4493).
Refactor vclock map to be exactly 4 bytes in size to fit all 32
replicas regardless of the compiler used
(see in this commit).
Fix crash when the replication applier rollbacks a transaction
(gh-4730, gh-4776).
Fix segmentation fault on master side when one of the replicas
transitions from anonymous to normal (gh-4731).
Local space operations are now counted in 0th vclock component. Every
instance may have its own 0-th vclock component not matching others’.
Local space operations are not replicated at all, even as NOPs
(gh-4114).
Gc consumers are now ordered by their vclocks and not by vclock
signatures. Only the WALS that contain no entries needed by any of
the consumers are deleted (gh-4114).
Lua
json: :decode() does not spoil instance’s options with per-call
ones (when it is called with the second argument) (gh-4761).
Handle empty input for uri.format() properly (gh-4779).
os.environ() is now changed when os.setenv() is called
(gh-4733).
netbox.self:call/eval() now returns the same types as
netbox_connection:call/eval. Previously it could return a
tuple or box.error cdata (gh-4513).
box.tuple.* namespace is cleaned up from private functions.
box.tuple.is() description is added to documentation (gh-4684).
tarantoolctlrockssearch: fix the --all flag (gh-4529).
tarantoolctlrocksremove: fix the --force flag (gh-3632).
libev: backport fix for listening for more then 1024 file descriptors
on Mac OS (gh-3867).
SQL
Fix box.stat() behavior: now it collects statistics on the
PREPARE and EXECUTE methods as expected (gh-4756).
Add ability to drop any table constraint using the following
statement:
ALTERTABLE<table_name>DROPCONSTRAINT<constraint_name>.
Previously, it was possible to drop only foreign key constraints with
such a statement (gh-4120). Read more in Alter Table.
“No such constraint” error now contains the name of the table this
constraint belongs to.
Add an empty body to the UNPREPARE IProto response (gh-4769).
Reset all the placeholders’ bound values after execution of a
prepared statement (gh-4825).
The inserted values are inserted in the order in which they are given
in case of INSERT into space with autoincrement (gh-4256).
Types related changes
Rework the NUMBER type in SQL: now it completely matches with
NoSQL definition. Integers inserted into a field of the NUMBER
type are no longer forced to floating point representation;
CASTASNUMBER operation applied to an integer value doesn’t
change it; CASTASNUMBER operation applied to a boolean value
now converts it into 1, 0 or NULL depending on particular
boolean value (gh-4233). Read more in
Data Type Conversion.
Fix the CASTASNUMBER operation applied to blob values: floating
point representation of the result is no longer forced (gh-4463).
Fix integer overflow error during addition of the integer and
floating point values stored in the SCALAR column (gh-4369).
Explicit and implicit cast from string containing floating point
value to integer or unsigned types are disallowed.
Maximum length of a blob value that is allowed to be cast to integer
or unsigned types are limited to 12287 bytes.
Fix wrong result of CAST() operator from blob to integer type in case
a blob value does not have terminating ‘\0’ (gh-4766).
HTTP client
When building Tarantool with bundled libcurl, link it with the
c-ares library by default (gh-4591).
LuaJIT
__pairs/__ipairs metamethods handling is removed since we
faced the issues with the backward compatibility between Lua 5.1 and
Lua 5.2 within Tarantool modules as well as other third party code
(gh-4770).
Introduce luajit-gdb.py extension with commands for inspecting
LuaJIT internals. The extension obliges one to provide gdbinfo for
libluajit, otherwise loading fails. The extension provides the
following commands:
lj-arch dumps values of LJ_64 and LJ_GC64 macro definitions
lj-tv dumps the type and GCobj info related to the given
TValue
lj-str dumps the contents of the given GCstr
lj-tab dumps the contents of the given GCtab
lj-stack dumps Lua stack of the given lua_State
lj-state shows current VM, GC and JIT states
lj-gc shows current GC stats
Fix string to number conversion: current implementation respects the
buffer length (gh-4773).
“FFI sandwich” (*) detection is introduced. If sandwich is detected
while trace recording the recording is aborted. The sandwich detected
while mcode execution leads to the platform panic.
luaJIT_setmode call is prohibited while mcode execution and leads to
the platform panic.
(*) The following stack mix is called FFI sandwich:
Lua-FFI->Croutine->Lua-CAPI->LuaVM.
This sort of re-entrancy is explicitly not supported by LuaJIT compiler.
For more info see gh-4427.
Vinyl
Fix assertion fault due to triggered dump process during secondary
index build (gh-4810).
Misc
Fix crashes at attempts to use -e and -l command line options
concatenated with their values, like this: -eprint(100)
(gh-4775).
Fix inability to upgrade from 2.1 if there was an automatically
generated sequence (gh-4771).
Prettify the error message for user.grant(): no extra ’ ’ for
universal privileges (gh-714).
Update libopenssl version to 1.1.1f since the previous one was
EOLed (gh-4830).
Building from sources
Update the decNumber library to silence the build warning
produced on too long integer constant
(see in this commit).
Fix static build (-DBUILD_STATIC=ON) when libunwind depends
on liblzma (gh-4551).
Tarantool 2.3.3
Release: v. 2.3.3
Date: 2020-07-17 Tag: 2.3.3-1-g43af95e
Overview
2.3.3 is the last stable version of the 2.3 release series. The label
stable means we have all planned features implemented and we see no
high-impact issues.
This release resolves roughly 26 issues since the latest stable version.
There may be bugs in less common areas, please feel free to file an
issue at GitHub.
Please note, this release contains no new features.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new features
of the 2.x series.
Bugs fixed
Core
Fixed a bug in altering a normal index to a functional one (n/a).
Fixed a couple of internal symbols dangling in global namespace _G
(gh-4812).
Fixed bug when on_shutdown triggers were not executed after EOF
(gh-4703).
Fixed assert outdated due to multikey index arrival (gh-5132).
Fixed confusing implicit requirements for tuple fields (gh-5027).
Added needed key validation to space_before_replace (gh-5017).
Fixed check of index field map size which led to crash (gh-5084).
Fixed NULL pointer dereference when merger is called via the binary
protocol (say, via net.box) (gh-4954).
Fixed crash when invalid JSON was used in update() (gh-5135).
Replication
Fixed possible ER_TUPLE_FOUND error when bootstrapping replicas in an
1.10/2.1.1 cluster (gh-4924).
Fixed tx boundary check for half-applied txns (gh-5125).
Fixed replication tx boundaries after local space rework (gh-4928).
Lua
Fixed error while closing socket.tcp_server socket (gh-4087).
SQL
Fixed wrong order of rows as a result of query containing column of
SCALAR type in ORDER BY clause (gh-4697).
Fixed bug with the display of collation for scalar fields in <SELECT>
result, when sql_full_metadata is enabled (gh-4755).
Block using HASH indexes in SQL since scheduler is unable to use it
properly (gh-4659).
Fixed races and corner cases in box (re)configuration (gh-4231).
Vinyl
Fixed crash during compaction due to tuples with size exceeding
vinyl_max_tuple_size setting (gh-4864).
Fixed crash during recovery of vinyl index due to the lack of file
descriptors (gh-4805).
Fixed crash during executing upsert changing primary key in debug
mode (gh-5005).
Fixed crash due to triggered dump process during secondary index
creation (gh-5042).
Fixed crash/deadlock (depending on build type) during dump process
scheduling and concurrent DDL operation (gh-4821).
Fixed crash during read of prepared but still not yet not committed
statement (gh-3395).
Fixed squashing set and arithmetic upsert operations (gh-5106).
Create missing folders for vinyl spaces and indexes if needed to
avoid confusing fails of tarantool started from backup (gh-5090).
Fixed crash during squash of many (more than 4000) upserts modifying
the same key (gh-4957).
Memtx
Fixed concurrent replaces on index building. Tuples are now
referenced on all needed execution paths (gh-4973).
Tarantool 2.3.2
Release: v. 2.3.2
Date: 2020-04-20 Tag: 2.3.2-1-g9be641b
Overview
2.3.2 is the first stable version of the 2.3 release series. The label
stable means we have all planned features implemented and we see no
high-impact issues.
This release resolves roughly 39 issues since the latest beta version.
There may be bugs in less common areas, please feel free to file an
issue at GitHub.
Please note, this release contains no new features.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new features
of the 2.x series.
Bugs fixed
Core
fiber.storage is cleaned between requests,
and can be used as a
request-local storage. Previously fiber.storage could contain
some old values in the beginning of an iproto request execution, and
it needed to be nullified manually. Now the cleanup is unneeded
(gh-4662).
tuple/space/index:update()/upsert() were fixed
not to turn a value into an infinity when a float value was added to
or subtracted from a float column and exceeded the float value range
(gh-4701).
Fix potential execution abort when operating the system runs under
heavy memory load (gh-4722).
Make RTREE indexes handle the out of memory error: before this fix,
OOM during the recovery of an RTREE index resulted in segmentation
fault (gh-4619).
Fix the error message returned on using an already dropped sequence
(gh-4753).
Add cancellation guard to avoid WAL thread stuck (gh-4127).
Fix execution abort when memtx_memory and vinyl_memory are
set to more than 4398046510080 bytes. Now an error message is
returned (gh-4705).
Add Lua output format support for box.session.push() (gh-4686).
Replication
Fix rebootstrap procedure not working in case replica itself is
listed in box.cfg.replication (gh-4759).
Fix possible user password leaking via replication logs (gh-4493).
Fix crash when the replication applier rollbacks a transaction
(gh-4730, gh-4776).
Fix segmentation fault on master side when one of the replicas
transitions from anonymous to normal (gh-4731).
Local space operations are now counted in 0th vclock component. Every
instance may have its own 0-th vclock component not matching others’.
Local space operations are not replicated at all, even as NOPs
(gh-4114).
Gc consumers are now ordered by their vclocks and not by vclock
signatures. Only the WALS that contain no entries needed by any of
the consumers are deleted (gh-4114).
Lua
json: :decode() does not spoil instance’s options with per-call
ones (when it is called with the second argument) (gh-4761).
Handle empty input for uri.format() properly (gh-4779).
os.environ() is now changed when os.setenv() is called
(gh-4733).
netbox.self:call/eval() now returns the same types as
netbox_connection:call/eval. Previously it could return a
tuple or box.error cdata (gh-4513).
box.tuple.* namespace is cleaned up from private functions.
box.tuple.is() description is added to documentation (gh-4684).
tarantoolctlrockssearch: fix the --all flag (gh-4529).
tarantoolctlrocksremove: fix the --force flag (gh-3632).
libev: backport fix for listening for more then 1024 file descriptors
on Mac OS (gh-3867).
SQL
Fix box.stat() behavior: now it collects statistics on the
PREPARE and EXECUTE methods as expected (gh-4756).
Add an empty body to the UNPREPARE IProto response (gh-4769).
Reset all the placeholders’ bound values after execution of a
prepared statement (gh-4825).
The inserted values are inserted in the order in which they are given
in case of INSERT into space with autoincrement (gh-4256).
HTTP client
When building Tarantool with bundled libcurl, link it with the
c-ares library by default (gh-4591).
LuaJIT
__pairs/__ipairs metamethods handling is removed since we
faced the issues with the backward compatibility between Lua 5.1 and
Lua 5.2 within Tarantool modules as well as other third party code
(gh-4770).
Introduce luajit-gdb.py extension with commands for inspecting
LuaJIT internals. The extension obliges one to provide gdbinfo for
libluajit, otherwise loading fails. The extension provides the
following commands:
lj-arch dumps values of LJ_64 and LJ_GC64 macro definitions
lj-tv dumps the type and GCobj info related to the given
TValue
lj-str dumps the contents of the given GCstr
lj-tab dumps the contents of the given GCtab
lj-stack dumps Lua stack of the given lua_State
lj-state shows current VM, GC and JIT states
lj-gc shows current GC stats
Fix string to number conversion: current implementation respects the
buffer length (gh-4773).
“FFI sandwich” (*) detection is introduced. If sandwich is detected
while trace recording the recording is aborted. The sandwich detected
while mcode execution leads to the platform panic.
luaJIT_setmode call is prohibited while mcode execution and leads to
the platform panic.
(*) The following stack mix is called FFI sandwich:
Lua-FFI -> C routine -> Lua-C API -> Lua VM
This sort of re-entrancy is explicitly not supported by LuaJIT compiler.
For more info see gh-4427.
Vinyl
Fix assertion fault due to triggered dump process during secondary
index build (gh-4810).
Misc
Fix crashes at attempts to use -e and -l command line options
concatenated with their values, like this: -eprint(100)
(gh-4775).
Fix inability to upgrade from 2.1 if there was an automatically
generated sequence (gh-4771).
Update libopenssl version to 1.1.1f since the previous one was
EOLed (gh-4830).
Fix static build (-DBUILD_STATIC=ON) when libunwind depends
on liblzma (gh-4551).
Tarantool 2.3.1
Release: v. 2.3.1
Date: 2019-12-31 Tag: 2.3.1-0-g5a1a220
Overview
2.3.1 is the beta version of the 2.3 release series.
This release introduces roughly 38 features and resolves 102 bugs since
the 2.2.1 version. There may be bugs in less common areas. If you find
any, feel free to report an issue at
GitHub.
Notable changes are:
field name and JSON path updates
anonymous replica
new DOUBLE SQL type (and new ‘double’ box field type)
stored and indexed decimals (and new ‘decimal’ field type)
fiber.top()
feed data from a memory during replica initial join
SQL prepared statements
sessions settings service space
Aside of that many other features have been implemented and considerable
amount of bugs have been fixed.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
There are changes labeled with [Breaking change]. It means that the
old behaviour was considered error-prone and therefore changed to
protect users from unintended mistakes. However, there is a little
probability that someone can lean on the old behaviour, and this label
is to bring attention to the things that have been changed.
SQL
Introduce prepared statements support and prepared statements cache
(gh-2592, gh-3292). Using of prepared statements allows to eliminate
overhead of transmitting a statement text over a network and parsing
it each time before execution. Aside of this, it allows to acquire
binding parameters and result set columns metainformation prior to
actual execution of a statement. This feature is vital for
implementing standard DBMS APIs, such as ODBC and JDBC.
[Breaking change] Introduce _session_setting service space as
replacement for PRAGMA keyword (gh-4511). All frontends (C, Lua, SQL,
binary protocol) can use this space to access or update session
settings. Removed count_changes, short_column_names,
sql_compound_select_limit, vdbe_addoptrace pragmas.
Transformed others into _session_settings tuples.
Extend SQL result set metadata (gh-4407), In addition to the name
and type fields, the collation, is_nullable,
is_autoincrement, and span fields are added. These new fields
are shown when the full_metadata session setting is enabled but
always sent via binary protocol.
Add an ability to disable check constraints (gh-4244). Example:
ALTERTABLEfoo{ENABLE|DISABLE}CHECKCONSTRAINTbar;. For
details of using from Lua, refer to
documentation.
AUTOINCREMENT for multipart primary key (gh-4217). The auto-increment
feature can be set to any INTEGER or UNSIGNED field of
PRIMARYKEY using one of the two ways:
Allow to create a view from any CTE (common table expression) using
WITH clause (gh-4149).
Support user-defined functions in SQL. box.schema.func.create()
API has been extended and should be used to make some function
available in SQL. For details on fields added, refer to the
description here: (doc-879).
Usage of legacy mechanismbox.internal.sql_function_create is
forbidden now (gh-2200, gh-2233, gh-4113).
Scalar functions MIN/MAX are renamed to LEAST/GREATEST
(gh-4405)
Introduce WITHENGINE clause for CREATETABLE statement
(gh-4422). To allow a user to specify engine as per table option,
CREATETABLE statement has been extended with optional
WITHENGINE=<engine_name> clause. This clause comes at the end
of CREATETABLE statement. For example:
Display line and position in syntax errors (gh-2611).
Make constraint names unique within a table (gh-3503).
The SQL standard requires PRIMARYKEY, UNIQUE, FOREIGNKEY and CHECK
constraints to have the unique name within a table. Now Tarantool/SQL
follows this requirement. Please refer to (doc-1053).
Optimization: a tuple already stores a map of offsets of indexed
values. After the change, when a field after an indexed field is
accessed, the tuple is decoded from the indexed field rather then
from beginning (gh-4267).
Core
[Breaking change] Drop rows_per_wal option of box.cfg()
in favor of wal_max_size (gh-3762).
Decimals can now be stored in spaces. The corresponding field type is
introduced: decimal. Decimal values are also allowed in the
scalar, any, and number fields. Decimal values can be
indexed (gh-4333). Also refer to documentation on
Add support for decimals in update operations (gh-4413).
tuple:update() and <space_object>:update() now support
decimal operands for arithmetic operations (‘+’ and ‘-’). The syntax
is as usual, for example:
Insertion (‘!’) and assignment (‘=’) are also supported. See also the
full description of the update() function in
documentation.
Allow to encode/decode decimals to MsgPack and to encode to
YAML and JSON. Part of (gh-4333);
485439e3;
documentation: (doc-992).
Introduce field name and JSON path updates (gh-1261).
Example of update
by a field name: box.space.test:update({{'=','foo',42}}).
JSON path update allows to change a value that is nested inside an array
or a map. It provides convenient syntax (that is also available for
connectors), consumes less space in WAL than replace, and is faster
than replaces written in Lua. Example:
box.space.test:update({{'=','foo.bar[1]',42}}). Please refer to
documentation here: (doc-1051).
Introduce double field type. Part of (gh-3812). Though is not very
usable in Lua, this new field type has been added in box as a
base for the SQL DOUBLE type.
vinyl: don’t pin index for iterator lifetime (prerequisite for
snapshot iterators).
02da82ea
vinyl: don’t exempt dropped indexes from dump and compaction
(prerequisite for snapshot iterators).
d7387ec9
Replication
box.info().replication shows applier/replay’s latest error
message. Now it also shows the errno description for system errors
when it’s applicable (gh-4402).
Feed data from a memory during replica initial join (gh-1271). Aside of
obvious speed up from reading from a memory instead of a disk, a read
view that is acquired to perform an initial join may be a way more
recent, that eliminates the need to play all xlog files since a last
snapshot. Now relay need to send only changes that occur during
initial join to finally join a replica.
Introduce a new replica type - anonymous replica (gh-3186). Anonymous
replica is not present in cluster space and so there is no limitation
for its count in a replica set. Anonymous replica is read-only, but
can be deanonymized and enabled for writes. Please refer to
documentation: (doc-1050) for
API and details.
Lua
Expose require('tarantool').package which is ‘Tarantool’ for the
community version and ‘Tarantool Enterprise’ for the enterprise
version (gh-4408). This value is already displayed in a console
greeting and in box.info().package, but it was not accessible
from Lua before the first box.cfg{<...>} call.
decimal: add modulo operator (decimal.new(172.51)%1==0.51),
part of (gh-4403).
[Breaking change] JSON and msgpack serializers now raise an error
when a depth of data nesting exceeds the encode_max_depth option
value. The default value of the option has been increased from 32 to
128. The encode_deep_as_nil option is added to give an ability to
set the old behaviour back (gh-4434). Notes:
These options can be set by using json.cfg({<...>}) or
msgpack.cfg({<...>}).
box data modification functions (insert, replace,
update and upsert) follow the options of the default
msgpack serializer instance, and now these functions raise an
error on too many levels of nested data by default rather than cut
the data silently. This behaviour can be configured using
msgpack.cfg({<...>}).
previously,box.tuple.new(), space:update(),
space:upsert() and several other functions did not follow
encode_max_depth option; now they do (see also the Bug
fixed section).
previously,json.cfg and msgpack.cfg tables was not
updated when an option had changed; now they show actual values
(see also the Bug fixed section).
Show line and column in json.decode() errors (gh-3316).
Exit gracefully when a main script throws an error: notify systemd,
log the error (gh-4382).
key_def: accept both field and fieldno in
key_def.new(<...>) (gh-4519). Originally key_def.new(<...>)
accepted only fieldno to allow creation with
<index_object>.parts as argument. However, index definition
format (<space_object>.create_index(<...>)) is different and
requires field. Now both are supported.
Enable __pairs and __ipairs metamethods from Lua 5.2 (gh-4560).
We still conform Lua 5.1 API that is not always compatible with Lua
5.2. The change is only about those metamethods.
Implement a new function fiber.top(). It returns a table with all
fibers alive and lists their CPU consumption. For details, refer to
documentation.
(gh-2694)
Expose errno field for box.error objects representing system
errors. Part of (gh-4402).
HTTP client
Add accept_encoding option for HTTP client. For details, refer to
description here: (doc-1036).
(gh-4232).
Modify type of a binding value in query response metainformation:
always return INTEGER rather than UNSIGNED, even for positive values.
This is necessary for consistency with integer literal types.
b7d595ac.
Reuse noSQL way to compare floating point values with integral ones.
This allows to handle corner cases like
SELECT18446744073709551615.0>18446744073709551615 uniformly.
73a4a525.
Create or alter a table with a foreign key may lead to wrong bytecode
generation that may cause a crash or wrong result (gh-4495).
Allow to update a scalar value using SQL in a space that was created
from Lua and contains array, map or any fields (gh-4189).
Note: Tarantool/SQL provides operations on scalar types and does not
support ‘array’ and ‘map’ per se.
Allow nil to be returned from user-defined function (created with
box.schema.func.create()).
1b39cbcf
Don’t drop a manually created sequence in DROP TABLE statement.
a1155c8b
Remove grants associated with the table in DROP TABLE statement
(gh-4546).
Fix segfault in sql_expr_coll() when SUBSTR() is called
without arguments.
4c13972f
Fix converting of floating point values from range [2^63, 2^64] to
integer (gh-4526).
Make type string case lower everywhere: in error messages, meta
headers, and results of the typeof() SQL function.
ee60d31d
Make theLENGTH() function to accept boolean argument (gh-4462).
Make implicit cast from BOOLEAN to TEXT to return uppercase for
consistency with explicit cast (gh-4462).
Fix segfault on binding a value as LIKE argument (gh-4566).
For user-defined functions, verify that the returned value is of the
type specified in the function definition (gh-4387).
Start using comprehensive serializer luaL_tofield() to prepare
LUA arguments for user-defined functions. This allows to support
cdata types returned from Lua function (gh-4387).
An error is raised when a user-defined function returns too many
values (gh-4387).
Store a name of user-defined function in VDBE program instead of
pointer. This allows to normally handle the situation when a
user-defined function has been deleted to the moment of the VDBE code
execution (gh-4176).
Fix casting of VARBINARY value to a NUMBER (gh-4356)
Print the data type instead of the data itself in diag_set() in
case of binary data. The reason of this patch is that LibYAML
converts the whole error message to base64 in case of
non-printable symbols. Part of (gh-4356).
Remove ENGINE from the list of the reserved keywords and allow to
use it for identifiers: we are going to use the word as a name of
some fields for tables forming informational schema.
Fix segfault when LEAST() or GREATEST() built-in function is
invoked without arguments (gh-4453).
Fix dirty memory access when constructing query plan involving search
of floating point value in index over integer field (gh-4558).
INDEXEDBY clause now obligates the query planner to choose
provided index.
49fedfe3
Core
Make functional index creation transactional (gh-4401)
Randomize the next checkpoint time after manual box.snapshot()
execution also (gh-4432).
Fix memory leak in call/eval in case of a transaction is not
committed (gh-4388)
Eliminate warning re strip_core option of box.cfg() on MacOS
and FreeBSD (gh-4464)
The msgpack serializer that is under box.tuple.new() (called
tuple serializer) now reflects options set by
msgpack.cfg({<...>}). Part of (gh-4434). Aside of
box.tuple.new() behaviour itself, it may affect
tuple:frommap(), methods of key_def Lua module, tuple and table
merger sources, net.box results of :select() and :execute()
calls, and xlog Lua module.
box functions update and upsert now follow
msgpack.cfg({encode_max_depth=<...>} option. Part of (gh-4434).
fiber: make sure the guard page is created; refuse to create a new
fiber otherwise (gh-4541). It is possible in case of heavy memory
usage, say, when there is no resources to split VMAs.
recovery: build secondary indices in the hot standby mode without
waiting till the main instance termination (gh-4135).
Fix error message for incorrect return value of functional index
extractor function (gh-4553).
Was: “Key format doesn’t match one defined in functional index ‘’
of space ‘’: supplied key type is invalid: expected boolean”
Now: “<…>: expected array”
JSON path index now consider is_nullable property when a space had a
format (gh-4520).
Forbid 00000000-0000-0000-0000-000000000000 as the value of
box.cfg({<...>}) options: replicaset_uuid and
instance_uuid (gh-4282). It did not work as expected: the nil UUID
was treated as absence of the value.
Update cache of universe privileges without reconnect (gh-2763).
net.box: fix memory leak in net_box:connect(<URI>) (gh-4588).
net.box: don’t fire the on_connect trigger on schema update
(gh-4593). Also don’t fire the on_disconnect trigger if a connection
never entered into the active state (e.g. when the first schema
fetch is failed).
func: fix use-after-free on function unload.
fa2893ea
Don’t destroy a session until box.session.on_disconnect(<...>)
triggers are finished (gh-4627). This means, for example, that
box.session.id() can be safely invoked from the on_disconnect
trigger. Before this change box.session.id() returned garbage
(usually 0) after yield in the on_disconnect trigger. Note:
tarantool/queue module is
affected by this problem in some
scenarios. It is
especially suggested to update Tarantool at least to this release if
you’re using this module.
func: Fix box.schema.func.drop(<..>) to unload unused modules
(gh-4648). Also fix box.schema.func.create(<..>) to avoid loading a
module again when another function from the module is loaded.
Encode Lua number -2^63 as integer in msgpack.encode() and box’s
functions (gh-4672).
Forbid to drop admin’s universe access.
2de398ff.
Bootstrap and recovery work on behalf of admin and should be able to
fill in the system spaces. Drop of admin’s access may lead to an
unrecoverable cluster.
Refactor rope library to eliminate virtual calls to increase
performance of the library (mainly for JSON path updates).
baa4659c
Refactor update operation code to avoid extra region-related
arguments to take some performance boost (mainly for JSON path
updates).
dba9dba7
Error logging has been removed in engine_find() to get rid of the
error message duplication.
35177fe0.
decimal: Fix encoding of numbers with positive exponent. Follow-up
(gh-692).
Increment schema version on DDL operations where it did not performed
before: alter of trigger, check constraint and foreign key
constraint. Part of (gh-2592).
Set last_row_time to now in relay_new and
relay_start (gh-4431).
Do not abort replication on ER_UNKNOWN_REPLICA (gh-4455).
Enter orphan mode on manual replication configuration change (gh-4424).
Disallow bootstrap of read-only masters (gh-4321).
Prefer to bootstrap a replica from a fully bootstrapped instance
rather than from an instance that is in the process of bootstrapping
(gh-4527). This change enables the case when two nodes (B, C) are being
bootstrapped simultaneously using the one that is already
bootstrapped (A), while A is configured to replicate from {B, C} and
B – from {A, C}.
Return immediately from box.cfg{<...>} when an instance is
reconfigured with replication_connect_quorum=0 (gh-3760). This
change also fixes the behaviour of reconfiguration with non-zero
replication_connect_quorum: box.cfg{<...>} returns
immediately regardless of whether connections to upstreams are
established.
Apply replication settings of box.cfg({<...>}) in a strict order
(gh-4433).
Auto reconnect a replica if password is invalid (gh-4550).
box.session.su(<username>) now correctly reports an error for
<username> longer than BOX_NAME_MAX which is 65000.
8b6bdb43
Was: ‘C++ exception’
Now: ‘name length <…> is greater than BOX_NAME_MAX’
Use empty password when a URI in box.cfg{replication=<...>} is
like login@host:port (gh-4605). The behaviour matches the
net.box’s one now. Explicit login:@host:port was necessary
before, otherwise a replica displayed the following error: > Missing
mandatory field ‘tuple’ in request
Cancel a replica joining thread forcefully on Tarantool instance
exit (gh-4528).
Fix the applier to run the <space>.before_replace trigger during
initial join (gh-4417).
Lua
Fix segfault on ffi.C._say() without filename (gh-4336).
Fix pwd.getpwall() and pwd.getgrall() hang on CentOS 6 and
FreeBSD 12 (gh-4428, gh-4447).
json.encode() now follows encode_max_depth option for arrays that
leads to a segfault on recursive Lua tables with numeric keys
(gh-4366).
fio.mktree() now reports an error for existing non-directory file
(gh-4439).
json.cfg and msgpack.cfg tables were not updated when an
option is changed. Part of (gh-4434).
Fix handling of a socket read error in the console client
(console.connect(<URI>) or tarantoolctlconnect/enter<...>).
89ec1d97
Handle the “not enough memory” error gracefully when it is raised
from lua_newthread() (gh-4556). There are several cases when a new
Lua thread is created:
Start executing a Lua function call or an eval request (from a
binary protocol, SQL or with box.func.<...>:call()).
Create of a new fiber.
Start execution of a trigger.
Start of encoding into a YAML format (yaml.encode()).
Fix stack-use-after-scope in json.decode() (gh-4637).
Allow to register several functions using
box.schema.func.create(), whose names are different only in
letters case (gh-4561). This make function names work consistently with
other names in tarantool (except SQL, of course).
Fix decimal comparison with nil. Follow-up (gh-692).
A pointer returned by msgpack.decode*(cdata<[char]const*>)
functions can be assigned to buffer.rpos now (and the same for
msgpackffi) (gh-3926). All those functions now return
cdata<char*> or cdata<constchar*> depending of a passed
argument. Example of the code that did not work:
res,buf.rpos=msgpack.decode(buf.rpos,buf:size()).
lua/pickle: fix typo that leads to reject of negative integers for
‘i’ (integer) and ‘N’ (big-endian integer) formats in pickle.pack().
e2d9f664
HTTP client
Use bundled libcurl rather than system-wide by default.
(gh-4318, gh-4180, gh-4288,
gh-4389, gh-4397). This closes several known
problems that were fixed in recent libcurl versions, including segfaults,
hangs, memory leaks and performance problems.
Fix assertion fail after a curl write error (gh-4232).
Disable verbose mode when {verbose=false} is passed.
72613bb0
Console Lua output
A new Lua output format is still in the alpha stage and has the known
flaws, but we are working to make it rich and stable.
Output box.NULL as "box.NULL" rather than
"cdata<void*>:NULL", part of (gh-3834) (in quotes for now, yes,
due to (gh-4585)
Add semicolon (;) as responses delimiter (EOS, end of
stream/statement), analogue of YAMLs end-of-document (...)
marker. This is vital for remote clients to determine the end of a
particular response, part of (gh-3834).
Fix hang in the console client (console.connect(<URI>) or
tarantoolctlconnect/enter<...>) after
\setoutputlua[,block] command, part of (gh-3834). In order to
overcome it, two changes have been made:
Parse \setoutputlua[,block] command on a client prior to
sending it to a server, store current responses delimiter (EOS)
and use it to determine end of responses.
Send \setoutput<...> command with a default output mode when
establishing a connection (it is matter if different default modes
are set).
Provide an ability to get or set current responses delimiter using
console.eos([<...>]), part of (gh-3834).
Fix the “Data segment size exceeds process limit” error on
FreeBSD/x64: do not change resource limits when it is not necessary
(gh-4537).
fold: keep type of emitted CONV in sync with its mode.
LuaJIT#524 This
fixes the following assertion fail: > asm_conv: Assertion
`((IRType)((ir->t).irt & IRT_TYPE)) != st’ failed
Misc
Support systemd’s NOTIFY_SOCKET on OS X (gh-4436).
Fix linking with static openssl library (gh-4437).
Get rid of warning re empty NOTIFY_SOCKET variable (gh-4305).
rocks: fix ‘invalid date format’ error when installing a packed rock
(gh-4481).
Remove libyaml from rpm/deb dependencies, because we use bunbled
version of libyaml for the packages (since 2.2.1) (gh-4442).
Fix CLI boolean options handling in tarantoolctlcat<...>, such
as --show-system (gh-4076).
Fix segfault (out of bounds access) when a stack unwinding error
occurs at backtrace printing (gh-4636). Backtrace is printed on the
SIGFPE and SIGSEGV signals or when LuaJIT finds itself in the
unrecoverable state (lua_atpanic()).
Fix LTO warnings that were treated as errors in a release build
(gh-4512).
Tarantool 2.2.3
Release: v. 2.2.3
Date: 2020-04-20 Tag: 2.2.3-1-g98ecc90
Overview
2.2.3 is the last stable version of the 2.2 release series. The label
stable means we have all planned features implemented and we see no
high-impact issues.
This release resolves roughly 34 issues since the latest stable version.
There may be bugs in less common areas, please feel free to file an
issue at GitHub.
Please note, this release contains no new features.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new features
of the 2.x series.
Bugs fixed
Core
fiber.storage is cleaned between requests,
and can be used as a
request-local storage. Previously fiber.storage could contain
some old values in the beginning of an iproto request execution, and
it needed to be nullified manually. Now the cleanup is unneeded
(gh-4662).
tuple/space/index:update()/upsert() were fixed
not to turn a value into an infinity when a float value was added to
or subtracted from a float column and exceeded the float value range
(gh-4701).
Fix potential execution abort when operating the system runs under
heavy memory load (gh-4722).
Make RTREE indexes handle the out of memory error: before this fix,
OOM during the recovery of an RTREE index resulted in segmentation
fault (gh-4619).
Fix the error message returned on using an already dropped sequence
(gh-4753).
Add cancellation guard to avoid WAL thread stuck (gh-4127).
Fix execution abort when memtx_memory and vinyl_memory are
set to more than 4398046510080 bytes. Now an error message is
returned (gh-4705).
Replication
Fix rebootstrap procedure not working in case replica itself is
listed in box.cfg.replication (gh-4759).
Fix possible user password leaking via replication logs (gh-4493).
Fix crash when the replication applier rollbacks a transaction
(gh-4730, (gh-4776).
Local space operations are now counted in 0th vclock component. Every
instance may have its own 0-th vclock component not matching others’.
Local space operations are not replicated at all, even as NOPs
(gh-4114).
Gc consumers are now ordered by their vclocks and not by vclock
signatures. Only the WALS that contain no entries needed by any of
the consumers are deleted (gh-4114).
Lua
json: :decode() doesn’t spoil instance’s options with per-call
ones (when it is called with the second argument) (gh-4761).
Handle empty input for uri.format() properly (gh-4779).
os.environ() is now changed when os.setenv() is called
(gh-4733).
netbox.self:call/eval() now returns the same types as
netbox_connection:call/eval. Previously it could return a
tuple or box.error cdata (gh-4513).
box.tuple.* namespace is cleaned up from private functions.
box.tuple.is() description is added to documentation (gh-4684).
tarantoolctlrockssearch: fix the --all flag (gh-4529).
tarantoolctlrocksremove: fix the --force flag (gh-3632).
libev: backport fix for listening for more then 1024 file descriptors
on Mac OS (gh-3867).
SQL
Fix box.stat() behavior: now it collects statistics on the
PREPARE and EXECUTE methods as expected (gh-4756).
The inserted values are inserted in the order in which they are given
in case of INSERT into space with autoincrement (gh-4256).
HTTP client
When building Tarantool with bundled libcurl, link it with the
c-ares library by default (gh-4591).
LuaJIT
__pairs/__ipairs metamethods handling is removed since we
faced the issues with the backward compatibility between Lua 5.1 and
Lua 5.2 within Tarantool modules as well as other third party code
(gh-4770).
Introduce luajit-gdb.py extension with commands for inspecting
LuaJIT internals. The extension obliges one to provide gdbinfo for
libluajit, otherwise loading fails. The extension provides the
following commands:
lj-arch dumps values of LJ_64 and LJ_GC64 macro definitions
lj-tv dumps the type and GCobj info related to the given
TValue
lj-str dumps the contents of the given GCstr
lj-tab dumps the contents of the given GCtab
lj-stack dumps Lua stack of the given lua_State
lj-state shows current VM, GC and JIT states
lj-gc shows current GC stats
Fix string to number conversion: current implementation respects the
buffer length (gh-4773).
“FFI sandwich”(*) detection is introduced. If sandwich is detected
while trace recording the recording is aborted. The sandwich detected
while mcode execution leads to the platform panic.
luaJIT_setmode call is prohibited while mcode execution and leads to
the platform panic.
(*) The following stack mix is called FFI sandwich:
Lua-FFI -> C routine -> Lua-C API -> Lua VM
This sort of re-entrancy is explicitly not supported by LuaJIT compiler.
For more info see gh-4427.
Vinyl
Fix assertion fault due to triggered dump process during secondary
index build (gh-4810).
Misc
Fix crashes at attempts to use -e and -l command line options
concatenated with their values, like this: -eprint(100)
(gh-4775).
Fix inability to upgrade from 2.1 if there was an automatically
generated sequence (gh-4771).
Update libopenssl version to 1.1.1f since the previous one was
EOLed (gh-4830).
Building from sources
Fix build of the decNumber library under OSX (gh-4580).
Fix static build (-DBUILD_STATIC=ON) when libunwind depends
on liblzma (gh-4551).
Tarantool 2.2.2
Release: v. 2.2.2
Date: 2019-12-31 Tag: 2.2.2-0-g0a577ff
Overview
2.2.2 is the first stable version of the 2.2 release series. The label
stable means we have all planned features implemented and we see no
high-impact issues.
This release resolves roughly 75 issues since the latest beta version.
There may be bugs in less common areas, please feel free to file an
issue at GitHub.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 2.x series.
Functionality added or changed
There are changes labeled with [Breaking change]. It means that the
old behaviour was considered error-prone and therefore changed to
protect users from unintended mistakes. However, there is a little
probability that someone can lean on the old behaviour, and this label
is to bring attention to the things that have been changed.
Core
[Breaking change] Drop rows_per_walbox.cfg() option in
favor of wal_max_size (gh-3762)
Lua
[Breaking change] json and msgpack serializers now raise an error
when a depth of data nesting exceeds encode_max_depth option
value. The default value of the option is increased from 32 to 128.
encode_deep_as_nil option was added to give ability to set the
old behaviour back (gh-4434). Note: Those options can be set using
json.cfg({<...>}) or msgpack.cfg({<...>}). Note: box data
modification functions (insert, replace, update,
upsert) follows options of default msgpack serializer instance
and now they will raise an error by default on too nested data rather
then cut them silently. This behaviour can be configured using
msgpack.cfg({<...>}). Note: box.tuple.new(),
space:update(), space:upsert() and several other functions
did not follow encode_max_depth option, now they do (see also
‘Bug fixes’). Note: json.cfg and msgpack.cfg tables did not
updated when an option is changed, now they show actual values (see
also ‘Bug fixes’).
Show line and column in json.decode() errors (gh-3316)
Exit gracefully when a main script throws an error: notify systemd,
log the error (gh-4382)
key_def: accept both field and fieldno in
key_def.new(<...>) (gh-4519). Originally key_def.new(<...>)
accepts only fieldno to allow creation with
<index_object>.parts as argument. However index definition format
(<space_object>.create_index(<...>)) is different and requires
field. Now both are supported.
Enable __pairs and __ipairs metamethods from Lua 5.2 (gh-4560).
We still conform Lua 5.1 API, which is not always compatible with Lua
5.2. The change is only about those metamethods.
Misc
tarantoolctl: allow to start instances with delayed box.cfg{}
(gh-4435)
Add package builds and deployment for the following Linux distros:
Modify type of a binding value in a query response metainformation:
always return INTEGER rather then UNSIGNED, even for positive values.
This is necessary for consistency with integer literal types.
c5246686.
Reuse noSQL way to compare floating point values with integral ones.
This allows to handle corner cases like
SELECT18446744073709551615.0>18446744073709551615 uniformly.
12431ed4.
Create or alter of a table with a foreign key may lead to wrong
bytecode generation that may cause a crash or wrong result (gh-4495)
Allow to update a scalar value using SQL in a space that was created
from Lua and contains ‘array’, ‘map’ or ‘any’ field (gh-4189). Note:
Tarantool/SQL provides operations on scalar types and does not
support ‘array’ and ‘map’ per se.
INDEXEDBY clause now obligates the query planner to choose
provided index,
411be0f0
Fix dirty memory access when constructing query plan involving search
of floating point value in index over integer field (gh-4558)
Randomize the next checkpoint time also after a manual
box.snapshot() (gh-4432)
Fix memory leak in call / eval in the case when a transaction is not
committed (gh-4388)
Eliminate warning re ‘strip_core’ box.cfg option on MacOS and
FreeBSD (gh-4464)
The msgpack serializer that is under box.tuple.new() (called
tuple serializer) did not reflect options set by
msgpack.cfg({<...>}), part of (gh-4434). Aside of
box.tuple.new() behaviour itself, it may affect tuple:frommap(),
methods of key_def Lua module, tuple and table merger sources,
net.box results of :select() and :execute() calls, xlog Lua
module.
box’s update and upsert now follow
msgpack.cfg({encode_max_depth=<...>} option, part of (gh-4434)
fiber: make sure the guard page is created, refuse to create a new
fiber otherwise (gh-4541). It is possible in case of heavy memory
pressure, say, when there is no resources to split VMAs.
recovery: build secondary indices in the hot standby mode without
waiting till the main instance termination (gh-4135)
Fix error message for incorrect return value of functional index
extractor function (gh-4553)
Was: “Key format doesn’t match one defined in functional index ‘’
of space ‘’: supplied key type is invalid: expected boolean’
Now: “<…>: expected array”
JSON path index did ignore is_nullable property when a space had a
format (gh-4520)
Forbid 00000000-0000-0000-0000-000000000000 as
replicaset_uuid and instance_uuidbox.cfg({<...>})
options value, (gh-4282). It did not work as expected: the nil UUID was
treated as absence of a value.
Update cache of universe privileges without reconnect
(gh-2763)
net.box: fix memory leak in net_box:connect(<URI>)
(gh-4588)
net.box: don’t fire on_connect trigger at schema update
(gh-4593).
Also don’t fire on_disconnect trigger if a connection never
entered into ‘active’ state (e.g. when a first schema fetch is
failed).
func: fix use after free on function unload,
64f4d06a
Fix bootstrap.snap file in order to overcome the following warning,
(gh-4510) > xlog.c:1934 E> can’t open tx: bootstrap: has some data
after eof marker at 5902
Don’t destroy a session until box.session.on_disconnect(<...>)
triggers will be finished (gh-4627). This means that, say,
box.session.id() can be safely invoked from the on_disconnect
trigger. Before this change box.session.id() returns garbage
(usually 0) after yield in the on_disconnect trigger. Note:
tarantool/queue module is affected by this problem in some
scenarious. It is
especially suggested to update tarantool at least to this release if
you’re using this module.
func: box.schema.func.drop(<..>) did not unload unused modules
(gh-4648). Also box.schema.func.create(<..>) did load of a module
again even when another function from the module is loaded.
Encode Lua number -2^63 as integer in msgpack.encode() and box’s
functions (gh-4672)
Prefer to bootstrap a replica from a fully bootstrapped instance
rather than currently bootstrapping one (gh-4527). This change enables
the case when two nodes (B, C) are being bootstrapped simultaneously
using the one that is already bootstrapped (A), while A is configured
to replicate from {B, C} and B from {A, C}.
Return immediately from box.cfg{<...>} when an instance is
reconfigured with replication_connect_quorum=0 (gh-3760)
This change also fixes the behaviour of reconfiguration with non-zero
replication_connect_quorum: box.cfg{<...>} returns
immediately regardless of whether connections to upstreams are
established.
Apply replication box.cfg({<...>}) settings in a strict order
(gh-4433)
Auto reconnect a replica if password is invalid
(gh-4550)
box.session.su(<username>) now reports an error correctly for
<username> longer then BOX_NAME_MAX, which is 65000,
43e29191
Was: ‘C++ exception’ Now: ‘name length <…> is greater than
BOX_NAME_MAX’
Use empty password when an URI in box.cfg{replication=<...>} is
like login@host:port (gh-4605). The behaviour match net.box’s one
now. Explicit login:@host:port was necessary before, otherwise a
replica shows the following error: > Missing mandatory field ‘tuple’
in request
Fix segfault on ffi.C._say() without filename
(gh-4336)
Fix pwd.getpwall() and pwd.getgrall() hang on CentOS 6 and
FreeBSD 12 (gh-4428, gh-4447)
json.encode() now follows encode_max_depth option for arrays that
leads to a segfault on recursive Lua tables with numeric keys
(gh-4366)
fio.mktree() now reports an error for existing non-directory file
(gh-4439)
Update json.cfg and msgpack.cfg tables when an option is
changed, part of (gh-4434)
Fix handling of a socket read error on the console client
(console.connect(<URI>) or tarantoolctlconnect/enter<...>),
b0b19992
Handle ‘not enough memory’ gracefully when it is raised from
lua_newthread() (gh-4556). There are several places where a new Lua
thread is created:
Start execution a Lua function call or an eval request (from a
binary protocol, SQL or with box.func.<...>:call()).
Create of a new fiber.
Start execution of a trigger.
Start of encoding into a YAML format (yaml.encode()).
Fix stack-use-after-scope in json.decode()
(gh-4637)
HTTP client
Use bundled libcurl rather than system-wide by default,
(gh-4318,
gh-4180,
gh-4288,
gh-4389,
gh-4397). This closes several known problems
that were fixed in recent libcurl versions, including segfaults,
hangs, memory leaks and performance problems.
Disable verbose mode when {verbose=false} is passed,
5f3d9015
Fix assertion fail after curl write error
(gh-4232)
Console Lua output
The new Lua output format is still in the alpha stage and has known
flaws, but we are working to make it rich and stable.
Output box.NULL as "box.NULL" rather then
"cdata<void*>:NULL", part of (gh-3834) (in quotes for now, yes,
due to (gh-4585)
Add semicolon (;) as responses delimiter (EOS, end of
stream/statement), analogue of YAMLs end-of-document (...)
marker. This is vital for remote clients to determine an end of a
particular response, part of (gh-3834).
Fix hang in the console client (console.connect(<URI>) or
tarantoolctlconnect/enter<...>) after
\setoutputlua[,block] command, part of (gh-3834). In order to
overcome it two changes were made:
Parse \setoutputlua[,block] command on a client prior to
sending it to a server, store current responses delimiter (EOS)
and use it to determine end of responses.
Send \setoutput<...> command with a default output mode when
establishing a connection (it is matter if different default modes
are set).
Provide ability to get or set current responses delimiter using
console.eos([<...>]), part of (gh-3834)
Fixed ‘Data segment size exceeds process limit’ error on FreeBSD/x64:
do not change resource limits when it is not necessary
(gh-4537)
fold: keep type of emitted CONV in sync with its mode,
LuaJIT#524 This
fixes the following assertion fail: > asm_conv: Assertion
`((IRType)((ir->t).irt & IRT_TYPE)) != st’ failed
Get rid of warning re empty NOTIFY_SOCKET variable
(gh-4305)
rocks: fix ‘invalid date format’ error when installing a packed rock
(gh-4481)
Remove libyaml from rpm/deb dependencies, because we use bunbled
version of libyaml for the packages (since 2.2.1)
(gh-4442)
Fix boolean CLI options handling in tarantoolctlcat<...>, such
as --show-system
(gh-4076)
Fix segfault (out of bounds access) when unwinding error occurs at
backtrace printing (gh-4636). Backtrace is printed on SIGFPE and
SIGSEGV signal or when LuaJIT find itself in unrecoverable state
(lua_atpanic()).
Building from sources
Fix for GCC 4.8.5, which is default version on CentOS 7
(gh-4438)
Release: v. 2.2.1.
Release type: beta. Release date: 2019-08-02.
Overview
This is a beta version of the 2.2 series. The label
“beta” means we have no critical issues and all planned features are there.
The goal of this release is to introduce new indexing features, extend SQL
feature set, and improve integration with the core.
Compatibility
Tarantool 2.x is backward compatible with Tarantool 1.10.x in binary data layout,
client-server protocol and replication protocol.
You can upgrade using the box.schema.upgrade()
procedure.
-- Multikey indexes (for memtx tree & vinyl);-- cannot be primary; may be non-uniques=box.schema.space.create('clients',{engine='vinyl'})pk=s:create_index('pk')phone_type=s:create_index('phone_type',{unique=false,parts={{'[3][*].type','str'}}})s:insert({1,'James',{{type='home',number='999'},{type='work',number='777'}}})s:insert({2,'Bob',{{type='work',number='888'}}})s:insert({3,'Alice',{{type='home',number='333'}}})
-- Functional multikey indexes: define is_multikey = true-- in function definition and return a table of keys from functionlua_code=[[function(tuple) local address = string.split(tuple[2]) local ret = {} for _, v in pairs(address) do table.insert(ret, {utf8.upper(v)}) end return ret end]]box.schema.func.create('addr_extractor',{body=lua_code,is_deterministic=true,is_sandboxed=true,opts={is_multikey=true}})s=box.schema.space.create('withdata')pk=s:create_index('name',{parts={1,'string'}})idx=s:create_index('addr',{unique=false,func=box.func.addr_extractor.id,parts={{1,'string',collation='unicode_ci'}}})s:insert({"James","SIS Building Lambeth London UK"})s:insert({"Sherlock","221B Baker St Marylebone London NW1 6XE UK"})
Partial core dumps, which are now on by default.
It is now possible to avoid dumping tuples at all during core dump.
Data definition statements, such as create or alter index, which do not yield,
can now be used in a transaction. This in practice includes all statements
except creating an index on a non-empty space, or changing a format on
a non-empty space.
It is now possible to set a sequence not only for the first part of the index:
s.index.pk:alter{sequence={field=2}}
Allow to call box.session.exists() and box.session.fd()
without any arguments.
New function introduced to get an index key from a tuple:
(Engines) New protocol (called SWIM) implemented to keep
a table of cluster members.
(Engines) Removed yields from Vinyl DDL on commit triggers.
(Engines) Improved performance of SELECT-s on memtx spaces.
The drawback is that now every memtx-tree tuple consumes extra 8 bytes for
a search hint.
(Engines) Indexes of memtx spaces are now built in background fibers.
This means that we do not block the event loop during index build anymore.
Replication applier now can apply transactions which were concurrent
on the master concurrently on replica. This dramatically improves replication
peak performance, from ~50K writes per second to 200K writes per second and
higher on a single instance.
Transaction boundaries introduced to replication protocol.
This means that Tarantool replication is now transaction-safe, and also
reduces load on replica write ahead log in case the master uses a lot of
multi-statement transactions.
I.e. [1, 3] tuple is updated as [1, 4] and have replaced tuple [2, 4].
This logic is implemented by preventive tuple deletion from all corresponding
indexes in SQL.
(SQL) Now SQL’s integer type is stored as integer in space’s format.
It was stored as scalar before, which made comparisons slow.
It may be set before the first call to box.cfg() and is fired during
box.cfg() before user data recovery start. To set the trigger, say:
box.ctl.on_schema_init(new_trig,old_trig)
(Server) A new option for the snapshot daemon,
box.cfg.checkpoint_wal_threshold,
allows to limit the maximum disk size of maintained WALs.
Once the configured threshold is exceeded, the WAL thread notifies the
che ckpoint daemon that it’s time to make a new checkpoint and delete old WAL files.
Notice the incompatible change: Tarantool 1.10 requires read/write/execute
privileges on an object to allow create, drop or alter. These privileges are
no longer sufficient in 2.1. To remedy the problem, Tarantool 2.1 automatically
grants create/drop/alter privileges on an object if a user has
read/write/execute privileges on it during schema upgrade.
But old scripts may stop working if read/write/execute is granted after
schema upgrade.
Additionally, create/drop/alter privileges are already supported in 1.10,
which also supports the old semantics of read/write/execute.
You are encouraged to grant new privileges in 1.10 before upgrade
and modify your scripts.
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 2 improvements and resolves roughly 8 issues
since the 1.10.14 version.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Fixed a bug when fields could be removed from a table stored in a
variable when a logging function was called on this variable (for
example, log.info(a)) (gh-3853).
Fixed a logging bug: when logging tables with fields that have
reserved internal names (such as pid) in the plain log format,
such fields weren’t logged (gh-3853).
Added the message field when logging tables without such field in
the JSON log format (gh-3853).
Fixed an assertion on malformed JSON message written to the log
(gh-7955).
Vinyl
Fixed a bug that could result in select() skipping an existing
tuple after a rolled back delete() (gh-7947).
LuaJIT
Backported patches from vanilla LuaJIT trunk (gh-7230). In the scope of
this activity, the following issues have been resolved:
Fix overflow check in unpack() optimized by a compiler.
Fix recording of tonumber() with cdata argument for failed
conversions (gh-7655).
Fix concatenation operation on cdata. It always raises an error now.
Fix io.close() for already closed standard output.
Fix trace execution and stitching inside vmevent handler (gh-6782).
Fixed emit_loadi() on x86/x64 emitting xor between condition
check and jump instructions.
Fix stack top for error message when raising the OOM error (gh-3840).
Disabled math.modf compilation due to its rare usage and difficulties
with proper implementation of the corresponding JIT machinery.
Fixed inconsistent behaviour on signed zeros for JIT-compiled unary
minus (gh-6976).
Fixed IR_HREF hash calculations for non-string GC objects for
GC64.
Fixed assembling of type-check-only variant of IR_SLOAD.
Fixed the Lua stack dump command (lj-stack) not working on Python
2. Previously, it used arguments unpacking within the list
initialization, which is not supported in Python 2 (gh-7458).
Backported patches from vanilla LuaJIT trunk (gh-8069). In the scope of
this activity, the following issues have been resolved:
Fixed loop realigment for dual-number mode
Fixed os.date() for wider libc strftime() compatibility.
Fiber
Fixed the assertion fail in cord_on_yield (gh-6647).
Log
Fixed an incorrect facility value in syslog on Alpine (gh-8269).
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 10 improvements and resolves roughly 20 issues
since the 1.10.13 version.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Updated libyaml to the version with fixed stack overflows.
Bugs fixed
Core
Fixed a memory leak in the interactive console (gh-6817).
Fixed an assertion fail when passing a tuple without the primary key
fields to a before_replace trigger. Now the tuple format is
checked before the execution of before_replace triggers and after
each of them (gh-6780).
Now inserting a tuple with a wrong id field into the \_priv
space returns the correct error (gh-6295).
Fixed a bug that was making all fibers created with
fiber_attr_setstacksize() leak until the thread exit. Their
stacks also leaked except when fiber_set_joinable(...,true) was
used.
Fixed a crash that happened when Tarantool was launched with multiple
-e or -l options without spaces between the options and their
values (gh-5747).
Fixed the usage of box.session.peer() in
box.session.on_disconnect() triggers. Now it’s safe to assume
that box.session.peer() returns the address of the disconnected
peer, not nil, as it used to (gh-7014).
Fixed a bug in the sequence cache that could result in an error
creating a new sequence (gh-5306).
Vinyl
Immediate removal of compacted run files created after the last
checkpoint optimization now works for the initial JOIN stage of a
replica (gh-6568).
Fixed a crash during the recovery of a secondary index in case the
primary index contains incompatible phantom tuples (gh-6778).
Fixed a bug in the vinyl upsert squashing optimization that could
lead to a segmentation fault error (gh-5080).
Fixed a bug in the vinyl read iterator that could result in a
significant performance degradation of range select requests in the
presence of an intensive write workload (gh-5700).
Replication
Fixed replicas failing to bootstrap when the master has just
restarted (gh-6966).
LuaJIT
Fixed the top part of Lua stack (red zone, free slots, top slot)
unwinding in the lj-stack command.
Added the value of g->gc.mmudata field to lj-gc output.
Fixed a bug with string.char() builtin recording when no
arguments are provided (gh-6371, gh-6548).
Actually made JIT respect the maxirconst trace limit while
recording (gh-6548).
Backported patches from vanilla LuaJIT trunk (gh-6548, gh-7230).
In the scope of this activity, the following issues have been resolved:
Now initialization of zero-filled struct is compiled (gh-4630,
gh-5885).
Actually implemented maxirconst option for tuning JIT
compiler.
Fixed JIT stack of Lua slots overflow during recording for
metamethod calls.
Fixed bytecode dump unpatching for JLOOP in up-recursion compiled
functions.
Fixed FOLD rule for strength reduction of widening in cdata
indexing.
Fixed string.char() recording without arguments.
Fixed print() behaviour with the reloaded default metatable
for numbers.
tonumber("-0") now saves the sign of number for conversion.
tonumber() now gives predictable results for negative
non-base-10 numbers.
Fixed write barrier for debug.setupvalue() and
lua_setupvalue().
jit.p now flushes and closes output file after run, not at
program exit.
Fixed jit.p profiler interaction with GC finalizers.
Fixed the case for partial recording of vararg function body with
the fixed number of result values in with LJ_GC64
(i.e. LJ_FR2 enabled) (gh-7172).
Fixed handling of errors during trace snapshot restore.
Box
Added the check of the iterator type in the select, count,
and pairs methods of the index object. Iterator can now be passed
to these methods directly: box.index.ALL, box.index.GT, and
so on (gh-6501).
Recovery
With the force_recovery cfg option, Tarantool is now able to boot
from snap/xlog combinations where xlog covers changes
committed both before and after the snap was created. For
example, 0...0.xlog that covers everything up to vclock
{1:15} and 0...09.snap corresponding to vclock {1:9}
(gh-6794).
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 1 improvement and resolves roughly 13 issues
since the 1.10.12 version.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Fixed memory leak in interactive console (gh-6817).
Fixed an assertion fail when passing tuple without primary key fields
to before_replace trigger. Now tuple format is checked before the
execution of before_replace triggers and after each one (gh-6780).
Now inserting a tuple with the wrong id field into the _priv space
returns the correct error (gh-6295).
Fixed a bug due to which all fibers created with
fiber_attr_setstacksize() leaked until the thread exit. Their
stacks also leaked except when fiber_set_joinable(...,true) was
used.
Fixed a crash when Tarantool was launched with multiple -e or -l
options without a space between the option and the value (gh-5747).
Vinyl
Immediate removal of compacted run files created after the last
checkpoint optimization now works for replica’s initial JOIN stage
(gh-6568).
Fixed crash during recovery of a secondary index in case the primary
index contains incompatible phantom tuples (gh-6778).
Replication
Fixed replicas failing to bootstrap when master is just re-started
(gh-6966).
LuaJIT
Fixed top part of Lua stack (red zone, free slots, top slot)
unwinding in lj-stack command.
Added the value of g->gc.mmudata field to lj-gc output.
string.char() builtin recording is fixed in case when no
arguments are given (gh-6371, gh-6548).
Actually made JIT respect maxirconst trace limit while recording
(gh-6548).
Box
Added iterator type checking and allow passing iterator as a
box.index.{ALL,GT,…} directly (gh-6501).
Recovery
When force_recovery cfg option is set, Tarantool is able to boot
from snap/xlog combinations where xlog covers changes
committed both before and after snap creation. For example,
0...0.xlog, covering everything up to vclock{1:15} and
0...09.snap, corresponding to vclock{1:9} (gh-6794).
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 3 improvements and resolves roughly 10 issues
since the 1.10.11 version.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Bump debian package compatibility level to 10 (gh-5429). Bump minimal
required debhelper to version 10 (except for Ubuntu Xenial).
Bugs fixed
Core
Fixed a crash caused by a race between box.session.push() and closing
connection (gh-6520).
Fixed crash in case a fiber changing box.cfg.listen is woken up
(gh-6480).
Fixed box.cfg.listen not reverted to the old address in case the new
one is invalid (gh-6092).
Replication
Fixed replica reconnecting to a living master on any
box.cfg{replication=...} change. Such reconnects could lead to
replica failing to restore connection for replication_timeout
seconds (gh-4669).
LuaJIT
Fixed the order VM registers are allocated by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Fixed inconsistency while searching for an error function when
unwinding a C protected frame to handle a runtime error (e.g. an
error in __gc handler).
Lua
When error is raised during encoding call results, auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Prior to the fix it leads to undefined behaviour during the next
usage of this Lua coroutine (gh-4617).
Fixed Lua C API misuse, when the error is raised during call results
encoding on unprotected coroutine and expected to be catched on the
different one, that is protected (gh-6248).
Triggers
Fixed possibility crash in case when trigger removes itself. Fixed
possibility crash in case when someone destroy trigger, when it’s
yield (gh-6266).
Build
The Debian package does not depend on binutils anymore (gh-6699).
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 2 improvements and resolves roughly 18 issues
since version 1.10.10.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Some changes are labeled as [Breaking change].
It means that the old behavior was considered error-prone
and therefore changed to protect users from unintended mistakes.
However, there is a small probability that someone can rely on the old behavior,
and this label is to bring attention to the things that have been changed.
Functionality added or changed
LuaJIT
Introduced support for LJ_DUALNUM mode in luajit-gdb.py
(gh-6224).
[Breaking change]fiber.wakeup() in Lua and
fiber_wakeup() in C became NOP on the currently running fiber.
Previously they allowed “ignoring” the next yield or sleep, which
resulted in unexpected erroneous wake-ups. Calling these functions
right before fiber.create() in Lua or fiber_start() in C
could lead to a crash (in debug build) or undefined behaviour (in
release build) (gh-6043).
There was a single use case for the previous behaviour: rescheduling
in the same event loop iteration, which is not the same as
fiber.sleep(0) in Lua and fiber_sleep(0) in C. It could be
done in the following way:
in C:
fiber_wakeup(fiber_self());fiber_yield();
and in Lua:
fiber.self():wakeup()fiber.yield()
To get the same effect in C, one can now use fiber_reschedule().
In Lua, it is now impossible to reschedule the current fiber directly
in the same event loop iteration. One can reschedule self
through a second fiber, but it is strongly discouraged:
-- do not use this codelocalself=fiber.self()fiber.new(function()self:wakeup()end)fiber.sleep(0)
Fixed memory leak on box.on_commit() and
box.on_rollback() (gh-6025).
Fixed invalid results of the json module’s encode
function when it was used from the Lua garbage collector. For
example, this could happen in functions used as ffi.gc()
(gh-6050).
Fixed console client connection failure in case of request timeout
(gh-6249).
Added a missing broadcast to net.box.future:discard() so that now
fibers waiting for a request result wake up when the request is discarded
(gh-6250).
Fixed a bug when iterators became invalid (up to crash) after schema change
(gh-6147).
Fixed crash in case of reloading a compiled module when the new module lacks some functions
present in the former code. In turn, this event triggers a fallback procedure where we restore old functions,
but instead of restoring each function, we process a sole entry only, leading to the crash later
when these restored functions are called
(gh-5968).
Vinyl
Fixed possible keys divergence during secondary index build, which
might lead to missing tuples
(gh-6045).
Fix crash which may occur while switching read_only mode due to duplicating
transaction in tx writer list (gh-5934).
Fixed the race between Vinyl garbage collection and compaction that
resulted in a broken vylog and recovery failure
(gh-5436).
Replication
Fixed replication occasionally stopping with ER_INVALID_MSGPACK
when the replica is under high load (gh-4040).
LuaJIT
Fixed optimization for single-char strings in the IR_BUFPUT assembly
routine.
Fixed slots alignment in the lj-stack command output when LJ_GC64
is enabled (gh-5876).
Fixed dummy frame unwinding in the lj-stack command.
Fixed detection of inconsistent renames even in the presence of sunk
values (gh-4252, gh-5049, gh-5118).
Fixed the VM register allocation order provided by LuaJIT frontend in case
of BC_ISGE and BC_ISGT (gh-6227).
Lua
When an error occurs during encoding call results, the auxiliary
lightuserdata value is not removed from the main Lua coroutine stack.
Before the fix, it led to undefined behaviour during the next
usage of this Lua coroutine (gh-4617).
Fixed a Lua C API misuse when the error is raised during call results
encoding in an unprotected coroutine and expected to be caught in a
different, protected coroutine (gh-6248).
Triggers
Fixed a possible crash in case trigger removes itself. Fixed a
possible crash in case someone destroys a trigger when it
yields (gh-6266).
The label “stable” means there are 1.10.x-based applications running in
production for quite a while without known crashes, incorrect results or
other showstopper bugs.
This release introduces 12 improvements and resolves roughly 3 issues
since version 1.10.9.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol.
Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Functionality added or changed
Build
Tarantool build infrastructure now requires CMake version 3.1 or later.
Binary packages for Fedora 33 (gh-5502) are now available.
Binary packages for CentOS 6 and Debian Jessie won’t be published since this version.
Backported the -DENABLE_LTO=ON/OFF CMake option (gh-3117,
gh-3743).
It is useful for building packages for Fedora 33 (gh-5502).
The built-in zstd is upgraded from v1.3.3 to v1.4.8
(part of gh-5502).
libcurl symbols in the case of bundled libcurl are now exported
(gh-5223, gh-5542).
SMTP and SMTPS protocols are now enabled in the bundled libcurl (gh-4559).
The libcurl headers are now shipped to system path ${PREFIX}/include/tarantool
when libcurl is included as a bundled library or in a static build
(gh-4559).
Testing
Tarantool CI/CD has migrated to GitHub Actions (gh-5662).
Implemented a self-sufficient LuaJIT testing environment. As a result,
LuaJIT build system is now partially ported to CMake and all testing
machinery is enclosed within the tarantool/luajit
repository (gh-4862, gh-5470).
Python 3 is now the default in the test infrastructure (gh-5652).
Bugs fixed
Core
Extensive usage of uri and uuid modules with debug log level
no longer leads to crashes or corrupted results of the functions from these
modules.
Same problem is resolved for using these modules from the callbacks passed to ffi.gc(),
and for some functions from the modules fio, box.tuple, and iconv
(gh-5632).
Lua
Fixed the -e option, when tarantool used to enter the interactive mode when
stdin is a TTY. Now, tarantool-e'print"Hello"' doesn’t enter the
interactive mode, but just prints “Hello” and exits
(gh-5040).
Build
Recovering with force_recovery option now deletes vylog files newer than the snapshot.
It helps an instance recover after incidents during a checkpoint (gh-5823).
1.10.9 is the next stable release in the
long-term support (LTS) version
1.10.x release series. The label “stable” means there are 1.10.x-based
applications running in production for quite a while without known
crashes, incorrect results or other showstopper bugs.
This release introduces one improvement and resolves roughly 7 issues
since the 1.10.8 version.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol. Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Don’t start an ‘example’ instance after installing Tarantool
(gh-4507).
Before this release the tarantool package for Debian and Ubuntu used to
automatically enable and start an ‘example’ instance, which would
listen on the TCP port 3301. Since this release the instance file
is installed to /etc/tarantool/instances.available/example.lua,
but isn’t enabled by default and not started anymore. You can enable
and start it with the following commands:
Existing configuration will not be updated automatically at package
update. If you don’t the need example instance, you can stop and
disable it with the following commands:
fiber.cond:wait() now correctly throws an error when a fiber is
cancelled, instead of ignoring the timeout and returning without any
signs of an error (gh-5013).
Fixed a memory corruption issue, which was most visible on macOS, but
could affect any system (gh-5312).
A dynamic module now gets correctly unloaded from memory in case of
an attempt to load a non-existing function from it (gh-5475).
The fiber region (the box region) won’t be invalidated on a read-only
transaction (gh-5427, gh-5623).
LuaJIT
Dispatching __call metamethod no longer causes address clashing
(gh-4518, (gh-4649).
Fixed a false positive panic when yielding in debug hook
(gh-5649).
Lua
An attempt to use a net.box connection which is not established
yet now results in a correctly reported error (gh-4787).
Fixed a hang which occurred when tarantool ran a user script with
the -e option and this script exited with an error (like with
tarantool-e'assert(false)') (gh-4983).
1.10.8 is the next stable release of the 1.10.x series. The label
“stable” means there are 1.10.x-based applications running in production
for quite a while without known crashes, incorrect results or other
showstopper bugs.
This release resolves roughly 7 issues since the 1.10.7 version. There
may be bugs in less common areas. If you find any, feel free to report
an issue at GitHub.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol. Please
upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Functionality added or changed
Module API
Exposed the box region, key_def and several other functions in order
to implement external tuple.keydef and tuple.merger modules on top of
them (gh-5273, gh-5384).
Bugs fixed
Core
Fixed fibers switch-over to prevent JIT machinery misbehavior. Trace
recording is aborted when fiber yields the execution. The yield
occurring while the compiled code is being run (it’s likely a
function with a yield underneath called via LuaJIT FFI) leads to the
platform panic (gh-1700, gh-4491).
Fixed fibers switch-over to prevent implicit GC disabling. The yield
occurring while user-defined __gc metamethod is running leads to the
platform panic.
Lua
Fixed unhandled Lua error that might lead to memory leaks and
inconsistencies in <space_object>:frommap(),
<key_def_object>:compare(), <merge_source>:select()
(gh-5382).
LuaJIT
Fixed the error occurring on loading luajit-gdb.py with Python2
(gh-4828).
Misc
Fixed potential lag on boot up procedure when system’s password
database is slow in access (gh-5034).
Module API
Get rid of typedef redefinitions for compatibility with C99
(gh-5313).
1.10.7 is the next stable release of the 1.10.x series. The label
“stable” means there are 1.10.x-based applications running in production
for quite a while without known crashes, incorrect results or other
showstopper bugs.
This release resolves roughly 14 issues since 1.10.6. There may be bugs
in less common areas. If you find any, feel free to report an issue at
GitHub.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol. Please
upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
1.10.6 is the next stable release of the 1.10.x series. The label
“stable” means there are 1.10.x-based applications running in production
for quite a while without known crashes, incorrect results or other
showstopper bugs.
This release resolves roughly 20 issues since 1.10.5. There may be bugs
in less common areas. If you find any, feel free to report an issue at
GitHub.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol. Please
upgrade using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Bugs fixed
Core
fiber.storage is cleaned between requests, and can be used as a
request-local storage. Previously fiber.storage could contain
some old values in the beginning of an iproto request execution, and
it needed to be nullified manually. Now the cleanup is unneeded
(gh-4662).
tuple/space/index:update()/upsert() were fixed
not to turn a value into an infinity when a float value was added to
or subtracted from a float column and exceeded the float value range
(gh-4701).
Make RTREE indexes handle the out of memory error: before this fix,
OOM during the recovery of an RTREE index resulted in segmentation
fault (gh-4619).
Add cancellation guard to avoid WAL thread stuck (gh-4127).
Replication
Fix the rebootstrap procedure not working if the replica itself is
listed in box.cfg.replication (gh-4759).
Fix possible user password leaking via replication logs
(gh-4493).
Local space operations are now counted in 0th vclock component. Every
instance may have its own 0-th vclock component not matching others’.
Local space operations are not replicated at all, even as NOPs
(gh-4114).
Gc consumers are now ordered by their vclocks and not by vclock
signatures. Only the WALS that contain no entries needed by any of
the consumers are deleted (gh-4114).
Lua
json: :decode() doesn’t spoil instance’s options with per-call
ones (when it is called with the second argument) (gh-4761).
os.environ() is now changed when os.setenv() is called
(gh-4733).
netbox.self:call/eval() now returns the same types as
netbox_connection:call/eval. Previously it could return a
tuple or box.error cdata (gh-4513).
libev: backport fix for listening for more then 1024 file descriptors
on Mac OS (gh-3867).
HTTP client
When building Tarantool with bundled libcurl, link it with the
c-ares library by default (gh-4591).
LuaJIT
__pairs/__ipairs metamethods handling is removed since we
faced the issues with the backward compatibility between Lua 5.1 and
Lua 5.2 within Tarantool modules as well as other third party code
(gh-4770).
Introduce luajit-gdb.py extension with commands for inspecting
LuaJIT internals. The extension obliges one to provide gdbinfo for
libluajit, otherwise loading fails. The extension provides the
following commands:
lj-arch dumps values of LJ_64 and LJ_GC64 macro definitions
lj-tv dumps the type and GCobj info related to the given
TValue
lj-str dumps the contents of the given GCstr
lj-tab dumps the contents of the given GCtab
lj-stack dumps Lua stack of the given lua_State
lj-state shows current VM, GC and JIT states
lj-gc shows current GC stats
Fix string to number conversion: current implementation respects the
buffer length (gh-4773).
“FFI sandwich”(*) detection is introduced. If sandwich is detected
while trace recording the recording is aborted. The sandwich detected
while mcode execution leads to the platform panic.
luaJIT_setmode call is prohibited while mcode execution and leads to
the platform panic.
(*) The following stack mix is called FFI sandwich:
Lua-FFI -> C routine -> Lua-C API -> Lua VM
This sort of re-entrancy is explicitly not supported by LuaJIT compiler.
For more info see (gh-4427).
Vinyl
Fix assertion fault due to triggered dump process during secondary
index build (gh-4810).
Misc
Fix crashes at attempts to use -e and -l command line options
concatenated with their values, like this: -eprint(100)
(gh-4775).
Update libopenssl version to 1.1.1f since the previous one was
EOLed (gh-4830).
Building from sources
Fix static build (-DBUILD_STATIC=ON) when libunwind depends
on liblzma (gh-4551).
1.10.5 is the next stable release of the 1.10.x series. The label
“stable” means there are 1.10.x-based applications running in production
for quite a while without known crashes, incorrect results or other
showstopper bugs.
This release resolves roughly 30 issues since 1.10.4. There may be bugs
in less common areas. If you find any, feel free to report an issue at
GitHub.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary
data layout, client-server protocol and replication protocol. Please
upgrade
using the box.schema.upgrade() procedure to unlock all the new
features of the 1.10.x series.
Functionality added or changed
Lua
Exit gracefully when a main script throws an error: notify systemd,
log the error (gh-4382).
Enable __pairs and __ipairs metamethods from Lua 5.2
(gh-4560). We still conform Lua 5.1 API that is not always
compatible with Lua 5.2. The change is only about those metamethods.
Misc
Add package builds and deployment for the following Linux distros:
fiber: make sure the guard page is created; refuse to create a new
fiber otherwise (gh-4541). It is possible in case of heavy
memory usage, say, when there is no resources to split VMAs.
Forbid 00000000-0000-0000-0000-000000000000 as the value of
box.cfg({<...>}) options: replicaset_uuid and
instance_uuid (gh-4282). It did not work as expected:
the nil UUID was treated as absence of the value.
Update cache of universe privileges without reconnect (gh-2763).
net.box: don’t fire the on_connect trigger on schema update
(gh-4593). Also don’t fire the on_disconnect trigger
if a connection never entered into the active state
(e.g. when the first schema fetch is failed).
func: fix use-after-free on function unload.
fce9cf96
Don’t destroy a session until box.session.on_disconnect(<...>)
triggers are finished (gh-4627). This means, for example, that
box.session.id() can be safely invoked from the on_disconnect
trigger. Before this change box.session.id() returned garbage
(usually 0) after yield in the on_disconnect trigger. Note:
tarantool/queue module is
affected by this problem in some
scenarios. It is
especially suggested to update Tarantool at least to this release if
you’re using this module.
Handle OOM gracefully during allocating a buffer for binary protocol
response.
5c5a4e2d
func: Fix box.schema.func.drop(<..>) to unload unused modules
(gh-4648). Also fix box.schema.func.create(<..>)
to avoid loading a module again when another function from the module is loaded.
Encode Lua number -2^63 as integer in msgpack.encode() and box’s
functions (gh-4672).
Replication
Prefer to bootstrap a replica from a fully bootstrapped instance
rather than from an instance that is in the process of bootstrapping
(gh-4527).
This change enables the case when two nodes (B, C) are being
bootstrapped simultaneously using the one that is already
bootstrapped (A), while A is configured to replicate from {B, C} and
B – from {A, C}.
Return immediately from box.cfg{<...>} when an instance is
reconfigured with replication_connect_quorum=0
(gh-3760).
This change also fixes the behaviour of reconfiguration with non-zero
replication_connect_quorum: box.cfg{<...>} returns
immediately regardless of whether connections to upstreams are
established.
Auto reconnect a replica if password is invalid (gh-4550).
Use empty password when a URI in box.cfg{replication=<...>} is
like login@host:port (gh-4605).
This behaviour matches the net.box’s one now.
Explicit login:@host:port was necessary
before, otherwise a replica displayed the following error:
Apply replication settings of box.cfg({<...>}) in the strict
order (gh-4433).
Lua
Fix handling of a socket read error in the console client
(console.connect(<URI>) or tarantoolctlconnect/enter<...>).
1f86e6cc
Handle the “not enough memory” error gracefully when it is raised
from lua_newthread() (gh-4556). There are several cases
when a new Lua thread is created:
Start executing a Lua function call or an eval request (from a
binary protocol, SQL or with box.func.<...>:call()).
Create of a new fiber.
Start execution of a trigger.
Start of encoding into a YAML format (yaml.encode()).
Fix stack-use-after-scope in json.decode() (gh-4637).
Allow to use cdata<structibuf*> (e.g. buffer.IBUF_SHARED) as
the argument to msgpack.encode().
6d38f0c5
Before this change the cdata<structibuf> type was allowed, but
not the corresponding pointer type.
A pointer returned by msgpack.decode*(cdata<[char]const*>)
functions can be assigned to buffer.rpos now (and the same for
msgpackffi) (gh-3926).
All those functions now return
cdata<char*> or cdata<constchar*> depending of a passed
argument. Example of the code that did not work:
res,buf.rpos=msgpack.decode(buf.rpos,buf:size()).
Fix race in fio.mktree() when two tarantool processes create the
same directory tree simultaneously (gh-4660). This problem affects
tarantool/cartrige, see
cartrige#gh-382.
HTTP client
Disable verbose mode when {verbose=false} is passed.
28f8a5eb
Fix assertion fail after a curl write error (gh-4232).
LuaJIT
Fix the “Data segment size exceeds process limit” error on
FreeBSD/x64: do not change resource limits when it is not necessary
(gh-4537).
fold: keep type of emitted CONV in sync with its mode.
LuaJIT#524 This
fixes the following assertion fail:
Fix CLI boolean options handling in tarantoolctlcat<...>, such
as --show-system (gh-4076).
Fix segfault (out of bounds access) when a stack unwinding error
occurs at backtrace printing (gh-4636). Backtrace is printed
on SIGFPE and SIGSEGV signals or when LuaJIT finds itself in the unrecoverable
state (lua_atpanic()).
1.10.4 is the next stable (lts) release in the 1.10 series.
The label ‘stable’ means we have had systems running in production without known crashes,
bad results or other showstopper bugs for quite a while now.
This release resolves about 50 issues since 1.10.3.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary data layout,
client-server protocol and replication protocol.
Please upgrade using the box.schema.upgrade()
procedure to unlock all the new features of the 1.10.x series when migrating
from 1.9 version.
Functionality added or changed
(Engines) Improve dump start/stop logging. When initiating memory dump, print
how much memory is going to be dumped, expected dump rate, ETA, and the recent
write rate. Upon dump completion, print observed dump rate in addition to dump
size and duration.
(Engines) Look up key in reader thread. If a key isn’t found in the tuple cache,
we fetch it from a run file. In this case disk read and page decompression is
done by a reader thread, however key lookup in the fetched page is still
performed by the TX thread. Since pages are immutable, this could as well
be done by the reader thread, which would allow us to save some precious CPU
cycles for TX
(gh-4257).
(Lua) Add debug.sourcefile() and debug.sourcedir() helpers
(and debug.__file__ and debug.__dir__shortcuts) to determine
the location of a current Lua source file.
Part of (gh-4193).
(HTTP client) Add max_total_connections option in addition to
max_connections to allow more fine-grained tuning of libcurl
connection cache. Don’t restrict the total connections` with a constant value
by default, but use libcurl’s default, which scales the threshold according
to easy handles count
(gh-3945).
Bugs fixed
(Vinyl) Fix assertion failure in vy_tx_handle_deferred_delete
1.10.3 is the next stable (lts) release in the 1.10 series.
The label ‘stable’ means we have had systems running in production without known crashes,
bad results or other showstopper bugs for quite a while now.
This release resolves 69 issues since 1.10.2.
Compatibility
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary data layout, client-server protocol and replication protocol.
Please upgrade using the box.schema.upgrade() procedure to unlock all the new features of the 1.10.x series when migrating from 1.9 version.
This is the first stable (lts) release in the 1.10
series.
Also, Tarantool 1.10.2 is a major release that deprecates Tarantool 1.9.2.
It resolves 95 issues since 1.9.2.
Tarantool 1.10.x is backward compatible with Tarantool 1.9.x in binary data
layout, client-server protocol and replication protocol.
You can upgrade using the box.schema.upgrade()
procedure.
The goal of this release is to significantly increase vinyl stability and
introduce automatic rebootstrap of a Tarantool replica set.
Functionality added or changed:
(Engines) support ALTER for non-empty vinyl spaces
(gh-1653).
(Engines) tuples stored in the vinyl cache are not shared among the indexes
of the same space
(gh-3478).
(Engines) keep a stack of UPSERTS in vy_read_iterator
(gh-1833).
(Engines) box.ctl.reset_stat(), a function to reset vinyl statistics
(gh-3198).
(Server) a way to detect that a Tarantool process was
started / restarted by tarantoolctl
(TARANTOOLCTL and TARANTOOL_RESTARTED
env vars)
(gh-3384,
gh-3215).
(Server) net_msg_max
configuration parameter to restrict the number of allocated fibers
(gh-3320).
This is the successor of the 1.7.6 stable release.
The goal of this release is increased maturity of vinyl and master-master replication,
and it contributes a number of features to this cause. Please follow the download
instructions at https://tarantool.io/en/download/download.html to download and install
a package for your operating system.
(Security) new function box.session.euid() to return effective user.
Effective user can be different from authenticated user in case of setuid
functions or box.session.su.
(gh-2994).
(Security) new super role, with superuser access. Grant ‘super’ to guest to
disable access control.
(gh-3022).
(Security) on_auth trigger is now fired in case of both successful and
failed authentication.
(gh-3039).
(Replication/recovery) new replication configuration algorithm: if replication
doesn’t connect to replication_quorum peers in replication_connect_timeout
seconds, the server start continues but the server enters the new orphan status,
which is basically read-only, until the replicas connect to each other.
(gh-3151 and
gh-2958).
(Replication/recovery) after replication connect at startup, the server does
not start processing write requests before
syncing up syncing up with all connected peers.
(Replication/recovery) box.once() no longer fails on a read-only replica
but waits.
(gh-2537).
(Replication/recovery) force_recovery can now skip a corrupted xlog file.
(gh-3076).
(Replication/recovery) improved replication monitoring: box.info.replication
shows peer ip:port and correct replication lag even for idle peers.
(gh-2753 and
gh-2689).
(Application server) new before triggers which can be used for conflict
resolution in master-master replication.
(gh-2993).
(Application server) http client now correctly parses cookies and supports
http+unix:// paths.
(gh-3040 and
gh-2801).
(Application server) fio rock now supports file_exists(),
rename() works across filesystems, and read() without arguments
reads the whole file.
(gh-2924,
gh-2751 and
gh-2925).
(Application server) fio rock errors now follow Tarantool function call
conventions and always return an error message in addition to the error flag.
(Application server) digest rock now supports pbkdf2 password hashing
algorithm, useful in PCI/DSS compliant applications.
(gh-2874).
(Application server) box.info.memory() provides a high-level overview of
server memory usage, including networking, Lua, transaction and index memory.
(gh-934).
(Database) it is now possible to add missing tuple fields to an index,
which is very useful when adding an index along with the evolution of the
database schema.
gh-2988).
(Database) lots of improvements in field type support when creating or
altering spaces and indexes.
(gh-2893,
gh-3011 and
gh-3008).
(Database) it is now possible to turn on is_nullable property on a field
even if the space is not empty, the change is instantaneous.
(gh-2973).
This is an alpha release which delivers support for a substantial subset
of the ISO/IEC 9075:2011 SQL standard, including joins, subqueries and views.
SQL is a major feature of the 1.8 release series, in which we plan to add
support for ODBC and JDBC connectors, SQL triggers, prepared statements,
security and roles,
and generally ensure SQL is a first class query language in Tarantool.
Functionality added or changed:
A new function box.sql.execute() (later changed to box.execute
in Tarantool 2.1) was added to query Tarantool databases
using SQL statements, e.g.:
tarantool> box.sql.execute([[SELECT * FROM _schema]]);
SQL and Lua are fully interoperable.
New meta-commands introduced to Tarantool’s console.
You can now set input language to either SQL or Lua, e.g.:
tarantool> \set language sql
tarantool> SELECT * FROM _schema
tarantool> \set language lua
tarantool> print("Hello, world!")
Layout of box.space._index has been extended to support
is_nullable
and collation features.
All new indexes created on columns with is_nullable or collation
properties will have the new definition format.
Please update your client libraries if you plan to use these new features
(gh-2802).
fiber_name() now raises an exception instead of truncating long fiber names.
We found that some Lua modules such as expirationd use fiber.name()
as a key to identify background tasks. If a name is truncated, this fact was
silently missed. The new behavior allows to detect bugs caused by fiber.name()
truncation. Please use fiber.name(name,{truncate=true}) to emulate
the old behavior
(gh-2622).
space:format() is now validated on DML operations.
Previously space:format() was only used by client libraries, but starting
from Tarantool 1.7.6, field types in space:format() are validated on the
server side on every DML operation, and field names can be used in indexes
and Lua code. If you used space:format() in a non-standard way,
please update layout and type names according to the official documentation for
space formats.
Functionality added or changed:
Hybrid schema-less + schemaful data model.
Earlier Tarantool versions allowed to store arbitrary MessagePack documents in spaces.
Starting from Tarantool 1.7.6, you can use
space:format() to define schema restrictions and constraints
for tuples in spaces. Defined field types are automatically validated on every DML operation,
and defined field names can be used instead of field numbers in Lua code.
A new function tuple:tomap() was added to convert a tuple into a key-value Lua dictionary.
NULL values in unique and non-unique indexes.
By default, all fields in Tarantool are “NOT NULL”.
Starting from Tarantool 1.7.6, you can use
is_nullable option in space:format()
or inside an index part definition
to allow storing NULL in indexes.
Tarantool partially implements
three-valued logic
from the SQL standard and allows storing multiple NULL values in unique indexes
(gh-1557).
Sequences and a new implementation of auto_increment().
Tarantool 1.7.6 introduces new
sequence number generators (like CREATE SEQUENCE in SQL).
This feature is used to implement new persistent auto increment in spaces
(gh-389).
Vinyl: introduced gap locks in Vinyl transaction manager.
The new locking mechanism in Vinyl TX manager reduces the number of conflicts in transactions
(gh-2671).
Partial emulation of LuaSocket on top of Tarantool Socket
(gh-2727).
Developer tools:
Integration with IntelliJ IDEA with debugging support.
Now you can use IntelliJ IDEA as an IDE to develop and debug Lua applications for Tarantool.
See Using IDE.
Release type: stable. Release date: 2017-08-22. Tag: 1.7.5.
Release: doc-289
or v. 1.7.5.
This is a stable release in the 1.7 series.
This release resolves more than 160 issues since 1.7.4.
Functionality added or changed:
(Vinyl) a new force_recovery
mode to recover broken disk files.
Use box.cfg{force_recovery=true} to recover corrupted data files
after hardware issues or power outages
(gh-2253).
Memtx: stable index:pairs() iterators for the TREE index.
TREE iterators are automatically restored to a proper position after index’s modifications
(gh-1796).
(Memtx) predictable order for non-unique TREE indexes.
Non-unique TREE indexes preserve the sort order for duplicate entries
(gh-2476).
(Memtx+Vinyl) dynamic configuration of max tuple size.
Now box.cfg.memtx_max_tuple_size and box.cfg.vinyl_max_tuple_size
configuration options can be changed on the fly without need to restart the server
(gh-2667).
(Memtx+Vinyl) new implementation.
Space truncation doesn’t cause re-creation of all indexes any more
(gh-618).
Extended the maximal length of all identifiers from 32 to 65k characters.
Space, user and function names are not limited by 32 characters anymore
(gh-944).
Heartbeat messages for replication.
Replication client now sends the selective acknowledgments for processed
records and automatically re-establish stalled connections.
This feature also changes box.info.replication[replica_id].vclock.
to display committed vclock of remote replica
(gh-2484).
Keep track of remote replicas during WAL maintenance.
Replication master now automatically preserves xlogs needed for remote replicas
(gh-748).
Hot code reload for stored C stored procedures.
Use box.schema.func.reload('modulename.function')
to reload dynamic shared libraries on the fly
(gh-910).
Package manager based on LuaRocks.
Use tarantoolctlrocksinstallMODULENAME to install MODULENAME Lua module
from https://rocks.tarantool.org/.
(gh-2067).
Lua 5.1 command line options.
Tarantool binary now supports ‘-i’, ‘-e’, ‘-m’ and ‘-l’ command line options
(gh-1265).
Experimental GC64 mode for LuaJIT.
GC64 mode allow to operate the full address space on 64-bit hosts.
Enable via -DLUAJIT_ENABLE_GC64=ONcompile-time configuration option
(gh-2643).
Stack traces now contain symbols names on all supported platforms.
Previous versions of Tarantool didn’t display meaningful function names in
fiber.info() on non-x86 platforms
(gh-2103).
Allowed to create fiber with custom stack size from C API
(gh-2438).
This is a release candidate in the 1.7 series.
Vinyl Engine, the flagship feature of 1.7.x, is now feature complete.
Incompatible changes
box.cfg() options were changed to add Vinyl support:
snap_dir renamed to memtx_dir
slab_alloc_arena (gigabytes) renamed to memtx_memory (bytes),
default value changed from 1Gb to 256MB
slab_alloc_minimal renamed to memtx_min_tuple_size
slab_alloc_maximal renamed to memtx_max_tuple_size
slab_alloc_factor is deprecated, not relevant in 1.7.x
snapshot_count renamed to checkpoint_count
snapshot_period renamed to checkpoint_interval
logger renamed to log
logger_nonblock renamed to log_nonblock
logger_level renamed to log_level
replication_source renamed to replication
panic_on_snap_error=true and panic_on_wal_error=true
superseded by force_recovery=false
Until Tarantool 1.8, you can use deprecated parameters for both
initial and runtime configuration, but such usage will print
a warning in the server log
(gh-1927 and
gh-2042).
Hot standy mode is now off by default. Tarantool automatically detects
another running instance in the same wal_dir and refuses to start.
Use box.cfg{hot_standby=true} to enable the hot standby mode
(gh-775).
UPSERT via a secondary key was banned to avoid unclear semantics
(gh-2226).
box.info and box.info.replication format was changed to display
information about upstream and downstream connections
((gh-723):
Added box.info.replication[instance_id].downstream.vclock to display
the last sent row to remote replica.
Added box.info.replication[instance_id].id.
Added box.info.replication[instance_id].lsn.
Moved box.info.replication[instance_id].{vclock,status,error} to
box.info.replication[instance_id].upstream.{vclock,status,error}.
All registered replicas from box.space._cluster are included to
box.info.replication output.
box.info.server.id renamed box.info.id
box.info.server.lsn renamed box.info.lsn
box.info.server.uuid renamed box.info.uuid
box.info.cluster.signature renamed to box.info.signature
box.info.id and box.info.lsn now return nil instead of -1
during initial cluster bootstrap.
net.box: added per-request options to all requests:
conn.call(func_name,arg1,arg2,...) changed to
conn.call(func_name,{arg1,arg2,...},opts)
conn.eval(func_name,arg1,arg2,...) changed to
conn.eval(func_name,{arg1,arg2,...},opts)
All requests now support timeout=<seconds>, buffer=<ibuf> options.
Added connect_timeout option to netbox.connect().
netbox:timeout() and conn:timeout() are now deprecated.
Use netbox.connect(host,port,{call_16=true}) for
1.6.x-compatible behavior
(gh-2195).
systemd configuration changed to support Type=Notify / sd_notify().
Now systemctlstarttarantool@INSTANCE will wait until Tarantool
has started and recovered from xlogs. The recovery status is reported to
systemctlstatustarantool@INSTANCE
(gh-1923).
log module now doesn’t prefix all messages with the full path to
tarantool binary when used without box.cfg()
(gh-1876).
require('log').logger_pid() was renamed to require('log').pid()
(gh-2917).
Removed Lua 5.0 compatible defines and functions
(gh-2396):
luaL_reg removed in favor of luaL_Reg
luaL_getn(L,i) removed in favor of lua_objlen(L,i)
luaL_setn(L,i,j) removed (was no-op)
lua_ref(L,lock) removed in favor of luaL_ref(L,lock)
lua_getref(L,ref) removed in favor of lua_rawgeti(L,LUA_REGISTRYINDEX,(ref))
lua_unref(L,ref) removed in favor of luaL_unref(L,ref)
math.mod() removed in favor of math.fmod()
string.gfind() removed in favor of string.gmatch()
Functionality added or changed:
(Vinyl) multi-level compaction.
The compaction scheduler now groups runs of the same range into levels to
reduce the write amplification during compaction. This design allows Vinyl
to support 1:100+ ram:disk use-cases
(gh-1821).
(Vinyl) bloom filters for sorted runs.
Bloom filter is a probabilistic data structure which can be used to test
whether a requested key is present in a run file without reading the actual
file from the disk. Bloom filter may have false-positive matches but
false-negative matches are impossible. This feature reduces the number
of seeks needed for random lookups and speeds up REPLACE/DELETE with
enabled secondary keys
(gh-1919).
(Vinyl) key-level cache for point lookups and range queries.
Vinyl storage engine caches selected keys and key ranges instead of
entire disk pages like in traditional databases. This approach is more
efficient because the cache is not polluted with raw disk data
(gh-1692).
(Vinyl) implemented`).
Now all in-memory indexes of a space store pointers to the same tuples
instead of cached secondary key index data. This feature significantly
reduces the memory footprint in case of secondary keys
(gh-1908).
(Vinyl) new implementation of initial state transfer of JOIN command in
replication protocol. New replication protocol fixes problems with
consistency and secondary keys. We implemented a special kind of low-cost
database-wide read-view to avoid dirty reads in JOIN procedure. This trick
wasn’t not possible in traditional B-Tree based databases
(gh-2001).
(Vinyl) index-wide mems/runs.
Removed ranges from in-memory and and the stop layer of LSM tree on disk
(gh-2209).
(Vinyl) coalesce small ranges.
Before dumping or compacting a range, consider coalescing it with its
neighbors
(gh-1735).
(Vinyl) implemented transnational journal for metadata.
Now information about all Vinyl files is logged in a special .vylog file
(gh-1967).
(Memtx+Vinyl) implemented low-level Lua API to create consistent backups.
of Memtx + Vinyl data. The new feature provides box.backup.start()/stop()
functions to create backups of all spaces.
box.backup.start() pauses the
Tarantool garbage collector and returns the list of files to copy. These files then
can be copied be any third-party tool, like cp, ln, tar, rsync, etc.
box.backup.stop() lets the garbage collector continue.
Created backups can be restored instantly by copying into a new directory
and starting a new Tarantool instance. No special preparation, conversion
or unpacking is needed
(gh-1916).
(Vinyl) added statistics for background workers to box.info.vinyl()
(gh-2005).
(Memtx+Vinyl) reduced the memory footprint for indexes which keys are
sequential and start from the first field. This optimization was necessary
for secondary keys in Vinyl, but we optimized Memtx as well
(gh-2046).
LuaJIT was rebased on the latest 2.1.0b3 with out patches
(gh-2396):
Added JIT compiler backend for ARM64
Added JIT compiler backend and interpreter for MIPS64
Added some more Lua 5.2 and Lua 5.3 extensions
Fixed several bugs
Removed Lua 5.0 legacy (see incompatible changes above).
Enabled a new smart string hashing algorithm in LuaJIT to avoid significant
slowdown when a lot of collisions are generated.
Contributed by Yury Sokolov (@funny-falcon) and Nick Zavaritsky (@mejedi).
See https://github.com/tarantool/luajit/pull/2.
box.snapshot() now updates mtime of a snapshot file if there were no
changes to the database since the last snapshot.
(gh-2045).
Implemented space:bsize() to return the memory size utilized by all
tuples of the space.
Contributed by Roman Tokarev (@rtokarev).
(gh-2043).
This is the second beta release in the 1.7 series.
Incompatible changes:
Broken coredump() Lua function was removed.
Use gdb-batch-ex"generate-core-file"-p$PID instead
(gh-1886).
Vinyl disk layout was changed since 1.7.2 to add ZStandard compression and improve
the performance of secondary keys.
Use the replication mechanism to upgrade from 1.7.2 beta
(gh-1656).
Functionality added or changed:
Substantial progress on stabilizing the Vinyl storage engine:
Fix most known crashes and bugs with bad results.
Switch to use XLOG/SNAP format for all data files.
Enable ZStandard compression for all data files.
Squash UPSERT operations on the fly and merge hot keys using a
background fiber.
Significantly improve the performance of index:pairs() and index:count().
Remove unnecessary conflicts from transactions.
In-memory level was mostly replaced by memtx data structures.
Specialized allocators are used in most places.
We’re still actively working on Vinyl and plan to add multi-level
compaction and improve the performance of secondary keys in 1.7.4.
This implies a data format change.
Support for DML requests for space:on_replace() triggers
(gh-587).
UPSERT can be used with the empty list of operations
(gh-1854).
Lua functions to manipulate environment variables
(gh-1718).
Lua library to read Tarantool snapshots and xlogs
(gh-1782).
New play and cat commands in tarantoolctl
(gh-1861).
Improve support for the large number of active network clients.
Issue#5#1892.
Support for space:pairs(key,iterator-type) syntax
(gh-1875).
Automatic cluster bootstrap now also works without authorization
(gh-1589).
Replication retries to connect to master indefinitely
(gh-1511).
Temporary spaces now work with box.cfg{read_only=true}
(gh-1378).
The maximum length of space names increased to 64 bytes (was 32)
(gh-2008).
A new binary protocol command for CALL, which no more restricts a function
to returning an array of tuples and allows returning an arbitrary MsgPack/JSON
result, including scalars, nil and void (nothing).
The old CALL is left intact for backward compatibility. It will be removed
in the next major release. All programming language drivers will be gradually
changed to use the new CALL
(gh-1296).
Functionality added or changed:
Vinyl storage engine finally reached the beta stage.
This release fixes more than 90 bugs in Vinyl, in particular, removing
unpredictable latency spikes, all known crashes and bad/lost result bugs.
new cooperative multitasking based architecture to eliminate latency spikes,
support for non-sequential multi-part keys,
support for secondary keys,
support for auto_increment(),
number, integer, scalar field types in indexes,
INSERT, REPLACE and UPDATE return new tuple, like in memtx.
We’re still actively working on Vinyl and plan to add zstd compression
and a new memory allocator for Vinyl in-memory index in 1.7.3.
This implies a data format change which we plan to implement before 1.7
becomes generally available.
Tab-based autocompletion in the interactive console,
require('console').connect(), tarantoolctlenter and
tarantoolctlconnect commands
(gh-86 and
gh-1790).
Use the TAB key to auto complete the names of Lua variables, functions
and meta-methods.
A new implementation of net.box improving performance and solving problems
when the Lua garbage collector handles dead connections
(gh-799,
gh-800,
gh-1138 and
gh-1750).
memtx snapshots and xlog files are now compressed on the fly using the fast
ZStandard compression algorithm.
Compression options are configured automatically to get an optimal trade-off
between CPU utilization and disk throughput.
fiber.cond() - a new synchronization mechanism for cooperative multitasking
(gh-1731).
Tarantool can now be installed using universal Snappy packages
(http://snapcraft.io/) with snapinstalltarantool--channel=beta.
Debian and Ubuntu packages start a ready-to-use example.lua instance on
a clean installation of the package.
The default instance grants universe permissions for guest user and listens
on “localhost:3313”.
This is the first alpha in the 1.7 series.
The main feature of this release is a new storage engine, called “vinyl”.
Vinyl is a write optimized storage engine, allowing the amount
of data stored exceed the amount of available RAM 10-100x times.
Vinyl is a continuation of the Sophia engine from 1.6, and
effectively a fork and a distant relative of Dmitry Simonenko’s
Sophia. Sophia is superseded and replaced by Vinyl.
Internally it is organized as a log structured merge tree.
However, it takes a serious effort to improve on the traditional
deficiencies of log structured storage, such as poor read performance
and unpredictable write latency. A single index
is range partitioned among many LSM data structures, each having its
own in-memory buffers of adjustable size. Range partitioning allows
merges of LSM levels to be more granular, as well as to prioritize
hot ranges over cold ones in access to resources, such as RAM and
I/O. The merge scheduler is designed to minimize write latency
while ensuring read performance stays within acceptable limits.
Vinyl today only supports a primary key index. The index
can consist of up to 256 parts, like in MemTX, up from 8 in
Sophia. Partial key reads are supported.
Support of non-sequential multi part keys, as well as secondary keys
is on the short term todo.
Our intent is to remove all limitations currently present in
Vinyl, making it a first class citizen in Tarantool.
Functionality added or changed:
The disk-based storage engine, which was called sophia or phia
in earlier versions, is superseded by the vinyl storage engine.
There are new types for indexed fields.
The LuaJIT version is updated.
Automatic replica set bootstrap (for easier configuration of a new replica set)
is supported.
The space_object:inc() function is removed.
The space_object:dec() function is removed.
The space_object:bsize() function is added.
The box.coredump() function is removed, for an alternative see
Core dumps.
The hot_standby configuration option is added.
Configuration parameters revised or renamed:
slab_alloc_arena (in gigabytes) to memtx_memory (in bytes),
slab_alloc_minimal to memtx_min_tuple_size,
slab_alloc_maximal to memtx_max_tuple_size,
replication_source to replication,
snap_dir to memtx_dir,
logger to log,
logger_nonblock to log_nonblock,
snapshot_count to checkpoint_count,
snapshot_period to checkpoint_interval,
panic_on_wal_error and panic_on_snap_error united under force_recovery.
Until Tarantool 1.8, you can use deprecated parameters
for both initial and runtime configuration, but Tarantool will display a warning.
Also, you can specify both deprecated and up-to-date parameters, provided
that their values are harmonized. If not, Tarantool will display an error.
Automatic replication cluster bootstrap; it’s now much
easier to configure a new replication cluster.
Since February 15, 2017, due to Tarantool issue (gh-2040)
there no longer is a storage engine named sophia.
It will be superseded in version 1.7 by the vinyl storage engine.
Incompatible changes:
Support for SHA-0 (digest.sha()) was removed due to OpenSSL upgrade.
Tarantool binary now dynamically links with libssl.so during compile time
instead of loading it at the run time.
Fedora 22 packages were deprecated (EOL).
Functionality added or changed:
Tab-based autocompletion in the interactive console
(gh-86).
LUA_PATH and LUA_CPATH environment variables taken into account,
like in PUC-RIO Lua (gh-1428).
Search for .dylib as well as for .so libraries in OS X
(gh-810).
A new box.cfg{read_only=true} option to emulate master-slave
behavior (gh-246).
if_not_exists=true option added to box.schema.user.grant
(gh-1683).
clock_realtime()/monotonic() functions added to the public C API
(gh-1455).
space:count(key,opts) introduced as an alias for
space.index.primary:count(key,opts)
(gh-1391).
Upgrade script for 1.6.4 -> 1.6.8 -> 1.6.9
(gh-1281).
RPM packages for CentOS 7 / RHEL 7 and Fedora 22+ now use native systemd
configuration without legacy sysvinit shell scripts. Systemd provides its own
facilities for multi-instance management. To upgrade, perform the
following steps:
Ensure that INSTANCENAME.lua file is present in /etc/tarantool/instances.available.
Stop INSTANCENAME using tarantoolctlstopINSTANCENAME.
Start INSTANCENAME using systemctlstarttarantool@INSTANCENAME.
Enable INSTANCENAME during system boot using systemctlenabletarantool@INTANCENAME.
/etc/tarantool/instance.enabled directory is now deprecated for systemd-enabled platforms.
Sophia was upgraded to v2.1 to fix upsert, memory corruption and other bugs.
Sophia v2.1 doesn’t support old v1.1 data format. Please use Tarantool
replication to upgrade
(gh-1222).
Ubuntu Vivid, Fedora 20, Fedora 21 were deprecated due to EOL.
i686 packages were deprecated. Please use our RPM and DEB specs to build
these on your own infrastructure.
Tarantool 1.6.8 fully supports ARMv7 and ARMv8 (aarch64) processors.
Now it is possible to use Tarantool on a wide range of consumer devices,
starting from popular Raspberry PI 2 to coin-size embedded boards and
no-name mini-micro-nano-PCs
(gh-1153).
(Also qemu works well, but we don’t have real hardware to check.)
Tuple comparator functions were optimized, providing up to 30% performance
boost when an index key consists of 2, 3 or more parts
(gh-969).
Tuple allocator changes give another 15% performance improvement
(gh-1298).
Replication relay performance was improved by reducing the amount of data
directory re-scans
(gh-1150).
A random delay was introduced into snapshot daemon, reducing the chance
that multiple instances take a snapshot at the same time
(gh-732).
Sophia storage engine was upgraded to v2.1:
serializable Snapshot Isolation (SSI),
RAM storage mode,
anti-cache storage mode,
persistent caching storage mode,
implemented AMQ Filter,
LRU mode,
separate compression for hot and cold data,
snapshot implementation for Faster Recovery,
upsert reorganizations and fixes,
new performance metrics.
Please note “Incompatible changes” above.
Allow to remove servers with non-zero LSN from _cluster space
(gh-1219).
net.box now automatically reloads space and index definitions
(gh-1183).
The maximal number of indexes in space was increased to 128
(gh-1311).
New native systemd configuration with support of instance management
and daemon supervision (CentOS 7 and Fedora 22+ only).
Please note “Incompatible changes” above
(gh-1264).
Clang compiler support was added on FreeBSD.
(gh-786).
Support for musl libc, used by Alpine Linux and Docker images, was added
(gh-1249).
Added support for GCC 6.0.
Ubuntu Wily, Xenial and Fedora 22, 23 and 24 are now supported
distributions for which we build official packages.
box.info.cluster.uuid can be used to retrieve cluster UUID
(gh-1117).
Numerous improvements in the documentation, added documentation
for syslog, clock, fiber.storage packages, updated
the built-in tutorial.
New rocks and packages:
Tarantool switched to a new Docker-based cloud build infrastructure
The new buildbot significantly decreases commit-to-package time.
The official repositories at http://tarantool.org now
contain the latest version of the server, rocks and connectors.
See http://github.com/tarantool/build
memcached - memcached text and binary protocol implementation for Tarantool.
Turns Tarantool into a persistent memcached with master-master replication.
See https://github.com/tarantool/memcached
The syntax of upsert command has been changed
and an extra key argument was removed from it. The primary
key for look up is now always taken from the tuple, which is the
second argument of upsert. upsert() was added fairly late at
a release cycle and the design had an obvious bug which we had
to fix. Sorry for this.
fiber.channel.broadcast() was removed since it wasn’t used by
anyone and didn’t work properly.
tarantoolctl reload command renamed to eval.
Functionality added or changed:
logger option now accepts a syntax for syslog output. Use uri-style
syntax for file, pipe or syslog log destination.
replication_source now accepts an array of URIs,
so each replica can have up to 30 peers.
RTREE index now accept two types of distance functions:
euclid and manhattan.
fio.abspath() - a new function in fio rock to convert
a relative path to absolute.
The process title now can be set with an on-board title rock.
This release uses LuaJIT 2.1.
New rocks:
memcached - makes Tarantool understand Memcached binary protocol.
Text protocol support is in progress and will be added to the rock
itself, without changes to the server core.
Release 1.6.6
Release type: maintenance. Release date: 2015-08-28.
Release: v. 1.6.6
Tarantool 1.6 is no longer getting major new features,
although it will be maintained.
The developers are concentrating on Tarantool version 1.9.
Incompatible changes:
A new schema of _index system space which accommodates
multi-dimensional RTREE indexes. Tarantool 1.6.6 works fine
with an old snapshot and system spaces, but you will not
be able to start Tarantool 1.6.5 with a data directory
created by Tarantool 1.6.6, neither will you be able
to query Tarantool 1.6.6 schema with 1.6.5 net.box.
box.info.snapshot_pid is renamed to box.info.snapshot_in_progress
Functionality added or changed:
Threaded architecture for network. Network I/O has finally
been moved to a separate thread, increasing single instance
performance by up to 50%.
Threaded architecture for checkpointing. Tarantool no longer
forks to create a snapshot, but uses a separate thread,
accessing data via a consistent read view.
This eliminates all known latency spikes caused by
snapshotting.
Stored procedures in C/C++. Stored procedures in C/C++
provide speed (3-4 times, compared to a Lua version in
our measurements), as well as unlimited extensibility
power. Since C/C++ procedures run in the same memory
space as the database, they are also an easy tool
to corrupt database memory.
See The C API description.
Multidimensional RTREE index. RTREE index type
now support a large (up to 32) number of dimensions.
RTREE data structure has been optimized to actually use
R*-TREE.
We’re working on further improvements of the index,
in particular, configurable distance function.
See https://github.com/tarantool/tarantool/wiki/R-tree-index-quick-start-and-usage
New upsert command available in the binary protocol
and in stored functions. The key advantage of upsert
is that it’s much faster with write-optimized storage
(sophia storage engine), but some caveats exists as well.
See (gh-905)
for details. Even though upsert performance advantage is most
prominent with sophia engine, it works with all storage engines.
Better memory diagnostics information for fibers, tuple and
index arena. Try a new command box.slab.stats(), for
detailed information about tuple/index slabs, fiber.info() now
displays information about memory used by the fiber.
Update and delete now work using a secondary index, if the
index is unique.
Authentication triggers. Set box.session.on_auth triggers
to catch authentication events. Trigger API is improved
to display all defined triggers, easily remove old triggers.
Manifold performance improvements of net.box built-in package.
Performance optimizations of BITSET index.
panic_on_wal_error is a dynamic configuration option now.
iproto sync field is available in Lua as session.sync().
box.once() - a new method to invoke code once in an
instance and replica set lifetime. Use once() to set
up spaces and uses, as well as do schema upgrade in
production.
box.error.last() to return the last error in a session.
New rocks:
jit.*, jit.dump, jit.util, jit.vmdef modules of LuaJIT 2.0
are now available as built-ins.
See http://luajit.org/ext_jit.html
strict built-in package, banning use of undeclared variables in
Lua. Strict mode is on when Tarantool is compiled with debug.
Turn on/off with require('strict').on()/require('strict').off().
pg and mysql rocks, available at http://rocks.tarantool.org -
working with MySQL and PostgreSQL from Tarantool.
gperftools rock, available at http://rocks.tarantool.org -
getting performance data using Google’s gperf from Tarantool.
csv built-in rock, to parse and load CSV (comma-separated
values) data.
TARANTOOL_BASE_VERSION is the Community version which the Enterprise version is based on.
REVISION is the SDK revision. Besides Tarantool itself, it includes the tt utility, a set of open and closed source modules, and examples. Learn more from Package contents.
Added a readable error for the case when the flight recoder fails
to write data due to insufficient free space on the disk device.
Previously, it was sending a SIGBUS error (gh-196).
Fixed a crash in the flight recorder caused by non-thread-safe log
recording from multiple threads (gh-226).
Fixed a bug in the flight recorder reader implementation that resulted in
a hang or error while trying to open an empty section (gh-187).
r467
Breaking changes
Default audit log format was changed to CSV.
Functionality added or changed
Enterprise
Implemented user-defined audit events. Now it’s possible to log custom
messages to the audit log from Lua (gh-65).
[Breaking change] Switched the default audit log format to CSV. The
format can be switched back to JSON using the new box.cfg.audit_format
configuration option (gh-66).
Implemented the audit log filter. Now, it’s possible to enable logging only
for a subset of all audit events using the new box.cfg.audit_filter
configuration option (gh-67).
Core
Implement constraints and foreign keys. Now a user can create function constraints and foreign key relations
(gh-6436).
Changed log level of some information messages from critical to info
(gh-4675).
Added predefined system events: box.status, box.id, box.election
and box.schema (gh-6260).
Introduced transaction isolation levels in Lua and IPROTO (gh-6930).
Vinyl
Disabled the deferred DELETE optimization in Vinyl to avoid possible
performance degradation of secondary index reads. Now, to enable the
optimization, one has to set the defer_deletes flag in space options
(gh-4501).
Lua
Added support of console autocompletion for net.box objects stream
and future (gh-6305).
Datetime
Parse method to allow converting string literals in extended iso-8601
Added bundling of GNU libunwind to support backtrace feature on
AARCH64 architecture and distributives that don’t provide libunwind
package.
Re-enabled backtrace feature for all RHEL distributions by default, except
for AARCH64 architecture and ancient GCC versions, which lack compiler
features required for backtrace (gh-4611).
Bugs fixed
Enterprise
Disabled audit log unless explicitly configured (gh-39). Before this change,
audit events were written to stderr if box.cfg.audit_log wasn’t set. Now,
audit log is disabled in this case.
Disabled audit logging of replicated events (gh-59). Now, replicated events
(for example, user creation) are logged only on the origin, never on a
replica.
Core
Banned DDL operations in space on_replace triggers, since they could lead
to a crash (gh-6920).
Fixed a bug due to which all fibers created with fiber_attr_setstacksize()
leaked until the thread exit. Their stacks also leaked except when
fiber_set_joinable(...,true) was used.
Fixed a crash in mvcc connected with secondary index conflict (gh-6452).
Fixed a bug which resulted in wrong space count (gh-6421).
Select in RO transaction now reads confirmed data, like a standalone (auotcommit) select does
(gh-6452).
Replication
Fixed potential obsolete data write in synchronious replication
due to race in accessing terms while disk write operation is in
progress and not yet completed.
Fixed replicas failing to bootstrap when master is just re-started (gh-6966).
Lua
Fixed the behavior of tarantool console on SIGINT. Now Ctrl+C discards
the current input and prints the new prompt (gh-2717).
Triggers
Fixed assertion or segfault when MP_EXT received via net.box (gh-6766).
Now ROUND() properly support INTEGER and DECIMAL as the first
argument (gh-6988).
Datetime
Intervals received after datetime arithmetic operations may be improperly
normalized if result was negative
The Tarantool release policy is changing to become more clear and intuitive.
The new policy uses a SemVer-like versioning format,
and introduces a new version lifecycle with more long-time support series.
This document explains the new release policy, versioning rules, and release series lifecycle.
The 2.x.y series since the 2.10.0 release.
Development for this new release starts with version 2.10.0-beta1.
The future 3.0.0 series.
Here are the most significant changes from the legacy release policy:
The third number in the version label doesn’t distinguish between
pre-release (alpha and beta) and release versions.
Instead, it is used for patch (bugfix-only) releases.
Pre-release versions have suffixes, like 3.0.0-alpha1.
In the legacy release policy, 1.10 was a long-term support (LTS) series,
while 2.x.y had stable releases, but wasn’t an LTS series.
Now both series are long-term supported.
The topics below describe the new versioning policy in more detail.
Versioning policy
Release series and versions
The new Tarantool release policy is based on having several release series,
each with its own lifecycle, pre-release and release versions.
Release series
Release series is a sequence of development and production-ready versions
with linear evolution toward a defined roadmap.
A series has a distinct lifecycle and certain compatibility guarantees within itself and with other series.
The intended support time for each series is at least two years since the first release.
Release version
Release version is a Tarantool distribution which is thoroughly tested and ready for production usage.
It is bound to a certain commit.
Release version label consists of three numbers:
MAJOR.MINOR.PATCH
These numbers correspond to the three types of release versions:
Major release
Major release is the first release version of its own
release series.
It introduces new features and can have a few backward-incompatible changes.
Such release changes the first version number:
MAJOR.0.0
3.0.0
Minor release
Minor release introduces a few new features, but guarantees backward compatibility.
There can be a few bugs fixed as well.
Such release changes the second version number:
MAJOR.MINOR.0
3.1.0
3.2.0
Patch release
Patch release fixes bugs from an earlier release, but doesn’t introduce new features.
Such release changes the third version number:
MAJOR.MINOR.PATCH
3.0.1
3.0.2
Release versions conform to a set of requirements:
The release has gone through pre-release testing and adoption
in the internal projects until there were no doubts regarding its stability.
There are no known bugs in the typical usage scenarios.
There are no degradations from the previous release or release series, in case of a major release.
Backwards compatibility is guaranteed between all versions in the same release series.
It is also appreciated, but not guaranteed between different release series (major number changes).
See compatibility guarantees page for details.
Pre-release versions
Pre-release version
Pre-release versions are the ones published for testing and evaluation,
and not intended for production use.
Such versions use the same pattern with an additional suffix:
MAJOR.MINOR.PATCH-suffix
There are a few types of pre-release versions:
Development build
Development builds reflect the state of current development process.
They’re used entirely for development and testing,
and not intended for any external use.
Development builds have suffixes made with $(gitdescribe--always--long)-dev:
Alpha version has some of the features planned in the release series.
It can be incomplete or unstable, and can break the backwards compatibility
with the previous release series.
Alpha versions are published for early adopters and developers of dependent components,
such as connectors and modules.
Beta version has all the features which are planned for the release series.
It is a good choice to start developing a new application.
Readiness of a feature can be checked in a beta version to decide whether to remove the feature,
finish it later, or replace it with something else.
A beta version can still have a known bug in the new functionality,
or a known degradation since the previous release series that affects a common use case.
MAJOR.MINOR.PATCH-betaN
3.0.0-beta1
3.0.0-beta2
Note that the development of 2.10.0, the first release under the new policy,
starts with version 2.10.0-beta1.
Release candidate
Release candidate is used to fix bugs, mature the functionality,
and collect feedback before an upcoming release.
Release candidate has the same feature set as the preceding beta version
and doesn’t have known bugs in typical usage scenarios
or degradations from the previous release series.
Release candidate is a good choice to set up a staging server.
The early development stage goes on until the first major release.
Alpha, beta, and release candidate versions are published at this stage.
The stage splits into two phases:
Development of a new functionality through alpha and beta versions.
Features can be added and, sometimes, removed in this phase.
Stabilization starts with the first release candidate version.
Feature set doesn’t change in this phase.
Support
The stage starts when the first release is published.
The release series now is an object of only backward compatible changes.
At this stage, all known security problems and all found
degradations since the previous series are being fixed.
The series receives degradation fixes and other bugfixes during the support stage
and until the series transitions into the end of life (EOL) stage.
The decision of whether to fix a particular problem in a particular release series
depends on the impact of the problem, risks around backward compatibility, and the
complexity of backporting a fix.
The release series might receive new features at this stage,
but only in a backward compatible manner.
Also, a release candidate may be published to collect feedback before the release version.
During the support period a release series receives new versions of supported Linux
distributives to build infrastructure.
The intended duration of the support period for each series is at least two years.
End of life
A series reaches the end of life (EOL) when the last release in the series is
published. The series will not receive updates anymore.
In modules, connectors and tools, we don’t guarantee support of any release series
that reaches EOL.
A release series cannot reach EOL until the vast majority of production environments,
for which we have commitments and SLAs, is updated to a newer series.
Versions per lifecycle stage
Stage
Version types
Examples
Early development
Alpha, beta, release candidate
3.0.0-alpha1
3.0.0-beta1
3.0.0-rc1
3.0.0-dev
Support
Release candidate, release
3.0.0
3.0.1-rc1
3.0.1-dev
End of life
None
N/A
Example of a release series
A release series in an early development stage can have
the following version sequence:
Since the first release version, the series comes into a support stage.
Then it can proceed with a version sequence like the following:
3.0.0 (release of a new major version)
3.0.1-rc1
...
3.0.1-rc4
3.0.1 (release with some bugs fixed but no new features)
3.1.0-rc1
...
3.1.0-rc6
3.1.0 (release with new features and, possibly, extra fixed bugs)
Eventually, the support stage stops and the release series comes to the
end of life (EOL) stage.
No new versions are released since then.
Note
See all currently supported Tarantool versions in Releases.
Compatibility guarantees
Backwards compatibility is guaranteed between all versions in the same release series.
It is also appreciated but not guaranteed between different release series (major number changes).
Pre-releases and releases of one release series are compatible in all
senses defined below (any release with any release):
Pre-releases and releases of consequent series are compatible by data
layout, binary protocol, and replication protocol.
No guarantees are given regarding compatibility between
pre-releases/releases of non-consequent release series if the opposite
is not stated in the release notes.
No guarantees are given regarding compatibility between alpha/beta
versions and between alpha/beta and pre-release/release even within one series.
Binary data layout
Any newer release (its runtime) is backward compatible with any older one.
It means the more recent release can work on top of data
(*.xlog, *.snap, *.vylog, *.run) from the older one.
All functionality of the older release can work in this configuration.
The same compatibility is maintained between release series as well.
An attempt to use a new feature results in one of the options:
The attempt is successful.
There is an error message about the old data layout.
The error does not lead to service outage or data corruption.
There is a way to avoid the message, if an instance upgrades the data layout
by calling the box.schema.upgrade(). The call enables
all new release features (when all instances of the replicaset are processed on the same Tarantool version).
Binary protocol
All binary protocol requests operational in an older release keep working in a newer one.
Responses have the same format, but mappings may contain fields not present in the older release.
A net.box client of an older release can work
with a server running a newer release. However, net.box features introduced in the newer release won’t work.
A net.box client of a newer release is fully operational with a server
running a older release. However, only the features implemented in the older release will work.
Replication protocol
An instance running on a newer release can work as:
upstream (master) of an instance with an older release
downstream (replica) without database schema upgrade.
The database schema upgrade (box.schema.upgrade()) must be performed when all replicaset instances
run on the same Tarantool version.
An application should not lean on internal schema representation because it can be changed with the upgrade.
Lua code
If a code is processed on an older release, it will operate with the same effect on a
newer one. However, only meaningful code counts.
If any code throws an error but starts doing something useful, the change is considered compatible.
There is still room for new functionality: adding new options (fields in a table argument),
new arguments to the end, more fields to a return table, and more return values (multireturn).
Adding a new built-in module or a new global value is considered as a compatible change.
Adding a new field to an existing metatable is okay if the field is not listed
in the Lua 5.1 Reference Manual.
Otherwise, it should be proven that it won’t break any meaningful code.
Examples of compatible changes:
Add __pairs, __ipairs to a metatable of a userdata/cdata object.
The fields are not from Lua 5.1, and the userdata/cdata has no default behaviour
for pairs() and ipairs() calls.
Add or extend the __lt or __le metamethod
(if the attempt to use <, <= etc. leads to an error before the change).
Extend existing __eq metamethod implementation
(if the attempt to use it leads to an error before the change).
Examples of incompatible changes:
Add __pairs, __ipairs to a metatable of a table
(it already has a defined behavior before the change).
Add the __eq metamethod (any pair of Lua objects already has a defined behavior).
SQL code
If any request is processed on an older release, it will operate with the same effect on a
newer one (except the requests that always lead to an error).
Examples of compatible changes:
Add a new keyword.
Add a new type.
Add a new built-in function.
Add a new system table that has a name starting with an underscore.
Add a new collation.
Add an implicit or explicit cast rule for a set of operations {X} and a list
of types [Y] if [operation from {X}]([list of values of [Y] types]) had not been
implemented before the change.
Change the order of tuples in the result set of SELECT in case ORDERBY is not specified.
Technically, those changes may break some working code in case of a name clash,
but the probability of it is negligible.
Examples of incompatible changes:
Change the result of working implicit or explicit cast.
Change of a literal type.
C code
If a module or a C stored procedure runs on an older release,
it will operate with the same effect on a newer one.
It is okay to add a new function or structure to the public C API.
It must use one of the Tarantool prefixes (box_, fiber_, luaT_, luaM_ and so on) or some new prefix.
A symbol from a used library must not be exported directly
because the library may be used in a module by itself, and the clash can lead to problems.
Exception: when the whole public API of the library is exported (as for libcurl).
Do not introduce new functions or structures with the lua_ and luaL_ prefixes.
Those prefixes are for the Lua runtime.
Use luaT_ for Tarantool-specific functions, and luaM_ for general-purpose ones.
Tarantool is an open source database that can store everything in RAM.
Use Tarantool as a cache with the ability to save data to disk.
Tarantool serves up to a million requests per second,
allows for secondary index searches, and has SQL support.
In Tarantool, you can execute code alongside data.
This allows for faster operations.
Implement any business logic in Lua.
Get rid of stale entries, sync with other data sources, implement an HTTP service.
We have a special Telegram chat
for contributors.
We speak Russian and English in the chat.
This is the easiest way to get your questions answered.
Many people are afraid to ask questions because they believe they are
“wasting the experts’ time,” but we don’t really think so.
Contributors are important to us.
You can leave your feedback or share ideas in different ways:
The simplest way is to fill
the feedback form.
All you need to do is fill in one product comment field and click “Send.”
You can optionally provide your email address.
If you wish, we can involve you in the product development process.
A more technical way is to create a ticket on GitHub.
If you have a suggestion for a new feature or information about a bug,
create a new GitHub issue.
The link leads to the tarantool/tarantool repository.
To leave feedback for our other projects on GitHub, select “Issues” > “New issue.”
If Telegram is inconvenient for you or simply isn’t working,
you can leave your comment on tarantool.io.
Fill out the form at the bottom of the site and leave your email.
We read every request and respond to them usually within 2 days.
How to contribute
There are many ways to contribute to Tarantool:
Code: Contribute to the code.
We have components written in C, Lua, Python, Go, and other languages.
Write: Improve documentation, write blog posts, create tutorials or solution pages.
Q&A: Share your experience on Stack Overflow with the
#tarantool tag.
Spread the word: Share your accomplishments on social media using the
#tarantool hashtag (or CC @tarantooldb on Twitter).
Tarantool ecosystem
Tarantool has a large ecosystem of tools.
We divide the ecosystem into four large blocks:
Tarantool itself.
Modules for Tarantool. They can be written in C and Lua.
Connectors for programming languages.
Applied tools. See the curated
Awesome Tarantool list,
which also includes external tools.
To start contributing, check the “good first issue” tag
in the issues section of any of our repositories.
These are beginner to intermediate tasks that will
help you get comfortable with the tool.
See the list of tasks
for the tarantool/tarantool repository.
There is a review queue in each of our repositories,
so your changes may not be reviewed immediately.
We usually give the first answer within two days.
Depending on the ticket and its complexity, the review time may take a week or more.
Please do not hesitate to tag the maintainer in your GitHub ticket.
Read on to learn about contributing to different ecosystem blocks.
Documentation: How to report and fix problems
There are several ways to improve the documentation:
The easiest one is to leave your comment on the web documentation page.
To use the built-in feedback form, select the text that you want to comment on,
press Ctrl+Enter, type your comment in the pop-up window,
and click Submit.
On mobile screens, an Error? button appears at the bottom of the screen,
which opens the same pop-up window.
You can point out an error,
provide feedback on the current article, or suggest changes.
We review each comment and work with it.
Advanced: All Tarantool documentation tasks can be found in the
repository.
Go to any task and suggest your changes.
We write our documentation using
reStructuredText markup,
and we have a writing style guide.
After you make the change, build the documentation locally and
see how it works. This can be done automatically in Docker.
To learn more, check the README of the tarantool/doc repository.
Some Tarantool projects have their documentation in the code repository.
This is typical for modules, for example, metrics.
This is done on purpose, so the developers themselves can update it faster.
You can find instructions for building such documentation in the code repository.
If you find that the documentation provided in the README of a module or
a connector is incomplete or wrong, the best way to influence this is to fix it
yourself. Clone the repository, fix the bug, and suggest changes in a pull request.
It will take you five minutes but it will help the whole community.
If you cannot fix it for any reason, create a ticket in the repository
and report the error. It will be fixed promptly.
How to contribute to modules
Tarantool is a database with an embedded application server.
This means you can write any code in C or Lua and pack it in distributable modules.
We have official and unofficial modules.
Here are some of our official modules:
HTTP server: HTTP server implementation
with middleware support.
queue: Tarantool implementation of
the persistent message queue.
metrics: Ready-to-use solution for
collecting metrics.
Official modules are provided in our organization on GitHub.
All modules are distributed through our package manager, which is
pre-installed with Tarantool.
That also applies to unofficial modules, which means that
other users can get your module easily.
Tasks for contributors can be found in the issues section of any repository
under the “good first issue” tag. These tasks are beginner or intermediate
in terms of difficulty level, so you can comfortably get used to the module of your interest.
You can find the contact of the current maintainer in the MAINTAINERS file, located
in the root of the repository. If there is no such file, please
let us know.
We will respond within two days.
If you see that the project does not have a maintainer or is inactive, you can
become its maintainer yourself.
See the How to become a maintainer section.
Creating a new module
You can also create custom modules and share them with the community.
Look at the module template
and write your own.
How to contribute to Tarantool Core
Tarantool is written mostly in C.
Some parts are in C++ and Lua.
Your contributions to Tarantool Core
may take longer to review because we want the code to be reliable.
Read about Tarantool architecture and main modules on the
developer site and on
GitHub.
In Tarantool development, we strive to follow the standards laid out in
our style and contribution guides.
These documents explain how to format your code and commits as well as
how to write tests without breaking anything accidentally.
The guidelines also help you create patches that are easy to check, which allows
quickly pushing changes to master.
You can suggest a patch using the fork and pull mechanism on GitHub: Make changes to your
copy of the repository and submit it to us for review. Check the
GitHub documentation
to learn how to do it.
How to write tests
A database is a product that is expected to be as reliable as possible.
We at Tarantool created test-run, a dedicated test framework for developing
scripts that test Tarantool itself.
Writing your own test is not difficult. Check out the following examples:
We also have a CI workflow that automatically checks build and test coverage for new
changes on all supported operating systems.
The workflow is launched after every commit to the repository.
We have many tasks for QA specialists. Our QA team provides test coverage for our products,
helps develop the test framework, and introduces and maintains new tools to test
the stability of our releases.
For modules, we use luatest—
our fork of a framework popular in the Lua community,
enhanced and optimized for our tasks.
See examples.
of writing tests for a module.
How to contribute to language connectors
A connector is a library that provides an API to access Tarantool from
a programming language. Tarantool uses its own binary protocol for access,
and the connector’s task is to transfer user requests to the database and
application server in the required format.
Data access connectors have already been implemented for all major languages.
If you want to write your own connector,
you first need to familiarize yourself with the Tarantool binary protocol.
Read the protocol description to learn more.
We consider the following connectors as references:
You can look at them to understand how to do it right.
Some connectors in the Tarantool ecosystem are supported by the Tarantool team.
Others are developed and supported exclusively by the community.
All of them have their pros and cons. See the
complete list of connectors and their recommended versions.
If you are using a community connector and want to implement
new features for it or fix a bug, send your PRs via GitHub to the connector repository.
If you have questions for the author of the connector, check the
MAINTAINERS file for the repository maintainer’s contact.
If there is no such file, send us a message on Telegram.
We will help you figure it out. We usually answer within one day.
How to contribute to tools
The Tarantool ecosystem has tools that facilitate the workflow,
help with application deployment, or allow working with Kubernetes.
Here are some of the tools created by the Tarantool team:
tt:
a CLI utility for creating and managing Tarantool applications.
Maintainers are people who can merge PRs or commit to master.
We expect maintainers to answer questions and tickets on time as well as do code reviews.
If you need to get a review but no one responds within a week, take a look at the
Maintainers section of the repository’s README.md.
Write to the person listed there.
If you have not received an answer within 3–4 days, you can escalate the question
on Telegram.
A repository may have no maintainers (empty Maintainers list in README.md),
or the existing maintainers may be inactive. In this case, you can become a maintainer yourself.
We think it’s better if the repository is maintained by a newbie than if the
repository is dead. So don’t be shy: we love maintainers and help them figure it all out.
All you need to do is fill out
this form.
Tell us what repository you want to access,
the reason (inactivity, the maintainer is not responding),
and how to contact you.
We will consider your application in 1 day and either give you the rights
or tell you what else needs to be done.
How to write release notes
Below are some best practices to make changelogs consistent, neat, and human-oriented.
Language
Use the past tense to describe changed or fixed behavior.
Examples
Fixed false positive panic when yielding in debug hook (gh-5649).
The CMake option for hinting that the result will be distributed is
-DENABLE_DIST=ON. With this option, makeinstall
installs tarantoolctl files in addition to tarantool files.
Make RPM and Debian packages
This step is optional. It’s only for people who want to redistribute
Tarantool. We highly recommend to use official packages from the
tarantool.org web-site.
However, you can build RPM and Debian packages using
PackPack. Consult
Build RPM or Deb package using packpack
for details.
Verify your Tarantool installation
$# if you installed tarantool locally after build
$tarantool
$# - OR -
$# if you didn't install tarantool locally after build
$./src/tarantool
In some cases, you may want to create a Tarantool module in C rather than in Lua.
For example, to work with specific hardware or low-level system interfaces.
If a defect changes user-visible server behavior, it needs a bug report,
even if it is a small defect. Report the bug at
GitHub.
When reporting a bug, try to come up with a test case right away. Set the
current maintenance milestone for the bug fix, and specify the series.
Assign the bug to yourself. Put the status to ‘In progress’ Once the patch is
ready, put the bug to ‘In review’ and solicit a review for the fix.
Once there is a positive code review, push the patch and set the status to ‘Closed’
Patches for bugs should contain a reference to the respective
GitHub issue page or
at least the issue id. Each patch should have a test, unless coming up with one is
difficult in the current framework, in which case QA should be alerted.
There are two things you need to do when your patch makes it into the master:
put the bug to ‘fix committed’,
delete the remote branch.
How to write a commit message
Any commit needs a helpful message. Mind the following guidelines when committing
to any of Tarantool repositories at GitHub.
Separate subject from body with a blank line.
Try to limit the subject line to 50 characters or so.
Start the subject line with a capital letter unless it prefixed with a
subsystem name and semicolon:
memtx:
vinyl:
xlog:
replication:
recovery:
iproto:
net.box:
lua:
sql:
Do not end the subject line with a period.
Do not put “gh-xx”, “closes #xxx” to the subject line.
Use the imperative mood in the subject line.
A properly formed Git commit subject line should always be able to complete
the following sentence: “If applied, this commit will /your subject line here/”.
Use your real name and real email address.
For Tarantool team members, @tarantool.org email is preferred, but not
mandatory.
A template:
Summarize changes in 50 characters or less
More detailed explanatory text, if necessary.
Wrap it to 72 characters or so.
In some contexts, the first line is treated as the subject of the
commit, and the rest of the text as the body.
The blank line separating the summary from the body is critical
(unless you omit the body entirely); various tools like `log`,
`shortlog` and `rebase` can get confused if you run the two together.
Explain the problem that this commit is solving. Focus on why you
are making this change as opposed to how (the code explains that).
Are there side effects or other unintuitive consequences of this
change? Here's the place to explain them.
Further paragraphs come after blank lines.
- Bullet points are okay, too.
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here.
Fixes #123
Closes #456
Needed for #859
See also #343, #789
People usually read technical documentation because they want something
up and running quickly. Write simpler, more concise sentences.
Split the content into smaller paragraphs to improve readability.
This will also eliminate the need for using |br| and help us translate content faster.
Any paragraph over 6 sentences is large.
Keep your audience in mind
Consider your audience’s level. A getting started guide should be written
in simpler terms than an advanced internals description.
If you choose to use metaphors to clarify a concept, make sure they are relatable
for an international audience of IT professionals.
Don’t say “we”
Only use the pronoun “we” in entry-level texts like getting started guides.
In other cases, avoid using “we”, because it is unclear who that is exactly.
Consider how Gentoo does it.
Stick to the facts
Use measurable facts instead of personal judgments.
Different users may have different ideas of what “often”, “slow”, or “small” means.
Bad example: This parameter is rarely updated.
Good example: This parameter is updated every two hours or more rarely.
Refer to absolute time
Temporal adverbs like “today”, “currently”, “now”, “in the future”, etc. are relative –
that is, they are based on the time the documentation is created.
Instead of these words, use absolute terms like version numbers or years.
The meaning of those terms doesn’t change over time.
If technical documentation is tied semantically to the time it was created,
it increases the risk of the documentation becoming obsolete.
Bad example: Previously, the functionality worked differently.
Currently, it supports SSL.
Good example: Before version x.y.z, the functionality worked differently.
Since version x.y.z, it supports SSL.
Express one idea in a sentence
Say exactly one thing in a sentence.
If you want to define or clarify something, do it in a separate sentence.
Simple sentences are easier to read, understand and translate.
Don’t
Do
Dogs (I have three of them) are my favorite animals.
Their names are Ace, Bingo and Charm; Charm is the youngest one.
Dogs are my favorite animals.
I have three of them.
Their names are Ace, Bingo and Charm.
Charm is the youngest one.
memtx (the in-memory storage engine) is the default and was the first to arrive.
memtx is an in-memory storage engine.
It is the default and was the first to arrive.
The replica set from where the bucket is being migrated is called the source;
the target replica set where the bucket is being migrated to is called the destination.
The replica set from where the bucket is being migrated is called the source.
The target replica set where the bucket is being migrated to is called the destination.
Put examples next to theory
It’s best if examples immediately follow the concept they illustrate.
The readers wouldn’t want to look for the examples in a different part of the article.
Specify link text
When you provide a link, clearly specify
where it leads. In this way, you will not mislead the reader.
Lists and tables help split heavy content into manageable chunks.
To make tables maintainable and easy to translate,
use the list-table directive, as described in the Tarantool
table markup reference.
Translators find it hard to work with content “drawn” with ASCII characters,
because it requires adjusting the number of spaces and manually counting characters.
Bad example:
Good example:
Format code as code
Format large code fragments using the code-block directive, indicating the language.
For shortercodesnippets, make sure that only code goes in the backticks.
Non-code shouldn’t be formatted as code, because this confuses users (and translators, too).
Check our guidelines on
writing about code.
For more about formatting, check out the Tarantool
markup reference.
Word choice
Instance vs server
We say “instance” rather than “server” to refer to a Tarantool
server instance. This keeps the manual terminology consistent with names like
/etc/tarantool/instances.enabled in the Tarantool environment.
Wrong usage: “Replication allows multiple Tarantool servers to work with copies
of the same database.”
Correct usage: “Replication allows multiple Tarantool instances to work with
copies of the same database.”
Don’t use i.e. and e.g.
Don’t use the following contractions:
“i.e.”—from
the Latin “id est”. Use “that is” or “which means” instead.
“e.g.”—from
the Latin “exempli gratia”. Use “for example” or “such as” instead.
Many people, especially non-native English speakers,
aren’t familiar with the
“i.e.” and “e.g.” contractions
or don’t know the difference between them.
For this reason, it’s best to avoid using them.
Spelling and punctuation
Tarantool capitalization
The word “Tarantool” is capitalized because it’s a product name.
The only context where it can start with a lowercase “t” is code.
Learn more about code formatting in Tarantool documentation.
US vs British spelling
Use the US English spelling.
Check your spelling and punctuation
Consider checking spelling, grammar, and punctuation with special tools like
LanguageTool or Grammarly.
Dashes
Special symbols like dashes, quotation marks, and apostrophes look the same
across all Tarantool documentation in a single language.
This is because the documentation builder
renders specific character sequences in the source into correct typographic characters.
Tarantool documentarians are recommended to use the en dash (–) only.
Type two hyphens to insert it: --. Add spaces on both sides of the dash.
Don’t use a single hyphen as a dash.
Use the dash for the following purposes:
To separate extra information.
To mark a break in a sentence.
To mark ranges like 4–16 GB (don’t surround the dash with spaces in this case).
When indicating a range like codeelement1–codeelement2, escape the series of hyphens using
character-level inline markup.
Otherwise, the RST interpreter will perceive the dash as part of the RST syntax:
``box.begin()``\--``box.commit()``
Ending punctuation in lists and tables
The following recommendations are for the English language only.
You can find similar guidelines for the Russian language in the
external reference for Russian proofreaders.
Lists
There are two kinds of lists:
Where each item forms a complete sentence.
Where each item is a phrase of three or less words or a term.
In the former case, start each item with a capital letter and end with a period.
In the latter case, start it with a lowercase letter and
add no ending punctuation (no period, no comma, no semicolon).
A list should be formatted uniformly:
choose the first or second rule for all items in a list.
The sentence preceding a list can end either with a semicolon or a period.
Don’t add redundant conjunctions like “and”/”or” before the last list item.
General English punctuation rules still apply for text in lists.
Tables
For the text in cells, use periods or other end punctuation
only if the cells contain complete sentences or a mixture of fragments and sentences.
(This is also a
Microsoft guideline
for the English language.)
Besides, make sure that your table punctuation is consistent – either
all similar list/table items end with a period or they all don’t.
In the example below, all items in the second column don’t have
ending punctuation. Meanwhile, all items in the fourth column end with a period,
because they are a mix of fragments and sentences:
This section covers the specifics of localizing Tarantool into Russian.
If you are translating Tarantool docs into Russian,
be sure to check out our translation guidelines.
Lua manages memory automatically by running a garbage collector from time to time to collect all dead objects (that is, objects that are no longer accessible from Lua). https://www.lua.org/manual/5.1/manual.html#2.10
A thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system.
Lua application
Lua-приложение, приложение на языке Lua
Tarantool’s native language for writing applications is Lua.
memtx
memtx
instance
экземпляр
implicit casting
неявное приведение типов
database
база данных
Release policy
Релизная политика
A set of rules for releasing and naming new distributions of Tarantool: where we add new features and where we don’t, how we give them numbers, what versions are suitable to use in production.
field
поле
Fields are distinct data values, contained in a tuple. They play the same role as «row columns» or «record fields» in relational databases.
(SQL) A clause in SQL is a part of a query that lets you filter or customizes how you want your data to be queried to you.
expression
выражение
predicate
предикат
(SQL) Predicates, which specify conditions that can be evaluated to SQL three-valued logic (3VL) (true/false/unknown) or Boolean truth values and are used to limit the effects of statements and queries, or to change program flow.
query
запрос
(SQL) Queries retrieve the data based on specific criteria. A query is a statement that returns a result set (possibly empty).
result set
результат запроса
(SQL) An SQL result set is a set of rows from a database, as well as metadata about the query such as the column names, and the types and sizes of each column. A result set is effectively a table.
statement
инструкция
(SQL) A statement is any text that the database engine recognizes as a valid command.
(SQL) Любой текст, который распознаётся движком БД как команда. Инструкция состоит из ключевых слов и выражений языка SQL, которые предписывают Tarantool выполнять какие-либо действия с базой данных.
(SQL) A series of SQL statements sent to the server at once is called a batch.
(SQL) Серия SQL-инструкций (statements), отправляемая на сервер вместе
production configuration
конфигурация производственной среды
deployment
развертывание
Transforming a mechanical, electrical, or computer system from a packaged to an operational state. IT infrastructure deployment typically involves defining the sequence of operations or steps, often referred to as a deployment plan, that must be carried to deliver changes into a target system environment.
roll back
отменить
транзакцию
deploy to production
IT infrastructure deployment typically involves defining the sequence of operations or steps, often referred to as a deployment plan, that must be carried to deliver changes into a target system environment. Production environment is a setting where software and other products are actually put into operation for their intended uses by end users
operations
эксплуатация
(DevOps) Information technology operations, or IT operations, are the set of all processes and services that are both provisioned by an IT staff to their internal or external clients and used by themselves, to run themselves as a business.
to deploy
Transforming a mechanical, electrical, or computer system from a packaged to an operational state. IT infrastructure deployment typically involves defining the sequence of operations or steps, often referred to as a deployment plan, that must be carried to deliver changes into a target system environment.
deployment plan
A sequence of operations or steps that must be carried to deliver changes into a target system environment.
production environment
производственная среда
Production environment is a term used mostly by developers to describe the setting where software and other products are actually put into operation for their intended uses by end users.
failover
восстановление после сбоев
In computing and related technologies such as networking, failover is switching to a redundant or standby computer server, system, hardware component or network upon the failure or abnormal termination of the previously active application, server, system, hardware component, or network.
directory
директория
bucket
сегмент
select
выберите, выбрать
To select a checkbox
Localization guidelines
Use this guide when localizing Tarantool into Russian.
Tone of voice
General voice
We address IT specialists fairly knowledgeable in their respective fields.
The goal of our translations is to help these people understand how to use Tarantool.
Think of us as their colleagues and address them as such.
Be professional but friendly.
Don’t command or patronize.
Use colloquial speech but avoid being too familiar.
It’s all about the golden mean.
Modal verbs
Think twice when translating modal verbs.
Avoid using expressions like «вы должны», because they sound like a demand in Russian,
and «вам придётся», because it implies that our readers will face a lot of trouble.
Be careful with «нельзя».
Make it easy for the user to read the documentation.
Gender neutrality
Use gender-neutral expressions like «сделать самостоятельно» instead of «сделать самому», etc.
Term choice
Though not all of our readers may be fluent in English,
they write in English-based programming languages
and are used to seeing error messages in English.
Therefore, if they see an unfamiliar and/or more archaic Russian term
for a familiar concept, they might have trouble correlating them.
We don’t want our audience to feel confused, so we prefer newer terms.
We also provide the English equivalent for a term
if it is used in the article for the first time.
If you feel like an older Russian term may sound more familiar for a part of the audience
(for example, those with a math background),
consider adding it in parentheses along with the English equivalent.
Don’t repeat the parentheses throughout the text.
A similar rule applies to
introducing terms in Tarantool documentation.
Term choice examples
First time
All following times
state machine
машина состояний (конечный автомат, state machine)
машина состояний
write-ahead log; WAL
журнал упреждающей записи (write-ahead log, WAL)
журнал упреждающей записи; WAL; журнал WAL (using a descriptor)
Best practices
Be creative
Please avoid word-for-word translations.
Let the resulting text sound as though it was originally written in Russian.
Less is more
Be concise and don’t repeat yourself. Fewer words are the best option most of the time.
Don’t
Do
Профиль доступа можно назначить для любой роли пользователя,
созданной администратором.
А к ролям по умолчанию привязать профили доступа не получится,
поскольку такие роли редактировать нельзя.
Профиль доступа можно назначить для любой роли пользователя,
созданной администратором.
Исключение составляют роли по умолчанию,
поскольку их нельзя редактировать.
Topic and focus
Avoid English word order.
The Russian speech is structured with topic and focus
(тема и рема).
The topic is the given in the sentence, something we already know.
The focus is whatever new/important information is provided in the sentence
about the topic.
In written Russian, the focus most often stands at the end of the sentence,
while in English, sentences may start with it.
It is recommended to use systemd
for managing the application instances and accessing log entries.
Для управления экземплярами приложения и доступа к записям журнала
рекомендуется использовать systemd.
Do not specify working directories of the instances in this configuration.
Не указывайте в этой конфигурации рабочие директории экземпляров.
No bureaucratese
Avoid overly formal, bureaucratic language whenever possible.
Prefer verbs over verbal nouns,
and don’t use «являться» and «осуществляться» unless it’s absolutely necessary.
Сообщение исчезнет, как только вы покинете данную страницу.
Сообщение исчезнет, как только вы покинете страницу.
Проверка истечения срока действия паролей производится раз в 30 минут.
Раз в 30 минут система проверяет, не истек ли срок действия паролей.
Consistency
Use one term for one concept throughout the article.
For example, only translate production as «производственная среда»
and not as «эксплуатационная среда» throughout your article.
It’s not about synonyms, but about terms: we don’t want people to get confused.
Avoid elliptical sentences
Don’t
Do
Defaults to root.
По умолчанию — root.
Значение по умолчанию — root.
Pronoun collocations
Do all the pronouns point to the exact nouns you want them to?
Example (how not to):
Прежде чем добавить запись в конфигурацию, укажите к ней путь.
In the example, it is not quite clear what «к ней» means – to the
record or to the configuration. For more on this issue, check out
the writers’ reference at «Ошибкариум».
Be critical towards your text
Don’t forget to proofread your translation. Check your text at least twice.
Be nice to your peers
If you review others’ translations, be gentle and kind.
Everyone makes mistakes, and nobody likes to be punished for them.
You can use phrasings like “I suggest” or “it’s a good idea to… .”
Defining and using terms
What are concepts and terms
To write well about a certain subject matter,
one needs to know its details
and use the right, carefully selected words for them.
These details are called concepts, and the words for them are called terms.
concept
A concept is the idea of an object, attribute, or action.
It is independent of languages, audience, and products. It just exists.
For example, a large database can be partitioned into smaller instances.
Those instances are easier to operate, and their throughput
often exceeds the throughput of a single large database instance.
The instances can exchange data to keep it consistent between them.
term
A term is a word explicitly selected by the authors of a particular text
to denote a concept in a particular language
for a particular audience.
For example, in Tarantool, we use the term “[database] sharding” to denote the
concept described in the previous example.
Use preferred terms
The purpose of using terms is writing concisely and unambiguously,
which is good for the readers.
But selecting terms is hard.
Often, the community favors two or more terms for one concept,
so there’s no obvious choice.
Selecting and consistently using any of them is much better
than not making a choice and using a random term every time.
This is why it’s also helpful to restrict the usage of some terms explicitly.
restricted term
A restricted term is a word that the authors explicitly
prohibited to use for denoting a concept.
Such a word is sometimes used as a term
for the same concept elsewhere – in the
community, in books, or in other product documentation.
Sometimes this word is used to denote a similar but different concept.
In this case, the right choice of terms helps us differentiate between concepts.
For example, in Tarantool, we don’t use the term “[database] segmentation”
to denote what we call “database sharding.”
Nevertheless, other authors might do so.
We also use the term “[database] partitioning” to denote
a wider concept, which includes sharding among other things.
Define terms by explaining concepts
We always want to document definitions for the most important concepts,
as well as for concepts unique to Tarantool.
Define every term in the document that you find most appropriate for it.
You don’t have to create a dedicated glossary page containing all the definitions.
To define a term, use the glossary directive in the following way:
..glossary::
term
definition text
term2
definition text
There can be several glossary directives in a Sphinx documentation project
and even in a single document.
This page has two of them, for example.
The Sphinx documentation
has an extensive glossary that can be used as a reference.
Introduce terms on first entry
When you use a term in a document for the first time, define it
and provide synonyms, a translation, examples, and/or links.
It will help readers learn the term and understand the concept behind it.
Define the term or give a link to the definition.
Database sharding is a type of horizontal partitioning.
To give a link to the definition, use the term role:
For example, this is a link to the definition of :term:`concept`.
Like any rST role, it can have :term:`custom text <concept>`.
The resulting output will look like this:
For example, this is a link to the definition of concept.
Like any rST role, it can have custom text.
With acronyms, you can also use the abbr role:
Delete the corresponding :abbr:`PVC (persistent volume claim)`...
It produces a tooltip link: PVC.
Provide synonyms, including the restricted terms.
Only do it on the first entry of a term.
Database sharding (also known as …) is a type of…
When writing in Russian, it’s good to add the corresponding English term.
Readers may be more familiar with it or can search it online.
Шардирование (сегментирование, sharding) — это…
Give examples or links to extra reading where you can.
Markup reference
Tarantool documentation is built via the
Sphinx engine and is written in
reStructuredText.
This section will guide you through our typical documentation formatting cases.
Paragraphs contain text and may contain inline markup: emphasis,
strong emphasis, interpretedtext, inlineliterals.
Text can be organized in bullet-lists:
* This is a bullet list.
* Bullets can be "*", "+", or "-".
- Lists can be nested. And it is good to indent them with 4 spaces.
or in enumerated lists:
1. This is an enumerated list.
2. Tarantool build uses only arabic numbers as enumerators.
#. You can put #. instead of point numbers and Sphinx will
recognize it as an enumerated list.
Wrapping text
It’s good practice to wrap lines in documentation source text.
It makes source better readable and results in lesser gitdiff’s.
The recommended limit is 80 characters per line for plain text.
In new documents, try to wrap lines by sentences,
or by parts of a complex sentence.
Don’t wrap formatted text if it affects rST readability and/or HTML output.
However, wrapping with proper indentation shouldn’t break things.
Indentation
In rST, indents play exactly the same role as in Python: they denote object
boundaries and nesting.
For example, a list starts with a marker, then come some spaces and text.
From there, all lines relating to that list item must be at the
same indentation level. We can continue the list item by creating a second
paragraph in it. To do that we have to leave it at the same level.
We can put a new object inside: another list, or a block of code. Then we have
to indent 4 more spaces.
It’s best if all indents are multiples of 4 spaces, even in lists. Otherwise
the document is not consistent. Also, it is much easier to put indents
with tabs than manually.
Note that you have to use two or three spaces instead of one.
It is allowed in rST markup:
|...|...|...|...
* unordered list
#. ordered list
..directive::
|...|...|...|...
Example:
|...|...|...|...
#. List item 1.
Paragraph continues.
Second paragraph.
#. List item 2.
* Nested list item.
..code-block:: bash
# this code block is in a nested list item
* Another nested list item.
|...|...|...|...
Resulting output:
List item 1.
Paragraph continues.
Second paragraph.
List item 2.
Nested list item.
# this code block is in a nested list item
Another nested list item.
Making comments
Sometimes we may need to leave comments in an rST file.
To make Sphinx ignore some text during processing,
use the following per-line notation with ..// as the comment marker:
.. // your comment here
The starting characters ..// do not interfere with the other rST markup, and
they are easy to find both visually and using grep.
To find comments in source files, go ahead with something like this:
$ grep-n"\.\. //"doc/reference/**/*.rst
doc/reference/reference_lua/box.rst:47:.. // moved to "User Guide > 5. Server administration":doc/reference/reference_lua/box.rst:48:.. // /book/box/triggers...
If you’re working with PyCharm or other similar IDE, links in the console will be clickable
and will lead right to the source file and string.
Check it out!
These comments don’t work properly in nested documentation, though.
For example, if you leave a comment in module -> object -> method,
Sphinx ignores the comment and all nested content that follows
in the method description.
The underlining should be exactly the same length as the heading text above it.
Mismatching length will result in a build warning.
Sphinx allows using other characters and styles to format headings.
Indeed, using this markup consistently helps us better reuse and move content.
It also helps us recognize the heading level immediately without reading
the whole document and calculating levels.
If you’re going to make a 4th or 5th level heading,
you probably need to split the document instead.
Title headings
The top-level heading of each document plays the important role of a document title.
Title’s text is used in several places:
Literally as a <h1> tag in HTML or top-level heading in other formats.
Text in the breadcrumbs — the path to the document shown above the text.
ard to navigate in a hierarchy of more than three heading levels.
Links and references
Linking to other documentation pages
To create a link to another document in our documentation, we use the :doc: role.
For example, this link points to the document /reference/reference_lua/box_error.rst:
Our convention is to put the full path to the referred document so that we can
easily replace the path if it changes.
Note that we can omit the .rst part of the filename.
You can use the target document’s title as the link text.
To do so, omit the text in the link definition:
To generate a link to the certain place in the page, we use the :ref: role.
For this purpose, we add our own labels for linking to any place in this documentation.
Our naming convention is as follows:
Character set: a through z, 0 through 9, hyphen, underscore.
Format: pathhyphenfilenamehyphentag
Example:
.._c_api-box_index-iterator_type:
where:
c_api is the directory name,
box_index is the file name (without “.rst”), and
iterator_type is the tag.
Use a hyphen “-” to delimit the path and the file name. In the documentation
source, we use only underscores “_” in paths and file names, reserving the hyphen “-”
as the delimiter for local links.
The tag can be anything meaningful. The only guideline is for Tarantool syntax
items (such as members), where the preferred tag syntax is
module_or_object_namehyphenmember_name. For example, box_space-drop.
To add a link to an anchor, use the following syntax:
Check out the :ref:`Quick start guide <vshard-quick-start>`.
To make an external link, use the following syntax:
Feel free to report an issue at `Tarantool GitHub <https://github.com/tarantool/tarantool/issues>`_.
Avoid separating the link and the target definition, like this:
Feel free to report an issue at `Tarantool GitHub`_.
.._Tarantool GitHub: https://github.com/tarantool/tarantool/issues
because every separated link tends to cause troubles when this documentation
is translated to other languages.
Tables
Tables are very useful and rST markup
offers
different ways to create them.
We prefer list-tables because they allow you to put as much content as you need
without painting ASCII-style borders:
..container:: table
..list-table:::widths: 25 75
:header-rows: 1
* - Name
- Use
* - :doc:`/reference/reference_lua/box_ctl/wait_ro`- Wait until ``box.info.ro`` is true
Notice that we use * and then - in tables because it is more readable
when rows and columns marked differently.
Writing about code
When writing articles, you need to format code specially, separating it from
other text. This document will guide you through typical cases when
it is recommended to use code highlighting.
Defining what code is
In general, code is any text, processed by a machine. It is also probably code
if the expression contains characters that ordinary words do not have,
such as _,{},[],..
Also, you should format the expression as code if it fits at least one
of the items in the list below:
parts of a programming language: names of classes, variables, and functions,
short expressions, data types and so on,
multiline fragments of application logs,
example link which the reader will not open: example.com, https://example.com:80,
parts of URL, like port number,
package names,
CLI app names.
Items we don’t format as code:
names of products, organizations and services, for example, Tarantool,
memtx, vinyl
well-established terms such as stdin and stdout
Keep in mind that grammar doesn’t apply to code, even inline.
Correct: “use shellcheck to analyze your Bash code”.
Incorrect: “shellcheck your Bash code”. Please do not use code
as a verb.
Even worse: “shellcheck your Bash code”. There’s no such word in English
and we don’t explain what to use.
Cursed: “try shellchecking your Bash code”. There’s no such word
and no such application.
Code blocks and inline code
If you have to choose between inline code and code block highlighting,
pay attention to the following guidelines:
Code snippets
Use code blocks when you have to highlight multiple lines of code.
Also, use it if your code snippet contains a standalone element
that is not a part of the article’s text.
For code snippets, we use the code-block::languagedirective.
You can enable syntax highlighting if you specify the language for the snippet.
The most commonly used highlighting languages are:
tarantoolsession – interactive Tarantool session,
where command lines start with tarantool> prompt.
console – interactive console session, where command lines
start with $ or #.
lua, bash or c for programming languages.
text for cases when we want the code block to have no highlighting.
Sphinx uses the Pygments library for highlighting source code.
For a complete list of possible languages, see the
list of Pygments lexers.
For example, a code snippet in Lua:
..code-block::luaforpageinpaged_iter("X",10)doprint("New Page. Number Of Tuples = "..#page)fori=1,#page,1doprint(page[i])endend
Lua syntax is highlighted in the output:
forpageinpaged_iter("X",10)doprint("New Page. Number Of Tuples = "..#page)fori=1,#page,1doprint(page[i])endend
Note that in code blocks you can write comments and translate them:
.. //Here is the first comment... //Here is the second comment.
Inline code
Use inline code when you need to wrap a short snippet of code in text, such as
variable name or function definition. Keep in mind that inline code
doesn’t have syntax highlighting.
To format some inline text as code, enclose it with double ` characters
or use the :code: role:
* Formatting code with backticks: ``echo "Hello world!"``.
* Formatting code with a role: :code:`echo "Hello world!"`.
Both options produce the same output:
Formatting code with backticks: echo"Helloworld!".
Formatting code with a role: echo"Helloworld!".
Notes on using inline-code
If you have expressions such as id==4, you should format the whole
expression as code inline. Also, you can use the words “equals”,
“doesn’t equal” or other similar words without formatting expression
as code. Both variants are correct.
Inline code can be used to highlight expressions that are hard to read,
for example, words containing il, Il or O0.
Highlighting variables in code
If you need to mark up a placeholder inside code inline, use the :samp: or
our custom :extsamp: role, like this:
Notice two backslashes before the curly brackets in the first line.
They are needed to escape curly brackets from Lua syntax.
As you can see, :extsamp: extends the abilities of :samp:.
It allows you to highlight placeholders in both italics and bold
and avoid escaping curly brackets.
:extsamp: has the following syntax:
{*{element}*} for italic
{**{element}**} for bold
If you need to mark up a placeholder in code block, use
the following syntax:
If you need to highlight some file standalone name or path to file in text, use
the :file: role.
You can use curly braces inside this role
to mark up a replaceable part:
To mention a GUI element, use the :guilabel: directive:
Click the :guilabel:`OK` button.
Admonitions
Sometimes you need to highlight a piece of information. For this purpose we use
admonitions.
In Tarantool we have 3 variants of css-style for admonitions:
Note:
..note::
Note
This is a note. We use it to highlight extra information that might be
helpful for users.
For example, here we provide a user with extra information
about using net_box.new() function.
Warning:
..warning::
Warning
This is a warning. As you might guess, we use it to warn users about something.
For example, in the description of box.session.on_connect()
trigger we warn a user about some consequences of his actions.
Important:
..important::
Important
This block contains essential information that the user should know while doing something.
Custom admonition:
..admonition:: Your title
:class: fact
Your title
This is a fact. fact is our custom CSS class. Use it when neither note
nor warning doesn’t fit.
Note that this type requires a title.
For example, here we highlight the rules that
are necessary to read, and that’s why we use fact.
The docutils documentation
offers many more variants for admonitions, but for now these three are enough for us.
If you think that it is time to create the new style for some of these types,
feel free to contribute or contact us to create a task.
Documenting the API
This document contains general guidelines for describing the Tarantool API,
as well as examples and templates.
Style
Please write as simply as possible. Describe functionality using short sentences in the present simple tense.
A short sentence consists of no more than two clauses.
Consider using LanguageTool or Grammarly
to check your English.
For more style-related specifics, consult the Language and style section.
Indicating the version
For every new module, function, or method, specify the version it first appears in.
For a new parameter, specify the version it first appears in if this parameter is a “feature”
and the version it’s been introduced in differs from
the version introducing the function/method and all other parameters.
To specify the version, use the following Sphinx directive:
Since :doc:`2.10.0 </release/2.10.0>`.
This is a link to the release notes on the Tarantool documentation website.
The result looks like this:
Since Tarantool 2.10.0.
This is a link to the release notes on the Tarantool documentation website.
Language of the general description
Use one of the two options:
Start with a verb in the imperative mood. Example: Create a fiber.
Start with a noun. Example: The directory where memtx stores snapshot files.
Checklist
Each list item is a characteristic to be described. Some items can be optional.
If the parameter is optional, make sure it is enclosed in square brackets
in the function declaration (in the “heading”).
Do not mark parameters additionally as “optional” or “required”:
..function:: format(URI-components-table[, include-password])
Construct a URI from components.
:param URI-components-table: a series of ``name:value`` pairs, one for each component
:param include-password: boolean. If this is supplied and is ``true``, then
the password component is rendered in clear text,
otherwise it is omitted.
Configuration parameters
Configuration parameters are not to be confused with class and method parameters.
Configuration parameters are passed to Tarantool via the command line or in an initialization file.
You can find a list of Tarantool configuration parameters in the configuration reference.
In the “Possible errors” section of a function or class method,
consider explaining what happens if any parameter hasn’t been defined or has the wrong value.
Examples and templates
Module functions
We use the Sphinx directives ..module::
and ..function:: to describe functions of Tarantool modules:
..module:: fiber
..function:: create(function [, function-arguments])
Create and start a fiber. The fiber is created and begins to run immediately.
:param function: the function to be associated with the fiber
:param function-arguments: what will be passed to function.
:return: created fiber object
:rtype: userdata
**Example:** ..code-block::tarantoolsession tarantool> fiber = require('fiber') --- ... tarantool> function function_name() > print("I'm a fiber") > end --- ... tarantool> fiber_object = fiber.create(function_name); print("Fiber started") I'm a fiber Fiber started --- ...
Create and start a fiber. The fiber is created and begins to run immediately.
Parameters:
function – the function to be associated with the fiber
function-arguments – what will be passed to function.
Return:
created fiber object
Rtype:
userdata
Example:
tarantool> fiber=require('fiber')---...tarantool> functionfunction_name() > print("I'm a fiber") > end---...tarantool> fiber_object=fiber.create(function_name);print("Fiber started")I'm a fiberFiber started---...
Class methods and data
Methods are described similarly to functions, but the ..class::
directive, unlike ..module::, requires nesting.
As for data, it’s enough to write the description, the return type, and an example.
Here is the example documentation describing
the method and data of the index_object class:
..class:: index_object
..method:: get(key)
Search for a tuple :ref:`via the given index <box_index-note>`.
:param index_object index_object: :ref:`object reference
<app_server-object_reference>`
:param scalar/table key: values to be matched against the index key
:return: the tuple whose index-key fields are equal to the passed key values
:rtype: tuple
**Possible errors:*** No such index
* Wrong type
* More than one tuple matches
**Complexity factors:** index size, index type.
See also :ref:`space_object:get() <box_space-get>`.
**Example:** ..code-block::tarantoolsession tarantool> box.space.tester.index.primary:get(2) --- - [2, 'Music'] ... ..data:: unique
True if the index is unique, false if the index is not unique.
:rtype: boolean
..code-block::tarantoolsession tarantool> box.space.tester.index.primary.unique --- - true ...
.._cfg_basic-vinyl_dir:..confval:: vinyl_dir
Since version 1.7.1.
A directory where vinyl files or subdirectories will be stored. Can be
relative to :ref:`work_dir <cfg_basic-work_dir>`. If not specified, defaults
to ``work_dir``.
|
| Type: string
A directory where vinyl files or subdirectories will be stored. Can be
relative to work_dir. If not specified, defaults
to work_dir.
Type: string
Images
Images are useful in explanations of concepts and structures.
When you introduce a term or describe a structure of multiple interconnected parts
(such as a cluster), consider illustrating it with a diagram. If you are explaining how to
use a GUI, check if a screenshot can make the doc clearer.
Note that illustrations should complement the text, not replace it. Even with an image,
the text should be enough for readers to understand the topic.
Don’t overuse images: they are harder to support than text. Use them only if they bring
an obvious benefit.
Diagrams
There is a basic set of diagram elements – blocks, arrows, and other – to use in Tarantool docs.
It is stored in this Miro board. It also provides
basic rules for creating diagrams.
Size
There are two sizes of diagram elements:
M – bigger elements to use in diagrams with a small number of elements.
S – smaller elements to use in diagrams with a big number of elements.
Avoid changing the size of diagram elements unless it’s absolutely necessary.
The diagrams should have the same width. This guarantees that their elements have the same
size on pages. The examples in the Miro board have frames of the right width.
Copy the frame and and place your diagram in it without changing the frame width.
Exporting
To save the diagram to a file:
Make the frame transparent so that it isn’t shown in the resulting image (set its color
to “no color”).
Select all elements together with the frame and click Copy as image
in the context menu (under the three dots). The image will
be copied to the clipboard.
Paste the image from the clipboard to any graphic editor, for example, GIMP.
Remove the Miro logo in the bottom right corner.
Export/save the image to PNG.
Screenshots
Take screenshots with any tool you like.
Ensure screenshot consistency on the page:
Screenshots must show the same environment: operating system, product version,
visual theme, and so on.
The configuration and data must be consistent. For example, if you’ve shown spaces
with data on a screenshot, subsequent screenshots must have the same data, too.
Size and resolution must be the same across the page unless you want to zoom in to
a specific part of the screen.
Markup
Insert the images using the image directive:
..image:: images/example_diagram.png
:alt: Example diagram alt text
Update submodules and generate documentation sources from code
A big part of documentation sources comes from several other projects,
connected as Git submodules.
To include their latest contents in the docs, run these two steps.
This will initialize Git submodules and update them to the top of the stable
branch in each repository.
gitsubmoduleupdate can sometimes fail, for example,
when you have changes in submodules’ files.
You can reinitialize submodules to fix the problem.
Caution: all untracked changes in submodules will be lost!
gitsubmoduledeinit-f.
gitsubmoduleupdate--init
Note that there’s an option to update submodule repositories with a make command.
However, it’s intended for use in a CI environment and not on a local machine.
Generate documentation source files from the source code
Copy these files to the right places under the ./doc/ directory.
If you’re editing submodules locally, repeat this step
to view the updated results.
Now you’re ready to build and preview the documentation locally.
Build and run the documentation on your machine
When editing the documentation, you can set up a live-reload server.
It will build your documentation and serve it on 127.0.0.1:8000.
Every time you make changes in the source files, it will rebuild the docs
and refresh the browser page.
First build will take some time.
When it’s done, open 127.0.0.1:8000 in the browser.
Now when you make changes, they will be rebuilt in a few seconds,
and the browser tab with preview will reload automatically.
You can also build the docs manually with makehtml,
and then serve them using python3 built-in server:
Here 2>&1 redirects the stderr output to stdout, and then tee both
shows in on screen and writes to a file.
Vale
Tarantool documentation uses the Vale linter for checking grammar, style, and word usage.
Its configuration is placed in the vale.ini file located in the root project directory.
To enable RST support in Vale, you need to install Sphinx.
Then, you can enable Vale integration in your IDE, for example:
Translate the strings in the updated files and then commit the changes.
How to contribute
To contribute to documentation, use the
REST
format for drafting and submit your updates as a
pull request
via GitHub.
To comply with the writing and formatting style, use the
guidelines
provided in the documentation, common sense and existing documents.
Notes:
If you suggest creating a new documentation section (a whole new
page), it has to be saved to the relevant section at GitHub.
If you want to contribute to localizing this documentation (for example, into
Russian), add your translation strings to .po files stored in the
corresponding locale directory (for example, /locale/ru/LC_MESSAGES/
for Russian). See more about localizing with Sphinx at
http://www.sphinx-doc.org/en/stable/intl.html.
Sphinx-build warnings reference
This document will guide you through the warnings that can be raised by Sphinx
while building the docs.
Below are the most frequent warnings and the ways to solve them.
Bullet list ends without a blank line; unexpected unindent
Similar warning: Block quote ends without a blank line; unexpected unindent
Example:
* The last point of bullet list
This text should start after a blank line
Solution:
* The last point of bullet list
This text should start after a blank line
Could not lex literal_block as “…”. Highlighting skipped
This warning means that there’s a code-block with an unknown lexer.
Most probably, it’s a typo.
Check out the full list of Pygments lexers
for the right spelling.
Example:
..code-block:: cxx
// some code here
Solution:
..code-block:: cpp
// some code here
However, sometimes there’s no appropriate lexer or the code snippet can’t be
lexed properly. In that case, use code-block::text.
Duplicate explicit target name: “…”
Example:
*`Install <https://git-scm.com/book/en/v2/Getting-Started-Installing-Git>`_``git``, the version control system.
*`Install <https://linuxize.com/post/how-to-unzip-files-in-linux/>`_
the ``unzip`` utility.
Solution:
Sphinx-builder raises warnings when we call different targets the same name.
Sphinx developers recommend
using double underlines __ in such cases to avoid this.
*`Install <https://git-scm.com/book/en/v2/Getting-Started-Installing-Git>`__``git``, the version control system.
*`Install <https://linuxize.com/post/how-to-unzip-files-in-linux/>`__
the ``unzip`` utility.
Document isn’t included in any toctree
This warning means that you forgot to put the document name in the toctree.
Solution:
If you don’t want to include the document in a toctree,
place the :orphan: directive at the top of the file.
If this file is already included somewhere or reused, add it to the _includes directory.
Sphinx ignores everything in this directory
because we list it among exclude_patterns in conf.py.
Duplicate label “…”, other instance in “…/…/…”
This happens if you include the contents of a file into another file,
when the included file has tags in it.
In this, Sphinx thinks the tags are repeated.
Solution:
As in the previous case, add the file to _includes or avoid using tags in it.
Malformed hyperlink target
Similar warning: Unknown target name: “…”
Check the target spelling and the tag syntax.
Example:
.. _box_space-index_func
See the :ref:`Creating a functional index <box_space-index_func>` section.
Solution:
A semicolon is missing in the tag definition:
.._box_space-index_func:
Anonymous hyperlink mismatch
Warning example: Anonymous hyperlink mismatch: 1 references but 0 targets.
Check the hyperlink formatting.
Example:
Read more in `Lua Manual <https://www.lua.org/manual/5.3`__.
Solution:
A closing greater-than sign is missing in the tag definition:
Read more in `Lua Manual <https://www.lua.org/manual/5.3>`__.
Toctree contains reference to nonexisting document ‘…’
Example:
This may happen when you refer to a wrong path to a document.
The reStructuredText syntax is based on indentation, much like in Python.
All lines in a block of content must be equally indented.
An increase or decrease in indentation denotes the end of the current block and
the beginning of a new one.
Example:
Note: In the following examples, dots stand for indentation spaces.
For example, |..| denotes a two-space indentation.
|..|* (Engines) Improve dump start/stop logging. When initiating memory dump, print
how much memory is going to be dumped, the expected dump rate, ETA, and the recent
write rate.
Solution:
*|...|(Engines) Improve dump start/stop logging. When initiating memory dump, print
|....|how much memory is going to be dumped, the expected dump rate, ETA, and the recent
|....|write rate.
Sphinx did not recognize the file path correctly
due to a missing slash at the beginning, so let’s just put it there:
:doc:`/reference/reference_lua/box_space/update`
Documentation infrastructure
This section of the documentation guidelines
discusses some of the support activities that ensure the correct building of
documentation.
Adding submodules
The documentation source files are mainly stored in the
documentation repository.
However, in some cases, they are stored in the
repositories of other Tarantool-related products
or modules, such as
Monitoring.
If you are working with source files from a product or module repository,
add that repository as a submodule to the
documentation repository
and configure other necessary settings.
This will ensure that the entire
body of Tarantool documentation,
presented on the official website,
is built properly.
Now define what directories and files are to be copied from
the submodule repository to the documentation repository before building
documentation. These settings are defined in the build_submodules.sh file
in the root directory of the documentation repository.
Here are some real submodule examples
that show the logic of the settings.
metrics
The content source files for the metrics submodule are in the
./doc/monitoring directory of the submodule repository.
In the final documentation view, the content should appear in the
Monitoring
chapter (https://www.tarantool.io/en/doc/latest/book/monitoring/).
To make this work:
Create a directory at ./doc/book/monitoring/.
Copy the entire content of the ./modules/metrics/doc/monitoring/ directory to
./doc/book/monitoring/.
Here are the corresponding lines in build_submodules.sh:
The ${project_root} variable is defined earlier in the file as project_root=$(pwd).
This is because the documentation build has to start from the documentation repository root
directory.
3. Update .gitignore
Finally, add paths to the copied directories and files to .gitignore.
Git workflow
Branching
Use one branch for a single task, unless you’re fixing typos or markup on several pages.
Long commit histories are hard to manage and sometimes end up stale.
Start a new branch from the last commit on latest.
Make sure to update your local version of latest with gitpull.
Otherwise, you may have to rebase later.
Name your branch so it’s clear what you’re doing. Examples:
short-issue-description
gh-1234-short-issue-description
your-github-handle/short-issue-description
Important
It is not recommended to submit PRs to the documentation repository
from forks.
Because of a GitHub failsafe mechanism, it is impossible to view changes from a fork
on the development website.
Creating branches directly in the repository results in a more convenient workflow.
Linking issues and PRs
When a PR is linked to an issue:
You can go from the issue straight to the PR by clicking the link in the right column.
The issue will be automatically closed when you close the PR.
Specify the issue(s) you want to close in the description of your PR. GitHub will connect them if you use specific
keywords.
Here are some of them:
Closes #1234
Resolves #1234
Fixes #1234
If your PR closes more than one issue, mention each of them:
Most of the time, one-line commit messages are sufficient for documentation changes.
When you squash commits at merge, the resulting commit message is a sum of all commit messages in the PR.
It is advised to include the “resolves” string in the first commit.
Otherwise, there’s a risk that this line won’t be included in the merge commit.
Convey the nature of the change and possibly the reason why it was made.
Don’t specify the files you’ve changed or the issue you’re working on.
The file names can be looked up in the “Files” section of the PR, and the PR description has the issue number(s).
Try keeping the commit title 50 characters or shorter.
Use the imperative mood.
Start with a capital letter, don’t add ending punctuation.
(Optional) Use the telegraphic style, or “headlinese”, dropping the articles.
Good examples
gitcommit-m"Expandsectiononmsgpack"
gitcommit-m"AdddetailsonIPROTO_BALLOT"
gitcommit-m"Createnewstructure"
gitcommit-m"Improvegrammar"
Bad examples
gitcommit-m"Fixgh-2007,secondcommit"
gitcommit-m“Changedthefilebox_protocol.rst”
gitcommit-m"addedmorelistitems"
Selecting a reviewer
Ideally, a PR should have two reviewers: a subject matter expert (SME) and a documentarian.
The SME checks the facts, and the documentarian checks the language and style.
If you’re not sure who the SME for an issue is, try the following:
Check the issue description. The SME is often mentioned there explicitly.
Note who created the issue and who was involved in the discussion.
Merging
Merge when your document is ready and good enough.
For external contributors, merging is blocked until a reviewer’s approval.
Always squash commits.
Make sure the commit message mentions all relevant issues with “resolves” or “fixes”.
Make sure you’ve
attributed
all participants with Co-authored-by.
C Style Guide
We use Git for revision control. The latest development is happening in the
default branch (currently master). Our git repository is hosted on GitHub,
and can be checked out with gitclonegit://github.com/tarantool/tarantool.git
(anonymous read-only access).
If you have any questions about Tarantool internals, please post them on
StackOverflow or
ask Tarantool developers directly in telegram.
However, we have some additional guidelines, either unique to Tarantool or
deviating from the Kernel guidelines. Below we rewrite the Linux kernel
coding style according to the Tarantool’s style features.
Tarantool coding style
This is a short document describing the preferred coding style for the
Tarantool developers and contributors. We insist on following these rules
in order to make our code consistent and understandable to any developer.
Chapter 1: Indentation
Tabs are 8 characters (8-width tabs, not 8 whitespaces), and thus indentations
are also 8 characters. There are heretic movements that try to make indentations
4 (or even 2!) characters deep, and that is akin to trying to define the
value of PI to be 3.
Rationale: The whole idea behind indentation is to clearly define where
a block of control starts and ends. Especially when you’ve been looking
at your screen for 20 straight hours, you’ll find it a lot easier to see
how the indentation works if you have large indentations.
Now, some people will claim that having 8-character indentations makes
the code move too far to the right, and makes it hard to read on a
80-character terminal screen. The answer to that is that if you need
more than 3 levels of indentation, you’re screwed anyway, and should fix
your program.
8-char indents make things easier to read and have the added
benefit of warning you when you’re nesting your functions too deep.
Heed that warning.
The preferred way to ease multiple indentation levels in a switch statement is
to align the switch and its subordinate case labels in the same column
instead of double-indenting the case labels. E.g.:
switch(suffix){case'G':case'g':mem<<=30;break;case'M':case'm':mem<<=20;break;case'K':case'k':mem<<=10;/* fall through */default:break;}
Don’t put multiple statements on a single line unless you have
something to hide:
if(condition)do_this;do_something_everytime;
Don’t put multiple assignments on a single line either. Avoid tricky expressions.
Outside of comments and documentation, spaces are never
used for indentation, and the above example is deliberately broken.
Get a decent editor and don’t leave whitespace at the end of lines.
Chapter 2: Breaking long lines and strings
Coding style is all about readability and maintainability using commonly
available tools.
The limit on the length of lines is 80 columns and this is a strongly
preferred limit. As for comments, the same limit of 80 columns is applied.
Statements longer than 80 columns will be broken into sensible chunks, unless
exceeding 80 columns significantly increases readability and does not hide
information. Descendants are always substantially shorter than the parent and
are placed substantially to the right. The same applies to function headers
with a long argument list.
Chapter 3: Placing Braces and Spaces
The other issue that always comes up in C styling is the placement of
braces. Unlike the indent size, there are few technical reasons to
choose one placement strategy over the other, but the preferred way, as
shown to us by the prophets Kernighan and Ritchie, is to put the opening
brace last on the line, and put the closing brace first, thus:
if(xistrue){wedoy}
This applies to all non-function statement blocks (if, switch, for,
while, do). E.g.:
However, there is one special case, namely functions: they have the
opening brace at the beginning of the next line, thus:
intfunction(intx){bodyoffunction}
Heretic people all over the world have claimed that this inconsistency
is … well … inconsistent, but all right-thinking people know that
(a) K&R are right and (b) K&R are right. Besides, functions are
special anyway (you can’t nest them in C).
Note that the closing brace is empty on a line of its own, except in
the cases where it is followed by a continuation of the same statement,
i.e. a while in a do-statement or an else in an if-statement, like
this:
do{bodyofdo-loop}while(condition);
and
if(x==y){..}elseif(x>y){...}else{....}
Rationale: K&R.
Also, note that this brace-placement also minimizes the number of empty
(or almost empty) lines, without any loss of readability. Thus, as the
supply of new-lines on your screen is not a renewable resource (think
25-line terminal screens here), you have more empty lines to put
comments on.
Do not unnecessarily use braces where a single statement will do.
if(condition)action();
and
if(condition)do_this();elsedo_that();
This does not apply if only one branch of a conditional statement is a single
statement; in the latter case use braces in both branches:
Tarantool style for use of spaces depends (mostly) on
function-versus-keyword usage. Use a space after (most) keywords. The
notable exceptions are sizeof, typeof, alignof, and __attribute__,
which look somewhat like functions (and are usually used with parentheses,
although they are not required in the language, as in: sizeofinfo after
structfileinfoinfo; is declared).
So use a space after these keywords:
if,switch,case,for,do,while
but not with sizeof, typeof, alignof, or __attribute__. E.g.,
s=sizeof(structfile);
Do not add spaces around (inside) parenthesized expressions. This example is
bad:
s=sizeof(structfile);
When declaring pointer data or a function that returns a pointer type, the
preferred use of * is adjacent to the data name or function name and not
adjacent to the type name. Examples:
no space before the postfix increment & decrement unary operators:
++--
no space after the prefix increment & decrement unary operators:
++--
and no space around the . and -> structure member operators.
Do not split a cast operator from its argument with a whitespace,
e.g. (ssize_t)inj->iparam.
Do not leave trailing whitespace at the ends of lines. Some editors with
smart indentation will insert whitespace at the beginning of new lines as
appropriate, so you can start typing the next line of code right away.
However, some such editors do not remove the whitespace if you end up not
putting a line of code there, such as if you leave a blank line. As a result,
you end up with lines containing trailing whitespace.
Git will warn you about patches that introduce trailing whitespace, and can
optionally strip the trailing whitespace for you; however, if applying a series
of patches, this may make later patches in the series fail by changing their
context lines.
Chapter 4: Naming
C is a Spartan language, and so should your naming be. Unlike Modula-2
and Pascal programmers, C programmers do not use cute names like
ThisVariableIsATemporaryCounter. A C programmer would call that
variable tmp, which is much easier to write, and not the least more
difficult to understand.
HOWEVER, while mixed-case names are frowned upon, descriptive names for
global variables are a must. To call a global function foo is a
shooting offense.
GLOBAL variables (to be used only if you really need them) need to
have descriptive names, as do global functions. If you have a function
that counts the number of active users, you should call that
count_active_users() or similar, you should not call it cntusr().
Encoding the type of a function into the name (so-called Hungarian
notation) is brain damaged - the compiler knows the types anyway and can
check those, and it only confuses the programmer. No wonder MicroSoft
makes buggy programs.
LOCAL variable names should be short, and to the point. If you have
some random integer loop counter, it should probably be called i.
Calling it loop_counter is non-productive, if there is no chance of it
being misunderstood. Similarly, tmp can be just about any type of
variable that is used to hold a temporary value.
If you are afraid to mix up your local variable names, you have another
problem, which is called the function-growth-hormone-imbalance syndrome.
See chapter 6 (Functions).
For function naming we have a convention is to use:
new/delete for functions which
allocate + initialize and destroy + deallocate an object,
create/destroy for functions which initialize/destroy an object
but do not handle memory management,
init/free for functions which initialize/destroy libraries and subsystems.
Chapter 5: Typedefs
Please don’t use things like vps_t.
It’s a mistake to use typedef for structures and pointers. When you see a
vps_ta;
in the source, what does it mean?
In contrast, if it says
structvirtual_container*a;
you can actually tell what a is.
Lots of people think that typedefs helpreadability. Not so. They are
useful only for:
Totally opaque objects (where the typedef is actively used to hide
what the object is).
Example: pte_t etc. opaque objects that you can only access using
the proper accessor functions.
Note
Opaqueness and accessorfunctions are not good in themselves.
The reason we have them for things like pte_t etc. is that there
really is absolutely zero portably accessible information there.
Clear integer types, where the abstraction helps avoid confusion
whether it is int or long.
u8/u16/u32 are perfectly fine typedefs, although they fit into
point 4 better than here.
Note
Again - there needs to be a reason for this. If something is
unsignedlong, then there’s no reason to do
typedef unsigned long myflags_t;
but if there is a clear reason for why it under certain circumstances
might be an unsignedint and under other configurations might be
unsignedlong, then by all means go ahead and use a typedef.
When you use sparse to literally create a new type for
type-checking.
New types which are identical to standard C99 types, in certain
exceptional circumstances.
Although it would only take a short amount of time for the eyes and
brain to become accustomed to the standard types like uint32_t,
some people object to their use anyway.
When editing existing code which already uses one or the other set
of types, you should conform to the existing choices in that code.
Maybe there are other cases too, but the rule should basically be to NEVER
EVER use a typedef unless you can clearly match one of those rules.
In general, a pointer, or a struct that has elements that can reasonably
be directly accessed should never be a typedef.
Chapter 6: Functions
Functions should be short and sweet, and do just one thing. They should
fit on one or two screenfuls of text (the ISO/ANSI screen size is 80x24,
as we all know), and do one thing and do that well.
The maximum length of a function is inversely proportional to the
complexity and indentation level of that function. So, if you have a
conceptually simple function that is just one long (but simple)
case-statement, where you have to do lots of small things for a lot of
different cases, it’s OK to have a longer function.
However, if you have a complex function, and you suspect that a
less-than-gifted first-year high-school student might not even
understand what the function is all about, you should adhere to the
maximum limits all the more closely. Use helper functions with
descriptive names (you can ask the compiler to in-line them if you think
it’s performance-critical, and it will probably do a better job of it
than you would have done).
Another measure of the function is the number of local variables. They
shouldn’t exceed 5-10, or you’re doing something wrong. Re-think the
function, and split it into smaller pieces. A human brain can
generally easily keep track of about 7 different things, anything more
and it gets confused. You know you’re brilliant, but maybe you’d like
to understand what you did 2 weeks from now.
In function prototypes, include parameter names with their data types.
Although this is not required by the C language, it is preferred in Tarantool
because it is a simple way to add valuable information for the reader.
Note that we place the function return type on the line before the name and signature.
Chapter 7: Centralized exiting of functions
Albeit deprecated by some people, the equivalent of the goto statement is
used frequently by compilers in form of the unconditional jump instruction.
The goto statement comes in handy when a function exits from multiple
locations and some common work such as cleanup has to be done. If there is no
cleanup needed then just return directly.
Choose label names which say what the goto does or why the goto exists. An
example of a good name could be out_free_buffer: if the goto frees buffer.
Avoid using GW-BASIC names like err1: and err2:, as you would have to
renumber them if you ever add or remove exit paths, and they make correctness
difficult to verify anyway.
The rationale for using gotos is:
unconditional statements are easier to understand and follow
nesting is reduced
errors by not updating individual exit points when making
modifications are prevented
saves the compiler work to optimize redundant code away ;)
A common type of bug to be aware of is oneerrbugs which look like this:
err:kfree(foo->bar);kfree(foo);returnret;
The bug in this code is that on some exit paths foo is NULL. Normally the
fix for this is to split it up into two error labels err_free_bar: and
err_free_foo::
Ideally you should simulate errors to test all exit paths.
Chapter 8: Commenting
Comments are good, but there is also a danger of over-commenting. NEVER
try to explain HOW your code works in a comment: it’s much better to
write the code so that the working is obvious, and it’s a waste of
time to explain badly written code.
Generally, you want your comments to tell WHAT your code does, not HOW.
Also, try to avoid putting comments inside a function body: if the
function is so complex that you need to separately comment parts of it,
you should probably go back to chapter 6 for a while. You can make
small comments to note or warn about something particularly clever (or
ugly), but try to avoid excess. Instead, put the comments at the head
of the function, telling people what it does, and possibly WHY it does
it.
When commenting the Tarantool C API functions, please use Doxygen comment format,
Javadoc flavor, i.e. @tag rather than \\tag.
The main tags in use are @param, @retval, @return, @see,
@note and @todo.
Every function, except perhaps a very short and obvious one, should have a
comment. A sample function comment may look like below:
/** * Write all data to a descriptor. * * This function is equivalent to 'write', except it would ensure * that all data is written to the file unless a non-ignorable * error occurs. * * @retval 0 Success * @retval 1 An error occurred (not EINTR) */staticintwrite_all(intfd,void*data,size_tlen);
It’s also important to comment data types, whether they are basic types or
derived ones. To this end, use just one data declaration per line (no commas
for multiple data declarations). This leaves you room for a small comment on
each item, explaining its use.
Public structures and important structure members should be commented as well.
In C comments out of functions and inside of functions should be different in
how they are started. Everything else is wrong. Below are correct examples.
/** comes for documentation comments, /* for local not documented comments.
However the difference is vague already, so the rule is simple:
out of function use /**, inside use /*.
/** * Out of function comment, option 1. *//** Out of function comment, option 2. */intfunction(){/* Comment inside function, option 1. *//* * Comment inside function, option 2. */}
If a function has declaration and implementation separated, the function comment
should be for the declaration. Usually in the header file. Don’t duplicate the
comment.
A comment and the function signature should be synchronized. Double-check if the
parameter names are the same as used in the comment, and mean the same.
Especially when you change one of them - ensure you changed the other.
Chapter 9: Macros, Enums and RTL
Names of macros defining constants and labels in enums are capitalized.
#define CONSTANT 0x12345
Enums are preferred when defining several related constants.
CAPITALIZED macro names are appreciated but macros resembling functions
may be named in lower case.
Generally, inline functions are preferable to macros resembling functions.
Macros with multiple statements should be enclosed in a do - while block:
#define macrofun(a, b, c) \ do { \ if (a == 5) \ do_this(b, c); \ } while (0)
Things to avoid when using macros:
macros that affect control flow:
#define FOO(x) \ do { \ if (blah(x) < 0) \ return -EBUGGERED; \ } while (0)
is a very bad idea. It looks like a function call but exits the calling
function; don’t break the internal parsers of those who will read the code.
macros that depend on having a local variable with a magic name:
#define FOO(val) bar(index, val)
might look like a good thing, but it’s confusing as hell when one reads the
code and it’s prone to breakage from seemingly innocent changes.
macros with arguments that are used as l-values: FOO(x)=y; will
bite you if somebody e.g. turns FOO into an inline function.
forgetting about precedence: macros defining constants using expressions
must enclose the expression in parentheses. Beware of similar issues with
macros using parameters.
ret is a common name for a local variable - __foo_ret is less likely
to collide with an existing variable.
Chapter 10: Allocating memory
Prefer specialized allocators like region, mempool, smalloc to
malloc()/free() for any performance-intensive or large memory allocations.
Repetitive use of malloc()/free() can lead to memory fragmentation
and should therefore be avoided.
Always free all allocated memory, even allocated at start-up. We aim at being
valgrind leak-check clean, and in most cases it’s just as easy to free() the
allocated memory as it is to write a valgrind suppression. Freeing all allocated
memory is also dynamic-load friendly: assuming a plug-in can be dynamically
loaded and unloaded multiple times, reload should not lead to a memory leak.
Chapter 11: The inline disease
There appears to be a common misperception that gcc has a magic “make me
faster” speedup option called inline. While the use of inlines can be
appropriate, it very often is not. Abundant use of the inline keyword leads to
a much bigger kernel, which in turn slows the system as a whole down, due to a
bigger icache footprint for the CPU and simply because there is less memory
available for the pagecache. Just think about it; a pagecache miss causes a
disk seek, which easily takes 5 milliseconds. There are a LOT of cpu cycles
that can go into these 5 milliseconds.
A reasonable rule of thumb is to not put inline at functions that have more
than 3 lines of code in them. An exception to this rule are the cases where
a parameter is known to be a compiletime constant, and as a result of this
constantness you know the compiler will be able to optimize most of your
function away at compile time.
Often people argue that adding inline to functions that are static and used
only once is always a win since there is no space tradeoff. While this is
technically correct, gcc is capable of inlining these automatically without
help, and the maintenance issue of removing the inline when a second user
appears outweighs the potential value of the hint that tells gcc to do
something it would have done anyway.
Chapter 12: Function return values and names
Functions can return values of many different kinds, and one of the
most common is a value indicating whether the function succeeded or
failed.
In 99.99999% of all cases in Tarantool we return 0 on success, non-zero on error
(-1 usually). Errors are saved into a diagnostics area which is global per fiber.
We never return error codes as a result of a function.
Functions whose return value is the actual result of a computation, rather
than an indication of whether the computation succeeded, are not subject to
this rule. Generally they indicate failure by returning some out-of-range
result. Typical examples would be functions that return pointers; they use
NULL or the mechanism to report failure.
Chapter 13: Editor modelines and other cruft
Some editors can interpret configuration information embedded in source files,
indicated with special markers. For example, emacs interprets lines marked
like this:
Do not include any of these in source files. People have their own personal
editor configurations, and your source files should not override them. This
includes markers for indentation and mode configuration. People may use their
own custom mode, or may have some other magic method for making indentation
work correctly.
Chapter 14: Conditional Compilation
Wherever possible, don’t use preprocessor conditionals (#if, #ifdef) in
.c files; doing so makes code harder to read and logic harder to follow. Instead,
use such conditionals in a header file defining functions for use in those .c
files, providing no-op stub versions in the #else case, and then call those
functions unconditionally from .c files. The compiler will avoid generating
any code for the stub calls, producing identical results, but the logic will
remain easy to follow.
Prefer to compile out entire functions, rather than portions of functions or
portions of expressions. Rather than putting an #ifdef in an expression,
factor out part or all of the expression into a separate helper function and
apply the condition to that function.
If you have a function or variable which may potentially go unused in a
particular configuration, and the compiler would warn about its definition
going unused, do not compile it and use #if for this.
At the end of any non-trivial #if or #ifdef block (more than a few lines),
place a comment after the #endif on the same line, noting the conditional
expression used. For instance:
Use #pragmaonce in the headers. As the header guards we refer to this
construction:
#ifndef THE_HEADER_IS_INCLUDED#define THE_HEADER_IS_INCLUDED// ... the header code ...#endif // THE_HEADER_IS_INCLUDED
It works fine, but the guard name THE_HEADER_IS_INCLUDED tends to
become outdated when the file is moved or renamed. This is especially
painful with multiple files having the same name in the project, but
different path. For instance, we have 3 error.h files, which means for
each of them we need to invent a new header guard name, and not forget to
update them if the files are moved or renamed.
For that reason we use #pragmaonce in all the new code, which shortens
the header file down to this:
#pragma once// ... header code ...
Chapter 16: Other
We don’t apply ! operator to non-boolean values. It means, to check
if an integer is not 0, you use !=0. To check if a pointer is not NULL,
you use !=NULL. The same for ==.
Select GNU C99 extensions are acceptable. It’s OK to mix declarations and
statements, use true and false.
The C Programming Language, Second Edition
by Brian W. Kernighan and Dennis M. Ritchie.
Prentice Hall, Inc., 1988.
ISBN 0-13-110362-8 (paperback), 0-13-110370-9 (hardback).
The Practice of Programming
by Brian W. Kernighan and Rob Pike.
Addison-Wesley, Inc., 1999.
ISBN 0-201-61586-X.
GNU manuals - where in compliance with K&R
and this text - for cpp, gcc, gcc internals and indent
This document gives coding conventions for the Python code comprising
the standard library in the main Python distribution. Please see the
companion informational PEP describing style guidelines for the C code
in the C implementation of Python [1].
This document and PEP 257 (Docstring Conventions) were adapted from
Guido’s original Python Style Guide essay, with some additions from
Barry’s style guide [2].
A Foolish Consistency is the Hobgoblin of Little Minds
One of Guido’s key insights is that code is read much more often than
it is written. The guidelines provided here are intended to improve
the readability of code and make it consistent across the wide
spectrum of Python code. As PEP 20 says, “Readability counts”.
A style guide is about consistency. Consistency with this style guide
is important. Consistency within a project is more important.
Consistency within one module or function is the most important.
But most importantly: know when to be inconsistent – sometimes the
style guide just doesn’t apply. When in doubt, use your best
judgment. Look at other examples and decide what looks best. And
don’t hesitate to ask!
Two good reasons to break a particular rule:
When applying the rule would make the code less readable, even for
someone who is used to reading code that follows the rules.
To be consistent with surrounding code that also breaks it (maybe
for historic reasons) – although this is also an opportunity to
clean up someone else’s mess (in true XP style).
Code lay-out
Indentation
Use 4 spaces per indentation level.
For really old code that you don’t want to mess up, you can continue
to use 8-space tabs.
Continuation lines should align wrapped elements either vertically
using Python’s implicit line joining inside parentheses, brackets and
braces, or using a hanging indent. When using a hanging indent the
following considerations should be applied; there should be no
arguments on the first line and further indentation should be used to
clearly distinguish itself as a continuation line.
Yes:
# Aligned with opening delimiterfoo=long_function_name(var_one,var_two,var_three,var_four)# More indentation included to distinguish this from the rest.deflong_function_name(var_one,var_two,var_three,var_four):print(var_one)
No:
# Arguments on first line forbidden when not using vertical alignmentfoo=long_function_name(var_one,var_two,var_three,var_four)# Further indentation required as indentation is not distinguishabledeflong_function_name(var_one,var_two,var_three,var_four):print(var_one)
Optional:
# Extra indentation is not necessary.foo=long_function_name(var_one,var_two,var_three,var_four)
The closing brace/bracket/parenthesis on multi-line constructs may
either line up under the first non-whitespace character of the last
line of list, as in:
The most popular way of indenting Python is with spaces only. The
second-most popular way is with tabs only. Code indented with a
mixture of tabs and spaces should be converted to using spaces
exclusively. When invoking the Python command line interpreter with
the -t option, it issues warnings about code that illegally mixes
tabs and spaces. When using -tt these warnings become errors.
These options are highly recommended!
For new projects, spaces-only are strongly recommended over tabs.
Most editors have features that make this easy to do.
Maximum Line Length
Limit all lines to a maximum of 79 characters.
There are still many devices around that are limited to 80 character
lines; plus, limiting windows to 80 characters makes it possible to
have several windows side-by-side. The default wrapping on such
devices disrupts the visual structure of the code, making it more
difficult to understand. Therefore, please limit all lines to a
maximum of 79 characters. For flowing long blocks of text (docstrings
or comments), limiting the length to 72 characters is recommended.
The preferred way of wrapping long lines is by using Python’s implied
line continuation inside parentheses, brackets and braces. Long lines
can be broken over multiple lines by wrapping expressions in
parentheses. These should be used in preference to using a backslash
for line continuation.
Backslashes may still be appropriate at times. For example, long,
multiple with-statements cannot use implicit continuation, so
backslashes are acceptable:
Make sure to indent the continued line appropriately. The preferred
place to break around a binary operator is after the operator, not
before it. Some examples:
classRectangle(Blob):def__init__(self,width,height,color='black',emphasis=None,highlight=0):if(width==0andheight==0andcolor=='red'andemphasis=='strong'orhighlight>100):raiseValueError("sorry, you lose")ifwidth==0andheight==0and(color=='red'oremphasisisNone):raiseValueError("I don't think so -- values are %s, %s"%(width,height))Blob.__init__(self,width,height,color,emphasis,highlight)
Blank Lines
Separate top-level function and class definitions with two blank
lines.
Method definitions inside a class are separated by a single blank
line.
Extra blank lines may be used (sparingly) to separate groups of
related functions. Blank lines may be omitted between a bunch of
related one-liners (e.g. a set of dummy implementations).
Use blank lines in functions, sparingly, to indicate logical sections.
Python accepts the control-L (i.e. ^L) form feed character as
whitespace; Many tools treat these characters as page separators, so
you may use them to separate pages of related sections of your file.
Note, some editors and web-based code viewers may not recognize
control-L as a form feed and will show another glyph in its place.
Encodings (PEP 263)
Code in the core Python distribution should always use the ASCII or
Latin-1 encoding (a.k.a. ISO-8859-1). For Python 3.0 and beyond,
UTF-8 is preferred over Latin-1, see PEP 3120.
Files using ASCII should not have a coding cookie. Latin-1 (or UTF-8)
should only be used when a comment or docstring needs to mention an
author name that requires Latin-1; otherwise, using \x, \u or
\U escapes is the preferred way to include non-ASCII data in
string literals.
For Python 3.0 and beyond, the following policy is prescribed for the
standard library (see PEP 3131): All identifiers in the Python
standard library MUST use ASCII-only identifiers, and SHOULD use
English words wherever feasible (in many cases, abbreviations and
technical terms are used which aren’t English). In addition, string
literals and comments must also be in ASCII. The only exceptions are
(a) test cases testing the non-ASCII features, and
(b) names of authors. Authors whose names are not based on the
latin alphabet MUST provide a latin transliteration of their
names.
Open source projects with a global audience are encouraged to adopt a
similar policy.
Imports
Imports should usually be on separate lines, e.g.:
Yes:importosimportsysNo:importsys,os
It’s okay to say this though:
fromsubprocessimportPopen,PIPE
Imports are always put at the top of the file, just after any module
comments and docstrings, and before module globals and constants.
Imports should be grouped in the following order:
standard library imports
related third party imports
local application/library specific imports
You should put a blank line between each group of imports.
Put any relevant __all__ specification after the imports.
Relative imports for intra-package imports are highly discouraged.
Always use the absolute package path for all imports. Even now that
PEP 328 is fully implemented in Python 2.5, its style of explicit
relative imports is actively discouraged; absolute imports are more
portable and usually more readable.
When importing a class from a class-containing module, it’s usually
okay to spell this:
More than one space around an assignment (or other) operator to
align it with another.
Yes:
x=1y=2long_variable=3
No:
x=1y=2long_variable=3
Other Recommendations
Always surround these binary operators with a single space on either
side: assignment (=), augmented assignment (+=, -=
etc.), comparisons (==, <, >, !=, <>, <=,
>=, in, notin, is, isnot), Booleans (and,
or, not).
If operators with different priorities are used, consider adding
whitespace around the operators with the lowest priority(ies). Use
your own judgement; however, never use more than one space, and
always have the same amount of whitespace on both sides of a binary
operator.
While sometimes it’s okay to put an if/for/while with a small body
on the same line, never do this for multi-clause statements. Also
avoid folding such long lines!
Comments that contradict the code are worse than no comments. Always
make a priority of keeping the comments up-to-date when the code
changes!
Comments should be complete sentences. If a comment is a phrase or
sentence, its first word should be capitalized, unless it is an
identifier that begins with a lower case letter (never alter the case
of identifiers!).
If a comment is short, the period at the end can be omitted. Block
comments generally consist of one or more paragraphs built out of
complete sentences, and each sentence should end in a period.
You should use two spaces after a sentence-ending period.
When writing English, Strunk and White apply.
Python coders from non-English speaking countries: please write your
comments in English, unless you are 120% sure that the code will never
be read by people who don’t speak your language.
Block Comments
Block comments generally apply to some (or all) code that follows
them, and are indented to the same level as that code. Each line of a
block comment starts with a # and a single space (unless it is
indented text inside the comment).
Paragraphs inside a block comment are separated by a line containing a
single #.
Inline Comments
Use inline comments sparingly.
An inline comment is a comment on the same line as a statement.
Inline comments should be separated by at least two spaces from the
statement. They should start with a # and a single space.
Inline comments are unnecessary and in fact distracting if they state
the obvious. Don’t do this:
x=x+1# Increment x
But sometimes, this is useful:
x=x+1# Compensate for border
Documentation Strings
Conventions for writing good documentation strings
(a.k.a. “docstrings”) are immortalized in PEP 257.
Write docstrings for all public modules, functions, classes, and
methods. Docstrings are not necessary for non-public methods, but
you should have a comment that describes what the method does. This
comment should appear after the def line.
PEP 257 describes good docstring conventions. Note that most
importantly, the """ that ends a multiline docstring should be
on a line by itself, and preferably preceded by a blank line, e.g.:
"""Return a foobangOptional plotz says to frobnicate the bizbaz first."""
For one liner docstrings, it’s okay to keep the closing """ on
the same line.
Version Bookkeeping
If you have to have Subversion, CVS, or RCS crud in your source file,
do it as follows.
__version__="$Revision$"# $Source$
These lines should be included after the module’s docstring, before
any other code, separated by a blank line above and below.
Naming Conventions
The naming conventions of Python’s library are a bit of a mess, so
we’ll never get this completely consistent – nevertheless, here are
the currently recommended naming standards. New modules and packages
(including third party frameworks) should be written to these
standards, but where an existing library has a different style,
internal consistency is preferred.
Descriptive: Naming Styles
There are a lot of different naming styles. It helps to be able to
recognize what naming style is being used, independently from what
they are used for.
The following naming styles are commonly distinguished:
b (single lowercase letter)
B (single uppercase letter)
lowercase
lower_case_with_underscores
UPPERCASE
UPPER_CASE_WITH_UNDERSCORES
CapitalizedWords (or CapWords, or CamelCase – so named because
of the bumpy look of its letters [3]). This is also sometimes known
as StudlyCaps.
Note: When using abbreviations in CapWords, capitalize all the
letters of the abbreviation. Thus HTTPServerError is better than
HttpServerError.
mixedCase (differs from CapitalizedWords by initial lowercase
character!)
Capitalized_Words_With_Underscores (ugly!)
There’s also the style of using a short unique prefix to group related
names together. This is not used much in Python, but it is mentioned
for completeness. For example, the os.stat() function returns a
tuple whose items traditionally have names like st_mode,
st_size, st_mtime and so on. (This is done to emphasize the
correspondence with the fields of the POSIX system call struct, which
helps programmers familiar with that.)
The X11 library uses a leading X for all its public functions. In
Python, this style is generally deemed unnecessary because attribute
and method names are prefixed with an object, and function names are
prefixed with a module name.
In addition, the following special forms using leading or trailing
underscores are recognized (these can generally be combined with any
case convention):
_single_leading_underscore: weak “internal use” indicator.
E.g. fromMimport* does not import objects whose name starts
with an underscore.
single_trailing_underscore_: used by convention to avoid
conflicts with Python keyword, e.g.
Tkinter.Toplevel(master,class_='ClassName')
__double_leading_underscore: when naming a class attribute,
invokes name mangling (inside class FooBar, __boo becomes
_FooBar__boo; see below).
__double_leading_and_trailing_underscore__: “magic” objects or
attributes that live in user-controlled namespaces.
E.g. __init__, __import__ or __file__. Never invent
such names; only use them as documented.
Prescriptive: Naming Conventions
Names to Avoid
Never use the characters ‘l’ (lowercase letter el), ‘O’ (uppercase
letter oh), or ‘I’ (uppercase letter eye) as single character variable
names.
In some fonts, these characters are indistinguishable from the
numerals one and zero. When tempted to use ‘l’, use ‘L’ instead.
Package and Module Names
Modules should have short, all-lowercase names. Underscores can be
used in the module name if it improves readability. Python packages
should also have short, all-lowercase names, although the use of
underscores is discouraged.
Since module names are mapped to file names, and some file systems are
case insensitive and truncate long names, it is important that module
names be chosen to be fairly short – this won’t be a problem on Unix,
but it may be a problem when the code is transported to older Mac or
Windows versions, or DOS.
When an extension module written in C or C++ has an accompanying
Python module that provides a higher level (e.g. more object oriented)
interface, the C/C++ module has a leading underscore
(e.g. _socket).
Class Names
Almost without exception, class names use the CapWords convention.
Classes for internal use have a leading underscore in addition.
Exception Names
Because exceptions should be classes, the class naming convention
applies here. However, you should use the suffix “Error” on your
exception names (if the exception actually is an error).
Global Variable Names
(Let’s hope that these variables are meant for use inside one module
only.) The conventions are about the same as those for functions.
Modules that are designed for use via fromMimport* should use
the __all__ mechanism to prevent exporting globals, or use the
older convention of prefixing such globals with an underscore (which
you might want to do to indicate these globals are “module
non-public”).
Function Names
Function names should be lowercase, with words separated by
underscores as necessary to improve readability.
mixedCase is allowed only in contexts where that’s already the
prevailing style (e.g. threading.py), to retain backwards
compatibility.
Function and method arguments
Always use self for the first argument to instance methods.
Always use cls for the first argument to class methods.
If a function argument’s name clashes with a reserved keyword, it is
generally better to append a single trailing underscore rather than
use an abbreviation or spelling corruption. Thus class_ is better
than clss. (Perhaps better is to avoid such clashes by using a
synonym.)
Method Names and Instance Variables
Use the function naming rules: lowercase with words separated by
underscores as necessary to improve readability.
Use one leading underscore only for non-public methods and instance
variables.
To avoid name clashes with subclasses, use two leading underscores to
invoke Python’s name mangling rules.
Python mangles these names with the class name: if class Foo has an
attribute named __a, it cannot be accessed by Foo.__a. (An
insistent user could still gain access by calling Foo._Foo__a.)
Generally, double leading underscores should be used only to avoid
name conflicts with attributes in classes designed to be subclassed.
Note: there is some controversy about the use of __names (see below).
Constants
Constants are usually defined on a module level and written in all
capital letters with underscores separating words. Examples include
MAX_OVERFLOW and TOTAL.
Designing for inheritance
Always decide whether a class’s methods and instance variables
(collectively: “attributes”) should be public or non-public. If in
doubt, choose non-public; it’s easier to make it public later than to
make a public attribute non-public.
Public attributes are those that you expect unrelated clients of your
class to use, with your commitment to avoid backward incompatible
changes. Non-public attributes are those that are not intended to be
used by third parties; you make no guarantees that non-public
attributes won’t change or even be removed.
We don’t use the term “private” here, since no attribute is really
private in Python (without a generally unnecessary amount of work).
Another category of attributes are those that are part of the
“subclass API” (often called “protected” in other languages). Some
classes are designed to be inherited from, either to extend or modify
aspects of the class’s behavior. When designing such a class, take
care to make explicit decisions about which attributes are public,
which are part of the subclass API, and which are truly only to be
used by your base class.
With this in mind, here are the Pythonic guidelines:
Public attributes should have no leading underscores.
If your public attribute name collides with a reserved keyword,
append a single trailing underscore to your attribute name. This is
preferable to an abbreviation or corrupted spelling. (However,
not withstanding this rule, ‘cls’ is the preferred spelling for any
variable or argument which is known to be a class, especially the
first argument to a class method.)
Note 1:
See the argument name recommendation above for class methods.
For simple public data attributes, it is best to expose just the
attribute name, without complicated accessor/mutator methods. Keep
in mind that Python provides an easy path to future enhancement,
should you find that a simple data attribute needs to grow
functional behavior. In that case, use properties to hide
functional implementation behind simple data attribute access
syntax.
Note 1:
Properties only work on new-style classes.
Note 2:
Try to keep the functional behavior side-effect free,
although side-effects such as caching are generally fine.
Note 3:
Avoid using properties for computationally expensive operations;
the attribute notation makes the caller believe that access is
(relatively) cheap.
If your class is intended to be subclassed, and you have attributes
that you do not want subclasses to use, consider naming them with
double leading underscores and no trailing underscores. This
invokes Python’s name mangling algorithm, where the name of the
class is mangled into the attribute name. This helps avoid
attribute name collisions should subclasses inadvertently contain
attributes with the same name.
Note 1:
Note that only the simple class name is used in the mangled
name, so if a subclass chooses both the same class name and
attribute name, you can still get name collisions.
Note 2:
Name mangling can make certain uses, such as debugging and
__getattr__(), less convenient. However the name mangling
algorithm is well documented and easy to perform manually.
Note 3:
Not everyone likes name mangling. Try to balance the
need to avoid accidental name clashes with potential use by
advanced callers.
Programming style is art. There is some arbitrariness to the rules, but there
are sound rationales for them. It is useful not only to provide sound advice on
style but to understand the underlying rationale behind the
style recommendations:
4 spaces instead of tabs. PIL suggests using two spaces, but a programmer looks
at code from 4 to 8 hours a day, so it’s simpler to distinguish indentation
with 4 spaces. Why spaces? Similar representation everywhere.
You can use vim modelines:
-- vim:ts=4 ss=4 sw=4 expandtab
A file should ends w/ one newline symbol, but shouldn’t ends w/ blank line
(two newline symbols).
Every do/while/for/if/function should indent 4 spaces.
Related or/and in if must be enclosed in the round brackets (). Example:
-- Goodif(a==trueandb==false)or(a==falseandb==true)then<...>end-- Badifa==trueandb==falseora==falseandb==truethen<...>end-- Good but not explicitifa^b==truethenend
Type conversion
Do not use concatenation to convert to string or addition to convert to number
(use tostring/tonumber instead):
Extra blank lines may be used (sparingly) to separate groups of related
functions. Blank lines may be omitted between several related one-liners
(for example, a set of dummy implementations).
Use blank lines in functions (sparingly) to indicate logical sections:
Delete whitespace at EOL (strongly forbidden. Use :s/\s\+$//gc in vim
to delete them).
Avoid global variables
Avoid using global variables. In exceptional cases, start the name of such a variable with _G,
add a prefix, or add a table instead of a prefix:
-- Very badfunctionbad_global_example()endfunctiongood_local_example()end-- Good_G.modulename_good_local_example=good_local_example-- Better_G.modulename={}_G.modulename.good_local_example=good_local_example
Always use a prefix to avoid name conflicts.
Naming
Names of variables/”objects” and “methods”/functions: snake_case.
Names of “classes”: CamelCase.
Private variables/methods (future properties) of objects start with
underscores <object>._<name>. Avoid syntax like
localfunctionprivate_methods(self)end.
Boolean: naming is_<...>, isnt_<...>, has_, hasnt_ is good style.
For “very local” variables:
t is for tables
i, j are for indexing
n is for counting
k, v is what you get out of pairs() (are acceptable, _ if unused)
i, v is what you get out of ipairs() (are acceptable, _ if unused)
k/key is for table keys
v/val/value is for values that are passed around
x/y/z is for generic math quantities
s/str/string is for strings
c is for 1-char strings
f/func/cb are for functions
status,<rv>.. or ok,<rv>.. is what you get out of pcall/xpcall
buf,sz is a (buffer, size) pair
<name>_p is for pointers
t0.. is for timestamps
err is for errors
Abbreviations are acceptable if they’re very common or if they’re unambiguous and you’ve documented them.
Global variables are spelled in ALL_CAPS. If it’s a system variable, it starts with an underscore
(_G/_VERSION/..).
Modules are named in snake_case (avoid underscores and dashes): for example, ‘luasql’, not
‘Lua-SQL’.
*_mt and *_methods defines metatable and methods table.
Idioms and patterns
Always use round brackets in call of functions except multiple cases (common lua
style idioms):
*.cfg{} functions (box.cfg/memcached.cfg/..)
ffi.cdef[[]] function
Avoid the following constructions:
<func>’<name>’. Strongly avoid require’..’.
functionobject:method()end. Use functionobject.method(self)end instead.
Semicolons as table separators. Only use commas.
Semicolons at the end of line. Use semicolons only to split multiple statements on one line.
Unnecessary function creation (closures/..).
Avoid implicit casting to boolean in if conditions like ifxthen or ifnotxthen.
Such expressions will likely result in troubles with box.NULL.
Instead of those conditions, use ifx~=nilthen and ifx==nilthen.
Modules
Don’t start modules with license/authors/descriptions, you can write it in
LICENSE/AUTHORS/README files.
To write modules, use one of the two patterns (don’t use modules()):
Don’t forget to comment your Lua code. You shouldn’t comment Lua syntax (assume that the reader already
knows the Lua language). Instead, tell about functions/variable names/etc.
Start a sentence with a capital letter and end with a period.
Multiline comments: use matching (--[[]]--) instead of simple
(--[[]]).
Public function comments:
--- Copy any table (shallow and deep version).-- * deepcopy: copies all levels-- * shallowcopy: copies only first level-- Supports __copy metamethod for copying custom tables with metatables.-- @function gsplit-- @table inp original table-- @shallow[opt] sep flag for shallow copy-- @returns table (copy)
Testing
Use the tap module for writing efficient tests. Example of a test file:
#!/usr/bin/env tarantoollocaltest=require('tap').test('table')test:plan(31)do-- Check basic table.copy (deepcopy).localexample_table={{1,2,3},{"help, I'm very nested",{{{}}}}}localcopy_table=table.copy(example_table)test:is_deeply(example_table,copy_table,"checking, that deepcopy behaves ok")test:isnt(example_table,copy_table,"checking, that tables are different")test:isnt(example_table[1],copy_table[1],"checking, that tables are different")test:isnt(example_table[2],copy_table[2],"checking, that tables are different")test:isnt(example_table[2][2],copy_table[2][2],"checking, that tables are different")test:isnt(example_table[2][2][1],copy_table[2][2][1],"checking, that tables are different")end<...>os.exit(test:check()and0or1)
When you test your code, the output will be something like this:
TAP version 131..31ok - checking, that deepcopy behaves ok
ok - checking, that tables are different
ok - checking, that tables are different
ok - checking, that tables are different
ok - checking, that tables are different
ok - checking, that tables are different
...
Error handling
Be generous in what you accept and strict in what you return.
With error handling, this means that you must provide an error object as the second
multi-return value in case of error. The error object can be a string, a Lua
table, cdata, or userdata. In the latter three cases, it must have a __tostring metamethod
defined.
In case of error, use nil for the first return value. This makes the error
hard to ignore.
When checking function return values, check the first argument first. If it’s
nil, look for error in the second argument:
To check the code style, Tarantool uses luacheck. It analyses different
aspects of code, such as unused variables, and sometimes it checks more aspects than needed.
So there is an agreement to ignore some warnings generated by luacheck:
"212/self",-- Unused argument <self>."411",-- Redefining a local variable."421",-- Shadowing a local variable."431",-- Shadowing an upvalue."432",-- Shadowing an upvalue argument.

























 blocks in a single search, where N is the number of
elements in the B-tree. In the simplest case, writes are done similarly: the
algorithm finds the block that holds the necessary element and updates (inserts)
its value.
blocks in a single search, where N is the number of
elements in the B-tree. In the simplest case, writes are done similarly: the
algorithm finds the block that holds the necessary element and updates (inserts)
its value.




 or, alternatively,
or, alternatively,
 , where N is
the total size of all tree elements, L0 is the level zero size, and x is the
level size ratio (the
, where N is
the total size of all tree elements, L0 is the level zero size, and x is the
level size ratio (the  = 40 (the disk-to-
memory ratio), the plot would look something like this:
= 40 (the disk-to-
memory ratio), the plot would look something like this:





 to run.
Conversely, in a classical LSM tree, both read and write speeds can differ by a
factor of hundreds (best case scenario) or even thousands (worst case scenario).
For example, adding just one element to L0 can cause it to overflow, which can
trigger a chain reaction in levels L1, L2, and so on. Lookups may find the
needed element in L0 or may need to scan all of the tree levels. It’s also
necessary to optimize reads within a single level to achieve speeds comparable
to those of a B-tree. Fortunately, most disadvantages can be mitigated or even
eliminated with additional algorithms and data structures. Let’s take a closer
look at these disadvantages and how they’re dealt with in Tarantool.
to run.
Conversely, in a classical LSM tree, both read and write speeds can differ by a
factor of hundreds (best case scenario) or even thousands (worst case scenario).
For example, adding just one element to L0 can cause it to overflow, which can
trigger a chain reaction in levels L1, L2, and so on. Lookups may find the
needed element in L0 or may need to scan all of the tree levels. It’s also
necessary to optimize reads within a single level to achieve speeds comparable
to those of a B-tree. Fortunately, most disadvantages can be mitigated or even
eliminated with additional algorithms and data structures. Let’s take a closer
look at these disadvantages and how they’re dealt with in Tarantool.